KNIME - Esplorazione del flusso di lavoro
Se controlli i nodi nel flusso di lavoro, puoi vedere che contiene quanto segue:
Lettore di file,
Color Manager
Partitioning
Studente dell'albero decisionale
Predittore dell'albero decisionale
Score
Tavolo interattivo
Grafico a dispersione
Statistics
Questi sono facilmente visibili in Outline visualizza come mostrato qui -

Ogni nodo fornisce una funzionalità specifica nel flusso di lavoro. Vedremo ora come configurare questi nodi per soddisfare la funzionalità desiderata. Tieni presente che discuteremo solo di quei nodi che sono rilevanti per noi nel contesto corrente di esplorazione del flusso di lavoro.
Lettore di file
Il nodo del lettore di file è illustrato nella schermata seguente:

C'è una descrizione nella parte superiore della finestra fornita dal creatore del flusso di lavoro. Indica che questo nodo legge il set di dati per adulti. Il nome del file èadult.csvcome si vede dalla descrizione sotto il simbolo del nodo. IlFile Reader ha due uscite: una va a Color Manager nodo e l'altro va a Statistics nodo.
Se fai clic con il pulsante destro del mouse sul file File Manager, verrà visualizzato un menu popup come segue:

Il Configurel'opzione di menu consente la configurazione del nodo. IlExecutemenu esegue il nodo. Notare che se il nodo è già stato eseguito e se è in uno stato verde, questo menu è disabilitato. Inoltre, notare la presenza diEdit Note Descriptionopzione di menu. Ciò ti consente di scrivere la descrizione per il tuo nodo.
Ora seleziona il file Configure opzione di menu, mostra la schermata contenente i dati dal file adult.csv come si vede nello screenshot qui -

Quando esegui questo nodo, i dati verranno caricati nella memoria. L'intero codice del programma di caricamento dati è nascosto all'utente. Ora puoi apprezzare l'utilità di tali nodi: non è richiesta alcuna codifica.
Il nostro prossimo nodo è il Color Manager.
Color Manager
Seleziona il Color Managernodo e vai nella sua configurazione facendo clic destro su di esso. Apparirà una finestra di dialogo per le impostazioni dei colori. Seleziona ilincome colonna dall'elenco a discesa.
Il tuo schermo sarebbe simile al seguente:

Notare la presenza di due vincoli. Se il reddito è inferiore a 50K, il datapoint acquisirà il colore verde e se è maggiore assumerà il colore rosso. Vedrai le mappature dei punti dati quando guarderemo il grafico a dispersione più avanti in questo capitolo.
Partizionamento
Nell'apprendimento automatico, di solito dividiamo tutti i dati disponibili in due parti. La parte più grande viene utilizzata nell'addestramento del modello, mentre la parte più piccola viene utilizzata per il test. Esistono diverse strategie utilizzate per partizionare i dati.
Per definire il partizionamento desiderato, fare clic con il tasto destro del mouse sul file Partitioning e seleziona il file Configureopzione. Vedrai la seguente schermata:

Nel caso, il modellatore di sistema ha utilizzato l'estensione Relativemodalità (%) e i dati vengono suddivisi in un rapporto 80:20. Durante la divisione, i punti dati vengono raccolti in modo casuale. Ciò garantisce che i dati del test non siano distorti. In caso di campionamento lineare, il restante 20% dei dati utilizzati per il test potrebbe non rappresentare correttamente i dati di addestramento in quanto potrebbero essere totalmente distorti durante la raccolta.
Se sei sicuro che durante la raccolta dei dati la casualità sia garantita, puoi selezionare il campionamento lineare. Una volta che i dati sono pronti per l'addestramento del modello, inseriscili nel nodo successivo, che è il fileDecision Tree Learner.
Studente dell'albero decisionale
Il Decision Tree Learnercome suggerisce il nome, il nodo utilizza i dati di addestramento e crea un modello. Controlla l'impostazione di configurazione di questo nodo, che è raffigurata nello screenshot qui sotto -

Come vedi il file Class è income. Quindi l'albero verrebbe costruito in base alla colonna del reddito e questo è ciò che stiamo cercando di ottenere in questo modello. Vogliamo una separazione delle persone che hanno un reddito maggiore o minore di 50K.
Dopo che questo nodo è stato eseguito correttamente, il tuo modello sarà pronto per il test.
Predittore dell'albero decisionale
Il nodo Decision Tree Predictor applica il modello sviluppato al set di dati di test e allega le previsioni del modello.

L'output del predittore viene inviato a due diversi nodi: Scorer e Scatter Plot. Successivamente, esamineremo l'output della previsione.
Marcatore
Questo nodo genera il file confusion matrix. Per visualizzarlo, fare clic con il tasto destro sul nodo. Vedrai il seguente menu a comparsa:

Clicca il View: Confusion Matrix opzione di menu e la matrice apparirà in una finestra separata come mostrato nello screenshot qui -
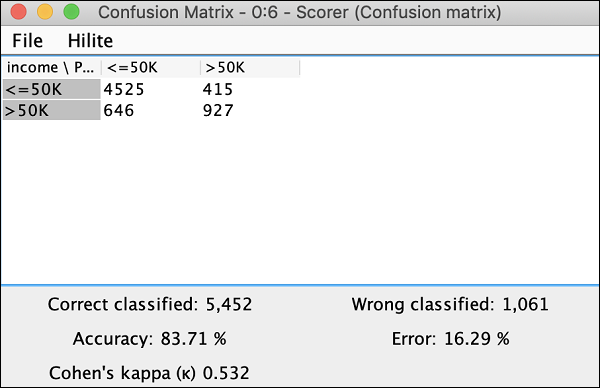
Indica che la precisione del nostro modello sviluppato è dell'83,71%. Se non sei soddisfatto di questo, puoi giocare con altri parametri nella costruzione del modello, in particolare, potresti voler rivedere e pulire i tuoi dati.
Grafico a dispersione
Per vedere il grafico a dispersione della distribuzione dei dati, fare clic con il pulsante destro del mouse su Scatter Plot nodo e selezionare l'opzione di menu Interactive View: Scatter Plot. Vedrai la seguente trama:

Il grafico fornisce la distribuzione di persone con gruppi di reddito diversi in base alla soglia di 50.000 in due punti colorati diversi: rosso e blu. Questi erano i colori fissati nel nostroColor Managernodo. La distribuzione è relativa all'età come tracciata sull'asse x. È possibile selezionare una caratteristica diversa per l'asse x modificando la configurazione del nodo.
La finestra di dialogo di configurazione è mostrata qui dove abbiamo selezionato il file marital-status come caratteristica per l'asse x.
Questo completa la nostra discussione sul modello predefinito fornito da KNIME. Ti suggeriamo di riprendere gli altri due nodi (Statistiche e Tabella interattiva) nel modello per il tuo studio personale.
Passiamo ora alla parte più importante del tutorial: creare il tuo modello.