COBOL-クイックガイド
COBOLの概要
COBOLは高級言語です。COBOLの動作方法を理解する必要があります。コンピューターは、0と1のバイナリストリームであるマシンコードのみを理解します。COBOLコードは、を使用してマシンコードに変換する必要がありますcompiler。コンパイラを介してプログラムソースを実行します。コンパイラは最初に構文エラーをチェックし、次にそれを機械語に変換します。コンパイラは、として知られている出力ファイルを作成しますload module。この出力ファイルには、0と1の形式の実行可能コードが含まれています。
COBOLの進化
1950年代、世界の西部でビジネスが成長していたとき、操作を簡単にするためにさまざまなプロセスを自動化する必要があり、これによりビジネスデータ処理用の高級プログラミング言語が誕生しました。
1959年、COBOLはCODASYL(Conference on Data Systems Language)によって開発されました。
次のバージョンであるCOBOL-61は、1961年にリリースされ、いくつかの改訂が加えられました。
1968年、COBOLは商用利用の標準言語としてANSIによって承認されました(COBOL-68)。
1974年と1985年に再び改訂され、それぞれCOBOL-74とCOBOL-85という名前の後続バージョンが開発されました。
2002年に、オブジェクト指向COBOLがリリースされました。これは、カプセル化されたオブジェクトをCOBOLプログラミングの通常の部分として使用できます。
COBOLの重要性
COBOLは、最初に広く使用された高水準プログラミング言語でした。それはユーザーフレンドリーな英語のような言語です。すべての指示は、簡単な英語の単語でコーディングできます。
COBOLは、自己文書化言語としても使用されます。
COBOLは、膨大なデータ処理を処理できます。
COBOLは、以前のバージョンと互換性があります。
COBOLには効果的なエラーメッセージがあるため、バグの解決が容易になります。
COBOLの機能
標準語
COBOLは、IBM AS / 400、パーソナル・コンピューターなどのマシンでコンパイルおよび実行できる標準言語です。
ビジネス指向
COBOLは、財務ドメイン、防衛ドメインなどに関連するビジネス指向のアプリケーション向けに設計されています。高度なファイル処理機能により、大量のデータを処理できます。
堅牢な言語
COBOLは、その多数のデバッグおよびテストツールがほとんどすべてのコンピュータープラットフォームで利用できるため、堅牢な言語です。
構造化言語
論理制御構造はCOBOLで使用できるため、読み取りと変更が容易になります。COBOLにはさまざまな部門があるため、デバッグは簡単です。
Windows / LinuxへのCOBOLのインストール
単純なCOBOLプログラムの作成と学習に使用できる、Windowsで使用できる無料のメインフレームエミュレーターが多数あります。
そのようなエミュレーターの1つがHerculesです。これは、以下に示すいくつかの簡単な手順に従ってWindowsに簡単にインストールできます。
Herculesエミュレータをダウンロードしてインストールします。Herculesエミュレータは、Herculesのホームサイト(www.hercules-390.eu)から入手できます。
Windowsマシンにパッケージをインストールすると、次のようなフォルダが作成されます。 C:/hercules/mvs/cobol。
コマンドプロンプト(CMD)を実行し、CMDのディレクトリC:/ hercules / mvs / cobolにアクセスします。
JCLおよびCOBOLプログラムを作成および実行するためのさまざまなコマンドに関する完全なガイドは、次の場所にあります。
www.jaymoseley.com/hercules/installmvs/instmvs2.htm
Herculesは、最新の64ビットz / Architectureに加えて、メインフレームSystem / 370およびESA / 390アーキテクチャーのオープンソースソフトウェア実装です。Herculesは、Linux、Windows、Solaris、FreeBSD、およびMac OSXで動作します。
ユーザーは、シンクライアント、ダミー端末、仮想クライアントシステム(VCS)、仮想デスクトップシステム(VDS)など、さまざまな方法でメインフレームサーバーに接続できます。すべての有効なユーザーには、Z / OSインターフェース(TSO / EまたはISPF)に入るログインIDが与えられます。
COBOLプログラムのコンパイル
JCLを使用してCOBOLプログラムをバッチモードで実行するには、プログラムをコンパイルする必要があり、すべてのサブプログラムでロードモジュールが作成されます。JCLは、実行時に実際のプログラムではなく、ロードモジュールを使用します。ロードライブラリは連結され、実行時にJCLに与えられます。JCLLIB または STEPLIB。
COBOLプログラムのコンパイルに使用できるメインフレームコンパイラユーティリティは多数あります。一部の企業は、次のような変更管理ツールを使用しています。Endevor、プログラムのすべてのバージョンをコンパイルして保存します。これは、プログラムに加えられた変更を追跡するのに役立ちます。
//COMPILE JOB ,CLASS = 6,MSGCLASS = X,NOTIFY = &SYSUID
//*
//STEP1 EXEC IGYCRCTL,PARM = RMODE,DYNAM,SSRANGE
//SYSIN DD DSN = MYDATA.URMI.SOURCES(MYCOBB),DISP = SHR
//SYSLIB DD DSN = MYDATA.URMI.COPYBOOK(MYCOPY),DISP = SHR
//SYSLMOD DD DSN = MYDATA.URMI.LOAD(MYCOBB),DISP = SHR
//SYSPRINT DD SYSOUT=*
//*IGYCRCTLは、IBMCOBOLコンパイラー・ユーティリティーです。コンパイラー・オプションは、PARMパラメーターを使用して渡されます。上記の例では、RMODEは、プログラムで相対アドレッシングモードを使用するようにコンパイラに指示します。COBOLプログラムは、SYSINパラメーターを使用して渡されます。コピーブックは、SYSLIB内のプログラムによって使用されるライブラリーです。
COBOLプログラムの実行
以下に示すのは、プログラムMYPROGが入力ファイルMYDATA.URMI.INPUTを使用して実行され、スプールに書き込まれる2つの出力ファイルを生成するJCLの例です。
//COBBSTEP JOB CLASS = 6,NOTIFY = &SYSUID
//
//STEP10 EXEC PGM = MYPROG,PARM = ACCT5000
//STEPLIB DD DSN = MYDATA.URMI.LOADLIB,DISP = SHR
//INPUT1 DD DSN = MYDATA.URMI.INPUT,DISP = SHR
//OUT1 DD SYSOUT=*
//OUT2 DD SYSOUT=*
//SYSIN DD *
//CUST1 1000
//CUST2 1001
/*MYPROGのロードモジュールはMYDATA.URMI.LOADLIBにあります。上記のJCLは、DB2以外のCOBOLモジュールにのみ使用できることに注意してください。
COBOL-DB2プログラムの実行
COBOL-DB2プログラムを実行するために、専用のIBMユーティリティーがJCLおよびプログラムで使用されます。DB2領域と必要なパラメーターは、ユーティリティーへの入力として渡されます。
COBOL-DB2プログラムを実行する際の手順は次のとおりです。
COBOL-DB2プログラムがコンパイルされると、ロード・モジュールとともにDBRM(データベース要求モジュール)が作成されます。DBRMには、構文が正しいことがチェックされたCOBOLプログラムのSQLステートメントが含まれています。
DBRMは、COBOLが実行されるDB2領域(環境)にバインドされています。これは、JCLのIKJEFT01ユーティリティーを使用して実行できます。
バインドステップの後、JCLへの入力としてロードライブラリとDBRMライブラリを使用してIKJEFT01を使用してCOBOL-DB2プログラムが実行されます。
//STEP001 EXEC PGM = IKJEFT01
//*
//STEPLIB DD DSN = MYDATA.URMI.DBRMLIB,DISP = SHR
//*
//input files
//output files
//SYSPRINT DD SYSOUT=*
//SYSABOUT DD SYSOUT=*
//SYSDBOUT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//DISPLAY DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(MYCOBB) PLAN(PLANNAME) PARM(parameters to cobol program) -
LIB('MYDATA.URMI.LOADLIB')
END
/*上記の例では、MYCOBBは、IKJEFT01を使用して実行されるCOBOL-DB2プログラムです。プログラム名、DB2サブシステムID(SSID)、およびDB2プラン名は、SYSTSINDDステートメント内で渡されることに注意してください。DBRMライブラリはSTEPLIBで指定されています。
COBOLプログラム構造は、次の画像に示すように分割で構成されています。
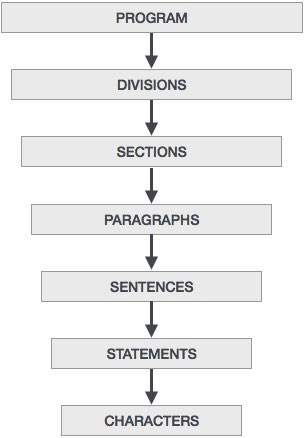
これらの部門の簡単な紹介を以下に示します-
Sectionsプログラムロジックの論理的な細分化です。セクションは段落のコレクションです。
Paragraphsセクションまたは部門の下位区分です。これは、ユーザー定義または事前定義された名前の後にピリオドが続き、0個以上の文/エントリで構成されます。
Sentences1つ以上のステートメントの組み合わせです。文は手順部にのみ表示されます。文はピリオドで終わる必要があります。
Statements いくつかの処理を実行する意味のあるCOBOLステートメントです。
Characters は階層の最下位であり、分割することはできません。
次の例では、上記の用語をCOBOLプログラムと相互に関連付けることができます。
PROCEDURE DIVISION.
A0000-FIRST-PARA SECTION.
FIRST-PARAGRAPH.
ACCEPT WS-ID - Statement-1 -----|
MOVE '10' TO WS-ID - Statement-2 |-- Sentence - 1
DISPLAY WS-ID - Statement-3 -----|
.部門
COBOLプログラムは、4つの部門で構成されています。
識別課
これは、すべてのCOBOLプログラムの最初で唯一の必須の除算です。プログラマーとコンパイラーは、この区分を使用してプログラムを識別します。この部門では、PROGRAM-IDが唯一の必須段落です。PROGRAM-IDは、1〜30文字で構成できるプログラム名を指定します。
次の例を使用してみてください Live Demo オンラインオプション。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
PROCEDURE DIVISION.
DISPLAY 'Welcome to Tutorialspoint'.
STOP RUN.以下は JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Welcome to Tutorialspoint環境課
環境分割は、プログラムへの入力ファイルと出力ファイルを指定するために使用されます。それは2つのセクションで構成されています-
Configuration sectionプログラムが作成および実行されるシステムに関する情報を提供します。それは2つの段落で構成されています-
ソースコンピュータ-プログラムのコンパイルに使用されるシステム。
オブジェクトコンピュータ-プログラムの実行に使用されるシステム。
Input-Output sectionプログラムで使用されるファイルに関する情報を提供します。それは2つの段落で構成されています-
ファイル制御-プログラムで使用される外部データセットの情報を提供します。
IO制御-プログラムで使用されるファイルの情報を提供します。
ENVIRONMENT DIVISION.
CONFIGURATION SECTION.
SOURCE-COMPUTER. XXX-ZOS.
OBJECT-COMPUTER. XXX-ZOS.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT FILEN ASSIGN TO DDNAME
ORGANIZATION IS SEQUENTIAL.データ部門
データ除算は、プログラムで使用される変数を定義するために使用されます。それは4つのセクションで構成されています-
File section ファイルのレコード構造を定義するために使用されます。
Working-Storage section プログラムで使用される一時変数とファイル構造を宣言するために使用されます。
Local-Storage section作業ストレージセクションに似ています。唯一の違いは、プログラムが実行を開始するたびに変数が割り当てられ、初期化されることです。
Linkage section 外部プログラムから受信したデータ名を説明するために使用されます。
COBOL Program
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT FILEN ASSIGN TO INPUT.
ORGANIZATION IS SEQUENTIAL.
ACCESS IS SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD FILEN
01 NAME PIC A(25).
WORKING-STORAGE SECTION.
01 WS-STUDENT PIC A(30).
01 WS-ID PIC 9(5).
LOCAL-STORAGE SECTION.
01 LS-CLASS PIC 9(3).
LINKAGE SECTION.
01 LS-ID PIC 9(5).
PROCEDURE DIVISION.
DISPLAY 'Executing COBOL program using JCL'.
STOP RUN.ザ・ JCL 上記のCOBOLプログラムを実行するには、次のようにします。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//INPUT DD DSN = ABC.EFG.XYZ,DISP = SHR上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Executing COBOL program using JCL手続き課
プロシージャ分割は、プログラムのロジックを含めるために使用されます。これは、データ分割で定義された変数を使用する実行可能ステートメントで構成されます。この部門では、段落名とセクション名はユーザー定義です。
手続き部には少なくとも1つのステートメントが必要です。この部門での実行を終了する最後のステートメントは、STOP RUN 呼び出し側プログラムで使用されるか、 EXIT PROGRAM これは、呼び出されたプログラムで使用されます。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NAME PIC A(30).
01 WS-ID PIC 9(5) VALUE 12345.
PROCEDURE DIVISION.
A000-FIRST-PARA.
DISPLAY 'Hello World'.
MOVE 'TutorialsPoint' TO WS-NAME.
DISPLAY "My name is : "WS-NAME.
