アマゾンウェブサービス-クイックガイド
2006年に、 Amazon Web Services (AWS) Webサービスの形でITサービスを市場に提供し始めました。 cloud computing。このクラウドを使用すると、事前に多くの時間を費やすサーバーやその他のITインフラストラクチャを計画する必要がありません。代わりに、これらのサービスは数百または数千のサーバーを数分で即座に起動し、結果をより速く提供できます。AWSのコスト効率を高めるために、前払い費用や長期的なコミットメントなしで、使用した分だけ支払います。
今日、AWSは、信頼性が高く、スケーラブルで、低コストのインフラストラクチャプラットフォームをクラウドで提供し、世界190か国の多数のビジネスに電力を供給しています。
クラウドコンピューティングとは何ですか?
Cloud computing はインターネットベースのコンピューティングサービスであり、リモートサーバーの大規模なグループがネットワーク化されて、一元化されたデータストレージ、およびコンピュータサービスやリソースへのオンラインアクセスを可能にします。
クラウドコンピューティングを使用すると、組織は、インフラストラクチャを独自に構築、運用、および改善するのではなく、共有コンピューティングおよびストレージリソースを使用できます。
クラウドコンピューティングは、以下の機能を可能にするモデルです。
ユーザーは、リソースをオンデマンドでプロビジョニングおよびリリースできます。
リソースは、負荷に応じて自動的にスケールアップまたはスケールダウンできます。
リソースは、適切なセキュリティを備えたネットワーク経由でアクセスできます。
クラウドサービスプロバイダーは、リソースの種類と使用量に基づいて顧客に課金する従量課金モデルを有効にすることができます。
雲の種類
クラウドには、パブリッククラウド、プライベートクラウド、ハイブリッドクラウドの3種類があります。
パブリッククラウド
パブリッククラウドでは、サードパーティのサービスプロバイダーが、インターネットを介して顧客がリソースとサービスを利用できるようにします。お客様のデータおよび関連するセキュリティは、サービスプロバイダーが所有するインフラストラクチャにあります。
プライベートクラウド
プライベートクラウドもパブリッククラウドとほぼ同様の機能を提供しますが、データとサービスは組織または顧客の組織に対してのみサードパーティによって管理されます。このタイプのクラウドでは、主要な制御はインフラストラクチャを制御するため、セキュリティ関連の問題は最小限に抑えられます。
ハイブリッドクラウド
ハイブリッドクラウドは、プライベートクラウドとパブリッククラウドの両方を組み合わせたものです。プライベートクラウドまたはパブリッククラウドで実行するかどうかの決定は、通常、データとアプリケーションの機密性、業界の認定、必要な標準、規制などのさまざまなパラメーターに依存します。
クラウドサービスモデル
クラウドには、IaaS、PaaS、SaaSの3種類のサービスモデルがあります。
IaaS
IaaSは Infrastructure as a Service。処理、ストレージ、およびネットワーク接続をオンデマンドでプロビジョニングする機能をユーザーに提供します。このサービスモデルを使用して、顧客はこれらのリソースで独自のアプリケーションを開発できます。
PaaS
PaaSは Platform as a Service。ここで、サービスプロバイダーは、データベース、キュー、ワークフローエンジン、電子メールなどのさまざまなサービスを顧客に提供します。その後、顧客はこれらのコンポーネントを使用して独自のアプリケーションを構築できます。サービス、リソースの可用性、およびデータのバックアップは、顧客がアプリケーションの機能にさらに集中できるようにするサービスプロバイダーによって処理されます。
SaaS
SaaSは Software as a Service。名前が示すように、ここでは、サードパーティプロバイダーがエンドユーザーアプリケーションに、ユーザーの作成や管理など、アプリケーションレベルでの管理機能を提供しています。また、顧客が独自の企業ロゴや色などを使用できるなど、ある程度のカスタマイズも可能です。
クラウドコンピューティングの利点
クラウドコンピューティングが提供しなければならない最も重要な利点のいくつかのリストはここにあります-
Cost-Efficient−独自のサーバーとツールの構築は、必要になるずっと前に、高価なハードウェアを注文、支払い、インストール、および構成する必要があるため、時間と費用がかかります。ただし、クラウドコンピューティングを使用する場合は、使用した金額とコンピューティングリソースを使用したときにのみ支払います。このように、クラウドコンピューティングは費用効果が高いです。
Reliability−クラウドコンピューティングプラットフォームは、社内のITインフラストラクチャよりもはるかに管理された信頼性の高い一貫したサービスを提供します。24時間年中無休で365日のサービスを保証します。サーバーのいずれかに障害が発生した場合、ホストされているアプリケーションとサービスを利用可能なサーバーのいずれかに簡単に移行できます。
Unlimited Storage−クラウドコンピューティングはほぼ無制限のストレージ容量を提供します。つまり、ストレージスペースが不足したり、現在のストレージスペースの可用性を高めたりすることを心配する必要はありません。必要なだけアクセスできます。
Backup & Recovery−データをクラウドに保存し、バックアップして復元することは、物理デバイスに保存するよりも比較的簡単です。クラウドサービスプロバイダーは、データを回復するのに十分なテクノロジーも備えているため、いつでもデータを回復できるという便利さがあります。
Easy Access to Information−クラウドに登録すると、その時点でインターネットに接続されていれば、世界中のどこからでもアカウントにアクセスできます。選択したアカウントの種類によって異なるさまざまなストレージおよびセキュリティ機能があります。
クラウドコンピューティングのデメリット
クラウドコンピューティングには素晴らしい一連の利点がありますが、いくつかの欠点もあり、その効率について疑問が生じることがよくあります。
セキュリティ上の問題
セキュリティはクラウドコンピューティングの主要な問題です。クラウドサービスプロバイダーは、最高のセキュリティ標準と業界認定を実装していますが、データと重要なファイルを外部サービスプロバイダーに保存することには常にリスクが伴います。
AWSクラウドインフラストラクチャは、最も柔軟で安全なクラウドネットワークになるように設計されています。スケーラブルで信頼性の高いプラットフォームを提供し、お客様がアプリケーションとデータを迅速かつ安全にデプロイできるようにします。
技術的な問題
クラウドサービスプロバイダーは毎日多数のクライアントにサービスを提供しているため、システムに重大な問題が発生し、ビジネスプロセスが一時的に停止される場合があります。さらに、インターネット接続がオフラインの場合、クラウドからアプリケーション、サーバー、またはデータにアクセスすることはできません。
サービスプロバイダーの切り替えは簡単ではありません
クラウドサービスプロバイダーは、クラウドを柔軟に使用および統合できることをベンダーに約束していますが、クラウドサービスの切り替えは簡単ではありません。ほとんどの組織は、現在のクラウドアプリケーションを別のプラットフォームでホストおよび統合することが難しいと感じるかもしれません。Linuxプラットフォームで開発されたアプリケーションがMicrosoftDevelopment Framework(.Net)で正しく動作しないなど、相互運用性とサポートの問題が発生する可能性があります。
これがの基本構造です AWS EC2、 どこ EC2Elastic ComputeCloudの略です。EC2を使用すると、ユーザーは要件に応じてさまざまな構成の仮想マシンを使用できます。さまざまな設定オプション、個々のサーバーのマッピング、さまざまな価格設定オプションなどが可能です。これらについては、AWS製品のセクションで詳しく説明します。以下は、アーキテクチャの図式表現です。

Note −上の図では S3Simple StorageServiceの略です。これにより、ユーザーはAPI呼び出しを使用してさまざまなタイプのデータを保存および取得できます。コンピューティング要素は含まれていません。このトピックについては、AWS製品のセクションで詳しく説明します。
負荷分散
Load balancing単に、Webサーバーを介してハードウェアまたはソフトウェアをロードすることを意味します。これにより、サーバーとアプリケーションの効率が向上します。以下は、ロードバランシングを使用したAWSアーキテクチャの図式表現です。
ハードウェアロードバランサーは、従来のWebアプリケーションアーキテクチャで使用される非常に一般的なネットワークアプライアンスです。
AWSは、Elastic Load Balancingサービスを提供し、トラフィックをEC2インスタンスに複数の利用可能なソースに分散し、AmazonEC2ホストを負荷分散ローテーションから動的に追加および削除します。
Elastic Load Balancing 負荷分散容量を動的に拡大および縮小してトラフィック需要に適応し、スティッキーセッションをサポートしてより高度なルーティングニーズに対応できます。
AmazonCloud-front
コンテンツ配信、つまりWebサイトの配信に使用されます。エッジロケーションのグローバルネットワークを使用して、動的、静的、およびストリーミングコンテンツを含めることができます。ユーザー側のコンテンツのリクエストは、最も近いエッジの場所に自動的にルーティングされるため、パフォーマンスが向上します。
Amazon Cloud-frontは、AmazonS3やAmazonEC2などの他のAmazonWebサービスと連携するように最適化されています。また、AWS以外のオリジンサーバーでも正常に機能し、同様の方法で元のファイルを保存します。
アマゾンウェブサービスでは、契約や毎月のコミットメントはありません。私たちは、サービスを通じて提供するコンテンツと同じかそれより少ないコンテンツに対してのみ支払います。
弾性ロードバランサー
これは、トラフィックをWebサーバーに分散するために使用され、パフォーマンスを向上させます。AWSは、トラフィックが複数の利用可能なゾーンを介してEC2インスタンスに分散される、Elastic Load Balancingサービスを提供し、AmazonEC2ホストを負荷分散ローテーションから動的に追加および削除します。
Elastic Load Balancingは、トラフィックの状態に応じて、負荷分散容量を動的に拡大および縮小できます。
セキュリティ管理
AmazonのElasticCompute Cloud(EC2)は、セキュリティグループと呼ばれる機能を提供します。これは、インバウンドネットワークファイアウォールに似ており、EC2インスタンスに到達できるプロトコル、ポート、および送信元IP範囲を指定する必要があります。
各EC2インスタンスには、1つ以上のセキュリティグループを割り当てることができます。各セキュリティグループは、適切なトラフィックを各インスタンスにルーティングします。セキュリティグループは、EC2インスタンスへのアクセスを制限する特定のサブネットまたはIPアドレスを使用して設定できます。
エラスティックキャッシュ
Amazon Elastic Cacheは、クラウドのメモリキャッシュを管理するWebサービスです。メモリ管理では、キャッシュは非常に重要な役割を果たし、サービスの負荷を軽減し、頻繁に使用される情報をキャッシュすることでデータベース層のパフォーマンスとスケーラビリティを向上させます。
Amazon RDS
Amazon RDS(Relational Database Service)は、MySQL、Oracle、またはMicrosoft SQLServerデータベースエンジンと同様のアクセスを提供します。同じクエリ、アプリケーション、およびツールをAmazonRDSで使用できます。
データベースソフトウェアに自動的にパッチを適用し、ユーザーの指示に従ってバックアップを管理します。また、ポイントインタイムリカバリもサポートしています。先行投資は不要で、使用したリソースに対してのみ支払います。
EC2インスタンスでのRDMSのホスティング
Amazon RDSを使用すると、ユーザーはMySQL、Oracle、SQL Server、DB2などの任意のRDBMS(リレーショナルデータベース管理システム)をEC2インスタンスにインストールし、必要に応じて管理できます。
Amazon EC2は、ネットワーク接続ストレージと同様にAmazon EBS(Elastic Block Storage)を使用します。EC2インスタンスで実行されているすべてのデータとログは、Amazon EBSボリュームに配置する必要があります。これは、データベースホストに障害が発生した場合でも利用できます。
Amazon EBSボリュームは、アベイラビリティーゾーン内に自動的に冗長性を提供し、シンプルディスクのアベイラビリティーを向上させます。さらに、ボリュームがデータベースのニーズに対して十分でない場合は、ボリュームを追加してデータベースのパフォーマンスを向上させることができます。
Amazon RDSを使用して、サービスプロバイダーがストレージを管理し、データの管理のみに重点を置いています。
ストレージとバックアップ
AWSクラウドは、ウェブアプリケーションのデータとアセットを保存、アクセス、バックアップするためのさまざまなオプションを提供します。Amazon S3(Simple Storage Service)は、Web上のどこからでも、いつでも、任意の量のデータを保存および取得するために使用できる単純なWebサービスインターフェイスを提供します。
Amazon S3は、データをと呼ばれるリソース内のオブジェクトとして保存します buckets。ユーザーは、要件ごとにバケット内に必要な数のオブジェクトを格納でき、バケットからオブジェクトを読み取り、書き込み、および削除できます。
Amazon EBSは、ブロックストレージとしてアクセスする必要があり、データベースパーティションやアプリケーションログなど、実行中のインスタンスの存続期間を超えて永続性を必要とするデータに効果的です。
AmazonEBSボリュームは最大1TBまで最大化でき、これらのボリュームをストライプ化して、ボリュームを大きくし、パフォーマンスを向上させることができます。プロビジョニングされたIOPSボリュームは、ストレージのパフォーマンスと一貫性に敏感なデータベースワークロードのニーズを満たすように設計されています。
Amazon EBSは現在、ボリュームあたり最大1,000IOPSをサポートしています。複数のボリュームをストライプ化して、インスタンスごとに数千のIOPSをアプリケーションに配信できます。
自動スケーリング
AWSクラウドアーキテクチャと従来のホスティングモデルの違いは、AWSがトラフィックの変化を処理するためにオンデマンドでウェブアプリケーションフリートを動的にスケーリングできることです。
従来のホスティングモデルでは、トラフィック予測モデルは通常、予測されるトラフィックの前にホストをプロビジョニングするために使用されます。AWSでは、フリートをスケールアウトおよびスケールインするための一連のトリガーに従って、インスタンスをオンザフライでプロビジョニングできます。AmazonAutoScalingは、オンデマンドで拡大または縮小できるサーバーの容量グループを作成できます。
AWSでのWebホスティングに関する重要な考慮事項
以下は、ウェブホスティングに関する重要な考慮事項の一部です-
物理ネットワークデバイスは必要ありません
AWSでは、AWSアプリケーションのファイアウォール、ルーター、ロードバランサーなどのネットワークデバイスは物理デバイス上に存在しなくなり、ソフトウェアソリューションに置き換えられました。
高品質のソフトウェアソリューションを保証するために、複数のオプションが利用可能です。負荷分散には、Zeus、HAProxy、Nginx、Poundなどを選択します。VPN接続を確立するには、OpenVPN、OpenSwan、Vyattaなどを選択します。
セキュリティ上の懸念はありません
AWSは、すべてのホストがロックダウンされる、より安全なモデルを提供します。Amazon EC2では、セキュリティグループはアーキテクチャ内のホストのタイプごとに設計されており、要件に応じてアーキテクチャ内のホスト間のアクセスを最小限に抑えるために、さまざまなシンプルで階層化されたセキュリティモデルを作成できます。
データセンターの可用性
EC2インスタンスは、AWSリージョンのほとんどのアベイラビリティーゾーンで簡単に利用でき、高可用性と信頼性の両方を実現するために、データセンター全体にアプリケーションをデプロイするためのモデルを提供します。
AWS管理コンソールは、アマゾンウェブサービスを管理するためのウェブアプリケーションです。AWS管理コンソールは、選択可能なさまざまなサービスのリストで構成されています。また、請求など、アカウントに関連するすべての情報も提供します。
このコンソールは、Amazon S3バケットの操作、Amazon EC2インスタンスの起動と接続、AmazonCloudWatchアラームの設定などのAWSタスクを実行するための組み込みのユーザーインターフェイスを提供します。
以下は、AmazonEC2サービス用のAWS管理コンソールのスクリーンショットです。

