Elasticsearch-クイックガイド
Elasticsearchは、ApacheLuceneベースの検索サーバーです。Shay Banonによって開発され、2010年に公開されました。現在はElasticsearchBVによって管理されています。最新バージョンは7.0.0です。
Elasticsearchは、リアルタイムの分散型オープンソース全文検索および分析エンジンです。RESTful Webサービスインターフェイスからアクセスでき、スキーマレスJSON(JavaScript Object Notation)ドキュメントを使用してデータを保存します。Javaプログラミング言語に基づいて構築されているため、Elasticsearchはさまざまなプラットフォームで実行できます。これにより、ユーザーは非常に大量のデータを非常に高速で探索できます。
一般的な機能
Elasticsearchの一般的な機能は次のとおりです-
Elasticsearchは、ペタバイト単位の構造化データと非構造化データまでスケーラブルです。
Elasticsearchは、MongoDBやRavenDBなどのドキュメントストアの代わりに使用できます。
Elasticsearchは、非正規化を使用して検索パフォーマンスを向上させます。
Elasticsearchは人気のあるエンタープライズ検索エンジンの1つであり、現在Wikipedia、The Guardian、StackOverflow、GitHubなどの多くの大規模な組織で使用されています。
Elasticsearchはオープンソースであり、Apacheライセンスバージョン2.0で利用できます。
重要な概念
Elasticsearchの重要な概念は次のとおりです-
ノード
これは、Elasticsearchの単一の実行中のインスタンスを指します。単一の物理サーバーと仮想サーバーは、RAM、ストレージ、処理能力などの物理リソースの機能に応じて、複数のノードに対応します。
集まる
これは、1つ以上のノードのコレクションです。Clusterは、データ全体のすべてのノードにわたって集合的なインデックス作成および検索機能を提供します。
インデックス
これは、さまざまなタイプのドキュメントとそのプロパティのコレクションです。Indexは、シャードの概念を使用してパフォーマンスを向上させます。たとえば、一連のドキュメントには、ソーシャルネットワーキングアプリケーションのデータが含まれています。
資料
これは、JSON形式で定義された特定の方法でのフィールドのコレクションです。すべてのドキュメントはタイプに属し、インデックス内にあります。すべてのドキュメントは、UIDと呼ばれる一意の識別子に関連付けられています。
シャード
インデックスは水平方向にシャードに分割されます。つまり、各シャードにはドキュメントのすべてのプロパティが含まれていますが、インデックスよりも少ない数のJSONオブジェクトが含まれています。水平方向の分離により、シャードは独立したノードになり、任意のノードに保存できます。プライマリシャードはインデックスの元の水平部分であり、これらのプライマリシャードはレプリカシャードに複製されます。
レプリカ
Elasticsearchを使用すると、ユーザーはインデックスとシャードのレプリカを作成できます。レプリケーションは、障害が発生した場合のデータの可用性を向上させるだけでなく、これらのレプリカで並列検索操作を実行することにより、検索のパフォーマンスを向上させます。
利点
ElasticsearchはJavaで開発されているため、ほぼすべてのプラットフォームで互換性があります。
Elasticsearchはリアルタイムです。つまり、1秒後に、追加されたドキュメントがこのエンジンで検索可能になります。
Elasticsearchは分散されているため、大規模な組織での拡張と統合が容易になります。
Elasticsearchに存在するゲートウェイの概念を使用すると、完全バックアップを簡単に作成できます。
Elasticsearchでは、Apache Solrと比較すると、マルチテナンシーの処理が非常に簡単です。
Elasticsearchは応答としてJSONオブジェクトを使用します。これにより、Elasticsearchサーバーを多数の異なるプログラミング言語で呼び出すことができます。
Elasticsearchは、テキストレンダリングをサポートしないものを除いて、ほぼすべてのドキュメントタイプをサポートします。
短所
Elasticsearchは、CSV、XML、およびJSON形式で可能なApache Solrとは異なり、要求および応答データの処理(JSONでのみ可能)に関して多言語サポートを備えていません。
時折、Elasticsearchにはスプリットブレインの状況の問題があります。
ElasticsearchとRDBMSの比較
Elasticsearchでは、インデックスはRDBMS(Relation Database Management System)のテーブルに似ています。すべてのインデックスがElasticsearchのドキュメントのコレクションであるのと同様に、すべてのテーブルは行のコレクションです。
次の表は、これらの用語を直接比較したものです。
| Elasticsearch | RDBMS |
|---|---|
| 集まる | データベース |
| シャード | シャード |
| インデックス | テーブル |
| フィールド | カラム |
| 資料 | 行 |
この章では、Elasticsearchのインストール手順について詳しく説明します。
ローカルコンピューターにElasticsearchをインストールするには、以下の手順に従う必要があります-
Step 1−コンピュータにインストールされているJavaのバージョンを確認してください。Java7以降である必要があります。次のようにして確認できます−
Windowsオペレーティングシステム(OS)の場合(コマンドプロンプトを使用)-
> java -versionUNIX OSの場合(ターミナルを使用)-
$ echo $JAVA_HOMEStep 2 −オペレーティングシステムに応じて、以下のようにwww.elastic.coからElasticsearchをダウンロードします−
Windows OSの場合は、ZIPファイルをダウンロードします。
UNIX OSの場合は、TARファイルをダウンロードします。
Debian OSの場合、DEBファイルをダウンロードします。
Red Hatおよびその他のLinuxディストリビューションの場合は、RPNファイルをダウンロードしてください。
APTおよびYumユーティリティを使用して、Elasticsearchを多くのLinuxディストリビューションにインストールすることもできます。
Step 3 − Elasticsearchのインストールプロセスは簡単で、OSごとに以下に説明します−
Windows OS− zipパッケージを解凍すると、Elasticsearchがインストールされます。
UNIX OS− tarファイルを任意の場所に抽出すると、Elasticsearchがインストールされます。
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS−公開署名キーをダウンロードしてインストールします
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -以下に示すようにリポジトリ定義を保存します-
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list次のコマンドを使用して更新を実行します-
$ sudo apt-get updateこれで、次のコマンドを使用してインストールできます-
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
公開署名鍵をダウンロードしてインストールします-
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch「/etc/yum.repos.d/」ディレクトリの.repoサフィックスが付いたファイルに次のテキストを追加します。たとえば、elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md次のコマンドを使用してElasticsearchをインストールできるようになりました
sudo yum install elasticsearchStep 4−Elasticsearchのホームディレクトリとbinフォルダ内に移動します。Windowsの場合はelasticsearch.batファイルを実行します。または、UNIX rum Elasticsearchファイルの場合は、コマンドプロンプトを使用してターミナルから同じことを実行できます。
Windowsの場合
> cd elasticsearch-2.1.0/bin
> elasticsearchLinuxの場合
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote − Windowsの場合、JAVA_HOMEが設定されていないというエラーが表示される場合があります。環境変数で「C:\ ProgramFiles \ Java \ jre1.8.0_31」またはJavaをインストールした場所に設定してください。
Step 5− Elasticsearch Webインターフェースのデフォルトポートは9200です。または、binディレクトリにあるelasticsearch.ymlファイル内のhttp.portを変更することで変更できます。サーバーが稼働しているかどうかは、参照して確認できますhttp://localhost:9200。次の方法で、インストールされたElasticsearchに関する情報を含むJSONオブジェクトを返します-
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6−このステップでは、Kibanaをインストールしましょう。LinuxおよびWindowsにインストールする場合は、以下のそれぞれのコードに従ってください。
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Kibana forWindowsをからダウンロード https://www.elastic.co/products/kibana. リンクをクリックすると、以下のようなホームページが表示されます-
解凍してKibanaホームディレクトリに移動し、実行します。
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batこの章では、Elasticsearchにインデックス、マッピング、データを追加する方法を学びましょう。このチュートリアルで説明する例では、このデータの一部が使用されることに注意してください。
インデックスの作成
次のコマンドを使用して、インデックスを作成できます-
PUT school応答
インデックスが作成されると、次の出力が表示されます-
{"acknowledged": true}データを追加する
Elasticsearchは、次のコードに示すように、インデックスに追加したドキュメントを保存します。ドキュメントには、ドキュメントの識別に使用されるいくつかのIDが与えられます。
リクエストボディ
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}応答
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}ここでは、別の同様のドキュメントを追加しています。
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}応答
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}このようにして、次の章での作業に必要なサンプルデータを追加し続けます。
Kibanaでのサンプルデータの追加
Kibanaは、データにアクセスして視覚化を作成するためのGUI駆動型ツールです。このセクションでは、サンプルデータを追加する方法を理解しましょう。
Kibanaホームページで、次のオプションを選択してサンプルeコマースデータを追加します-
次の画面には、視覚化とデータを追加するためのボタンが表示されます-
[データの追加]をクリックすると、データがeコマースという名前のインデックスに追加されたことを確認する次の画面が表示されます。
どのシステムやソフトウェアでも、新しいバージョンにアップグレードするときは、いくつかの手順に従って、アプリケーションの設定、構成、データなどを維持する必要があります。これらの手順は、新しいシステムでアプリケーションを安定させるため、またはデータの整合性を維持するために必要です(データが破損するのを防ぎます)。
Elasticsearchをアップグレードするには、次の手順に従う必要があります-
からアップグレードドキュメントを読む https://www.elastic.co/
UAT、E2E、SIT、DEV環境などの非実稼働環境でアップグレードされたバージョンをテストします。
以前のElasticsearchバージョンへのロールバックは、データのバックアップなしでは不可能であることに注意してください。したがって、上位バージョンにアップグレードする前に、データのバックアップをお勧めします。
完全なクラスター再起動またはローリングアップグレードを使用してアップグレードできます。ローリングアップグレードは新しいバージョン用です。移行にローリングアップグレード方式を使用している場合、サービスの停止はないことに注意してください。
アップグレードの手順
本番クラスターをアップグレードする前に、開発環境でアップグレードをテストしてください。
データをバックアップします。データのスナップショットがない限り、以前のバージョンにロールバックすることはできません。
アップグレードプロセスを開始する前に、機械学習ジョブを閉じることを検討してください。機械学習ジョブはローリングアップグレード中も実行を継続できますが、アップグレードプロセス中のクラスターのオーバーヘッドが増加します。
ElasticStackのコンポーネントを次の順序でアップグレードします-
- Elasticsearch
- Kibana
- Logstash
- Beats
- APMサーバー
6.6以前からのアップグレード
バージョン6.0〜6.6からElasticsearch 7.1.0に直接アップグレードするには、繰り越す必要のある5.xインデックスを手動で再インデックスし、クラスター全体を再起動する必要があります。
クラスター全体の再起動
クラスター全体の再起動のプロセスには、クラスター内の各ノードをシャットダウンし、各ノードを7xにアップグレードしてから、クラスターを再起動することが含まれます。
以下は、クラスターを完全に再起動するために実行する必要のある高レベルの手順です。
- シャードの割り当てを無効にする
- インデックス作成を停止し、同期フラッシュを実行します
- すべてのノードをシャットダウンします
- すべてのノードをアップグレードする
- プラグインをアップグレードする
- アップグレードされた各ノードを起動します
- すべてのノードがクラスターに参加するのを待ち、黄色のステータスを報告します
- 割り当てを再度有効にする
割り当てが再度有効になると、クラスターはレプリカシャードのデータノードへの割り当てを開始します。この時点で、インデックス作成と検索を再開しても安全ですが、すべてのプライマリシャードとレプリカシャードが正常に割り当てられ、すべてのノードのステータスが緑色になるまで待つことができれば、クラスターはより迅速に回復します。
Webのアプリケーションプログラミングインターフェイス(API)は、その特定のWebアプリケーションのソフトウェアコンポーネントにアクセスするための関数呼び出しまたはその他のプログラミング命令のグループです。たとえば、Facebook APIは、開発者がFacebookからデータやその他の機能にアクセスしてアプリケーションを作成するのに役立ちます。生年月日またはステータスの更新の場合があります。
Elasticsearchは、JSON overHTTPによってアクセスされるRESTAPIを提供します。Elasticsearchは、これから説明するいくつかの規則を使用します。
複数のインデックス
APIでのほとんどの操作、主に検索やその他の操作は、1つまたは複数のインデックスに対するものです。これにより、ユーザーはクエリを1回実行するだけで、複数の場所または利用可能なすべてのデータを検索できます。複数のインデックスで操作を実行するために、さまざまな表記法が使用されます。この章では、それらのいくつかについて説明します。
カンマ区切り表記
POST /index1,index2,index3/_searchリクエストボディ
{
"query":{
"query_string":{
"query":"any_string"
}
}
}応答
any_stringを含むindex1、index2、index3のJSONオブジェクト。
_allすべてのインデックスのキーワード
POST /_all/_searchリクエストボディ
{
"query":{
"query_string":{
"query":"any_string"
}
}
}応答
すべてのインデックスからのJSONオブジェクトで、any_stringが含まれています。
ワイルドカード(*、+、–)
POST /school*/_searchリクエストボディ
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}応答
CBSEを含む学校で始まるすべてのインデックスからのJSONオブジェクト。
または、次のコードを使用することもできます-
POST /school*,-schools_gov /_searchリクエストボディ
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}応答
「school」で始まり、schools_govからではなく、CBSEを含むすべてのインデックスからのJSONオブジェクト。
いくつかのURLクエリ文字列パラメータもあります-
- ignore_unavailable− URLに存在する1つ以上のインデックスが存在しない場合、エラーは発生しないか、操作は停止されません。たとえば、schoolsインデックスは存在しますが、book_shopsは存在しません。
POST /school*,book_shops/_searchリクエストボディ
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}リクエストボディ
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}次のコードを検討してください-
POST /school*,book_shops/_search?ignore_unavailable = trueリクエストボディ
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}応答(エラーなし)
CBSEを含む学校で始まるすべてのインデックスからのJSONオブジェクト。
allow_no_indices
trueこのパラメーターの値は、ワイルドカードを含むURLの結果にインデックスがない場合に、エラーを防ぎます。たとえば、schools_pri −で始まるインデックスはありません。
POST /schools_pri*/_search?allow_no_indices = trueリクエストボディ
{
"query":{
"match_all":{}
}
}応答(エラーなし)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
このパラメーターは、ワイルドカードを拡張してオープンインデックスまたはクローズドインデックスにする必要があるか、あるいは両方を実行する必要があるかを決定します。このパラメーターの値は、オープンとクローズ、またはなしとすべてにすることができます。
たとえば、インデックススクールを閉じる-
POST /schools/_close応答
{"acknowledged":true}次のコードを検討してください-
POST /school*/_search?expand_wildcards = closedリクエストボディ
{
"query":{
"match_all":{}
}
}応答
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}インデックス名での日付数学のサポート
Elasticsearchは、日付と時刻に従ってインデックスを検索する機能を提供します。日付と時刻を特定の形式で指定する必要があります。たとえば、accountdetail-2015.12.30、indexは、2015年12月30日の銀行口座の詳細を格納します。数学演算を実行して、特定の日付または日付と時刻の範囲の詳細を取得できます。
日付数学インデックス名の形式-
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_nameは式の一部であり、アカウントの詳細など、すべての日付計算インデックスで同じままです。date_math_exprには、now-2dのように日付と時刻を動的に決定する数式が含まれています。date_formatには、YYYY.MM.ddのようなインデックスに日付が書き込まれる形式が含まれます。今日の日付が2015年12月30日の場合、<accountdetail- {now-2d {YYYY.MM.dd}}>はaccountdetail-2015.12.28を返します。
| 式 | に解決します |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 |
| <accountdetail- {now {YYYY.MM}}> | accountdetail-2015.12 |
これで、Elasticsearchで使用できる、指定された形式で応答を取得するために使用できる一般的なオプションのいくつかが表示されます。
かなりの結果
URLクエリパラメータを追加するだけで、適切にフォーマットされたJSONオブジェクトで応答を取得できます。つまり、pretty = trueです。
POST /schools/_search?pretty = trueリクエストボディ
{
"query":{
"match_all":{}
}
}応答
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….人間が読める形式の出力
このオプションは、統計応答を人間が読める形式(人間= trueの場合)またはコンピューターが読み取れる形式(人間= falseの場合)に変更できます。たとえば、別のコンピュータプログラムで応答を使用する必要がある場合、human = trueの場合はdistance_kilometer = 20KM、human = falseの場合はdistance_meter = 20000です。
応答フィルタリング
field_pathパラメーターにフィールドを追加することで、より少ないフィールドへの応答をフィルター処理できます。例えば、
POST /schools/_search?filter_path = hits.totalリクエストボディ
{
"query":{
"match_all":{}
}
}応答
{"hits":{"total":3}}Elasticsearchは、シングルドキュメントAPIとマルチドキュメントAPIを提供し、API呼び出しはそれぞれ単一のドキュメントと複数のドキュメントを対象としています。
インデックスAPI
特定のマッピングを使用してそれぞれのインデックスにリクエストが行われたときに、インデックス内のJSONドキュメントを追加または更新すると便利です。たとえば、次のリクエストは、JSONオブジェクトをインデックススクールとアンダースクールマッピングに追加します-
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}自動インデックス作成
JSONオブジェクトを特定のインデックスに追加するように要求され、そのインデックスが存在しない場合、このAPIは自動的にそのインデックスと、その特定のJSONオブジェクトの基になるマッピングを作成します。この機能は、elasticsearch.ymlファイルにある次のパラメーターの値をfalseに変更することで無効にできます。
action.auto_create_index:false
index.mapper.dynamic:false次のパラメータの値を変更することで、特定のパターンのインデックス名のみが許可されるインデックスの自動作成を制限することもできます。
action.auto_create_index:+acc*,-bank*Note −ここで、+は許可されていることを示し、–は許可されていないことを示します。
バージョニング
Elasticsearchはバージョン管理機能も提供します。バージョンクエリパラメータを使用して、特定のドキュメントのバージョンを指定できます。
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}バージョン管理はリアルタイムプロセスであり、リアルタイム検索操作の影響を受けません。
バージョニングには2つの最も重要なタイプがあります-
内部バージョン管理
内部バージョン管理は、1から始まり、更新ごとに増分するデフォルトのバージョンであり、削除が含まれます。
外部バージョン管理
ドキュメントのバージョン管理がサードパーティのバージョン管理システムなどの外部システムに保存されている場合に使用されます。この機能を有効にするには、version_typeをexternalに設定する必要があります。ここで、Elasticsearchは外部システムによって指定されたバージョン番号を保存し、自動的にインクリメントしません。
操作タイプ
操作タイプは、作成操作を強制するために使用されます。これは、既存のドキュメントの上書きを回避するのに役立ちます。
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}自動ID生成
インデックス操作でIDが指定されていない場合、ElasticsearchはそのドキュメントのIDを自動的に生成します。
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}APIを取得する
APIは、特定のドキュメントに対してgetリクエストを実行することにより、タイプJSONオブジェクトを抽出するのに役立ちます。
pre class="prettyprint notranslate" > GET schools/_doc/5上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}この操作はリアルタイムであり、インデックスのリフレッシュレートの影響を受けません。
バージョンを指定することもできます。そうすると、Elasticsearchはそのバージョンのドキュメントのみをフェッチします。
リクエストで_allを指定して、ElasticsearchがすべてのタイプでそのドキュメントIDを検索し、最初に一致したドキュメントを返すようにすることもできます。
その特定のドキュメントからの結果に必要なフィールドを指定することもできます。
GET schools/_doc/5?_source_includes=name,fees上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}getリクエストに_sourceパーツを追加するだけで、結果のソースパーツをフェッチすることもできます。
GET schools/_doc/5?_source上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}リフレッシュパラメータをtrueに設定することで、get操作を実行する前にシャードをリフレッシュすることもできます。
APIを削除します
ElasticsearchにHTTPDELETEリクエストを送信することで、特定のインデックス、マッピング、またはドキュメントを削除できます。
DELETE schools/_doc/4上記のコードを実行すると、次の結果が得られます-
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}ドキュメントのバージョンを指定して、その特定のバージョンを削除できます。ルーティングパラメータを指定して、特定のユーザーからドキュメントを削除できます。ドキュメントがその特定のユーザーに属していない場合、操作は失敗します。この操作では、GETAPIと同じように更新とタイムアウトのオプションを指定できます。
APIの更新
この操作を実行するためにスクリプトが使用され、取得および再インデックス作成中に更新が発生していないことを確認するためにバージョン管理が使用されます。たとえば、スクリプトを使用して学校の授業料を更新できます-
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}更新されたドキュメントにgetリクエストを送信することで、更新を確認できます。
このAPIは、Elasticsearchでコンテンツを検索するために使用されます。ユーザーは、クエリ文字列をパラメータとしてgetリクエストを送信して検索することも、postリクエストのメッセージ本文にクエリを投稿することもできます。主にすべての検索APIは、マルチインデックス、マルチタイプです。
マルチインデックス
Elasticsearchを使用すると、すべてのインデックスまたは特定のインデックスに存在するドキュメントを検索できます。たとえば、centralを含む名前のすべてのドキュメントを検索する必要がある場合は、次のように実行できます。
GET /_all/_search?q=city:paprola上記のコードを実行すると、次の応答が返されます-
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}URI検索
ユニフォームリソース識別子を使用した検索操作では、多くのパラメータを渡すことができます。
| S.No | パラメータと説明 |
|---|---|
| 1 | Q このパラメーターは、クエリ文字列を指定するために使用されます。 |
| 2 | lenient このパラメーターは、クエリ文字列を指定するために使用されます。このパラメーターをtrueに設定するだけで、フォーマットベースのエラーを無視できます。デフォルトではfalseです。 |
| 3 | fields このパラメーターは、クエリ文字列を指定するために使用されます。 |
| 4 | sort このパラメーターを使用すると、並べ替えられた結果を取得できます。このパラメーターに指定できる値は、fieldName、fieldName:asc / fieldname:descです。 |
| 5 | timeout このパラメーターを使用して検索時間を制限できます。応答には、指定された時間のヒットのみが含まれます。デフォルトでは、タイムアウトはありません。 |
| 6 | terminate_after クエリが早期に終了するようになると、シャードごとに指定された数のドキュメントに応答を制限できます。デフォルトでは、terminate_afterはありません。 |
| 7 | from ヒットのインデックスから開始して戻ります。デフォルトは0です。 |
| 8 | size 返されるヒット数を示します。デフォルトは10です。 |
ボディ検索をリクエストする
リクエスト本文でクエリDSLを使用してクエリを指定することもできます。前の章ですでに多くの例が示されています。そのような例の1つをここに示します-
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}上記のコードを実行すると、次の応答が返されます-
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}集計フレームワークは、検索クエリによって選択されたすべてのデータを収集し、データの複雑な要約を作成するのに役立つ多くのビルディングブロックで構成されています。集計の基本構造を以下に示します-
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}さまざまな種類の集計があり、それぞれに独自の目的があります。これらについては、この章で詳しく説明します。
メトリックの集計
これらの集計は、集計されたドキュメントのフィールドの値からマトリックスを計算するのに役立ち、場合によってはスクリプトからいくつかの値を生成できます。
数値行列は、平均集計のように単一値であるか、統計のように複数値です。
平均集計
この集計は、集計されたドキュメントに存在する数値フィールドの平均を取得するために使用されます。例えば、
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}カーディナリティ集約
この集計により、特定のフィールドの個別の値の数がわかります。
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note −料金には2つの異なる値があるため、カーディナリティの値は2です。
拡張統計集計
この集計により、集計されたドキュメントの特定の数値フィールドに関するすべての統計が生成されます。
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}最大集計
この集計では、集計されたドキュメント内の特定の数値フィールドの最大値が検出されます。
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}最小集計
この集計では、集計されたドキュメント内の特定の数値フィールドの最小値が検索されます。
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}合計集計
この集計では、集計されたドキュメントの特定の数値フィールドの合計が計算されます。
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}地理的位置の目的で、地理的境界の集約や地理的重心の集約などの特殊なケースで使用される他のメトリック集約がいくつかあります。
統計集計
集約されたドキュメントから抽出された数値の統計を計算する複数値メトリック集約。
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}集約メタデータ
メタタグを使用して、リクエスト時に集計に関するデータを追加し、それに応じて取得することができます。
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}これらのAPIは、設定、エイリアス、マッピング、インデックステンプレートなどのインデックスのすべての側面を管理する役割を果たします。
インデックスの作成
このAPIは、インデックスの作成に役立ちます。インデックスは、ユーザーがJSONオブジェクトを任意のインデックスに渡すときに自動的に作成することも、その前に作成することもできます。インデックスを作成するには、設定、マッピング、エイリアスを含むPUTリクエストを送信するか、本文を含まない単純なリクエストを送信する必要があります。
PUT colleges上記のコードを実行すると、次のような出力が得られます。
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}上記のコマンドにいくつかの設定を追加することもできます-
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}上記のコードを実行すると、次のような出力が得られます。
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}インデックスの削除
このAPIは、インデックスを削除するのに役立ちます。その特定のインデックスの名前で削除リクエストを渡す必要があります。
DELETE /colleges_allまたは*を使用するだけで、すべてのインデックスを削除できます。
インデックスを取得
このAPIは、getリクエストを1つまたは複数のインデックスに送信するだけで呼び出すことができます。これにより、インデックスに関する情報が返されます。
GET colleges上記のコードを実行すると、次のような出力が得られます。
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}_allまたは*を使用すると、すべてのインデックスの情報を取得できます。
インデックスが存在します
インデックスの存在は、そのインデックスにgetリクエストを送信するだけで判断できます。HTTP応答が200の場合、それは存在します。404の場合、存在しません。
HEAD colleges上記のコードを実行すると、次のような出力が得られます。
200-OKインデックス設定
URLの最後に_settingsキーワードを追加するだけで、インデックス設定を取得できます。
GET /colleges/_settings上記のコードを実行すると、次のような出力が得られます。
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}インデックス統計
このAPIは、特定のインデックスに関する統計を抽出するのに役立ちます。最後にインデックスURLと_statsキーワードを指定してgetリクエストを送信する必要があります。
GET /_stats上記のコードを実行すると、次のような出力が得られます。
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………流す
インデックスのフラッシュプロセスにより、現在トランザクションログにのみ保持されているデータがLuceneにも永続的に保持されるようになります。これにより、Luceneインデックスが開かれた後、トランザクションログからデータのインデックスを再作成する必要がないため、リカバリ時間が短縮されます。
POST colleges/_flush上記のコードを実行すると、次のような出力が得られます。
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}通常、さまざまなElasticsearchAPIの結果はJSON形式で表示されます。しかし、JSONは常に読みやすいわけではありません。そのため、Elasticsearchでcat API機能を利用できるため、結果の印刷形式を読みやすく、理解しやすくすることができます。cat APIで使用されるさまざまなパラメーターがあり、それらはさまざまな目的を果たします。たとえば、Vという用語は出力を冗長にします。
この章では、catAPIについて詳しく学びましょう。
詳細
詳細な出力は、catコマンドの結果を適切に表示します。以下の例では、クラスターに存在するさまざまなインデックスの詳細を取得します。
GET /_cat/indices?v上記のコードを実行すると、次のような応答が得られます。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bヘッダー
ヘッダーとも呼ばれるhパラメーターは、コマンドで指定された列のみを表示するために使用されます。
GET /_cat/nodes?h=ip,port上記のコードを実行すると、次のような応答が得られます。
127.0.0.1 9300ソート
sortコマンドは、クエリ内の指定された列でテーブルを並べ替えることができるクエリ文字列を受け入れます。デフォルトの並べ替えは昇順ですが、これは:descを列に追加することで変更できます。
以下の例は、ファイルされたインデックスパターンの降順で配置されたテンプレートの結果を示しています。
GET _cat/templates?v&s=order:desc,index_patterns上記のコードを実行すると、次のような応答が得られます。
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099カウント
countパラメーターは、クラスター全体のドキュメントの総数のカウントを提供します。
GET /_cat/count?v上記のコードを実行すると、次のような応答が得られます。
epoch timestamp count
1557633536 03:58:56 17809クラスターAPIは、クラスターとそのノードに関する情報を取得し、それらに変更を加えるために使用されます。このAPIを呼び出すには、ノード名、アドレス、または_localを指定する必要があります。
GET /_nodes/_local上記のコードを実行すると、次のような応答が得られます。
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………クラスターヘルス
このAPIは、「health」キーワードを追加することにより、クラスターのヘルスに関するステータスを取得するために使用されます。
GET /_cluster/health上記のコードを実行すると、次のような応答が得られます。
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}クラスター状態
このAPIは、「state」キーワードURLを追加することにより、クラスターに関する状態情報を取得するために使用されます。状態情報には、バージョン、マスターノード、その他のノード、ルーティングテーブル、メタデータ、およびブロックが含まれます。
GET /_cluster/state上記のコードを実行すると、次のような応答が得られます。
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………クラスター統計
このAPIは、「stats」キーワードを使用してクラスターに関する統計を取得するのに役立ちます。このAPIは、シャード番号、ストアサイズ、メモリ使用量、ノード数、ロール、OS、およびファイルシステムを返します。
GET /_cluster/stats上記のコードを実行すると、次のような応答が得られます。
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….クラスター更新設定
このAPIを使用すると、「settings」キーワードを使用してクラスターの設定を更新できます。設定には、永続的(再起動全体に適用)と一時的(完全なクラスター再起動後も存続しない)の2種類があります。
ノード統計
このAPIは、クラスターのもう1つのノードの統計を取得するために使用されます。ノードの統計はクラスターとほぼ同じです。
GET /_nodes/stats上記のコードを実行すると、次のような応答が得られます。
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….ノードhot_threads
このAPIは、クラスター内の各ノードの現在のホットスレッドに関する情報を取得するのに役立ちます。
GET /_nodes/hot_threads上記のコードを実行すると、次のような応答が得られます。
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:Elasticsearchでは、JSONに基づくクエリを使用して検索が実行されます。クエリは2つの句で構成されています-
Leaf Query Clauses −これらの句は、特定のフィールドで特定の値を検索するmatch、term、またはrangeです。
Compound Query Clauses −これらのクエリは、リーフクエリ句と他の複合クエリを組み合わせて、必要な情報を抽出します。
Elasticsearchは多数のクエリをサポートしています。クエリはクエリキーワードで始まり、JSONオブジェクトの形式で条件とフィルターが内部にあります。さまざまなタイプのクエリについて、以下で説明します。
すべてのクエリに一致
これは最も基本的なクエリです。すべてのコンテンツを返し、すべてのオブジェクトのスコアは1.0です。
POST /schools/_search
{
"query":{
"match_all":{}
}
}上記のコードを実行すると、次の結果が得られます-
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}全文クエリ
これらのクエリは、章やニュース記事などのテキスト全体を検索するために使用されます。このクエリは、その特定のインデックスまたはドキュメントに関連付けられているアナライザーに従って機能します。このセクションでは、さまざまなタイプのフルテキストクエリについて説明します。
一致クエリ
このクエリは、テキストまたはフレーズを1つ以上のフィールドの値と照合します。
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}マルチマッチクエリ
このクエリは、複数のフィールドを持つテキストまたはフレーズに一致します。
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}クエリ文字列クエリ
このクエリは、クエリパーサーとquery_stringキーワードを使用します。
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….用語レベルのクエリ
これらのクエリは主に、数値、日付、列挙型などの構造化データを処理します。
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}上記のコードを実行すると、次のような応答が得られます。
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..範囲クエリ
このクエリは、指定された値の範囲内の値を持つオブジェクトを検索するために使用されます。このために、-などの演算子を使用する必要があります
- gte −以上
- gt −より大きい-より大きい
- lte −以下以下
- lt −未満
たとえば、以下のコードを確認してください-
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}−などの他のタイプの用語レベルのクエリもあります。
Exists query −特定のフィールドにnull以外の値がある場合。
Missing query −これは、既存のクエリとは完全に反対です。このクエリは、特定のフィールドがないオブジェクト、またはnull値を持つフィールドを検索します。
Wildcard or regexp query −このクエリは、正規表現を使用してオブジェクト内のパターンを検索します。
複合クエリ
これらのクエリは、and、or、not、異なるインデックス、または関数呼び出しなどのブール演算子を使用して相互にマージされたさまざまなクエリのコレクションです。
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}ジオクエリ
これらのクエリは、地理的位置と地理的ポイントを扱います。これらのクエリは、任意の場所に近い学校やその他の地理的オブジェクトを見つけるのに役立ちます。ジオポイントデータ型を使用する必要があります。
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}上記のコードを実行すると、次のような応答が得られます。
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}次に、上記で作成したインデックスにデータを投稿します。
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}マッピングは、インデックスに保存されているドキュメントの概要です。これは、geo_pointや文字列などのデータ型と、動的に追加されたフィールドのマッピングを制御するためのドキュメントとルールに存在するフィールドの形式を定義します。
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}上記のコードを実行すると、次のような応答が得られます。
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}フィールドデータ型
Elasticsearchは、ドキュメント内のフィールドに対してさまざまなデータ型をサポートしています。Elasticsearchでフィールドを格納するために使用されるデータ型については、ここで詳しく説明します。
コアデータ型
これらは、text、keyword、date、long、double、boolean、ipなどの基本的なデータ型であり、ほとんどすべてのシステムでサポートされています。
複雑なデータ型
これらのデータ型は、コアデータ型の組み合わせです。これらには、配列、JSONオブジェクト、ネストされたデータ型が含まれます。ネストされたデータ型の例を以下に示します&minus
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}上記のコードを実行すると、次のような応答が得られます。
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}別のサンプルコードを以下に示します-
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}上記のコードを実行すると、次のような応答が得られます。
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}次のコマンドを使用して、上記のドキュメントを確認できます-
GET /accountdetails/_mappings?include_type_name=falseマッピングタイプの削除
Elasticsearch 7.0.0以降で作成されたインデックスは、_default_マッピングを受け入れなくなりました。6.xで作成されたインデックスは、Elasticsearch6.xでも以前と同じように機能します。タイプは7.0のAPIで非推奨になりました。
検索操作中にクエリが処理されると、任意のインデックスのコンテンツが分析モジュールによって分析されます。このモジュールは、アナライザー、トークナイザー、tokenfilters、charfiltersで構成されています。アナライザーが定義されていない場合、デフォルトでは、組み込みのアナライザー、トークン、フィルター、およびトークナイザーが分析モジュールに登録されます。
次の例では、他のアナライザーが指定されていない場合に使用される標準アナライザーを使用します。文法に基づいて文を分析し、文で使用される単語を生成します。
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}上記のコードを実行すると、次のような応答が得られます。
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}標準アナライザーの構成
カスタム要件を取得するために、さまざまなパラメーターを使用して標準アナライザーを構成できます。
次の例では、max_token_lengthが5になるように標準アナライザーを構成します。
このために、最初にmax_length_tokenパラメーターを持つアナライザーを使用してインデックスを作成します。
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}次に、以下に示すテキストを使用してアナライザーを適用します。トークンは最初に2つのスペースがあり、最後に2つのスペースがあるため、表示されないことに注意してください。「is」という単語の場合、先頭にスペースがあり、末尾にスペースがあります。それらすべてをとると、スペース付きの4文字になり、単語にはなりません。カウントされる単語にするために、少なくとも最初または最後に非スペース文字が必要です。
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}上記のコードを実行すると、次のような応答が得られます。
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}さまざまなアナライザーのリストとその説明を以下の表に示します。
| S.No | アナライザーと説明 |
|---|---|
| 1 | Standard analyzer (standard) このアナライザーには、ストップワードとmax_token_length設定を設定できます。デフォルトでは、ストップワードリストは空で、max_token_lengthは255です。 |
| 2 | Simple analyzer (simple) このアナライザーは小文字のトークナイザーで構成されています。 |
| 3 | Whitespace analyzer (whitespace) このアナライザーは、空白のトークナイザーで構成されています。 |
| 4 | Stop analyzer (stop) stopwordsとstopwords_pathを構成できます。デフォルトでは、英語のストップワードに初期化されたストップワードとstopwords_pathには、ストップワードを含むテキストファイルへのパスが含まれています。 |
トークナイザー
トークナイザーは、Elasticsearchのテキストからトークンを生成するために使用されます。テキストは、空白やその他の句読点を考慮してトークンに分割できます。Elasticsearchには、カスタムアナライザーで使用できるトークン化機能が多数組み込まれています。
文字ではない文字に遭遇するたびにテキストを用語に分割するが、すべての用語を小文字にするトークナイザーの例を以下に示します。
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}上記のコードを実行すると、次のような応答が得られます。
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}トークナイザーとその説明のリストを以下の表に示します-
| S.No | トークナイザーと説明 |
|---|---|
| 1 | Standard tokenizer (standard) これは文法ベースのトークナイザーに基づいて構築されており、max_token_lengthをこのトークナイザー用に構成できます。 |
| 2 | Edge NGram tokenizer (edgeNGram) min_gram、max_gram、token_charsなどの設定をこのトークナイザーに設定できます。 |
| 3 | Keyword tokenizer (keyword) これにより、入力全体が出力として生成され、buffer_sizeを設定できます。 |
| 4 | Letter tokenizer (letter) これにより、文字以外が検出されるまで単語全体がキャプチャされます。 |
Elasticsearchは、その機能を担当するいくつかのモジュールで構成されています。これらのモジュールには、次の2種類の設定があります。
Static Settings−これらの設定は、Elasticsearchを開始する前にconfig(elasticsearch.yml)ファイルで構成する必要があります。これらの設定による変更を反映するには、クラスター内のすべての関連ノードを更新する必要があります。
Dynamic Settings −これらの設定はライブElasticsearchで設定できます。
この章の次のセクションでは、Elasticsearchのさまざまなモジュールについて説明します。
クラスターレベルのルーティングとシャードの割り当て
クラスターレベルの設定により、異なるノードへのシャードの割り当てと、クラスターをリバランスするためのシャードの再割り当てが決定されます。これらは、シャードの割り当てを制御するための次の設定です。
クラスターレベルのシャード割り当て
| 設定 | 可能な値 | 説明 |
|---|---|---|
| cluster.routing.allocation.enable | ||
| すべて | このデフォルト値により、すべての種類のシャードにシャードを割り当てることができます。 | |
| 予備選挙 | これにより、プライマリシャードに対してのみシャードの割り当てが可能になります。 | |
| new_primaries | これにより、新しいインデックスのプライマリシャードにのみシャードを割り当てることができます。 | |
| なし | これにより、シャードの割り当ては許可されません。 | |
| cluster.routing.allocation .node_concurrent_recoveries | 数値(デフォルトでは2) | これにより、同時シャードリカバリの数が制限されます。 |
| cluster.routing.allocation .node_initial_primaries_recoveries | 数値(デフォルトでは4) | これにより、並列の初期一次リカバリーの数が制限されます。 |
| cluster.routing.allocation .same_shard.host | ブール値(デフォルトではfalse) | これにより、同じ物理ノード内の同じシャードの複数のレプリカの割り当てが制限されます。 |
| indexs.recovery.concurrent _streams | 数値(デフォルトでは3) | これは、ピアシャードからのシャードリカバリ時にノードごとに開いているネットワークストリームの数を制御します。 |
| indexs.recovery.concurrent _small_file_streams | 数値(デフォルトでは2) | これにより、シャードリカバリ時にサイズが5MB未満の小さなファイルのノードあたりのオープンストリームの数が制御されます。 |
| cluster.routing.rebalance.enable | ||
| すべて | このデフォルト値により、あらゆる種類のシャードのバランスをとることができます。 | |
| 予備選挙 | これにより、プライマリシャードに対してのみシャードバランシングが可能になります。 | |
| レプリカ | これにより、レプリカシャードに対してのみシャードバランシングが可能になります。 | |
| なし | これにより、いかなる種類のシャードバランシングも許可されません。 | |
| cluster.routing.allocation .allow_rebalance | ||
| 常に | このデフォルト値は常にリバランスを許可します。 | |
| indexs_primaries _active | これにより、クラスター内のすべてのプライマリシャードが割り当てられたときにリバランスが可能になります。 | |
| Indices_all_active | これにより、すべてのプライマリシャードとレプリカシャードが割り当てられたときにリバランスが可能になります。 | |
| cluster.routing.allocation.cluster _concurrent_rebalance | 数値(デフォルトでは2) | これにより、クラスター内の同時シャードバランシングの数が制限されます。 |
| cluster.routing.allocation .balance.shard | フロート値(デフォルトでは0.45f) | これは、すべてのノードに割り当てられたシャードの重み係数を定義します。 |
| cluster.routing.allocation .balance.index | フロート値(デフォルトでは0.55f) | これは、特定のノードに割り当てられたインデックスごとのシャード数の比率を定義します。 |
| cluster.routing.allocation .balance.threshold | 負でないfloat値(デフォルトでは1.0f) | これは、実行する必要のある操作の最小最適化値です。 |
ディスクベースのシャード割り当て
| 設定 | 可能な値 | 説明 |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | ブール値(デフォルトではtrue) | これにより、ディスク割り当て決定機能が有効または無効になります。 |
| cluster.routing.allocation.disk.watermark.low | 文字列値(デフォルトでは85%) | これは、ディスクの最大使用量を示します。この時点以降、他のシャードをそのディスクに割り当てることはできません。 |
| cluster.routing.allocation.disk.watermark.high | 文字列値(デフォルトでは90%) | これは、割り当て時の最大使用量を示します。割り当て時にこのポイントに達すると、Elasticsearchはそのシャードを別のディスクに割り当てます。 |
| cluster.info.update.interval | 文字列値(デフォルトでは30秒) | これは、ディスク使用量のチェックの間隔です。 |
| cluster.routing.allocation.disk.include_relocations | ブール値(デフォルトではtrue) | これにより、ディスク使用量を計算するときに、現在割り当てられているシャードを考慮するかどうかが決まります。 |
発見
このモジュールは、クラスターがその中のすべてのノードの状態を検出して維持するのに役立ちます。ノードがノードに追加またはノードから削除されると、クラスターの状態が変化します。クラスター名の設定は、異なるクラスター間に論理的な違いを作成するために使用されます。クラウドベンダーが提供するAPIの使用に役立つモジュールがいくつかあり、それらは以下のとおりです。
- Azureディスカバリー
- EC2ディスカバリー
- Google ComputeEngineの発見
- 禅の発見
ゲートウェイ
このモジュールは、クラスターの完全な再起動の間、クラスターの状態とシャードデータを維持します。このモジュールの静的設定は次のとおりです-
| 設定 | 可能な値 | 説明 |
|---|---|---|
| Gateway.expected_nodes | 数値(デフォルトでは0) | ローカル・シャードのリカバリーのためにクラスター内にあると予想されるノードの数。 |
| Gateway.expected_master_nodes | 数値(デフォルトでは0) | リカバリーを開始する前にクラスター内にあると予想されるマスターノードの数。 |
| Gateway.expected_data_nodes | 数値(デフォルトでは0) | リカバリーを開始する前にクラスターで予期されるデータノードの数。 |
| Gateway.recover_after_time | 文字列値(デフォルトでは5m) | これは、ディスク使用量のチェックの間隔です。 |
| cluster.routing.allocation。disk.include_relocations | ブール値(デフォルトではtrue) | これは、クラスターに参加しているノードの数に関係なく、リカバリー・プロセスが開始を待機する時間を指定します。 gateway.recover_ after_nodes |
HTTP
このモジュールは、HTTPクライアントとElasticsearchAPI間の通信を管理します。このモジュールは、http.enabledの値をfalseに変更することで無効にできます。
以下は、このモジュールを制御するための設定(elasticsearch.ymlで構成)です-
| S.No | 設定と説明 |
|---|---|
| 1 | http.port これはElasticsearchにアクセスするためのポートであり、範囲は9200〜9300です。 |
| 2 | http.publish_port このポートはhttpクライアント用であり、ファイアウォールの場合にも役立ちます。 |
| 3 | http.bind_host これはhttpサービスのホストアドレスです。 |
| 4 | http.publish_host これはhttpクライアントのホストアドレスです。 |
| 5 | http.max_content_length これは、httpリクエストのコンテンツの最大サイズです。デフォルト値は100mbです。 |
| 6 | http.max_initial_line_length これはURLの最大サイズであり、デフォルト値は4kbです。 |
| 7 | http.max_header_size これは最大httpヘッダーサイズであり、デフォルト値は8kbです。 |
| 8 | http.compression これにより、圧縮のサポートが有効または無効になり、デフォルト値はfalseになります。 |
| 9 | http.pipelinig これにより、HTTPパイプラインが有効または無効になります。 |
| 10 | http.pipelining.max_events これにより、HTTPリクエストを閉じる前にキューに入れられるイベントの数が制限されます。 |
インデックス
このモジュールは、すべてのインデックスに対してグローバルに設定される設定を維持します。以下の設定は、主にメモリ使用量に関連しています-
サーキットブレーカー
これは、操作によってOutOfMemroyErrorが発生するのを防ぐために使用されます。この設定は、主にJVMヒープサイズを制限します。たとえば、indexes.breaker.total.limit設定は、デフォルトでJVMヒープの70%になります。
フィールドデータキャッシュ
これは主にフィールドに集約するときに使用されます。割り当てるのに十分なメモリを用意することをお勧めします。フィールドデータキャッシュに使用されるメモリの量は、indexes.fielddata.cache.size設定を使用して制御できます。
ノードクエリキャッシュ
このメモリは、クエリ結果をキャッシュするために使用されます。このキャッシュは、最近使用されていない(LRU)エビクションポリシーを使用します。Indices.queries.cahce.size設定は、このキャッシュのメモリサイズを制御します。
インデックスバッファ
このバッファは、新しく作成されたドキュメントをインデックスに保存し、バッファがいっぱいになるとそれらをフラッシュします。indexs.memory.index_buffer_sizeのように設定すると、このバッファーに割り当てられるヒープの量が制御されます。
シャードリクエストキャッシュ
このキャッシュは、すべてのシャードのローカル検索データを格納するために使用されます。キャッシュは、インデックスの作成中に有効にすることも、URLパラメータを送信して無効にすることもできます。
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": trueインデックスの回復
リカバリプロセス中にリソースを制御します。以下は設定です-
| 設定 | デフォルト値 |
|---|---|
| indexs.recovery.concurrent_streams | 3 |
| indexs.recovery.concurrent_small_file_streams | 2 |
| indexs.recovery.file_chunk_size | 512kb |
| indexs.recovery.translog_ops | 1000 |
| indexs.recovery.translog_size | 512kb |
| indexs.recovery.compress | true |
| indexs.recovery.max_bytes_per_sec | 40mb |
TTL間隔
存続時間(TTL)間隔は、ドキュメントが削除されるまでの時間を定義します。以下は、このプロセスを制御するための動的設定です。
| 設定 | デフォルト値 |
|---|---|
| indexs.ttl.interval | 60年代 |
| indexs.ttl.bulk_size | 1000 |
ノード
各ノードには、データノードにするかどうかを選択できます。このプロパティは、変更することで変更できますnode.data設定。値を次のように設定しますfalse ノードがデータノードではないことを定義します。
これらは、すべてのインデックスに対して作成され、インデックスの設定と動作を制御するモジュールです。たとえば、インデックスが使用できるシャードの数や、プライマリシャードがそのインデックスに対して持つことができるレプリカの数などです。インデックス設定には2つのタイプがあります。
- Static −これらは、インデックス作成時またはクローズドインデックスでのみ設定できます。
- Dynamic −これらはライブインデックスで変更できます。
静的インデックス設定
次の表に、静的インデックス設定のリストを示します。
| 設定 | 可能な値 | 説明 |
|---|---|---|
| index.number_of_shards | デフォルトは5、最大1024 | インデックスに必要なプライマリシャードの数。 |
| index.shard.check_on_startup | デフォルトはfalseです。真実でありえます | シャードを開く前に、シャードの破損をチェックする必要があるかどうか。 |
| index.codec | LZ4圧縮。 | データの保存に使用される圧縮のタイプ。 |
| index.routing_partition_size | 1 | カスタムルーティング値が移動できるシャードの数。 |
| index.load_fixed_bitset_filters_eagerly | false | キャッシュされたフィルターがネストされたクエリ用にプリロードされているかどうかを示します |
動的インデックス設定
次の表に、動的インデックス設定のリストを示します。
| 設定 | 可能な値 | 説明 |
|---|---|---|
| index.number_of_replicas | デフォルトは1 | 各プライマリシャードが持つレプリカの数。 |
| index.auto_expand_replicas | ダッシュで区切られた下限と上限(0-5) | クラスター内のデータノードの数に基づいて、レプリカの数を自動拡張します。 |
| index.search.idle.after | 30秒 | シャードが検索アイドルと見なされるまで、シャードが検索を受信できない、またはリクエストを取得できない期間。 |
| index.refresh_interval | 1秒 | インデックスへの最近の変更を検索に表示する更新操作を実行する頻度。 |
| index.blocks.read_only | 1真/偽 | インデックスとインデックスメタデータを読み取り専用にするにはtrueに設定し、書き込みとメタデータの変更を許可するにはfalseに設定します。 |
インデックスを作成する前に、ドキュメントを変換する必要がある場合があります。たとえば、ドキュメントからフィールドを削除したり、フィールドの名前を変更してからインデックスを作成したりします。これは、取り込みノードによって処理されます。
クラスター内のすべてのノードには取り込む機能がありますが、特定のノードによってのみ処理されるようにカスタマイズすることもできます。
関係するステップ
取り込みノードの動作には2つのステップが含まれます-
- パイプラインの作成
- ドキュメントの作成
パイプラインを作成する
以下に示すように、最初にプロセッサを含むパイプラインを作成し、次にパイプラインを実行します。
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}上記のコードを実行すると、次の結果が得られます-
{
"acknowledged" : true
}ドキュメントを作成する
次に、パイプラインコンバーターを使用してドキュメントを作成します。
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}上記のコードを実行すると、次のような応答が得られます。
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}次に、以下に示すように、GETコマンドを使用して上記で作成したドキュメントを検索します-
GET /logs/_doc/1上記のコードを実行すると、次の結果が得られます-
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}21が整数になっていることが上でわかります。
パイプラインなし
ここで、パイプラインを使用せずにドキュメントを作成します。
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2上記のコードを実行すると、次の結果が得られます-
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}上記のように、11はパイプラインが使用されていない文字列であることがわかります。
インデックスのライフサイクルの管理には、シャードのサイズやパフォーマンス要件などの要因に基づいた管理アクションの実行が含まれます。インデックスライフサイクル管理(ILM)APIを使用すると、時間の経過とともにインデックスを管理する方法を自動化できます。
この章では、ILMAPIとその使用法のリストを示します。
ポリシー管理API
| API名 | 目的 | 例 |
|---|---|---|
| ライフサイクルポリシーを作成します。 | ライフサイクルポリシーを作成します。指定されたポリシーが存在する場合、ポリシーは置き換えられ、ポリシーバージョンがインクリメントされます。 | PUT_ilm / policy / policy_id |
| ライフサイクルポリシーを取得します。 | 指定されたポリシー定義を返します。ポリシーのバージョンと最終更新日が含まれます。ポリシーが指定されていない場合は、定義されているすべてのポリシーを返します。 | GET_ilm / policy / policy_id |
| ライフサイクルポリシーを削除する | 指定されたライフサイクルポリシー定義を削除します。現在使用中のポリシーは削除できません。ポリシーがインデックスの管理に使用されている場合、要求は失敗し、エラーを返します。 | DELETE_ilm / policy / policy_id |
インデックス管理API
| API名 | 目的 | 例 |
|---|---|---|
| ライフサイクルステップAPIに移動します。 | インデックスを指定されたステップに手動で移動し、そのステップを実行します。 | POST_ilm / move / index |
| ポリシーを再試行します。 | ポリシーをエラーが発生したステップに戻し、ステップを実行します。 | POSTインデックス/ _ilm /再試行 |
| インデックスAPI編集からポリシーを削除します。 | 割り当てられたライフサイクルポリシーを削除し、指定されたインデックスの管理を停止します。インデックスパターンが指定されている場合、一致するすべてのインデックスから割り当てられたポリシーを削除します。 | POSTインデックス/ _ilm / remove |
運用管理API
| API名 | 目的 | 例 |
|---|---|---|
| インデックスライフサイクル管理ステータスAPIを取得します。 | ILMプラグインのステータスを返します。応答のoperation_modeフィールドには、STARTED、STOPPING、またはSTOPPEDの3つの状態のいずれかが表示されます。 | GET / _ilm / status |
| インデックスライフサイクル管理APIを開始します。 | ILMプラグインが現在停止している場合は、それを開始します。クラスターが形成されると、ILMが自動的に開始されます。 | POST / _ilm / start |
| インデックスライフサイクル管理APIを停止します。 | すべてのライフサイクル管理操作を停止し、ILMプラグインを停止します。これは、クラスターでメンテナンスを実行していて、ILMがインデックスに対してアクションを実行しないようにする必要がある場合に役立ちます。 | POST / _ilm / stop |
| ライフサイクルAPIについて説明します。 | 現在実行中のフェーズ、アクション、ステップなど、インデックスの現在のライフサイクル状態に関する情報を取得します。インデックスがそれぞれに入力された日時、実行フェーズの定義、および障害に関する情報を表示します。 | GET index / _ilm / Explain |
これは、SQLのようなクエリをElasticsearchに対してリアルタイムで実行できるようにするコンポーネントです。Elasticsearch SQLは、SQLとElasticsearchの両方を理解し、Elasticsearchの機能を活用することで、大規模なリアルタイムでのデータの読み取りと処理を容易にするトランスレーターと考えることができます。
ElasticsearchSQLの利点
It has native integration −基になるストレージに応じて、関連するノードに対してすべてのクエリが効率的に実行されます。
No external parts − Elasticsearchにクエリを実行するために、追加のハードウェア、プロセス、ランタイム、またはライブラリは必要ありません。
Lightweight and efficient − SQLを採用および公開して、適切な全文検索をリアルタイムで実行できるようにします。
例
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}上記のコードを実行すると、次のような応答が得られます。
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}SQLクエリ
次の例は、SQLクエリをフレーム化する方法を示しています-
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}上記のコードを実行すると、次のような応答が得られます。
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note −上記のSQLクエリを変更することにより、さまざまな結果セットを取得できます。
クラスターの状態を監視するために、監視機能は各ノードからメトリックを収集し、Elasticsearchインデックスに保存します。Elasticsearchでのモニタリングに関連するすべての設定は、各ノードのelasticsearch.ymlファイル、または可能であれば動的クラスター設定のいずれかで設定する必要があります。
監視を開始するには、クラスター設定を確認する必要があります。これは、次の方法で実行できます。
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}スタック内の各コンポーネントは、それ自体を監視し、ルーティングとインデックス作成(ストレージ)の両方のためにそれらのドキュメントをElasticsearch本番クラスターに転送する役割を果たします。Elasticsearchのルーティングおよびインデックス作成プロセスは、コレクターおよびエクスポーターと呼ばれるものによって処理されます。
コレクター
コレクターは、収集間隔ごとに1回実行され、モニターすることを選択したElasticsearchのパブリックAPIからデータを取得します。データ収集が終了すると、データはエクスポーターにまとめて渡され、監視クラスターに送信されます。
収集されるデータ型ごとにコレクターは1つだけです。各コレクターは、0個以上の監視ドキュメントを作成できます。
輸出業者
エクスポーターは、Elastic Stackソースから収集されたデータを取得し、それをモニタリングクラスターにルーティングします。複数のエクスポーターを構成することは可能ですが、一般的なデフォルトのセットアップでは、単一のエクスポーターを使用します。エクスポーターは、ノードレベルとクラスターレベルの両方で構成できます。
Elasticsearchには2つのタイプのエクスポーターがあります-
local −このエクスポーターは、データを同じクラスターにルーティングします
http −HTTP経由でアクセス可能なサポートされているElasticsearchクラスターにデータをルーティングするために使用できる優先エクスポーター。
エクスポーターがモニタリングデータをルーティングする前に、特定のElasticsearchリソースを設定する必要があります。これらのリソースには、テンプレートと取り込みパイプラインが含まれます
ロールアップジョブは、インデックスパターンで指定されたインデックスのデータを要約し、それを新しいインデックスにロールアップする定期的なタスクです。次の例では、異なる日付タイムスタンプを持つsensorという名前のインデックスを作成します。次に、cronジョブを使用して、これらのインデックスからデータを定期的にロールアップするロールアップジョブを作成します。
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}上記のコードを実行すると、次の結果が得られます-
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}次に、他のドキュメントにも2番目のドキュメントなどを追加します。
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}ロールアップジョブを作成する
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}cronパラメーターは、ジョブがアクティブになるタイミングと頻度を制御します。ロールアップジョブのcronスケジュールがトリガーされると、最後のアクティブ化後に中断したところからロールアップが開始されます。
ジョブが実行されてデータが処理されたら、DSLクエリを使用して検索を実行できます。
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}頻繁に検索されるインデックスは、再構築に時間がかかり、効率的な検索に役立つため、メモリに保持されます。一方で、めったにアクセスしないインデックスもあるかもしれません。これらのインデックスはメモリを占有する必要はなく、必要に応じて再構築できます。このようなインデックスは、凍結インデックスとして知られています。
Elasticsearchは、シャードが検索されるたびに、フリーズされたインデックスの各シャードの一時的なデータ構造を構築し、検索が完了するとすぐにこれらのデータ構造を破棄します。Elasticsearchはこれらの一時的なデータ構造をメモリに保持しないため、フリーズされたインデックスは通常のインデックスよりもはるかに少ないヒープを消費します。これにより、ディスクとヒープの比率を他の方法よりもはるかに高くすることができます。
凍結と解凍の例
次の例では、インデックスをフリーズおよびフリーズ解除します-
POST /index_name/_freeze
POST /index_name/_unfreeze凍結されたインデックスの検索は、実行が遅くなると予想されます。凍結されたインデックスは、高い検索負荷を対象としていません。インデックスがフリーズされていないときに同じ検索がミリ秒単位で完了した場合でも、フリーズされたインデックスの検索が完了するまでに数秒または数分かかる場合があります。
凍結インデックスの検索
ノードごとに同時にロードされるフリーズされたインデックスの数は、search_throttledスレッドプール内のスレッドの数によって制限されます。デフォルトでは1です。フリーズされたインデックスを含めるには、クエリパラメータ-ignore_throttled = falseを使用して検索リクエストを実行する必要があります。
GET /index_name/_search?q=user:tpoint&ignore_throttled=false凍結インデックスの監視
凍結インデックスは、検索スロットリングとメモリ効率の高いシャード実装を使用する通常のインデックスです。
GET /_cat/indices/index_name?v&h=i,sthElasticsearchはjarファイルを提供します。このファイルは任意のJavaIDEに追加でき、Elasticsearchに関連するコードをテストするために使用できます。Elasticsearchが提供するフレームワークを使用して、さまざまなテストを実行できます。この章では、これらのテストについて詳しく説明します。
- ユニットテスト
- 統合テスト
- ランダム化されたテスト
前提条件
テストを開始するには、Elasticsearchテストの依存関係をプログラムに追加する必要があります。この目的でmavenを使用でき、pom.xmlに以下を追加できます。
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetupは、Elasticsearchノードを開始および停止し、インデックスを作成するように初期化されています。
EsSetup esSetup = new EsSetup();createIndexを指定したesSetup.execute()関数はインデックスを作成します。設定、タイプ、およびデータを指定する必要があります。
ユニットテスト
ユニットテストは、JUnitとElasticsearchテストフレームワークを使用して実行されます。ノードとインデックスはElasticsearchクラスを使用して作成でき、テストメソッドでテストを実行できます。このテストには、ESTestCaseクラスとESTokenStreamTestCaseクラスが使用されます。
統合テスト
統合テストでは、クラスター内の複数のノードを使用します。このテストには、ESIntegTestCaseクラスが使用されます。テストケースの準備作業を簡単にするさまざまな方法があります。
| S.No | 方法と説明 |
|---|---|
| 1 | refresh() クラスタ内のすべてのインデックスが更新されます |
| 2 | ensureGreen() グリーンヘルスクラスターの状態を保証します |
| 3 | ensureYellow() 黄色のヘルスクラスター状態を保証します |
| 4 | createIndex(name) このメソッドに渡された名前でインデックスを作成します |
| 5 | flush() クラスタ内のすべてのインデックスがフラッシュされます |
| 6 | flushAndRefresh() flush()およびrefresh() |
| 7 | indexExists(name) 指定されたインデックスの存在を確認します |
| 8 | clusterService() クラスタサービスのJavaクラスを返します |
| 9 | cluster() テストクラスタークラスを返します |
クラスターメソッドのテスト
| S.No | 方法と説明 |
|---|---|
| 1 | ensureAtLeastNumNodes(n) クラスター内のノードの最小数が指定された数以上であることを確認します。 |
| 2 | ensureAtMostNumNodes(n) クラスター内のノードの最大数が指定された数以下になるようにします。 |
| 3 | stopRandomNode() クラスター内のランダムノードを停止するには |
| 4 | stopCurrentMasterNode() マスターノードを停止するには |
| 5 | stopRandomNonMaster() マスターノードではないクラスター内のランダムノードを停止します。 |
| 6 | buildNode() 新しいノードを作成します |
| 7 | startNode(settings) 新しいノードを開始します |
| 8 | nodeSettings() ノード設定を変更するには、このメソッドをオーバーライドします。 |
クライアントへのアクセス
クライアントは、クラスター内のさまざまなノードにアクセスし、何らかのアクションを実行するために使用されます。ESIntegTestCase.client()メソッドは、ランダムなクライアントを取得するために使用されます。Elasticsearchは、クライアントにアクセスするための他のメソッドも提供します。これらのメソッドには、ESIntegTestCase.internalCluster()メソッドを使用してアクセスできます。
| S.No | 方法と説明 |
|---|---|
| 1 | iterator() これは、利用可能なすべてのクライアントにアクセスするのに役立ちます。 |
| 2 | masterClient() これにより、マスターノードと通信しているクライアントが返されます。 |
| 3 | nonMasterClient() これにより、マスターノードと通信していないクライアントが返されます。 |
| 4 | clientNodeClient() これにより、現在クライアントノード上にあるクライアントが返されます。 |
ランダム化されたテスト
このテストは、考えられるすべてのデータを使用してユーザーのコードをテストするために使用されるため、将来、どのタイプのデータでも障害が発生することはありません。このテストを実行するには、ランダムデータが最適なオプションです。
ランダムデータの生成
このテストでは、Randomクラスは、RandomizedTestによって提供されるインスタンスによってインスタンス化され、さまざまなタイプのデータを取得するための多くのメソッドを提供します。
| 方法 | 戻り値 |
|---|---|
| getRandom() | ランダムクラスのインスタンス |
| randomBoolean() | ランダムブール値 |
| randomByte() | ランダムバイト |
| randomShort() | ランダムショート |
| randomInt() | ランダム整数 |
| randomLong() | ランダムロング |
| randomFloat() | ランダムフロート |
| randomDouble() | ランダムダブル |
| randomLocale() | ランダムロケール |
| randomTimeZone() | ランダムなタイムゾーン |
| randomFrom() | 配列からのランダム要素 |
アサーション
ElasticsearchAssertionsクラスとElasticsearchGeoAssertionsクラスには、テスト時にいくつかの一般的なチェックを実行するために使用されるアサーションが含まれています。たとえば、ここに示されているコードを観察します-
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Kibanaダッシュボードは、視覚化と検索のコレクションです。ダッシュボードのコンテンツを配置、サイズ変更、編集してから、ダッシュボードを保存して共有することができます。この章では、ダッシュボードを作成および編集する方法を説明します。
ダッシュボードの作成
Kibanaホームページで、以下に示すように、左側のコントロールバーからダッシュボードオプションを選択します。これにより、新しいダッシュボードを作成するように求められます。
ダッシュボードにビジュアライゼーションを追加するには、[追加]メニューを選択し、使用可能なビルド済みのビジュアライゼーションから選択します。リストから次の視覚化オプションを選択しました。
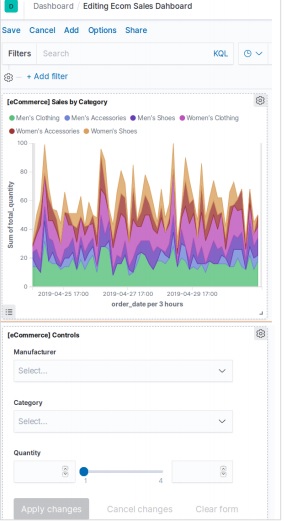
上記のビジュアライゼーションを選択すると、次のようなダッシュボードが表示されます。後でダッシュボードを追加および編集して、要素を変更したり、新しい要素を追加したりできます。
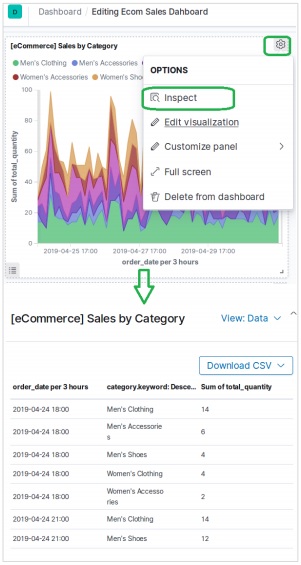
要素の検査
ビジュアライゼーションパネルメニューを選択して選択することにより、ダッシュボード要素を検査できます Inspect。これにより、ダウンロード可能な要素の背後にあるデータが表示されます。
ダッシュボードの共有
以下に示すように、共有メニューを選択し、ハイパーリンクを取得するオプションを選択することで、ダッシュボードを共有できます。

Kibanaホームページで利用可能な検出機能を使用すると、さまざまな角度からデータセットを探索できます。選択したインデックスパターンのデータを検索およびフィルタリングできます。データは通常、一定期間にわたる値の分布の形で入手できます。
eコマースデータサンプルを調べるには、 Discover下の図に示すようなアイコン。これにより、チャートとともにデータが表示されます。
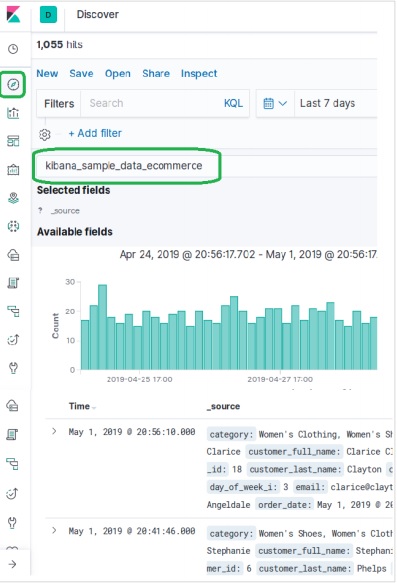
時間によるフィルタリング
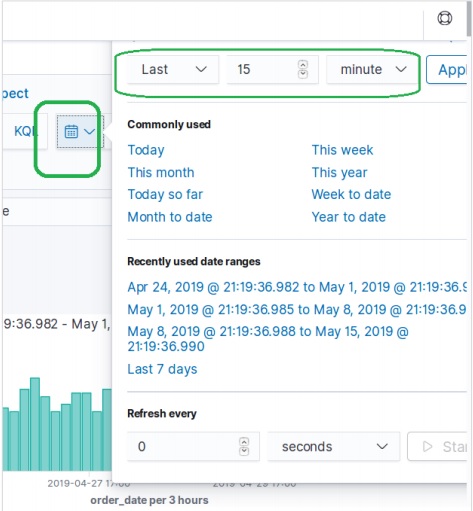
特定の時間間隔でデータを除外するには、以下に示すように時間フィルターオプションを使用します。デフォルトでは、フィルターは15分に設定されています。
フィールドによるフィルタリング
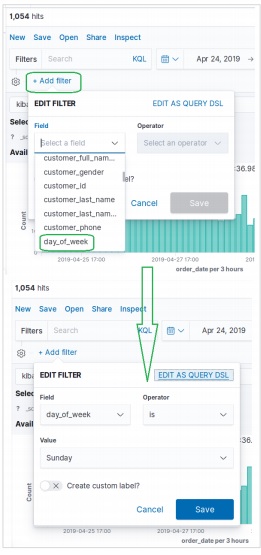
データセットは、を使用してフィールドでフィルタリングすることもできます。 Add Filter以下に示すオプション。ここでは、1つ以上のフィールドを追加し、フィルターが適用された後に対応する結果を取得します。この例では、フィールドを選択しますday_of_week 次に、そのフィールドの演算子として is と値として Sunday。
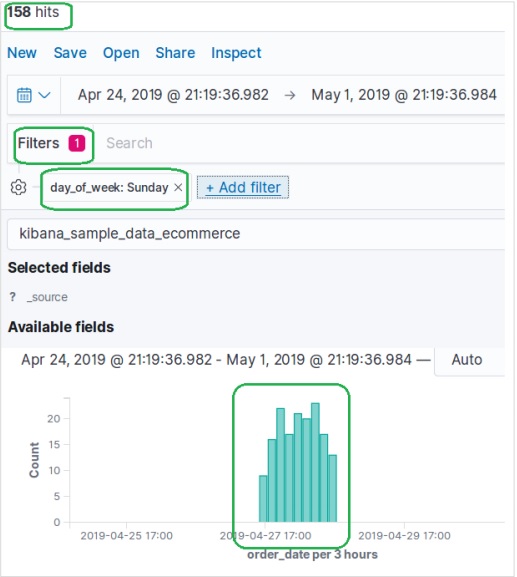
次に、上記のフィルター条件で[保存]をクリックします。適用されたフィルター条件を含む結果セットを以下に示します。
データテーブルは、構成された集計の生データを表示するために使用される視覚化のタイプです。データテーブルを使用して表示される集計には、さまざまな種類があります。データテーブルを作成するには、ここで詳細に説明する手順を実行する必要があります。
視覚化する
Kibanaのホーム画面には、Elasticsearchに保存されているインデックスから視覚化と集計を作成できるオプション名Visualizeがあります。次の画像はオプションを示しています。
データテーブルを選択
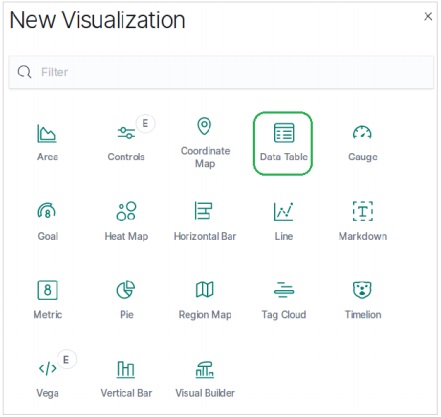
次に、利用可能なさまざまな視覚化オプションの中からデータテーブルオプションを選択します。このオプションは次の画像に示されています&miuns;
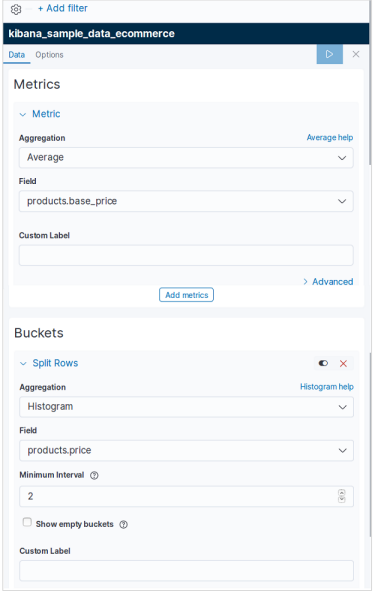
指標を選択
次に、データテーブルの視覚化を作成するために必要なメトリックを選択します。この選択により、使用する集計のタイプが決まります。このためのeコマースデータセットから、以下に示す特定のフィールドを選択します。
上記のデータテーブルの構成を実行すると、次の画像に示すような結果が得られます-
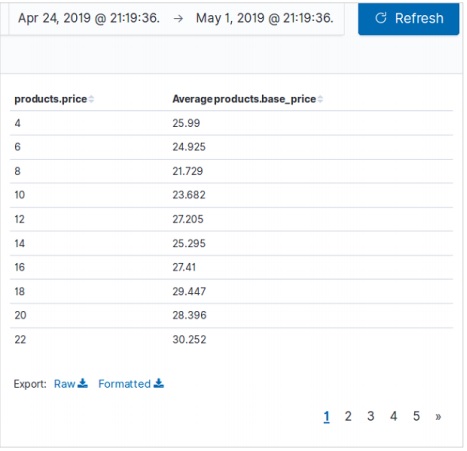
地域マップは、地理マップにメトリックを表示します。さまざまな強度でさまざまな地理的領域に固定されたデータを確認するのに役立ちます。通常、暗い色合いは高い値を示し、明るい色合いは低い値を示します。
この視覚化を作成する手順は、次のように詳細に説明されています。
視覚化する
このステップでは、Kibanaホーム画面の左側のバーにある視覚化ボタンに移動し、新しい視覚化を追加するオプションを選択します。
次の画面は、リージョンマップオプションを選択する方法を示しています。
指標を選択する
次の画面では、リージョンマップの作成に使用するメトリックを選択するように求められます。ここでは、メトリックとして平均価格を選択し、視覚化の作成に使用されるバケットのフィールドとしてcountry_iso_codeを選択します。
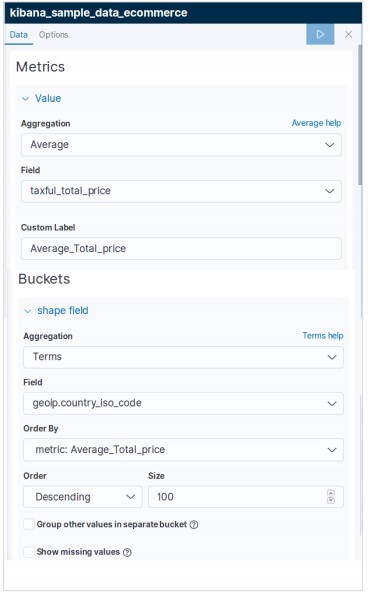
以下の最終結果は、選択を適用した後のリージョンマップを示しています。ラベルに記載されている色合いとその値に注意してください。
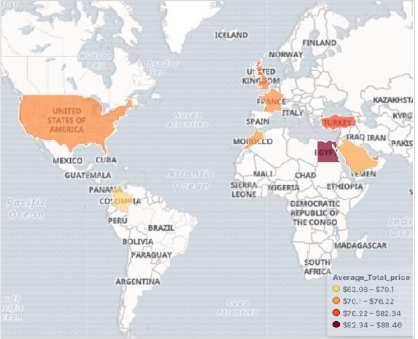
円グラフは、最も単純で有名な視覚化ツールの1つです。これは、データをそれぞれ異なる色の円のスライスとして表します。パーセンテージデータ値とともにラベルを円と一緒に表示できます。円はドーナツの形をとることもできます。
視覚化する
Kibanaのホーム画面には、Elasticsearchに保存されているインデックスから視覚化と集計を作成できるオプション名Visualizeがあります。以下に示すオプションとして、新しいビジュアライゼーションを追加し、円グラフを選択することを選択します。
指標を選択する
次の画面では、円グラフの作成に使用する指標を選択するように求められます。ここでは、基本単価のカウントをメトリックとして選択し、バケット集計をヒストグラムとして選択します。また、最小間隔は20として選択されます。したがって、価格は20を範囲として値のブロックとして表示されます。
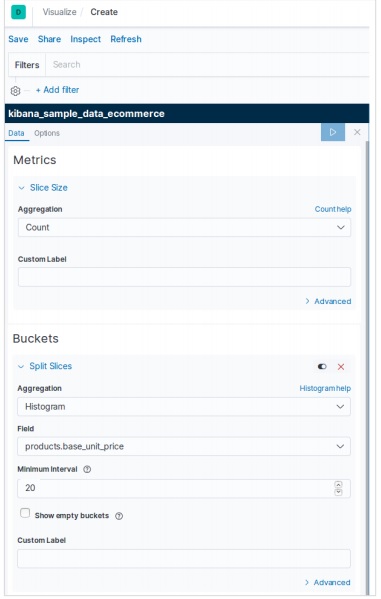
以下の結果は、選択を適用した後の円グラフを示しています。ラベルに記載されている色合いとその値に注意してください。

円グラフオプション
円グラフの下の[オプション]タブに移動すると、外観を変更するためのさまざまな構成オプションと、円グラフのデータ表示の配置を確認できます。次の例では、円グラフはドーナツとして表示され、ラベルは上部に表示されます。
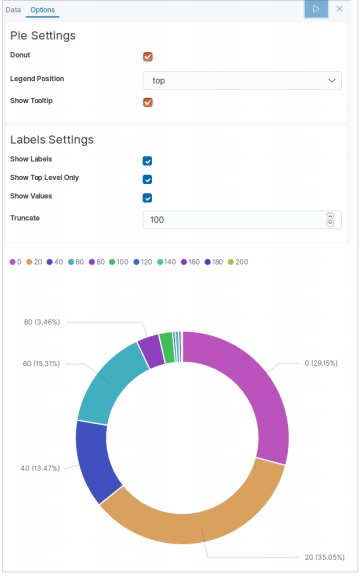
面グラフは折れ線グラフの拡張であり、折れ線グラフと軸の間の領域がいくつかの色で強調表示されます。棒グラフは、値の範囲に編成され、軸に対してプロットされたデータを表します。水平バーまたは垂直バーのいずれかで構成できます。
この章では、Kibanaを使用して作成されたこれら3種類のグラフすべてを確認します。前の章で説明したように、eコマースインデックスのデータを引き続き使用します。
面グラフ
Kibanaのホーム画面には、Elasticsearchに保存されているインデックスから視覚化と集計を作成できるオプション名Visualizeがあります。以下の画像に示すオプションとして、新しいビジュアライゼーションを追加し、面グラフを選択します。
指標を選択する
次の画面では、面グラフの作成に使用するメトリックを選択するように求められます。ここでは、集計メトリックのタイプとして合計を選択します。次に、メトリックとして使用するフィールドとしてtotal_quantityフィールドを選択します。X軸で、order_dateフィールドを選択し、指定されたメトリックでシリーズを5のサイズに分割しました。

上記の構成を実行すると、出力として次の面グラフが得られます-
横棒グラフ
同様に、横棒グラフの場合、Kibanaホーム画面から新しいビジュアライゼーションを選択し、横棒のオプションを選択します。次に、下の画像に示すようにメトリックを選択します。ここでは、提出された名前付き製品数量の集計としてSumを選択します。次に、フィールド注文日の日付ヒストグラムを持つバケットを選択します。
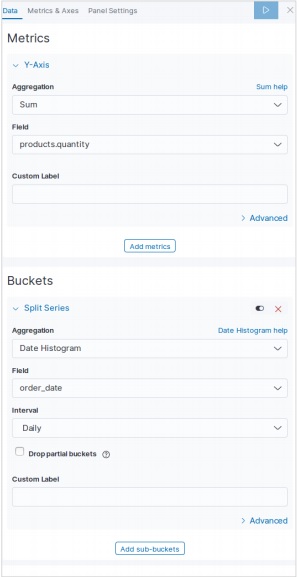
上記の構成を実行すると、以下に示すような横棒グラフが表示されます。
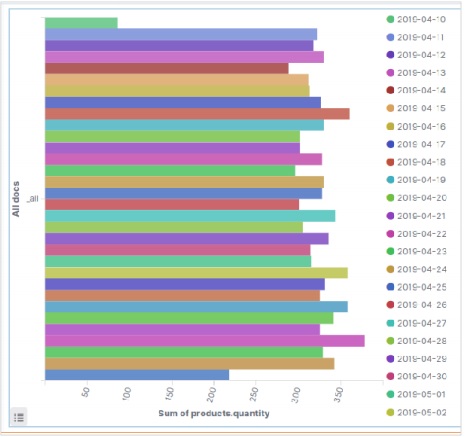
縦棒グラフ
縦棒グラフの場合、Kibanaホーム画面から新しいビジュアライゼーションを選択し、縦棒のオプションを選択します。次に、下の画像に示すようにメトリックを選択します。
ここでは、productquantityという名前のフィールドの集計としてSumを選択します。次に、週間隔のフィールド注文日の日付ヒストグラムのあるバケットを選択します。
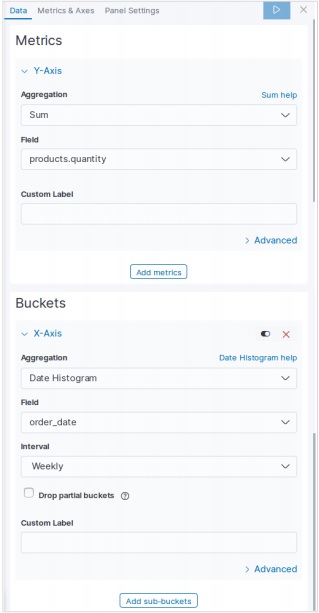
上記の構成を実行すると、以下に示すようなチャートが生成されます-
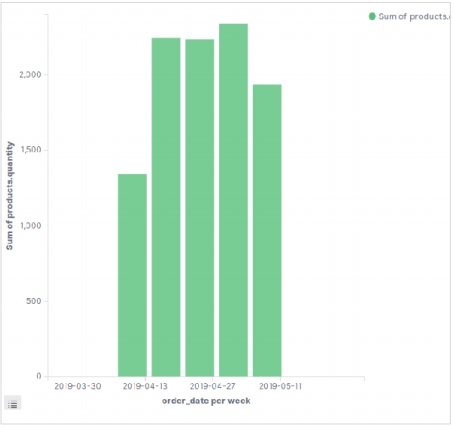
時系列は、特定の時系列におけるデータのシーケンスの表現です。たとえば、月の初日から最終日までの各日のデータ。データポイント間の間隔は一定のままです。時間コンポーネントを含むデータセットは、時系列として表すことができます。
この章では、サンプルのeコマースデータセットを使用し、各日の注文数のカウントをプロットして時系列を作成します。
指標を選択
まず、時系列の作成に使用するインデックスパターン、データフィールド、間隔を選択します。サンプルのeコマースデータセットから、フィールドとしてorder_dateを選択し、間隔として1dを選択します。私たちは使用しますPanel Optionsこれらの選択を行うためのタブ。また、このタブの他の値をデフォルトのままにして、時系列のデフォルトの色と形式を取得します。
の中に Data タブでは、集計オプションとしてカウントを選択し、すべてとしてオプションごとにグループ化し、時系列グラフのラベルを付けます。
結果
この構成の最終結果は次のようになります。の期間を使用していることに注意してくださいMonth to Dateこのグラフの場合。期間が異なれば、結果も異なります。
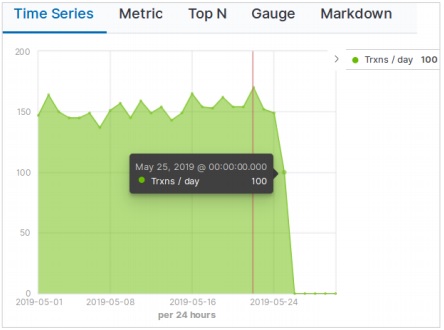
タグクラウドは、ほとんどがキーワードとメタデータであるテキストを視覚的に魅力的な形式で表します。それらはさまざまな角度で配置され、さまざまな色とフォントサイズで表されます。これは、データ内で最も目立つ用語を見つけるのに役立ちます。目立ちやすさは、用語の頻度、タグの一意性、または特定の用語に付けられた重みなどの1つ以上の要因によって決定できます。以下に、タグクラウドを作成する手順を示します。
視覚化する
Kibanaのホーム画面には、Elasticsearchに保存されているインデックスから視覚化と集計を作成できるオプション名Visualizeがあります。新しいビジュアライゼーションを追加し、以下に示すオプションとしてタグクラウドを選択します-
指標を選択する
次の画面では、タグクラウドの作成に使用するメトリックを選択するように求められます。ここでは、集計メトリックのタイプとしてカウントを選択します。次に、タグとして使用するキーワードとしてproductnameフィールドを選択します。
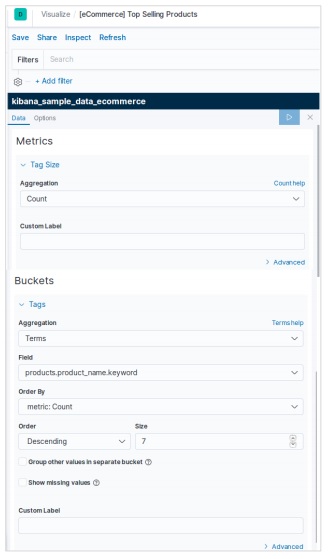
ここに示す結果は、選択を適用した後の円グラフを示しています。ラベルに記載されている色合いとその値に注意してください。

タグクラウドオプション
に移動すると optionsタグクラウドの下のタブには、タグクラウドのデータ表示の外観と配置を変更するためのさまざまな構成オプションが表示されます。以下の例では、タグクラウドが表示され、タグが水平方向と垂直方向の両方に広がっています。
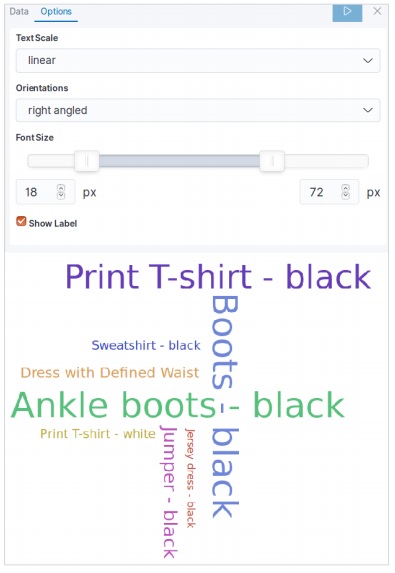
ヒートマップは、さまざまな色合いがグラフのさまざまな領域を表す視覚化の一種です。値は連続的に変化する可能性があるため、色の色rの色合いは値とともに変化します。これらは、連続的に変化するデータと離散データの両方を表すのに非常に役立ちます。
この章では、sample_data_flightsという名前のデータセットを使用してヒートマップチャートを作成します。その中で、フライトの出発国と目的国という名前の変数を考慮し、カウントします。
Kibanaのホーム画面には、Elasticsearchに保存されているインデックスから視覚化と集計を作成できるオプション名Visualizeがあります。新しいビジュアライゼーションを追加し、以下に示すオプションとしてヒートマップを選択します&mimus;
指標を選択する
次の画面では、ヒートマップチャートの作成に使用するメトリックを選択するように求められます。ここでは、集計メトリックのタイプとしてカウントを選択します。次に、Y軸のバケットについて、OriginCountryフィールドの集計として[用語]を選択します。X軸には、使用するフィールドとして同じ集計を選択しますが、DestCountryを選択します。どちらの場合も、バケットのサイズを5として選択します。

上記の構成を実行すると、次のようにヒートマップチャートが生成されます。
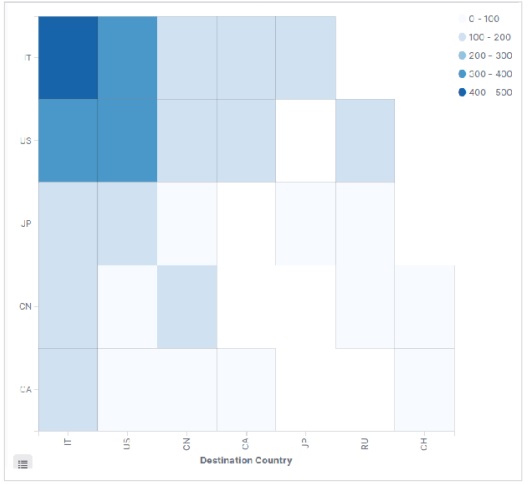
Note −グラフが1年間のデータを収集して効果的なヒートマップチャートを作成できるように、日付範囲を今年として許可する必要があります。
CanvasアプリケーションはKibanaの一部であり、動的で複数ページのピクセルパーフェクトなデータ表示を作成できます。チャートやメトリックだけでなく、インフォグラフィックを作成する機能が、ユニークで魅力的なものになっています。この章では、キャンバスのさまざまな機能と、キャンバスのワークパッドの使用方法について説明します。
キャンバスを開く
Kibanaホームページに移動し、下の図に示すようにオプションを選択します。それはあなたが持っているキャンバスワークパッドのリストを開きます。調査にはeコマースの収益追跡を選択します。
ワークパッドのクローン作成
クローンを作成します [eCommerce] Revenue Tracking私たちの研究で使用されるワークパッド。クローンを作成するには、このワークパッドの名前で行を強調表示してから、下の図に示すようにクローンボタンを使用します-
上記のクローンの結果として、次の名前の新しいワークパッドを取得します。 [eCommerce] Revenue Tracking – Copy 開くと、以下のインフォグラフィックが表示されます。
それは素敵な写真やチャートと一緒にカテゴリごとの総売上高と収益を説明します。
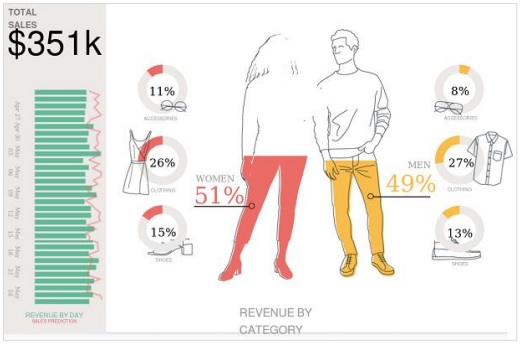
ワークパッドの変更
右側のタブにあるオプションを使用して、ワークパッドのスタイルと図を変更できます。ここでは、下の図に示すように別の色を選択して、ワークパッドの背景色を変更することを目指しています。色の選択はすぐに有効になり、次のような結果が得られます-

Kibanaは、さまざまなソースからのログデータの視覚化にも役立ちます。ログは、インフラストラクチャの状態、パフォーマンスのニーズ、セキュリティ違反の分析などの重要な分析ソースです。Kibanaは、Webサーバーログ、elasticsearchログ、クラウドウォッチログなどのさまざまなログに接続できます。
Logstashログ
Kibanaでは、logstashログに接続して視覚化できます。まず、以下に示すように、Kibanaホーム画面から[ログ]ボタンを選択します-
次に、[ソース構成の変更]オプションを選択します。これにより、ソースとしてLogstashを選択するオプションが表示されます。以下の画面には、ログソースとして使用できる他のタイプのオプションも表示されます。
ライブログテーリング用にデータをストリーミングしたり、ストリーミングを一時停止して履歴ログデータに集中したりできます。ログをストリーミングしている場合、最新のログがコンソールの下部に表示されます。
詳細については、Logstashチュートリアルを参照してください。