Sistemi integrati - Guida rapida
Sistema
Un sistema è una disposizione in cui tutte le sue unità assemblano lavorano insieme secondo una serie di regole. Può anche essere definito come un modo di lavorare, organizzare o svolgere uno o più compiti secondo un piano fisso. Ad esempio, un orologio è un sistema di visualizzazione dell'ora. I suoi componenti seguono una serie di regole per mostrare l'ora. Se una delle sue parti si guasta, l'orologio smetterà di funzionare. Quindi possiamo dire che, in un sistema, tutti i suoi sottocomponenti dipendono l'uno dall'altro.
Sistema incorporato
Come suggerisce il nome, Embedded significa qualcosa che è collegato a un'altra cosa. Un sistema integrato può essere pensato come un sistema hardware di computer in cui è incorporato un software. Un sistema integrato può essere un sistema indipendente o può far parte di un sistema di grandi dimensioni. Un sistema integrato è un microcontrollore o un sistema basato su microprocessore progettato per eseguire un'attività specifica. Ad esempio, un allarme antincendio è un sistema integrato; percepirà solo fumo.
Un sistema integrato ha tre componenti:
Ha hardware.
Ha un software applicativo.
Ha un sistema operativo in tempo reale (RTOS) che supervisiona il software applicativo e fornisce un meccanismo per consentire al processore di eseguire un processo secondo la pianificazione seguendo un piano per controllare le latenze. RTOS definisce il modo in cui funziona il sistema. Imposta le regole durante l'esecuzione del programma applicativo. Un sistema embedded su piccola scala potrebbe non avere RTOS.
Quindi possiamo definire un sistema embedded come un sistema di controllo in tempo reale basato su microcontrollore, basato su software, affidabile.
Caratteristiche di un sistema integrato
Single-functioned- Un sistema integrato di solito esegue un'operazione specializzata e fa lo stesso ripetutamente. Ad esempio: un cercapersone funziona sempre come un cercapersone.
Tightly constrained- Tutti i sistemi informatici hanno vincoli sulle metriche di progettazione, ma quelli su un sistema embedded possono essere particolarmente rigidi. Le metriche di progettazione sono una misura delle caratteristiche di un'implementazione come il costo, le dimensioni, la potenza e le prestazioni. Deve avere le dimensioni adatte a un singolo chip, deve funzionare abbastanza velocemente da elaborare i dati in tempo reale e consumare una potenza minima per prolungare la durata della batteria.
Reactive and Real time- Molti sistemi integrati devono reagire continuamente ai cambiamenti nell'ambiente del sistema e devono calcolare determinati risultati in tempo reale senza alcun ritardo. Considera un esempio di un controllore di crociera per auto; monitora continuamente e reagisce ai sensori di velocità e freno. Deve calcolare l'accelerazione o la de-accelerazione ripetutamente entro un tempo limitato; un calcolo ritardato può causare il mancato controllo dell'auto.
Microprocessors based - Deve essere basato su microprocessore o microcontrollore.
Memory- Deve avere una memoria, poiché il suo software di solito è integrato nella ROM. Non necessita di memorie secondarie nel computer.
Connected - Deve avere periferiche collegate per collegare dispositivi di input e output.
HW-SW systems- Il software viene utilizzato per maggiori funzionalità e flessibilità. L'hardware viene utilizzato per prestazioni e sicurezza.
Vantaggi
- Facilmente personalizzabile
- Basso consumo energetico
- A basso costo
- Prestazioni migliorate
Svantaggi
- Elevato sforzo di sviluppo
- Time to market più lungo
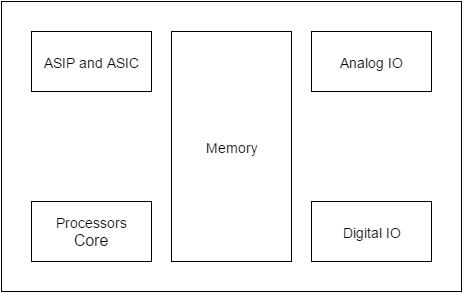
Struttura di base di un sistema integrato
La seguente illustrazione mostra la struttura di base di un sistema integrato:

Sensor- Misura la grandezza fisica e la converte in un segnale elettrico che può essere letto da un osservatore o da qualsiasi strumento elettronico come un convertitore A2D. Un sensore memorizza la quantità misurata.
A-D Converter - Un convertitore analogico-digitale converte il segnale analogico inviato dal sensore in un segnale digitale.
Processor & ASICs - I processori elaborano i dati per misurare l'output e archiviarlo nella memoria.
D-A Converter - Un convertitore da digitale ad analogico converte i dati digitali forniti dal processore in dati analogici
Actuator - Un attuatore confronta l'uscita fornita dal convertitore DA con l'uscita effettiva (prevista) in esso memorizzata e memorizza l'uscita approvata.
Il processore è il cuore di un sistema embedded. È l'unità di base che prende input e produce un output dopo l'elaborazione dei dati. Per un progettista di sistemi embedded, è necessario avere la conoscenza sia dei microprocessori che dei microcontrollori.
Processori in un sistema
Un processore ha due unità essenziali:
- Unità di controllo del flusso di programma (CU)
- Unità di esecuzione (UE)
La CU include un'unità di recupero per il recupero delle istruzioni dalla memoria. L'UE dispone di circuiti che implementano le istruzioni relative all'operazione di trasferimento dei dati e alla conversione dei dati da un modulo all'altro.
L'UE include l'unità aritmetica e logica (ALU) e anche i circuiti che eseguono le istruzioni per un'attività di controllo del programma come l'interruzione o il passaggio a un'altra serie di istruzioni.
Un processore esegue i cicli di recupero ed esegue le istruzioni nella stessa sequenza in cui vengono recuperate dalla memoria.
Tipi di processori
I processori possono essere delle seguenti categorie:
Processore per uso generico (GPP)
- Microprocessor
- Microcontroller
- Processore integrato
- Processore di segnale digitale
- Processore multimediale
Processore di sistema specifico dell'applicazione (ASSP)
Processori di istruzioni specifiche dell'applicazione (ASIP)
Core (i) GPP o core ASIP su un circuito ASIC (Application Specific Integrated Circuit) o su un circuito VLSI (Very Large Scale Integration).
Microprocessore
Un microprocessore è un singolo chip VLSI con una CPU. Inoltre, può anche avere altre unità come allenatori, unità aritmetiche di elaborazione in virgola mobile e unità di pipeline che aiutano nell'elaborazione più rapida delle istruzioni.
Il ciclo fetch-and-execute dei microprocessori della generazione precedente era guidato da una frequenza di clock dell'ordine di ~ 1 MHz. I processori ora funzionano a una frequenza di clock di 2 GHz
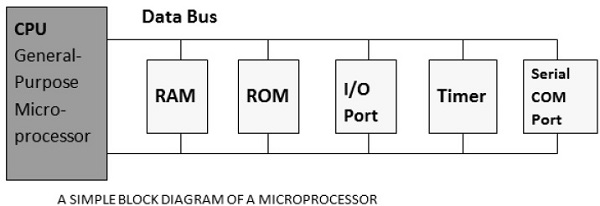
Microcontrollore
Un microcontrollore è un'unità VLSI a chip singolo (chiamata anche microcomputer) che, pur avendo capacità di calcolo limitate, possiede una capacità di input / output potenziata e un numero di unità funzionali su chip.
| processore | RAM | rom |
| Porta I / O | Timer | Porta COM seriale |
I microcontrollori sono particolarmente utilizzati nei sistemi embedded per applicazioni di controllo in tempo reale con memoria di programma e dispositivi su chip.
Microprocessore vs microcontrollore
Diamo ora uno sguardo alle differenze più notevoli tra un microprocessore e un microcontrollore.
| Microprocessore | Microcontrollore |
|---|---|
| I microprocessori sono multitasking in natura. Può eseguire più attività contemporaneamente. Ad esempio, sul computer possiamo riprodurre musica mentre scriviamo testo nell'editor di testo. | Orientato a un singolo compito. Ad esempio, una lavatrice è progettata solo per lavare i vestiti. |
| RAM, ROM, porte I / O e timer possono essere aggiunti esternamente e possono variare in numero. | RAM, ROM, porte I / O e timer non possono essere aggiunti esternamente. Questi componenti devono essere incorporati insieme su un chip e sono fissati in numeri. |
| I progettisti possono decidere il numero di porte di memoria o I / O necessarie. | Il numero fisso per la memoria o l'I / O rende un microcontrollore ideale per un'attività limitata ma specifica. |
| Il supporto esterno della memoria esterna e delle porte I / O rende un sistema basato su microprocessore più pesante e costoso. | I microcontrollori sono leggeri ed economici di un microprocessore. |
| I dispositivi esterni richiedono più spazio e il loro consumo energetico è maggiore. | Un sistema basato su microcontrollore consuma meno energia e occupa meno spazio. |
I microcontrollori 8051 funzionano con bus dati a 8 bit. Quindi possono supportare una memoria dati esterna fino a 64K e una memoria di programma esterna di 64k al massimo. Collettivamente, 8051 microcontrollori possono indirizzare 128k di memoria esterna.
Quando dati e codice si trovano in blocchi di memoria diversi, l'architettura viene indicata come Harvard architecture. Nel caso in cui dati e codice si trovino nello stesso blocco di memoria, si fa riferimento all'architettura comeVon Neumann architecture.
Von Neumann Architecture
L'architettura Von Neumann è stata proposta per la prima volta da uno scienziato informatico John von Neumann. In questa architettura, esiste un percorso dati o un bus sia per l'istruzione che per i dati. Di conseguenza, la CPU esegue un'operazione alla volta. Recupera un'istruzione dalla memoria o esegue operazioni di lettura / scrittura sui dati. Quindi un'istruzione fetch e un'operazione sui dati non possono avvenire simultaneamente, condividendo un bus comune.
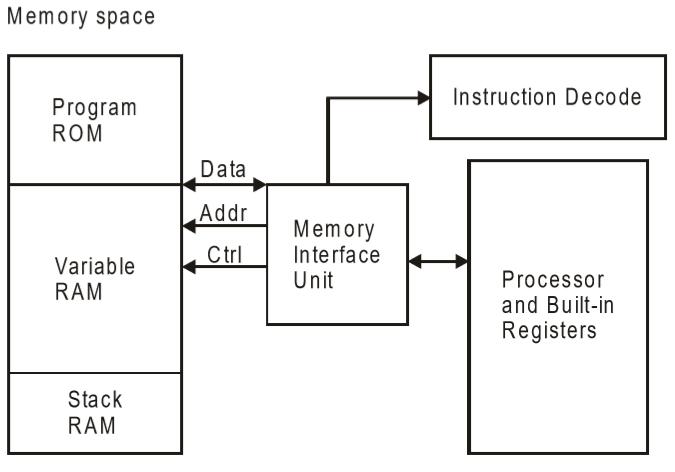
L'architettura Von-Neumann supporta hardware semplice. Consente l'utilizzo di un'unica memoria sequenziale. Le velocità di elaborazione odierne superano di gran lunga i tempi di accesso alla memoria e utilizziamo una quantità di memoria (cache) molto veloce ma piccola locale al processore.
Architettura di Harvard
L'architettura di Harvard offre memoria separata e bus di segnale per istruzioni e dati. Questa architettura ha l'archiviazione dei dati interamente contenuta all'interno della CPU e non è possibile accedere all'archiviazione delle istruzioni come dati. I computer hanno aree di memoria separate per istruzioni di programma e dati che utilizzano bus dati interni, consentendo l'accesso simultaneo sia alle istruzioni che ai dati.
I programmi dovevano essere caricati da un operatore; il processore non è riuscito ad avviarsi da solo. In un'architettura di Harvard, non è necessario che i due ricordi condividano le proprietà.
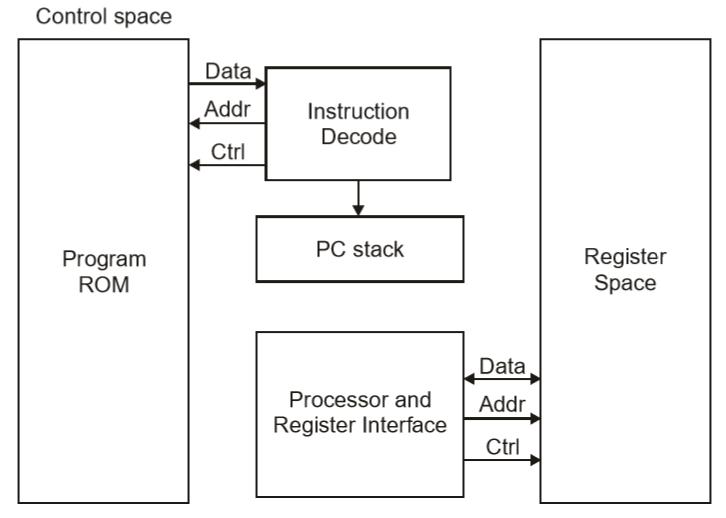
Von-Neumann Architecture vs Harvard Architecture
I seguenti punti distinguono l'architettura Von Neumann dall'architettura di Harvard.
| Architettura Von-Neumann | Architettura di Harvard |
|---|---|
| Memoria unica da condividere con codice e dati. | Memorie separate per codice e dati. |
| Il processore deve recuperare il codice in un ciclo di clock separato e i dati in un altro ciclo di clock. Quindi richiede due cicli di clock. | Un ciclo di clock singolo è sufficiente, poiché vengono utilizzati bus separati per accedere al codice e ai dati. |
| Maggiore velocità, quindi meno tempo. | Più lento nella velocità, quindi più dispendioso in termini di tempo. |
| Semplice nel design. | Complesso nel design. |
CISC e RISC
CISC è un computer con set di istruzioni complesso. È un computer che può indirizzare un gran numero di istruzioni.
All'inizio degli anni '80, i progettisti di computer raccomandavano che i computer usassero meno istruzioni con costrutti semplici in modo che possano essere eseguite molto più velocemente all'interno della CPU senza dover utilizzare la memoria. Tali computer sono classificati come computer con set di istruzioni ridotto o RISC.
