Mahout - Guida rapida
Viviamo in un'epoca in cui le informazioni sono disponibili in abbondanza. Il sovraccarico di informazioni è cresciuto a tal punto che a volte diventa difficile gestire le nostre piccole cassette postali! Immagina il volume di dati e registrazioni che alcuni siti web popolari (come Facebook, Twitter e Youtube) devono raccogliere e gestire su base giornaliera. Non è raro che anche siti Web meno conosciuti ricevano grandi quantità di informazioni in blocco.
Normalmente ricorriamo ad algoritmi di data mining per analizzare i dati in blocco per identificare le tendenze e trarre conclusioni. Tuttavia, nessun algoritmo di data mining può essere abbastanza efficiente da elaborare set di dati di grandi dimensioni e fornire risultati in tempi rapidi, a meno che le attività di calcolo non vengano eseguite su più macchine distribuite sul cloud.
Ora abbiamo nuovi framework che ci consentono di suddividere un'attività di calcolo in più segmenti ed eseguire ogni segmento su una macchina diversa. Mahout è un framework di data mining di questo tipo che normalmente viene eseguito insieme all'infrastruttura Hadoop in background per gestire enormi volumi di dati.
Cos'è Apache Mahout?
Un mahout è colui che guida un elefante come suo padrone. Il nome deriva dalla sua stretta associazione con Apache Hadoop che utilizza un elefante come logo.
Hadoop è un framework open source di Apache che consente di archiviare ed elaborare i big data in un ambiente distribuito su cluster di computer utilizzando semplici modelli di programmazione.
Apache Mahoutè un progetto open source utilizzato principalmente per la creazione di algoritmi di apprendimento automatico scalabili. Implementa le più diffuse tecniche di apprendimento automatico come:
- Recommendation
- Classification
- Clustering
Apache Mahout è iniziato come sottoprogetto di Lucene di Apache nel 2008. Nel 2010, Mahout è diventato un progetto di primo livello di Apache.
Caratteristiche di Mahout
Le caratteristiche primitive di Apache Mahout sono elencate di seguito.
Gli algoritmi di Mahout sono scritti sopra Hadoop, quindi funziona bene in ambiente distribuito. Mahout utilizza la libreria Apache Hadoop per scalare in modo efficace nel cloud.
Mahout offre al programmatore un framework pronto per l'uso per eseguire attività di data mining su grandi volumi di dati.
Mahout consente alle applicazioni di analizzare grandi insiemi di dati in modo efficace e rapido.
Include diverse implementazioni di cluster abilitate per MapReduce come k-means, fuzzy k-means, Canopy, Dirichlet e Mean-Shift.
Supporta le implementazioni di classificazione Naive Bayes distribuite e Naive Bayes complementari.
Viene fornito con funzionalità di funzione fitness distribuite per la programmazione evolutiva.
Include matrici e librerie vettoriali.
Applicazioni di Mahout
Aziende come Adobe, Facebook, LinkedIn, Foursquare, Twitter e Yahoo utilizzano Mahout internamente.
Foursquare ti aiuta a scoprire luoghi, cibo e intrattenimento disponibili in una particolare area. Utilizza il motore di raccomandazione di Mahout.
Twitter utilizza Mahout per la modellazione degli interessi degli utenti.
Yahoo! usa Mahout per il pattern mining.
Apache Mahout è una libreria di machine learning altamente scalabile che consente agli sviluppatori di utilizzare algoritmi ottimizzati. Mahout implementa le più diffuse tecniche di machine learning come consigli, classificazione e clustering. Pertanto, è prudente avere una breve sezione sull'apprendimento automatico prima di andare oltre.
Cos'è l'apprendimento automatico?
L'apprendimento automatico è una branca della scienza che si occupa di programmare i sistemi in modo tale che imparino e migliorino automaticamente con l'esperienza. Qui apprendere significa riconoscere e comprendere i dati di input e prendere decisioni sagge sulla base dei dati forniti.
È molto difficile soddisfare tutte le decisioni basate su tutti i possibili input. Per affrontare questo problema, vengono sviluppati algoritmi. Questi algoritmi costruiscono la conoscenza da dati specifici e dall'esperienza passata con i principi di statistica, teoria della probabilità, logica, ottimizzazione combinatoria, ricerca, apprendimento per rinforzo e teoria del controllo.
