HBase-概要
1970年以来、RDBMSはデータストレージとメンテナンス関連の問題のソリューションです。ビッグデータの出現後、企業はビッグデータを処理することの利点を認識し、Hadoopのようなソリューションを選択し始めました。
Hadoopはビッグデータを保存するために分散ファイルシステムを使用し、MapReduceはそれを処理します。Hadoopは、任意、半、または非構造化など、さまざまな形式の巨大なデータの保存と処理に優れています。
Hadoopの制限
Hadoopはバッチ処理のみを実行でき、データは順次にのみアクセスされます。つまり、最も単純なジョブであっても、データセット全体を検索する必要があります。
処理されたときの巨大なデータセットは、別の巨大なデータセットになります。これも順次処理する必要があります。この時点で、単一の時間単位で任意のデータポイントにアクセスするための新しいソリューションが必要です(ランダムアクセス)。
Hadoopランダムアクセスデータベース
HBase、Cassandra、couchDB、Dynamo、MongoDBなどのアプリケーションは、大量のデータを格納し、ランダムな方法でデータにアクセスするデータベースの一部です。
HBaseとは何ですか?
HBaseは、Hadoopファイルシステム上に構築された分散列指向データベースです。これはオープンソースプロジェクトであり、水平方向にスケーラブルです。
HBaseは、大量の構造化データへの迅速なランダムアクセスを提供するように設計されたGoogleの大きなテーブルに似たデータモデルです。これは、Hadoopファイルシステム(HDFS)によって提供されるフォールトトレランスを活用します。
これはHadoopエコシステムの一部であり、Hadoopファイルシステム内のデータへのランダムなリアルタイムの読み取り/書き込みアクセスを提供します。
データは、直接またはHBaseを介してHDFSに保存できます。データコンシューマーは、HBaseを使用してHDFSのデータをランダムに読み取り/アクセスします。HBaseはHadoopファイルシステムの上にあり、読み取りおよび書き込みアクセスを提供します。

HBaseとHDFS
| HDFS | HBase |
|---|---|
| HDFSは、大きなファイルを保存するのに適した分散ファイルシステムです。 | HBaseは、HDFS上に構築されたデータベースです。 |
| HDFSは、個々のレコードの高速ルックアップをサポートしていません。 | HBaseは、より大きなテーブルの高速ルックアップを提供します。 |
| 高遅延のバッチ処理を提供します。バッチ処理の概念はありません。 | 数十億のレコードからの単一行への低遅延アクセス(ランダムアクセス)を提供します。 |
| データへの順次アクセスのみを提供します。 | HBaseは内部でハッシュテーブルを使用してランダムアクセスを提供し、データをインデックス付きHDFSファイルに保存してルックアップを高速化します。 |
HBaseのストレージメカニズム
HBaseは column-oriented databaseその中のテーブルは行でソートされています。テーブルスキーマは、キーと値のペアである列ファミリーのみを定義します。テーブルには複数の列ファミリーがあり、各列ファミリーには任意の数の列を含めることができます。後続の列値は、ディスクに連続して保存されます。テーブルの各セル値にはタイムスタンプがあります。要するに、HBaseでは:
- テーブルは行のコレクションです。
- 行は列ファミリーのコレクションです。
- 列ファミリーは、列のコレクションです。
- 列は、キーと値のペアのコレクションです。
以下に、HBaseのテーブルのスキーマの例を示します。
| 乱暴な | カラムファミリー | カラムファミリー | カラムファミリー | カラムファミリー | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
列指向および行指向
列指向データベースは、データテーブルをデータの行としてではなく、データの列のセクションとして格納するデータベースです。まもなく、列ファミリが作成されます。
| 行指向データベース | 列指向データベース |
|---|---|
| オンライントランザクションプロセス(OLTP)に適しています。 | オンライン分析処理(OLAP)に適しています。 |
| このようなデータベースは、少数の行と列用に設計されています。 | 列指向データベースは、巨大なテーブル用に設計されています。 |
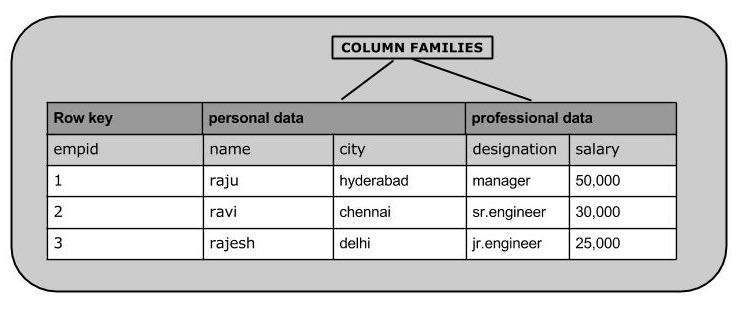
次の画像は、列指向データベースの列ファミリーを示しています。
HBaseとRDBMS
| HBase | RDBMS |
|---|---|
| HBaseはスキーマがなく、固定列スキーマの概念がありません。列ファミリーのみを定義します。 | RDBMSは、テーブルの構造全体を記述するスキーマによって管理されます。 |
| 幅の広いテーブル用に作られています。HBaseは水平方向にスケーラブルです。 | 薄くて小さなテーブル用に作られています。スケーリングが難しい。 |
| HBaseにはトランザクションはありません。 | RDBMSはトランザクションです。 |
| データが非正規化されています。 | 正規化されたデータがあります。 |
| 半構造化データと構造化データに適しています。 | 構造化データに適しています。 |
HBaseの機能
- HBaseは線形にスケーラブルです。
- 自動障害サポートがあります。
- 一貫した読み取りと書き込みを提供します。
- ソースと宛先の両方として、Hadoopと統合されます。
- クライアント用の簡単なJavaAPIがあります。
- クラスタ間でのデータレプリケーションを提供します。
HBaseを使用する場所
Apache HBaseは、ビッグデータへのランダムなリアルタイムの読み取り/書き込みアクセスを行うために使用されます。
コモディティハードウェアのクラスターの上に非常に大きなテーブルをホストします。
Apache HBaseは、GoogleのBigtableをモデルにした非リレーショナルデータベースです。BigtableはGoogleファイルシステム上で動作します。同様に、ApacheHBaseはHadoopとHDFS上で動作します。
HBaseのアプリケーション
- 重いアプリケーションを作成する必要がある場合はいつでも使用されます。
- HBaseは、利用可能なデータへの高速ランダムアクセスを提供する必要がある場合に常に使用されます。
- Facebook、Twitter、Yahoo、Adobeなどの企業はHBaseを社内で使用しています。
HBaseの履歴
| 年 | イベント |
|---|---|
| 2006年11月 | GoogleはBigTableに関する論文を発表しました。 |
| 2007年2月 | 最初のHBaseプロトタイプは、Hadoopの貢献として作成されました。 |
| 2007年10月 | Hadoop0.15.0とともに最初に使用可能なHBaseがリリースされました。 |
| 2008年1月 | HBaseはHadoopのサブプロジェクトになりました。 |
| 2008年10月 | HBase0.18.1がリリースされました。 |
| 2009年1月 | HBase0.19.0がリリースされました。 |
| 2009年9月 | HBase0.20.0がリリースされました。 |
| 2010年5月 | HBaseはApacheのトップレベルプロジェクトになりました。 |