Guida veloce
L'architettura di un sistema descrive i suoi componenti principali, le loro relazioni (strutture) e il modo in cui interagiscono tra loro. L'architettura e il design del software includono diversi fattori contributivi come strategia aziendale, attributi di qualità, dinamiche umane, design e ambiente IT.

Possiamo separare l'architettura e la progettazione del software in due fasi distinte: l'architettura del software e la progettazione del software. InArchitecture, le decisioni non funzionali sono espresse e separate dai requisiti funzionali. Nella progettazione vengono soddisfatti i requisiti funzionali.
Architettura software
L'architettura funge da blueprint for a system. Fornisce un'astrazione per gestire la complessità del sistema e stabilire un meccanismo di comunicazione e coordinamento tra i componenti.
Definisce a structured solution per soddisfare tutti i requisiti tecnici e operativi, ottimizzando al contempo gli attributi di qualità comuni come prestazioni e sicurezza.
Inoltre, implica una serie di decisioni significative sull'organizzazione relative allo sviluppo del software e ciascuna di queste decisioni può avere un impatto considerevole sulla qualità, la manutenibilità, le prestazioni e il successo complessivo del prodotto finale. Queste decisioni comprendono:
Selezione degli elementi strutturali e delle loro interfacce di cui è composto il sistema.
Comportamento come specificato nelle collaborazioni tra questi elementi.
Composizione di questi elementi strutturali e comportamentali in un grande sottosistema.
Le decisioni architettoniche sono in linea con gli obiettivi aziendali.
Gli stili architettonici guidano l'organizzazione.
Progettazione software
La progettazione del software fornisce un file design planche descrive gli elementi di un sistema, come si adattano e lavorano insieme per soddisfare i requisiti del sistema. Gli obiettivi di avere un piano di progettazione sono i seguenti:
Per negoziare i requisiti di sistema e definire le aspettative con i clienti, il marketing e il personale di gestione.
Agire come modello durante il processo di sviluppo.
Guida le attività di implementazione, inclusi progettazione dettagliata, codifica, integrazione e test.
Viene prima della progettazione dettagliata, della codifica, dell'integrazione e del test e dopo l'analisi del dominio, l'analisi dei requisiti e l'analisi dei rischi.
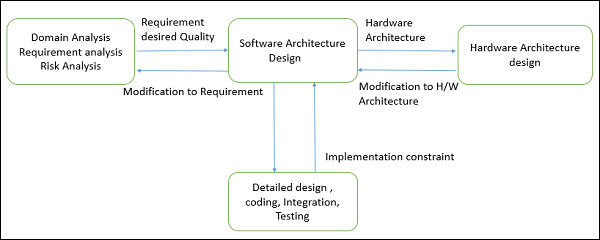
Obiettivi dell'architettura
L'obiettivo principale dell'architettura è identificare i requisiti che influenzano la struttura dell'applicazione. Un'architettura ben strutturata riduce i rischi aziendali associati alla creazione di una soluzione tecnica e crea un ponte tra i requisiti tecnici e aziendali.
Alcuni degli altri obiettivi sono i seguenti:
Esponi la struttura del sistema, ma nascondi i dettagli di implementazione.
Realizza tutti i casi d'uso e gli scenari.
Cerca di soddisfare le esigenze dei vari stakeholder.
Gestisci i requisiti funzionali e di qualità.
Ridurre l'obiettivo della proprietà e migliorare la posizione di mercato dell'organizzazione.
Migliora la qualità e le funzionalità offerte dal sistema.
Migliora la fiducia esterna nell'organizzazione o nel sistema.
Limitazioni
L'architettura del software è ancora una disciplina emergente all'interno dell'ingegneria del software. Presenta le seguenti limitazioni:
Mancanza di strumenti e modi standardizzati per rappresentare l'architettura.
Mancanza di metodi di analisi per prevedere se l'architettura si tradurrà in un'implementazione che soddisfa i requisiti.
Mancanza di consapevolezza dell'importanza della progettazione architettonica per lo sviluppo del software.
Mancanza di comprensione del ruolo dell'architetto del software e scarsa comunicazione tra le parti interessate.
Mancanza di comprensione del processo di progettazione, esperienza di progettazione e valutazione del design.
Ruolo dell'architetto del software
Un Software Architect fornisce una soluzione che il team tecnico può creare e progettare per l'intera applicazione. Un architetto del software dovrebbe avere esperienza nelle seguenti aree:
Competenza nel design
Esperto nella progettazione di software, inclusi diversi metodi e approcci come la progettazione orientata agli oggetti, la progettazione guidata dagli eventi, ecc.
Guida il team di sviluppo e coordina gli sforzi di sviluppo per l'integrità del design.
Dovrebbe essere in grado di rivedere le proposte di progettazione e il compromesso tra di loro.
Competenza nel dominio
Esperto del sistema in fase di sviluppo e programma per l'evoluzione del software.
Assistere nel processo di indagine sui requisiti, assicurando completezza e coerenza.
Coordinare la definizione del modello di dominio per il sistema in fase di sviluppo.
Competenza tecnologica
Esperto sulle tecnologie disponibili che aiuta nell'implementazione del sistema.
Coordinare la selezione di linguaggio di programmazione, framework, piattaforme, database, ecc.
Competenza metodologica
Esperto in metodologie di sviluppo software che possono essere adottate durante SDLC (Software Development Life Cycle).
Scegli gli approcci appropriati per lo sviluppo che aiutano l'intero team.
Ruolo nascosto dell'architetto del software
Facilita il lavoro tecnico tra i membri del team e rafforza il rapporto di fiducia nel team.
Specialista dell'informazione che condivide la conoscenza e ha una vasta esperienza.
Proteggi i membri del team da forze esterne che li distrarrebbero e apporterebbero meno valore al progetto.
Deliverables dell'architetto
Una serie di obiettivi funzionali chiari, completi, coerenti e raggiungibili
Una descrizione funzionale del sistema, con almeno due strati di decomposizione
Un concetto per il sistema
Un progetto sotto forma di sistema, con almeno due strati di decomposizione
Una nozione di tempistica, attributi dell'operatore e piani operativi e di implementazione
Viene seguito un documento o processo che garantisce la scomposizione funzionale e il controllo della forma delle interfacce
Attributi di qualità
La qualità è una misura di eccellenza o lo stato di essere liberi da carenze o difetti. Gli attributi di qualità sono le proprietà del sistema che sono separate dalla funzionalità del sistema.
L'implementazione degli attributi di qualità rende più facile distinguere un buon sistema da uno cattivo. Gli attributi sono fattori generali che influenzano il comportamento di runtime, la progettazione del sistema e l'esperienza dell'utente.
Possono essere classificati come:
Attributi statici di qualità
Riflette la struttura di un sistema e di un'organizzazione, direttamente correlati all'architettura, al design e al codice sorgente. Sono invisibili all'utente finale, ma influenzano i costi di sviluppo e manutenzione, ad esempio: modularità, testabilità, manutenibilità, ecc.
Attributi di qualità dinamici
Riflette il comportamento del sistema durante la sua esecuzione. Sono direttamente correlati all'architettura del sistema, al design, al codice sorgente, alla configurazione, ai parametri di distribuzione, all'ambiente e alla piattaforma.
Sono visibili all'utente finale ed esistono in fase di runtime, ad esempio throughput, robustezza, scalabilità, ecc.
Scenari di qualità
Gli scenari di qualità specificano come evitare che un errore diventi un errore. Possono essere divisi in sei parti in base alle specifiche degli attributi:
Source - Un'entità interna o esterna come persone, hardware, software o infrastrutture fisiche che generano lo stimolo.
Stimulus - Una condizione che deve essere considerata quando arriva su un sistema.
Environment - Lo stimolo si verifica entro determinate condizioni.
Artifact - Un intero sistema o parte di esso come processori, canali di comunicazione, archiviazione persistente, processi ecc.
Response - Un'attività intrapresa dopo l'arrivo di uno stimolo come rilevare guasti, recuperare da guasto, disabilitare la sorgente dell'evento ecc.
Response measure - Dovrebbe misurare le risposte avvenute in modo che i requisiti possano essere testati.
Attributi di qualità comuni
La tabella seguente elenca gli attributi di qualità comuni che un'architettura software deve avere:
| Categoria | Attributo di qualità | Descrizione |
|---|---|---|
| Qualità del design | Integrità concettuale | Definisce la consistenza e la coerenza del design complessivo. Ciò include il modo in cui sono progettati componenti o moduli. |
| Manutenibilità | Capacità del sistema di subire modifiche con una certa facilità. | |
| Riusabilità | Definisce la capacità dei componenti e dei sottosistemi di essere adatti per l'uso in altre applicazioni. | |
| Qualità di runtime | Interoperabilità | Capacità di uno o più sistemi di operare con successo comunicando e scambiando informazioni con altri sistemi esterni scritti e gestiti da soggetti esterni. |
| Gestibilità | Definisce quanto è facile per gli amministratori di sistema gestire l'applicazione. | |
| Affidabilità | Capacità di un sistema di rimanere operativo nel tempo. | |
| Scalabilità | Capacità di un sistema di gestire l'aumento del carico senza influire sulle prestazioni del sistema o la capacità di essere prontamente ampliato. | |
| Sicurezza | Capacità di un sistema di prevenire azioni dannose o accidentali al di fuori degli usi previsti. | |
| Prestazione | Indicazione della capacità di risposta di un sistema per eseguire qualsiasi azione entro un dato intervallo di tempo. | |
| Disponibilità | Definisce la proporzione di tempo in cui il sistema è funzionale e funzionante. Può essere misurato come percentuale del tempo di inattività totale del sistema in un periodo predefinito. | |
| Qualità del sistema | Supportabilità | Capacità del sistema di fornire informazioni utili per identificare e risolvere problemi quando non funziona correttamente. |
| Testabilità | Misura la facilità con cui creare criteri di test per il sistema e i suoi componenti. | |
| Qualità degli utenti | Usabilità | Definisce in che misura l'applicazione soddisfa i requisiti dell'utente e del consumatore essendo intuitiva. |
| Qualità dell'architettura | Correttezza | Responsabilità per soddisfare tutti i requisiti del sistema. |
| Qualità non runtime | Portabilità | Capacità del sistema di funzionare in diversi ambienti informatici. |
| Integralità | Capacità di far funzionare correttamente insieme componenti sviluppati separatamente del sistema. | |
| Modificabilità | Facilità con cui ogni sistema software può adattarsi alle modifiche al proprio software. | |
| Attributi di qualità aziendale | Costo e programma | Costo del sistema rispetto al time to market, durata prevista del progetto e utilizzo del legacy. |
| Commerciabilità | Uso del sistema rispetto alla concorrenza sul mercato. |
L'architettura del software è descritta come l'organizzazione di un sistema, in cui il sistema rappresenta un insieme di componenti che svolgono le funzioni definite.
Stile architettonico
Il architectural style, chiamato anche come architectural pattern, è un insieme di principi che plasma un'applicazione. Definisce un quadro astratto per una famiglia di sistemi in termini di modello di organizzazione strutturale.
Lo stile architettonico è responsabile di:
Fornire un lessico di componenti e connettori con regole su come possono essere combinati.
Migliora il partizionamento e consenti il riutilizzo del design fornendo soluzioni ai problemi che si verificano di frequente.
Descrivere un modo particolare per configurare una raccolta di componenti (un modulo con interfacce ben definite, riutilizzabile e sostituibile) e connettori (collegamento di comunicazione tra i moduli).
Il software creato per i sistemi basati su computer mostra uno dei tanti stili architettonici. Ogni stile descrive una categoria di sistema che comprende:
Un insieme di tipi di componenti che svolgono una funzione richiesta dal sistema.
Un insieme di connettori (chiamata di subroutine, chiamata di procedura remota, flusso di dati e socket) che consentono la comunicazione, il coordinamento e la cooperazione tra i diversi componenti.
Vincoli semantici che definiscono come i componenti possono essere integrati per formare il sistema.
Un layout topologico dei componenti che indica le loro interrelazioni di runtime.
Progettazione architettonica comune
La tabella seguente elenca gli stili architettonici che possono essere organizzati in base all'area di interesse principale:
| Categoria | Progettazione architettonica | Descrizione |
|---|---|---|
| Comunicazione | Bus dei messaggi | Prescrive l'uso di un sistema software in grado di ricevere e inviare messaggi utilizzando uno o più canali di comunicazione. |
| Architettura orientata ai servizi (SOA) | Definisce le applicazioni che espongono e consumano funzionalità come servizio utilizzando contratti e messaggi. | |
| Distribuzione | Client / server | Separare il sistema in due applicazioni, in cui il client effettua richieste al server. |
| 3 livelli o N livelli | Separa la funzionalità in segmenti separati con ogni segmento che è un livello situato su un computer fisicamente separato. | |
| Dominio | Progettazione basata sul dominio | Incentrato sulla modellazione di un dominio aziendale e sulla definizione di oggetti aziendali basati su entità all'interno del dominio aziendale. |
| Struttura | Basato su componenti | Suddividi la progettazione dell'applicazione in componenti logici o funzionali riutilizzabili che espongono interfacce di comunicazione ben definite. |
| Stratificato | Dividi le preoccupazioni dell'applicazione in gruppi impilati (livelli). | |
| Orientato agli oggetti | Basato sulla divisione delle responsabilità di un'applicazione o di un sistema in oggetti, ciascuno contenente i dati e il comportamento relativo all'oggetto. |
Tipi di architettura
Esistono quattro tipi di architettura dal punto di vista di un'impresa e, collettivamente, queste architetture vengono denominate enterprise architecture.
Business architecture - Definisce la strategia di business, governance, organizzazione e processi aziendali chiave all'interno di un'impresa e si concentra sull'analisi e sulla progettazione dei processi aziendali.
Application (software) architecture - Funge da modello per i singoli sistemi applicativi, le loro interazioni e le loro relazioni con i processi aziendali dell'organizzazione.
Information architecture - Definisce le risorse di dati logiche e fisiche e le risorse di gestione dei dati.
Information technology (IT) architecture - Definisce gli elementi costitutivi hardware e software che costituiscono il sistema informativo complessivo dell'organizzazione.
Processo di progettazione dell'architettura
Il processo di progettazione dell'architettura si concentra sulla scomposizione di un sistema in diversi componenti e sulle loro interazioni per soddisfare requisiti funzionali e non funzionali. Gli input chiave per la progettazione dell'architettura software sono:
I requisiti prodotti dalle attività di analisi.
L'architettura hardware (l'architetto del software a sua volta fornisce i requisiti all'architetto del sistema, che configura l'architettura hardware).
Il risultato o l'output del processo di progettazione dell'architettura è un file architectural description. Il processo di progettazione dell'architettura di base è composto dai seguenti passaggi:
Comprendi il problema
Questo è il passaggio più cruciale perché influisce sulla qualità del design che segue.
Senza una chiara comprensione del problema, non è possibile creare una soluzione efficace.
Molti progetti e prodotti software sono considerati fallimenti perché in realtà non hanno risolto un problema aziendale valido o hanno un ritorno sull'investimento (ROI) riconoscibile.
Identifica gli elementi di design e le loro relazioni
In questa fase, costruire una linea di base per la definizione dei confini e del contesto del sistema.
Scomposizione del sistema nelle sue componenti principali in base ai requisiti funzionali. La scomposizione può essere modellata utilizzando una matrice di struttura di progettazione (DSM), che mostra le dipendenze tra gli elementi di progettazione senza specificare la granularità degli elementi.
In questa fase, la prima convalida dell'architettura viene eseguita descrivendo un numero di istanze di sistema e questa fase viene definita progettazione architettonica basata sulla funzionalità.
Valuta il progetto dell'architettura
A ogni attributo di qualità viene fornita una stima, quindi, al fine di raccogliere misure qualitative o dati quantitativi, viene valutato il progetto.
Implica la valutazione dell'architettura per la conformità ai requisiti degli attributi di qualità architettonica.
Se tutti gli attributi di qualità stimati sono conformi allo standard richiesto, il processo di progettazione architettonica è terminato.
In caso contrario, si entra nella terza fase della progettazione dell'architettura software: la trasformazione dell'architettura. Se l'attributo di qualità osservato non soddisfa i suoi requisiti, è necessario creare un nuovo design.
Trasforma il design dell'architettura
Questa fase viene eseguita dopo una valutazione del progetto architettonico. Il progetto architettonico deve essere modificato fino a soddisfare completamente i requisiti degli attributi di qualità.
Si occupa di selezionare soluzioni di design per migliorare gli attributi di qualità preservando la funzionalità del dominio.
Un disegno viene trasformato applicando operatori di disegno, stili o modelli. Per la trasformazione, prendi il progetto esistente e applica operatori di progettazione come decomposizione, replica, compressione, astrazione e condivisione delle risorse.
Il progetto viene nuovamente valutato e lo stesso processo viene ripetuto più volte se necessario e persino eseguito in modo ricorsivo.
Le trasformazioni (cioè le soluzioni di ottimizzazione degli attributi di qualità) generalmente migliorano uno o alcuni attributi di qualità mentre influenzano negativamente gli altri
Principi chiave dell'architettura
Di seguito sono riportati i principi chiave da considerare durante la progettazione di un'architettura:
Costruisci per cambiare invece di costruire per durare
Considera come l'applicazione potrebbe dover cambiare nel tempo per affrontare nuovi requisiti e sfide e crea la flessibilità necessaria per supportarla.
Riduci il rischio e modello da analizzare
Utilizza strumenti di progettazione, visualizzazioni, sistemi di modellazione come UML per acquisire requisiti e decisioni di progettazione. Anche gli impatti possono essere analizzati. Non formalizzare il modello nella misura in cui sopprime la capacità di iterare e adattare facilmente il progetto.
Usa modelli e visualizzazioni come strumento di comunicazione e collaborazione
Una comunicazione efficiente del design, delle decisioni e delle modifiche in corso al design è fondamentale per una buona architettura. Usa modelli, viste e altre visualizzazioni dell'architettura per comunicare e condividere il progetto in modo efficiente con tutte le parti interessate. Ciò consente una comunicazione rapida delle modifiche al design.
Identificare e comprendere le decisioni ingegneristiche chiave e le aree in cui vengono commessi più spesso gli errori. Investire nell'ottenere le decisioni chiave giuste la prima volta per rendere il progetto più flessibile e con meno probabilità di essere interrotto dai cambiamenti.
Usa un approccio incrementale e iterativo
Inizia con l'architettura di base e poi evolvi le architetture candidate mediante test iterativi per migliorare l'architettura. Aggiungi in modo iterativo i dettagli al design su più passaggi per ottenere l'immagine grande o giusta e quindi concentrati sui dettagli.
Principi chiave di progettazione
Di seguito sono riportati i principi di progettazione da considerare per ridurre al minimo i costi, i requisiti di manutenzione e massimizzare l'estensibilità, l'usabilità dell'architettura:
Separazione degli interessi
Dividere i componenti del sistema in caratteristiche specifiche in modo che non vi siano sovrapposizioni tra le funzionalità dei componenti. Ciò fornirà un'elevata coesione e un basso accoppiamento. Questo approccio evita l'interdipendenza tra i componenti del sistema che aiuta a mantenere il sistema facile.
Principio di responsabilità unica
Ogni singolo modulo di un sistema dovrebbe avere una responsabilità specifica, che aiuta l'utente a comprendere chiaramente il sistema. Dovrebbe anche aiutare con l'integrazione del componente con altri componenti.
Principio di minima conoscenza
Qualsiasi componente o oggetto non dovrebbe avere la conoscenza dei dettagli interni di altri componenti. Questo approccio evita l'interdipendenza e aiuta la manutenibilità.
Riduci al minimo i grandi progetti in anticipo
Ridurre al minimo la progettazione di grandi dimensioni in anticipo se i requisiti di un'applicazione non sono chiari. Se è possibile modificare i requisiti, evitare di creare un progetto di grandi dimensioni per l'intero sistema.
Non ripetere la funzionalità
La funzionalità Non ripetere specifica che la funzionalità dei componenti non deve essere ripetuta e quindi un pezzo di codice deve essere implementato in un solo componente. La duplicazione di funzionalità all'interno di un'applicazione può rendere difficile l'implementazione delle modifiche, diminuire la chiarezza e introdurre potenziali incongruenze.
Preferisci la composizione all'ereditarietà durante il riutilizzo della funzionalità
L'ereditarietà crea dipendenza tra classi figlie e classi madri e quindi blocca il libero utilizzo delle classi figlie. Al contrario, la composizione offre un grande livello di libertà e riduce le gerarchie di ereditarietà.
Identifica i componenti e raggruppali in livelli logici
Componenti di identità e area di interesse necessari nel sistema per soddisfare i requisiti. Quindi raggruppare questi componenti correlati in un livello logico, che aiuterà l'utente a comprendere la struttura del sistema ad alto livello. Evitare di mescolare componenti di diversi tipi di preoccupazioni nello stesso strato.
Definire il protocollo di comunicazione tra i livelli
Comprendere come i componenti comunicheranno tra loro, il che richiede una conoscenza completa degli scenari di distribuzione e dell'ambiente di produzione.
Definisci il formato dei dati per un livello
Vari componenti interagiranno tra loro tramite il formato dei dati. Non mischiare i formati dei dati in modo che le applicazioni siano facili da implementare, estendere e mantenere. Cerca di mantenere lo stesso formato dei dati per un livello, in modo che i vari componenti non debbano codificare / decodificare i dati durante la comunicazione tra loro. Riduce un sovraccarico di elaborazione.
I componenti del servizio di sistema dovrebbero essere astratti
Il codice relativo alla sicurezza, alle comunicazioni o ai servizi di sistema come la registrazione, la creazione di profili e la configurazione deve essere astratto nei componenti separati. Non mescolare questo codice con la logica aziendale, poiché è facile estendere il design e mantenerlo.
Eccezioni di progettazione e meccanismo di gestione delle eccezioni
Definire le eccezioni in anticipo, aiuta i componenti a gestire errori o situazioni indesiderate in modo elegante. La gestione delle eccezioni sarà la stessa in tutto il sistema.
Convenzioni di denominazione
Le convenzioni di denominazione dovrebbero essere definite in anticipo. Forniscono un modello coerente che aiuta gli utenti a comprendere facilmente il sistema. È più facile per i membri del team convalidare il codice scritto da altri e quindi aumenterà la manutenibilità.
L'architettura software coinvolge la struttura di alto livello dell'astrazione del sistema software, utilizzando la scomposizione e la composizione, con stile architettonico e attributi di qualità. La progettazione di un'architettura software deve essere conforme ai principali requisiti di funzionalità e prestazioni del sistema, oltre a soddisfare i requisiti non funzionali come affidabilità, scalabilità, portabilità e disponibilità.
Un'architettura software deve descrivere il proprio gruppo di componenti, le loro connessioni, le interazioni tra di loro e la configurazione di distribuzione di tutti i componenti.
Un'architettura software può essere definita in molti modi:
UML (Unified Modeling Language) - UML è una delle soluzioni orientate agli oggetti utilizzate nella modellazione e progettazione del software.
Architecture View Model (4+1 view model) - Il modello di visualizzazione dell'architettura rappresenta i requisiti funzionali e non funzionali dell'applicazione software.
ADL (Architecture Description Language) - ADL definisce l'architettura del software formalmente e semanticamente.
UML
UML è l'acronimo di Unified Modeling Language. È un linguaggio pittorico utilizzato per creare progetti software. UML è stato creato da Object Management Group (OMG). La bozza della specifica UML 1.0 è stata proposta all'OMG nel gennaio 1997. Serve come standard per l'analisi dei requisiti software e per i documenti di progettazione che sono la base per lo sviluppo di un software.
UML può essere descritto come un linguaggio di modellazione visuale per scopi generali per visualizzare, specificare, costruire e documentare un sistema software. Sebbene UML sia generalmente utilizzato per modellare il sistema software, non è limitato all'interno di questo confine. Viene anche utilizzato per modellare sistemi non software come i flussi di processo in un'unità di produzione.
Gli elementi sono come componenti che possono essere associati in modi diversi per creare un'immagine UML completa, nota come diagram. Quindi, è molto importante comprendere i diversi diagrammi per implementare la conoscenza nei sistemi della vita reale. Abbiamo due ampie categorie di diagrammi e sono ulteriormente suddivisi in sottocategorie, ad esStructural Diagrams e Behavioral Diagrams.
Diagrammi strutturali
I diagrammi strutturali rappresentano gli aspetti statici di un sistema. Questi aspetti statici rappresentano quelle parti di un diagramma che costituisce la struttura principale ed è quindi stabile.
Queste parti statiche sono rappresentate da classi, interfacce, oggetti, componenti e nodi. Gli schemi strutturali possono essere suddivisi come segue:
- Diagramma di classe
- Diagramma dell'oggetto
- Schema dei componenti
- Diagramma di distribuzione
- Diagramma del pacchetto
- Struttura composita
La tabella seguente fornisce una breve descrizione di questi diagrammi:
| Sr.No. | Diagramma e descrizione |
|---|---|
| 1 | Class Rappresenta l'orientamento agli oggetti di un sistema. Mostra come le classi sono staticamente correlate. |
| 2 | Object Rappresenta un insieme di oggetti e le loro relazioni in fase di esecuzione e rappresenta anche la vista statica del sistema. |
| 3 | Component Descrive tutti i componenti, le loro interrelazioni, interazioni e interfaccia del sistema. |
| 4 | Composite structure Descrive la struttura interna del componente comprese tutte le classi, le interfacce del componente, ecc. |
| 5 | Package Descrive la struttura e l'organizzazione del pacchetto. Copre le classi nel pacchetto e i pacchetti all'interno di un altro pacchetto. |
| 6 | Deployment I diagrammi di distribuzione sono un insieme di nodi e le loro relazioni. Questi nodi sono entità fisiche in cui vengono distribuiti i componenti. |
Diagrammi comportamentali
I diagrammi comportamentali catturano fondamentalmente l'aspetto dinamico di un sistema. Gli aspetti dinamici sono fondamentalmente le parti mutevoli / mobili di un sistema. UML ha i seguenti tipi di diagrammi comportamentali:
- Usa il diagramma dei casi
- Diagramma di sequenza
- Diagramma di comunicazione
- Diagramma grafico di stato
- Diagramma delle attività
- Panoramica delle interazioni
- Diagramma di sequenza temporale
La tabella seguente fornisce una breve descrizione di questi diagrammi:
| Sr.No. | Diagramma e descrizione |
|---|---|
| 1 | Use case Descrive le relazioni tra le funzionalità e i loro controllori interni / esterni. Questi controller sono noti come attori. |
| 2 | Activity Descrive il flusso di controllo in un sistema. Consiste di attività e collegamenti. Il flusso può essere sequenziale, simultaneo o ramificato. |
| 3 | State Machine/state chart Rappresenta il cambiamento di stato guidato dagli eventi di un sistema. Fondamentalmente descrive il cambiamento di stato di una classe, interfaccia, ecc. Utilizzato per visualizzare la reazione di un sistema da fattori interni / esterni. |
| 4 | Sequence Visualizza la sequenza di chiamate in un sistema per eseguire una funzionalità specifica. |
| 5 | Interaction Overview Combina diagrammi di attività e sequenza per fornire una panoramica del flusso di controllo del sistema e del processo aziendale. |
| 6 | Communication Uguale al diagramma di sequenza, tranne per il fatto che si concentra sul ruolo dell'oggetto. Ogni comunicazione è associata a un ordine di sequenza, numero più i messaggi passati. |
| 7 | Time Sequenced Descrive le modifiche tramite messaggi di stato, condizione ed eventi. |
Modello di visualizzazione dell'architettura
Un modello è una descrizione completa, di base e semplificata dell'architettura software composta da più viste da una particolare prospettiva o punto di vista.
Una vista è una rappresentazione di un intero sistema dal punto di vista di un insieme correlato di preoccupazioni. Viene utilizzato per descrivere il sistema dal punto di vista di diverse parti interessate come utenti finali, sviluppatori, project manager e tester.
4 + 1 Visualizza modello
Il modello di visualizzazione 4 + 1 è stato progettato da Philippe Kruchten per descrivere l'architettura di un sistema ad alta intensità di software basato sull'uso di viste multiple e simultanee. È unmultiple viewmodello che affronta le diverse caratteristiche e preoccupazioni del sistema. Standardizza i documenti di progettazione del software e rende il progetto facilmente comprensibile da tutte le parti interessate.
È un metodo di verifica dell'architettura per studiare e documentare la progettazione dell'architettura software e copre tutti gli aspetti dell'architettura software per tutte le parti interessate. Fornisce quattro viste essenziali:
The logical view or conceptual view - Descrive il modello a oggetti del progetto.
The process view - Descrive le attività del sistema, cattura gli aspetti di concorrenza e sincronizzazione del progetto.
The physical view - Descrive la mappatura del software sull'hardware e riflette il suo aspetto distribuito.
The development view - Descrive l'organizzazione o la struttura statica del software nel suo sviluppo dell'ambiente.
Questo modello di visualizzazione può essere esteso aggiungendo un'altra visualizzazione chiamata scenario view o use case viewper utenti finali o clienti di sistemi software. È coerente con altre quattro viste e viene utilizzata per illustrare l'architettura che funge da vista "più una", modello di vista (4 + 1). La figura seguente descrive l'architettura del software utilizzando il modello di cinque viste simultanee (4 + 1).