CISC vs RISC
I seguenti punti differenziano un CISC da un RISC:
| CISC | RISC |
|---|---|
| Set di istruzioni più ampio. Facile da programmare | Set di istruzioni più piccolo. Difficile da programmare. |
| Progettazione più semplice del compilatore, considerando un set di istruzioni più ampio. | Progettazione complessa del compilatore. |
| Molte modalità di indirizzamento che causano formati di istruzioni complessi. | Poche modalità di indirizzamento, correzione del formato delle istruzioni. |
| La lunghezza delle istruzioni è variabile. | La lunghezza delle istruzioni varia. |
| Cicli di clock più elevati al secondo. | Ciclo di clock basso al secondo. |
| L'enfasi è sull'hardware. | L'enfasi è sul software. |
| L'unità di controllo implementa un set di istruzioni di grandi dimensioni utilizzando l'unità di micro-programma. | Ogni istruzione deve essere eseguita dall'hardware. |
| Esecuzione più lenta, poiché le istruzioni devono essere lette dalla memoria e decodificate dall'unità di decodifica. | Esecuzione più rapida, poiché ogni istruzione deve essere eseguita dall'hardware. |
| Il pipelining non è possibile. | È possibile il pipelining delle istruzioni, considerando un singolo ciclo di clock. |
Compilatori e assemblatori
Compilatore
Un compilatore è un programma per computer (o un insieme di programmi) che trasforma il codice sorgente scritto in un linguaggio di programmazione (il linguaggio sorgente) in un altro linguaggio per computer (normalmente formato binario). Il motivo più comune per la conversione è creare un programma eseguibile. Il nome "compilatore" viene utilizzato principalmente per i programmi che traducono il codice sorgente da un linguaggio di programmazione di alto livello a un linguaggio di basso livello (ad esempio, linguaggio assembly o codice macchina).
Cross-compilatore
Se il programma compilato può essere eseguito su un computer con CPU o sistema operativo diverso dal computer su cui il compilatore ha compilato il programma, quel compilatore è noto come cross-compilatore.
Decompilatore
Un programma in grado di tradurre un programma da una lingua di basso livello a una lingua di alto livello è chiamato decompilatore.
Convertitore di lingue
Un programma che traduce programmi scritti in diverse lingue di alto livello è normalmente chiamato traduttore di lingue, traduttore da sorgente a sorgente o convertitore di lingua.
È probabile che un compilatore esegua le seguenti operazioni:
- Preprocessing
- Parsing
- Analisi semantica (traduzione diretta dalla sintassi)
- Generazione di codice
- Ottimizzazione del codice
Assemblatori
Un assemblatore è un programma che prende le istruzioni di base del computer (chiamate linguaggio assembly) e le converte in un modello di bit che il processore del computer può utilizzare per eseguire le sue operazioni di base. Un assemblatore crea codice oggetto traducendo i mnemonici delle istruzioni di assemblaggio in codici operativi, risolvendo i nomi simbolici in posizioni di memoria. Il linguaggio Assembly utilizza un mnemonico per rappresentare ciascuna operazione della macchina di basso livello (codice operativo).
Strumenti di debug in un sistema integrato
Il debug è un processo metodico per trovare e ridurre il numero di bug in un programma per computer o in un componente hardware elettronico, in modo che funzioni come previsto. Il debug è difficile quando i sottosistemi sono strettamente collegati, perché un piccolo cambiamento in un sottosistema può creare bug in un altro. Gli strumenti di debug utilizzati nei sistemi embedded differiscono notevolmente in termini di tempo di sviluppo e funzionalità di debug. Discuteremo qui i seguenti strumenti di debug:
- Simulators
- Starter kit microcontrollore
- Emulator
Simulatori
Il codice viene testato per l'MCU / sistema simulandolo sul computer host utilizzato per lo sviluppo del codice. I simulatori cercano di modellare il comportamento del microcontrollore completo nel software.
Funzioni dei simulatori
Un simulatore svolge le seguenti funzioni:
Definisce il processore o la famiglia di dispositivi di elaborazione, nonché le sue varie versioni per il sistema di destinazione.
Monitora le informazioni dettagliate di una parte del codice sorgente con etichette e argomenti simbolici mentre l'esecuzione continua per ogni singolo passaggio.
Fornisce lo stato della RAM e delle porte simulate del sistema di destinazione per ogni singola fase di esecuzione.
Monitora la risposta del sistema e determina la velocità effettiva.
Fornisce traccia dell'output del contenuto del contatore del programma rispetto ai registri del processore.
Fornisce il significato dettagliato del presente comando.
Monitora le informazioni dettagliate dei comandi del simulatore mentre vengono immessi dalla tastiera o selezionati dal menu.
Supporta le condizioni (fino a 8 o 16 o 32 condizioni) e punti di interruzione incondizionati.
Fornisce punti di interruzione e traccia che sono insieme l'importante strumento di test e debug.
Facilita la sincronizzazione delle periferiche interne e dei ritardi.
Starter Kit microcontrollore
Uno starter kit per microcontrollore è composto da:
- Scheda hardware (scheda di valutazione)
- Programmatore integrato nel sistema
- Alcuni strumenti software come compilatore, assemblatore, linker, ecc.
- A volte, un IDE e una versione di valutazione limitata dalla dimensione del codice di un compilatore.
Un grande vantaggio di questi kit rispetto ai simulatori è che funzionano in tempo reale e quindi consentono una facile verifica della funzionalità di input / output. Gli starter kit, tuttavia, sono del tutto sufficienti e l'opzione più economica per sviluppare semplici progetti di microcontrollori.
Emulatori
Un emulatore è un kit hardware o un programma software o può essere entrambi che emula le funzioni di un sistema informatico (il guest) in un altro sistema informatico (l'host), diverso dal primo, in modo che il comportamento emulato assomigli molto al comportamento del sistema reale (l'ospite).
L'emulazione si riferisce alla capacità di un programma per computer in un dispositivo elettronico di emulare (imitare) un altro programma o dispositivo. L'emulazione si concentra sulla creazione di un ambiente informatico originale. Gli emulatori hanno la capacità di mantenere una connessione più stretta con l'autenticità dell'oggetto digitale. Un emulatore aiuta l'utente a lavorare su qualsiasi tipo di applicazione o sistema operativo su una piattaforma in modo simile a come il software viene eseguito come nel suo ambiente originale.
Dispositivi periferici nei sistemi integrati
I sistemi incorporati comunicano con il mondo esterno tramite le loro periferiche, come ad esempio seguire & mins;
- Interfacce di comunicazione seriale (SCI) come RS-232, RS-422, RS-485, ecc.
- Interfaccia di comunicazione seriale sincrona come I2C, SPI, SSC e ESSI
- Universal Serial Bus (USB)
- Schede multimediali (schede SD, Compact Flash, ecc.)
- Reti come Ethernet, LonWorks, ecc.
- Bus di campo come CAN-Bus, LIN-Bus, PROFIBUS, ecc.
- imers come PLL, Capture / Compare e Time Processing Units.
- I / O discreto noto anche come GPIO (General Purpose Input / Output)
- Da analogico a digitale / Da digitale ad analogico (ADC / DAC)
- Debug come porte JTAG, ISP, ICSP, BDM Port, BITP e DP9
Criteri per la scelta del microcontrollore
Quando si sceglie un microcontrollore, assicurarsi che soddisfi il compito in questione e che sia conveniente. Dobbiamo vedere se un microcontrollore a 8 bit, 16 bit o 32 bit può gestire al meglio le esigenze di elaborazione di un'attività. Inoltre, i seguenti punti dovrebbero essere tenuti a mente quando si sceglie un microcontrollore:
Speed - Qual è la velocità massima supportata dal microcontrollore?
Packaging- È DIP a 40 pin (pacchetto Dual-inline) o QFP (pacchetto Quad flat)? Questo è importante in termini di spazio, assemblaggio e prototipazione del prodotto finale.
Power Consumption - Questo è un criterio importante per i prodotti alimentati a batteria.
Amount of RAM and ROM sul chip.
Count of I/O pins and Timers sul chip.
Cost per Unit - Questo è importante in termini di costo finale del prodotto in cui deve essere utilizzato il microcontrollore.
Inoltre, assicurati di avere strumenti come compilatori, debugger e assemblatori, disponibili con il microcontrollore. La cosa più importante di tutte è che dovresti acquistare un microcontrollore da una fonte affidabile.
Breve storia dell'8051
Il primo microprocessore 4004 è stato inventato da Intel Corporation. 8085 e 8086Anche i microprocessori furono inventati da Intel. Nel 1981, Intel ha introdotto un microcontrollore a 8 bit chiamato8051. È stato indicato comesystem on a chipperché aveva 128 byte di RAM, 4K byte di ROM su chip, due timer, una porta seriale e 4 porte (8 bit di larghezza), tutto su un singolo chip. Quando divenne molto popolare, Intel permise ad altri produttori di creare e commercializzare versioni diverse di 8051 con il suo codice compatibile con 8051. Significa che se scrivi il tuo programma per una versione di 8051, funzionerà anche su altre versioni, indipendentemente dalla produttore. Ciò ha portato a diverse versioni con diverse velocità e quantità di RAM su chip.
8051 Flavors / Members
8052 microcontroller- 8052 ha tutte le caratteristiche standard del microcontrollore 8051 oltre a 128 byte extra di RAM e un timer extra. Ha anche 8K byte di ROM del programma su chip invece di 4K byte.
8031 microcontroller- È un altro membro della famiglia 8051. Questo chip è spesso indicato come 8051 senza ROM, poiché ha 0K byte di ROM su chip. È necessario aggiungere una ROM esterna per utilizzarlo, che contiene il programma da recuperare ed eseguire. Questo programma può avere dimensioni fino a 64 KB. Ma nel processo di aggiunta della ROM esterna all'8031, ha perso 2 porte su 4 porte. Per risolvere questo problema, possiamo aggiungere un I / O esterno all'8031
Confronto tra 8051 membri della famiglia
La tabella seguente confronta le funzioni disponibili in 8051, 8052 e 8031.
| Caratteristica | 8051 | 8052 | 8031 |
|---|---|---|---|
| ROM (byte) | 4K | 8 MILA | 0K |
| RAM (byte) | 128 | 256 | 128 |
| Timer | 2 | 3 | 2 |
| Pin I / O | 32 | 32 | 32 |
| Porta seriale | 1 | 1 | 1 |
| Fonti di interrupt | 6 | 8 | 6 |
Caratteristiche del microcontrollore 8051
Un microcontrollore 8051 viene fornito in bundle con le seguenti caratteristiche:
- 4 KB di byte di memoria di programma (ROM) su chip
- 128 byte di memoria dati su chip (RAM)
- Quattro banchi di registri
- 128 flag software definiti dall'utente
- Bus dati bidirezionale a 8 bit
- Bus indirizzi unidirezionale a 16 bit
- 32 registri per uso generico ciascuno di 8 bit
- Timer a 16 bit (di solito 2, ma possono avere più o meno)
- Tre interrupt interni e due esterni
- Quattro porte a 8 bit, (il modello corto ha due porte a 8 bit)
- Contatore di programma a 16 bit e puntatore dati
- 8051 può anche avere una serie di funzioni speciali come UART, ADC, amplificatore operazionale, ecc.
Schema a blocchi del microcontrollore 8051
La seguente illustrazione mostra lo schema a blocchi di un microcontrollore 8051 -
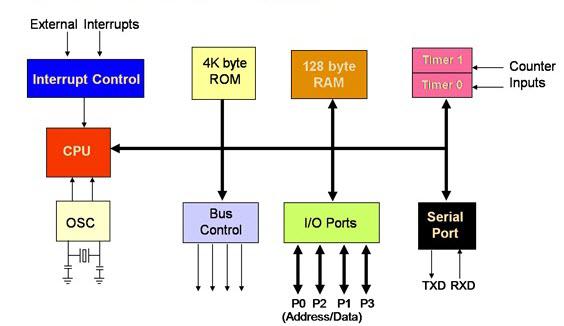
Nell'8051, le operazioni di I / O vengono eseguite utilizzando quattro porte e 40 pin. Il seguente diagramma dei pin mostra i dettagli dei 40 pin. La porta operativa I / O riserva 32 pin dove ogni porta ha 8 pin. Gli altri 8 pin sono designati come V cc , GND, XTAL1, XTAL2, RST, EA (bar), ALE / PROG (bar) e PSEN (bar).
È un PDIP a 40 pin (Plastic Dual Inline Package)
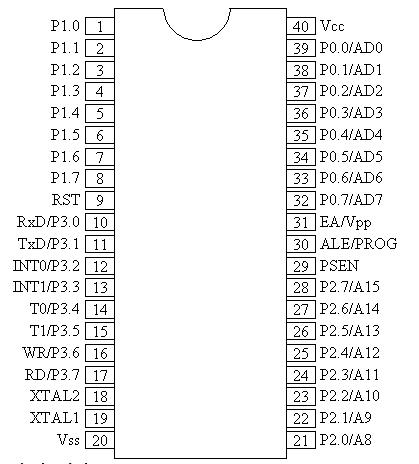
Note- In un pacchetto DIP, puoi riconoscere il primo pin e l'ultimo pin dal taglio al centro dell'IC. Il primo perno è a sinistra di questo segno di taglio e l'ultimo perno (cioè il 40 ° perno in questo caso) è a destra del segno di taglio.
Porte I / O e loro funzioni
Le quattro porte P0, P1, P2 e P3 utilizzano ciascuna 8 pin, il che le rende porte a 8 bit. Al RESET, tutte le porte vengono configurate come ingressi, pronte per essere utilizzate come porte di ingresso. Quando il primo 0 viene scritto su una porta, diventa un output. Per riconfigurarlo come ingresso, è necessario inviare un 1 a una porta.
Porta 0 (Pin n. 32 - Pin n. 39)
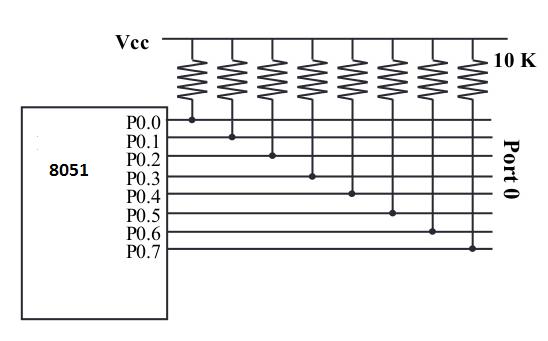
Dispone di 8 pin (da 32 a 39). Può essere utilizzato per input o output. A differenza delle porte P1, P2 e P3, normalmente colleghiamo P0 a resistori di pull-up da 10K-ohm per usarlo come porta di ingresso o uscita essendo uno scarico aperto.
