SAS - Guida rapida
SAS sta per Statistical Analysis Software. È stato creato nell'anno 1960 dall'Istituto SAS. Dal 1 gennaio 1960, SAS è stato utilizzato per la gestione dei dati, business intelligence, analisi predittiva, analisi descrittiva e prescrittiva, ecc. Da allora, molte nuove procedure e componenti statistiche sono state introdotte nel software.
Con l'introduzione di JMP (Jump) per le statistiche, SAS ha sfruttato il Graphical user Interfaceche è stato introdotto dal Macintosh. Jump è fondamentalmente utilizzato per applicazioni come Six Sigma, design, controllo qualità, ingegneria e analisi scientifica.
SAS è indipendente dalla piattaforma, il che significa che puoi eseguire SAS su qualsiasi sistema operativo Linux o Windows. SAS è guidato da programmatori SAS che utilizzano diverse sequenze di operazioni sui set di dati SAS per creare report adeguati per l'analisi dei dati.
Nel corso degli anni SAS ha aggiunto numerose soluzioni al proprio portafoglio prodotti. Ha soluzioni per Data Governance, Data Quality, Big Data Analytics, Text Mining, Gestione delle frodi, Scienze della salute, ecc. Possiamo tranquillamente presumere che SAS abbia una soluzione per ogni dominio aziendale.
Per avere uno sguardo all'elenco dei prodotti disponibili è possibile visitare SAS Components
Perché usiamo SAS
La SAS è fondamentalmente lavorata su grandi set di dati. Con l'aiuto del software SAS è possibile eseguire varie operazioni sui dati come:
- Gestione dei dati
- Analisi statistica
- Creazione di report con una grafica perfetta
- Pianificazione aziendale
- Ricerca operativa e gestione del progetto
- Miglioramento di qualità
- Sviluppo di applicazioni
- Estrazione dati
- Trasformazione dei dati
- Aggiornamento e modifica dei dati
Se parliamo dei componenti di SAS, in SAS sono disponibili più di 200 componenti.
| Sr.No. | Componente SAS e loro utilizzo |
|---|---|
| 1 | Base SAS È un componente fondamentale che contiene funzionalità di gestione dei dati e un linguaggio di programmazione per l'analisi dei dati. È anche il più utilizzato. |
| 2 | SAS/GRAPH Crea grafici, presentazioni per una migliore comprensione e mostra il risultato in un formato appropriato. |
| 3 | SAS/STAT Eseguire l'analisi statistica con l'analisi della varianza, la regressione, l'analisi multivariata, l'analisi di sopravvivenza e l'analisi psicometrica, l'analisi del modello misto. |
| 4 | SAS/OR Ricerche operative. |
| 5 | SAS/ETS Econometria e analisi delle serie storiche. |
| 6 | SAS/IML C Linguaggio a matrice interattivo. |
| 7 | SAS/AF Facilità di applicazioni. |
| 8 | SAS/QC Controllo di qualità. |
| 9 | SAS/INSIGHT Estrazione dei dati. |
| 10 | SAS/PH Analisi di studi clinici. |
| 11 | SAS/Enterprise Miner Estrazione dei dati. |
Tipi di software SAS
- Windows o PC SAS
- SAS EG (Guida aziendale)
- SAS EM (Enterprise Miner ie for Predictive Analysis)
- Significa SAS
- Statistiche SAS
Per lo più utilizziamo Window SAS nell'organizzazione e negli istituti di formazione. Alcune organizzazioni utilizzano Linux ma non esiste un'interfaccia utente grafica quindi è necessario scrivere codice per ogni query. Ma in Windows SAS ci sono molte utility disponibili che aiutano molto i programmatori e riducono anche il tempo di scrittura dei codici.
Una finestra SaS ha 5 parti.
| Sr.No. | Finestra SAS e loro utilizzo |
|---|---|
| 1 | Log Window Una finestra di log è come una finestra di esecuzione in cui possiamo controllare l'esecuzione del programma SAS. In questa finestra possiamo controllare anche gli errori. È molto importante controllare ogni volta la finestra di registro dopo aver eseguito il programma. In modo che possiamo avere una corretta comprensione dell'esecuzione del nostro programma. |
| 2 | Editor Window
La finestra dell'editor è quella parte di SAS in cui scriviamo tutti i codici. È come un blocco note. |
| 3 | Output Window La finestra di output è la finestra dei risultati in cui possiamo vedere l'output del nostro programma. |
| 4 | Result Window È come un indice per tutti gli output. Qui sono elencati tutti i programmi che abbiamo eseguito in una sessione del SAS ed è possibile aprire l'output facendo clic sul risultato dell'output. Ma questi sono menzionati solo in una sessione del SAS. Se chiudiamo il software e poi lo apriamo, la finestra dei risultati sarà vuota. |
| 5 | Explore Window Qui tutte le biblioteche elencate. È inoltre possibile sfogliare i file supportati da SAS del sistema da qui. |
Biblioteche in SAS
Le biblioteche sono come l'archiviazione in SAS. È possibile creare una libreria e salvare tutti i programmi simili in quella libreria. SAS ti offre la possibilità di creare più librerie. Una libreria SAS è lunga solo 8 caratteri.
Sono disponibili due tipi di librerie in SAS:
| Sr.No. | Finestra SAS e loro utilizzo |
|---|---|
| 1 | Temporary or Work Library Questa è la libreria predefinita di SAS. Tutti i programmi che creiamo vengono memorizzati in questa libreria di lavoro se non assegniamo loro nessun'altra libreria. Puoi controllare questa libreria di lavoro nella finestra Esplora. Se si crea un programma SAS e non gli si è assegnata alcuna libreria permanente, se si termina la sessione dopo di che si avvia nuovamente il software, questo programma non sarà nella libreria di lavoro. Perché sarà presente nella libreria Work solo fino a quando la sessione durerà una. |
| 2 | Permanent Library Queste sono le librerie permanenti di SAS. Possiamo creare una nuova libreria SAS utilizzando le utilità SAS o scrivendo i codici nella finestra dell'editor. Queste librerie sono denominate come permanenti perché se creiamo un programma in SAS e lo salviamo in queste librerie permanenti, queste saranno disponibili finché le vogliamo. |
SAS Institute Inc. ha rilasciato gratuitamente SAS University Editionche è abbastanza buono per imparare la programmazione SAS. Fornisce tutte le funzionalità necessarie per apprendere nella programmazione SAS BASE che a sua volta consente di apprendere qualsiasi altro componente SAS.
Il processo di download e installazione di SAS University Edition è molto semplice. È disponibile come macchina virtuale che deve essere eseguita in un ambiente virtuale. È necessario che il software di virtualizzazione sia già installato nel PC prima di poter eseguire il software SAS. In questo tutorial useremoVMware. Di seguito sono riportati i dettagli dei passaggi per scaricare, configurare l'ambiente SAS e verificare l'installazione.
Scarica SAS University Edition
SAS University Editionè disponibile per il download all'URL SAS University Edition . Scorri verso il basso per leggere i requisiti di sistema prima di iniziare il download. La seguente schermata viene visualizzata visitando questo URL.
Configurazione del software di virtualizzazione
Scorri verso il basso nella stessa pagina per individuare l'installazione stpe-1. Questo passaggio fornisce i collegamenti per ottenere il software di virtualizzazione più adatto a te. Nel caso in cui tu abbia già uno di questi software installato nel tuo sistema, puoi saltare questo passaggio.

Software di virtualizzazione ad avvio rapido
Se sei completamente nuovo nell'ambiente di virtualizzazione, puoi familiarizzare con esso passando attraverso le seguenti guide e video disponibili come passaggio 2. Ancora una volta puoi saltare questo passaggio nel caso in cui tu abbia già familiarità.

Scarica il file zip
Nel passaggio 3 è possibile scegliere la versione appropriata di SAS University Edition compatibile con l'ambiente di virtualizzazione di cui si dispone. Viene scaricato come file zip con un nome simile a unvbasicvapp__9411005__vmx__en__sp0__1.zip
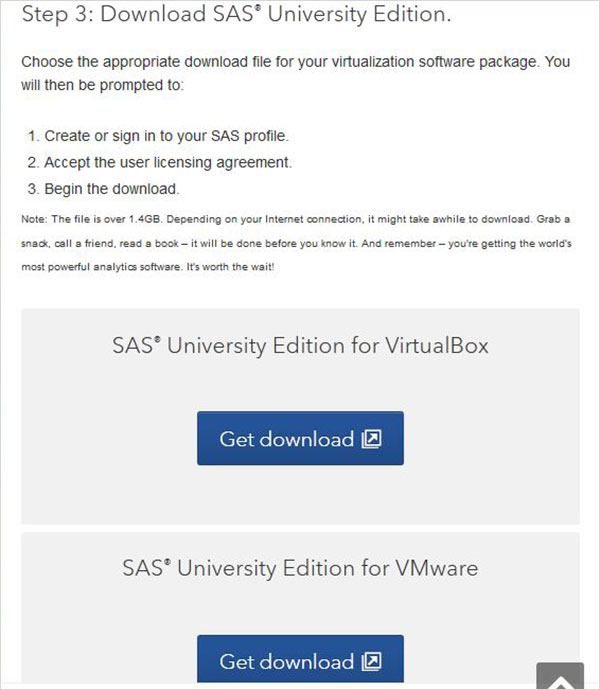
Decomprimere il file zip
Il file zip sopra deve essere decompresso e archiviato in una directory appropriata. Nel nostro caso abbiamo scelto il file zip VMware che mostra i seguenti file dopo la decompressione.
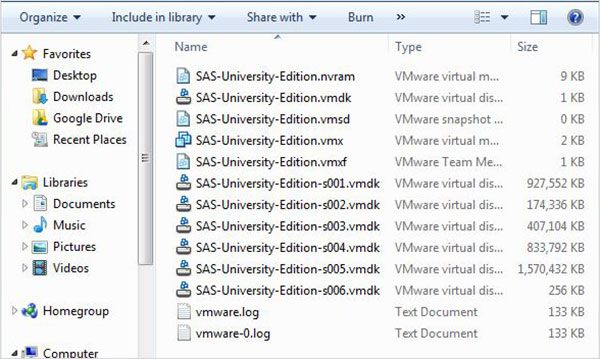
Caricamento della macchina virtuale
Avvia il lettore VMware (o la workstation) e apri il file che termina con l'estensione .vmx. Viene visualizzata la schermata seguente. Si prega di notare le impostazioni di base come la memoria e lo spazio su disco rigido allocati alla VM.
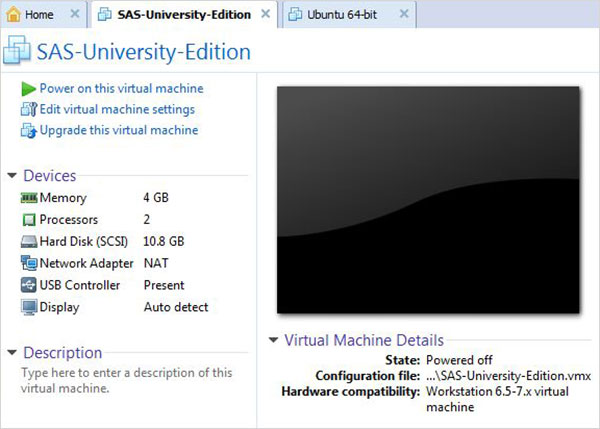
Accendi la macchina virtuale
Clicca il Power on this virtual machineaccanto alla freccia verde per avviare la macchina virtuale. Viene visualizzata la seguente schermata.

La schermata seguente viene visualizzata quando la VM SAS è nello stato di caricamento, dopodiché la VM in esecuzione richiede di andare a un percorso URL che aprirà l'ambiente SAS.
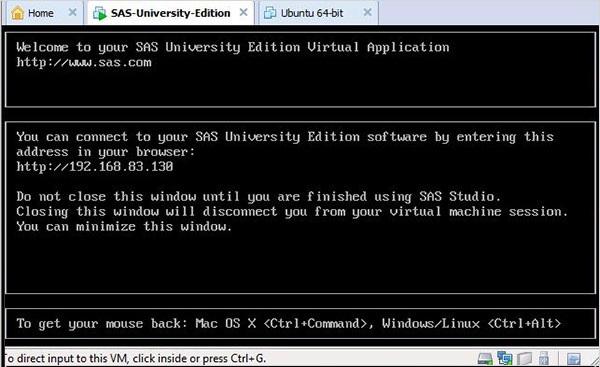
Avvio di SAS studio
Apri una nuova scheda del browser e carica l'URL sopra (che differisce da un PC all'altro). Viene visualizzata la schermata seguente che indica che l'ambiente SAS è pronto.
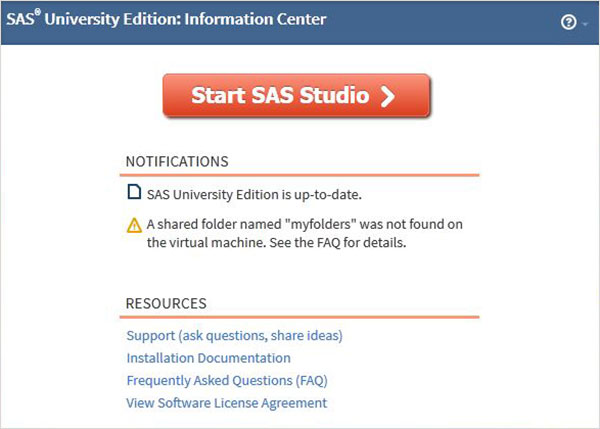
L'ambiente SAS
Facendo clic su Start SAS Studio otteniamo l'ambiente SAS che per impostazione predefinita si apre in modalità visual programmer come mostrato di seguito.
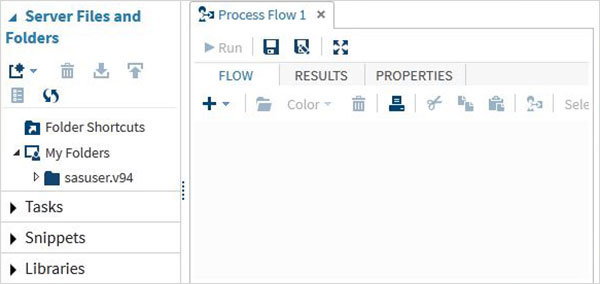
Possiamo anche cambiarlo in modalità programmatore SAS facendo clic sul menu a discesa.
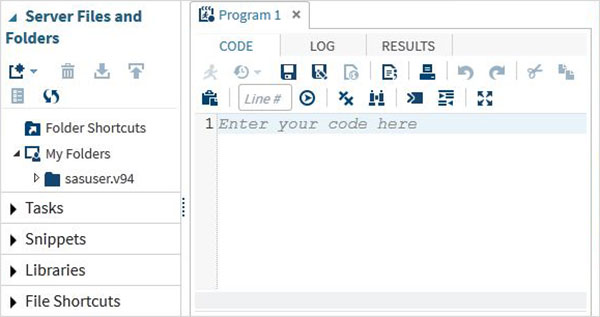
Ora siamo pronti per scrivere programmi SAS.
I programmi SAS vengono creati utilizzando un'interfaccia utente nota come SAS Studio.
Di seguito è riportata una descrizione delle varie finestre e del loro utilizzo.
Finestra principale SAS
Questa è la finestra che vedi entrando nell'ambiente SAS. A sinistra c'è il fileNavigation Paneutilizzato per navigare tra le varie funzioni di programmazione. A destra c'è il fileWork Area che viene utilizzato per scrivere il codice ed eseguirlo.

Completamento automatico del codice
Questa è una funzionalità molto potente che aiuta a ottenere la sintassi corretta delle parole chiave SAS e fornisce un collegamento alla documentazione per quella parola chiave.
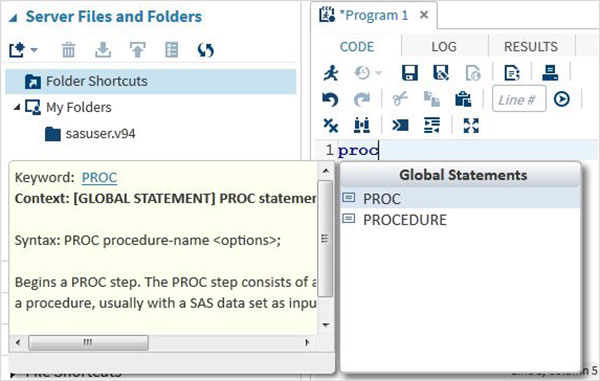
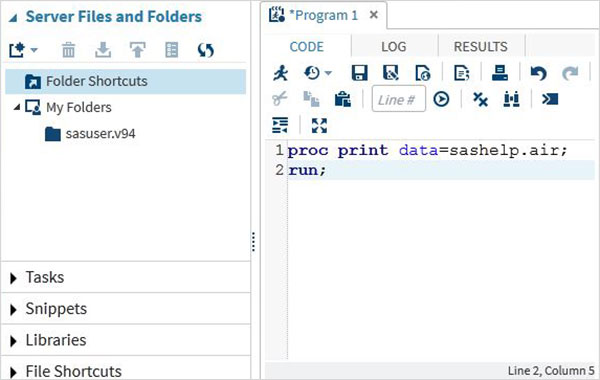
Esecuzione del programma
L'esecuzione del codice avviene premendo l'icona Esegui, che è la prima icona da sinistra o il pulsante F3.
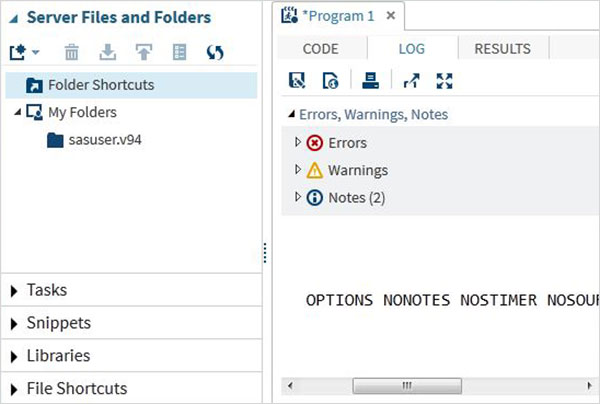
Registro del programma
Il registro del codice eseguito è disponibile sotto il file Logtab. Descrive gli errori, le avvertenze o le note sull'esecuzione del programma. Questa è la finestra in cui ottieni tutti gli indizi per risolvere il tuo codice.
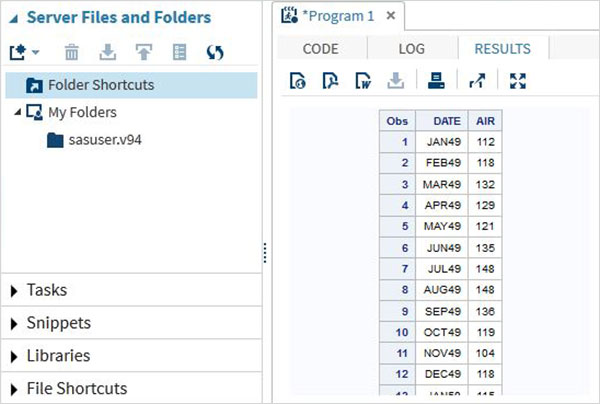
Risultato del programma
Il risultato dell'esecuzione del codice è visualizzato nella scheda RISULTATI. Per impostazione predefinita, sono formattati come tabelle html.
Schede del programma
L'Area di navigazione contiene funzionalità per creare e gestire i programmi. Fornisce inoltre le funzionalità predefinite da utilizzare con il programma.
File e cartelle del server
In questa scheda possiamo creare programmi aggiuntivi, importare dati da analizzare e interrogare i dati esistenti. Può anche essere utilizzato per creare collegamenti alle cartelle.
Compiti
La scheda Attività fornisce funzionalità per utilizzare programmi SAS incorporati fornendo solo le variabili di input. Ad esempio, nella cartella delle statistiche è possibile trovare un programma SAS per eseguire la regressione lineare fornendo solo il nome del set di dati SAS e i nomi delle variabili.
Snippet
La scheda frammenti fornisce funzionalità per scrivere macro SAS e generare file dal set di dati esistente

Librerie di programmi
SAS memorizza i set di dati nelle librerie SAS. La libreria temporanea è disponibile solo per una singola sessione ed è denominata WORK. Ma le biblioteche permanenti sono sempre disponibili.
Collegamenti ai file
Questa scheda viene utilizzata per accedere ai file archiviati all'esterno dell'ambiente SAS. I collegamenti a tali file vengono memorizzati in questa scheda.
La programmazione SAS prevede prima la creazione / lettura dei set di dati nella memoria e poi l'analisi su questi dati. Dobbiamo capire il flusso in cui viene scritto un programma per raggiungere questo obiettivo.
Struttura del programma SAS
Il diagramma seguente mostra i passaggi da scrivere nella sequenza data per creare un programma SAS.
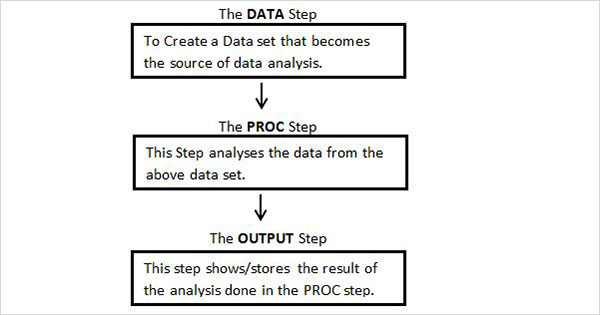
Ogni programma SAS deve avere tutti questi passaggi per completare la lettura dei dati di input, analizzare i dati e fornire l'output dell'analisi. Anche ilRUN l'istruzione alla fine di ogni passaggio è necessaria per completare l'esecuzione di quella fase.
Passaggio DATI
Questa fase prevede il caricamento del set di dati richiesto nella memoria SAS e l'identificazione delle variabili (chiamate anche colonne) del set di dati. Cattura anche i record (chiamati anche osservazioni o soggetti). La sintassi per l'istruzione DATA è la seguente.
Sintassi
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;Esempio
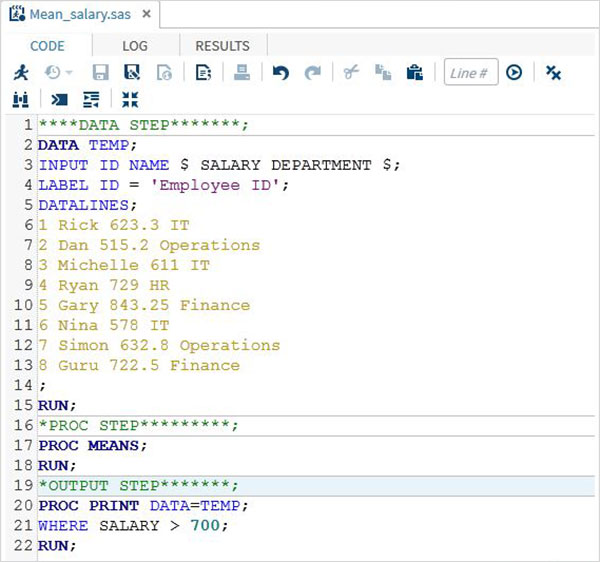
L'esempio seguente mostra un semplice caso di denominazione del set di dati, definizione delle variabili, creazione di nuove variabili e immissione dei dati. Qui le variabili stringa hanno un $ alla fine e i valori numerici sono senza.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;Passaggio PROC
Questo passaggio implica il richiamo di una procedura incorporata SAS per analizzare i dati.
Sintassi
PROC procedure_name options; #The name of the proc.
RUN;Esempio
L'esempio seguente mostra l'utilizzo di MEANS procedura per stampare i valori medi delle variabili numeriche nel data set.
PROC MEANS;
RUN;Il passaggio OUTPUT
I dati dei set di dati possono essere visualizzati con istruzioni di output condizionali.
Sintassi
PROC PRINT DATA = data_set;
OPTIONS;
RUN;Esempio
L'esempio seguente mostra l'utilizzo della clausola where nell'output per produrre solo pochi record dal set di dati.
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
RUN;Il programma SAS completo
Di seguito è riportato il codice completo per ciascuno dei passaggi precedenti.
Output del programma
RESULTS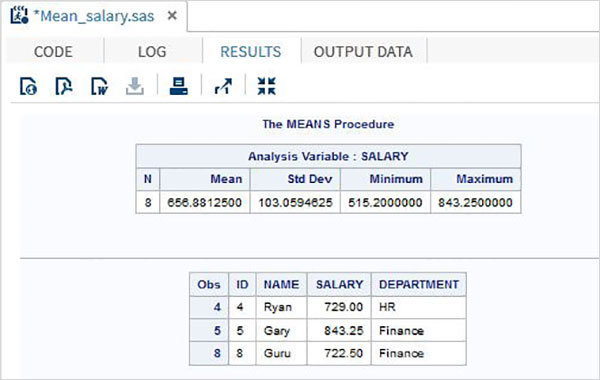
Come qualsiasi altro linguaggio di programmazione, il linguaggio SAS ha le proprie regole di sintassi per creare i programmi SAS.
I tre componenti di qualsiasi programma SAS - Dichiarazioni, Variabili e Set di dati seguono le seguenti regole sulla sintassi.
Dichiarazioni SAS
Le dichiarazioni possono iniziare ovunque e finire ovunque. Un punto e virgola alla fine dell'ultima riga segna la fine dell'istruzione.
Molte istruzioni SAS possono trovarsi sulla stessa riga, con ogni istruzione che termina con un punto e virgola.
Lo spazio può essere utilizzato per separare i componenti in un'istruzione del programma SAS.
Le parole chiave SAS non fanno distinzione tra maiuscole e minuscole.
Ogni programma SAS deve terminare con un'istruzione RUN.
Nomi variabili SAS
Le variabili in SAS rappresentano una colonna nel data set SAS. I nomi delle variabili seguono le regole seguenti.
Può contenere un massimo di 32 caratteri.
Non può includere spazi vuoti.
Deve iniziare con le lettere dalla A alla Z (senza distinzione tra maiuscole e minuscole) o un trattino basso (_).
Può includere numeri ma non come primo carattere.
I nomi delle variabili non fanno distinzione tra maiuscole e minuscole.
Esempio
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.Set di dati SAS
L'istruzione DATA segna la creazione di un nuovo set di dati SAS. Le regole per la creazione del set di dati sono le seguenti.
Una singola parola dopo l'istruzione DATA indica un nome di set di dati temporaneo. Ciò significa che il set di dati viene cancellato alla fine della sessione.
Il nome del set di dati può essere preceduto da un nome di libreria che lo rende un set di dati permanente. Il che significa che il set di dati persiste al termine della sessione.
Se il nome del data set SAS viene omesso, SAS crea un data set temporaneo con un nome generato da SAS come - DATA1, DATA2 ecc.
Esempio
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;Estensioni di file SAS
I programmi SAS, i file di dati ei risultati dei programmi vengono salvati con varie estensioni in Windows.
*.sas - Rappresenta il file di codice SAS che può essere modificato utilizzando l'editor SAS o qualsiasi editor di testo.
*.log - Rappresenta il file di registro SAS che contiene informazioni quali errori, avvisi e dettagli del set di dati per un programma SAS inviato.
*.mht / *.html - Rappresenta il file dei risultati SAS.
*.sas7bdat −Rappresenta file di dati SAS che contiene un set di dati SAS inclusi nomi di variabili, etichette e risultati dei calcoli.
Commenti in SAS
I commenti nel codice SAS vengono specificati in due modi. Di seguito sono riportati questi due formati.
*Messaggio; scrivi commento
Un commento sotto forma di *message;non può contenere punto e virgola o virgolette senza corrispondenza al suo interno. Inoltre non dovrebbe esserci alcun riferimento a nessuna istruzione macro all'interno di tali commenti. Può estendersi su più righe e può essere di qualsiasi lunghezza. Di seguito è riportato un esempio di commento a riga singola:
* This is comment ;Di seguito è riportato un esempio di commento su più righe:
* This is first line of the comment
* This is second line of the comment;/ * messaggio * / tipo di commento
Un commento sotto forma di /*message*/viene utilizzato più frequentemente e non può essere annidato. Ma può estendersi su più righe e può essere di qualsiasi lunghezza. Di seguito è riportato un esempio di commento a riga singola:
/* This is comment */Di seguito è riportato un esempio di commento su più righe:
/* This is first line of the comment
* This is second line of the comment */I dati disponibili per un programma SAS per l'analisi vengono indicati come set di dati SAS. Viene creato utilizzando il passaggio DATA. SAS può leggere una varietà di file come le sue origini datiCSV, Excel, Access, SPSS and also raw data. Ha anche molte origini dati integrate disponibili per l'uso.
I set di dati vengono chiamati temporary Data Set se vengono utilizzati dal programma SAS e quindi eliminati dopo l'esecuzione della sessione.
Ma se viene memorizzato in modo permanente per un utilizzo futuro, viene chiamato permanent Data set. Tutti i set di dati permanenti vengono archiviati in una libreria specifica.
Il set di dati SAS è archiviato sotto forma di righe e colonne e denominato anche tabella di dati SAS. Di seguito vediamo gli esempi di set di dati permanenti che sono incorporati e rossi da fonti esterne.
Set di dati integrati SAS
Questi set di dati sono già disponibili nel software SAS installato. Possono essere esplorati e utilizzati nella formulazione di espressioni campione per l'analisi dei dati. Per esplorare questi set di dati vai aLibraries -> My Libraries -> SASHELP. Espandendolo, vediamo l'elenco dei nomi di tutti i Data Set incorporati disponibili.
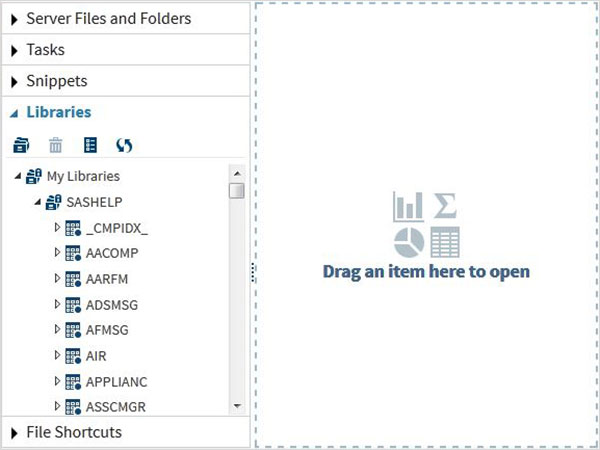
Scorriamo verso il basso per individuare un Data Set denominato CARSFacendo doppio clic su questo set di dati lo si apre nel riquadro della finestra di destra dove possiamo esplorarlo ulteriormente. Possiamo anche ridurre a icona il riquadro di sinistra utilizzando il pulsante di ingrandimento della vista sotto il riquadro di destra.
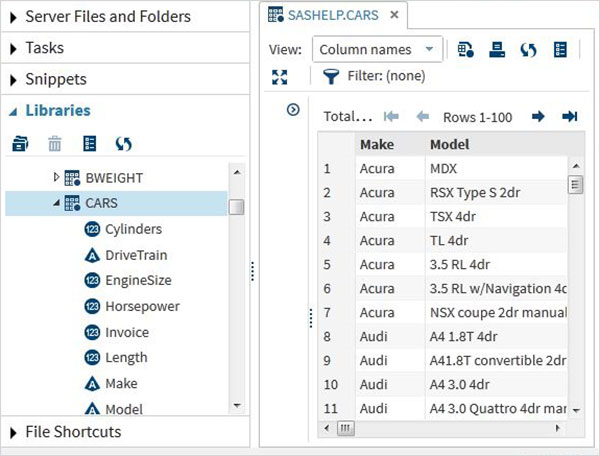
Possiamo scorrere verso destra utilizzando la barra di scorrimento in basso per esplorare tutte le colonne ed i loro valori nella tabella.
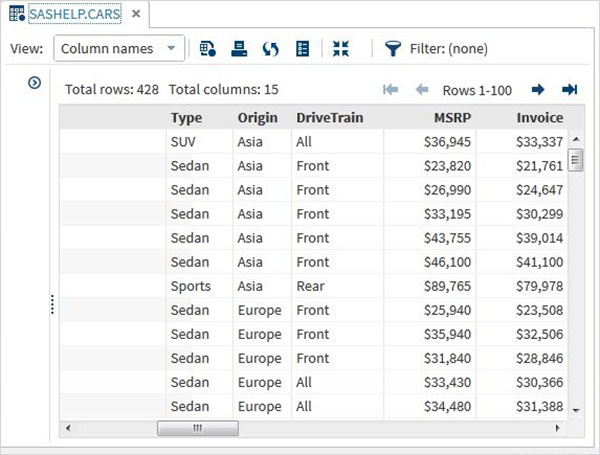
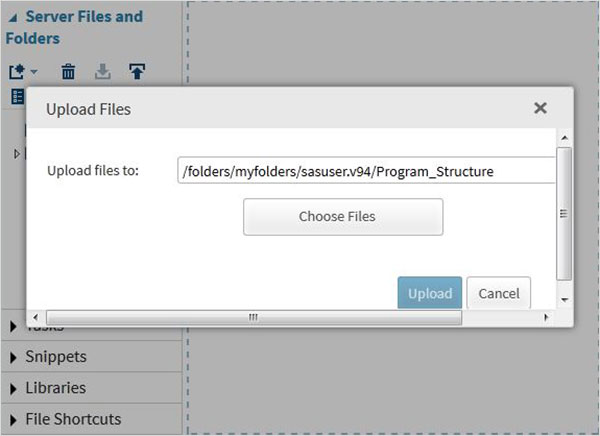
Importazione di set di dati esterni
Possiamo esportare i nostri file come set di dati utilizzando la funzione di importazione disponibile in SAS Studio. Ma questi file devono essere disponibili nelle cartelle del server SAS. Quindi dobbiamo caricare i file di dati di origine nella cartella SAS utilizzando l'opzione di caricamento inServer Files and Folders.
Successivamente usiamo il file sopra in un programma SAS importandolo. Per fare questo usiamo l'opzioneTasks -> Utilities -> Import data come mostrato di seguito. Fare doppio clic sul pulsante Importa dati che apre la finestra a destra per scegliere il file per il set di dati.
Avanti Fare clic su Select Filespulsante sotto il programma di importazione dei dati nel riquadro di destra. Di seguito è riportato l'elenco dei tipi di file che possono essere importati.
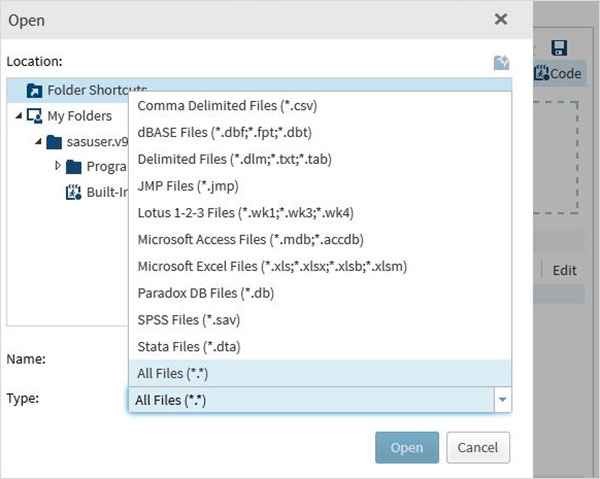
Scegliamo il file "dipendente.txt" memorizzato nel sistema locale e facciamo importare il file come mostrato di seguito.
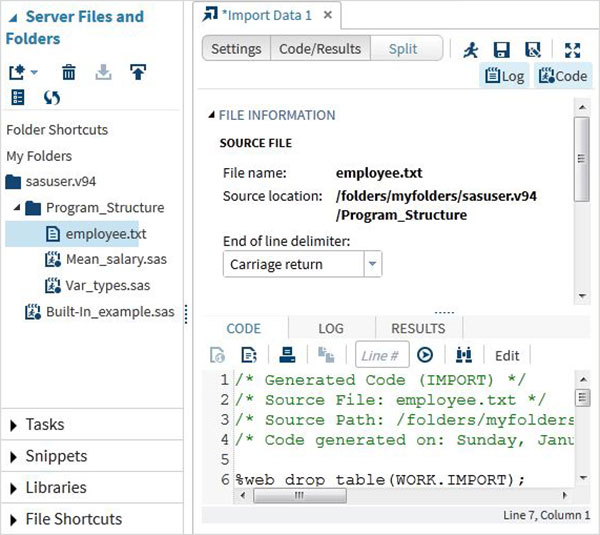
Visualizza i dati importati
Possiamo visualizzare i dati importati eseguendo il codice di importazione predefinito generato utilizzando l'opzione Esegui
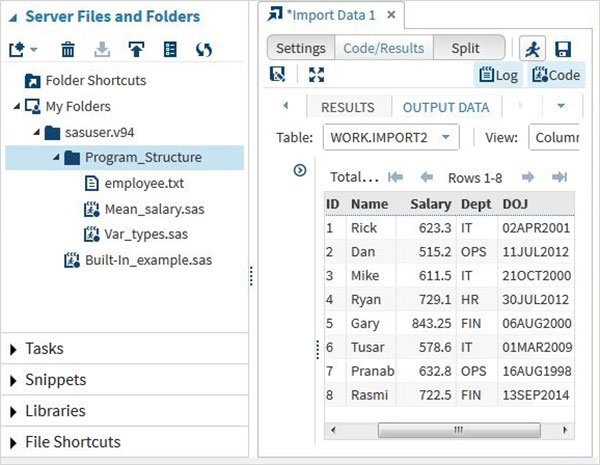
Possiamo importare qualsiasi altro tipo di file utilizzando lo stesso approccio di cui sopra e utilizzarlo in vari programmi SAS.
In generale, le variabili in SAS rappresentano i nomi delle colonne delle tabelle di dati che sta analizzando. Ma può essere utilizzato anche per altri scopi come usarlo come contatore in un ciclo di programmazione. Nel capitolo corrente vedremo l'uso delle variabili SAS come nomi di colonna di SAS Data Set.
Tipi di variabili SAS
SAS ha tre tipi di variabili come di seguito:
Variabili numeriche
Questo è il tipo di variabile predefinito. Queste variabili vengono utilizzate nelle espressioni matematiche.
Sintassi
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.Nella sintassi precedente, l'istruzione INPUT mostra la dichiarazione di variabili numeriche.
Esempio
INPUT ID SALARY COMM_PERCENT;Variabili di carattere
Le variabili carattere vengono utilizzate per i valori non utilizzati nelle espressioni matematiche. Sono trattati come testo o stringhe. Una variabile diventa una variabile carattere aggiungendo $ sing con uno spazio alla fine del nome della variabile.
Sintassi
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.Nella sintassi precedente, l'istruzione INPUT mostra la dichiarazione delle variabili carattere.
Esempio
INPUT FNAME $ LNAME $ ADDRESS $;Variabili di data
Queste variabili vengono trattate solo come date e devono essere in formati di data validi. Una variabile diventa una variabile di data aggiungendo un formato di data con uno spazio alla fine del nome della variabile.
Sintassi
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.Nella sintassi precedente, l'istruzione INPUT mostra la dichiarazione delle variabili di data.
Esempio
INPUT DOB DATE11. START_DATE MMDDYY10. ;Uso di variabili nel programma SAS
Le variabili di cui sopra sono utilizzate nel programma SAS come mostrato negli esempi seguenti.
Esempio
Il codice seguente mostra come i tre tipi di variabili vengono dichiarati e utilizzati in un programma SAS
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;Nell'esempio precedente tutte le variabili carattere sono dichiarate seguite da un segno $ e le variabili data sono dichiarate seguite da un formato data. L'output del programma precedente è il seguente.
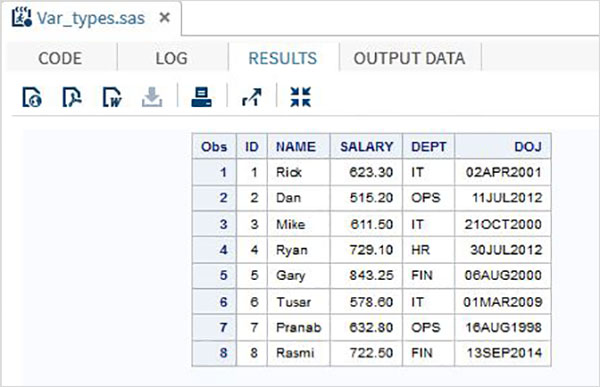
Utilizzo delle variabili
Le variabili sono molto utili nell'analisi dei dati. Sono utilizzati nelle espressioni in cui viene applicata l'analisi statistica. Vediamo un esempio di analisi del set di dati integrato denominatoCARS che è presente sotto Libraries → My Libraries → SASHELP. Fare doppio clic su di esso per esplorare le variabili e i loro tipi di dati.

