HBase-インストール
この章では、HBaseのインストール方法と初期構成方法について説明します。HBaseを続行するにはJavaとHadoopが必要であるため、JavaとHadoopをダウンロードしてシステムにインストールする必要があります。
インストール前のセットアップ
Linux環境にHadoopをインストールする前に、を使用してLinuxをセットアップする必要があります。 ssh(セキュアシェル)。Linux環境をセットアップするには、以下の手順に従ってください。
ユーザーの作成
まず、HadoopファイルシステムをUnixファイルシステムから分離するために、Hadoop用に別のユーザーを作成することをお勧めします。以下の手順に従って、ユーザーを作成します。
- コマンド「su」を使用してルートを開きます。
- コマンド「useraddusername」を使用して、rootアカウントからユーザーを作成します。
- これで、コマンド「suusername」を使用して既存のユーザーアカウントを開くことができます。
Linuxターミナルを開き、次のコマンドを入力してユーザーを作成します。
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSHセットアップとキー生成
起動、停止、分散デーモンシェル操作など、クラスターでさまざまな操作を実行するには、SSHセットアップが必要です。Hadoopのさまざまなユーザーを認証するには、Hadoopユーザーに公開鍵と秘密鍵のペアを提供し、それをさまざまなユーザーと共有する必要があります。
次のコマンドは、SSHを使用してキーと値のペアを生成するために使用されます。id_rsa.pubからauthorized_keysに公開鍵をコピーし、authorized_keysファイルにそれぞれ所有者、読み取り、および書き込みのアクセス許可を付与します。
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keyssshを確認する
ssh localhostJavaのインストール
JavaはHadoopとHBaseの主な前提条件です。まず、「java-version」を使用してシステム内のJavaの存在を確認する必要があります。javaversionコマンドの構文を以下に示します。
$ java -versionすべてが正常に機能する場合は、次の出力が得られます。
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)システムにJavaがインストールされていない場合は、以下の手順に従ってJavaをインストールしてください。
ステップ1
次のリンクOracleJavaにアクセスして、java(JDK <最新バージョン> -X64.tar.gz)をダウンロードします。
次に jdk-7u71-linux-x64.tar.gz システムにダウンロードされます。
ステップ2
通常、ダウンロードしたJavaファイルはDownloadsフォルダーにあります。それを確認し、抽出しますjdk-7u71-linux-x64.gz 次のコマンドを使用してファイルします。
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzステップ3
すべてのユーザーがJavaを使用できるようにするには、Javaを「/ usr / local /」の場所に移動する必要があります。rootを開き、次のコマンドを入力します。
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitステップ4
設定用 PATH そして JAVA_HOME 変数については、次のコマンドを追加してください ~/.bashrc ファイル。
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/bin次に、すべての変更を現在実行中のシステムに適用します。
$ source ~/.bashrcステップ5
次のコマンドを使用して、Javaの代替を構成します。
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jar次に、 java -version 上で説明したように端末からのコマンド。
Hadoopのダウンロード
Javaをインストールした後、Hadoopをインストールする必要があります。まず、以下に示すように、「Hadoopバージョン」コマンドを使用してHadoopの存在を確認します。
hadoop versionすべてが正常に機能する場合は、次の出力が得られます。
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarシステムがHadoopを見つけられない場合は、システムにHadoopをダウンロードしてください。これを行うには、以下のコマンドに従います。
次のコマンドを使用して、Apache SoftwareFoundationからhadoop-2.6.0をダウンロードして抽出します。
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitHadoopのインストール
必要なモードのいずれかでHadoopをインストールします。ここでは、疑似分散モードでのHBase機能を示しているため、Hadoopを疑似分散モードでインストールします。
インストールには次の手順を使用します Hadoop 2.4.1。
ステップ1-Hadoopのセットアップ
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME次に、すべての変更を現在実行中のシステムに適用します。
$ source ~/.bashrcステップ2-Hadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルを変更する必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaでHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所を含む値。
export JAVA_HOME=/usr/local/jdk1.7.0_71Hadoopを構成するには、以下のファイルを編集する必要があります。
core-site.xml
ザ・ core-site.xml fileには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>タグと</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
ザ・ hdfs-site.xml ファイルには、Hadoopインフラストラクチャを格納するローカルファイルシステムのレプリケーションデータの値、ネームノードパス、データノードパスなどの情報が含まれています。
以下のデータを想定します。
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: 上記のファイルでは、すべてのプロパティ値がユーザー定義であり、Hadoopインフラストラクチャに応じて変更を加えることができます。
yarn-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。ヤーンサイト.xmlファイルを開き、<configuration $ gt;、</ configuration $ gt;の間に次のプロパティを追加します。このファイルのタグ。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはyarn-site.xmlのテンプレートが含まれています。まず、ファイルをコピーする必要がありますmapred-site.xml.template に mapred-site.xml 次のコマンドを使用してファイルします。
$ cp mapred-site.xml.template mapred-site.xml開いた mapred-site.xml ファイルを作成し、<configuration>タグと</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoopのインストールの確認
次の手順は、Hadoopのインストールを確認するために使用されます。
ステップ1-名前ノードの設定
次のようにコマンド「hdfsnamenode-format」を使用してnamenodeを設定します。
$ cd ~
$ hdfs namenode -format期待される結果は以下のとおりです。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ステップ2-Hadoopdfsを確認する
次のコマンドは、dfsを開始するために使用されます。このコマンドを実行すると、Hadoopファイルシステムが起動します。
$ start-dfs.sh期待される出力は次のとおりです。
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ステップ3-ヤーンスクリプトの検証
次のコマンドを使用して、yarnスクリプトを開始します。このコマンドを実行すると、yarnデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです。
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outステップ4-ブラウザでHadoopにアクセスする
Hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070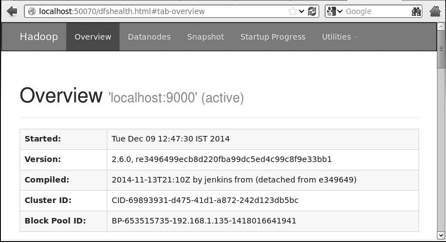
ステップ5-クラスターのすべてのアプリケーションを確認する
クラスタのすべてのアプリケーションにアクセスするためのデフォルトのポート番号は8088です。このサービスにアクセスするには、次のURLを使用してください。
http://localhost:8088/
HBaseのインストール
HBaseは、スタンドアロンモード、疑似分散モード、および完全分散モードの3つのモードのいずれかでインストールできます。
スタンドアロンモードでのHBaseのインストール
HBaseフォームの最新の安定バージョンをダウンロードします http://www.interior-dsgn.com/apache/hbase/stable/「wget」コマンドを使用し、tar「zxvf」コマンドを使用して抽出します。次のコマンドを参照してください。
$cd usr/local/
$wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz以下に示すように、スーパーユーザーモードに移行し、HBaseフォルダーを/ usr / localに移動します。
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/スタンドアロンモードでのHBaseの構成
HBaseに進む前に、次のファイルを編集してHBaseを構成する必要があります。
hbase-env.sh
HBaseのJavaホームを設定して開きます hbase-env.shconfフォルダーからのファイル。以下に示すように、JAVA_HOME環境変数を編集し、既存のパスを現在のJAVA_HOME変数に変更します。
cd /usr/local/Hbase/conf
gedit hbase-env.shこれにより、HBaseのenv.shファイルが開きます。今、既存のものを交換してくださいJAVA_HOME 以下に示すように、現在の値との値。
export JAVA_HOME=/usr/lib/jvm/java-1.7.0hbase-site.xml
これはHBaseのメイン構成ファイルです。/ usr / local / HBaseのHBaseホームフォルダーを開いて、データディレクトリを適切な場所に設定します。confフォルダー内に、いくつかのファイルがあります。hbase-site.xml 以下に示すようにファイルします。
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xml内部 hbase-site.xmlファイルには、<configuration>タグと</ configuration>タグがあります。それらの中で、以下に示すように、「hbase.rootdir」という名前のプロパティキーの下にHBaseディレクトリを設定します。
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>これで、HBaseのインストールと構成の部分が正常に完了します。を使用してHBaseを起動できますstart-hbase.shHBaseのbinフォルダーで提供されるスクリプト。そのためには、HBaseホームフォルダーを開き、以下に示すようにHBase開始スクリプトを実行します。
$cd /usr/local/HBase/bin
$./start-hbase.shすべてがうまくいけば、HBase開始スクリプトを実行しようとすると、HBaseが開始したことを示すメッセージが表示されます。
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out疑似分散モードでのHBaseのインストール
ここで、HBaseが疑似分散モードでどのようにインストールされているかを確認しましょう。
HBaseの構成
HBaseに進む前に、ローカルシステムまたはリモートシステムでHadoopとHDFSを構成し、それらが実行されていることを確認してください。HBaseが実行されている場合は、停止します。
hbase-site.xml
hbase-site.xmlファイルを編集して、次のプロパティを追加します。
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>どのモードでHBaseを実行する必要があるかについて説明します。ローカルファイルシステムの同じファイルで、hdfs://// URI構文を使用して、HDFSインスタンスアドレスであるhbase.rootdirを変更します。ローカルホストのポート8030でHDFSを実行しています。
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>HBaseの起動
構成が終了したら、HBaseホームフォルダーを参照し、次のコマンドを使用してHBaseを起動します。
$cd /usr/local/HBase
$bin/start-hbase.shNote: HBaseを起動する前に、Hadoopが実行されていることを確認してください。
HDFSでのHBaseディレクトリの確認
HBaseはHDFSにディレクトリを作成します。作成されたディレクトリを表示するには、Hadoop binを参照し、次のコマンドを入力します。
$ ./bin/hadoop fs -ls /hbaseすべてがうまくいけば、次の出力が得られます。
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsマスターの開始と停止
「local-master-backup.sh」を使用すると、最大10台のサーバーを起動できます。HBase、masterのホームフォルダーを開き、次のコマンドを実行して起動します。
$ ./bin/local-master-backup.sh 2 4バックアップマスターを強制終了するには、そのプロセスIDが必要です。これは、という名前のファイルに保存されます。 “/tmp/hbase-USER-X-master.pid.” 次のコマンドを使用して、バックアップマスターを強制終了できます。
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9RegionServerの開始と停止
次のコマンドを使用して、単一のシステムから複数のリージョンサーバーを実行できます。
$ .bin/local-regionservers.sh start 2 3リージョンサーバーを停止するには、次のコマンドを使用します。
$ .bin/local-regionservers.sh stop 3
HBaseShellを開始しています
HBaseを正常にインストールした後、HBaseシェルを起動できます。以下に、HBaseシェルを開始するために従う必要のある一連の手順を示します。ターミナルを開き、スーパーユーザーとしてログインします。
Hadoopファイルシステムを起動します
以下に示すように、Hadoopホームsbinフォルダーを参照し、Hadoopファイルシステムを起動します。
$cd $HADOOP_HOME/sbin
$start-all.shHBaseを起動します
HBaseルートディレクトリのbinフォルダーを参照し、HBaseを起動します。
$cd /usr/local/HBase
$./bin/start-hbase.shHBaseマスターサーバーを起動します
これは同じディレクトリになります。以下のように起動します。
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)開始リージョン
以下に示すように、リージョンサーバーを起動します。
$./bin/./local-regionservers.sh start 3HBaseシェルを起動します
次のコマンドを使用して、HBaseシェルを起動できます。
$cd bin
$./hbase shellこれにより、以下に示すようにHBaseシェルプロンプトが表示されます。
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>HBaseWebインターフェース
HBaseのWebインターフェースにアクセスするには、ブラウザーに次のURLを入力します。
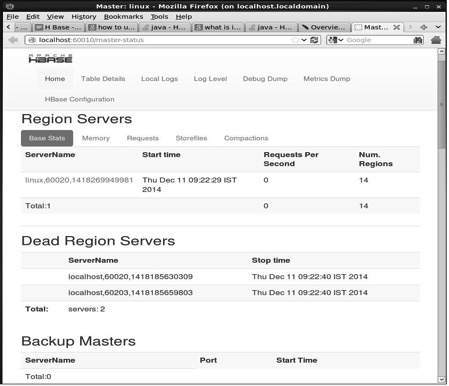
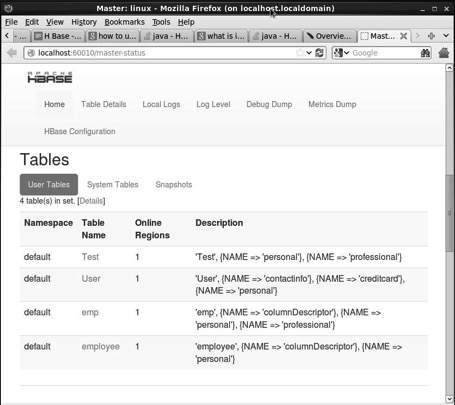
http://localhost:60010このインターフェースには、現在実行中のリージョンサーバー、バックアップマスター、およびHBaseテーブルが一覧表示されます。
HBaseリージョンサーバーとバックアップマスター
HBaseテーブル
Java環境の設定
Javaライブラリを使用してHBaseと通信することもできますが、Java APIを使用してHBaseにアクセスする前に、それらのライブラリのクラスパスを設定する必要があります。
クラスパスの設定
プログラミングを続行する前に、クラスパスをHBaseライブラリに設定します。 .bashrcファイル。開いた.bashrc 以下に示すように、いずれかのエディターで。
$ gedit ~/.bashrc以下に示すように、HBaseライブラリ(HBaseのlibフォルダー)のクラスパスを設定します。
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*これは、JavaAPIを使用してHBaseにアクセスする際の「クラスが見つかりません」という例外を防ぐためです。