È anche designato come AD0-AD7, consentendo di utilizzarlo sia come indirizzo che come dati. Nel caso di 8031 (cioè ROMless Chip), quando abbiamo bisogno di accedere alla ROM esterna, allora P0 sarà usato sia per Address che per Data Bus. ALE (Pin no 31) indica se P0 ha indirizzo o dati. Quando ALE = 0, fornisce i dati D0-D7, ma quando ALE = 1 ha indirizzo A0-A7. Nel caso in cui non sia disponibile alcuna connessione di memoria esterna, P0 deve essere collegato esternamente a una resistenza di pull-up da 10K-ohm.
MOV A,#0FFH ;(comments: A=FFH(Hexadecimal i.e. A=1111 1111)
MOV P0,A ;(Port0 have 1's on every pin so that it works as Input)Porta 1 (pin da 1 a 8)
È una porta a 8 bit (pin da 1 a 8) e può essere utilizzata sia come input che come output. Non necessita di resistenze pull-up perché sono già collegate internamente. Al ripristino, la porta 1 viene configurata come porta di ingresso. Il codice seguente può essere utilizzato per inviare valori alternati di 55H e AAH alla porta 1.
;Toggle all bits of continuously
MOV A,#55
BACK:
MOV P2,A
ACALL DELAY
CPL A ;complement(invert) reg. A
SJMP BACKSe la porta 1 è configurata per essere utilizzata come porta di uscita, quindi per usarla di nuovo come porta di ingresso, programmarla scrivendo 1 su tutti i suoi bit come nel codice seguente.
;Toggle all bits of continuously
MOV A ,#0FFH ;A = FF hex
MOV P1,A ;Make P1 an input port
MOV A,P1 ;get data from P1
MOV R7,A ;save it in Reg R7
ACALL DELAY ;wait
MOV A,P1 ;get another data from P1
MOV R6,A ;save it in R6
ACALL DELAY ;wait
MOV A,P1 ;get another data from P1
MOV R5,A ;save it in R5Porta 2 (pin da 21 a 28)
La porta 2 occupa un totale di 8 pin (pin da 21 a 28) e può essere utilizzata sia per le operazioni di input che di output. Proprio come P1 (Porta 1), anche P2 non richiede resistenze di pull-up esterne perché sono già collegate internamente. Deve essere utilizzato insieme a P0 per fornire l'indirizzo a 16 bit per la memoria esterna. Quindi è anche designato come (A0 – A7), come mostrato nel diagramma dei pin. Quando l'8051 è collegato a una memoria esterna, fornisce il percorso per gli 8 bit superiori dell'indirizzo a 16 bit e non può essere utilizzato come I / O. Al ripristino, la porta 2 viene configurata come porta di ingresso. Il codice seguente può essere utilizzato per inviare valori alternati di 55H e AAH alla porta 2.
;Toggle all bits of continuously
MOV A,#55
BACK:
MOV P2,A
ACALL DELAY
CPL A ; complement(invert) reg. A
SJMP BACKSe la porta 2 è configurata per essere utilizzata come porta di uscita, quindi per utilizzarla di nuovo come porta di ingresso, programmarla scrivendo 1 su tutti i suoi bit come nel codice seguente.
;Get a byte from P2 and send it to P1
MOV A,#0FFH ;A = FF hex
MOV P2,A ;make P2 an input port
BACK:
MOV A,P2 ;get data from P2
MOV P1,A ;send it to Port 1
SJMP BACK ;keep doing thatPorta 3 (pin da 10 a 17)
È anche di 8 bit e può essere utilizzato come ingresso / uscita. Questa porta fornisce alcuni segnali estremamente importanti. P3.0 e P3.1 sono rispettivamente RxD (ricevitore) e TxD (trasmettitore) e vengono utilizzati collettivamente per la comunicazione seriale. I pin P3.2 e P3.3 vengono utilizzati per gli interrupt esterni. P3.4 e P3.5 vengono utilizzati rispettivamente per i timer T0 e T1. P3.6 e P3.7 sono pin di scrittura (WR) e di lettura (RD). Questi sono pin bassi attivi, significa che saranno attivi quando viene assegnato loro 0 e questi sono usati per fornire operazioni di lettura e scrittura alla ROM esterna nei sistemi basati su 8031.
| P3 Bit | Funzione | Pin |
|---|---|---|
| P3.0 | RxD | 10 |
| P3.1 < | TxD | 11 |
| P3.2 < | Complemento di INT0 | 12 |
| P3.3 < | INT1 | 13 |
| P3.4 < | T0 | 14 |
| P3.5 < | T1 | 15 |
| P3.6 < | WR | 16 |
| P3.7 < | Complemento di RD | 17 |
Doppio ruolo della porta 0 e della porta 2
Dual role of Port 0- La porta 0 è anche designata come AD0-AD7, poiché può essere utilizzata sia per i dati che per la gestione degli indirizzi. Durante il collegamento di un 8051 alla memoria esterna, la porta 0 può fornire sia l'indirizzo che i dati. Il microcontrollore 8051 quindi multiplexa l'ingresso come indirizzo o dati per salvare i pin.
Dual role of Port 2- Oltre a funzionare come I / O, la porta P2 viene utilizzata anche per fornire il bus di indirizzi a 16 bit per la memoria esterna insieme alla porta 0. La porta P2 è anche designata come (A8– A15), mentre la porta 0 fornisce gli 8 bit inferiori tramite A0-A7. In altre parole, possiamo dire che quando un 8051 è collegato a una memoria esterna (ROM) che può essere al massimo fino a 64KB e questo è possibile tramite bus di indirizzi a 16 bit perché sappiamo 216 = 64KB. Port2 viene utilizzata per gli 8 bit superiori dell'indirizzo a 16 bit e non può essere utilizzata per I / O e questo è il modo in cui viene indirizzato qualsiasi codice di programma della ROM esterna.
Collegamento hardware dei pin
Vcc - Il pin 40 fornisce l'alimentazione al chip ed è +5 V.
Gnd - Il pin 20 fornisce la massa per il riferimento.
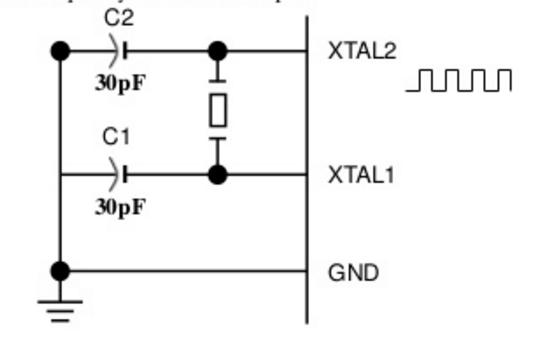
XTAL1, XTAL2 (Pin no 18 & Pin no 19)- 8051 ha un oscillatore su chip ma richiede un clock esterno per eseguirlo. Un cristallo di quarzo è collegato tra i pin XTAL1 e XTAL2 del chip. Questo cristallo necessita anche di due condensatori da 30pF per generare un segnale della frequenza desiderata. Un lato di ogni condensatore è collegato a terra. 8051 IC è disponibile in varie velocità e tutto dipende da questo cristallo di quarzo, ad esempio, un microcontrollore da 20 MHz richiede un cristallo con una frequenza non superiore a 20 MHz.
RST (Pin No. 9)- È un pin di ingresso e un pin alto attivo. Dopo aver applicato un impulso alto su questo pin, ovvero 1, il microcontrollore si resetterà e terminerà tutte le attività. Questo processo è noto comePower-On Reset. L'attivazione di un reset all'accensione causerà la perdita di tutti i valori nel registro. Imposterà un contatore del programma su tutti gli 0. Per garantire un ingresso valido di Reset, l'impulso alto deve essere alto per un minimo di due cicli macchina prima che possa andare basso, il che dipende dal valore del condensatore e dalla velocità con cui si carica. (Machine Cycle è la quantità minima di frequenza che una singola istruzione richiede in esecuzione).
EA or External Access (Pin No. 31)- È un pin di input. Questo pin è un pin basso attivo; dopo aver applicato un impulso basso, viene attivato. In caso di microcontrollore (8051/52) con ROM on-chip, il pin EA (bar) è collegato a V cc . Ma in un microcontrollore 8031 che non dispone di una ROM su chip, il codice viene memorizzato in una ROM esterna e quindi recuperato dal microcontrollore. In questo caso, dobbiamo collegare il (pin no 31) EA a Gnd per indicare che il codice del programma è memorizzato esternamente.
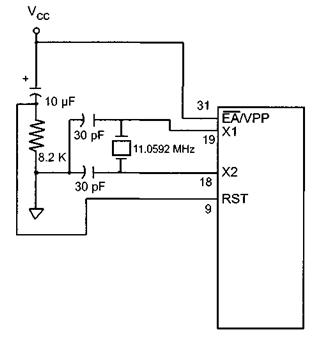
PSEN or Program store Enable (Pin No 29)- Anche questo è un pin basso attivo, cioè viene attivato dopo aver applicato un impulso basso. È un pin di uscita e viene utilizzato insieme al pin EA nei sistemi basati su 8031 (cioè ROMLESS) per consentire l'archiviazione del codice del programma nella ROM esterna.
ALE or (Address Latch Enable)- Questo è un pin di uscita ed è attivo alto. Viene utilizzato soprattutto per 8031 IC per collegarlo alla memoria esterna. Può essere utilizzato per decidere se i pin P0 verranno utilizzati come bus indirizzo o bus dati. Quando ALE = 1, i pin P0 funzionano come bus dati e quando ALE = 0, i pin P0 agiscono come bus indirizzo.
Porte I / O e indirizzabilità dei bit
È una funzionalità più utilizzata dell'8051 durante la scrittura del codice per l'8051. A volte è necessario accedere solo a 1 o 2 bit della porta invece che all'intero 8 bit. 8051 fornisce la capacità di accedere ai singoli bit delle porte.
Durante l'accesso a una porta in modo single-bit, usiamo la sintassi "SETB X. Y" dove X è il numero di porta (da 0 a 3) e Y è un numero di bit (da 0 a 7) per i bit di dati D0-D7 dove D0 è l'LSB e D7 è l'MSB. Ad esempio, "SETB P1.5" imposta il bit alto 5 della porta 1.
Il codice seguente mostra come cambiare continuamente il bit P1.2.
AGAIN:
SETB P1.2
ACALL DELAY
CLR P1.2
ACALL DELAY
SJMP AGAINIstruzioni a bit singolo
| Istruzioni | Funzione |
|---|---|
| Bit SETB | Imposta il bit (bit = 1) |
| Bit di CLR | azzera il bit (bit = 0) |
| Bit CPL | completare il bit (bit = NOT bit) |
| Bit JB, bersaglio | salta al target se bit = 1 (salta se bit) |
| Bit JNB, destinazione | salta al target se bit = 0 (salta se nessun bit) |
| Bit JBC, destinazione | salta alla destinazione se bit = 1, cancella bit (salta se bit, quindi cancella) |
Contatore di programma
Il Program Counter è un registro a 16 o 32 bit che contiene l'indirizzo della successiva istruzione da eseguire. Il PC passa automaticamente alla successiva posizione di memoria sequenziale ogni volta che viene caricata un'istruzione. Le operazioni di salto, salto e interruzione caricano il contatore del programma con un indirizzo diverso dalla posizione sequenziale successiva.
L'attivazione di un reset all'accensione causerà la perdita di tutti i valori nel registro. Significa che il valore del PC (contatore del programma) è 0 al reset, costringendo la CPU a recuperare il primo codice operativo dalla posizione di memoria ROM 0000. Significa che dobbiamo posizionare il primo byte dell'upcode nella posizione ROM 0000 perché è lì che il La CPU si aspetta di trovare la prima istruzione
Ripristina il vettore
Il significato del vettore di ripristino è che punta il processore all'indirizzo di memoria che contiene la prima istruzione del firmware. Senza il vettore di ripristino, il processore non saprebbe da dove iniziare l'esecuzione. Dopo il ripristino, il processore carica il Program Counter (PC) con il valore del vettore di ripristino da una posizione di memoria predefinita. Sull'architettura CPU08, questo è nella posizione$FFFE:$FFFF.
Quando il vettore di ripristino non è necessario, gli sviluppatori normalmente lo danno per scontato e non programmano nell'immagine finale. Di conseguenza, il processore non si avvia sul prodotto finale. È un errore comune che si verifica durante la fase di debug.
Stack Pointer
Lo stack è implementato nella RAM e per accedervi viene utilizzato un registro della CPU chiamato registro SP (Stack Pointer). Il registro SP è un registro a 8 bit e può indirizzare indirizzi di memoria compresi tra 00h e FFh. Inizialmente, il registro SP contiene il valore 07 per puntare alla posizione 08 come prima posizione utilizzata per lo stack dall'8051.
Quando il contenuto di un registro della CPU viene memorizzato in uno stack, viene chiamata operazione PUSH. Quando il contenuto di uno stack viene memorizzato in un registro della CPU, viene chiamata operazione POP. In altre parole, un registro viene inserito nello stack per salvarlo e estratto dallo stack per recuperarlo.
Ciclo infinito
Un ciclo infinito o un ciclo infinito può essere identificato come una sequenza di istruzioni in un programma per computer che viene eseguito all'infinito in un ciclo, per i seguenti motivi:
- loop senza condizioni di terminazione.
- loop con una condizione di terminazione che non può mai essere soddisfatta.
- loop con una condizione di terminazione che fa ricominciare il ciclo.
Tali cicli infiniti normalmente impedivano ai sistemi operativi più vecchi di non rispondere, poiché un ciclo infinito consuma tutto il tempo disponibile del processore. Le operazioni di I / O in attesa di input dell'utente sono anche chiamate "loop infiniti". Una possibile causa del "blocco" di un computer è un ciclo infinito; altre cause includonodeadlock e access violations.
I sistemi integrati, a differenza di un PC, non "chiudono" mai un'applicazione. Passano inattivi attraverso un ciclo infinito in attesa che si verifichi un evento sotto forma di interruzione o di un filepre-scheduled task. Per risparmiare energia, alcuni processori entrano in specialesleep o wait modes invece di girare al minimo attraverso un ciclo infinito, ma usciranno da questa modalità su un timer o su un interrupt esterno.
