人工知能-クイックガイド
コンピュータや機械の発明以来、さまざまなタスクを実行する能力は飛躍的に成長し続けました。人間は、多様な作業領域、速度の向上、時間に対するサイズの縮小という観点から、コンピューターシステムの能力を開発してきました。
人工知能という名前のコンピュータサイエンスの分野は、人間と同じくらいインテリジェントなコンピュータまたはマシンの作成を追求しています。
人工知能とは何ですか?
人工知能の父であるジョン・マッカーシーによれば、それは「インテリジェントマシン、特にインテリジェントコンピュータプログラムを作成するための科学と工学」です。
人工知能は making a computer, a computer-controlled robot, or a software think intelligently、同様の方法で、知的な人間は考えます。
AIは、人間の脳がどのように考え、問題を解決しようとして人間がどのように学び、決定し、働くかを研究し、この研究の結果をインテリジェントなソフトウェアとシステムの開発の基礎として使用することによって実現されます。
AIの哲学
コンピュータシステムの力、人間の好奇心を利用している間、彼は「機械は人間のように考え、行動できるのだろうか」と疑問に思います。
このように、AIの開発は、人間が高く評価しているマシンで同様のインテリジェンスを作成することを目的として始まりました。
AIの目標
To Create Expert Systems −インテリジェントな動作を示し、ユーザーに学習、デモンストレーション、説明、およびアドバイスを提供するシステム。
To Implement Human Intelligence in Machines −人間のように理解し、考え、学び、行動するシステムを作成する。
AIに貢献するものは何ですか?
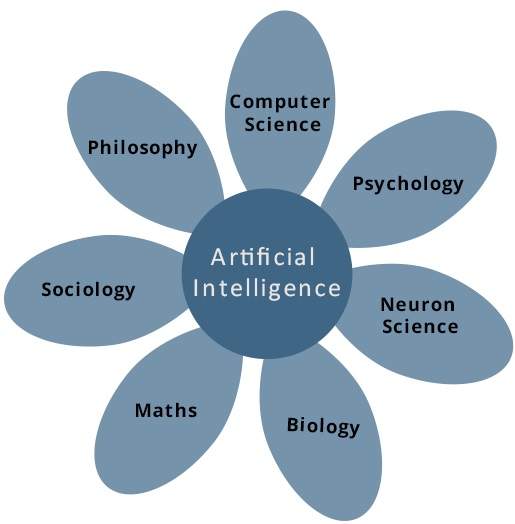
人工知能は、コンピューターサイエンス、生物学、心理学、言語学、数学、工学などの分野に基づく科学技術です。AIの主な目的は、推論、学習、問題解決など、人間の知能に関連するコンピューター機能の開発にあります。
以下の領域のうち、1つまたは複数の領域がインテリジェントシステムの構築に貢献できます。
AIを使用しない場合と使用する場合のプログラミング
AIを使用しない場合と使用する場合のプログラミングは、次の点で異なります。
| AIを使わないプログラミング | AIを使ったプログラミング |
|---|---|
| AIのないコンピュータプログラムは答えることができます specific それが解決することを意図している質問。 | AIを備えたコンピュータプログラムは答えることができます generic それが解決することを意図している質問。 |
| プログラムを変更すると、その構造が変更されます。 | AIプログラムは、高度に独立した情報をまとめることで、新しい変更を吸収できます。したがって、プログラムの構造に影響を与えることなく、プログラムのほんのわずかな情報でも変更できます。 |
| 変更は迅速かつ簡単ではありません。プログラムに悪影響を与える可能性があります。 | すばやく簡単なプログラム変更。 |
AIテクニックとは何ですか?
現実の世界では、知識にはいくつかの歓迎されない特性があります-
- そのボリュームは想像を絶するほど巨大です。
- それはよく組織化されていないか、よくフォーマットされていません。
- それは絶えず変化し続けます。
AIテクニックは、次のような方法で知識を効率的に整理して使用する方法です。
- それはそれを提供する人々によって知覚できるはずです。
- エラーを修正するために簡単に変更できる必要があります。
- 不完全または不正確ですが、多くの状況で役立つはずです。
AI技術は、搭載されている複雑なプログラムの実行速度を向上させます。
AIの応用
AIは、次のようなさまざまな分野で支配的です。
Gaming − AIは、チェス、ポーカー、三目並べなどの戦略ゲームで重要な役割を果たします。このゲームでは、機械がヒューリスティックな知識に基づいて多数の可能な位置を考えることができます。
Natural Language Processing −人間が話す自然言語を理解するコンピュータと対話することが可能です。
Expert Systems−機械、ソフトウェア、および特別な情報を統合して、推論とアドバイスを与えるアプリケーションがいくつかあります。ユーザーに説明やアドバイスを提供します。
Vision Systems−これらのシステムは、コンピューター上の視覚入力を理解、解釈、および理解します。例えば、
スパイ飛行機が写真を撮り、それを使って空間情報や地域の地図を把握します。
医師は臨床エキスパートシステムを使用して患者を診断します。
警察は、法医学の芸術家によって作成された保存された肖像画で犯罪者の顔を認識することができるコンピュータソフトウェアを使用しています。
Speech Recognition−一部のインテリジェントシステムは、人間が話している間、文とその意味の観点から言語を聞いて理解することができます。さまざまなアクセント、俗語、背景のノイズ、寒さによる人間のノイズの変化などを処理できます。
Handwriting Recognition−手書き認識ソフトウェアは、紙にペンで、または画面にスタイラスで書かれたテキストを読み取ります。文字の形を認識し、編集可能なテキストに変換できます。
Intelligent Robots−ロボットは、人間が与えたタスクを実行できます。それらには、光、熱、温度、動き、音、バンプ、圧力などの実世界からの物理データを検出するセンサーがあります。彼らは、インテリジェンスを発揮するために、効率的なプロセッサ、複数のセンサー、および巨大なメモリを備えています。さらに、彼らは自分の過ちから学ぶことができ、新しい環境に適応することができます。
AIの歴史
これが20世紀のAIの歴史です-
| 年 | マイルストーン/イノベーション |
|---|---|
| 1923年 | 「ロッサムのユニバーサルロボット」(RUR)という名前のカレルチャペックの戯曲がロンドンで始まり、英語で「ロボット」という言葉が最初に使用されました。 |
| 1943年 | ニューラルネットワークの基礎が築かれました。 |
| 1945年 | コロンビア大学の卒業生であるIsaacAsimovは、ロボット工学という用語を作り出しました。 |
| 1950年 | Alan Turingは、インテリジェンスの評価のためにチューリングテストを導入し、Computing Machinery andIntelligenceを公開しました。クロードシャノンは、検索としてチェスプレイの詳細分析を公開しました。 |
| 1956年 | ジョンマッカーシーは、人工知能という用語を作り出しました。カーネギーメロン大学で最初に実行されたAIプログラムのデモンストレーション。 |
| 1958年 | John McCarthyは、AI用のLISPプログラミング言語を発明しました。 |
| 1964年 | MITでのDannyBobrowの論文は、コンピューターが代数の文章題を正しく解決するのに十分なほど自然言語を理解できることを示しました。 |
| 1965年 | MITのJosephWeizenbaumは、英語での対話を続けるインタラクティブな問題であるELIZAを作成しました。 |
| 1969年 | スタンフォード研究所の科学者たちは、移動、知覚、問題解決を備えたロボット、Shakeyを開発しました。 |
| 1973年 | エディンバラ大学のAssemblyRoboticsグループは、視覚を使用してモデルを見つけて組み立てることができる、有名なスコットランドのロボットであるFreddyを構築しました。 |
| 1979年 | 最初のコンピューター制御の自動運転車、スタンフォードカートが製造されました。 |
| 1985年 | ハロルド・コーエンは、描画プログラムAaronを作成し、デモンストレーションしました。 |
| 1990年 | AIのすべての分野での大きな進歩-
|
| 1997年 | ディープブルーチェスプログラムは、当時の世界チェスチャンピオンであるギャリーカスパロフを打ち負かしました。 |
| 2000年 | インタラクティブロボットペットが市販されます。MITは、感情を表現する顔をしたロボット、キスメットを展示しています。ロボットノマドは南極の遠隔地を探索し、隕石を見つけます。 |
人工知能を研究している間、あなたは知性が何であるかを知る必要があります。この章では、インテリジェンスのアイデア、インテリジェンスのタイプ、およびコンポーネントについて説明します。
インテリジェンスとは何ですか?
関係や類推を計算、推論、認識し、経験から学び、記憶から情報を保存および取得し、問題を解決し、複雑なアイデアを理解し、自然言語を流暢に使用し、分類し、一般化し、新しい状況に適応するシステムの能力。
インテリジェンスの種類
アメリカの発達心理学者であるハワードガードナーが説明したように、インテリジェンスにはさまざまな要素があります。
| インテリジェンス | 説明 | 例 |
|---|---|---|
| 言語インテリジェンス | 音韻論(スピーチ音)、構文(文法)、および意味論(意味)のメカニズムを話し、認識し、使用する能力。 | ナレーター、オレーター |
| ミュージカルインテリジェンス | 音の意味、音程、リズムの理解を創造し、コミュニケーションし、理解する能力。 | ミュージシャン、歌手、作曲家 |
| 論理数学的知性 | アクションやオブジェクトがない場合に関係を使用して理解する能力。複雑で抽象的なアイデアを理解する。 | 数学者、科学者 |
| 空間インテリジェンス | 視覚的または空間的情報を認識し、それを変更し、オブジェクトを参照せずに視覚的画像を再作成し、3D画像を構築し、それらを移動および回転する機能。 | 地図リーダー、宇宙飛行士、物理学者 |
| 身体運動知能 | 身体の全体または一部を使用して、問題やファッション製品を解決し、細かい運動技能と粗い運動技能を制御し、オブジェクトを操作する能力。 | プレーヤー、ダンサー |
| 個人内インテリジェンス | 自分の感情、意図、動機を区別する能力。 | ゴータムブッダ |
| 対人知能 | 他の人の感情、信念、意図を認識し、区別する能力。 | マスコミュニケーター、インタビュアー |
あなたは機械またはシステムが artificially intelligent 少なくとも1つ、多くてもすべてのインテリジェンスが搭載されている場合。
インテリジェンスは何で構成されていますか?
インテリジェンスは無形です。−で構成されています
- Reasoning
- Learning
- 問題解決
- Perception
- 言語インテリジェンス