Gli algoritmi sviluppati costituiscono la base di varie applicazioni come:
- Elaborazione della visione
- Elaborazione del linguaggio
- Previsione (ad esempio, tendenze del mercato azionario)
- Riconoscimento del modello
- Games
- Estrazione dei dati
- Sistemi esperti
- Robotics
L'apprendimento automatico è un'area vasta ed è ben oltre lo scopo di questo tutorial coprire tutte le sue funzionalità. Esistono diversi modi per implementare le tecniche di apprendimento automatico, tuttavia i più utilizzati sonosupervised e unsupervised learning.
Apprendimento supervisionato
L'apprendimento supervisionato si occupa di apprendere una funzione dai dati di formazione disponibili. Un algoritmo di apprendimento supervisionato analizza i dati di addestramento e produce una funzione dedotta, che può essere utilizzata per mappare nuovi esempi. Esempi comuni di apprendimento supervisionato includono:
- classificare le e-mail come spam,
- etichettare le pagine web in base al loro contenuto e
- riconoscimento vocale.
Esistono molti algoritmi di apprendimento supervisionato come reti neurali, Support Vector Machines (SVM) e classificatori Naive Bayes. Mahout implementa il classificatore Naive Bayes.
Apprendimento senza supervisione
L'apprendimento senza supervisione ha senso per i dati senza etichetta senza avere alcun set di dati predefinito per la sua formazione. L'apprendimento senza supervisione è uno strumento estremamente potente per analizzare i dati disponibili e cercare modelli e tendenze. È più comunemente usato per raggruppare input simili in gruppi logici. Gli approcci comuni all'apprendimento senza supervisione includono:
- k-means
- mappe auto-organizzate e
- raggruppamento gerarchico
Raccomandazione
Il consiglio è una tecnica diffusa che fornisce ottimi consigli basati sulle informazioni dell'utente come acquisti precedenti, clic e valutazioni.
Amazon utilizza questa tecnica per visualizzare un elenco di articoli consigliati che potrebbero interessarti, traendo informazioni dalle tue azioni passate. Esistono motori di raccomandazione che funzionano dietro Amazon per acquisire il comportamento degli utenti e consigliare gli articoli selezionati in base alle tue azioni precedenti.
Facebook utilizza la tecnica dei consiglieri per identificare e consigliare la "lista di persone che potresti conoscere".

Classificazione
Classificazione, nota anche come categorization, è una tecnica di apprendimento automatico che utilizza dati noti per determinare come classificare i nuovi dati in un insieme di categorie esistenti. La classificazione è una forma di apprendimento supervisionato.
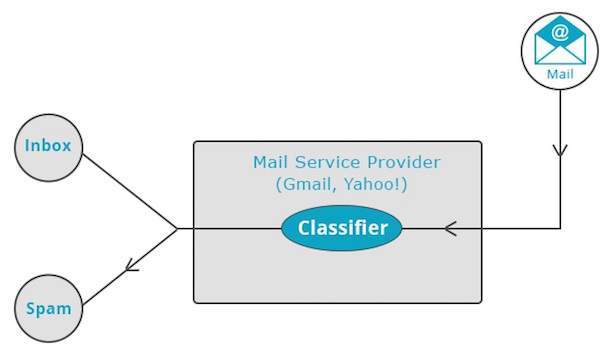
Fornitori di servizi di posta come Yahoo! e Gmail utilizzano questa tecnica per decidere se un nuovo messaggio deve essere classificato come spam. L'algoritmo di categorizzazione si allena analizzando le abitudini degli utenti di contrassegnare determinati messaggi come spam. Sulla base di ciò, il classificatore decide se una futura posta debba essere depositata nella tua casella di posta o nella cartella spam.
L'applicazione iTunes utilizza la classificazione per preparare le playlist.
Clustering
Il clustering viene utilizzato per formare gruppi o cluster di dati simili basati su caratteristiche comuni. Il clustering è una forma di apprendimento senza supervisione.
Motori di ricerca come Google e Yahoo! utilizzare tecniche di clustering per raggruppare dati con caratteristiche simili.
I newsgroup utilizzano tecniche di clustering per raggruppare vari articoli in base ad argomenti correlati.
Il motore di clustering passa attraverso i dati di input completamente e in base alle caratteristiche dei dati, decide in quale cluster devono essere raggruppati. Dai un'occhiata al seguente esempio.