Interrompe
Gli interrupt sono principalmente meccanismi hardware che indicano al programma che si è verificato un evento. Possono verificarsi in qualsiasi momento e sono quindi asincroni rispetto al flusso del programma. Richiedono una gestione speciale da parte del processore e vengono infine gestiti da una routine di servizio interrupt (ISR) corrispondente. Le interruzioni devono essere gestite rapidamente. Se impieghi troppo tempo a riparare un'interruzione, potresti perdere un'altra interruzione.
Little Endian Vs Big Endian
Sebbene i numeri vengano sempre visualizzati nello stesso modo, non vengono memorizzati nello stesso modo in memoria. Le macchine Big-Endian memorizzano il byte di dati più significativo nell'indirizzo di memoria più basso. Una macchina Big-Endian memorizza 0x12345678 come -
ADD+0: 0x12
ADD+1: 0x34
ADD+2: 0x56
ADD+3: 0x78Le macchine Little-Endian, invece, memorizzano il byte di dati meno significativo nell'indirizzo di memoria più basso. Una macchina Little-Endian memorizza 0x12345678 come -
ADD+0: 0x78
ADD+1: 0x56
ADD+2: 0x34
ADD+3: 0x12I linguaggi Assembly sono stati sviluppati per fornire mnemonicso simboli per le istruzioni del codice a livello macchina. I programmi in linguaggio assembly sono costituiti da mnemonici, quindi dovrebbero essere tradotti in codice macchina. Un programma responsabile di questa conversione è noto comeassembler. Il linguaggio assembly è spesso definito come un linguaggio di basso livello perché funziona direttamente con la struttura interna della CPU. Per programmare in linguaggio assembly, un programmatore deve conoscere tutti i registri della CPU.
Diversi linguaggi di programmazione come C, C ++, Java e vari altri linguaggi sono chiamati linguaggi di alto livello perché non si occupano dei dettagli interni di una CPU. Al contrario, un assemblatore viene utilizzato per tradurre un programma in linguaggio assembly in codice macchina (a volte chiamato ancheobject code o opcode). Allo stesso modo, un compilatore traduce un linguaggio di alto livello in codice macchina. Ad esempio, per scrivere un programma in linguaggio C, è necessario utilizzare un compilatore C per tradurre il programma in linguaggio macchina.
Struttura del linguaggio assembly
Un programma in linguaggio assembly è una serie di istruzioni, che sono istruzioni in linguaggio assembly come ADD e MOV o istruzioni chiamate directives.
Un instruction dice alla CPU cosa fare, mentre un file directive (chiamato anche pseudo-instructions) dà istruzioni all'assemblatore. Ad esempio, le istruzioni ADD e MOV sono comandi che la CPU esegue, mentre ORG e END sono direttive assembler. L'assembler posiziona il codice operativo nella posizione di memoria 0 quando viene utilizzata la direttiva ORG, mentre END indica la fine del codice sorgente. Un'istruzione nel linguaggio del programma è composta dai seguenti quattro campi:
[ label: ] mnemonics [ operands ] [;comment ]Una parentesi quadra ([]) indica che il campo è facoltativo.
Il label fieldconsente al programma di fare riferimento a una riga di codice in base al nome. I campi dell'etichetta non possono superare un certo numero di caratteri.
Il mnemonics e operands fieldsinsieme svolgono il vero lavoro del programma e portano a termine i compiti. Dichiarazioni come ADD A, C & MOV C, # 68 dove ADD e MOV sono gli mnemonici, che producono opcode; "A, C" e "C, # 68" sono operandi. Questi due campi potrebbero contenere direttive. Le direttive non generano codice macchina e sono usate solo dall'assemblatore, mentre le istruzioni sono tradotte in codice macchina per l'esecuzione della CPU.
1.0000 ORG 0H ;start (origin) at location 0
2 0000 7D25 MOV R5,#25H ;load 25H into R5
3.0002 7F34 MOV R7,#34H ;load 34H into R7
4.0004 7400 MOV A,#0 ;load 0 into A
5.0006 2D ADD A,R5 ;add contents of R5 to A
6.0007 2F ADD A,R7 ;add contents of R7 to A
7.0008 2412 ADD A,#12H ;add to A value 12 H
8.000A 80FE HERE: SJMP HERE ;stay in this loop
9.000C END ;end of asm source fileIl comment field inizia con un punto e virgola che è un indicatore di commento.
Notare l'etichetta "QUI" nel programma. Qualsiasi etichetta che fa riferimento a un'istruzione dovrebbe essere seguita da due punti.
Assemblaggio ed esecuzione di un programma 8051
Qui discuteremo della forma di base di un linguaggio assembly. I passaggi per creare, assemblare ed eseguire un programma in linguaggio assembly sono i seguenti:
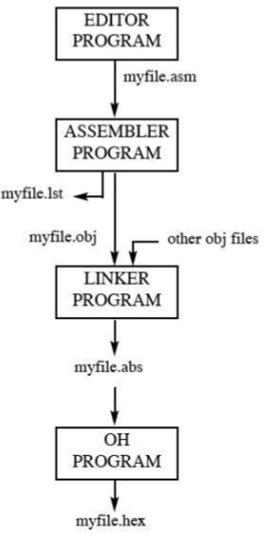
Innanzitutto, utilizziamo un editor per digitare un programma simile al programma sopra. Editor come il programma EDIT di MS-DOS fornito con tutti i sistemi operativi Microsoft possono essere utilizzati per creare o modificare un programma. L'editor deve essere in grado di produrre un file ASCII. L'estensione "asm" per il file sorgente viene utilizzata da un assemblatore nel passaggio successivo.
Il file sorgente "asm" contiene il codice del programma creato nel passaggio 1. Viene fornito a un assemblatore 8051. L'assembler converte quindi le istruzioni in linguaggio assembly in istruzioni in codice macchina e produce un file.obj file (file oggetto) e un file .lst file(file di elenco). È anche chiamato comesource file, ecco perché alcuni assemblatori richiedono che questo file abbia le estensioni "src". Il file "lst" è facoltativo. È molto utile per il programma perché elenca tutti i codici operativi e gli indirizzi nonché gli errori rilevati dagli assemblatori.
Gli assemblatori richiedono un terzo passaggio chiamato linking. Il programma di collegamento accetta uno o più file oggetto e produce un file oggetto assoluto con estensione "abs".
Successivamente, il file "abs" viene inviato a un programma chiamato "OH" (convertitore da oggetto a esadecimale), che crea un file con estensione "hex" pronto per essere masterizzato nella ROM.
Tipo di dati
Il microcontrollore 8051 contiene un singolo tipo di dati di 8 bit e ogni registro ha anche una dimensione di 8 bit. Il programmatore deve scomporre i dati più grandi di 8 bit (da 00 a FFH o a 255 in decimale) in modo che possano essere elaborati dalla CPU.
DB (Definisci byte)
La direttiva DB è la direttiva dati più utilizzata nell'assembler. Viene utilizzato per definire i dati a 8 bit. Può anche essere utilizzato per definire i dati in formato decimale, binario, esadecimale o ASCII. Per i decimali, la "D" dopo il numero decimale è facoltativa, ma è necessaria per "B" (binario) e "Hl" (esadecimale).
Per indicare ASCII, è sufficiente inserire i caratteri tra virgolette ("come questo"). L'assemblatore genera automaticamente il codice ASCII per i numeri / caratteri. La direttiva DB è l'unica direttiva che può essere utilizzata per definire stringhe ASCII più grandi di due caratteri; pertanto, dovrebbe essere utilizzato per tutte le definizioni di dati ASCII. Di seguito vengono forniti alcuni esempi di DB:
ORG 500H
DATA1: DB 28 ;DECIMAL (1C in hex)
DATA2: DB 00110101B ;BINARY (35 in hex)
DATA3: DB 39H ;HEX
ORG 510H
DATA4: DB "2591" ;ASCII NUMBERS
ORG 520H
DATA6: DA "MY NAME IS Michael" ;ASCII CHARACTERSÈ possibile utilizzare virgolette singole o doppie attorno alle stringhe ASCII. DB viene utilizzato anche per allocare la memoria in blocchi di dimensioni di byte.
Direttive dell'assemblatore
Alcune delle direttive dell'8051 sono le seguenti:
ORG (origin)- La direttiva di origine viene utilizzata per indicare l'inizio dell'indirizzo. Prende i numeri in formato esadecimale o decimale. Se H viene fornito dopo il numero, il numero viene considerato esadecimale, altrimenti decimale. L'assembler converte il numero decimale in hexa.
EQU (equate)- Viene utilizzato per definire una costante senza occupare una posizione di memoria. EQU associa un valore costante a un'etichetta dati in modo che l'etichetta appaia nel programma, il suo valore costante verrà sostituito dall'etichetta. Durante l'esecuzione dell'istruzione "MOV R3, #COUNT", il registro R3 verrà caricato con il valore 25 (notare il segno #). Il vantaggio di usare EQU è che il programmatore può cambiarlo una volta e l'assembler cambierà tutte le sue occorrenze; il programmatore non deve cercare l'intero programma.
END directive- Indica la fine del file sorgente (asm). La direttiva END è l'ultima riga del programma; qualsiasi cosa dopo la direttiva END viene ignorata dall'assembler.
Etichette in linguaggio Assembly
Tutte le etichette in linguaggio assembly devono seguire le regole riportate di seguito:
Ogni nome di etichetta deve essere univoco. I nomi utilizzati per le etichette nella programmazione in linguaggio assembly sono costituiti da lettere alfabetiche sia maiuscole che minuscole, numeri da 0 a 9 e caratteri speciali come punto interrogativo (?), Punto (.), Al tasso @, trattino basso (_), e dollaro ($).
Il primo carattere dovrebbe essere in carattere alfabetico; non può essere un numero.
Le parole riservate non possono essere utilizzate come etichetta nel programma. Ad esempio, le parole ADD e MOV sono le parole riservate, poiché sono mnemonici di istruzioni.
I registri vengono utilizzati nella CPU per memorizzare temporaneamente informazioni che potrebbero essere dati da elaborare o un indirizzo che punta ai dati che devono essere recuperati. Nell'8051 esiste un tipo di dati a 8 bit, da MSB (bit più significativo) D7 a LSB (bit meno significativo) D0. Con il tipo di dati a 8 bit, qualsiasi tipo di dati superiore a 8 bit deve essere suddiviso in blocchi di 8 bit prima di essere elaborato.
I registri più utilizzati dell'8051 sono A (accumulatore), B, R0-R7, DPTR (puntatore dati) e PC (contatore programma). Tutti questi registri sono di 8 bit, eccetto DPTR e PC.
Registri di archiviazione in 8051
Discuteremo i seguenti tipi di registri di archiviazione qui:
- Accumulator
- Registro R.
- Registro B.
- Puntatore dati (DPTR)
- Contatore programma (PC)
- Stack Pointer (SP)
Accumulatore
L'accumulatore, registro A, viene utilizzato per tutte le operazioni aritmetiche e logiche. Se l'accumulatore non è presente, ogni risultato di ogni calcolo (addizione, moltiplicazione, spostamento, ecc.) Deve essere memorizzato nella memoria principale. L'accesso alla memoria principale è più lento dell'accesso a un registro come l'accumulatore perché la tecnologia utilizzata per la grande memoria principale è più lenta (ma più economica) di quella utilizzata per un registro.
I registri "R"
I registri "R" sono un insieme di otto registri, vale a dire, R0, da R1 a R7. Questi registri funzionano come registri di memorizzazione ausiliari o temporanei in molte operazioni. Considera un esempio della somma di 10 e 20. Memorizza una variabile 10 in un accumulatore e un'altra variabile 20, diciamo, nel registro R4. Per elaborare l'operazione di aggiunta, eseguire il seguente comando:
ADD A,R4Dopo aver eseguito questa istruzione, l'accumulatore conterrà il valore 30. Pertanto i registri "R" sono ausiliari o molto importanti helper registers. Il solo Accumulatore non sarebbe molto utile se non fosse per questi registri "R". I registri "R" servono per la memorizzazione temporanea dei valori.
Facciamo un altro esempio. Aggiungeremo i valori in R1 e R2 insieme e poi sottrarremo i valori di R3 e R4 dal risultato.
MOV A,R3 ;Move the value of R3 into the accumulator
ADD A,R4 ;Add the value of R4
MOV R5,A ;Store the resulting value temporarily in R5
MOV A,R1 ;Move the value of R1 into the accumulator
ADD A,R2 ;Add the value of R2
SUBB A,R5 ;Subtract the value of R5 (which now contains R3 + R4)Come puoi vedere, abbiamo usato R5 per trattenere temporaneamente la somma di R3 e R4. Naturalmente, questo non è il modo più efficiente per calcolare (R1 + R2) - (R3 + R4), ma illustra l'uso dei registri "R" come un modo per memorizzare i valori temporaneamente.

Il registro "B"
Il registro "B" è molto simile all'accumulatore nel senso che può contenere un valore di 8 bit (1 byte). Il registro "B" viene utilizzato solo da due istruzioni 8051:MUL AB e DIV AB. Per moltiplicare o dividere rapidamente e facilmente A per un altro numero, è possibile memorizzare l'altro numero in "B" e utilizzare queste due istruzioni. Oltre a utilizzare le istruzioni MUL e DIV, il registro "B" viene spesso utilizzato come un altro registro di memorizzazione temporanea, molto simile a un nono registro R.
Il puntatore dati
Il Data Pointer (DPTR) è l'unico registro a 16 bit (2 byte) accessibile all'utente dell'8051. L'accumulatore, i registri R0 – R7 e il registro B sono registri di valore a 1 byte. DPTR è pensato per puntare ai dati. Viene utilizzato dall'8051 per accedere alla memoria esterna utilizzando l'indirizzo indicato da DPTR. DPTR è l'unico registro a 16 bit disponibile e viene spesso utilizzato per memorizzare valori a 2 byte.
Il contatore del programma
Il Program Counter (PC) è un indirizzo a 2 byte che indica all'8051 dove si trova nella memoria l'istruzione successiva da eseguire. Il PC parte da 0000h quando l'8051 si inizializza e viene incrementato ogni volta che viene eseguita un'istruzione. Il PC non è sempre incrementato di 1. Alcune istruzioni possono richiedere 2 o 3 byte; in questi casi, il PC verrà incrementato di 2 o 3.
Branch, jump, e interruptle operazioni caricano il contatore del programma con un indirizzo diverso dalla posizione sequenziale successiva. L'attivazione di un reset all'accensione causerà la perdita di tutti i valori nel registro. Significa che il valore del PC è 0 al ripristino, costringendo la CPU a recuperare il primo codice operativo dalla posizione della ROM 0000. Significa che dobbiamo posizionare il primo byte dell'upcode nella posizione della ROM 0000 perché è lì che la CPU si aspetta di trovare il prima istruzione.
