MongoDB - Guida rapida
MongoDB è un database multipiattaforma orientato ai documenti che fornisce alte prestazioni, alta disponibilità e facile scalabilità. MongoDB lavora sul concetto di raccolta e documento.
Banca dati
Il database è un contenitore fisico per le raccolte. Ogni database ottiene il proprio set di file sul file system. Un singolo server MongoDB ha in genere più database.
Collezione
La raccolta è un gruppo di documenti MongoDB. È l'equivalente di una tabella RDBMS. Esiste una raccolta all'interno di un singolo database. Le raccolte non applicano uno schema. I documenti all'interno di una raccolta possono avere campi diversi. In genere, tutti i documenti di una raccolta hanno uno scopo simile o correlato.
Documento
Un documento è un insieme di coppie chiave-valore. I documenti hanno uno schema dinamico. Schema dinamico significa che i documenti nella stessa raccolta non devono avere lo stesso insieme di campi o struttura e i campi comuni nei documenti di una raccolta possono contenere diversi tipi di dati.
La tabella seguente mostra la relazione tra la terminologia RDBMS e MongoDB.
| RDBMS | MongoDB |
|---|---|
| Banca dati | Banca dati |
| tavolo | Collezione |
| Tupla / riga | Documento |
| colonna | Campo |
| Table Join | Documenti incorporati |
| Chiave primaria | Chiave primaria (chiave predefinita _id fornita da mongodb stesso) |
| Server database e client | |
| Mysqld / Oracle | mongod |
| mysql / sqlplus | mongo |
Documento di esempio
L'esempio seguente mostra la struttura del documento di un sito blog, che è semplicemente una coppia di valori chiave separati da virgole.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}_idè un numero esadecimale di 12 byte che assicura l'unicità di ogni documento. È possibile fornire _id durante l'inserimento del documento. Se non lo fornisci, MongoDB fornisce un ID univoco per ogni documento. Questi 12 byte i primi 4 byte per il timestamp corrente, i successivi 3 byte per l'ID macchina, i prossimi 2 byte per l'ID di processo del server MongoDB e i 3 byte rimanenti sono semplici VALORI incrementali.
Qualsiasi database relazionale ha una struttura tipica dello schema che mostra il numero di tabelle e la relazione tra queste tabelle. Mentre in MongoDB, non esiste il concetto di relazione.
Vantaggi di MongoDB rispetto a RDBMS
Schema less- MongoDB è un database di documenti in cui una raccolta contiene documenti diversi. Il numero di campi, il contenuto e la dimensione del documento possono variare da un documento all'altro.
La struttura di un singolo oggetto è chiara.
Nessun join complesso.
Capacità di interrogazione profonda. MongoDB supporta le query dinamiche sui documenti utilizzando un linguaggio di query basato sui documenti potente quasi quanto SQL.
Tuning.
Ease of scale-out - MongoDB è facile da scalare.
Conversione / mappatura di oggetti dell'applicazione in oggetti di database non necessari.
Utilizza la memoria interna per archiviare il working set (con finestre), consentendo un accesso più rapido ai dati.
Perché utilizzare MongoDB?
Document Oriented Storage - I dati vengono archiviati sotto forma di documenti in stile JSON.
Indice su qualsiasi attributo
Replica e alta disponibilità
Auto-sharding
Query dettagliate
Aggiornamenti rapidi sul posto
Supporto professionale di MongoDB
Dove utilizzare MongoDB?
- Big Data
- Gestione e consegna dei contenuti
- Infrastruttura mobile e sociale
- Gestione dei dati utente
- Hub dati
Vediamo ora come installare MongoDB su Windows.
Installa MongoDB su Windows
Per installare MongoDB su Windows, scarica prima l'ultima versione di MongoDB da https://www.mongodb.org/downloads. Assicurati di ottenere la versione corretta di MongoDB a seconda della versione di Windows. Per ottenere la tua versione di Windows, apri il prompt dei comandi ed esegui il seguente comando.
C:\>wmic os get osarchitecture
OSArchitecture
64-bit
C:\>Le versioni a 32 bit di MongoDB supportano solo database più piccoli di 2 GB e sono adatti solo per scopi di test e valutazione.
Ora estrai il file scaricato in c: \ drive o in qualsiasi altra posizione. Assicurati che il nome della cartella estratta sia mongodb-win32-i386- [versione] o mongodb-win32-x86_64- [versione]. Qui [versione] è la versione del download di MongoDB.
Quindi, apri il prompt dei comandi ed esegui il seguente comando.
C:\>move mongodb-win64-* mongodb
1 dir(s) moved.
C:\>Nel caso in cui tu abbia estratto MongoDB in una posizione diversa, vai a quel percorso usando il comando cd FOLDER/DIR e ora esegui il processo sopra indicato.
MongoDB richiede una cartella di dati per memorizzare i suoi file. La posizione predefinita per la directory dei dati di MongoDB è c: \ data \ db. Quindi è necessario creare questa cartella utilizzando il prompt dei comandi. Eseguire la seguente sequenza di comandi.
C:\>md data
C:\md data\dbSe devi installare MongoDB in una posizione diversa, devi specificare un percorso alternativo per \data\db impostando il percorso dbpath in mongod.exe. Per lo stesso, emetti i seguenti comandi.
Nel prompt dei comandi, vai alla directory bin presente nella cartella di installazione di MongoDB. Supponiamo che la mia cartella di installazione siaD:\set up\mongodb
C:\Users\XYZ>d:
D:\>cd "set up"
D:\set up>cd mongodb
D:\set up\mongodb>cd bin
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"Questo mostrerà waiting for connections messaggio sull'output della console, che indica che il processo mongod.exe è in esecuzione correttamente.
Ora per eseguire MongoDB, è necessario aprire un altro prompt dei comandi ed emettere il seguente comando.
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>Questo mostrerà che MongoDB è installato ed eseguito correttamente. La prossima volta che esegui MongoDB, devi emettere solo comandi.
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
D:\set up\mongodb\bin>mongo.exeInstalla MongoDB su Ubuntu
Esegui il seguente comando per importare la chiave GPG pubblica di MongoDB:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10Crea un file /etc/apt/sources.list.d/mongodb.list utilizzando il seguente comando.
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen'
| sudo tee /etc/apt/sources.list.d/mongodb.listOra emetti il seguente comando per aggiornare il repository:
sudo apt-get updateQuindi installa MongoDB utilizzando il seguente comando:
apt-get install mongodb-10gen = 2.2.3Nell'installazione precedente, 2.2.3 è attualmente rilasciata la versione MongoDB. Assicurati di installare sempre l'ultima versione. Ora MongoDB è installato correttamente.
Avvia MongoDB
sudo service mongodb startInterrompi MongoDB
sudo service mongodb stopRiavvia MongoDB
sudo service mongodb restartPer utilizzare MongoDB eseguire il seguente comando.
mongoQuesto ti connetterà all'esecuzione dell'istanza di MongoDB.
Aiuto MongoDB
Per ottenere un elenco di comandi, digita db.help()nel client MongoDB. Questo ti darà un elenco di comandi come mostrato nello screenshot seguente.

Statistiche MongoDB
Per ottenere statistiche sul server MongoDB, digita il comando db.stats()nel client MongoDB. Questo mostrerà il nome del database, il numero della raccolta e i documenti nel database. L'output del comando è mostrato nella seguente schermata.

I dati in MongoDB hanno uno schema.documents flessibile nella stessa raccolta. Non è necessario che abbiano lo stesso insieme di campi o struttura e i campi comuni nei documenti di una raccolta possono contenere diversi tipi di dati.
Alcune considerazioni durante la progettazione di Schema in MongoDB
Progetta il tuo schema in base ai requisiti dell'utente.
Combina gli oggetti in un documento se li utilizzerai insieme. Altrimenti separali (ma assicurati che non ci sia bisogno di join).
Duplica i dati (ma limitato) perché lo spazio su disco è economico rispetto al tempo di calcolo.
Unisci durante la scrittura, non durante la lettura.
Ottimizza il tuo schema per i casi d'uso più frequenti.
Esegui aggregazioni complesse nello schema.
Esempio
Supponiamo che un cliente abbia bisogno di un progetto di database per il suo blog / sito web e veda le differenze tra il design dello schema RDBMS e MongoDB. Il sito web ha i seguenti requisiti.
- Ogni post ha il titolo, la descrizione e l'URL univoci.
- Ogni post può avere uno o più tag.
- Ogni post ha il nome del suo editore e il numero totale di Mi piace.
- Ogni post ha commenti forniti dagli utenti insieme al loro nome, messaggio, data-time e Mi piace.
- In ogni post possono esserci zero o più commenti.
Nello schema RDBMS, la progettazione per i requisiti di cui sopra avrà un minimo di tre tabelle.

Mentre si trova nello schema MongoDB, il design avrà un post di raccolta e la seguente struttura:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}Quindi, mentre mostri i dati, in RDBMS devi unire tre tabelle e in MongoDB, i dati verranno mostrati da una sola raccolta.
In questo capitolo vedremo come creare un database in MongoDB.
L'uso di Command
MongoDB use DATABASE_NAMEviene utilizzato per creare database. Il comando creerà un nuovo database se non esiste, altrimenti restituirà il database esistente.
Sintassi
Sintassi di base di use DATABASE l'affermazione è la seguente:
use DATABASE_NAMEEsempio
Se vuoi usare un database con nome <mydb>, poi use DATABASE dichiarazione sarebbe la seguente -
>use mydb
switched to db mydbPer controllare il database attualmente selezionato, utilizzare il comando db
>db
mydbSe vuoi controllare l'elenco dei tuoi database, usa il comando show dbs.
>show dbs
local 0.78125GB
test 0.23012GBIl database creato (mydb) non è presente nell'elenco. Per visualizzare il database, è necessario inserire almeno un documento in esso.
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBIn MongoDB il database predefinito è test. Se non hai creato alcun database, le raccolte verranno archiviate nel database di test.
In questo capitolo vedremo come rilasciare un database usando il comando MongoDB.
Il metodo dropDatabase ()
MongoDB db.dropDatabase() comando viene utilizzato per eliminare un database esistente.
Sintassi
Sintassi di base di dropDatabase() il comando è il seguente:
db.dropDatabase()Questo cancellerà il database selezionato. Se non hai selezionato alcun database, verrà eliminato il database "test" predefinito.
Esempio
Innanzitutto, controlla l'elenco dei database disponibili utilizzando il comando, show dbs.
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
>Se desideri eliminare un nuovo database <mydb>, poi dropDatabase() il comando sarebbe il seguente:
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>Ora controlla l'elenco dei database.
>show dbs
local 0.78125GB
test 0.23012GB
>In questo capitolo vedremo come creare una raccolta utilizzando MongoDB.
Il metodo createCollection ()
MongoDB db.createCollection(name, options) viene utilizzato per creare la raccolta.
Sintassi
Sintassi di base di createCollection() il comando è il seguente:
db.createCollection(name, options)Al comando, name è il nome della raccolta da creare. Options è un documento e viene utilizzato per specificare la configurazione della raccolta.
| Parametro | genere | Descrizione |
|---|---|---|
| Nome | Corda | Nome della raccolta da creare |
| Opzioni | Documento | (Facoltativo) Specificare le opzioni sulla dimensione della memoria e sull'indicizzazione |
Il parametro Options è facoltativo, quindi è necessario specificare solo il nome della raccolta. Di seguito è riportato l'elenco delle opzioni che puoi utilizzare:
| Campo | genere | Descrizione |
|---|---|---|
| limitato | Booleano | (Facoltativo) Se true, abilita una raccolta con limite. La raccolta con limite è una raccolta di dimensioni fisse che sovrascrive automaticamente le voci meno recenti quando raggiunge la dimensione massima.If you specify true, you need to specify size parameter also. |
| autoIndexId | Booleano | (Facoltativo) Se true, crea automaticamente l'indice nel campo _id. S Il valore predefinito è false. |
| taglia | numero | (Facoltativo) Specifica una dimensione massima in byte per una raccolta limitata. If capped is true, then you need to specify this field also. |
| max | numero | (Facoltativo) Specifica il numero massimo di documenti consentiti nella raccolta con limite. |
Durante l'inserimento del documento, MongoDB controlla prima il campo delle dimensioni della raccolta limitata, quindi controlla il campo massimo.
Esempi
Sintassi di base di createCollection() metodo senza opzioni è il seguente:
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>Puoi controllare la collezione creata usando il comando show collections.
>show collections
mycollection
system.indexesL'esempio seguente mostra la sintassi di createCollection() metodo con poche opzioni importanti -
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>In MongoDB, non è necessario creare una raccolta. MongoDB crea la raccolta automaticamente, quando inserisci un documento.
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>In questo capitolo vedremo come rilasciare una raccolta utilizzando MongoDB.
Il metodo drop ()
MongoDB's db.collection.drop() viene utilizzato per eliminare una raccolta dal database.
Sintassi
Sintassi di base di drop() il comando è il seguente:
db.COLLECTION_NAME.drop()Esempio
Innanzitutto, controlla le raccolte disponibili nel tuo database mydb.
>use mydb
switched to db mydb
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>Ora rilascia la raccolta con il nome mycollection.
>db.mycollection.drop()
true
>Controlla di nuovo l'elenco delle raccolte nel database.
>show collections
mycol
system.indexes
tutorialspoint
>Il metodo drop () restituirà true, se la raccolta selezionata viene rilasciata correttamente, altrimenti restituirà false.
MongoDB supporta molti tipi di dati. Alcuni di loro sono -
String- Questo è il tipo di dati più comunemente utilizzato per memorizzare i dati. La stringa in MongoDB deve essere valida in UTF-8.
Integer- Questo tipo viene utilizzato per memorizzare un valore numerico. Il numero intero può essere a 32 o 64 bit a seconda del server.
Boolean - Questo tipo viene utilizzato per memorizzare un valore booleano (vero / falso).
Double - Questo tipo viene utilizzato per memorizzare valori in virgola mobile.
Min/ Max keys - Questo tipo viene utilizzato per confrontare un valore con gli elementi BSON più basso e più alto.
Arrays - Questo tipo viene utilizzato per memorizzare array o elenchi o più valori in una chiave.
Timestamp- ctimestamp. Questo può essere utile per registrare quando un documento è stato modificato o aggiunto.
Object - Questo tipo di dati viene utilizzato per i documenti incorporati.
Null - Questo tipo viene utilizzato per memorizzare un valore Null.
Symbol- Questo tipo di dati viene utilizzato in modo identico a una stringa; tuttavia, è generalmente riservato alle lingue che utilizzano un tipo di simbolo specifico.
Date - Questo tipo di dati viene utilizzato per memorizzare la data o l'ora corrente nel formato dell'ora UNIX. È possibile specificare la propria data e l'ora creando l'oggetto Data e inserendo giorno, mese, anno in esso.
Object ID - Questo tipo di dati viene utilizzato per memorizzare l'ID del documento.
Binary data - Questo tipo di dati viene utilizzato per memorizzare dati binari.
Code - Questo tipo di dati viene utilizzato per memorizzare il codice JavaScript nel documento.
Regular expression - Questo tipo di dati viene utilizzato per memorizzare l'espressione regolare.
In questo capitolo impareremo come inserire un documento nella raccolta MongoDB.
Il metodo insert ()
Per inserire dati nella raccolta di MongoDB, è necessario utilizzare MongoDB insert() o save() metodo.
Sintassi
La sintassi di base di insert() il comando è il seguente:
>db.COLLECTION_NAME.insert(document)Esempio
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})Qui mycolè il nome della nostra collezione, come creato nel capitolo precedente. Se la raccolta non esiste nel database, MongoDB creerà questa raccolta e vi inserirà un documento.
Nel documento inserito, se non specifichiamo il parametro _id, MongoDB assegna un ObjectId univoco per questo documento.
_id è un numero esadecimale di 12 byte univoco per ogni documento in una raccolta. 12 byte sono suddivisi come segue:
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id,
3 bytes incrementer)Per inserire più documenti in una singola query, puoi passare un array di documenti nel comando insert ().
Esempio
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])Per inserire il documento puoi usare db.post.save(document)anche. Se non specifichi_id nel documento quindi save() il metodo funzionerà come insert()metodo. Se si specifica _id, sostituirà tutti i dati del documento contenente _id come specificato nel metodo save ().
In questo capitolo impareremo come interrogare un documento dalla raccolta MongoDB.
Il metodo find ()
Per eseguire query sui dati dalla raccolta MongoDB, è necessario utilizzare MongoDB find() metodo.
Sintassi
La sintassi di base di find() il metodo è il seguente:
>db.COLLECTION_NAME.find()find() il metodo visualizzerà tutti i documenti in modo non strutturato.
Il metodo pretty ()
Per visualizzare i risultati in modo formattato, puoi usare pretty() metodo.
Sintassi
>db.mycol.find().pretty()Esempio
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Oltre al metodo find (), esiste findOne() metodo, che restituisce un solo documento.
RDBMS clausola Where Equivalenti in MongoDB
Per interrogare il documento sulla base di alcune condizioni, è possibile utilizzare le seguenti operazioni.
| Operazione | Sintassi | Esempio | Equivalente RDBMS |
|---|---|---|---|
| Uguaglianza | {<key>: <value>} | db.mycol.find ({"by": "tutorials point"}). pretty () | where by = 'tutorials point' |
| Meno di | {<key>: {$ lt: <value>}} | db.mycol.find ({"mi piace": {$ lt: 50}}). pretty () | dove mi piace <50 |
| Minore di uguale | {<key>: {$ lte: <value>}} | db.mycol.find ({"mi piace": {$ lte: 50}}). pretty () | dove mi piace <= 50 |
| Più grande di | {<key>: {$ gt: <value>}} | db.mycol.find ({"mi piace": {$ gt: 50}}). pretty () | dove mi piace> 50 |
| Maggiore di uguale a | {<key>: {$ gte: <value>}} | db.mycol.find ({"mi piace": {$ gte: 50}}). pretty () | dove mi piace> = 50 |
| Non uguale | {<key>: {$ ne: <value>}} | db.mycol.find ({"mi piace": {$ ne: 50}}). pretty () | dove piace! = 50 |
AND in MongoDB
Sintassi
Nel find() , se si passano più chiavi separandole con "," MongoDB lo tratta come ANDcondizione. Di seguito è riportata la sintassi di base diAND -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()Esempio
L'esempio seguente mostrerà tutti i tutorial scritti da "tutorials point" e il cui titolo è "MongoDB Overview".
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}Nell'esempio sopra riportato, la clausola dove sarà equivalente ' where by = 'tutorials point' AND title = 'MongoDB Overview' '. È possibile passare un numero qualsiasi di coppie chiave e valore nella clausola find.
O in MongoDB
Sintassi
Per eseguire query sui documenti in base alla condizione OR, è necessario utilizzare $orparola chiave. Di seguito è riportata la sintassi di base diOR -
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()Esempio
L'esempio seguente mostrerà tutti i tutorial scritti da "tutorials point" o il cui titolo è "MongoDB Overview".
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Utilizzo di AND e OR insieme
Esempio
Il seguente esempio mostrerà i documenti con Mi piace maggiori di 10 e il cui titolo è "Panoramica MongoDB" o "Punto tutorial". La clausola SQL equivalente è'where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')'
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>MongoDB's update() e save()i metodi vengono utilizzati per aggiornare il documento in una raccolta. Il metodo update () aggiorna i valori nel documento esistente mentre il metodo save () sostituisce il documento esistente con il documento passato nel metodo save ().