すべてのコンポーネントを簡単に見ていきましょう-
Reasoning−これは、判断、意思決定、および予測の基礎を提供できるようにする一連のプロセスです。大きく2つのタイプがあります-
| 帰納的推理 | 演繹的推論 |
|---|---|
| それは、幅広い一般的な声明を出すために特定の観察を行います。 | それは一般的な声明から始まり、特定の論理的な結論に到達する可能性を検討します。 |
| 声明ですべての前提が真であるとしても、帰納的推論は結論が偽であることを可能にします。 | 一般にあるクラスの事柄に当てはまる場合、そのクラスのすべてのメンバーにも当てはまります。 |
| 例-「ニタは教師です。ニタは勤勉です。したがって、すべての教師は勤勉です。」 | 例-「60歳以上のすべての女性は祖母です。シャリーニは65歳です。したがって、シャリーニは祖母です。」 |
Learning−何かを勉強したり、練習したり、教えたり、体験したりすることで知識やスキルを身につける活動です。学習は、研究対象の意識を高めます。
学習能力は、人間、一部の動物、およびAI対応システムによって所有されています。学習は次のように分類されます-
Auditory Learning−聞くことと聞くことによって学ぶことです。たとえば、録音された音声講義を聞いている学生。
Episodic Learning−目撃した、または経験した一連の出来事を思い出して学ぶこと。これは直線的で整然としています。
Motor Learning−筋肉の正確な動きによる学習です。たとえば、オブジェクトの選択、書き込みなど。
Observational Learning−他の人を見て模倣することによって学ぶこと。たとえば、子供は親を模倣して学習しようとします。
Perceptual Learning−以前に見た刺激を認識することを学んでいます。たとえば、オブジェクトと状況を識別して分類します。
Relational Learning−絶対的な特性ではなく、関係的な特性に基づいてさまざまな刺激を区別することを学ぶ必要があります。たとえば、前回塩辛くなったジャガイモを調理するときに、大さじ1杯の塩を加えて調理したときに「少し少ない」塩を加える。
Spatial Learning −画像、色、地図などの視覚刺激を通じて学習します。たとえば、人は実際に道路をたどる前にロードマップを作成することができます。
Stimulus-Response Learning−特定の刺激が存在するときに特定の行動を実行することを学習しています。たとえば、犬はドアベルを聞いて耳を上げます。
Problem Solving −それは、既知または未知のハードルによってブロックされている何らかの道をたどることによって、現在の状況から望ましい解決策を認識し、到達しようとするプロセスです。
問題解決には、 decision making、これは、複数の選択肢の中から最適な選択肢を選択して、目的の目標を達成するプロセスです。
Perception −感覚情報を取得、解釈、選択、整理するプロセスです。
知覚は推定します sensing。人間では、知覚は感覚器官によって助けられます。AIの領域では、知覚メカニズムにより、センサーによって取得されたデータが意味のある方法でまとめられます。
Linguistic Intelligence−口頭および書記言語を使用、理解、話し、書く能力です。対人コミュニケーションにおいて重要です。
人間と機械の知能の違い
人間はパターンによって知覚しますが、機械は一連のルールとデータによって知覚します。
人間はパターンごとに情報を保存および呼び出し、機械はアルゴリズムを検索することによってそれを行います。たとえば、番号40404040はパターンが単純であるため、覚えやすく、保存しやすく、思い出しやすいものです。
人間は、オブジェクトの一部が欠落しているか歪んでいる場合でも、オブジェクト全体を把握できます。一方、マシンはそれを正しく行うことができません。
人工知能の領域は、幅と幅が非常に広いです。進めながら、AIの領域で広く一般的で繁栄している研究分野を検討します-

音声および音声認識
これらの両方の用語は、ロボット工学、エキスパートシステム、および自然言語処理で一般的です。これらの用語は同じ意味で使用されますが、目的は異なります。
| 音声認識 | 音声認識 |
|---|---|
| 音声認識は、理解と理解を目的としています WHAT 話されました。 | 音声認識の目的は、認識することです WHO 話している。 |
| これは、ハンズフリーコンピューティング、マップ、またはメニューナビゲーションで使用されます。 | 声調、声の高さ、アクセントなどを分析して人を識別するために使用されます。 |
| 機械は話者に依存しないため、音声認識のトレーニングは必要ありません。 | この認識システムは人を対象としているため、トレーニングが必要です。 |
| 話者に依存しない音声認識システムの開発は困難です。 | 話者に依存する音声認識システムは、比較的簡単に開発できます。 |
音声および音声認識システムの動作
マイクで話されたユーザー入力は、システムのサウンドカードに送られます。コンバーターは、アナログ信号を音声処理用の同等のデジタル信号に変換します。データベースは、単語を認識するために音のパターンを比較するために使用されます。最後に、逆のフィードバックがデータベースに与えられます。
このソース言語テキストは、翻訳エンジンへの入力になり、翻訳エンジンはそれをターゲット言語テキストに変換します。それらは、インタラクティブGUI、語彙の大規模データベースなどでサポートされています。
研究分野の実際のアプリケーション
AIが日常生活の中で一般の人々にサービスを提供しているアプリケーションは数多くあります-
| シニア番号 | 研究分野 | 実生活アプリケーション |
|---|---|---|
| 1 | Expert Systems 例-飛行追跡システム、臨床システム。 |

|
| 2 | Natural Language Processing 例:Google Now機能、音声認識、自動音声出力。 |

|
| 3 | Neural Networks 例-顔認識、文字認識、手書き認識などのパターン認識システム。 |

|
| 4 | Robotics 例-移動、スプレー、塗装、精密チェック、穴あけ、洗浄、コーティング、彫刻などのための産業用ロボット。 |

|
| 5 | Fuzzy Logic Systems 例-家庭用電化製品、自動車など。 |

|
AIのタスク分類
AIのドメインは次のように分類されます Formal tasks, Mundane tasks, そして Expert tasks.

| 人工知能のタスクドメイン | ||
|---|---|---|
| 平凡な(通常の)タスク | 正式なタスク | エキスパートタスク |
知覚
|
|
|
自然言語処理
|
ゲーム
|
科学的分析 |
| 常識 | 検証 | 財務分析 |
| 推論 | 定理証明 | 医療診断 |
| プレーニング | 創造性 | |
ロボット工学
|
||
人間は学ぶ mundane (ordinary) tasks彼らの誕生以来。彼らは知覚、話す、言語を使う、そして機関車によって学びます。後で、正式なタスクと専門家のタスクをこの順序で学習します。
人間にとって、ありふれたタスクは学ぶのが最も簡単です。マシンにありふれたタスクを実装しようとする前に、同じことが当てはまると考えられていました。以前は、AIのすべての作業はありふれたタスクドメインに集中していました。
その後、マシンには、日常的なタスクを処理するために、より多くの知識、複雑な知識表現、および複雑なアルゴリズムが必要であることが判明しました。という訳だwhy AI work is more prospering in the Expert Tasks domain 現在、エキスパートタスクドメインには常識のないエキスパート知識が必要であるため、表現と処理が簡単になります。
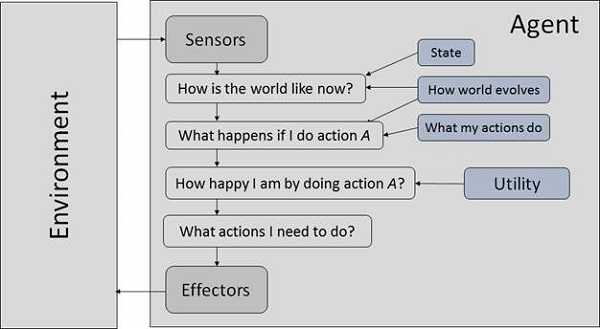
AIシステムは、エージェントとその環境で構成されています。エージェントは自分の環境で行動します。環境には他のエージェントが含まれている可能性があります。
エージェントと環境とは何ですか?
アン agent を通してその環境を知覚できるものは何でも sensors を通じてその環境に作用します effectors.
A human agent センサーと平行に目、耳、鼻、舌、皮膚などの感覚器官と、エフェクター用の手、脚、口などの他の器官があります。
A robotic agent センサー用のカメラと赤外線距離計、およびエフェクター用のさまざまなモーターとアクチュエーターに取って代わります。
A software agent プログラムおよびアクションとしてビット文字列をエンコードしました。

エージェントの用語
Performance Measure of Agent −エージェントがどれだけ成功するかを決定する基準です。
Behavior of Agent −これは、エージェントが特定の一連の知覚の後に実行するアクションです。
Percept −特定のインスタンスでのエージェントの知覚入力です。
Percept Sequence −エージェントがこれまでに認識してきたすべての歴史です。
Agent Function −これは、プリセプトシーケンスからアクションへのマップです。
合理性
合理性とは、合理的で、賢明で、判断力のある状態に他なりません。
合理性は、エージェントが何を認識したかに応じて、期待されるアクションと結果に関係します。有用な情報を得るために行動を起こすことは、合理性の重要な部分です。
理想的な合理的エージェントとは何ですか?
理想的な合理的エージェントは、以下に基づいて、パフォーマンス測定値を最大化するために期待されるアクションを実行できるエージェントです。
- その知覚シーケンス
- 組み込みのナレッジベース
エージェントの合理性は以下に依存します-
ザ・ performance measures、成功の度合いを決定します。
エージェントの Percept Sequence 今まで。
エージェントの prior knowledge about the environment。
ザ・ actions エージェントが実行できること。
合理的エージェントは常に正しい行動を実行します。正しい行動とは、与えられた知覚シーケンスでエージェントを最も成功させる行動を意味します。エージェントが解決する問題は、パフォーマンス測定、環境、アクチュエータ、およびセンサー(PEAS)によって特徴付けられます。
知的エージェントの構造
エージェントの構造は次のように見ることができます-
- エージェント=アーキテクチャ+エージェントプログラム
- アーキテクチャ=エージェントが実行する機械。
- エージェントプログラム=エージェント機能の実装。
単純な反射エージェント
- 彼らは現在の認識にのみ基づいて行動を選択します。
- それらは、現在の教訓に基づいてのみ正しい決定がなされた場合にのみ合理的です。
- 彼らの環境は完全に観察可能です。
Condition-Action Rule −状態(条件)をアクションにマッピングするルールです。

モデルベースの反射エージェント
彼らは世界のモデルを使用して行動を選択します。それらは内部状態を維持します。
Model −「世界で物事がどのように起こるか」についての知識。
Internal State −知覚履歴に応じた現在の状態の観察されていない側面の表現です。
Updating the state requires the information about −
- 世界がどのように進化するか。
- エージェントの行動が世界にどのように影響するか。

目標ベースのエージェント
彼らは目標を達成するために彼らの行動を選びます。意思決定をサポートする知識が明示的にモデル化され、それによって変更が可能になるため、目標ベースのアプローチは反射エージェントよりも柔軟性があります。
Goal −望ましい状況の説明です。

ユーティリティベースのエージェント
彼らは、各州の選好(効用)に基づいて行動を選択します。
−の場合、目標は不十分です。
相反する目標があり、そのうち達成できるのはごくわずかです。
目標には達成の不確実性があり、成功の可能性と目標の重要性を比較検討する必要があります。
環境の性質
一部のプログラムは完全に動作します artificial environment キーボード入力、データベース、コンピューターファイルシステム、および画面上の文字出力に限定されます。
対照的に、一部のソフトウェアエージェント(ソフトウェアロボットまたはソフトボット)は、リッチで無制限のソフトボットドメインに存在します。シミュレータにはvery detailed, complex environment。ソフトウェアエージェントは、多数のアクションからリアルタイムで選択する必要があります。顧客のオンライン設定をスキャンし、顧客に興味深いアイテムを表示するように設計されたソフトボットは、real だけでなく、 artificial 環境。
一番有名な artificial environment それは Turing Test environment、1つの実際のエージェントと他の人工エージェントが同じ地面でテストされます。ソフトウェアエージェントが人間と同じように実行することは非常に難しいため、これは非常に困難な環境です。
チューリングテスト
システムのインテリジェントな動作の成功は、チューリングテストで測定できます。
2人と評価対象の機械がテストに参加します。2人のうち、1人がテスターの役割を果たします。それらのそれぞれは、異なる部屋に座っています。テスターは、誰が機械で誰が人間であるかを認識していません。彼は質問を入力して両方のインテリジェンスに送信することで質問し、入力された応答を受け取ります。
このテストは、テスターをだますことを目的としています。テスターが人間の応答からマシンの応答を判断できない場合、そのマシンはインテリジェントであると言われます。
環境の特性
環境には複数の特性があります-
Discrete / Continuous−環境の明確に定義された明確な状態の数が限られている場合、環境は離散的です(たとえば、チェス)。それ以外の場合は継続的です(たとえば、運転)。
Observable / Partially Observable−知覚から各時点での環境の完全な状態を判断することが可能である場合、それは観察可能です。それ以外の場合は、部分的にしか観察できません。
Static / Dynamic−エージェントの動作中に環境が変化しない場合、環境は静的です。それ以外の場合は動的です。
Single agent / Multiple agents −環境には、エージェントと同じまたは異なる種類の他のエージェントが含まれている場合があります。
Accessible / Inaccessible −エージェントの感覚装置が環境の完全な状態にアクセスできる場合、そのエージェントは環境にアクセスできます。
Deterministic / Non-deterministic−環境の次の状態が、現在の状態とエージェントのアクションによって完全に決定される場合、環境は決定論的です。それ以外の場合は、非決定論的です。
Episodic / Non-episodic−エピソード環境では、各エピソードは、エージェントが認識して行動することで構成されます。そのアクションの質は、エピソード自体に依存します。後続のエピソードは、前のエピソードのアクションに依存しません。エージェントが先を考える必要がないため、一時的な環境ははるかに単純です。
検索は、AIにおける問題解決の普遍的な手法です。タイルゲーム、数独、クロスワードなどのシングルプレイヤーゲームがいくつかあります。検索アルゴリズムは、そのようなゲームの特定の位置を検索するのに役立ちます。
シングルエージェントパスファインディングの問題
3X3 8タイル、4X4 15タイル、5X5 24タイルパズルなどのゲームは、シングルエージェントパス検索の課題です。それらは、空白のタイルを持つタイルのマトリックスで構成されています。プレイヤーは、ある目的を達成するために、タイルを垂直または水平に空白のスペースにスライドさせてタイルを配置する必要があります。
単一エージェントの経路探索問題の他の例は、巡回セールスマン問題、ルービックキューブ、および定理証明です。
検索用語
Problem Space−検索が行われる環境です。(状態のセットとそれらの状態を変更するための演算子のセット)
Problem Instance −初期状態+目標状態です。
Problem Space Graph−問題の状態を表します。状態はノードで示され、演算子はエッジで示されます。
Depth of a problem −初期状態から目標状態までの最短パスまたは演算子の最短シーケンスの長さ。
Space Complexity −メモリに保存されるノードの最大数。
Time Complexity −作成されるノードの最大数。
Admissibility −常に最適解を見つけるアルゴリズムの特性。
Branching Factor −問題空間グラフの子ノードの平均数。
Depth −初期状態から目標状態までの最短経路の長さ。
ブルートフォース検索戦略
ドメイン固有の知識を必要としないため、最も単純です。それらは、可能な状態の数が少ない場合でも正常に機能します。
要件-
- 状態の説明
- 有効な演算子のセット
- 初期状態
- 目標状態の説明
幅優先探索
ルートノードから開始し、最初に隣接ノードを探索して、次のレベルの隣接ノードに向かって移動します。解が見つかるまで、一度に1つのツリーを生成します。FIFOキューデータ構造を使用して実装できます。この方法は、ソリューションへの最短経路を提供します。
場合 branching factor次いで、(所与のノードの子ノードの平均数)= Bと深さ= D、レベルD = B用のノードの数D。
最悪の場合に作成されるノードの総数は、b + b 2 + b 3 +…+ bdです。
Disadvantage−ノードの各レベルは次のノードを作成するために保存されるため、多くのメモリスペースを消費します。ノードを格納するためのスペース要件は指数関数的です。
その複雑さはノードの数に依存します。重複ノードをチェックできます。

深さ優先探索
これは、LIFOスタックデータ構造を使用して再帰的に実装されます。幅優先法と同じノードのセットを、順序が異なるだけで作成します。
シングルパス上のノードはルートノードからリーフノードまでの各反復で保存されるため、ノードを保存するためのスペース要件は線形です。分岐係数bと深さmの場合、ストレージスペースはbmです。
Disadvantage−このアルゴリズムは終了せず、1つのパスで無限に進行する場合があります。この問題の解決策は、カットオフ深度を選択することです。理想的なカットオフがdであり、選択したカットオフがdより小さい場合、このアルゴリズムは失敗する可能性があります。選択したカットオフがdより大きい場合、実行時間が長くなります。
その複雑さは、パスの数によって異なります。重複ノードはチェックできません。

双方向検索
初期状態から前方に検索し、目標状態から後方に検索して、両方が一致するまで共通の状態を識別します。
初期状態からのパスは、目標状態からの逆パスと連結されます。各検索は、パス全体の半分までしか実行されません。
均一コスト検索
ソートは、ノードへのパスのコストを増加させることで行われます。常に最小コストのノードを拡張します。各遷移のコストが同じである場合、幅優先探索と同じです。
コストの昇順でパスを探索します。
Disadvantage−コストがC *以下の長いパスが複数存在する可能性があります。均一コスト検索では、それらすべてを調査する必要があります。
反復深化深さ-最初の検索
レベル1まで深さ優先探索を実行し、最初からやり直して、レベル2まで完全な深さ優先探索を実行し、解決策が見つかるまでこのように続行します。
すべての下位ノードが生成されるまで、ノードは作成されません。ノードのスタックのみを保存します。深さdで解が見つかると、アルゴリズムは終了します。深さで作成されたノードの数DはBとDと深さでD-1はBであるD-1。
さまざまなアルゴリズムの複雑さの比較
さまざまな基準に基づいたアルゴリズムのパフォーマンスを見てみましょう-
| 基準 | 幅優先 | 深さ優先 | 双方向 | 均一なコスト | インタラクティブな深化 |
|---|---|---|---|---|---|
| 時間 | b d | b m | b d / 2 | b d | b d |
| スペース | b d | b m | b d / 2 | b d | b d |
| 最適性 | はい | 番号 | はい | はい | はい |
| 完全 | はい | 番号 | はい | はい | はい |
情報に基づく(ヒューリスティック)検索戦略
考えられる状態が多数ある大きな問題を解決するには、問題固有の知識を追加して、検索アルゴリズムの効率を高める必要があります。
ヒューリスティック評価関数
それらは、2つの状態間の最適パスのコストを計算します。スライドタイルゲームのヒューリスティック関数は、各タイルがその目標状態から行う移動の数をカウントし、すべてのタイルのこれらの移動数を加算することによって計算されます。
純粋なヒューリスティック検索
ヒューリスティック値の順序でノードを展開します。すでに展開されているノードのクローズドリストと、作成されているが展開されていないノードのオープンリストの2つのリストが作成されます。
各反復で、ヒューリスティック値が最小のノードが展開され、そのすべての子ノードが作成され、クローズドリストに配置されます。次に、ヒューリスティック関数が子ノードに適用され、ヒューリスティック値に従ってオープンリストに配置されます。短いパスは保存され、長いパスは破棄されます。
検索
これは、最良優先探索の最もよく知られた形式です。すでに高価なパスの拡張を回避しますが、最も有望なパスを最初に拡張します。
f(n)= g(n)+ h(n)、ここで
- g(n)ノードに到達するための(これまでの)コスト
- h(n)ノードからゴールに到達するための推定コスト
- f(n)nから目標までのパスの推定総コスト。f(n)を増やすことにより、優先度付きキューを使用して実装されます。
貪欲な最良優先探索
目標に最も近いと推定されるノードを拡張します。f(n)= h(n)に基づいてノードを拡張します。優先キューを使用して実装されます。
Disadvantage−ループに陥る可能性があります。最適ではありません。
ローカル検索アルゴリズム
それらは、将来のソリューションから開始し、次に隣接するソリューションに移動します。終了する前にいつでも中断された場合でも、有効なソリューションを返すことができます。
山登り検索
これは、問題の任意の解決策から始まり、解決策の1つの要素を段階的に変更することによって、より良い解決策を見つけようとする反復アルゴリズムです。変更によってより良いソリューションが生成される場合は、増分変更が新しいソリューションと見なされます。このプロセスは、それ以上の改善がなくなるまで繰り返されます。
関数Hill-Climbing(problem)は、極大値である状態を返します。
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage −このアルゴリズムは完全でも、最適でもありません。
ローカルビーム検索
このアルゴリズムでは、任意の時点でk個の状態を保持します。最初に、これらの状態はランダムに生成されます。これらのk状態の後続は、目的関数の助けを借りて計算されます。これらの後継者のいずれかが目的関数の最大値である場合、アルゴリズムは停止します。
それ以外の場合、(初期のk個の状態と状態の後続のk個= 2k)状態がプールに配置されます。次に、プールは数値でソートされます。最高のk状態が新しい初期状態として選択されます。このプロセスは、最大値に達するまで続きます。
関数BeamSearch(problem、k)は、解の状態を返します。
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
end焼き鈍し法
アニーリングは、金属を加熱および冷却して内部構造を変更し、その物理的特性を変更するプロセスです。金属が冷えると、その新しい構造が押収され、金属は新しく得られた特性を保持します。シミュレーテッドアニーリングプロセスでは、温度は可変に保たれます。
最初に温度を高く設定し、アルゴリズムが進むにつれてゆっくりと「冷却」します。温度が高い場合、アルゴリズムはより悪い解を高頻度で受け入れることができます。
開始
- k = 0を初期化します。L =変数の整数。
- i→jから性能差Δを求めます。
- Δ<= 0の場合は受け入れ、exp(-Δ/ T(k))> random(0,1)の場合は受け入れます。
- L(k)ステップについて、ステップ1と2を繰り返します。
- k = k + 1;
基準が満たされるまで、手順1〜4を繰り返します。
終わり
巡回セールスマン問題
このアルゴリズムの目的は、都市から始まり、途中ですべての都市を1回だけ訪問し、同じ開始都市で終わる低コストのツアーを見つけることです。
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
ファジー論理システム(FLS)は、不完全、あいまい、歪んだ、または不正確な(ファジー)入力に応答して、許容できるが明確な出力を生成します。
ファジーロジックとは何ですか?
ファジー論理(FL)は、人間の推論に似た推論の方法です。FLのアプローチは、デジタル値YESとNOの間のすべての中間的な可能性を含む人間の意思決定の方法を模倣します。
コンピュータが理解できる従来の論理ブロックは、正確な入力を受け取り、TRUEまたはFALSEとして明確な出力を生成します。これは、人間のYESまたはNOに相当します。
ファジー論理の発明者であるLotfiZadehは、コンピューターとは異なり、人間の意思決定には、次のようなYESとNOの間のさまざまな可能性が含まれていることを観察しました。
| 確かにそう |
| おそらくはい |
| 言うことはできません |
| おそらくいいえ |
| 確かにありません |
ファジーロジックは、明確な出力を実現するために、入力の可能性のレベルで機能します。
実装
小型のマイクロコントローラーから大規模なネットワーク化されたワークステーションベースの制御システムまで、さまざまなサイズと機能を備えたシステムに実装できます。
ハードウェア、ソフトウェア、または両方の組み合わせで実装できます。
なぜファジーロジックなのか?
ファジー論理は、商業的および実用的な目的に役立ちます。
- 機械や消費者製品を制御できます。
- それは正確な推論を与えないかもしれませんが、許容できる推論を与えます。
- ファジー論理は、エンジニアリングの不確実性に対処するのに役立ちます。
ファジー論理システムアーキテクチャ
図のように4つの主要部分があります-
Fuzzification Module−鮮明な数値であるシステム入力をファジー集合に変換します。入力信号を次のような5つのステップに分割します。
| LP | xはラージポジティブ |
| MP | xはミディアムポジティブ |
| S | xは小さい |
| MN | xはミディアムネガティブです |
| LN | xはラージネガティブ |
Knowledge Base −専門家によって提供されたIF-THENルールを格納します。
Inference Engine −入力とIF-THENルールにファジー推論を行うことにより、人間の推論プロセスをシミュレートします。
Defuzzification Module −推論エンジンによって取得されたファジーセットを鮮明な値に変換します。

ザ・ membership functions work on 変数のファジー集合。
メンバーシップ機能
メンバーシップ関数を使用すると、言語用語を定量化し、ファジーセットをグラフィカルに表すことができます。Amembership functionファジィための集合A談話Xの宇宙におけるμのように定義されるA:X→[0,1]。
ここで、Xの各要素は0から1までの値にマップされます。membership value または degree of membership。これは、Xの要素のファジー集合Aに対するメンバーシップの程度を定量化します。
- x軸は論議領界を表します。
- y軸は、[0、1]間隔のメンバーシップの程度を表します。
数値をファジー化するために適用可能な複数のメンバーシップ関数が存在する可能性があります。複雑な関数を使用しても出力の精度が向上しないため、単純なメンバーシップ関数が使用されます。
のすべてのメンバーシップ関数 LP, MP, S, MN, そして LN 以下のように表示されます-

三角形のメンバーシップ関数の形状は、台形、シングルトン、ガウスなど、他のさまざまなメンバーシップ関数の形状の中で最も一般的です。
ここで、5レベルファジファイアへの入力は-10ボルトから+10ボルトまで変化します。したがって、対応する出力も変更されます。
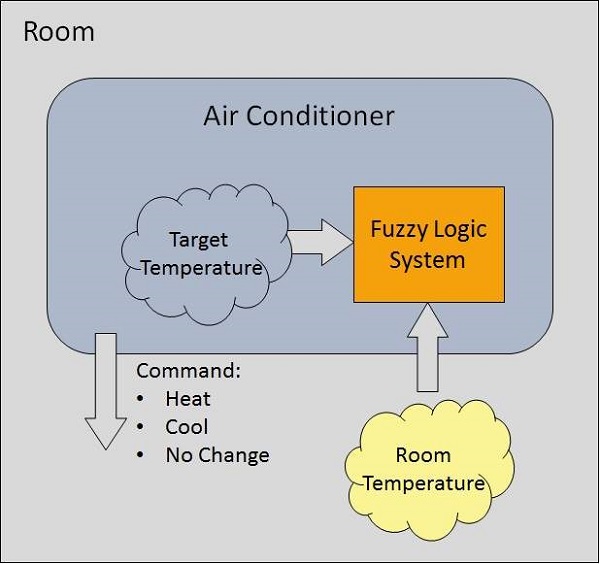
ファジー論理システムの例
5レベルのファジー論理システムを備えた空調システムを考えてみましょう。このシステムは、室温と目標温度値を比較することにより、エアコンの温度を調整します。
アルゴリズム
- 言語変数と用語を定義する(開始)
- それらのメンバーシップ関数を作成します。(開始)
- ルールの知識ベースを構築する(開始)
- メンバーシップ関数を使用して、鮮明なデータをファジーデータセットに変換します。(ファジー化)
- ルールベースでルールを評価します。(推論エンジン)
- 各ルールの結果を組み合わせます。(推論エンジン)
- 出力データをファジーでない値に変換します。(非ファジー化)
開発
Step 1 − Define linguistic variables and terms
言語変数は、単純な単語または文の形式の入力変数と出力変数です。室温の場合、冷たい、暖かい、熱いなどは言語用語です。
温度(t)= {非常に冷たい、冷たい、暖かい、非常に暖かい、熱い}
このセットのすべてのメンバーは言語用語であり、全体的な温度値の一部をカバーできます。
Step 2 − Construct membership functions for them
温度変数のメンバーシップ関数は次のとおりです-
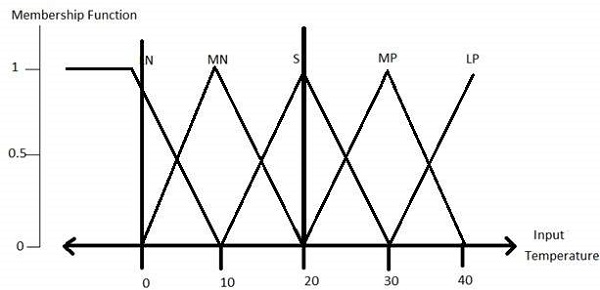
Step3 − Construct knowledge base rules
空調システムが提供すると予想される室温値と目標温度値のマトリックスを作成します。
| 室温。/目標 | とても寒い | コールド | 暖かい | ホット | とても暑い |
|---|---|---|---|---|---|
| とても寒い | 変化なし | 熱 | 熱 | 熱 | 熱 |
| コールド | 涼しい | 変化なし | 熱 | 熱 | 熱 |
| 暖かい | 涼しい | 涼しい | 変化なし | 熱 | 熱 |
| ホット | 涼しい | 涼しい | 涼しい | 変化なし | 熱 |
| とても暑い | 涼しい | 涼しい | 涼しい | 涼しい | 変化なし |
IF-THEN-ELSE構造の形式で、一連のルールをナレッジベースに組み込みます。
| シニア番号 | 状態 | アクション |
|---|---|---|
| 1 | IF Temperature =(Cold OR Very_Cold)AND target = Warm THEN | 熱 |
| 2 | IF Temperature =(Hot OR Very_Hot)AND target = Warm THEN | 涼しい |
| 3 | IF(温度=暖かい)AND(ターゲット=暖かい)THEN | 変化なし |
Step 4 − Obtain fuzzy value
ファジー集合演算は、ルールの評価を実行します。ORとANDに使用される演算は、それぞれ最大と最小です。評価のすべての結果を組み合わせて、最終結果を作成します。この結果はあいまいな値です。
Step 5 − Perform defuzzification
次に、出力変数のメンバーシップ関数に従って非ファジー化が実行されます。

ファジィ論理の応用分野
ファジー論理の主な応用分野は次のとおりです。
Automotive Systems
- 自動変速機
- 4輪ステアリング
- 車両環境制御
Consumer Electronic Goods
- Hi-Fiシステム
- Photocopiers
- スチルカメラとビデオカメラ
- Television
Domestic Goods
- 電子レンジ
- Refrigerators
- Toasters
- 掃除機
- 洗濯機
Environment Control
- エアコン/乾燥機/ヒーター
- Humidifiers
FLSの利点
ファジー推論内の数学的概念は非常に単純です。
ファジーロジックの柔軟性により、ルールを追加または削除するだけでFLSを変更できます。
ファジー論理システムは、不正確で歪んだノイズの多い入力情報を受け取る可能性があります。
FLSは、構築と理解が容易です。
ファジー論理は、人間の推論や意思決定に似ているため、医学を含むすべての生活分野における複雑な問題の解決策です。
FLSのデメリット
- ファジーシステム設計への体系的なアプローチはありません。
- それらは単純な場合にのみ理解できます。
- 高精度を必要としない問題に適しています。
自然言語処理(NLP)は、英語などの自然言語を使用してインテリジェントシステムと通信するAI方式を指します。
自然言語の処理は、ロボットのようなインテリジェントシステムを指示どおりに実行したい場合、対話ベースの臨床エキスパートシステムからの決定を聞きたい場合などに必要です。
NLPの分野では、人間が使用する自然言語を使用して有用なタスクを実行するコンピューターを作成します。NLPシステムの入力と出力は次のようになります。
- Speech
- 書かれたテキスト
NLPのコンポーネント
与えられたようにNLPの2つのコンポーネントがあります-
自然言語理解(NLU)
理解には以下のタスクが含まれます-
- 自然言語で与えられた入力を有用な表現にマッピングします。
- 言語のさまざまな側面を分析します。
自然言語生成(NLG)
これは、内部表現から自然言語の形で意味のあるフレーズや文を生成するプロセスです。
それは以下を含みます-
Text planning −ナレッジベースから関連コンテンツを取得することも含まれます。
Sentence planning −必要な単語の選択、意味のあるフレーズの形成、文のトーンの設定が含まれます。
Text Realization −文の計画を文の構造にマッピングしています。
NLUはNLGよりも難しいです。
NLUの難しさ
NLは非常に豊かな形と構造を持っています。
非常にあいまいです。あいまいさにはさまざまなレベルがあります-
Lexical ambiguity −単語レベルなどの非常に原始的なレベルです。
たとえば、「ボード」という単語を名詞または動詞として扱いますか?
Syntax Level ambiguity −文はさまざまな方法で解析できます。
たとえば、「彼は赤い帽子でカブトムシを持ち上げました。」−キャップを使ってカブトムシを持ち上げましたか、それとも赤いキャップの付いたカブトムシを持ち上げましたか?
Referential ambiguity−代名詞を使用して何かを参照します。たとえば、リマはガウリに行きました。彼女は「私は疲れています」と言いました。−正確に誰が疲れていますか?
1つの入力は異なる意味を意味する場合があります。
多くの入力は同じことを意味する可能性があります。
NLPの用語
Phonology −音を体系的に整理する研究です。
Morphology −それは原始的な意味のある単位からの単語の構成の研究です。
Morpheme −それは言語における意味の原始的な単位です。
Syntax−文を作るために単語を並べることを指します。また、文やフレーズにおける単語の構造的役割を決定することも含まれます。
Semantics −単語の意味と、単語を意味のあるフレーズや文に組み合わせる方法に関係しています。
Pragmatics −さまざまな状況での文の使用と理解、および文の解釈がどのように影響を受けるかを扱います。
Discourse −直前の文が次の文の解釈にどのように影響するかを扱います。
World Knowledge −世界に関する一般的な知識が含まれています。
NLPの手順
一般的な5つのステップがあります-
Lexical Analysis−単語の構造を特定して分析する必要があります。言語の辞書とは、言語内の単語やフレーズの集まりを意味します。字句解析は、txtのチャンク全体を段落、文、および単語に分割します。
Syntactic Analysis (Parsing)−文章中の単語を文法的に分析し、単語間の関係を示すように配置します。「学校は男の子に行く」などの文は、英語の構文アナライザーによって拒否されます。

Semantic Analysis−テキストから正確な意味または辞書の意味を引き出します。テキストの意味がチェックされます。これは、タスクドメイン内の構文構造とオブジェクトをマッピングすることによって行われます。セマンティックアナライザーは、「ホットアイスクリーム」などの文を無視します。
Discourse Integration−文の意味は、その直前の文の意味によって異なります。また、直後の文の意味も持ちます。
Pragmatic Analysis−この間、言われたことは実際の意味に再解釈されます。それには、現実世界の知識を必要とする言語の側面を導き出すことが含まれます。
構文分析の実装の側面
構文分析のために研究者が開発したアルゴリズムはたくさんありますが、以下の簡単な方法のみを検討します。
- 文脈自由文法
- トップダウンパーサー
それらを詳しく見てみましょう-
文脈自由文法
これは、書き換えルールの左側に1つの記号が付いたルールで構成される文法です。文を解析するための文法を作成しましょう-
「鳥が穀物をつつく」
Articles (DET)− a | | インクルード
Nouns−鳥| 鳥| 穀物| 穀類
Noun Phrase (NP)−冠詞+名詞| 冠詞+形容詞+名詞
= DET N | DET ADJ N
Verbs−ペック| 序列| つついた
Verb Phrase (VP)− NP V | V NP
Adjectives (ADJ)−美しい| 小さい| チャープ
解析ツリーは文を構造化された部分に分解し、コンピューターがそれを簡単に理解して処理できるようにします。解析アルゴリズムがこの解析ツリーを構築するためには、どのツリー構造が合法であるかを記述する一連の書き換えルールを構築する必要があります。
これらのルールは、特定のシンボルが他のシンボルのシーケンスによってツリー内で展開される可能性があることを示しています。一階述語論理によれば、名詞句(NP)と動詞句(VP)の2つの文字列がある場合、NPとそれに続くVPを組み合わせた文字列は文です。文の書き直し規則は次のとおりです-
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET→a | インクルード
ADJ→美しい| 止まる
N→鳥| 鳥| 穀物| 穀類
V→ペック| ペック| つつく
解析ツリーは次のように作成できます-

ここで、上記の書き換えルールについて考えてみましょう。Vは「ペック」または「ペック」の両方に置き換えることができるため、「鳥が穀物をペックする」などの文が誤って許可される可能性があります。つまり、主語と動詞の一致エラーは正しいものとして承認されます。
Merit −最も単純なスタイルの文法、したがって広く使用されているスタイル。
Demerits −
それらは非常に正確ではありません。たとえば、「穀物が鳥をつつく」は、パーサーによれば構文的に正しいですが、意味がない場合でも、パーサーはそれを正しい文と見なします。
高精度を引き出すには、複数の文法セットを用意する必要があります。単数形と複数形のバリエーション、受動態文などを解析するために完全に異なるルールのセットが必要になる場合があります。これにより、管理できない膨大なルールのセットが作成される可能性があります。
トップダウンパーサー
ここで、パーサーはS記号で始まり、完全に終端記号で構成されるまで、入力文の単語のクラスに一致する終端記号のシーケンスに書き直そうとします。
次に、これらは入力文でチェックされ、一致するかどうかが確認されます。そうでない場合は、別のルールセットを使用してプロセスを最初からやり直します。これは、文の構造を説明する特定のルールが見つかるまで繰り返されます。
Merit −実装は簡単です。
Demerits −
- エラーが発生した場合は検索プロセスを繰り返す必要があるため、非効率的です。
- 作業速度が遅い。
エキスパートシステム(ES)は、AIの著名な研究領域の1つです。スタンフォード大学コンピュータサイエンス学部の研究者によって紹介されました。
エキスパートシステムとは何ですか?
エキスパートシステムは、特定のドメインの複雑な問題を、並外れた人間の知性と専門知識のレベルで解決するために開発されたコンピュータアプリケーションです。
エキスパートシステムの特徴
- ハイパフォーマンス
- Understandable
- Reliable
- 応答性が高い
エキスパートシステムの機能
エキスパートシステムは次のことができます-
- Advising
- 意思決定における人間の指導と支援
- Demonstrating
- ソリューションの導出
- Diagnosing
- Explaining
- 入力の解釈
- 結果の予測
- 結論を正当化する
- 問題に対する代替オプションの提案
彼らはすることができません-
- 人間の意思決定者の交代
- 人間の能力を持っている
- 不十分な知識ベースに対して正確な出力を生成する
- 自分の知識を磨く
エキスパートシステムのコンポーネント
ESのコンポーネントは次のとおりです。
- 知識ベース
- 推論エンジン
- ユーザーインターフェース
それらを1つずつ簡単に見てみましょう-

知識ベース
ドメイン固有の高品質な知識が含まれています。
知性を発揮するには知識が必要です。ESの成功は、主に非常に正確で正確な知識の収集に依存します。
知識とは何ですか?
データは事実の収集です。情報は、タスクドメインに関するデータと事実として編成されています。Data, information, そして past experience 一緒に組み合わされたものは知識と呼ばれます。
ナレッジベースのコンポーネント
ESの知識ベースは、事実とヒューリスティックの両方の知識のストアです。
Factual Knowledge −これは、タスクドメインの知識エンジニアや学者によって広く受け入れられている情報です。
Heuristic Knowledge −それは、練習、正確な判断、評価の能力、そして推測についてです。
知識表現
これは、知識ベースで知識を整理および形式化するために使用される方法です。これは、IF-THEN-ELSEルールの形式です。
知識の獲得
エキスパートシステムの成功は、知識ベースに保存されている情報の品質、完全性、および正確さに大きく依存します。
知識ベースは、さまざまな専門家、学者、および Knowledge Engineers。知識エンジニアは、共感、迅速な学習、およびケース分析のスキルを備えた人物です。
彼は、対象分野の専門家から、職場での記録、インタビュー、観察などによって情報を取得します。次に、干渉マシンで使用されるように、情報を意味のある方法で分類および整理します。知識エンジニアは、ESの開発も監視します。
推論エンジン
推論エンジンによる効率的な手順とルールの使用は、正確で完璧なソリューションを差し引くために不可欠です。
知識ベースのESの場合、推論エンジンは知識ベースから知識を取得して操作し、特定のソリューションに到達します。
ルールベースのESの場合、それは−
以前のルール適用から取得したファクトにルールを繰り返し適用します。
必要に応じて、ナレッジベースに新しいナレッジを追加します。
複数のルールが特定のケースに適用できる場合のルールの競合を解決します。
解決策を推奨するために、推論エンジンは次の戦略を使用します-
- 前向き連鎖
- 後向き連鎖
前向き連鎖
質問に答えるのはエキスパートシステムの戦略です、 “What can happen next?”
ここで、推論エンジンは条件と派生のチェーンをたどり、最終的に結果を推測します。それはすべての事実と規則を考慮し、解決策を結論付ける前にそれらを分類します。
この戦略は、結論、結果、または効果に取り組むために続きます。たとえば、金利の変化の影響としての株式市場の状況の予測。

後向き連鎖
この戦略で、エキスパートシステムは質問への答えを見つけます、 “Why this happened?”
すでに起こったことに基づいて、推論エンジンは、この結果に対して過去に起こった可能性のある条件を見つけようとします。この戦略は、原因または理由を見つけるために実行されます。たとえば、人間の血液がんの診断。
ユーザーインターフェース
ユーザーインターフェイスは、ESのユーザーとES自体の間の相互作用を提供します。タスクドメインに精通しているユーザーが使用できるように、一般的に自然言語処理です。ESのユーザーは、必ずしも人工知能の専門家である必要はありません。
ESがどのようにして特定の推奨事項に到達したかを説明します。説明は次の形式で表示される場合があります-
- 画面に表示される自然言語。
- 自然言語での口頭のナレーション。
- 画面に表示されるルール番号のリスト。
ユーザーインターフェイスにより、控除の信頼性を簡単に追跡できます。
効率的なESユーザーインターフェイスの要件
これは、ユーザーが可能な限り短い方法で目標を達成するのに役立つはずです。
これは、ユーザーの既存または望ましい作業慣行に合わせて機能するように設計する必要があります。
そのテクノロジーは、ユーザーの要件に適応できる必要があります。逆ではありません。
ユーザー入力を効率的に利用する必要があります。
エキスパートシステムの制限
簡単で完全なソリューションを提供できるテクノロジーはありません。大規模なシステムはコストがかかり、かなりの開発時間とコンピューターリソースを必要とします。ESには、次のような制限があります。
- テクノロジーの限界
- 知識の習得が難しい
- ESの維持が難しい
- 高い開発コスト
エキスパートシステムの応用
次の表は、ESを適用できる場所を示しています。
| 応用 | 説明 |
|---|---|
| デザインドメイン | カメラレンズデザイン、自動車デザイン。 |
| 医療分野 | 観察されたデータから病気の原因を推測する診断システム、人間の医療活動を実施します。 |
| 監視システム | 観測されたシステムまたは長い石油パイプラインでの漏れ監視などの規定された動作とデータを継続的に比較します。 |
| プロセス制御システム | 監視に基づいて物理プロセスを制御します。 |
| ナレッジドメイン | 車両、コンピューターの故障を見つける。 |
| ファイナンス/コマース | 詐欺の可能性、疑わしい取引、株式市場の取引、航空会社のスケジューリング、貨物のスケジューリングの検出。 |
エキスパートシステム技術
利用可能なESテクノロジーにはいくつかのレベルがあります。エキスパートシステム技術には以下が含まれます-
Expert System Development Environment− ES開発環境には、ハードウェアとツールが含まれます。彼らは-
ワークステーション、ミニコンピューター、メインフレーム。
次のような高レベルのシンボリックプログラミング言語 LISt Programming(LISP)と PROグラメーションen LOGique(PROLOG)。
大規模なデータベース。
Tools −エキスパートシステムの開発に伴う労力とコストを大幅に削減します。
マルチウィンドウを備えた強力なエディターとデバッグツール。
それらはラピッドプロトタイピングを提供します
モデル、知識表現、および推論設計の定義を組み込みます。
Shells−シェルは、知識ベースのないエキスパートシステムに他なりません。シェルは、開発者に知識獲得、推論エンジン、ユーザーインターフェイス、および説明機能を提供します。たとえば、いくつかのシェルが以下に示されています-
エキスパートシステムを作成するための完全に開発されたJavaAPIを提供するJavaエキスパートシステムシェル(JESS)。
Vidwanは、1993年にムンバイのNational Center for Software Technologyで開発されたシェルです。これにより、IF-THENルールの形式での知識のエンコードが可能になります。
エキスパートシステムの開発:一般的なステップ
ES開発のプロセスは反復的です。ESを開発する手順は次のとおりです。
問題のあるドメインを特定する
- 問題は、それを解決するエキスパートシステムに適している必要があります。
- ESプロジェクトのタスクドメインの専門家を見つけます。
- システムの費用対効果を確立します。
システムの設計
ESテクノロジーを特定する
他のシステムやデータベースとの統合の程度を知り、確立します。
概念がドメイン知識を最もよく表すことができる方法を理解してください。
プロトタイプを開発する
ナレッジベースから:ナレッジエンジニアは次のことを行います-
- 専門家からドメイン知識を取得します。
- If-THEN-ELSEルールの形式で表現します。
プロトタイプのテストと改良
知識エンジニアは、サンプルケースを使用して、パフォーマンスの欠陥についてプロトタイプをテストします。
エンドユーザーはESのプロトタイプをテストします。
ESを開発して完成させる
ESと、エンドユーザー、データベース、その他の情報システムなど、環境のすべての要素との相互作用をテストして確認します。
ESプロジェクトを適切に文書化します。
ESを使用するようにユーザーをトレーニングします。
システムの保守
定期的なレビューと更新により、ナレッジベースを最新の状態に保ちます。
他の情報システムが進化するにつれて、それらのシステムとの新しいインターフェースに対応します。
エキスパートシステムの利点
Availability −ソフトウェアの大量生産により、容易に入手できます。
Less Production Cost−製造コストはリーズナブルです。これにより、手頃な価格になります。
Speed−彼らは素晴らしいスピードを提供します。それらは、個人が投入する作業の量を減らします。
Less Error Rate −ヒューマンエラーに比べてエラー率が低い。
Reducing Risk −人体に危険な環境で働くことができます。
Steady response −動き、緊張、倦怠感を感じることなく、着実に機能します。
ロボット工学は、インテリジェントで効率的なロボットの作成の研究を扱う人工知能の分野です。
ロボットとは?
ロボットは、実世界の環境で動作する人工エージェントです。
目的
ロボットは、オブジェクトの物理的特性を認識、選択、移動、変更、破壊することによってオブジェクトを操作すること、またはそれによって人員が退屈したり、気を散らしたり、疲れたりすることなく反復的な機能を実行することから解放することを目的としています。
ロボティクスとは何ですか?
ロボット工学はAIの一部門であり、ロボットの設計、構築、および応用のための電気工学、機械工学、およびコンピューターサイエンスで構成されています。
ロボット工学の側面
ロボットは持っています mechanical construction、フォーム、または特定のタスクを実行するために設計された形状。
彼らは持っている electrical components 機械に電力を供給し、制御します。
それらはいくつかのレベルを含んでいます computer program それは、ロボットが何を、いつ、どのように行うかを決定します。
ロボットシステムと他のAIプログラムの違い
これが2つの違いです-
| AIプログラム | ロボット |
|---|---|
| それらは通常、コンピューターで刺激された世界で動作します。 | それらは実際の物理世界で動作します |
| AIプログラムへの入力は、記号とルールで行われます。 | ロボットへの入力は、音声波形または画像の形式のアナログ信号です。 |
| それらを操作するには、汎用コンピューターが必要です。 | センサーとエフェクターを備えた特別なハードウェアが必要です。 |
ロボット移動
移動は、ロボットがその環境内を移動できるようにするメカニズムです。移動にはさまざまな種類があります-
- Legged
- Wheeled
- 脚と車輪付きの移動の組み合わせ
- 追跡されたスリップ/スキッド
脚のある移動
このタイプの移動は、歩行、ジャンプ、速歩、ホップ、上り下りなどを実演しながら、より多くの電力を消費します。
動きを実現するには、より多くのモーターが必要です。不規則または滑らかすぎる表面により、車輪付きの移動により多くの電力を消費する、起伏の多い地形や滑らかな地形に適しています。安定性の問題があるため、実装は少し難しいです。
1本、2本、4本、6本のさまざまな脚が付属しています。ロボットに複数の脚がある場合、移動には脚の調整が必要です。
可能な総数 gaits (脚全体のそれぞれのリフトおよびリリースイベントの定期的なシーケンス)ロボットが移動できるのは、脚の数によって異なります。
ロボットにk個の脚がある場合、可能なイベントの数N =(2k-1)!。
二足歩行ロボット(k = 2)の場合、可能なイベントの数はN =(2k-1)です!=(2 * 2-1)!= 3!= 6。
したがって、6つの異なるイベントが考えられます-
- 左足を持ち上げる
- 左足を離す
- 右足を持ち上げる
- 右足を離す
- 両足を一緒に持ち上げる
- 両方の足を一緒に解放します
k = 6レッグの場合、39916800の可能なイベントがあります。したがって、ロボットの複雑さは脚の数に正比例します。

車輪付き移動
動きを実現するために必要なモーターの数が少なくて済みます。ホイールの数が多いほど安定性の問題が少なくなるため、実装は少し簡単です。脚のある移動に比べて電力効率が良いです。
Standard wheel −ホイールアクスルとコンタクトの周りを回転します
Castor wheel −ホイールアクスルとオフセットステアリングジョイントを中心に回転します。
Swedish 45o and Swedish 90o wheels −オムニホイール、接触点の周り、ホイールの車軸の周り、およびローラーの周りを回転します。
Ball or spherical wheel −技術的に実装が難しい全方向ホイール。

スリップ/スキッドロコモーション
このタイプでは、車両は戦車のようにトラックを使用します。ロボットは、同じ方向または反対方向に異なる速度でトラックを動かすことによって操縦されます。線路と地面の接触面積が大きいため、安定性があります。

ロボットのコンポーネント
ロボットは次のように構成されています-
Power Supply −ロボットは、バッテリー、太陽光発電、油圧、または空気圧の電源から電力を供給されます。
Actuators −エネルギーを動きに変換します。
Electric motors (AC/DC) −回転運動に必要です。
Pneumatic Air Muscles −空気を吸い込むと約40%収縮します。
Muscle Wires −電流を流すと5%収縮します。
Piezo Motors and Ultrasonic Motors −産業用ロボットに最適です。
Sensors−タスク環境に関するリアルタイム情報の知識を提供します。ロボットには、環境の深さを計算するための視覚センサーが装備されています。触覚センサーは、人間の指先のタッチ受容器の機械的特性を模倣します。
コンピュータビジョン
これは、ロボットが見ることができるAIの技術です。コンピュータビジョンは、安全、セキュリティ、健康、アクセス、および娯楽の分野で重要な役割を果たします。
コンピュータビジョンは、単一の画像または画像の配列から有用な情報を自動的に抽出、分析、および理解します。このプロセスには、自動視覚理解を実現するためのアルゴリズムの開発が含まれます。
コンピュータビジョンシステムのハードウェア
これには以下が含まれます-
- 電源
- カメラなどの画像取得デバイス
- プロセッサ
- ソフトウェア
- システムを監視するための表示装置
- カメラスタンド、ケーブル、コネクタなどのアクセサリ
コンピュータビジョンのタスク
OCR −コンピューターの分野では、スキャンしたドキュメントを編集可能なテキストに変換するソフトウェアである光学式文字リーダーがスキャナーに付属しています。
Face Detection−多くの最先端カメラにはこの機能が搭載されており、顔を読み取ってその完璧な表情を撮影することができます。これは、ユーザーが正しい一致でソフトウェアにアクセスできるようにするために使用されます。
Object Recognition −スーパーマーケット、カメラ、BMW、GM、ボルボなどの高級車に搭載されています。
Estimating Position −人体の腫瘍の位置と同様に、カメラに対する物体の位置を推定しています。
コンピュータビジョンのアプリケーションドメイン
- Agriculture
- 自動運転車
- Biometrics
- 文字認識
- フォレンジック、セキュリティ、および監視
- 工業品質検査
- 顔認識
- ジェスチャー分析
- Geoscience
- 医用画像
- 汚染モニタリング
- プロセス制御
- リモートセンシング
- Robotics
- Transport
ロボット工学の応用
ロボット工学は、次のようなさまざまな分野で役立ってきました。
Industries −ロボットは、材料の取り扱い、切断、溶接、カラーコーティング、穴あけ、研磨などに使用されます。
Military−自律型ロボットは、戦争中にアクセスできない危険なゾーンに到達する可能性があります。防衛研究開発機構(DRDO)によって開発されたDakshという名前のロボットは、生命を脅かす物体を安全に破壊するために機能しています。
Medicine −ロボットは、数百の臨床試験を同時に実行し、恒久的な障害者をリハビリし、脳腫瘍などの複雑な手術を行うことができます。
Exploration −宇宙探査に使用されるロボットロッククライマー、海洋探査に使用される水中ドローンなどがその例です。
Entertainment −ディズニーのエンジニアは、映画製作用に何百ものロボットを作成しました。
AIのさらに別の研究分野であるニューラルネットワークは、人間の神経系の自然なニューラルネットワークから着想を得ています。
人工ニューラルネットワーク(ANN)とは何ですか?
最初のニューロコンピューターの発明者であるロバート・ヘクト・ニールセン博士は、ニューラルネットワークを次のように定義しています。
「...外部入力への動的な状態応答によって情報を処理する、多数の単純で高度に相互接続された処理要素で構成されるコンピューティングシステム。」
ANNの基本構造
ANNのアイデアは、正しい接続を行うことによる人間の脳の働きは、シリコンとワイヤーを生き物として使用して模倣できるという信念に基づいています。 neurons そして dendrites。
人間の脳は860億の神経細胞で構成されています neurons. それらは他の千のセルに接続されています Axons.外部環境からの刺激または感覚器官からの入力は、樹状突起によって受け入れられます。これらの入力は電気インパルスを生成し、ニューラルネットワークをすばやく通過します。その後、ニューロンはメッセージを他のニューロンに送信して問題を処理するか、メッセージを転送しません。

ANNは複数で構成されています nodes、生物学的模倣 neurons人間の脳の。ニューロンはリンクによって接続されており、相互作用します。ノードは入力データを受け取り、そのデータに対して簡単な操作を実行できます。これらの操作の結果は他のニューロンに渡されます。各ノードでの出力は、activation または node value.
各リンクはに関連付けられています weight.ANNは、重み値を変更することによって行われる学習が可能です。次の図は、単純なANN-を示しています。

人工ニューラルネットワークの種類
2つの人工ニューラルネットワークトポロジがあります- FeedForward そして Feedback.
FeedForward ANN
このANNでは、情報の流れは単方向です。ユニットは、情報を受信しない他のユニットに情報を送信します。フィードバックループはありません。これらは、パターンの生成/認識/分類に使用されます。それらは固定の入力と出力を持っています。
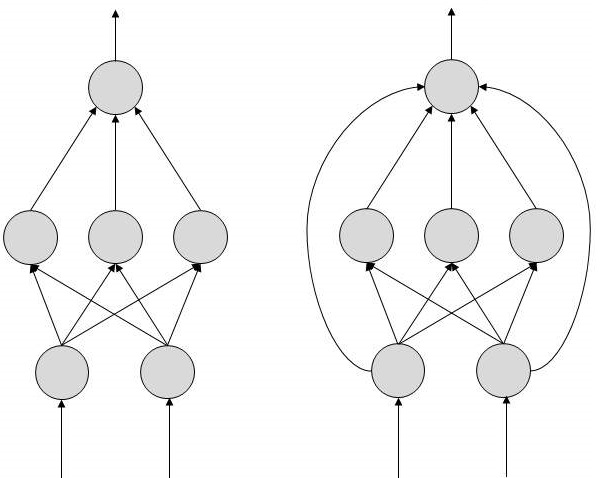
フィードバックANN
ここでは、フィードバックループが許可されています。それらは連想メモリで使用されます。
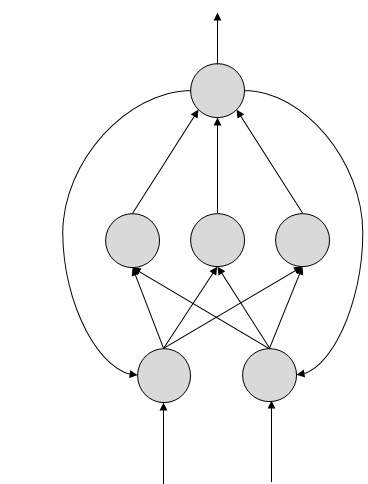
ANNの働き
示されているトポロジー図では、各矢印は2つのニューロン間の接続を表し、情報の流れの経路を示しています。各接続には重みがあり、2つのニューロン間の信号を制御する整数です。
ネットワークが「良好または望ましい」出力を生成する場合、重みを調整する必要はありません。ただし、ネットワークが「不十分または望ましくない」出力またはエラーを生成した場合、システムはその後の結果を改善するために重みを変更します。
ANNでの機械学習
ANNは学習することができ、訓練を受ける必要があります。いくつかの学習戦略があります-
Supervised Learning−それはANN自体よりも学者である教師を含みます。たとえば、教師は、教師がすでに回答を知っているいくつかのサンプルデータをフィードします。
たとえば、パターン認識。ANNは認識しながら推測を思い付きます。次に、教師はANNに回答を提供します。次に、ネットワークは推測を教師の「正解」と比較し、エラーに応じて調整を行います。
Unsupervised Learning−既知の回答を持つサンプルデータセットがない場合に必要です。たとえば、非表示のパターンを検索します。この場合、クラスタリング、つまり要素のセットを未知のパターンに従ってグループに分割することは、存在する既存のデータセットに基づいて実行されます。
Reinforcement Learning−この戦略は観察に基づいて構築されました。ANNは、その環境を観察することによって決定を下します。観測値が負の場合、ネットワークはその重みを調整して、次回に必要な別の決定を下せるようにします。
バックプロパゲーションアルゴリズム
これは、トレーニングまたは学習アルゴリズムです。例によって学びます。ネットワークに実行させたいことの例をアルゴリズムに送信すると、ネットワークの重みが変更され、トレーニングの終了時に特定の入力に対して目的の出力を生成できるようになります。
バックプロパゲーションネットワークは、単純なパターン認識およびマッピングタスクに最適です。
ベイジアンネットワーク(BN)
これらは、確率変数のセット間の確率的関係を表すために使用されるグラフィカル構造です。ベイジアンネットワークは、Belief Networks または Bayes Nets. BNは不確実なドメインについて推論します。
これらのネットワークでは、各ノードは特定の命題を持つ確率変数を表します。たとえば、医療診断ドメインでは、ノードCancerは患者が癌を持っているという命題を表します。
ノードを接続するエッジは、これらの確率変数間の確率的依存関係を表します。2つのノードのうち、一方が他方に影響を与えている場合、それらは影響の方向に直接接続されている必要があります。変数間の関係の強さは、各ノードに関連付けられた確率によって定量化されます。
BN内のアークには、有向アークをたどるだけではノードに戻れないという唯一の制約があります。したがって、BNは有向非巡回グラフ(DAG)と呼ばれます。
BNは、複数値の変数を同時に処理できます。BN変数は2つの次元で構成されています-
- 前置詞の範囲
- 各前置詞に割り当てられた確率。
離散確率変数の有限集合X = {X 1、X 2、…、Xn }を考えます。ここで、各変数X iは、Val(X i)で表される有限集合から値をとることができます。変数からの有向リンクがある場合はX I変数に、Xのjは、その後、変数Xは、iが変数の親になるのX jの変数間の直接の依存関係を示します。
BNの構造は、事前の知識と観測データを組み合わせるのに理想的です。BNを使用すると、因果関係を学習し、さまざまな問題領域を理解し、データが欠落している場合でも将来のイベントを予測できます。
ベイジアンネットワークの構築
知識エンジニアはベイジアンネットワークを構築できます。知識エンジニアがそれを構築する際に取らなければならないいくつかのステップがあります。
Example problem−肺がん。患者は息切れに苦しんでいます。彼は肺がんの疑いで医者を訪ねた。医師は、肺がんを除いて、結核や気管支炎など、患者が抱える可能性のある他のさまざまな病気があることを知っています。
Gather Relevant Information of Problem
- 患者は喫煙者ですか?はいの場合、癌と気管支炎の可能性が高くなります。
- 患者は大気汚染にさらされていますか?はいの場合、どのような大気汚染ですか?
- X線を撮ると陽性のX線はTBまたは肺がんのいずれかを示します。
Identify Interesting Variables
知識エンジニアは質問に答えようとします-
- どのノードを表しますか?
- 彼らはどのような価値観をとることができますか?彼らはどの状態になりますか?
とりあえず、離散値のみのノードについて考えてみましょう。変数は、一度にこれらの値の1つだけを取る必要があります。
Common types of discrete nodes are −
Boolean nodes −これらは命題を表し、2進値TRUE(T)およびFALSE(F)を取ります。
Ordered values−ノード汚染は、患者の汚染への曝露の程度を表す{低、中、高}の値を表し、取得する場合があります。
Integral values− Ageと呼ばれるノードは、1〜120の可能な値で患者の年齢を表す場合があります。この初期段階でも、モデリングの選択が行われています。
肺がんの例で考えられるノードと値-
| ノード名 | タイプ | 値 | ノードの作成 |
|---|---|---|---|
| 汚染 | バイナリ | {低、高、中} |

|
| 喫煙者 | ブール値 | {TRUE、FASLE} | |
| 肺がん | ブール値 | {TRUE、FASLE} | |
| X線 | バイナリ | {ポジティブ、ネガティブ} |
Create Arcs between Nodes
ネットワークのトポロジは、変数間の定性的な関係をキャプチャする必要があります。
たとえば、患者が肺がんになる原因は何ですか?-汚染と喫煙。次に、ノードPollutionとノードSmokerからノードLung-Cancerにアークを追加します。
同様に、患者が肺がんを患っている場合、X線の結果は陽性になります。次に、ノードLung-CancerからノードX-Rayにアークを追加します。

Specify Topology
従来、BNは、円弧が上から下を向くように配置されていました。ノードXの親ノードのセットは、Parents(X)によって与えられます。
肺癌:ノードは、二つの親(理由または原因)が汚染及び喫煙者ノードが、喫煙者でありますancestorノードX線の。同様に、X線はノードLung-Cancerの子(結果または影響)であり、successorノードの喫煙者と汚染。
Conditional Probabilities
次に、接続されたノード間の関係を定量化します。これは、各ノードの条件付き確率分布を指定することによって行われます。ここでは離散変数のみが考慮されるため、これは次の形式を取ります。Conditional Probability Table (CPT).
まず、ノードごとに、それらの親ノードの値の可能なすべての組み合わせを調べる必要があります。そのような組み合わせはそれぞれ、instantiation親セットの。親ノード値の個別のインスタンス化ごとに、子が取る確率を指定する必要があります。
例えば、肺癌ノードの親は汚染および喫煙。それらは可能な値= {(H、T)、(H、F)、(L、T)、(L、F)}を取ります。CPTは、これらの各症例のがんの確率をそれぞれ<0.05、0.02、0.03、0.001>と指定しています。
各ノードには、次のように関連付けられた条件付き確率があります-

ニューラルネットワークの応用
人間には簡単だが機械には難しいタスクを実行できます-
Aerospace −自動操縦航空機、航空機の故障検出。
Automotive −自動車案内システム。
Military −武器の向きと操縦、ターゲットトラッキング、オブジェクトの識別、顔認識、信号/画像の識別。
Electronics −コードシーケンス予測、ICチップレイアウト、チップ障害分析、マシンビジョン、音声合成。
Financial −不動産鑑定、ローンアドバイザー、住宅ローン審査、社債格付け、ポートフォリオ取引プログラム、企業財務分析、通貨価値予測、ドキュメントリーダー、クレジットアプリケーション評価者。
Industrial −製造プロセス管理、製品設計と分析、品質検査システム、溶接品質分析、紙品質予測、化学製品設計分析、化学プロセスシステムの動的モデリング、機械保守分析、プロジェクト入札、計画、および管理。
Medical −がん細胞分析、EEGおよびECG分析、補綴物の設計、移植時間オプティマイザー。
Speech −音声認識、音声分類、テキストから音声への変換。
Telecommunications −画像とデータの圧縮、自動化された情報サービス、リアルタイムの音声言語翻訳。
Transportation −トラックブレーキシステムの診断、車両のスケジューリング、ルーティングシステム。
Software −顔認識、光学式文字認識などのパターン認識。
Time Series Prediction − ANNは、資源と自然災害の予測を行うために使用されます。
Signal Processing −ニューラルネットワークは、オーディオ信号を処理し、補聴器で適切にフィルタリングするようにトレーニングできます。
Control − ANNは、物理的な車両の操舵決定を行うためによく使用されます。
Anomaly Detection − ANNはパターンの認識に精通しているため、パターンに適合しない異常が発生したときに出力を生成するようにトレーニングすることもできます。
AIはそのような信じられないほどのスピードで開発されており、時には魔法のように見えます。研究者や開発者の間では、AIが非常に強くなり、人間が制御するのが困難になる可能性があるという意見があります。
人間は、人間自身が脅威にさらされているように見える可能性のあるすべてのインテリジェンスを導入することによってAIシステムを開発しました。
プライバシーへの脅威
音声を認識し、自然言語を理解するAIプログラムは、理論的には電子メールや電話での各会話を理解することができます。
人間の尊厳への脅威
AIシステムは、すでにいくつかの業界で人間に取って代わり始めています。それは、看護、外科医、裁判官、警察官などの倫理に関係する威厳のある地位を保持している分野の人々に取って代わるべきではありません。
安全への脅威
自己改善型AIシステムは、人間よりも強力になる可能性があり、目標の達成を阻止するのが非常に困難になる可能性があり、意図しない結果につながる可能性があります。
AIの領域で頻繁に使用される用語のリストは次のとおりです-
| シニア番号 | 用語と意味 |
|---|---|
| 1 | Agent エージェントは、1つまたは複数の目標に向けられた自律的で目的のある推論が可能なシステムまたはソフトウェアプログラムです。彼らは、アシスタント、ブローカー、ボット、ドロイド、インテリジェントエージェント、ソフトウェアエージェントとも呼ばれます。 |
| 2 | Autonomous Robot 外部制御や影響を受けず、独立して制御できるロボット。 |
| 3 | Backward Chaining 問題の理由/原因のために後方に取り組む戦略。 |
| 4 | Blackboard これは、協力するエキスパートシステム間の通信に使用されるコンピュータ内部のメモリです。 |
| 5 | Environment これは、エージェントが住む実世界または計算世界の一部です。 |
| 6 | Forward Chaining 問題の結論/解決に向けて前進する戦略。 |
| 7 | Heuristics 試行錯誤、評価、実験に基づいた知識です。 |
| 8 | Knowledge Engineering 人間の専門家やその他のリソースから知識を取得する。 |
| 9 | Percepts これは、エージェントが環境に関する情報を取得する形式です。 |
| 10 | Pruning AIシステムにおける不要で無関係な考慮事項を上書きします。 |
| 11 | Rule これは、エキスパートシステムで知識ベースを表す形式です。それはIF-THEN-ELSEの形式です。 |
| 12 | Shell シェルは、エキスパートシステムの推論エンジン、知識ベース、およびユーザーインターフェイスの設計に役立つソフトウェアです。 |
| 13 | Task これは、エージェントが達成しようとしている目標です。 |
| 14 | Turing Test 人間の知性と比較して機械の知性をテストするためにAllanTuringによって開発されたテスト。 |