Apprendimento automatico: supervisionato
L'apprendimento supervisionato è uno degli importanti modelli di apprendimento coinvolti nelle macchine di formazione. Questo capitolo parla in dettaglio della stessa cosa.
Algoritmi per l'apprendimento supervisionato
Sono disponibili diversi algoritmi per l'apprendimento supervisionato. Alcuni degli algoritmi ampiamente utilizzati dell'apprendimento supervisionato sono mostrati di seguito:
- k-Nearest Neighbors
- Alberi decisionali
- Naive Bayes
- Regressione logistica
- Supporta macchine vettoriali
Man mano che procediamo in questo capitolo, discutiamo in dettaglio di ciascuno degli algoritmi.
k-Nearest Neighbors
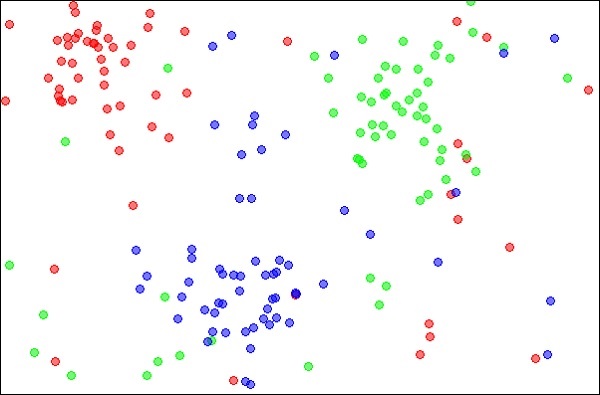
K-Nearest Neighbors, chiamato semplicemente kNN, è una tecnica statistica che può essere utilizzata per risolvere problemi di classificazione e regressione. Parliamo del caso di classificare un oggetto sconosciuto usando kNN. Considera la distribuzione degli oggetti come mostrato nell'immagine sotto riportata -
Fonte:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Il diagramma mostra tre tipi di oggetti, contrassegnati nei colori rosso, blu e verde. Quando esegui il classificatore kNN sul set di dati sopra, i limiti per ogni tipo di oggetto saranno contrassegnati come mostrato di seguito:

Fonte:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Ora, considera un nuovo oggetto sconosciuto che vuoi classificare come rosso, verde o blu. Questo è illustrato nella figura seguente.
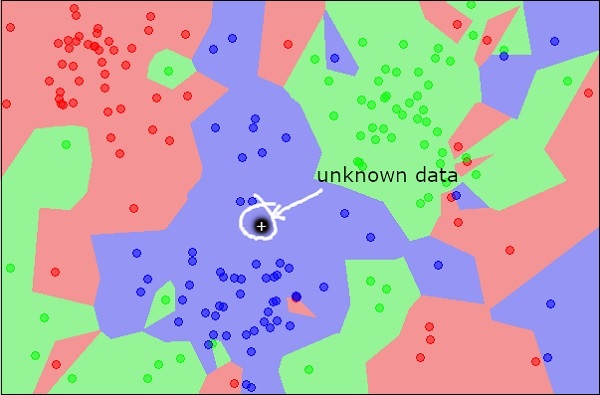
Come lo vedi visivamente, il punto dati sconosciuto appartiene a una classe di oggetti blu. Matematicamente, questo può essere concluso misurando la distanza di questo punto sconosciuto con ogni altro punto nel set di dati. Quando lo fai, saprai che la maggior parte dei suoi vicini sono di colore blu. La distanza media dagli oggetti rossi e verdi sarebbe sicuramente maggiore della distanza media dagli oggetti blu. Pertanto, questo oggetto sconosciuto può essere classificato come appartenente alla classe blu.
L'algoritmo kNN può essere utilizzato anche per problemi di regressione. L'algoritmo kNN è disponibile come pronto per l'uso nella maggior parte delle librerie ML.