Metodo MongoDB Update ()
Il metodo update () aggiorna i valori nel documento esistente.
Sintassi
La sintassi di base di update() il metodo è il seguente:
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)Esempio
Considera che la raccolta mycol ha i seguenti dati.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}L'esempio seguente imposterà il nuovo titolo "New MongoDB Tutorial" dei documenti il cui titolo è "MongoDB Overview".
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>Per impostazione predefinita, MongoDB aggiornerà solo un singolo documento. Per aggiornare più documenti, è necessario impostare un parametro "multi" su true.
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})Metodo MongoDB Save ()
Il save() sostituisce il documento esistente con il nuovo documento passato nel metodo save ().
Sintassi
La sintassi di base di MongoDB save() metodo è mostrato di seguito -
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})Esempio
L'esempio seguente sostituirà il documento con _id "5983548781331adf45ec5".
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>In questo capitolo impareremo come eliminare un documento utilizzando MongoDB.
Il metodo remove ()
MongoDB's remove()viene utilizzato per rimuovere un documento dalla raccolta. Il metodo remove () accetta due parametri. Uno è il criterio di eliminazione e il secondo è justOne flag.
deletion criteria - (Facoltativo) i criteri di eliminazione in base ai documenti verranno rimossi.
justOne - (Facoltativo) se impostato su true o 1, rimuovere solo un documento.
Sintassi
Sintassi di base di remove() il metodo è il seguente:
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)Esempio
Considera che la raccolta mycol ha i seguenti dati.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}L'esempio seguente rimuoverà tutti i documenti il cui titolo è "Panoramica MongoDB".
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>Rimuovi solo uno
Se sono presenti più record e si desidera eliminare solo il primo record, impostare justOne parametro in remove() metodo.
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)Rimuovi tutti i documenti
Se non specifichi criteri di eliminazione, MongoDB eliminerà interi documenti dalla raccolta. This is equivalent of SQL's truncate command.
>db.mycol.remove({})
>db.mycol.find()
>In MongoDB, proiezione significa selezionare solo i dati necessari piuttosto che selezionare tutti i dati di un documento. Se un documento ha 5 campi e devi mostrarne solo 3, seleziona solo 3 campi da essi.
Il metodo find ()
MongoDB's find(), spiegato nel documento di query di MongoDB, accetta un secondo parametro opzionale che è l'elenco dei campi che si desidera recuperare. In MongoDB, quando eseguifind()metodo, quindi visualizza tutti i campi di un documento. Per limitare ciò, è necessario impostare un elenco di campi con valore 1 o 0. 1 viene utilizzato per mostrare il campo mentre 0 viene utilizzato per nascondere i campi.
Sintassi
La sintassi di base di find() metodo con proiezione è il seguente:
>db.COLLECTION_NAME.find({},{KEY:1})Esempio
Considera che la raccolta mycol ha i seguenti dati:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}L'esempio seguente visualizzerà il titolo del documento durante l'interrogazione del documento.
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>notare che _id viene sempre visualizzato durante l'esecuzione find() metodo, se non vuoi questo campo, devi impostarlo come 0.
In questo capitolo impareremo come limitare i record usando MongoDB.
Il metodo Limit ()
Per limitare i record in MongoDB, è necessario utilizzare limit()metodo. Il metodo accetta un argomento di tipo numerico, che è il numero di documenti che si desidera visualizzare.
Sintassi
La sintassi di base di limit() il metodo è il seguente:
>db.COLLECTION_NAME.find().limit(NUMBER)Esempio
Considera la raccolta myycol ha i seguenti dati.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}L'esempio seguente visualizzerà solo due documenti durante l'interrogazione del documento.
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>Se non specifichi l'argomento numero in limit() metodo quindi visualizzerà tutti i documenti della raccolta.
Metodo MongoDB Skip ()
Oltre al metodo limit (), esiste un altro metodo skip() che accetta anche argomenti di tipo numerico e viene utilizzato per saltare il numero di documenti.
Sintassi
La sintassi di base di skip() il metodo è il seguente:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)Esempio
L'esempio seguente visualizzerà solo il secondo documento.
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>Tieni presente che il valore predefinito in skip() metodo è 0.
In questo capitolo impareremo come ordinare i record in MongoDB.
Il metodo sort ()
Per ordinare i documenti in MongoDB, devi usare sort()metodo. Il metodo accetta un documento contenente un elenco di campi insieme al loro ordinamento. Per specificare l'ordinamento vengono utilizzati 1 e -1. 1 è usato per l'ordine crescente mentre -1 è usato per l'ordine decrescente.
Sintassi
La sintassi di base di sort() il metodo è il seguente:
>db.COLLECTION_NAME.find().sort({KEY:1})Esempio
Considera la raccolta myycol ha i seguenti dati.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}L'esempio seguente visualizzerà i documenti ordinati per titolo in ordine decrescente.
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>Tieni presente che se non specifichi la preferenza di ordinamento, allora sort() il metodo visualizzerà i documenti in ordine crescente.
Gli indici supportano la risoluzione efficiente delle query. Senza indici, MongoDB deve scansionare ogni documento di una raccolta per selezionare quei documenti che corrispondono all'istruzione della query. Questa scansione è altamente inefficiente e richiede che MongoDB elabori un grande volume di dati.
Gli indici sono strutture di dati speciali, che memorizzano una piccola parte del set di dati in una forma facile da attraversare. L'indice memorizza il valore di un campo specifico o di un insieme di campi, ordinato in base al valore del campo come specificato nell'indice.
Il metodo sureIndex ()
Per creare un indice è necessario utilizzare il metodo sureIndex () di MongoDB.
Sintassi
La sintassi di base di ensureIndex() metodo è il seguente ().
>db.COLLECTION_NAME.ensureIndex({KEY:1})Qui la chiave è il nome del campo in cui si desidera creare l'indice e 1 è per l'ordine crescente. Per creare un indice in ordine decrescente è necessario utilizzare -1.
Esempio
>db.mycol.ensureIndex({"title":1})
>In ensureIndex() metodo puoi passare più campi, per creare indice su più campi.
>db.mycol.ensureIndex({"title":1,"description":-1})
>ensureIndex()metodo accetta anche un elenco di opzioni (che sono opzionali). Di seguito è riportato l'elenco:
| Parametro | genere | Descrizione |
|---|---|---|
| sfondo | Booleano | Crea l'indice in background in modo che la creazione di un indice non blocchi altre attività del database. Specificare true per creare in background. Il valore predefinito èfalse. |
| unico | Booleano | Crea un indice univoco in modo che la raccolta non accetti l'inserimento di documenti in cui la chiave o le chiavi dell'indice corrispondono a un valore esistente nell'indice. Specificare true per creare un indice univoco. Il valore predefinito èfalse. |
| nome | corda | Il nome dell'indice. Se non specificato, MongoDB genera un nome di indice concatenando i nomi dei campi indicizzati e l'ordinamento. |
| dropDups | Booleano | Crea un indice univoco su un campo che potrebbe avere duplicati. MongoDB indicizza solo la prima occorrenza di una chiave e rimuove tutti i documenti dalla raccolta che contengono le occorrenze successive di quella chiave. Specificare true per creare un indice univoco. Il valore predefinito èfalse. |
| sparse | Booleano | Se true, l'indice fa riferimento solo ai documenti con il campo specificato. Questi indici utilizzano meno spazio ma si comportano in modo diverso in alcune situazioni (in particolare gli ordinamenti). Il valore predefinito èfalse. |
| expireAfterSeconds | numero intero | Specifica un valore, in secondi, come TTL per controllare per quanto tempo MongoDB conserva i documenti in questa raccolta. |
| v | versione indice | Il numero di versione dell'indice. La versione dell'indice predefinita dipende dalla versione di MongoDB in esecuzione durante la creazione dell'indice. |
| pesi | documento | Il peso è un numero compreso tra 1 e 99.999 e denota la significatività del campo rispetto agli altri campi indicizzati in termini di punteggio. |
| lingua di default | corda | Per un indice di testo, la lingua che determina l'elenco di parole non significative e le regole per stemmer e tokenizer. Il valore predefinito èenglish. |
| language_override | corda | Per un indice di testo, specificare il nome del campo nel documento che contiene, la lingua da sostituire alla lingua predefinita. Il valore predefinito è la lingua. |
Le operazioni di aggregazione elaborano i record di dati e restituiscono i risultati calcolati. Le operazioni di aggregazione raggruppano i valori di più documenti e possono eseguire una serie di operazioni sui dati raggruppati per restituire un unico risultato. In SQL count (*) e con group by è un equivalente dell'aggregazione mongodb.
Il metodo aggregate ()
Per l'aggregazione in MongoDB, dovresti usare aggregate() metodo.
Sintassi
Sintassi di base di aggregate() il metodo è il seguente:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)Esempio
Nella raccolta hai i seguenti dati:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},Ora dalla raccolta sopra, se vuoi visualizzare un elenco che indica quanti tutorial sono scritti da ciascun utente, allora utilizzerai quanto segue aggregate() metodo -
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>La query SQL equivalente per il caso d'uso precedente sarà select by_user, count(*) from mycol group by by_user.
Nell'esempio sopra, abbiamo raggruppato i documenti per campo by_usere ad ogni occorrenza di by_user il valore precedente di sum viene incrementato. Di seguito è riportato un elenco di espressioni di aggregazione disponibili.
| Espressione | Descrizione | Esempio |
|---|---|---|
| $ somma | Riassume il valore definito da tutti i documenti nella raccolta. | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$somma: "$ piace"}}}]) |
| $ avg | Calcola la media di tutti i valori dati da tutti i documenti nella raccolta. | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$avg : "$piace"}}}]) |
| $ min | Ottiene il minimo dei valori corrispondenti da tutti i documenti nella raccolta. | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$min: "$ likes"}}}]) |
| $ max | Ottiene il massimo dei valori corrispondenti da tutti i documenti nella raccolta. | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$max : "$piace"}}}]) |
| $ push | Inserisce il valore in una matrice nel documento risultante. | db.mycol.aggregate ([{$ group: {_id: "$by_user", url : {$push: "$ url"}}}]) |
| $ addToSet | Inserisce il valore in una matrice nel documento risultante ma non crea duplicati. | db.mycol.aggregate ([{$group : {_id : "$by_user ", url: {$addToSet : "$url "}}}]) |
| $ primo | Ottiene il primo documento dai documenti di origine in base al raggruppamento. Tipicamente questo ha senso solo insieme ad alcuni stage "$ sort" precedentemente applicati. | db.mycol.aggregate ([{$group : {_id : "$by_user ", first_url: {$first : "$url "}}}]) |
| $ last | Ottiene l'ultimo documento dai documenti di origine in base al raggruppamento. Tipicamente questo ha senso solo insieme ad alcuni stage "$ sort" precedentemente applicati. | db.mycol.aggregate ([{$group : {_id : "$by_user ", last_url: {$last : "$url "}}}]) |
Concetto di pipeline
Nel comando UNIX, shell pipeline significa la possibilità di eseguire un'operazione su un input e utilizzare l'output come input per il comando successivo e così via. MongoDB supporta anche lo stesso concetto nel framework di aggregazione. Esiste una serie di fasi possibili e ciascuna di queste viene presa come una serie di documenti come input e produce una serie di documenti risultante (o il documento JSON finale risultante alla fine della pipeline). Questo può quindi essere utilizzato a sua volta per la fase successiva e così via.
Di seguito sono riportate le possibili fasi del framework di aggregazione:
$project - Utilizzato per selezionare alcuni campi specifici da una raccolta.
$match - Questa è un'operazione di filtraggio e quindi può ridurre la quantità di documenti che vengono forniti come input per la fase successiva.
$group - Questo fa l'effettiva aggregazione come discusso sopra.
$sort - Ordina i documenti.
$skip - Con questo, è possibile saltare in avanti nell'elenco dei documenti per una data quantità di documenti.
$limit - Questo limita la quantità di documenti da guardare, dal numero dato a partire dalle posizioni correnti.
$unwind- Viene utilizzato per srotolare documenti che utilizzano array. Quando si utilizza un array, i dati sono una specie di preunione e questa operazione verrà annullata per avere nuovamente i singoli documenti. Quindi con questa fase aumenteremo la quantità di documenti per la fase successiva.
La replica è il processo di sincronizzazione dei dati su più server. La replica fornisce ridondanza e aumenta la disponibilità dei dati con più copie di dati su diversi server di database. La replica protegge un database dalla perdita di un singolo server. La replica consente inoltre di eseguire il ripristino da errori hardware e interruzioni del servizio. Con copie aggiuntive dei dati, è possibile dedicarne una al ripristino di emergenza, al reporting o al backup.
Perché la replica?
- Per mantenere i tuoi dati al sicuro
- Disponibilità di dati elevata (24 * 7)
- Ripristino di emergenza
- Nessun tempo di inattività per la manutenzione (come backup, ricostruzioni di indici, compattazione)
- Ridimensionamento in lettura (copie extra da leggere)
- Il set di repliche è trasparente per l'applicazione
Come funziona la replica in MongoDB
MongoDB ottiene la replica tramite l'uso del set di repliche. Un set di repliche è un gruppo dimongodistanze che ospitano lo stesso set di dati. In una replica, un nodo è il nodo primario che riceve tutte le operazioni di scrittura. Tutte le altre istanze, come le secondarie, applicano le operazioni dal primario in modo che abbiano lo stesso set di dati. Il set di repliche può avere un solo nodo primario.
Il set di repliche è un gruppo di due o più nodi (generalmente sono richiesti almeno 3 nodi).
In un set di repliche, un nodo è il nodo primario ei nodi rimanenti sono secondari.
Tutti i dati vengono replicati dal nodo primario a quello secondario.
Al momento del failover automatico o della manutenzione, l'elezione stabilisce per primario e viene eletto un nuovo nodo primario.
Dopo il ripristino del nodo guasto, si unisce di nuovo al set di repliche e funziona come nodo secondario.
Viene mostrato un tipico diagramma della replica di MongoDB in cui l'applicazione client interagisce sempre con il nodo primario e il nodo primario replica quindi i dati sui nodi secondari.

Funzionalità del set di repliche
- Un cluster di N nodi
- Ogni nodo può essere primario
- Tutte le operazioni di scrittura vanno alla primaria
- Failover automatico
- Ripristino automatico
- Elezione consensuale delle primarie
Configurazione di un set di repliche
In questo tutorial, convertiremo l'istanza MongoDB autonoma in un set di repliche. Per convertire in set di repliche, di seguito sono riportati i passaggi:
Arresto già in esecuzione sul server MongoDB.
Avvia il server MongoDB specificando l'opzione - replSet. Di seguito è riportata la sintassi di base di --replSet -
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"Esempio
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0Avvierà un'istanza mongod con il nome rs0, sulla porta 27017.
Ora avvia il prompt dei comandi e connettiti a questa istanza di mongod.
Nel client Mongo, immetti il comando rs.initiate() per avviare un nuovo set di repliche.
Per controllare la configurazione del set di repliche, emettere il comando rs.conf(). Per controllare lo stato del set di repliche, emettere il comandors.status().
Aggiungi membri al set di repliche
Per aggiungere membri al set di repliche, avviare le istanze di mongod su più macchine. Ora avvia un client mongo e invia un comandors.add().
Sintassi
La sintassi di base di rs.add() il comando è il seguente:
>rs.add(HOST_NAME:PORT)Esempio
Supponiamo che il nome dell'istanza di mongod sia mongod1.net ed è in esecuzione in porto 27017. Per aggiungere questa istanza al set di repliche, emettere il comandors.add() nel client Mongo.
>rs.add("mongod1.net:27017")
>Puoi aggiungere l'istanza mongod al set di repliche solo quando sei connesso al nodo primario. Per verificare se sei connesso alla primaria o meno, esegui il comandodb.isMaster() in mongo client.
Lo sharding è il processo di archiviazione dei record di dati su più macchine ed è l'approccio di MongoDB per soddisfare le esigenze di crescita dei dati. Con l'aumentare della dimensione dei dati, una singola macchina potrebbe non essere sufficiente per memorizzare i dati né fornire una velocità di lettura e scrittura accettabile. Sharding risolve il problema con il ridimensionamento orizzontale. Con lo sharding, aggiungi più macchine per supportare la crescita dei dati e le richieste di operazioni di lettura e scrittura.
Perché lo sharding?
- Nella replica, tutte le scritture vanno al nodo master
- Le query sensibili alla latenza vanno ancora al master
- Il set di repliche singolo ha una limitazione di 12 nodi
- La memoria non può essere abbastanza grande quando il set di dati attivo è grande
- Il disco locale non è abbastanza grande
- Il ridimensionamento verticale è troppo costoso
Sharding in MongoDB
Il diagramma seguente mostra lo sharding in MongoDB usando il cluster sharded.

Nel diagramma seguente, ci sono tre componenti principali:
Shards- I frammenti vengono utilizzati per memorizzare i dati. Forniscono elevata disponibilità e coerenza dei dati. Nell'ambiente di produzione, ogni frammento è un set di repliche separato.
Config Servers- I server di configurazione memorizzano i metadati del cluster. Questi dati contengono una mappatura del set di dati del cluster sui frammenti. Il router di query utilizza questi metadati per indirizzare le operazioni a frammenti specifici. Nell'ambiente di produzione, i cluster frammentati hanno esattamente 3 server di configurazione.
Query Routers- I router di query sono fondamentalmente istanze di mongo, si interfacciano con le applicazioni client e dirigono le operazioni allo shard appropriato. Il router di query elabora e indirizza le operazioni a frammenti, quindi restituisce i risultati ai client. Un cluster frammentato può contenere più di un router di query per suddividere il carico di richieste del client. Un client invia richieste a un router di query. In genere, un cluster partizionato ha molti router di query.
In questo capitolo vedremo come creare un backup in MongoDB.
Esegui il dump dei dati MongoDB
Per creare il backup del database in MongoDB, dovresti usare mongodumpcomando. Questo comando scaricherà tutti i dati del tuo server nella directory dump. Sono disponibili molte opzioni per limitare la quantità di dati o creare backup del server remoto.
Sintassi
La sintassi di base di mongodump il comando è il seguente:
>mongodumpEsempio
Avvia il tuo server mongod. Supponendo che il tuo server mongod sia in esecuzione su localhost e sulla porta 27017, apri un prompt dei comandi e vai alla directory bin della tua istanza mongodb e digita il comandomongodump
Considera che la raccolta mycol ha i seguenti dati.
>mongodumpIl comando si connetterà al server in esecuzione su 127.0.0.1 e porto 27017 e riporta tutti i dati del server nella directory /bin/dump/. Di seguito è riportato l'output del comando -

Di seguito è riportato un elenco delle opzioni disponibili che possono essere utilizzate con mongodump comando.
| Sintassi | Descrizione | Esempio |
|---|---|---|
| mongodump --host HOST_NAME --port PORT_NUMBER | Questo comando eseguirà il backup di tutti i database dell'istanza di mongod specificata. | mongodump --host tutorialspoint.com --port 27017 |
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | Questo comando eseguirà il backup solo del database specificato nel percorso specificato. | mongodump --dbpath / data / db / --out / data / backup / |
| mongodump --collection COLLECTION --db DB_NAME | Questo comando eseguirà il backup solo della raccolta specificata del database specificato. | mongodump --collection mycol --db test |
Ripristinare i dati
Per ripristinare i dati di backup di MongoDB mongorestoreviene utilizzato il comando. Questo comando ripristina tutti i dati dalla directory di backup.
