Toolkit del linguaggio naturale - Parsing
Analisi e sua rilevanza nella PNL
La parola "Parsing" la cui origine è dal latino ‘pars’ (che significa ‘part’), viene utilizzato per trarre il significato esatto o il significato del dizionario dal testo. È anche chiamata analisi sintattica o analisi della sintassi. Confrontando le regole della grammatica formale, l'analisi della sintassi controlla la significatività del testo. La frase come "Dammi un gelato caldo", ad esempio, verrebbe rifiutata dal parser o dall'analizzatore sintattico.
In questo senso, possiamo definire l'analisi o l'analisi sintattica o l'analisi della sintassi come segue:
Può essere definito come il processo di analisi delle stringhe di simboli in linguaggio naturale conforme alle regole della grammatica formale.
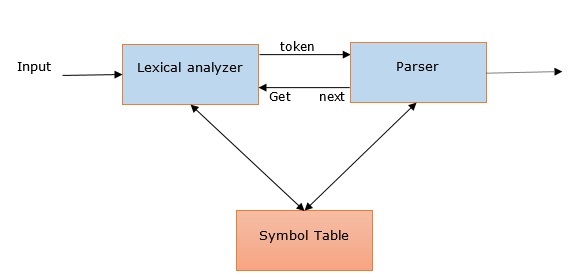
Possiamo capire l'importanza dell'analisi in PNL con l'aiuto dei seguenti punti:
Parser viene utilizzato per segnalare qualsiasi errore di sintassi.
Aiuta a recuperare da errori che si verificano comunemente in modo che l'elaborazione del resto del programma possa essere continuata.
L'albero di analisi viene creato con l'aiuto di un parser.
Il parser viene utilizzato per creare la tabella dei simboli, che svolge un ruolo importante nella PNL.
Il parser viene utilizzato anche per produrre rappresentazioni intermedie (IR).
Analisi profonda e superficiale
| Analisi profonda | Analisi superficiale |
|---|---|
| Nell'analisi approfondita, la strategia di ricerca fornirà una struttura sintattica completa a una frase. | È il compito di analizzare una parte limitata delle informazioni sintattiche dal compito dato. |
| È adatto per complesse applicazioni NLP. | Può essere utilizzato per applicazioni NLP meno complesse. |
| I sistemi di dialogo e il riepilogo sono esempi di applicazioni NLP in cui viene utilizzata l'analisi approfondita. | L'estrazione di informazioni e il text mining sono esempi di applicazioni NLP in cui viene utilizzata l'analisi approfondita. |
| È anche chiamato analisi completa. | È anche chiamato chunking. |
Vari tipi di parser
Come discusso, un parser è fondamentalmente un'interpretazione procedurale della grammatica. Trova un albero ottimale per la frase data dopo aver cercato nello spazio di una varietà di alberi. Vediamo di seguito alcuni dei parser disponibili:
Analizzatore di discesa ricorsivo
L'analisi discendente ricorsiva è una delle forme più semplici di analisi. Di seguito sono riportati alcuni punti importanti sul parser di discesa ricorsiva:
Segue un processo dall'alto verso il basso.
Tenta di verificare che la sintassi del flusso di input sia corretta o meno.
Legge la frase in ingresso da sinistra a destra.
Un'operazione necessaria per il parser a discesa ricorsiva è leggere i caratteri dal flusso di input e confrontarli con i terminali dalla grammatica.
Parser con riduzione Maiusc
Di seguito sono riportati alcuni punti importanti sul parser shift-reduce:
Segue un semplice processo dal basso verso l'alto.
Cerca di trovare una sequenza di parole e frasi che corrispondano al lato destro di una produzione grammaticale e le sostituisce con il lato sinistro della produzione.
Il precedente tentativo di trovare una sequenza di parole continua finché l'intera frase non viene ridotta.
In altre parole semplici, il parser shift-reduce inizia con il simbolo di input e cerca di costruire l'albero del parser fino al simbolo di inizio.
Analizzatore di grafici
Di seguito sono riportati alcuni punti importanti sul parser di grafici:
È principalmente utile o adatto per grammatiche ambigue, comprese le grammatiche delle lingue naturali.
Applica la programmazione dinamica ai problemi di analisi.
A causa della programmazione dinamica, i risultati ipotizzati parziali vengono memorizzati in una struttura chiamata "grafico".
Il "grafico" può anche essere riutilizzato.
Parser Regexp
L'analisi dell'espressione regolare è una delle tecniche di analisi più utilizzate. Di seguito sono riportati alcuni punti importanti sul parser Regexp:
Come suggerisce il nome, utilizza un'espressione regolare definita sotto forma di grammatica sopra una stringa con tag POS.
Fondamentalmente utilizza queste espressioni regolari per analizzare le frasi di input e generare un albero di analisi da questo.
Esempio
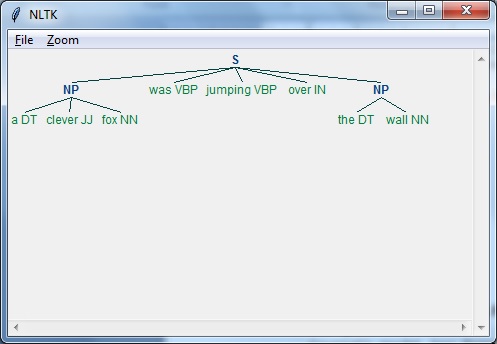
Di seguito è riportato un esempio funzionante di Regexp Parser:
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Produzione
Analisi delle dipendenze
Dependency Parsing (DP), un moderno meccanismo di analisi, il cui concetto principale è che ogni unità linguistica, cioè le parole, si relaziona tra loro tramite un collegamento diretto. Questi collegamenti diretti sono in realtà‘dependencies’in linguistica. Ad esempio, il diagramma seguente mostra la grammatica delle dipendenze per la frase“John can hit the ball”.

Pacchetto NLTK
Abbiamo seguito i due modi per eseguire l'analisi delle dipendenze con NLTK:
Analizzatore di dipendenze probabilistico e proiettivo
Questo è il primo modo in cui possiamo eseguire l'analisi delle dipendenze con NLTK. Ma questo parser ha la restrizione dell'addestramento con un set limitato di dati di addestramento.
Analizzatore di Stanford
Questo è un altro modo in cui possiamo eseguire l'analisi delle dipendenze con NLTK. Il parser di Stanford è un parser di dipendenze all'avanguardia. NLTK ha un involucro attorno ad esso. Per usarlo dobbiamo scaricare le seguenti due cose:
Il parser Stanford CoreNLP .
Modello linguistico per la lingua desiderata. Ad esempio, il modello in lingua inglese.
Esempio
Una volta scaricato il modello, possiamo usarlo tramite NLTK come segue:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Produzione
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]