Lucene-最初のアプリケーション
この章では、LuceneFrameworkを使用した実際のプログラミングについて学習します。Luceneフレームワークを使用して最初の例を書き始める前に、Lucene-環境セットアップチュートリアルで説明されているように、Lucene環境が適切にセットアップされていることを確認する必要があります。EclipseIDEの実用的な知識があることをお勧めします。
次に、見つかった検索結果の数を出力する簡単な検索アプリケーションを作成します。このプロセス中に作成されたインデックスのリストも表示されます。
ステップ1-Javaプロジェクトを作成する
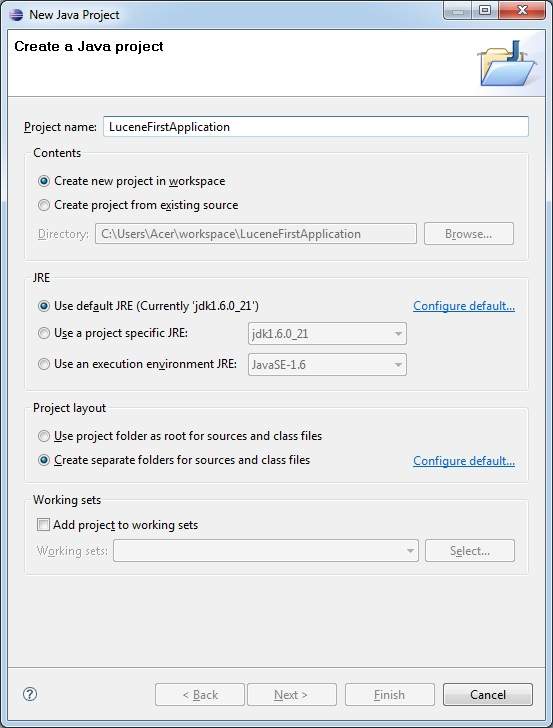
最初のステップは、EclipseIDEを使用して単純なJavaプロジェクトを作成することです。オプションに従ってくださいFile > New -> Project 最後に選択します Java Projectウィザードリストからのウィザード。プロジェクトに次の名前を付けますLuceneFirstApplication ウィザードウィンドウを次のように使用する-
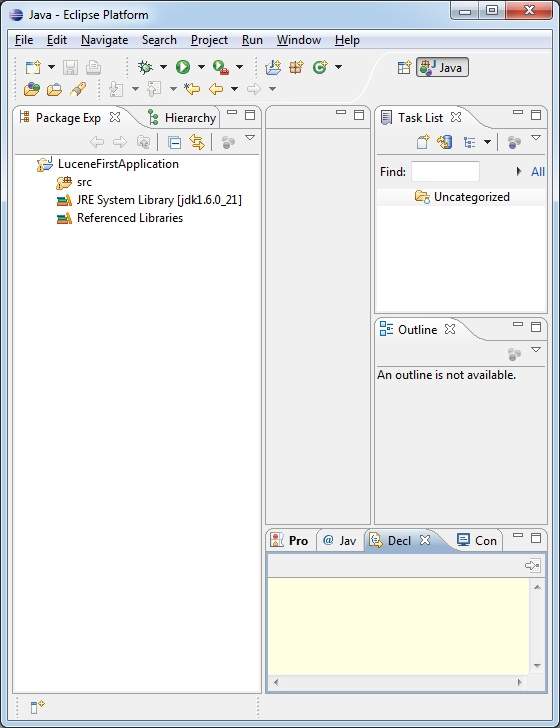
プロジェクトが正常に作成されると、次のコンテンツが作成されます。 Project Explorer −
ステップ2-必要なライブラリを追加する
Luceneコアフレームワークライブラリをプロジェクトに追加しましょう。これを行うには、プロジェクト名を右クリックしますLuceneFirstApplication 次に、コンテキストメニューで使用可能な次のオプションに従います。 Build Path -> Configure Build Path 次のようにJavaビルドパスウィンドウを表示するには-

今すぐ使用 Add External JARs 下で利用可能なボタン Libraries Luceneインストールディレクトリから次のコアJARを追加するタブ-
- lucene-core-3.6.2
ステップ3-ソースファイルを作成する
次に、実際のソースファイルを作成します。 LuceneFirstApplication事業。まず、というパッケージを作成する必要がありますcom.tutorialspoint.lucene. これを行うには、パッケージエクスプローラーセクションでsrcを右クリックし、オプションに従います。 New -> Package。
次に作成します LuceneTester.java およびその他のJavaクラス com.tutorialspoint.lucene パッケージ。
LuceneConstants.java
このクラスは、サンプルアプリケーション全体で使用されるさまざまな定数を提供するために使用されます。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
このクラスは、 .txt file フィルタ。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
このクラスは、Luceneライブラリを使用して検索できるように、生データにインデックスを付けるために使用されます。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}Searcher.java
このクラスは、インデクサーによって作成されたインデックスを検索して、要求されたコンテンツを検索するために使用されます。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
このクラスは、luceneライブラリのインデックス作成および検索機能をテストするために使用されます。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
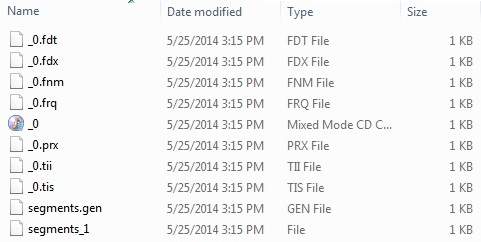
}ステップ4-データとインデックスディレクトリの作成
record1.txtからrecord10.txtまでの10個のテキストファイルを使用して、学生の名前やその他の詳細を含め、ディレクトリに配置しました。 E:\Lucene\Data。テストデータ。インデックスディレクトリパスは次のように作成する必要がありますE:\Lucene\Index。このプログラムを実行すると、そのフォルダに作成されたインデックスファイルのリストが表示されます。
ステップ5-プログラムの実行
ソース、生データ、データディレクトリ、インデックスディレクトリの作成が完了すると、プログラムをコンパイルして実行する準備が整います。これを行うには、LuceneTester.Java ファイルタブがアクティブで、いずれかを使用します Run EclipseIDEで利用可能なオプションまたは使用 Ctrl + F11 コンパイルして実行するには LuceneTester応用。アプリケーションが正常に実行されると、EclipseIDEのコンソールに次のメッセージが出力されます-
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: E:\Lucene\Data\record4.txtプログラムを正常に実行すると、次のコンテンツが含まれます。 index directory −