DISPLAY "My ID is : "WS-ID.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Hello World
My name is : TutorialsPoint
My ID is : 12345キャラクターセット
「文字」は階層の最下位にあり、それ以上分割することはできません。COBOL文字セットには、以下に示す78文字が含まれています。
| シニア番号 | キャラクターと説明 |
|---|---|
| 1 | A-Z アルファベット(大文字) |
| 2 | a-z アルファベット(小文字) |
| 3 | 0-9 数値 |
| 4 |
スペース |
| 5 | + プラス記号 |
| 6 | - マイナス記号またはハイフン |
| 7 | * アスタリスク |
| 8 | / スラッシュ |
| 9 | $ 通貨記号 |
| 10 | , コンマ |
| 11 | ; セミコロン |
| 12 | . 小数点または期間 |
| 13 | " 引用符 |
| 14 | ( 左括弧 |
| 15 | ) 右括弧 |
| 16 | > 大なり記号 |
| 17 | < 未満 |
| 18 | : 結腸 |
| 19 | ' アポストロフィ |
| 20 | = 等号 |
コーディングシート
COBOLのソース・プログラムは、コンパイラーが受け入れ可能な形式で作成する必要があります。COBOLプログラムは、COBOLコーディングシートに記述されています。コーディングシートの各行には80文字の位置があります。
文字の位置は、次の5つのフィールドにグループ化されます-
| ポジション | フィールド | 説明 |
|---|---|---|
| 1-6 | 列番号 | 行番号用に予約されています。 |
| 7 | インジケータ | コメントを示すアスタリスク(*)、継続を示すハイフン(-)、およびフォームフィードを示すスラッシュ(/)を含めることができます。 |
| 8-11 | エリアA | すべてのCOBOLの区分、セクション、段落、およびいくつかの特別なエントリは、エリアAで開始する必要があります。 |
| 12-72 | エリアB | すべてのCOBOLステートメントは、エリアBで開始する必要があります。 |
| 73-80 | 識別エリア | プログラマーは必要に応じて使用できます。 |
例
次の例は、COBOLコーディングシートを示しています。
000100 IDENTIFICATION DIVISION. 000100
000200 PROGRAM-ID. HELLO. 000101
000250* THIS IS A COMMENT LINE 000102
000300 PROCEDURE DIVISION. 000103
000350 A000-FIRST-PARA. 000104
000400 DISPLAY “Coding Sheet”. 000105
000500 STOP RUN. 000106JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Coding Sheet文字列
文字列は、個々の文字を組み合わせて形成されます。文字列は
- Comment,
- リテラル、または
- COBOLワード。
すべての文字列はで終了する必要があります separators。セパレータは、文字列を区切るために使用されます。
頻繁に使用される区切り文字-スペース、コンマ、ピリオド、アポストロフィ、左/右括弧、および引用符。
コメント
コメントは、プログラムの実行に影響を与えない文字列です。文字の任意の組み合わせにすることができます。
コメントには2つのタイプがあります-
コメント行
コメント行は任意の列に書き込むことができます。コンパイラーは、コメント行の構文をチェックせず、文書化のために扱います。
コメントエントリ
コメントエントリは、識別部門のオプションの段落に含まれているエントリです。それらはエリアBで書かれており、プログラマーはそれを参照用に使用します。
で強調表示されているテキスト Bold 次の例でコメント化されたエントリです-
000100 IDENTIFICATION DIVISION. 000100
000150 PROGRAM-ID. HELLO. 000101
000200 AUTHOR. TUTORIALSPOINT. 000102
000250* THIS IS A COMMENT LINE 000103
000300 PROCEDURE DIVISION. 000104
000350 A000-FIRST-PARA. 000105
000360/ First Para Begins - Documentation Purpose 000106
000400 DISPLAY “Comment line”. 000107
000500 STOP RUN. 000108JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Comment Lineリテラル
リテラルは、プログラムに直接ハードコードされている定数です。次の例では、「HelloWorld」はリテラルです。
PROCEDURE DIVISION.
DISPLAY 'Hello World'.以下で説明するように、リテラルには2つのタイプがあります-
英数字リテラル
英数字リテラルは、引用符またはアポストロフィで囲まれています。長さは最大160文字です。アポストロフィまたは引用符は、ペアになっている場合にのみリテラルの一部にすることができます。リテラルの開始と終了は、アポストロフィまたは引用符のいずれかで同じである必要があります。
Example
次の例は、有効な英数字リテラルと無効な英数字リテラルを示しています。
Valid:
‘This is valid’
"This is valid"
‘This isn’’t invalid’
Invalid:
‘This is invalid”
‘This isn’t valid’数値文字
Numeric Literalは、0から9、+、–、または小数点までの数字の組み合わせです。長さは最大18文字です。記号を右端の文字にすることはできません。小数点は最後に表示されるべきではありません。
Example
次の例は、有効な数値リテラルと無効な数値リテラルを示しています-
Valid:
100
+10.9
-1.9
Invalid:
1,00
10.
10.9-COBOLワード
COBOL Wordは、予約語またはユーザー定義語の文字列です。長さは最大30文字です。
ユーザー定義の
ユーザー定義の単語は、ファイル、データ、レコード、段落名、およびセクションの命名に使用されます。ユーザー定義の単語を形成するときは、アルファベット、数字、およびハイフンを使用できます。COBOLの予約語は使用できません。
予約語
予約語は、COBOLで事前定義された単語です。私たちがよく使う予約語の種類は次のとおりです−
Keywords ADD、ACCEPT、MOVEなどのように。
Special characters +、-、*、<、<=などの単語
Figurative constants は、ZERO、SPACESなどの定数値です。比喩定数のすべての定数値を次の表に示します。
比喩的な定数
| シニア番号 | 比喩的な定数と説明 |
|---|---|
| 1 | HIGH-VALUES 降順で最も高い位置にある1つ以上の文字。 |
| 2 | LOW-VALUES 1つ以上の文字のバイナリ表現はゼロです。 |
| 3 | ZERO/ZEROES 変数のサイズに応じて、1つ以上のゼロ。 |
| 4 | SPACES 1つ以上のスペース。 |
| 5 | QUOTES 一重引用符または二重引用符。 |
| 6 | ALL literal データ項目をリテラルで埋めます。 |
データ除算は、プログラムで使用される変数を定義するために使用されます。COBOLでデータを記述するには、次の用語を理解する必要があります。
- データ名
- レベル番号
- 画像句
- 価値条項
01 TOTAL-STUDENTS PIC9(5) VALUE '125'.
| | | |
| | | |
| | | |
Level Number Data Name Picture Clause Value Clauseデータ名
データ名は、プロシージャ部門で使用する前に、データ部門で定義する必要があります。ユーザー定義の名前が必要です。予約語は使用できません。データ名は、実際のデータが格納されているメモリ位置を参照します。エレメンタリータイプまたはグループタイプにすることができます。
例
次の例は、有効なデータ名と無効なデータ名を示しています-
Valid:
WS-NAME
TOTAL-STUDENTS
A100
100B
Invalid:
MOVE (Reserved Words)
COMPUTE (Reserved Words)
100 (No Alphabet)
100+B (+ is not allowed)レベル番号
レベル番号は、レコード内のデータのレベルを指定するために使用されます。これらは、基本アイテムとグループアイテムを区別するために使用されます。基本アイテムをグループ化して、グループアイテムを作成できます。
| シニア番号 | レベル番号と説明 |
|---|---|
| 1 | 01 レコードの説明エントリ |
| 2 | 02 to 49 グループとエレメンタリーアイテム |
| 3 | 66 条項アイテムの名前を変更する |
| 4 | 77 細分化できないもの |
| 5 | 88 条件名エントリ |
Elementary itemsこれ以上分割することはできません。レベル番号、データ名、画像句、および値句(オプション)は、基本項目を説明するために使用されます。
Group items1つ以上の基本アイテムで構成されます。レベル番号、データ名、および値句(オプション)は、グループ項目を説明するために使用されます。グループレベル番号は常に01です。
例
次の例は、グループアイテムとエレメンタリーアイテムを示しています-
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NAME PIC X(25). ---> ELEMENTARY ITEM
01 WS-CLASS PIC 9(2) VALUE '10'. ---> ELEMENTARY ITEM
01 WS-ADDRESS. ---> GROUP ITEM
05 WS-HOUSE-NUMBER PIC 9(3). ---> ELEMENTARY ITEM
05 WS-STREET PIC X(15). ---> ELEMENTARY ITEM
05 WS-CITY PIC X(15). ---> ELEMENTARY ITEM
05 WS-COUNTRY PIC X(15) VALUE 'INDIA'. ---> ELEMENTARY ITEM画像句
Picture句は、次の項目を定義するために使用されます-
Data type数値、アルファベット、または英数字にすることができます。数値タイプは0から9までの数字のみで構成されます。アルファベットタイプは文字AからZとスペースで構成されます。英数字タイプは、数字、文字、および特殊文字で構成されます。
Sign数値データで使用できます。+または–のいずれかになります。
Decimal point position数値データで使用できます。想定位置は小数点の位置であり、データには含まれていません。
Length データ項目によって使用されるバイト数を定義します。
Picture句で使用される記号-
| シニア番号 | 記号と説明 |
|---|---|
| 1 | 9 数値 |
| 2 | A アルファベット |
| 3 | X 英数字 |
| 4 | V 暗黙の10進数 |
| 5 | S 符号 |
| 6 | P 想定される10進数 |
例
次の例は、PIC句の使用法を示しています-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC S9(3)V9(2).
01 WS-NUM2 PIC PPP999.
01 WS-NUM3 PIC S9(3)V9(2) VALUE -123.45.
01 WS-NAME PIC A(6) VALUE 'ABCDEF'.
01 WS-ID PIC X(5) VALUE 'A121$'.
PROCEDURE DIVISION.
DISPLAY "WS-NUM1 : "WS-NUM1.
DISPLAY "WS-NUM2 : "WS-NUM2.
DISPLAY "WS-NUM3 : "WS-NUM3.
DISPLAY "WS-NAME : "WS-NAME.
DISPLAY "WS-ID : "WS-ID.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : +000.00
WS-NUM2 : .000000
WS-NUM3 : -123.45
WS-NAME : ABCDEF
WS-ID : A121$価値条項
Value句は、データ項目を初期化するために使用されるオプションの句です。値は、数値リテラル、英数字リテラル、または比喩定数にすることができます。グループアイテムとエレメンタリーアイテムの両方で使用できます。
例
次の例は、VALUE句の使用法を示しています。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 99V9 VALUE IS 3.5.
01 WS-NAME PIC A(6) VALUE 'ABCD'.
01 WS-ID PIC 99 VALUE ZERO.
PROCEDURE DIVISION.
DISPLAY "WS-NUM1 : "WS-NUM1.
DISPLAY "WS-NAME : "WS-NAME.
DISPLAY "WS-ID : "WS-ID.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 03.5
WS-NAME : ABCD
WS-ID : 00COBOL動詞は、データ処理のプロシージャー部門で使用されます。ステートメントは常にCOBOL動詞で始まります。さまざまなタイプのアクションを持ついくつかのCOBOL動詞があります。
入力/出力動詞
入出力動詞は、ユーザーからデータを取得し、COBOLプログラムの出力を表示するために使用されます。このプロセスでは、次の2つの動詞が使用されます-
動詞を受け入れる
Accept動詞は、日付、時刻、曜日などのデータをオペレーティングシステムから、またはユーザーから直接取得するために使用されます。プログラムがユーザーからのデータを受け入れる場合は、JCLを介して渡す必要があります。次の例に示すように、オペレーティングシステムからデータを取得するときに、FROMオプションが含まれます。
ACCEPT WS-STUDENT-NAME.
ACCEPT WS-DATE FROM SYSTEM-DATE.動詞を表示する
表示動詞は、COBOLプログラムの出力を表示するために使用されます。
DISPLAY WS-STUDENT-NAME.
DISPLAY "System date is : " WS-DATE.COBOL PROGRAM
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STUDENT-NAME PIC X(25).
01 WS-DATE PIC X(10).
PROCEDURE DIVISION.
ACCEPT WS-STUDENT-NAME.
ACCEPT WS-DATE FROM DATE.
DISPLAY "Name : " WS-STUDENT-NAME.
DISPLAY "Date : " WS-DATE.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//INPUT DD DSN=PROGRAM.DIRECTORY,DISP=SHR
//SYSIN DD *
TutorialsPoint
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Name : TutorialsPoint
Date : 200623動詞を初期化する
Initialize動詞は、グループアイテムまたは基本アイテムを初期化するために使用されます。RENAME句のあるデータ名は初期化できません。数値データ項目はZEROESに置き換えられます。英数字またはアルファベットのデータ項目はスペースに置き換えられます。REPLACING項を含めると、次の例に示すように、データ項目を指定された置換値に初期化できます。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NAME PIC A(30) VALUE 'ABCDEF'.
01 WS-ID PIC 9(5).
01 WS-ADDRESS.
05 WS-HOUSE-NUMBER PIC 9(3).
05 WS-COUNTRY PIC X(15).
05 WS-PINCODE PIC 9(6) VALUE 123456.
PROCEDURE DIVISION.
A000-FIRST-PARA.
INITIALIZE WS-NAME, WS-ADDRESS.
INITIALIZE WS-ID REPLACING NUMERIC DATA BY 12345.
DISPLAY "My name is : "WS-NAME.
DISPLAY "My ID is : "WS-ID.
DISPLAY "Address : "WS-ADDRESS.
DISPLAY "House Number : "WS-HOUSE-NUMBER.
DISPLAY "Country : "WS-COUNTRY.
DISPLAY "Pincode : "WS-PINCODE.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
My name is :
My ID is : 12345
Address : 000 000000
House Number : 000
Country :
Pincode : 000000動詞を動かす
移動動詞は、ソースデータから宛先データにデータをコピーするために使用されます。基本データ項目とグループデータ項目の両方で使用できます。グループデータ項目には、MOVE CORRESPONDING / CORRが使用されます。try itオプションでは、MOVECORRが機能していません。ただし、メインフレームサーバーでは機能します。
文字列からデータを移動する場合、MOVE(x:l)が使用されます。ここで、xは開始位置、lは長さです。宛先データ項目のPIC句がソースデータ項目のPIC句よりも小さい場合、データは切り捨てられます。宛先データ項目のPIC句がソースデータ項目のPIC句よりも大きい場合、ゼロまたはスペースが追加のバイトに追加されます。次の例はそれを明確にします。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9).
01 WS-NUM2 PIC 9(9).
01 WS-NUM3 PIC 9(5).
01 WS-NUM4 PIC 9(6).
01 WS-ADDRESS.
05 WS-HOUSE-NUMBER PIC 9(3).
05 WS-COUNTRY PIC X(5).
05 WS-PINCODE PIC 9(6).
01 WS-ADDRESS1.
05 WS-HOUSE-NUMBER1 PIC 9(3).
05 WS-COUNTRY1 PIC X(5).
05 WS-PINCODE1 PIC 9(6).
PROCEDURE DIVISION.
