KNIME - Guida rapida
Lo sviluppo di modelli di Machine Learning è sempre considerato molto impegnativo a causa della sua natura criptica. In generale, per sviluppare applicazioni di machine learning, devi essere un buon sviluppatore con esperienza nello sviluppo basato sui comandi. L'introduzione di KNIME ha portato lo sviluppo di modelli di Machine Learning nella sfera di un uomo comune.
KNIME fornisce un'interfaccia grafica (una GUI user friendly) per l'intero sviluppo. In KNIME, devi semplicemente definire il flusso di lavoro tra i vari nodi predefiniti forniti nel suo repository. KNIME fornisce diversi componenti predefiniti chiamati nodi per varie attività come la lettura dei dati, l'applicazione di vari algoritmi ML e la visualizzazione dei dati in vari formati. Pertanto, per lavorare con KNIME, non è richiesta alcuna conoscenza di programmazione. Non è eccitante?
I prossimi capitoli di questo tutorial ti insegneranno come padroneggiare l'analisi dei dati utilizzando diversi algoritmi ML ben testati.
La piattaforma KNIME Analytics è disponibile per Windows, Linux e MacOS. In questo capitolo, esaminiamo i passaggi per l'installazione della piattaforma su Mac. Se usi Windows o Linux, segui le istruzioni di installazione fornite nella pagina di download di KNIME. L'installazione binaria per tutte e tre le piattaforme è disponibile sulla pagina di KNIME .
Installazione su Mac
Scarica l'installazione binaria dal sito ufficiale di KNIME. Fare doppio clic sul file scaricatodmgfile per avviare l'installazione. Al termine dell'installazione, trascina l'icona di KNIME nella cartella Applicazioni come mostrato qui -


Fare doppio clic sull'icona KNIME per avviare la piattaforma di analisi KNIME. Inizialmente, ti verrà chiesto di impostare una cartella dell'area di lavoro per salvare il tuo lavoro. Il tuo schermo avrà il seguente aspetto:
Puoi impostare la cartella selezionata come predefinita e la prossima volta che avvii KNIME, non lo farà

mostra di nuovo questa finestra di dialogo.
Dopo un po ', la piattaforma KNIME verrà avviata sul desktop. Questo è il banco di lavoro in cui porteresti il tuo lavoro di analisi. Vediamo ora le varie porzioni del banco da lavoro.
Quando KNIME si avvia, vedrai la seguente schermata:

Come è stato evidenziato nello screenshot, il workbench è composto da diverse viste. Le visualizzazioni che ci vengono immediatamente utilizzate sono contrassegnate nello screenshot ed elencate di seguito:
Workspace
Outline
Repository dei nodi
KNIME Explorer
Console
Description
Man mano che procediamo in questo capitolo, impariamo questi punti di vista ciascuno in dettaglio.
Visualizzazione area di lavoro
La vista più importante per noi è il WorkspaceVisualizza. Qui è dove creeresti il tuo modello di machine learning. La visualizzazione dell'area di lavoro è evidenziata nello screenshot qui sotto:

Lo screenshot mostra un'area di lavoro aperta. Imparerai presto come aprire un'area di lavoro esistente.
Ogni area di lavoro contiene uno o più nodi. Imparerai il significato di questi nodi più avanti nel tutorial. I nodi sono collegati tramite frecce. Generalmente, il flusso del programma è definito da sinistra a destra, sebbene non sia necessario. Puoi spostare liberamente ogni nodo ovunque nell'area di lavoro. Le linee di collegamento tra i due si sposterebbero in modo appropriato per mantenere la connessione tra i nodi. Puoi aggiungere / rimuovere connessioni tra i nodi in qualsiasi momento. Per ogni nodo può essere opzionalmente aggiunta una piccola descrizione.
Vista struttura
La visualizzazione dell'area di lavoro potrebbe non essere in grado di mostrarti l'intero flusso di lavoro alla volta. Questo è il motivo per cui viene fornita la vista struttura.