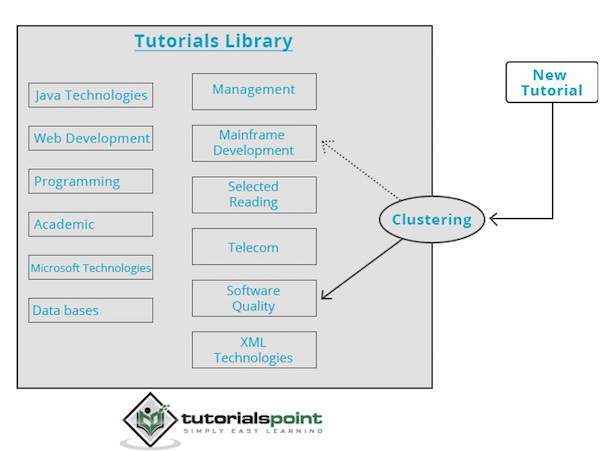
La nostra libreria di tutorial contiene argomenti su vari argomenti. Quando riceviamo un nuovo tutorial su TutorialsPoint, viene elaborato da un motore di clustering che decide, in base al suo contenuto, dove deve essere raggruppato.
Questo capitolo ti insegna come configurare mahout. Java e Hadoop sono i prerequisiti di mahout. Di seguito sono riportati i passaggi per scaricare e installare Java, Hadoop e Mahout.
Configurazione preinstallazione
Prima di installare Hadoop in ambiente Linux, è necessario configurare Linux utilizzando ssh(Secure Shell). Seguire i passaggi indicati di seguito per configurare l'ambiente Linux.
Creazione di un utente
Si consiglia di creare un utente separato per Hadoop per isolare il file system Hadoop dal file system Unix. Seguire i passaggi indicati di seguito per creare un utente:
Aprire root utilizzando il comando "su".
- Crea un utente dall'account root utilizzando il comando “useradd username”.
Ora puoi aprire un account utente esistente utilizzando il comando “su username”.
Apri il terminale Linux e digita i seguenti comandi per creare un utente.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfigurazione SSH e generazione di chiavi
La configurazione di SSH è necessaria per eseguire diverse operazioni su un cluster come l'avvio, l'arresto e le operazioni della shell del demone distribuito. Per autenticare diversi utenti di Hadoop, è necessario fornire una coppia di chiavi pubblica / privata per un utente Hadoop e condividerla con utenti diversi.
I seguenti comandi vengono utilizzati per generare una coppia chiave-valore utilizzando SSH, copiare le chiavi pubbliche da id_rsa.pub in authorized_keys e fornire rispettivamente le autorizzazioni di proprietario, lettura e scrittura al file authorized_keys.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysVerifica ssh
ssh localhostInstallazione di Java
Java è il prerequisito principale per Hadoop e HBase. Prima di tutto, dovresti verificare l'esistenza di Java nel tuo sistema usando "java -version". Di seguito viene fornita la sintassi del comando della versione Java.
$ java -versionDovrebbe produrre il seguente output.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se non hai Java installato nel tuo sistema, segui i passaggi indicati di seguito per l'installazione di Java.
Step 1
Scarica java (JDK <ultima versione> - X64.tar.gz) visitando il seguente collegamento: Oracle
Poi jdk-7u71-linux-x64.tar.gz is downloaded sul tuo sistema.
Step 2
In genere, trovi il file Java scaricato nella cartella Download. Verificalo ed estrai il filejdk-7u71-linux-x64.gz file utilizzando i seguenti comandi.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
Per rendere Java disponibile a tutti gli utenti, è necessario spostarlo nella posizione "/ usr / local /". Apri root e digita i seguenti comandi.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
Per l'allestimento PATH e JAVA_HOME variabili, aggiungi i seguenti comandi a ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binOra verifica il file java -version comando dal terminale come spiegato sopra.
Download di Hadoop
Dopo aver installato Java, è necessario installare inizialmente Hadoop. Verificare l'esistenza di Hadoop utilizzando il comando "Hadoop version" come mostrato di seguito.
hadoop versionDovrebbe produrre il seguente output:
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarSe il tuo sistema non è in grado di individuare Hadoop, scarica Hadoop e installalo sul tuo sistema. Segui i comandi indicati di seguito per farlo.
Scarica ed estrai hadoop-2.6.0 da Apache Software Foundation utilizzando i seguenti comandi.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstallazione di Hadoop
Installa Hadoop in una delle modalità richieste. Qui, stiamo dimostrando le funzionalità di HBase in modalità pseudo-distribuita, quindi installa Hadoop in modalità pseudo-distribuita.
Seguire i passaggi indicati di seguito per l'installazione Hadoop 2.4.1 sul tuo sistema.
Passaggio 1: configurazione di Hadoop
Puoi impostare le variabili d'ambiente Hadoop aggiungendo i seguenti comandi a ~/.bashrc file.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEOra applica tutte le modifiche al sistema attualmente in esecuzione.
$ source ~/.bashrcPassaggio 2: configurazione di Hadoop
Puoi trovare tutti i file di configurazione di Hadoop nella posizione "$ HADOOP_HOME / etc / hadoop". È necessario apportare modifiche a tali file di configurazione in base alla propria infrastruttura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPer sviluppare programmi Hadoop in Java, è necessario reimpostare le variabili d'ambiente Java in hadoop-env.sh file sostituendo JAVA_HOME valore con la posizione di Java nel sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71Di seguito è riportato l'elenco dei file che devi modificare per configurare Hadoop.
core-site.xml
Il core-site.xml file contiene informazioni come il numero di porta utilizzato per l'istanza Hadoop, la memoria allocata per il file system, il limite di memoria per la memorizzazione dei dati e la dimensione dei buffer di lettura / scrittura.
Apri core-site.xml e aggiungi la seguente proprietà tra i tag <configuration>, </configuration>:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
Il hdfs-site.xmlfile contiene informazioni come il valore dei dati di replica, il percorso namenode e i percorsi datanode dei file system locali. Significa il luogo in cui si desidera archiviare l'infrastruttura Hadoop.
Supponiamo i seguenti dati:
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeApri questo file e aggiungi le seguenti proprietà tra i tag <configuration>, </configuration> in questo file.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:Nel file sopra, tutti i valori delle proprietà sono definiti dall'utente. Puoi apportare modifiche in base alla tua infrastruttura Hadoop.
mapred-site.xml
Questo file viene utilizzato per configurare il filato in Hadoop. Apri il file mapred-site.xml e aggiungi la seguente proprietà tra i tag <configuration>, </configuration> in questo file.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Questo file viene utilizzato per specificare quale framework MapReduce stiamo utilizzando. Per impostazione predefinita, Hadoop contiene un modello di mapred-site.xml. Prima di tutto, è necessario copiare il file damapred-site.xml.template per mapred-site.xml file utilizzando il seguente comando.
$ cp mapred-site.xml.template mapred-site.xmlAperto mapred-site.xml file e aggiungi le seguenti proprietà tra i tag <configuration>, </configuration> in questo file.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verifica dell'installazione di Hadoop
I seguenti passaggi vengono utilizzati per verificare l'installazione di Hadoop.
Passaggio 1: configurazione del nodo del nome
Impostare il namenode utilizzando il comando "hdfs namenode -format" come segue:
$ cd ~
$ hdfs namenode -formatIl risultato atteso è il seguente:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Passaggio 2: verifica di Hadoop dfs
Il seguente comando viene utilizzato per avviare dfs. Questo comando avvia il tuo file system Hadoop.
$ start-dfs.shL'output previsto è il seguente:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Passaggio 3: verifica dello script del filato
Il seguente comando viene utilizzato per avviare lo script del filato. L'esecuzione di questo comando avvierà i tuoi demoni filati.
$ start-yarn.shL'output previsto è il seguente:
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outPassaggio 4: accesso a Hadoop sul browser
Il numero di porta predefinito per accedere a hadoop è 50070. Utilizza il seguente URL per ottenere i servizi Hadoop sul tuo browser.
http://localhost:50070/
Passaggio 5: verifica tutte le applicazioni per il cluster
Il numero di porta predefinito per accedere a tutte le applicazioni del cluster è 8088. Utilizzare il seguente URL per visitare questo servizio.
http://localhost:8088/
Download di Mahout
Mahout è disponibile nel sito Mahout . Scarica Mahout dal collegamento fornito nel sito web. Ecco lo screenshot del sito web.

Passo 1
Scarica Apache mahout dal link http://mirror.nexcess.net/apache/mahout/ utilizzando il seguente comando.
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gzPoi mahout-distribution-0.9.tar.gz verrà scaricato nel tuo sistema.
Passo 2
Sfoglia la cartella dove mahout-distribution-0.9.tar.gz viene memorizzato ed estrai il file jar scaricato come mostrato di seguito.
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzRepository Maven
Di seguito è riportato il pom.xml per creare Apache Mahout utilizzando Eclipse.