A000-FIRST-PARA.
MOVE 123456789 TO WS-NUM1.
MOVE WS-NUM1 TO WS-NUM2 WS-NUM3.
MOVE WS-NUM1(3:6) TO WS-NUM4.
MOVE 123 TO WS-HOUSE-NUMBER.
MOVE 'INDIA' TO WS-COUNTRY.
MOVE 112233 TO WS-PINCODE.
MOVE WS-ADDRESS TO WS-ADDRESS1.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUM3 : " WS-NUM3
DISPLAY "WS-NUM4 : " WS-NUM4
DISPLAY "WS-ADDRESS : " WS-ADDRESS
DISPLAY "WS-ADDRESS1 : " WS-ADDRESS1
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 123456789
WS-NUM2 : 123456789
WS-NUM3 : 56789
WS-NUM4 : 345678
WS-ADDRESS : 123INDIA112233
WS-ADDRESS1 : 123INDIA112233法的措置
次の表は、法的措置に関する情報を示しています-
| アルファベット | 英数字 | 数値 | |
|---|---|---|---|
| アルファベット | 可能 | 可能 | ありえない |
| 英数字 | 可能 | 可能 | 可能 |
| 数値 | ありえない | 可能 | 可能 |
動詞を追加する
Add動詞は、2つ以上の数値を加算し、その結果をデスティネーションオペランドに格納するために使用されます。
構文
以下に示すのは、2つ以上の数値を追加するための構文です-
ADD A B TO C D
ADD A B C TO D GIVING E
ADD CORR WS-GROUP1 TO WS-GROUP2構文1では、A、B、Cが追加され、結果がCに格納されます(C = A + B + C)。A、B、Dが追加され、結果がDに格納されます(D = A + B + D)。
構文2では、A、B、C、Dが追加され、結果がEに格納されます(E = A + B + C + D)。
構文3では、WS-GROUP1およびWS-GROUP2内のサブグループ項目が追加され、結果がWS-GROUP2に格納されます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9) VALUE 10 .
01 WS-NUM2 PIC 9(9) VALUE 10.
01 WS-NUM3 PIC 9(9) VALUE 10.
01 WS-NUM4 PIC 9(9) VALUE 10.
01 WS-NUMA PIC 9(9) VALUE 10.
01 WS-NUMB PIC 9(9) VALUE 10.
01 WS-NUMC PIC 9(9) VALUE 10.
01 WS-NUMD PIC 9(9) VALUE 10.
01 WS-NUME PIC 9(9) VALUE 10.
PROCEDURE DIVISION.
ADD WS-NUM1 WS-NUM2 TO WS-NUM3 WS-NUM4.
ADD WS-NUMA WS-NUMB WS-NUMC TO WS-NUMD GIVING WS-NUME.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUM3 : " WS-NUM3
DISPLAY "WS-NUM4 : " WS-NUM4
DISPLAY "WS-NUMA : " WS-NUMA
DISPLAY "WS-NUMB : " WS-NUMB
DISPLAY "WS-NUMC : " WS-NUMC
DISPLAY "WS-NUMD : " WS-NUMD
DISPLAY "WS-NUME : " WS-NUME
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 000000010
WS-NUM2 : 000000010
WS-NUM3 : 000000030
WS-NUM4 : 000000030
WS-NUMA : 000000010
WS-NUMB : 000000010
WS-NUMC : 000000010
WS-NUMD : 000000010
WS-NUME : 000000040動詞を引く
減算動詞は、減算演算に使用されます。
構文
以下に、減算演算の構文を示します-
SUBTRACT A B FROM C D
SUBTRACT A B C FROM D GIVING E
SUBTRACT CORR WS-GROUP1 TO WS-GROUP2構文1では、AとBがCに加算および減算されます。結果は、Cに格納されます(C = C-(A + B))。AとBが加算され、Dから減算されます。結果はDに格納されます(D = D-(A + B))。
構文2では、A、B、CがDに加算および減算されます。結果は、Eに格納されます(E = D-(A + B + C))
構文3では、WS-GROUP1およびWS-GROUP2内のサブグループ項目が減算され、結果がWS-GROUP2に格納されます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9) VALUE 10 .
01 WS-NUM2 PIC 9(9) VALUE 10.
01 WS-NUM3 PIC 9(9) VALUE 100.
01 WS-NUM4 PIC 9(9) VALUE 100.
01 WS-NUMA PIC 9(9) VALUE 10.
01 WS-NUMB PIC 9(9) VALUE 10.
01 WS-NUMC PIC 9(9) VALUE 10.
01 WS-NUMD PIC 9(9) VALUE 100.
01 WS-NUME PIC 9(9) VALUE 10.
PROCEDURE DIVISION.
SUBTRACT WS-NUM1 WS-NUM2 FROM WS-NUM3 WS-NUM4.
SUBTRACT WS-NUMA WS-NUMB WS-NUMC FROM WS-NUMD GIVING WS-NUME.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUM3 : " WS-NUM3
DISPLAY "WS-NUM4 : " WS-NUM4
DISPLAY "WS-NUMA : " WS-NUMA
DISPLAY "WS-NUMB : " WS-NUMB
DISPLAY "WS-NUMC : " WS-NUMC
DISPLAY "WS-NUMD : " WS-NUMD
DISPLAY "WS-NUME : " WS-NUME
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 000000010
WS-NUM2 : 000000010
WS-NUM3 : 000000080
WS-NUM4 : 000000080
WS-NUMA : 000000010
WS-NUMB : 000000010
WS-NUMC : 000000010
WS-NUMD : 000000100
WS-NUME : 000000070動詞を掛ける
乗算動詞は、乗算演算に使用されます。
構文
以下に示すのは、2つ以上の数値を乗算するための構文です。
MULTIPLY A BY B C
MULTIPLY A BY B GIVING E構文1では、AとBが乗算され、結果がBに格納されます(B = A * B)。AとCは乗算され、結果はCに格納されます(C = A * C)。
構文2では、AとBが乗算され、結果がEに格納されます(E = A * B)。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9) VALUE 10 .
01 WS-NUM2 PIC 9(9) VALUE 10.
01 WS-NUM3 PIC 9(9) VALUE 10.
01 WS-NUMA PIC 9(9) VALUE 10.
01 WS-NUMB PIC 9(9) VALUE 10.
01 WS-NUMC PIC 9(9) VALUE 10.
PROCEDURE DIVISION.
MULTIPLY WS-NUM1 BY WS-NUM2 WS-NUM3.
MULTIPLY WS-NUMA BY WS-NUMB GIVING WS-NUMC.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUM3 : " WS-NUM3
DISPLAY "WS-NUMA : " WS-NUMA
DISPLAY "WS-NUMB : " WS-NUMB
DISPLAY "WS-NUMC : " WS-NUMC
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 000000010
WS-NUM2 : 000000100
WS-NUM3 : 000000100
WS-NUMA : 000000010
WS-NUMB : 000000010
WS-NUMC : 000000100動詞を分割する
除算動詞は除算演算に使用されます。
構文
以下に除算演算の構文を示します-
DIVIDE A INTO B
DIVIDE A BY B GIVING C REMAINDER R構文1では、BはAで除算され、結果はBに格納されます(B = B / A)。
構文2では、AをBで除算し、結果をC(C = A / B)に格納し、余りをRに格納します。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9) VALUE 5.
01 WS-NUM2 PIC 9(9) VALUE 250.
01 WS-NUMA PIC 9(9) VALUE 100.
01 WS-NUMB PIC 9(9) VALUE 15.
01 WS-NUMC PIC 9(9).
01 WS-REM PIC 9(9).
PROCEDURE DIVISION.
DIVIDE WS-NUM1 INTO WS-NUM2.
DIVIDE WS-NUMA BY WS-NUMB GIVING WS-NUMC REMAINDER WS-REM.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUMA : " WS-NUMA
DISPLAY "WS-NUMB : " WS-NUMB
DISPLAY "WS-NUMC : " WS-NUMC
DISPLAY "WS-REM : " WS-REM
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 000000005
WS-NUM2 : 000000050
WS-NUMA : 000000100
WS-NUMB : 000000015
WS-NUMC : 000000006
WS-REM : 000000010計算ステートメント
Computeステートメントは、COBOLで算術式を記述するために使用されます。これは、加算、減算、乗算、および除算の代わりになります。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9) VALUE 10 .
01 WS-NUM2 PIC 9(9) VALUE 10.
01 WS-NUM3 PIC 9(9) VALUE 10.
01 WS-NUMA PIC 9(9) VALUE 50.
01 WS-NUMB PIC 9(9) VALUE 10.
01 WS-NUMC PIC 9(9).
PROCEDURE DIVISION.
COMPUTE WS-NUMC= (WS-NUM1 * WS-NUM2) - (WS-NUMA / WS-NUMB) + WS-NUM3.
DISPLAY "WS-NUM1 : " WS-NUM1
DISPLAY "WS-NUM2 : " WS-NUM2
DISPLAY "WS-NUM3 : " WS-NUM3
DISPLAY "WS-NUMA : " WS-NUMA
DISPLAY "WS-NUMB : " WS-NUMB
DISPLAY "WS-NUMC : " WS-NUMC
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 : 000000010
WS-NUM2 : 000000010
WS-NUM3 : 000000010
WS-NUMA : 000000050
WS-NUMB : 000000010
WS-NUMC : 000000105COBOLレイアウトは、各フィールドの使用法とそこに存在する値の説明です。以下は、COBOLで使用されるデータ記述エントリです。
- 条項を再定義する
- 条項の名前を変更
- 使用条項
- Copybooks
条項を再定義する
Redefines句は、異なるデータ記述を持つストレージを定義するために使用されます。1つ以上のデータ項目が同時に使用されていない場合、同じストレージを別のデータ項目に使用できます。したがって、同じストレージを異なるデータ項目で参照できます。
構文
以下は、Redefines句の構文です-
01 WS-OLD PIC X(10).
01 WS-NEW1 REDEFINES WS-OLD PIC 9(8).
01 WS-NEW2 REDEFINES WS-OLD PIC A(10).使用されるパラメータの詳細は次のとおりです-
- WS-OLDは再定義されたアイテムです
- WS-NEW1とWS-NEW2はアイテムを再定義しています
再定義されたアイテムと再定義されたアイテムのレベル番号は同じである必要があり、66または88のレベル番号にすることはできません。再定義項目でVALUE句を使用しないでください。ファイルセクションで、01レベル番号のredefines句を使用しないでください。再定義定義は、再定義する次のデータ記述である必要があります。再定義されたアイテムは、常に再定義されたアイテムと同じ値になります。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-DESCRIPTION.
05 WS-DATE1 VALUE '20140831'.
10 WS-YEAR PIC X(4).
10 WS-MONTH PIC X(2).
10 WS-DATE PIC X(2).
05 WS-DATE2 REDEFINES WS-DATE1 PIC 9(8).
PROCEDURE DIVISION.
DISPLAY "WS-DATE1 : "WS-DATE1.
DISPLAY "WS-DATE2 : "WS-DATE2.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が生成されます-
WS-DATE1 : 20140831
WS-DATE2 : 20140831条項の名前を変更
Renames句は、既存のデータ項目に異なる名前を付けるために使用されます。これは、データ名を再グループ化し、それらに新しい名前を付けるために使用されます。新しいデータ名は、グループ間または基本アイテム間で名前を変更できます。レベル番号66は名前変更用に予約されています。
Syntax
以下は、Renames句の構文です-
01 WS-OLD.
10 WS-A PIC 9(12).
10 WS-B PIC X(20).
10 WS-C PIC A(25).
10 WS-D PIC X(12).
66 WS-NEW RENAMES WS-A THRU WS-C.名前の変更は同じレベルでのみ可能です。上記の例では、WS-A、WS-B、およびWS-Cは同じレベルにあります。名前変更定義は、名前を変更する次のデータ記述である必要があります。レベル番号が01、77、または66の名前変更は使用しないでください。名前の変更に使用されるデータ名は、順番に入力する必要があります。occur句のあるデータ項目は名前を変更できません。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-DESCRIPTION.
05 WS-NUM.
10 WS-NUM1 PIC 9(2) VALUE 20.
10 WS-NUM2 PIC 9(2) VALUE 56.
05 WS-CHAR.
10 WS-CHAR1 PIC X(2) VALUE 'AA'.
10 WS-CHAR2 PIC X(2) VALUE 'BB'.
66 WS-RENAME RENAMES WS-NUM2 THRU WS-CHAR2.
PROCEDURE DIVISION.
DISPLAY "WS-RENAME : " WS-RENAME.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-RENAME : 56AABB使用条項
Usage句は、フォーマットデータが保存されているオペレーティングシステムを指定します。レベル番号66または88では使用できません。グループでusage句が指定されている場合、すべての基本項目は同じusage句を持ちます。Usage句で使用できるさまざまなオプションは次のとおりです-
表示
データ項目はASCII形式で保存され、各文字は1バイトを使用します。デフォルトの使用法です。
次の例では、必要なバイト数を計算します-
01 WS-NUM PIC S9(5)V9(3) USAGE IS DISPLAY.
It requires 8 bytes as sign and decimal doesn't require any byte.
01 WS-NUM PIC 9(5) USAGE IS DISPLAY.
It requires 5 bytes as sign.計算/ COMP
データ項目はバイナリ形式で保存されます。ここで、データ項目は整数でなければなりません。
次の例では、必要なバイト数を計算します-
01 WS-NUM PIC S9(n) USAGE IS COMP.
If 'n' = 1 to 4, it takes 2 bytes.
If 'n' = 5 to 9, it takes 4 bytes.
If 'n' = 10 to 18, it takes 8 bytes.COMP-1
データ項目はRealまたはFloatに似ており、単精度浮動小数点数として表されます。内部的には、データは16進形式で格納されます。COMP-1はPIC句を受け入れません。ここで、1ワードは4バイトに相当します。
COMP-2
データ項目はLongまたはDoubleに似ており、倍精度浮動小数点数として表されます。内部的には、データは16進形式で格納されます。COMP-2はPIC句を指定していません。ここで、2ワードは8バイトに相当します。
COMP-3
データ項目はパック10進形式で保存されます。各桁は0.5バイト(1ニブル)を占め、符号は右端のニブルに格納されます。
次の例では、必要なバイト数を計算します-
01 WS-NUM PIC 9(n) USAGE IS COMP.
Number of bytes = n/2 (If n is even)
Number of bytes = n/2 + 1(If n is odd, consider only integer part)
01 WS-NUM PIC 9(4) USAGE IS COMP-3 VALUE 21.
It requires 2 bytes of storage as each digit occupies half a byte.
01 WS-NUM PIC 9(5) USAGE IS COMP-3 VALUE 21.
It requires 3 bytes of storage as each digit occupies half a byte.コピーブック
COBOLコピーブックは、データ構造を定義するコードの選択です。特定のデータ構造が多くのプログラムで使用されている場合、同じデータ構造を再度書き込む代わりに、コピーブックを使用できます。COPYステートメントを使用して、プログラムにコピーブックを含めます。COPYステートメントはWorkingStorageセクションで使用されます。
次の例には、COBOLプログラム内のコピーブックが含まれています。
DATA DIVISION.
WORKING-STORAGE SECTION.
COPY ABC.ここでABCはコピーブック名です。ABCコピーブックの以下のデータ項目は、プログラム内で使用できます。
01 WS-DESCRIPTION.
05 WS-NUM.
10 WS-NUM1 PIC 9(2) VALUE 20.
10 WS-NUM2 PIC 9(2) VALUE 56.
05 WS-CHAR.
10 WS-CHAR1 PIC X(2) VALUE 'AA'.
10 WS-CHAR2 PIC X(2) VALUE 'BB'.条件文は、プログラマーが指定した特定の条件に応じて実行フローを変更するために使用されます。条件文は常にtrueまたはfalseに評価されます。条件は、IF、Evaluate、およびPerformステートメントで使用されます。さまざまな種類の条件は次のとおりです-
- IF条件ステートメント
- 関係条件
- サイン条件
- クラス条件
- 条件-名前条件
- 否定条件
- 複合状態
IF条件ステートメント
IFステートメントは条件をチェックします。条件が真の場合、IFブロックが実行されます。条件がfalseの場合、ELSEブロックが実行されます。
END-IFIFブロックを終了するために使用されます。IFブロックを終了するには、END-IFの代わりにピリオドを使用できます。ただし、複数のIFブロックにはEND-IFを使用することをお勧めします。
Nested-IF−別のIFブロック内に表示されるIFブロック。ネストされたIFステートメントの深さに制限はありません。
構文
以下は、IF条件ステートメントの構文です-
IF [condition] THEN
[COBOL statements]
ELSE
[COBOL statements]
END-IF.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9).
01 WS-NUM2 PIC 9(9).
01 WS-NUM3 PIC 9(5).
01 WS-NUM4 PIC 9(6).
PROCEDURE DIVISION.
A000-FIRST-PARA.
MOVE 25 TO WS-NUM1 WS-NUM3.
MOVE 15 TO WS-NUM2 WS-NUM4.
IF WS-NUM1 > WS-NUM2 THEN
DISPLAY 'IN LOOP 1 - IF BLOCK'
IF WS-NUM3 = WS-NUM4 THEN
DISPLAY 'IN LOOP 2 - IF BLOCK'
ELSE
DISPLAY 'IN LOOP 2 - ELSE BLOCK'
END-IF
ELSE
DISPLAY 'IN LOOP 1 - ELSE BLOCK'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
IN LOOP 1 - IF BLOCK
IN LOOP 2 - ELSE BLOCK関係条件
関係条件は、2つのオペランドを比較します。いずれも、識別子、リテラル、または算術式です。数値フィールドの代数的比較は、サイズや使用法の句に関係なく行われます。
For non-numeric operands
同じサイズの2つの非数値オペランドを比較する場合、文字は左から対応する位置と最後に到達するまで比較されます。より多くの文字を含むオペランドは、より大きく宣言されます。
サイズが等しくない2つの数値以外のオペランドを比較する場合、オペランドのサイズが等しくなるまで短いデータ項目の最後にスペースが追加され、前のポイントで説明した規則に従って比較されます。
構文
以下に、関係条件ステートメントの構文を示します。
[Data Name/Arithmetic Operation]
[IS] [NOT]
[Equal to (=),Greater than (>), Less than (<),
Greater than or Equal (>=), Less than or equal (<=) ]
[Data Name/Arithmetic Operation]Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(9).
01 WS-NUM2 PIC 9(9).
PROCEDURE DIVISION.
A000-FIRST-PARA.
MOVE 25 TO WS-NUM1.
MOVE 15 TO WS-NUM2.
IF WS-NUM1 IS GREATER THAN OR EQUAL TO WS-NUM2 THEN
DISPLAY 'WS-NUM1 IS GREATER THAN WS-NUM2'
ELSE
DISPLAY 'WS-NUM1 IS LESS THAN WS-NUM2'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が生成されます-
WS-NUM1 IS GREATER THAN WS-NUM2サイン条件
符号条件は、数値オペランドの符号をチェックするために使用されます。指定された数値がゼロより大きいか、小さいか、または等しいかを判別します。
構文
以下は、Sign条件ステートメントの構文です-
[Data Name/Arithmetic Operation]
[IS] [NOT]
[Positive, Negative or Zero]
[Data Name/Arithmetic Operation]Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC S9(9) VALUE -1234.
01 WS-NUM2 PIC S9(9) VALUE 123456.
PROCEDURE DIVISION.
A000-FIRST-PARA.
IF WS-NUM1 IS POSITIVE THEN
DISPLAY 'WS-NUM1 IS POSITIVE'.
IF WS-NUM1 IS NEGATIVE THEN
DISPLAY 'WS-NUM1 IS NEGATIVE'.
IF WS-NUM1 IS ZERO THEN
DISPLAY 'WS-NUM1 IS ZERO'.
IF WS-NUM2 IS POSITIVE THEN
DISPLAY 'WS-NUM2 IS POSITIVE'.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が生成されます-
WS-NUM1 IS NEGATIVE
WS-NUM2 IS POSITIVEクラス条件
クラス条件は、オペランドにアルファベットまたは数値データのみが含まれているかどうかを確認するために使用されます。スペースは、ALPHABETIC、ALPHABETIC-LOWER、およびALPHABETIC-UPPERで考慮されます。
構文
以下は、クラス条件ステートメントの構文です。
[Data Name/Arithmetic Operation>]
[IS] [NOT]
[NUMERIC, ALPHABETIC, ALPHABETIC-LOWER, ALPHABETIC-UPPER]
[Data Name/Arithmetic Operation]Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC X(9) VALUE 'ABCD '.
01 WS-NUM2 PIC 9(9) VALUE 123456789.
PROCEDURE DIVISION.
A000-FIRST-PARA.
IF WS-NUM1 IS ALPHABETIC THEN
DISPLAY 'WS-NUM1 IS ALPHABETIC'.
IF WS-NUM1 IS NUMERIC THEN
DISPLAY 'WS-NUM1 IS NUMERIC'.
IF WS-NUM2 IS NUMERIC THEN
DISPLAY 'WS-NUM2 IS NUMERIC'.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-NUM1 IS ALPHABETIC
WS-NUM2 IS NUMERIC条件名条件
条件名はユーザー定義の名前です。これには、ユーザーが指定した値のセットが含まれています。ブール変数のように動作します。これらはレベル番号88で定義されています。PIC句はありません。
構文
以下は、ユーザー定義の条件ステートメントの構文です。
88 [Condition-Name] VALUE [IS, ARE] [LITERAL] [THRU LITERAL].Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM PIC 9(3).
88 PASS VALUES ARE 041 THRU 100.
88 FAIL VALUES ARE 000 THRU 40.
PROCEDURE DIVISION.
A000-FIRST-PARA.
MOVE 65 TO WS-NUM.
IF PASS
DISPLAY 'Passed with ' WS-NUM ' marks'.
IF FAIL
DISPLAY 'FAILED with ' WS-NUM 'marks'.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Passed with 065 marks否定条件
否定条件は、NOTキーワードを使用して指定されます。条件が真で、その前にNOTを指定した場合、その最終値は偽になります。
構文
以下は、否定条件ステートメントの構文です。
IF NOT [CONDITION]
COBOL Statements
END-IF.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(2) VALUE 20.
01 WS-NUM2 PIC 9(9) VALUE 25.
PROCEDURE DIVISION.
A000-FIRST-PARA.
IF NOT WS-NUM1 IS LESS THAN WS-NUM2 THEN
DISPLAY 'IF-BLOCK'
ELSE
DISPLAY 'ELSE-BLOCK'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
ELSE-BLOCK複合状態
結合条件には、論理演算子ANDまたはORを使用して接続された2つ以上の条件が含まれます。
構文
以下は、結合された条件ステートメントの構文です-
IF [CONDITION] AND [CONDITION]
COBOL Statements
END-IF.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-NUM1 PIC 9(2) VALUE 20.
01 WS-NUM2 PIC 9(2) VALUE 25.
01 WS-NUM3 PIC 9(2) VALUE 20.
PROCEDURE DIVISION.
A000-FIRST-PARA.
IF WS-NUM1 IS LESS THAN WS-NUM2 AND WS-NUM1=WS-NUM3 THEN
DISPLAY 'Both condition OK'
ELSE
DISPLAY 'Error'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Both condition OK動詞を評価する
Evaluate動詞は、一連のIF-ELSEステートメントの代わりになります。複数の条件を評価するために使用できます。これは、CプログラムのSWITCHステートメントに似ています。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-A PIC 9 VALUE 0.
PROCEDURE DIVISION.
MOVE 3 TO WS-A.
EVALUATE TRUE
WHEN WS-A > 2
DISPLAY 'WS-A GREATER THAN 2'
WHEN WS-A < 0
DISPLAY 'WS-A LESS THAN 0'
WHEN OTHER
DISPLAY 'INVALID VALUE OF WS-A'
END-EVALUATE.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-A GREATER THAN 2ファイルの各レコードを最後まで読み取るなど、何度も実行する必要のあるタスクがいくつかあります。COBOLで使用されるループステートメントは次のとおりです。
- スルーを実行する
- まで実行する
- 時間を実行します
- 変化を実行する
スルーを実行する
実行スルーは、シーケンスの最初と最後の段落名を指定して一連の段落を実行するために使用されます。最後の段落を実行した後、コントロールは戻されます。
インラインパフォーマンス
PERFORM内のステートメントは、END-PERFORMに到達するまで実行されます。
構文
以下は、インライン実行の構文です-
PERFORM
DISPLAY 'HELLO WORLD'
END-PERFORM.アウトオブラインパフォーマンス
ここでは、ステートメントが1つの段落で実行されてから、制御が他の段落またはセクションに移されます。
構文
以下は、Out-of-lineperformの構文です。
PERFORM PARAGRAPH1 THRU PARAGRAPH2Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
PROCEDURE DIVISION.
A-PARA.
PERFORM DISPLAY 'IN A-PARA'
END-PERFORM.
PERFORM C-PARA THRU E-PARA.
B-PARA.
DISPLAY 'IN B-PARA'.
STOP RUN.
C-PARA.
DISPLAY 'IN C-PARA'.
D-PARA.
DISPLAY 'IN D-PARA'.
E-PARA.
DISPLAY 'IN E-PARA'.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
IN A-PARA
IN C-PARA
IN D-PARA
IN E-PARA
IN B-PARAまで実行する
'perform until'では、指定された条件が真になるまで段落が実行されます。「Withtestbefore」はデフォルトの条件であり、段落内のステートメントを実行する前に条件がチェックされることを示します。
構文
以下は、performuntil-の構文です。
PERFORM A-PARA UNTIL COUNT=5
PERFORM A-PARA WITH TEST BEFORE UNTIL COUNT=5
PERFORM A-PARA WITH TEST AFTER UNTIL COUNT=5Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-CNT PIC 9(1) VALUE 0.
PROCEDURE DIVISION.
A-PARA.
PERFORM B-PARA WITH TEST AFTER UNTIL WS-CNT>3.
STOP RUN.
B-PARA.
DISPLAY 'WS-CNT : 'WS-CNT.
ADD 1 TO WS-CNT.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-CNT : 0
WS-CNT : 1
WS-CNT : 2
WS-CNT : 3時間を実行します
'perform times'では、指定された回数だけ段落が実行されます。
構文
以下は実行時間の構文です-
PERFORM A-PARA 5 TIMES.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
PROCEDURE DIVISION.
A-PARA.
PERFORM B-PARA 3 TIMES.
STOP RUN.
B-PARA.
DISPLAY 'IN B-PARA'.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
IN B-PARA
IN B-PARA
IN B-PARA変化を実行する
実行可変では、Until句の条件が真になるまで段落が実行されます。
構文
以下は、performvariingの構文です。
PERFORM A-PARA VARYING A FROM 1 BY 1 UNTIL A = 5.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-A PIC 9 VALUE 0.
PROCEDURE DIVISION.
A-PARA.
PERFORM B-PARA VARYING WS-A FROM 1 BY 1 UNTIL WS-A=5
STOP RUN.
B-PARA.
DISPLAY 'IN B-PARA ' WS-A.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
IN B-PARA 1
IN B-PARA 2
IN B-PARA 3
IN B-PARA 4ステートメントに移動
GO TOステートメントは、プログラムの実行フローを変更するために使用されます。GO TOステートメントでは、転送は順方向にのみ行われます。段落を終了するために使用されます。使用されるさまざまなタイプのGOTOステートメントは次のとおりです。
無条件GOTO
GO TO para-name.条件付きGOTO
GO TO para-1 para-2 para-3 DEPENDING ON x.'x'が1に等しい場合、制御は最初の段落に移されます。'x'が2に等しい場合、制御は2番目の段落に移されます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-A PIC 9 VALUE 2.
PROCEDURE DIVISION.
A-PARA.
DISPLAY 'IN A-PARA'
GO TO B-PARA.
B-PARA.
DISPLAY 'IN B-PARA '.
GO TO C-PARA D-PARA DEPENDING ON WS-A.
C-PARA.
DISPLAY 'IN C-PARA '.
D-PARA.
DISPLAY 'IN D-PARA '.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます。
IN A-PARA
IN B-PARA
IN D-PARACOBOLの文字列処理ステートメントは、文字列に対して複数の機能操作を実行するために使用されます。以下は文字列処理ステートメントです-
- Inspect
- String
- Unstring
検査する
検査動詞は、文字列内の文字をカウントまたは置換するために使用されます。文字列操作は、英数字、数値、またはアルファベットの値に対して実行できます。検査操作は左から右に実行されます。文字列操作に使用されるオプションは次のとおりです-
集計
集計オプションは、文字列文字をカウントするために使用されます。
Syntax
以下は、集計オプションの構文です。
INSPECT input-string
TALLYING output-count FOR ALL CHARACTERS使用されるパラメータは次のとおりです。
- input-string-文字がカウントされる文字列。
- output-count-文字数を保持するデータ項目。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-CNT1 PIC 9(2) VALUE 0.
01 WS-CNT2 PIC 9(2) VALUE 0.
01 WS-STRING PIC X(15) VALUE 'ABCDACDADEAAAFF'.
PROCEDURE DIVISION.
INSPECT WS-STRING TALLYING WS-CNT1 FOR CHARACTER.
DISPLAY "WS-CNT1 : "WS-CNT1.
INSPECT WS-STRING TALLYING WS-CNT2 FOR ALL 'A'.
DISPLAY "WS-CNT2 : "WS-CNT2
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-CNT1 : 15
WS-CNT2 : 06交換
置換オプションは、文字列文字を置換するために使用されます。
Syntax
以下は、オプションの置換の構文です-
INSPECT input-string REPLACING ALL char1 BY char2.使用されるパラメータは−です
input-string −文字がchar1からchar2に置き換えられる文字列。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STRING PIC X(15) VALUE 'ABCDACDADEAAAFF'.
PROCEDURE DIVISION.
DISPLAY "OLD STRING : "WS-STRING.
INSPECT WS-STRING REPLACING ALL 'A' BY 'X'.
DISPLAY "NEW STRING : "WS-STRING.
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
OLD STRING : ABCDACDADEAAAFF
NEW STRING : XBCDXCDXDEXXXFFストリング
文字列動詞は、文字列を連結するために使用されます。STRINGステートメントを使用すると、2つ以上の文字列を組み合わせて、より長い文字列を形成できます。「DelimitedBy」句は必須です。
Syntax
以下は文字列動詞の構文です-
STRING ws-string1 DELIMITED BY SPACE
ws-string2 DELIMITED BY SIZE
INTO ws-destination-string
WITH POINTER ws-count
ON OVERFLOW DISPLAY message1
NOT ON OVERFLOW DISPLAY message2
END-STRING.使用されるパラメータの詳細は次のとおりです-
- ws-string1およびws-string2:連結する入力文字列
- ws-string:出力文字列
- ws-count:新しい連結文字列の長さをカウントするために使用されます
- 区切り文字は文字列の終わりを指定します
- ポインタとオーバーフローはオプションです
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STRING PIC A(30).
01 WS-STR1 PIC A(15) VALUE 'Tutorialspoint'.
01 WS-STR2 PIC A(7) VALUE 'Welcome'.
01 WS-STR3 PIC A(7) VALUE 'To AND'.
01 WS-COUNT PIC 99 VALUE 1.
PROCEDURE DIVISION.
STRING WS-STR2 DELIMITED BY SIZE
WS-STR3 DELIMITED BY SPACE
WS-STR1 DELIMITED BY SIZE
INTO WS-STRING
WITH POINTER WS-COUNT
ON OVERFLOW DISPLAY 'OVERFLOW!'
END-STRING.
DISPLAY 'WS-STRING : 'WS-STRING.
DISPLAY 'WS-COUNT : 'WS-COUNT.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-STRING : WelcomeToTutorialspoint
WS-COUNT : 25文字列を解除する
文字列解除動詞は、1つの文字列を複数のサブ文字列に分割するために使用されます。DelimitedBy句は必須です。
Syntax
Unstring動詞の構文は次のとおりです-
UNSTRING ws-string DELIMITED BY SPACE
INTO ws-str1, ws-str2
WITH POINTER ws-count
ON OVERFLOW DISPLAY message
NOT ON OVERFLOW DISPLAY message
END-UNSTRING.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STRING PIC A(30) VALUE 'WELCOME TO TUTORIALSPOINT'.
01 WS-STR1 PIC A(7).
01 WS-STR2 PIC A(2).
01 WS-STR3 PIC A(15).
01 WS-COUNT PIC 99 VALUE 1.
PROCEDURE DIVISION.
UNSTRING WS-STRING DELIMITED BY SPACE
INTO WS-STR1, WS-STR2, WS-STR3
END-UNSTRING.
DISPLAY 'WS-STR1 : 'WS-STR1.
DISPLAY 'WS-STR2 : 'WS-STR2.
DISPLAY 'WS-STR3 : 'WS-STR3.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-STR1 : WELCOME
WS-STR2 : TO
WS-STR3 : TUTORIALSPOINTCOBOLの配列は、テーブルと呼ばれます。配列は線形データ構造であり、同じタイプの個々のデータ項目のコレクションです。テーブルのデータ項目は内部でソートされます。
テーブル宣言
テーブルはデータ部で宣言されています。 Occurs句はテーブルを定義するために使用されます。Occurs句は、データ名定義の繰り返しを示します。02から49までのレベル番号でのみ使用できます。Redefinesでoccurs句を使用しないでください。1次元および2次元のテーブルの説明は次のとおりです。
一次元テーブル
1次元のテーブルでは、 occurs句は宣言で1回だけ使用されます。WSTABLEは、テーブルを含むグループアイテムです。WS-Bは、10回発生するテーブル要素に名前を付けます。
Syntax
以下は、1次元テーブルを定義するための構文です。
01 WS-TABLE.
05 WS-A PIC A(10) OCCURS 10 TIMES.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A PIC A(10) VALUE 'TUTORIALS' OCCURS 5 TIMES.
PROCEDURE DIVISION.
DISPLAY "ONE-D TABLE : "WS-TABLE.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
ONE-D TABLE : TUTORIALS TUTORIALS TUTORIALS TUTORIALS TUTORIALS二次元テーブル
両方のデータ要素が可変長である2次元テーブルが作成されます。参考までに、構文を確認してから、テーブルの分析を試みてください。最初のアレイ(WS-A)は1〜10回発生し、内部アレイ(WS-C)は1〜5回発生する可能性があります。WS-Aのエントリごとに、対応するWS-Cの5つのエントリがあります。
Syntax
以下は、2次元テーブルを定義するための構文です。
01 WS-TABLE.
05 WS-A OCCURS 10 TIMES.
10 WS-B PIC A(10).
10 WS-C OCCURS 5 TIMES.
15 WS-D PIC X(6).Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A OCCURS 2 TIMES.
10 WS-B PIC A(10) VALUE ' TUTORIALS'.
10 WS-C OCCURS 2 TIMES.
15 WS-D PIC X(6) VALUE ' POINT'.
PROCEDURE DIVISION.
DISPLAY "TWO-D TABLE : "WS-TABLE.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
TWO-D TABLE : TUTORIALS POINT POINT TUTORIALS POINT POINT添字
テーブルの個々の要素には、添え字を使用してアクセスできます。添え字の値の範囲は、1からテーブルが出現する回数までです。下付き文字は任意の正の数にすることができます。データ分割での宣言は必要ありません。これは、occurs句を使用して自動的に作成されます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A OCCURS 3 TIMES.
10 WS-B PIC A(2).
10 WS-C OCCURS 2 TIMES.
15 WS-D PIC X(3).
PROCEDURE DIVISION.
MOVE '12ABCDEF34GHIJKL56MNOPQR' TO WS-TABLE.
DISPLAY 'WS-TABLE : ' WS-TABLE.
DISPLAY 'WS-A(1) : ' WS-A(1).
DISPLAY 'WS-C(1,1) : ' WS-C(1,1).
DISPLAY 'WS-C(1,2) : ' WS-C(1,2).
DISPLAY 'WS-A(2) : ' WS-A(2).
DISPLAY 'WS-C(2,1) : ' WS-C(2,1).
DISPLAY 'WS-C(2,2) : ' WS-C(2,2).
DISPLAY 'WS-A(3) : ' WS-A(3).
DISPLAY 'WS-C(3,1) : ' WS-C(3,1).
DISPLAY 'WS-C(3,2) : ' WS-C(3,2).
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
WS-TABLE : 12ABCDEF34GHIJKL56MNOPQR
WS-A(1) : 12ABCDEF
WS-C(1,1) : ABC
WS-C(1,2) : DEF
WS-A(2) : 34GHIJKL
WS-C(2,1) : GHI
WS-C(2,2) : JKL
WS-A(3) : 56MNOPQR
WS-C(3,1) : MNO
WS-C(3,2) : PQRインデックス
テーブル要素には、インデックスを使用してアクセスすることもできます。インデックスは、テーブルの先頭からの要素の変位です。インデックスは、INDEXEDBY句を使用してOccurs句で宣言されます。インデックスの値は、SETステートメントとPERFORMVaryingオプションを使用して変更できます。
Syntax
以下は、テーブルでインデックスを定義するための構文です。
01 WS-TABLE.
05 WS-A PIC A(10) OCCURS 10 TIMES INDEXED BY I.Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A OCCURS 3 TIMES INDEXED BY I.
10 WS-B PIC A(2).
10 WS-C OCCURS 2 TIMES INDEXED BY J.
15 WS-D PIC X(3).
PROCEDURE DIVISION.
MOVE '12ABCDEF34GHIJKL56MNOPQR' TO WS-TABLE.
PERFORM A-PARA VARYING I FROM 1 BY 1 UNTIL I >3
STOP RUN.
A-PARA.
PERFORM C-PARA VARYING J FROM 1 BY 1 UNTIL J>2.
C-PARA.
DISPLAY WS-C(I,J).JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
ABC
DEF
GHI
JKL
MNO
PQRセットステートメント
Setステートメントは、インデックス値を変更するために使用されます。動詞の設定は、インデックス値を初期化、インクリメント、またはデクリメントするために使用されます。これは、検索およびすべて検索とともに使用され、テーブル内の要素を検索します。
Syntax
以下は、Setステートメントを使用するための構文です-
SET I J TO positive-number
SET I TO J
SET I TO 5
SET I J UP BY 1
SET J DOWN BY 5Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A OCCURS 3 TIMES INDEXED BY I.
10 WS-B PIC A(2).
10 WS-C OCCURS 2 TIMES INDEXED BY J.
15 WS-D PIC X(3).
PROCEDURE DIVISION.
MOVE '12ABCDEF34GHIJKL56MNOPQR' TO WS-TABLE.
SET I J TO 1.
DISPLAY WS-C(I,J).
SET I J UP BY 1.
DISPLAY WS-C(I,J).
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
ABC
JKL探す
検索は線形検索方法であり、テーブル内の要素を検索するために使用されます。ソートされたテーブルとソートされていないテーブルで実行できます。インデックス句で宣言されたテーブルにのみ使用されます。インデックスの初期値から始まります。検索された要素が見つからない場合、インデックスは自動的に1ずつインクリメントされ、テーブルの最後まで続きます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-A PIC X(1) OCCURS 18 TIMES INDEXED BY I.
01 WS-SRCH PIC A(1) VALUE 'M'.
PROCEDURE DIVISION.
MOVE 'ABCDEFGHIJKLMNOPQR' TO WS-TABLE.
SET I TO 1.
SEARCH WS-A
AT END DISPLAY 'M NOT FOUND IN TABLE'
WHEN WS-A(I) = WS-SRCH
DISPLAY 'LETTER M FOUND IN TABLE'
END-SEARCH.
STOP RUN.JCL 上記のCOBOLプログラムを実行します。
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
LETTER M FOUND IN TABLEすべて検索
Search Allは、テーブル内の要素を検索するために使用されるバイナリ検索方法です。[すべて検索]オプションでは、テーブルを並べ替えた順序にする必要があります。インデックスは初期化を必要としません。二分探索では、テーブルは2つの半分に分割され、検索された要素がどちらの半分に存在するかを決定します。このプロセスは、要素が見つかるか、最後に到達するまで繰り返されます。
Example
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-TABLE.
05 WS-RECORD OCCURS 10 TIMES ASCENDING KEY IS WS-NUM INDEXED BY I.
10 WS-NUM PIC 9(2).
10 WS-NAME PIC A(3).
PROCEDURE DIVISION.
MOVE '12ABC56DEF34GHI78JKL93MNO11PQR' TO WS-TABLE.
SEARCH ALL WS-RECORD
AT END DISPLAY 'RECORD NOT FOUND'
WHEN WS-NUM(I) = 93
DISPLAY 'RECORD FOUND '
DISPLAY WS-NUM(I)
DISPLAY WS-NAME(I)
END-SEARCH.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO上記のプログラムをコンパイルして実行すると、次の結果が得られます-
RECORD FOUND
93
MNOCOBOLのファイルの概念は、C / C ++のファイルの概念とは異なります。COBOLで「ファイル」の基本を学習している間、両方の言語の概念を相互に関連付けることはできません。代わりに、単純なテキストファイルをCOBOLで使用することはできません。PS (Physical Sequential) そして VSAMファイルが使用されます。PSファイルについては、このモジュールで説明します。
COBOLでのファイル処理を理解するには、基本的な用語を知っている必要があります。これらの用語は、ファイル処理の基本を理解するためにのみ役立ちます。さらに詳細な用語については、「ファイル処理動詞」の章で説明します。以下は基本的な用語です-
- Field
- Record
- 物理的記録
- 論理レコード
- File
次の例は、これらの用語を理解するのに役立ちます-
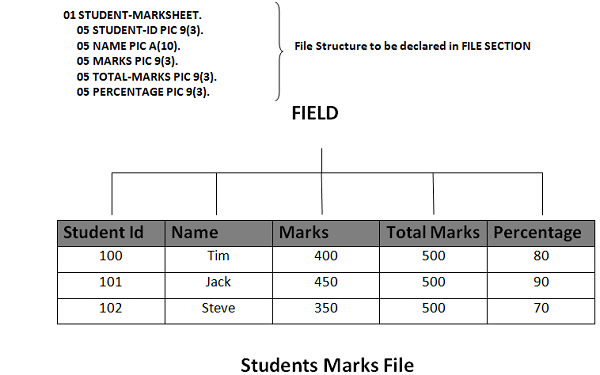
フィールド
フィールドは、要素に関して保存されているデータを示すために使用されます。これは、上記の例に示されているように、学生ID、名前、マーク、合計マーク、パーセンテージなどの単一の要素を表します。任意のフィールドの文字数はフィールドサイズと呼ばれます。たとえば、学生名は10文字にすることができます。フィールドは次の属性を持つことができます-
Primary keys各レコードに固有であり、特定のレコードを識別するために使用されるフィールドです。たとえば、学生マークファイルでは、各学生は主キーを形成する一意の学生IDを持ちます。
Secondary keys関連データの検索に使用される一意または非一意のフィールドです。たとえば、学生マークファイルでは、学生IDが不明な場合、学生のフルネームを副キーとして使用できます。
Descriptorsフィールドは、エンティティを説明するために使用されます。たとえば、学生のマークファイルでは、レコードに意味を追加するマークとパーセンテージフィールドは既知の記述子です。
記録
レコードは、エンティティを説明するために使用されるフィールドのコレクションです。1つ以上のフィールドが一緒になってレコードを形成します。たとえば、学生マークファイルでは、学生ID、名前、マーク、合計マーク、およびパーセンテージが1つのレコードを形成します。レコード内のすべてのフィールドの累積サイズは、レコードサイズと呼ばれます。ファイルに存在するレコードは、固定長または可変長の場合があります。
物理的記録
物理レコードは、外部デバイスに存在する情報です。ブロックとも呼ばれます。
論理レコード
論理レコードは、プログラムによって使用される情報です。COBOLプログラムでは、一度に処理できるレコードは1つだけであり、論理レコードと呼ばれます。
ファイル
ファイルは、関連するレコードのコレクションです。たとえば、学生マークファイルはすべての学生の記録で構成されています。
ファイル編成は、レコードがファイル内でどのように編成されているかを示します。レコードへのアクセス効率を高めるために、ファイルにはさまざまな種類の組織があります。以下は、ファイル編成スキームのタイプです-
- シーケンシャルファイル編成
- インデックス付きシーケンシャルファイル編成
- 相対的なファイル編成
このモジュールの構文は、それぞれの用語とともに言及されており、プログラムでの使用法のみを参照しています。これらの構文を使用する完全なプログラムについては、「ファイル処理動詞」の章で説明します。
シーケンシャルファイル編成
シーケンシャルファイルは、シーケンシャルな順序で保存およびアクセスされるレコードで構成されます。以下は、シーケンシャルファイル編成の主要な属性です-
レコードは順番に読み取ることができます。10番目のレコードを読み取るには、前の9つのレコードすべてを読み取る必要があります。
レコードは順番に書き込まれます。間に新しいレコードを挿入することはできません。新しいレコードは常にファイルの最後に挿入されます。
レコードをシーケンシャルファイルに配置した後は、レコードを削除、短縮、または延長することはできません。
レコードの順序は、一度挿入すると変更できません。
レコードの更新が可能です。新しいレコード長が古いレコード長と同じである場合、レコードを上書きできます。
順次出力ファイルは、印刷に適したオプションです。
構文
以下は、シーケンシャルファイル編成の構文です-
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name-jcl
ORGANIZATION IS SEQUENTIALインデックス付きシーケンシャルファイル編成
インデックス付きシーケンシャルファイルは、シーケンシャルにアクセスできるレコードで構成されます。直接アクセスも可能です。それは2つの部分で構成されています-
Data File シーケンシャルスキームのレコードが含まれます。
Index File データファイル内の主キーとそのアドレスが含まれます。
以下は、シーケンシャルファイル編成の主要な属性です-
レコードは、順次ファイル編成の場合と同じように、順次に読み取ることができます。
主キーがわかっている場合は、レコードにランダムにアクセスできます。インデックスファイルはレコードのアドレスを取得するために使用され、レコードはデータファイルからフェッチされます。
ソートされたインデックスは、キー値をファイル内のレコードの位置に関連付けるこのファイルシステムで維持されます。
レコードをフェッチするために代替インデックスを作成することもできます。
構文
以下は、インデックス付きシーケンシャルファイル編成の構文です-
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name-jcl
ORGANIZATION IS INDEXED
RECORD KEY IS primary-key
ALTERNATE RECORD KEY IS rec-key相対ファイル構成
相対ファイルは、順序付けられたレコードで構成されます relative address。以下は、相対的なファイル編成の主要な属性です-
レコードは、シーケンシャルおよびインデックス付きファイル編成の場合と同様に、シーケンシャルな順序で読み取ることができます。
レコードには、関係調を使用してアクセスできます。関係調は、ファイルの先頭のアドレスを基準にしたレコードの場所を表します。
レコードは関係調を使用して挿入できます。相対アドレスは、相対キーを使用して計算されます。
相対ファイルは、レコードへの最速のアクセスを提供します。
このファイルシステムの主な欠点は、いくつかの中間レコードが欠落している場合、それらもスペースを占有することです。
構文
以下は、相対的なファイル編成の構文です-
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name-jcl
ORGANIZATION IS RELATIVE
RELATIVE KEY IS rec-keyこれまで、ファイル編成スキームが議論されてきました。ファイル編成スキームごとに、さまざまなアクセスモードを使用できます。ファイルアクセスモードの種類は次のとおりです-
- シーケンシャルアクセス
- ランダムアクセス
- ダイナミックアクセス
このモジュールの構文は、それぞれの用語とともに言及されており、プログラムでの使用法のみを参照しています。これらの構文を使用する完全なプログラムについては、次の章で説明します。
シーケンシャルアクセス
アクセスモードがシーケンシャルの場合、選択したファイル構成に応じてレコードの取得方法が変わります。
にとって sequential files、レコードは、挿入されたのと同じ順序でアクセスされます。
にとって indexed files、レコードのフェッチに使用されるパラメーターは、レコードキー値です。
にとって relative files、相対レコードキーは、レコードを取得するために使用されます。
構文
以下は、シーケンシャルアクセスモードの構文です。
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS SEQUENTIAL
ACCESS MODE IS SEQUENTIAL
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS INDEXED
ACCESS MODE IS SEQUENTIAL
RECORD KEY IS rec-key1
ALTERNATE RECORD KEY IS rec-key2
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS RELATIVE
ACCESS MODE IS SEQUENTIAL
RELATIVE KEY IS rec-key1ランダムアクセス
アクセスモードがランダムの場合、選択したファイル構成に応じてレコードの取得方法が変わります。
にとって indexed files、レコードは、プライマリキーまたは代替キーのキーフィールドに配置された値に従ってアクセスされます。1つ以上の代替インデックスが存在する可能性があります。
にとって relative files 、レコードは相対レコードキーを介して取得されます。
構文
以下はランダムアクセスモードの構文です-
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS INDEXED
ACCESS MODE IS RANDOM
RECORD KEY IS rec-key1
ALTERNATE RECORD KEY IS rec-key2
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS RELATIVE
ACCESS MODE IS RANDOM
RELATIVE KEY IS rec-key1ダイナミックアクセス
動的アクセスは、同じプログラムでシーケンシャルアクセスとランダムアクセスの両方をサポートします。動的アクセスでは、1つのファイル定義を使用して、一部のレコードに順次アクセスし、他のレコードにキーでアクセスするなど、順次処理とランダム処理の両方を実行します。
相対ファイルとインデックス付きファイルの場合、動的アクセスモードでは、READステートメントのNEXT句を使用して、ファイルの読み取り中にシーケンシャルアクセスモードとランダムアクセスモードを切り替えることができます。NEXTおよびREAD機能については、次の章で説明します。
構文
以下は、動的アクセスモードの構文です。
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS SEQUENTIAL
ACCESS MODE IS DYNAMIC
RECORD KEY IS rec-key1
ALTERNATE RECORD KEY IS rec-key2
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT file-name ASSIGN TO dd-name
ORGANIZATION IS RELATIVE
ACCESS MODE IS DYNAMIC
RELATIVE KEY IS rec-key1ファイル処理動詞は、ファイルに対してさまざまな操作を実行するために使用されます。以下はファイル処理動詞です-
- Open
- Read
- Write
- Rewrite
- Delete
- Start
- Close
動詞を開く
開くは、実行する必要がある最初のファイル操作です。Openが成功した場合、ファイルに対してそれ以上の操作のみが可能です。ファイルを開いた後でのみ、ファイル構造内の変数を処理できます。FILE STATUS 変数は、各ファイル操作の後に更新されます。
構文
OPEN "mode" file-name.ここで、file-nameは文字列リテラルであり、ファイルに名前を付けるために使用します。ファイルは次のモードで開くことができます-
| シニア番号 | モードと説明 |
|---|---|
| 1 | Input 入力モードは既存のファイルに使用されます。このモードでは、ファイルの読み取りのみが可能であり、ファイルに対する他の操作は許可されていません。 |
| 2 | Output 出力モードは、ファイルにレコードを挿入するために使用されます。もしsequential fileが使用され、ファイルがいくつかのレコードを保持している場合、既存のレコードが最初に削除され、次に新しいレコードがファイルに挿入されます。それは起こらないでしょうindexed file または relative file。 |
| 3 | Extend 拡張モードは、レコードを追加するために使用されます。 sequential file。このモードでは、レコードは最後に挿入されます。ファイルアクセスモードがRandom または Dynamic、その後、拡張モードは使用できません。 |
| 4 | I-O 入出力モードは、ファイルのレコードの読み取りと再書き込みに使用されます。 |
動詞を読む
読み取り動詞は、ファイルレコードを読み取るために使用されます。readの機能は、ファイルからレコードをフェッチすることです。各読み取り動詞で、ファイル構造に読み取ることができるレコードは1つだけです。読み取り操作を実行するには、ファイルをINPUTモードまたはIOモードで開きます。各読み取りステートメントで、ファイルポインターがインクリメントされるため、連続するレコードが読み取られます。
構文
以下は、ファイルアクセスモードがシーケンシャルの場合にレコードを読み取るための構文です。
READ file-name NEXT RECORD INTO ws-file-structure
AT END DISPLAY 'End of File'
NOT AT END DISPLAY 'Record Details:' ws-file-structure
END-READ.使用されるパラメータは次のとおりです-
NEXT RECORDはオプションであり、索引付き順次ファイルが順次読み取られるときに指定されます。
INTO句はオプションです。ws-file-structureは、READステートメントから値を取得するためにWorkingStorageセクションで定義されています。
AT END条件は、ファイルの終わりに達するとTrueになります。
Example−次の例では、行順次編成を使用して既存のファイルを読み取ります。このプログラムは、を使用してコンパイルおよび実行できます。Live Demo ファイルに存在するすべてのレコードを表示するオプション。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT STUDENT ASSIGN TO 'input.txt'
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD STUDENT.
01 STUDENT-FILE.
05 STUDENT-ID PIC 9(5).
05 NAME PIC A(25).
WORKING-STORAGE SECTION.
01 WS-STUDENT.
05 WS-STUDENT-ID PIC 9(5).
05 WS-NAME PIC A(25).
01 WS-EOF PIC A(1).
PROCEDURE DIVISION.
OPEN INPUT STUDENT.
PERFORM UNTIL WS-EOF='Y'
READ STUDENT INTO WS-STUDENT
AT END MOVE 'Y' TO WS-EOF
NOT AT END DISPLAY WS-STUDENT
END-READ
END-PERFORM.
CLOSE STUDENT.
STOP RUN.で利用可能な入力ファイルデータを想定します。 input.txt ファイルには次のものが含まれています-
20003 Mohtashim M.
20004 Nishant Malik
20005 Amitabh Bachhan上記のプログラムをコンパイルして実行すると、次の結果が得られます-
20003 Mohtashim M.
20004 Nishant Malik
20005 Amitabh Bachhan構文
以下は、ファイルアクセスモードがランダムな場合にレコードを読み取るための構文です。
READ file-name RECORD INTO ws-file-structure
KEY IS rec-key
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'Record Details: ' ws-file-structure
END-READ.Example−次の例では、インデックス付き組織を使用して既存のファイルを読み取ります。このプログラムは、を使用してコンパイルおよび実行できます。JCLメインフレームでは、ファイルに存在するすべてのレコードが表示されます。メインフレームサーバーでは、テキストファイルを使用しません。代わりに、PSファイルを使用します。
メインフレームに存在するファイルの内容が上記の例のinput.txtファイルと同じであると仮定します。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT STUDENT ASSIGN TO IN1
ORGANIZATION IS INDEXED
ACCESS IS RANDOM
RECORD KEY IS STUDENT-ID
FILE STATUS IS FS.
DATA DIVISION.
FILE SECTION.
FD STUDENT.
01 STUDENT-FILE.
05 STUDENT-ID PIC 9(5).
05 NAME PIC A(25).
WORKING-STORAGE SECTION.
01 WS-STUDENT.
05 WS-STUDENT-ID PIC 9(5).
05 WS-NAME PIC A(25).
PROCEDURE DIVISION.
OPEN INPUT STUDENT.
MOVE 20005 TO STUDENT-ID.
READ STUDENT RECORD INTO WS-STUDENT-FILE
KEY IS STUDENT-ID
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY WS-STUDENT-FILE
END-READ.
CLOSE STUDENT.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//IN1 DD DSN = STUDENT-FILE-NAME,DISP=SHR上記のプログラムをコンパイルして実行すると、次の結果が得られます-
20005 Amitabh Bachhan動詞を書く
書き込み動詞は、ファイルにレコードを挿入するために使用されます。レコードが書き込まれると、レコードバッファで使用できなくなります。レコードをファイルに挿入する前に、値をレコードバッファーに移動してから、書き込み動詞を実行します。
書き込みステートメントは、 FROM作業用ストレージ変数からレコードを直接書き込むオプション。Fromはオプションの句です。アクセスモードがシーケンシャルの場合、レコードを書き込むには、ファイルを出力モードまたは拡張モードで開く必要があります。アクセスモードがランダムまたは動的である場合、レコードを書き込むには、ファイルを出力モードまたはIOモードで開く必要があります。
構文
以下は、ファイル編成がシーケンシャルである場合にレコードを読み取るための構文です。
WRITE record-buffer [FROM ws-file-structure]
END-WRITE.以下は、ファイル編成がインデックス付きまたは相対的である場合にレコードを読み取るための構文です。
WRITE record-buffer [FROM ws-file-structure]
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'Record Inserted'
END-WRITE.Example −次の例は、組織がシーケンシャルである場合に、新しいファイルに新しいレコードを挿入する方法を示しています。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT STUDENT ASSIGN TO OUT1
ORGANIZATION IS SEQUENTIAL
ACCESS IS SEQUENTIAL
FILE STATUS IS FS.
DATA DIVISION.
FILE SECTION.
FD STUDENT
01 STUDENT-FILE.
05 STUDENT-ID PIC 9(5).
05 NAME PIC A(25).
05 CLASS PIC X(3).
WORKING-STORAGE SECTION.
01 WS-STUDENT.
05 WS-STUDENT-ID PIC 9(5).
05 WS-NAME PIC A(25).
05 WS-CLASS PIC X(3).
PROCEDURE DIVISION.
OPEN EXTEND STUDENT.
MOVE 1000 TO STUDENT-ID.
MOVE 'Tim' TO NAME.
MOVE '10' TO CLASS.
WRITE STUDENT-FILE
END-WRITE.
CLOSE STUDENT.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//OUT1 DD DSN = OUTPUT-FILE-NAME,DISP = (NEW,CATALOG,DELETE)上記のプログラムをコンパイルして実行すると、出力ファイルに新しいレコードが追加されます。
1000 Tim 10動詞を書き直す
書き換え動詞は、レコードを更新するために使用されます。書き換え操作を行うには、ファイルをIOモードで開く必要があります。読み取り操作が成功した後にのみ使用できます。Rewrite動詞は、最後に読み取られたレコードを上書きします。
構文
以下は、ファイル編成がシーケンシャルである場合にレコードを読み取るための構文です。
REWRITE record-buffer [FROM ws-file-structure]
END-REWRITE.以下は、ファイル編成がインデックス付きまたは相対的である場合にレコードを読み取るための構文です。
REWRITE record-buffer [FROM ws-file-structure]
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'Record Updated'
END-REWRITE.Example −次の例は、前の書き込みステップで挿入した既存のレコードを更新する方法を示しています−
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT STUDENT ASSIGN TO IN1
ORGANIZATION IS INDEXED
ACCESS IS RANDOM
RECORD KEY IS STUDENT-ID
FILE STATUS IS FS.
DATA DIVISION.
FILE SECTION.
FD STUDENT
01 STUDENT-FILE.
05 STUDENT-ID PIC 9(4).
05 NAME PIC A(12).
05 CLASS PIC X(3).
WORKING-STORAGE SECTION.
01 WS-STUDENT.
05 WS-STUDENT-ID PIC 9(5).
05 WS-NAME PIC A(25).
05 WS-CLASS PIC X(3).
PROCEDURE DIVISION.
OPEN I-O STUDENT.
MOVE '1000' TO STUDENT-ID.
READ STUDENT
KEY IS STUDENT-ID
INVALID KEY DISPLAY ‘KEY IS NOT EXISTING’
END-READ.
MOVE 'Tim Dumais' TO NAME.
REWRITE STUDENT-FILE
END-REWRITE.
CLOSE STUDENT.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//IN1 DD DSN = OUTPUT-FILE-NAME,DISP = SHR上記のプログラムをコンパイルして実行すると、レコードが更新されます-
1000 Tim Dumais 10動詞を削除する
動詞の削除は、インデックス付きファイルと相対ファイルでのみ実行できます。ファイルはIOモードで開く必要があります。シーケンシャルファイル編成では、レコードを削除することはできません。シーケンシャルアクセスモードの場合、Readステートメントによって最後に読み取られたレコードは削除されます。ランダムアクセスモードでは、レコードキーを指定してから削除操作を実行します。
構文
以下は、レコードを削除するための構文です-
DELETE file-name RECORD
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'Record Deleted'
END-DELETE.Example −既存のレコードを削除する−
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT STUDENT ASSIGN TO OUT1
ORGANIZATION IS INDEXED
ACCESS IS RANDOM
RECORD KEY IS STUDENT-ID
FILE STATUS IS FS.
DATA DIVISION.
FILE SECTION.
FD STUDENT
01 STUDENT-FILE.
05 STUDENT-ID PIC 9(4).
05 NAME PIC A(12).
05 CLASS PIC X(3).
WORKING-STORAGE SECTION.
01 WS-STUDENT.
05 WS-STUDENT-ID PIC 9(5).
05 WS-NAME PIC A(25).
05 WS-CLASS PIC X(3).
PROCEDURE DIVISION.
OPEN I-O STUDENT.
MOVE '1000' TO STUDENT-ID.
DELETE STUDENT RECORD
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'Record Deleted'
END-DELETE.
CLOSE STUDENT.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//OUT1 DD DSN = OUTPUT-FILE-NAME,DISP = SHR上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Record Deleted動詞を開始
開始動詞は、インデックス付きファイルと相対ファイルでのみ実行できます。これは、ファイルポインタを特定のレコードに配置するために使用されます。アクセスモードはシーケンシャルまたはダイナミックである必要があります。ファイルはIOまたは入力モードで開く必要があります。
構文
以下は、特定のレコードにポインタを置くための構文です-
START file-name KEY IS [=, >, <, NOT, <= or >=] rec-key
INVALID KEY DISPLAY 'Invalid Key'
NOT INVALID KEY DISPLAY 'File Pointer Updated'
END-START.動詞を閉じる
Close動詞は、ファイルを閉じるために使用されます。閉じる操作を実行すると、ファイル構造内の変数を処理できなくなります。プログラムとファイル間のリンクが失われます。
構文
以下は、ファイルを閉じるための構文です-
CLOSE file-name.COBOLサブルーチンは、独立してコンパイルすることはできますが、独立して実行することはできないプログラムです。サブルーチンには2つのタイプがあります。internal subroutines お気に入り Perform ステートメントと external CALL動詞のようなサブルーチン。
動詞を呼び出す
呼び出し動詞は、あるプログラムから別のプログラムに制御を移すために使用されます。CALL動詞を含むプログラムはCalling Program 呼び出されているプログラムは、 Called Program。呼び出し側プログラムの実行は、呼び出されたプログラムが実行を終了するまで停止します。Exit Programステートメントは、制御を戻すために呼び出されたプログラムで使用されます。
呼び出されたプログラムの制約
以下は、呼び出されるプログラム要件です-
Linkage section呼び出されたプログラムで定義する必要があります。これは、プログラムで渡されるデータ要素で構成されます。データ項目にはValue句を含めないでください。PIC句は、呼び出し側プログラムを介して渡される変数と互換性がある必要があります。
Procedure division using には、呼び出し側プログラムから渡された変数のリストがあり、順序はCall動詞で説明されているものと同じである必要があります。
Exit programステートメントは、呼び出されたプログラムで制御を戻すために使用されます。これは、呼び出されたプログラムの最後のステートメントである必要があります。
パラメータは、2つの方法でプログラム間で渡すことができます-
- 参照による
- コンテンツ別
参照による呼び出し
呼び出されたプログラムの変数の値が変更された場合、それらの新しい値は呼び出し元のプログラムに反映されます。場合BY 句が指定されていない場合、変数は常に参照によって渡されます。
構文
以下は、参照によるサブルーチンの呼び出しの構文です。
CALL sub-prog-name USING variable-1, variable-2.Example
次の例はMAIN呼び出しプログラムであり、UTILは呼び出されたプログラムです-
IDENTIFICATION DIVISION.
PROGRAM-ID. MAIN.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STUDENT-ID PIC 9(4) VALUE 1000.
01 WS-STUDENT-NAME PIC A(15) VALUE 'Tim'.
PROCEDURE DIVISION.
CALL 'UTIL' USING WS-STUDENT-ID, WS-STUDENT-NAME.
DISPLAY 'Student Id : ' WS-STUDENT-ID
DISPLAY 'Student Name : ' WS-STUDENT-NAME
STOP RUN.呼び出されたプログラム
IDENTIFICATION DIVISION.
PROGRAM-ID. UTIL.
DATA DIVISION.
LINKAGE SECTION.
01 LS-STUDENT-ID PIC 9(4).
01 LS-STUDENT-NAME PIC A(15).
PROCEDURE DIVISION USING LS-STUDENT-ID, LS-STUDENT-NAME.
DISPLAY 'In Called Program'.
MOVE 1111 TO LS-STUDENT-ID.
EXIT PROGRAM.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = MAIN上記のプログラムをコンパイルして実行すると、次の結果が得られます-
In Called Program
Student Id : 1111
Student Name : Timコンテンツによる呼び出し
呼び出されたプログラムの変数の値が変更された場合、それらの新しい値は呼び出し元のプログラムに反映されません。
構文
以下は、コンテンツによるサブルーチンの呼び出しの構文です。
CALL sub-prog-name USING
BY CONTENT variable-1, BY CONTENT variable-2.Example
次の例はMAIN呼び出しプログラムであり、UTILは呼び出されたプログラムです-
IDENTIFICATION DIVISION.
PROGRAM-ID. MAIN.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-STUDENT-ID PIC 9(4) VALUE 1000.
01 WS-STUDENT-NAME PIC A(15) VALUE 'Tim'.
PROCEDURE DIVISION.
CALL 'UTIL' USING BY CONTENT WS-STUDENT-ID, BY CONTENT WS-STUDENT-NAME.
DISPLAY 'Student Id : ' WS-STUDENT-ID
DISPLAY 'Student Name : ' WS-STUDENT-NAME
STOP RUN.呼び出されたプログラム
IDENTIFICATION DIVISION.
PROGRAM-ID. UTIL.
DATA DIVISION.
LINKAGE SECTION.
01 LS-STUDENT-ID PIC 9(4).
01 LS-STUDENT-NAME PIC A(15).
PROCEDURE DIVISION USING LS-STUDENT-ID, LS-STUDENT-NAME.
DISPLAY 'In Called Program'.
MOVE 1111 TO LS-STUDENT-ID.
EXIT PROGRAM.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = MAIN上記のプログラムをコンパイルして実行すると、次の結果が得られます-
In Called Program
Student Id : 1000
Student Name : Tim通話の種類
呼び出しには2つのタイプがあります-
Static CallプログラムがNODYNAMコンパイラオプションを使用してコンパイルされたときに発生します。静的に呼び出されたプログラムは、コンパイル時にストレージにロードされます。
Dynamic CallプログラムがDYNAMおよびNODLLコンパイラオプションを使用してコンパイルされたときに発生します。動的に呼び出されたプログラムは、実行時にストレージにロードされます。
ファイル内のデータの並べ替えまたは2つ以上のファイルのマージは、ほとんどすべてのビジネス指向のアプリケーションで一般的に必要です。ソートは、レコードを昇順または降順で並べ替えるために使用されるため、順次処理を実行できます。COBOLでファイルをソートするために使用される2つの手法があります-
External sortJCLのSORTユーティリティを使用してファイルをソートするために使用されます。これについては、JCLの章で説明しました。今のところ、内部ソートに焦点を当てます。
Internal sort COBOLプログラム内のファイルをソートするために使用されます。 SORT 動詞はファイルをソートするために使用されます。
動詞を並べ替え
COBOLのソートプロセスでは3つのファイルが使用されます-
Input file 昇順または降順で並べ替える必要のあるファイルです。
Work fileソートプロセスの進行中にレコードを保持するために使用されます。入力ファイルレコードは、ソートプロセスのために作業ファイルに転送されます。このファイルは、SDエントリの下のファイルセクションで定義する必要があります。
Output fileソートプロセス後に取得するファイルです。これは、Sort動詞の最終出力です。
構文
以下は、ファイルをソートするための構文です-
SORT work-file ON ASCENDING KEY rec-key1
[ON DESCENDING KEY rec-key2]
USING input-file GIVING output-file.SORTは次の操作を実行します-
作業ファイルをIOモードで、入力ファイルをINPUTモードで、出力ファイルをOUTPUTモードで開きます。
入力ファイルに存在するレコードを作業ファイルに転送します。
SORT-FILEをrec-keyで昇順/降順で並べ替えます。
ソートされたレコードを作業ファイルから出力ファイルに転送します。
入力ファイルと出力ファイルを閉じて、作業ファイルを削除します。
Example
次の例では、INPUTは昇順でソートする必要がある入力ファイルです-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT INPUT ASSIGN TO IN.
SELECT OUTPUT ASSIGN TO OUT.
SELECT WORK ASSIGN TO WRK.
DATA DIVISION.
FILE SECTION.
FD INPUT.
01 INPUT-STUDENT.
05 STUDENT-ID-I PIC 9(5).
05 STUDENT-NAME-I PIC A(25).
FD OUTPUT.
01 OUTPUT-STUDENT.
05 STUDENT-ID-O PIC 9(5).
05 STUDENT-NAME-O PIC A(25).
SD WORK.
01 WORK-STUDENT.
05 STUDENT-ID-W PIC 9(5).
05 STUDENT-NAME-W PIC A(25).
PROCEDURE DIVISION.
SORT WORK ON ASCENDING KEY STUDENT-ID-O
USING INPUT GIVING OUTPUT.
DISPLAY 'Sort Successful'.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//IN DD DSN = INPUT-FILE-NAME,DISP = SHR
//OUT DD DSN = OUTPUT-FILE-NAME,DISP = SHR
//WRK DD DSN = &&TEMP上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Sort Successful動詞をマージする
2つ以上の同じ順序のファイルは、Mergeステートメントを使用して結合されます。マージプロセスで使用されるファイル-
- 入力ファイル-入力-1、入力-2
- 作業ファイル
- 出力ファイル
構文
以下は、2つ以上のファイルをマージするための構文です-
MERGE work-file ON ASCENDING KEY rec-key1
[ON DESCENDING KEY rec-key2]
USING input-1, input-2 GIVING output-file.マージは次の操作を実行します-
作業ファイルをIOモードで、入力ファイルをINPUTモードで、出力ファイルをOUTPUTモードで開きます。
入力ファイルに存在するレコードを作業ファイルに転送します。
SORT-FILEをrec-keyで昇順/降順で並べ替えます。
ソートされたレコードを作業ファイルから出力ファイルに転送します。
入力ファイルと出力ファイルを閉じて、作業ファイルを削除します。
Example
次の例では、INPUT1とINPUT2は、昇順でマージされる入力ファイルです。
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT INPUT1 ASSIGN TO IN1.
SELECT INPUT2 ASSIGN TO IN2.
SELECT OUTPUT ASSIGN TO OUT.
SELECT WORK ASSIGN TO WRK.
DATA DIVISION.
FILE SECTION.
FD INPUT1.
01 INPUT1-STUDENT.
05 STUDENT-ID-I1 PIC 9(5).
05 STUDENT-NAME-I1 PIC A(25).
FD INPUT2.
01 INPUT2-STUDENT.
05 STUDENT-ID-I2 PIC 9(5).
05 STUDENT-NAME-I2 PIC A(25).
FD OUTPUT.
01 OUTPUT-STUDENT.
05 STUDENT-ID-O PIC 9(5).
05 STUDENT-NAME-O PIC A(25).
SD WORK.
01 WORK-STUDENT.
05 STUDENT-ID-W PIC 9(5).
05 STUDENT-NAME-W PIC A(25).
PROCEDURE DIVISION.
MERGE WORK ON ASCENDING KEY STUDENT-ID-O
USING INPUT1, INPUT2 GIVING OUTPUT.
DISPLAY 'Merge Successful'.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = HELLO
//IN1 DD DSN=INPUT1-FILE-NAME,DISP=SHR
//IN2 DD DSN=INPUT2-FILE-NAME,DISP=SHR
//OUT DD DSN = OUTPUT-FILE-NAME,DISP=SHR
//WRK DD DSN = &&TEMP上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Merge Successfulこれまで、COBOLでのファイルの使用法を学びました。ここで、COBOLプログラムがDB2とどのように相互作用するかについて説明します。次の用語が含まれます-
- 埋め込みSQL
- DB2アプリケーションプログラミング
- ホスト変数
- SQLCA
- SQLクエリ
- Cursors
埋め込みSQL
埋め込みSQLステートメントは、標準のSQL操作を実行するためにCOBOLプログラムで使用されます。埋め込みSQLステートメントは、アプリケーションプログラムがコンパイルされる前に、SQLプロセッサによって前処理されます。COBOLは、Host Language。COBOL-DB2アプリケーションは、COBOLとDB2の両方を含むアプリケーションです。
埋め込みSQLステートメントは、通常のSQLステートメントと同じように機能しますが、若干の変更が加えられています。たとえば、クエリの出力は、次のように参照される事前定義された変数のセットに送信されます。Host Variables。追加のINTO句がSELECTステートメントに配置されます。
DB2アプリケーションプログラミング
以下は、COBOL-DB2プログラムをコーディングする際に従うべき規則です。
すべてのSQLステートメントは次のように区切る必要があります EXEC SQL そして ENDEXEC.。
SQLステートメントはエリアBでコーディングする必要があります。
プログラムで使用されるすべてのテーブルは、WorkingStorageセクションで宣言する必要があります。これは、INCLUDE ステートメント。
INCLUDEおよびDECLARETABLE以外のすべてのSQLステートメントは、プロシージャー部に表示される必要があります。
ホスト変数
ホスト変数は、テーブルからデータを受信したり、テーブルにデータを挿入したりするために使用されます。プログラムとDB2の間で渡されるすべての値に対して、ホスト変数を宣言する必要があります。それらは、Working-Storageセクションで宣言されています。
ホスト変数をグループアイテムにすることはできませんが、ホスト構造でグループ化することはできます。彼らはすることはできませんRenamed または Redefined。SQLステートメントでホスト変数を使用し、接頭辞としてcolon (:).。
構文
以下は、ホスト変数を宣言し、Working-Storageセクションにテーブルを含めるための構文です。
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE table-name
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 STUDENT-REC.
05 STUDENT-ID PIC 9(4).
05 STUDENT-NAME PIC X(25).
05 STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.SQLCA
SQLCAは、DB2がSQL実行のフィードバックをプログラムに渡すためのSQL通信領域です。実行が成功したかどうかをプログラムに通知します。SQLCAには、次のような事前定義された変数がいくつかあります。SQLCODEエラーコードが含まれています。SQLCODEの値「000」は、正常に実行されたことを示します。
構文
以下は、Working-StorageセクションでSQLCAを宣言するための構文です。
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.SQLクエリ
Student-Id、Student-Name、およびStudent-Addressを含む「Student」という名前のテーブルが1つあると仮定します。
STUDENTテーブルには次のデータが含まれています-
Student Id Student Name Student Address
1001 Mohtashim M. Hyderabad
1002 Nishant Malik Delhi
1003 Amitabh Bachan Mumbai
1004 Chulbul Pandey Lucknow次の例は、の使用法を示しています SELECT COBOLプログラムでのクエリ-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.
EXEC SQL
INCLUDE STUDENT
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 WS-STUDENT-REC.
05 WS-STUDENT-ID PIC 9(4).
05 WS-STUDENT-NAME PIC X(25).
05 WS-STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.
PROCEDURE DIVISION.
EXEC SQL
SELECT STUDENT-ID, STUDENT-NAME, STUDENT-ADDRESS
INTO :WS-STUDENT-ID, :WS-STUDENT-NAME, WS-STUDENT-ADDRESS FROM STUDENT
WHERE STUDENT-ID=1004
END-EXEC.
IF SQLCODE = 0
DISPLAY WS-STUDENT-RECORD
ELSE DISPLAY 'Error'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP001 EXEC PGM = IKJEFT01
//STEPLIB DD DSN = MYDATA.URMI.DBRMLIB,DISP = SHR
//SYSPRINT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(HELLO) PLAN(PLANNAME) -
END
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
1004 Chulbul Pandey Lucknow次の例は、の使用法を示しています INSERT COBOLプログラムでのクエリ-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.
EXEC SQL
INCLUDE STUDENT
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 WS-STUDENT-REC.
05 WS-STUDENT-ID PIC 9(4).
05 WS-STUDENT-NAME PIC X(25).
05 WS-STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.
PROCEDURE DIVISION.
MOVE 1005 TO WS-STUDENT-ID.
MOVE 'TutorialsPoint' TO WS-STUDENT-NAME.
MOVE 'Hyderabad' TO WS-STUDENT-ADDRESS.
EXEC SQL
INSERT INTO STUDENT(STUDENT-ID, STUDENT-NAME, STUDENT-ADDRESS)
VALUES (:WS-STUDENT-ID, :WS-STUDENT-NAME, WS-STUDENT-ADDRESS)
END-EXEC.
IF SQLCODE = 0
DISPLAY 'Record Inserted Successfully'
DISPLAY WS-STUDENT-REC
ELSE DISPLAY 'Error'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP001 EXEC PGM = IKJEFT01
//STEPLIB DD DSN = MYDATA.URMI.DBRMLIB,DISP=SHR
//SYSPRINT DD SYSOUT = *
//SYSUDUMP DD SYSOUT = *
//SYSOUT DD SYSOUT = *
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(HELLO) PLAN(PLANNAME) -
END
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Record Inserted Successfully
1005 TutorialsPoint Hyderabad次の例は、の使用法を示しています UPDATE COBOLプログラムでのクエリ-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.
EXEC SQL
INCLUDE STUDENT
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 WS-STUDENT-REC.
05 WS-STUDENT-ID PIC 9(4).
05 WS-STUDENT-NAME PIC X(25).
05 WS-STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.
PROCEDURE DIVISION.
MOVE 'Bangalore' TO WS-STUDENT-ADDRESS.
EXEC SQL
UPDATE STUDENT SET STUDENT-ADDRESS=:WS-STUDENT-ADDRESS
WHERE STUDENT-ID = 1003
END-EXEC.
IF SQLCODE = 0
DISPLAY 'Record Updated Successfully'
ELSE DISPLAY 'Error'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP001 EXEC PGM = IKJEFT01
//STEPLIB DD DSN = MYDATA.URMI.DBRMLIB,DISP = SHR
//SYSPRINT DD SYSOUT = *
//SYSUDUMP DD SYSOUT = *
//SYSOUT DD SYSOUT = *
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(HELLO) PLAN(PLANNAME) -
END
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Record Updated Successfully以下 example の使用法を示しています DELETE COBOLプログラムでのクエリ-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.
EXEC SQL
INCLUDE STUDENT
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 WS-STUDENT-REC.
05 WS-STUDENT-ID PIC 9(4).
05 WS-STUDENT-NAME PIC X(25).
05 WS-STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.
PROCEDURE DIVISION.
MOVE 1005 TO WS-STUDENT-ID.
EXEC SQL
DELETE FROM STUDENT
WHERE STUDENT-ID=:WS-STUDENT-ID
END-EXEC.
IF SQLCODE = 0
DISPLAY 'Record Deleted Successfully'
ELSE DISPLAY 'Error'
END-IF.
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP001 EXEC PGM = IKJEFT01
//STEPLIB DD DSN = MYDATA.URMI.DBRMLIB,DISP=SHR
//SYSPRINT DD SYSOUT = *
//SYSUDUMP DD SYSOUT = *
//SYSOUT DD SYSOUT = *
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(HELLO) PLAN(PLANNAME) -
END
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
Record Deleted Successfullyカーソル
カーソルは、一度に複数の行の選択を処理するために使用されます。これらは、クエリのすべての結果を保持するデータ構造です。これらは、作業保管セクションまたは手順部門で定義できます。以下は、カーソルに関連する操作です。
- Declare
- Open
- Close
- Fetch
カーソルを宣言する
カーソルの宣言は、Working-StorageセクションまたはProcedureDivisionで行うことができます。最初のステートメントは、実行不可能なステートメントであるDECLAREステートメントです。
EXEC SQL
DECLARE STUDCUR CURSOR FOR
SELECT STUDENT-ID, STUDENT-NAME, STUDENT-ADDRESS FROM STUDENT
WHERE STUDENT-ID >:WS-STUDENT-ID
END-EXEC.開いた
カーソルを使用する前に、Openステートメントを実行する必要があります。Openステートメントは、SELECTを実行できるように準備します。
EXEC SQL
OPEN STUDCUR
END-EXEC.閉じる
Closeステートメントは、カーソルによって占有されていたすべてのメモリーを解放します。プログラムを終了する前にカーソルを閉じる必要があります。
EXEC SQL
CLOSE STUDCUR
END-EXEC.フェッチ
Fetchステートメントはカーソルを識別し、その値をINTO句に入れます。一度に1行を取得するため、Fetchステートメントはループでコーディングされます。
EXEC SQL
FETCH STUDCUR
INTO :WS-STUDENT-ID, :WS-STUDENT-NAME, WS-STUDENT-ADDRESS
END-EXEC.次の例は、STUDENTテーブルからすべてのレコードをフェッチするためのカーソルの使用法を示しています-
IDENTIFICATION DIVISION.
PROGRAM-ID. HELLO.
DATA DIVISION.
WORKING-STORAGE SECTION.
EXEC SQL
INCLUDE SQLCA
END-EXEC.
EXEC SQL
INCLUDE STUDENT
END-EXEC.
EXEC SQL BEGIN DECLARE SECTION
END-EXEC.
01 WS-STUDENT-REC.
05 WS-STUDENT-ID PIC 9(4).
05 WS-STUDENT-NAME PIC X(25).
05 WS-STUDENT-ADDRESS X(50).
EXEC SQL END DECLARE SECTION
END-EXEC.
EXEC SQL
DECLARE STUDCUR CURSOR FOR
SELECT STUDENT-ID, STUDENT-NAME, STUDENT-ADDRESS FROM STUDENT
WHERE STUDENT-ID >:WS-STUDENT-ID
END-EXEC.
PROCEDURE DIVISION.
MOVE 1001 TO WS-STUDENT-ID.
PERFORM UNTIL SQLCODE = 100
EXEC SQL
FETCH STUDCUR
INTO :WS-STUDENT-ID, :WS-STUDENT-NAME, WS-STUDENT-ADDRESS
END-EXEC
DISPLAY WS-STUDENT-REC
END-PERFORM
STOP RUN.JCL 上記のCOBOLプログラムを実行するには-
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP001 EXEC PGM=IKJEFT01
//STEPLIB DD DSN=MYDATA.URMI.DBRMLIB,DISP=SHR
//SYSPRINT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(HELLO) PLAN(PLANNAME) -
END
/*上記のプログラムをコンパイルして実行すると、次の結果が得られます-
1001 Mohtashim M. Hyderabad
1002 Nishant Malik Delhi
1003 Amitabh Bachan Mumbai
1004 Chulbul Pandey Lucknow