La vista struttura mostra una vista in miniatura dell'intero spazio di lavoro. All'interno di questa visualizzazione è presente una finestra di zoom che è possibile scorrere per visualizzare le diverse parti del flusso di lavoro nel fileWorkspace Visualizza.
Repository dei nodi
Questa è la prossima visualizzazione importante nel workbench. Il repository Node elenca i vari nodi disponibili per le tue analisi. L'intero repository è ben classificato in base alle funzioni del nodo. Troverai categorie come:
IO
Views
Analytics

Sotto ogni categoria troverai diverse opzioni. Espandi semplicemente la visualizzazione di ciascuna categoria per vedere cosa hai lì. Sotto ilIO categoria, troverai i nodi per leggere i tuoi dati in vari formati di file, come ARFF, CSV, PMML, XLS, ecc.

A seconda del formato dei dati della sorgente di input, selezionerai il nodo appropriato per leggere il set di dati.
A questo punto, probabilmente hai capito lo scopo di un nodo. Un nodo definisce un certo tipo di funzionalità che puoi includere visivamente nel tuo flusso di lavoro.
Il nodo Analytics definisce i vari algoritmi di machine learning, come Bayes, Clustering, Decision Tree, Ensemble Learning e così via.

L'implementazione di questi vari algoritmi ML è fornita in questi nodi. Per applicare qualsiasi algoritmo nella tua analisi, prendi semplicemente il nodo desiderato dal repository e aggiungilo al tuo spazio di lavoro. Collega l'output del nodo del lettore di dati all'input di questo nodo ML e il tuo flusso di lavoro viene creato.
Ti suggeriamo di esplorare i vari nodi disponibili nel repository.
KNIME Explorer
La prossima vista importante nel workbench è Explorer visualizzare come mostrato nello screenshot qui sotto -

Le prime due categorie elencano gli spazi di lavoro definiti sul server KNIME. La terza opzione LOCALE viene utilizzata per archiviare tutti gli spazi di lavoro creati sulla macchina locale. Prova ad espandere queste schede per vedere i vari spazi di lavoro predefiniti. In particolare, espandere la scheda ESEMPI.
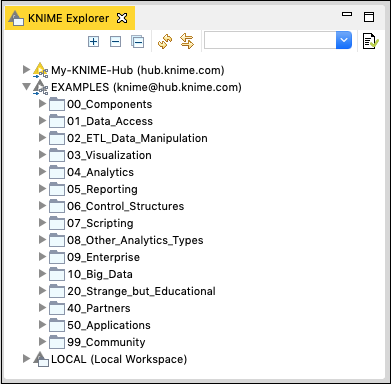
KNIME fornisce diversi esempi per iniziare con la piattaforma. Nel prossimo capitolo utilizzerai uno di questi esempi per familiarizzare con la piattaforma.
Vista console
Come indica il nome, il file Console view fornisce una visualizzazione dei vari messaggi della console durante l'esecuzione del flusso di lavoro.

Il Console view è utile per diagnosticare il flusso di lavoro e esaminare i risultati dell'analisi.
Visualizzazione descrizione
L'ultima visione importante che è di immediata rilevanza per noi è il DescriptionVisualizza. Questa visualizzazione fornisce una descrizione di un elemento selezionato nell'area di lavoro. Una vista tipica è mostrata nello screenshot qui sotto:

La vista sopra mostra la descrizione di un file File Readernodo. Quando selezioni il fileFile Readernodo nel tuo spazio di lavoro, vedrai la sua descrizione in questa vista. Facendo clic su qualsiasi altro nodo viene visualizzata la descrizione del nodo selezionato. Pertanto, questa visualizzazione diventa molto utile nelle fasi iniziali dell'apprendimento quando non si conosce con precisione lo scopo dei vari nodi nell'area di lavoro e / o nel repository dei nodi.
Barra degli strumenti
Oltre alle viste sopra descritte, il workbench ha altre viste come la barra degli strumenti. La barra degli strumenti contiene varie icone che facilitano un'azione rapida. Le icone sono abilitate / disabilitate a seconda del contesto. Puoi vedere l'azione che ogni icona esegue passando il mouse su di essa. La schermata seguente mostra l'azione eseguita daConfigure icona.