Sintassi
La sintassi di base di mongorestore il comando è -
>mongorestoreDi seguito è riportato l'output del comando -

Quando prepari una distribuzione di MongoDB, dovresti cercare di capire come la tua applicazione reggerà in produzione. È una buona idea sviluppare un approccio coerente e ripetibile alla gestione dell'ambiente di distribuzione in modo da ridurre al minimo eventuali sorprese una volta entrati in produzione.
L'approccio migliore include la prototipazione della configurazione, l'esecuzione di test di carico, il monitoraggio delle metriche chiave e l'utilizzo di tali informazioni per ridimensionare la configurazione. La parte fondamentale dell'approccio consiste nel monitorare in modo proattivo l'intero sistema: questo ti aiuterà a capire come resisterà il tuo sistema di produzione prima della distribuzione e a determinare dove dovrai aggiungere capacità. Avere informazioni su potenziali picchi nell'utilizzo della memoria, ad esempio, potrebbe aiutare a spegnere un incendio di blocco in scrittura prima che inizi.
Per monitorare la tua distribuzione, MongoDB fornisce alcuni dei seguenti comandi:
mongostato
Questo comando controlla lo stato di tutte le istanze di mongod in esecuzione e restituisce i contatori delle operazioni del database. Questi contatori includono inserimenti, query, aggiornamenti, eliminazioni e cursori. Il comando mostra anche quando si verificano errori di pagina e mostra la percentuale di blocco. Ciò significa che stai esaurendo la memoria, raggiungi la capacità di scrittura o hai qualche problema di prestazioni.
Per eseguire il comando, avvia la tua istanza mongod. In un altro prompt dei comandi, vai abin directory della tua installazione di mongodb e digita mongostat.
D:\set up\mongodb\bin>mongostatDi seguito è riportato l'output del comando -

mongotop
Questo comando tiene traccia e segnala l'attività di lettura e scrittura dell'istanza di MongoDB in base alla raccolta. Per impostazione predefinita,mongotoprestituisce informazioni in ogni secondo, che puoi modificare di conseguenza. È necessario verificare che questa attività di lettura e scrittura corrisponda all'intenzione dell'applicazione e non si stanno attivando troppe scritture alla volta sul database, si legge troppo spesso da un disco o si stanno superando le dimensioni del working set.
Per eseguire il comando, avvia la tua istanza mongod. In un altro prompt dei comandi, vai abin directory della tua installazione di mongodb e digita mongotop.
D:\set up\mongodb\bin>mongotopDi seguito è riportato l'output del comando -
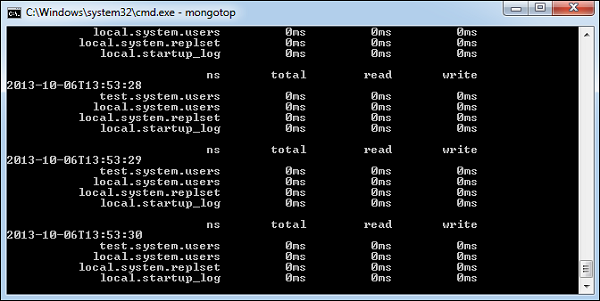
Cambiare mongotop comando per restituire le informazioni meno frequentemente, specificare un numero specifico dopo il comando mongotop.
D:\set up\mongodb\bin>mongotop 30L'esempio precedente restituirà valori ogni 30 secondi.
Oltre agli strumenti MongoDB, 10gen fornisce un servizio di monitoraggio ospitato gratuito, MongoDB Management Service (MMS), che fornisce una dashboard e ti offre una visualizzazione delle metriche dell'intero cluster.
In questo capitolo impareremo come configurare il driver JDBC di MongoDB.
Installazione
Prima di iniziare a utilizzare MongoDB nei programmi Java, è necessario assicurarsi di avere il driver JDBC MongoDB e Java configurato sulla macchina. Puoi controllare il tutorial Java per l'installazione di Java sulla tua macchina. Ora, controlliamo come configurare il driver JDBC di MongoDB.
Devi scaricare il jar dal percorso Download mongo.jar . Assicurati di scaricare l'ultima versione di esso.
Devi includere mongo.jar nel tuo classpath.
Connetti al database
Per connettere il database, è necessario specificare il nome del database, se il database non esiste, MongoDB lo crea automaticamente.
Di seguito è riportato lo snippet di codice per connettersi al database:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}Ora compiliamo ed eseguiamo il programma sopra per creare il nostro database myDb come mostrato di seguito.
$javac ConnectToDB.java
$java ConnectToDBAll'esecuzione, il programma sopra ti dà il seguente output.
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}Crea una raccolta
Per creare una raccolta, createCollection() metodo di com.mongodb.client.MongoDatabase viene utilizzata la classe.
Di seguito è riportato lo snippet di codice per creare una raccolta:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection created successfullyRecupero / selezione di una raccolta
Per ottenere / selezionare una raccolta dal database, getCollection() metodo di com.mongodb.client.MongoDatabase viene utilizzata la classe.
Di seguito è riportato il programma per ottenere / selezionare una raccolta:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection created successfully
Collection myCollection selected successfullyInserisci un documento
Per inserire un documento in MongoDB, insert() metodo di com.mongodb.client.MongoCollection viene utilizzata la classe.
Di seguito è riportato lo snippet di codice per inserire un documento:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection sampleCollection selected successfully
Document inserted successfullyRecupera tutti i documenti
Per selezionare tutti i documenti dalla raccolta, find() metodo di com.mongodb.client.MongoCollectionviene utilizzata la classe. Questo metodo restituisce un cursore, quindi è necessario iterare questo cursore.
Di seguito è riportato il programma per selezionare tutti i documenti -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = http://www.tutorialspoint.com/rethinkdb/, by = tutorials point
}}Aggiorna documento
Per aggiornare un documento dalla raccolta, updateOne() metodo di com.mongodb.client.MongoCollection viene utilizzata la classe.
Di seguito è riportato il programma per selezionare il primo documento -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}Elimina un documento
Per eliminare un documento dalla raccolta, è necessario utilizzare il file deleteOne() metodo del com.mongodb.client.MongoCollection classe.
Di seguito è riportato il programma per eliminare un documento:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection sampleCollection selected successfully
Document deleted successfully...Far cadere una raccolta
Per eliminare una raccolta da un database, è necessario utilizzare il drop() metodo del com.mongodb.client.MongoCollection classe.
Di seguito è riportato il programma per eliminare una raccolta:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection sampleCollection selected successfully
Collection dropped successfullyElenco di tutte le collezioni
Per elencare tutte le raccolte in un database, è necessario utilizzare il file listCollectionNames() metodo del com.mongodb.client.MongoDatabase classe.
Di seguito è riportato il programma per elencare tutte le raccolte di un database:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}Durante la compilazione, il programma sopra ti dà il seguente risultato:
Connected to the database successfully
Collection created successfully
myCollection
myCollection1
myCollection5Metodi MongoDB rimanenti save(), limit(), skip(), sort() ecc. funzionano come spiegato nel tutorial successivo.
Per utilizzare MongoDB con PHP, è necessario utilizzare il driver MongoDB PHP. Scarica il driver dall'URL Scarica driver PHP . Assicurati di scaricare l'ultima versione di esso. Ora decomprimi l'archivio e metti php_mongo.dll nella directory dell'estensione PHP ("ext" per impostazione predefinita) e aggiungi la seguente riga al tuo file php.ini -
extension = php_mongo.dllEffettua una connessione e seleziona un database
Per effettuare una connessione, è necessario specificare il nome del database, se il database non esiste, MongoDB lo crea automaticamente.
Di seguito è riportato lo snippet di codice per connettersi al database:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selectedCrea una raccolta
Di seguito è riportato lo snippet di codice per creare una raccolta:
<?php
// connect to mongodb
$m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; $collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selected
Collection created succsessfullyInserisci un documento
Per inserire un documento in MongoDB, insert() viene utilizzato il metodo.
Di seguito è riportato lo snippet di codice per inserire un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array( "title" => "MongoDB", "description" => "database", "likes" => 100, "url" => "http://www.tutorialspoint.com/mongodb/", "by" => "tutorials point" ); $collection->insert($document);
echo "Document inserted successfully";
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document inserted successfullyTrova tutti i documenti
Per selezionare tutti i documenti dalla raccolta, viene utilizzato il metodo find ().
Di seguito è riportato lo snippet di codice per selezionare tutti i documenti:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}Aggiorna un documento
Per aggiornare un documento, è necessario utilizzare il metodo update ().
Nel seguente esempio, aggiorneremo il titolo del documento inserito in MongoDB Tutorial. Di seguito è riportato lo snippet di codice per aggiornare un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"), array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}Elimina un documento
Per eliminare un documento, è necessario utilizzare il metodo remove ().
Nel seguente esempio, rimuoveremo i documenti che hanno il titolo MongoDB Tutorial. Di seguito è riportato lo snippet di codice per eliminare un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false); echo "Documents deleted successfully"; // now display the available documents $cursor = $collection->find(); // iterate cursor to display title of documents echo "Updated document"; foreach ($cursor as $document) { echo $document["title"] . "\n";
}
?>Quando il programma viene eseguito, produrrà il seguente risultato:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Documents deleted successfullyNell'esempio precedente, il secondo parametro è di tipo booleano e viene utilizzato per justOne campo di remove() metodo.
Metodi MongoDB rimanenti findOne(), save(), limit(), skip(), sort() ecc. funziona come spiegato sopra.
Le relazioni in MongoDB rappresentano il modo in cui i vari documenti sono logicamente correlati tra loro. Le relazioni possono essere modellate tramiteEmbedded e Referencedapprocci. Tali relazioni possono essere 1: 1, 1: N, N: 1 o N: N.
Consideriamo il caso della memorizzazione degli indirizzi per gli utenti. Quindi, un utente può avere più indirizzi rendendo questa relazione 1: N.
Di seguito è riportata la struttura del documento di esempio di user documento -
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}Di seguito è riportata la struttura del documento di esempio di address documento -
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}Modellazione di relazioni incorporate
Nell'approccio incorporato, incorporeremo il documento dell'indirizzo all'interno del documento dell'utente.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}Questo approccio mantiene tutti i dati correlati in un unico documento, il che ne semplifica il recupero e la manutenzione. L'intero documento può essere recuperato in una singola query come:
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})Nota che nella query sopra, db e users sono rispettivamente il database e la raccolta.
Lo svantaggio è che se il documento incorporato continua a crescere di dimensioni eccessive, può influire sulle prestazioni di lettura / scrittura.
Modellazione delle relazioni referenziate
Questo è l'approccio per progettare una relazione normalizzata. In questo approccio, sia il documento dell'utente che quello dell'indirizzo verranno conservati separatamente, ma il documento dell'utente conterrà un campo che farà riferimento al documento dell'indirizzoid campo.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}Come mostrato sopra, il documento utente contiene il campo array address_idsche contiene ObjectId degli indirizzi corrispondenti. Usando questi ObjectID, possiamo interrogare i documenti dell'indirizzo e ottenere i dettagli dell'indirizzo da lì. Con questo approccio, avremo bisogno di due query: la prima per recuperare il fileaddress_ids campi da user documento e il secondo da cui recuperare questi indirizzi address collezione.
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})Come visto nell'ultimo capitolo delle relazioni di MongoDB, per implementare una struttura di database normalizzata in MongoDB, usiamo il concetto di Referenced Relationships indicato anche come Manual Referencesin cui memorizziamo manualmente l'ID del documento di riferimento all'interno di un altro documento. Tuttavia, nei casi in cui un documento contiene riferimenti da diverse raccolte, possiamo usareMongoDB DBRefs.
DBRefs vs riferimenti manuali
Come scenario di esempio, in cui utilizzeremmo DBRefs invece di riferimenti manuali, consideriamo un database in cui memorizziamo diversi tipi di indirizzi (casa, ufficio, posta, ecc.) In diverse raccolte (address_home, address_office, address_mailing, ecc.). Ora, quando auseril documento della raccolta fa riferimento a un indirizzo, è inoltre necessario specificare in quale raccolta esaminare in base al tipo di indirizzo. In tali scenari in cui un documento fa riferimento a documenti di molte raccolte, dovremmo usare DBRefs.
Utilizzando DBRefs
Ci sono tre campi in DBRefs:
$ref - Questo campo specifica la raccolta del documento di riferimento
$id - Questo campo specifica il campo _id del documento di riferimento
$db - Questo è un campo opzionale e contiene il nome del database in cui si trova il documento di riferimento
Considera un documento utente di esempio con un campo DBRef address come mostrato nello snippet di codice -
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home", "$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}Il address Il campo DBRef qui specifica che si trova il documento dell'indirizzo di riferimento address_home raccolta sotto tutorialspoint database e ha un ID di 534009e4d852427820000002.
Il codice seguente cerca dinamicamente nella raccolta specificata da $ref parametro (address_home nel nostro caso) per un documento con id come specificato da $id parametro in DBRef.
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})Il codice sopra restituisce il seguente documento di indirizzo presente in address_home raccolta -
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}In questo capitolo, impareremo le query coperte.
Che cos'è una query coperta?
Secondo la documentazione ufficiale di MongoDB, una query coperta è una query in cui:
- Tutti i campi della query fanno parte di un indice.
- Tutti i campi restituiti nella query si trovano nello stesso indice.
Poiché tutti i campi presenti nella query fanno parte di un indice, MongoDB soddisfa le condizioni della query e restituisce il risultato utilizzando lo stesso indice senza effettivamente guardare all'interno dei documenti. Poiché gli indici sono presenti nella RAM, il recupero dei dati dagli indici è molto più veloce rispetto al recupero dei dati tramite la scansione dei documenti.
Utilizzo delle query coperte
Per testare le query coperte, considera il seguente documento in users raccolta -
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}Per prima cosa creeremo un indice composto per users raccolta sui campi gender e user_name utilizzando la seguente query -
>db.users.ensureIndex({gender:1,user_name:1})Ora, questo indice coprirà la seguente query:
>db.users.find({gender:"M"},{user_name:1,_id:0})Vale a dire che per la query sopra, MongoDB non esaminerà i documenti del database. Invece recupererebbe i dati richiesti dai dati indicizzati che è molto veloce.
Poiché il nostro indice non include _idcampo, lo abbiamo escluso esplicitamente dal set di risultati della nostra query, poiché MongoDB per impostazione predefinita restituisce il campo _id in ogni query. Quindi la seguente query non sarebbe stata coperta all'interno dell'indice creato sopra -
>db.users.find({gender:"M"},{user_name:1})Infine, ricorda che un indice non può coprire una query se:
- Uno qualsiasi dei campi indicizzati è un array
- Qualsiasi campo indicizzato è un documento secondario
L'analisi delle query è un aspetto molto importante per misurare l'efficacia del database e del progetto di indicizzazione. Impareremo a conoscere i più usati$explain e $hint interrogazioni.
Utilizzando $ spiegare
Il $explainL'operatore fornisce informazioni sulla query, sugli indici utilizzati in una query e altre statistiche. È molto utile quando si analizza il livello di ottimizzazione dei propri indici.
Nell'ultimo capitolo, avevamo già creato un indice per il file users raccolta sui campi gender e user_name utilizzando la seguente query -
>db.users.ensureIndex({gender:1,user_name:1})Ora useremo $explain sulla seguente query -
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()La query precedente discover () restituisce il seguente risultato analizzato:
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1 }, { "$maxElement" : 1
}
]
]
}
}Ora esamineremo i campi in questo set di risultati:
Il vero valore di indexOnly indica che questa query ha utilizzato l'indicizzazione.
Il cursorcampo specifica il tipo di cursore utilizzato. Il tipo BTreeCursor indica che è stato utilizzato un indice e fornisce anche il nome dell'indice utilizzato. BasicCursor indica che è stata eseguita una scansione completa senza utilizzare alcun indice.
n indica il numero di documenti corrispondenti restituiti.
nscannedObjects indica il numero totale di documenti scansionati.
nscanned indica il numero totale di documenti o voci di indice scansionati.
Utilizzando $ hint
Il $hintobbliga Query Optimizer a utilizzare l'indice specificato per eseguire una query. Ciò è particolarmente utile quando si desidera testare le prestazioni di una query con indici diversi. Ad esempio, la seguente query specifica l'indice sui campigender e user_name da utilizzare per questa query -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})Per analizzare la query sopra utilizzando $ spiegare -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()Dati modello per operazioni atomiche
L'approccio consigliato per mantenere l'atomicità sarebbe quello di mantenere tutte le informazioni correlate, che vengono frequentemente aggiornate insieme in un unico documento utilizzando embedded documents. Ciò assicurerebbe che tutti gli aggiornamenti per un singolo documento siano atomici.
Considera il seguente documento sui prodotti:
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}In questo documento abbiamo incorporato le informazioni del cliente che acquista il prodotto nel file product_bought_bycampo. Ora, ogni volta che un nuovo cliente acquista il prodotto, controlleremo prima se il prodotto è ancora disponibile utilizzandoproduct_availablecampo. Se disponibile, ridurremo il valore del campo product_available e inseriremo il documento incorporato del nuovo cliente nel campo product_bought_by. Noi useremofindAndModify comando per questa funzionalità perché cerca e aggiorna il documento nello stesso passaggio.
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1}, $push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})Il nostro approccio al documento incorporato e all'utilizzo della query findAndModify garantisce che le informazioni sull'acquisto del prodotto vengano aggiornate solo se il prodotto è disponibile. E l'intera transazione nella stessa query è atomica.
Al contrario, considera lo scenario in cui potremmo aver mantenuto la disponibilità del prodotto e le informazioni su chi ha acquistato il prodotto, separatamente. In questo caso, controlleremo prima se il prodotto è disponibile utilizzando la prima query. Quindi nella seconda query aggiorneremo le informazioni di acquisto. Tuttavia, è possibile che tra le esecuzioni di queste due query, qualche altro utente abbia acquistato il prodotto e non sia più disponibile. Senza saperlo, la nostra seconda query aggiornerà le informazioni di acquisto in base al risultato della nostra prima query. Ciò renderà il database incoerente perché abbiamo venduto un prodotto che non è disponibile.
Considera il seguente documento di users raccolta -
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}Il documento sopra contiene un file address sub-document e a tags array.
Indicizzazione dei campi della matrice
Supponiamo di voler cercare i documenti dell'utente in base ai tag dell'utente. Per questo, creeremo un indice sull'array di tag nella raccolta.
La creazione di un indice su un array a sua volta crea voci di indice separate per ciascuno dei suoi campi. Quindi nel nostro caso, quando creiamo un indice su un array di tag, verranno creati indici separati per i suoi valori musica, cricket e blog.
Per creare un indice sull'array di tag, utilizzare il codice seguente:
>db.users.ensureIndex({"tags":1})Dopo aver creato l'indice, possiamo cercare nel campo dei tag della raccolta in questo modo:
>db.users.find({tags:"cricket"})Per verificare che venga utilizzata l'indicizzazione corretta, utilizzare quanto segue explain comando -
>db.users.find({tags:"cricket"}).explain()Il comando precedente ha dato come risultato "cursore": "BtreeCursor tags_1" che conferma che viene utilizzata l'indicizzazione corretta.
Indicizzazione dei campi del documento secondario
Supponiamo di voler cercare documenti in base a campi città, stato e codice PIN. Poiché tutti questi campi fanno parte del campo del sottodocumento dell'indirizzo, creeremo un indice su tutti i campi del sottodocumento.
Per creare un indice su tutti e tre i campi del sottodocumento, utilizzare il codice seguente:
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})Una volta creato l'indice, possiamo cercare uno qualsiasi dei campi del documento secondario utilizzando questo indice come segue:
>db.users.find({"address.city":"Los Angeles"})Ricorda che l'espressione della query deve seguire l'ordine dell'indice specificato. Quindi l'indice creato sopra supporterebbe le seguenti query:
>db.users.find({"address.city":"Los Angeles","address.state":"California"})Supporterà anche la seguente query:
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})In questo capitolo apprenderemo le limitazioni all'indicizzazione e gli altri suoi componenti.
Overhead extra
Ogni indice occupa un po 'di spazio e causa un sovraccarico su ogni inserimento, aggiornamento ed eliminazione. Quindi, se usi raramente la tua raccolta per operazioni di lettura, ha senso non usare gli indici.
Utilizzo della RAM
Poiché gli indici sono memorizzati nella RAM, è necessario assicurarsi che la dimensione totale dell'indice non superi il limite di RAM. Se la dimensione totale aumenta la dimensione della RAM, inizierà a eliminare alcuni indici, causando una perdita di prestazioni.
Limitazioni delle query
L'indicizzazione non può essere utilizzata nelle query che utilizzano -
- Espressioni regolari o operatori di negazione come $nin, $no, ecc.
- Operatori aritmetici come $ mod, ecc.
- $ clausola where
Quindi, è sempre consigliabile controllare l'utilizzo dell'indice per le tue query.
Limiti chiave dell'indice
A partire dalla versione 2.6, MongoDB non creerà un indice se il valore del campo dell'indice esistente supera il limite della chiave dell'indice.
Inserimento di documenti che superano il limite della chiave di indice
MongoDB non inserirà alcun documento in una raccolta indicizzata se il valore del campo indicizzato di questo documento supera il limite della chiave dell'indice. Lo stesso è il caso delle utility mongorestore e mongoimport.
Intervalli massimi
- Una raccolta non può contenere più di 64 indici.
- La lunghezza del nome dell'indice non può superare i 125 caratteri.
- Un indice composto può avere un massimo di 31 campi indicizzati.
Abbiamo utilizzato MongoDB Object Id in tutti i capitoli precedenti. In questo capitolo capiremo la struttura di ObjectId.
Un ObjectId è un tipo BSON a 12 byte con la seguente struttura:
- I primi 4 byte che rappresentano i secondi trascorsi dall'epoca unix
- I prossimi 3 byte sono l'identificatore della macchina
- I prossimi 2 byte sono costituiti da process id
- Gli ultimi 3 byte sono un valore di contatore casuale
MongoDB utilizza ObjectIds come valore predefinito di _idcampo di ogni documento, che viene generato durante la creazione di qualsiasi documento. La complessa combinazione di ObjectId rende unici tutti i campi _id.
Creazione di un nuovo ID oggetto
Per generare un nuovo ObjectId utilizzare il codice seguente:
>newObjectId = ObjectId()L'istruzione precedente ha restituito il seguente id generato in modo univoco:
ObjectId("5349b4ddd2781d08c09890f3")Invece di MongoDB che genera l'ObjectId, puoi anche fornire un ID a 12 byte -
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")Creazione di timestamp di un documento
Poiché _id ObjectId per impostazione predefinita memorizza il timestamp a 4 byte, nella maggior parte dei casi non è necessario memorizzare l'ora di creazione di alcun documento. Puoi recuperare l'ora di creazione di un documento utilizzando il metodo getTimestamp -
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()Ciò restituirà l'ora di creazione di questo documento nel formato di data ISO -
ISODate("2014-04-12T21:49:17Z")Conversione di ObjectId in String
In alcuni casi, potrebbe essere necessario il valore di ObjectId in un formato stringa. Per convertire ObjectId in stringa, utilizzare il codice seguente:
>newObjectId.strIl codice sopra restituirà il formato stringa del Guid -
5349b4ddd2781d08c09890f3Secondo la documentazione di MongoDB, Map-reduceè un paradigma di elaborazione dei dati per condensare grandi volumi di dati in utili risultati aggregati. MongoDB utilizzamapReducecomando per operazioni di riduzione della mappa. MapReduce viene generalmente utilizzato per l'elaborazione di set di dati di grandi dimensioni.
Comando MapReduce
Di seguito è riportata la sintassi del comando mapReduce di base:
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)La funzione map-reduce prima interroga la raccolta, quindi mappa i documenti dei risultati per emettere coppie chiave-valore, che vengono quindi ridotte in base alle chiavi che hanno più valori.
Nella sintassi sopra -
map è una funzione javascript che mappa un valore con una chiave ed emette una coppia chiave-valore
reduce è una funzione javascript che riduce o raggruppa tutti i documenti aventi la stessa chiave
out specifica la posizione del risultato della query di riduzione della mappa
query specifica i criteri di selezione facoltativi per la selezione dei documenti
sort specifica i criteri di ordinamento facoltativi
limit specifica il numero massimo facoltativo di documenti da restituire
Utilizzando MapReduce
Considera la seguente struttura del documento che memorizza i post degli utenti. Il documento memorizza user_name dell'utente e lo stato del post.
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}Ora useremo una funzione mapReduce sul nostro file posts collection per selezionare tutti i post attivi, raggrupparli sulla base di user_name e quindi contare il numero di post di ciascun utente utilizzando il seguente codice:
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)La query mapReduce sopra restituisce il seguente risultato:
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}Il risultato mostra che un totale di 4 documenti corrispondevano alla query (stato: "attivo"), la funzione mappa ha emesso 4 documenti con coppie chiave-valore e infine la funzione di riduzione ha raggruppato documenti mappati aventi le stesse chiavi in 2.
Per vedere il risultato di questa query mapReduce, usa l'operatore find -
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()La query precedente fornisce il seguente risultato che indica che entrambi gli utenti tom e mark hanno due post in stati attivi -
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }In modo simile, le query MapReduce possono essere utilizzate per costruire query di aggregazione complesse di grandi dimensioni. L'uso di funzioni Javascript personalizzate fa uso di MapReduce che è molto flessibile e potente.
A partire dalla versione 2.4, MongoDB ha iniziato a supportare gli indici di testo per la ricerca all'interno del contenuto della stringa. IlText Search utilizza tecniche di stemming per cercare parole specificate nei campi stringa eliminando le parole di stop con stemming come a, an, the, ecc. Attualmente MongoDB supporta circa 15 lingue.
Abilitazione della ricerca di testo
Inizialmente, Text Search era una funzionalità sperimentale ma a partire dalla versione 2.6, la configurazione è abilitata per impostazione predefinita. Ma se stai usando la versione precedente di MongoDB, devi abilitare la ricerca di testo con il seguente codice:
>db.adminCommand({setParameter:true,textSearchEnabled:true})Creazione di un indice di testo
Considera il seguente documento sotto posts raccolta contenente il testo del post e i suoi tag -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Creeremo un indice di testo nel campo post_text in modo da poter cercare all'interno del testo dei nostri post -
>db.posts.ensureIndex({post_text:"text"})Utilizzo dell'indice di testo
Ora che abbiamo creato l'indice di testo nel campo post_text, cercheremo tutti i post contenenti la parola tutorialspoint nel loro testo.
>db.posts.find({$text:{$search:"tutorialspoint"}})Il comando precedente ha restituito i seguenti documenti risultato con la parola tutorialspoint nel testo del loro post -
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}Se stai usando vecchie versioni di MongoDB, devi usare il seguente comando:
>db.posts.runCommand("text",{search:" tutorialspoint "})L'utilizzo della ricerca testuale migliora notevolmente l'efficienza della ricerca rispetto alla ricerca normale.
Eliminazione dell'indice di testo
Per eliminare un indice di testo esistente, trova prima il nome dell'indice utilizzando la seguente query:
>db.posts.getIndexes()Dopo aver ottenuto il nome del tuo indice dalla query precedente, esegui il seguente comando. Qui,post_text_text è il nome dell'indice.
>db.posts.dropIndex("post_text_text")Le espressioni regolari vengono spesso utilizzate in tutte le lingue per cercare un modello o una parola in qualsiasi stringa. MongoDB fornisce anche funzionalità di espressione regolare per la corrispondenza del modello di stringa utilizzando il$regexoperatore. MongoDB utilizza PCRE (Perl Compatible Regular Expression) come linguaggio di espressioni regolari.
A differenza della ricerca di testo, non è necessario eseguire alcuna configurazione o comando per utilizzare le espressioni regolari.
Considera la seguente struttura del documento in posts raccolta contenente il testo del post e i suoi tag -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Utilizzo dell'espressione regex
La seguente query regex cerca tutti i post contenenti string tutorialspoint in esso -
>db.posts.find({post_text:{$regex:"tutorialspoint"}})La stessa query può essere scritta anche come:
>db.posts.find({post_text:/tutorialspoint/})Utilizzo dell'espressione regex con case insensitive
Per rendere insensibile alle maiuscole / minuscole di ricerca, utilizziamo $options parametro con valore $i. Il comando seguente cercherà le stringhe con la parolatutorialspoint, indipendentemente dal caso più piccolo o maiuscolo -
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})Uno dei risultati restituiti da questa query è il seguente documento che contiene la parola tutorialspoint in diversi casi -
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}Utilizzo di regex per elementi array
Possiamo anche usare il concetto di regex sul campo array. Ciò è particolarmente importante quando implementiamo la funzionalità dei tag. Quindi, se vuoi cercare tutti i post con tag che iniziano dalla parola tutorial (tutorial o tutorial o tutorialpoint o tutorialphp), puoi usare il seguente codice:
>db.posts.find({tags:{$regex:"tutorial"}})Ottimizzazione delle query di espressioni regolari
Se i campi del documento sono indexed, la query utilizzerà valori indicizzati per corrispondere all'espressione regolare. Ciò rende la ricerca molto veloce rispetto all'espressione regolare che scansiona l'intera raccolta.
Se l'espressione regolare è un file prefix expression, tutte le corrispondenze devono iniziare con una determinata stringa di caratteri. Ad esempio, se l'espressione regex è^tut, quindi la query deve cercare solo le stringhe che iniziano con tut.
RockMongo è uno strumento di amministrazione di MongoDB che ti consente di gestire server, database, raccolte, documenti, indici e molto altro ancora. Fornisce un modo molto intuitivo per leggere, scrivere e creare documenti. È simile allo strumento PHPMyAdmin per PHP e MySQL.
Download di RockMongo
Puoi scaricare l'ultima versione di RockMongo da qui: https://github.com/iwind/rockmongo
Installazione di RockMongo
Una volta scaricato, puoi decomprimere il pacchetto nella cartella principale del server e rinominare la cartella estratta in rockmongo. Apri qualsiasi browser web e accedi al fileindex.phppagina dalla cartella rockmongo. Immettere admin / admin rispettivamente come nome utente / password.
Lavorare con RockMongo
Vedremo ora alcune operazioni di base che puoi eseguire con RockMongo.
Creazione di un nuovo database
Per creare un nuovo database, fare clic su Databasestab. ClicCreate New Database. Nella schermata successiva, fornire il nome del nuovo database e fare clic suCreate. Vedrai un nuovo database che viene aggiunto nel pannello di sinistra.
Creazione di una nuova raccolta
Per creare una nuova raccolta all'interno di un database, fare clic su quel database dal pannello di sinistra. Clicca sulNew Collectionlink in alto. Fornisci il nome richiesto della raccolta. Non preoccuparti per gli altri campi di Is Capped, Size e Max. Clicca suCreate. Verrà creata una nuova collezione e potrai vederla nel pannello di sinistra.
Creazione di un nuovo documento
Per creare un nuovo documento, fai clic sulla raccolta in cui desideri aggiungere i documenti. Quando fai clic su una raccolta, sarai in grado di vedere tutti i documenti all'interno di quella raccolta elencati lì. Per creare un nuovo documento, fare clic suInsertlink in alto. È possibile immettere i dati del documento in formato JSON o array e fare clic suSave.
Esporta / Importa dati
Per importare / esportare i dati di qualsiasi raccolta, fare clic su quella raccolta e quindi fare clic su Export/Importlink sul pannello superiore. Segui le istruzioni successive per esportare i dati in un formato zip, quindi importa lo stesso file zip per importare nuovamente i dati.
GridFSè la specifica MongoDB per l'archiviazione e il recupero di file di grandi dimensioni come immagini, file audio, file video, ecc. È una specie di file system per archiviare i file ma i suoi dati sono archiviati nelle raccolte MongoDB. GridFS ha la capacità di memorizzare file anche più grandi del suo limite di dimensione del documento di 16 MB.
GridFS divide un file in blocchi e memorizza ogni blocco di dati in un documento separato, ciascuno della dimensione massima 255k.
GridFS per impostazione predefinita utilizza due raccolte fs.files e fs.chunksper memorizzare i metadati del file e i blocchi. Ogni blocco è identificato dal proprio campo _id ObjectId univoco. Il file fs. funge da documento genitore. Ilfiles_id Il campo nel documento fs.chunks collega il blocco al suo genitore.
Di seguito è riportato un documento di esempio della raccolta fs.files -
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}Il documento specifica il nome del file, la dimensione del blocco, la data di caricamento e la lunghezza.
Di seguito è riportato un documento di esempio del documento fs.chunks -
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}Aggiunta di file a GridFS
Ora memorizzeremo un file mp3 usando GridFS usando l'estensione putcomando. Per questo, useremo ilmongofiles.exe utility presente nella cartella bin della cartella di installazione di MongoDB.
Apri il prompt dei comandi, vai a mongofiles.exe nella cartella bin della cartella di installazione di MongoDB e digita il codice seguente:
>mongofiles.exe -d gridfs put song.mp3Qui, gridfsè il nome del database in cui verrà archiviato il file. Se il database non è presente, MongoDB creerà automaticamente un nuovo documento al volo. Song.mp3 è il nome del file caricato. Per vedere il documento del file nel database, puoi usare la query di ricerca -
>db.fs.files.find()Il comando precedente ha restituito il seguente documento:
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}Possiamo anche vedere tutti i chunk presenti nella raccolta fs.chunks relativi al file memorizzato con il seguente codice, utilizzando l'id del documento restituito nella query precedente -
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})Nel mio caso, la query ha restituito 40 documenti, il che significa che l'intero documento mp3 è stato diviso in 40 blocchi di dati.
Capped collectionssono raccolte circolari di dimensione fissa che seguono l'ordine di inserimento per supportare prestazioni elevate per le operazioni di creazione, lettura ed eliminazione. Con circolare, significa che quando la dimensione fissa assegnata alla raccolta è esaurita, inizierà a eliminare il documento più vecchio nella raccolta senza fornire alcun comando esplicito.
Le raccolte limitate limitano gli aggiornamenti ai documenti se l'aggiornamento determina un aumento delle dimensioni del documento. Poiché le raccolte con limite archiviano i documenti nell'ordine di archiviazione su disco, garantisce che la dimensione del documento non aumenti la dimensione allocata sul disco. Le raccolte con limite sono le migliori per archiviare le informazioni di registro, i dati della cache o qualsiasi altro dato ad alto volume.
Creazione di una collezione limitata
Per creare una raccolta con limite, usiamo il normale comando createCollection ma con capped opzione come true e specificando la dimensione massima della raccolta in byte.
>db.createCollection("cappedLogCollection",{capped:true,size:10000})Oltre alla dimensione della raccolta, possiamo anche limitare il numero di documenti nella raccolta utilizzando l'estensione max parametro -
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})Se desideri verificare se una raccolta è limitata o meno, utilizza quanto segue isCapped comando -
>db.cappedLogCollection.isCapped()Se è presente una raccolta esistente che intendi convertire in limitata, puoi farlo con il seguente codice:
>db.runCommand({"convertToCapped":"posts",size:10000})Questo codice convertirà la nostra raccolta esistente posts a una raccolta limitata.
Interrogazione raccolta limitata
Per impostazione predefinita, una query di ricerca su una raccolta limitata mostrerà i risultati in ordine di inserzione. Ma se vuoi che i documenti vengano recuperati in ordine inverso, usa il filesort comando come mostrato nel codice seguente -
>db.cappedLogCollection.find().sort({$natural:-1})Ci sono pochi altri punti importanti riguardanti le collezioni limitate che vale la pena conoscere:
Non possiamo eliminare documenti da una raccolta limitata.
Non sono presenti indici predefiniti in una raccolta con limite, nemmeno nel campo _id.
Durante l'inserimento di un nuovo documento, MongoDB non deve effettivamente cercare un posto per ospitare il nuovo documento sul disco. Può inserire alla cieca il nuovo documento in coda alla raccolta. Ciò rende molto veloci le operazioni di inserimento nelle raccolte limitate.
Allo stesso modo, durante la lettura dei documenti, MongoDB restituisce i documenti nello stesso ordine in cui sono presenti sul disco. Ciò rende l'operazione di lettura molto veloce.
MongoDB non ha funzionalità di incremento automatico predefinite, come i database SQL. Per impostazione predefinita, utilizza ObjectId a 12 byte per_idcampo come chiave primaria per identificare in modo univoco i documenti. Tuttavia, potrebbero esserci scenari in cui si potrebbe desiderare che il campo _id abbia un valore incrementato automaticamente diverso da ObjectId.
Poiché questa non è una funzionalità predefinita in MongoDB, realizzeremo questa funzionalità a livello di codice utilizzando un file counters raccolta come suggerito dalla documentazione di MongoDB.
Utilizzo di Counter Collection
Considera quanto segue productsdocumento. Vogliamo che il campo _id sia unauto-incremented integer sequence a partire da 1,2,3,4 fino a n.
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}Per questo, crea un file counters raccolta, che terrà traccia dell'ultimo valore della sequenza per tutti i campi della sequenza.
>db.createCollection("counters")Ora, inseriremo il seguente documento nella raccolta dei contatori con productid come chiave -
{
"_id":"productid",
"sequence_value": 0
}Il campo sequence_value tiene traccia dell'ultimo valore della sequenza.
Usa il codice seguente per inserire questo documento di sequenza nella raccolta dei contatori:
>db.counters.insert({_id:"productid",sequence_value:0})Creazione della funzione Javascript
Ora creeremo una funzione getNextSequenceValueche prenderà il nome della sequenza come input, incrementerà il numero di sequenza di 1 e restituirà il numero di sequenza aggiornato. Nel nostro caso, il nome della sequenza èproductid.
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}Utilizzo della funzione Javascript
Ora useremo la funzione getNextSequenceValue durante la creazione di un nuovo documento e l'assegnazione del valore della sequenza restituito come campo _id del documento.
Inserisci due documenti di esempio utilizzando il codice seguente:
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})Come puoi vedere, abbiamo utilizzato la funzione getNextSequenceValue per impostare il valore per il campo _id.
Per verificare la funzionalità, recuperiamo i documenti utilizzando il comando find -
>db.products.find()La query precedente ha restituito i seguenti documenti con il campo _id autoincrementato:
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }