分散システムにおけるクエリの最適化
この章では、分散データベースシステムでのクエリの最適化について説明します。
分散クエリ処理アーキテクチャ
分散データベースシステムでは、クエリの処理は、グローバルレベルとローカルレベルの両方での最適化で構成されます。クエリは、クライアントまたは制御サイトのデータベースシステムに入ります。ここでは、ユーザーが検証され、クエリがチェックされ、変換され、グローバルレベルで最適化されます。
アーキテクチャは次のように表すことができます-
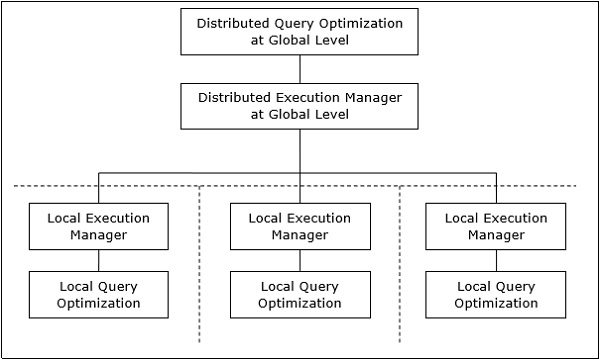
グローバルクエリのローカルクエリへのマッピング
グローバルクエリをローカルクエリにマッピングするプロセスは、次のように実現できます。
グローバルクエリに必要なテーブルには、複数のサイトに分散されたフラグメントがあります。ローカルデータベースには、ローカルデータに関する情報のみがあります。制御サイトは、グローバルデータディクショナリを使用して分布に関する情報を収集し、フラグメントからグローバルビューを再構築します。
レプリケーションがない場合、グローバルオプティマイザーはフラグメントが格納されているサイトでローカルクエリを実行します。レプリケーションがある場合、グローバルオプティマイザーは、通信コスト、ワークロード、およびサーバー速度に基づいてサイトを選択します。
グローバルオプティマイザーは、分散実行プランを生成して、サイト間で発生するデータ転送の量を最小限に抑えます。計画には、フラグメントの場所、クエリステップを実行する必要がある順序、および中間結果の転送に関連するプロセスが記載されています。
ローカルクエリは、ローカルデータベースサーバーによって最適化されます。最後に、ローカルクエリの結果は、水平フラグメントの場合は結合操作、垂直フラグメントの場合は結合操作によってマージされます。
たとえば、次のプロジェクトスキーマが、ニューデリー、コルカタ、ハイデラバードの都市に応じて水平方向に断片化されているとします。
事業
| PId | 市 | 部門 | 状態 |
ステータスが「進行中」であるすべてのプロジェクトの詳細を取得するクエリがあるとします。
グローバルクエリは&inus;になります
$$ \ sigma_ {status} = {\ small "ongoing"} ^ {(PROJECT)} $$
ニューデリーのサーバーでのクエリは次のようになります-
$$ \ sigma_ {status} = {\ small "ongoing"} ^ {({NewD} _- {PROJECT})} $$
コルカタのサーバーでのクエリは次のようになります-
$$ \ sigma_ {status} = {\ small "ongoing"} ^ {({Kol} _- {PROJECT})} $$
ハイデラバードのサーバーでのクエリは次のようになります-
$$ \ sigma_ {status} = {\ small "ongoing"} ^ {({Hyd} _- {PROJECT})} $$
全体的な結果を得るには、次のように3つのクエリの結果を結合する必要があります。
$ \ sigma_ {status} = {\ small "ongoing"} ^ {({NewD} _- {PROJECT})} \ cup \ sigma_ {status} = {\ small "ongoing"} ^ {({kol} _- {PROJECT})} \ cup \ sigma_ {status} = {\ small "ongoing"} ^ {({Hyd} _- {PROJECT})} $
分散クエリの最適化
分散クエリの最適化には、クエリの必要な結果を生成する多数のクエリツリーの評価が必要です。これは主に、複製および断片化されたデータが大量に存在するためです。したがって、目標は、最良の解決策ではなく、最適な解決策を見つけることです。
分散クエリ最適化の主な問題は次のとおりです。
- 分散システムにおけるリソースの最適な利用。
- クエリ取引。
- クエリのソリューションスペースの削減。
分散システムにおけるリソースの最適な利用
分散システムには、クエリに関連する操作を実行するために、さまざまなサイトに多数のデータベースサーバーがあります。以下は、最適なリソース使用率のためのアプローチです-
Operation Shipping−オペレーションシッピングでは、オペレーションはクライアントサイトではなく、データが保存されているサイトで実行されます。その後、結果はクライアントサイトに転送されます。これは、オペランドが同じサイトで使用できる操作に適しています。例:選択およびプロジェクト操作。
Data Shipping−データ配布では、データフラグメントがデータベースサーバーに転送され、そこで操作が実行されます。これは、オペランドが異なるサイトに分散されている操作で使用されます。これは、通信コストが低く、ローカルプロセッサがクライアントサーバーよりもはるかに遅いシステムにも適しています。
Hybrid Shipping−これはデータとオペレーションシッピングの組み合わせです。ここで、データフラグメントは高速プロセッサに転送され、そこで操作が実行されます。その後、結果はクライアントサイトに送信されます。

クエリ取引
分散データベースシステムのクエリ取引アルゴリズムでは、分散クエリの制御/クライアントサイトは買い手と呼ばれ、ローカルクエリが実行されるサイトは売り手と呼ばれます。買い手は、売り手を選択し、グローバルな結果を再構築するためのいくつかの選択肢を策定します。バイヤーの目標は、最適なコストを達成することです。
アルゴリズムは、買い手が売り手サイトにサブクエリを割り当てることから始まります。最適なプランは、最終結果を再構築するための通信コストと組み合わせて、販売者によって提案されたローカルに最適化されたクエリプランから作成されます。グローバル最適計画が策定されると、クエリが実行されます。
クエリのソリューションスペースの削減
最適なソリューションには、通常、ソリューションスペースの削減が含まれるため、クエリとデータ転送のコストが削減されます。これは、集中型システムのヒューリスティックと同様に、一連のヒューリスティックルールを通じて実現できます。
以下はいくつかのルールです-
できるだけ早く選択および投影操作を実行します。これにより、通信ネットワーク上のデータフローが減少します。
特定のサイトに関係のない選択条件を排除することにより、水平フラグメントの操作を簡素化します。
複数のサイトにあるフラグメントで構成される結合および結合操作の場合、フラグメント化されたデータをほとんどのデータが存在するサイトに転送し、そこで操作を実行します。
半結合操作を使用して、結合されるタプルを修飾します。これにより、データ転送の量が減り、通信コストが削減されます。
分散クエリツリーで共通のリーフとサブツリーをマージします。