Lo Stack Pointer (SP)
Lo Stack Pointer, come tutti i registri eccetto DPTR e PC, può contenere un valore a 8 bit (1 byte). Lo Stack Pointer indica la posizione da cui il valore successivo deve essere rimosso dallo stack. Quando un valore viene inserito nello stack, il valore di SP viene incrementato e quindi il valore viene memorizzato nella posizione di memoria risultante. Quando un valore viene estratto dallo stack, il valore viene restituito dalla posizione di memoria indicata da SP, quindi il valore di SP viene decrementato.
Questo ordine di operazione è importante. SP verrà inizializzato a 07h quando viene inizializzato l'8051. Se un valore viene inserito nello stack nello stesso momento, il valore verrà memorizzato nell'indirizzo RAM interno 08h perché l'8051 prima incrementerà il valore di SP (da 07h a 08h) e quindi memorizzerà il valore inserito in quella memoria indirizzo (08h). SP viene modificato direttamente dall'8051 da sei istruzioni: PUSH, POP, ACALL, LCALL, RET e RETI.
Spazio ROM nell'8051
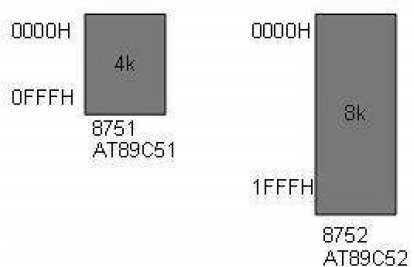
Alcuni membri della famiglia dell'8051 hanno solo 4K byte di ROM su chip (ad esempio 8751, AT8951); alcuni hanno una ROM 8K come AT89C52, e ci sono alcuni membri della famiglia con 32K byte e 64K byte di ROM su chip come Dallas Semiconductor. Il punto da ricordare è che nessun membro della famiglia 8051 può accedere a più di 64K byte di codice operativo poiché il contatore del programma nell'8051 è un registro a 16 bit (da 0000 a FFFF).
La prima posizione della ROM del programma all'interno dell'8051 ha l'indirizzo 0000H, mentre l'ultima posizione può essere diversa a seconda delle dimensioni della ROM sul chip. Tra i membri della famiglia 8051, AT8951 ha $ k byte di ROM su chip con un indirizzo di memoria da 0000 (prima posizione) a 0FFFH (ultima posizione).
8051 Flag bit e registro PSW
Il registro della parola di stato del programma (PSW) è un registro a 8 bit, noto anche come flag register. Ha una larghezza di 8 bit, ma ne viene utilizzato solo 6 bit. I due bit inutilizzati sonouser-defined flags. Vengono chiamate quattro delle bandiereconditional flags, il che significa che indicano una condizione che risulta dopo l'esecuzione di un'istruzione. Questi quattro sonoCY (Trasportare), AC (trasporto ausiliario), P (parità) e OV(overflow). I bit RS0 e RS1 vengono utilizzati per modificare i registri del banco. La figura seguente mostra il registro della parola di stato del programma.
Il registro PSW contiene quei bit di stato che riflettono lo stato corrente della CPU.
| CY | circa | F0 | RS1 | RS0 | OV | - | P |
|---|
| CY | PSW.7 | Porta bandiera |
| corrente alternata | PSW.6 | Flag di trasporto ausiliario |
| F0 | PSW.5 | Flag 0 disponibile per l'utente per scopi generali. |
| RS1 | PSW.4 | Registra il selettore del banco bit 1 |
| RS0 | PSW.3 | Registra il selettore del banco bit 0 |
| OV | PSW.2 | Bandiera di overflow |
| - | PSW.1 | BANDIERA definibile dall'utente |
| P | PSW.0 | BANDIERE DI PARITÀ. Impostato / cancellato dall'hardware durante il ciclo di istruzione per indicare il numero pari / dispari di 1 bit nell'accumulatore. |
È possibile selezionare il bit del banco di registro corrispondente utilizzando i bit RS0 e RS1.
| RS1 | RS2 | Register Bank | Indirizzo |
|---|---|---|---|
| 0 | 0 | 0 | 00H-07H |
| 0 | 1 | 1 | 08H-0FH |
| 1 | 0 | 2 | 10H-17H |
| 1 | 1 | 3 | 18H-1FH |
CY, the carry flag- Questo flag di riporto viene impostato (1) ogni volta che viene eseguita una traslazione dal bit D7. Viene influenzato dopo un'operazione di addizione o sottrazione a 8 bit. Può anche essere reimpostato su 1 o 0 direttamente da un'istruzione come "SETB C" e "CLR C" dove "SETB" sta per set bit carry e "CLR" sta per clear carry.
AC, auxiliary carry flag- Se c'è un riporto da D3 e D4 durante un'operazione ADD o SUB, viene impostato il bit AC; in caso contrario, viene cancellato. Viene utilizzato per l'istruzione per eseguire operazioni aritmetiche decimali in codice binario.
P, the parity flag- Il flag di parità rappresenta il numero di 1 solo nel registro dell'accumulatore. Se il registro A contiene un numero dispari di 1, allora P = 1; e per un numero pari di 1, P = 0.
OV, the overflow flag- Questo flag viene impostato ogni volta che il risultato di un'operazione di numero con segno è troppo grande, causando l'overflow del bit di ordine elevato nel bit di segno. Viene utilizzato solo per rilevare errori nelle operazioni aritmetiche con segno.
Esempio
Mostra lo stato dei flag CY, AC e P dopo l'aggiunta di 9CH e 64H nelle seguenti istruzioni.
MOV A, # 9CH
AGGIUNGI A, # 64H
Solution: 9C 10011100
+64 01100100
100 00000000
CY = 1 since there is a carry beyond D7 bit
AC = 0 since there is a carry from D3 to D4
P = 0 because the accumulator has even number of 1'sIl microcontrollore 8051 ha un totale di 128 byte di RAM. Discuteremo dell'allocazione di questi 128 byte di RAM ed esamineremo il loro utilizzo come stack e registro.
Allocazione dello spazio di memoria RAM nell'8051
Ai 128 byte di RAM all'interno dell'8051 viene assegnato l'indirizzo da 00 a 7FH. È possibile accedervi direttamente come posizioni di memoria e sono suddivisi in tre diversi gruppi come segue:
32 byte da 00H a 1FH sono riservati ai banchi di registri e allo stack.
16 byte da 20H a 2FH sono riservati alla memoria di lettura / scrittura indirizzabile a bit.
80 byte da 30H a 7FH vengono utilizzati per l'archiviazione in lettura e scrittura; si chiama comescratch pad. Queste 80 posizioni RAM sono ampiamente utilizzate allo scopo di memorizzare dati e parametri dai programmatori 8051.

Registrare le banche in 8051
Un totale di 32 byte di RAM sono riservati ai banchi di registri e allo stack. Questi 32 byte sono suddivisi in quattro banchi di registri in cui ogni banco ha 8 registri, R0 – R7. Le posizioni RAM da 0 a 7 sono riservate per il banco 0 di R0 – R7 dove R0 è la posizione RAM 0, R1 è la posizione RAM 1, R2 è la posizione 2 e così via, fino alla posizione di memoria 7, che appartiene a R7 del banco 0.
Il secondo banco di registri R0 – R7 inizia dalla posizione 08 della RAM e va alle posizioni OFH. Il terzo banco di R0 – R7 inizia dalla locazione di memoria 10H e va alla locazione 17H. Infine, le posizioni RAM da 18H a 1FH vengono riservate per il quarto banco di R0-R7.
Banca registro predefinita
Se le locazioni RAM 00–1F sono riservate per i quattro banchi di registri, a quale banco di registri di R0 – R7 abbiamo accesso quando l'8051 è acceso? La risposta è banca di registro 0; cioè, si accede alle posizioni RAM da 0 a 7 con i nomi da R0 a R7 durante la programmazione dell'8051. Perché è molto più semplice fare riferimento a queste posizioni RAM con nomi come R0 a R7, piuttosto che con le loro posizioni di memoria.
Come cambiare banca di registro
Il banco di registro 0 è l'impostazione predefinita quando l'8051 è acceso. Possiamo passare agli altri banchi usando il registro PSW. I bit D4 e D3 del PSW vengono utilizzati per selezionare il banco di registri desiderato, poiché sono accessibili tramite le istruzioni bit indirizzabili SETB e CLR. Ad esempio, "SETB PSW.3" imposterà PSW.3 = 1 e selezionerà il registro del banco 1.
| RS1 | RS2 | Banca selezionata |
|---|---|---|
| 0 | 0 | Bank0 |
| 0 | 1 | Bank1 |
| 1 | 0 | Bank2 |
| 1 | 1 | Bank3 |
Stack e sue operazioni
Stack nell'8051
Lo stack è una sezione di una RAM utilizzata dalla CPU per memorizzare informazioni come dati o indirizzo di memoria su base temporanea. La CPU necessita di quest'area di archiviazione considerando un numero limitato di registri.
Modalità di accesso agli stack
Poiché lo stack è una sezione di una RAM, ci sono dei registri all'interno della CPU che puntano ad essa. Il registro utilizzato per accedere allo stack è noto come registro del puntatore dello stack. Il puntatore dello stack nell'8051 è largo 8 bit e può assumere un valore compreso tra 00 e FFH. Quando l'8051 viene inizializzato, il registro SP contiene il valore 07H. Ciò significa che la posizione della RAM 08 è la prima posizione utilizzata per lo stack. L'operazione di memorizzazione di un registro della CPU nello stack è nota come filePUSHe riportare il contenuto dallo stack in un registro della CPU è chiamato a POP.
Spingendo nella pila
Nell'8051, lo stack pointer (SP) punta all'ultima posizione utilizzata dello stack. Quando i dati vengono inseriti nello stack, il puntatore dello stack (SP) viene incrementato di 1. Quando viene eseguito PUSH, il contenuto del registro viene salvato nello stack e SP viene incrementato di 1. Per inserire i registri nello stack, devono utilizzare i loro indirizzi RAM. Ad esempio, l'istruzione "PUSH 1" inserisce il registro R1 nello stack.
Saltando dalla pila
Reinserire il contenuto della pila in un dato registro è l'opposto del processo di push. Ad ogni operazione pop, il primo byte dello stack viene copiato nel registro specificato dall'istruzione e il puntatore dello stack viene decrementato una volta.
Il flusso del programma procede in modo sequenziale, da un'istruzione all'istruzione successiva, a meno che non venga eseguita un'istruzione di trasferimento del controllo. I vari tipi di istruzioni di trasferimento del controllo in linguaggio assembly includono salti condizionali o incondizionati e istruzioni di chiamata.
Istruzioni per loop e salti
Looping nell'8051
La ripetizione di una sequenza di istruzioni un certo numero di volte viene chiamata a loop. Un'istruzioneDJNZ reg, labelviene utilizzato per eseguire un'operazione di loop. In questa istruzione, un registro viene decrementato di 1; se non è zero, 8051 salta all'indirizzo di destinazione a cui fa riferimento l'etichetta.
Il registro viene caricato con il contatore del numero di ripetizioni prima dell'inizio del ciclo. In questa istruzione, sia il decremento dei registri che la decisione di saltare sono combinati in un'unica istruzione. I registri possono essere uno qualsiasi di R0 – R7. Il contatore può anche essere una posizione della RAM.
Esempio
Multiply 25 by 10 using the technique of repeated addition.
Solution- La moltiplicazione può essere ottenuta aggiungendo ripetutamente il moltiplicatore, tante volte quanto il moltiplicatore. Per esempio,
25 * 10 = 250 (FAH)
25 + 25 + 25 + 25 + 25 + 25 + 25 + 25 + 25 + 25 = 250
MOV A,#0 ;A = 0,clean ACC
MOV R2,#10 ; the multiplier is replaced in R2
Add A,#25 ;add the multiplicand to the ACC
AGAIN:DJNZ R2,
AGAIN:repeat until R2 = 0 (10 times)
MOV R5 , A ;save A in R5 ;R5 (FAH)Drawback in 8051 - Azione in loop con l'istruzione DJNZ Reg labelè limitato solo a 256 iterazioni. Se non viene eseguito un salto condizionale, viene eseguita l'istruzione successiva al salto.
Loop all'interno di un loop
Quando usiamo un ciclo all'interno di un altro ciclo, si chiama a nested loop. Vengono utilizzati due registri per contenere il conteggio quando il conteggio massimo è limitato a 256. Quindi utilizziamo questo metodo per ripetere l'azione più volte di 256.
Example
Scrivi un programma per -
- Caricare l'accumulatore con il valore 55H.
- Completa l'ACC 700 volte.
Solution- Poiché 700 è maggiore di 255 (la capacità massima di qualsiasi registro), vengono utilizzati due registri per contenere il conteggio. Il codice seguente mostra come utilizzare due registri, R2 e R3, per il conteggio.
MOV A,#55H ;A = 55H
NEXT: MOV R3,#10 ;R3 the outer loop counter
AGAIN:MOV R2,#70 ;R2 the inner loop counter
CPL A ;complementAltri salti condizionali
La tabella seguente elenca i salti condizionali usati in 8051 -
| Istruzioni | Azione |
|---|---|
| JZ | Salta se A = 0 |
| JNZ | Salta se LA ≠ 0 |
| DJNZ | Decrementa e salta se registro 0 |
| CJNE A, dati | Salta se A ≠ dati |
| CJNE reg, #data | Salta se byte ≠ dati |
| JC | Salta se CY = 1 |
| JNC | Salta se CY ≠ 1 |
| JB | Salta se bit = 1 |
| JNB | Salta se bit = 0 |
| JBC | Salta se bit = 1 e cancella bit |
JZ (jump if A = 0)- In questa istruzione viene verificato il contenuto dell'accumulatore. Se è zero, l'8051 salta all'indirizzo di destinazione. L'istruzione JZ può essere utilizzata solo per l'accumulatore, non si applica a nessun altro registro.
JNZ (jump if A is not equal to 0)- In questa istruzione, il contenuto dell'accumulatore viene verificato per essere diverso da zero. Se non è zero, l'8051 salta all'indirizzo di destinazione.
JNC (Jump if no carry, jumps if CY = 0)- Il bit di flag Carry nel registro flag (o PSW) viene utilizzato per decidere se saltare o meno l '"etichetta JNC". La CPU guarda il carry flag per vedere se è sollevato (CY = 1). Se non viene sollevato, la CPU inizia a recuperare ed eseguire istruzioni dall'indirizzo dell'etichetta. Se CY = 1, non salterà ma eseguirà l'istruzione successiva sotto JNC.
JC (Jump if carry, jumps if CY = 1) - Se CY = 1, salta all'indirizzo di destinazione.
JB (jump if bit is high)
JNB (jump if bit is low)
Note - Va notato che tutti i salti condizionali sono salti brevi, ovvero l'indirizzo del target deve essere compreso tra –128 e +127 byte del contenuto del contatore del programma.
Istruzioni di salto incondizionato
Ci sono due salti incondizionati nell'8051 -
LJMP (long jump)- LJMP è un'istruzione a 3 byte in cui il primo byte rappresenta il codice operativo e il secondo e il terzo byte rappresentano l'indirizzo a 16 bit della posizione di destinazione. L'indirizzo di destinazione a 2 byte consente di passare a qualsiasi posizione di memoria da 0000 a FFFFH.
SJMP (short jump)- È un'istruzione a 2 byte in cui il primo byte è il codice operativo e il secondo byte è l'indirizzo relativo della posizione di destinazione. L'indirizzo relativo va da 00H a FFH che è diviso in salti in avanti e indietro; cioè da –128 a +127 byte di memoria rispetto all'indirizzo del PC corrente (contatore di programma). In caso di salto in avanti, l'indirizzo di destinazione può trovarsi in uno spazio di 127 byte dal PC corrente. In caso di salto all'indietro, l'indirizzo di destinazione può trovarsi entro –128 byte dal PC corrente.
Calcolo dell'indirizzo di salto breve
Tutti i salti condizionali (JNC, JZ e DJNZ) sono salti brevi perché sono istruzioni a 2 byte. In queste istruzioni, il primo byte rappresenta il codice operativo e il secondo byte rappresenta l'indirizzo relativo. L'indirizzo di destinazione è sempre relativo al valore del contatore del programma. Per calcolare l'indirizzo di destinazione, il secondo byte viene aggiunto al PC dell'istruzione immediatamente sotto il salto. Dai un'occhiata al programma riportato di seguito -
Line PC Op-code Mnemonic Operand
1 0000 ORG 0000
2 0000 7800 MOV R0,#003
3 0002 7455 MOV A,#55H0
4 0004 6003 JZ NEXT
5 0006 08 INC R0
6 0007 04 AGAIN: INC A
7 0008 04 INC A
8 0009 2477 NEXT: ADD A, #77h
9 000B 5005 JNC OVER
10 000D E4 CLR A
11 000E F8 MOV R0, A
12 000F F9 MOV R1, A
13 0010 FA MOV R2, A
14 0011 FB MOV R3, A
15 0012 2B OVER: ADD A, R3
16 0013 50F2 JNC AGAIN
17 0015 80FE HERE: SJMP HERE
18 0017 ENDCalcolo dell'indirizzo di destinazione del salto all'indietro
In caso di salto in avanti, il valore di spostamento è un numero positivo compreso tra 0 e 127 (da 00 a 7F in esadecimale). Tuttavia, per un salto all'indietro, lo spostamento è un valore negativo compreso tra 0 e –128.
Istruzioni CALL
CALL viene utilizzato per chiamare una subroutine o un metodo. Le subroutine vengono utilizzate per eseguire operazioni o attività che devono essere eseguite frequentemente. Ciò rende un programma più strutturato e consente di risparmiare spazio di memoria. Sono disponibili due istruzioni: LCALL e ACALL.
LCALL (chiamata lunga)
LCALL è un'istruzione a 3 byte in cui il primo byte rappresenta il codice operativo e il secondo e il terzo byte vengono utilizzati per fornire l'indirizzo della subroutine di destinazione. LCALL può essere utilizzato per chiamare subroutine disponibili nello spazio degli indirizzi di 64 KB dell'8051.
Per tornare correttamente al punto dopo l'esecuzione della subroutine richiamata, la CPU salva l'indirizzo dell'istruzione immediatamente sotto LCALL nello stack. Pertanto, quando viene chiamata una subroutine, il controllo viene trasferito a quella subroutine e il processore salva il PC (contatore del programma) sullo stack e inizia a recuperare le istruzioni dalla nuova posizione. L'istruzione RET (ritorno) trasferisce nuovamente il controllo al chiamante dopo aver terminato l'esecuzione della subroutine. Ogni subroutine utilizza RET come ultima istruzione.
ACALL (chiamata assoluta)
ACALL è un'istruzione a 2 byte, a differenza di LCALL che è di 3 byte. L'indirizzo di destinazione della subroutine deve essere compreso tra 2K byte poiché per l'indirizzo vengono utilizzati solo 11 bit dei 2 byte. La differenza tra ACALL e LCALL è che l'indirizzo di destinazione per LCALL può essere ovunque all'interno dello spazio degli indirizzi di 64 KB dell'8051, mentre l'indirizzo di destinazione di CALL è compreso in un intervallo di 2 KB.
Un addressing modesi riferisce a come stai indirizzando una data posizione di memoria. Esistono cinque modi diversi o cinque modalità di indirizzamento per eseguire questa istruzione che sono le seguenti:
- Modalità di indirizzamento immediato
- Modalità di indirizzamento diretto
- Registra la modalità di indirizzamento diretto
- Registra la modalità di indirizzamento indiretto
- Modalità di indirizzamento indicizzato
Modalità di indirizzamento immediato
Cominciamo con un esempio.
MOV A, #6AHIn generale possiamo scrivere,
MOV A, #dataÈ definito come immediate perché i dati a 8 bit vengono trasferiti immediatamente all'accumulatore (operando di destinazione).
La figura seguente descrive l'istruzione di cui sopra e la sua esecuzione. Il codice operativo 74H viene salvato all'indirizzo 0202. I dati 6AH vengono salvati all'indirizzo 0203 nella memoria del programma. Dopo aver letto il codice operativo 74H, i dati al successivo indirizzo di memoria del programma vengono trasferiti all'accumulatore A (E0H è l'indirizzo dell'accumulatore). Poiché l'istruzione è di 2 byte e viene eseguita in un ciclo, il contatore del programma verrà incrementato di 2 e punterà a 0204 della memoria del programma.
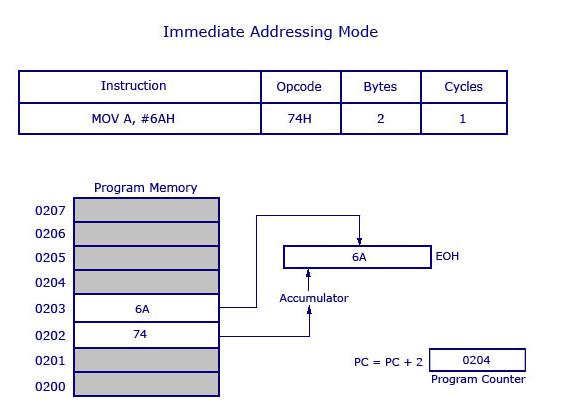
Note- Il simbolo "#" prima di 6AH indica che l'operando è un dato (8 bit). In assenza di "#", il numero esadecimale verrebbe considerato come indirizzo.
Modalità di indirizzamento diretto
Questo è un altro modo per indirizzare un operando. Qui, l'indirizzo dei dati (dati di origine) viene fornito come operando. Facciamo un esempio.
MOV A, 04HIl banco di registri # 0 (4 ° registro) ha l'indirizzo 04H. Quando viene eseguita l'istruzione MOV, i dati memorizzati nel registro 04H vengono spostati nell'accumulatore. Poiché il registro 04H contiene i dati 1FH, 1FH viene spostato nell'accumulatore.
Note- Non abbiamo usato "#" nella modalità di indirizzamento diretto, a differenza della modalità immediata. Se avessimo usato "#", il valore del dato 04H sarebbe stato trasferito all'accumulatore invece di 1FH.
Ora, dai un'occhiata alla seguente illustrazione. Mostra come viene eseguita l'istruzione.
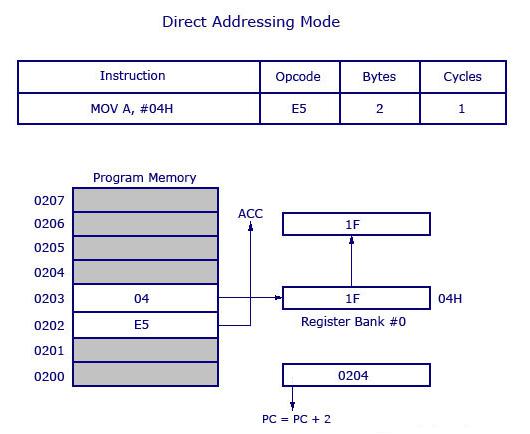
Come mostrato nell'illustrazione sopra, questa è un'istruzione a 2 byte che richiede 1 ciclo per essere completata. Il PC verrà incrementato di 2 e punterà a 0204. Il codice operativo per l'istruzione MOV A, l'indirizzo è E5H. Quando viene eseguita l'istruzione a 0202 (E5H), l'accumulatore viene reso attivo e pronto a ricevere i dati. Quindi il PC va all'indirizzo successivo come 0203 e cerca l'indirizzo della posizione di 04H in cui si trovano i dati di origine (da trasferire all'accumulatore). A 04H, il controllo trova il dato 1F e lo trasferisce all'accumulatore e quindi l'esecuzione è completata.
Registra la modalità di indirizzamento diretto
In questa modalità di indirizzamento, usiamo direttamente il nome del registro (come operando sorgente). Cerchiamo di capire con l'aiuto di un esempio.
MOV A, R4Alla volta, i registri possono assumere valori da R0 a R7. Esistono 32 di questi registri. Per utilizzare 32 registri con solo 8 variabili per indirizzare i registri, vengono utilizzati banchi di registri. Sono presenti 4 banchi di registri denominati da 0 a 3. Ciascun banco comprende 8 registri denominati da R0 a R7.
Alla volta, è possibile selezionare un singolo banco di registri. La selezione di una banca del registro è resa possibile tramite un fileSpecial Function Register (SFR) denominato Processor Status Word(PSW). PSW è un SFR a 8 bit in cui ogni bit può essere programmato secondo necessità. I bit sono designati da PSW.0 a PSW.7. PSW.3 e PSW.4 vengono utilizzati per selezionare i banchi di registri.
Ora, dai un'occhiata alla seguente illustrazione per avere una chiara comprensione di come funziona.
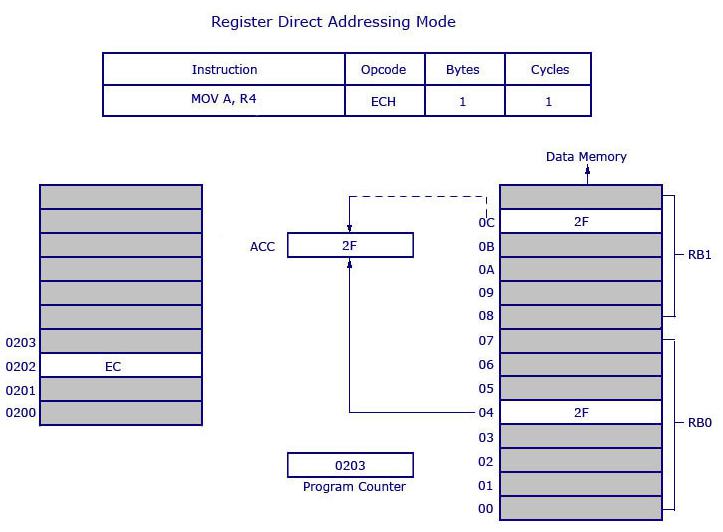
Opcode EC è utilizzato per MOV A, R4. L'opcode è memorizzato all'indirizzo 0202 e quando viene eseguito, il controllo va direttamente a R4 del banco di registri rispettato (che è selezionato in PSW). Se si seleziona il banco di registri # 0, i dati da R4 del banco di registri # 0 verranno spostati nell'accumulatore. Qui 2F è memorizzato alle 04H. 04H rappresenta l'indirizzo di R4 del banco di registri # 0.
Il movimento dei dati (2F) è evidenziato in grassetto. 2F viene trasferito all'accumulatore dalla posizione di memoria dati 0C H ed è mostrato come linea tratteggiata. 0CH è l'ubicazione dell'indirizzo del registro 4 (R4) del banco di registro n. 1. L'istruzione sopra è di 1 byte e richiede 1 ciclo per l'esecuzione completa. Ciò significa che è possibile salvare la memoria del programma utilizzando la modalità di indirizzamento diretto del registro.
Registra la modalità di indirizzamento indiretto
In questa modalità di indirizzamento, l'indirizzo dei dati viene memorizzato nel registro come operando.
MOV A, @R0Qui il valore all'interno di R0 è considerato come un indirizzo, che contiene i dati da trasferire all'accumulatore. Example: Se R0 ha il valore 20H e i dati 2FH sono memorizzati all'indirizzo 20H, il valore 2FH verrà trasferito all'accumulatore dopo aver eseguito questa istruzione. Vedere la figura seguente.
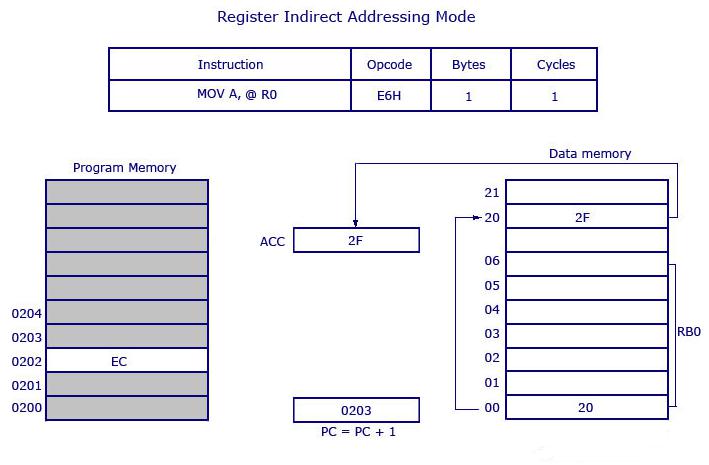
Quindi il codice operativo per MOV A, @R0è E6H. Supponendo che sia selezionato il banco di registri # 0, R0 del banco di registri # 0 contiene i dati 20H. Il controllo del programma si sposta a 20H dove individua i dati 2FH e trasferisce 2FH all'accumulatore. Questa è un'istruzione a 1 byte e il contatore del programma aumenta di 1 e si sposta a 0203 della memoria del programma.
Note- Solo R0 e R1 possono formare un'istruzione di indirizzamento indiretto del registro. In altre parole, il programmatore può creare un'istruzione utilizzando @ R0 o @ R1. Sono consentiti tutti i banchi di registro.
Modalità di indirizzamento indicizzato
Faremo due esempi per comprendere il concetto di modalità di indirizzamento indicizzato. Dai un'occhiata alle seguenti istruzioni:
MOVC A, @A+DPTR
e
MOVC A, @A+PC
dove DPTR è il puntatore di dati e PC è il contatore del programma (entrambi sono registri a 16 bit). Considera il primo esempio.
MOVC A, @A+DPTRL'operando di origine è @ A + DPTR. Contiene i dati di origine da questa posizione. Qui stiamo aggiungendo il contenuto di DPTR con il contenuto corrente dell'accumulatore. Questa aggiunta darà un nuovo indirizzo che è l'indirizzo dei dati di origine. I dati puntati da questo indirizzo vengono quindi trasferiti all'accumulatore.
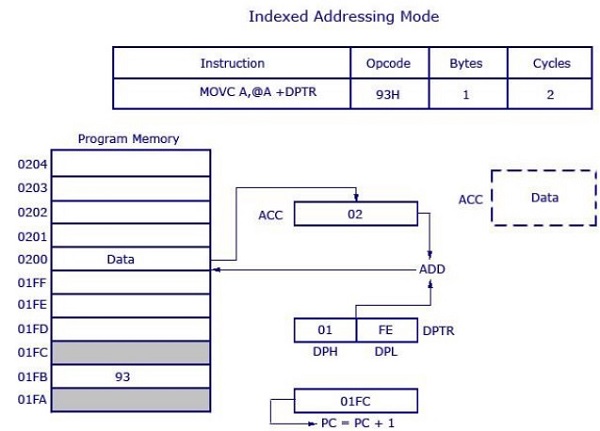
Il codice operativo è 93H. DPTR ha il valore 01FE, dove 01 si trova in DPH (8 bit superiori) e FE si trova in DPL (8 bit inferiori). L'accumulatore ha il valore 02H. Quindi viene eseguita un'aggiunta a 16 bit e 01FE H + 02H restituisce 0200 H. I dati nella posizione 0200H verranno trasferiti all'accumulatore. Il valore precedente all'interno dell'accumulatore (02H) verrà sostituito con il nuovo dato da 0200H. I nuovi dati nell'accumulatore sono evidenziati nell'illustrazione.
Questa è un'istruzione a 1 byte con 2 cicli necessari per l'esecuzione e il tempo di esecuzione richiesto per questa istruzione è elevato rispetto alle istruzioni precedenti (che erano tutte a 1 ciclo ciascuna).
L'altro esempio MOVC A, @A+PCfunziona allo stesso modo dell'esempio precedente. Invece di aggiungere DPTR con l'accumulatore, qui i dati all'interno del contatore di programma (PC) vengono aggiunti con l'accumulatore per ottenere l'indirizzo di destinazione.
Uno Special Function Register (o Special Purpose Register, o semplicemente Special Register) è un registro all'interno di un microprocessore che controlla o monitora le varie funzioni di un microprocessore. Poiché i registri speciali sono strettamente legati a qualche funzione o stato speciale del processore, potrebbero non essere direttamente scrivibili dalle normali istruzioni (come aggiungi, sposta, ecc.). Invece, alcuni registri speciali in alcune architetture di processori richiedono istruzioni speciali per modificarli.
Nell'8051, i registri A, B, DPTR e PSW fanno parte del gruppo di registri comunemente indicato come SFR (registri di funzioni speciali). È possibile accedere a un SFR tramite il suo nome o il suo indirizzo.
La tabella seguente mostra un elenco di SFR e i loro indirizzi.
| Indirizzo byte | Indirizzo bit | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| FF | |||||||||
| F0 | F7 | F6 | F5 | F4 | F3 | F2 | F1 | F0 | B |
| E0 | E7 | E6 | E5 | E4 | E3 | E2 | E1 | E0 | ACC |
| D0 | D7 | D6 | D5 | D4 | D3 | D2 | - | D0 | PSW |
| B8 | - | - | - | AVANTI CRISTO | BB | BA | B9 | B8 | IP |
| B0 | B7 | B6 | B5 | B4 | B3 | B2 | B1 | B0 | P3 |
| A2 | AF | - | - | corrente alternata | AB | aa | A9 | A8 | IE |
| A0 | A7 | A6 | A5 | A4 | A3 | A2 | A1 | A0 | P2 |
| 99 | Non bit indirizzabile | SBUF | |||||||
| 98 | 9F | 9E | 9D | 9C | 9B | 9A | 99 | 98 | SCON |
| 90 | 97 | 96 | 95 | 94 | 93 | 92 | 91 | 90 | P1 |
| 8D | Non bit indirizzabile | TH1 | |||||||
| 8C | Non bit indirizzabile | TH0 | |||||||
| 8B | Non bit indirizzabile | TL1 | |||||||
| 8A | Non bit indirizzabile | TL0 | |||||||
| 89 | Non bit indirizzabile | TMOD | |||||||
| 88 | 8F | 8E | 8D | 8C | 8B | 8A | 89 | 88 | TCON |
| 87 | Non bit indirizzabile | PCON | |||||||
| 83 | Non bit indirizzabile | DPH | |||||||
| 82 | Non bit indirizzabile | DPL | |||||||
| 81 | Non bit indirizzabile | SP | |||||||
| 80 | 87 | 87 | 85 | 84 | 83 | 82 | 81 | 80 | P0 |
Considera i seguenti due punti sugli indirizzi SFR.
Un registro di funzione speciale può avere un indirizzo compreso tra 80H e FFH. Questi indirizzi sono superiori a 80H, poiché gli indirizzi da 00 a 7FH sono gli indirizzi della memoria RAM all'interno dell'8051.
Non tutto lo spazio indirizzi da 80 a FF viene utilizzato dall'SFR. Le posizioni inutilizzate, da 80H a FFH, sono riservate e non devono essere utilizzate dal programmatore 8051.
| CY | PSW.7 | Porta bandiera |
| corrente alternata | PSW.6 | Flag di trasporto ausiliario |
| F0 | PSW.5 | Flag 0 disponibile per l'utente per scopi generali. |
| RS1 | PSW.4 | Registra il selettore del banco bit 1 |
| RS0 | PSW.3 | Registra il selettore del banco bit 0 |
| OV | PSW.2 | Bandiera di overflow |
| - | PSW.1 | BANDIERA definibile dall'utente |
| P | PSW.0 | BANDIERE DI PARITÀ. Impostato / cancellato dall'hardware durante il ciclo di istruzione per indicare il numero pari / dispari di 1 bit nell'accumulatore. |
Nell'esempio seguente, i nomi dei registri SFR vengono sostituiti con i relativi indirizzi.
| CY | corrente alternata | F0 | RS1 | RS0 | OV | - | P |
|---|
È possibile selezionare il bit del banco di registro corrispondente utilizzando i bit RS0 e RS1.
| RS1 | RS2 | Register Bank | Indirizzo |
|---|---|---|---|
| 0 | 0 | 0 | 00H-07H |
| 0 | 1 | 1 | 08H-0FH |
| 1 | 0 | 2 | 10H-17H |
| 1 | 1 | 3 | 18H-1FH |
La Program Status Word (PSW) contiene bit di stato che riflettono lo stato corrente della CPU. Le varianti 8051 forniscono un registro di funzioni speciali, PSW, con queste informazioni di stato. L'8251 fornisce due flag di stato aggiuntivi, Z e N, che sono disponibili in un secondo registro di funzioni speciali chiamato PSW1.
UN timerè un tipo specializzato di orologio che viene utilizzato per misurare gli intervalli di tempo. Un timer che conta da zero in su per misurare il tempo trascorso è spesso chiamato astopwatch. È un dispositivo che esegue il conto alla rovescia da un intervallo di tempo specificato e viene utilizzato per generare un ritardo, ad esempio una clessidra è un timer.
UN counterè un dispositivo che memorizza (e talvolta visualizza) il numero di volte in cui si è verificato un particolare evento o processo, rispetto a un segnale di clock. Viene utilizzato per contare gli eventi che si verificano all'esterno del microcontrollore. In elettronica, i contatori possono essere implementati abbastanza facilmente utilizzando circuiti di tipo registro come un flip-flop.
Differenza tra un timer e un contatore
I punti che differenziano un timer da un contatore sono i seguenti:
| Timer | Counter |
|---|---|
| Il registro viene incrementato ad ogni ciclo macchina. | Il registro viene incrementato considerando la transizione da 1 a 0 in corrispondenza di un pin di ingresso esterno (T0, T1). |
| La velocità di conteggio massima è 1/12 della frequenza dell'oscillatore. | La velocità di conteggio massima è 1/24 della frequenza dell'oscillatore. |
| Un timer utilizza la frequenza dell'orologio interno e genera un ritardo. | Un contatore utilizza un segnale esterno per contare gli impulsi. |
Timer dell'8051 e relativi registri associati
L'8051 ha due timer, Timer 0 e Timer 1. Possono essere usati come timer o come contatori di eventi. Sia il timer 0 che il timer 1 hanno una larghezza di 16 bit. Poiché l'8051 segue un'architettura a 8 bit, si accede a ogni 16 bit come due registri separati di byte basso e byte alto.
Timer 0 Registro
Si accede al registro a 16 bit del Timer 0 come byte alto e basso. Il registro di byte basso è chiamato TL0 (Timer 0 byte basso) e il registro di byte alto è chiamato TH0 (Timer 0 byte alto). È possibile accedere a questi registri come qualsiasi altro registro. Ad esempio, l'istruzioneMOV TL0, #4H sposta il valore nel byte basso del Timer # 0.
Registro timer 1
Si accede al registro a 16 bit del Timer 1 come byte alto e basso. Il registro di byte basso è chiamato TL1 (Timer 1 byte basso) e il registro di byte alto è chiamato TH1 (Timer 1 byte alto). È possibile accedere a questi registri come qualsiasi altro registro. Ad esempio, l'istruzioneMOV TL1, #4H sposta il valore nel byte basso del timer 1.
TMOD (modalità timer) Registrati
Sia il timer 0 che il timer 1 utilizzano lo stesso registro per impostare le varie modalità di funzionamento del timer. È un registro a 8 bit in cui i 4 bit inferiori sono messi da parte per il Timer 0 e i quattro bit superiori per i Timer. In ogni caso, i 2 bit inferiori vengono utilizzati per impostare in anticipo la modalità timer e i 2 bit superiori vengono utilizzati per specificare la posizione.
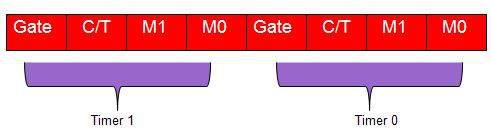
Gate - Quando è impostato, il timer funziona solo quando INT (0,1) è alto.
C/T - Bit di selezione contatore / temporizzatore.
M1 - Modalità bit 1.
M0 - Modalità bit 0.
CANCELLO
Ogni timer ha un mezzo per avviare e arrestare. Alcuni timer lo fanno tramite software, altri tramite hardware e alcuni hanno controlli sia software che hardware. I timer 8051 hanno controlli sia software che hardware. L'avvio e l'arresto di un timer sono controllati dal software utilizzando l'istruzioneSETB TR1 e CLR TR1 per il timer 1 e SETB TR0 e CLR TR0 per timer 0.
L'istruzione SETB viene utilizzata per avviarla e viene arrestata dall'istruzione CLR. Queste istruzioni avviano e arrestano i timer finché GATE = 0 nel registro TMOD. I timer possono essere avviati e arrestati da una sorgente esterna impostando GATE = 1 nel registro TMOD.
C / T (OROLOGIO / TIMER)
Questo bit nel registro TMOD viene utilizzato per decidere se un timer viene utilizzato come file delay generator o un event manager. Se C / T = 0, viene utilizzato come timer per la generazione del ritardo del timer. La sorgente del clock per creare il ritardo è la frequenza del cristallo dell'8051. Se C / T = 0, la frequenza del cristallo collegata all'8051 decide anche la velocità alla quale il timer dell'8051 scatta a intervalli regolari.
La frequenza del timer è sempre 1/12 della frequenza del cristallo collegato all'8051. Sebbene vari sistemi basati sull'8051 abbiano una frequenza XTAL da 10 MHz a 40 MHz, normalmente lavoriamo con la frequenza XTAL di 11.0592 MHz. Questo perché il baud rate per la comunicazione seriale dell'8051.XTAL = 11.0592 consente al sistema 8051 di comunicare con il PC senza errori.
M1 / M2
| M1 | M2 | Modalità |
|---|---|---|
| 0 | 0 | Modalità timer a 13 bit. |
| 0 | 1 | Modalità timer a 16 bit. |
| 1 | 0 | Modalità di ricarica automatica a 8 bit. |
| 1 | 1 | Modalità versato. |
Diverse modalità di timer
Modalità 0 (modalità timer a 13 bit)
Sia il timer 1 che il timer 0 in modalità 0 funzionano come contatori a 8 bit (con un prescaler di divisione per 32). Il registro del timer è configurato come un registro a 13 bit composto da tutti gli 8 bit di TH1 e dai 5 bit inferiori di TL1. I 3 bit superiori di TL1 sono indeterminati e devono essere ignorati. L'impostazione del flag di esecuzione (TR1) non cancella il registro. Il flag di interruzione del timer TF1 viene impostato quando il conteggio passa da tutti gli 1 a tutti gli 0. Il funzionamento della modalità 0 è lo stesso per il timer 0 come per il timer 1.
Modalità 1 (modalità timer a 16 bit)
La modalità timer "1" è un timer a 16 bit ed è una modalità comunemente utilizzata. Funziona allo stesso modo della modalità a 13 bit, tranne per il fatto che vengono utilizzati tutti i 16 bit. TLx viene incrementato da 0 a un massimo di 255. Una volta raggiunto il valore 255, TLx si reimposta a 0 e quindi THx viene incrementato di 1. Essendo un timer completo a 16 bit, il timer può contenere fino a 65536 valori distinti e tornerà a 0 dopo 65.536 cicli macchina.