Abilitazione / disabilitazione delle visualizzazioni
Le varie visualizzazioni che hai visto finora possono essere attivate / disattivate facilmente. Fare clic sull'icona Chiudi nella visualizzazioneclosela vista. Per ripristinare la visualizzazione, vai aViewopzione di menu e selezionare la vista desiderata. La vista selezionata verrà aggiunta al workbench.

Ora, poiché hai familiarizzato con il workbench, ti mostrerò come eseguire un flusso di lavoro e studiare le analisi eseguite da esso.
KNIME ha fornito diversi buoni flussi di lavoro per facilitare l'apprendimento. In questo capitolo, prenderemo in esame uno dei flussi di lavoro forniti nell'installazione per spiegare le varie funzionalità e la potenza della piattaforma di analisi. Useremo un semplice classificatore basato su un fileDecision Tree per il nostro studio.
Caricamento del classificatore dell'albero decisionale
In KNIME Explorer individua il seguente flusso di lavoro:
LOCAL / Example Workflows / Basic Examples / Building a Simple ClassifierQuesto è mostrato anche nello screenshot qui sotto come riferimento rapido -

Fare doppio clic sull'elemento selezionato per aprire il flusso di lavoro. Osserva la visualizzazione Area di lavoro. Vedrai il flusso di lavoro contenente diversi nodi. Lo scopo di questo flusso di lavoro è prevedere il gruppo di reddito dagli attributi democratici del set di dati per adulti presi da UCI Machine Learning Repository. Il compito di questo modello ML è classificare le persone in una regione specifica come aventi un reddito maggiore o minore di 50.000.
Il Workspace vista insieme al suo contorno è mostrato nello screenshot qui sotto -

Notare la presenza di diversi nodi raccolti dal file Nodesrepository e collegato in un flusso di lavoro tramite frecce. La connessione indica che l'output di un nodo viene fornito all'ingresso del nodo successivo. Prima di apprendere la funzionalità di ciascuno dei nodi nel flusso di lavoro, eseguiamo prima l'intero flusso di lavoro.
Flusso di lavoro in esecuzione
Prima di esaminare l'esecuzione del flusso di lavoro, è importante comprendere il rapporto sullo stato di ciascun nodo. Esamina qualsiasi nodo nel flusso di lavoro. Nella parte inferiore di ogni nodo troverai un indicatore di stato contenente tre cerchi. Il nodo Decision Tree Learner è mostrato nella schermata seguente:

L'indicatore di stato è rosso a indicare che questo nodo non è stato eseguito finora. Durante l'esecuzione, si accende il cerchio centrale di colore giallo. In caso di esecuzione riuscita, l'ultimo cerchio diventa verde. Ci sono più indicatori per darti le informazioni sullo stato in caso di errori. Li imparerai quando si verifica un errore durante l'elaborazione.
Si noti che attualmente gli indicatori su tutti i nodi sono rossi a indicare che nessun nodo è stato eseguito finora. Per eseguire tutti i nodi, fare clic sulla seguente voce di menu:
Node → Execute All
Dopo un po ', scoprirai che ogni indicatore di stato del nodo è diventato verde, indicando che non ci sono errori.
Nel prossimo capitolo esploreremo le funzionalità dei vari nodi del flusso di lavoro.
Se controlli i nodi nel flusso di lavoro, puoi vedere che contiene quanto segue:
Lettore di file,
Color Manager
Partitioning
Studente dell'albero decisionale
Predittore dell'albero decisionale
Score
Tavolo interattivo
Grafico a dispersione
Statistics
Questi sono facilmente visibili in Outline visualizza come mostrato qui -

