ApachePresto-クイックガイド
データ分析は、生データを分析して関連情報を収集し、より良い意思決定を行うプロセスです。これは主に、ビジネス上の意思決定を行うために多くの組織で使用されます。ビッグデータ分析には大量のデータが含まれ、このプロセスは非常に複雑であるため、企業はさまざまな戦略を使用します。
たとえば、Facebookは、データ駆動型で世界最大のデータウェアハウス企業の1つです。Facebookのウェアハウスデータは、大規模な計算のためにHadoopに保存されます。その後、ウェアハウスデータがペタバイトに増加したとき、彼らは低遅延の新しいシステムを開発することを決定しました。2012年、Facebookチームのメンバーは“Presto” ペタバイトのデータでも迅速に動作するインタラクティブなクエリ分析用。
Apache Prestoとは何ですか?
Apache Prestoは、分散並列クエリ実行エンジンであり、低レイテンシとインタラクティブなクエリ分析用に最適化されています。Prestoはクエリを簡単に実行し、ギガバイトからペタバイトまでダウンタイムなしで拡張できます。
1つのPrestoクエリで、HDFS、MySQL、Cassandra、Hiveなどの複数のデータソースからのデータを処理できます。PrestoはJavaに組み込まれており、他のデータインフラストラクチャコンポーネントと簡単に統合できます。Prestoは強力であり、Airbnb、DropBox、Groupon、Netflixなどの大手企業が採用しています。
Presto-機能
Prestoには次の機能が含まれています-
- シンプルで拡張可能なアーキテクチャ。
- プラグ可能なコネクタ-Prestoは、クエリのメタデータとデータを提供するプラグ可能なコネクタをサポートしています。
- パイプライン化された実行-不要なI / Oレイテンシのオーバーヘッドを回避します。
- ユーザー定義関数-アナリストは、カスタムユーザー定義関数を作成して簡単に移行できます。
- ベクトル化された柱状処理。
Presto-メリット
ApachePrestoが提供するメリットのリストは次のとおりです-
- 特殊なSQL操作
- インストールとデバッグが簡単
- シンプルなストレージの抽象化
- ペタバイトのデータを低レイテンシで迅速にスケーリング
Presto-アプリケーション
Prestoは、今日の最高の産業用アプリケーションのほとんどをサポートしています。注目すべきアプリケーションのいくつかを見てみましょう。
Facebook− Facebookは、データ分析のニーズに対応するためにPrestoを構築しました。Prestoは、高速のデータを簡単にスケーリングします。
Teradata− Teradataは、ビッグデータ分析とデータウェアハウジングのエンドツーエンドソリューションを提供します。PrestoへのTeradataの貢献により、より多くの企業がすべての分析ニーズを簡単に実現できるようになります。
Airbnb− Prestoは、Airbnbデータインフラストラクチャの不可欠な部分です。ええと、何百人もの従業員がこのテクノロジーを使って毎日クエリを実行しています。
なぜプレスト?
Prestoは標準のANSISQLをサポートしているため、データアナリストや開発者にとって非常に簡単です。Javaで構築されていますが、メモリ割り当てとガベージコレクションに関連するJavaコードの一般的な問題を回避します。Prestoには、Hadoopに適したコネクタアーキテクチャがあります。ファイルシステムを簡単に接続できます。
Prestoは複数のHadoopディストリビューションで実行されます。さらに、PrestoはHadoopプラットフォームから連絡を取り、Cassandra、リレーショナルデータベース、またはその他のデータストアにクエリを実行できます。このクロスプラットフォームの分析機能により、Prestoユーザーはギガバイトからペタバイトのデータから最大のビジネス価値を引き出すことができます。
Prestoのアーキテクチャは、従来のMPP(超並列処理)DBMSアーキテクチャとほぼ同じです。次の図は、Prestoのアーキテクチャを示しています。

上の図は、さまざまなコンポーネントで構成されています。次の表で、各コンポーネントについて詳しく説明します。
| S.No | コンポーネントと説明 |
|---|---|
| 1.1。 | Client クライアント(Presto CLI)は、SQLステートメントをコーディネーターに送信して結果を取得します。 |
| 2.2。 | Coordinator コーディネーターはマスターデーモンです。コーディネーターは最初にSQLクエリを解析し、次にクエリの実行を分析して計画します。スケジューラーはパイプラインの実行を実行し、最も近いノードに作業を割り当て、進行状況を監視します。 |
| 3.3。 | Connector ストレージプラグインはコネクタと呼ばれます。Hive、HBase、MySQL、Cassandraなどがコネクタとして機能します。それ以外の場合は、カスタムを実装することもできます。コネクタは、クエリのメタデータとデータを提供します。コーディネーターはコネクターを使用して、クエリプランを構築するためのメタデータを取得します。 |
| 4.4。 | Worker コーディネーターはタスクをワーカーノードに割り当てます。ワーカーはコネクタから実際のデータを取得します。最後に、ワーカーノードは結果をクライアントに配信します。 |
Presto-ワークフロー
Prestoは、ノードのクラスター上で実行される分散システムです。Prestoの分散クエリエンジンは、インタラクティブな分析用に最適化されており、複雑なクエリ、集計、結合、ウィンドウ関数など、標準のANSISQLをサポートしています。Prestoアーキテクチャはシンプルで拡張可能です。Prestoクライアント(CLI)は、SQLステートメントをマスターデーモンコーディネーターに送信します。
スケジューラーは実行パイプラインを介して接続します。スケジューラーは、データに最も近いノードに作業を割り当て、進行状況を監視します。コーディネーターはタスクを複数のワーカーノードに割り当て、最後にワーカーノードが結果をクライアントに返します。クライアントは、出力プロセスからデータをプルします。拡張性が重要な設計です。Hive、HBase、MySQLなどのプラグ可能なコネクタは、クエリのメタデータとデータを提供します。Prestoは、これらのさまざまな種類のデータソースに対してSQLクエリ機能を簡単に提供できる「シンプルなストレージ抽象化」を使用して設計されました。
実行モデル
Prestoは、SQLセマンティクスをサポートするように設計された演算子を使用して、カスタムクエリおよび実行エンジンをサポートします。スケジューリングの改善に加えて、すべての処理はメモリ内にあり、異なるステージ間でネットワーク全体にパイプライン処理されます。これにより、不要なI / Oレイテンシのオーバーヘッドが回避されます。
この章では、Prestoをマシンにインストールする方法について説明します。Prestoの基本的な要件を見てみましょう。
- LinuxまたはMacOS
- Javaバージョン8
それでは、次の手順を続けてPrestoをマシンにインストールしましょう。
Javaインストールの確認
うまくいけば、あなたはすでにあなたのマシンにJavaバージョン8をインストールしているので、次のコマンドを使ってそれを確認するだけです。
$ java -versionJavaがマシンに正常にインストールされている場合は、インストールされているJavaのバージョンを確認できます。Javaがインストールされていない場合は、次の手順に従ってJava8をマシンにインストールします。
JDKをダウンロードします。次のリンクにアクセスして、JDKの最新バージョンをダウンロードします。
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
最新バージョンはJDK8u 92で、ファイルは「jdk-8u92-linux-x64.tar.gz」です。お使いのマシンにファイルをダウンロードしてください。
その後、ファイルを抽出し、特定のディレクトリに移動します。
次に、Javaの代替を設定します。最後に、Javaがマシンにインストールされます。
ApachePrestoのインストール
次のリンクにアクセスして、Prestoの最新バージョンをダウンロードします。
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.149/
これで、最新バージョンの「presto-server-0.149.tar.gz」がマシンにダウンロードされます。
tarファイルを抽出する
を抽出します tar 次のコマンドを使用してファイル-
$ tar -zxf presto-server-0.149.tar.gz
$ cd presto-server-0.149構成設定
「データ」ディレクトリを作成します
Prestoのアップグレード時に簡単に保存できるように、ログやメタデータなどを保存するために使用するデータディレクトリをインストールディレクトリの外に作成します。次のコードを使用して定義されます-
$ cd
$ mkdir dataパスが配置されているパスを表示するには、コマンド「pwd」を使用します。この場所は、次のnode.propertiesファイルで割り当てられます。
「etc」ディレクトリを作成します
次のコードを使用して、Prestoインストールディレクトリ内にetcディレクトリを作成します-
$ cd presto-server-0.149
$ mkdir etcこのディレクトリには、構成ファイルが保持されます。各ファイルを1つずつ作成していきましょう。
ノードのプロパティ
Prestoノードプロパティファイルには、各ノードに固有の環境構成が含まれています。次のコードを使用して、etcディレクトリ(etc / node.properties)内に作成されます-
$ cd etc
$ vi node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/../workspace/Prestoすべての変更を行った後、ファイルを保存し、ターミナルを終了します。ここにnode.data 上記で作成したデータディレクトリのロケーションパスです。 node.id 各ノードの一意の識別子を表します。
JVM構成
etcディレクトリ(etc / jvm.config)内にファイル「jvm.config」を作成します。このファイルには、Java仮想マシンの起動に使用されるコマンドラインオプションのリストが含まれています。
$ cd etc
$ vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize = 32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError = kill -9 %pすべての変更を行った後、ファイルを保存し、ターミナルを終了します。
構成プロパティ
etcディレクトリ(etc / config.properties)内にファイル「config.properties」を作成します。このファイルには、Prestoサーバーの構成が含まれています。テスト用に単一のマシンをセットアップする場合、Prestoサーバーは、次のコードを使用して定義された調整プロセスとしてのみ機能できます。
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080ここに、
coordinator −マスターノード。
node-scheduler.include-coordinator −コーディネーターでの作業のスケジューリングを許可します。
http-server.http.port −HTTPサーバーのポートを指定します。
query.max-memory=5GB −分散メモリの最大量。
query.max-memory-per-node=1GB −ノードあたりのメモリの最大量。
discovery-server.enabled − Prestoは、Discoveryサービスを使用して、クラスター内のすべてのノードを検索します。
discovery.uri −ディスカバリーサーバーへのURI。
複数のマシンのPrestoサーバーをセットアップする場合、Prestoは調整プロセスとワーカープロセスの両方として機能します。この構成設定を使用して、複数のマシンでPrestoサーバーをテストします。
コーディネーターの構成
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080ワーカーの構成
$ cd etc
$ vi config.properties
coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery.uri = http://localhost:8080ログのプロパティ
etcディレクトリ(etc / log.properties)内にファイル「log.properties」を作成します。このファイルには、名前付きロガー階層の最小ログレベルが含まれています。次のコードを使用して定義されます-
$ cd etc
$ vi log.properties
com.facebook.presto = INFOファイルを保存して、ターミナルを終了します。ここでは、DEBUG、INFO、WARN、ERRORなどの4つのログレベルが使用されます。デフォルトのログレベルはINFOです。
カタログのプロパティ
etcディレクトリ(etc / catalog)内にディレクトリ「catalog」を作成します。これは、データのマウントに使用されます。たとえば、作成しますetc/catalog/jmx.properties 以下の内容でマウントします jmx connector jmxカタログとして-
$ cd etc
$ mkdir catalog $ cd catalog
$ vi jmx.properties
connector.name = jmxPrestoを起動します
Prestoは、次のコマンドを使用して開始できます。
$ bin/launcher start次に、これに似た応答が表示されます。
Started as 840Prestoを実行する
Prestoサーバーを起動するには、次のコマンドを使用します-
$ bin/launcher runPrestoサーバーを正常に起動すると、「var / log」ディレクトリにログファイルが表示されます。
launcher.log −このログはランチャーによって作成され、サーバーのstdoutおよびstderrストリームに接続されます。
server.log −これはPrestoが使用するメインログファイルです。
http-request.log −サーバーが受信したHTTP要求。
これで、Presto構成設定がマシンに正常にインストールされました。PrestoCLIをインストールする手順を続けましょう。
PrestoCLIをインストールします
Presto CLIは、クエリを実行するためのターミナルベースのインタラクティブシェルを提供します。
次のリンクにアクセスして、PrestoCLIをダウンロードします。
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.149/
これで、「presto-cli-0.149-executable.jar」がマシンにインストールされます。
CLIを実行する
presto-cliをダウンロードしたら、実行元の場所にコピーします。この場所は、コーディネーターにネットワークアクセスできる任意のノードです。まず、Jarファイルの名前をPrestoに変更します。次に、それを実行可能にしますchmod + x 次のコードを使用したコマンド-
$ mv presto-cli-0.149-executable.jar presto
$ chmod +x presto次のコマンドを使用してCLIを実行します。
./presto --server localhost:8080 --catalog jmx --schema default
Here jmx(Java Management Extension) refers to catalog and default referes to schema.次の応答が表示されます。
presto:default>ターミナルで「jps」コマンドを入力すると、実行中のデーモンが表示されます。
Prestoを停止します
すべての実行を実行した後、次のコマンドを使用してprestoサーバーを停止できます-
$ bin/launcher stopこの章では、Prestoの構成設定について説明します。
Presto Verifier
Presto Verifierを使用して、別のデータベース(MySQLなど)に対してPrestoをテストしたり、2つのPrestoクラスターを相互にテストしたりできます。
MySQLでデータベースを作成する
MySQLサーバーを開き、次のコマンドを使用してデータベースを作成します。
create database testこれで、サーバーに「テスト」データベースが作成されました。テーブルを作成し、次のクエリでロードします。
CREATE TABLE verifier_queries(
id INT NOT NULL AUTO_INCREMENT,
suite VARCHAR(256) NOT NULL,
name VARCHAR(256),
test_catalog VARCHAR(256) NOT NULL,
test_schema VARCHAR(256) NOT NULL,
test_prequeries TEXT,
test_query TEXT NOT NULL,
test_postqueries TEXT,
test_username VARCHAR(256) NOT NULL default 'verifier-test',
test_password VARCHAR(256),
control_catalog VARCHAR(256) NOT NULL,
control_schema VARCHAR(256) NOT NULL,
control_prequeries TEXT,
control_query TEXT NOT NULL,
control_postqueries TEXT,
control_username VARCHAR(256) NOT NULL default 'verifier-test',
control_password VARCHAR(256),
session_properties_json TEXT,
PRIMARY KEY (id)
);構成設定の追加
プロパティファイルを作成して、ベリファイアを構成します-
$ vi config.properties
suite = mysuite
query-database = jdbc:mysql://localhost:3306/tutorials?user=root&password=pwd
control.gateway = jdbc:presto://localhost:8080
test.gateway = jdbc:presto://localhost:8080
thread-count = 1ここで、 query-database フィールドに、次の詳細を入力します-mysqlデータベース名、ユーザー名、およびパスワード。
JARファイルのダウンロード
次のリンクにアクセスして、Presto-verifierjarファイルをダウンロードします。
https://repo1.maven.org/maven2/com/facebook/presto/presto-verifier/0.149/
今バージョン “presto-verifier-0.149-executable.jar” がマシンにダウンロードされます。
JARを実行する
次のコマンドを使用してJARファイルを実行します。
$ mv presto-verifier-0.149-executable.jar verifier
$ chmod+x verifierベリファイアを実行
次のコマンドを使用してベリファイアを実行します。
$ ./verifier config.propertiesテーブルを作成する
で簡単なテーブルを作成しましょう “test” 次のクエリを使用してデータベース。
create table product(id int not null, name varchar(50))テーブルを挿入
テーブルを作成した後、次のクエリを使用して2つのレコードを挿入します。
insert into product values(1,’Phone')
insert into product values(2,’Television’)ベリファイアクエリを実行する
ベリファイアターミナル(./verifier config.propeties)で次のサンプルクエリを実行して、ベリファイアの結果を確認します。
サンプルクエリ
insert into verifier_queries (suite, test_catalog, test_schema, test_query,
control_catalog, control_schema, control_query) values
('mysuite', 'mysql', 'default', 'select * from mysql.test.product',
'mysql', 'default', 'select * from mysql.test.product');ここに、 select * from mysql.test.product クエリはmysqlカタログを参照します。 test データベース名と productテーブル名です。このようにして、Prestoサーバーを使用してmysqlコネクタにアクセスできます。
ここでは、2つの同じselectクエリが相互にテストされ、パフォーマンスが確認されます。同様に、他のクエリを実行してパフォーマンス結果をテストできます。2つのPrestoクラスターを接続して、パフォーマンス結果を確認することもできます。
この章では、Prestoで使用される管理ツールについて説明します。PrestoのWebインターフェイスから始めましょう。
Webインターフェイス
Prestoは、クエリを監視および管理するためのWebインターフェイスを提供します。コーディネーターの構成プロパティで指定されたポート番号からアクセスできます。
PrestoサーバーとPrestoCLIを起動します。次に、次のURLからWebインターフェイスにアクセスできます-http://localhost:8080/
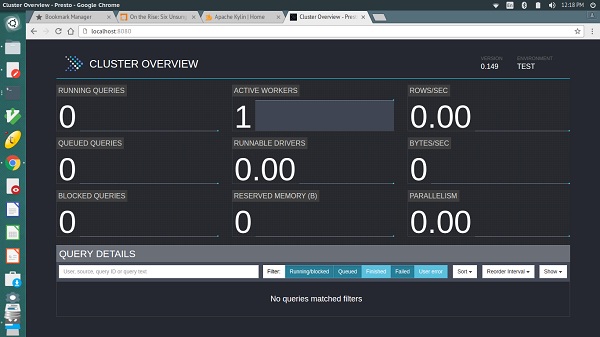
出力は上記の画面のようになります。
ここで、メインページには、一意のクエリID、クエリテキスト、クエリの状態、完了率、ユーザー名、このクエリの発信元などの情報とともに、クエリのリストがあります。最新のクエリが最初に実行され、次に完了または未完了のクエリが下部に表示されます。
Prestoでのパフォーマンスの調整
Prestoクラスターにパフォーマンス関連の問題がある場合は、デフォルトの構成設定を次の設定に変更します。
構成プロパティ
task. info -refresh-max-wait −コーディネーターの作業負荷を軽減します。
task.max-worker-threads −プロセスを分割し、各ワーカーノードに割り当てます。
distributed-joins-enabled −ハッシュベースの分散結合。
node-scheduler.network-topology −ネットワークトポロジをスケジューラに設定します。
JVM設定
デフォルトのJVM設定を次の設定に変更します。これは、ガベージコレクションの問題を診断するのに役立ちます。
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics = 2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount = 1この章では、Prestoでクエリを作成して実行する方法について説明します。Prestoでサポートされている基本的なデータ型を見てみましょう。
基本的なデータ型
次の表に、Prestoの基本的なデータ型を示します。
| S.No | データ型と説明 |
|---|---|
| 1.1。 | VARCHAR 可変長文字データ |
| 2.2。 | BIGINT 64ビットの符号付き整数 |
| 3.3。 | DOUBLE 64ビット浮動小数点倍精度値 |
| 4.4。 | DECIMAL 固定精度の10進数。たとえば、DECIMAL(10,3)-10は精度、つまり合計桁数、3は小数点として表されるスケール値です。スケールはオプションで、デフォルト値は0です。 |
| 5.5。 | BOOLEAN ブール値trueおよびfalse |
| 6.6。 | VARBINARY 可変長バイナリデータ |
| 7。 | JSON JSONデータ |
| 8.8。 | DATE 年-月-日として表される日付データ型 |
| 9.9。 | TIME, TIMESTAMP, TIMESTAMP with TIME ZONE TIME-時刻(時-分-秒-ミリ秒) タイムスタンプ-日付と時刻 タイムスタンプ付きのタイムスタンプ-値からのタイムゾーン付きの日付と時刻 |
| 10.10。 | INTERVAL 日付と時刻のデータ型をストレッチまたは拡張する |
| 11.11。 | ARRAY 指定されたコンポーネントタイプの配列。たとえば、ARRAY [5,7] |
| 12.12。 | MAP 指定されたコンポーネントタイプ間でマップします。たとえば、MAP(ARRAY ['one'、 'two']、ARRAY [5,7]) |
| 13.13。 | ROW 名前付きフィールドで構成される行構造 |
Presto-演算子
Presto演算子を次の表に示します。
| S.No | オペレーターと説明 |
|---|---|
| 1.1。 | 算術演算子 Prestoは、+、-、*、/、%などの算術演算子をサポートしています |
| 2.2。 | 関係演算子 <、>、<=、> =、=、<> |
| 3.3。 | 論理演算子 AND、OR、NOT |
| 4.4。 | 範囲演算子 範囲演算子は、特定の範囲の値をテストするために使用されます。Prestoは、BETWEEN、IS NULL、IS NOT NULL、GREATEST、およびLEASTをサポートします |
| 5.5。 | 10進演算子 2進算術10進演算子は、10進型の2進算術演算を実行します。単項10進演算子--- operator 否定を実行します |
| 6.6。 | 文字列演算子 ザ・ ‘||’ operator 文字列の連結を実行します |
| 7。 | 日付と時刻の演算子 日付と時刻のデータ型に対して算術加算および減算演算を実行します |
| 8.8。 | 配列演算子 添え字operator []-配列の要素にアクセスします 連結演算子|| -配列を同じタイプの配列または要素と連結します |
| 9.9。 | マップ演算子 マップ添え字演算子[]-マップから特定のキーに対応する値を取得します |
今のところ、Prestoでいくつかの簡単な基本クエリを実行することについて話し合っていました。この章では、重要なSQL関数について説明します。
数学関数
数学関数は数式を操作します。次の表に、機能のリストを詳しく説明します。
| S.No. | 機能と説明 |
|---|---|
| 1.1。 | abs(x) の絶対値を返します x |
| 2.2。 | cbrt(x) の立方根を返します x |
| 3.3。 | 天井(x) を返します x 最も近い整数に切り上げられた値 |
| 4.4。 | ceil(x) 天井(x)のエイリアス |
| 5.5。 | 度(x) の度数を返します x |
| 6.6。 | e(x) オイラーの数のdouble値を返します |
| 7。 | exp(x) オイラーの数の指数値を返します |
| 8.8。 | 床(x) 戻り値 x 最も近い整数に切り捨てられます |
| 9.9。 | from_base(string,radix) 基数として解釈される文字列の値を返します |
| 10.10。 | ln(x) の自然対数を返します x |
| 11.11。 | log2(x) の底2の対数を返します x |
| 12.12。 | log10(x) の10を底とする対数を返します x |
| 13.13。 | log(x,y) ベースを返します y の対数 x |
| 14.14。 | mod(n、m) のモジュラス(剰余)を返します n で割った m |
| 15.15。 | pi() 円周率の値を返します。結果はdouble値として返されます |
| 16.16。 | power(x、p) 値の累乗を返します ‘p’ に x 値 |
| 17.17。 | pow(x,p) power(x、p)のエイリアス |
| 18.18。 | ラジアン(x) 角度を変換します x 度ラジアン |
| 19。 | rand() ラジアン()のエイリアス |
| 20。 | ランダム() 疑似乱数値を返します |
| 21。 | rand(n) random()のエイリアス |
| 22。 | round(x) xの丸められた値を返します |
| 23。 | round(x,d) x の丸め値 ‘d’ 小数位 |
| 24。 | sign(x) xの符号関数を返します。 引数が0の場合は0 引数が0より大きい場合は1 引数が0未満の場合は-1 二重引数の場合、関数はさらに-を返します 引数がNaNの場合はNaN 引数が+ Infinityの場合は1 引数が-Infinityの場合は-1 |
| 25。 | sqrt(x) の平方根を返します x |
| 26。 | to_base(x、radix) 戻り値の型はアーチャーです。結果は、の基数として返されます。x |
| 27。 | truncate(x) の値を切り捨てます x |
| 28。 | width_bucket(x、bound1、bound2、n) のビン番号を返します x 指定されたbound1およびbound2の境界とn個のバケット |
| 29。 | width_bucket(x、bins) のビン番号を返します x 配列ビンによって指定されたビンに従って |
三角関数
三角関数の引数は、radians()として表されます。次の表に機能を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | acos(x) 逆コサイン値(x)を返します |
| 2.2。 | asin(x) 逆正弦値(x)を返します |
| 3.3。 | atan(x) 逆タンジェント値(x)を返します |
| 4.4。 | atan2(y、x) 逆タンジェント値(y / x)を返します |
| 5.5。 | cos(x) コサイン値(x)を返します |
| 6.6。 | cosh(x) 双曲線余弦値(x)を返します |
| 7。 | sin(x) サイン値(x)を返します |
| 8.8。 | tan(x) タンジェント値(x)を返します |
| 9.9。 | tanh(x) 双曲線タンジェント値(x)を返します |
ビットごとの関数
次の表に、ビット単位の関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | bit_count(x、ビット) ビット数を数える |
| 2.2。 | bitwise_and(x、y) 2ビットのビットごとのAND演算を実行し、 x そして y |
| 3.3。 | bitwise_or(x、y) 2ビット間のビットごとのOR演算 x, y |
| 4.4。 | bitwise_not(x) ビット単位のビット演算ではありません x |
| 5.5。 | bitwise_xor(x、y) ビットのXOR演算 x, y |
文字列関数
次の表に、文字列関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | concat(string1、...、stringN) 指定された文字列を連結します |
| 2.2。 | 長さ(文字列) 指定された文字列の長さを返します |
| 3.3。 | lower(文字列) 文字列の小文字の形式を返します |
| 4.4。 | アッパー(文字列) 指定された文字列の大文字の形式を返します |
| 5.5。 | lpad(文字列、サイズ、パッド文字列) 指定された文字列の左パディング |
| 6.6。 | ltrim(文字列) 文字列から先頭の空白を削除します |
| 7。 | replace(文字列、検索、置換) 文字列値を置き換えます |
| 8.8。 | リバース(文字列) 文字列に対して実行された操作を逆にします |
| 9.9。 | rpad(文字列、サイズ、パッド文字列) 指定された文字列の右パディング |
| 10.10。 | rtrim(文字列) 文字列から末尾の空白を削除します |
| 11.11。 | split(文字列、区切り文字) 区切り文字で文字列を分割し、最大のサイズの配列を返します |
| 12.12。 | split_part(文字列、区切り文字、インデックス) 区切り文字で文字列を分割し、フィールドインデックスを返します |
| 13.13。 | strpos(文字列、部分文字列) 文字列内の部分文字列の開始位置を返します |
| 14.14。 | substr(string、start) 指定された文字列の部分文字列を返します |
| 15.15。 | substr(文字列、開始、長さ) 特定の長さの指定された文字列の部分文字列を返します |
| 16.16。 | トリム(文字列) 文字列から先頭と末尾の空白を削除します |
日付と時刻の関数
次の表に、日付と時刻の関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | 現在の日付 現在の日付を返します |
| 2.2。 | 現在の時刻 現在の時刻を返します |
| 3.3。 | current_timestamp 現在のタイムスタンプを返します |
| 4.4。 | current_timezone() 現在のタイムゾーンを返します |
| 5.5。 | now() 現在の日付、タイムスタンプとタイムゾーンを返します |
| 6.6。 | 現地時間 現地時間を返します |
| 7。 | localtimestamp ローカルタイムスタンプを返します |
正規表現関数
次の表に、正規表現関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | regexp_extract_all(string、pattern) パターンの正規表現と一致する文字列を返します |
| 2.2。 | regexp_extract_all(文字列、パターン、グループ) パターンとグループの正規表現に一致する文字列を返します |
| 3.3。 | regexp_extract(string、pattern) パターンの正規表現と一致する最初の部分文字列を返します |
| 4.4。 | regexp_extract(string、pattern、group) パターンとグループの正規表現に一致する最初の部分文字列を返します |
| 5.5。 | regexp_like(string、pattern) パターンに一致する文字列を返します。文字列が返される場合、値はtrueになり、それ以外の場合はfalseになります。 |
| 6.6。 | regexp_replace(string、pattern) 式に一致する文字列のインスタンスをパターンに置き換えます |
| 7。 | regexp_replace(文字列、パターン、置換) 式に一致する文字列のインスタンスをパターンに置き換えて置き換えます |
| 8.8。 | regexp_split(string、pattern) 指定されたパターンの正規表現を分割します |
JSON関数
次の表に、JSON関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | json_array_contains(json、value) 値がjson配列に存在することを確認してください。値が存在する場合はtrueを返し、存在しない場合はfalseを返します。 |
| 2.2。 | json_array_get(json_array、index) json配列のインデックスの要素を取得します |
| 3.3。 | json_array_length(json) json配列で長さを返します |
| 4.4。 | json_format(json) json構造形式を返します |
| 5.5。 | json_parse(string) 文字列をjsonとして解析します |
| 6.6。 | json_size(json、json_path) 値のサイズを返します |
URL関数
次の表に、URL関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | url_extract_host(url) URLのホストを返します |
| 2.2。 | url_extract_path(url) URLのパスを返します |
| 3.3。 | url_extract_port(url) URLのポートを返します |
| 4.4。 | url_extract_protocol(url) URLのプロトコルを返します |
| 5.5。 | url_extract_query(url) URLのクエリ文字列を返します |
集計関数
次の表に、集計関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | avg(x) 指定された値の平均を返します |
| 2.2。 | min(x、n) 2つの値から最小値を返します |
| 3.3。 | max(x、n) 2つの値から最大値を返します |
| 4.4。 | sum(x) 値の合計を返します |
| 5.5。 | カウント(*) 入力行の数を返します |
| 6.6。 | count(x) 入力値の数を返します |
| 7。 | チェックサム(x) のチェックサムを返します x |
| 8.8。 | 任意(x) の任意の値を返します x |
色関数
次の表に、カラー関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | bar(x、width) rgblow_colorとhigh_colorを使用して単一のバーをレンダリングします |
| 2.2。 | bar(x、width、low_color、high_color) 指定された幅で単一のバーをレンダリングします |
| 3.3。 | 色(文字列) 入力した文字列の色の値を返します |
| 4.4。 | render(x、color) ANSIカラーコードを使用して特定の色を使用して値xをレンダリングします |
| 5.5。 | render(b) ブール値bを受け入れ、ANSIカラーコードを使用して緑をtrueまたは赤をfalseにレンダリングします |
| 6.6。 | rgb(red, green, blue) 0から255の範囲のintパラメータとして提供される3つのコンポーネントカラー値のRGB値をキャプチャするカラー値を返します |
配列関数
次の表に、配列関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | array_max(x) 配列内の最大要素を検索します |
| 2.2。 | array_min(x) 配列内の最小要素を検索します |
| 3.3。 | array_sort(x) 配列内の要素を並べ替えます |
| 4.4。 | array_remove(x、element) 配列から特定の要素を削除します |
| 5.5。 | concat(x、y) 2つの配列を連結します |
| 6.6。 | contains(x、element) 配列内の指定された要素を検索します。存在する場合はtrueが返され、存在しない場合はfalseが返されます。 |
| 7。 | array_position(x、element) 配列内の指定された要素の位置を見つけます |
| 8.8。 | array_intersect(x、y) 2つの配列間の共通部分を実行します |
| 9.9。 | element_at(array、index) 配列要素の位置を返します |
| 10.10。 | スライス(x、開始、長さ) 特定の長さで配列要素をスライスします |
Teradata関数
次の表に、Teradata関数を示します。
| S.No | 機能と説明 |
|---|---|
| 1.1。 | index(string、substring) 指定された部分文字列を持つ文字列のインデックスを返します |
| 2.2。 | substring(string、start) 指定された文字列の部分文字列を返します。ここで開始インデックスを指定できます |
| 3.3。 | substring(string、start、length) 文字列の特定の開始インデックスと長さに対して、指定された文字列の部分文字列を返します |
MySQLコネクタは、外部MySQLデータベースをクエリするために使用されます。
前提条件
MySQLサーバーのインストール。
構成設定
うまくいけば、あなたはあなたのマシンにmysqlサーバーをインストールしました。Prestoサーバーでmysqlプロパティを有効にするには、ファイルを作成する必要があります“mysql.properties” に “etc/catalog”ディレクトリ。次のコマンドを発行して、mysql.propertiesファイルを作成します。
$ cd etc $ cd catalog
$ vi mysql.properties
connector.name = mysql
connection-url = jdbc:mysql://localhost:3306
connection-user = root
connection-password = pwdファイルを保存して、ターミナルを終了します。上記のファイルでは、connection-passwordフィールドにmysqlパスワードを入力する必要があります。
MySQLサーバーでデータベースを作成する
MySQLサーバーを開き、次のコマンドを使用してデータベースを作成します。
create database tutorialsこれで、サーバーに「チュートリアル」データベースが作成されました。データベースタイプを有効にするには、クエリウィンドウで「チュートリアルを使用」コマンドを使用します。
テーブルを作成する
Let’s create a simple table on “tutorials” database.
create table author(auth_id int not null, auth_name varchar(50),topic varchar(100))Insert Table
After creating a table, insert three records using the following query.
insert into author values(1,'Doug Cutting','Hadoop')
insert into author values(2,’James Gosling','java')
insert into author values(3,'Dennis Ritchie’,'C')Select Records
To retrieve all the records, type the following query.
Query
select * from authorResult
auth_id auth_name topic
1 Doug Cutting Hadoop
2 James Gosling java
3 Dennis Ritchie CAs of now, you have queried data using MySQL server. Let’s connect Mysql storage plugin to Presto server.
Connect Presto CLI
Type the following command to connect MySql plugin on Presto CLI.
./presto --server localhost:8080 --catalog mysql --schema tutorialsYou will receive the following response.
presto:tutorials>Here “tutorials” refers to schema in mysql server.
List Schemas
To list out all the schemas in mysql, type the following query in Presto server.
Query
presto:tutorials> show schemas from mysql;Result
Schema
--------------------
information_schema
performance_schema
sys
tutorialsFrom this result, we can conclude the first three schemas as predefined and the last one as created by yourself.
List Tables from Schema
Following query lists out all the tables in tutorials schema.
Query
presto:tutorials> show tables from mysql.tutorials;Result
Table
--------
authorWe have created only one table in this schema. If you have created multiple tables, it will list out all the tables.
Describe Table
To describe the table fields, type the following query.
Query
presto:tutorials> describe mysql.tutorials.author;Result
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Show Columns from Table
Query
presto:tutorials> show columns from mysql.tutorials.author;Result
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Access Table Records
To fetch all the records from mysql table, issue the following query.
Query
presto:tutorials> select * from mysql.tutorials.author;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CFrom this result, you can retrieve mysql server records in Presto.
Create Table Using as Command
Mysql connector doesn’t support create table query but you can create a table using as command.
Query
presto:tutorials> create table mysql.tutorials.sample as
select * from mysql.tutorials.author;Result
CREATE TABLE: 3 rowsYou can’t insert rows directly because this connector has some limitations. It cannot support the following queries −
- create
- insert
- update
- delete
- drop
To view the records in the newly created table, type the following query.
Query
presto:tutorials> select * from mysql.tutorials.sample;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CJava Management Extensions (JMX) gives information about the Java Virtual Machine and software running inside JVM. The JMX connector is used to query JMX information in Presto server.
As we have already enabled “jmx.properties” file under “etc/catalog” directory. Now connect Prest CLI to enable JMX plugin.
Presto CLI
Query
$ ./presto --server localhost:8080 --catalog jmx --schema jmxResult
You will receive the following response.
presto:jmx>JMX Schema
To list out all the schemas in “jmx”, type the following query.
Query
presto:jmx> show schemas from jmx;Result
Schema
--------------------
information_schema
currentShow Tables
To view the tables in the “current” schema, use the following command.
Query 1
presto:jmx> show tables from jmx.current;Result
Table
------------------------------------------------------------------------------
com.facebook.presto.execution.scheduler:name = nodescheduler
com.facebook.presto.execution:name = queryexecution
com.facebook.presto.execution:name = querymanager
com.facebook.presto.execution:name = remotetaskfactory
com.facebook.presto.execution:name = taskexecutor
com.facebook.presto.execution:name = taskmanager
com.facebook.presto.execution:type = queryqueue,name = global,expansion = global
………………
……………….Query 2
presto:jmx> select * from jmx.current.”java.lang:type = compilation";Result
node | compilationtimemonitoringsupported | name | objectname | totalcompilationti
--------------------------------------+------------------------------------+--------------------------------+----------------------------+-------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | true | HotSpot 64-Bit Tiered Compilers | java.lang:type=Compilation | 1276Query 3
presto:jmx> select * from jmx.current."com.facebook.presto.server:name = taskresource";Result
node | readfromoutputbuffertime.alltime.count
| readfromoutputbuffertime.alltime.max | readfromoutputbuffertime.alltime.maxer
--------------------------------------+---------------------------------------+--------------------------------------+---------------------------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | 92.0 | 1.009106149 |The Hive connector allows querying data stored in a Hive data warehouse.
Prerequisites
- Hadoop
- Hive
Hopefully you have installed Hadoop and Hive on your machine. Start all the services one by one in the new terminal. Then, start hive metastore using the following command,
hive --service metastorePresto uses Hive metastore service to get the hive table’s details.
Configuration Settings
Create a file “hive.properties” under “etc/catalog” directory. Use the following command.
$ cd etc $ cd catalog
$ vi hive.properties
connector.name = hive-cdh4
hive.metastore.uri = thrift://localhost:9083After making all the changes, save the file and quit the terminal.
Create Database
Create a database in Hive using the following query −
Query
hive> CREATE SCHEMA tutorials;After the database is created, you can verify it using the “show databases” command.
Create Table
Create Table is a statement used to create a table in Hive. For example, use the following query.
hive> create table author(auth_id int, auth_name varchar(50),
topic varchar(100) STORED AS SEQUENCEFILE;Insert Table
Following query is used to insert records in hive’s table.
hive> insert into table author values (1,’ Doug Cutting’,Hadoop),
(2,’ James Gosling’,java),(3,’ Dennis Ritchie’,C);Start Presto CLI
You can start Presto CLI to connect Hive storage plugin using the following command.
$ ./presto --server localhost:8080 --catalog hive —schema tutorials;You will receive the following response.
presto:tutorials >List Schemas
To list out all the schemas in Hive connector, type the following command.
Query
presto:tutorials > show schemas from hive;Result
default
tutorialsList Tables
To list out all the tables in “tutorials” schema, use the following query.
Query
presto:tutorials > show tables from hive.tutorials;Result
authorFetch Table
Following query is used to fetch all the records from hive’s table.
Query
presto:tutorials > select * from hive.tutorials.author;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CThe Kafka Connector for Presto allows to access data from Apache Kafka using Presto.
Prerequisites
Download and install the latest version of the following Apache projects.
- Apache ZooKeeper
- Apache Kafka
Start ZooKeeper
Start ZooKeeper server using the following command.
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesNow, ZooKeeper starts port on 2181.
Start Kafka
Start Kafka in another terminal using the following command.
$ bin/kafka-server-start.sh config/server.propertiesAfter kafka starts, it uses the port number 9092.
TPCH Data
Download tpch-kafka
$ curl -o kafka-tpch
https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_
0811-1.0.shNow you have downloaded the loader from Maven central using the above command. You will get a similar response as the following.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
5 21.6M 5 1279k 0 0 83898 0 0:04:30 0:00:15 0:04:15 129k
6 21.6M 6 1407k 0 0 86656 0 0:04:21 0:00:16 0:04:05 131k
24 21.6M 24 5439k 0 0 124k 0 0:02:57 0:00:43 0:02:14 175k
24 21.6M 24 5439k 0 0 124k 0 0:02:58 0:00:43 0:02:15 160k
25 21.6M 25 5736k 0 0 128k 0 0:02:52 0:00:44 0:02:08 181k
………………………..Then, make it executable using the following command,
$ chmod 755 kafka-tpchRun tpch-kafka
Run the kafka-tpch program to preload a number of topics with tpch data using the following command.
Query
$ ./kafka-tpch load --brokers localhost:9092 --prefix tpch. --tpch-type tiny結果
2016-07-13T16:15:52.083+0530 INFO main io.airlift.log.Logging Logging
to stderr
2016-07-13T16:15:52.124+0530 INFO main de.softwareforge.kafka.LoadCommand
Processing tables: [customer, orders, lineitem, part, partsupp, supplier,
nation, region]
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-1
de.softwareforge.kafka.LoadCommand Loading table 'customer' into topic 'tpch.customer'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-2
de.softwareforge.kafka.LoadCommand Loading table 'orders' into topic 'tpch.orders'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-3
de.softwareforge.kafka.LoadCommand Loading table 'lineitem' into topic 'tpch.lineitem'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-4
de.softwareforge.kafka.LoadCommand Loading table 'part' into topic 'tpch.part'...
