Nozioni di base sull'etichettatura di parti del discorso (POS)
Cos'è il tagging POS?
Il tagging, una sorta di classificazione, è l'assegnazione automatica della descrizione dei token. Chiamiamo il descrittore s 'tag', che rappresenta una delle parti del discorso (nomi, verbi, avverbi, aggettivi, pronomi, congiunzione e loro sottocategorie), informazioni semantiche e così via.
D'altra parte, se parliamo di tagging Part-of-Speech (POS), può essere definito come il processo di conversione di una frase sotto forma di un elenco di parole, in un elenco di tuple. Qui, le tuple hanno la forma di (word, tag). Possiamo anche chiamare il tagging POS un processo di assegnazione di una delle parti del discorso alla parola data.
La tabella seguente rappresenta la notifica POS più frequente utilizzata nel corpus Penn Treebank -
| Suor n | Etichetta | Descrizione |
|---|---|---|
| 1 | NNP | Nome proprio, singolare |
| 2 | NNPS | Nome proprio, plurale |
| 3 | PDT | Pre determinante |
| 4 | POS | Fine possessivo |
| 5 | PRP | Pronome personale |
| 6 | PRP $ | Pronome possessivo |
| 7 | RB | Avverbio |
| 8 | RBR | Avverbio, comparativo |
| 9 | RBS | Avverbio, superlativo |
| 10 | RP | Particella |
| 11 | SYM | Simbolo (matematico o scientifico) |
| 12 | PER | per |
| 13 | UH | Interiezione |
| 14 | VB | Verbo, forma base |
| 15 | VBD | Verbo, passato |
| 16 | VBG | Verbo, gerundio / participio presente |
| 17 | VBN | Verbo, passato |
| 18 | WP | Wh-pronome |
| 19 | WP $ | Possessivo pronome wh |
| 20 | WRB | Wh-avverbio |
| 21 | # | Cancelletto |
| 22 | $ | Simbolo del dollaro |
| 23 | . | Punteggiatura finale della frase |
| 24 | , | Virgola |
| 25 | : | Due punti, punto e virgola |
| 26 | ( | Carattere parentesi quadra sinistra |
| 27 | ) | Carattere parentesi quadra destra |
| 28 | " | Virgolette doppie diritte |
| 29 | ' | Virgoletta singola aperta |
| 30 | " | Virgolette doppie aperte a sinistra |
| 31 | ' | Virgoletta singola chiusa a destra |
| 32 | " | Virgolette doppie aperte a destra |
Esempio
Facci capire con un esperimento Python -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Produzione
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Perché tagging POS?
La codifica POS è una parte importante della PNL perché funziona come prerequisito per ulteriori analisi della PNL come segue:
- Chunking
- Sintassi Parsing
- Estrazione delle informazioni
- Traduzione automatica
- Sentiment Analysis
- Analisi grammaticale e disambiguazione del senso delle parole
TaggerI - Classe base
Tutti i tagger risiedono nel pacchetto nltk.tag di NLTK. La classe base di questi tagger èTaggerI, significa che tutti i tagger ereditano da questa classe.
Methods - La classe TaggerI ha i seguenti due metodi che devono essere implementati da tutte le sue sottoclassi -
tag() method - Come suggerisce il nome, questo metodo accetta un elenco di parole come input e restituisce un elenco di parole contrassegnate come output.
evaluate() method - Con l'aiuto di questo metodo, possiamo valutare l'accuratezza del tagger.
La base del tagging POS
La linea di base o il passaggio di base del tagging POS è Default Tagging, che può essere eseguito utilizzando la classe DefaultTagger di NLTK. La codifica predefinita assegna semplicemente lo stesso tag POS a ogni token. La codifica predefinita fornisce anche una linea di base per misurare i miglioramenti della precisione.
DefaultTagger classe
La codifica predefinita viene eseguita utilizzando DefaultTagging class, che accetta il singolo argomento, cioè il tag che vogliamo applicare.
Come funziona?
Come detto in precedenza, tutti i tagger vengono ereditati da TaggerIclasse. IlDefaultTagger è ereditato da SequentialBackoffTagger che è una sottoclasse di TaggerI class. Cerchiamo di capirlo con il seguente diagramma:
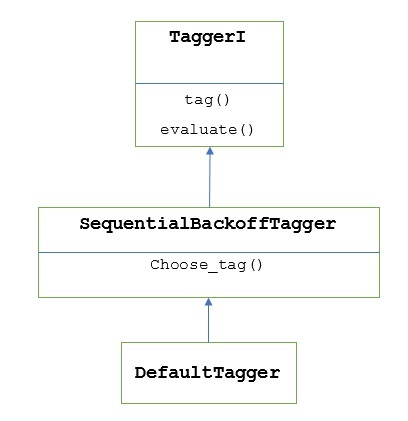
Come parte di SeuentialBackoffTagger, il DefaultTagger deve implementare il metodo choose_tag () che accetta i seguenti tre argomenti.
- Elenco dei token
- Indice del token corrente
- Elenco dei token precedenti, ovvero la cronologia
Esempio
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Produzione
[('Tutorials', 'NN'), ('Point', 'NN')]In questo esempio, abbiamo scelto un tag sostantivo perché sono i tipi di parole più comuni. Inoltre,DefaultTagger è anche molto utile quando scegliamo il tag POS più comune.
Valutazione dell'accuratezza
Il DefaultTaggerè anche la base per la valutazione dell'accuratezza dei tagger. Questo è il motivo per cui possiamo usarlo insiemeevaluate()metodo per misurare l'accuratezza. Ilevaluate() Il metodo prende un elenco di token con tag come gold standard per valutare il tagger.
Di seguito è riportato un esempio in cui abbiamo utilizzato il nostro tagger predefinito, named exptagger, creato sopra, per valutare l'accuratezza di un sottoinsieme di treebank frasi con tag corpus -
Esempio
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Produzione
0.13198749536374715L'output sopra mostra che scegliendo NN per ogni tag, possiamo ottenere circa il 13% di test di accuratezza su 1000 voci di treebank corpus.
Contrassegnare un elenco di frasi
Piuttosto che contrassegnare una singola frase, il NLTK TaggerI class ci fornisce anche un file tag_sents()metodo con l'aiuto del quale possiamo taggare un elenco di frasi. Di seguito è riportato l'esempio in cui abbiamo contrassegnato due semplici frasi
Esempio
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Produzione
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]Nell'esempio precedente, abbiamo utilizzato il nostro tagger predefinito creato in precedenza denominato exptagger.
Annullare il contrassegno di una frase
Possiamo anche rimuovere il tag di una frase. NLTK fornisce il metodo nltk.tag.untag () per questo scopo. Richiederà una frase con tag come input e fornisce un elenco di parole senza tag. Vediamo un esempio:
Esempio
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Produzione
['Tutorials', 'Point']