Ogni nodo fornisce una funzionalità specifica nel flusso di lavoro. Vedremo ora come configurare questi nodi per soddisfare la funzionalità desiderata. Tieni presente che discuteremo solo di quei nodi che sono rilevanti per noi nel contesto corrente di esplorazione del flusso di lavoro.
Lettore di file
Il nodo del lettore di file è illustrato nella schermata seguente:

C'è una descrizione nella parte superiore della finestra fornita dal creatore del flusso di lavoro. Indica che questo nodo legge il set di dati per adulti. Il nome del file èadult.csvcome si vede dalla descrizione sotto il simbolo del nodo. IlFile Reader ha due uscite: una va a Color Manager nodo e l'altro va a Statistics nodo.
Se fai clic con il pulsante destro del mouse sul file File Manager, verrà visualizzato un menu popup come segue:

Il Configurel'opzione di menu consente la configurazione del nodo. IlExecutemenu esegue il nodo. Notare che se il nodo è già stato eseguito e se è in uno stato verde, questo menu è disabilitato. Inoltre, notare la presenza diEdit Note Descriptionopzione di menu. Ciò ti consente di scrivere la descrizione per il tuo nodo.
Ora seleziona il file Configure opzione di menu, mostra la schermata contenente i dati dal file adult.csv come si vede nello screenshot qui -

Quando esegui questo nodo, i dati verranno caricati nella memoria. L'intero codice del programma di caricamento dati è nascosto all'utente. Ora puoi apprezzare l'utilità di tali nodi: non è richiesta alcuna codifica.
Il nostro prossimo nodo è il Color Manager.
Color Manager
Seleziona il Color Managernodo e vai nella sua configurazione facendo clic destro su di esso. Apparirà una finestra di dialogo per le impostazioni dei colori. Seleziona ilincome colonna dall'elenco a discesa.
Il tuo schermo sarebbe simile al seguente:

Notare la presenza di due vincoli. Se il reddito è inferiore a 50K, il datapoint acquisirà il colore verde e se è maggiore assumerà il colore rosso. Vedrai le mappature dei punti dati quando guarderemo il grafico a dispersione più avanti in questo capitolo.
Partizionamento
Nell'apprendimento automatico, di solito dividiamo tutti i dati disponibili in due parti. La parte più grande viene utilizzata nell'addestramento del modello, mentre la parte più piccola viene utilizzata per il test. Esistono diverse strategie utilizzate per partizionare i dati.
Per definire il partizionamento desiderato, fare clic con il tasto destro del mouse sul file Partitioning e seleziona il file Configureopzione. Vedrai la seguente schermata:

Nel caso, il modellatore di sistema ha utilizzato l'estensione Relativemodalità (%) e i dati vengono suddivisi in un rapporto 80:20. Durante la divisione, i punti dati vengono raccolti in modo casuale. Ciò garantisce che i dati del test non siano distorti. In caso di campionamento lineare, il restante 20% dei dati utilizzati per il test potrebbe non rappresentare correttamente i dati di addestramento in quanto potrebbero essere totalmente distorti durante la raccolta.
Se sei sicuro che durante la raccolta dei dati la casualità sia garantita, puoi selezionare il campionamento lineare. Una volta che i dati sono pronti per l'addestramento del modello, inseriscili nel nodo successivo, che è il fileDecision Tree Learner.
Studente dell'albero decisionale
Il Decision Tree Learnercome suggerisce il nome, il nodo utilizza i dati di addestramento e crea un modello. Controlla l'impostazione di configurazione di questo nodo, che è raffigurata nello screenshot qui sotto -

Come vedi il file Class è income. Quindi l'albero verrebbe costruito in base alla colonna del reddito e questo è ciò che stiamo cercando di ottenere in questo modello. Vogliamo una separazione delle persone che hanno un reddito maggiore o minore di 50K.
Dopo che questo nodo è stato eseguito correttamente, il tuo modello sarà pronto per il test.
Predittore dell'albero decisionale
Il nodo Decision Tree Predictor applica il modello sviluppato al set di dati di test e allega le previsioni del modello.

