Mahout - Raggruppamento
Il raggruppamento è la procedura per organizzare elementi o elementi di una data raccolta in gruppi in base alla somiglianza tra gli elementi. Ad esempio, le applicazioni relative alla pubblicazione di notizie in linea raggruppano i loro articoli di notizie utilizzando il clustering.
Applicazioni del clustering
Il clustering è ampiamente utilizzato in molte applicazioni come la ricerca di mercato, il riconoscimento di modelli, l'analisi dei dati e l'elaborazione delle immagini.
Il clustering può aiutare i professionisti del marketing a scoprire gruppi distinti nella loro base di clienti. E possono caratterizzare i loro gruppi di clienti in base ai modelli di acquisto.
Nel campo della biologia, può essere utilizzato per derivare tassonomie di piante e animali, classificare geni con funzionalità simili e ottenere informazioni sulle strutture inerenti alle popolazioni.
Il raggruppamento aiuta nell'identificazione di aree con un uso del suolo simile in un database di osservazione della terra.
Il clustering aiuta anche a classificare i documenti sul Web per la scoperta delle informazioni.
Il clustering viene utilizzato nelle applicazioni di rilevamento dei valori anomali come il rilevamento di frodi con carte di credito.
Come funzione di data mining, Cluster Analysis funge da strumento per ottenere informazioni dettagliate sulla distribuzione dei dati per osservare le caratteristiche di ciascun cluster.
Usando Mahout, possiamo raggruppare un dato insieme di dati. I passaggi richiesti sono i seguenti:
Algorithm È necessario selezionare un algoritmo di clustering adatto per raggruppare gli elementi di un cluster.
Similarity and Dissimilarity È necessario disporre di una regola per verificare la somiglianza tra gli elementi appena incontrati e gli elementi nei gruppi.
Stopping Condition È necessaria una condizione di arresto per definire il punto in cui non è richiesto il raggruppamento.
Procedura di clustering
Per raggruppare i dati forniti è necessario:
Avvia il server Hadoop. Crea le directory richieste per l'archiviazione dei file nel file system Hadoop. (Creare directory per file di input, file di sequenza e output cluster in caso di canopy).
Copiare il file di input nel file system Hadoop dal file system Unix.
Preparare il file di sequenza dai dati di input.
Esegui uno degli algoritmi di clustering disponibili.
Ottieni i dati raggruppati.
Avvio di Hadoop
Mahout funziona con Hadoop, quindi assicurati che il server Hadoop sia attivo e funzionante.
$ cd HADOOP_HOME/bin
$ start-all.shPreparazione delle directory dei file di input
Crea directory nel file system Hadoop per archiviare il file di input, i file di sequenza e i dati raggruppati utilizzando il seguente comando:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
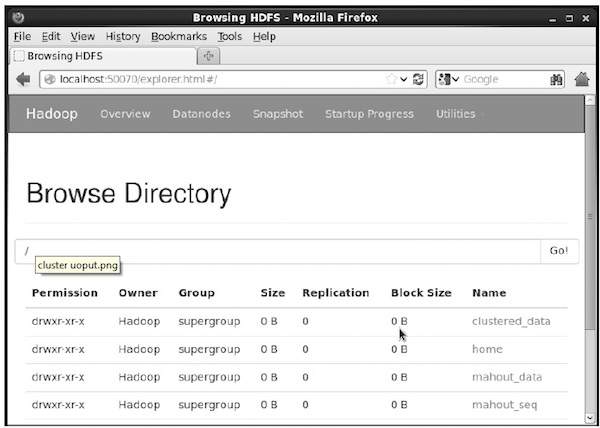
$ hadoop fs -p mkdir /mahout_seqPuoi verificare se la directory è stata creata utilizzando l'interfaccia web hadoop nel seguente URL: http://localhost:50070/
Ti dà l'output come mostrato di seguito:
Copia del file di input su HDFS
Ora, copia il file di dati di input dal file system Linux alla directory mahout_data nel file system Hadoop come mostrato di seguito. Supponiamo che il tuo file di input sia mydata.txt e si trovi nella directory / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/Preparazione del file di sequenza
Mahout ti fornisce un'utilità per convertire il file di input specificato in un formato di file di sequenza. Questa utilità richiede due parametri.
- La directory del file di input in cui risiedono i dati originali.
- La directory del file di output in cui devono essere archiviati i dati raggruppati.
Di seguito è riportato il prompt della guida di mahout seqdirectory utilità.
Step 1:Vai alla home directory di Mahout. Puoi ottenere aiuto dall'utilità come mostrato di seguito:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryGenera il file di sequenza utilizzando l'utilità utilizzando la seguente sintassi:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/Algoritmi di clustering
Mahout supporta due algoritmi principali per il clustering, ovvero:
- Raggruppamento del baldacchino
- K-significa raggruppamento
Raggruppamento del baldacchino
Il clustering del baldacchino è una tecnica semplice e veloce utilizzata da Mahout per scopi di raggruppamento. Gli oggetti verranno trattati come punti in uno spazio semplice. Questa tecnica viene spesso utilizzata come passaggio iniziale in altre tecniche di clustering come il clustering k-means. È possibile eseguire un lavoro Canopy utilizzando la seguente sintassi:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>Il lavoro Canopy richiede una directory del file di input con il file di sequenza e una directory di output in cui devono essere archiviati i dati raggruppati.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30Otterrai i dati raggruppati generati nella directory di output specificata.
K-significa raggruppamento
Il clustering K-means è un importante algoritmo di clustering. L'algoritmo di clustering k in k-means rappresenta il numero di cluster in cui i dati devono essere suddivisi. Ad esempio, il valore k specificato in questo algoritmo è selezionato come 3, l'algoritmo dividerà i dati in 3 cluster.
Ogni oggetto sarà rappresentato come vettore nello spazio. Inizialmente k punti saranno scelti dall'algoritmo in modo casuale e trattati come centri, ogni oggetto più vicino a ciascun centro viene raggruppato. Esistono diversi algoritmi per la misura della distanza e l'utente deve scegliere quello richiesto.
Creating Vector Files
A differenza dell'algoritmo Canopy, l'algoritmo k-means richiede file vettoriali come input, quindi è necessario creare file vettoriali.
Per generare file vettoriali dal formato di file di sequenza, Mahout fornisce l'estensione seq2parse utilità.
Di seguito sono riportate alcune delle opzioni di seq2parseutilità. Crea file vettoriali usando queste opzioni.
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Dopo aver creato i vettori, procedere con l'algoritmo k-mean. La sintassi per eseguire il lavoro k-means è la seguente:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>Il lavoro di clustering K-means richiede la directory dei vettori di input, la directory dei cluster di output, la misura della distanza, il numero massimo di iterazioni da eseguire e un valore intero che rappresenta il numero di cluster in cui devono essere suddivisi i dati di input.