H2O-インストール
H2Oは、以下に示す5つの異なるオプションで構成および使用できます。
Pythonでインストール
Rにインストール
WebベースのフローGUI
Hadoop
アナコンダクラウド
以降のセクションでは、使用可能なオプションに基づいたH2Oのインストール手順を説明します。オプションの1つを使用する可能性があります。
Pythonでインストール
PythonでH2Oを実行するには、インストールにいくつかの依存関係が必要です。それでは、H2Oを実行するための最小限の依存関係のインストールを開始しましょう。
依存関係のインストール
依存関係をインストールするには、次のpipコマンドを実行します-
$ pip install requestsコンソールウィンドウを開き、上記のコマンドを入力して、requestsパッケージをインストールします。次のスクリーンショットは、Macマシンでの上記のコマンドの実行を示しています-
リクエストをインストールした後、以下に示すようにさらに3つのパッケージをインストールする必要があります-
$ pip install tabulate
$ pip install "colorama >= 0.3.8"
$ pip install future依存関係の最新のリストは、H2OGitHubページで入手できます。この記事の執筆時点では、次の依存関係がページにリストされています。
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2古いバージョンの削除
上記の依存関係をインストールした後、既存のH2Oインストールをすべて削除する必要があります。これを行うには、次のコマンドを実行します-
$ pip uninstall h2o最新バージョンのインストール
ここで、次のコマンドを使用して最新バージョンのH2Oをインストールしましょう-
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oインストールが正常に完了すると、画面に次のメッセージが表示されます-
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1インストールのテスト
インストールをテストするために、H2Oインストールで提供されるサンプルアプリケーションの1つを実行します。まず、次のコマンドを入力してPythonプロンプトを起動します-
$ Python3Pythonインタープリターが起動したら、Pythonコマンドプロンプトで次のPythonステートメントを入力します-
>>>import h2o上記のコマンドは、H2Oパッケージをプログラムにインポートします。次に、次のコマンドを使用してH2Oシステムを初期化します-
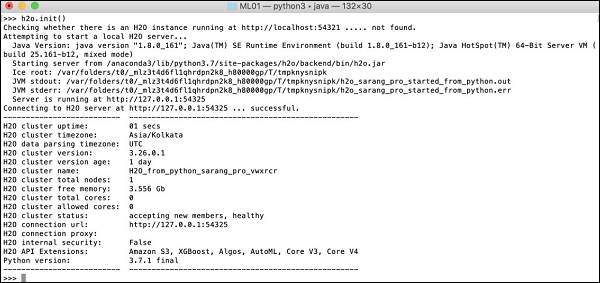
>>>h2o.init()画面にはクラスター情報が表示され、この段階では次のようになります。
これで、サンプルコードを実行する準備が整いました。Pythonプロンプトで次のコマンドを入力して実行します。
>>>h2o.demo("glm")デモは、一連のコマンドを備えたPythonノートブックで構成されています。各コマンドを実行すると、その出力がすぐに画面に表示され、次の手順に進むためにキーを押すように求められます。ノートブックの最後のステートメントを実行する際の部分的なスクリーンショットを次に示します-
この段階でPythonのインストールが完了し、独自の実験の準備が整います。
Rにインストール
R開発用のH2Oのインストールは、インストールにRプロンプトを使用することを除いて、Python用のインストールと非常によく似ています。
Rコンソールの起動
マシンのRアプリケーションアイコンをクリックして、Rコンソールを起動します。次のスクリーンショットに示すように、コンソール画面が表示されます-
H2Oのインストールは、上記のRプロンプトで実行されます。RStudioを使用する場合は、Rコンソールサブウィンドウにコマンドを入力します。
古いバージョンの削除
まず、Rプロンプトで次のコマンドを使用して古いバージョンを削除します-
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }依存関係のダウンロード
次のコードを使用してH2Oの依存関係をダウンロードします-
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}H2Oのインストール
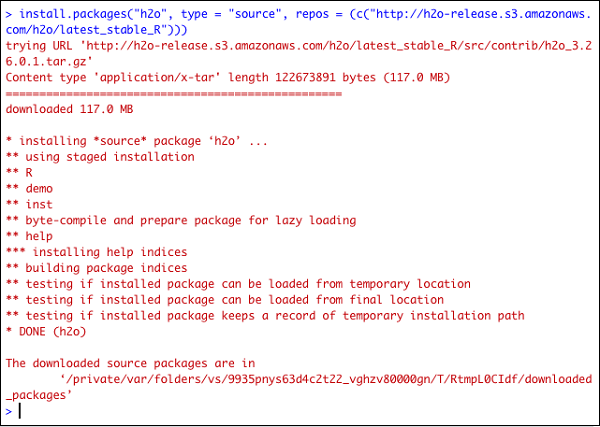
Rプロンプトで次のコマンドを入力してH2Oをインストールします-
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))次のスクリーンショットは、期待される出力を示しています-
RにH2Oをインストールする別の方法があります。
CRANからRにインストール
CRANからRをインストールするには、Rプロンプトで次のコマンドを使用します-
> install.packages("h2o")ミラーを選択するように求められます-
--- Please select a CRAN mirror for use in this session ---
ミラーサイトのリストを表示するダイアログボックスが画面に表示されます。最寄りの場所またはお好みのミラーを選択してください。
インストールのテスト
Rプロンプトで、次のコードを入力して実行します-
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)生成される出力は、次のスクリーンショットに示すようになります-
これで、RでのH2Oのインストールが完了しました。
WebGUIフローのインストール
GUIフローをインストールするには、H20サイトからインストールファイルをダウンロードします。ダウンロードしたファイルをお好みのフォルダに解凍します。インストールにh2o.jarファイルが含まれていることに注意してください。次のコマンドを使用して、コマンドウィンドウでこのファイルを実行します-
$ java -jar h2o.jarしばらくすると、コンソールウィンドウに次のように表示されます。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:フローを開始するには、指定されたURLを開きます http://localhost:54321お使いのブラウザで。次の画面が表示されます-
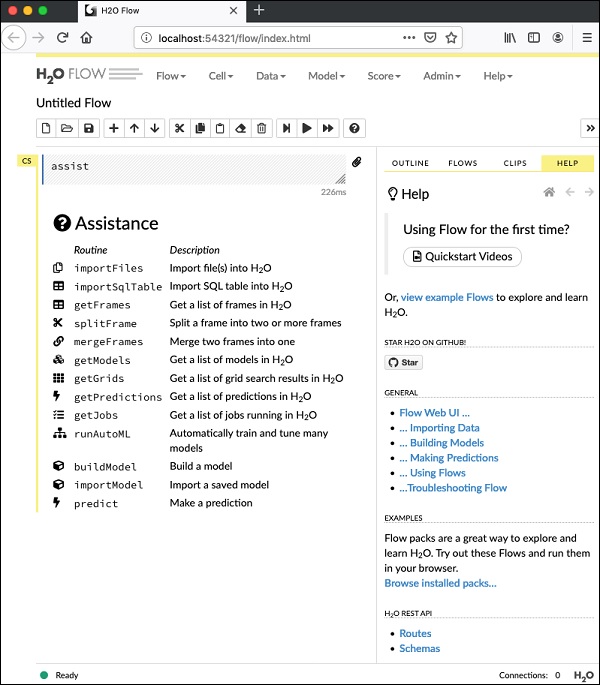
この段階で、Flowのインストールは完了です。
Hadoop / AnacondaCloudにインストールする
経験豊富な開発者でない限り、ビッグデータでH2Oを使用することは考えられません。ここで、H2Oモデルは数テラバイトの巨大なデータベースで効率的に実行されると言えば十分です。データがHadoopインストールまたはクラウドにある場合は、H2Oサイトに記載されている手順に従って、それぞれのデータベースにデータをインストールします。
マシンにH2Oを正常にインストールしてテストしたので、実際の開発の準備が整いました。まず、コマンドプロンプトからの開発を確認します。以降のレッスンでは、H2Oフローでモデルテストを行う方法を学習します。
コマンドプロンプトでの開発
ここで、H2Oを使用して、機械学習アプリケーションの開発に無料で利用できる有名なアイリスデータセットの植物を分類することを検討しましょう。
シェルウィンドウで次のコマンドを入力して、Pythonインタープリターを起動します-
$ Python3これにより、Pythonインタープリターが起動します。次のコマンドを使用してh2oプラットフォームをインポートします-
>>> import h2o分類にはランダムフォレストアルゴリズムを使用します。これは、H2ORandomForestEstimatorパッケージで提供されます。次のようにimportステートメントを使用してこのパッケージをインポートします-
>>> from h2o.estimators import H2ORandomForestEstimatorinitメソッドを呼び出してH2o環境を初期化します。
>>> h2o.init()初期化が正常に完了すると、コンソールにクラスター情報とともに次のメッセージが表示されます。
Checking whether there is an H2O instance running at http://localhost:54321 . connected.次に、H2Oでimport_fileメソッドを使用して虹彩データをインポートします。
>>> data = h2o.import_file('iris.csv')次のスクリーンショットに示すように進行状況が表示されます-

ファイルがメモリにロードされた後、ロードされたテーブルの最初の10行を表示することでこれを確認できます。あなたはhead そうする方法−
>>> data.head()次の出力が表形式で表示されます。
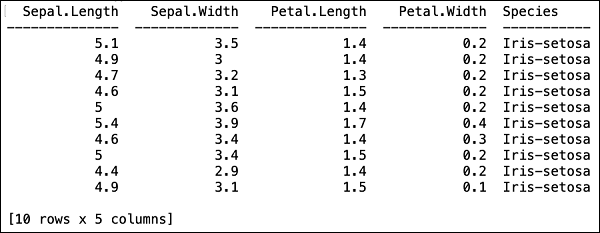
このテーブルには、列名も表示されます。最初の4つの列をMLアルゴリズムの機能として使用し、最後の列クラスを予測出力として使用します。最初に次の2つの変数を作成することにより、MLアルゴリズムの呼び出しでこれを指定します。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'次に、split_frameメソッドを呼び出して、データをトレーニングとテストに分割します。
>>> train, test = data.split_frame(ratios = [0.8])データは80:20の比率で分割されます。トレーニングには80%、テストには20%のデータを使用します。
次に、組み込みのランダムフォレストモデルをシステムにロードします。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)上記の呼び出しでは、ツリーの数を50に、ツリーの最大深度を20に、交差検定の折り畳みの数を10に設定しました。次に、モデルをトレーニングする必要があります。これを行うには、trainメソッドを次のように呼び出します。
>>> model.train(x = features, y = output, training_frame = train)trainメソッドは、最初の2つのパラメーターとして以前に作成した機能と出力を受け取ります。トレーニングデータセットはtrainに設定されています。これは、完全なデータセットの80%です。トレーニング中、ここに示すように進行状況が表示されます-
モデル構築プロセスが終了したら、モデルをテストします。これを行うには、トレーニング済みのモデルオブジェクトでmodel_performanceメソッドを呼び出します。
>>> performance = model.model_performance(test_data=test)上記のメソッド呼び出しでは、パラメーターとしてテストデータを送信しました。
モデルのパフォーマンスである出力を確認するときが来ました。これを行うには、パフォーマンスを印刷するだけです。
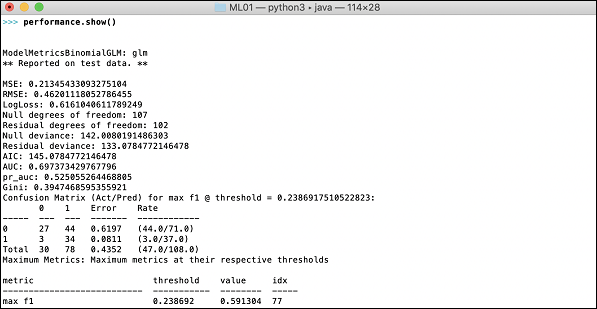
>>> print (performance)これにより、次の出力が得られます-
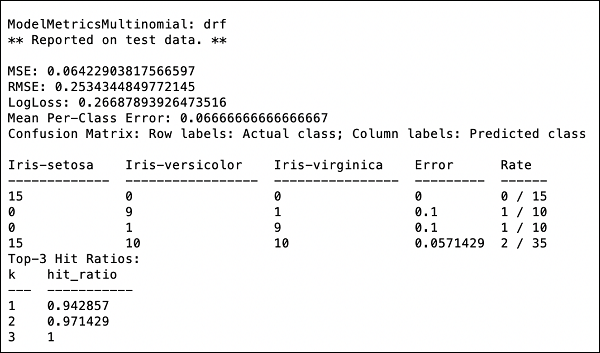
出力には、平均二乗誤差(MSE)、二乗平均平方根誤差(RMSE)、LogLoss、さらには混同行列が表示されます。
Jupyterで実行
コマンドからの実行を確認し、コードの各行の目的も理解しました。コード全体をJupyter環境で、行ごとに実行することも、プログラム全体を一度に実行することもできます。完全なリストはここにあります-
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)コードを実行し、出力を観察します。これで、データセットにランダムフォレストアルゴリズムを適用してテストすることがいかに簡単であるかを理解できます。H20のパワーは、この機能をはるかに超えています。同じデータセットで別のモデルを試して、パフォーマンスを向上できるかどうかを確認する場合はどうでしょうか。これについては、次のセクションで説明します。
別のアルゴリズムの適用
ここで、以前のデータセットに勾配ブースティングアルゴリズムを適用して、そのパフォーマンスを確認する方法を学習します。上記の完全なリストでは、以下のコードで強調表示されているように、2つの小さな変更を加えるだけで済みます-
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)コードを実行すると、次の出力が得られます-
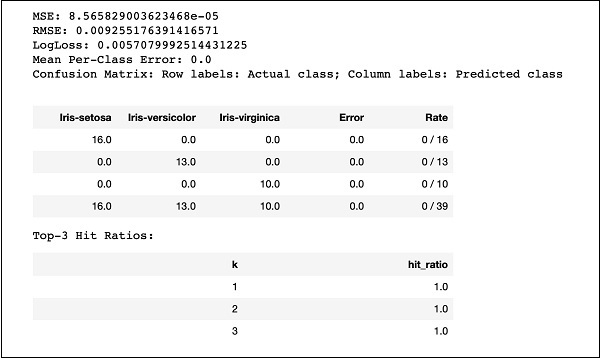
MSE、RMSE、混同行列などの結果を前の出力と比較して、実稼働展開に使用するものを決定するだけです。実際のところ、いくつかの異なるアルゴリズムを適用して、目的に合った最適なアルゴリズムを決定できます。