AWSにアクセスする方法は?
Step 1−サービスをクリックします。さまざまなサービスのリストを取得します。

Step 2 −カテゴリのリストから選択肢を選択すると、次のスクリーンショットでコンピュータやデータベースカテゴリなどのサブカテゴリが選択されていることがわかります。

Step 3 −選択したサービスを選択すると、そのサービスのコンソールが開きます。
ダッシュボードのカスタマイズ
サービスショートカットの作成
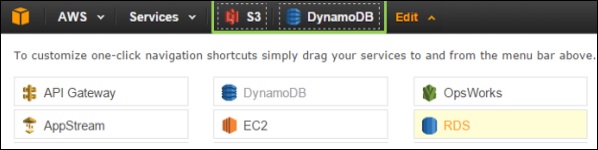
ナビゲーションバーの[編集]メニューをクリックすると、サービスのリストが表示されます。メニューバーからナビゲーションバーにドラッグするだけで、ショートカットを作成できます。

サービスショートカットの追加
サービスをメニューバーからナビゲーションバーにドラッグすると、ショートカットが作成されて追加されます。また、任意の順序で配置することもできます。次のスクリーンショットでは、S3、EMR、およびDynamoDBサービスのショートカットを作成しました。

サービスショートカットの削除
ショートカットを削除するには、編集メニューをクリックして、ナビゲーションバーからサービスメニューにショートカットをドラッグします。ショートカットは削除されます。次のスクリーンショットでは、EMRサービスのショートカットを削除しています。
地域の選択
サービスの多くは地域固有であり、リソースを管理できるように地域を選択する必要があります。AWS Identity and Access Management(IAM)のように、一部のサービスではリージョンを選択する必要がありません。
地域を選択するには、まずサービスを選択する必要があります。(コンソールの左側にある)オレゴンメニューをクリックしてから、地域を選択します

パスワードの変更
AWSアカウントのパスワードを変更できます。パスワードを変更するには、次の手順に従います。
Step 1 −ナビゲーションバーの左側にあるアカウント名をクリックします。

Step 2− [セキュリティ資格情報]を選択すると、さまざまなオプションを含む新しいページが開きます。パスワードオプションを選択してパスワードを変更し、指示に従います。
Step 3 −サインイン後、パスワードを変更して指示に従うための特定のオプションがあるページが再び開きます。

成功すると、確認メッセージが表示されます。
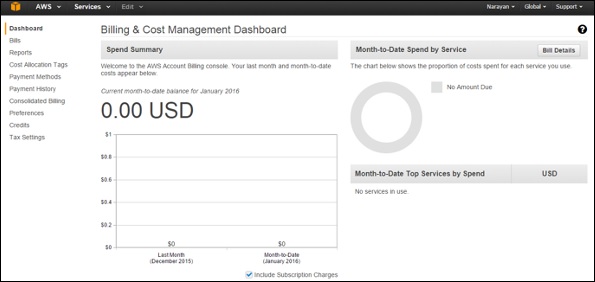
あなたの請求情報を知っている
ナビゲーションバーのアカウント名をクリックし、[請求とコスト管理]オプションを選択します。

これで、お金のセクションに関連するすべての情報を含む新しいページが開きます。このサービスを使用して、AWSの請求書を支払い、使用量と予算の見積もりを監視できます。
アマゾンウェブサービスが提供するAWSコンソールモバイルアプリを使用すると、ユーザーは選択したサービスのリソースを表示でき、選択したリソースタイプの限定された管理機能もサポートします。
以下は、モバイルアプリを使用してアクセスできるさまざまなサービスとサポートされている機能です。
EC2(Elastic Compute Cloud)
- インスタンスを参照、フィルタリング、検索します。
- 構成の詳細を表示します。
- CloudWatchメトリクスとアラームのステータスを確認します。
- 開始、停止、再起動、終了などのインスタンスに対して操作を実行します。
- セキュリティグループのルールを管理します。
- ElasticIPアドレスを管理します。
- ブロックデバイスを表示します。
弾性負荷分散
- ロードバランサーを参照、フィルタリング、検索します。
- アタッチされたインスタンスの構成の詳細を表示します。
- ロードバランサーにインスタンスを追加および削除します。
S3
- バケットを参照し、そのプロパティを表示します。
- オブジェクトのプロパティを表示します。
ルート53
- ホストゾーンを参照および表示します。
- レコードセットの詳細を参照および表示します。
RDS(リレーショナルデータベースサービス)
- インスタンスを参照、フィルタリング、検索、再起動します。
- 構成の詳細、セキュリティ、およびネットワーク設定を表示します。
自動スケーリング
- グループの詳細、ポリシー、メトリック、およびアラームを表示します。
- 状況に応じてインスタンスの数を管理します。
弾性ビーンズトーク
- アプリケーションとイベントを表示します。
- 環境構成を表示し、環境CNAMEをスワップします。
- アプリサーバーを再起動します。
DynamoDB
- テーブルと、メトリック、インデックス、アラームなどの詳細を表示します。
CloudFormation
- スタックステータス、タグ、パラメーター、出力、イベント、およびリソースを表示します。
OpsWorks
- スタック、レイヤー、インスタンス、およびアプリケーションの構成の詳細を表示します。
- インスタンスとそのログを表示し、それらを再起動します。
CloudWatch
- リソースのCloudWatchグラフを表示します。
- CloudWatchアラームをステータスと時間で一覧表示します。
- アラームのアクション構成。
サービスダッシュボード
- 利用可能なサービスとそのステータスに関する情報を提供します。
- ユーザーの請求に関連するすべての情報。
- ユーザーを切り替えて、複数のアカウントのリソースを表示します。
AWSモバイルアプリの機能
AWSモバイルアプリにアクセスするには、既存のAWSアカウントが必要です。アカウントの資格情報を使用してIDを作成し、メニューで地域を選択するだけです。このアプリを使用すると、同時に複数のIDにサインインしたままにすることができます。
セキュリティ上の理由から、パスコードでデバイスを保護し、IAMユーザーの資格情報を使用してアプリにログインすることをお勧めします。デバイスを紛失した場合は、IAMユーザーを非アクティブ化して、不正アクセスを防ぐことができます。
ルートアカウントは、モバイルコンソールを介して非アクティブ化することはできません。AWS Multi-Factor Authentication(MFA)を使用している間は、アカウントのセキュリティ上の理由から、ハードウェアMFAデバイスまたは仮想MFAを別のモバイルデバイスで使用することをお勧めします。
最新バージョンは1.14です。アプリのメニューには、私たちの経験を共有したり、質問をしたりするためのフィードバックリンクがあります。
AWSアカウントの使い方は?
AWSサービスにアクセスする手順は次のとおりです-
- AWSアカウントを作成します。
- AWSサービスにサインアップします。
- パスワードを作成し、アカウントの資格情報にアクセスします。
- クレジットセクションでサービスをアクティブ化します。
AWSアカウントを作成する
Amazonは、ユーザーがAWSのさまざまなコンポーネントを使用および学習できるように、完全に機能する1年間の無料アカウントを提供しています。EC2、S3、DynamoDBなどのAWSサービスに無料でアクセスできます。ただし、消費されるリソースに基づいて特定の制限があります。
Step 1 − AWSアカウントを作成するには、このリンクを開きます https://aws.amazon.com 新しいアカウントにサインアップして、必要な詳細を入力します。
すでにアカウントをお持ちの場合は、既存のAWSパスワードを使用してサインインできます。

Step 2−メールアドレスを入力したら、このフォームに記入してください。Amazonはこの情報を使用して、アカウントの請求、請求、識別を行います。アカウントを作成したら、必要なサービスにサインアップします。
Step 3−サービスにサインアップするには、支払い情報を入力します。Amazonは、ファイル上のカードに対して最小限のトランザクションを実行して、カードが有効であることを確認します。この料金は地域によって異なります。
Step 4−次に、本人確認です。Amazonは、提供された連絡先番号を確認するためにコールバックを行います。
Step 5−サポートプランを選択します。Basic、Developer、Business、Enterpriseなどのプランのいずれかにサブスクライブします。基本プランは費用がかからず、リソースも限られているため、AWSに慣れておくとよいでしょう。
Step 6−最後のステップは確認です。リンクをクリックして再度ログインすると、AWS管理コンソールにリダイレクトされます。
これでアカウントが作成され、AWSサービスを利用するために使用できるようになりました。
AWSアカウント識別子
AWSは、各AWSアカウントに2つの一意のIDを割り当てます。
- AWSアカウントID
- 円錐形のユーザーID
AWSアカウントID
これは123456789000のような12桁の番号であり、Amazon Resource Names(ARN)を構築するために使用されます。このIDは、リソースを他のAWSアカウントのリソースと区別するのに役立ちます。
AWSアカウント番号を知るには、次のスクリーンショットに示すように、AWS管理コンソールのナビゲーションバーの右上にある[サポート]をクリックします。

コニカル文字列ユーザーID
これは、1234abcdef1234のような英数字の長い文字列です。このIDは、クロスアカウントアクセス、つまり別のAWSアカウントのリソースにアクセスするためのAmazonS3バケットポリシーで使用されます。
アカウントエイリアス
アカウントエイリアスはサインインページのURLであり、デフォルトでアカウントIDが含まれています。このURLを会社名でカスタマイズしたり、前のURLを上書きしたりすることもできます。
独自のAWSアカウントエイリアスを作成/削除する方法は?
Step 1 − AWS管理コンソールにサインインし、次のリンクを使用してIAMコンソールを開きます https://console.aws.amazon.com/iam/
Step 2 −カスタマイズリンクを選択し、選択したエイリアスを作成します。
Step 3−エイリアスを削除するには、カスタマイズリンクをクリックしてから、[はい、削除]ボタンをクリックします。これによりエイリアスが削除され、アカウントIDに戻ります。

多要素認証
Multi Factor Authentication (MFA)ユーザーがAWSWebサイトまたはサービスにアクセスするときに、承認された認証デバイスまたはSMSテキストメッセージから一意の認証コードを入力することをユーザーに認証することにより、追加のセキュリティを提供します。MFAコードが正しい場合、AWSサービスにアクセスできるのはユーザーのみです。
要件
MFAサービスを使用するには、ユーザーはデバイス(ハードウェアまたは仮想)をIAMユーザーまたはAWSルートアカウントに割り当てる必要があります。ユーザーに割り当てられた各MFAデバイスは一意である必要があります。つまり、ユーザーは別のユーザーのデバイスからコードを入力して認証することはできません。
MFAデバイスを有効にする方法は?
Step 1 −次のリンクを開きますhttps://console.aws.amazon.com/iam/
Step 2 − Webページで、右側のナビゲーションペインからユーザーを選択して、ユーザー名のリストを表示します。
Step 3−セキュリティ資格情報まで下にスクロールし、MFAを選択します。[MFAをアクティブ化]をクリックします。
Step 4 −指示に従うと、MFAデバイスがアカウントでアクティブ化されます。

MFAデバイスを有効にする方法は3つあります-
SMSMFAデバイス
この方法では、MFAは、ユーザーのSMS互換モバイルデバイスの電話番号を使用してIAMユーザーを構成する必要があります。ユーザーがサインインすると、AWSはSMSテキストメッセージで6桁のコードをユーザーのモバイルデバイスに送信します。ユーザーは、適切なユーザーを認証するために、サインイン時に2番目のWebページに同じコードを入力する必要があります。このSMSベースのMFAは、AWSルートアカウントでは使用できません。
ハードウェアMFAデバイス
この方法では、MFAでは、MFAデバイス(ハードウェア)をIAMユーザーまたはAWSルートアカウントに割り当てる必要があります。デバイスは、時間同期されたワンタイムパスワードアルゴリズムに基づいて6桁の数値コードを生成します。ユーザーは、適切なユーザーを認証するために、サインイン時に2番目のWebページでデバイスから同じコードを入力する必要があります。
仮想MFAデバイス
この方法では、MFAでは、MFAデバイス(仮想)をIAMユーザーまたはAWSルートアカウントに割り当てる必要があります。仮想デバイスは、物理デバイスをエミュレートするモバイルデバイス上で実行されるソフトウェアアプリケーション(モバイルアプリ)です。デバイスは、時間同期されたワンタイムパスワードアルゴリズムに基づいて6桁の数値コードを生成します。ユーザーは、適切なユーザーを認証するために、サインイン時に2番目のWebページでデバイスから同じコードを入力する必要があります。

AWS Identity&Access Management(IAM)
IAMは、リソースへのアクセスが制限された状態でIAMを使用するユーザーを表すためにAWSで作成するユーザーエンティティです。したがって、rootアカウントはAWSリソースに無制限にアクセスできるため、日常のアクティビティでrootアカウントを使用する必要はありません。

IAMでユーザーを作成する方法は?
Step 1 −リンクを開く https://console.aws.amazon.com/iam/ AWSマネジメントコンソールにサインインします。
Step 2 −左側のナビゲーションペインで[ユーザー]オプションを選択して、すべてのユーザーのリストを開きます。
Step 3− [新しいユーザーの作成]オプションを使用して新しいユーザーを作成することもできます。新しいウィンドウが開きます。作成するユーザー名を入力します。作成オプションを選択すると、新しいユーザーが作成されます。

Step 4− [ユーザーのセキュリティ資格情報の表示]リンクを選択して、アクセスキーIDと秘密キーを確認することもできます。[資格情報のダウンロード]オプションを使用して、これらの詳細をコンピューターに保存することもできます。
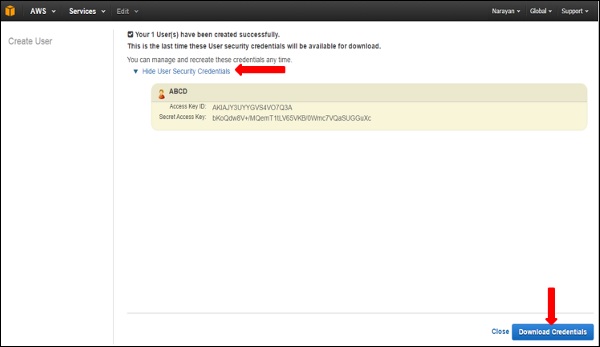
Step 5 −パスワードの作成、MFAデバイスの管理、セキュリティ証明書の管理、アクセスキーの作成/削除、ユーザーのグループへの追加など、ユーザー自身のセキュリティ資格情報を管理できます。

オプションであり、Webページで利用できる機能は他にもたくさんあります。
Amazon EC2 (Elastic Compute Cloud)は、AWSクラウドでサイズ変更可能なコンピューティング容量を提供するウェブサービスインターフェースです。これは、開発者がWebスケーリングおよびコンピューティングリソースを完全に制御できるように設計されています。
EC2インスタンスは、要件に応じてサイズを変更したり、インスタンスの数を拡大または縮小したりできます。これらのインスタンスは、1つ以上の地理的な場所または地域で起動できます。Availability Zones (AZs)。各リージョンは、同じリージョン内の低遅延ネットワークによって接続された、異なる場所にある複数のAZで構成されています。

EC2コンポーネント
AWS EC2では、ユーザーはEC2コンポーネント、オペレーティングシステムのサポート、セキュリティ対策、料金体系などについて知っておく必要があります。
オペレーティングシステムのサポート
Amazon EC2は、Red Hat Enterprise、SUSE Enterprise、Oracle Enterprise Linux、UNIX、Windows Serverなどの追加のライセンス料を支払う必要がある複数のOSをサポートしています。これらのOSは、Amazon Virtual Private Cloud(VPC)と組み合わせて実装する必要があります。 。
セキュリティ
ユーザーは、AWSアカウントの可視性を完全に制御できます。AWS EC2では、セキュリティシステムにより、要件に応じてグループを作成し、実行中のインスタンスをその中に配置できます。他のグループが通信できるグループ、およびインターネット上のIPサブネットが通信できるグループを指定できます。
価格設定
AWSは、リソースのタイプ、アプリケーションのタイプ、およびデータベースに応じて、さまざまな価格設定オプションを提供します。これにより、ユーザーはリソースを構成し、それに応じて料金を計算できます。
フォールトトレランス
Amazon EC2を使用すると、ユーザーはそのリソースにアクセスして、フォールトトレラントアプリケーションを設計できます。EC2は、フォールトトレランスと安定性のためのアベイラビリティーゾーンと呼ばれる地理的領域と孤立した場所も含みます。セキュリティ上の理由から、地域のデータセンターの正確な場所は共有されていません。
ユーザーがインスタンスを起動するときは、インスタンスが実行されるのと同じリージョンにあるAMIを選択する必要があります。インスタンスは複数のアベイラビリティーゾーンに分散され、障害時に継続的なサービスを提供します。ElasticIP(EIP)アドレスを使用して、障害が発生したインスタンスアドレスを他のゾーンで同時に実行されているインスタンスにすばやくマッピングし、サービスの遅延を回避します。
移行
このサービスにより、ユーザーは既存のアプリケーションをEC2に移動できます。ストレージデバイスあたり80.00ドル、データの読み込みに1時間あたり2.49ドルかかります。このサービスは、移動するデータが大量にあるユーザーに適しています。
EC2の機能
EC2の主な機能のいくつかのリストは次のとおりです-
Reliable− Amazon EC2は、インスタンスの交換が迅速に可能な信頼性の高い環境を提供します。サービスレベルアグリーメントのコミットメントは、Amazon EC2リージョンごとに99.9%の可用性です。
Designed for Amazon Web Services− Amazon EC2は、Amazon S3、Amazon RDS、Amazon DynamoDB、AmazonSQSなどのAmazonサービスで正常に動作します。幅広いアプリケーションにわたるコンピューティング、クエリ処理、およびストレージのための完全なソリューションを提供します。
Secure − AmazonEC2はAmazonVirtual Private Cloudで動作し、リソースに安全で堅牢なネットワークを提供します。
Flexible Tools − Amazon EC2は、開発者とシステム管理者が障害アプリケーションを構築し、一般的な障害状況から自分自身を分離するためのツールを提供します。
Inexpensive− Amazon EC2は、私たちが使用するリソースに対してのみ支払うことを望んでいます。これには、オンデマンドインスタンス、リザーブドインスタンス、スポットインスタンスなど、要件に応じて選択できる複数の購入プランが含まれます。
AWSEC2の使用方法
Step 1 − AWSアカウントにサインインし、次のリンクを使用してIAMコンソールを開きます https://console.aws.amazon.com/iam/.
Step 2 −ナビゲーションパネルで、グループを作成/表示し、指示に従います。
Step 3−IAMユーザーを作成します。ナビゲーションペインでユーザーを選択します。次に、新しいユーザーを作成し、ユーザーをグループに追加します。
Step 4 −次の手順を使用して仮想プライベートクラウドを作成します。
次のリンクを使用して、AmazonVPCコンソールを開きます- https://console.aws.amazon.com/vpc/
ナビゲーションパネルからVPCを選択します。次に、キーペアを作成したのと同じリージョンを選択します。
VPCダッシュボードで[VPCウィザードの開始]を選択します。
VPC設定ページを選択し、単一サブネットのVPCが選択されていることを確認します。[選択]を選択します。
パブリックサブネットページが1つあるVPCが開きます。名前フィールドにVPC名を入力し、他の設定はデフォルトのままにします。
[Create VPC]を選択してから、[OK]を選択します。
Step 5 − WebServerSGセキュリティグループを作成し、次の手順を使用してルールを追加します。
VPCコンソールで、ナビゲーションパネルの[セキュリティグループ]を選択します。
[セキュリティグループの作成]を選択し、グループ名、名前タグなどの必要な詳細を入力します。
メニューからVPCIDを選択します。次に、[はい、作成]ボタンを選択します。
これでグループが作成されます。[インバウンドルール]タブで編集オプションを選択して、ルールを作成します。
Step 6 −次の手順を使用して、EC2インスタンスをVPCで起動します。
次のリンクを使用してEC2コンソールを開きます- https://console.aws.amazon.com/ec2/
ダッシュボードでインスタンスの起動オプションを選択します。
新しいページが開きます。インスタンスタイプを選択し、構成を提供します。次に、[次へ:インスタンスの詳細の構成]を選択します。
新しいページが開きます。ネットワークリストからVPCを選択します。サブネットリストからサブネットを選択し、他の設定はデフォルトのままにします。
[タグインスタンス]ページが表示されるまで[次へ]をクリックします。
Step 7− [タグインスタンス]ページで、インスタンスに名前を付けたタグを指定します。[次へ:セキュリティグループの構成]を選択します。
Step 8− [セキュリティグループの構成]ページで、[既存のセキュリティグループを選択する]オプションを選択します。以前に作成したWebServerSGグループを選択し、[レビューして起動]を選択します。
Step 9 − [インスタンスの起動の確認]ページでインスタンスの詳細を確認し、[起動]ボタンをクリックします。
Step 10−ポップアップダイアログボックスが開きます。既存のキーペアを選択するか、新しいキーペアを作成します。次に、確認チェックボックスを選択し、[インスタンスの起動]ボタンをクリックします。
名前が示すように、自動スケーリングを使用すると、ユーザーが設定した指示に従って、AmazonEC2インスタンスを自動的にスケールアップまたはスケールダウンできます。インスタンスの最小数や最大数などのパラメーターは、ユーザーが設定します。これを使用すると、使用しているAmazon EC2インスタンスの数は、パフォーマンスを維持するために需要が増加すると自動的に増加し、コストを最小限に抑えるために需要が減少すると自動的に減少します。
Auto Scaling毎時、毎日、または毎週の使用量で変動するアプリケーションに特に効果的です。AutoScalingはAmazonCloudWatchによって有効にされており、追加費用なしで利用できます。AWS CloudWatchを使用して、CPU使用率、ネットワークトラフィックなどを測定できます。
弾性負荷分散
Elastic Load Balancing(ELB)は、着信リクエストトラフィックを複数のAmazon EC2インスタンスに自動的に分散し、より高いフォールトトレランスを実現します。不適合インスタンスを検出し、不適合インスタンスがラウンドロビン方式で復元されるまで、トラフィックを適合インスタンスに自動的に再ルーティングします。ただし、より複雑なルーティングアルゴリズムが必要な場合は、AmazonRoute53などの他のサービスを選択してください。
ELBは、次の3つのコンポーネントで構成されています。
ロードバランサー
これには、インターネット/イントラネットを介して着信するリクエストの監視と処理が含まれ、それらが登録されているEC2インスタンスに配信されます。
制御サービス
これには、必要に応じてロードバランサーを追加および削除することにより、着信トラフィックに応じて処理能力を自動的にスケーリングすることが含まれます。また、インスタンスの適合性チェックも実行します。
SSLターミネーション
ELBはSSLターミネーションを提供し、ELBに接続されたEC2インスタンス内でSSLをエンコードおよびデコードする貴重なCPUサイクルを節約します。X.509証明書はELB内で構成する必要があります。EC2インスタンスでのこのSSL接続はオプションであり、終了することもできます。
ELBの特徴
以下はELBの最も顕著な特徴です-
ELSは、負荷パターンを徐々に増やしながら、1秒あたり無制限のリクエストを処理するように設計されています。
トラフィックを受け入れるようにEC2インスタンスとロードバランサーを設定できます。
情報の全体的な流れに影響を与えることなく、要件に応じてロードバランサーを追加/削除できます。
オンライン試験やオンライン取引などのリクエストの急増に対応するようには設計されていません。
お客様は、単一のアベイラビリティーゾーン内または複数のゾーン間でElastic Load Balancingを有効にして、アプリケーションのパフォーマンスをさらに安定させることができます。
ロードバランサーを作成する方法は?
Step 1 −このリンクを使用してAmazon EC2コンソールに移動します− https://console.aws.amazon.com/ec2/。
Step 2 −右側のリージョンメニューからロードバランサーリージョンを選択します。
Step 3−ナビゲーションペインから[ロードバランサー]を選択し、[ロードバランサーの作成]オプションを選択します。ポップアップウィンドウが開き、必要な詳細を入力する必要があります。
Step 4 − [ロードバランサー名]ボックス:ロードバランサーの名前を入力します。
Step 5 −ボックス内にLBを作成:インスタンス用に選択したものと同じネットワークを選択します。
Step 6 −デフォルトのVPCを選択した場合は、[Advanced VPCconfigurationを有効にする]を選択します。
Step 7− [追加]ボタンをクリックすると、次のスクリーンショットに示すように、使用可能なサブネットのリストからサブネットを選択するための新しいポップアップが表示されます。アベイラビリティーゾーンごとに1つのサブネットのみを選択します。[高度なVPC構成を有効にする]を選択しない場合、このウィンドウは表示されません。
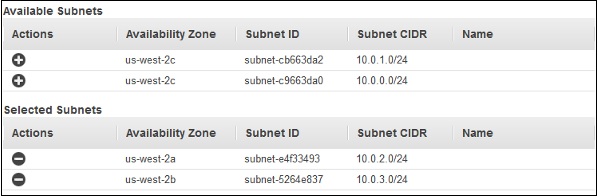
Step 8− [次へ]を選択します。ポップアップウィンドウが開きます。ネットワークとしてVPCを選択した後、セキュリティグループをロードバランサーに割り当てます。
Step 9 −指示に従って、セキュリティグループをロードバランサーに割り当て、[次へ]をクリックします。
Step 10−新しいポップアップが開き、健康診断の構成の詳細とデフォルト値が表示されます。値は独自に設定できますが、これらはオプションです。[次へ:EC2インスタンスの追加]をクリックします。

Step 11−ポップアップウィンドウが開き、登録済みインスタンスなどのインスタンスに関する情報が表示されます。[ADD EC2 Instance]オプションを選択してインスタンスをロードバランサーに追加し、必要な情報を入力します。[タグの追加]をクリックします。
Step 12−ロードバランサーへのタグの追加はオプションです。タグを追加するには、[タグの追加]ページをクリックして、キー、値などの詳細をタグに入力します。次に、[タグの作成]オプションを選択します。[レビューして作成]ボタンをクリックします。
設定を確認できるレビューページが開きます。編集リンクを選択して設定を変更することもできます。
Step 13 − [作成]をクリックしてロードバランサーを作成し、[閉じる]ボタンをクリックします。
ロードバランサーを削除する方法は?
Step 1 −このリンクを使用してAmazon EC2コンソールに移動します− https://console.aws.amazon.com/ec2/。
Step 2 −ナビゲーションペインから[ロードバランサー]オプションを選択します。
Step 3 − [ロードバランサー]を選択し、[アクション]ボタンをクリックします。
Step 4− [削除]ボタンをクリックします。警告ウィンドウが表示されたら、[はい、削除]ボタンをクリックします。
Amazon WorkSpacesは、クラウド内のフルマネージドデスクトップコンピューティングサービスであり、顧客がクラウドベースのデスクトップをエンドユーザーに提供できるようにします。これにより、エンドユーザーは、ラップトップ、iPad、Kindle Fire、Androidタブレットなど、選択したデバイスを使用してドキュメント、アプリケーション、およびリソースにアクセスできます。このサービスは、クラウドベースの「サービスとしてのデスクトップ」(DaaS)に対する顧客の高まる需要を満たすために開始されました。
使い方?
各WorkSpaceは、AWSクラウドでホストされているWindows7のように見える永続的なWindowsServer 2008R2インスタンスです。デスクトップはPCoIPを介してユーザーにストリーミングされ、バックアップされたデータはデフォルトで12時間ごとに取得されます。
ユーザー要件
ユーザー側では、TCPおよびUDPのオープンポートを使用したインターネット接続が必要です。彼らは自分のデバイスに無料のAmazonWorkSpacesクライアントアプリケーションをダウンロードする必要があります。
Amazonワークスペースを作成する方法は?
Step 1−VPCを作成して設定します。(これについては、VPCの章で詳しく説明します。)
Step 2 −次の手順を使用してADディレクトリを作成します。
次のリンクを使用して、Amazon WorkSpaceConsoleを開きます- https://console.aws.amazon.com/workspaces/
ナビゲーションパネルで[ディレクトリ]、[ディレクトリの設定]の順に選択します。
新しいページが開きます。[シンプルADの作成]ボタンを選択し、必要な詳細を入力します。

[VPC]セクションで、VPCの詳細を入力し、[次のステップ]を選択します。

情報を確認するためのレビューページが開きます。正しくない場合は変更を加えてから、[シンプルADの作成]ボタンをクリックします。
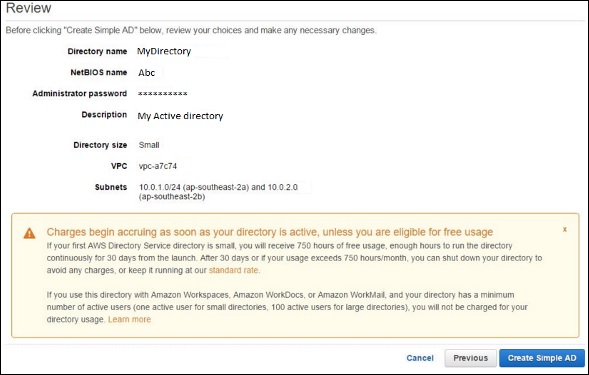
Step 3 −次の手順を使用してWorkSpaceを作成します。
次のリンクを使用して、Amazon WorkSpaceConsoleを開きます- https://console.aws.amazon.com/workspaces/
ワークスペースを選択 and 次に、ナビゲーションパネルでWorkSpacesオプションを起動します。

クラウドディレクトリを選択します。このディレクトリ内のすべてのユーザーのWorkDocsを有効/無効にしてから、[はい、次へ]ボタンをクリックします。
新しいページが開きます。新しいユーザーの詳細を入力し、Create Usersボタン。ユーザーがWorkSpaceリストに追加されたら、[次へ]を選択します。

[WorkSpacesバンドル]ページの値フィールドに必要なバンドルの数を入力し、[次へ]を選択します。
レビューページが開きます。詳細を確認し、必要に応じて変更してください。[ワークスペースの起動]を選択します。

アカウントを確認するメッセージが表示された後、WorkSpacesを使用できます。
Step 4 −次の手順を使用してWorkSpacesをテストします。
次のリンクを使用して、AmazonWorkSpacesクライアントアプリケーションをダウンロードしてインストールします- https://clients.amazonworkspaces.com/。

アプリケーションを実行します。初めて、メールで受け取った登録コードを入力し、[登録]をクリックする必要があります。
ユーザーのユーザー名とパスワードを入力して、WorkSpaceに接続します。[サインイン]を選択します。