Successivamente possiamo produrre un riepilogo delle statistiche di alcune di queste variabili utilizzando le opzioni Attività in SAS studio. Vai aTasks -> Statistics -> Summary Statisticse fare doppio clic per aprire la finestra come mostrato di seguito. Scegli set di datiSASHELP.CARSe seleziona le tre variabili: MPG_CITY, MPG_Highway e Weight sotto le Analysis Variables. Tenere premuto il tasto Ctrl mentre si selezionano le variabili facendo clic. Fare clic su Esegui.

Fare clic sulla scheda dei risultati dopo i passaggi precedenti. Mostra il riepilogo statistico delle tre variabili scelte. L'ultima colonna indica il numero di osservazioni (record) utilizzate nell'analisi.
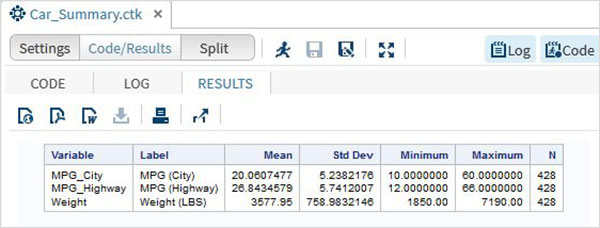
Le stringhe in SAS sono i valori racchiusi tra una coppia di virgolette singole. Anche le variabili stringa vengono dichiarate aggiungendo uno spazio e un segno $ alla fine della dichiarazione della variabile. SAS ha molte potenti funzioni per analizzare e manipolare le stringhe.
Dichiarazione di variabili stringa
Possiamo dichiarare le variabili stringa e i loro valori come mostrato di seguito. Nel codice seguente dichiariamo due variabili carattere di lunghezza 6 e 5. La parola chiave LENGTH viene utilizzata per dichiarare le variabili senza creare osservazioni multiple.
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;Eseguendo il codice precedente otteniamo l'output che mostra i nomi delle variabili ei loro valori.
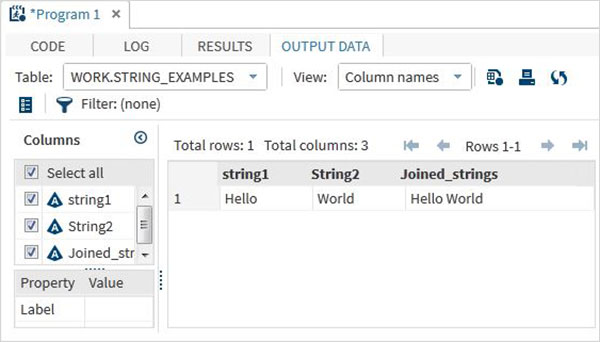
Funzioni stringa
Di seguito sono riportati gli esempi di alcune funzioni SAS che vengono utilizzate di frequente.
SUBSTRN
Questa funzione estrae una sottostringa utilizzando le posizioni iniziale e finale. In caso di mancata menzione della posizione finale, estrae tutti i caratteri fino alla fine della stringa.
Sintassi
SUBSTRN('stringval',p1,p2)Di seguito la descrizione dei parametri utilizzati:
- stringval è il valore della variabile stringa.
- p1 è la posizione iniziale dell'estrazione.
- p2 è la posizione finale di estrazione.
Esempio
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;Eseguendo il codice precedente otteniamo l'output che mostra il risultato della funzione substrn.

TRIMN
Questa funzione rimuove lo spazio finale da una stringa.
Sintassi
TRIMN('stringval')Di seguito la descrizione dei parametri utilizzati:
- stringval è il valore della variabile stringa.
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;Eseguendo il codice precedente otteniamo l'output che mostra il risultato della funzione TRIMN.
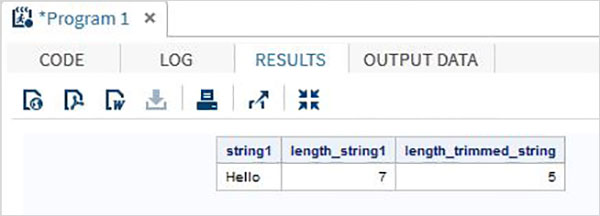
Gli array in SAS vengono utilizzati per archiviare e recuperare una serie di valori utilizzando un valore di indice. L'indice rappresenta la posizione in un'area di memoria riservata.
Sintassi
In SAS un array viene dichiarato utilizzando la seguente sintassi:
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESNella sintassi sopra -
ARRAY è la parola chiave SAS per dichiarare un array.
ARRAY-NAME è il nome dell'array che segue la stessa regola dei nomi delle variabili.
SUBSCRIPT è il numero di valori che l'array memorizzerà.
($) è un parametro facoltativo da utilizzare solo se l'array memorizzerà i valori dei caratteri.
VARIABLE-LIST è l'elenco facoltativo di variabili che sono i segnaposto per i valori degli array.
ARRAY-VALUESsono i valori effettivi archiviati nell'array. Possono essere dichiarati qui o possono essere letti da un file o dataline.
Esempi di dichiarazione di array
Gli array possono essere dichiarati in molti modi utilizzando la sintassi precedente. Di seguito sono riportati gli esempi.
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;Accesso ai valori degli array
È possibile accedere ai valori archiviati in un array utilizzando il printprocedura come mostrato di seguito. Dopo essere stato dichiarato utilizzando uno dei metodi precedenti, i dati vengono forniti utilizzando l'istruzione DATALINES.
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
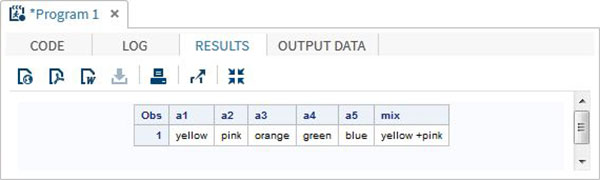
Utilizzo dell'operatore OF
L'operatore OF viene utilizzato durante l'analisi dei dati da un array per eseguire calcoli sull'intera riga di un array. Nell'esempio seguente applichiamo la Somma e la Media dei valori in ogni riga.
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
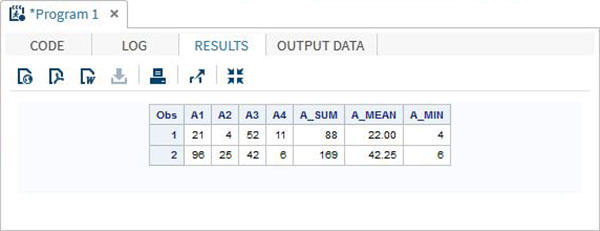
Utilizzando l'operatore IN
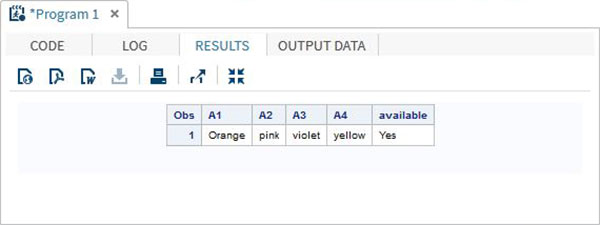
È inoltre possibile accedere al valore in un array utilizzando l'operatore IN che verifica la presenza di un valore nella riga dell'array. Nell'esempio sottostante controlliamo la disponibilità del colore "Giallo" nei dati. Questo valore fa distinzione tra maiuscole e minuscole.
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
SAS può gestire un'ampia varietà di formati di dati numerici. Utilizza questi formati alla fine dei nomi delle variabili per applicare un formato numerico specifico ai dati. SAS utilizza due tipi di formati numerici. Uno per leggere formati specifici dei dati numerici che viene chiamatoinformat e un altro per visualizzare i dati numerici in un formato specifico chiamato come output format.
Sintassi
La sintassi per un'informazione numerica è -
Varname Formatnamew.dDi seguito la descrizione dei parametri utilizzati:
Varname è il nome della variabile.
Formatname è il nome del nome del formato numerico applicato alla variabile.
w è il numero massimo di colonne di dati (comprese le cifre dopo il decimale e il punto decimale stesso) che possono essere memorizzate per la variabile.
d è il numero di cifre a destra del decimale.
Lettura di formati numerici
Di seguito è riportato un elenco dei formati utilizzati per leggere i dati in SAS.
Formati numerici di input
| Formato | Uso |
|---|---|
| n. | Numero massimo "n" di colonne senza punto decimale. |
| n.p | Numero massimo "n" di colonne con punti decimali "p". |
| COMMAn.p | Numero massimo "n" di colonne con posizioni decimali "p" che rimuove qualsiasi virgola o segno di dollaro. |
| COMMAn.p | Numero massimo "n" di colonne con posizioni decimali "p" che rimuove qualsiasi virgola o segno di dollaro. |
Visualizzazione dei formati numerici
Simile all'applicazione del formato durante la lettura dei dati, di seguito è riportato un elenco dei formati utilizzati per visualizzare i dati nell'output di un programma SAS.
Formati numerici di output
| Formato | Uso |
|---|---|
| n. | Scrivi il numero massimo "n" di cifre senza punto decimale. |
| n.p | Scrivere il numero massimo di colonne "np" con punti decimali "p". |
| DOLLARn.p | Scrivi il numero massimo "n" di colonne con p cifre decimali, il simbolo del dollaro iniziale e una virgola al millesimo posto. |
Nota:
Se il numero di cifre dopo il punto decimale è inferiore all'identificatore di formato, allorazeros will be appended alla fine.
Se il numero di cifre dopo il punto decimale è maggiore dell'identificatore di formato, sarà l'ultima cifra rounded off.
Esempi
Gli esempi seguenti illustrano gli scenari precedenti.
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.Un operatore in SAS è un simbolo utilizzato in un'espressione matematica, logica o di confronto. Questi simboli sono integrati nel linguaggio SAS e molti operatori possono essere combinati in un'unica espressione per fornire un output finale.
Di seguito è riportato un elenco di categorie di operatori SAS.
- Operatori aritmetici
- Operatori logici
- Operatori di confronto
- Operatori minimo / massimo
- Operatore di concatenazione
Vedremo ciascuno di uno per uno. Gli operatori vengono sempre utilizzati con variabili che fanno parte dei dati analizzati dal programma SAS.
Operatori aritmetici
La tabella seguente descrive i dettagli degli operatori aritmetici. Supponiamo due variabili di datiV1 e V2con valori 8 e 4 rispettivamente.
| Operatore | Descrizione | Esempio |
|---|---|---|
| + | Aggiunta | V1 + V2 = 12 |
| - | Sottrazione | V1-V2 = 4 |
| * | Moltiplicazione | V1 * V2 = 32 |
| / | Divisione | V1 / V2 = 2 |
| ** | Esponenziazione | V1 ** V2 = 4096 |
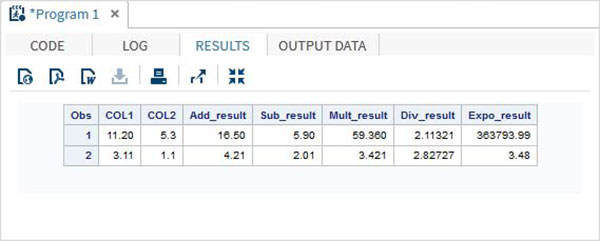
Esempio
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;Eseguendo il codice sopra, otteniamo il seguente output.
Operatori logici
La tabella seguente descrive i dettagli degli operatori logici. Questi operatori valutano il valore di Verità di un'espressione. Quindi il risultato degli operatori logici è sempre 1 o 0. Supponiamo che due variabili di datiV1 e V2con valori 8 e 4 rispettivamente.
| Operatore | Descrizione | Esempio |
|---|---|---|
| & | L'operatore AND. Se entrambi i valori dei dati restituiscono true, il risultato è 1 altrimenti è 0. | (V1> 2 & V2> 3) restituisce 0. |
| | | L'operatore OR. Se uno qualsiasi dei valori dei dati restituisce true, il risultato è 1, altrimenti è 0. | (V1> 9 e V2> 3) è 1. |
| ~ | L'operatore NOT. Il risultato dell'operatore NOT sotto forma di un'espressione il cui valore è FALSE o un valore mancante è 1 altrimenti è 0. | NOT (V1> 3) è 1. |
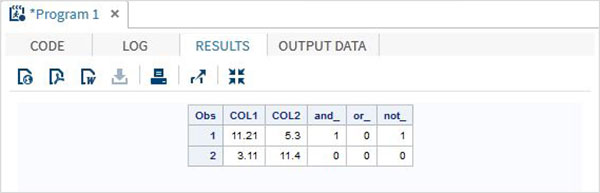
Esempio
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Eseguendo il codice sopra, otteniamo il seguente output.
Operatori di confronto
La tabella seguente descrive i dettagli degli operatori di confronto. Questi operatori confrontano i valori delle variabili e il risultato è un valore di verità presentato da 1 per TRUE e 0 per False. Supponiamo due variabili di datiV1 e V2con valori 8 e 4 rispettivamente.
| Operatore | Descrizione | Esempio |
|---|---|---|
| = | L'operatore EQUAL. Se entrambi i valori dei dati sono uguali, il risultato è 1 altrimenti è 0. | (V1 = 8) restituisce 1. |
| ^ = | L'operatore NON UGUALE. Se entrambi i valori dei dati non sono uguali, il risultato è 1 altrimenti è 0. | (V1 ^ = V2) restituisce 1. |
| < | L'operatore MENO DI. | (V2 <V2) restituisce 1. |
| <= | L'operatore MENO DI o UGUALE A. | (V2 <= 4) restituisce 1. |
| > | L'operatore MAGGIORE DI. | (V2> V1) restituisce 1. |
| > = | L'operatore MAGGIORE DI O UGUALE A. | (V2> = V1) restituisce 0. |
| IN | L'operatore IN. Se il valore della variabile è uguale a uno qualsiasi dei valori in un dato elenco di valori, restituisce 1 altrimenti restituisce 0. | V1 in (5,7,9,8) restituisce 1. |
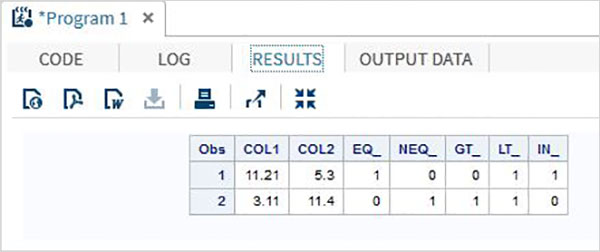
Esempio
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;Eseguendo il codice sopra, otteniamo il seguente output.
Operatori minimo / massimo
La tabella seguente descrive i dettagli degli operatori Minimo / Massimo. Questi operatori confrontano i valori delle variabili su una riga e viene restituito il valore minimo o massimo dall'elenco dei valori nelle righe.
| Operatore | Descrizione | Esempio |
|---|---|---|
| MIN | L'operatore MIN. Restituisce il valore minimo dall'elenco dei valori nella riga. | MIN (45.2,11.6,15.41) restituisce 11.6 |
| MAX | L'operatore MAX. Restituisce il valore massimo dall'elenco dei valori nella riga. | MAX (45.2,11.6,15.41) restituisce 45.2 |
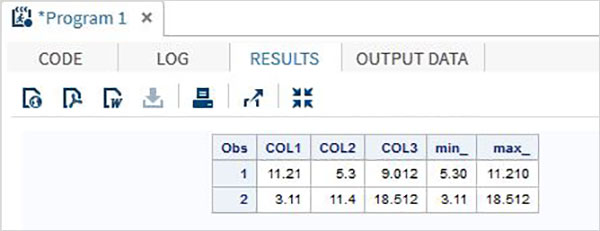
Esempio
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;Eseguendo il codice sopra, otteniamo il seguente output.
Operatore di concatenazione
La tabella seguente descrive i dettagli dell'operatore di concatenazione. Questo operatore concatena due o più valori di stringa. Viene restituito un singolo valore di carattere.
| Operatore | Descrizione | Esempio |
|---|---|---|
| || | L'operatore concatenato. Restituisce la concatenazione di due o più valori. | "Ciao" || " World 'dà Hello World |
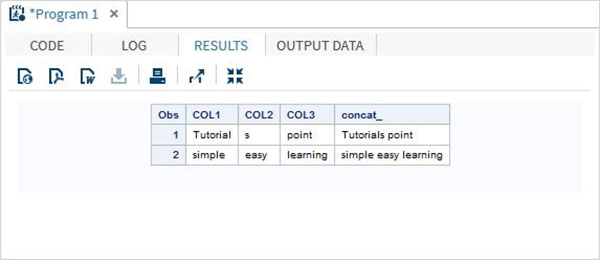
Esempio
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;Eseguendo il codice sopra, otteniamo il seguente output.
Precedenza degli operatori
La precedenza degli operatori indica l'ordine di valutazione dei molteplici operatori presenti nell'espressione complessa. La tabella seguente descrive l'ordine di precedenza con in un gruppo di operatori.
| Gruppo | Ordine | Simboli |
|---|---|---|
| Gruppo I | Da destra a sinistra | ** + - NON MIN MAX |
| Gruppo II | Da sinistra a destra | * / |
| Gruppo III | Da sinistra a destra | + - |
| Gruppo IV | Da sinistra a destra | || |
| Gruppo V | Da sinistra a destra | <<= => => |
Potrebbero verificarsi situazioni in cui un blocco di codice deve essere eseguito più volte. In generale, le istruzioni vengono eseguite in sequenza: la prima istruzione in una funzione viene eseguita per prima, seguita dalla seconda e così via. Ma quando vuoi che lo stesso insieme di istruzioni venga eseguito ancora e ancora, abbiamo bisogno dell'aiuto di Loops.
In SAS il looping viene eseguito utilizzando l'istruzione DO. È anche chiamatoDO Loop. Di seguito è riportata la forma generale di un ciclo DO in SAS.
Diagramma di flusso

Di seguito sono riportati i tipi di loop DO in SAS.
| Sr.No. | Tipo e descrizione del loop |
|---|---|
| 1 | Indice DO. Il ciclo continua dal valore iniziale fino al valore finale della variabile indice. |
| 2 | FARE MENTRE. Il ciclo continua finché la condizione while non diventa falsa. |
| 3 | FARE FINO A. Il ciclo continua fino a quando la condizione UNTIL diventa True. |
Le strutture decisionali richiedono che il programmatore specifichi una o più condizioni che devono essere valutate o testate dal programma, insieme a una o più istruzioni da eseguire se la condizione è determinata truee, facoltativamente, altre istruzioni da eseguire se si determina che la condizione è false.
Di seguito è riportata la forma generale di una tipica struttura decisionale presente nella maggior parte dei linguaggi di programmazione:
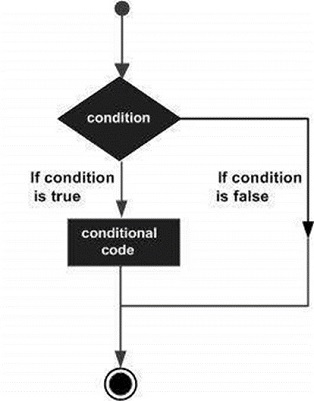
SAS fornisce i seguenti tipi di dichiarazioni sul processo decisionale. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Tipo di istruzione e descrizione |
|---|---|
| 1 | Istruzione IF. Un if statementconsiste in una condizione. Se la condizione è vera, vengono recuperati i dati specifici. |
| 2 | Istruzione IF-THEN-ELSE. Un if statement seguita dall'istruzione else, che viene eseguita quando la condizione booleana è falsa. |
| 3 | Istruzione IF-THEN-ELSE-IF. Un if statement seguita dall'istruzione else, che è ancora seguita da un'altra coppia di istruzioni IF-THEN. |
| 4 | Istruzione IF-THEN-DELETE. Un if statement consiste in una condizione, che quando vera cancella i dati specifici dalle osservazioni. |
SAS ha un'ampia varietà di funzioni integrate che aiutano nell'analisi e nell'elaborazione dei dati. Queste funzioni vengono utilizzate come parte delle istruzioni DATA. Prendono le variabili di dati come argomenti e restituiscono il risultato che viene memorizzato in un'altra variabile. A seconda del tipo di funzione, il numero di argomenti necessari può variare. Alcune funzioni accettano zero argomenti mentre altre accettano un numero fisso di variabili. Di seguito è riportato un elenco dei tipi di funzioni fornite da SAS.
Sintassi
La sintassi generale per l'utilizzo di una funzione in SAS è la seguente.
FUNCTIONNAME(argument1, argument2...argumentn)Qui l'argomento può essere una costante, una variabile, un'espressione o un'altra funzione.
Categorie di funzioni
A seconda del loro utilizzo, le funzioni in SAS sono classificate come di seguito.
- Mathematical
- Data e ora
- Character
- Truncation
- Miscellaneous
Funzioni matematiche
Queste sono le funzioni utilizzate per applicare alcuni calcoli matematici sui valori delle variabili.
Esempi
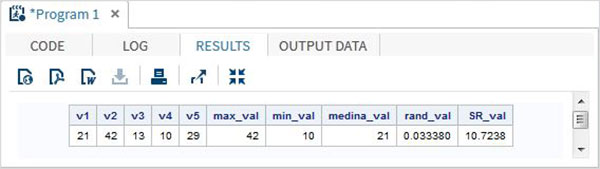
Il seguente programma SAS mostra l'uso di alcune importanti funzioni matematiche.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;Quando viene eseguito il codice precedente, otteniamo il seguente output:
Funzioni di data e ora
Queste sono le funzioni utilizzate per elaborare i valori di data e ora.
Esempi
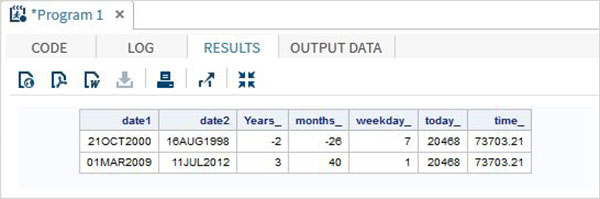
Il programma SAS di seguito mostra l'uso delle funzioni di data e ora.
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;Quando viene eseguito il codice precedente, otteniamo il seguente output:
Funzioni dei caratteri
Queste sono le funzioni utilizzate per elaborare caratteri o valori di testo.
Esempi
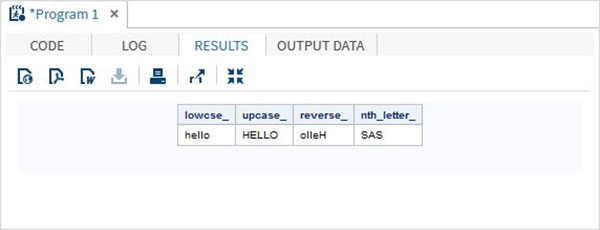
Il seguente programma SAS mostra l'uso delle funzioni dei caratteri.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;Quando viene eseguito il codice precedente, otteniamo il seguente output:
Funzioni di troncamento
Queste sono le funzioni utilizzate per troncare i valori numerici.
Esempi
Il seguente programma SAS mostra l'uso delle funzioni di troncamento.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;Quando viene eseguito il codice precedente, otteniamo il seguente output:

Funzioni varie
Vediamo ora di comprendere le varie funzioni di SAS con alcuni esempi.
Esempi
Il seguente programma SAS mostra l'utilizzo di funzioni varie.
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;Quando viene eseguito il codice precedente, otteniamo il seguente output:

I metodi di input vengono utilizzati per leggere i dati grezzi. I dati grezzi possono provenire da una fonte esterna o da linee di dati in streaming. L'istruzione di input crea una variabile con il nome assegnato a ciascun campo. Quindi devi creare una variabile nell'istruzione di input. La stessa variabile verrà mostrata nell'output di SAS Dataset. Di seguito sono riportati diversi metodi di input disponibili in SAS.
- Metodo di input elenco
- Metodo di input denominato
- Metodo di input della colonna
- Metodo di input formattato
I dettagli di ciascun metodo di input sono descritti di seguito.
Metodo di input elenco
In questo metodo le variabili sono elencate con i tipi di dati. I dati grezzi vengono analizzati attentamente in modo che l'ordine delle variabili dichiarate corrisponda ai dati. Il delimitatore (solitamente spazio) dovrebbe essere uniforme tra qualsiasi coppia di colonne adiacenti. Eventuali dati mancanti causeranno problemi nell'output poiché il risultato sarà errato.
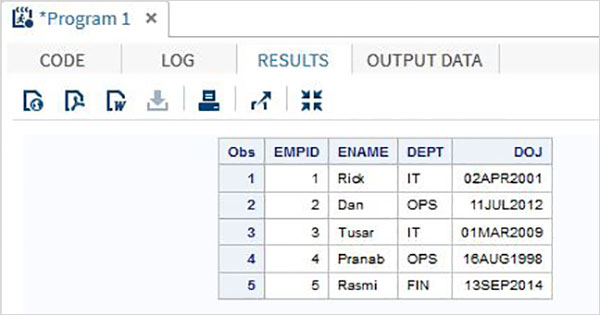
Esempio
Il codice e l'output seguenti mostrano l'uso del metodo di input list.
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;Eseguendo il codice bove otteniamo il seguente output.
Metodo di input denominato
In questo metodo le variabili sono elencate con i tipi di dati. I dati grezzi vengono modificati per avere nomi di variabili dichiarati davanti ai dati corrispondenti. Il delimitatore (solitamente spazio) dovrebbe essere uniforme tra qualsiasi coppia di colonne adiacenti.
Esempio
Il codice e l'output seguenti mostrano l'utilizzo del metodo di input denominato.
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;Eseguendo il codice bove otteniamo il seguente output.
Metodo di input della colonna
In questo metodo le variabili sono elencate con i tipi di dati e la larghezza delle colonne che specificano il valore della singola colonna di dati. Ad esempio, se il nome di un dipendente contiene un massimo di 9 caratteri e ciascun nome di dipendente inizia dalla decima colonna, la larghezza della colonna per la variabile del nome del dipendente sarà 10-19.
Esempio
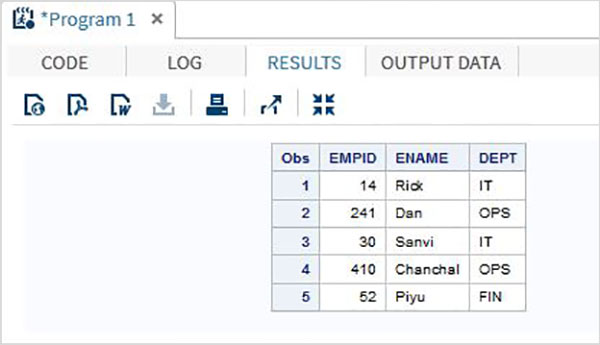
Il codice seguente mostra l'uso del metodo di input della colonna.
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
Metodo di input formattato
In questo metodo le variabili vengono lette da un punto iniziale fisso fino a quando non viene incontrato uno spazio. Poiché ogni variabile ha un punto di partenza fisso, il numero di colonne tra qualsiasi coppia di variabili diventa la larghezza della prima variabile. Il carattere "@n" viene utilizzato per specificare la posizione della colonna iniziale di una variabile come ennesima colonna.
Esempio
Il codice seguente mostra l'utilizzo di Formatted Input Method
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;Quando eseguiamo il codice sopra, produce il seguente risultato:
SAS ha una potente funzione di programmazione chiamata Macrosche ci consente di evitare sezioni ripetitive di codice e di utilizzarle più e più volte quando necessario. Aiuta anche a creare variabili dinamiche all'interno del codice che possono assumere valori diversi per istanze di esecuzione diverse dello stesso codice. Le macro possono anche essere dichiarate per blocchi di codice che verranno riutilizzati più volte in modo simile alle variabili macro. Vedremo entrambi questi negli esempi seguenti.
Variabili macro
Queste sono le variabili che contengono un valore da utilizzare ancora e ancora da un programma SAS. Vengono dichiarati all'inizio di un programma SAS e richiamati successivamente nel corpo del programma. Possono essere di portata globale o locale.
Variabile Macro globale
Sono chiamate variabili macro globali perché possono accedervi da qualsiasi programma SAS disponibile nell'ambiente SAS. In generale sono le variabili assegnate dal sistema a cui si accede da più programmi. Un esempio generale è la data di sistema.
Esempio
Di seguito è riportato un esempio della variabile SAS denominata SYSDATE che rappresenta la data di sistema. Considerare uno scenario per stampare la data di sistema nel titolo del report SAS ogni giorno in cui viene generato il report. Il titolo mostrerà la data e il giorno correnti senza che noi codifichiamo alcun valore per loro. Usiamo il set di dati SAS integrato chiamato CARS disponibile nella libreria SASHELP.
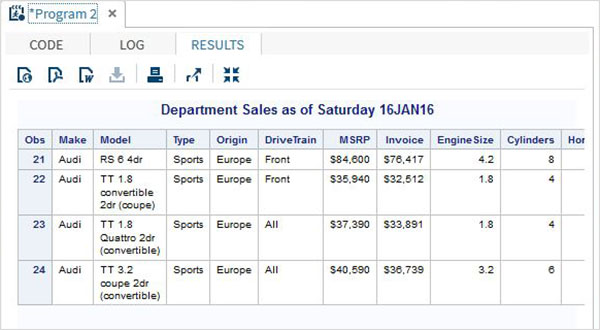
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Variabile Macro locale
È possibile accedere a queste variabili dai programmi SAS in cui sono dichiarate come parte del programma. Sono tipicamente utilizzati per fornire diverse variabili alle stesse istruzioni SAS sl che possono elaborare diverse osservazioni di un set di dati.
Sintassi
Le variabili locali sono contrassegnate con la sintassi seguente.
% LET (Macro Variable Name) = Value;Qui il campo Valore può assumere qualsiasi valore numerico, di testo o di data come richiesto dal programma. Il nome della variabile macro è qualsiasi variabile SAS valida.
Esempio
Le variabili vengono utilizzate dalle istruzioni SAS utilizzando l'estensione & carattere aggiunto all'inizio del nome della variabile. Di seguito il programma ci fornisce tutte le osservazioni del marchio "Audi" e del tipo "Sport". Nel caso in cui vogliamo il risultato didifferent make, dobbiamo modificare il valore della variabile make_namesenza modificare nessun'altra parte del programma. In caso di programmi bring, questa variabile può essere riferita ripetutamente in qualsiasi istruzione SAS.
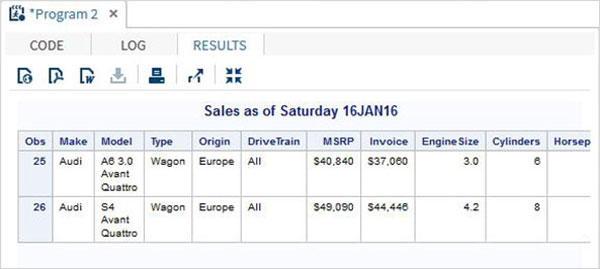
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;Quando viene eseguito il codice precedente, otteniamo lo stesso output del programma precedente. Ma cambiamo il filetype name per 'Wagon'ed eseguire lo stesso programma. Otterremo il risultato seguente.
Programmi macro
Macro è un gruppo di istruzioni SAS a cui si fa riferimento con un nome e per usarlo nel programma ovunque, utilizzando quel nome. Inizia con un'istruzione% MACRO e termina con l'istruzione% MEND.
Sintassi
Le variabili locali sono dichiarate con la sintassi seguente.
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);Esempio
Il programma seguente rimuove un gruppo di staemnets SAT sotto una macro denominata 'show_result'; Questa macro viene chiamata da altre istruzioni SAS.
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);Quando il codice precedente viene eseguito, otteniamo il seguente output.

Macro di uso comune
SAS ha molte istruzioni MACRO integrate nel linguaggio di programmazione SAS. Sono utilizzati da altri programmi SAS senza dichiararli esplicitamente. Esempi comuni sono: terminare un programma quando viene soddisfatta una condizione o acquisire il valore di runtime di una variabile nel registro del programma. Di seguito sono riportati alcuni esempi.
Macro% PUT
Questa istruzione macro scrive testo o informazioni sulle variabili macro nel registro SAS. Nell'esempio seguente il valore della variabile "oggi" viene scritto nel registro del programma.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;Quando il codice precedente viene eseguito, otteniamo il seguente output.

Macro% RETURN
L'esecuzione di questa macro causa la normale chiusura della macro attualmente in esecuzione quando una determinata condizione risulta essere vera. Nell'esempio seguente quando il valore della variabile"val" diventa 10, la macro termina altrimenti continua.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;Quando il codice precedente viene eseguito, otteniamo il seguente output.

Macro% END
Questa definizione di macro contiene un file %DO %WHILEciclo che termina, come richiesto, con un'istruzione% END. Nell'esempio seguente, la macro denominata test accetta un input dell'utente ed esegue il ciclo DO utilizzando questo valore di input. La fine del ciclo DO viene raggiunta tramite l'istruzione% end mentre la fine della macro viene raggiunta tramite l'istruzione% mend.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)Quando il codice precedente viene eseguito, otteniamo il seguente output.

Le date IN SAS sono un caso speciale di valori numerici. A ogni giorno viene assegnato un valore numerico specifico a partire dal 1 gennaio 1960. A questa data viene assegnato il valore 0 e la data successiva ha un valore 1 e così via. I giorni precedenti a questa data sono rappresentati da -1, -2 e così via. Con questo approccio SAS può rappresentare qualsiasi data nel futuro e qualsiasi data nel passato.
Quando SAS legge i dati da un'origine, converte i dati letti in un formato di data specifico come specificato nel formato della data. La variabile per memorizzare il valore della data viene dichiarata con le informazioni appropriate richieste. La data di output viene mostrata utilizzando i formati dei dati di output.
SAS Date Informat
I dati di origine possono essere letti correttamente utilizzando informazioni sulla data specifiche come mostrato di seguito. La cifra alla fine dell'informat indica la larghezza minima della stringa della data da leggere completamente utilizzando l'informat. Una larghezza inferiore darà un risultato errato. con SAS V9, esiste un formato di data genericoanydtdte15. che può elaborare qualsiasi input di data.
| Data di input | Larghezza della data | Informat |
|---|---|---|
| 03/11/2014 | 10 | mmddyy10. |
| 03/11/14 | 8 | mmddyy8. |
| 11 dicembre 2012 | 20 | worddate20. |
| 14mar2011 | 9 | data9. |
| 14-marzo-2011 | 11 | data11. |
| 14-marzo-2011 | 15 | anydtdte15. |
Esempio
Il codice seguente mostra la lettura di diversi formati di data. Notare che tutti i valori di output sono solo numeri poiché non abbiamo applicato alcuna istruzione di formato ai valori di output.
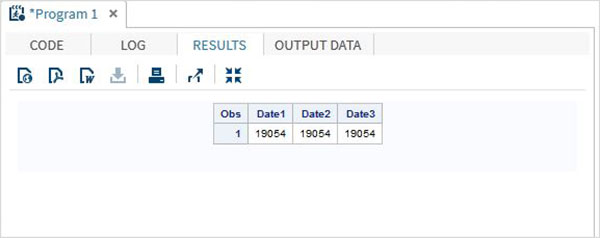
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Formato di output della data SAS
Le date dopo essere state lette, possono essere convertite in un altro formato come richiesto dal display. Ciò si ottiene utilizzando l'istruzione di formato per i tipi di data. Prendono gli stessi formati degli informat.
Esempio
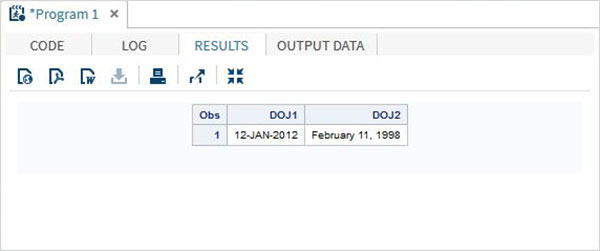
Nell'esempio seguente la data viene letta in un formato ma visualizzata in un altro formato.
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
SAS può leggere dati da varie fonti che includono molti formati di file. I formati di file utilizzati nell'ambiente SAS sono discussi di seguito.
- Set di dati ASCII (testo)
- Dati delimitati
- Dati Excel
- Dati gerarchici
Lettura del set di dati ASCII (testo)
Questi sono i file che contengono i dati in formato testo. I dati sono solitamente delimitati da uno spazio, ma possono esserci anche diversi tipi di delimitatori che SAS può gestire. Consideriamo un file ASCII contenente i dati del dipendente. Leggiamo questo file utilizzando l'estensioneInfile dichiarazione disponibile in SAS.
Esempio
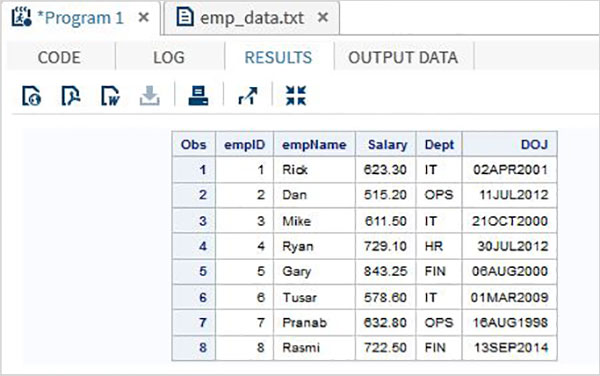
Nell'esempio seguente leggiamo il file di dati denominato emp_data.txt dall'ambiente locale.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Lettura di dati delimitati
Questi sono i file di dati in cui i valori delle colonne sono separati da un carattere di delimitazione come una virgola o una pipeline ecc. In questo caso usiamo il dlm opzione in infile dichiarazione.
Esempio
Nell'esempio seguente leggiamo il file di dati denominato emp.csv dall'ambiente locale.
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Lettura dei dati di Excel
SAS può leggere direttamente un file Excel utilizzando la funzione di importazione. Come visto nel capitolo Set di dati SAS, può gestire un'ampia varietà di tipi di file, incluso MS excel. Supponendo che il file emp.xls sia disponibile localmente nell'ambiente SAS.
Esempio
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;Il codice sopra legge i dati dal file excel e fornisce lo stesso output dei due tipi di file sopra.
Lettura di file gerarchici
In questi file i dati sono presenti in formato gerarchico. Per una data osservazione c'è un record di intestazione sotto il quale sono menzionati molti record di dettaglio. Il numero di record di dettagli può variare da un'osservazione all'altra. Di seguito è riportata un'illustrazione di un file gerarchico.
Nel file sottostante sono elencati i dettagli di ogni dipendente in ogni dipartimento. Il primo record è il record di intestazione che menziona il dipartimento e il record successivo pochi record che iniziano con DTLS sono i record dei dettagli.
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452Esempio
Per leggere il file gerarchico utilizziamo il codice seguente in cui identifichiamo il record di intestazione con una clausola IF e utilizziamo un ciclo do per elaborare il record di dettagli.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.

Simile alla lettura di set di dati, SAS può scrivere set di dati in diversi formati. Può scrivere dati da file SAS in normali file di testo, che possono essere letti da altri programmi software. Usi SASPROC EXPORT per scrivere set di dati.
PROC EXPORT
Si tratta di una procedura incorporata SAS utilizzata per esportare i set di dati SAS per la scrittura dei dati in file di diversi formati.
Sintassi
La sintassi di base per scrivere la procedura in SAS è:
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);Di seguito la descrizione dei parametri utilizzati:
SAS data-setè il nome del set di dati che viene esportato. SAS può condividere i set di dati dal suo ambiente con altre applicazioni creando file che possono essere letti da diversi sistemi operativi. Utilizza la funzione EXPORT incorporata per estrarre i file di set di dati in una varietà di formati. In questo capitolo vedremo come scrivere set di dati SAS utilizzandoproc export insieme alle opzioni dlm e dbms.
SAS data-set-options viene utilizzato per specificare un sottoinsieme di colonne da esportare.
filename è il nome del file in cui vengono scritti i dati.
identifier è usato per menzionare il delimitatore che verrà scritto nel file.
LABEL opzione viene utilizzata per menzionare il nome delle variabili scritte nel file.
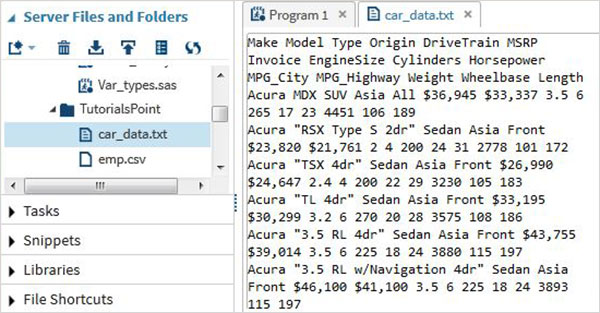
Esempio
Useremo il set di dati SAS denominato cars disponibile nella libreria SASHELP. Lo esportiamo come file di testo delimitato da spazi con il codice come mostrato nel seguente programma.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;Durante l'esecuzione del codice sopra possiamo vedere l'output come un file di testo e fare clic con il tasto destro su di esso per vedere il suo contenuto come mostrato di seguito.
Scrittura di un file CSV
Per scrivere un file delimitato da virgole possiamo usare l'opzione dlm con un valore "csv". Il codice seguente scrive il file car_data.csv.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;Quando si esegue il codice sopra, si ottiene l'output di seguito.

Scrittura di un file delimitato da tabulazioni
Per scrivere un file delimitato da tabulazioni possiamo usare il dlmopzione con un valore "tab". Il codice seguente scrive il filecar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;I dati possono anche essere scritti come file HTML che vedremo nel capitolo sul sistema di distribuzione dell'output.
È possibile concatenare più set di dati SAS per fornire un singolo set di dati utilizzando l'estensione SETdichiarazione. Il numero totale di osservazioni nel set di dati concatenato è la somma del numero di osservazioni nei set di dati originali. L'ordine delle osservazioni è sequenziale. Tutte le osservazioni della prima serie di dati sono seguite da tutte le osservazioni della seconda serie di dati e così via.
Idealmente tutti i set di dati combinati hanno le stesse variabili, ma nel caso in cui abbiano un numero diverso di variabili, nel risultato vengono visualizzate tutte le variabili, con valori mancanti per il set di dati più piccolo.
Sintassi
La sintassi di base per l'istruzione SET in SAS è:
SET data-set 1 data-set 2 data-set 3.....;Di seguito la descrizione dei parametri utilizzati:
data-set1,data-set2 sono nomi di set di dati scritti uno dopo l'altro.
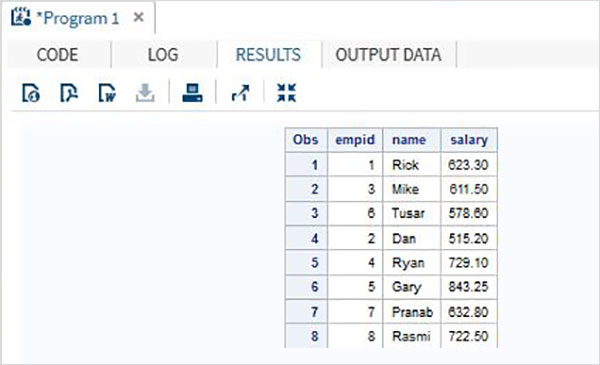
Esempio
Considera i dati dei dipendenti di un'organizzazione che sono disponibili in due diversi set di dati, uno per il reparto IT e un altro per il reparto non IT. Per ottenere i dettagli completi di tutti i dipendenti, concateniamo entrambi i set di dati utilizzando l'istruzione SET mostrata di seguito.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Scenari
Quando abbiamo molte variazioni nei set di dati per la concatenazione, il risultato delle variabili può differire ma il numero totale di osservazioni nel set di dati concatenato è sempre la somma delle osservazioni in ciascun set di dati. Considereremo di seguito molti scenari su questa variazione.
Diverso numero di variabili
Se uno dei set di dati originali ha un numero di variabili maggiore di un altro, i set di dati vengono comunque combinati, ma nel set di dati più piccolo tali variabili appaiono come mancanti.
Esempio
Nell'esempio seguente il primo set di dati ha una variabile aggiuntiva denominata DOJ. Nel risultato il valore di DOJ per il secondo set di dati apparirà come mancante.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.

Nome variabile diverso
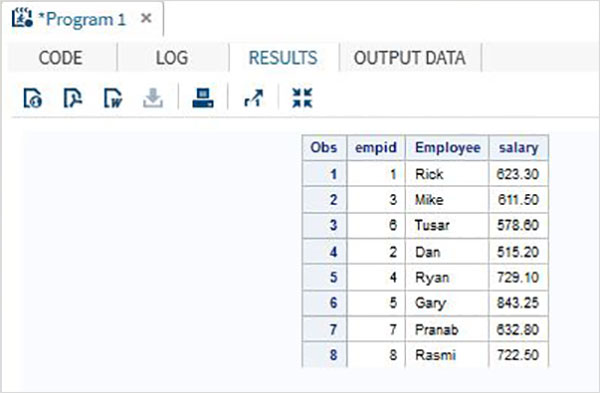
In questo scenario i set di dati hanno lo stesso numero di variabili ma il nome di una variabile è diverso tra loro. In quel caso una normale concatenazione produrrà tutte le variabili nel set di risultati e darà risultati mancanti per le due variabili che differiscono. Sebbene non possiamo modificare il nome della variabile nei set di dati originali, possiamo applicare la funzione RENAME nel set di dati concatenato che creiamo. Ciò produrrà lo stesso risultato di una normale concatenazione, ma ovviamente con un nuovo nome di variabile al posto di due diversi nomi di variabile presenti nel set di dati originale.
Esempio
Nell'esempio seguente il set di dati ITDEPT ha il nome della variabile ename considerando che il set di dati NON_ITDEPT ha il nome della variabile empname.Ma entrambe queste variabili rappresentano lo stesso tipo (carattere). Applichiamo ilRENAME funzione nell'istruzione SET come mostrato di seguito.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
Diverse lunghezze variabili
Se le lunghezze delle variabili nei due set di dati sono diverse dal set di dati concatenato avranno valori in cui alcuni dati vengono troncati per la variabile di lunghezza inferiore. Succede se il primo set di dati ha una lunghezza inferiore. Per risolvere questo problema, applichiamo la lunghezza maggiore a entrambi i set di dati come mostrato di seguito.
Esempio
Nell'esempio seguente la variabile enameè di lunghezza 5 nel primo set di dati e 7 nel secondo. Durante la concatenazione, applichiamo l'istruzione LENGTH nel set di dati concatenato per impostare la lunghezza di ename su 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
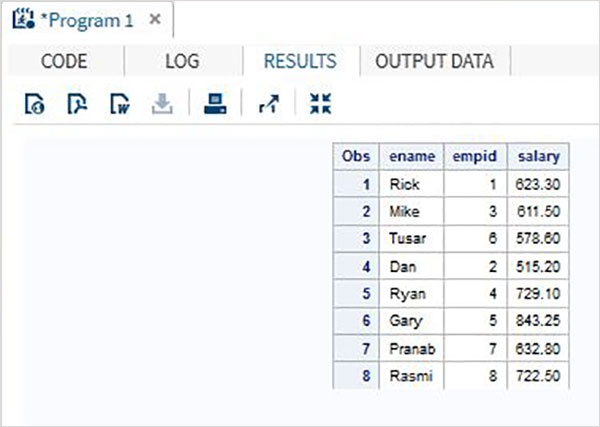
È possibile unire più set di dati SAS in base a una variabile comune specifica per fornire un unico set di dati. Questo viene fatto usando ilMERGE dichiarazione e BYdichiarazione. Il numero totale di osservazioni nel set di dati unito è spesso inferiore alla somma del numero di osservazioni nei set di dati originali. È perché le variabili formano entrambi i set di dati vengono unite come un unico record in base a quando c'è una corrispondenza nel valore della variabile comune.
Esistono due prerequisiti per l'unione dei set di dati indicati di seguito:
- i set di dati di input devono avere almeno una variabile comune su cui fondersi.
- i set di dati di input devono essere ordinati in base alle variabili comuni che verranno utilizzate per l'unione.
Sintassi
La sintassi di base per l'istruzione MERGE e BY in SAS è:
MERGE Data-Set 1 Data-Set 2
BY Common VariableDi seguito la descrizione dei parametri utilizzati:
Data-set1,Data-set2 sono nomi di set di dati scritti uno dopo l'altro.
Common Variable è la variabile in base ai cui valori corrispondenti verranno uniti i set di dati.
Unione dei dati
Cerchiamo di capire l'unione dei dati con l'aiuto di un esempio.
Esempio
Considera due data set SAS, uno contenente l'ID dipendente con nome e stipendio e un altro contenente ID dipendente con ID dipendente e reparto. In questo caso per ottenere le informazioni complete per ogni dipendente possiamo unire questi due set di dati. Il set di dati finale avrà ancora un'osservazione per dipendente, ma conterrà sia le variabili salariale che di reparto.
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINIl risultato precedente si ottiene utilizzando il codice seguente in cui viene utilizzata la variabile comune (ID) nell'istruzione BY. Si noti che le osservazioni in entrambi i set di dati sono già ordinate nella colonna ID.
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;Valori mancanti nella colonna corrispondente
Possono verificarsi casi in cui alcuni valori della variabile comune non corrisponderanno tra i set di dati. In questi casi, i set di dati vengono comunque uniti ma forniscono valori mancanti nel risultato.
Esempio
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINUnire solo le corrispondenze
Per evitare i valori mancanti nel risultato, possiamo considerare di mantenere solo le osservazioni con valori corrispondenti per la variabile comune. Ciò si ottiene utilizzando ilINdichiarazione. L'istruzione di unione del programma SAS deve essere modificata.
Esempio
Nell'esempio seguente, il file IN= valore mantiene solo le osservazioni in cui i valori di entrambi i set di dati SALARY e DEPT incontro.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;All'esecuzione del programma SAS di cui sopra con la parte modificata sopra, otteniamo il seguente output.
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINSottoporre un set di dati SAS significa estrarre una parte del set di dati selezionando un numero inferiore di variabili o un numero inferiore di osservazioni o entrambi. Mentre il sottoinserimento delle variabili viene eseguito utilizzandoKEEP e DROP dichiarazione, l'impostazione secondaria delle osservazioni viene eseguita utilizzando DELETE dichiarazione.
Anche i dati risultanti dall'operazione di sottoinsieme sono contenuti in un nuovo set di dati che può essere utilizzato per ulteriori analisi. L'impostazione secondaria viene utilizzata principalmente allo scopo di analizzare una parte del set di dati senza utilizzare quelle variabili o osservazioni che potrebbero non essere rilevanti per l'analisi.
Variabili di sottoinsieme
In questo metodo estraiamo solo poche variabili dall'intero set di dati.
Sintassi
La sintassi di base per le variabili di impostazione secondaria in SAS è:
KEEP var1 var2 ... ;
DROP var1 var2 ... ;Di seguito la descrizione dei parametri utilizzati:
var1 and var2 sono i nomi delle variabili dal set di dati che devono essere conservati o eliminati.
Esempio
Considera il set di dati SAS di seguito contenente i dettagli dei dipendenti di un'organizzazione. Se siamo interessati solo a ottenere i valori Name e Department dal set di dati, possiamo utilizzare il codice seguente.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
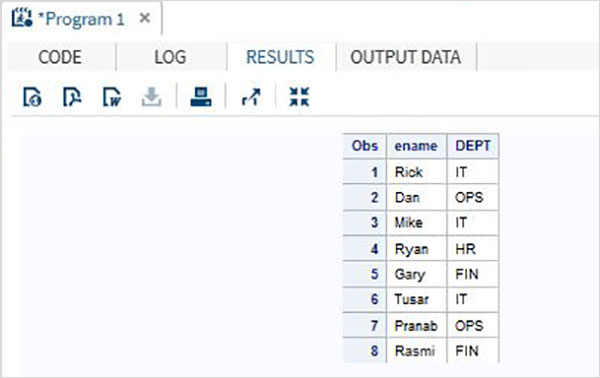
Lo stesso risultato può essere ottenuto eliminando le variabili che non sono richieste. Il codice seguente lo illustra.
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Osservazioni sottoinsieme
In questo metodo estraiamo solo poche osservazioni dall'intero set di dati.
Sintassi
Usiamo PROC FREQ che tiene traccia delle osservazioni selezionate per il nuovo set di dati.
La sintassi per le osservazioni delle impostazioni secondarie è:
IF Var Condition THEN DELETE ;Di seguito la descrizione dei parametri utilizzati:
Var è il nome della variabile in base al cui valore verranno eliminate le osservazioni utilizzando la condizione specificata.
Esempio
Considera il set di dati SAS di seguito contenente i dettagli dei dipendenti di un'organizzazione. Se siamo interessati solo a ottenere i dati per i dipendenti con stipendio superiore a 700, utilizziamo il codice seguente.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
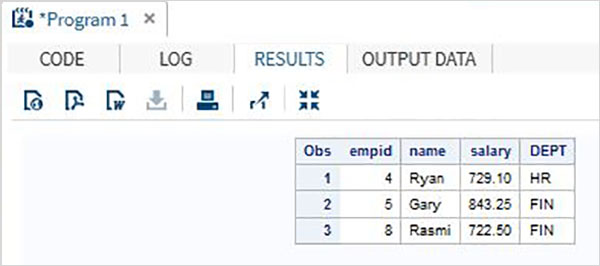
A volte si preferisce mostrare i dati analizzati in un formato diverso da quello in cui sono già presenti nel data set. Ad esempio, vogliamo aggiungere il segno del dollaro e due cifre decimali a una variabile che contiene informazioni sul prezzo. Oppure potremmo voler mostrare una variabile di testo, tutta in maiuscolo. Possiamo usareFORMAT per applicare i formati SAS integrati e PROC FORMATè applicare formati definiti dall'utente. Anche un unico formato può essere applicato a più variabili.
Sintassi
La sintassi di base per l'applicazione dei formati SAS integrati è:
format variable name format nameDi seguito la descrizione dei parametri utilizzati:
variable name è il nome della variabile utilizzato nel set di dati.
format name è il formato dati da applicare alla variabile.
Esempio
Consideriamo il set di dati SAS di seguito contenente i dettagli dei dipendenti di un'organizzazione. Vogliamo mostrare tutti i nomi in maiuscolo. Ilformatstatement viene utilizzato per ottenere questo risultato.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.

Utilizzando PROC FORMAT
Possiamo anche usare PROC FORMATper formattare i dati. Nell'esempio seguente assegniamo nuovi valori alla variabile DEPT exapnding il nome del reparto.
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;Quando il codice precedente viene eseguito, otteniamo il seguente output.
SAS offre un ampio supporto alla maggior parte dei database relazionali più diffusi utilizzando query SQL all'interno di programmi SAS. La maggior parte dellaANSI SQLla sintassi è supportata. La proceduraPROC SQLviene utilizzato per elaborare le istruzioni SQL. Questa procedura non solo può restituire il risultato di una query SQL, ma può anche creare tabelle e variabili SAS. L'esempio di tutti questi scenari è descritto di seguito.
Sintassi
La sintassi di base per l'utilizzo di PROC SQL in SAS è:
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;Di seguito la descrizione dei parametri utilizzati:
la query SQL viene scritta sotto l'istruzione PROC SQL seguita dall'istruzione QUIT.
Di seguito vedremo come questa procedura SAS può essere utilizzata per il CRUD (Crea, Leggi, Aggiorna ed Elimina) operazioni in SQL.
Operazione di creazione SQL
Usando SQL possiamo creare nuovi set di dati da dati grezzi. Nell'esempio seguente, prima dichiariamo un set di dati denominato TEMP contenente i dati grezzi. Quindi scriviamo una query SQL per creare una tabella dalle variabili di questo set di dati.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
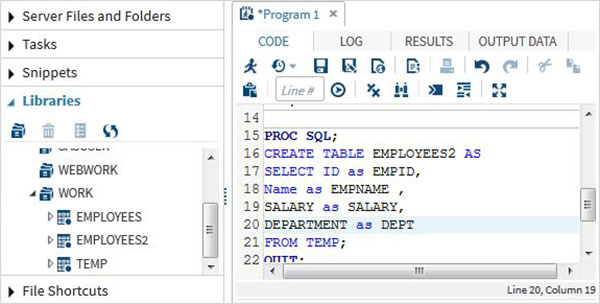
Operazione di lettura SQL
L'operazione di lettura in SQL implica la scrittura di query SQL SELECT per leggere i dati dalle tabelle. In Il programma seguente interroga il data set SAS denominato CARS disponibile nella libreria SASHELP. La query recupera alcune delle colonne del set di dati.
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
SQL SELECT con clausola WHERE
Il programma seguente interroga il set di dati CARS con a whereclausola. Nel risultato otteniamo solo l'osservazione che ha come "Audi" e il tipo "Sport".
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
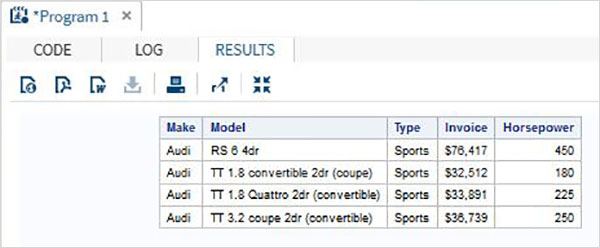
Operazione SQL UPDATE
Possiamo aggiornare la tabella SAS utilizzando l'istruzione SQL Update. Di seguito creiamo prima una nuova tabella denominata EMPLOYEES2 e quindi la aggiorniamo utilizzando l'istruzione SQL UPDATE.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:

Operazione SQL DELETE
L'operazione di eliminazione in SQL implica la rimozione di determinati valori dalla tabella utilizzando l'istruzione SQL DELETE. Continuiamo a utilizzare i dati dell'esempio precedente e cancelliamo le righe dalla tabella in cui lo stipendio dei dipendenti è maggiore di 900.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:

L'output di un programma SAS può essere convertito in forme più intuitive come .html o PDF. Questo viene fatto usando il ODSdichiarazione disponibile in SAS. ODS sta peroutput delivery system.Viene utilizzato principalmente per formattare i dati di output di un programma SAS in rapporti piacevoli che sono buoni da guardare e capire. Ciò aiuta anche a condividere l'output con altre piattaforme e prodotti software. Può anche combinare i risultati di più istruzioni PROC in un unico file.
Sintassi
La sintassi di base per l'utilizzo dell'istruzione ODS in SAS è:
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;Di seguito la descrizione dei parametri utilizzati:
PATHrappresenta l'istruzione utilizzata in caso di output HTML. In altri tipi di output includiamo il percorso nel nome del file.
Style rappresenta uno degli stili integrati disponibili nell'ambiente SAS.
Creazione dell'output HTML
Creiamo output HTML utilizzando l'istruzione HTML ODS. Nell'esempio seguente creiamo un file html nel percorso desiderato. Applichiamo uno stile disponibile nella libreria degli stili. Possiamo vedere il file di output nel percorso citato e possiamo scaricarlo per salvarlo in un ambiente diverso dall'ambiente SAS. Si noti che abbiamo due istruzioni SQL proc ed entrambi i loro output vengono catturati in un unico file.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
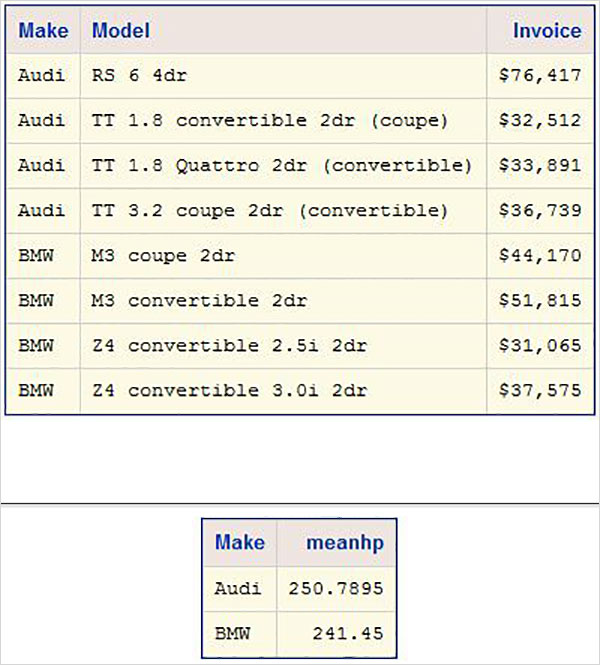
Creazione di output PDF
Nell'esempio seguente creiamo un file PDF nel percorso desiderato. Applichiamo uno stile disponibile nella libreria degli stili. Possiamo vedere il file di output nel percorso citato e possiamo scaricarlo per salvarlo in un ambiente diverso dall'ambiente SAS. Si noti che abbiamo due istruzioni SQL proc ed entrambi i loro output vengono catturati in un unico file.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
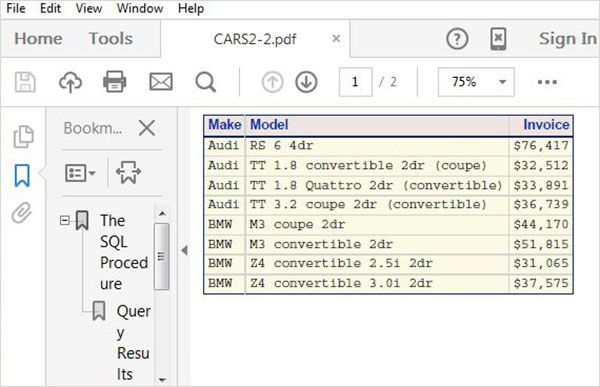
Creazione di output TRF (Word)
Nell'esempio seguente creiamo un file RTF nel percorso desiderato. Applichiamo uno stile disponibile nella libreria degli stili. Possiamo vedere il file di output nel percorso citato e possiamo scaricarlo per salvarlo in un ambiente diverso dall'ambiente SAS. Si noti che abbiamo due istruzioni SQL proc ed entrambi i loro output vengono catturati in un unico file.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;Quando viene eseguito il codice sopra, otteniamo il seguente risultato:
La simulazione è una tecnica computazionale che utilizza calcoli ripetuti su molti campioni casuali diversi per stimare una quantità statistica. Usando SAS possiamo simulare dati complessi che hanno proprietà statistiche specificate nel sistema del mondo reale. Usiamo software per costruire un modello del sistema e generare numericamente dati che possono essere utilizzati per una migliore comprensione del comportamento del sistema del mondo reale. Parte dell'arte di progettare un modello di simulazione al computer è decidere quali aspetti del sistema reale è necessario includere nel modello in modo che i dati generati dal modello possano essere utilizzati per prendere decisioni efficaci. A causa di questa complessità, SAS dispone di un componente software dedicato per la simulazione.
Viene chiamato il componente software SAS utilizzato nella creazione della simulazione SAS SAS Simulation Studio. La sua interfaccia utente grafica fornisce un set completo di strumenti per la creazione, l'esecuzione e l'analisi dei risultati di modelli di simulazione di eventi discreti.
Di seguito sono elencati diversi tipi di distribuzioni statistiche su cui è possibile applicare la simulazione SAS.
- SIMULA I DATI DA UNA DISTRIBUZIONE CONTINUA
- SIMULA I DATI DA UNA DISTRIBUZIONE DISCRETA
- SIMULA I DATI DA UNA MISCELA DI DISTRIBUZIONI
- SIMULA I DATI DA UNA DISTRIBUZIONE COMPLESSA
- SIMULA I DATI DA UNA DISTRIBUZIONE MULTIVARIATA
- APPROSSIMATIVA DI UNA DISTRIBUZIONE DI CAMPIONAMENTO
- VALUTARE LE STIME DI REGRESSIONE
Un istogramma è una visualizzazione grafica dei dati utilizzando barre di diverse altezze. Raggruppa i vari numeri nel set di dati in molti intervalli. Rappresenta anche la stima della probabilità di distribuzione di una variabile continua. In SAS ilPROC UNIVARIATE viene utilizzato per creare istogrammi con le opzioni seguenti.
Sintassi
La sintassi di base per creare un istogramma in SAS è:
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET è il nome del set di dati utilizzato.
variables sono i valori usati per tracciare l'istogramma.
Istogramma semplice
Viene creato un semplice istogramma specificando il nome della variabile e l'intervallo da considerare per raggruppare i valori.
Esempio
Nell'esempio seguente, consideriamo i valori minimo e massimo della potenza variabile e prendiamo un intervallo di 50. Quindi i valori formano un gruppo in passi di 50.
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;Quando eseguiamo il codice sopra, otteniamo il seguente output:
Istogramma con adattamento della curva
Possiamo adattare alcune curve di distribuzione nell'istogramma utilizzando opzioni aggiuntive.
Esempio
Nell'esempio seguente adattiamo una curva di distribuzione con valori medi e di deviazione standard indicati come EST. Questa opzione utilizza e stima dei parametri.
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;Quando eseguiamo il codice sopra, otteniamo il seguente output:

Un grafico a barre rappresenta i dati in barre rettangolari con lunghezza della barra proporzionale al valore della variabile. SAS utilizza la proceduraPROC SGPLOTper creare grafici a barre. Possiamo disegnare barre sia semplici che in pila nel grafico a barre. Nel grafico a barre a ciascuna delle barre possono essere assegnati colori diversi.
Sintassi
La sintassi di base per creare un grafico a barre in SAS è:
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - è il nome del set di dati utilizzato.
variables - sono i valori usati per tracciare l'istogramma.
Grafico a barre semplice
Un semplice grafico a barre è un grafico a barre in cui una variabile del set di dati è rappresentata come barre.
Esempio
Lo script seguente creerà un grafico a barre che rappresenta la lunghezza delle auto sotto forma di barre.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;Quando eseguiamo il codice sopra, otteniamo il seguente output:
Grafico a barre in pila
Un grafico a barre in pila è un grafico a barre in cui una variabile del set di dati viene calcolata rispetto a un'altra variabile.
Esempio
Lo script seguente creerà un grafico a barre in pila in cui la lunghezza delle auto viene calcolata per ciascun tipo di auto. Usiamo l'opzione group per specificare la seconda variabile.
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;Quando eseguiamo il codice sopra, otteniamo il seguente output:
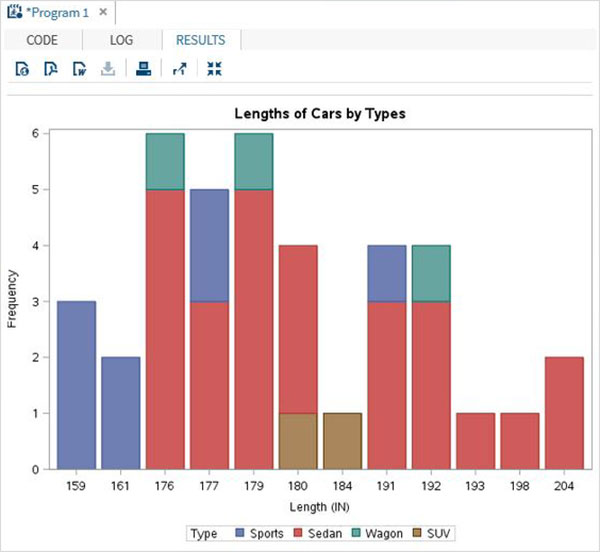
Grafico a barre raggruppato
Il grafico a barre raggruppato viene creato per mostrare come i valori di una variabile vengono distribuiti in una cultura.
Esempio
Lo script seguente creerà un grafico a barre raggruppato in cui la lunghezza delle auto è raggruppata attorno al tipo di auto. Quindi vediamo due barre adiacenti alla lunghezza 191, una per il tipo di auto "Berlina" e un'altra per il tipo di auto "Wagon" .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;Quando eseguiamo il codice sopra, otteniamo il seguente output:

Un grafico a torta è una rappresentazione di valori come fette di un cerchio con colori diversi. Le sezioni vengono etichettate e nel grafico vengono rappresentati anche i numeri corrispondenti a ciascuna sezione.
In SAS il grafico a torta viene creato utilizzando PROC TEMPLATE che prende i parametri per controllare la percentuale, le etichette, il colore, il titolo ecc.
Sintassi
La sintassi di base per creare un grafico a torta in SAS è:
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable è il valore per il quale creiamo il grafico a torta.
Grafico a torta semplice
In questo grafico a torta prendiamo una singola variabile dal set di dati. Il grafico a torta viene creato con il valore delle fette che rappresenta la frazione del conteggio della variabile rispetto al valore totale della variabile.
Esempio
Nell'esempio seguente ogni sezione rappresenta la frazione del tipo di auto dal numero totale di auto.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
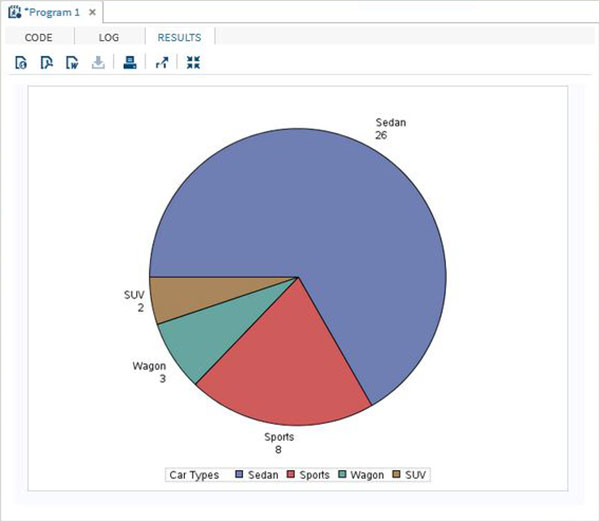
Grafico a torta con etichette dati
In questo grafico a torta rappresentiamo sia il valore frazionario che il valore percentuale per ogni fetta. Cambiamo anche la posizione dell'etichetta in modo che si trovi all'interno del grafico. Lo stile di aspetto del grafico viene modificato utilizzando l'opzione DATASKIN. Utilizza uno degli stili incorporati, disponibili nell'ambiente SAS.
Esempio
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
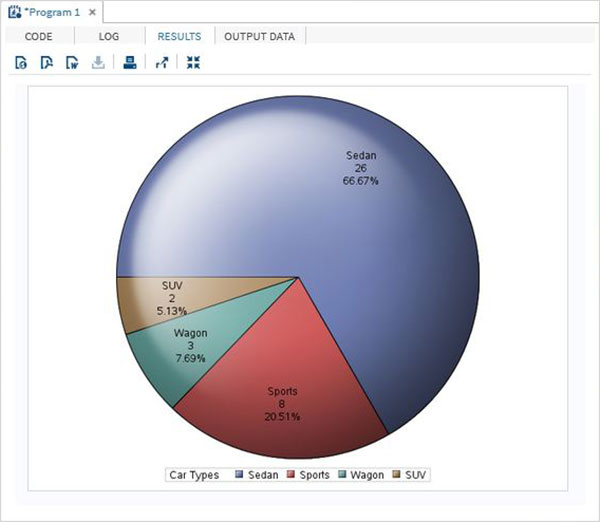
Grafico a torta raggruppato
In questo grafico a torta il valore della variabile presentata nel grafico è raggruppato rispetto a un'altra variabile dello stesso set di dati. Ogni gruppo diventa un cerchio e il grafico ha tanti cerchi concentrici quanti sono i gruppi disponibili.
Esempio
Nell'esempio seguente raggruppiamo il grafico rispetto alla variabile denominata "Make". Poiché sono disponibili due valori ("Audi" e "BMW"), otteniamo due cerchi concentrici che rappresentano ciascuno segmenti di tipi di auto della propria marca.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
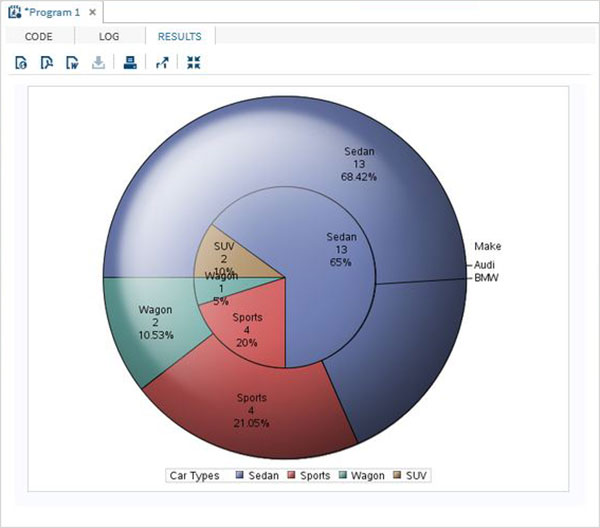
Un grafico a dispersione è un tipo di grafico che utilizza i valori di due variabili tracciate su un piano cartesiano. Di solito viene utilizzato per scoprire la relazione tra due variabili. In SAS usiamoPROC SGSCATTER per creare grafici a dispersione.
Si noti che creiamo il set di dati denominato CARS1 nel primo esempio e utilizziamo lo stesso set di dati per tutti i set di dati successivi. Questo set di dati rimane nella libreria di lavoro fino alla fine della sessione SAS.
Sintassi
La sintassi di base per creare un grafico a dispersione in SAS è:
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;Di seguito è riportata la descrizione dei parametri utilizzati:
DATASET è il nome del set di dati.
VARIABLE è la variabile utilizzata dal set di dati.
Grafico a dispersione semplice
In un semplice grafico a dispersione scegliamo due variabili dal dataset e le raggruppiamo rispetto a una terza variabile. Possiamo anche etichettare i dati. Il risultato mostra come le due variabili sono disperse nel fileCartesian plane.
Esempio
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
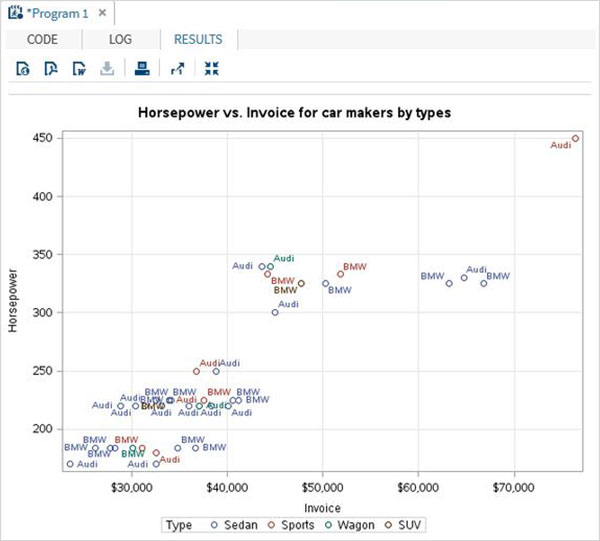
Grafico a dispersione con previsione
possiamo usare un parametro di stima per prevedere la forza della correlazione tra disegnando un'ellisse attorno ai valori. Usiamo le opzioni aggiuntive nella procedura per disegnare l'ellisse come mostrato di seguito.
Esempio
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;Quando eseguiamo il codice sopra, otteniamo il seguente output:

Matrice di dispersione
Possiamo anche avere un grafico a dispersione che coinvolge più di due variabili raggruppandole in coppie. Nell'esempio seguente consideriamo tre variabili e disegniamo una matrice del grafico a dispersione. Otteniamo 3 coppie di matrici risultanti.
Esempio
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
Un Boxplot è una rappresentazione grafica di gruppi di dati numerici attraverso i loro quartili. I box plot possono anche avere linee che si estendono verticalmente dalle scatole (baffi) che indicano la variabilità al di fuori dei quartili superiore e inferiore. La parte inferiore e superiore della scatola sono sempre il primo e il terzo quartile e la fascia all'interno della scatola è sempre il secondo quartile (la mediana). In SAS viene creato un semplice Boxplot utilizzandoPROC SGPLOT e il boxplot pannellato viene creato utilizzando PROC SGPANEL.
Si noti che creiamo il set di dati denominato CARS1 nel primo esempio e utilizziamo lo stesso set di dati per tutti i set di dati successivi. Questo set di dati rimane nella libreria di lavoro fino alla fine della sessione SAS.
Sintassi
La sintassi di base per creare un boxplot in SAS è:
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - è il nome del set di dati utilizzato.
VARIABLE - è il valore utilizzato per tracciare il Boxplot.
Boxplot semplice
In un semplice Boxplot scegliamo una variabile dal set di dati e un'altra per formare una categoria. I valori della prima variabile sono classificati in un numero di gruppi pari al numero di valori distinti nella seconda variabile.
Esempio
Nell'esempio seguente scegliamo la variabile di potenza come prima variabile e digitiamo come variabile di categoria. Quindi otteniamo boxplot per la distribuzione dei valori di potenza per ogni tipo di auto.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
Boxplot in pannelli verticali
Possiamo dividere i Boxplots di una variabile in molti pannelli verticali (colonne). Ogni pannello contiene i grafici a scatole per tutte le variabili categoriali. Ma i grafici a scatole sono ulteriormente raggruppati utilizzando un'altra terza variabile che divide il grafico in più pannelli.
Esempio
Nell'esempio seguente abbiamo pannellato il grafico utilizzando la variabile "make". Poiché ci sono due valori distinti di "make", otteniamo due pannelli verticali.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
Boxplot in pannelli orizzontali
Possiamo dividere i Boxplots di una variabile in molti pannelli orizzontali (righe). Ogni pannello contiene i grafici a scatole per tutte le variabili categoriali. Ma i grafici a scatole sono ulteriormente raggruppati utilizzando un'altra terza variabile che divide il grafico in più pannelli. Nell'esempio seguente abbiamo pannellato il grafico utilizzando la variabile "make". Poiché ci sono due valori distinti di "make", otteniamo due pannelli orizzontali.
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;Quando eseguiamo il codice sopra, otteniamo il seguente output:
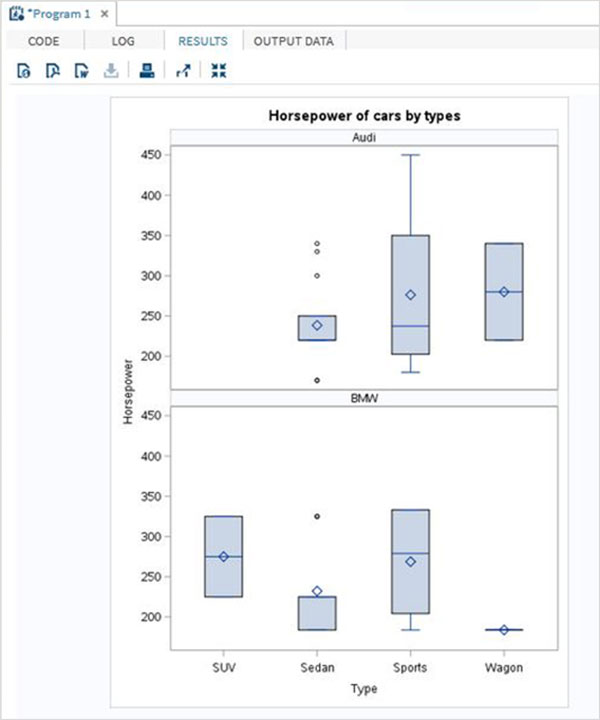
La media aritmetica è il valore ottenuto sommando il valore di variabili numeriche e quindi dividendo la somma per il numero di variabili. Si chiama anche Media. In SAS la media aritmetica viene calcolata utilizzandoPROC MEANS. Utilizzando questa procedura SAS possiamo trovare la media di tutte le variabili o di alcune variabili di un set di dati. Possiamo anche formare gruppi e trovare la media di variabili di valori specifici per quel gruppo.
Sintassi
La sintassi di base per il calcolo della media aritmetica in SAS è:
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;Di seguito è riportata la descrizione dei parametri utilizzati:
DATASET - è il nome del set di dati utilizzato.
Variables - sono il nome della variabile dal set di dati.
Media di un set di dati
La media di ciascuna delle variabili numeriche in un set di dati viene calcolata utilizzando PROC fornendo solo il nome del set di dati senza alcuna variabile.
Esempio
Nell'esempio seguente troviamo la media di tutte le variabili numeriche nel dataset SAS denominato CARS. Specifichiamo che il numero massimo di cifre dopo la cifra decimale sia 2 e troviamo anche la somma di tali variabili.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente output:
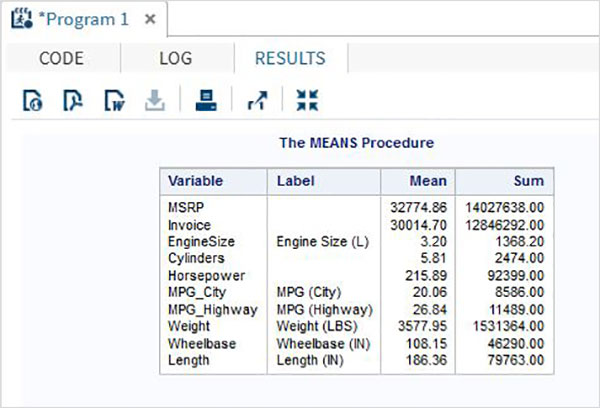
Media delle variabili selezionate
Possiamo ottenere la media di alcune delle variabili fornendo i loro nomi nel file var opzione.
Esempio
Di seguito calcoliamo la media di tre variabili.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente output:
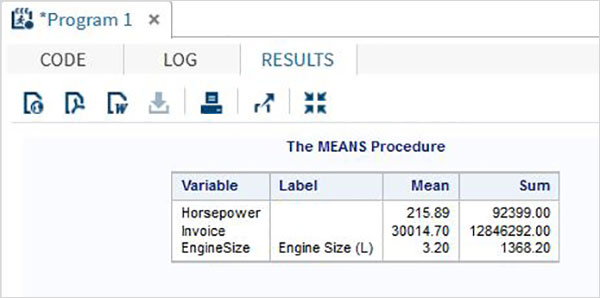
Significa per classe
Possiamo trovare la media delle variabili numeriche organizzandole in gruppi utilizzando alcune altre variabili.
Esempio
Nell'esempio sotto troviamo la media della potenza variabile per ogni tipo sotto ogni marca dell'auto.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente output:
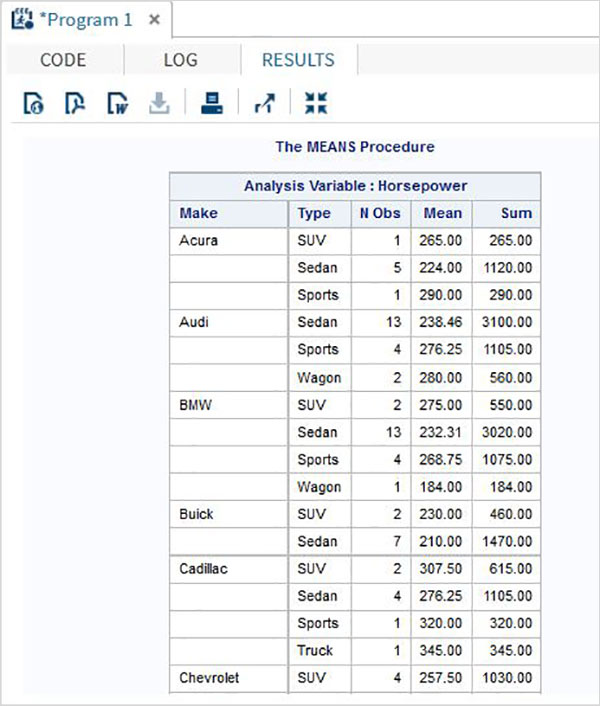
La deviazione standard (SD) è una misura della variabilità dei dati in un set di dati. Matematicamente misura quanto distanti o vicini sono ogni valore al valore medio di un set di dati. Un valore di deviazione standard vicino a 0 indica che i punti dati tendono ad essere molto vicini alla media del set di dati e una deviazione standard alta indica che i punti dati sono distribuiti su una gamma più ampia di valori
In SAS i valori SD vengono misurati utilizzando PROC MEAN e PROC SURVEYMEANS.
Utilizzando PROC MEANS
Per misurare la SD utilizzando proc meansscegliamo l'opzione STD nel passaggio PROC. Evidenzia i valori SD per ogni variabile numerica presente nel set di dati.
Sintassi
La sintassi di base per il calcolo della deviazione standard in SAS è:
PROC means DATA = dataset STD;Di seguito la descrizione dei parametri utilizzati:
Dataset - è il nome del set di dati.
Esempio
Nell'esempio seguente creiamo il data set CARS1 dal data set CARS nella libreria SASHELP. Scegliamo l'opzione STD con PROC significa passo.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;Quando eseguiamo il codice precedente, fornisce il seguente output:
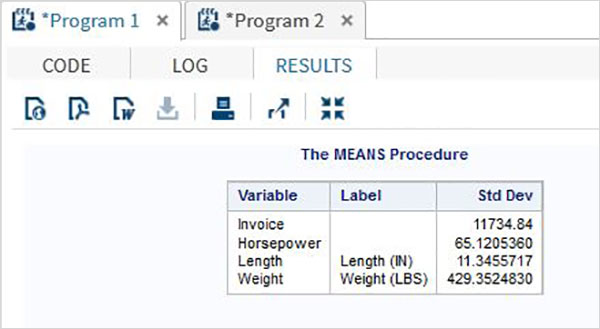
Utilizzo di PROC SURVEYMEANS
Questa procedura viene utilizzata anche per la misurazione della SD insieme ad alcune funzionalità avanzate come la misurazione della SD per le variabili categoriali e per fornire stime della varianza.
Sintassi
La sintassi per l'utilizzo di PROC SURVEYMEANS è:
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;Di seguito la descrizione dei parametri utilizzati:
BY - indica le variabili utilizzate per creare gruppi di osservazioni.
CLASS - indica le variabili utilizzate per le variabili categoriali.
VAR - indica le variabili per le quali verrà calcolata la SD.
Esempio
L'esempio seguente descrive l'uso di class opzione che crea le statistiche per ciascuno dei valori nella variabile di classe.
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Quando eseguiamo il codice precedente, fornisce il seguente output:
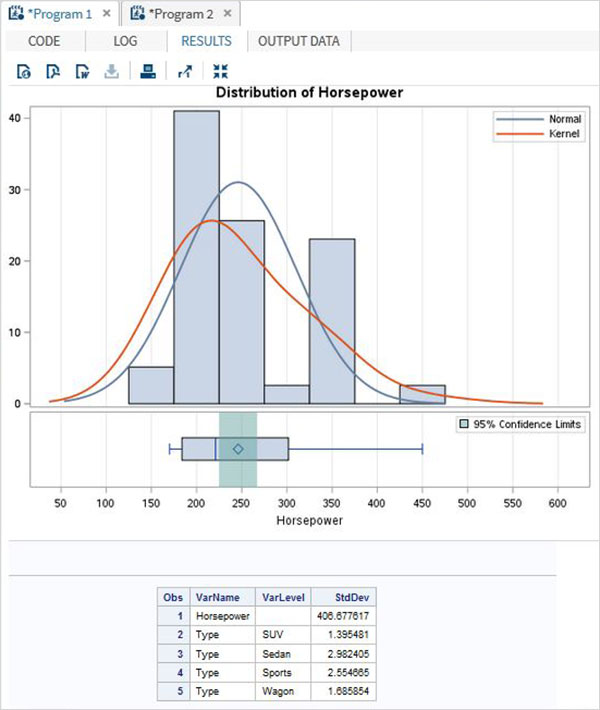
Utilizzando l'opzione BY
Il codice seguente fornisce un esempio dell'opzione BY. In esso il risultato è raggruppato per ogni valore nell'opzione BY.
Esempio
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;Quando eseguiamo il codice precedente, fornisce il seguente output:
Risultato per make = "Audi"

Risultato per make = "BMW"
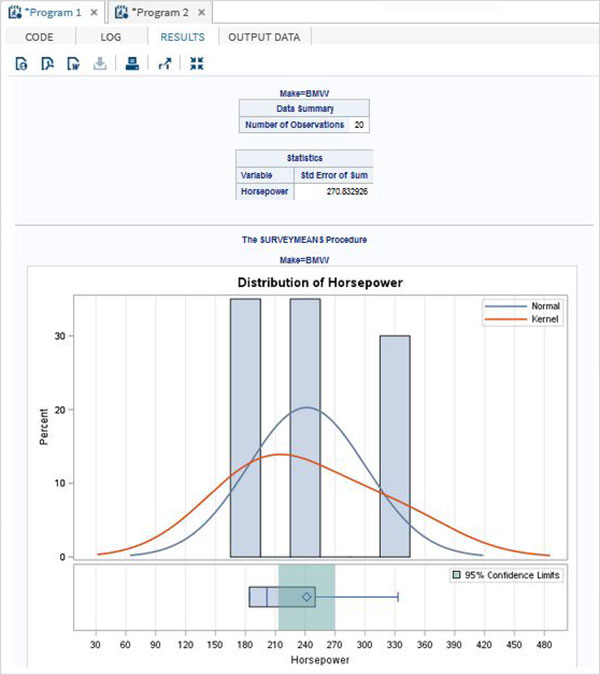
Una distribuzione di frequenza è una tabella che mostra la frequenza dei punti dati in un set di dati. Ogni voce nella tabella contiene la frequenza o il conteggio delle occorrenze di valori all'interno di un particolare gruppo o intervallo e in questo modo la tabella riassume la distribuzione dei valori nel campione.
SAS fornisce una procedura chiamata PROC FREQ per calcolare la distribuzione di frequenza dei punti dati in un set di dati.
Sintassi
La sintassi di base per il calcolo della distribuzione di frequenza in SAS è:
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Variables_1 sono i nomi delle variabili del set di dati di cui è necessario calcolare la distribuzione di frequenza.
Variables_2 sono le variabili che hanno classificato il risultato della distribuzione di frequenza.
Distribuzione di frequenza variabile singola
Possiamo determinare la distribuzione di frequenza di una singola variabile usando PROC FREQ.In questo caso il risultato mostrerà la frequenza di ogni valore della variabile. Il risultato mostra anche la distribuzione percentuale, la frequenza cumulativa e la percentuale cumulativa.
Esempio
Nell'esempio seguente troviamo la distribuzione di frequenza della variabile di potenza per il set di dati denominato CARS1 che viene creato dalla libreria SASHELP.CARS.Possiamo vedere il risultato diviso in due categorie di risultati. Uno per ogni marca dell'auto.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:

Distribuzione di frequenze variabili multiple
Possiamo trovare le distribuzioni di frequenza per più variabili che le raggruppa in tutte le possibili combinazioni.
Esempio
Nell'esempio seguente calcoliamo la distribuzione di frequenza per la marca di un'auto per grouped by car type e anche la distribuzione di frequenza di ogni tipo di automobile grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
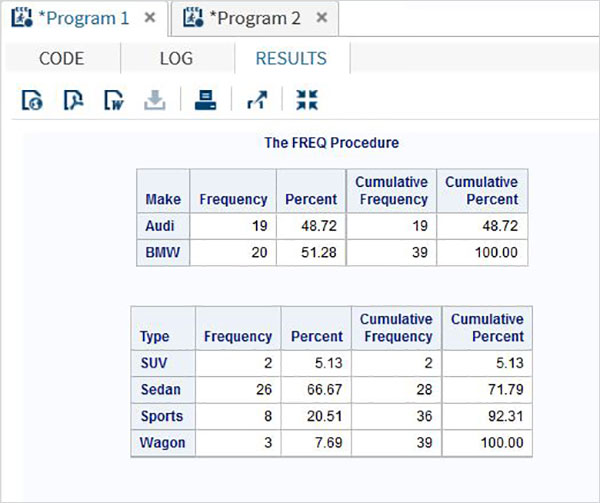
Distribuzione della frequenza con il peso
Con l'opzione peso possiamo calcolare la distribuzione di frequenza polarizzata con il peso della variabile. Qui il valore della variabile viene preso come numero di osservazioni invece che come conteggio del valore.
Esempio
Nell'esempio seguente calcoliamo la distribuzione di frequenza delle variabili marca e tipo con peso assegnato alla potenza.
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
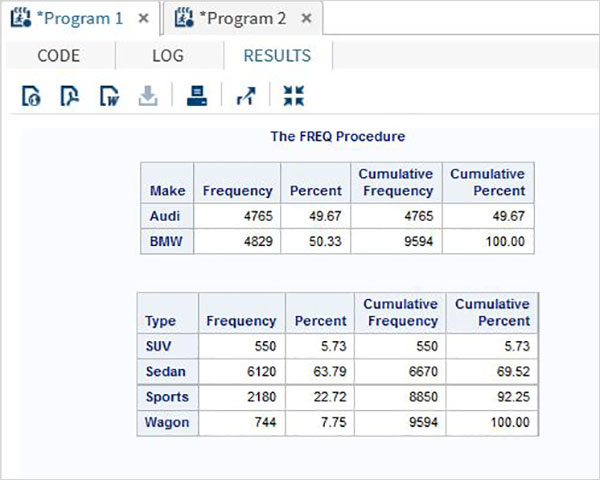
La tabulazione incrociata implica la produzione di tabelle incrociate chiamate anche tabelle contingenti utilizzando tutte le possibili combinazioni di due o più variabili. In SAS viene creato utilizzandoPROC FREQ insieme con il TABLESopzione. Ad esempio, se abbiamo bisogno della frequenza di ogni modello per ogni marca in ogni categoria di tipo di auto, allora dobbiamo usare l'opzione TABELLE di PROC FREQ.
Sintassi
La sintassi di base per applicare la tabulazione incrociata in SAS è:
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Variable_1 and Variable_2 sono i nomi delle variabili del set di dati di cui è necessario calcolare la distribuzione di frequenza.
Esempio
Considera il caso di trovare quanti tipi di auto sono disponibili per ciascuna marca di auto dal set di dati cars1 che viene creato SASHELP.CARScome mostrato di seguito. In questo caso abbiamo bisogno dei valori di frequenza individuali e della somma dei valori di frequenza tra le marche e tra i tipi. Possiamo osservare che il risultato mostra i valori nelle righe e nelle colonne.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
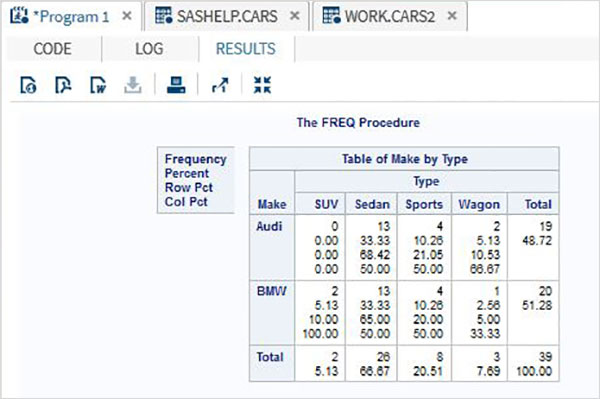
Tabulazione incrociata di 3 variabili
Quando abbiamo tre variabili possiamo raggrupparne 2 e incrociare ciascuna di queste due con la terza variabile. Quindi nel risultato abbiamo due tabelle incrociate.
Esempio
Nell'esempio sotto troviamo la frequenza di ogni tipo di auto e di ogni modello di auto rispetto alla marca dell'auto. Inoltre usiamo le opzioni nocol e norow per evitare i valori di somma e percentuale.
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
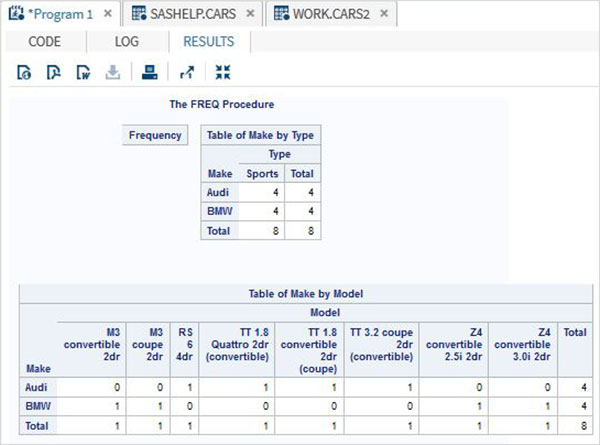
Tabulazione incrociata di 4 variabili
Con 4 variabili, il numero di combinazioni accoppiate aumenta a 4. Ogni variabile del gruppo 1 è accoppiata a ciascuna variabile del gruppo 2.
Esempio
Nell'esempio sotto troviamo la frequenza di lunghezza dell'auto per ogni marca e ogni modello. Allo stesso modo la frequenza di potenza per ogni marca e ogni modello.
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
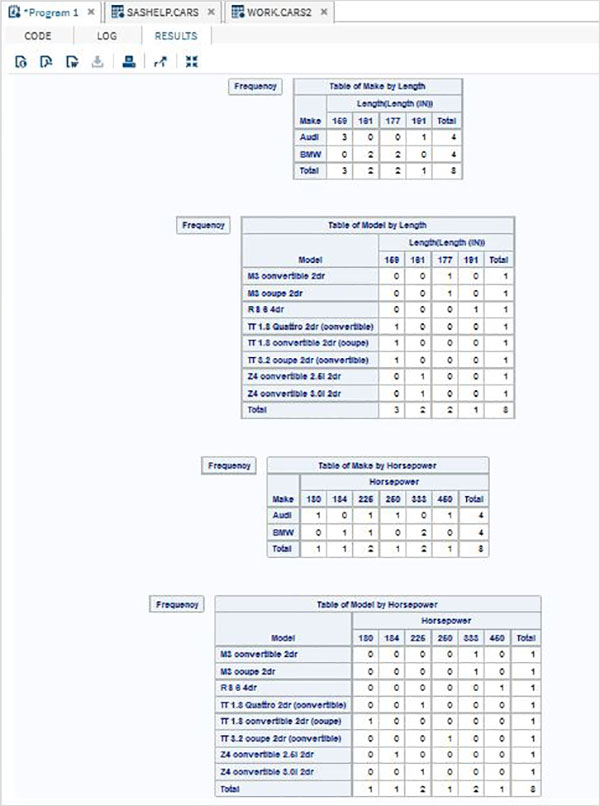
I test T vengono eseguiti per calcolare i limiti di confidenza per uno o due campioni indipendenti confrontando le loro medie e differenze medie. La procedura SAS denominataPROC TTEST serve per eseguire test t su una singola variabile e su una coppia di variabili.
Sintassi
La sintassi di base per applicare PROC TTEST in SAS è:
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Variable_1 and Variable_2 sono i nomi delle variabili del set di dati utilizzato nel test t.
Esempio
Di seguito vediamo un test t campione in cui trovare la stima del test t per la potenza variabile con limiti di confidenza del 95 percento.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
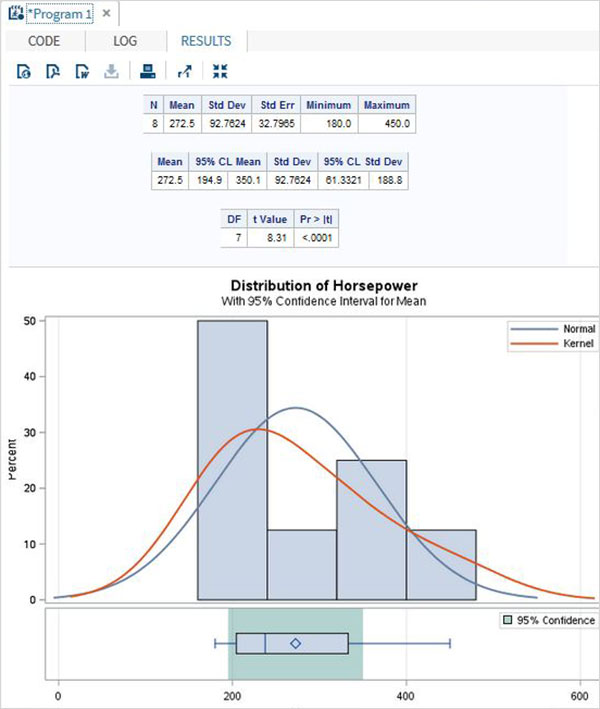
T-test accoppiato
Il test T accoppiato viene eseguito per verificare se due variabili dipendenti sono statisticamente diverse l'una dall'altra o meno.
Esempio
Poiché la lunghezza e il peso di un'auto dipendono l'uno dall'altro, applichiamo il test T accoppiato come mostrato di seguito.
proc ttest data = cars1 ;
paired weight*length;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Test t su due campioni
Questo test t è progettato per confrontare le medie della stessa variabile tra due gruppi.
Esempio
Nel nostro caso confrontiamo la media della potenza variabile tra le due diverse marche di auto ("Audi" e "BMW").
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
L'analisi di correlazione si occupa delle relazioni tra variabili. Il coefficiente di correlazione è una misura dell'associazione lineare tra due variabili.I valori del coefficiente di correlazione sono sempre compresi tra -1 e +1. SAS fornisce la proceduraPROC CORR per trovare i coefficienti di correlazione tra una coppia di variabili in un set di dati.
Sintassi
La sintassi di base per applicare PROC CORR in SAS è:
PROC CORR DATA = dataset options;
VAR variable;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Options è l'opzione aggiuntiva con procedure come tracciare una matrice ecc.
Variable è il nome della variabile del set di dati utilizzato per trovare la correlazione.
Esempio
I coefficienti di correlazione tra una coppia di variabili disponibili in un set di dati possono essere ottenuti utilizzando i loro nomi nell'istruzione VAR. Nell'esempio seguente utilizziamo il set di dati CARS1 e otteniamo il risultato che mostra i coefficienti di correlazione tra potenza e peso.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Correlazione tra tutte le variabili
I coefficienti di correlazione tra tutte le variabili disponibili in un dataset possono essere ottenuti semplicemente applicando la procedura con il nome del dataset.
Esempio
Nell'esempio seguente utilizziamo il set di dati CARS1 e otteniamo il risultato che mostra i coefficienti di correlazione tra ciascuna coppia di variabili.
proc corr data = cars1 ;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
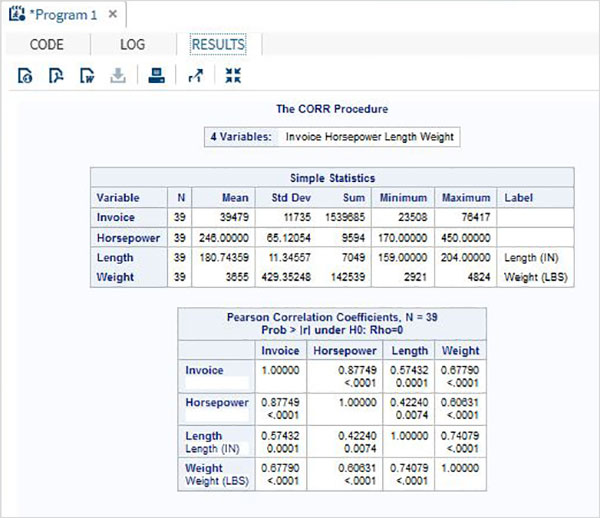
Matrice di correlazione
Possiamo ottenere una matrice del grafico a dispersione tra le variabili scegliendo l'opzione per tracciare la matrice nel file PROC dichiarazione.
Esempio
Nell'esempio seguente otteniamo la matrice tra potenza e peso.
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
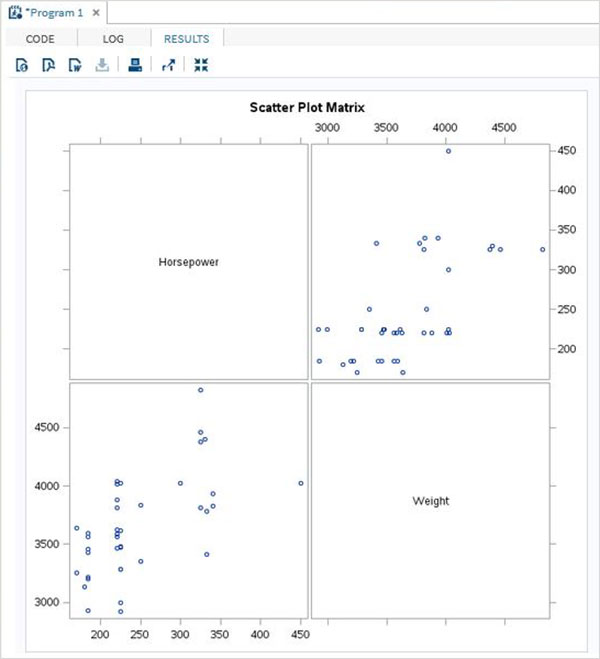
La regressione lineare viene utilizzata per identificare la relazione tra una variabile dipendente e una o più variabili indipendenti. Viene proposto un modello della relazione e le stime dei valori dei parametri vengono utilizzate per sviluppare un'equazione di regressione stimata.
Vengono quindi utilizzati vari test per determinare se il modello è soddisfacente. In tal caso, l'equazione di regressione stimata può essere utilizzata per prevedere il valore della variabile dipendente dati i valori per le variabili indipendenti. In SAS la proceduraPROC REG viene utilizzato per trovare il modello di regressione lineare tra due variabili.
Sintassi
La sintassi di base per applicare PROC REG in SAS è:
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
variable_1 and variable_2 sono i nomi delle variabili del set di dati utilizzati per trovare la correlazione.
Esempio
L'esempio seguente mostra il processo per trovare la correlazione tra le due variabili potenza e peso di un'auto utilizzando PROC REG. Nel risultato vediamo i valori di intercetta che possono essere usati per formare l'equazione di regressione.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
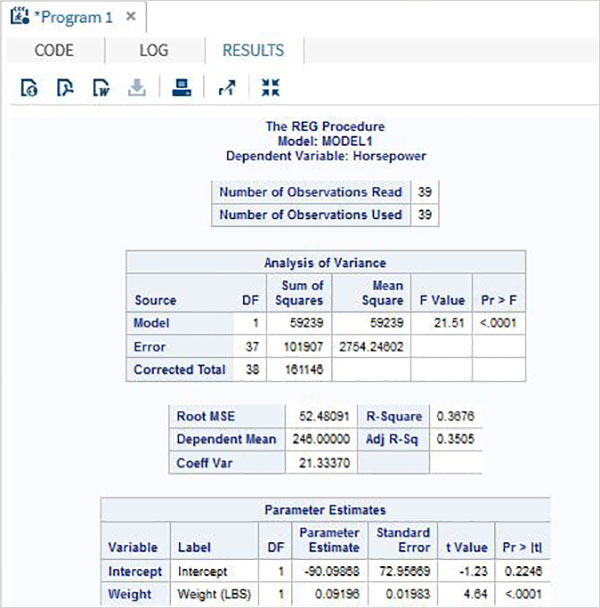
Il codice sopra fornisce anche la visualizzazione grafica di varie stime del modello come mostrato di seguito. Essendo una procedura SAS avanzata, semplicemente non si ferma a dare i valori di intercettazione come output.
L'analisi di Bland-Altman è un processo per verificare il grado di accordo o disaccordo tra due metodi progettati per misurare gli stessi parametri. Un'elevata correlazione tra i metodi indica che nell'analisi dei dati è stato scelto un campione sufficientemente buono. In SAS creiamo un grafico Bland-Altman calcolando la media, il limite superiore e il limite inferiore dei valori delle variabili. Quindi usiamo PROC SGPLOT per creare il grafico Bland-Altman.
Sintassi
La sintassi di base per applicare PROC SGPLOT in SAS è:
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
SCATTER dichiarazione cerata il grafico del diagramma a dispersione del valore fornito sotto forma di X e Y.
REFLINE crea una linea di riferimento orizzontale o verticale.
Esempio
Nell'esempio seguente prendiamo il risultato di due esperimenti generati da due metodi denominati nuovo e vecchio. Calcoliamo le differenze nei valori delle variabili e anche la media delle variabili della stessa osservazione. Calcoliamo anche i valori di deviazione standard da utilizzare nel limite superiore e inferiore del calcolo.
Il risultato mostra un grafico Bland-Altman come grafico a dispersione.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Modello avanzato
In un modello migliorato del programma precedente otteniamo l'adattamento della curva del livello di confidenza al 95%.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Un test chi-quadrato viene utilizzato per esaminare l'associazione tra due variabili categoriali. Può essere utilizzato per verificare sia il grado di dipendenza che il grado di indipendenza tra le variabili. Usi SASPROC FREQ insieme all'opzione chisq per determinare il risultato del test Chi-quadrato.
Sintassi
La sintassi di base per applicare PROC FREQ per il test chi-quadrato in SAS è:
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);Di seguito la descrizione dei parametri utilizzati:
Dataset è il nome del set di dati.
Variables sono i nomi delle variabili del set di dati utilizzati nel test chi quadrato.
Percentage Values nell'istruzione TESTP rappresentano la percentuale dei livelli della variabile.
Esempio
Nell'esempio seguente consideriamo un test chi-quadrato sulla variabile denominata type nel set di dati SASHELP.CARS. Questa variabile ha sei livelli e assegniamo una percentuale a ciascun livello secondo il progetto del test.
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:

Otteniamo anche il grafico a barre che mostra la deviazione del tipo di variabile come mostrato nello screenshot seguente.
Chi quadrato a due vie
Il test Chi-quadrato a due vie viene utilizzato quando applichiamo i test a due variabili del set di dati.
Esempio
Nell'esempio seguente applichiamo il test chi-quadrato su due variabili denominate tipo e origine. Il risultato mostra la forma tabellare di tutte le combinazioni di queste due variabili.
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
Il test esatto di Fisher è un test statistico utilizzato per determinare se esistono associazioni non casuali tra due variabili categoriali.In SAS questo viene eseguito utilizzando PROC FREQ. Usiamo l'opzione Tabelle per utilizzare le due variabili sottoposte al test Fisher Exact.
Sintassi
La sintassi di base per applicare il test Fisher Exact in SAS è:
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;Di seguito la descrizione dei parametri utilizzati:
dataset è il nome del set di dati.
Variable_1*Variable_2 sono le variabili che formano il set di dati.
Applicazione del test esatto di Fisher
Per applicare il test esatto di Fisher, scegliamo due variabili categoriali denominate Test1 e Test2 e il loro risultato. Usiamo PROC FREQ per applicare il test mostrato di seguito.
Esempio
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
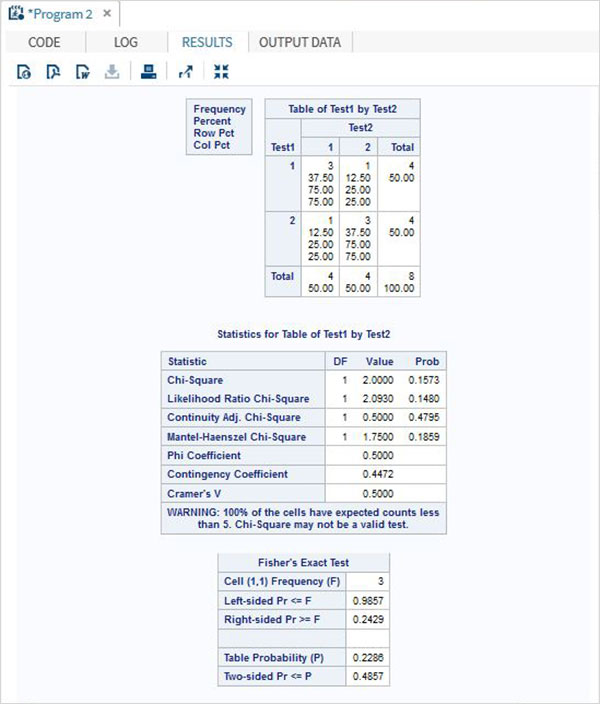
L'analisi della misura ripetuta viene utilizzata quando tutti i membri di un campione casuale vengono misurati in una serie di condizioni diverse. Quando il campione viene esposto a turno a ciascuna condizione, la misurazione della variabile dipendente viene ripetuta. L'utilizzo di uno standard ANOVA in questo caso non è appropriato perché non riesce a modellare la correlazione tra le misure ripetute.
Si dovrebbe essere chiari sulla differenza tra a repeated measures design e a simple multivariate design. Per entrambi, i membri del campione vengono misurati in diverse occasioni, o prove, ma nel disegno delle misure ripetute, ciascuna prova rappresenta la misurazione della stessa caratteristica in una condizione diversa.
In SAS PROC GLM viene utilizzato per eseguire analisi di misure ripetute.
Sintassi
La sintassi di base per PROC GLM in SAS è:
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;Di seguito la descrizione dei parametri utilizzati:
dataset è il nome del set di dati.
CLASS attribuisce alle variabili la variabile utilizzata come variabile di classificazione.
MODEL definisce il modello da adattare utilizzando determinate variabili dal dataset.
REPEATED definisce il numero di misure ripetute di ciascun gruppo per testare l'ipotesi.
Esempio
Considera l'esempio sotto in cui abbiamo due gruppi di persone sottoposte al test dell'effetto di un farmaco. Il tempo di reazione di ogni persona viene registrato per ciascuno dei quattro tipi di farmaci testati. Qui vengono eseguite 5 prove per ogni gruppo di persone per vedere la forza della correlazione tra gli effetti dei quattro tipi di farmaci.
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:
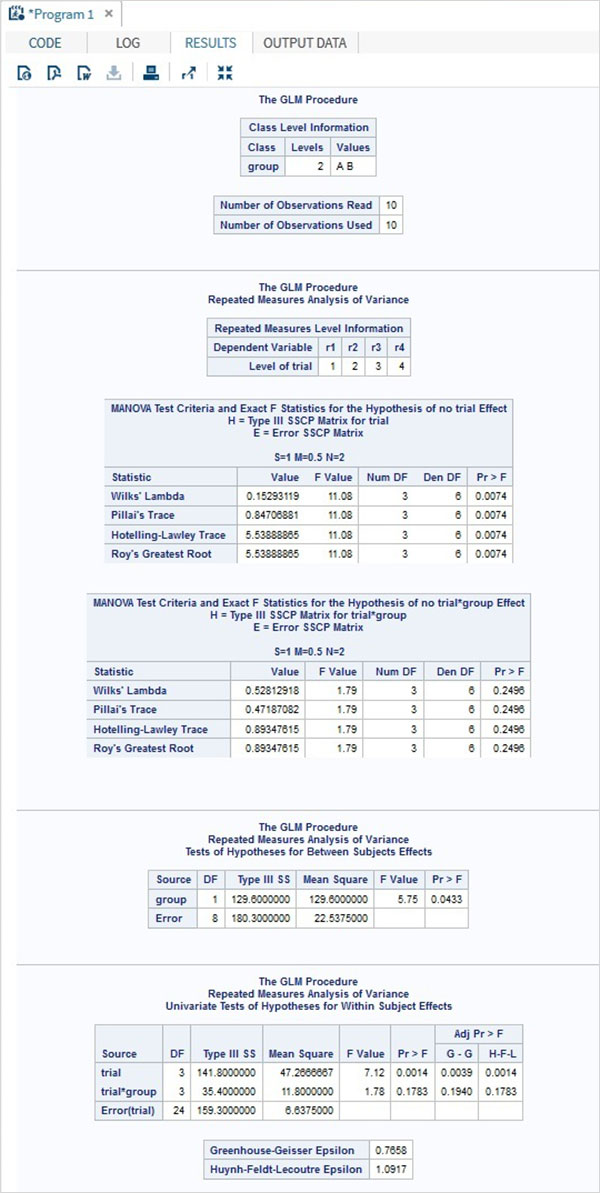
ANOVA sta per Analisi della varianza. In SAS si utilizzaPROC ANOVA. Esegue l'analisi dei dati da un'ampia varietà di disegni sperimentali. In questo processo, una variabile di risposta continua, nota come variabile dipendente, viene misurata in condizioni sperimentali identificate da variabili di classificazione, note come variabili indipendenti. Si presume che la variazione nella risposta sia dovuta a effetti nella classificazione, con l'errore casuale che tiene conto della variazione rimanente.
Sintassi
La sintassi di base per applicare PROC ANOVA in SAS è:
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;Di seguito la descrizione dei parametri utilizzati:
dataset è il nome del set di dati.
CLASS attribuisce alle variabili la variabile utilizzata come variabile di classificazione.
MODEL definisce il modello da adattare utilizzando determinate variabili dal set di dati.
Variable_1 and Variable_2 sono i nomi delle variabili del set di dati utilizzato nell'analisi.
MEANS definisce il tipo di calcolo e confronto delle medie.
Applicazione di ANOVA
Vediamo ora di comprendere il concetto di applicazione di ANOVA in SAS.
Esempio
Consideriamo il set di dati SASHELP.CARS. Qui studiamo la dipendenza tra le variabili tipo di automobile e la loro potenza. Poiché il tipo di automobile è una variabile con valori categoriali, la prendiamo come variabile di classe e utilizziamo entrambe queste variabili nel MODELLO.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:

Applicare ANOVA con MEANS
Vediamo ora il concetto di applicare ANOVA con MEANS in SAS.
Esempio
Possiamo anche estendere il modello applicando la dichiarazione MEANS in cui utilizziamo il metodo Studentized della Turchia per confrontare i valori medi di vari tipi di auto.Le categorie di tipi di auto sono elencate con il valore medio della potenza in ciascuna categoria insieme ad alcuni valori aggiuntivi come errore medio quadrato ecc.
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;Quando il codice sopra viene eseguito, otteniamo il seguente risultato:

Il test di ipotesi è l'uso della statistica per determinare la probabilità che una data ipotesi sia vera. Il normale processo di verifica delle ipotesi consiste in quattro passaggi come mostrato di seguito.
Passo 1
Formulare l'ipotesi nulla H0 (comunemente, che le osservazioni siano il risultato del puro caso) e l'ipotesi alternativa H1 (comunemente, che le osservazioni mostrino un effetto reale combinato con una componente di variazione casuale).
Passo 2
Identificare una statistica di prova che può essere utilizzata per valutare la verità dell'ipotesi nulla.
Passaggio 3
Calcola il valore P, che è la probabilità che una statistica test significativa almeno quanto quella osservata sarebbe ottenuta assumendo che l'ipotesi nulla fosse vera. Più piccolo è il valore P, più forte è l'evidenza contro l'ipotesi nulla.
Passaggio 4
Confronta il valore p con un valore di significatività alfa accettabile (a volte chiamato valore alfa). Se p <= alfa, che l'effetto osservato è statisticamente significativo, l'ipotesi nulla è esclusa e l'ipotesi alternativa è valida.
Il linguaggio di programmazione SAS ha funzionalità per eseguire vari tipi di test di ipotesi, come mostrato di seguito.
| Test | Descrizione | SAS PROC |
|---|---|---|
| T-Test | Un test t viene utilizzato per verificare se la media di una variabile è significativamente diversa da un valore ipotizzato. Determiniamo anche se le medie per due gruppi indipendenti sono significativamente diverse e se le medie per gruppi dipendenti o appaiati sono significativamente diverse. | PROC TTEST |
| ANOVA | Viene anche utilizzato per confrontare le medie quando è presente una variabile categoriale indipendente. Vogliamo utilizzare ANOVA unidirezionale durante il test per vedere se le medie della variabile dipendente dall'intervallo sono diverse in base alla variabile categoriale indipendente. | PROC ANOVA |
| Chi-Square | Usiamo la bontà di adattamento del chi quadrato per valutare se le frequenze di una variabile categorica potessero verificarsi per caso. L'uso di un test del chi quadrato è necessario se le proporzioni di una variabile categoriale sono un valore ipotizzato. | PROC FREQ |
| Linear Regression | La regressione lineare semplice viene utilizzata quando si desidera verificare quanto bene una variabile predice un'altra variabile. La regressione lineare multipla consente di testare quanto bene più variabili predicono una variabile di interesse. Quando si utilizza la regressione lineare multipla, assumiamo inoltre che le variabili predittive siano indipendenti. | PROC REG |