ETLテスト-クイックガイド
データウェアハウスシステムのデータは、ETL(抽出、変換、読み込み)ツールで読み込まれます。名前が示すように、次の3つの操作を実行します-
Oracle、Microsoft、またはその他のリレーショナルデータベースであるトランザクションシステムからデータを抽出します。
データクレンジング操作を実行してデータを変換してから、
データをOLAPデータウェアハウスにロードします。
ETLツールを使用してスプレッドシートやCSVファイルなどのフラットファイルからデータを抽出し、データ分析とレポートのためにOLAPデータウェアハウスにロードすることもできます。それをよりよく理解するために例を見てみましょう。
例
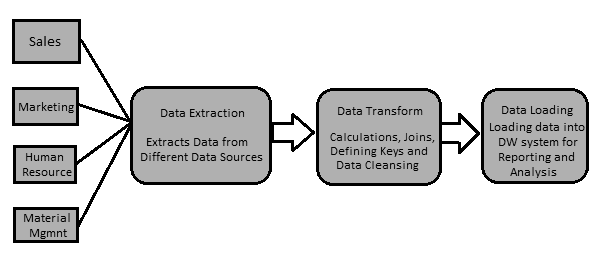
営業、人事、資材管理、EWMなどの複数の部門を持つ製造会社があるとします。これらの部門はすべて、作業に関する情報を維持するために使用する個別のデータベースを持ち、各データベースには異なるテクノロジー、ランドスケープ、テーブルがあります名前、列など。企業が履歴データを分析してレポートを生成する場合は、これらのデータソースからすべてのデータを抽出してデータウェアハウスにロードし、分析作業のために保存する必要があります。
ETLツールは、これらすべての異種データソースからデータを抽出し、データを変換して(計算の適用、フィールド、キーの結合、誤ったデータフィールドの削除など)、データウェアハウスにロードします。後で、さまざまなビジネスインテリジェンス(BI)ツールを使用して、このデータを使用して意味のあるレポート、ダッシュボード、および視覚化を生成できます。
ETLツールとBIツールの違い
ETLツールは、さまざまなデータソースからデータを抽出し、データを変換して、DWシステムにロードするために使用されます。ただし、BIツールを使用して、エンドユーザー向けのインタラクティブなアドホックレポート、上級管理職向けのダッシュボード、月次、四半期、および年次の取締役会のデータ視覚化を生成します。
最も一般的なETLツールには次のものがあります-SAPBO Data Services(BODS)、Informatica – Power Center、Microsoft – SSIS、Oracle Data Integrator ODI、Talend Open Studio、CloverETLオープンソースなど。
人気のあるBIツールには、SAP Business Objects、SAP Lumira、IBM Cognos、JasperSoft、Microsoft BI Platform、Tableau、Oracle Business Intelligence EnterpriseEditionなどがあります。
ETLプロセス
ここで、ETL手順に含まれる主要な手順についてもう少し詳しく説明します。
データの抽出
これには、さまざまな異種データソースからデータを抽出することが含まれます。トランザクションシステムからのデータ抽出は、要件と使用中のETLツールによって異なります。これは通常、夜間や週末にジョブを実行するなど、営業時間外にスケジュールされたジョブを実行することによって行われます。
データの変換
これには、データをDWシステムに簡単にロードできる適切な形式に変換することが含まれます。データ変換には、計算の適用、結合、およびデータの主キーと外部キーの定義が含まれます。たとえば、データベースにない総収益の%が必要な場合は、変換に%式を適用し、データをロードします。同様に、異なる列にユーザーの姓と名がある場合は、データをロードする前に連結操作を適用できます。一部のデータは変換を必要としません。そのようなデータはとして知られていますdirect move または pass through data。
データ変換には、データの修正とデータのクレンジング、誤ったデータの削除、不完全なデータ形成、およびデータエラーの修正も含まれます。また、データの整合性と、互換性のないデータをDWシステムにロードする前のフォーマットも含まれます。
DWシステムへのデータのロード
これには、分析レポートと情報のためにデータをDWシステムにロードすることが含まれます。ターゲットシステムは、単純な区切りフラットファイルまたはデータウェアハウスにすることができます。
ETLツール機能
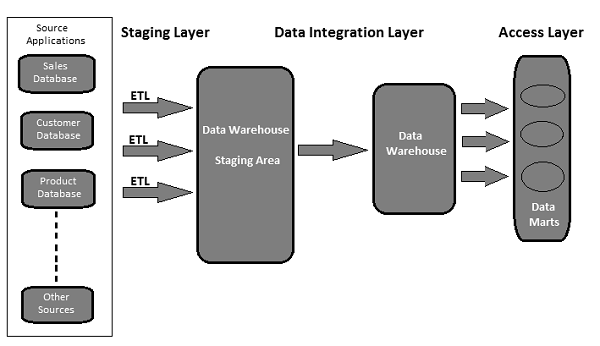
典型的なETLツールベースのデータウェアハウスは、ステージング領域、データ統合、およびアクセスレイヤーを使用してその機能を実行します。通常は3層アーキテクチャです。
Staging Layer −ステージングレイヤーまたはステージングデータベースは、さまざまなソースデータシステムから抽出されたデータを格納するために使用されます。
Data Integration Layer −統合レイヤーは、ステージングレイヤーからデータを変換し、データをデータベースに移動します。データベースでは、データは階層グループに配置されます。 dimensions、そしてに facts そして aggregate facts。DWシステムのファクトテーブルとディメンションテーブルの組み合わせは、schema。