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>Questo capitolo tratta la popolare tecnica di apprendimento automatico chiamata recommendation, i suoi meccanismi e come scrivere un'applicazione che implementa la raccomandazione Mahout.
Raccomandazione
Ti sei mai chiesto come fa Amazon a presentare un elenco di articoli consigliati per attirare la tua attenzione su un particolare prodotto a cui potresti essere interessato!
Supponi di voler acquistare il libro "Mahout in Action" da Amazon:
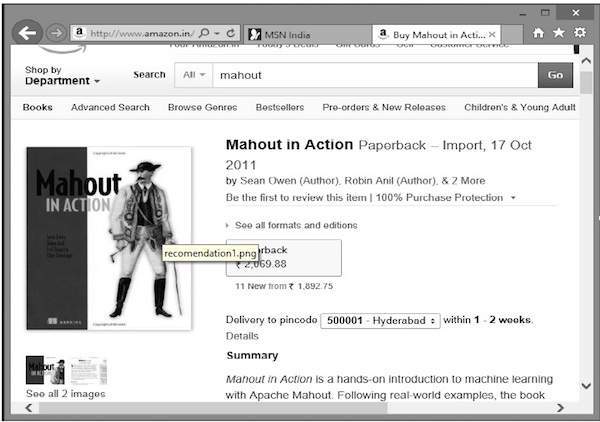
Insieme al prodotto selezionato, Amazon mostra anche un elenco di articoli consigliati correlati, come mostrato di seguito.

Tali elenchi di raccomandazioni vengono prodotti con l'aiuto di recommender engines. Mahout fornisce motori di raccomandazione di diversi tipi come:
- consiglieri basati sugli utenti,
- consiglieri basati sugli articoli e
- molti altri algoritmi.
Motore di raccomandazione Mahout
Mahout ha un motore di raccomandazione non distribuito e non basato su Hadoop. Dovresti passare un documento di testo con le preferenze dell'utente per gli elementi. E l'output di questo motore sarebbe la stima delle preferenze di un particolare utente per altri elementi.
Esempio
Considera un sito web che vende beni di consumo come cellulari, gadget e relativi accessori. Se vogliamo implementare le funzionalità di Mahout in un sito del genere, possiamo creare un motore di raccomandazione. Questo motore analizza i dati degli acquisti passati degli utenti e consiglia nuovi prodotti sulla base di questi.
I componenti forniti da Mahout per costruire un motore di raccomandazione sono i seguenti:
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
Dall'archivio dati, il modello di dati viene preparato e passato come input al motore di raccomandazione. Il motore di raccomandazione genera i consigli per un particolare utente. Di seguito è riportata l'architettura del motore di raccomandazione.
Architettura del motore di raccomandazione

Creazione di un suggeritore utilizzando Mahout
Ecco i passaggi per sviluppare un semplice suggeritore:
Passaggio 1: creare l'oggetto DataModel
Il costruttore di PearsonCorrelationSimilarityclass richiede un oggetto modello dati, che contiene un file che contiene i dettagli di utenti, elementi e preferenze di un prodotto. Ecco il file del modello di dati di esempio:
1,00,1.0
1,01,2.0
1,02,5.0
1,03,5.0
1,04,5.0
2,00,1.0
2,01,2.0
2,05,5.0
2,06,4.5
2,02,5.0
3,01,2.5
3,02,5.0
3,03,4.0
3,04,3.0
4,00,5.0
4,01,5.0
4,02,5.0
4,03,0.0Il DataModelobject richiede l'oggetto file, che contiene il percorso del file di input. Crea il fileDataModel oggetto come mostrato di seguito.
DataModel datamodel = new FileDataModel(new File("input file"));Passaggio 2: creare un oggetto UserSimilarity
Creare UserSimilarity oggetto utilizzando PearsonCorrelationSimilarity classe come mostrato di seguito:
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);Passaggio 3: creare l'oggetto UserNeroute
Questo oggetto calcola un "quartiere" di utenti come un dato utente. Esistono due tipi di quartieri:
NearestNUserNeighborhood- Questa classe calcola un vicinato costituito dagli n utenti più vicini a un dato utente. "Nearest" è definito dalla UserSimilarity data.
ThresholdUserNeighborhood- Questa classe calcola un quartiere composto da tutti gli utenti la cui somiglianza con un dato utente incontra o supera una certa soglia. La somiglianza è definita dalla data UserSimilarity.