L'output del predittore viene inviato a due diversi nodi: Scorer e Scatter Plot. Successivamente, esamineremo l'output della previsione.
Marcatore
Questo nodo genera il file confusion matrix. Per visualizzarlo, fare clic con il tasto destro sul nodo. Vedrai il seguente menu a comparsa:

Clicca il View: Confusion Matrix opzione di menu e la matrice apparirà in una finestra separata come mostrato nello screenshot qui -
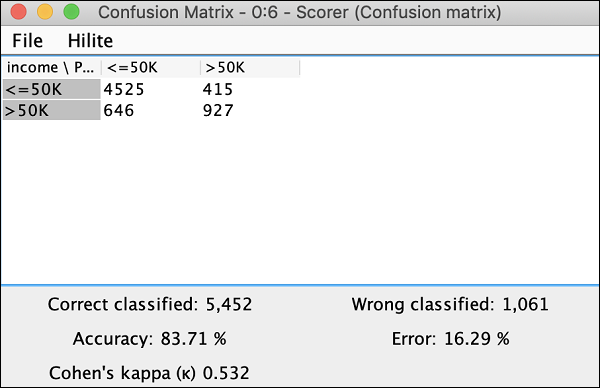
Indica che la precisione del nostro modello sviluppato è dell'83,71%. Se non sei soddisfatto di questo, puoi giocare con altri parametri nella costruzione del modello, in particolare, potresti voler rivedere e pulire i tuoi dati.
Grafico a dispersione
Per vedere il grafico a dispersione della distribuzione dei dati, fare clic con il pulsante destro del mouse su Scatter Plot nodo e selezionare l'opzione di menu Interactive View: Scatter Plot. Vedrai la seguente trama:

Il grafico fornisce la distribuzione di persone con gruppi di reddito diversi in base alla soglia di 50.000 in due punti colorati diversi: rosso e blu. Questi erano i colori fissati nel nostroColor Managernodo. La distribuzione è relativa all'età come tracciata sull'asse x. È possibile selezionare una caratteristica diversa per l'asse x modificando la configurazione del nodo.
La finestra di dialogo di configurazione è mostrata qui dove abbiamo selezionato il file marital-status come caratteristica per l'asse x.
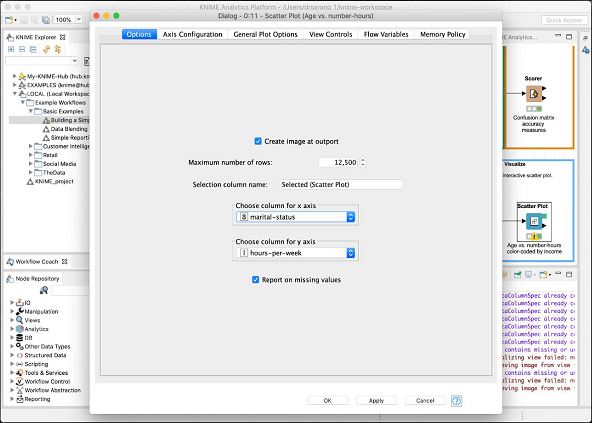
Questo completa la nostra discussione sul modello predefinito fornito da KNIME. Ti suggeriamo di riprendere gli altri due nodi (Statistiche e Tabella interattiva) nel modello per il tuo studio personale.
Passiamo ora alla parte più importante del tutorial: creare il tuo modello.
In questo capitolo costruirai il tuo modello di machine learning per classificare gli impianti in base ad alcune caratteristiche osservate. Useremo il notoiris set di dati da UCI Machine Learning Repositoryper questo scopo. Il set di dati contiene tre diverse classi di piante. Addestreremo il nostro modello per classificare una pianta sconosciuta in una di queste tre classi.
Inizieremo con la creazione di un nuovo flusso di lavoro in KNIME per la creazione dei nostri modelli di apprendimento automatico.
Creazione del flusso di lavoro
Per creare un nuovo flusso di lavoro, seleziona la seguente opzione di menu nel workbench KNIME.
File → NewVedrai la seguente schermata:

Seleziona il New KNIME Workflow opzione e fare clic su Nextpulsante. Nella schermata successiva, ti verrà chiesto il nome desiderato per il flusso di lavoro e la cartella di destinazione per salvarlo. Immettere queste informazioni come desiderato e fare clicFinish per creare un nuovo spazio di lavoro.
Un nuovo spazio di lavoro con il nome dato verrà aggiunto al file Workspace guarda come si vede qui -
Ora aggiungerai i vari nodi in questo spazio di lavoro per creare il tuo modello. Prima di aggiungere nodi, devi scaricare e preparare il fileiris set di dati per il nostro utilizzo.
Preparazione del set di dati
Scarica il set di dati iris dal sito UCI Machine Learning Repository Scarica il set di dati Iris . Il file iris.data scaricato è in formato CSV. Apporteremo alcune modifiche per aggiungere i nomi delle colonne.
Apri il file scaricato nel tuo editor di testo preferito e aggiungi la seguente riga all'inizio.
sepal length, petal length, sepal width, petal width, classQuando il nostro File Reader node legge questo file, prenderà automaticamente i campi sopra come nomi di colonna.
Ora inizierai ad aggiungere vari nodi.
Aggiunta di un lettore di file
Vai al Node Repository visualizzare, digitare "file" nella casella di ricerca per individuare il file File Readernodo. Questo è visto nello screenshot qui sotto:

Seleziona e fai doppio clic sul file File Readerper aggiungere il nodo all'area di lavoro. In alternativa, puoi utilizzare la funzione di trascinamento della selezione per aggiungere il nodo nell'area di lavoro. Dopo aver aggiunto il nodo, dovrai configurarlo. Fare clic con il tasto destro sul nodo e selezionare il fileConfigureopzione di menu. Lo hai fatto nella lezione precedente.
La schermata delle impostazioni appare come la seguente dopo il caricamento del file di dati.

Per caricare il tuo set di dati, fai clic su Browsee selezionare la posizione del file iris.data. Il nodo caricherà il contenuto del file che viene visualizzato nella parte inferiore della finestra di configurazione. Una volta verificato che il file di dati sia posizionato correttamente e caricato, fare clic suOK per chiudere la finestra di dialogo di configurazione.
Ora aggiungerai alcune annotazioni a questo nodo. Fare clic con il tasto destro sul nodo e selezionareNew Workflow Annotationopzione di menu. Una casella di annotazione apparirà sullo schermo come mostrato nello screenshot qui:
Fare clic all'interno della casella e aggiungere la seguente annotazione:
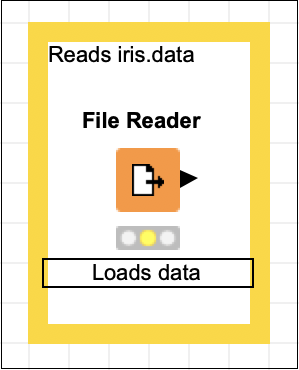
Reads iris.dataFare clic in un punto qualsiasi al di fuori della casella per uscire dalla modalità di modifica. Ridimensiona e posiziona la casella attorno al nodo come desiderato. Infine, fai doppio clic sul fileNode 1 testo sotto il nodo per modificare questa stringa come segue:
Loads dataA questo punto, lo schermo apparirà come segue:
Aggiungeremo ora un nuovo nodo per partizionare il nostro set di dati caricato in addestramento e test.
Aggiunta del nodo di partizionamento
Nel Node Repository finestra di ricerca, digita alcuni caratteri per individuare il file Partitioning nodo, come si vede nello screenshot qui sotto -
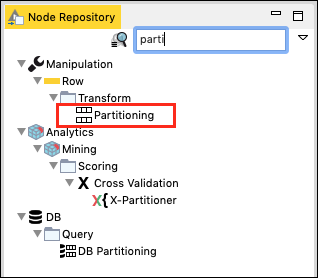
Aggiungi il nodo al nostro spazio di lavoro. Impostare la sua configurazione come segue:
Relative (%) : 95
Draw RandomlyLo screenshot seguente mostra i parametri di configurazione.

Quindi, effettua la connessione tra i due nodi. Per fare ciò, fare clic sull'output del fileFile Reader nodo, tieni premuto il pulsante del mouse, apparirà una linea di elastico, trascinala sull'ingresso di Partitioningnodo, rilascia il pulsante del mouse. Viene ora stabilita una connessione tra i due nodi.
Aggiungere l'annotazione, modificare la descrizione, posizionare il nodo e la vista dell'annotazione come desiderato. Lo schermo dovrebbe apparire come il seguente in questa fase:

Successivamente, aggiungeremo il file k-Means nodo.
Aggiunta di k-Means Node
Seleziona il k-Meansnode dal repository e aggiungerlo all'area di lavoro. Se vuoi aggiornare le tue conoscenze sull'algoritmo k-Means, cerca la sua descrizione nella vista descrittiva del workbench. Questo è mostrato nello screenshot qui sotto -

Per inciso, puoi cercare la descrizione di diversi algoritmi nella finestra di descrizione prima di prendere una decisione finale su quale usare.
Apri la finestra di dialogo di configurazione per il nodo. Useremo le impostazioni predefinite per tutti i campi come mostrato qui -

Clic OK per accettare le impostazioni predefinite e chiudere la finestra di dialogo.
Imposta l'annotazione e la descrizione come segue:
Annotazione: classifica i cluster
Descrizione: eseguire il clustering
Collega l'uscita superiore di Partitioning nodo all'ingresso di k-Meansnodo. Riposiziona i tuoi elementi e lo schermo dovrebbe avere il seguente aspetto:

Successivamente, aggiungeremo un file Cluster Assigner nodo.
Aggiunta di un assegnatore di cluster
Il Cluster Assignerassegna nuovi dati a un set esistente di prototipi. Richiede due input: il modello prototipo e il datatable contenente i dati di input. Cerca la descrizione del nodo nella finestra di descrizione che è rappresentata nello screenshot qui sotto -

Quindi, per questo nodo devi fare due connessioni:
L'output del modello cluster PMML di Partitioning nodo → Prototipi Input di Cluster Assigner
Uscita della seconda partizione di Partitioning nodo → Dati di input di Cluster Assigner
Queste due connessioni sono mostrate nello screenshot qui sotto:

Il Cluster Assignernon necessita di alcuna configurazione speciale. Accetta solo le impostazioni predefinite.
Ora aggiungi alcune annotazioni e descrizioni a questo nodo. Riorganizza i tuoi nodi. Lo schermo dovrebbe essere simile al seguente:

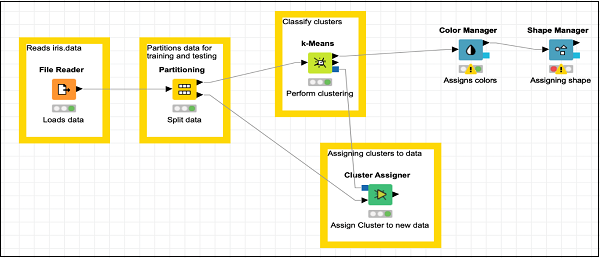
A questo punto, il nostro raggruppamento è completato. Abbiamo bisogno di visualizzare graficamente l'output. Per questo, aggiungeremo un grafico a dispersione. Imposteremo i colori e le forme per tre classi in modo diverso nel grafico a dispersione. Pertanto, filtreremo l'output dik-Means nodo prima attraverso il Color Manager nodo e poi attraverso Shape Manager nodo.
Aggiunta di Color Manager
Individua il file Color Managernodo nel repository. Aggiungilo all'area di lavoro. Lascia la configurazione ai valori predefiniti. Nota che devi aprire la finestra di dialogo di configurazione e premereOKper accettare le impostazioni predefinite. Imposta il testo della descrizione per il nodo.
Effettua una connessione dall'output di k-Means all'input di Color Manager. Lo schermo apparirà come il seguente in questa fase:

Aggiunta di Shape Manager
Individua il file Shape Managernel repository e aggiungerlo all'area di lavoro. Lascia la sua configurazione ai valori predefiniti. Come il precedente, devi aprire la finestra di dialogo di configurazione e premereOKper impostare i valori predefiniti. Stabilire la connessione dall'output diColor Manager all'input di Shape Manager. Imposta la descrizione per il nodo.
Lo schermo dovrebbe essere simile al seguente:
Ora aggiungerai l'ultimo nodo nel nostro modello e questo è il grafico a dispersione.
Aggiunta di un grafico a dispersione
Individuare Scatter Plotnodo nel repository e aggiungerlo all'area di lavoro. Collega l'uscita diShape Manager all'input di Scatter Plot. Lascia la configurazione ai valori predefiniti. Imposta la descrizione.
Infine, aggiungi un'annotazione di gruppo ai tre nodi aggiunti di recente
Annotazione: visualizzazione
Riposizionare i nodi come desiderato. Lo schermo dovrebbe apparire come il seguente in questa fase.
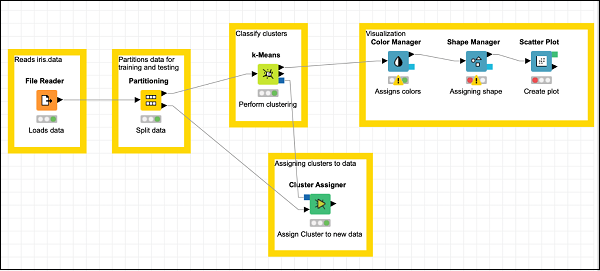
Questo completa il compito della costruzione del modello.
Per testare il modello, eseguire le seguenti opzioni di menu: Node → Execute All
Se tutto va bene, il segnale di stato nella parte inferiore di ogni nodo diventerà verde. In caso contrario, dovrai cercare il fileConsole visualizzare gli errori, correggerli e rieseguire il flusso di lavoro.
Ora sei pronto per visualizzare l'output previsto del modello. Per questo, fai clic con il pulsante destro del mouse suScatter Plot nodo e selezionare le seguenti opzioni di menu: Interactive View: Scatter Plot
Questo è mostrato nello screenshot qui sotto -

Vedresti il grafico a dispersione sullo schermo come mostrato qui -

È possibile eseguire diverse visualizzazioni modificando gli assi xey. A tal fine, fare clic sul menu delle impostazioni nell'angolo in alto a destra del grafico a dispersione. Apparirà un menu popup come mostrato nello screenshot qui sotto -

È possibile impostare i vari parametri per il grafico in questa schermata per visualizzare i dati da diversi aspetti.
Questo completa il nostro compito di costruzione del modello.
KNIME fornisce uno strumento grafico per la creazione di modelli di Machine Learning. In questo tutorial, hai imparato come scaricare e installare KNIME sulla tua macchina.
Sommario
Hai imparato le varie visualizzazioni fornite nel workbench KNIME. KNIME fornisce diversi flussi di lavoro predefiniti per il tuo apprendimento. Abbiamo utilizzato uno di questi flussi di lavoro per apprendere le capacità di KNIME. KNIME fornisce diversi nodi preprogrammati per leggere i dati in vari formati, analizzare i dati utilizzando diversi algoritmi ML e infine visualizzare i dati in molti modi diversi. Verso la fine del tutorial, hai creato il tuo modello partendo da zero. Abbiamo utilizzato il noto dataset dell'iride per classificare le piante utilizzando l'algoritmo k-Means.
Ora sei pronto per utilizzare queste tecniche per le tue analisi.
Lavoro futuro
Se sei uno sviluppatore e desideri utilizzare i componenti KNIME nelle tue applicazioni di programmazione, sarai felice di sapere che KNIME si integra in modo nativo con un'ampia gamma di linguaggi di programmazione come Java, R, Python e molti altri.