Access Layer −アクセスレイヤーは、分析レポートおよび情報のためにデータを取得するためにエンドユーザーによって使用されます。
次の図は、3つのレイヤーがどのように相互作用するかを示しています。
ETLテストは、データが本番データウェアハウスシステムに移動される前に実行されます。と呼ばれることもありますtable balancing または production reconciliation。これは、その範囲とこれを完了するために実行する手順の点でデータベーステストとは異なります。
ETLテストの主な目的は、分析レポート用のデータを処理する前に発生するデータの欠陥と一般的なエラーを特定して軽減することです。
ETLテスト–実行するタスク
これは、ETLテストに関連する一般的なタスクのリストです-
- レポートに使用するデータを理解する
- データモデルを確認する
- ソースからターゲットへのマッピング
- ソースデータのデータチェック
- パッケージとスキーマの検証
- ターゲットシステムでのデータ検証
- データ変換の計算と集計ルールの検証
- ソースシステムとターゲットシステム間のサンプルデータの比較
- ターゲットシステムでのデータの整合性と品質チェック
- データのパフォーマンステスト
ETLテストとデータベーステストはどちらもデータ検証を伴いますが、同じではありません。ETLテストは通常、データウェアハウスシステム内のデータに対して実行されますが、データベーステストは通常、データがさまざまなアプリケーションからトランザクションデータベースに送られるトランザクションシステムで実行されます。
ここでは、ETLテストとデータベーステストの主な違いを強調しました。
ETLテスト
ETLテストには、次の操作が含まれます-
ソースシステムからターゲットシステムへのデータ移動の検証。
ソースシステムとターゲットシステムのデータ数の検証。
要件と期待に応じたデータ抽出、変換の検証。
テーブルの関係(結合とキー)が変換中に保持されているかどうかを確認します。
一般的なETLテストツールには次のものがあります QuerySurge, Informatica、など。
データベーステスト
データベーステストでは、データの正確性、データの正確性、および有効な値に重点が置かれます。以下の操作が含まれます-
主キーと外部キーが維持されているかどうかを確認します。
テーブルの列に有効なデータ値があるかどうかを確認します。
列のデータ精度を検証します。 Example −月数の列の値は12を超えてはなりません。
列に欠落しているデータを確認します。実際に有効な値を持つ必要があるnull列があるかどうかを確認してください。
一般的なデータベーステストツールには、 Selenium, QTP、など。
次の表は、データベースとETLのテストの主な機能とそれらの比較を示しています。
| 関数 | データベーステスト | ETLテスト |
|---|---|---|
| 主な目標 | データの検証と統合 | BIレポートのデータ抽出、変換、および読み込み |
| 該当するシステム | ビジネスフローが発生するトランザクションシステム | 履歴データを含み、ビジネスフロー環境にないシステム |
| 一般的なツール | QTP、Seleniumなど。 | QuerySurge、Informaticaなど。 |
| ビジネスニーズ | 複数のアプリケーションからのデータを統合するために使用され、深刻な影響を及ぼします。 | 分析レポート、情報、および予測に使用されます。 |
| モデリング | ER法 | 多次元 |
| データベースタイプ | 通常、OLTPシステムで使用されます | OLAPシステムに適用されます |
| データ・タイプ | より多くの結合を持つ正規化されたデータ | 結合が少なく、インデックスが多く、集計が多い非正規化データ。 |
ETLテストの分類は、テストとレポートの目的に基づいて行われます。テストカテゴリは組織の標準によって異なり、クライアントの要件によっても異なります。一般に、ETLテストは次の点に基づいて分類されます-
Source to Target Count Testing −ソースシステムとターゲットシステムのレコード数の照合が含まれます。
Source to Target Data Testing−ソースシステムとターゲットシステム間のデータ検証が含まれます。また、ターゲットシステムでのデータ統合としきい値チェックおよび重複データチェックも含まれます。
Data Mapping or Transformation Testing−ソースシステムとターゲットシステムのオブジェクトのマッピングを確認します。また、ターゲットシステムのデータの機能をチェックすることも含まれます。
End-User Testing−レポート内のデータが期待どおりであるかどうかを確認するために、エンドユーザー向けのレポートを生成する必要があります。これには、レポートの偏差を見つけ、レポート検証のためにターゲットシステムのデータをクロスチェックすることが含まれます。