Qui stiamo usando ThresholdUserNeighborhood e imposta il limite di preferenza a 3.0.
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, model);Passaggio 4: creare un oggetto di raccomandazione
Creare UserbasedRecomenderoggetto. Passa tutti gli oggetti creati sopra al suo costruttore come mostrato di seguito.
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);Passaggio 5: consiglia articoli a un utente
Consiglia prodotti a un utente utilizzando il metodo Recommend () di Recommenderinterfaccia. Questo metodo richiede due parametri. Il primo rappresenta l'ID utente dell'utente a cui dobbiamo inviare i consigli e il secondo rappresenta il numero di consigli da inviare. Ecco l'utilizzo direcommender() metodo:
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}Example Program
Di seguito è riportato un programma di esempio per impostare la raccomandazione. Prepara i consigli per l'utente con l'ID utente 2.
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class Recommender {
public static void main(String args[]){
try{
//Creating data model
DataModel datamodel = new FileDataModel(new File("data")); //data
//Creating UserSimilarity object.
UserSimilarity usersimilarity = new PearsonCorrelationSimilarity(datamodel);
//Creating UserNeighbourHHood object.
UserNeighborhood userneighborhood = new ThresholdUserNeighborhood(3.0, usersimilarity, datamodel);
//Create UserRecomender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, userneighborhood, usersimilarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}catch(Exception e){}
}
}Compilare il programma utilizzando i seguenti comandi:
javac Recommender.java
java RecommenderDovrebbe produrre il seguente output:
RecommendedItem [item:3, value:4.5]
RecommendedItem [item:4, value:4.0]Il raggruppamento è la procedura per organizzare gli elementi o gli elementi di una data raccolta in gruppi in base alla somiglianza tra gli elementi. Ad esempio, le applicazioni relative alla pubblicazione di notizie in linea raggruppano i loro articoli di notizie utilizzando il clustering.
Applicazioni del clustering
Il clustering è ampiamente utilizzato in molte applicazioni come la ricerca di mercato, il riconoscimento di modelli, l'analisi dei dati e l'elaborazione delle immagini.
Il clustering può aiutare i professionisti del marketing a scoprire gruppi distinti nella loro base di clienti. E possono caratterizzare i loro gruppi di clienti in base ai modelli di acquisto.
Nel campo della biologia, può essere utilizzato per derivare tassonomie di piante e animali, classificare geni con funzionalità simili e ottenere informazioni sulle strutture inerenti alle popolazioni.
Il raggruppamento aiuta nell'identificazione di aree di uso del suolo simile in un database di osservazione della terra.
Il clustering aiuta anche a classificare i documenti sul Web per la scoperta delle informazioni.
Il clustering viene utilizzato nelle applicazioni di rilevamento dei valori anomali come il rilevamento di frodi con carte di credito.
Come funzione di data mining, Cluster Analysis funge da strumento per ottenere informazioni dettagliate sulla distribuzione dei dati per osservare le caratteristiche di ciascun cluster.
Usando Mahout, possiamo raggruppare un dato insieme di dati. I passaggi richiesti sono i seguenti:
Algorithm È necessario selezionare un algoritmo di clustering appropriato per raggruppare gli elementi di un cluster.
Similarity and Dissimilarity È necessario disporre di una regola per verificare la somiglianza tra gli elementi appena incontrati e gli elementi nei gruppi.
Stopping Condition È necessaria una condizione di arresto per definire il punto in cui non è richiesto il raggruppamento.
Procedura di clustering
Per raggruppare i dati forniti è necessario:
Avvia il server Hadoop. Crea le directory richieste per l'archiviazione dei file nel file system Hadoop. (Creare directory per file di input, file di sequenza e output cluster in caso di canopy).
Copiare il file di input nel file system Hadoop dal file system Unix.
Preparare il file di sequenza dai dati di input.
Esegui uno degli algoritmi di clustering disponibili.
Ottieni i dati raggruppati.
Avvio di Hadoop
Mahout funziona con Hadoop, quindi assicurati che il server Hadoop sia attivo e funzionante.