Alberi decisionali
Di seguito è mostrato un semplice albero decisionale in formato diagramma di flusso:
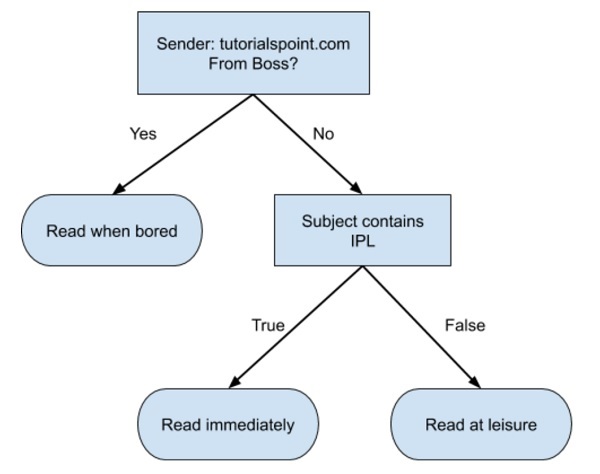
Scriveresti un codice per classificare i dati di input in base a questo diagramma di flusso. Il diagramma di flusso è autoesplicativo e banale. In questo scenario, stai tentando di classificare un'e-mail in arrivo per decidere quando leggerla.
In realtà, gli alberi decisionali possono essere ampi e complessi. Sono disponibili diversi algoritmi per creare e attraversare questi alberi. In qualità di appassionato di machine learning, devi comprendere e padroneggiare queste tecniche di creazione e attraversamento di alberi decisionali.
Naive Bayes
Naive Bayes viene utilizzato per creare classificatori. Supponi di voler selezionare (classificare) frutti di diverso tipo da un cesto di frutta. È possibile utilizzare caratteristiche come il colore, la dimensione e la forma di un frutto. Ad esempio, qualsiasi frutto di colore rosso, di forma rotonda e di circa 10 cm di diametro può essere considerato come una mela. Quindi, per addestrare il modello, dovresti utilizzare queste funzionalità e testare la probabilità che una determinata funzionalità corrisponda ai vincoli desiderati. Le probabilità di diverse caratteristiche vengono quindi combinate per arrivare a una probabilità che un dato frutto sia una mela. Naive Bayes generalmente richiede un piccolo numero di dati di addestramento per la classificazione.
Regressione logistica
Guarda il diagramma seguente. Mostra la distribuzione dei punti dati nel piano XY.

Dal diagramma, possiamo ispezionare visivamente la separazione dei punti rossi dai punti verdi. Puoi disegnare una linea di confine per separare questi punti. Ora, per classificare un nuovo punto dati, dovrai solo determinare su quale lato della linea si trova il punto.
Supporta macchine vettoriali
Guarda la seguente distribuzione dei dati. Qui le tre classi di dati non possono essere separate linearmente. Le curve di confine non sono lineari. In tal caso, trovare l'equazione della curva diventa un lavoro complesso.
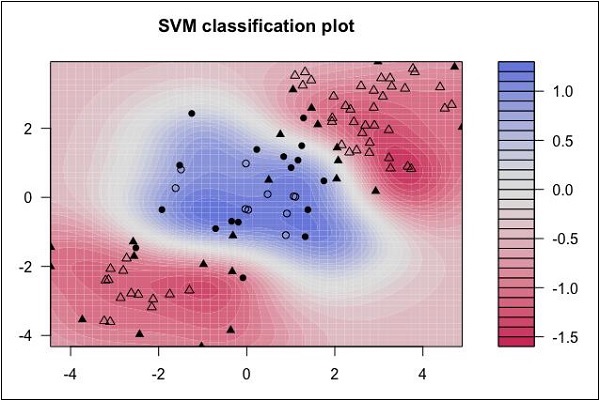
Fonte: http://uc-r.github.io/svm
Le Support Vector Machines (SVM) sono utili per determinare i limiti di separazione in tali situazioni.