分散DBMS-クイックガイド
組織が適切に機能するためには、適切に管理されたデータベースが必要です。最近では、データベースは本質的に一元化されていました。しかし、グローバリゼーションの進展に伴い、組織は世界中で多様化する傾向にあります。中央データベースではなく、ローカルサーバーにデータを分散することを選択する場合があります。したがって、の概念が到着しましたDistributed Databases。
この章では、データベースとデータベース管理システム(DBMS)の概要を説明します。データベースは、関連データの順序付けられたコレクションです。DBMSは、データベースで動作するソフトウェアパッケージです。DBMSの詳細な調査は、「LearnDBMS」という名前のチュートリアルで入手できます。この章では、DDBMSの研究が容易に行えるように、主要な概念を改訂します。カバーされる3つのトピックは、データベーススキーマ、データベースのタイプ、およびデータベースの操作です。
データベースおよびデータベース管理システム
A database特定の目的のために構築された関連データの順序付けられたコレクションです。データベースは、複数のテーブルのコレクションとして編成できます。テーブルは、実世界の要素またはエンティティを表します。各テーブルには、エンティティの特徴を表すいくつかの異なるフィールドがあります。
たとえば、会社のデータベースには、プロジェクト、従業員、部門、製品、および財務記録のテーブルが含まれる場合があります。Employeeテーブルのフィールドは、Name、Company_Id、Date_of_Joiningなどです。
A database management systemデータベースの作成と保守を可能にするプログラムのコレクションです。DBMSは、データベース内のデータの定義、構築、操作、および共有を容易にするソフトウェアパッケージとして利用できます。データベースの定義には、データベースの構造の説明が含まれます。データベースの構築には、任意の記憶媒体へのデータの実際の保存が含まれます。操作とは、データベースから情報を取得し、データベースを更新し、レポートを生成することです。データを共有すると、さまざまなユーザーやプログラムがデータにアクセスしやすくなります。
DBMSアプリケーション領域の例
- 現金自動預け払い機
- 列車予約システム
- 従業員管理システム
- 学生情報システム
DBMSパッケージの例
- MySQL
- Oracle
- SQLサーバー
- dBASE
- FoxPro
- PostgreSQLなど
データベーススキーマ
データベーススキーマは、データベースの設計時に指定され、頻繁に変更されないデータベースの説明です。データの編成、データ間の関係、およびデータに関連する制約を定義します。
データベースは多くの場合、 three-schema architecture または ANSISPARC architecture。このアーキテクチャの目標は、ユーザーアプリケーションを物理データベースから分離することです。3つのレベルは-
Internal Level having Internal Schema −データベースの物理構造、内部ストレージの詳細、およびアクセスパスについて説明します。
Conceptual Level having Conceptual Schema−データの物理ストレージの詳細を隠しながら、データベース全体の構造を記述します。これは、エンティティ、属性とそのデータ型と制約、ユーザー操作と関係を示しています。
External or View Level having External Schemas or Views −データベースの残りの部分を非表示にしながら、特定のユーザーまたはユーザーのグループに関連するデータベースの部分を記述します。
DBMSの種類
DBMSには4つのタイプがあります。
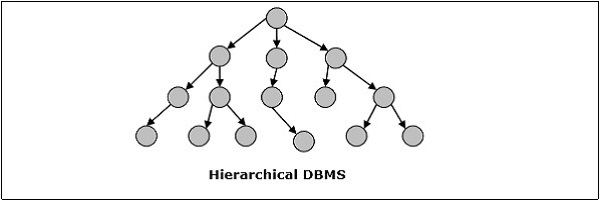
階層型DBMS
階層型DBMSでは、データベース内のデータ間の関係が確立され、1つのデータ要素が別のデータ要素の従属として存在します。データ要素には親子関係があり、「ツリー」データ構造を使用してモデル化されます。これらは非常に高速でシンプルです。
ネットワークDBMS
データベース内のデータ間の関係がネットワークの形で多対多のタイプであるネットワークDBMS。多数の多対多の関係が存在するため、構造は一般に複雑です。ネットワークDBMSは、「グラフ」データ構造を使用してモデル化されます。

リレーショナルDBMS
リレーショナルデータベースでは、データベースはリレーションの形式で表されます。各リレーションはエンティティをモデル化し、値のテーブルとして表されます。リレーションまたはテーブルでは、行はタプルと呼ばれ、単一のレコードを示します。列はフィールドまたは属性と呼ばれ、エンティティの特性を示します。RDBMSは、最も人気のあるデータベース管理システムです。
例-学生関係-

オブジェクト指向DBMS
オブジェクト指向DBMSは、オブジェクト指向プログラミングパラダイムのモデルから派生しています。これらは、データベースに格納されている整合性のあるデータと、プログラムの実行で見られる一時的なデータの両方を表すのに役立ちます。それらは、オブジェクトと呼ばれる小さくて再利用可能な要素を使用します。各オブジェクトには、データ部分と、データを処理する一連の操作が含まれています。オブジェクトとその属性は、リレーショナルテーブルモデルに格納されるのではなく、ポインタを介してアクセスされます。
例-単純化された銀行口座オブジェクト指向データベース-

分散DBMS
分散データベースは、コンピューターネットワークまたはインターネットを介して分散される相互接続されたデータベースのセットです。分散データベース管理システム(DDBMS)は、分散データベースを管理し、データベースをユーザーに対して透過的にするメカニズムを提供します。これらのシステムでは、組織のすべてのコンピューティングリソースを最適に使用できるように、データが意図的に複数のノードに分散されます。
DBMSの操作
データベースに対する4つの基本的な操作は、作成、取得、更新、および削除です。
CREATE データベース構造とデータの入力-データベースリレーションの作成には、データ構造、データ型、および格納するデータの制約を指定することが含まれます。
Example −学生テーブルを作成するSQLコマンド−
CREATE TABLE STUDENT (
ROLL INTEGER PRIMARY KEY,
NAME VARCHAR2(25),
YEAR INTEGER,
STREAM VARCHAR2(10)
);データ形式が定義されると、実際のデータはその形式に従っていくつかの記憶媒体に保存されます。
Example 単一のタプルを学生テーブルに挿入するSQLコマンド-
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM)
VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');RETRIEVEデータベースからの情報–情報の取得には、通常、テーブルのサブセットを選択するか、いくつかの計算が実行された後にテーブルからデータを表示することが含まれます。これは、テーブルを照会することによって行われます。
Example − Computer Scienceストリームのすべての学生の名前を取得するには、次のSQLクエリを実行する必要があります。
SELECT NAME FROM STUDENT
WHERE STREAM = 'COMPUTER SCIENCE';UPDATE 保存された情報とデータベース構造の変更–テーブルの更新には、既存のテーブルの行の古い値を新しい値に変更することが含まれます。
Example −ストリームをElectronicsからElectronics and Communicationsに変更するSQLコマンド−
UPDATE STUDENT
SET STREAM = 'ELECTRONICS AND COMMUNICATIONS'
WHERE STREAM = 'ELECTRONICS';データベースの変更とは、テーブルの構造を変更することを意味します。ただし、テーブルの変更にはいくつかの制限があります。
Example −新しいフィールドまたは列、たとえば住所をStudentテーブルに追加するには、次のSQLコマンドを使用します−
ALTER TABLE STUDENT
ADD ( ADDRESS VARCHAR2(50) );DELETE 保存された情報またはテーブル全体の削除–特定の情報を削除するには、特定の条件を満たすテーブルから選択した行を削除します。
Example- 4にあるすべての学生を削除するには番目の彼らが渡しているとき、私たちは、SQLコマンドを使用し、現在年を-
DELETE FROM STUDENT
WHERE YEAR = 4;または、テーブル全体をデータベースから削除することもできます。
Example −学生テーブルを完全に削除するために使用されるSQLコマンドは次のとおりです。
DROP TABLE STUDENT;この章では、DDBMSの概念を紹介します。分散データベースには、世界中に地理的に分散している可能性のあるデータベースがいくつかあります。分散DBMSは、ユーザーには単一のデータベースとして表示されるように分散データベースを管理します。この章の後半では、分散データベースにつながる要因、その長所と短所について説明します。
A distributed database は、相互接続された複数のデータベースのコレクションであり、コンピュータネットワークを介して通信するさまざまな場所に物理的に分散しています。
特徴
コレクション内のデータベースは、論理的に相互に関連しています。多くの場合、それらは単一の論理データベースを表します。
データは複数のサイトに物理的に保存されます。各サイトのデータは、他のサイトから独立したDBMSで管理できます。
サイト内のプロセッサはネットワークを介して接続されています。マルチプロセッサ構成はありません。
分散データベースは、疎結合のファイルシステムではありません。
分散データベースにはトランザクション処理が組み込まれていますが、トランザクション処理システムと同義ではありません。
分散データベース管理システム
分散データベース管理システム(DDBMS)は、分散データベースがすべて1つの場所に格納されているかのように管理する集中型ソフトウェアシステムです。
特徴
分散データベースの作成、取得、更新、削除に使用されます。
データベースを定期的に同期し、配布がユーザーに対して透過的になるアクセスメカニズムを提供します。
これにより、任意のサイトで変更されたデータが普遍的に更新されます。
大量のデータが同時に多数のユーザーによって処理およびアクセスされるアプリケーション領域で使用されます。
異種データベースプラットフォーム向けに設計されています。
データベースの機密性とデータの整合性を維持します。
DDBMSを促進する要因
次の要因により、DDBMSへの移行が促進されます-
Distributed Nature of Organizational Units−現在のほとんどの組織は、世界中に物理的に分散している複数のユニットに細分化されています。各ユニットには、独自のローカルデータのセットが必要です。したがって、組織のデータベース全体が分散されます。
Need for Sharing of Data−複数の組織単位は、多くの場合、相互に通信し、データとリソースを共有する必要があります。これには、同期して使用する必要がある共通データベースまたは複製データベースが必要です。
Support for Both OLTP and OLAP−オンライントランザクション処理(OLTP)とオンライン分析処理(OLAP)は、共通のデータを持つ可能性のある多様なシステムで機能します。分散データベースシステムは、同期されたデータを提供することにより、これらの両方の処理を支援します。
Database Recovery− DDBMSで使用される一般的な手法の1つは、異なるサイト間でのデータの複製です。データの複製は、いずれかのサイトのデータベースが破損した場合のデータ復旧に自動的に役立ちます。破損したサイトの再構築中に、ユーザーは他のサイトのデータにアクセスできます。したがって、データベースの障害はユーザーにとってほとんど目立たなくなる可能性があります。
Support for Multiple Application Software−ほとんどの組織は、それぞれが特定のデータベースをサポートするさまざまなアプリケーションソフトウェアを使用しています。DDBMSは、異なるプラットフォーム間で同じデータを使用するための統一された機能を提供します。
分散データベースの利点
以下は、集中型データベースに対する分散型データベースの利点です。
Modular Development−集中型データベースシステムで、システムを新しい場所または新しいユニットに拡張する必要がある場合、アクションには、既存の機能の大幅な労力と中断が必要です。ただし、分散データベースでは、現在の機能を中断することなく、新しいコンピューターとローカルデータを新しいサイトに追加し、最終的に分散システムに接続するだけで作業できます。
More Reliable−データベースに障害が発生した場合、集中型データベースのシステム全体が停止します。ただし、分散システムでは、コンポーネントに障害が発生した場合、システムの機能が継続してパフォーマンスが低下する可能性があります。したがって、DDBMSの方が信頼性が高くなります。
Better Response−データが効率的に配布される場合、ローカルデータ自体からユーザーの要求に対応できるため、応答が速くなります。一方、集中型システムでは、すべてのクエリが中央コンピュータを通過して処理される必要があるため、応答時間が長くなります。
Lower Communication Cost−分散データベースシステムでは、データが主に使用される場所にローカルに配置されている場合、データ操作の通信コストを最小限に抑えることができます。これは、集中型システムでは実行できません。
分散データベースの逆境
以下は、分散データベースに関連するいくつかの逆境です。
Need for complex and expensive software − DDBMSは、複数のサイト間でデータの透過性と調整を提供するために、複雑で多くの場合高価なソフトウェアを必要とします。
Processing overhead −単純な操作でも、サイト全体でデータを均一にするために、多数の通信と追加の計算が必要になる場合があります。
Data integrity −複数のサイトでデータを更新する必要があると、データの整合性に問題が生じます。
Overheads for improper data distribution−クエリの応答性は、適切なデータ分散に大きく依存します。不適切なデータ配布は、多くの場合、ユーザー要求への応答が非常に遅くなります。
チュートリアルのこの部分では、分散データベース環境の設計に役立つさまざまな側面について学習します。この章は、分散データベースの種類から始まります。分散データベースは、さらに分割された同種データベースと異種データベースに分類できます。この章の次のセクションでは、分散アーキテクチャ、つまりクライアント–サーバー、ピア– to –ピア、およびマルチ–DBMSについて説明します。最後に、レプリケーションやフラグメンテーションなどのさまざまな設計の選択肢が紹介されています。
分散データベースの種類
分散データベースは、次の図に示すように、同種および異種の分散データベース環境に大まかに分類でき、それぞれにさらに細分化されています。

均質な分散データベース
同種の分散データベースでは、すべてのサイトが同一のDBMSとオペレーティングシステムを使用します。その特性は次のとおりです。
サイトは非常によく似たソフトウェアを使用しています。
サイトは、同一のDBMSまたは同じベンダーのDBMSを使用しています。
各サイトは他のすべてのサイトを認識しており、他のサイトと協力してユーザーの要求を処理します。
データベースは、単一のデータベースであるかのように、単一のインターフェースを介してアクセスされます。
同種分散データベースの種類
同種分散データベースには2つのタイプがあります-
Autonomous−各データベースは独立しており、独自に機能します。これらは制御アプリケーションによって統合され、メッセージパッシングを使用してデータの更新を共有します。
Non-autonomous −データは同種のノードに分散され、中央またはマスターDBMSがサイト全体のデータ更新を調整します。
異種分散データベース
異種分散データベースでは、サイトごとにオペレーティングシステム、DBMS製品、データモデルが異なります。その特性は次のとおりです。
異なるサイトは、異なるスキーマとソフトウェアを使用しています。
システムは、リレーショナル、ネットワーク、階層、オブジェクト指向などのさまざまなDBMSで構成されている場合があります。
スキーマが異なるため、クエリ処理は複雑です。
ソフトウェアが異なるため、トランザクション処理は複雑です。
サイトは他のサイトを認識していない可能性があるため、ユーザー要求の処理における協力は限られています。
異種分散データベースの種類
Federated −異種データベースシステムは本質的に独立しており、単一のデータベースシステムとして機能するように統合されています。
Un-federated −データベースシステムは、データベースにアクセスするための中央調整モジュールを採用しています。
分散DBMSアーキテクチャ
DDBMSアーキテクチャは通常、3つのパラメータに応じて開発されます-
Distribution −さまざまなサイト間でのデータの物理的分布を示します。
Autonomy −データベースシステムの制御の分布と、各構成DBMSが独立して動作できる程度を示します。
Heterogeneity −データモデル、システムコンポーネント、およびデータベースの均一性または非類似性を指します。
建築モデル
一般的なアーキテクチャモデルのいくつかは次のとおりです。
- クライアント-DDBMSのサーバーアーキテクチャ
- ピアツーピアDDBMSのピアアーキテクチャ
- マルチ-DBMSアーキテクチャ
クライアント-DDBMSのサーバーアーキテクチャ
これは、機能がサーバーとクライアントに分割されている2レベルのアーキテクチャです。サーバー機能には、主にデータ管理、クエリ処理、最適化、トランザクション管理が含まれます。クライアント機能には、主にユーザーインターフェイスが含まれます。ただし、整合性チェックやトランザクション管理などの機能がいくつかあります。
2つの異なるクライアント-サーバーアーキテクチャは-
- シングルサーバーマルチクライアント
- 複数サーバー複数クライアント(次の図に表示)

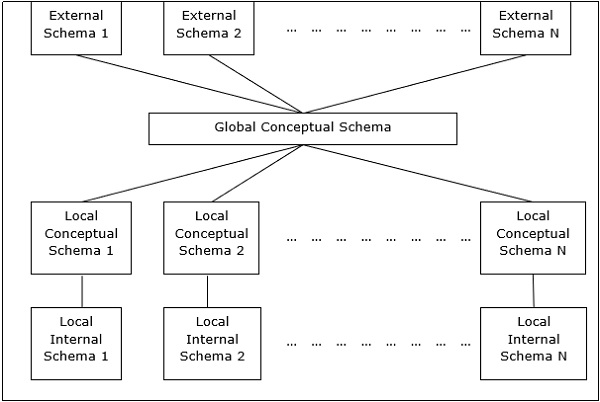
DDBMSのピアツーピアアーキテクチャ
これらのシステムでは、各ピアはデータベースサービスを提供するためのクライアントとサーバーの両方として機能します。ピアはリソースを他のピアと共有し、アクティビティを調整します。
このアーキテクチャには通常、4つのレベルのスキーマがあります-
Global Conceptual Schema −データのグローバル論理ビューを示します。
Local Conceptual Schema −各サイトの論理データ編成を示しています。
Local Internal Schema −各サイトの物理データ編成を示しています。
External Schema −データのユーザービューを示します。
マルチDBMSアーキテクチャ
これは、2つ以上の自律データベースシステムの集合によって形成された統合データベースシステムです。
マルチDBMSは、6つのレベルのスキーマで表現できます-
Multi-database View Level −統合された分散データベースのサブセットで構成される複数のユーザービューを示します。
Multi-database Conceptual Level −グローバル論理マルチデータベース構造定義で構成される統合マルチデータベースを示します。
Multi-database Internal Level −さまざまなサイトおよびマルチデータベースからローカルデータへのマッピングにわたるデータ分散を示します。
Local database View Level −ローカルデータのパブリックビューを示します。
Local database Conceptual Level −各サイトのローカルデータ編成を示しています。
Local database Internal Level −各サイトの物理データ編成を示しています。
マルチDBMSには2つの設計上の選択肢があります-
- マルチデータベースの概念レベルのモデル。
- マルチデータベースの概念レベルのないモデル。


代替設計
DDBMSのテーブルの配布設計の選択肢は次のとおりです。
- 複製および断片化されていない
- 完全に複製
- 部分的に複製
- Fragmented
- Mixed
複製および断片化されていない
この設計の代替案では、さまざまなテーブルがさまざまなサイトに配置されます。データは、最も使用されるサイトに近接するように配置されます。異なるサイトに配置されたテーブルの情報を結合するために必要なクエリの割合が低いデータベースシステムに最適です。適切な配布戦略が採用されている場合、この代替設計は、データ処理中の通信コストを削減するのに役立ちます。
完全に複製
この設計の代替案では、各サイトに、すべてのデータベーステーブルのコピーが1つ保存されます。各サイトにはデータベース全体の独自のコピーがあるため、クエリは非常に高速であり、通信コストはごくわずかです。それどころか、データの大規模な冗長性は、更新操作中に莫大なコストを必要とします。したがって、これは、データベースの更新回数が少ないのに、多数のクエリを処理する必要があるシステムに適しています。
部分的に複製
テーブルのコピーまたはテーブルの一部は、さまざまなサイトに保存されます。テーブルの配布は、アクセスの頻度に応じて行われます。これは、テーブルにアクセスする頻度がサイトごとに大幅に異なるという事実を考慮に入れています。テーブル(または部分)のコピーの数は、アクセスクエリが実行される頻度と、アクセスクエリを生成するサイトによって異なります。
断片化
この設計では、テーブルはフラグメントまたはパーティションと呼ばれる2つ以上の部分に分割され、各フラグメントは異なるサイトに格納できます。これは、テーブルに格納されているすべてのデータが特定のサイトで必要になることはめったにないという事実を考慮しています。さらに、断片化により並列処理が増加し、より優れたディザスタリカバリが提供されます。ここでは、システム内の各フラグメントのコピーは1つだけです。つまり、冗長データはありません。
3つのフラグメンテーション手法は次のとおりです。
- 垂直方向の断片化
- 水平方向の断片化
- ハイブリッドフラグメンテーション
混合分布
これは、断片化と部分的な複製の組み合わせです。ここで、テーブルは最初に任意の形式(水平または垂直)でフラグメント化され、次にこれらのフラグメントは、フラグメントにアクセスする頻度に応じて、異なるサイト間で部分的に複製されます。
前の章では、さまざまな代替設計を紹介しました。この章では、デザインの採用に役立つ戦略について学習します。戦略は大きく複製と断片化に分けることができます。ただし、ほとんどの場合、2つの組み合わせが使用されます。
データレプリケーション
データ複製は、データベースの個別のコピーを2つ以上のサイトに保存するプロセスです。これは、分散データベースで一般的なフォールトトレランス手法です。
データレプリケーションの利点
Reliability −いずれかのサイトに障害が発生した場合でも、別のサイトでコピーを入手できるため、データベースシステムは引き続き機能します。
Reduction in Network Load−データのローカルコピーが利用できるため、特にプライムアワーの時間帯に、ネットワークの使用量を減らしてクエリ処理を実行できます。データの更新は、プライム時間以外に実行できます。
Quicker Response −データのローカルコピーが利用できるため、クエリ処理が迅速になり、その結果、応答時間が短縮されます。
Simpler Transactions−トランザクションでは、異なるサイトにあるテーブルの結合数が少なくて済み、ネットワーク全体での調整が最小限で済みます。したがって、それらは本質的に単純になります。
データレプリケーションのデメリット
Increased Storage Requirements−データの複数のコピーを維持すると、ストレージコストが増加します。必要なストレージスペースは、集中型システムに必要なストレージの倍数です。
Increased Cost and Complexity of Data Updating−データ項目が更新されるたびに、更新は異なるサイトのデータのすべてのコピーに反映される必要があります。これには、複雑な同期技術とプロトコルが必要です。
Undesirable Application – Database coupling−複雑な更新メカニズムを使用しない場合、データの不整合を取り除くには、アプリケーションレベルでの複雑な調整が必要です。これにより、望ましくないアプリケーションとデータベースの結合が発生します。
一般的に使用されるレプリケーション手法には、次のものがあります。
- スナップショットレプリケーション
- ほぼリアルタイムのレプリケーション
- プルレプリケーション
断片化
断片化は、テーブルを小さなテーブルのセットに分割するタスクです。テーブルのサブセットは呼び出されますfragments。断片化には、水平、垂直、およびハイブリッド(水平と垂直の組み合わせ)の3つのタイプがあります。水平方向の断片化は、さらに2つの手法に分類できます。プライマリ水平方向の断片化と派生水平方向の断片化です。
フラグメント化は、元のテーブルがフラグメントから再構築できるような方法で実行する必要があります。これは、必要なときにいつでもフラグメントから元のテーブルを再構築できるようにするために必要です。この要件は「再構成性」と呼ばれます。
断片化の利点
データは使用場所の近くに保存されるため、データベースシステムの効率が向上します。
データはローカルで利用できるため、ほとんどのクエリにはローカルクエリ最適化手法で十分です。
関係のないデータがサイトで利用できないため、データベースシステムのセキュリティとプライバシーを維持できます。
断片化のデメリット
異なるフラグメントからのデータが必要な場合、アクセス速度が非常に速くなる可能性があります。
再帰的な断片化の場合、再構築の仕事には高価な技術が必要になります。
異なるサイトにデータのバックアップコピーがない場合、サイトに障害が発生した場合にデータベースが無効になる可能性があります。
垂直方向の断片化
垂直フラグメンテーションでは、テーブルのフィールドまたは列がフラグメントにグループ化されます。再構成性を維持するために、各フラグメントにはテーブルの主キーフィールドが含まれている必要があります。垂直方向の断片化は、データのプライバシーを強化するために使用できます。
たとえば、大学のデータベースが、次のスキーマを持つStudentテーブルに登録されているすべての学生のレコードを保持しているとします。
学生
| Regd_No | 名前 | コース | 住所 | 学期 | 料金 | マーク |
現在、料金の詳細はアカウントセクションで管理されています。この場合、設計者は次のようにデータベースをフラグメント化します-
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;水平方向の断片化
水平方向の断片化は、1つ以上のフィールドの値に従ってテーブルのタプルをグループ化します。水平方向の断片化も、再構築のルールを確認する必要があります。各水平フラグメントには、元のベーステーブルのすべての列が含まれている必要があります。
たとえば、学生スキーマで、コンピュータサイエンスコースのすべての学生の詳細をコンピュータサイエンス学部で維持する必要がある場合、設計者は次のようにデータベースを水平方向に断片化します。
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";ハイブリッドフラグメンテーション
ハイブリッドフラグメンテーションでは、水平フラグメンテーション手法と垂直フラグメンテーション手法を組み合わせて使用します。これは、最小限の無関係な情報でフラグメントを生成するため、最も柔軟なフラグメンテーション手法です。ただし、元のテーブルの再構築は、多くの場合、コストのかかる作業です。
ハイブリッドフラグメンテーションは、2つの代替方法で実行できます-
最初に、水平フラグメントのセットを生成します。次に、1つ以上の水平フラグメントから垂直フラグメントを生成します。
最初に、垂直フラグメントのセットを生成します。次に、1つ以上の垂直フラグメントから水平フラグメントを生成します。
ディストリビューションの透過性は、ディストリビューションの内部の詳細がユーザーから隠されているため、分散データベースの特性です。DDBMS設計者は、テーブルをフラグメント化し、フラグメントを複製して、さまざまなサイトに保存することを選択できます。ただし、ユーザーはこれらの詳細を知らないため、分散データベースは他の集中型データベースと同じように使いやすいと感じています。
流通の透明性の3つの次元は次のとおりです。
- 場所の透明性
- 断片化の透明性
- レプリケーションの透過性
場所の透明性
場所の透過性により、ユーザーは、ユーザーのサイトにローカルに格納されているかのように、任意のテーブルまたはテーブルのフラグメントに対してクエリを実行できます。テーブルまたはそのフラグメントが分散データベースシステムのリモートサイトに格納されているという事実は、エンドユーザーには完全に気付かれることはありません。リモートサイトのアドレスとアクセスメカニズムは完全に隠されています。
場所の透過性を組み込むために、DDBMSは、更新された正確なデータディクショナリとデータの場所の詳細を含むDDBMSディレクトリにアクセスできる必要があります。
断片化の透過性
断片化の透過性により、ユーザーは、断片化されていないかのように任意のテーブルをクエリできます。したがって、ユーザーがクエリを実行しているテーブルが実際にはフラグメントまたはいくつかのフラグメントの和集合であるという事実を隠します。また、フラグメントがさまざまな場所にあるという事実も隠します。
これは、SQLビューのユーザーにいくぶん似ています。ユーザーは、テーブル自体ではなくテーブルのビューを使用していることを知らない場合があります。
レプリケーションの透過性
レプリケーションの透過性により、データベースのレプリケーションがユーザーから隠されます。これにより、ユーザーは、テーブルのコピーが1つしかないかのようにテーブルをクエリできます。
レプリケーションの透過性は、同時実行の透過性と障害の透過性に関連付けられています。ユーザーがデータ項目を更新するたびに、更新はテーブルのすべてのコピーに反映されます。ただし、この操作はユーザーに知られてはなりません。これは並行性の透過性です。また、サイトに障害が発生した場合でも、ユーザーは障害を知らなくても、複製されたコピーを使用してクエリを続行できます。これが障害の透過性です。
OHPフィルムの組み合わせ
分散データベースシステムでは、設計者は、記載されているすべての透明度がかなりの程度維持されていることを確認する必要があります。設計者は、テーブルをフラグメント化し、複製して、さまざまなサイトに保存することを選択できます。すべてエンドユーザーに気づかれません。ただし、完全な配布の透過性は困難な作業であり、かなりの設計作業が必要です。
データベース制御とは、データベースの本物のユーザーとアプリケーションに正しいデータを提供するために規制を施行するタスクを指します。ユーザーが正しいデータを利用できるようにするには、すべてのデータがデータベースで定義されている整合性制約に準拠している必要があります。さらに、データベースのセキュリティとプライバシーを維持するために、許可されていないユーザーからデータを選別する必要があります。データベース制御は、データベース管理者(DBA)の主要なタスクの1つです。
データベース制御の3つの次元は次のとおりです。
- Authentication
- アクセス権
- 整合性制約
認証
分散データベースシステムでは、認証は正当なユーザーのみがデータリソースにアクセスできるプロセスです。
認証は2つのレベルで実施できます-
Controlling Access to Client Computer−このレベルでは、データベースサーバーへのユーザーインターフェイスを提供するクライアントコンピューターへのログイン中のユーザーアクセスが制限されます。最も一般的な方法は、ユーザー名とパスワードの組み合わせです。ただし、高度なセキュリティデータには、生体認証などのより高度な方法を使用できます。
Controlling Access to the Database Software−このレベルでは、データベースソフトウェア/管理者がいくつかの資格情報をユーザーに割り当てます。ユーザーは、これらの資格情報を使用してデータベースにアクセスできます。方法の1つは、データベースサーバー内にログインアカウントを作成することです。
アクセス権
ユーザーのアクセス権とは、テーブルの作成、テーブルの削除、テーブル内のタプルの追加/削除/更新、またはテーブルへのクエリなど、DBMS操作に関してユーザーに付与される特権を指します。
分散環境では、テーブルの数が多く、ユーザーの数も多いため、ユーザーに個別のアクセス権を割り当てることはできません。したがって、DDBMSは特定の役割を定義します。ロールは、データベースシステム内で特定の特権を持つ構成です。さまざまな役割が定義されると、個々のユーザーにこれらの役割の1つが割り当てられます。多くの場合、役割の階層は、組織の権限と責任の階層に従って定義されます。
たとえば、次のSQLステートメントは、ロール「Accountant」を作成してから、このロールをユーザー「ABC」に割り当てます。
CREATE ROLE ACCOUNTANT;
GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT;
GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT;
GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT;
COMMIT;
GRANT ACCOUNTANT TO ABC;
COMMIT;セマンティック整合性制御
セマンティック整合性制御は、データベースシステムの整合性制約を定義および適用します。
整合性制約は次のとおりです-
- データ型の整合性の制約
- エンティティ整合性の制約
- 参照整合性制約
データ型の整合性の制約
データ型制約は、指定されたデータ型のフィールドに適用できる値の範囲と操作の種類を制限します。
たとえば、テーブル「HOSTEL」に、ホステル番号、ホステル名、収容人数の3つのフィールドがあるとします。ホステル番号は大文字の「H」で始まり、NULLにすることはできません。また、容量は150を超えてはなりません。次のSQLコマンドをデータ定義に使用できます。
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) NOT NULL,
H_NAME VARCHAR2(15),
CAPACITY INTEGER,
CHECK ( H_NO LIKE 'H%'),
CHECK ( CAPACITY <= 150)
);エンティティ整合性制御
エンティティ整合性制御は、各タプルが他のタプルから一意に識別できるようにルールを適用します。このために主キーが定義されます。主キーは、タプルを一意に識別できる一連の最小フィールドです。エンティティ整合性制約は、テーブル内の2つのタプルが主キーに対して同一の値を持つことはできず、主キーの一部であるフィールドがNULL値を持つことはできないことを示しています。
たとえば、上記のホステルテーブルでは、次のSQLステートメントを使用してホステル番号を主キーとして割り当てることができます(チェックは無視されます)。
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) PRIMARY KEY,
H_NAME VARCHAR2(15),
CAPACITY INTEGER
);参照整合性の制約
参照整合性制約は、外部キーのルールを規定します。外部キーは、関連テーブルの主キーであるデータテーブルのフィールドです。参照整合性制約は、外部キーフィールドの値が、参照されるテーブルの主キーの値の中にあるか、完全にNULLである必要があるという規則を定めています。
たとえば、学生がホステルに住むことを選択できる学生テーブルについて考えてみましょう。これを含めるには、ホステルテーブルの主キーを学生テーブルの外部キーとして含める必要があります。次のSQLステートメントにはこれが組み込まれています-
CREATE TABLE STUDENT (
S_ROLL INTEGER PRIMARY KEY,
S_NAME VARCHAR2(25) NOT NULL,
S_COURSE VARCHAR2(10),
S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL
);クエリが配置されると、最初にスキャン、解析、および検証されます。次に、クエリツリーやクエリグラフなど、クエリの内部表現が作成されます。次に、データベーステーブルから結果を取得するための代替実行戦略が考案されます。クエリ処理に最も適切な実行戦略を選択するプロセスは、クエリ最適化と呼ばれます。
DDBMSのクエリ最適化の問題
DDBMSでは、クエリの最適化は重要なタスクです。次の要因により、代替戦略の数が指数関数的に増加する可能性があるため、複雑さが高くなります。
- 多数のフラグメントの存在。
- さまざまなサイト間でのフラグメントまたはテーブルの配布。
- 通信リンクの速度。
- ローカル処理機能の不一致。
したがって、分散システムでは、多くの場合、ターゲットは、最適な実行戦略ではなく、クエリ処理の適切な実行戦略を見つけることです。クエリを実行する時間は、次の合計です。
- クエリをデータベースに伝達する時間です。
- ローカルクエリフラグメントを実行する時間。
- さまざまなサイトからデータを収集する時間です。
- 結果をアプリケーションに表示する時間です。
クエリ処理
クエリ処理は、クエリの配置からクエリの結果の表示までのすべてのアクティビティのセットです。手順は次の図に示すとおりです-

関係代数
関係代数は、リレーショナルデータベースモデルの基本的な操作セットを定義します。一連の関係代数演算は、関係代数式を形成します。この式の結果は、データベースクエリの結果を表します。
基本的な操作は次のとおりです。
- Projection
- Selection
- Union
- Intersection
- Minus
- Join
投影
射影操作は、テーブルのフィールドのサブセットを表示します。これにより、テーブルの垂直パーティションが作成されます。
Syntax in Relational Algebra
$$ \ pi _ {<{AttributeList}>} {(<{テーブル名}>)} $$
たとえば、次の学生データベースについて考えてみましょう。
|
|
||||
| Roll_No | Name | Course | Semester | Gender |
| 2 | アミット・プラサド | BCA | 1 | 男性 |
| 4 | ヴァルシャ・ティワリ | BCA | 1 | 女性 |
| 5 | Asif Ali | MCA | 2 | 男性 |
| 6 | ジョーウォーレス | MCA | 1 | 男性 |
| 8 | シヴァニアイアンガー | BCA | 1 | 女性 |
すべての学生の名前とコースを表示する場合は、次の関係代数式を使用します。
$$\pi_{Name,Course}{(STUDENT)}$$
選択
選択操作は、特定の条件を満たすテーブルのタプルのサブセットを表示します。これにより、テーブルの水平パーティションが作成されます。
Syntax in Relational Algebra
$$ \ sigma _ {<{Conditions}>} {(<{Table Name}>)} $$
たとえば、Studentテーブルで、MCAコースを選択したすべての学生の詳細を表示する場合は、次の関係代数式を使用します。
$$\sigma_{Course} = {\small "BCA"}^{(STUDENT)}$$
射影演算と選択演算の組み合わせ
ほとんどのクエリでは、射影操作と選択操作の組み合わせが必要です。これらの式を書くには2つの方法があります-
- 一連の投影および選択操作を使用します。
- 名前変更操作を使用して中間結果を生成します。
たとえば、BCAコースのすべての女子学生の名前を表示するには-
- 一連の射影および選択演算を使用した関係代数式
$$\pi_{Name}(\sigma_{Gender = \small "Female" AND \: Course = \small "BCA"}{(STUDENT)})$$
- 名前変更操作を使用して中間結果を生成する関係代数式
$$FemaleBCAStudent \leftarrow \sigma_{Gender = \small "Female" AND \: Course = \small "BCA"} {(STUDENT)}$$
$$Result \leftarrow \pi_{Name}{(FemaleBCAStudent)}$$
連合
Pが演算の結果であり、Qが別の演算の結果である場合、PとQの和集合($p \cup Q$)は、PまたはQのいずれか、あるいは両方に重複のないすべてのタプルのセットです。
たとえば、セメスター1またはBCAコースのいずれかにあるすべての学生を表示するには-
$$Sem1Student \leftarrow \sigma_{Semester = 1}{(STUDENT)}$$
$$BCAStudent \leftarrow \sigma_{Course = \small "BCA"}{(STUDENT)}$$
$$Result \leftarrow Sem1Student \cup BCAStudent$$
交差点
Pが演算の結果であり、Qが別の演算の結果である場合、PとQの共通部分( $p \cap Q$ )は、PとQの両方にあるすべてのタプルのセットです。
たとえば、次の2つのスキーマがあるとします-
EMPLOYEE
| EmpID | 名前 | 市 | 部門 | 給料 |
PROJECT
| PId | 市 | 部門 | 状態 |
プロジェクトがあり、従業員が住んでいるすべての都市の名前を表示するには-
$$CityEmp \leftarrow \pi_{City}{(EMPLOYEE)}$$
$$CityProject \leftarrow \pi_{City}{(PROJECT)}$$
$$Result \leftarrow CityEmp \cap CityProject$$
マイナス
Pが操作の結果であり、Qが別の操作の結果である場合、P-Qは、QではなくPにあるすべてのタプルのセットです。
たとえば、進行中のプロジェクトがないすべての部門を一覧表示するには(ステータス=進行中のプロジェクト)-
$$AllDept \leftarrow \pi_{Department}{(EMPLOYEE)}$$
$$ProjectDept \leftarrow \pi_{Department} (\sigma_{Status = \small "ongoing"}{(PROJECT)})$$
$$Result \leftarrow AllDept - ProjectDept$$
参加する
結合操作は、2つの異なるテーブル(クエリの結果)の関連するタプルを1つのテーブルに結合します。
たとえば、銀行データベースのCustomerとBranchの2つのスキーマを次のように考えます。
CUSTOMER
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
BRANCH
| BranchID | 支店名 | IFSCコード | 住所 |
支店の詳細とともに従業員の詳細を一覧表示するには-
$$Result \leftarrow CUSTOMER \bowtie_{Customer.BranchID=Branch.BranchID}{BRANCH}$$
SQLクエリの関係代数への変換
SQLクエリは、最適化の前に同等のリレーショナル代数式に変換されます。クエリは、最初は小さなクエリブロックに分解されます。これらのブロックは、同等のリレーショナル代数式に変換されます。最適化には、各ブロックの最適化と、クエリ全体の最適化が含まれます。
例
次のスキーマを考えてみましょう-
社員
| EmpID | 名前 | 市 | 部門 | 給料 |
事業
| PId | 市 | 部門 | 状態 |
WORKS
| EmpID | PID | 時間 |
例1
平均給与よりも少ない給与を稼いでいるすべての従業員の詳細を表示するために、SQLクエリを記述します-
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;このクエリには、ネストされたサブクエリが1つ含まれています。したがって、これは2つのブロックに分割できます。
内側のブロックは-
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;このクエリの結果がAvgSalの場合、外側のブロックは-です。
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;内部ブロックの関係代数式-
$$AvgSal \leftarrow \Im_{AVERAGE(Salary)}{EMPLOYEE}$$
外側のブロックの関係代数式-
$$ \ sigma_ {Salary <{AvgSal}>} {EMPLOYEE} $$
例2
従業員「ArunKumar」のすべてのプロジェクトのプロジェクトIDとステータスを表示するには、SQLクエリを記述します-
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));このクエリには、ネストされた2つのサブクエリが含まれています。したがって、次のように3つのブロックに分割できます。
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;(ここで、ArunEmpIDとArunPIDは内部クエリの結果です)
3つのブロックの関係代数式は次のとおりです。
$$ArunEmpID \leftarrow \pi_{EmpID}(\sigma_{Name = \small "Arun Kumar"} {(EMPLOYEE)})$$
$$ArunPID \leftarrow \pi_{PID}(\sigma_{EmpID = \small "ArunEmpID"} {(WORKS)})$$
$$Result \leftarrow \pi_{PID, Status}(\sigma_{PID = \small "ArunPID"} {(PROJECT)})$$
関係代数演算子の計算
関係代数演算子の計算はさまざまな方法で実行でき、それぞれの選択肢は access path。
代替計算は、3つの主な要因に依存します-
- 演算子タイプ
- 使用可能なメモリ
- ディスク構造
関係代数演算の実行を実行する時間は、-の合計です。
- タプルを処理する時間です。
- テーブルのタプルをディスクからメモリにフェッチする時間。
タプルを処理する時間は、ストレージからタプルをフェッチする時間よりも非常に短いため、特に分散システムでは、ディスクアクセスは、リレーショナル式のコストを計算するためのメトリックと見なされることがよくあります。
選択の計算
選択操作の計算は、選択条件の複雑さとテーブルの属性のインデックスの可用性に依存します。
以下は、インデックスに応じた計算の選択肢です。
No Index−テーブルがソートされておらず、インデックスがない場合、選択プロセスには、テーブルのすべてのディスクブロックのスキャンが含まれます。各ブロックがメモリに取り込まれ、ブロック内の各タプルが選択条件を満たすかどうかが調べられます。条件が満たされると、出力として表示されます。これは、各タプルがメモリに取り込まれ、各タプルが処理されるため、最もコストのかかるアプローチです。
B+ Tree Index−ほとんどのデータベースシステムは、B +ツリーインデックスに基づいて構築されています。選択条件がこのB +ツリーインデックスのキーであるフィールドに基づいている場合、このインデックスは結果の取得に使用されます。ただし、複雑な条件で選択ステートメントを処理すると、ディスクブロックへのアクセス数が多くなり、場合によってはテーブルの完全なスキャンが必要になることがあります。
Hash Index−ハッシュインデックスが使用され、そのキーフィールドが選択条件で使用される場合、ハッシュインデックスを使用してタプルを取得することは簡単なプロセスになります。ハッシュインデックスは、ハッシュ関数を使用して、ハッシュ値に対応するキー値が格納されているバケットのアドレスを検索します。インデックス内のキー値を見つけるために、ハッシュ関数が実行され、バケットアドレスが見つかります。バケット内のキー値が検索されます。一致するものが見つかった場合、実際のタプルがディスクブロックからメモリにフェッチされます。
結合の計算
PとQなどの2つのテーブルを結合する場合、結合条件が満たされているかどうかをテストするために、Pの各タプルをQの各タプルと比較する必要があります。条件が満たされると、対応するタプルが連結され、重複するフィールドが削除され、結果の関係に追加されます。したがって、これは最もコストのかかる操作です。
結合を計算するための一般的なアプローチは次のとおりです。
ネストループアプローチ
これは、従来の結合アプローチです。これは、次の擬似コードで説明できます(表PおよびQ、タプルtuple_pおよびtuple_q、結合属性a)-
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-pソートマージアプローチ
このアプローチでは、2つのテーブルが結合属性に基づいて個別にソートされ、ソートされたテーブルがマージされます。レコード数が非常に多く、メモリに収容できないため、外部ソーティング手法が採用されています。個々のテーブルが並べ替えられると、並べ替えられた各テーブルがメモリに読み込まれ、結合属性に基づいてマージされ、結合されたタプルが書き出されます。
ハッシュ結合アプローチ
このアプローチは、パーティショニングフェーズとプロービングフェーズの2つのフェーズで構成されます。パーティショニングフェーズでは、テーブルPとQが2セットの互いに素なパーティションに分割されます。共通のハッシュ関数が決定されます。このハッシュ関数は、タプルをパーティションに割り当てるために使用されます。プロービングフェーズでは、Pのパーティション内のタプルがQの対応するパーティションのタプルと比較されます。それらが一致する場合、それらは書き出されます。
リレーショナル代数式を計算するための代替アクセスパスが導出されると、最適なアクセスパスが決定されます。この章では、集中型システムでのクエリの最適化について説明し、次の章では、分散システムでのクエリの最適化について学習します。
一元化されたシステムでは、クエリ処理は次の目的で実行されます。
クエリの応答時間の最小化(ユーザーのクエリに対して結果を生成するのにかかる時間)。
システムスループット(特定の時間内に処理される要求の数)を最大化します。
処理に必要なメモリとストレージの量を減らします。
並列処理を増やします。
クエリの解析と翻訳
最初に、SQLクエリがスキャンされます。次に、構文エラーとデータ型の正確さを探すために解析されます。クエリがこのステップに合格すると、クエリはより小さなクエリブロックに分解されます。次に、各ブロックは同等のリレーショナル代数式に変換されます。
クエリ最適化の手順
クエリの最適化には、クエリツリーの生成、プランの生成、クエリプランのコードの生成という3つのステップが含まれます。
Step 1 − Query Tree Generation
クエリツリーは、リレーショナル代数式を表すツリーデータ構造です。クエリのテーブルはリーフノードとして表されます。関係代数演算は、内部ノードとして表されます。ルートはクエリ全体を表します。
実行中、内部ノードは、そのオペランドテーブルが使用可能な場合は常に実行されます。その後、ノードは結果テーブルに置き換えられます。このプロセスは、ルートノードが実行されて結果テーブルに置き換えられるまで、すべての内部ノードに対して続行されます。
たとえば、次のスキーマについて考えてみましょう。
社員
| EmpID | EName | 給料 | 部門番号 | 入社の日 |
部門
| Dいいえ | DName | ロケーション |
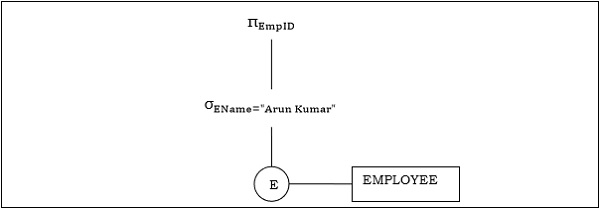
例1
クエリを次のように考えてみましょう。
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
対応するクエリツリーは次のようになります-
例2
結合を含む別のクエリについて考えてみましょう。
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
以下は、上記のクエリのクエリツリーです。

Step 2 − Query Plan Generation
クエリツリーが生成された後、クエリプランが作成されます。クエリプランは、クエリツリー内のすべての操作のアクセスパスを含む拡張クエリツリーです。アクセスパスは、ツリー内の関係演算の実行方法を指定します。たとえば、選択操作には、選択のためのB +ツリーインデックスの使用に関する詳細を提供するアクセスパスを含めることができます。
さらに、クエリプランには、中間テーブルをあるオペレーターから次のオペレーターに渡す方法、一時テーブルを使用する方法、操作をパイプライン化/結合する方法も記載されています。
Step 3− Code Generation
コード生成は、クエリ最適化の最終ステップです。これはクエリの実行可能形式であり、その形式は基盤となるオペレーティングシステムの種類によって異なります。クエリコードが生成されると、Execution Managerはそれを実行し、結果を生成します。
クエリ最適化へのアプローチ
クエリ最適化のアプローチの中で、徹底的な検索とヒューリスティックベースのアルゴリズムが主に使用されます。
徹底的な検索の最適化
これらの手法では、クエリに対して、考えられるすべてのクエリプランが最初に生成され、次に最適なプランが選択されます。これらの手法は最良のソリューションを提供しますが、ソリューションスペースが大きいため、時間とスペースが指数関数的に複雑になります。たとえば、動的計画法。
ヒューリスティックベースの最適化
ヒューリスティックベースの最適化では、クエリの最適化にルールベースの最適化アプローチを使用します。これらのアルゴリズムは、多項式の時間と空間の複雑さを持っています。これは、全数検索ベースのアルゴリズムの指数関数的な複雑さよりも低くなっています。ただし、これらのアルゴリズムは必ずしも最良のクエリプランを生成するとは限りません。
一般的なヒューリスティックルールのいくつかは次のとおりです。
結合操作の前に、選択操作とプロジェクト操作を実行します。これは、選択操作とプロジェクト操作をクエリツリーの下に移動することによって行われます。これにより、結合に使用できるタプルの数が減ります。
他の操作の前に、最初に最も制限の厳しい選択/プロジェクト操作を実行します。
非常に大きなサイズの中間テーブルになるため、製品間の操作は避けてください。
この章では、分散データベースシステムでのクエリの最適化について説明します。
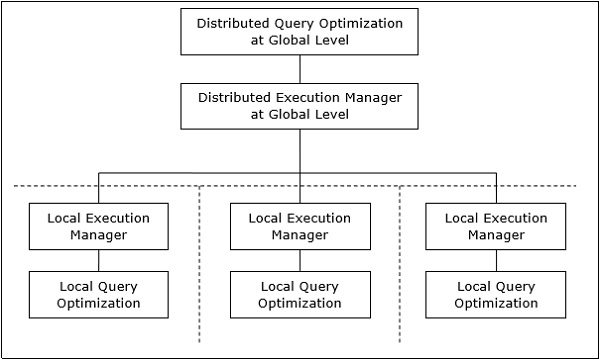
分散クエリ処理アーキテクチャ
分散データベースシステムでは、クエリの処理は、グローバルレベルとローカルレベルの両方での最適化で構成されます。クエリは、クライアントまたは制御サイトのデータベースシステムに入ります。ここでは、ユーザーが検証され、クエリがチェックされ、変換され、グローバルレベルで最適化されます。
アーキテクチャは次のように表すことができます-
グローバルクエリのローカルクエリへのマッピング
グローバルクエリをローカルクエリにマッピングするプロセスは、次のように実現できます。
グローバルクエリに必要なテーブルには、複数のサイトに分散されたフラグメントがあります。ローカルデータベースには、ローカルデータに関する情報のみがあります。制御サイトは、グローバルデータディクショナリを使用して分布に関する情報を収集し、フラグメントからグローバルビューを再構築します。
レプリケーションがない場合、グローバルオプティマイザーはフラグメントが格納されているサイトでローカルクエリを実行します。レプリケーションがある場合、グローバルオプティマイザーは、通信コスト、ワークロード、およびサーバー速度に基づいてサイトを選択します。
グローバルオプティマイザは、サイト間で発生するデータ転送の量が最小になるように、分散実行プランを生成します。計画には、フラグメントの場所、クエリステップを実行する必要がある順序、および中間結果の転送に関連するプロセスが記載されています。
ローカルクエリは、ローカルデータベースサーバーによって最適化されます。最後に、ローカルクエリの結果は、水平フラグメントの場合は結合操作、垂直フラグメントの場合は結合操作によってマージされます。
たとえば、次のプロジェクトスキーマが、ニューデリー、コルカタ、ハイデラバードの都市に応じて水平方向に断片化されているとします。
事業
| PId | 市 | 部門 | 状態 |
ステータスが「進行中」であるすべてのプロジェクトの詳細を取得するクエリがあるとします。
グローバルクエリは&inus;になります
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
ニューデリーのサーバーでのクエリは次のようになります-
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
コルカタのサーバーでのクエリは次のようになります-
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
ハイデラバードのサーバーでのクエリは次のようになります-
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
全体的な結果を得るには、次のように3つのクエリの結果を結合する必要があります。
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
分散クエリの最適化
分散クエリの最適化には、クエリの必要な結果を生成する多数のクエリツリーの評価が必要です。これは主に、複製および断片化されたデータが大量に存在するためです。したがって、目標は、最良の解決策ではなく、最適な解決策を見つけることです。
分散クエリ最適化の主な問題は次のとおりです。
- 分散システムにおけるリソースの最適な利用。
- クエリ取引。
- クエリのソリューションスペースの削減。
分散システムにおけるリソースの最適な利用
分散システムには、クエリに関連する操作を実行するために、さまざまなサイトに多数のデータベースサーバーがあります。以下は、最適なリソース使用率のためのアプローチです-
Operation Shipping−オペレーションシッピングでは、オペレーションはクライアントサイトではなく、データが保存されているサイトで実行されます。その後、結果はクライアントサイトに転送されます。これは、オペランドが同じサイトで使用できる操作に適しています。例:選択およびプロジェクト操作。
Data Shipping−データ配布では、データフラグメントがデータベースサーバーに転送され、そこで操作が実行されます。これは、オペランドが異なるサイトに分散されている操作で使用されます。これは、通信コストが低く、ローカルプロセッサがクライアントサーバーよりもはるかに遅いシステムにも適しています。
Hybrid Shipping−これはデータとオペレーションシッピングの組み合わせです。ここで、データフラグメントは高速プロセッサに転送され、そこで操作が実行されます。その後、結果はクライアントサイトに送信されます。

クエリ取引
分散データベースシステムのクエリ取引アルゴリズムでは、分散クエリの制御/クライアントサイトは買い手と呼ばれ、ローカルクエリが実行されるサイトは売り手と呼ばれます。買い手は、売り手を選択し、グローバルな結果を再構築するためのいくつかの選択肢を策定します。バイヤーの目標は、最適なコストを達成することです。
アルゴリズムは、買い手が売り手サイトにサブクエリを割り当てることから始まります。最適なプランは、最終結果を再構築するための通信コストと組み合わせて、販売者によって提案されたローカルに最適化されたクエリプランから作成されます。グローバル最適計画が策定されると、クエリが実行されます。
クエリのソリューションスペースの削減
最適なソリューションには、通常、ソリューションスペースの削減が含まれるため、クエリとデータ転送のコストが削減されます。これは、集中型システムのヒューリスティックと同様に、一連のヒューリスティックルールを通じて実現できます。
以下はいくつかのルールです-
できるだけ早く選択および投影操作を実行します。これにより、通信ネットワーク上のデータフローが減少します。
特定のサイトに関係のない選択条件を排除することにより、水平フラグメントの操作を簡素化します。
複数のサイトにあるフラグメントで構成される結合および結合操作の場合、フラグメント化されたデータをほとんどのデータが存在するサイトに転送し、そこで操作を実行します。
半結合操作を使用して、結合されるタプルを修飾します。これにより、データ転送の量が減り、通信コストが削減されます。
分散クエリツリーで共通のリーフとサブツリーをマージします。
この章では、トランザクション処理のさまざまな側面について説明します。また、トランザクションに含まれる低レベルのタスク、トランザクションの状態、およびトランザクションのプロパティについても学習します。最後の部分では、スケジュールとスケジュールの直列化可能性について説明します。
トランザクション
トランザクションは、データベース操作のコレクションを含むプログラムであり、データ処理の論理ユニットとして実行されます。トランザクションで実行される操作には、データの挿入、削除、更新、取得などの1つ以上のデータベース操作が含まれます。これは、完全に実行されるか、まったく実行されないアトミックプロセスです。データの更新を行わずにデータの取得のみを行うトランザクションは、読み取り専用トランザクションと呼ばれます。
各高レベルの操作は、いくつかの低レベルのタスクまたは操作に分割できます。たとえば、データ更新操作は3つのタスクに分割できます-
read_item() −ストレージからメインメモリにデータ項目を読み取ります。
modify_item() −メインメモリ内のアイテムの値を変更します。
write_item() −変更した値をメインメモリからストレージに書き込みます。
データベースへのアクセスは、read_item()およびwrite_item()操作に制限されています。同様に、すべてのトランザクションについて、読み取りと書き込みが基本的なデータベース操作を形成します。
トランザクション操作
トランザクションで実行される低レベルの操作は次のとおりです。
begin_transaction −トランザクション実行の開始を指定するマーカー。
read_item or write_item −トランザクションの一部としてメインメモリ操作とインターリーブされる可能性のあるデータベース操作。
end_transaction −トランザクションの終了を指定するマーカー。
commit −トランザクションが完全に正常に完了し、取り消されないことを指定するシグナル。
rollback−トランザクションが失敗したため、データベース内のすべての一時的な変更が取り消されたことを指定するシグナル。コミットされたトランザクションはロールバックできません。
トランザクション状態
トランザクションは、アクティブ、部分的にコミット、コミット、失敗、および中止の5つの状態のサブセットを通過する場合があります。
Active−トランザクションが入る初期状態はアクティブ状態です。トランザクションは、読み取り、書き込み、またはその他の操作を実行している間、この状態のままになります。
Partially Committed −トランザクションの最後のステートメントが実行された後、トランザクションはこの状態になります。
Committed −トランザクションが正常に完了し、システムチェックがコミット信号を発行した後、トランザクションはこの状態になります。
Failed −通常の実行が続行できなくなった、またはシステムチェックが失敗したことが検出されると、トランザクションは部分的にコミットされた状態またはアクティブな状態から失敗した状態になります。
Aborted −これは、障害後にトランザクションがロールバックされ、データベースがトランザクション開始前の状態に復元された後の状態です。
次の状態遷移図は、トランザクション内の状態と、状態の変化を引き起こす低レベルのトランザクション操作を示しています。
トランザクションの望ましいプロパティ
すべてのトランザクションは、ACIDプロパティを維持する必要があります。原子性、一貫性、分離、および耐久性。
Atomicity−このプロパティは、トランザクションが処理のアトミックユニットであること、つまり、トランザクション全体が実行されるか、まったく実行されないことを示します。部分的な更新は存在しないはずです。
Consistency−トランザクションは、データベースをある一貫性のある状態から別の一貫性のある状態に移行する必要があります。データベース内のデータ項目に悪影響を与えることはありません。
Isolation−トランザクションは、システム内で唯一のトランザクションであるかのように実行する必要があります。同時に実行されている他の同時トランザクションからの干渉があってはなりません。
Durability −コミットされたトランザクションによって変更が発生した場合、その変更はデータベース内で永続的であり、障害が発生しても失われないようにする必要があります。
スケジュールと競合
多数の同時トランザクションがあるシステムでは、 schedule操作の実行の合計順序です。n個のトランザクションで構成されるスケジュールSが与えられた場合、たとえばT1、T2、T3………..Tn; トランザクションTiの場合、Tiの操作はスケジュールSに規定されているとおりに実行する必要があります。
スケジュールの種類
スケジュールには2つのタイプがあります-
Serial Schedules−シリアルスケジュールでは、どの時点でも、アクティブなトランザクションは1つだけです。つまり、トランザクションの重複はありません。これを次のグラフに示します-

Parallel Schedules−並列スケジュールでは、複数のトランザクションが同時にアクティブになります。つまり、トランザクションには、時間的に重複する操作が含まれます。これを次のグラフに示します-

スケジュールの競合
複数のトランザクションで構成されるスケジュールでは、 conflict2つのアクティブなトランザクションが互換性のない操作を実行すると発生します。次の3つの条件がすべて同時に存在する場合、2つの操作は競合していると言われます-
2つの操作は、異なるトランザクションの一部です。
両方の操作が同じデータ項目にアクセスします。
操作の少なくとも1つはwrite_item()操作です。つまり、データ項目を変更しようとします。
直列化可能性
A serializable schedule'n'トランザクションの数は、同じ 'n'トランザクションで構成されるシリアルスケジュールと同等の並列スケジュールです。シリアル化可能なスケジュールには、並列スケジュールのCPU使用率の向上を確認しながら、シリアルスケジュールの正確さが含まれます。
スケジュールの同等性
2つのスケジュールの同等性は、次のタイプになります。
Result equivalence −同じ結果を生成する2つのスケジュールは、結果が同等であると言われます。
View equivalence −同様の方法で同様のアクションを実行する2つのスケジュールは、ビューが同等であると言われます。
Conflict equivalence − 2つのスケジュールは、両方に同じトランザクションセットが含まれ、競合する操作のペアの順序が同じである場合、競合が同等であると言われます。
同時実行制御技術により、トランザクションのACIDプロパティとスケジュールの直列化可能性を維持しながら、複数のトランザクションが同時に実行されます。
この章では、並行性制御のさまざまなアプローチについて学習します。
ロックベースの同時実行制御プロトコル
ロックベースの同時実行制御プロトコルは、データ項目をロックするという概念を使用します。Alockデータ項目に関連付けられた変数であり、そのデータ項目に対して読み取り/書き込み操作を実行できるかどうかを決定します。一般に、データ項目を2つのトランザクションで同時にロックできるかどうかを示すロック互換性マトリックスが使用されます。
ロックベースの同時実行制御システムは、1フェーズまたは2フェーズのロックプロトコルを使用できます。
単相ロックプロトコル
この方法では、各トランザクションは使用前にアイテムをロックし、使用が終了するとすぐにロックを解除します。このロック方法は最大の同時実行性を提供しますが、常に直列化可能性を強制するわけではありません。
二相ロックプロトコル
この方法では、すべてのロック操作が最初のロック解除またはロック解除操作の前に行われます。トランザクションは2つのフェーズで構成されます。最初のフェーズでは、トランザクションは必要なすべてのロックのみを取得し、ロックを解放しません。これは、拡張またはgrowing phase。2番目のフェーズでは、トランザクションはロックを解放し、新しいロックを要求できません。これは、shrinking phase。
2フェーズロックプロトコルに従うすべてのトランザクションは、シリアル化可能であることが保証されています。ただし、このアプローチでは、競合する2つのトランザクション間の並列処理が低くなります。
タイムスタンプ同時実行制御アルゴリズム
タイムスタンプベースの同時実行制御アルゴリズムは、トランザクションのタイムスタンプを使用してデータ項目への同時アクセスを調整し、直列化可能性を確保します。タイムスタンプは、トランザクションの開始時刻を表す、DBMSによってトランザクションに与えられる一意の識別子です。
これらのアルゴリズムにより、トランザクションはタイムスタンプで指定された順序でコミットされます。古いトランザクションは若いトランザクションの前にシステムに入るので、古いトランザクションは若いトランザクションの前にコミットする必要があります。
タイムスタンプベースの同時実行制御技術は、同等のシリアルスケジュールが参加トランザクションの経過時間の順に並べられるように、シリアル化可能なスケジュールを生成します。
タイムスタンプベースの同時実行制御アルゴリズムのいくつかは次のとおりです。
- 基本的なタイムスタンプの並べ替えアルゴリズム。
- 保守的なタイムスタンプの並べ替えアルゴリズム。
- タイムスタンプの順序に基づくマルチバージョンアルゴリズム。
タイムスタンプベースの順序付けは、直列化可能性を適用するために3つのルールに従います-
Access Rule− 2つのトランザクションが同じデータ項目に同時にアクセスしようとすると、操作が競合するため、古いトランザクションが優先されます。これにより、若いトランザクションは古いトランザクションが最初にコミットするのを待ちます。
Late Transaction Rule−若いトランザクションがデータ項目を書き込んだ場合、古いトランザクションはそのデータ項目の読み取りまたは書き込みを許可されません。このルールは、若いトランザクションがすでにコミットされた後、古いトランザクションがコミットされないようにします。
Younger Transaction Rule −若いトランザクションは、古いトランザクションによってすでに書き込まれているデータ項目を読み書きできます。
楽観的同時実行制御アルゴリズム
競合率が低いシステムでは、すべてのトランザクションの直列化可能性を検証するタスクによってパフォーマンスが低下する可能性があります。このような場合、直列化可能性のテストはコミット直前に延期されます。競合率が低いため、シリアル化できないトランザクションを中止する可能性も低くなります。このアプローチは、楽観的同時実行制御手法と呼ばれます。
このアプローチでは、トランザクションのライフサイクルは次の3つのフェーズに分けられます-
Execution Phase −トランザクションはデータ項目をメモリにフェッチし、それらに対して操作を実行します。
Validation Phase −トランザクションは、データベースへの変更のコミットが直列化可能性テストに合格することを確認するためのチェックを実行します。
Commit Phase −トランザクションは、メモリ内の変更されたデータ項目をディスクに書き戻します。
このアルゴリズムは、3つのルールを使用して、検証フェーズで直列化可能性を適用します。
Rule 1-二つのトランザクションTを考えると、私とTのJ Tがあれば、私はTデータ項目読んでいるjが書いているが、その後、T Iの実行フェーズでは、オーバーラップTとすることはできませんJさんフェーズコミット。T jは、Tiが実行を終了した後にのみコミットできます。
Rule 2-二つのトランザクションTを考えると、私とTのjがT場合、私はTのことをデータ項目書き込んでいるjが読んでいるが、その後、T IさんがTではない重複相はできるコミットJの実行フェーズ」。T jは、Tiがすでにコミットした後でのみ実行を開始できます。
Rule 3- Tが与えられた二つのトランザクションIおよびTのjはTがあれば、私はTデータ項目書き込んでいるjがも書いているが、その後、T Iさんは相コミットは、オーバーラップTとすることはできませんJさんフェーズコミット。T jは、Tiがすでにコミットした後でのみコミットを開始できます。
分散システムにおける並行性制御
このセクションでは、上記の手法が分散データベースシステムにどのように実装されているかを見ていきます。
分散型ツーフェーズロックアルゴリズム
分散型2フェーズロックの基本原理は、基本的な2フェーズロックプロトコルと同じです。ただし、分散システムには、ロックマネージャーとして指定されたサイトがあります。ロックマネージャーは、トランザクションモニターからのロック取得要求を制御します。さまざまなサイトのロックマネージャ間の調整を実施するために、少なくとも1つのサイトに、すべてのトランザクションを表示し、ロックの競合を検出する権限が与えられます。
ロックの競合を検出できるサイトの数に応じて、分散型2フェーズロックアプローチには3つのタイプがあります。
Centralized two-phase locking−このアプローチでは、1つのサイトが中央ロックマネージャーとして指定されます。環境内のすべてのサイトは、中央ロックマネージャーの場所を認識しており、トランザクション中に中央ロックマネージャーからロックを取得します。
Primary copy two-phase locking−このアプローチでは、いくつかのサイトがロック管理センターとして指定されます。これらの各サイトには、定義された一連のロックを管理する責任があります。すべてのサイトは、どのロックコントロールセンターがどのデータテーブル/フラグメントアイテムのロックを管理する責任があるかを知っています。
Distributed two-phase locking−このアプローチでは、多数のロックマネージャーがあり、各ロックマネージャーがローカルサイトに格納されているデータ項目のロックを制御します。ロックマネージャの場所は、データの分散とレプリケーションに基づいています。
分散タイムスタンプ同時実行制御
集中型システムでは、トランザクションのタイムスタンプは物理的な時計の読み取り値によって決定されます。ただし、分散システムでは、サイトのローカルの物理的/論理クロックの読み取り値は、グローバルに一意ではないため、グローバルタイムスタンプとして使用できません。したがって、タイムスタンプは、サイトIDとそのサイトの時計の読み取り値の組み合わせで構成されます。
タイムスタンプの順序付けアルゴリズムを実装するために、各サイトには、トランザクションマネージャーごとに個別のキューを維持するスケジューラーがあります。トランザクション中に、トランザクションマネージャーはサイトのスケジューラーにロック要求を送信します。スケジューラーは、タイムスタンプの昇順で対応するキューに要求を置きます。リクエストは、タイムスタンプの順に、つまり最も古いものから順にキューの先頭から処理されます。
競合グラフ
もう1つの方法は、競合グラフを作成することです。このトランザクションでは、クラスが定義されています。トランザクションクラスには、読み取りセットと書き込みセットと呼ばれる2セットのデータ項目が含まれています。トランザクションの読み取りセットがクラスの読み取りセットのサブセットであり、トランザクションの書き込みセットがクラスの書き込みセットのサブセットである場合、トランザクションは特定のクラスに属します。読み取りフェーズでは、各トランザクションは、読み取りセット内のデータ項目に対して読み取り要求を発行します。書き込みフェーズでは、各トランザクションが書き込み要求を発行します。
アクティブなトランザクションが属するクラスの競合グラフが作成されます。これには、垂直、水平、および斜めのエッジのセットが含まれています。垂直エッジは、クラス内の2つのノードを接続し、クラス内の競合を示します。水平エッジは、2つのクラスにまたがる2つのノードを接続し、異なるクラス間の書き込みと書き込みの競合を示します。対角エッジは、2つのクラスにまたがる2つのノードを接続し、2つのクラス間の書き込み/読み取りまたは読み取り/書き込みの競合を示します。
競合グラフを分析して、同じクラス内または2つの異なるクラス間で2つのトランザクションを並行して実行できるかどうかを確認します。
分散楽観的同時実行制御アルゴリズム
分散された楽観的同時実行制御アルゴリズムは、楽観的同時実行制御アルゴリズムを拡張します。この拡張機能には、2つのルールが適用されます-
Rule 1−このルールによれば、トランザクションは、実行時にすべてのサイトでローカルに検証する必要があります。トランザクションがいずれかのサイトで無効であることが判明した場合、そのトランザクションは中止されます。ローカル検証により、トランザクションが実行されたサイトで直列化可能性が維持されることが保証されます。トランザクションがローカル検証テストに合格すると、グローバルに検証されます。
Rule 2−このルールによれば、トランザクションがローカル検証テストに合格した後、グローバルに検証する必要があります。グローバル検証により、2つの競合するトランザクションが複数のサイトで一緒に実行される場合、それらが一緒に実行されるすべてのサイトで同じ相対順序でコミットする必要があります。これには、検証後、コミットする前に、トランザクションが他の競合するトランザクションを待機する必要がある場合があります。この要件により、サイトで検証されるとすぐにトランザクションをコミットできない可能性があるため、アルゴリズムの楽観性が低下します。
この章では、データベースシステムのデッドロック処理メカニズムの概要を説明します。集中型データベースシステムと分散型データベースシステムの両方でデッドロック処理メカニズムを研究します。
デッドロックとは何ですか?
デッドロックは、各トランザクションが他のトランザクションによってロックされているデータ項目を待機しているときに、2つ以上のトランザクションを持つデータベースシステムの状態です。デッドロックは、待機グラフのサイクルで示すことができます。これは、頂点がトランザクションを示し、エッジがデータ項目の待機を示す有向グラフです。
たとえば、次の待機グラフでは、トランザクションT1は、T3によってロックされているデータ項目Xを待機しています。T3はT2によってロックされているYを待機しており、T2はT1によってロックされているZを待機しています。したがって、待機サイクルが形成され、どのトランザクションも実行を続行できません。

一元化されたシステムでのデッドロック処理
デッドロック処理には、3つの古典的なアプローチがあります。
- デッドロック防止。
- デッドロックの回避。
- デッドロックの検出と削除。
3つのアプローチはすべて、集中型データベースシステムと分散型データベースシステムの両方に組み込むことができます。
デッドロック防止
デッドロック防止アプローチでは、デッドロックにつながるロックをトランザクションが取得することはできません。慣例では、複数のトランザクションが同じデータアイテムのロックを要求すると、そのうちの1つだけにロックが付与されます。
最も一般的なデッドロック防止方法の1つは、すべてのロックを事前に取得することです。この方法では、トランザクションは実行を開始する前にすべてのロックを取得し、トランザクションの全期間にわたってロックを保持します。別のトランザクションがすでに取得したロックのいずれかを必要とする場合、必要なすべてのロックが使用可能になるまで待機する必要があります。このアプローチを使用すると、待機中のトランザクションがロックを保持していないため、システムがデッドロックされるのを防ぐことができます。
デッドロックの回避
デッドロック回避アプローチは、デッドロックが発生する前に処理します。トランザクションとロックを分析して、待機がデッドロックにつながるかどうかを判断します。
この方法は簡単に次のように述べることができます。トランザクションは実行を開始し、ロックする必要のあるデータ項目を要求します。ロックマネージャは、ロックが使用可能かどうかを確認します。使用可能な場合、ロックマネージャはデータ項目を割り当て、トランザクションはロックを取得します。ただし、アイテムが互換性のないモードで他のトランザクションによってロックされている場合、ロックマネージャはアルゴリズムを実行して、トランザクションを待機状態に保つことでデッドロックが発生するかどうかをテストします。したがって、アルゴリズムは、トランザクションを待機できるか、トランザクションの1つを中止するかを決定します。
この目的には2つのアルゴリズムがあります。 wait-die そして wound-wait。T1とT2の2つのトランザクションがあり、T1がすでにT2によってロックされているデータ項目をロックしようとしていると仮定します。アルゴリズムは次のとおりです-
Wait-Die− T1がT2よりも古い場合、T1は待機できます。それ以外の場合、T1がT2よりも若い場合、T1は中止され、後で再起動されます。
Wound-Wait− T1がT2よりも古い場合、T2は中止され、後で再起動されます。それ以外の場合、T1がT2よりも若い場合、T1は待機できます。
デッドロックの検出と削除
デッドロックの検出と削除のアプローチでは、デッドロック検出アルゴリズムが定期的に実行され、デッドロックが発生した場合は削除されます。トランザクションがロックを要求するときに、デッドロックをチェックしません。トランザクションがロックを要求すると、ロックマネージャはそれが使用可能かどうかを確認します。使用可能な場合、トランザクションはデータ項目をロックできます。それ以外の場合、トランザクションは待機できます。
ロック要求を許可する際の予防措置がないため、一部のトランザクションがデッドロックする可能性があります。デッドロックを検出するために、ロックマネージャは待機グラフにサイクルがあるかどうかを定期的にチェックします。システムがデッドロックしている場合、ロックマネージャは各サイクルからビクティムトランザクションを選択します。犠牲者は中止され、ロールバックされます。その後、再起動しました。被害者の選択に使用される方法のいくつかは次のとおりです。
- 最も若いトランザクションを選択します。
- データ項目が最も少ないトランザクションを選択します。
- 更新の実行回数が最も少ないトランザクションを選択します。
- 再起動のオーバーヘッドが最も少ないトランザクションを選択します。
- 2つ以上のサイクルに共通するトランザクションを選択してください。
このアプローチは主に、トランザクションが少なく、ロック要求への高速応答が必要なシステムに適しています。
分散システムでのデッドロック処理
分散データベースシステムでのトランザクション処理も分散されます。つまり、同じトランザクションが複数のサイトで処理される場合があります。集中型システムには存在しない分散データベースシステムでの2つの主なデッドロック処理の懸念は次のとおりです。transaction location そして transaction control。これらの懸念に対処すると、デッドロックは、デッドロック防止、デッドロック回避、またはデッドロックの検出と削除のいずれかによって処理されます。
トランザクションの場所
分散データベースシステムのトランザクションは複数のサイトで処理され、複数のサイトのデータ項目を使用します。データ処理の量は、これらのサイト間で均一に分散されていません。処理時間も異なります。したがって、同じトランザクションが一部のサイトでアクティブになり、他のサイトでは非アクティブになる場合があります。競合する2つのトランザクションがサイトにある場合、そのうちの1つが非アクティブ状態になっている可能性があります。この状態は、集中型システムでは発生しません。この懸念は、トランザクションの場所の問題と呼ばれます。
この懸念は、デイジーチェーンモデルによって対処される可能性があります。このモデルでは、トランザクションは、あるサイトから別のサイトに移動するときに特定の詳細を伝達します。詳細には、必要なテーブルのリスト、必要なサイトのリスト、アクセスしたテーブルとサイトのリスト、まだアクセスしていないテーブルとサイトのリスト、およびタイプ付きの取得したロックのリストがあります。コミットまたはアボートによってトランザクションが終了した後、関係するすべてのサイトに情報を送信する必要があります。
トランザクション制御
トランザクション制御は、分散データベースシステムでトランザクションを処理するために必要なサイトを指定および制御することに関係しています。トランザクションを処理する場所の選択や、制御の中心を指定する方法に関しては、次のような多くのオプションがあります。
- 1台のサーバーを制御の中心として選択できます。
- 制御の中心は、あるサーバーから別のサーバーに移動する場合があります。
- 制御の責任は、複数のサーバーで共有される場合があります。
分散デッドロック防止
集中型デッドロック防止の場合と同様に、分散型デッドロック防止アプローチでは、トランザクションは実行を開始する前にすべてのロックを取得する必要があります。これにより、デッドロックが防止されます。
トランザクションが開始されるサイトは、制御サイトとして指定されます。制御サイトは、データ項目が配置されているサイトにメッセージを送信して、項目をロックします。その後、確認を待ちます。すべてのサイトがデータ項目をロックしたことを確認すると、トランザクションが開始されます。サイトまたは通信リンクに障害が発生した場合、トランザクションはそれらが修復されるまで待機する必要があります。
実装は簡単ですが、このアプローチにはいくつかの欠点があります-
ロックの事前取得には、通信の遅延に長い時間がかかります。これにより、トランザクションに必要な時間が長くなります。
サイトまたはリンクに障害が発生した場合、サイトが回復するためにトランザクションは長時間待機する必要があります。その間、実行中のサイトでは、アイテムはロックされています。これにより、他のトランザクションが実行されなくなる可能性があります。
制御サイトに障害が発生すると、他のサイトと通信できなくなります。これらのサイトは、ロックされたデータアイテムを引き続きロックされた状態に保つため、ブロックされます。
分散デッドロックの回避
集中型システムと同様に、分散デッドロック回避は発生前にデッドロックを処理します。さらに、分散システムでは、トランザクションの場所とトランザクション制御の問題に対処する必要があります。トランザクションの分散性により、次の競合が発生する可能性があります-
- 同じサイト内の2つのトランザクション間の競合。
- 異なるサイトでの2つのトランザクション間の競合。
競合が発生した場合、分散待機ダイまたは分散創傷待機アルゴリズムに従って、トランザクションの1つが中止されるか、待機が許可される場合があります。
T1とT2の2つのトランザクションがあると仮定します。T1はサイトPに到着し、そのサイトでT2によってすでにロックされているデータ項目をロックしようとします。したがって、サイトPで競合が発生します。アルゴリズムは次のとおりです。
Distributed Wound-Die
T1がT2よりも古い場合、T1は待機できます。T1は、サイトPがすべてのサイトでT2が正常にコミットまたは中止したというメッセージを受信した後、実行を再開できます。
T1がT2よりも若い場合、T1は中止されます。サイトPの同時実行制御は、T1がT1を中止するためにアクセスしたすべてのサイトにメッセージを送信します。制御サイトは、すべてのサイトでT1が正常に中止されたときにユーザーに通知します。
Distributed Wait-Wait
T1がT2より古い場合は、T2を中止する必要があります。T2がサイトPでアクティブな場合、サイトPはT2を中止してロールバックし、このメッセージを他の関連サイトにブロードキャストします。T2がサイトPを離れたが、サイトQでアクティブである場合、サイトPはT2が中止されたことをブロードキャストします。次に、サイトLは中止してT2をロールバックし、このメッセージをすべてのサイトに送信します。
T1がT1よりも若い場合、T1は待機できます。T2が処理を完了したというメッセージをサイトPが受信した後、T1は実行を再開できます。
分散デッドロック検出
一元化されたデッドロック検出アプローチと同様に、デッドロックの発生は許可され、検出されると削除されます。トランザクションがロック要求を出すとき、システムはチェックを実行しません。実装のために、グローバルな待機グラフが作成されます。グローバル待機グラフにサイクルが存在する場合は、デッドロックが発生していることを示しています。ただし、トランザクションはネットワーク全体でリソースを待機するため、デッドロックを見つけることは困難です。
または、デッドロック検出アルゴリズムでタイマーを使用することもできます。各トランザクションは、トランザクションの終了が予想される期間に設定されたタイマーに関連付けられています。この時間内にトランザクションが終了しない場合、タイマーがオフになり、デッドロックの可能性が示されます。
デッドロック処理に使用される別のツールは、デッドロック検出器です。集中型システムでは、デッドロック検出器が1つあります。分散システムでは、複数のデッドロック検出器が存在する可能性があります。デッドロック検出器は、その制御下にあるサイトのデッドロックを見つけることができます。分散システムでのデッドロック検出には、3つの選択肢があります。
Centralized Deadlock Detector −1つのサイトが中央デッドロック検出器として指定されています。
Hierarchical Deadlock Detector −多数のデッドロック検出器が階層的に配置されています。
Distributed Deadlock Detector − All the sites participate in detecting deadlocks and removing them.
This chapter looks into replication control, which is required to maintain consistent data in all sites. We will study the replication control techniques and the algorithms required for replication control.
As discussed earlier, replication is a technique used in distributed databases to store multiple copies of a data table at different sites. The problem with having multiple copies in multiple sites is the overhead of maintaining data consistency, particularly during update operations.
In order to maintain mutually consistent data in all sites, replication control techniques need to be adopted. There are two approaches for replication control, namely −
- Synchronous Replication Control
- Asynchronous Replication Control
Synchronous Replication Control
In synchronous replication approach, the database is synchronized so that all the replications always have the same value. A transaction requesting a data item will have access to the same value in all the sites. To ensure this uniformity, a transaction that updates a data item is expanded so that it makes the update in all the copies of the data item. Generally, two-phase commit protocol is used for the purpose.
For example, let us consider a data table PROJECT(PId, PName, PLocation). We need to run a transaction T1 that updates PLocation to ‘Mumbai’, if PLocation is ‘Bombay’. If no replications are there, the operations in transaction T1 will be −
Begin T1:
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1;If the data table has two replicas in Site A and Site B, T1 needs to spawn two children T1A and T1B corresponding to the two sites. The expanded transaction T1 will be −
Begin T1:
Begin T1A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1A;
Begin T2A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T2A;
End T1;Asynchronous Replication Control
In asynchronous replication approach, the replicas do not always maintain the same value. One or more replicas may store an outdated value, and a transaction can see the different values. The process of bringing all the replicas to the current value is called synchronization.
A popular method of synchronization is store and forward method. In this method, one site is designated as the primary site and the other sites are secondary sites. The primary site always contains updated values. All the transactions first enter the primary site. These transactions are then queued for application in the secondary sites. The secondary sites are updated using rollout method only when a transaction is scheduled to execute on it.
Replication Control Algorithms
Some of the replication control algorithms are −
- Master-slave replication control algorithm.
- Distributed voting algorithm.
- Majority consensus algorithm.
- Circulating token algorithm.
Master-Slave Replication Control Algorithm
There is one master site and ‘N’ slave sites. A master algorithm runs at the master site to detect conflicts. A copy of slave algorithm runs at each slave site. The overall algorithm executes in the following two phases −
Transaction acceptance/rejection phase − When a transaction enters the transaction monitor of a slave site, the slave site sends a request to the master site. The master site checks for conflicts. If there aren’t any conflicts, the master sends an “ACK+” message to the slave site which then starts the transaction application phase. Otherwise, the master sends an “ACK-” message to the slave which then rejects the transaction.
Transaction application phase − Upon entering this phase, the slave site where transaction has entered broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it sends a “DONE” message to the master site. The master understands that the transaction has been completed and removes it from the pending queue.
Distributed Voting Algorithm
This comprises of ‘N’ peer sites, all of whom must “OK” a transaction before it starts executing. Following are the two phases of this algorithm −
Distributed transaction acceptance phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site resolves conflicts using priority based voting rules. If all the peer sites are “OK” with the transaction, the requesting site starts application phase. If any of the peer sites does not “OK” a transaction, the requesting site rejects the transaction.
Distributed transaction application phase − Upon entering this phase, the site where the transaction has entered, broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” message to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it lets the transaction manager know that the transaction has been completed.
Majority Consensus Algorithm
This is a variation from the distributed voting algorithm, where a transaction is allowed to execute when a majority of the peers “OK” a transaction. This is divided into three phases −
Voting phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site tests for conflicts using voting rules and keeps the conflicting transactions, if any, in pending queue. Then, it sends either an “OK” or a “NOT OK” message.
Transaction acceptance/rejection phase − If the requesting site receives a majority “OK” on the transaction, it accepts the transaction and broadcasts “ACCEPT” to all the sites. Otherwise, it broadcasts “REJECT” to all the sites and rejects the transaction.
Transaction application phase − When a peer site receives a “REJECT” message, it removes this transaction from its pending list and reconsiders all deferred transactions. When a peer site receives an “ACCEPT” message, it applies the transaction and rejects all the deferred transactions in the pending queue which are in conflict with this transaction. It sends an “ACK” to the requesting slave on completion.
Circulating Token Algorithm
In this approach the transactions in the system are serialized using a circulating token and executed accordingly against every replica of the database. Thus, all the transactions are accepted, i.e. none is rejected. This has two phases −
Transaction serialization phase − In this phase, all transactions are scheduled to run in a serialization order. Each transaction in each site is assigned a unique ticket from a sequential series, indicating the order of transaction. Once a transaction has been assigned a ticket, it is broadcasted to all the sites.
Transaction application phase − When a site receives a transaction along with its ticket, it places the transaction for execution according to its ticket. After the transaction has finished execution, this site broadcasts an appropriate message. A transaction ends when it has completed execution in all the sites.
A database management system is susceptible to a number of failures. In this chapter we will study the failure types and commit protocols. In a distributed database system, failures can be broadly categorized into soft failures, hard failures and network failures.
Soft Failure
Soft failure is the type of failure that causes the loss in volatile memory of the computer and not in the persistent storage. Here, the information stored in the non-persistent storage like main memory, buffers, caches or registers, is lost. They are also known as system crash. The various types of soft failures are as follows −
- Operating system failure.
- Main memory crash.
- Transaction failure or abortion.
- System generated error like integer overflow or divide-by-zero error.
- Failure of supporting software.
- Power failure.
Hard Failure
A hard failure is the type of failure that causes loss of data in the persistent or non-volatile storage like disk. Disk failure may cause corruption of data in some disk blocks or failure of the total disk. The causes of a hard failure are −
- Power failure.
- Faults in media.
- Read-write malfunction.
- Corruption of information on the disk.
- Read/write head crash of disk.
Recovery from disk failures can be short, if there is a new, formatted, and ready-to-use disk on reserve. Otherwise, duration includes the time it takes to get a purchase order, buy the disk, and prepare it.
Network Failure
Network failures are prevalent in distributed or network databases. These comprises of the errors induced in the database system due to the distributed nature of the data and transferring data over the network. The causes of network failure are as follows −
- Communication link failure.
- Network congestion.
- Information corruption during transfer.
- Site failures.
- Network partitioning.
Commit Protocols
Any database system should guarantee that the desirable properties of a transaction are maintained even after failures. If a failure occurs during the execution of a transaction, it may happen that all the changes brought about by the transaction are not committed. This makes the database inconsistent. Commit protocols prevent this scenario using either transaction undo (rollback) or transaction redo (roll forward).
Commit Point
The point of time at which the decision is made whether to commit or abort a transaction, is known as commit point. Following are the properties of a commit point.
It is a point of time when the database is consistent.
At this point, the modifications brought about by the database can be seen by the other transactions. All transactions can have a consistent view of the database.
At this point, all the operations of transaction have been successfully executed and their effects have been recorded in transaction log.
At this point, a transaction can be safely undone, if required.
At this point, a transaction releases all the locks held by it.
Transaction Undo
The process of undoing all the changes made to a database by a transaction is called transaction undo or transaction rollback. This is mostly applied in case of soft failure.
Transaction Redo
The process of reapplying the changes made to a database by a transaction is called transaction redo or transaction roll forward. This is mostly applied for recovery from a hard failure.
Transaction Log
A transaction log is a sequential file that keeps track of transaction operations on database items. As the log is sequential in nature, it is processed sequentially either from the beginning or from the end.
Purposes of a transaction log −
- To support commit protocols to commit or support transactions.
- To aid database recovery after failure.
A transaction log is usually kept on the disk, so that it is not affected by soft failures. Additionally, the log is periodically backed up to an archival storage like magnetic tape to protect it from disk failures as well.
Lists in Transaction Logs
The transaction log maintains five types of lists depending upon the status of the transaction. This list aids the recovery manager to ascertain the status of a transaction. The status and the corresponding lists are as follows −
A transaction that has a transaction start record and a transaction commit record, is a committed transaction – maintained in commit list.
A transaction that has a transaction start record and a transaction failed record but not a transaction abort record, is a failed transaction – maintained in failed list.
A transaction that has a transaction start record and a transaction abort record is an aborted transaction – maintained in abort list.
A transaction that has a transaction start record and a transaction before-commit record is a before-commit transaction, i.e. a transaction where all the operations have been executed but not committed – maintained in before-commit list.
A transaction that has a transaction start record but no records of before-commit, commit, abort or failed, is an active transaction – maintained in active list.
Immediate Update and Deferred Update
Immediate Update and Deferred Update are two methods for maintaining transaction logs.
In immediate update mode, when a transaction executes, the updates made by the transaction are written directly onto the disk. The old values and the updates values are written onto the log before writing to the database in disk. On commit, the changes made to the disk are made permanent. On rollback, changes made by the transaction in the database are discarded and the old values are restored into the database from the old values stored in the log.
In deferred update mode, when a transaction executes, the updates made to the database by the transaction are recorded in the log file. On commit, the changes in the log are written onto the disk. On rollback, the changes in the log are discarded and no changes are applied to the database.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
Transactions which are in active list and failed list are undone and written on the abort list.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions −
Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A “checkpoint” record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
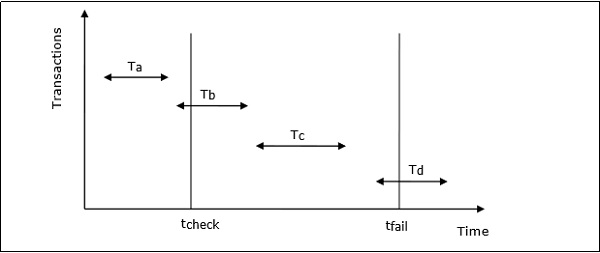
The actions that are taken by the recovery manager are −
- Nothing is done with Ta.
- Transaction redo is performed for Tb and Tc.
- Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
In a local database system, for committing a transaction, the transaction manager has to only convey the decision to commit to the recovery manager. However, in a distributed system, the transaction manager should convey the decision to commit to all the servers in the various sites where the transaction is being executed and uniformly enforce the decision. When processing is complete at each site, it reaches the partially committed transaction state and waits for all other transactions to reach their partially committed states. When it receives the message that all the sites are ready to commit, it starts to commit. In a distributed system, either all sites commit or none of them does.
The different distributed commit protocols are −
- One-phase commit
- Two-phase commit
- Three-phase commit
Distributed One-phase Commit
Distributed one-phase commit is the simplest commit protocol. Let us consider that there is a controlling site and a number of slave sites where the transaction is being executed. The steps in distributed commit are −
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site.
The slaves wait for “Commit” or “Abort” message from the controlling site. This waiting time is called window of vulnerability.
When the controlling site receives “DONE” message from each slave, it makes a decision to commit or abort. This is called the commit point. Then, it sends this message to all the slaves.
On receiving this message, a slave either commits or aborts and then sends an acknowledgement message to the controlling site.
Distributed Two-phase Commit
Distributed two-phase commit reduces the vulnerability of one-phase commit protocols. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site. When the controlling site has received “DONE” message from all slaves, it sends a “Prepare” message to the slaves.
The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
A slave that does not want to commit sends a “Not Ready” message. This may happen when the slave has conflicting concurrent transactions or there is a timeout.
Phase 2: Commit/Abort Phase
After the controlling site has received “Ready” message from all the slaves −
The controlling site sends a “Global Commit” message to the slaves.
The slaves apply the transaction and send a “Commit ACK” message to the controlling site.
When the controlling site receives “Commit ACK” message from all the slaves, it considers the transaction as committed.
After the controlling site has received the first “Not Ready” message from any slave −
The controlling site sends a “Global Abort” message to the slaves.
The slaves abort the transaction and send a “Abort ACK” message to the controlling site.
When the controlling site receives “Abort ACK” message from all the slaves, it considers the transaction as aborted.
Distributed Three-phase Commit
The steps in distributed three-phase commit are as follows −
Phase 1: Prepare Phase
The steps are same as in distributed two-phase commit.
Phase 2: Prepare to Commit Phase
- The controlling site issues an “Enter Prepared State” broadcast message.
- The slave sites vote “OK” in response.
Phase 3: Commit / Abort Phase
The steps are same as two-phase commit except that “Commit ACK”/”Abort ACK” message is not required.
In this chapter, we will look into the threats that a database system faces and the measures of control. We will also study cryptography as a security tool.
Database Security and Threats
Data security is an imperative aspect of any database system. It is of particular importance in distributed systems because of large number of users, fragmented and replicated data, multiple sites and distributed control.
Threats in a Database
Availability loss − Availability loss refers to non-availability of database objects by legitimate users.
Integrity loss − Integrity loss occurs when unacceptable operations are performed upon the database either accidentally or maliciously. This may happen while creating, inserting, updating or deleting data. It results in corrupted data leading to incorrect decisions.
Confidentiality loss − Confidentiality loss occurs due to unauthorized or unintentional disclosure of confidential information. It may result in illegal actions, security threats and loss in public confidence.
Measures of Control
The measures of control can be broadly divided into the following categories −
Access Control − Access control includes security mechanisms in a database management system to protect against unauthorized access. A user can gain access to the database after clearing the login process through only valid user accounts. Each user account is password protected.
Flow Control − Distributed systems encompass a lot of data flow from one site to another and also within a site. Flow control prevents data from being transferred in such a way that it can be accessed by unauthorized agents. A flow policy lists out the channels through which information can flow. It also defines security classes for data as well as transactions.
Data Encryption − Data encryption refers to coding data when sensitive data is to be communicated over public channels. Even if an unauthorized agent gains access of the data, he cannot understand it since it is in an incomprehensible format.
What is Cryptography?
Cryptography is the science of encoding information before sending via unreliable communication paths so that only an authorized receiver can decode and use it.
The coded message is called cipher text and the original message is called plain text. The process of converting plain text to cipher text by the sender is called encoding or encryption. The process of converting cipher text to plain text by the receiver is called decoding or decryption.
The entire procedure of communicating using cryptography can be illustrated through the following diagram −

Conventional Encryption Methods
In conventional cryptography, the encryption and decryption is done using the same secret key. Here, the sender encrypts the message with an encryption algorithm using a copy of the secret key. The encrypted message is then send over public communication channels. On receiving the encrypted message, the receiver decrypts it with a corresponding decryption algorithm using the same secret key.
Security in conventional cryptography depends on two factors −
A sound algorithm which is known to all.
A randomly generated, preferably long secret key known only by the sender and the receiver.
The most famous conventional cryptography algorithm is Data Encryption Standard or DES.
The advantage of this method is its easy applicability. However, the greatest problem of conventional cryptography is sharing the secret key between the communicating parties. The ways to send the key are cumbersome and highly susceptible to eavesdropping.
Public Key Cryptography
In contrast to conventional cryptography, public key cryptography uses two different keys, referred to as public key and the private key. Each user generates the pair of public key and private key. The user then puts the public key in an accessible place. When a sender wants to sends a message, he encrypts it using the public key of the receiver. On receiving the encrypted message, the receiver decrypts it using his private key. Since the private key is not known to anyone but the receiver, no other person who receives the message can decrypt it.
The most popular public key cryptography algorithms are RSA algorithm and Diffie– Hellman algorithm. This method is very secure to send private messages. However, the problem is, it involves a lot of computations and so proves to be inefficient for long messages.
The solution is to use a combination of conventional and public key cryptography. The secret key is encrypted using public key cryptography before sharing between the communicating parties. Then, the message is send using conventional cryptography with the aid of the shared secret key.
Digital Signatures
A Digital Signature (DS) is an authentication technique based on public key cryptography used in e-commerce applications. It associates a unique mark to an individual within the body of his message. This helps others to authenticate valid senders of messages.
Typically, a user’s digital signature varies from message to message in order to provide security against counterfeiting. The method is as follows −
The sender takes a message, calculates the message digest of the message and signs it digest with a private key.
The sender then appends the signed digest along with the plaintext message.
The message is sent over communication channel.
The receiver removes the appended signed digest and verifies the digest using the corresponding public key.
The receiver then takes the plaintext message and runs it through the same message digest algorithm.
If the results of step 4 and step 5 match, then the receiver knows that the message has integrity and authentic.
A distributed system needs additional security measures than centralized system, since there are many users, diversified data, multiple sites and distributed control. In this chapter, we will look into the various facets of distributed database security.
In distributed communication systems, there are two types of intruders −
Passive eavesdroppers − They monitor the messages and get hold of private information.
Active attackers − They not only monitor the messages but also corrupt data by inserting new data or modifying existing data.
Security measures encompass security in communications, security in data and data auditing.
Communications Security
In a distributed database, a lot of data communication takes place owing to the diversified location of data, users and transactions. So, it demands secure communication between users and databases and between the different database environments.
Security in communication encompasses the following −
Data should not be corrupt during transfer.
The communication channel should be protected against both passive eavesdroppers and active attackers.
In order to achieve the above stated requirements, well-defined security algorithms and protocols should be adopted.
Two popular, consistent technologies for achieving end-to-end secure communications are −
- Secure Socket Layer Protocol or Transport Layer Security Protocol.
- Virtual Private Networks (VPN).
Data Security
In distributed systems, it is imperative to adopt measure to secure data apart from communications. The data security measures are −
Authentication and authorization − These are the access control measures adopted to ensure that only authentic users can use the database. To provide authentication digital certificates are used. Besides, login is restricted through username/password combination.
Data encryption − The two approaches for data encryption in distributed systems are −
Internal to distributed database approach: The user applications encrypt the data and then store the encrypted data in the database. For using the stored data, the applications fetch the encrypted data from the database and then decrypt it.
External to distributed database: The distributed database system has its own encryption capabilities. The user applications store data and retrieve them without realizing that the data is stored in an encrypted form in the database.
Validated input − In this security measure, the user application checks for each input before it can be used for updating the database. An un-validated input can cause a wide range of exploits like buffer overrun, command injection, cross-site scripting and corruption in data.
Data Auditing
A database security system needs to detect and monitor security violations, in order to ascertain the security measures it should adopt. It is often very difficult to detect breach of security at the time of occurrences. One method to identify security violations is to examine audit logs. Audit logs contain information such as −
- Date, time and site of failed access attempts.
- Details of successful access attempts.
- Vital modifications in the database system.
- Access of huge amounts of data, particularly from databases in multiple sites.
All the above information gives an insight of the activities in the database. A periodical analysis of the log helps to identify any unnatural activity along with its site and time of occurrence. This log is ideally stored in a separate server so that it is inaccessible to attackers.