$ cd HADOOP_HOME/bin
$ start-all.shPreparazione delle directory dei file di input
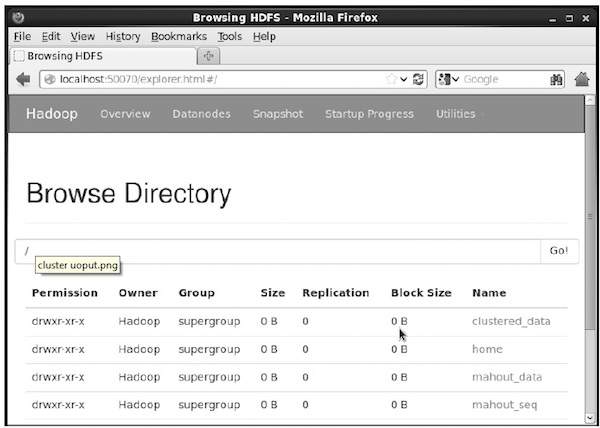
Crea directory nel file system Hadoop per archiviare il file di input, i file di sequenza e i dati raggruppati utilizzando il seguente comando:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
$ hadoop fs -p mkdir /mahout_seqPuoi verificare se la directory è stata creata utilizzando l'interfaccia web hadoop nel seguente URL: http://localhost:50070/
Ti dà l'output come mostrato di seguito:
Copia del file di input su HDFS
Ora, copia il file di dati di input dal file system Linux alla directory mahout_data nel file system Hadoop come mostrato di seguito. Supponiamo che il tuo file di input sia mydata.txt e si trovi nella directory / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/Preparazione del file di sequenza
Mahout ti fornisce un'utilità per convertire il file di input specificato in un formato di file di sequenza. Questa utility richiede due parametri.
- La directory del file di input in cui risiedono i dati originali.
- La directory del file di output in cui devono essere archiviati i dati raggruppati.
Di seguito è riportato il prompt della guida di mahout seqdirectory utilità.
Step 1:Vai alla home directory di Mahout. Puoi ottenere aiuto dall'utilità come mostrato di seguito:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryGenera il file di sequenza utilizzando l'utilità utilizzando la seguente sintassi:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/Algoritmi di clustering
Mahout supporta due algoritmi principali per il clustering, ovvero:
- Raggruppamento del baldacchino
- K-significa raggruppamento
Raggruppamento del baldacchino
Il clustering del baldacchino è una tecnica semplice e veloce utilizzata da Mahout per scopi di raggruppamento. Gli oggetti verranno trattati come punti in uno spazio semplice. Questa tecnica viene spesso utilizzata come passaggio iniziale in altre tecniche di clustering come il clustering k-means. È possibile eseguire un lavoro Canopy utilizzando la seguente sintassi:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>Il lavoro Canopy richiede una directory del file di input con il file di sequenza e una directory di output in cui devono essere archiviati i dati raggruppati.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30Otterrai i dati raggruppati generati nella directory di output specificata.
K-significa clustering
Il clustering K-means è un importante algoritmo di clustering. L'algoritmo di clustering k in k-means rappresenta il numero di cluster in cui i dati devono essere suddivisi. Ad esempio, il valore k specificato in questo algoritmo è selezionato come 3, l'algoritmo dividerà i dati in 3 cluster.
Ogni oggetto sarà rappresentato come vettore nello spazio. Inizialmente k punti saranno scelti dall'algoritmo in modo casuale e trattati come centri, ogni oggetto più vicino a ciascun centro viene raggruppato. Esistono diversi algoritmi per la misura della distanza e l'utente deve scegliere quello richiesto.
Creating Vector Files
A differenza dell'algoritmo Canopy, l'algoritmo k-means richiede file vettoriali come input, quindi è necessario creare file vettoriali.
Per generare file vettoriali dal formato di file di sequenza, Mahout fornisce l'estensione seq2parse utilità.
Di seguito sono riportate alcune delle opzioni di seq2parseutilità. Crea file vettoriali usando queste opzioni.
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Dopo aver creato i vettori, procedere con l'algoritmo k-means. La sintassi per eseguire il lavoro k-means è la seguente:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>Il lavoro di clustering K-means richiede la directory dei vettori di input, la directory dei cluster di output, la misura della distanza, il numero massimo di iterazioni da eseguire e un valore intero che rappresenta il numero di cluster in cui devono essere suddivisi i dati di input.
Cos'è la classificazione?
La classificazione è una tecnica di apprendimento automatico che utilizza dati noti per determinare come classificare i nuovi dati in un insieme di categorie esistenti. Per esempio,
L'applicazione iTunes utilizza la classificazione per preparare le playlist.
Fornitori di servizi di posta come Yahoo! e Gmail utilizzano questa tecnica per decidere se un nuovo messaggio deve essere classificato come spam. L'algoritmo di categorizzazione si allena analizzando le abitudini degli utenti di contrassegnare determinati messaggi come spam. Sulla base di ciò, il classificatore decide se una futura posta debba essere depositata nella tua casella di posta o nella cartella spam.
Come funziona la classificazione
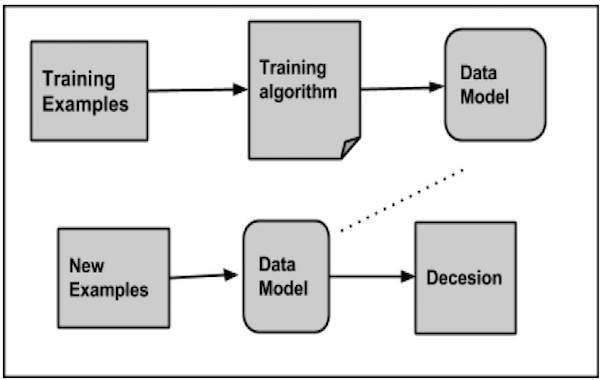
Durante la classificazione di un determinato insieme di dati, il sistema di classificazione esegue le seguenti azioni:
- Inizialmente viene preparato un nuovo modello di dati utilizzando uno qualsiasi degli algoritmi di apprendimento.
- Quindi il modello di dati preparato viene testato.
- Successivamente, questo modello di dati viene utilizzato per valutare i nuovi dati e per determinarne la classe.
Applicazioni di classificazione
Credit card fraud detection- Il meccanismo di classificazione viene utilizzato per prevedere le frodi con carte di credito. Utilizzando le informazioni storiche delle frodi precedenti, il classificatore può prevedere quali transazioni future potrebbero trasformarsi in frodi.
Spam e-mails - A seconda delle caratteristiche dei messaggi di spam precedenti, il classificatore determina se un messaggio di posta elettronica appena incontrato deve essere inviato alla cartella dello spam.
Classificatore Naive Bayes
Mahout utilizza l'algoritmo di classificazione Naive Bayes. Utilizza due implementazioni:
- Classificazione Naive Bayes distribuita
- Classificazione complementare Naive Bayes
Naive Bayes è una tecnica semplice per costruire classificatori. Non è un singolo algoritmo per l'addestramento di tali classificatori, ma una famiglia di algoritmi. Un classificatore Bayes costruisce modelli per classificare le istanze del problema. Queste classificazioni vengono effettuate utilizzando i dati disponibili.
Un vantaggio dell'ingenuo Bayes è che richiede solo una piccola quantità di dati di addestramento per stimare i parametri necessari per la classificazione.
Per alcuni tipi di modelli di probabilità, i classificatori bayesiani ingenui possono essere addestrati in modo molto efficiente in un ambiente di apprendimento supervisionato.
Nonostante i suoi presupposti troppo semplificati, i classificatori bayesiani ingenui hanno funzionato abbastanza bene in molte situazioni complesse del mondo reale.
Procedura di classificazione
I seguenti passaggi devono essere seguiti per implementare la classificazione:
- Genera dati di esempio
- Crea file di sequenza dai dati
- Converti file di sequenza in vettori
- Allena i vettori
- Prova i vettori
Passaggio 1: generazione di dati di esempio
Genera o scarica i dati da classificare. Ad esempio, puoi ottenere il file20 newsgroups dati di esempio dal seguente collegamento: http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
Crea una directory per memorizzare i dati di input. Scarica l'esempio come mostrato di seguito.
$ mkdir classification_example
$ cd classification_example
$tar xzvf 20news-bydate.tar.gz
wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gzPassaggio 2: creare file di sequenza
Crea un file di sequenza dall'esempio usando seqdirectoryutilità. La sintassi per generare la sequenza è data di seguito:
mahout seqdirectory -i <input file path> -o <output directory>Passaggio 3: converti i file di sequenza in vettori
Crea file vettoriali da file di sequenza usando seq2parseutilità. Le opzioni diseq2parse utilità sono riportate di seguito:
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Passaggio 4: addestra i vettori
Addestra i vettori generati usando il trainnbutilità. Le opzioni da utilizzaretrainnb utilità sono riportate di seguito:
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-cPassaggio 5: prova i vettori
Prova i vettori usando testnbutilità. Le opzioni da utilizzaretestnb utilità sono riportate di seguito:
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq