H2O-AutoML
AutoMLを使用するには、新しいJupyterノートブックを起動し、以下に示す手順に従います。
AutoMLのインポート
まず、次の2つのステートメントを使用して、H2OおよびAutoMLパッケージをプロジェクトにインポートします-
import h2o
from h2o.automl import H2OAutoMLH2Oを初期化する
次のステートメントを使用してh2oを初期化します-
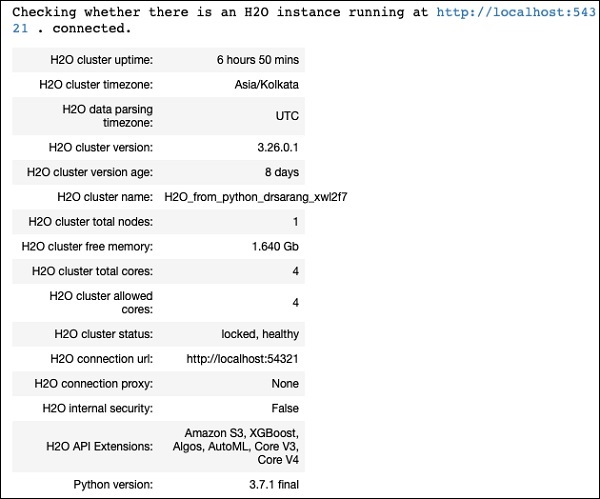
h2o.init()以下のスクリーンショットに示すように、画面にクラスター情報が表示されます。
データのロード
このチュートリアルの前半で使用したものと同じiris.csvデータセットを使用します。次のステートメントを使用してデータをロードします-
data = h2o.import_file('iris.csv')データセットの準備
特徴と予測列を決定する必要があります。以前の場合と同じ機能と予測列を使用します。次の2つのステートメントを使用して、機能と出力列を設定します-
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'トレーニングとテストのためにデータを80:20の比率で分割します-
train, test = data.split_frame(ratios=[0.8])AutoMLの適用
これで、データセットにAutoMLを適用する準備が整いました。AutoMLは、私たちが設定した一定の時間実行され、最適化されたモデルを提供します。次のステートメントを使用してAutoMLを設定します-
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)最初のパラメーターは、評価および比較するモデルの数を指定します。
2番目のパラメーターは、アルゴリズムが実行される時間を指定します。
次に示すように、AutoMLオブジェクトのtrainメソッドを呼び出します。
aml.train(x = features, y = output, training_frame = train)xを前に作成した特徴配列として指定し、yを出力変数として指定して予測値を示し、データフレームを次のように指定します。 train データセット。
コードを実行すると、次の出力が得られるまで5分間待つ必要があります(max_runtime_secsを300に設定します)。

リーダーボードの印刷
AutoML処理が完了すると、評価した30個のアルゴリズムすべてをランク付けするリーダーボードが作成されます。リーダーボードの最初の10レコードを表示するには、次のコードを使用します-
lb = aml.leaderboard
lb.head()実行時に、上記のコードは次の出力を生成します-
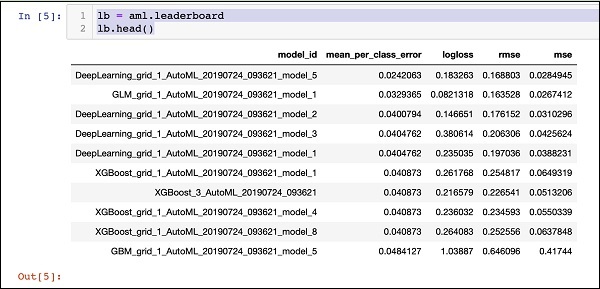
明らかに、DeepLearningアルゴリズムが最大のスコアを獲得しています。
テストデータの予測
これで、モデルがランク付けされました。テストデータでトップクラスのモデルのパフォーマンスを確認できます。これを行うには、次のコードステートメントを実行します-
preds = aml.predict(test)処理はしばらく続行され、完了すると次の出力が表示されます。

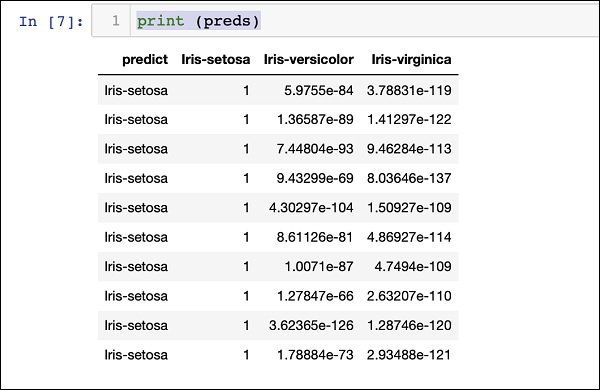
印刷結果
次のステートメントを使用して予測結果を出力します-
print (preds)上記のステートメントを実行すると、次の結果が表示されます-
すべてのランキングを印刷する
テストされたすべてのアルゴリズムのランクを確認する場合は、次のコードステートメントを実行します-
lb.head(rows = lb.nrows)上記のステートメントを実行すると、次の出力が生成されます(部分的に表示されます)-
結論
H2Oは、特定のデータセットにさまざまなMLアルゴリズムを適用するための使いやすいオープンソースプラットフォームを提供します。ディープラーニングを含むいくつかの統計アルゴリズムとMLアルゴリズムを提供します。テスト中に、これらのアルゴリズムに合わせてパラメーターを微調整できます。これは、コマンドラインまたはFlowと呼ばれる提供されているWebベースのインターフェイスを使用して行うことができます。H2Oは、パフォーマンスに基づいていくつかのアルゴリズム間のランキングを提供するAutoMLもサポートしています。H2Oはビッグデータでも優れたパフォーマンスを発揮します。これは、データサイエンティストがデータセットにさまざまな機械学習モデルを適用し、ニーズを満たすのに最適なモデルを選択するための恩恵です。