………………………
……………………….現在、Kafkaテーブルの顧客、注文、サプライヤーなどは、tpchを使用してロードされます。
構成設定の追加
Prestoサーバーに次のKafkaコネクタ構成設定を追加しましょう。
connector.name = kafka
kafka.nodes = localhost:9092
kafka.table-names = tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,
tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns = false上記の構成では、KafkaテーブルはKafka-tpchプログラムを使用してロードされます。
PrestoCLIを起動します
次のコマンドを使用してPrestoCLIを起動します。
$ ./presto --server localhost:8080 --catalog kafka —schema tpch;ここに “tpch" はKafkaコネクタのスキーマであり、次のような応答を受け取ります。
presto:tpch>リストテーブル
次のクエリは、のすべてのテーブルを一覧表示します “tpch” スキーマ。
クエリ
presto:tpch> show tables;結果
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplier顧客テーブルを説明する
次のクエリは説明します “customer” テーブル。
クエリ
presto:tpch> describe customer;結果
Column | Type | Comment
-------------------+---------+---------------------------------------------
_partition_id | bigint | Partition Id
_partition_offset | bigint | Offset for the message within the partition
_segment_start | bigint | Segment start offset
_segment_end | bigint | Segment end offset
_segment_count | bigint | Running message count per segment
_key | varchar | Key text
_key_corrupt | boolean | Key data is corrupt
_key_length | bigint | Total number of key bytes
_message | varchar | Message text
_message_corrupt | boolean | Message data is corrupt
_message_length | bigint | Total number of message bytesPrestoのJDBCインターフェースは、Javaアプリケーションへのアクセスに使用されます。
前提条件
presto-jdbc-0.150.jarをインストールします
次のリンクにアクセスして、JDBCjarファイルをダウンロードできます。
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.150/
jarファイルがダウンロードされたら、Javaアプリケーションのクラスパスに追加します。
簡単なアプリケーションを作成する
JDBCインターフェースを使用して簡単なJavaアプリケーションを作成しましょう。
コーディング-PrestoJdbcSample.java
import java.sql.*;
import com.facebook.presto.jdbc.PrestoDriver;
//import presto jdbc driver packages here.
public class PrestoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
connection = DriverManager.getConnection(
"jdbc:presto://localhost:8080/mysql/tutorials", "tutorials", “");
//connect mysql server tutorials database here
statement = connection.createStatement();
String sql;
sql = "select auth_id, auth_name from mysql.tutorials.author”;
//select mysql table author table two columns
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("auth_id");
String name = resultSet.getString(“auth_name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}ファイルを保存して、アプリケーションを終了します。ここで、1つのターミナルでPrestoサーバーを起動し、新しいターミナルを開いて結果をコンパイルして実行します。手順は次のとおりです-
コンパイル
~/Workspace/presto/presto-jdbc $ javac -cp presto-jdbc-0.149.jar PrestoJdbcSample.java実行
~/Workspace/presto/presto-jdbc $ java -cp .:presto-jdbc-0.149.jar PrestoJdbcSample出力
INFO: Logging initialized @146ms
ID: 1;
Name: Doug Cutting
ID: 2;
Name: James Gosling
ID: 3;
Name: Dennis RitchiePrestoカスタム関数を開発するためのMavenプロジェクトを作成します。
SimpleFunctionsFactory.java
SimpleFunctionsFactoryクラスを作成して、FunctionFactoryインターフェイスを実装します。
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.metadata.FunctionListBuilder;
import com.facebook.presto.metadata.SqlFunction;
import com.facebook.presto.spi.type.TypeManager;
import java.util.List;
public class SimpleFunctionFactory implements FunctionFactory {
private final TypeManager typeManager;
public SimpleFunctionFactory(TypeManager typeManager) {
this.typeManager = typeManager;
}
@Override
public List<SqlFunction> listFunctions() {
return new FunctionListBuilder(typeManager)
.scalar(SimpleFunctions.class)
.getFunctions();
}
}SimpleFunctionsPlugin.java
SimpleFunctionsPluginクラスを作成して、プラグインインターフェイスを実装します。
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.type.TypeManager;
import com.google.common.collect.ImmutableList;
import javax.inject.Inject;
import java.util.List;
import static java.util.Objects.requireNonNull;
public class SimpleFunctionsPlugin implements Plugin {
private TypeManager typeManager;
@Inject
public void setTypeManager(TypeManager typeManager) {
this.typeManager = requireNonNull(typeManager, "typeManager is null”);
//Inject TypeManager class here
}
@Override
public <T> List<T> getServices(Class<T> type){
if (type == FunctionFactory.class) {
return ImmutableList.of(type.cast(new SimpleFunctionFactory(typeManager)));
}
return ImmutableList.of();
}
}リソースファイルの追加
実装パッケージで指定されているリソースファイルを作成します。
(com.tutorialspoint.simple.functions.SimpleFunctionsPlugin)次に、リソースファイルの場所@ / path / to / resource /に移動します。
次に、変更を追加します。
com.facebook.presto.spi.Pluginpom.xml
次の依存関係をpom.xmlファイルに追加します。
<?xml version = "1.0"?>
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint.simple.functions</groupId>
<artifactId>presto-simple-functions</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>presto-simple-functions</name>
<description>Simple test functions for Presto</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-main</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
<build>
<finalName>presto-simple-functions</finalName>
<plugins>
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
</plugin>
</plugins>
</build>
</project>SimpleFunctions.java
Presto属性を使用してSimpleFunctionsクラスを作成します。
package com.tutorialspoint.simple.functions;
import com.facebook.presto.operator.Description;
import com.facebook.presto.operator.scalar.ScalarFunction;
import com.facebook.presto.operator.scalar.StringFunctions;
import com.facebook.presto.spi.type.StandardTypes;
import com.facebook.presto.type.LiteralParameters;
import com.facebook.presto.type.SqlType;
public final class SimpleFunctions {
private SimpleFunctions() {
}
@Description("Returns summation of two numbers")
@ScalarFunction(“mysum")
//function name
@SqlType(StandardTypes.BIGINT)
public static long sum(@SqlType(StandardTypes.BIGINT) long num1,
@SqlType(StandardTypes.BIGINT) long num2) {
return num1 + num2;
}
}アプリケーションが作成されたら、アプリケーションをコンパイルして実行します。JARファイルを生成します。ファイルをコピーし、JARファイルをターゲットのPrestoサーバープラグインディレクトリに移動します。
コンパイル
mvn compile実行
mvn package次に、Prestoサーバーを再起動し、Prestoクライアントに接続します。次に、以下で説明するようにカスタム関数適用を実行します。
$ ./presto --catalog mysql --schema defaultクエリ
presto:default> select mysum(10,10);結果
_col0
-------
20