Perché si chiama 4 + 1 invece di 5?
Il use case viewha un significato speciale in quanto descrive in dettaglio i requisiti di alto livello di un sistema mentre altre vedono i dettagli - come vengono realizzati tali requisiti. Quando tutte le altre quattro visualizzazioni sono state completate, è effettivamente ridondante. Tuttavia, tutte le altre visualizzazioni non sarebbero possibili senza di essa. L'immagine e la tabella seguenti mostrano in dettaglio la visualizzazione 4 + 1 -
| Logico | Processi | Sviluppo | Fisico | Scenario | |
|---|---|---|---|---|---|
| Descrizione | Mostra il componente (Oggetto) del sistema e la loro interazione | Mostra i processi / le regole del flusso di lavoro del sistema e il modo in cui questi processi comunicano, si concentra sulla visualizzazione dinamica del sistema | Fornisce viste dei blocchi predefiniti del sistema e descrive l'organizzazione statica dei moduli del sistema | Mostra l'installazione, la configurazione e la distribuzione dell'applicazione software | Mostra che il progetto è completo eseguendo la convalida e l'illustrazione |
| Visualizzatore / titolare della posta | Utente finale, analisti e designer | Integratori e sviluppatori | Programmatore e project manager software | Ingegnere di sistema, operatori, amministratori di sistema e installatori di sistema | Tutti i punti di vista delle loro opinioni e dei valutatori |
| Ritenere | Richieste funzionali | Requisiti non funzionali | Organizzazione del modulo software (riutilizzo della gestione del software, vincolo degli strumenti) | Requisito non funzionale relativo all'hardware sottostante | Coerenza e validità del sistema |
| UML - Diagramma | Classe, Stato, Oggetto, sequenza, Diagramma di comunicazione | Diagramma di attività | Componente, diagramma del pacchetto | Diagramma di distribuzione | Usa il diagramma dei casi |
Linguaggi di descrizione dell'architettura (ADL)
Un ADL è un linguaggio che fornisce sintassi e semantica per la definizione di un'architettura software. Si tratta di una specifica di notazione che fornisce funzionalità per modellare l'architettura concettuale di un sistema software, distinta dall'implementazione del sistema.
Gli ADL devono supportare i componenti dell'architettura, le loro connessioni, interfacce e configurazioni che sono l'elemento costitutivo della descrizione dell'architettura. È una forma di espressione da utilizzare nelle descrizioni dell'architettura e fornisce la capacità di scomporre i componenti, combinare i componenti e definire le interfacce dei componenti.
Un linguaggio di descrizione dell'architettura è un linguaggio di specifica formale, che descrive le funzionalità del software come processi, thread, dati e sottoprogrammi, nonché componenti hardware come processori, dispositivi, bus e memoria.
È difficile classificare o differenziare un ADL e un linguaggio di programmazione o un linguaggio di modellazione. Tuttavia, esistono i seguenti requisiti affinché una lingua possa essere classificata come ADL:
Dovrebbe essere appropriato per comunicare l'architettura a tutte le parti interessate.
Dovrebbe essere adatto per attività di creazione, perfezionamento e convalida dell'architettura.
Dovrebbe fornire una base per un'ulteriore implementazione, quindi deve essere in grado di aggiungere informazioni alla specifica ADL per consentire di derivare la specifica del sistema finale dall'ADL.
Dovrebbe avere la capacità di rappresentare la maggior parte degli stili architettonici comuni.
Dovrebbe supportare capacità analitiche o fornire implementazioni di prototipi di generazione rapida.
Il paradigma orientato agli oggetti (OO) ha preso forma dal concetto iniziale di un nuovo approccio di programmazione, mentre l'interesse per i metodi di progettazione e analisi è venuto molto più tardi. Il paradigma di progettazione e analisi OO è il risultato logico dell'ampia adozione dei linguaggi di programmazione OO.
Il primo linguaggio orientato agli oggetti è stato Simula (Simulation of real systems) che è stato sviluppato nel 1960 dai ricercatori del Norwegian Computing Center.
Nel 1970, Alan Kay e il suo gruppo di ricerca presso Xerox PARC ha creato un personal computer denominato Dynabook e il primo puro linguaggio di programmazione orientato agli oggetti (OOPL) - Smalltalk, per la programmazione del Dynabook.
Negli anni '80 Grady Boochha pubblicato un articolo intitolato Object Oriented Design che presentava principalmente un progetto per il linguaggio di programmazione Ada. Nelle edizioni successive, ha esteso le sue idee a un metodo di progettazione orientato agli oggetti completo.
Negli anni '90, Coad ha incorporato idee comportamentali in metodi orientati agli oggetti.
Le altre innovazioni significative sono state Object Modeling Techniques (OMT) di James Rum Baugh e Object-Oriented Software Engineering (OOSE) di Ivar Jacobson.
Introduzione al paradigma OO
Il paradigma OO è una metodologia significativa per lo sviluppo di qualsiasi software. La maggior parte degli stili o modelli di architettura come pipe e filtri, repository di dati e basati su componenti possono essere implementati utilizzando questo paradigma.
Concetti e terminologie di base dei sistemi orientati agli oggetti -
Oggetto
Un oggetto è un elemento del mondo reale in un ambiente orientato agli oggetti che può avere un'esistenza fisica o concettuale. Ogni oggetto ha -
Identità che lo distingue dagli altri oggetti del sistema.
Stato che determina le proprietà caratteristiche di un oggetto così come i valori delle proprietà che l'oggetto possiede.
Comportamento che rappresenta le attività visibili esternamente eseguite da un oggetto in termini di cambiamenti nel suo stato.
Gli oggetti possono essere modellati in base alle esigenze dell'applicazione. Un oggetto può avere un'esistenza fisica, come un cliente, un'auto, ecc .; o un'esistenza concettuale intangibile, come un progetto, un processo, ecc.
Classe
Una classe rappresenta una raccolta di oggetti con le stesse proprietà caratteristiche che mostrano un comportamento comune. Fornisce il progetto o la descrizione degli oggetti che possono essere creati da esso. La creazione di un oggetto come membro di una classe è chiamata istanziazione. Quindi, un oggetto è un fileinstance di una classe.
I componenti di una classe sono:
Un insieme di attributi per gli oggetti che devono essere istanziati dalla classe. Generalmente, diversi oggetti di una classe hanno qualche differenza nei valori degli attributi. Gli attributi sono spesso indicati come dati di classe.
Un insieme di operazioni che ritraggono il comportamento degli oggetti della classe. Le operazioni vengono anche chiamate funzioni o metodi.
Example
Consideriamo una classe semplice, Circle, che rappresenta il cerchio della figura geometrica in uno spazio bidimensionale. Gli attributi di questa classe possono essere identificati come segue:
- x – coord, per denotare la coordinata x del centro
- y – coord, per denotare la coordinata y del centro
- a, per indicare il raggio del cerchio
Alcune delle sue operazioni possono essere definite come segue:
- findArea (), un metodo per calcolare l'area
- findCircumference (), un metodo per calcolare la circonferenza
- scale (), un metodo per aumentare o diminuire il raggio
Incapsulamento
L'incapsulamento è il processo di associazione di attributi e metodi all'interno di una classe. Attraverso l'incapsulamento, i dettagli interni di una classe possono essere nascosti dall'esterno. Permette di accedere agli elementi della classe solo dall'esterno tramite l'interfaccia fornita dalla classe.
Polimorfismo
Il polimorfismo è originariamente una parola greca che significa la capacità di assumere più forme. Nel paradigma orientato agli oggetti, il polimorfismo implica l'utilizzo di operazioni in modi diversi, a seconda delle istanze su cui stanno operando. Il polimorfismo consente a oggetti con diverse strutture interne di avere un'interfaccia esterna comune. Il polimorfismo è particolarmente efficace durante l'implementazione dell'ereditarietà.
Example
Consideriamo due classi, Circle e Square, ciascuna con un metodo findArea (). Sebbene il nome e lo scopo dei metodi nelle classi siano gli stessi, l'implementazione interna, ovvero la procedura di calcolo di un'area, è diversa per ciascuna classe. Quando un oggetto della classe Circle invoca il suo metodo findArea (), l'operazione trova l'area del cerchio senza alcun conflitto con il metodo findArea () della classe Square.
Relationships
Per descrivere un sistema, devono essere fornite sia le specifiche dinamiche (comportamentali) che statiche (logiche) di un sistema. La specifica dinamica descrive le relazioni tra gli oggetti, ad esempio il passaggio di messaggi. E le specifiche statiche descrivono le relazioni tra le classi, ad esempio aggregazione, associazione ed ereditarietà.
Passaggio del messaggio
Qualsiasi applicazione richiede una serie di oggetti che interagiscono in modo armonioso. Gli oggetti in un sistema possono comunicare tra loro utilizzando il passaggio di messaggi. Supponiamo che un sistema abbia due oggetti: obj1 e obj2. L'oggetto obj1 invia un messaggio all'oggetto obj2, se obj1 vuole che obj2 esegua uno dei suoi metodi.
Composizione o aggregazione
L'aggregazione o composizione è una relazione tra classi mediante la quale una classe può essere composta da qualsiasi combinazione di oggetti di altre classi. Consente di posizionare oggetti direttamente all'interno del corpo di altre classi. L'aggregazione viene definita una relazione "parte-di" o "ha-una", con la capacità di navigare dall'intero alle sue parti. Un oggetto aggregato è un oggetto composto da uno o più altri oggetti.
Associazione
L'associazione è un gruppo di collegamenti aventi una struttura comune e un comportamento comune. L'associazione rappresenta la relazione tra gli oggetti di una o più classi. Un collegamento può essere definito come un'istanza di un'associazione. Il grado di un'associazione indica il numero di classi coinvolte in una connessione. Il grado può essere unario, binario o ternario.
- Una relazione unaria collega oggetti della stessa classe.
- Una relazione binaria collega oggetti di due classi.
- Una relazione ternaria collega oggetti di tre o più classi.
Eredità
È un meccanismo che consente di creare nuove classi a partire da classi esistenti estendendo e perfezionando le sue capacità. Le classi esistenti sono chiamate classi base / classi padre / superclassi e le nuove classi sono chiamate classi derivate / classi figlio / sottoclassi.
La sottoclasse può ereditare o derivare gli attributi ei metodi della / e superclasse a condizione che la superclasse lo consenta. Inoltre, la sottoclasse può aggiungere i propri attributi e metodi e può modificare qualsiasi metodo della superclasse. L'ereditarietà definisce una relazione "è - un".
Example
Da una classe Mammifero, è possibile derivare un certo numero di classi come Umano, Gatto, Cane, Mucca, ecc. Gli esseri umani, i gatti, i cani e le mucche hanno tutti le caratteristiche distinte dei mammiferi. Inoltre, ognuno ha le sue caratteristiche particolari. Si può dire che una mucca "è - un" mammifero.
Analisi OO
Nella fase di analisi orientata agli oggetti dello sviluppo del software, i requisiti di sistema vengono determinati, le classi vengono identificate e le relazioni tra le classi vengono riconosciute. Lo scopo dell'analisi OO è comprendere il dominio dell'applicazione e i requisiti specifici del sistema. Il risultato di questa fase è la specifica dei requisiti e l'analisi iniziale della struttura logica e della fattibilità di un sistema.
Le tre tecniche di analisi utilizzate insieme per l'analisi orientata agli oggetti sono la modellazione a oggetti, la modellazione dinamica e la modellazione funzionale.
Modellazione a oggetti
La modellazione a oggetti sviluppa la struttura statica del sistema software in termini di oggetti. Identifica gli oggetti, le classi in cui gli oggetti possono essere raggruppati e le relazioni tra gli oggetti. Identifica inoltre gli attributi e le operazioni principali che caratterizzano ciascuna classe.
Il processo di modellazione degli oggetti può essere visualizzato nei seguenti passaggi:
- Identifica gli oggetti e raggruppali in classi
- Identifica le relazioni tra le classi
- Creare un diagramma del modello a oggetti utente
- Definire gli attributi di un oggetto utente
- Definisci le operazioni che devono essere eseguite sulle classi
Modellazione dinamica
Dopo aver analizzato il comportamento statico del sistema, è necessario esaminarne il comportamento rispetto al tempo e ai cambiamenti esterni. Questo è lo scopo della modellazione dinamica.
La modellazione dinamica può essere definita come "un modo per descrivere come un singolo oggetto risponde agli eventi, sia eventi interni innescati da altri oggetti, sia eventi esterni innescati dal mondo esterno".
Il processo di modellazione dinamica può essere visualizzato nei seguenti passaggi:
- Identifica gli stati di ogni oggetto
- Identifica gli eventi e analizza l'applicabilità delle azioni
- Costruire un diagramma del modello dinamico, comprendente diagrammi di transizione di stato
- Esprimi ogni stato in termini di attributi dell'oggetto
- Convalidare i diagrammi di transizione di stato disegnati
Modellazione Funzionale
Il Functional Modeling è il componente finale dell'analisi orientata agli oggetti. Il modello funzionale mostra i processi che vengono eseguiti all'interno di un oggetto e come cambiano i dati, mentre si spostano tra i metodi. Specifica il significato delle operazioni di una modellazione a oggetti e le azioni di una modellazione dinamica. Il modello funzionale corrisponde al diagramma di flusso dei dati dell'analisi strutturata tradizionale.
Il processo di modellazione funzionale può essere visualizzato nei seguenti passaggi:
- Identifica tutti gli input e gli output
- Costruisci diagrammi di flusso di dati che mostrano le dipendenze funzionali
- Indicare lo scopo di ciascuna funzione
- Identifica i vincoli
- Specificare i criteri di ottimizzazione
Design orientato agli oggetti
Dopo la fase di analisi, il modello concettuale viene ulteriormente sviluppato in un modello orientato agli oggetti utilizzando la progettazione orientata agli oggetti (OOD). In OOD, i concetti indipendenti dalla tecnologia nel modello di analisi vengono mappati su classi di implementazione, vengono identificati i vincoli e vengono progettate le interfacce, ottenendo un modello per il dominio della soluzione. Lo scopo principale della progettazione OO è sviluppare l'architettura strutturale di un sistema.
Le fasi per la progettazione orientata agli oggetti possono essere identificate come:
- Definizione del contesto del sistema
- Progettare l'architettura del sistema
- Identificazione degli oggetti nel sistema
- Costruzione di modelli di design
- Specifica delle interfacce degli oggetti
OO Design può essere suddiviso in due fasi: progettazione concettuale e progettazione dettagliata.
Conceptual design
In questa fase vengono identificate tutte le classi necessarie per la realizzazione del sistema. Inoltre, a ciascuna classe vengono assegnate responsabilità specifiche. Il diagramma delle classi viene utilizzato per chiarire le relazioni tra le classi e il diagramma delle interazioni viene utilizzato per mostrare il flusso degli eventi. È anche conosciuto comehigh-level design.
Detailed design
In questa fase, attributi e operazioni vengono assegnati a ciascuna classe in base al proprio diagramma di interazione. I diagrammi della macchina a stati sono sviluppati per descrivere gli ulteriori dettagli del progetto. È anche conosciuto comelow-level design.
Principi di progettazione
Di seguito sono riportati i principali principi di progettazione:
Principle of Decoupling
È difficile mantenere un sistema con un insieme di classi altamente interdipendenti, poiché la modifica in una classe può comportare aggiornamenti a cascata di altre classi. In un progetto OO, l'accoppiamento stretto può essere eliminato introducendo nuove classi o ereditarietà.
Ensuring Cohesion
Una classe coesiva svolge una serie di funzioni strettamente correlate. Una mancanza di coesione significa: una classe svolge funzioni non correlate, sebbene non influisca sul funzionamento dell'intero sistema. Rende l'intera struttura del software difficile da gestire, espandere, mantenere e modificare.
Open-closed Principle
Secondo questo principio, un sistema dovrebbe potersi estendere per soddisfare i nuovi requisiti. L'implementazione esistente e il codice del sistema non devono essere modificati a seguito di un'espansione del sistema. Inoltre, le seguenti linee guida devono essere seguite nel principio aperto-chiuso:
Per ogni classe concreta, devono essere mantenute interfacce e implementazioni separate.
In un ambiente multithread, mantenere privati gli attributi.
Ridurre al minimo l'uso di variabili globali e variabili di classe.
Nell'architettura del flusso di dati, l'intero sistema software è visto come una serie di trasformazioni su pezzi consecutivi o insieme di dati di input, in cui i dati e le operazioni sono indipendenti l'uno dall'altro. In questo approccio, i dati entrano nel sistema e quindi fluiscono attraverso i moduli uno alla volta fino a quando non vengono assegnati a una destinazione finale (output o archivio dati).
Le connessioni tra i componenti o moduli possono essere implementate come flusso I / O, buffer I / O, condutture o altri tipi di connessioni. I dati possono essere volati nella topologia del grafico con cicli, in una struttura lineare senza cicli o in una struttura ad albero.
L'obiettivo principale di questo approccio è raggiungere le qualità di riutilizzo e modificabilità. È adatto per applicazioni che implicano una serie ben definita di trasformazioni o calcoli di dati indipendenti su input e output definiti in modo ordinato, come compilatori e applicazioni di elaborazione dati aziendali. Ci sono tre tipi di sequenze di esecuzione tra i moduli:
- Batch sequenziale
- Modalità pipe e filtro o pipeline non sequenziale
- Controllo di processo
Batch sequenziale
Il sequenziale batch è un modello di elaborazione dati classico, in cui un sottosistema di trasformazione dei dati può avviare il suo processo solo dopo che il suo sottosistema precedente è stato completamente completato:
Il flusso di dati trasporta un batch di dati nel suo insieme da un sottosistema a un altro.
Le comunicazioni tra i moduli avvengono tramite file temporanei intermedi che possono essere rimossi da sottosistemi successivi.
È applicabile alle applicazioni in cui i dati sono raggruppati in batch e ogni sottosistema legge i file di input correlati e scrive i file di output.
L'applicazione tipica di questa architettura include l'elaborazione dei dati aziendali come la fatturazione bancaria e delle utenze.

Vantaggi
Fornisce divisioni più semplici sui sottosistemi.
Ogni sottosistema può essere un programma indipendente che lavora sui dati di input e produce dati di output.
Svantaggi
Fornisce latenza elevata e velocità effettiva ridotta.
Non fornisce concorrenza e interfaccia interattiva.
Per l'implementazione è necessario un controllo esterno.
Architettura di tubi e filtri
Questo approccio pone l'accento sulla trasformazione incrementale dei dati per componente successivo. In questo approccio, il flusso di dati è guidato dai dati e l'intero sistema viene scomposto in componenti di origine dati, filtri, pipe e pozzi di dati.
Le connessioni tra i moduli sono un flusso di dati che è un buffer first-in / first-out che può essere un flusso di byte, caratteri o qualsiasi altro tipo di questo tipo. La caratteristica principale di questa architettura è la sua esecuzione simultanea e incrementata.
Filtro
Un filtro è un trasformatore di flusso di dati indipendente o trasduttori di flusso. Trasforma i dati del flusso di dati di input, lo elabora e scrive il flusso di dati trasformato su una pipe per l'elaborazione del filtro successivo. Funziona in modalità incrementale, in cui inizia a funzionare non appena i dati arrivano attraverso il tubo connesso. Esistono due tipi di filtri:active filter e passive filter.
Active filter
Il filtro attivo consente alle pipe collegate di inserire i dati e di estrarre i dati trasformati. Funziona con tubo passivo, che fornisce meccanismi di lettura / scrittura per tirare e spingere. Questa modalità viene utilizzata nella pipe e nel meccanismo di filtro UNIX.
Passive filter
Il filtro passivo consente ai tubi collegati di inserire ed estrarre i dati. Funziona con il pipe attivo, che estrae i dati da un filtro e li inserisce nel filtro successivo. Deve fornire un meccanismo di lettura / scrittura.

Vantaggi
Fornisce concorrenza e velocità effettiva elevata per un'eccessiva elaborazione dei dati.
Fornisce riusabilità e semplifica la manutenzione del sistema.
Fornisce modificabilità e basso accoppiamento tra i filtri.
Fornisce semplicità offrendo chiare divisioni tra due filtri qualsiasi collegati da un tubo.
Fornisce flessibilità supportando sia l'esecuzione sequenziale che parallela.
Svantaggi
Non adatto per interazioni dinamiche.
Un basso denominatore comune è necessario per la trasmissione di dati in formati ASCII.
Overhead della trasformazione dei dati tra i filtri.
Non fornisce ai filtri un modo per interagire in modo cooperativo per risolvere un problema.
Difficile configurare dinamicamente questa architettura.
Tubo
Le pipe sono senza stato e trasportano un flusso binario o di caratteri esistente tra due filtri. Può spostare un flusso di dati da un filtro all'altro. Le pipe utilizzano poche informazioni contestuali e non conservano informazioni sullo stato tra le istanze.
Architettura di controllo dei processi
È un tipo di architettura del flusso di dati in cui i dati non sono né sequenziali in batch né flussi in pipeline. Il flusso di dati proviene da un insieme di variabili, che controlla l'esecuzione del processo. Decompone l'intero sistema in sottosistemi o moduli e li collega.
Tipi di sottosistemi
Un'architettura di controllo del processo avrebbe un file processing unit per modificare le variabili di controllo del processo e a controller unit per calcolare l'ammontare delle modifiche.
Un'unità di controllo deve avere i seguenti elementi:
Controlled Variable- La variabile controllata fornisce i valori per il sistema sottostante e deve essere misurata dai sensori. Ad esempio, velocità nel sistema di controllo automatico della velocità.
Input Variable- Misura un input per il processo. Ad esempio, la temperatura dell'aria di ritorno nel sistema di controllo della temperatura
Manipulated Variable - Il valore della variabile manipolata viene regolato o modificato dal controller.
Process Definition - Include meccanismi per manipolare alcune variabili di processo.
Sensor - Ottiene i valori delle variabili di processo pertinenti al controllo e può essere utilizzato come riferimento di feedback per ricalcolare le variabili manipolate.
Set Point - È il valore desiderato per una variabile controllata.
Control Algorithm - Viene utilizzato per decidere come manipolare le variabili di processo.
Aree di applicazione
L'architettura di controllo del processo è adatta nei seguenti domini:
Progettazione di software di sistema integrato, in cui il sistema viene manipolato da dati variabili di controllo del processo.
Applicazioni, il cui scopo è mantenere proprietà specifiche degli output del processo a valori di riferimento dati.
Applicabile per auto-cruise control e sistemi di controllo della temperatura degli edifici.
Software di sistema in tempo reale per controllare i freni antibloccaggio delle automobili, le centrali nucleari, ecc.
Nell'architettura data center, i dati sono centralizzati e accedono frequentemente da altri componenti, che modificano i dati. Lo scopo principale di questo stile è raggiungere l'integralità dei dati. L'architettura centrata sui dati è costituita da diversi componenti che comunicano attraverso archivi di dati condivisi. I componenti accedono a una struttura dati condivisa e sono relativamente indipendenti, in quanto interagiscono solo attraverso l'archivio dati.
L'esempio più noto dell'architettura data-centered è un'architettura di database, in cui lo schema di database comune viene creato con il protocollo di definizione dei dati, ad esempio un insieme di tabelle correlate con campi e tipi di dati in un RDBMS.
Un altro esempio di architetture centrate sui dati è l'architettura web che ha uno schema di dati comune (cioè meta-struttura del web) e segue il modello di dati ipermediali ei processi comunicano attraverso l'uso di servizi di dati basati sul web condivisi.

Tipi di componenti
Esistono due tipi di componenti:
UN central datastruttura o archivio dati o archivio dati, che è responsabile della fornitura di archiviazione permanente dei dati. Rappresenta lo stato attuale.
UN data accessor o una raccolta di componenti indipendenti che operano sull'archivio dati centrale, eseguono calcoli e potrebbero restituire i risultati.
Le interazioni o la comunicazione tra gli utenti che accedono ai dati avvengono solo attraverso l'archivio dati. I dati sono l'unico mezzo di comunicazione tra i clienti. Il flusso di controllo differenzia l'architettura in due categorie:
- Stile di architettura del repository
- Stile di architettura della lavagna
Stile di architettura del repository
In Stile architettura repository, l'archivio dati è passivo e sono attivi i client (componenti software o agenti) dell'archivio dati, che controllano il flusso logico. I componenti partecipanti controllano l'archivio dati per eventuali modifiche.
Il client invia una richiesta al sistema per eseguire azioni (es. Inserire dati).
I processi di calcolo sono indipendenti e attivati dalle richieste in arrivo.
Se i tipi di transazioni in un flusso di input di transazioni attivano la selezione dei processi da eseguire, allora si tratta di un database tradizionale o di un'architettura di repository o di un repository passivo.
Questo approccio è ampiamente utilizzato nel DBMS, nel sistema informativo della biblioteca, nel repository dell'interfaccia in CORBA, nei compilatori e negli ambienti CASE (computer aided software engineering).

Vantaggi
Fornisce funzionalità di integrità dei dati, backup e ripristino.
Fornisce scalabilità e riutilizzabilità degli agenti poiché non hanno comunicazione diretta tra loro.
Riduce il sovraccarico dei dati temporanei tra i componenti software.
Svantaggi
È più vulnerabile ai guasti ed è possibile la replica o la duplicazione dei dati.
Elevata dipendenza tra la struttura dati dell'archivio dati e i suoi agenti.
I cambiamenti nella struttura dei dati influenzano fortemente i client.
L'evoluzione dei dati è difficile e costosa.
Costo dello spostamento dei dati sulla rete per i dati distribuiti.
Stile di architettura della lavagna
In Blackboard Architecture Style, l'archivio dati è attivo ei suoi client sono passivi. Pertanto il flusso logico è determinato dallo stato dei dati correnti nell'archivio dati. Ha una componente lavagna, che funge da archivio di dati centrale, e una rappresentazione interna è costruita e su cui agisce diversi elementi computazionali.
Nella lavagna sono memorizzati alcuni componenti che agiscono in modo indipendente sulla struttura dati comune.
In questo stile, i componenti interagiscono solo attraverso la lavagna. L'archivio dati avvisa i client ogni volta che viene apportata una modifica all'archivio dati.
Lo stato corrente della soluzione viene memorizzato nella lavagna e l'elaborazione viene attivata dallo stato della lavagna.
Il sistema invia notifiche note come trigger e dati ai client quando si verificano modifiche nei dati.
Questo approccio si trova in alcune applicazioni AI e applicazioni complesse, come il riconoscimento vocale, il riconoscimento delle immagini, il sistema di sicurezza e i sistemi di gestione delle risorse aziendali, ecc.
Se lo stato corrente della struttura dati centrale è il fattore scatenante principale della selezione dei processi da eseguire, il repository può essere una lavagna e questa origine dati condivisa è un agente attivo.
Una delle principali differenze con i sistemi di database tradizionali è che l'invocazione di elementi computazionali in un'architettura di lavagna è attivata dallo stato corrente della lavagna e non da input esterni.
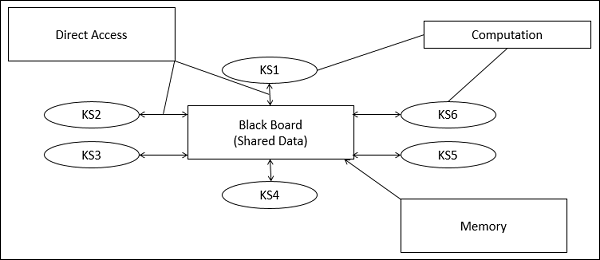
Parti del modello di lavagna
Il modello di lavagna viene solitamente presentato con tre parti principali:
Knowledge Sources (KS)
Fonti di conoscenza, note anche come Listeners o Subscriberssono unità distinte e indipendenti. Risolvono parti di un problema e aggregano risultati parziali. L'interazione tra le fonti di conoscenza avviene unicamente attraverso la lavagna.
Blackboard Data Structure
I dati sullo stato di risoluzione dei problemi sono organizzati in una gerarchia dipendente dall'applicazione. Le fonti di conoscenza apportano modifiche alla lavagna che portano in modo incrementale a una soluzione al problema.
Control
Il controllo gestisce le attività e controlla lo stato del lavoro.
Vantaggi
Fornisce scalabilità che consente di aggiungere o aggiornare facilmente la fonte della conoscenza.
Fornisce la concorrenza che consente a tutte le fonti di conoscenza di funzionare in parallelo poiché sono indipendenti l'una dall'altra.
Supporta la sperimentazione di ipotesi.
Supporta la riusabilità degli agenti della fonte di conoscenza.
Svantaggi
Il cambiamento di struttura della lavagna può avere un impatto significativo su tutti i suoi agenti poiché esiste una stretta dipendenza tra la lavagna e la fonte di conoscenza.
Può essere difficile decidere quando terminare il ragionamento poiché è prevista solo una soluzione approssimativa.
Problemi nella sincronizzazione di più agenti.
Le principali sfide nella progettazione e nel test del sistema.
L'architettura gerarchica vede l'intero sistema come una struttura gerarchica, in cui il sistema software è scomposto in moduli logici o sottosistemi a diversi livelli nella gerarchia. Questo approccio viene tipicamente utilizzato nella progettazione di software di sistema come protocolli di rete e sistemi operativi.
Nella progettazione della gerarchia del software di sistema, un sottosistema di basso livello fornisce servizi ai sottosistemi di livello superiore adiacenti, che invocano i metodi del livello inferiore. Il livello inferiore fornisce funzionalità più specifiche come servizi di I / O, transazioni, pianificazione, servizi di sicurezza, ecc. Il livello intermedio fornisce più funzioni dipendenti dal dominio come la logica aziendale e i servizi di elaborazione di base. Inoltre, il livello superiore fornisce funzionalità più astratte sotto forma di interfaccia utente come GUI, funzionalità di programmazione shell, ecc.
Viene anche utilizzato nell'organizzazione delle librerie di classi come la libreria di classi .NET nella gerarchia dello spazio dei nomi. Tutti i tipi di progettazione possono implementare questa architettura gerarchica e spesso combinarsi con altri stili di architettura.
Gli stili architettonici gerarchici sono suddivisi in:
- Main-subroutine
- Master-slave
- Macchina virtuale
Main-subroutine
Lo scopo di questo stile è riutilizzare i moduli e sviluppare liberamente singoli moduli o subroutine. In questo stile, un sistema software è suddiviso in subroutine utilizzando il raffinamento top-down in base alla funzionalità desiderata del sistema.
Questi perfezionamenti portano verticalmente fino a quando i moduli scomposti sono abbastanza semplici da avere la sua esclusiva responsabilità indipendente. La funzionalità può essere riutilizzata e condivisa da più chiamanti negli strati superiori.
Ci sono due modi in cui i dati vengono passati come parametri alle subroutine, vale a dire:
Pass by Value - Le subroutine utilizzano solo i dati passati, ma non possono modificarli.
Pass by Reference - I sottoprogrammi utilizzano e modificano il valore dei dati a cui fa riferimento il parametro.

Vantaggi
Facile da scomporre il sistema in base al perfezionamento della gerarchia.
Può essere utilizzato in un sottosistema di progettazione orientata agli oggetti.
Svantaggi
Vulnerabile in quanto contiene dati condivisi a livello globale.
Un accoppiamento stretto può causare più effetti a catena dei cambiamenti.
Master-Slave
Questo approccio applica il principio "divide et impera" e supporta il calcolo dei guasti e l'accuratezza computazionale. È una modifica dell'architettura della subroutine principale che fornisce affidabilità del sistema e tolleranza ai guasti.
In questa architettura, gli slave forniscono servizi duplicati al master e il master sceglie un particolare risultato tra gli schiavi mediante una certa strategia di selezione. Gli schiavi possono eseguire lo stesso compito funzionale con algoritmi e metodi diversi o funzionalità completamente diverse. Include il calcolo parallelo in cui tutti gli slave possono essere eseguiti in parallelo.

L'implementazione del pattern Master-Slave segue cinque passaggi:
Specificare come il calcolo dell'attività può essere suddiviso in un insieme di sotto-attività uguali e identificare i sotto-servizi necessari per elaborare una sotto-attività.
Specificare come calcolare il risultato finale dell'intero servizio con l'aiuto dei risultati ottenuti dall'elaborazione delle singole sotto-attività.
Definire un'interfaccia per il servizio secondario identificato nel passaggio 1. Verrà implementato dallo slave e utilizzato dal master per delegare l'elaborazione delle singole sotto-attività.
Implementare i componenti slave secondo le specifiche sviluppate nel passaggio precedente.
Implementare il master secondo le specifiche sviluppate nei passaggi da 1 a 3.
Applicazioni
Adatto per applicazioni in cui l'affidabilità del software è un problema critico.
Ampiamente applicato nelle aree del calcolo parallelo e distribuito.
Vantaggi
Calcolo più veloce e facile scalabilità.
Fornisce robustezza poiché gli slave possono essere duplicati.
Lo slave può essere implementato in modo diverso per ridurre al minimo gli errori semantici.
Svantaggi
Overhead di comunicazione.
Non tutti i problemi possono essere divisi.
Difficile da implementare e problema di portabilità.
Architettura della macchina virtuale
L'architettura della macchina virtuale pretende alcune funzionalità, che non sono native dell'hardware e / o del software su cui è implementata. Una macchina virtuale è costruita su un sistema esistente e fornisce un'astrazione virtuale, una serie di attributi e operazioni.
Nell'architettura della macchina virtuale, il master utilizza lo "stesso" sottoservizio "dello slave ed esegue funzioni come il lavoro diviso, la chiamata degli slave e la combinazione dei risultati. Consente agli sviluppatori di simulare e testare piattaforme, che non sono ancora state costruite, e simulare modalità "disastrose" che sarebbero troppo complesse, costose o pericolose da testare con il sistema reale.
Nella maggior parte dei casi, una macchina virtuale divide un linguaggio di programmazione o un ambiente applicativo da una piattaforma di esecuzione. L'obiettivo principale è fornireportability. L'interpretazione di un particolare modulo tramite una macchina virtuale può essere percepita come:
Il motore di interpretazione sceglie un'istruzione dal modulo da interpretare.
In base alle istruzioni, il motore aggiorna lo stato interno della macchina virtuale e il processo sopra viene ripetuto.
La figura seguente mostra l'architettura di un'infrastruttura VM standard su una singola macchina fisica.

Il hypervisor, chiamato anche virtual machine monitor, viene eseguito sul sistema operativo host e alloca le risorse corrispondenti a ciascun sistema operativo guest. Quando il guest effettua una chiamata di sistema, l'hypervisor la intercetta e la traduce nella corrispondente chiamata di sistema supportata dal sistema operativo host. L'hypervisor controlla l'accesso di ogni macchina virtuale alla CPU, alla memoria, all'archiviazione persistente, ai dispositivi I / O e alla rete.
Applicazioni
L'architettura della macchina virtuale è adatta nei seguenti domini:
Adatto per risolvere un problema mediante simulazione o traduzione se non esiste una soluzione diretta.
Le applicazioni di esempio includono interpreti di microprogrammazione, elaborazione XML, esecuzione del linguaggio di comando di script, esecuzione del sistema basato su regole, Smalltalk e linguaggio di programmazione tipizzato da interprete Java.
Esempi comuni di macchine virtuali sono interpreti, sistemi basati su regole, shell sintattiche e processori del linguaggio di comando.
Vantaggi
Portabilità e indipendenza dalla piattaforma della macchina.
Semplicità di sviluppo del software.
Fornisce flessibilità grazie alla possibilità di interrompere e interrogare il programma.
Simulazione per modello di lavoro in caso di disastro.
Introdurre modifiche in fase di esecuzione.
Svantaggi
Lenta esecuzione dell'interprete a causa della natura dell'interprete.
C'è un costo in termini di prestazioni a causa del calcolo aggiuntivo coinvolto nell'esecuzione.
Stile a strati
In questo approccio, il sistema è scomposto in un numero di livelli superiori e inferiori in una gerarchia e ogni livello ha la propria responsabilità esclusiva nel sistema.
Ogni livello è costituito da un gruppo di classi correlate che sono incapsulate in un pacchetto, in un componente distribuito o come un gruppo di subroutine nel formato della libreria dei metodi o del file di intestazione.
Ciascun livello fornisce un servizio al livello superiore e funge da client per il livello sottostante, ovvero la richiesta al livello i +1 richiama i servizi forniti dal livello i tramite l'interfaccia del livello i. La risposta può tornare al livello i +1 se l'attività è completata; altrimenti il livello i richiama continuamente i servizi dal livello i -1 sottostante.
Applicazioni
Lo stile a strati è adatto nelle seguenti aree:
Applicazioni che coinvolgono classi di servizi distinte che possono essere organizzate gerarchicamente.
Qualsiasi applicazione che può essere scomposta in parti specifiche dell'applicazione e della piattaforma.
Applicazioni che hanno chiare divisioni tra servizi principali, servizi critici e servizi di interfaccia utente, ecc.
Vantaggi
Design basato su livelli incrementali di astrazione.
Fornisce indipendenza dal miglioramento poiché le modifiche alla funzione di un livello interessano al massimo altri due livelli.
Separazione dell'interfaccia standard e sua implementazione.
Implementato utilizzando la tecnologia basata sui componenti che rende il sistema molto più semplice per consentire plug-and-play di nuovi componenti.
Ogni livello può essere una macchina astratta distribuita in modo indipendente che supporta la portabilità.
Facile scomporre il sistema in base alla definizione dei compiti in maniera raffinata top-down
Diverse implementazioni (con interfacce identiche) dello stesso livello possono essere utilizzate in modo intercambiabile
Svantaggi
Molte applicazioni o sistemi non sono facilmente strutturati in modo stratificato.
Prestazioni di runtime inferiori poiché la richiesta di un client o una risposta al client deve attraversare potenzialmente diversi livelli.
Esistono anche problemi di prestazioni relativi all'overhead del marshalling e del buffering dei dati da parte di ogni livello.
L'apertura della comunicazione tra gli strati può causare deadlock e il "bridging" può causare un accoppiamento stretto.
Le eccezioni e la gestione degli errori sono un problema nell'architettura a più livelli, poiché i guasti in un livello devono diffondersi verso l'alto a tutti i livelli chiamanti
L'obiettivo principale dell'architettura orientata all'interazione è separare l'interazione dell'utente dall'astrazione dei dati e dall'elaborazione dei dati aziendali. L'architettura software orientata all'interazione scompone il sistema in tre partizioni principali:
Data module - Il modulo dati fornisce l'astrazione dei dati e tutta la logica di business.
Control module - Il modulo di controllo identifica il flusso delle azioni di controllo e configurazione del sistema.
View presentation module - Il modulo Visualizza presentazione è responsabile della presentazione visiva o audio dell'output dei dati e fornisce anche un'interfaccia per l'input dell'utente.
L'architettura orientata all'interazione ha due stili principali: Model-View-Controller (MVC) e Presentation-Abstraction-Control(PAC). Sia MVC che PAC propongono la scomposizione di tre componenti e vengono utilizzati per applicazioni interattive come applicazioni web con più conversazioni e interazioni con l'utente. Sono diversi nel flusso di controllo e organizzazione. PAC è un'architettura gerarchica basata su agenti, ma MVC non ha una struttura gerarchica chiara.
Model-View-Controller (MVC)
MVC scompone una data applicazione software in tre parti interconnesse che aiutano a separare le rappresentazioni interne delle informazioni dalle informazioni presentate o accettate dall'utente.
| Modulo | Funzione |
|---|---|
| Modello | Incapsulamento dei dati sottostanti e della logica aziendale |
| Controller | Rispondere all'azione dell'utente e dirigere il flusso dell'applicazione |
| Visualizza | Formatta e presenta i dati dal modello all'utente. |
Modello
Il modello è un componente centrale di MVC che gestisce direttamente i dati, la logica e i vincoli di un'applicazione. Consiste di componenti di dati, che mantengono i dati grezzi dell'applicazione e la logica dell'applicazione per l'interfaccia.
È un'interfaccia utente indipendente e cattura il comportamento del dominio del problema dell'applicazione.
È la simulazione software specifica del dominio o l'implementazione della struttura centrale dell'applicazione.
Quando si è verificato un cambiamento nel suo stato, invia una notifica alla vista associata per produrre un output aggiornato e al controller per modificare il set di comandi disponibile.
Visualizza
La vista può essere utilizzata per rappresentare qualsiasi output di informazioni in forma grafica come diagramma o grafico. Consiste di componenti di presentazione che forniscono le rappresentazioni visive dei dati
Le viste richiedono informazioni dal loro modello e generano una rappresentazione di output per l'utente.
Sono possibili visualizzazioni multiple delle stesse informazioni, come un grafico a barre per la gestione e una visualizzazione tabellare per i contabili.
Controller
Un controller accetta un input e lo converte in comandi per il modello o la vista. Consiste di componenti di elaborazione dell'input che gestiscono l'input dell'utente modificando il modello.
Funge da interfaccia tra i modelli e le viste associati e i dispositivi di input.
Può inviare comandi al modello per aggiornare lo stato del modello e alla vista associata per modificare la presentazione della vista del modello.

MVC - I
È una versione semplice dell'architettura MVC in cui il sistema è diviso in due sottosistemi:
The Controller-View - La vista controller funge da interfaccia di input / output e l'elaborazione viene eseguita.
The Model - Il modello fornisce tutti i dati e servizi di dominio.
MVC-I Architecture
Il modulo modello notifica al modulo di visualizzazione del controller qualsiasi modifica dei dati in modo che qualsiasi visualizzazione dei dati grafici venga modificata di conseguenza. Il controller intraprende inoltre le azioni appropriate in caso di modifiche.

La connessione tra la vista del controller e il modello può essere progettata secondo uno schema (come mostrato nell'immagine sopra) di notifica di sottoscrizione in cui la vista del controller si iscrive al modello e il modello notifica la vista del controller di eventuali modifiche.
MVC - II
MVC – II è un miglioramento dell'architettura MVC-I in cui il modulo di visualizzazione e il modulo del controller sono separati. Il modulo modello svolge un ruolo attivo come in MVC-I fornendo tutte le funzionalità di base ei dati supportati dal database.
Il modulo di visualizzazione presenta i dati mentre il modulo del controller accetta la richiesta di input, convalida i dati di input, avvia il modello, la visualizzazione, la loro connessione e invia anche l'attività.
MVC-II Architecture

Applicazioni MVC
Le applicazioni MVC sono efficaci per le applicazioni interattive in cui sono necessarie più viste per un singolo modello di dati e per collegare facilmente una nuova o modificare la vista dell'interfaccia.
Le applicazioni MVC sono adatte per applicazioni in cui ci sono chiare divisioni tra i moduli in modo che diversi professionisti possano essere assegnati per lavorare su diversi aspetti di tali applicazioni contemporaneamente.
Advantages
Sono disponibili molti toolkit per framework di fornitori MVC.
Viste multiple sincronizzate con lo stesso modello di dati.
Facile da collegare nuove o sostituire le viste dell'interfaccia.
Utilizzato per lo sviluppo di applicazioni in cui professionisti esperti di grafica, professionisti della programmazione e professionisti dello sviluppo di database lavorano in un team di progetto progettato.
Disadvantages
Non adatto per applicazioni orientate agli agenti come applicazioni mobili e robotiche interattive.
Più coppie di controller e viste basate sullo stesso modello di dati rendono costosa qualsiasi modifica del modello di dati.
La divisione tra View e Controller non è chiara in alcuni casi.
Presentazione-Astrazione-Controllo (PAC)
In PAC, il sistema è organizzato in una gerarchia di molti agenti cooperanti (triadi). È stato sviluppato da MVC per supportare i requisiti dell'applicazione di più agenti oltre ai requisiti interattivi.
Ogni agente ha tre componenti:
The presentation component - Formatta la presentazione visiva e audio dei dati.
The abstraction component - Recupera ed elabora i dati.
The control component - Gestisce compiti come il flusso di controllo e comunicazione tra gli altri due componenti.
L'architettura PAC è simile a MVC, nel senso che il modulo di presentazione è come il modulo di visualizzazione di MVC. Il modulo di astrazione assomiglia al modulo modello di MVC e il modulo di controllo è come il modulo controller di MVC, ma differiscono nel flusso di controllo e organizzazione.
Non ci sono connessioni dirette tra componente di astrazione e componente di presentazione in ogni agente. Il componente di controllo in ogni agente è responsabile delle comunicazioni con altri agenti.
La figura seguente mostra un diagramma a blocchi per un singolo agente nella progettazione PAC.

PAC con più agenti
Nei PAC composti da più agenti, l'agente di primo livello fornisce i dati principali e le logiche di business. Gli agenti di livello inferiore definiscono presentazioni e dati specifici dettagliati. L'agente di livello intermedio o medio funge da coordinatore degli agenti di basso livello.
Ogni agente ha il proprio lavoro assegnato specifico.
Per alcuni agenti di medio livello le presentazioni interattive non sono necessarie, quindi non hanno un componente di presentazione.
Il componente di controllo è richiesto per tutti gli agenti attraverso i quali tutti gli agenti comunicano tra loro.
La figura seguente mostra gli agenti multipli che prendono parte al PAC.

Applications
Efficace per un sistema interattivo in cui il sistema può essere scomposto in molti agenti cooperanti in modo gerarchico.
Efficace quando ci si aspetta che l'accoppiamento tra gli agenti sia lento in modo che i cambiamenti su un agente non influiscano sugli altri.
Efficace per sistemi distribuiti in cui tutti gli agenti sono distribuiti a distanza e ognuno di essi ha le proprie funzionalità con dati e interfaccia interattiva.
Adatto per applicazioni con ricchi componenti GUI in cui ognuno di essi conserva i propri dati correnti e l'interfaccia interattiva e deve comunicare con altri componenti.
Vantaggi
Supporto per multi-tasking e multi-visualizzazione
Supporto per la riusabilità e l'estensibilità degli agenti
Facile da collegare un nuovo agente o modificarne uno esistente
Supporto per la concorrenza in cui più agenti sono in esecuzione in parallelo in thread diversi o dispositivi o computer diversi
Svantaggi
Sovraccarico dovuto al ponte di controllo tra presentazione e astrazione e alla comunicazione dei controlli tra gli agenti.
Difficile determinare il giusto numero di agenti a causa dell'accoppiamento lento e dell'elevata indipendenza tra gli agenti.
La completa separazione tra presentazione e astrazione per controllo in ogni agente genera complessità di sviluppo poiché le comunicazioni tra agenti avvengono solo tra i controlli degli agenti
Nell'architettura distribuita, i componenti sono presentati su piattaforme diverse e diversi componenti possono cooperare tra loro su una rete di comunicazione per raggiungere un obiettivo o un obiettivo specifico.
In questa architettura, l'elaborazione delle informazioni non è limitata a una singola macchina, ma è distribuita su diversi computer indipendenti.
Un sistema distribuito può essere dimostrato dall'architettura client-server che costituisce la base per architetture multi-tier; le alternative sono l'architettura del broker come CORBA e l'architettura orientata ai servizi (SOA).
Esistono diversi framework tecnologici per supportare architetture distribuite, inclusi .NET, J2EE, CORBA, servizi Web .NET, servizi Web AXIS Java e servizi Globus Grid.
Il middleware è un'infrastruttura che supporta adeguatamente lo sviluppo e l'esecuzione di applicazioni distribuite. Fornisce un buffer tra le applicazioni e la rete.
Si trova al centro del sistema e gestisce o supporta i diversi componenti di un sistema distribuito. Esempi sono monitor di elaborazione delle transazioni, convertitori di dati e controller di comunicazione, ecc.
Middleware come infrastruttura per sistema distribuito

La base di un'architettura distribuita è la sua trasparenza, affidabilità e disponibilità.
La tabella seguente elenca le diverse forme di trasparenza in un sistema distribuito:
| Sr.No. | Trasparenza e descrizione |
|---|---|
| 1 | Access Nasconde il modo in cui si accede alle risorse e le differenze nella piattaforma dati. |
| 2 | Location Nasconde dove si trovano le risorse. |
| 3 | Technology Nasconde all'utente diverse tecnologie come il linguaggio di programmazione e il sistema operativo. |
| 4 | Migration / Relocation Nascondi le risorse che possono essere spostate in un'altra posizione che sono in uso. |
| 5 | Replication Nascondi le risorse che possono essere copiate in più posizioni. |
| 6 | Concurrency Nascondi le risorse che possono essere condivise con altri utenti. |
| 7 | Failure Nasconde il fallimento e il ripristino delle risorse dall'utente. |
| 8 | Persistence Nasconde se una risorsa (software) è in memoria o su disco. |
Vantaggi
Resource sharing - Condivisione di risorse hardware e software.
Openness - Flessibilità nell'utilizzo di hardware e software di diversi fornitori.
Concurrency - Elaborazione simultanea per migliorare le prestazioni.
Scalability - Aumento della produttività aggiungendo nuove risorse.
Fault tolerance - La capacità di continuare a funzionare dopo che si è verificato un guasto.
Svantaggi
Complexity - Sono più complessi dei sistemi centralizzati.
Security - Più suscettibile agli attacchi esterni.
Manageability - Maggiore impegno richiesto per la gestione del sistema.
Unpredictability - Risposte imprevedibili a seconda dell'organizzazione del sistema e del carico di rete.
Sistema centralizzato vs sistema distribuito
| Criteri | Sistema centralizzato | Sistema distribuito |
|---|---|---|
| Economia | Basso | Alto |
| Disponibilità | Basso | Alto |
| Complessità | Basso | Alto |
| Consistenza | Semplice | Alto |
| Scalabilità | Povero | Buona |
| Tecnologia | Omogeneo | Eterogeneo |
| Sicurezza | Alto | Basso |
Architettura client-server
L'architettura client-server è l'architettura di sistema distribuito più comune che scompone il sistema in due principali sottosistemi o processi logici:
Client - Questo è il primo processo che invia una richiesta al secondo processo, ovvero il server.
Server - Questo è il secondo processo che riceve la richiesta, la esegue e invia una risposta al client.
In questa architettura, l'applicazione è modellata come un insieme di servizi forniti dai server e un insieme di client che utilizzano questi servizi. I server non devono conoscere i client, ma i client devono conoscere l'identità dei server e la mappatura dei processori ai processi non è necessariamente 1: 1

L'architettura client-server può essere classificata in due modelli in base alle funzionalità del client:
Modello thin client
Nel modello thin-client, tutta l'elaborazione dell'applicazione e la gestione dei dati è effettuata dal server. Il cliente è semplicemente responsabile dell'esecuzione del software di presentazione.
Utilizzato quando i sistemi legacy vengono migrati su architetture client server in cui il sistema legacy funge da server a sé stante con un'interfaccia grafica implementata su un client
Uno dei principali svantaggi è che pone un carico di elaborazione pesante sia sul server che sulla rete.
Modello Thick / Fat-client
Nel modello thick client, il server è responsabile solo della gestione dei dati. Il software sul client implementa la logica dell'applicazione e le interazioni con l'utente del sistema.
Più appropriato per i nuovi sistemi C / S in cui le capacità del sistema client sono note in anticipo
Più complesso di un modello thin client soprattutto per la gestione. Le nuove versioni dell'applicazione devono essere installate su tutti i client.
Vantaggi
Separazione delle responsabilità come la presentazione dell'interfaccia utente e l'elaborazione della logica di business.
Riusabilità dei componenti del server e potenziale di concorrenza
Semplifica la progettazione e lo sviluppo di applicazioni distribuite
Semplifica la migrazione o l'integrazione delle applicazioni esistenti in un ambiente distribuito.
Inoltre, fa un uso efficace delle risorse quando un gran numero di client accede a un server ad alte prestazioni.
Svantaggi
Mancanza di infrastrutture eterogenee per far fronte ai cambiamenti dei requisiti.
Complicazioni di sicurezza.
Disponibilità e affidabilità del server limitate.
Testabilità e scalabilità limitate.
Clienti grassi con presentazione e logica aziendale insieme.
Architettura multilivello (architettura a più livelli)
L'architettura multilivello è un'architettura client-server in cui le funzioni come la presentazione, l'elaborazione delle applicazioni e la gestione dei dati sono fisicamente separate. Separando un'applicazione in livelli, gli sviluppatori hanno la possibilità di modificare o aggiungere un livello specifico, invece di rielaborare l'intera applicazione. Fornisce un modello con cui gli sviluppatori possono creare applicazioni flessibili e riutilizzabili.

L'utilizzo più generale dell'architettura multi-livello è l'architettura a tre livelli. Un'architettura a tre livelli è in genere composta da un livello di presentazione, un livello di applicazione e un livello di archiviazione dati e può essere eseguita su un processore separato.
Livello di presentazione
Il livello di presentazione è il livello più alto dell'applicazione a cui gli utenti possono accedere direttamente come la pagina Web o la GUI del sistema operativo (interfaccia utente grafica). La funzione principale di questo livello è tradurre le attività e i risultati in qualcosa che l'utente possa capire. Comunica con altri livelli in modo da posizionare i risultati nel livello browser / client e in tutti gli altri livelli nella rete.
Livello applicazione (logica aziendale, livello logico o livello intermedio)
Il livello applicazione coordina l'applicazione, elabora i comandi, prende decisioni logiche, valuta ed esegue calcoli. Controlla la funzionalità di un'applicazione eseguendo un'elaborazione dettagliata. Inoltre, sposta ed elabora i dati tra i due livelli circostanti.
Livello dati
In questo livello, le informazioni vengono archiviate e recuperate dal database o dal file system. Le informazioni vengono quindi restituite per l'elaborazione e quindi nuovamente all'utente. Include i meccanismi di persistenza dei dati (server di database, condivisioni di file, ecc.) E fornisce API (Application Programming Interface) al livello dell'applicazione che fornisce metodi di gestione dei dati memorizzati.
Advantages
Prestazioni migliori rispetto a un approccio thin client ed è più semplice da gestire rispetto a un approccio thick client.
Migliora la riusabilità e la scalabilità: con l'aumentare delle richieste, è possibile aggiungere server aggiuntivi.
Fornisce supporto multi-threading e riduce anche il traffico di rete.
Fornisce manutenibilità e flessibilità
Disadvantages
Testabilità insoddisfacente a causa della mancanza di strumenti di test.
Affidabilità e disponibilità del server più critiche.
Broker Architectural Style
Broker Architectural Style è un'architettura middleware utilizzata nell'elaborazione distribuita per coordinare e abilitare la comunicazione tra server e client registrati. Qui, la comunicazione degli oggetti avviene attraverso un sistema middleware chiamato broker di richieste di oggetti (bus software).
Il client e il server non interagiscono direttamente tra loro. Il client e il server hanno una connessione diretta al suo proxy che comunica con il mediatore-broker.
Un server fornisce servizi registrando e pubblicando le proprie interfacce con il broker e i client possono richiedere i servizi dal broker in modo statico o dinamico mediante ricerca.
CORBA (Common Object Request Broker Architecture) è un buon esempio di implementazione dell'architettura broker.
Componenti dello stile architettonico del broker
I componenti dello stile architettonico del broker sono discussi nei seguenti punti:
Broker
Il broker è responsabile del coordinamento della comunicazione, come l'inoltro e l'invio dei risultati e delle eccezioni. Può essere un servizio orientato alle chiamate, un documento o un broker orientato ai messaggi a cui i client inviano un messaggio.
È responsabile dell'intermediazione delle richieste di servizio, dell'individuazione di un server appropriato, della trasmissione delle richieste e dell'invio delle risposte ai client.
Conserva le informazioni di registrazione dei server, comprese le loro funzionalità e servizi, nonché le informazioni sulla posizione.
Fornisce API per le richieste dei client, i server per rispondere, la registrazione o l'annullamento della registrazione dei componenti del server, il trasferimento dei messaggi e l'individuazione dei server.
Stub
Gli stub vengono generati al momento della compilazione statica e quindi distribuiti sul lato client che viene utilizzato come proxy per il client. Il proxy lato client funge da mediatore tra il cliente e il broker e fornisce ulteriore trasparenza tra questi e il cliente; un oggetto remoto appare come uno locale.
Il proxy nasconde l'IPC (comunicazione tra processi) a livello di protocollo ed esegue il marshalling dei valori dei parametri e l'annullamento del marshalling dei risultati dal server.
Skeleton
Lo scheletro viene generato dalla compilazione dell'interfaccia del servizio e quindi distribuito sul lato server, che viene utilizzato come proxy per il server. Il proxy lato server incapsula funzioni di rete specifiche del sistema di basso livello e fornisce API di alto livello per mediare tra il server e il broker.
Riceve le richieste, decomprime le richieste, annulla il marshalling degli argomenti del metodo, chiama il servizio appropriato e esegue anche il marshalling del risultato prima di rimandarlo al client.
Bridge
Un bridge può connettere due reti differenti in base a differenti protocolli di comunicazione. Media broker diversi tra cui DCOM, .NET remote e broker Java CORBA.
I bridge sono componenti opzionali, che nascondono i dettagli di implementazione quando due broker interagiscono e accettano richieste e parametri in un formato e li traducono in un altro formato.

Broker implementation in CORBA
CORBA è uno standard internazionale per un Object Request Broker, un middleware per gestire le comunicazioni tra oggetti distribuiti definiti da OMG (Object Management Group).

Architettura orientata ai servizi (SOA)
Un servizio è un componente della funzionalità aziendale che è ben definito, autonomo, indipendente, pubblicato e disponibile per essere utilizzato tramite un'interfaccia di programmazione standard. Le connessioni tra i servizi sono condotte da protocolli orientati ai messaggi comuni e universali come il protocollo del servizio Web SOAP, che può fornire richieste e risposte tra i servizi in modo approssimativo.
L'architettura orientata ai servizi è una progettazione client / server che supporta un approccio IT orientato al business in cui un'applicazione è costituita da servizi software e consumatori di servizi software (noti anche come client o richiedenti servizi).
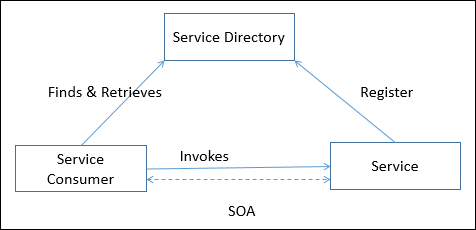
Caratteristiche di SOA
Un'architettura orientata ai servizi fornisce le seguenti funzionalità:
Distributed Deployment - Esporre i dati aziendali e la logica aziendale come unità di funzionalità vaghe, accoppiate, rilevabili, strutturate, basate su standard, a grana grossa e senza stato chiamate servizi.
Composability - Assemblare nuovi processi dai servizi esistenti che sono esposti a una granularità desiderata attraverso interfacce di reclamo ben definite, pubblicate e standard.
Interoperability - Condivisione di funzionalità e riutilizzo di servizi condivisi su una rete indipendentemente dai protocolli sottostanti o dalla tecnologia di implementazione.
Reusability - Scegli un fornitore di servizi e accedi alle risorse esistenti esposte come servizi.
Operazione SOA
La figura seguente illustra come funziona SOA:

Advantages
Il libero accoppiamento di orientamento al servizio offre alle aziende una grande flessibilità per utilizzare tutte le risorse disponibili per i servizi indipendentemente dalla piattaforma e dalle limitazioni tecnologiche.
Ogni componente del servizio è indipendente dagli altri servizi a causa della funzionalità del servizio senza stato.
L'implementazione di un servizio non influenzerà l'applicazione del servizio fintanto che l'interfaccia esposta non viene modificata.
Un client o qualsiasi servizio può accedere ad altri servizi indipendentemente dalla piattaforma, dalla tecnologia, dai fornitori o dalle implementazioni del linguaggio.
Riusabilità di risorse e servizi poiché i clienti di un servizio devono solo conoscere le sue interfacce pubbliche, la composizione del servizio.
Lo sviluppo di applicazioni aziendali basato su SOA è molto più efficiente in termini di tempo e costi.
Migliora la scalabilità e fornisce una connessione standard tra i sistemi.
Utilizzo efficiente ed efficace dei "servizi aziendali".
L'integrazione diventa molto più semplice e migliora l'interoperabilità intrinseca.
Complessità astratta per gli sviluppatori e stimola i processi aziendali più vicini agli utenti finali.
L'architettura basata sui componenti si concentra sulla scomposizione del progetto in singoli componenti funzionali o logici che rappresentano interfacce di comunicazione ben definite contenenti metodi, eventi e proprietà. Fornisce un livello più elevato di astrazione e divide il problema in sotto-problemi, ciascuno associato alle partizioni dei componenti.
L'obiettivo principale dell'architettura basata sui componenti è garantire component reusability. Un componente incapsula funzionalità e comportamenti di un elemento software in un'unità binaria riutilizzabile e auto-distribuibile. Esistono molti framework di componenti standard come COM / DCOM, JavaBean, EJB, CORBA, .NET, servizi Web e servizi di griglia. Queste tecnologie sono ampiamente utilizzate nella progettazione di applicazioni GUI desktop locali come componenti JavaBean grafici, componenti MS ActiveX e componenti COM che possono essere riutilizzati semplicemente trascinando e rilasciando.
La progettazione di software orientata ai componenti presenta molti vantaggi rispetto ai tradizionali approcci orientati agli oggetti come:
Riduzione dei tempi di commercializzazione e dei costi di sviluppo grazie al riutilizzo dei componenti esistenti.
Maggiore affidabilità con il riutilizzo dei componenti esistenti.
Cos'è un componente?
Un componente è un insieme di funzionalità ben definite modulare, portatile, sostituibile e riutilizzabile che ne incapsula l'implementazione e lo esporta come interfaccia di livello superiore.
Un componente è un oggetto software, destinato a interagire con altri componenti, incapsulando determinate funzionalità o un insieme di funzionalità. Ha un'interfaccia chiaramente definita ed è conforme a un comportamento consigliato comune a tutti i componenti all'interno di un'architettura.
Un componente software può essere definito come un'unità di composizione con un'interfaccia specificata contrattualmente e solo dipendenze di contesto esplicite. Cioè, un componente software può essere distribuito in modo indipendente ed è soggetto a composizione da parte di terzi.
Viste di un componente
Un componente può avere tre diverse visualizzazioni: visualizzazione orientata agli oggetti, visualizzazione convenzionale e visualizzazione relativa al processo.
Object-oriented view
Un componente è visto come un insieme di una o più classi cooperanti. Ogni classe di dominio del problema (analisi) e classe di infrastruttura (progettazione) viene spiegata per identificare tutti gli attributi e le operazioni che si applicano alla sua implementazione. Comporta anche la definizione delle interfacce che consentono alle classi di comunicare e cooperare.
Conventional view
È visto come un elemento funzionale o un modulo di un programma che integra la logica di elaborazione, le strutture dati interne necessarie per implementare la logica di elaborazione e un'interfaccia che consente di richiamare il componente e di passargli i dati.
Process-related view
In questa visualizzazione, invece di creare ogni componente da zero, il sistema sta costruendo da componenti esistenti mantenuti in una libreria. Man mano che viene formulata l'architettura del software, i componenti vengono selezionati dalla libreria e utilizzati per popolare l'architettura.
Un componente dell'interfaccia utente (UI) include griglie, pulsanti denominati controlli e componenti di utilità espongono un sottoinsieme specifico di funzioni utilizzate in altri componenti.
Altri tipi comuni di componenti sono quelli a uso intensivo di risorse, a cui non si accede frequentemente e che devono essere attivati utilizzando l'approccio just-in-time (JIT).
Molti componenti sono invisibili e vengono distribuiti in applicazioni aziendali aziendali e applicazioni Web Internet come Enterprise JavaBean (EJB), componenti .NET e componenti CORBA.
Caratteristiche dei componenti
Reusability- I componenti sono generalmente progettati per essere riutilizzati in diverse situazioni in diverse applicazioni. Tuttavia, alcuni componenti possono essere progettati per un'attività specifica.
Replaceable - I componenti possono essere liberamente sostituiti con altri componenti simili.
Not context specific - I componenti sono progettati per funzionare in diversi ambienti e contesti.
Extensible - Un componente può essere esteso da componenti esistenti per fornire un nuovo comportamento.
Encapsulated - Il componente AA raffigura le interfacce, che consentono al chiamante di utilizzare la sua funzionalità e non espone i dettagli dei processi interni o eventuali variabili interne o stato.
Independent - I componenti sono progettati per avere dipendenze minime da altri componenti.
Principi di progettazione basata sui componenti
Un progetto a livello di componente può essere rappresentato utilizzando una rappresentazione intermedia (ad esempio grafica, tabellare o basata su testo) che può essere tradotta in codice sorgente. La progettazione di strutture dati, interfacce e algoritmi dovrebbe essere conforme a linee guida consolidate per aiutarci a evitare l'introduzione di errori.
Il sistema software è scomposto in unità componenti riutilizzabili, coesive e incapsulate.
Ogni componente ha la propria interfaccia che specifica le porte richieste e le porte fornite; ogni componente nasconde la sua implementazione dettagliata.
Un componente dovrebbe essere esteso senza la necessità di apportare modifiche al codice interno o alla progettazione delle parti esistenti del componente.
La componente dipendente dalle astrazioni non dipende da altre componenti concrete, che aumentano la difficoltà di spendibilità.
Connettori collegati componenti, specificando e regolando l'interazione tra i componenti. Il tipo di interazione è specificato dalle interfacce dei componenti.
L'interazione dei componenti può assumere la forma di invocazioni di metodi, invocazioni asincrone, trasmissione, interazioni guidate da messaggi, comunicazioni di flussi di dati e altre interazioni specifiche del protocollo.
Per una classe server, è necessario creare interfacce specializzate per servire le principali categorie di client. Nell'interfaccia devono essere specificate solo le operazioni rilevanti per una particolare categoria di client.
Un componente può estendersi ad altri componenti e offrire comunque i propri punti di estensione. È il concetto di architettura basata su plug-in. Ciò consente a un plug-in di offrire un'altra API del plug-in.

Linee guida per la progettazione a livello di componente
Crea convenzioni di denominazione per i componenti specificati come parte del modello architettonico e quindi perfeziona o elabora come parte del modello a livello di componente.
Ottiene i nomi dei componenti architettonici dal dominio del problema e garantisce che abbiano un significato per tutte le parti interessate che visualizzano il modello architettonico.
Estrae le entità dei processi aziendali che possono esistere indipendentemente senza alcuna dipendenza associata da altre entità.
Riconosce e scopre queste entità indipendenti come nuovi componenti.
Utilizza nomi dei componenti dell'infrastruttura che riflettono il loro significato specifico dell'implementazione.
Modella le dipendenze da sinistra a destra e l'ereditarietà dall'alto (classe base) verso il basso (classi derivate).
Modella le dipendenze dei componenti come interfacce piuttosto che rappresentarle come una dipendenza diretta da componente a componente.
Conduzione della progettazione a livello di componente
Riconosce tutte le classi di progettazione che corrispondono al dominio del problema come definito nel modello di analisi e nel modello architettonico.
Riconosce tutte le classi di progettazione che corrispondono al dominio dell'infrastruttura.
Descrive tutte le classi di progettazione che non vengono acquisite come componenti riutilizzabili e specifica i dettagli del messaggio.
Identifica le interfacce appropriate per ogni componente ed elabora gli attributi e definisce i tipi di dati e le strutture dati necessarie per implementarli.
Descrive dettagliatamente il flusso di elaborazione all'interno di ciascuna operazione mediante pseudo codice o diagrammi di attività UML.
Descrive le origini dati persistenti (database e file) e identifica le classi richieste per gestirle.
Sviluppa ed elabora rappresentazioni comportamentali per una classe o un componente. Questo può essere fatto elaborando i diagrammi di stato UML creati per il modello di analisi ed esaminando tutti i casi d'uso rilevanti per la classe di progettazione.
Elabora diagrammi di distribuzione per fornire ulteriori dettagli di implementazione.
Dimostra l'ubicazione di pacchetti chiave o classi di componenti in un sistema utilizzando istanze di classe e designando hardware e ambiente del sistema operativo specifici.
La decisione finale può essere presa utilizzando principi e linee guida di progettazione stabiliti. I progettisti esperti considerano tutte (o la maggior parte) delle soluzioni di design alternative prima di stabilirsi sul modello di progettazione finale.
Vantaggi
Ease of deployment - Man mano che nuove versioni compatibili diventano disponibili, è più facile sostituire le versioni esistenti senza alcun impatto sugli altri componenti o sul sistema nel suo insieme.
Reduced cost - L'utilizzo di componenti di terze parti consente di ripartire i costi di sviluppo e manutenzione.
Ease of development - I componenti implementano interfacce ben note per fornire funzionalità definite, consentendo lo sviluppo senza influire su altre parti del sistema.
Reusable - L'uso di componenti riutilizzabili significa che possono essere utilizzati per distribuire i costi di sviluppo e manutenzione su diverse applicazioni o sistemi.
Modification of technical complexity - Un componente modifica la complessità attraverso l'uso di un contenitore di componenti e dei suoi servizi.
Reliability - L'affidabilità complessiva del sistema aumenta poiché l'affidabilità di ogni singolo componente aumenta l'affidabilità dell'intero sistema tramite il riutilizzo.
System maintenance and evolution - Facile da modificare e aggiornare l'implementazione senza influire sul resto del sistema.
Independent- Indipendenza e connettività flessibile dei componenti. Sviluppo indipendente di componenti da diversi gruppi in parallelo. Produttività per lo sviluppo del software e lo sviluppo futuro del software.
L'interfaccia utente è la prima impressione di un sistema software dal punto di vista dell'utente. Pertanto qualsiasi sistema software deve soddisfare il requisito dell'utente. L'interfaccia utente svolge principalmente due funzioni:
Accettazione dell'input dell'utente
Visualizzazione dell'output
L'interfaccia utente gioca un ruolo cruciale in qualsiasi sistema software. È forse l'unico aspetto visibile di un sistema software in quanto:
Gli utenti vedranno inizialmente l'architettura dell'interfaccia utente esterna del sistema software senza considerare la sua architettura interna.
Una buona interfaccia utente deve indurre l'utente a utilizzare il sistema software senza errori. Dovrebbe aiutare l'utente a comprendere facilmente il sistema software senza informazioni fuorvianti. Una cattiva interfaccia utente può causare un fallimento del mercato rispetto alla concorrenza del sistema software.
L'interfaccia utente ha la sua sintassi e semantica. La sintassi comprende tipi di componenti come testuali, icone, pulsanti, ecc. E l'usabilità riassume la semantica dell'interfaccia utente. La qualità dell'interfaccia utente è caratterizzata dal suo aspetto (sintassi) e dalla sua usabilità (semantica).
Esistono fondamentalmente due tipi principali di interfaccia utente: a) testuale b) grafica.
Il software in domini diversi può richiedere uno stile diverso della sua interfaccia utente, ad esempio la calcolatrice necessita solo di una piccola area per la visualizzazione di numeri numerici, ma una grande area per i comandi, una pagina web necessita di moduli, collegamenti, schede, ecc.
Interfaccia grafica utente
Un'interfaccia utente grafica è il tipo più comune di interfaccia utente disponibile oggi. È molto facile da usare perché fa uso di immagini, grafici e icone - ecco perché è chiamato "grafico".
È anche conosciuto come a WIMP interface perché fa uso di -
Windows - Un'area rettangolare sullo schermo in cui vengono eseguite le applicazioni di uso comune.
Icons - Un'immagine o un simbolo utilizzato per rappresentare un'applicazione software o un dispositivo hardware.
Menus - Un elenco di opzioni da cui l'utente può scegliere ciò di cui ha bisogno.
Pointers- Un simbolo come una freccia che si muove sullo schermo mentre l'utente muove il mouse. Aiuta l'utente a selezionare gli oggetti.
Progettazione dell'interfaccia utente
Inizia con l'analisi delle attività che comprende le attività principali dell'utente e il dominio del problema. Dovrebbe essere progettato in termini di terminologia dell'utente e inizio del lavoro dell'utente piuttosto che del programmatore.
Per eseguire l'analisi dell'interfaccia utente, il professionista deve studiare e comprendere quattro elementi:
Il users che interagirà con il sistema tramite l'interfaccia
Il tasks che gli utenti finali devono eseguire per svolgere il proprio lavoro
Il content che viene presentato come parte dell'interfaccia
Il work environment in cui verranno svolti questi compiti
La progettazione corretta o buona dell'interfaccia utente funziona in base alle capacità e alle limitazioni dell'utente, non alle macchine. Durante la progettazione dell'interfaccia utente, anche la conoscenza della natura del lavoro e dell'ambiente dell'utente è fondamentale.
Le attività da svolgere possono poi essere suddivise e assegnate all'utente o alla macchina, in base alla conoscenza delle capacità e dei limiti di ciascuna. Il design di un'interfaccia utente è spesso suddiviso in quattro diversi livelli:
The conceptual level - Descrive le entità di base considerando la vista dell'utente del sistema e le azioni possibili su di esse.
The semantic level - Descrive le funzioni svolte dal sistema, ovvero la descrizione dei requisiti funzionali del sistema, ma non si occupa del modo in cui l'utente richiamerà le funzioni.
The syntactic level - Descrive le sequenze di input e output necessarie per richiamare le funzioni descritte.
The lexical level - Determina come gli input e gli output sono effettivamente formati da operazioni hardware primitive.
La progettazione dell'interfaccia utente è un processo iterativo, in cui tutta l'iterazione spiega e perfeziona le informazioni sviluppate nei passaggi precedenti. Passaggi generali per la progettazione dell'interfaccia utente
Definisce gli oggetti e le azioni (operazioni) dell'interfaccia utente.
Definisce gli eventi (azioni dell'utente) che determineranno la modifica dello stato dell'interfaccia utente.
Indica come l'utente interpreta lo stato del sistema dalle informazioni fornite tramite l'interfaccia.
Descrivi ogni stato dell'interfaccia come apparirà effettivamente all'utente finale.
Creato da un utente o un ingegnere del software, che stabilisce il profilo degli utenti finali del sistema in base a età, sesso, capacità fisiche, istruzione, motivazione, obiettivi e personalità.
Considera la conoscenza sintattica e semantica dell'utente e classifica gli utenti come utenti principianti, intermittenti consapevoli e utenti frequenti informati.
Creato da un ingegnere del software che incorpora rappresentazioni di dati, architettura, interfaccia e procedurali del software.
Derivato dal modello di analisi dei requisiti e controllato dalle informazioni nella specifica dei requisiti che aiuta a definire l'utente del sistema.
Creato dagli implementatori del software che lavorano sull'aspetto dell'interfaccia combinato con tutte le informazioni di supporto (libri, video, file di aiuto) che descrivono la sintassi e la semantica del sistema.
Serve come traduzione del modello di progettazione e cerca di concordare con il modello mentale dell'utente in modo che gli utenti si sentano a proprio agio con il software e lo utilizzino in modo efficace.
Creato dall'utente durante l'interazione con l'applicazione. Contiene l'immagine del sistema che gli utenti portano nella loro testa.
Spesso chiamata la percezione del sistema dell'utente e la correttezza della descrizione dipendono dal profilo dell'utente e dalla familiarità generale con il software nel dominio dell'applicazione.
- Identifica i tuoi obiettivi di architettura all'inizio.
- Identifica il consumatore della nostra architettura.
- Identifica i vincoli.
Rivedere l'architettura frequentemente in occasione delle principali tappe del progetto e in risposta ad altre modifiche architettoniche significative.
L'obiettivo principale di una revisione dell'architettura è determinare la fattibilità delle architetture di base e candidate, che verificano correttamente l'architettura.
Collega i requisiti funzionali e gli attributi di qualità con la soluzione tecnica proposta. Aiuta anche a identificare i problemi e riconoscere le aree di miglioramento
Processo di sviluppo dell'interfaccia utente
Segue un processo a spirale come mostrato nel diagramma seguente:

Interface analysis
Si concentra o si concentra su utenti, attività, contenuti e ambiente di lavoro che interagiranno con il sistema. Definisce le attività umane e orientate al computer necessarie per ottenere la funzione di sistema.
Interface design
Definisce un insieme di oggetti dell'interfaccia, azioni e le loro rappresentazioni sullo schermo che consentono a un utente di eseguire tutte le attività definite in un modo che soddisfa ogni obiettivo di usabilità definito per il sistema.
Interface construction
Inizia con un prototipo che consente di valutare gli scenari di utilizzo e prosegue con gli strumenti di sviluppo per completare la costruzione.
Interface validation
Si concentra sulla capacità dell'interfaccia di implementare correttamente ogni attività dell'utente, adattarsi a tutte le variazioni delle attività, soddisfare tutti i requisiti utente generali e il grado in cui l'interfaccia è facile da usare e facile da imparare.
User Interface Models
Quando un'interfaccia utente viene analizzata e progettata, vengono utilizzati i seguenti quattro modelli:
User profile model
Design model
Implementation model
User's mental model
Considerazioni sulla progettazione dell'interfaccia utente
Centrato sull'utente
Un'interfaccia utente deve essere un prodotto incentrato sull'utente che coinvolge gli utenti durante tutto il ciclo di vita di sviluppo di un prodotto. Il prototipo di un'interfaccia utente dovrebbe essere disponibile per gli utenti e il feedback degli utenti dovrebbe essere incorporato nel prodotto finale.
Semplice e intuitivo
L'interfaccia utente offre semplicità e intuitività in modo che possa essere utilizzata rapidamente ed efficacemente senza istruzioni. La GUI è migliore dell'interfaccia utente testuale, poiché la GUI è composta da menu, finestre e pulsanti e viene gestita semplicemente utilizzando il mouse.
Date agli utenti il controllo
Non forzare gli utenti a completare sequenze predefinite. Dai loro delle opzioni: annullare o salvare e tornare al punto in cui erano stati interrotti. Utilizza i termini nell'interfaccia che gli utenti possono comprendere, anziché i termini di sistema o per sviluppatori.
Fornisci agli utenti alcune indicazioni che un'azione è stata eseguita, mostrando loro i risultati dell'azione o riconoscendo che l'azione è stata eseguita con successo.
Trasparenza
L'interfaccia utente deve essere trasparente per aiutare gli utenti a sentirsi come se stessero raggiungendo il computer e manipolando direttamente gli oggetti con cui stanno lavorando. L'interfaccia può essere resa trasparente fornendo agli utenti oggetti di lavoro anziché oggetti di sistema. Ad esempio, gli utenti dovrebbero capire che la loro password di sistema deve contenere almeno 6 caratteri, non quanti byte di memoria deve essere una password.
Usa la divulgazione progressiva
Fornisci sempre un facile accesso alle funzioni comuni e alle azioni utilizzate di frequente. Nascondi funzioni e azioni meno comuni e consenti agli utenti di esplorarle. Non cercare di mettere tutte le informazioni in una finestra principale. Usa la finestra secondaria per informazioni che non sono informazioni chiave.
Consistenza
L'interfaccia utente mantiene la coerenza all'interno e attraverso il prodotto, mantiene gli stessi risultati di interazione, i comandi ei menu dell'interfaccia utente dovrebbero avere lo stesso formato, la punteggiatura dei comandi dovrebbe essere simile ei parametri dovrebbero essere passati a tutti i comandi nello stesso modo. L'interfaccia utente non dovrebbe avere comportamenti che possano sorprendere gli utenti e dovrebbe includere i meccanismi che consentono agli utenti di recuperare dai propri errori.
Integrazione
Il sistema software dovrebbe integrarsi senza problemi con altre applicazioni come il blocco note di MS e MS-Office. Può utilizzare direttamente i comandi degli Appunti per eseguire lo scambio di dati.
Orientato ai componenti
La progettazione dell'interfaccia utente deve essere modulare e incorporare un'architettura orientata ai componenti in modo che la progettazione dell'interfaccia utente abbia gli stessi requisiti della progettazione del corpo principale del sistema software. I moduli possono essere facilmente modificati e sostituiti senza influire su altre parti del sistema.
Personalizzabile
L'architettura dell'intero sistema software incorpora moduli plug-in, che consentono a molte persone diverse di estendere il software in modo indipendente. Consente ai singoli utenti di scegliere tra vari moduli disponibili per soddisfare le preferenze e le esigenze personali.
Riduci il carico di memoria degli utenti
Non forzare gli utenti a ricordare e ripetere ciò che il computer dovrebbe fare per loro. Ad esempio, durante la compilazione di moduli in linea, i nomi dei clienti, gli indirizzi e i numeri di telefono devono essere ricordati dal sistema una volta che l'utente li ha inseriti o una volta che il record del cliente è stato aperto.
Le interfacce utente supportano il recupero della memoria a lungo termine fornendo agli utenti elementi da riconoscere anziché dover richiamare le informazioni.
Separazione
L'interfaccia utente deve essere separata dalla logica del sistema attraverso la sua implementazione per aumentare la riusabilità e la manutenibilità.
Approccio iterativo e incrementale
È un approccio iterativo e incrementale composto da cinque fasi principali che aiuta a generare soluzioni candidate. Questa soluzione candidata può essere ulteriormente perfezionata ripetendo questi passaggi e infine creare un progetto di architettura che si adatti al meglio alla nostra applicazione. Alla fine del processo, possiamo rivedere e comunicare la nostra architettura a tutte le parti interessate.
È solo un possibile approccio. Esistono molti altri approcci più formali che definiscono, riesaminano e comunicano l'architettura.
Identificare l'obiettivo dell'architettura
Identificare l'obiettivo dell'architettura che forma l'architettura e il processo di progettazione. Obiettivi impeccabili e definiti enfatizzano l'architettura, risolvono i giusti problemi nella progettazione e aiutano a determinare quando la fase corrente è stata completata e pronti per passare alla fase successiva.
Questo passaggio include le seguenti attività:
Esempi di attività di architettura includono la creazione di un prototipo per ottenere feedback sull'interfaccia utente di elaborazione degli ordini per un'applicazione Web, la creazione di un'applicazione di tracciamento degli ordini del cliente e la progettazione dell'autenticazione e dell'architettura di autorizzazione per un'applicazione al fine di eseguire una revisione della sicurezza.
Scenari chiave
Questo passaggio pone l'accento sul design che conta di più. Uno scenario è una descrizione ampia e esauriente dell'interazione di un utente con il sistema.
Gli scenari chiave sono quelli considerati gli scenari più importanti per il successo della tua applicazione. Aiuta a prendere decisioni sull'architettura. L'obiettivo è raggiungere un equilibrio tra gli obiettivi dell'utente, dell'azienda e del sistema. Ad esempio, l'autenticazione dell'utente è uno scenario chiave perché sono un'intersezione di un attributo di qualità (sicurezza) con funzionalità importanti (come un utente accede al sistema).
Panoramica dell'applicazione
Crea una panoramica dell'applicazione, che rende l'architettura più tangibile, collegandola a vincoli e decisioni del mondo reale. Consiste delle seguenti attività:
Identifica il tipo di applicazione
Identifica il tipo di applicazione se si tratta di un'applicazione mobile, un rich client, un'applicazione Internet avanzata, un servizio, un'applicazione web o una combinazione di questi tipi.
Identificare i vincoli di distribuzione
Scegli una topologia di distribuzione appropriata e risolvi i conflitti tra l'applicazione e l'infrastruttura di destinazione.
Identificare importanti stili di progettazione dell'architettura
Identifica importanti stili di progettazione dell'architettura come client / server, a strati, bus di messaggi, progettazione guidata dal dominio, ecc. Per migliorare il partizionamento e promuovere il riutilizzo del progetto fornendo soluzioni a problemi ricorrenti. Le applicazioni useranno spesso una combinazione di stili.
Identifica le tecnologie rilevanti
Identificare le tecnologie rilevanti considerando il tipo di applicazione che stiamo sviluppando, le nostre opzioni preferite per la topologia di distribuzione dell'applicazione e gli stili architettonici. La scelta delle tecnologie dipenderà anche dalle politiche dell'organizzazione, dai limiti dell'infrastruttura, dalle competenze sulle risorse e così via.
Problemi chiave o hotspot chiave
Durante la progettazione di un'applicazione, gli hot spot sono le zone in cui vengono commessi più spesso gli errori. Identifica i problemi chiave in base agli attributi di qualità e alle preoccupazioni trasversali. I potenziali problemi includono la comparsa di nuove tecnologie e requisiti aziendali critici.
Gli attributi di qualità sono le caratteristiche generali dell'architettura che influenzano il comportamento in fase di esecuzione, la progettazione del sistema e l'esperienza dell'utente. Le preoccupazioni trasversali sono le caratteristiche del nostro design che possono essere applicate a tutti i livelli, componenti e livelli.
Queste sono anche le aree in cui vengono commessi più spesso errori di progettazione ad alto impatto. Esempi di problematiche trasversali sono l'autenticazione e l'autorizzazione, la comunicazione, la gestione della configurazione, la gestione delle eccezioni e la convalida, ecc.
Soluzioni candidate
Dopo aver definito gli hotspot chiave, costruire l'architettura di base iniziale o il primo progetto di alto livello e quindi iniziare a compilare i dettagli per generare l'architettura candidata.
L'architettura candidata include il tipo di applicazione, l'architettura di distribuzione, lo stile architettonico, le scelte tecnologiche, gli attributi di qualità e le preoccupazioni trasversali. Se l'architettura candidata è un miglioramento, può diventare la linea di base da cui creare e testare nuove architetture candidate.
Convalida il progetto della soluzione candidata rispetto agli scenari e ai requisiti chiave che sono già stati definiti, prima di seguire iterativamente il ciclo e migliorare la progettazione.
Possiamo utilizzare picchi architettonici per scoprire le aree specifiche del progetto o per convalidare nuovi concetti. I picchi architettonici sono un prototipo di progettazione, che determinano la fattibilità di uno specifico percorso di progettazione, riducono il rischio e determinano rapidamente la fattibilità di approcci diversi. Testa i picchi architettonici rispetto a scenari chiave e hotspot.
Revisione dell'architettura
La revisione dell'architettura è il compito più importante per ridurre il costo degli errori e per trovare e risolvere i problemi architettonici il prima possibile. È un modo consolidato ed economico per ridurre i costi del progetto e le possibilità di fallimento del progetto.
Le valutazioni basate su scenari sono un metodo dominante per la revisione di un progetto di architettura che si concentra sugli scenari che sono più importanti dal punto di vista aziendale e che hanno il maggiore impatto sull'architettura. Di seguito sono riportate le metodologie di revisione comuni:
Metodo di analisi dell'architettura software (SAAM)
È stato originariamente progettato per valutare la modificabilità, ma in seguito è stato esteso per la revisione dell'architettura rispetto agli attributi di qualità.
Metodo di analisi del compromesso dell'architettura (ATAM)
È una versione raffinata e migliorata di SAAM, che rivede le decisioni architettoniche in relazione ai requisiti degli attributi di qualità e al modo in cui soddisfano particolari obiettivi di qualità.
Active Design Review (ADR)
È più adatto per architetture incomplete o in corso, che si concentrano maggiormente su una serie di problemi o su singole sezioni dell'architettura alla volta, piuttosto che eseguire una revisione generale.
Revisioni attive di progetti intermedi (ARID)
Combina l'aspetto ADR della revisione dell'architettura in corso con un focus su una serie di questioni e l'approccio ATAM e SAAM della revisione basata su scenari incentrata sugli attributi di qualità.
Metodo di analisi costi-benefici (CBAM)
Si concentra sull'analisi dei costi, dei vantaggi e delle implicazioni di pianificazione delle decisioni architetturali.
Analisi della modificabilità a livello di architettura (ALMA)
Stima la modificabilità dell'architettura per i sistemi informativi aziendali (BIS).
Metodo di valutazione dell'architettura familiare (FAAM)
Stima le architetture della famiglia dei sistemi informativi per l'interoperabilità e l'estensibilità.
Comunicare l'architettura Design
Dopo aver completato la progettazione dell'architettura, dobbiamo comunicare la progettazione alle altre parti interessate, che includono il team di sviluppo, gli amministratori di sistema, gli operatori, i titolari di aziende e altre parti interessate.
Esistono diversi metodi ben noti per descrivere l'architettura ad altri: -
Modello 4 + 1
Questo approccio utilizza cinque viste dell'architettura completa. Tra questi, quattro visualizzazioni (illogical view, il process view, il physical view, e il development view) descrivono l'architettura da diversi approcci. Una quinta visualizzazione mostra gli scenari e i casi d'uso del software. Consente agli stakeholder di vedere le caratteristiche dell'architettura che li interessano specificamente.
Architecture Description Language (ADL)
Questo approccio viene utilizzato per descrivere l'architettura del software prima dell'implementazione del sistema. Affronta le seguenti preoccupazioni: comportamento, protocollo e connettore.
Il vantaggio principale di ADL è che possiamo analizzare l'architettura per completezza, coerenza, ambiguità e prestazioni prima di iniziare formalmente l'uso del progetto.
Modellazione agile
Questo approccio segue il concetto che "il contenuto è più importante della rappresentazione". Assicura che i modelli creati siano semplici e di facile comprensione, sufficientemente accurati, dettagliati e coerenti.
I documenti del modello agile si rivolgono a clienti specifici e soddisfano gli sforzi di lavoro di quel cliente. La semplicità del documento garantisce la partecipazione attiva degli stakeholder alla modellazione del manufatto.
IEEE 1471
IEEE 1471 è l'abbreviazione di uno standard formalmente noto come ANSI / IEEE 1471-2000, "Recommended Practice for Architecture Description of Software-Intensive Systems". IEEE 1471 migliora il contenuto di una descrizione architettonica, in particolare, dando un significato specifico al contesto, alle viste e ai punti di vista.
Linguaggio di modellazione unificato (UML)
Questo approccio rappresenta tre viste di un modello di sistema. Ilfunctional requirements view (requisiti funzionali del sistema dal punto di vista dell'utente, inclusi i casi d'uso); the static structural view(oggetti, attributi, relazioni e operazioni inclusi i diagrammi delle classi); e ildynamic behavior view (collaborazione tra oggetti e modifiche allo stato interno degli oggetti, inclusi sequenza, attività e diagrammi di stato).