これで、WorkSpaceデスクトップが表示されます。このリンクを開くhttp://aws.amazon.com/workspaces/Webブラウザで。ナビゲートして、ページを表示できることを確認します。
「おめでとうございます!Amazon WorkSpacesクラウドディレクトリが作成され、最初のWorkSpaceが正しく機能し、インターネットにアクセスできるようになりました。」が受信されます。
AmazonWorkSpacesの機能
ネットワーク健康診断
このAWSWorkSpaces機能は、ネットワークとインターネット接続が機能しているかどうかを確認し、WorkSpacesとそれに関連する登録サービスにアクセスできるかどうかを確認し、ポート4172がUDPおよびTCPアクセス用に開いているかどうかを確認します。

クライアントの再接続
このAWSWorkSpaces機能を使用すると、ユーザーは切断するたびに認証情報を入力しなくてもWorkSpaceにアクセスできます。クライアントのデバイスにインストールされたアプリケーションは、アクセストークンを安全なストアに保存します。これは12時間有効で、適切なユーザーの認証に使用されます。ユーザーは、アプリケーションの[再接続]ボタンをクリックして、WorkSpaceにアクセスします。ユーザーはいつでもこの機能を無効にできます。

自動再開セッション
このAWSWorkSpaces機能を使用すると、クライアントは、ネットワーク接続の何らかの理由で切断されたセッションを20分以内に再開できます(デフォルトでは、4時間延長できます)。ユーザーは、グループポリシーセクションでいつでもこの機能を無効にできます。
ConsoleSearch
この機能により、管理者はユーザー名、バンドルタイプ、またはディレクトリでWorkSpacesを検索できます。

AmazonWorkSpacesのメリット
Easy to set up −お客様はAWS WorkSpacesプランを選択して、CPUタイプ、メモリ、ストレージとアプリケーション、デスクトップの数などの要件を提供できます。
Choice of devices and applications −お客様はAmazon WorkSpaceアプリケーションをデバイス(ラップトップ、iPad、タブレット)に無料でインストールでき、利用可能なリストからアプリケーションを選択できます。
Cost-effective − Amazon WorkSpacesは事前のコミットメントを必要とせず、顧客はデスクトップをカスタマイズするときに毎月支払います。
AWS Lambdaは、アプリケーション内のアクションを検査し、ユーザー定義コードをデプロイすることで応答するレスポンシブクラウドサービスです。 functions。複数のアベイラビリティーゾーンにまたがるコンピューティングリソースを自動的に管理し、新しいアクションがトリガーされたときにそれらをスケーリングします。
AWS Lambdaは、Java、Python、Node.jsで記述されたコードをサポートし、サービスはAmazon Linuxでサポートされている言語(Bash、Go、Rubyを含む)でプロセスを起動できます。
以下は、AWSLambdaを使用する際の推奨されるヒントです。
Lambda関数コードをステートレススタイルで記述します。
ハンドラーのスコープ外で関数変数を宣言しないでください。
+ rxのセットがあることを確認してください permissions アップロードされたZIP内のファイルで、Lambdaがユーザーに代わってコードを実行できるようにします。
不要になった古いLambda関数を削除します。
AWS Lambdaを設定する方法は?
以下の手順に従って、AWSLambdaを初めて設定します。
Step 1 −AWSアカウントにサインインします。
Step 2 −AWSサービスセクションからLambdaを選択します。

Step 3 −ブループリント(オプション)を選択し、[スキップ]ボタンをクリックします。

Step 4 −作成に必要な詳細を提供します Lambda function次のスクリーンショットに示すように、DynamoDBに新しいアイテムが追加されるたびに自動的にトリガーされるNode.jsコードを貼り付けます。必要なすべての権限を選択します。


Step 5 − [次へ]ボタンをクリックして、詳細を確認します。
Step 6 − [関数の作成]ボタンをクリックします。
これで、Lambdaサービスを選択して[Event Sources]タブを選択すると、レコードはありません。Lambda関数に少なくとも1つのソースを追加して機能させます。ここでは、DynamoDBテーブルを追加しています。
DynamoDBを使用してテーブルを作成しました(これについては、DynamoDBの章で詳しく説明します)。
Step 7 − [ストリーム]タブを選択し、Lambda関数に関連付けます。

このエントリは、LambdaServiceページの[EventSources]タブに表示されます。
Step 8−テーブルにいくつかのエントリを追加します。エントリが追加されて保存されると、Lambdaサービスが関数をトリガーする必要があります。Lambdaログを使用して確認できます。
Step 9−ログを表示するには、Lambdaサービスを選択し、「モニタリング」タブをクリックします。次に、CloudWatchで[ログの表示]をクリックします。

AWSLambdaのメリット
以下は、Lambdaタスクを使用する利点の一部です-
ラムダタスクは、AmazonSWFアクティビティタイプのように登録する必要はありません。
ワークフローですでに定義した既存のLambda関数を使用できます。
Lambda関数はAmazonSWFによって直接呼び出されます。それらを実装して実行するためのプログラムを設計する必要はありません。
Lambdaは、関数の実行を追跡するためのメトリックとログを提供します。
AWSLambdaの制限
以下は、ラムダ制限の3つのタイプです。
スロットル制限
スロットル制限は、アカウントごとに100回のLambda関数の同時実行であり、同じリージョン内のすべての関数にわたる同時実行の合計に適用されます。
関数の同時実行数を計算する式=(関数実行の平均期間)X(AWS Lambdaによって処理されたリクエストまたはイベントの数)。
スロットル制限に達すると、エラーコード429のスロットルエラーが返されます。15〜30分後に、作業を再開できます。スロットル制限は、AWSサポートセンターに連絡することで増やすことができます。
リソース制限
次の表は、Lambda関数のリソース制限のリストを示しています。
| 資源 | デフォルトの制限 |
|---|---|
| エフェメラルディスク容量( "/ tmp"スペース) | 512 MB |
| ファイル記述子の数 | 1,024 |
| プロセスとスレッドの数(合計) | 1,024 |
| リクエストごとの最大実行時間 | 300秒 |
| リクエスト本文のペイロードサイズを呼び出す | 6 MB |
| 応答本体のペイロードサイズを呼び出す | 6 MB |
サービス制限
次の表は、Lambda関数をデプロイするためのサービス制限のリストを示しています。
| 項目 | デフォルトの制限 |
|---|---|
| Lambda関数のデプロイパッケージサイズ(.zip / .jarファイル) | 50 MB |
| デプロイメントパッケージに圧縮できるコード/依存関係のサイズ(圧縮されていないzip / jarサイズ) | 250 MB |
| リージョンごとにアップロードできるすべてのデプロイメントパッケージの合計サイズ | 1.5 GB |
| アカウントごとのスケジュールされたイベントソースタイプの一意のイベントソースの数 | 50 |
| 各スケジュールされたイベントに接続できる一意のLambda関数の数 | 5 |
最新の更新された制限構造と詳細については、-をご覧ください。 https://docs.aws.amazon.com/lambda/latest/dg/limits.html/
Amazon Virtual Private Cloud (VPC)ユーザーが仮想ネットワークでAWSリソースを使用できるようにします。ユーザーは、独自のIPアドレス範囲の選択、サブネットの作成、ルートテーブルとネットワークゲートウェイの構成など、仮想ネットワーク環境を好きなようにカスタマイズできます。
AmazonVPCで使用できるAWSサービスのリストは次のとおりです。
- Amazon EC2
- Amazon Route 53
- Amazon WorkSpaces
- 自動スケーリング
- 弾性負荷分散
- AWSデータパイプライン
- 弾性ビーンズトーク
- Amazon Elastic Cache
- Amazon EMR
- Amazon OpsWorks
- Amazon RDS
- AmazonRedshift
Amazon VPCの使い方は?
VPCを作成する手順は次のとおりです。
VPCを作成する
Step 1 −次のリンクを使用してAmazon VPCコンソールを開きます− https://console.aws.amazon.com/vpc/
Step 2−ナビゲーションバーの右側にある[VPCの作成]オプションを選択します。他のサービスと同じ地域が選択されていることを確認してください。
Step 3 − [VPCウィザードの開始]オプションをクリックしてから、左側にある[単一のパブリックサブネットを持つVPC]オプションをクリックします。
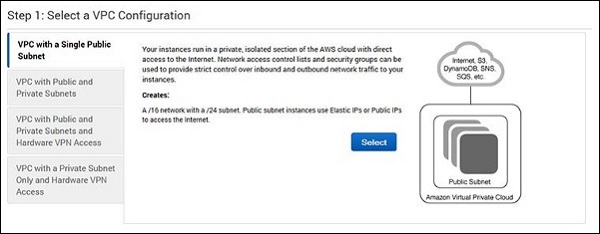
Step 4−構成ページが開きます。VPC名、サブネット名などの詳細を入力し、他のフィールドはデフォルトのままにします。[CreateVPC]ボタンをクリックします。

Step 5−進行中の作業を示すダイアログボックスが開きます。完了したら、[OK]ボタンを選択します。
[Your VPCs]ページが開き、使用可能なVPCのリストが表示されます。VPCの設定はここで変更できます。

VPCグループの選択/作成
Step 1 −次のリンクを使用してAmazon VPCコンソールを開きます− https://console.aws.amazon.com/vpc/
Step 2 −ナビゲーションバーでセキュリティグループオプションを選択してから、セキュリティグループの作成オプションを選択します。
Step 3 −フォームが開き、グループ名、名前タグなどの詳細を入力します。VPCメニューからVPCのIDを選択し、[はい、作成]ボタンを選択します。
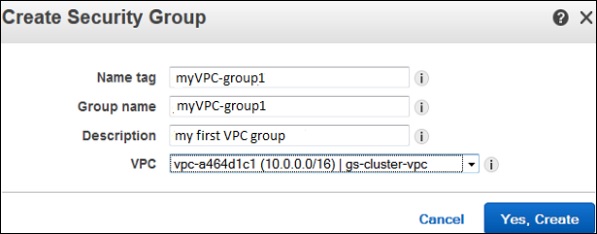
Step 4−グループのリストが開きます。リストからグループ名を選択し、ルールを設定します。次に、[保存]ボタンをクリックします。

インスタンスをVPCで起動する
Step 1 −次のリンクを使用してAmazon VPCコンソールを開きます− https://console.aws.amazon.com/vpc/
Step 2 −VPCとセキュリティグループの作成時と同じリージョンを選択します。
Step 3 −ナビゲーションバーで[インスタンスの起動]オプションを選択します。
Step 4−ページが開きます。使用するAMIを選択します。
Step 5−新しいページが開きます。インスタンスタイプを選択し、ハードウェア構成を選択します。次に、Next: Configure Instance Details。

Step 6− [ネットワーク]リストから最近作成されたVPCを選択し、[サブネット]リストからサブネットを選択します。他の設定はデフォルトのままにして、[タグインスタンス]ページまで[次へ]をクリックします。
Step 7− [タグインスタンス]ページで、インスタンスにNameタグをタグ付けします。これは、複数のインスタンスのリストからインスタンスを識別するのに役立ちます。[次へ:セキュリティグループの構成]をクリックします。
Step 8− [セキュリティグループの構成]ページで、最近作成したグループをリストから選択します。次に、[レビューして起動]ボタンを選択します。
Step 9 − [インスタンスの起動の確認]ページで、インスタンスの詳細を確認し、[起動]を選択します。
Step 10−ダイアログボックスが表示されます。[既存のキーペアを選択する]または[新しいキーペアを作成する]オプションを選択し、[インスタンスの起動]ボタンをクリックします。
Step 11 −インスタンスに関連するすべての詳細を表示する確認ページが開きます。
ElasticIPアドレスをVPCインスタンスに割り当てます
Step 1 −次のリンクを使用してAmazon VPCコンソールを開きます− https://console.aws.amazon.com/vpc/
Step 2 −ナビゲーションバーでElasticIPのオプションを選択します。
Step 3− [新しいアドレスの割り当て]を選択します。次に、[はい、割り当て]ボタンを選択します。
Step 4 −リストからElastic IPアドレスを選択し、[アクション]を選択して、[アドレスの関連付け]ボタンをクリックします。
Step 5−ダイアログボックスが開きます。まず、[関連付け]リストからインスタンスを選択します。次に、[インスタンス]リストからインスタンスを選択します。最後に、[はい、関連付けます]ボタンをクリックします。

VPCを削除する
VPCに関連付けられているリソースを失うことなく、VPCを削除するにはいくつかの手順があります。VPCを削除する手順は次のとおりです。
Step 1 −次のリンクを使用してAmazon VPCコンソールを開きます− https://console.aws.amazon.com/vpc/
Step 2 −ナビゲーションバーの[インスタンス]オプションを選択します。
Step 3 −リストからインスタンスを選択し、[アクション]→[インスタンスの状態]→[終了]ボタンを選択します。
Step 4−新しいダイアログボックスが開きます。[添付されたElasticIPを解放する]セクションを展開し、ElasticIPアドレスの横にあるチェックボックスを選択します。[はい、終了します]ボタンをクリックします。
Step 5 −次のリンクを使用してAmazon VPCコンソールを再度開きます− https://console.aws.amazon.com/vpc/
Step 6−ナビゲーションバーからVPCを選択します。次に、[アクション]を選択し、最後に[VPCの削除]ボタンをクリックします。
Step 7−確認メッセージが表示されます。[はい、削除]ボタンをクリックします。
VPCの機能
Many connectivity options − AmazonVPCにはさまざまな接続オプションがあります。
パブリックサブネットを介してVPCをインターネットに直接接続します。
プライベートサブネット経由でネットワークアドレス変換を使用してインターネットに接続します。
暗号化されたIPsecハードウェアVPN接続を介して企業のデータセンターに安全に接続します。
AWSアカウントを介して複数の仮想ネットワーク間でリソースを共有できる他のVPCにプライベートに接続します。
インターネットゲートウェイを使用せずにAmazonS3に接続し、S3バケット、そのユーザーリクエスト、グループなどを適切に制御します。
すべてのトラフィックを宛先に転送するようにAmazonVPCルートテーブルを設定することで、VPCとデータセンターの接続を組み合わせることができます。
Easy to use−要件に応じてネットワーク設定を選択することにより、非常に簡単な手順でVPCを簡単に作成できます。[Start VPC Wizard]をクリックすると、サブネット、IP範囲、ルートテーブル、セキュリティグループが自動的に作成されます。
Easy to backup data − Amazon EBSボリュームを使用して、データセンターからAmazonEC2インスタンスにデータを定期的にバックアップします。
Easy to extend network using Cloud −アプリケーションを移動し、追加のWebサーバーを起動し、VPCに接続してストレージ容量を増やします。
Amazon Route 53は、可用性と拡張性に優れたドメインネームシステム(DNS)Webサービスです。これは、開発者と企業が、www.mydomain.comのような人間が読める形式の名前を、コンピューターが相互に接続するために使用する192.0.2.1のような数値のIPアドレスに変換することにより、エンドユーザーをインターネットアプリケーションにルーティングするように設計されています。
Amazon Route 53を設定する方法は?
Route53を設定する手順は次のとおりです。
Step 1 −このリンクを使用してAmazon Route53コンソールを開きます− https://console.aws.amazon.com/route53/。
Step 2 −ナビゲーションバーの左上隅にある[ホストゾーンの作成]オプションをクリックします。


Step 3−フォームページが開きます。ドメイン名やコメントなどの必要な詳細を入力し、[作成]ボタンをクリックします。

Step 4−ドメインのホストゾーンが作成されます。委任セットと呼ばれる4つのDNSエンドポイントがあり、これらのエンドポイントはドメイン名ネームサーバー設定で更新する必要があります。

Step 5− godaddy.comの場合は、ドメインのコントロールパネルを選択し、Route 53DNSエンドポイントを更新します。残りのデフォルト値を削除します。更新には2〜3分かかります。
Step 6− Route 53コンソールに戻り、[go to recordsets]オプションを選択します。これにより、レコードセットのリストが表示されます。デフォルトでは、タイプNSとSOAの2つのレコードセットがあります。

Step 7−レコードセットを作成するには、[レコードセットの作成]オプションを選択します。名前、タイプ、エイリアス、TTL秒、値、ルーティングポリシーなど、必要な詳細を入力します。[レコードセットの保存]ボタンをクリックします。
Step 8 −選択したルーティングポリシーで異なるIPアドレスを指す同じドメイン名の2つのレコードセットが存在するように、他のリージョン用にもう1つのレコードセットを作成します。
完了すると、ユーザーリクエストはネットワークポリシーに基づいてルーティングされます。
Route53の特徴
ドメインの登録が簡単-.com、.net、.orgなどのすべてのレベルのドメインをRoute53から直接購入できます。
Highly reliable− Route53はAWSインフラストラクチャを使用して構築されています。DNSサーバーに対するその分散性は、エンドユーザーのアプリケーションをルーティングする一貫した機能を保証するのに役立ちます。
Scalable − Route 53は、ユーザーの操作なしで大量のクエリを自動的に処理するように設計されています。
Can be used with other AWS Services− Route53は他のAWSサービスでも機能します。ドメイン名をAmazonEC2インスタンス、Amazon S3バケット、Amazon、その他のAWSリソースにマッピングするために使用できます。
Easy to use −サインアップが簡単で、DNS設定を簡単に構成でき、DNSクエリにすばやく応答できます。
ヘルスチェック:Route53はアプリケーションのヘルスを監視します。停止が検出されると、ユーザーは正常なリソースに自動的にリダイレクトされます。
Cost-Effective −ドメインサービスと、サービスが各ドメインに対して応答するクエリの数に対してのみ支払います。
Secure − Route 53をAWS(IAM)と統合することにより、どのユーザーがRoute 53のどの部分にアクセスできるかを決定するなど、AWSアカウント内のすべてのユーザーを完全に制御できます。
AWS Direct Connectは、当社のネットワークからAWSの場所へのプライベートネットワーク接続を作成することを許可します。802.1q VLANを使用します。これは、複数の仮想インターフェイスに分割して、同じ接続を使用してパブリックリソースにアクセスできます。これにより、ネットワークコストが削減され、帯域幅が増加します。仮想インターフェイスは、要件に応じていつでも再構成できます。
AWS DirectConnectを使用するための要件
AWS Direct Connectを使用するには、ネットワークが次のいずれかの条件を満たす必要があります-
ネットワークはAWSDirectConnectの場所にある必要があります。利用可能なAWSDirect Connectの場所については、このリンクにアクセスしてくださいhttps://aws.amazon.com/directconnect/。
AWSパートナーネットワーク(APN)のメンバーであるAWS DirectConnectパートナーと連携する必要があります。AWS Direct Connectパートナーのリストを知るには、このリンクにアクセスしてください-https://aws.amazon.com/directconnect/
AWS Direct Connectに接続するには、サービスプロバイダーがポータブルである必要があります。
さらに、私たちのネットワークは次の必要な条件を満たす必要があります-
AWS Direct Connectへの接続には、シングルモードファイバー、1ギガビットイーサネットの場合は1000BASE-LX(1310nm)、または10ギガビットイーサネットの場合は10GBASE-LR(1310nm)が必要です。ポートのオートネゴシエーションを無効にする必要があります。これらの接続全体で802.1QVLANのサポートが利用可能である必要があります。
ネットワークは、ボーダーゲートウェイプロトコル(BGP)およびBGPMD5認証をサポートする必要があります。オプションで、双方向フォワーディング検出(BFD)を構成できます。
AWS Direct Connectを設定する方法は?
AWS DirectConnectを設定する手順は次のとおりです-
Step 1 −このリンクを使用してAWS Direct Connectコンソールを開きます− https://console.aws.amazon.com/directconnect/
step 2 −ナビゲーションバーからAWS DirectConnectリージョンを選択します。
step 3− AWS DirectConnectのウェルカムページが開きます。[直接接続の開始]を選択します。

step 4− [接続の作成]ダイアログボックスが開きます。必要な詳細を入力し、[作成]ボタンをクリックします。

AWSは、72時間以内に承認されたユーザーに確認メールを送信します。
Step 5 −次の手順を使用して仮想インターフェイスを作成します。
AWSコンソールページを再度開きます。
ナビゲーションバーで[接続]を選択し、[仮想インターフェイスの作成]を選択します。必要な詳細を入力し、[続行]ボタンをクリックします。

[ルーター構成のダウンロード]を選択し、[ダウンロード]ボタンをクリックします。


仮想インターフェイスを確認します(オプション)。AWS Direct Connect接続を確認するには、次の手順を使用します。
To verify virtual interface connection to the AWS cloud − tracerouteを実行し、AWS DirectConnect識別子がネットワークトレースに含まれていることを確認します。
To verify virtual interface connection to Amazon VPC − ping可能なAMIを使用して、仮想プライベートゲートウェイに接続されているVPCでAmazonEC2インスタンスを起動します。
インスタンスが実行されているときに、そのプライベートIPアドレスを取得し、IPアドレスにpingして応答を取得します。
ダイレクトコネクトの特徴
Reduces bandwidth costs−コストは両方の方法で削減されます。つまり、AWSとの間でデータを直接転送します。専用接続を介して転送されるデータは、インターネットデータ転送速度ではなく、AWS DirectConnectデータ転送速度の割引で課金されます。
Compatible with all AWS services − AWS Direct Connectはネットワークサービスであり、Amazon S3、Amazon EC2、Amazon VPCなど、インターネット経由でアクセス可能なすべてのAWSサービスをサポートします。
Private connectivity to Amazon VPC − AWS Direct Connectを使用して、ホームネットワークからAmazonVPCへのプライベート仮想インターフェースを高帯域幅で直接確立できます。
Elastic − AWS Direct Connectは、1Gbpsおよび10Gbps接続を提供し、要件に応じて複数の接続を確立するためのプロビジョニングを備えています。
Easy and simple−AWSマネジメントコンソールを使用してAWSDirectConnectに簡単にサインアップできます。このコンソールを使用すると、すべての接続と仮想インターフェイスを管理できます。
Amazon S3(Simple Storage Service)は、データとアプリケーションプログラムのオンラインバックアップとアーカイブ用に設計された、スケーラブルで高速、低コストのWebベースのサービスです。最大5TBのサイズのあらゆるタイプのファイルをアップロード、保存、およびダウンロードできます。このサービスにより、加入者は、Amazonが独自のWebサイトを運営するために使用するのと同じシステムにアクセスできます。加入者は、データのアクセス可能性、つまりプライベート/パブリックアクセスを制御できます。
S3を設定する方法は?
S3アカウントを設定する手順は次のとおりです。
Step 1 −このリンクを使用してAmazon S3コンソールを開きます− https://console.aws.amazon.com/s3/home
Step 2 −次の手順を使用してバケットを作成します。
プロンプトウィンドウが開きます。ページの下部にある[バケットの作成]ボタンをクリックします。

[バケットの作成]ダイアログボックスが開きます。必要な詳細を入力し、[作成]ボタンをクリックします。

バケットはAmazonS3で正常に作成されます。コンソールには、バケットとそのプロパティのリストが表示されます。

[静的ウェブサイトホスティング]オプションを選択します。ラジオボタン[ウェブサイトホスティングを有効にする]をクリックして、必要な詳細を入力します。

Step 3 −次の手順を使用して、オブジェクトをバケットに追加します。
次のリンクを使用してAmazonS3コンソールを開きます- https://console.aws.amazon.com/s3/home
[アップロード]ボタンをクリックします。

[ファイルの追加]オプションをクリックします。システムからアップロードするファイルを選択し、[開く]ボタンをクリックします。

アップロード開始ボタンをクリックします。ファイルはバケットにアップロードされます。
To open/download an object− Amazon S3コンソールの[オブジェクトとフォルダー]リストで、開く/ダウンロードするオブジェクトを右クリックします。次に、必要なオブジェクトを選択します。

S3オブジェクトを移動する方法は?
以下は、S3オブジェクトを移動する手順です。
step 1 − AmazonS3コンソールを開きます。
step 2−パネルで[ファイルとフォルダ]オプションを選択します。移動するオブジェクトを右クリックし、[切り取り]オプションをクリックします。

step 3−このオブジェクトが必要な場所を開きます。オブジェクトを移動するフォルダ/バケットを右クリックし、[貼り付け]オプションをクリックします。
オブジェクトを削除する方法は?
Step 1 − AmazonS3を開きます。
Step 2−パネルで[ファイルとフォルダ]オプションを選択します。削除するオブジェクトを右クリックします。削除オプションを選択します。
Step 3−確認のためにポップアップウィンドウが開きます。[OK]をクリックします。
バケツを空にする方法は?
Step 1 − AmazonS3コンソールを開きます。
Step 2 −空にするバケットを右クリックし、[バケットを空にする]オプションをクリックします。
Step 3−ポップアップウィンドウに確認メッセージが表示されます。それを注意深く読み、クリックしてくださいEmpty bucket 確認するボタン。
AmazonS3の機能
Low cost and Easy to Use − Amazon S3を使用すると、ユーザーは非常に低い料金で大量のデータを保存できます。
Secure− Amazon S3はSSLを介したデータ転送をサポートしており、データはアップロードされると自動的に暗号化されます。ユーザーは、AWS IAMを使用してバケットポリシーを設定することにより、データを完全に制御できます。
Scalable− Amazon S3を使用すると、ストレージの問題について心配する必要はありません。持っている限りのデータを保存し、いつでもアクセスできます。
Higher performance − AmazonS3はAmazonCloudFrontと統合されており、コンテンツを低レイテンシでエンドユーザーに配信し、最小限の使用を約束することなく高速のデータ転送を提供します。
Integrated with AWS services −AWSサービスと統合されたAmazonS3には、Amazon CloudFront、Amazon CLoudWatch、Amazon Kinesis、Amazon RDS、Amazon Route 53、Amazon VPC、AWS Lambda、Amazon EBS、Amazon DynamoDBなどが含まれます。
Amazon Elastic Block Store(EBS)は、永続データを保存するために使用されるブロックストレージシステムです。Amazon EBSは、可用性の高いブロックレベルのストレージボリュームを提供するため、EC2インスタンスに適しています。ボリュームには、汎用(SSD)、プロビジョニングされたIOPS(SSD)、および磁気の3つのタイプがあります。これらの3つのボリュームタイプは、パフォーマンス、特性、およびコストが異なります。
EBSボリュームタイプ
以下は3つのタイプです。
EBS汎用(SSD)
このボリュームタイプは、ルートディスクEC2ボリューム、中小規模のデータベースワークロード、頻繁にログにアクセスするワークロードなどの中小規模のワークロードに適しています。デフォルトでは、SSDは3 IOPS(1秒あたりの入力出力操作)/ GBをサポートします。 3 IOPSを与えると、10GBのボリュームは30IOPSを与えます。1つのボリュームのストレージ容量は1GBから1TBの範囲です。1つのボリュームのコストは、1か月でGBあたり0.10ドルです。
プロビジョニングされたIOPS(SSD)
このボリュームタイプは、最も要求の厳しいI / O集約型のトランザクションワークロード、大規模なリレーショナルワークロード、EMRおよびHadoopワークロードなどに適しています。デフォルトでは、IOPSSSDは30IOPS / GBをサポートし、10GBボリュームは300IOPSを提供します。1つのボリュームのストレージ容量は10GBから1TBの範囲です。1つのボリュームのコストは、プロビジョニングされたストレージの場合はGBあたり$ 0.125、プロビジョニングされたストレージの場合は1か月間$ 0.10です。
EBS磁気ボリューム
以前は標準ボリュームと呼ばれていました。このボリュームタイプは、データへのアクセス頻度が低いなどの理想的なワークロード、つまりリカバリ用のデータバックアップ、ログストレージなどに適しています。1つのボリュームのストレージ容量は10GBから1TBの範囲です。1つのボリュームのコストは、プロビジョニングされたストレージの場合、1GBあたり0.05ドル、プロビジョニングされたストレージの場合は0ドルです。100万回のI / O要求あたり05。
1つのインスタンスに接続されたボリューム
各アカウントは20EBSボリュームに制限されます。20を超えるEBSボリュームの要件については、Amazonのサポートチームにお問い合わせください。1つのインスタンスに最大20のボリュームを接続でき、各ボリュームのサイズは1GBから1TBの範囲です。
EC2インスタンスでは、インスタンスが実行されるまで利用可能なローカルストレージにデータを保存します。ただし、インスタンスをシャットダウンすると、データは失われます。したがって、何かを保存する必要がある場合は、ファイルをEC2インスタンスにアタッチすると、いつでもEBSボリュームにアクセスして読み取ることができるため、AmazonEBSに保存することをお勧めします。
AmazonEBSのメリット
Reliable and secure storage −各EBSボリュームは、コンポーネントの障害から保護するために、そのアベイラビリティーゾーンに自動的に応答します。
Secure− Amazonの柔軟なアクセス制御ポリシーにより、誰がどのEBSボリュームにアクセスできるかを指定できます。アクセス制御と暗号化により、データに対する多層防御の強力なセキュリティ戦略が提供されます。
Higher performance − Amazon EBSは、SSDテクノロジーを使用して、アプリケーションの一貫したI / Oパフォーマンスでデータ結果を提供します。
Easy data backup − Amazon EBSボリュームのポイントインタイムスナップショットを作成することで、データバックアップを保存できます。
Amazon EBSを設定する方法は?
Step 1 −次の手順を使用してAmazonEBSボリュームを作成します。
AmazonEC2コンソールを開きます。
ボリュームを作成するナビゲーションバーの領域を選択します。
ナビゲーションペインで、[ボリューム]を選択し、[ボリュームの作成]を選択します。
ボリュームタイプリスト、サイズ、IOPS、アベイラビリティーゾーンなどの必要な情報を入力し、[作成]ボタンをクリックします。

ボリューム名は、ボリュームリストに表示されます。

Step 2 −次の手順を使用して、スナップショットからEBSボリュームを保存します。
上記の1〜4の手順を繰り返して、ボリュームを作成します。
ボリュームの復元元の[スナップショットID]フィールドにスナップショットIDを入力し、推奨オプションのリストから選択します。
より多くのストレージが必要な場合は、[サイズ]フィールドでストレージサイズを変更します。
[はい] [作成]ボタンを選択します。
Step 3 −次の手順を使用して、EBSボリュームをインスタンスにアタッチします。
AmazonEC2コンソールを開きます。
ナビゲーションペインで[ボリューム]を選択します。ボリュームを選択し、[ボリュームのアタッチ]オプションをクリックします。

[ボリュームのアタッチ]ダイアログボックスが開きます。[インスタンス]フィールドにボリュームをアタッチするインスタンスの名前/ IDを入力するか、提案オプションのリストからボリュームを選択します。
[添付]ボタンをクリックします。
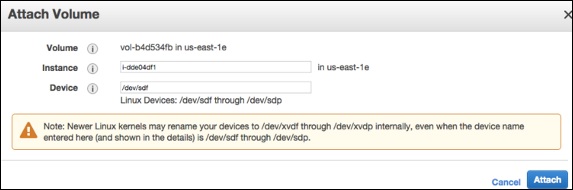
インスタンスに接続し、ボリュームを使用可能にします。
Step 4 −インスタンスからボリュームをデタッチします。
まず、cmdでコマンド/ dev / sdhを使用して、デバイスをアンマウントします。
AmazonEC2コンソールを開きます。
ナビゲーションペインで、[ボリューム]オプションを選択します。
ボリュームを選択し、[ボリュームのデタッチ]オプションをクリックします。

確認ダイアログボックスが開きます。[はい、取り外します]ボタンをクリックして確認します。

AWS Storage GatewayオンプレミスIT環境とAWSストレージインフラストラクチャ間の統合を提供します。ユーザーはAWSクラウドにデータを保存して、スケーラブルなデータセキュリティ機能と費用対効果の高いストレージを実現できます。
AWS Gatewayは、ボリュームベースとテープベースの2種類のストレージを提供します。

ボリュームゲートウェイ
このストレージタイプは、オンプレミスアプリケーションサーバーからインターネットスモールコンピューターシステムインターフェイス(iSCSI)デバイスとしてマウントできるクラウドバックアップストレージボリュームを提供します。
ゲートウェイキャッシュボリューム
AWS Storage Gatewayは、すべてのオンプレミスアプリケーションデータをAmazonS3のストレージボリュームに保存します。そのストレージボリュームは1GBから32TBの範囲で、最大20ボリュームで、合計ストレージは150TBです。これらのボリュームは、オンプレミスアプリケーションサーバーのiSCSIデバイスに接続できます。それは2つのカテゴリーに分類されます-
キャッシュストレージディスク
すべてのアプリケーションには、データを保存するためのストレージボリュームが必要です。このストレージタイプは、データがAWSのストレージボリュームに書き込まれるときに最初にデータを保存するために使用されます。キャッシュストレージディスクからのデータは、アップロードバッファからAmazonS3にアップロードされるのを待っています。キャッシュストレージディスクは、低遅延アクセスのために最後にアクセスされたデータを保持します。アプリケーションがデータを必要とする場合、Amazon S3をチェックする前に、キャッシュストレージディスクが最初にチェックされます。
キャッシュストレージに割り当てるディスク容量を決定するためのガイドラインはほとんどありません。既存のファイルストアサイズの少なくとも20%をキャッシュストレージとして割り当てる必要があります。アップロードバッファ以上である必要があります。
Upload buffer disk−このタイプのストレージディスクは、SSL接続を介してAmazonS3にアップロードされる前にデータを保存するために使用されます。ストレージゲートウェイは、SSL接続を介してアップロードバッファーからAWSにデータをアップロードします。
Snapshots− AmazonS3のストレージボリュームをバックアップする必要がある場合があります。これらのバックアップはインクリメンタルであり、snapshots。スナップショットは、AmazonEBSスナップショットとしてAmazonS3に保存されます。増分バックアップとは、新しいスナップショットが最後のスナップショット以降に変更されたデータのみをバックアップすることを意味します。スケジュールされた間隔で、または要件に従ってスナップショットを作成できます。
ゲートウェイに保存されたボリューム
仮想マシン(VM)がアクティブ化されると、ゲートウェイボリュームが作成され、オンプレミスの直接接続ストレージディスクにマップされます。したがって、アプリケーションがゲートウェイストレージボリュームからデータを読み書きするとき、マップされたオンプレミスディスクからデータを読み書きします。
ゲートウェイに保存されたボリュームを使用すると、プライマリデータをローカルに保存でき、オンプレミスアプリケーションにデータセット全体への低遅延アクセスを提供します。それらをiSCSIデバイスとしてオンプレミスのアプリケーションサーバーにマウントできます。サイズは1GBから16TBの範囲で、ゲートウェイあたり最大12のボリュームをサポートし、最大ストレージは192TBです。
ゲートウェイ-仮想テープライブラリ(VTL)
このストレージタイプは、ビジネスニーズに合わせてシームレスに拡張できる仮想テープインフラストラクチャを提供し、物理テープインフラストラクチャのプロビジョニング、スケーリング、および保守の運用上の負担を排除します。各ゲートウェイ-VTLは、メディアチェンジャーとテープドライブで事前構成されており、既存のクライアントバックアップアプリケーションでiSCSIデバイスとして使用できます。テープカートリッジは、データをアーカイブするために必要に応じて後で追加できます。
アーキテクチャで使用されるいくつかの用語を以下に説明します。
Virtual Tape−仮想テープは物理テープカートリッジに似ています。AWSクラウドに保存されます。仮想テープは、AWS StorageGatewayコンソールを使用する方法とAWSStorage GatewayAPIを使用する方法の2つの方法で作成できます。各仮想テープのサイズは100GBから2.5TBです。1つのゲートウェイのサイズは最大150TBで、一度に最大1500本のテープを使用できます。
Virtual Tape Library (VTL)−各ゲートウェイ-VTLには1つのVTLが付属しています。VTLは、オンプレミスでテープドライブを使用して利用できる物理テープライブラリに似ています。ゲートウェイは最初にデータをローカルに保存し、次にそれをVTLの仮想テープに非同期的にアップロードします。
Tape Drive− VTLテープドライブは、テープでI / O操作を実行できる物理テープドライブに似ています。各VTLは、iSCSIデバイスとしてバックアップアプリケーションに使用される10台のテープドライブで構成されています。
Media Changer− VTLメディアチェンジャーは、物理テープライブラリのストレージスロットとテープドライブ内でテープを移動するロボットに似ています。各VTLには、iSCSIデバイスとしてバックアップアプリケーションに使用されるメディアチェンジャーが1つ付属しています。
Virtual Tape Shelf (VTS) − VTSは、ゲートウェイVTLからVTSに、またはその逆にテープをアーカイブするために使用されます。
Archiving Tapes−バックアップソフトウェアがテープを排出すると、ゲートウェイはテープをVTSに移動して保存します。これは、データのアーカイブとバックアップに使用されます。
Retrieving Tapes − VTSにアーカイブされたテープは直接読み取ることができないため、アーカイブされたテープを読み取るには、AWS StorageGatewayコンソールまたはAWSStorage GatewayAPIを使用してゲートウェイVTLからテープを取得する必要があります。
CloudFront は CDN (Content Delivery Network)。Amazon S3バケットからデータを取得し、それを複数のデータセンターの場所に配布します。と呼ばれるデータセンターのネットワークを介してデータを配信しますedge locations。ユーザーがデータを要求すると、最も近いエッジの場所がルーティングされるため、遅延が最小になり、ネットワークトラフィックが少なくなり、データへのアクセスが高速になります。
AWS CloudFrontはどのようにコンテンツを配信しますか?
AWS CloudFrontは、次の手順でコンテンツを配信します。
Step 1 −ユーザーがWebサイトにアクセスし、画像ファイルのようにオブジェクトをダウンロードするように要求します。
Step 2 − DNSは、ユーザーリクエストを処理するために、リクエストを最も近いCloudFrontエッジロケーションにルーティングします。
Step 3−エッジロケーションで、CloudFrontは要求されたファイルのキャッシュをチェックします。見つかった場合は、それをユーザーに返します。それ以外の場合は、次のようにします。
最初にCloudFrontはリクエストを仕様と比較し、対応するファイルタイプの該当するオリジンサーバーに転送します。
オリジンサーバーはファイルをCloudFrontエッジロケーションに送り返します。
最初のバイトがオリジンから到着するとすぐに、CloudFrontはそれをユーザーに転送し始め、次に誰かが同じファイルを要求したときに、エッジロケーションのキャッシュにファイルを追加します。
Step 4−オブジェクトは、24時間、またはファイルヘッダーで指定された期間エッジキャッシュにあります。CloudFrontは次のことを行います-
CloudFrontは、オブジェクトの次のリクエストをユーザーのオリジンに転送して、エッジロケーションバージョンが更新されているかどうかを確認します。
エッジロケーションバージョンが更新されると、CloudFrontはそれをユーザーに配信します。
エッジロケーションのバージョンが更新されていない場合、originは最新バージョンをCloudFrontに送信します。CloudFrontはオブジェクトをユーザーに配信し、そのエッジの場所にあるキャッシュに最新バージョンを保存します。
CloudFrontの機能
Fast−エッジロケーションとCloudFrontの幅広いネットワークは、エンドユーザーに近いコンテンツのコピーをキャッシュします。これにより、レイテンシーが低下し、データ転送速度が高くなり、ネットワークトラフィックが低くなります。これらすべてがCloudFrontを高速にします。
Simple −使いやすいです。
Can be used with other AWS Services − Amazon CloudFrontは、Amazon S3、AmazonEC2などの他のAWSサービスと簡単に統合できるように設計されています。
Cost-effective − Amazon CloudFrontを使用して、ネットワークを介して配信するコンテンツに対してのみ支払いを行います。隠れた料金や前払い料金はありません。
Elastic− Amazon CloudFrontを使用すると、メンテナンスについて心配する必要がありません。需要が増減した場合、アクションが必要な場合、サービスは自動的に応答します。
Reliable − Amazon CloudFrontは、Amazonの信頼性の高いインフラストラクチャ上に構築されています。つまり、状況によっては、そのエッジロケーションがエンドユーザーを次に近いロケーションに自動的に再ルーティングします。
Global − Amazon CloudFrontは、ほとんどのリージョンにあるエッジロケーションのグローバルネットワークを使用します。
AWS CloudFrontをセットアップする方法は?
AWS CloudFrontは、次の手順を使用してセットアップできます。
Step 1 −次のリンクを使用してAWSマネジメントコンソールにサインインします− https://console.aws.amazon.com/
Step 2− Amazon S3をアップロードし、すべてのパーミッションパブリックを選択します。(コンテンツをS3バケットにアップロードする方法は第14章で説明されています)
Step 3 −次の手順を使用してCloudFrontWebディストリビューションを作成します。
次のリンクを使用してCloudFrontコンソールを開きます- https://console.aws.amazon.com/cloudfront/
コンテンツページの配信方法の選択のWebセクションにある[開始]ボタンをクリックします。
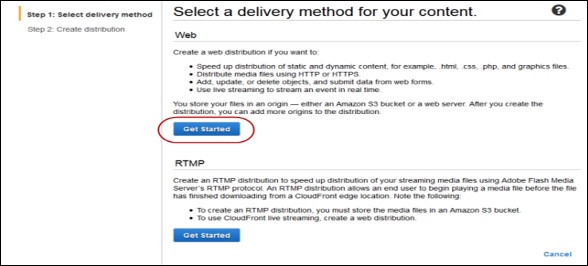
Create Distributionページが開きます。オリジンドメイン名で作成されたAmazonS3バケットを選択し、残りのフィールドはデフォルトのままにします。

[デフォルトのキャッシュ動作設定]ページが開きます。値をデフォルトのままにして、次のページに移動します。
配布設定ページが開きます。要件に従って詳細を入力し、[配布の作成]ボタンをクリックします。
[ステータス]列が[進行中]から[展開済み]に変わります。[有効にする]オプションを選択して、配布を有効にします。ドメイン名がディストリビューションリストに表示されるまで約15分かかります。
リンクをテストする
ディストリビューションを作成した後、CloudFrontはAmazon S3サーバーの場所を認識し、ユーザーはディストリビューションに関連付けられたドメイン名を認識します。ただし、そのドメイン名でAmazon S3バケットコンテンツへのリンクを作成し、CloudFrontにそれを提供させることもできます。これは多くの時間を節約するのに役立ちます。
オブジェクトをリンクする手順は次のとおりです-
Step 1−次のHTMLコードを新しいファイルにコピーし、CloudFrontがディストリビューションに割り当てたドメイン名をドメイン名の代わりに書き込みます。object-nameの代わりにAmazonS3バケットのファイル名を書き込みます。
<html>
<head>CloudFront Testing link</head>
<body>
<p>My Cludfront.</p>
<p><img src = "http://domain-name/object-name" alt = "test image"/>
</body>
</html>Step 2 −テキストを次のファイルに保存します .html 拡張。
Step 3−ブラウザでWebページを開き、リンクをテストして、正しく機能しているかどうかを確認します。そうでない場合は、設定をクロスチェックします。
Amazon RDS (Relational Database Service)は、リレーショナルデータベースの作成と運用を可能にするフルマネージドSQLデータベースクラウドサービスです。RDSを使用すると、費用効果が高くスケーラブルな方法で、どこからでもファイルやデータベースにアクセスできます。
AmazonRDSの機能
AmazonRDSには次の機能があります-
Scalable− Amazon RDSでは、AWSマネジメントコンソールまたはRDS固有のAPIを使用してリレーショナルデータベースをスケーリングできます。RDS要件を数分以内に増減できます。
Host replacement− Amazon RDSのハードウェアに障害が発生すると、これらの状況が発生することがあります。心配する必要はありません、それは自動的にアマゾンに置き換えられます。
Inexpensive− Amazon RDSを使用して、消費したリソースに対してのみ支払います。事前の長期的な取り組みはありません。
Secure − Amazon RDSは、ネットワークを完全に制御して、データベースと関連サービスにアクセスします。
Automatic backups − Amazon RDSは、過去5分間のトランザクションログを含むデータベース内のすべてをバックアップし、自動バックアップタイミングも管理します。
Software patching−データベースソフトウェアの最新のパッチをすべて自動的に取得します。DB Engine Version Managementを使用して、ソフトウェアにパッチを適用するタイミングを指定することもできます。
Amazon RDSを設定する方法は?
Step 1−AWS管理コンソールにログインします。次のリンクを使用して、AmazonRDSコンソールを開きます-https://console.aws.amazon.com/rds/
Step 2 − Amazon RDSコンソールの右上隅で、DBインスタンスを作成するリージョンを選択します。
Step 3 −ナビゲーションペインで[インスタンス]を選択し、[DBインスタンスの起動]ボタンをクリックします。
Step 4−DBインスタンスの起動ウィザードが開きます。必要に応じてインスタンスのタイプを選択して起動し、[選択]ボタンをクリックします。

Step 5 − [DBの詳細の指定]ページで、必要な詳細を入力し、[続行]ボタンをクリックします。

Step 6 −「追加構成」ページで、MySQL DBインスタンスを起動するために必要な追加情報を入力し、「続行」ボタンをクリックします。

Step 7 − [管理オプション]ページで、選択を行い、[続行]ボタンをクリックします。

Step 8 − [レビュー]ページで、詳細を確認し、[DBインスタンスの起動]ボタンをクリックします。

これで、DBインスタンスがDBインスタンスのリストに表示されます。
データベースをMySQLDBインスタンスに接続する方法は?
以下は、MySQLDBインスタンス上のデータベースに接続する手順です。
Step 1 −クライアントコンピューターのコマンドプロンプトに次のコマンドを入力して、MySQL DBインスタンス上のデータベースに接続します(MySQLモニターを使用)。
Step 2 − <myDBI>をDBインスタンスのDNS名に、<myusername>をマスターユーザー名に、<mypassword>をマスターパスワードに置き換えます。
PROMPT> mysql -h <myDBI> -P 3306 -u <myusername> -p上記のコマンドを実行すると、出力は次のようになります。
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 350
Server version: 5.2.33-log MySQL Community Server (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>DBインスタンスを削除する方法は?
タスクの完了後、DBインスタンスを削除して、課金されないようにする必要があります。次の手順に従って、DBインスタンスを削除します-
Step 1 − AWSマネジメントコンソールにサインインし、次のリンクを使用してAmazonRDSコンソールを開きます。
https://console.aws.amazon.com/rds/
Step 2 − [DBインスタンス]リストで、削除するDBインスタンスを選択します。
Step 3 − [インスタンスアクション]ボタンをクリックし、ドロップダウンメニューから[削除]オプションを選択します。
Step 4 − [最終スナップショットの作成]で[いいえ]を選択します。
Step 5 − [はい、削除]をクリックして、DBインスタンスを削除します。
AmazonRDSのコスト
Amazon RDSを使用する場合は、最低料金やセットアップ料金なしで、使用料のみを支払います。請求は以下の基準に基づいています-
Instance class −価格は、消費されたDBインスタンスのクラスに基づいています。
Running time −価格はインスタンス時間で計算されます。これは、1時間に実行される単一のインスタンスに相当します。
Storage −請求額は、GBごとに選択されたストレージ容量プランに従って計算されます。
I/O requests per month −請求構造には、請求サイクルで行われたストレージI / O要求の総数も含まれます。
Backup storage−データベースの100%までのバックアップストレージに追加料金はかかりません。このサービスは、アクティブなDBインスタンスに対してのみ無料です。
最新の更新された価格構造およびその他の詳細については、次のリンクにアクセスしてください- https://aws.amazon.com/rds/pricing/
Amazon DynamoDBはフルマネージドのNoSQLデータベースサービスであり、任意の量のデータを格納および取得できるデータベーステーブルを作成できます。複数のサーバー上のテーブルのデータトラフィックを自動的に管理し、パフォーマンスを維持します。また、分散データベースの運用とスケーリングの負担から顧客を解放します。したがって、ハードウェアのプロビジョニング、セットアップ、構成、レプリケーション、ソフトウェアのパッチ適用、クラスターのスケーリングなどは、Amazonによって管理されます。
コンピューターでDynamoDBを実行する方法は?
DynamoDBをセットアップする手順は次のとおりです。
Step 1 −DynamoDBをセットアップする手順は次のとおりです。
次のリンクを使用して、DynamoDB(.jarファイル)をダウンロードします。Windows、Linux、Macなどの複数のオペレーティングシステムをサポートします。
.tar.gz format − http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
.zip format −http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip。
ダウンロードが完了したら、コンテンツを抽出し、抽出したディレクトリを任意の場所にコピーします。
コマンドプロンプトを開き、DynamoDBLocal.jarを抽出したディレクトリに移動して、次のコマンドを実行します-
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDbこれで、組み込みのjavaScriptシェルにアクセスできるようになりました。
Step 2 −次の手順を使用してテーブルを作成します。
AWS管理コンソールを開き、DynamoDBを選択します。
テーブルを作成するリージョンを選択し、[テーブルの作成]ボタンをクリックします。

[テーブルの作成]ウィンドウが開きます。それぞれのフィールドに詳細を入力し、[続行]ボタンをクリックします。
最後に、詳細を表示できるレビューページが開きます。[作成]ボタンをクリックします。

これで、テーブル名がリストに表示され、Dynamoテーブルを使用できるようになります。

AmazonDynamoDBのメリット
管理 service− AmazonDynamoDBはマネージドサービスです。NoSQLのインストールを管理するために専門家を雇う必要はありません。開発者は、分散データベースクラスターのセットアップ、構成、進行中のクラスター操作の管理などについて心配する必要はありません。I/ Oパフォーマンス要件を満たすために、より多くのマシンリソースでデータのスケーリング、パーティション分割、および再パーティション化のすべての複雑さを処理します。
スケーラブル-AmazonDynamoDBは拡張できるように設計されています。各テーブルに保存できるデータ量の事前定義された制限について心配する必要はありません。任意の量のデータを保存および取得できます。DynamoDBは、テーブルが大きくなるにつれて保存されるデータの量に応じて自動的に拡散します。
高速-AmazonDynamoDBは、非常に低いレイテンシーで高スループットを提供します。DynamoDBのデータ配置とリクエストルーティングアルゴリズムの分散性により、データセットが大きくなるにつれて、レイテンシーは安定したままになります。
耐久性と hひどく available-Amazon DynamoDBは、少なくとも3つの異なるデータセンターの結果にデータを複製します。システムは、さまざまな障害状態でも動作し、データを提供します。
柔軟性:Amazon DynamoDBを使用すると、動的テーブルを作成できます。つまり、テーブルには、複数値の属性を含む任意の数の属性を含めることができます。
費用対効果:支払いは、最低料金なしで使用したものに対して行われます。その価格体系はシンプルで計算が簡単です。
Amazon Redshiftは、クラウド内のフルマネージドデータウェアハウスサービスです。そのデータセットは、数百ギガバイトからペタバイトの範囲です。データウェアハウスを作成する最初のプロセスは、と呼ばれる一連のコンピューティングリソースを起動することです。nodes、と呼ばれるグループに編成されています cluster。その後、クエリを処理できます。
Amazon Redshiftを設定する方法は?
以下は、AmazonRedshiftをセットアップする手順です。
Step 1 −次の手順を使用して、サインインしてRedshiftクラスターを起動します。
AWS管理コンソールにサインインし、次のリンクを使用してAmazonRedshiftコンソールを開きます- https://console.aws.amazon.com/redshift/
画面の右上隅にある[リージョン]メニューを使用して、クラスターを作成するリージョンを選択します。
[クラスターの起動]ボタンをクリックします。

「クラスターの詳細」ページが開きます。必要な詳細を入力し、レビューページまで[続行]ボタンをクリックします。

確認ページが開きます。[閉じる]ボタンをクリックして終了し、クラスターが[クラスター]リストに表示されるようにします。

リストからクラスターを選択し、クラスターステータス情報を確認します。このページには、クラスターのステータスが表示されます。

Step 2−クラスターへのクライアント接続を許可するようにセキュリティグループを構成します。Redshiftへのアクセスの承認は、クライアントがEC2インスタンスを承認するかどうかによって異なります。
EC2-VPCプラットフォームのセキュリティグループに対して、次の手順に従います。
Amazon Redshiftコンソールを開き、ナビゲーションペインで[クラスター]をクリックします。
目的のクラスターを選択します。その構成タブが開きます。

[セキュリティ]グループをクリックします。
[セキュリティグループ]ページが開いたら、[受信]タブをクリックします。
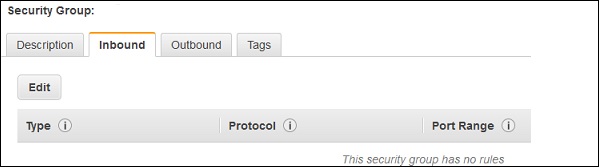
[編集]ボタンをクリックします。以下のようにフィールドを設定し、[保存]ボタンをクリックします。
Type −カスタムTCPルール。
Protocol −TCP。
Port Range−クラスターの起動時に使用したものと同じポート番号を入力します。デフォルトでは、AmazonRedshiftのポートは5439です。
Source − [カスタムIP]を選択し、0.0.0.0 / 0と入力します。

Step 3 − RedshiftClusterに接続します。
Redshift Clusterに接続するには、直接またはSSL経由の2つの方法があります。
直接接続する手順は次のとおりです。
SQLクライアントツールを使用してクラスターを接続します。PostgreSQLJDBCまたはODBCドライバーと互換性のあるSQLクライアントツールをサポートします。
以下のリンクを使用してダウンロードしてください- JDBC https://jdbc.postgresql.org/download/postgresql-8.4-703.jdbc4.jar
ODBC https://ftp.postgresql.org/pub/odbc/versions/msi/psqlodbc_08_04_0200.zip または64ビットマシンの場合はhttp://ftp.postgresql.org/pub/odbc/versions/msi/psqlodbc_09_00_0101x64.zip
次の手順を使用して、接続文字列を取得します。
Amazon Redshiftコンソールを開き、ナビゲーションペインで[クラスター]を選択します。
選択したクラスターを選択し、[構成]タブをクリックします。
次のスクリーンショットに示すように、クラスターデータベースのプロパティの下にJDBCURLが表示されたページが開きます。URLをコピーします。

次の手順を使用して、クラスターをSQL Workbench / Jに接続します。
SQL Workbench / Jを開きます。
[ファイル]を選択し、[接続]ウィンドウをクリックします。
[新しい接続プロファイルの作成]を選択し、名前などの必要な詳細を入力します。
[ドライバーの管理]をクリックし、[ドライバーの管理]ダイアログボックスが開きます。
[新しいエントリを作成]ボタンをクリックして、必要な詳細を入力します。

フォルダアイコンをクリックして、ドライバの場所に移動します。最後に、[開く]ボタンをクリックします。

[クラス名]ボックスと[サンプルURL]ボックスは空白のままにします。[OK]をクリックします。
リストからドライバーを選択します。
[URL]フィールドに、コピーしたJDBCURLを貼り付けます。
それぞれのフィールドにユーザー名とパスワードを入力します。
[自動コミット]ボックスを選択し、[プロファイルリストの保存]をクリックします。

AmazonRedshiftの機能
以下はAmazonRedshiftの機能です-
Supports VPC −ユーザーはVPC内でRedshiftを起動し、仮想ネットワーク環境を介してクラスターへのアクセスを制御できます。
Encryption − Redshiftに保存されているデータは、Redshiftでテーブルを作成するときに暗号化および構成できます。
SSL − SSL暗号化は、クライアントとRedshift間の接続を暗号化するために使用されます。
Scalable−数回クリックするだけで、Redshiftデータウェアハウス内のノード数を要件に応じて簡単にスケーリングできます。また、パフォーマンスを低下させることなく、ストレージ容量を拡張できます。
Cost-effective− Amazon Redshiftは、従来のデータウェアハウジング手法に代わる費用効果の高い方法です。先行投資、長期契約、オンデマンドの価格体系はありません。
Amazon Kinesisは、管理されたスケーラブルなクラウドベースのサービスであり、1秒あたりの大量のデータのストリーミングをリアルタイムで処理できます。リアルタイムアプリケーション向けに設計されており、開発者は複数のソースから任意の量のデータを取り込んで、EC2インスタンスで実行できるスケールアップとスケールダウンを行うことができます。
これは、イベントログやソーシャルメディアフィードなどの大規模な分散ストリームからデータをキャプチャ、保存、および処理するために使用されます。データを処理した後、Kinesisはそれを複数の消費者に同時に配布します。
Amazon KCLの使い方は?
これは、高速で移動するデータとその継続的な処理が必要な状況で使用されます。Amazon Kinesisは、次の状況で使用できます-
Data log and data feed intake−データをバッチ処理するのを待つ必要はありません。データが生成されるとすぐにAmazonKinesisストリームにデータをプッシュできます。また、データプロデューサーに障害が発生した場合のデータ損失を保護します。例:システムログとアプリケーションログはストリームに継続的に追加でき、必要に応じて数秒で利用できます。
Real-time graphs− Amazon Kinesisストリームを使用してグラフ/メトリックを抽出し、レポート結果を作成できます。データバッチを待つ必要はありません。
Real-time data analytics − Amazon Kinesisを使用して、リアルタイムのストリーミングデータ分析を実行できます。
Amazon Kinesisの制限は?
以下は、Amazon KinesisStreamsを使用する際に留意する必要がある特定の制限です-
ストリームのレコードには、デフォルトで最大24時間アクセスでき、拡張データ保持を有効にすることで最大7日間延長できます。
1つのレコード内のデータblob(Base64エンコード前のデータペイロード)の最大サイズは1メガバイト(MB)です。
1つのシャードは、1秒あたり最大1000のPUTレコードをサポートします。
制限に関する詳細については、次のリンクにアクセスしてください- https://docs.aws.amazon.com/kinesis/latest/dev/service-sizes-and-limits.html
Amazon Kinesisの使い方は?
AmazonKinesisを使用する手順は次のとおりです-
Step 1 −次の手順を使用してKinesis Streamをセットアップします−
AWSアカウントにサインインします。Amazon管理コンソールからAmazonKinesisを選択します。
[ストリームの作成]をクリックして、ストリーム名やシャードの数などの必須フィールドに入力します。[作成]ボタンをクリックします。

ストリームがストリームリストに表示されます。
Step 2−Kinesisストリームでユーザーを設定します。新しいユーザーを作成し、各ユーザーにポリシーを割り当てます(ユーザーを作成してユーザーにポリシーを割り当てるための上記の手順について説明しました)
Step 3−アプリケーションをAmazonKinesisに接続します。ここでは、ZoomdataをAmazonKinesisに接続しています。接続する手順は次のとおりです。
管理者としてZoomdataにログインし、メニューの[ソース]をクリックします。

キネシスアイコンを選択し、必要な詳細を入力します。[次へ]ボタンをクリックします。

[ストリーム]タブで目的のストリームを選択します。
[フィールド]タブで、必要に応じて一意のラベル名を作成し、[次へ]ボタンをクリックします。
[グラフ]タブで、データのグラフを有効にします。必要に応じて設定をカスタマイズし、[完了]ボタンをクリックして設定を保存します。
AmazonKinesisの機能
Real-time processing −株式取引価格のようにリアルタイムで情報を収集および分析することができます。そうでない場合は、データ出力レポートを待つ必要があります。
Easy to use − Amazon Kinesisを使用すると、新しいストリームを作成し、その要件を設定して、データのストリーミングをすばやく開始できます。
High throughput, elastic −株式取引価格のようにリアルタイムで情報を収集および分析することができます。そうでない場合は、データ出力レポートを待つ必要があります。
Integrate with other Amazon services − Amazon Redshift、Amazon S3、AmazonDynamoDBと統合できます。
Build kinesis applications− Amazon Kinesisは、リアルタイムデータ処理アプリケーションの設計と操作を可能にするクライアントライブラリを開発者に提供します。Amazon KinesisクライアントライブラリをJavaアプリケーションに追加すると、新しいデータが処理可能になったときに通知されます。
Cost-efficient− Amazon Kinesisは、あらゆる規模のワークロードに対してコスト効率が高いです。使用したリソースに対して支払いを行い、必要なスループットに対して1時間ごとに支払います。
Amazon Elastic MapReduce (EMR) は、Apache Hadoop、Apache Spark、Prestoなどのデータ処理フレームワークを簡単で費用効果の高い安全な方法で実行するためのマネージドフレームワークを提供するWebサービスです。
これは、データ分析、Webインデックス作成、データウェアハウジング、財務分析、科学シミュレーションなどに使用されます。
Amazon EMRを設定する方法は?
次の手順に従って、AmazonEMRを設定します-
Step 1 − AWSアカウントにサインインし、管理コンソールでAmazonEMRを選択します。
Step 2−クラスターログと出力データ用のAmazonS3バケットを作成します。(手順はAmazon S3セクションで詳細に説明されています)
Step 3 − AmazonEMRクラスターを起動します。
以下は、クラスターを作成してEMRで起動する手順です。
このリンクを使用して、AmazonEMRコンソールを開きます- https://console.aws.amazon.com/elasticmapreduce/home
[クラスターの作成]を選択し、[クラスター構成]ページで必要な詳細を入力します。
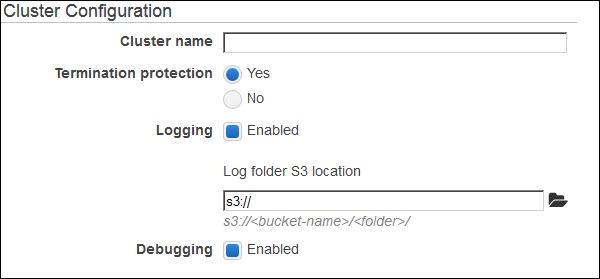
タグセクションオプションをデフォルトのままにして、続行します。
[ソフトウェア構成]セクションで、オプションをデフォルトとして平準化します。

[ファイルシステムの構成]セクションで、EMRFSのオプションをデフォルトで設定したままにします。EMRFSはHDFSの実装であり、AmazonEMRクラスターがAmazonS3にデータを保存できるようにします。

[Hardware Configuration]セクションで、[EC2インスタンスタイプ]フィールドで[m3.xlarge]を選択し、他の設定をデフォルトのままにします。[次へ]ボタンをクリックします。

[Security and Access]セクションの[EC2キーペア]で、[EC2キーペア]フィールドのリストからペアを選択し、他の設定はデフォルトのままにします。
[ブートストラップアクション]セクションで、フィールドをデフォルトで設定したままにして、[追加]ボタンをクリックします。ブートストラップアクションは、Hadoopがすべてのクラスターノードで開始される前にセットアップ中に実行されるスクリプトです。
[手順]セクションで、設定をデフォルトのままにして続行します。
[クラスターの作成]ボタンをクリックすると、[クラスターの詳細]ページが開きます。ここで、Hiveスクリプトをクラスターステップとして実行し、HueWebインターフェイスを使用してデータをクエリする必要があります。
Step 4 −次の手順を使用してHiveスクリプトを実行します。
Amazon EMRコンソールを開き、目的のクラスターを選択します。
[ステップ]セクションに移動して展開します。次に、[ステップの追加]ボタンをクリックします。
[ステップの追加]ダイアログボックスが開きます。必須フィールドに入力し、[追加]ボタンをクリックします。
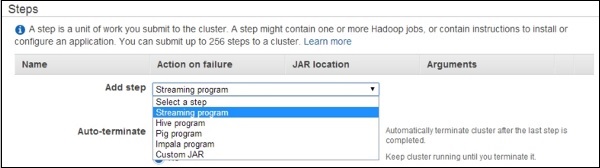
Hiveスクリプトの出力を表示するには、次の手順を使用します-
Amazon S3コンソールを開き、出力データに使用するS3バケットを選択します。
出力フォルダを選択します。
クエリは結果を別のフォルダに書き込みます。選択するos_requests。
出力はテキストファイルに保存されます。このファイルはダウンロードできます。
AmazonEMRのメリット
AmazonEMRのメリットは次のとおりです-
Easy to use − Amazon EMRは使いやすく、つまり、クラスター、Hadoop構成、ノードプロビジョニングなどのセットアップが簡単です。
Reliable −失敗したタスクを再試行し、パフォーマンスの低いインスタンスを自動的に置き換えるという意味で信頼性があります。
Elastic− Amazon EMRを使用すると、大量のインスタンスを計算して、任意の規模でデータを処理できます。インスタンスの数を簡単に増減できます。
Secure − Amazon EC2ファイアウォール設定を自動的に構成し、インスタンスへのネットワークアクセスを制御し、AmazonVPCでクラスターを起動します。
Flexible−クラスターの完全な制御とすべてのインスタンスへのルートアクセスを可能にします。また、追加のアプリケーションをインストールしたり、要件に応じてクラスターをカスタマイズしたりすることもできます。
Cost-efficient−価格は簡単に見積もることができます。使用されるインスタンスごとに1時間ごとに課金されます。
AWS Data Pipeline は、ユーザーが複数のAWSサービスに分散しているデータを統合し、単一の場所から分析できるように設計されたWebサービスです。
AWS Data Pipelineを使用すると、ソースからデータにアクセスして処理し、結果をそれぞれのAWSサービスに効率的に転送できます。
データパイプラインを設定する方法は?
データパイプラインを設定する手順は次のとおりです-
Step 1 −次の手順を使用してパイプラインを作成します。
AWSアカウントにサインインします。
このリンクを使用して、AWS DataPipelineコンソールを開きます- https://console.aws.amazon.com/datapipeline/
ナビゲーションバーで地域を選択します。
[新しいパイプラインの作成]ボタンをクリックします。
それぞれのフィールドに必要な詳細を入力します。
[ソース]フィールドで、[テンプレートを使用してビルド]を選択し、このテンプレートを選択します-ShellCommandActivityの使用を開始します。

[パラメータ]セクションは、テンプレートが選択されている場合にのみ開きます。S3入力フォルダーとShellコマンドをそのままにして、デフォルト値で実行します。S3出力フォルダーの横にあるフォルダーアイコンをクリックして、バケットを選択します。
[スケジュール]で、値をデフォルトのままにします。
パイプライン構成で、ログを有効のままにします。ログのS3の場所の下にあるフォルダーアイコンをクリックして、バケットを選択します。
[セキュリティ/アクセス]で、IAMロールの値をデフォルトのままにします。
[アクティブ化]ボタンをクリックします。
パイプラインを削除する方法は?
パイプラインを削除すると、関連するすべてのオブジェクトも削除されます。
Step 1 −パイプラインリストからパイプラインを選択します。
Step 2 − [アクション]ボタンをクリックして、[削除]を選択します。

Step 3−確認プロンプトウィンドウが開きます。[削除]をクリックします。
AWSデータパイプラインの機能
Simple and cost-efficient−ドラッグアンドドロップ機能により、コンソールでパイプラインを簡単に作成できます。そのビジュアルパイプラインクリエーターは、パイプラインテンプレートのライブラリを提供します。これらのテンプレートを使用すると、ログファイルの処理、AmazonS3へのデータのアーカイブなどのタスクのパイプラインを簡単に作成できます。
Reliable−そのインフラストラクチャは、フォールトトレラントな実行アクティビティ用に設計されています。アクティビティロジックまたはデータソースで障害が発生した場合、AWS DataPipelineは自動的にアクティビティを再試行します。障害が続く場合は、障害通知を送信します。実行の成功、失敗、アクティビティの遅延などの状況に対して、これらの通知アラートを構成することもできます。
Flexible − AWS Data Pipelineは、スケジューリング、トラッキング、エラー処理などのさまざまな機能を提供します。AmazonEMRジョブの実行、データベースに対して直接SQLクエリを実行する、AmazonEC2で実行されるカスタムアプリケーションを実行するなどのアクションを実行するように設定できます。
Amazon Machine Learning は、ユーザーのデータに基づくアルゴリズム、数学モデルを使用して予測アプリケーションを開発できるようにするサービスです。
Amazon Machine Learningは、Amazon S3、Redshift、RDSを介してデータを読み取り、AWS ManagementConsoleとAmazonMachine LearningAPIを介してデータを視覚化します。このデータは、S3バケットを介して他のAWSサービスにインポートまたはエクスポートできます。
「業界標準のロジスティック回帰」アルゴリズムを使用してモデルを生成します。
Amazon MachineLearningによって実行されるタスクの種類
Amazon Machine LearningServiceでは3種類のタスクを実行できます-
二項分類モデルは、2つの可能な結果のいずれか、つまり「はい」または「いいえ」を予測できます。
マルチクラス分類モデルは、複数の条件を予測できます。たとえば、顧客のオンライン注文を追跡できます。
回帰モデルは正確な値になります。回帰モデルは、製品のベストセラー価格または販売するユニット数を予測できます。
Amazon Machine Learningの使用方法は?
Step 1− AWSアカウントにサインインし、機械学習を選択します。[開始]ボタンをクリックします。

Step 2 − [標準設定]を選択し、[起動]をクリックします。

Step 3− [入力データ]セクションで、必要な詳細を入力し、S3またはRedshiftのいずれかのデータストレージの選択肢を選択します。[確認]ボタンをクリックします。
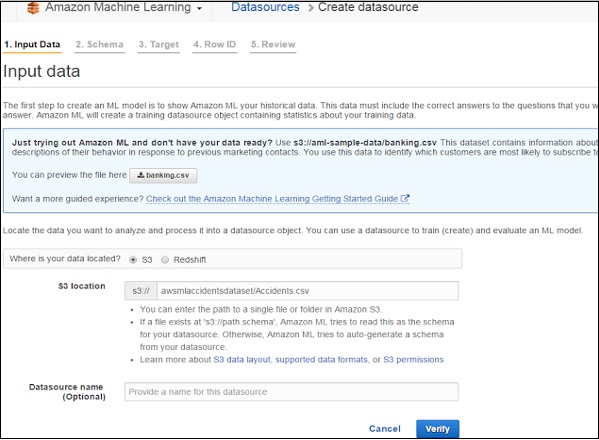
Step 4− S3ロケーション検証が完了すると、スキーマセクションが開きます。要件に従ってフィールドに入力し、次のステップに進みます。

Step 5 − [ターゲット]セクションで、[スキーマ]セクションで選択した変数を再度選択し、次の手順に進みます。

Step 6− [行ID]セクションの値をデフォルトのままにして、[レビュー]セクションに進みます。詳細を確認し、[続行]ボタンをクリックします。
以下は、機械学習サービスのスクリーンショットです。
Data Set Created by Machine Learning

Summary Made by Machine Learning

Exploring Performance Using Machine Learning

Amazon機械学習の機能
Easy to create machine learning models − Amazon S3、Amazon Redshift、Amazon RDSに保存されているデータからMLモデルを作成し、Amazon ML APIとウィザードを使用して、これらのモデルに予測を照会するのは簡単です。
High performance− Amazon ML予測APIをさらに使用して、アプリケーションの数十億の予測を生成できます。インタラクティブなWeb、モバイル、またはデスクトップアプリケーション内でそれらを使用できます。
Cost-efficient −セットアップ料金や事前の約束なしに、使用した分だけ支払います。
以下のサービスは、アプリケーションサービスセクションに分類されます-
- Amazon CloudSearch
- Amazon Simple Queue Services(SQS)
- Amazon Simple Notification Services(SNS)
- Amazon Simple Email Services(SES)
- アマゾンSWF
この章では、AmazonSWFについて説明します。
Amazon Simple Workflow Service (SWF)はタスクベースのAPIであり、分散アプリケーションコンポーネント間での作業の調整を容易にします。分散コンポーネントを調整し、信頼できる方法でそれらの実行状態を維持するためのプログラミングモデルとインフラストラクチャを提供します。Amazon SWFを使用すると、アプリケーションを差別化する側面の構築に集中できます。
A workflow は、目的を実行する一連のアクティビティです。これには、目的の出力を達成するためにアクティビティを調整するロジックが含まれます。
Workflow historyワークフローの実行開始以降に発生した各イベントの完全で一貫性のあるレコードで構成されます。それはSWFによって維持されます。
SWFの使い方は?
Step 1 − AWSアカウントにサインインし、サービスダッシュボードでSWFを選択します。
Step 2 − [サンプルウォークスルーの起動]ボタンをクリックします。

Step 3− [サンプルワークフローの実行]ウィンドウが開きます。[開始]ボタンをクリックします。

Step 4 − [ドメインの作成]セクションで、[新しいドメインの作成]ラジオボタンをクリックしてから、[続行]ボタンをクリックします。
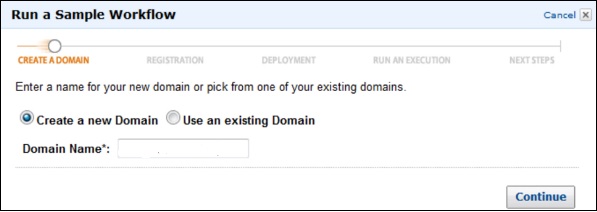
Step 5 − [登録]セクションで、指示を読み、[続行]ボタンをクリックします。

Step 6 − [展開]セクションで、目的のオプションを選択し、[続行]ボタンをクリックします。

Step 7 − [実行の実行]セクションで、目的のオプションを選択し、[この実行の実行]ボタンをクリックします。

最後に、SWFが作成され、リストで使用できるようになります。

AmazonSWFのメリット
ワークフローの実行に関するすべての情報がワークフロー履歴に保存されるため、アプリケーションをステートレスにすることができます。
ワークフローの実行ごとに、履歴は、スケジュールされたアクティビティ、それらの現在のステータス、および結果の記録を提供します。ワークフローの実行では、この情報を使用して次のステップを決定します。
履歴には、実行中のワークフローの実行を監視し、完了したワークフローの実行を確認するために使用できる詳細な手順が記載されています。
Amazon WorkMail以前はZocaloとして知られていました。これは、クラウドで実行されるマネージドメールおよびカレンダーサービスです。セキュリティ制御を提供し、事前にパッケージ化されたClick-to-Runバージョンを含む既存のPCおよびMacベースのOutlookクライアントで動作するように設計されています。また、ExchangeActiveSyncプロトコルを話すモバイルクライアントでも機能します。
その移行ツールを使用すると、メールボックスをオンプレミスの電子メールサーバーからサービスに移動でき、AppleのiPadとiPhone、Google Android、WindowsPhoneなどのMicrosoftExchangeActiveSyncプロトコルをサポートするすべてのデバイスで動作します。
Amazon WorkMailの使い方は?
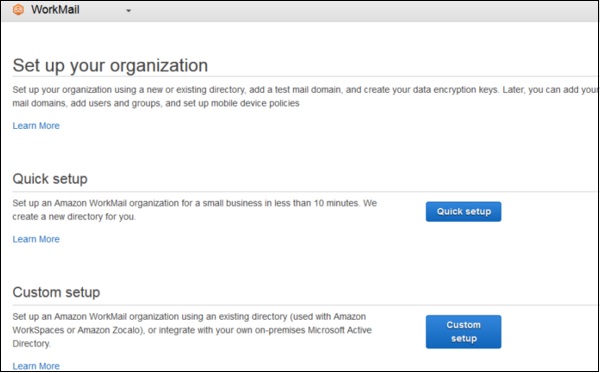
Step 1 − AWSアカウントにサインインし、次のリンクを使用してAmazon WorkMailコンソールを開きます− https://console.aws.amazon.com/workmail/
Step 2 − [開始]ボタンをクリックします。

Step 3 −目的のオプションを選択し、ナビゲーションバーの右上から地域を選択します。
Step 4−必要な詳細を入力し、次の手順に進んでアカウントを構成します。指示に従ってください。最後に、メールボックスは次のスクリーンショットに示すようになります。

AmazonWorkMailの機能
Secure − Amazon WorkMailは、AWS Key Management Serviceを使用して、暗号化キーでデータ全体を自動的に暗号化します。
Managed− Amazon WorkMailは、Eメールを完全に制御できるため、ソフトウェアのインストール、ハードウェアの保守と管理について心配する必要はありません。Amazon WorkMailは、これらすべてのニーズを自動的に処理します。
Accessibility − Amazon WorkMailは、WindowsとMac OSXの両方でMicrosoftOutlookをサポートします。したがって、ユーザーは追加の要件なしで既存の電子メールクライアントを使用できます。
Availability −ユーザーは、Microsoft Exchange ActiveSyncプロトコルを使用して、電子メール、連絡先、およびカレンダーをiOS、Android、WindowsPhoneなどとどこでも同期できます。
Cost-efficient − Amazon WorkMailは、最大50GBのストレージをユーザーあたり月額4ドルで請求します。