SAS - Distribuzioni di frequenza
Una distribuzione di frequenza è una tabella che mostra la frequenza dei punti dati in un set di dati. Ciascuna voce nella tabella contiene la frequenza o il conteggio delle occorrenze di valori all'interno di un particolare gruppo o intervallo e in questo modo la tabella riepiloga la distribuzione dei valori nel campione.
SAS fornisce una procedura chiamata PROC FREQ per calcolare la distribuzione di frequenza dei punti dati in un set di dati.
Sintassi
La sintassi di base per il calcolo della distribuzione di frequenza in SAS è:
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Variables_1 sono i nomi delle variabili del set di dati di cui è necessario calcolare la distribuzione di frequenza.
Variables_2 sono le variabili che hanno classificato il risultato della distribuzione di frequenza.
Distribuzione di frequenza variabile singola
Possiamo determinare la distribuzione di frequenza di una singola variabile usando PROC FREQ.In questo caso il risultato mostrerà la frequenza di ogni valore della variabile. Il risultato mostra anche la distribuzione percentuale, la frequenza cumulativa e la percentuale cumulativa.
Esempio
Nell'esempio seguente troviamo la distribuzione di frequenza della variabile di potenza per il set di dati denominato CARS1 che viene creato dalla libreria SASHELP.CARS.Possiamo vedere il risultato diviso in due categorie di risultati. Uno per ogni marca dell'auto.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:

Distribuzione di frequenze variabili multiple
Possiamo trovare le distribuzioni di frequenza per più variabili che le raggruppa in tutte le possibili combinazioni.
Esempio
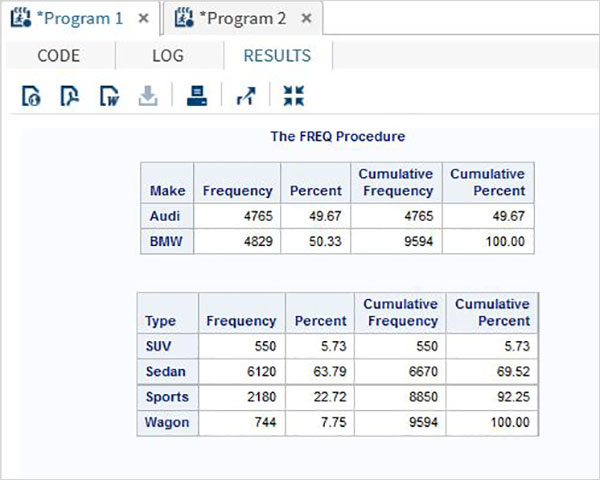
Nell'esempio seguente calcoliamo la distribuzione di frequenza per la marca di un'auto per grouped by car type e anche la distribuzione di frequenza di ogni tipo di automobile grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Distribuzione della frequenza con il peso
Con l'opzione peso possiamo calcolare la distribuzione di frequenza polarizzata con il peso della variabile. Qui il valore della variabile viene preso come numero di osservazioni invece che come conteggio del valore.
Esempio
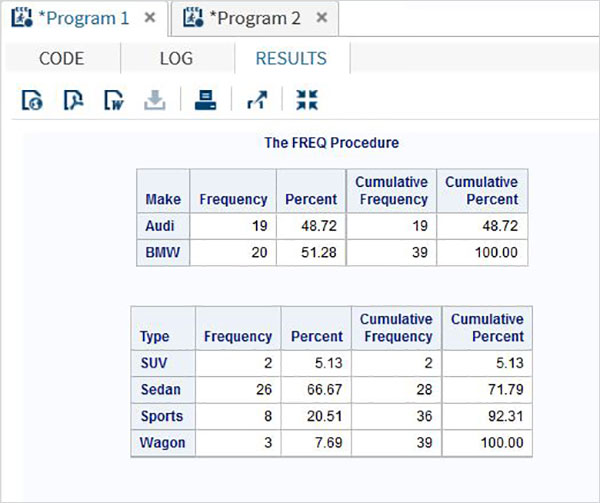
Nell'esempio seguente calcoliamo la distribuzione di frequenza delle variabili marca e tipo con peso assegnato alla potenza.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato: