美しいスープ-トラブルシューティング
エラー処理
BeautifulSoupで処理する必要があるエラーには主に2つの種類があります。これらの2つのエラーは、BeautifulSoup APIがエラーをスローするため、スクリプトからではなく、スニペットの構造から発生します。
2つの主なエラーは次のとおりです-
AttributeError
これは、ドット表記が現在のHTMLタグの兄弟タグを見つけられない場合に発生します。たとえば、「アンカータグ」がないためにこのエラーが発生した可能性があります。コストキーは、トラバースしてアンカータグが必要になると、エラーをスローします。
KeyError
このエラーは、必要なHTMLタグ属性が欠落している場合に発生します。たとえば、スニペットにdata-pid属性がない場合、pidキーはkey-errorをスローします。
結果を解析するときに上記の2つのエラーを回避するために、その結果はバイパスされ、不正な形式のスニペットがデータベースに挿入されないようにします-
except(AttributeError, KeyError) as er:
pass診断()
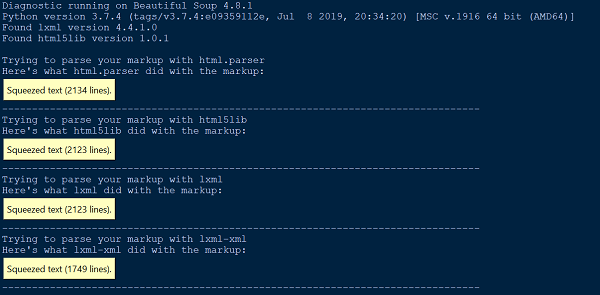
BeautifulSoupがドキュメントまたはHTMLに対して何をするのかを理解するのが難しい場合は、それをdiagnose()関数に渡すだけです。ドキュメントファイルをdiagnose()関数に渡すと、さまざまなパーサーのリストがドキュメントをどのように処理するかを示すことができます。
以下は、diagnose()関数の使用法を示す1つの例です。
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)出力
解析エラー
解析エラーには主に2つのタイプがあります。ドキュメントをBeautifulSoupにフィードすると、HTMLParseErrorなどの例外が発生する場合があります。また、BeautifulSoup解析ツリーが解析ドキュメントからの期待される結果と大きく異なる場合、予期しない結果が生じる可能性があります。
BeautifulSoupが原因で解析エラーが発生することはありません。BeautifulSoupにはパーサーコードが含まれていないため、使用する外部パーサー(html5lib、lxml)が原因です。上記の解析エラーを解決する1つの方法は、別のパーサーを使用することです。
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
passPythonの組み込みHTMLパーサーは、2つの最も一般的な解析エラーを引き起こします。HTMLParser.HTMLParserError:不正な形式の開始タグとHTMLParser.HTMLParserError:不正な終了タグです。これを解決するには、主にlxmlまたはhtml5libという別のパーサーを使用します。
予期しない動作のもう1つの一般的なタイプは、ドキュメント内にあることがわかっているタグが見つからないことです。ただし、find_all()を実行すると、[]が返されるか、find()がNoneを返します。
これは、Pythonの組み込みHTMLパーサーが、理解できないタグをスキップすることがあることが原因である可能性があります。
XMLパーサーエラー
デフォルトでは、BeautifulSoupパッケージはドキュメントをHTMLとして解析しますが、非常に使いやすく、beautifulsoup4を使用して非常にエレガントな方法で不正な形式のXMLを処理します。
ドキュメントをXMLとして解析するには、lxmlパーサーが必要であり、Beautifulsoupコンストラクターの2番目の引数として「xml」を渡すだけです。
soup = BeautifulSoup(markup, "lxml-xml")または
soup = BeautifulSoup(markup, "xml")一般的なXML解析エラーの1つは、次のとおりです。
AttributeError: 'NoneType' object has no attribute 'attrib'これは、find()またはfindall()関数の使用中に一部の要素が欠落しているか、定義されていない場合に発生する可能性があります。
その他の解析エラー
以下に示すのは、このセクションで説明する他の解析エラーの一部です。
環境問題
上記の解析エラーとは別に、スクリプトが1つのオペレーティングシステムでは機能するが別のオペレーティングシステムでは機能しない、ある仮想環境では機能するが別の仮想環境では機能しない、または機能しないなど、環境問題などの他の解析の問題が発生する場合があります。仮想環境の外。これらすべての問題は、2つの環境で使用可能なパーサーライブラリが異なることが原因である可能性があります。
現在の作業環境でのデフォルトのパーサーを知っているか、確認することをお勧めします。現在の作業環境で使用可能な現在のデフォルトのパーサーを確認するか、必要なパーサーライブラリを2番目の引数としてBeautifulSoupコンストラクターに明示的に渡すことができます。
大文字小文字を区別しません
HTMLタグと属性は大文字と小文字を区別しないため、3つのHTMLパーサーはすべてタグと属性の名前を小文字に変換します。ただし、大文字と小文字が混在するタグと属性を保持する場合は、ドキュメントをXMLとして解析することをお勧めします。
UnicodeEncodeError
以下のコードセグメントを調べてみましょう-
soup = BeautifulSoup(response, "html.parser")
print (soup)出力
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'上記の問題は、2つの主な状況が原因である可能性があります。コンソールが表示方法を認識していないUnicode文字を印刷しようとしている可能性があります。次に、ファイルに書き込もうとしていて、デフォルトのエンコーディングでサポートされていないUnicode文字を渡します。
上記の問題を解決する1つの方法は、次のように、スープを作成する前に応答テキスト/文字をエンコードして、目的の結果を取得することです。
responseTxt = response.text.encode('UTF-8')KeyError:[attr]
これは、問題のタグがattr属性を定義していないときにtag ['attr']にアクセスすることによって発生します。最も一般的なエラーは、「KeyError: 'href'」および「KeyError: 'class'」です。attrが定義されているかどうかわからない場合は、tag.get( 'attr')を使用してください。
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback actionAttributeError
次のようにAttributeErrorが発生する可能性があります-
AttributeError: 'list' object has no attribute 'find_all'上記のエラーは主に、find_all()が単一のタグまたは文字列を返すことを期待していたために発生します。ただし、soup.find_allは要素のPythonリストを返します。
あなたがする必要があるのは、リストを反復処理し、それらの要素からデータをキャッチすることです。