Retesting −ターゲットシステムのデータのバグと欠陥を修正し、データ検証のためにレポートを再実行する必要があります。
System Integration Testing−個々のシステムをすべてテストし、後で結果を組み合わせて、逸脱があるかどうかを確認します。これを実行するために使用できるアプローチには、トップダウン、ボトムアップ、およびハイブリッドの3つがあります。
データウェアハウスシステムの構造に基づいて、ETLテスト(使用するツールに関係なく)は次のカテゴリに分類できます-
新しいDWシステムテスト
このタイプのテストでは、新しいDWシステムが構築および検証されています。データ入力は顧客/エンドユーザーから、またさまざまなデータソースから取得され、新しいデータウェアハウスが作成されます。その後、データはETLツールを使用して新しいシステムで検証されます。
移行テスト
移行テストでは、お客様は既存のデータウェアハウスとETLを使用していますが、効率を向上させるための新しいETLツールを探しています。これには、新しいETLツールを使用した既存のシステムからのデータの移行が含まれます。
変更テスト
変更テストでは、新しいデータがさまざまなデータソースから既存のシステムに追加されます。お客様は、ETLの既存のルールを変更したり、新しいルールを追加したりすることもできます。
レポートテスト
レポートテストには、データ検証用のレポートの作成が含まれます。レポートは、DWシステムの最終出力です。レポートは、レイアウト、レポート内のデータ、および計算値に基づいてテストされます。
ETLテストは、データベーステストやその他の従来のテストとは異なります。ETLテストの実行中に、さまざまなタイプの課題に直面する必要がある場合があります。ここにいくつかの一般的な課題をリストしました-
ETLプロセス中のデータ損失。
データが正しくない、不完全である、または重複している。
DWシステムには履歴データが含まれているため、データ量が多すぎて非常に複雑であるため、ターゲットシステムでETLテストを実行できません。
ETLテスターには通常、ETLツールでジョブスケジュールを表示するためのアクセス権が提供されていません。レポートやレポート内のデータの最終的なレイアウトを確認するためのBIレポートツールにアクセスすることはほとんどできません。
データ量が多すぎて複雑なため、テストケースの生成と構築が困難です。
ETLテスターは通常、エンドユーザーレポートの要件と情報のビジネスフローについての知識を持っていません。
ETLテストには、ターゲットシステムでのデータ検証のためのさまざまな複雑なSQLの概念が含まれます。
テスターにソースからターゲットへのマッピング情報が提供されない場合があります。
不安定なテスト環境は、プロセスの開発とテストを遅らせます。
ETLテスターは、主に、データソースの検証、データの抽出、変換ロジックの適用、およびターゲットテーブルへのデータの読み込みを担当します。
ETLテスターの主な責任は以下のとおりです。
ソースシステムのテーブルを確認する
以下の操作が含まれます-
- カウントチェック
- レコードをソースデータと照合する
- データ型チェック
- スパムデータがロードされていないことを確認します
- 重複データを削除する
- すべてのキーが所定の位置にあることを確認してください
変換ロジックを適用する
変換ロジックは、データをロードする前に適用されます。以下の操作が含まれます-
データしきい値検証チェック。たとえば、年齢値は100を超えてはなりません。
変換ロジックが適用される前後のレコード数チェック。
ステージング領域から中間テーブルへのデータフローの検証。
代理キーチェック。
データの読み込み
データはステージング領域からターゲットシステムにロードされます。以下の操作が含まれます-
中間テーブルからターゲットシステムへのカウントチェックを記録します。
キーフィールドデータが欠落していないか、Nullでないことを確認してください。
集計値と計算されたメジャーがファクトテーブルにロードされているかどうかを確認します。
ターゲットテーブルに基づいてモデリングビューを確認します。
CDCが増分負荷テーブルに適用されているかどうかを確認します。
ディメンションテーブルのデータチェックと履歴テーブルのチェック。
ロードされたファクトとディメンションテーブルに基づいて、期待される結果に従ってBIレポートを確認します。
ETLツールのテスト
ETLテスターは、ツールとテストケースもテストする必要があります。以下の操作が含まれます-
- ETLツールとその機能をテストする
- ETLデータウェアハウスシステムをテストする
- テスト計画とテストケースを作成、設計、および実行します。
- フラットファイルのデータ転送をテストします。
テストプロセスを開始する前に、正しいETLテスト手法を定義することが重要です。すべての利害関係者からの承認を得て、ETLテストを実行するために正しい手法が選択されていることを確認する必要があります。この手法はテストチームによく知られており、テストプロセスに含まれる手順を知っている必要があります。
