Architettura centrata sui dati
Nell'architettura data center, i dati sono centralizzati e accedono frequentemente da altri componenti, che modificano i dati. Lo scopo principale di questo stile è raggiungere l'integralità dei dati. L'architettura data-center è composta da diversi componenti che comunicano attraverso archivi di dati condivisi. I componenti accedono a una struttura dati condivisa e sono relativamente indipendenti, in quanto interagiscono solo attraverso l'archivio dati.
L'esempio più noto dell'architettura data-centered è un'architettura di database, in cui lo schema di database comune viene creato con il protocollo di definizione dei dati, ad esempio un insieme di tabelle correlate con campi e tipi di dati in un RDBMS.
Un altro esempio di architetture centrate sui dati è l'architettura web che ha uno schema di dati comune (cioè la meta-struttura del Web) e segue il modello di dati ipermediali ei processi comunicano attraverso l'uso di servizi di dati basati sul web condivisi.

Tipi di componenti
Esistono due tipi di componenti:
UN central datastruttura o archivio dati o archivio dati, che è responsabile della fornitura di archiviazione permanente dei dati. Rappresenta lo stato attuale.
UN data accessor o una raccolta di componenti indipendenti che operano sull'archivio dati centrale, eseguono calcoli e potrebbero restituire i risultati.
Le interazioni o la comunicazione tra gli utenti che accedono ai dati avvengono solo attraverso l'archivio dati. I dati sono l'unico mezzo di comunicazione tra i clienti. Il flusso di controllo differenzia l'architettura in due categorie:
- Stile di architettura del repository
- Stile di architettura della lavagna
Stile di architettura del repository
In Stile architettura repository, l'archivio dati è passivo e sono attivi i client (componenti software o agenti) dell'archivio dati, che controllano il flusso logico. I componenti partecipanti controllano l'archivio dati per eventuali modifiche.
Il client invia una richiesta al sistema per eseguire azioni (es. Inserire dati).
I processi di calcolo sono indipendenti e attivati dalle richieste in arrivo.
Se i tipi di transazioni in un flusso di input di transazioni attivano la selezione dei processi da eseguire, allora si tratta di un database tradizionale o di un'architettura di repository o di un repository passivo.
Questo approccio è ampiamente utilizzato nel DBMS, nel sistema informativo della biblioteca, nel repository dell'interfaccia in CORBA, nei compilatori e negli ambienti CASE (computer aided software engineering).

Vantaggi
Fornisce funzionalità di integrità dei dati, backup e ripristino.
Fornisce scalabilità e riusabilità degli agenti poiché non hanno una comunicazione diretta tra loro.
Riduce il sovraccarico dei dati temporanei tra i componenti software.
Svantaggi
È più vulnerabile ai guasti ed è possibile la replica o la duplicazione dei dati.
Elevata dipendenza tra la struttura dati dell'archivio dati e i suoi agenti.
I cambiamenti nella struttura dei dati influenzano fortemente i client.
L'evoluzione dei dati è difficile e costosa.
Costo dello spostamento dei dati sulla rete per i dati distribuiti.
Stile di architettura della lavagna
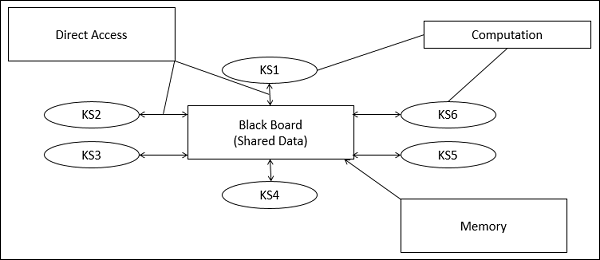
In Blackboard Architecture Style, l'archivio dati è attivo ei suoi client sono passivi. Pertanto il flusso logico è determinato dallo stato corrente dei dati nell'archivio dati. Ha una componente lavagna, che funge da archivio centrale di dati, e una rappresentazione interna è costruita e su cui agisce diversi elementi computazionali.
Nella lavagna sono memorizzati alcuni componenti che agiscono indipendentemente sulla struttura dati comune.
In questo stile, i componenti interagiscono solo attraverso la lavagna. L'archivio dati avvisa i client ogni volta che viene apportata una modifica all'archivio dati.
Lo stato corrente della soluzione viene memorizzato nella lavagna e l'elaborazione viene attivata dallo stato della lavagna.
Il sistema invia notifiche note come trigger e dati ai client quando si verificano modifiche nei dati.
Questo approccio si trova in alcune applicazioni AI e applicazioni complesse, come il riconoscimento vocale, il riconoscimento delle immagini, il sistema di sicurezza e i sistemi di gestione delle risorse aziendali ecc.
Se lo stato corrente della struttura dati centrale è il fattore scatenante principale della selezione dei processi da eseguire, il repository può essere una lavagna e questa origine dati condivisa è un agente attivo.
Una delle principali differenze con i sistemi di database tradizionali è che l'invocazione di elementi computazionali in un'architettura di lavagna è attivata dallo stato corrente della lavagna e non da input esterni.
Parti del modello di lavagna
Il modello di lavagna viene solitamente presentato con tre parti principali:
Knowledge Sources (KS)
Fonti di conoscenza, note anche come Listeners o Subscriberssono unità distinte e indipendenti. Risolvono parti di un problema e aggregano risultati parziali. L'interazione tra le fonti di conoscenza avviene unicamente attraverso la lavagna.
Blackboard Data Structure
I dati sullo stato di risoluzione dei problemi sono organizzati in una gerarchia dipendente dall'applicazione. Le fonti di conoscenza apportano modifiche alla lavagna che portano in modo incrementale a una soluzione al problema.
Control
Il controllo gestisce le attività e controlla lo stato del lavoro.
Vantaggi
Fornisce scalabilità che consente di aggiungere o aggiornare facilmente la fonte della conoscenza.
Fornisce la concorrenza che consente a tutte le fonti di conoscenza di funzionare in parallelo poiché sono indipendenti l'una dall'altra.
Supporta la sperimentazione per ipotesi.
Supporta la riusabilità degli agenti dell'origine della conoscenza.
Svantaggi
Il cambiamento di struttura della lavagna può avere un impatto significativo su tutti i suoi agenti poiché esiste una stretta dipendenza tra lavagna e fonte di conoscenza.
Può essere difficile decidere quando terminare il ragionamento poiché è prevista solo una soluzione approssimativa.
Problemi nella sincronizzazione di più agenti.
Le principali sfide nella progettazione e nel test del sistema.