Modalità 2 (ricarica automatica a 8 bit)
Entrambi i registri del timer sono configurati come contatori a 8 bit (TL1 e TL0) con ricaricamento automatico. Overflow da TL1 (TL0) imposta TF1 (TF0) e ricarica TL1 (TL0) con il contenuto di Th1 (TH0), preimpostato dal software. La ricarica lascia TH1 (TH0) invariato.
Il vantaggio della modalità di ricarica automatica è che puoi fare in modo che il timer contenga sempre un valore compreso tra 200 e 255. Se usi la modalità 0 o 1, dovresti controllare il codice per vedere l'overflow e, in tal caso, riportare il timer a 200. In questo caso preziose istruzioni controllano il valore e / o si ricaricano. Nella modalità 2, il microcontrollore si occupa di questo. Dopo aver configurato un timer in modalità 2, non devi preoccuparti di controllare se il timer è andato in overflow, né devi preoccuparti di ripristinare il valore perché l'hardware del microcontrollore farà tutto per te. La modalità di ricaricamento automatico viene utilizzata per stabilire una velocità di trasmissione comune.
Modalità 3 (modalità timer parziale)
La modalità timer "3" è nota come split-timer mode. Quando il timer 0 è impostato in modalità 3, diventano due timer separati a 8 bit. Il timer 0 è TL0 e il timer 1 è TH0. Entrambi i timer contano da 0 a 255 e, in caso di overflow, vengono ripristinati a 0. Tutti i bit che sono del Timer 1 saranno ora legati a TH0.
Quando il Timer 0 è in modalità split, il Timer 1 reale (cioè TH1 e TL1) può essere impostato nelle modalità 0, 1 o 2, ma non può essere avviato / arrestato poiché i bit che lo fanno sono ora collegati a TH0. Il timer reale 1 verrà incrementato ad ogni ciclo macchina.
Inizializzazione di un timer
Decidi la modalità timer. Considera un timer a 16 bit che funziona continuamente ed è indipendente da qualsiasi pin esterno.
Inizializza TMOD SFR. Usa i 4 bit più bassi di TMOD e considera il Timer 0. Mantieni i due bit, GATE 0 e C / T 0, come 0, poiché vogliamo che il timer sia indipendente dai pin esterni. Poiché la modalità a 16 bit è la modalità timer 1, cancellare T0M1 e impostare T0M0. In effetti, l'unico bit da attivare è il bit 0 di TMOD. Ora esegui la seguente istruzione:
MOV TMOD,#01hOra, il timer 0 è in modalità timer a 16 bit, ma il timer non è in esecuzione. Per avviare il timer in modalità di esecuzione, impostare il bit TR0 eseguendo la seguente istruzione:
SETB TR0Ora, il timer 0 inizierà immediatamente il conteggio, incrementato una volta ad ogni ciclo della macchina.
Leggere un timer
Un timer a 16 bit può essere letto in due modi. O leggi il valore effettivo del timer come un numero a 16 bit o rilevi quando il timer è in overflow.
Rilevamento overflow del timer
Quando un timer supera il valore più alto a 0, il microcontrollore imposta automaticamente il bit TFx nel registro TCON. Quindi, invece di controllare il valore esatto del timer, è possibile controllare il bit TFx. Se TF0 è impostato, il timer 0 è andato in overflow; se TF1 è impostato, il timer 1 è andato in overflow.
Un interrupt è un segnale al processore emesso dall'hardware o dal software che indica un evento che richiede attenzione immediata. Ogni volta che si verifica un interrupt, il controller completa l'esecuzione dell'istruzione corrente e avvia l'esecuzione di un fileInterrupt Service Routine (ISR) o Interrupt Handler. ISR dice al processore o al controller cosa fare quando si verifica l'interruzione. Gli interrupt possono essere interrupt hardware o interrupt software.
Interruzione hardware
Un interrupt hardware è un segnale di avviso elettronico inviato al processore da un dispositivo esterno, come un controller del disco o una periferica esterna. Ad esempio, quando si preme un tasto sulla tastiera o si sposta il mouse, vengono attivati interrupt hardware che fanno sì che il processore legga la sequenza di tasti o la posizione del mouse.
Interruzione software
Un interrupt software è causato da una condizione eccezionale o da un'istruzione speciale nel set di istruzioni che causa un interrupt quando viene eseguito dal processore. Ad esempio, se l'unità logica aritmetica del processore esegue un comando per dividere un numero per zero, per causare un'eccezione di divisione per zero, facendo sì che il computer abbandoni il calcolo o visualizzi un messaggio di errore. Le istruzioni di interrupt software funzionano in modo simile alle chiamate di subroutine.
Cos'è il polling?
Lo stato del monitoraggio continuo è noto come polling. Il microcontrollore continua a controllare lo stato di altri dispositivi; e mentre lo fa, non esegue altre operazioni e consuma tutto il tempo di elaborazione per il monitoraggio. Questo problema può essere risolto utilizzando gli interrupt.
Nel metodo di interruzione, il controller risponde solo quando si verifica un'interruzione. Pertanto, il controller non è tenuto a monitorare regolarmente lo stato (flag, segnali, ecc.) Dei dispositivi interfacciati e integrati.
Interrompe il polling di v / s
Ecco un'analogia che differenzia un'interruzione dal polling:
| Interrompere | Polling |
|---|---|
| Un'interruzione è come un file shopkeeper. Se uno ha bisogno di un servizio o di un prodotto, va da lui e lo informa delle sue esigenze. In caso di interruzioni, quando vengono ricevuti i flag oi segnali, notificano al controller che devono essere riparati. | Il metodo di polling è come un file salesperson. Il venditore va di porta in porta mentre richiede l'acquisto di un prodotto o servizio. Allo stesso modo, il controller continua a monitorare i flag o i segnali uno per uno per tutti i dispositivi e fornisce il servizio a qualsiasi componente che necessita del suo servizio. |
Routine di servizio di interruzione
Per ogni interrupt, deve esserci una routine di servizio di interrupt (ISR), o interrupt handler. Quando si verifica un interrupt, il microcontrollore esegue la routine del servizio di interrupt. Per ogni interruzione, c'è una posizione fissa in memoria che contiene l'indirizzo della sua routine di servizio di interruzione, ISR. La tabella delle posizioni di memoria accantonata per contenere gli indirizzi degli ISR è chiamata Tabella dei vettori di interrupt.
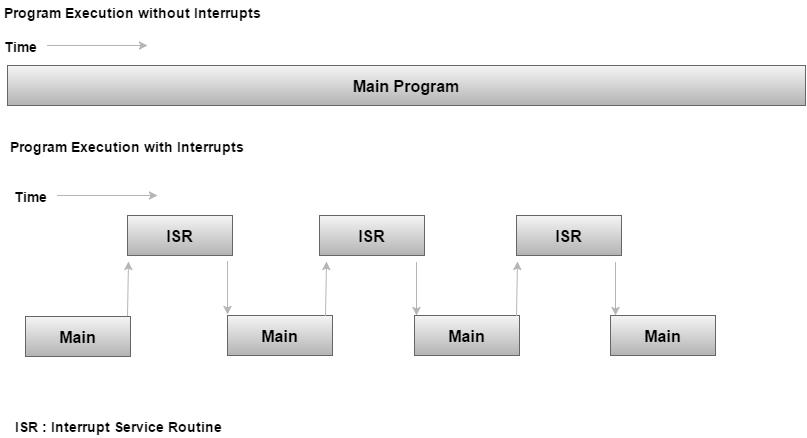
Tabella vettoriale di interruzione
Ci sono sei interrupt incluso RESET nell'8051.
| Interrompe | Posizione ROM (esadecimale) | Pin |
|---|---|---|
| Interrompe | Posizione ROM (HEX) | |
| Seriale COM (RI e TI) | 0023 | |
| Timer 1 interrompe (TF1) | 001B | |
| Interrupt HW esterno 1 (INT1) | 0013 | P3.3 (13) |
| Interrupt HW esterno 0 (INT0) | 0003 | P3.2 (12) |
| Timer 0 (TF0) | 000B | |
| Ripristina | 0000 | 9 |
Quando il pin di ripristino è attivato, l'8051 salta alla posizione dell'indirizzo 0000. Questo è il ripristino all'accensione.
Due interrupt sono riservati ai temporizzatori: uno per il temporizzatore 0 e uno per il temporizzatore 1. Le posizioni di memoria sono rispettivamente 000BH e 001BH nella tabella vettoriale degli interrupt.
Due interrupt sono riservati agli interrupt hardware esterni. Pin n. 12 e Pin n. 13 nella porta 3 sono rispettivamente per gli interrupt di processo esterni INT0 e INT1. Le posizioni di memoria sono rispettivamente 0003H e 0013H nella tabella del vettore di interrupt.
La comunicazione seriale ha un singolo interrupt che appartiene sia alla ricezione che alla trasmissione. La posizione di memoria 0023H appartiene a questo interrupt.
Passaggi per eseguire un interrupt
Quando un interrupt si attiva, il microcontrollore esegue i seguenti passaggi:
Il microcontrollore chiude l'istruzione attualmente in esecuzione e salva l'indirizzo dell'istruzione successiva (PC) sullo stack.
Inoltre salva internamente lo stato corrente di tutti gli interrupt (cioè, non nello stack).
Salta alla posizione di memoria della tabella vettoriale di interrupt che contiene l'indirizzo della routine di servizio degli interrupt.
Il microcontrollore ottiene l'indirizzo dell'ISR dalla tabella dei vettori di interrupt e vi salta. Inizia ad eseguire la subroutine del servizio di interruzione, che è RETI (ritorno dall'interruzione).
Dopo aver eseguito l'istruzione RETI, il microcontrollore ritorna nella posizione in cui era stato interrotto. Innanzitutto, ottiene l'indirizzo del contatore del programma (PC) dallo stack inserendo i primi byte dello stack nel PC. Quindi, inizia l'esecuzione da quell'indirizzo.
Edge Triggering vs Level Triggering
I moduli di interrupt sono di due tipi: trigger a livello o trigger su fronte.
| Livello attivato | Edge Triggered |
|---|---|
| Un modulo di interrupt attivato dal livello genera sempre un interrupt ogni volta che viene affermato il livello della sorgente di interrupt. | Un modulo di interrupt attivato dal fronte genera un interrupt solo quando rileva un fronte di asserzione della sorgente dell'interrupt. Il limite viene rilevato quando il livello della sorgente di interrupt cambia effettivamente. Può anche essere rilevato mediante campionamento periodico e rilevando un livello affermato quando il campione precedente è stato de-affermato. |
| Se l'origine dell'interrupt è ancora asserita quando il gestore di interrupt del firmware gestisce l'interrupt, il modulo di interrupt rigenererà l'interrupt, provocando il richiamo del gestore di interrupt. | I moduli di interrupt attivati dal fronte possono essere attivati immediatamente, indipendentemente dal comportamento della sorgente di interrupt. |
| Gli interrupt attivati dal livello sono ingombranti per il firmware. | Gli interrupt edge-trigger mantengono bassa la complessità del codice del firmware, riducono il numero di condizioni per il firmware e forniscono maggiore flessibilità quando gli interrupt vengono gestiti. |
Abilitazione e disabilitazione di un interrupt
Al ripristino, tutti gli interrupt vengono disabilitati anche se attivati. Gli interrupt devono essere abilitati utilizzando il software affinché il microcontrollore risponda a tali interrupt.
Il registro IE (interrupt enable) è responsabile dell'abilitazione e della disabilitazione dell'interrupt. IE è un registro indirizzabile a bit.
Interrupt Enable Register
| EA | - | ET2 | ES | ET1 | EX1 | ET0 | EX0 |
|---|
EA - Abilitazione / disabilitazione globale.
- - Indefinito.
ET2 - Abilitare l'interruzione del timer 2.
ES - Abilita l'interrupt della porta seriale.
ET1 - Abilita interrupt Timer 1.
EX1 - Abilita interrupt esterno 1.
ET0 - Abilita interrupt Timer 0.
EX0 - Abilita interrupt esterno 0.
Per abilitare un interrupt, eseguiamo i seguenti passaggi:
Il bit D7 del registro IE (EA) deve essere alto affinché il resto del registro abbia effetto.
Se EA = 1, gli interrupt verranno abilitati e riceveranno risposta se i bit corrispondenti in IE sono alti. Se EA = 0, nessun interrupt risponderà, anche se i pin associati nel registro IE sono alti.
Priorità interrupt in 8051
Possiamo modificare la priorità degli interrupt assegnando la priorità più alta a uno qualsiasi degli interrupt. Ciò si ottiene programmando un registro chiamatoIP (priorità di interruzione).
La figura seguente mostra i bit del registro IP. Dopo il ripristino, il registro IP contiene tutti gli 0. Per dare una priorità maggiore a qualsiasi interrupt, rendiamo alto il bit corrispondente nel registro IP.
| - | - | - | - | PT1 | PX1 | PT0 | PX0 |
|---|
| - | IP.7 | Non implementato. |
| - | IP.6 | Non implementato. |
| - | IP.5 | Non implementato. |
| - | IP.4 | Non implementato. |
| PT1 | IP.3 | Definisce il livello di priorità dell'interrupt del timer 1. |
| PX1 | IP.2 | Definisce il livello di priorità dell'interrupt esterno 1. |
| PT0 | IP.1 | Definisce il livello di priorità dell'interrupt del timer 0. |
| PX0 | IP.0 | Definisce il livello di priorità dell'interrupt esterno 0. |
Interrompi all'interno di Interrupt
Cosa succede se l'8051 sta eseguendo un ISR che appartiene a un interrupt e un altro si attiva? In questi casi, un interrupt ad alta priorità può interrompere un interrupt a bassa priorità. Questo è noto comeinterrupt inside interrupt. In 8051, un interrupt a bassa priorità può essere interrotto da un interrupt ad alta priorità, ma non da un altro interrupt a bassa priorità.
Attivazione di un interrupt dal software
Ci sono momenti in cui dobbiamo testare un ISR tramite simulazione. Questo può essere fatto con le semplici istruzioni per impostare l'interrupt alto e quindi far saltare l'8051 alla tabella dei vettori degli interrupt. Ad esempio, impostare il bit IE come 1 per il timer 1. Un'istruzioneSETB TF1 interromperà l'8051 in qualunque cosa stia facendo e lo costringerà a saltare alla tabella dei vettori di interruzione.