使用できるテスト手法にはさまざまな種類があります。この章では、テスト手法について簡単に説明します。
生産検証テスト
分析レポートと分析を実行するには、本番環境のデータが正しい必要があります。このテストは、実動システムに移動されたデータに対して実行されます。これには、本番システムでのデータ検証と、それをソースデータと比較することが含まれます。
ソースからターゲットへのカウントテスト
このタイプのテストは、テスターがテスト操作を実行する時間が少ないときに実行されます。これには、ソースシステムとターゲットシステムのデータ数のチェックが含まれます。ターゲットシステムのデータの値をチェックする必要はありません。また、データのマッピング後にデータが昇順であるか降順であるかは関係ありません。
ソースからターゲットへのデータテスト
このタイプのテストでは、テスターはソースシステムからターゲットシステムまでのデータ値を検証します。変換後、ソースシステムのデータ値とターゲットシステムの対応する値をチェックします。このタイプのテストは時間がかかり、通常は金融および銀行のプロジェクトで実行されます。
データ統合/しきい値検証テスト
このタイプのテストでは、テスターがデータの範囲を検証します。ターゲットシステムのすべてのしきい値は、期待どおりの結果であるかどうかがチェックされます。また、変換およびロード後に、複数のソースシステムからターゲットシステムにデータを統合することも含まれます。
Example −年齢属性の値は100を超えてはなりません。日付列DD / MM / YYで、月フィールドの値は12を超えてはなりません。
アプリケーション移行テスト
通常、アプリケーション移行テストは、古いアプリケーションから新しいアプリケーションシステムに移行するときに自動的に実行されます。このテストにより、多くの時間を節約できます。古いアプリケーションから抽出されたデータが新しいアプリケーションシステムのデータと同じであるかどうかをチェックします。
データチェックと制約テスト
これには、データ型チェック、データ長チェック、インデックスチェックなどのさまざまなチェックの実行が含まれます。ここで、テストエンジニアは次のシナリオを実行します-主キー、外部キー、NOT NULL、NULL、およびUNIQUE。
重複データチェックテスト
このテストには、ターゲットシステム内の重複データのチェックが含まれます。ターゲットシステムに大量のデータがある場合、本番システムに重複データがあり、分析レポートのデータが正しくない可能性があります。
重複する値は、次のようなSQLステートメントで確認できます。
Select Cust_Id, Cust_NAME, Quantity, COUNT (*)
FROM Customer
GROUP BY Cust_Id, Cust_NAME, Quantity HAVING COUNT (*) >1;以下の理由により、ターゲットシステムに重複データが表示されます-
- 主キーが定義されていない場合、重複する値が発生する可能性があります。
- 不正確なマッピングまたは環境問題のため。
- ソースからターゲットシステムへのデータ転送中の手動エラー。
データ変換テスト
データ変換テストは、単一のSQLステートメントを実行することによっては実行されません。これには時間がかかり、変換ルールを検証するために行ごとに複数のSQLクエリを実行する必要があります。テスターは、各行に対してSQLクエリを実行してから、出力をターゲットデータと比較する必要があります。
データ品質テスト
データ品質テストには、番号チェック、日付チェック、ヌルチェック、精度チェックなどの実行が含まれます。テスターは実行します Syntax Test 無効な文字、誤った大文字/小文字などを報告し、 Reference Tests データがデータモデルに従っているかどうかを確認します。
インクリメンタルテスト
インクリメンタルテストは、InsertステートメントとUpdateステートメントが期待どおりに実行されたかどうかを確認するために実行されます。このテストは、新旧のデータを使用して段階的に実行されます。
回帰試験
テスターが新しいエラーを見つけるのにも役立つ新しい機能を追加するためにデータ変換および集約ルールに変更を加える場合、それは回帰テストと呼ばれます。回帰テストで発生するデータのバグは、回帰と呼ばれます。
再テスト
コードを修正してからテストを実行すると、再テストと呼ばれます。
システム統合テスト
システム統合テストでは、システムのコンポーネントを個別にテストし、後でモジュールを統合します。システム統合を行うには、トップダウン、ボトムアップ、ハイブリッドの3つの方法があります。
ナビゲーションテスト
ナビゲーションテストは、システムのフロントエンドのテストとも呼ばれます。これには、フロントエンドレポートのすべての側面をチェックすることによるエンドユーザーの視点のテストが含まれます。さまざまなフィールドのデータ、計算、集計などが含まれます。
ETLテストは、ETLライフサイクルに関連するすべてのステップをカバーします。それは、ビジネス要件を理解することから始まり、要約レポートを生成するまでです。
ETLテストのライフサイクルでの一般的な手順を以下に示します-
ビジネス要件を理解する。
ビジネス要件の検証。
テスト見積もりは、テストケースを実行し、要約レポートを完成させるための見積もり時間を提供するために使用されます。
テスト計画には、ビジネス要件に従って入力に基づいてテスト手法を見つけることが含まれます。
テストシナリオとテストケースの作成。
テストケースの準備ができて承認されたら、次のステップは実行前チェックを実行することです。
すべてのテストケースを実行します。
最後のステップは、完全な要約レポートを生成し、閉鎖プロセスを提出することです。
ETLテストシナリオは、ETLテストプロセスを検証するために使用されます。次の表は、ETLテスターによって使用される最も一般的なシナリオとテストケースのいくつかを説明しています。
| テストシナリオ | テストケース |
|---|---|
構造の検証 |
これには、マッピングドキュメントに従ってソーステーブルとターゲットテーブルの構造を検証することが含まれます。 データ型は、ソースシステムとターゲットシステムで検証する必要があります。 ソースシステムとターゲットシステムのデータ型の長さは同じである必要があります。 データフィールドタイプとその形式は、ソースシステムとターゲットシステムで同じである必要があります。 ターゲットシステムの列名を検証します。 |
マッピングドキュメントの検証 |
これには、マッピングドキュメントを検証して、すべての情報が提供されていることを確認することが含まれます。マッピングドキュメントには、変更ログがあり、データ型、長さ、変換規則などを維持する必要があります。 |
制約を検証する |
これには、制約を検証し、それらが期待されるテーブルに適用されていることを確認することが含まれます。 |
データの整合性チェック |
これには、外部キーのような整合性制約の誤用をチェックすることが含まれます。 属性の長さとデータ型はテーブルによって異なる場合がありますが、セマンティックレイヤーでの定義は同じです。 |
データの完全性の検証 |
これには、すべてのデータがソースシステムからターゲットシステムにロードされているかどうかのチェックが含まれます。 ソースシステムとターゲットシステムのレコード数をカウントします。 境界値分析。 主キーの一意の値を検証します。 |
データの正確性の検証 |
これには、ターゲットシステムのデータの値の検証が含まれます。 スペルミスまたは不正確なデータが表にあります。 インポート時に整合性制約を無効にすると、Null、NotUniqueデータが保存されます。 |
データ変換の検証 |
これには、入力値と期待される結果のシナリオのスプレッドシートを作成し、エンドユーザーで検証することが含まれます。 シナリオを作成して、データ内の親子関係を検証します。 データプロファイリングを使用して、各フィールドの値の範囲を比較します。 ウェアハウス内のデータ型がデータモデルに記載されているものと同じであるかどうかを検証します。 |
データ品質の検証 |
これには、番号チェック、日付チェック、精度チェック、データチェック、ヌルチェックなどの実行が含まれます。 Example −日付形式は、すべての値で同じである必要があります。 |
ヌル検証 |
これには、そのフィールドでNotNullが指定されているNull値のチェックが含まれます。 |
重複検証 |
これには、データがソースシステムの複数の列から取得されている場合に、ターゲットシステムで重複する値を検証することが含まれます。 ビジネス要件に従って重複する値がある場合は、主キーとその他の列を検証します。 |
日付検証チェック |
ETLプロセスで実行されるさまざまなアクションの日付フィールドを検証しています。 日付検証を実行するための一般的なテストケース-
|
完全なデータ検証マイナスクエリ |
これには、マイナスクエリを使用してソーステーブルとターゲットテーブルの完全なデータセットを検証することが含まれます。
|
その他のテストシナリオ |
他のテストシナリオは、抽出プロセスがソースシステムから重複データを抽出しなかったことを確認することです。 テストチームは、ソースシステムから重複データが抽出されていないことを検証するために実行されるSQLステートメントのリストを維持します。 |
データクリーニング |
データをステージング領域にロードする前に、不要なデータを削除する必要があります。 |
ETLパフォーマンスチューニングは、ETLシステムが複数のユーザーとトランザクションの予想される負荷を処理できるかどうかを確認するために使用されます。パフォーマンスチューニングには通常、ETLシステムのサーバー側のワークロードが含まれます。マルチユーザー環境でサーバーの応答をテストし、ボトルネックを見つけるために使用されます。これらは、ソースシステムとターゲットシステム、システムのマッピング、セッション管理プロパティなどの構成にあります。
ETLテストのパフォーマンスチューニングを実行する方法は?
以下の手順に従って、ETLテストのパフォーマンス調整を実行します-
Step 1 −本番環境で変換されている負荷を見つけます。
Step 2 −同じ負荷の新しいデータを作成するか、本番データからローカルパフォーマンスサーバーに移動します。
Step 3 −必要な負荷が生成されるまで、ETLを無効にします。
Step 4 −データベースのテーブルから必要なデータの数を取得します。
Step 5− ETLの最後の実行を書き留め、ETLを有効にして、作成された負荷全体を変換するのに十分なストレスがかかるようにします。それを実行します
Step 6 − ETLの実行が完了したら、作成されたデータの数を取得します。
主要業績評価指標
- 負荷の変換にかかった合計時間を調べます。
- パフォーマンス時間が改善されたか低下したかを調べます。
- 予想される負荷全体が抽出され、転送されたことを確認します。
ETLテストの目標は、信頼できるデータを実現することです。データの信頼性は、テストサイクルをより効果的にすることで達成できます。
包括的なテスト戦略は、効果的なテストサイクルの設定です。テスト戦略は、データが移動するたびに、ETLプロセスの各段階のテスト計画をカバーし、ビジネスアナリスト、インフラストラクチャチーム、QAチーム、DBA、開発者、ビジネスユーザーなどの各利害関係者の責任を述べる必要があります。
すべての側面からテストの準備を確実にするために、テスト戦略が焦点を当てるべき重要な領域は次のとおりです。
テストの範囲-使用するテスト手法とタイプを説明します。
テスト環境のセットアップ。
テストデータの可用性-すべての/重要なビジネス要件をカバーするデータのような本番環境を用意することをお勧めします。
データ品質とパフォーマンスの受け入れ基準。
ETLテストでは、データの精度を使用して、データが期待どおりにターゲットシステムに正確にロードされているかどうかを確認します。データ精度を実行するための重要な手順は次のとおりです。
値の比較
値の比較では、ソースシステムとターゲットシステムのデータを、変換を最小限に抑えて、または変換せずに比較します。これは、Informaticaのソース修飾子変換などのさまざまなETLテストツールを使用して実行できます。
一部の発現変換は、データ精度テストでも実行できます。SQLステートメントでさまざまな集合演算子を使用して、ソースシステムとターゲットシステムのデータの精度を確認できます。一般的な演算子は、マイナス演算子と交差演算子です。これらの演算子の結果は、ターゲットシステムとソースシステムの値の偏差と見なすことができます。
重要なデータ列を確認する
重要なデータ列は、ソースシステムとターゲットシステムの個別の値を比較することで確認できます。重要なデータ列をチェックするために使用できるサンプルクエリを次に示します-
SELECT cust_name, Order_Id, city, count(*) FROM customer
GROUP BY cust_name, Order_Id, city;メタデータの確認には、マッピングドキュメントを使用したソーステーブル構造とターゲットテーブル構造の検証が含まれます。マッピングドキュメントには、ソース列とターゲット列、データ変換ルールとデータ型、ソースシステムとターゲットシステムのテーブルの構造を定義するすべてのフィールドの詳細が含まれています。
データ長チェック
ターゲット列のデータ型の長さは、ソース列のデータ型以上である必要があります。例を見てみましょう。ソーステーブルに名と姓があり、それぞれのデータ長が50文字として定義されているとします。その場合、ターゲットシステムのフルネーム列のターゲットデータ長は100以上である必要があります。
データ型チェック
データ型のチェックには、ソースとターゲットのデータ型を検証し、それらが同じであることを確認することが含まれます。変換後、ターゲットデータ型がソースデータと異なる可能性があります。したがって、変換規則も確認する必要があります。
制約/インデックスチェック
制約チェックには、設計仕様書に従ってインデックス値と制約を検証することが含まれます。Null値を持つことができないすべての列には、NotNull制約が必要です。主キーの列には、設計ドキュメントに従ってインデックスが付けられます。
データ変換の実行は、単一のSQLクエリを記述してから出力をターゲットと比較することでは達成できないため、少し複雑です。ETL Testing Data Transformationの場合、変換ルールを検証するために、行ごとに複数のSQLクエリを作成する必要がある場合があります。
まず、ソースデータがすべての変換ルールをテストするのに十分であることを確認します。データ変換のETLテストを成功させるための鍵は、変換ルールを適用するために、ソースシステムから正しく十分なサンプルデータを選択することです。
ETLテストデータ変換の主な手順は次のとおりです-
最初のステップは、入力データと期待される結果のシナリオのリストを作成し、ビジネス顧客とこれらを検証することです。これは、設計中に要件を収集するための優れたアプローチであり、テストの一部としても使用できます。
次のステップは、すべてのシナリオを含むテストデータを作成することです。ETL開発者を利用して、データセットにシナリオスプレッドシートを入力するプロセス全体を自動化し、シナリオが変更される可能性があるという理由で、汎用性とモビリティを実現します。
次に、データプロファイリングの結果を利用して、ターゲットデータとソースデータの間で各フィールドの値の範囲と送信を比較します。
代理キーなど、ETLで生成されたフィールドの正確な処理を検証します。
ウェアハウス内のデータ型の検証は、データモデルまたは設計で指定されたものと同じです。
参照整合性をテストするテーブル間にデータシナリオを作成します。
データ内の親子関係を検証します。
最後のステップは実行することです lookup transformation。ルックアップクエリは、集計なしでまっすぐであり、ソーステーブルごとに1つの値のみを返すことが期待されている必要があります。前のテストと同様に、ソース修飾子でルックアップテーブルを直接結合できます。そうでない場合は、ルックアップテーブルをソースのメインテーブルと結合するクエリを記述し、ターゲットの対応する列のデータを比較します。
ETLテスト中にデータ品質をチェックするには、ターゲットシステムにロードされているデータに対して品質チェックを実行する必要があります。以下のテストが含まれています-
番号チェック
数値の形式は、ターゲットシステム全体で同じである必要があります。たとえば、ソースシステムでは、列に番号を付ける形式は次のとおりです。x.30、ただし、ターゲットが 30、その後、プレフィックスなしでロードする必要があります x. ターゲット列番号。
日付チェック
日付形式は、ソースシステムとターゲットシステムの両方で一貫している必要があります。たとえば、すべてのレコードで同じである必要があります。標準形式はyyyy-mm-ddです。
精度チェック
精度値は、ターゲットテーブルに期待どおりに表示されるはずです。たとえば、ソーステーブルでは、値は15.2323422ですが、ターゲットテーブルでは、15.23または15のラウンドとして表示されます。
データチェック
これには、ビジネス要件に従ってデータをチェックすることが含まれます。特定の基準を満たさないレコードは除外する必要があります。
Example − date_id> = 2015およびAccount_Id!= '001'のレコードのみをターゲットテーブルにロードする必要があります。
ヌルチェック
一部の列には、そのフィールドの要件と可能な値に従ってNullが必要です。
Example −アクティブステータス列が「T」または「死亡」でない限り、終了日列はNullを表示する必要があります。
その他のチェック
From_Dateのような一般的なチェックはTo_Dateを超えてはなりません。
データの完全性のチェックは、ターゲットシステムのデータがロード後に期待どおりであることを確認するために行われます。
このために実行できる一般的なテストは次のとおりです。
集計関数(合計、最大、最小、カウント)の確認、
変換なしまたは単純な変換ありの列のソースとターゲット間のカウントと実際のデータをチェックおよび検証します。
カウント検証
ソーステーブルとターゲットテーブルのレコード数を比較します。次のクエリを書くことでそれを行うことができます-
SELECT count (1) FROM employee;
SELECT count (1) FROM emp_dim;データプロファイルの検証
これには、ソーステーブルとターゲットテーブル(ファクトまたはディメンション)のカウント、合計、最大などの集計関数のチェックが含まれます。
列データプロファイルの検証
これには、個別の値と各個別の値の行数の比較が含まれます。
SELECT city, count(*) FROM employee GROUP BY city;
SELECT city_id, count(*) FROM emp_dim GROUP BY city_id;重複データ検証
これには、ビジネス要件に従って一意である必要がある列または列の組み合わせの主キーと一意キーの検証が含まれます。次のクエリを使用して、重複データの検証を実行できます-
SELECT first_name, last_name, date_of_joining, count (1) FROM employee
GROUP BY first_name, last_name HAVING count(1)>1;システムのバックアップリカバリは、システムが障害からできるだけ早く復元され、重要なデータを失うことなくできるだけ早く操作が再開されるように計画されています。
ETLバックアップ回復テストは、データウェアハウスシステムがハードウェア、ソフトウェア、またはデータの損失を伴うネットワーク障害から正常に回復することを確認するために使用されます。
システムの可用性を最大化するには、適切なバックアップ計画を作成する必要があります。バックアップシステムは簡単に復元でき、データを失うことなく障害が発生したシステムを引き継ぐ必要があります。
ETLテストバックアップリカバリでは、アプリケーションまたはDWシステムを、ハードウェアコンポーネント、ソフトウェアクラッシュなどの極端な条件にさらします。次のステップは、リカバリプロセスが開始され、システム検証が行われ、データリカバリが達成されていることを確認することです。
ETLテストは、主にSQLスクリプトを使用して行われ、スプレッドシートにデータを収集します。ETLテストを実行するこのアプローチは、非常に時間がかかり、時間がかかり、エラーが発生しやすく、サンプルデータに対して実行されます。
手動ETLテストの技術的課題
ETLテストチームは、倉庫システム内のデータをテストするためにSQLクエリを作成し、SQLエディターを使用して手動で実行し、データをExcelスプレッドシートに入れて、手動で比較する必要があります。このプロセスは、時間がかかり、リソースを大量に消費し、非効率的です。
このプロセスを自動化するために、市場にはさまざまなツールがあります。最も一般的なETLテストツールは、QuerySurgeとInformatica DataValidationです。
QuerySurge
QuerySurgeは、ビッグデータ、データウェアハウス、およびETLプロセスをテストするために設計されたデータテストソリューションです。プロセス全体を自動化し、DevOps戦略にうまく適合させることができます。
QuerySurgeの主な機能は次のとおりです-
ユーザーがSQLを記述しなくても、テストQueryPairsをすばやく簡単に作成するためのクエリウィザードがあります。
再利用可能なクエリスニペットを備えたデザインライブラリがあります。カスタムQueryPairsを作成することもできます。
ソースファイルおよびデータストアのデータを、ターゲットのデータウェアハウスまたはビッグデータストアと比較できます。
数百万のデータの行と列を数分で比較できます。
これにより、ユーザーは、(1)すぐに、(2)任意の日付/時刻、または(3)イベントの終了後に自動的にテストを実行するようにスケジュールできます。
有益なレポートを作成したり、更新を表示したり、結果をチームに自動メールで送信したりできます。
プロセス全体を自動化するには、ETLソフトウェアがロードプロセスを完了した後、ETLツールがコマンドラインAPIを介してQuerySurgeを開始する必要があります。
QuerySurgeは自動的に無人で実行され、すべてのテストを実行してから、チームの全員に結果をメールで送信します。
QuerySurgeと同様に、Informatica Data Validationは、開発および実稼働環境でETLテストプロセスを高速化および自動化するのに役立つETLテストツールを提供します。これにより、完全で再現性があり、監査可能なテストカバレッジをより短い時間で提供できます。プログラミングスキルは必要ありません!
データウェアハウスシステムまたはBIアプリケーションをテストするには、データ中心のアプローチが必要です。ETLテストのベストプラクティスは、テストを実行するためのコストと時間を最小限に抑えるのに役立ちます。エンドユーザー向けに高品質のダッシュボードとレポートを生成するターゲットシステムにロードされるデータの品質を向上させます。
ETLテストで従うことができるいくつかのベストプラクティスをここにリストしました-
データを分析する
正しいデータモデルを設定するには、データを分析して要件を理解することが非常に重要です。要件を理解するために時間を費やし、ターゲットシステムの正しいデータモデルを用意することで、ETLの課題を減らすことができます。また、ソースシステム、データ品質を調査し、ETLモジュールの正しいデータ検証ルールを構築することも重要です。ETL戦略は、ソースシステムとターゲットシステムのデータ構造に基づいて策定する必要があります。
ソースシステムの不良データを修正する
エンドユーザーは通常、データの問題を認識していますが、それらを修正する方法がわかりません。これらのエラーを見つけて、ETLシステムに到達する前に修正することが重要です。これを解決する一般的な方法はETLの実行時ですが、ベストプラクティスは、ソースシステムのエラーを見つけて、ソースシステムレベルでエラーを修正する手順を実行することです。
互換性のあるETLツールを探す
一般的なETLのベストプラクティスの1つは、ソースシステムおよびターゲットシステムと最も互換性のあるツールを選択することです。ソースシステムとターゲットシステムのSQLスクリプトを生成するETLツールの機能により、処理時間とリソースを削減できます。これにより、環境内の最も適切な場所で変換を処理できます。
ETLジョブの監視
ETL実装中のもう1つのベストプラクティスは、ETLジョブのスケジューリング、監査、および監視であり、ロードが期待どおりに実行されることを確認します。
インクリメンタルデータを統合する
データウェアハウステーブルのサイズが大きく、ETLサイクルごとに更新できない場合があります。増分ロードにより、最後の更新以降に変更されたレコードのみがETLプロセスに取り込まれるようになり、スケーラビリティとシステムの更新にかかる時間に大きな影響を与えます。
通常、ソースシステムには、変更を簡単に識別するためのタイムスタンプや主キーがありません。このような問題は、プロジェクトの後の段階で特定された場合、非常にコストがかかる可能性があります。ETLのベストプラクティスの1つは、最初のソースシステムの調査でそのような側面をカバーすることです。この知識は、ETLチームが変更されたデータキャプチャの問題を特定し、最も適切な戦略を決定するのに役立ちます。
スケーラビリティ
提供されるETLソリューションがスケーラブルであることを確認することをお勧めします。実装時には、ETLソリューションがビジネス要件と将来の潜在的な成長に合わせてスケーラブルであることを確認する必要があります。