Lucene-インデックス作成プロセス
インデックス作成プロセスは、Luceneが提供するコア機能の1つです。次の図は、インデックス作成プロセスとクラスの使用法を示しています。IndexWriterは、インデックス作成プロセスの最も重要でコアなコンポーネントです。
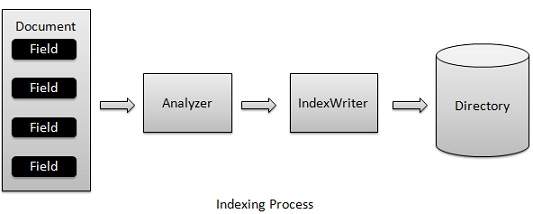
私たちは、追加資料(複数可)を含むフィールド(複数可)を使用してドキュメント(複数可)を解析IndexWriterにアナライザをして、作成/オープン/編集必要に応じてインデックスとストアが/でそれらを更新するディレクトリ。IndexWriterは、インデックスを更新または作成するために使用されます。インデックスの読み取りには使用されません。
次に、基本的な例を使用して、インデックス作成プロセスの理解を開始するためのステップバイステップのプロセスを示します。
ドキュメントを作成する
テキストファイルからluceneドキュメントを取得するメソッドを作成します。
名前としてのキーとインデックス付けされるコンテンツとしての値を含むキーと値のペアであるさまざまなタイプのフィールドを作成します。
分析するフィールドを設定します。この場合、検索操作に必要のないa、am、are、areなどのデータを含めることができるため、コンテンツのみを分析します。
新しく作成されたフィールドをドキュメントオブジェクトに追加し、呼び出し元のメソッドに返します。
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}IndexWriterを作成する
IndexWriterクラスは、インデックス作成プロセス中にインデックスを作成/更新するコアコンポーネントとして機能します。次の手順に従って、IndexWriterを作成します-
Step 1 −IndexWriterのオブジェクトを作成します。
Step 2 −インデックスが保存される場所を指すLuceneディレクトリを作成します。
Step 3 −インデックスディレクトリで作成されたIndexWriterオブジェクト、バージョン情報およびその他の必須/オプションのパラメータを持つ標準アナライザを初期化します。
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}インデックス作成プロセスを開始します
次のプログラムは、インデックス作成プロセスを開始する方法を示しています-
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}アプリケーション例
インデックス作成プロセスをテストするには、Luceneアプリケーションテストを作成する必要があります。
| ステップ | 説明 |
|---|---|
| 1 | 名前でプロジェクトを作成LuceneFirstApplicationパッケージの下com.tutorialspoint.luceneで説明したように最初のアプリケーションの章-のLuceneを。Lucene-First Applicationの章で作成されたプロジェクトをこの章で使用して、インデックス作成プロセスを理解することもできます。 |
| 2 | Lucene-最初のアプリケーションの章で説明されているように、LuceneConstants.java、TextFileFilter.java、およびIndexer.javaを作成します。残りのファイルは変更しないでください。 |
| 3 | 以下のようにLuceneTester.javaを作成します。 |
| 4 | アプリケーションをクリーンアップしてビルドし、ビジネスロジックが要件に従って機能していることを確認します。 |
LuceneConstants.java
このクラスは、サンプルアプリケーション全体で使用されるさまざまな定数を提供するために使用されます。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
このクラスは、 .txt ファイルフィルター。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
このクラスは、Luceneライブラリを使用して検索できるように、生データにインデックスを付けるために使用されます。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}LuceneTester.java
このクラスは、Luceneライブラリのインデックス作成機能をテストするために使用されます。
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}データとインデックスディレクトリの作成
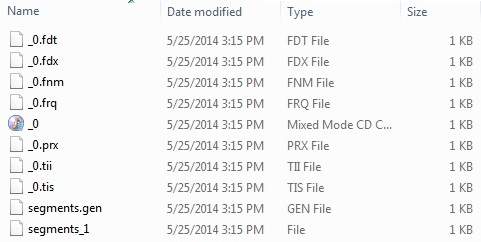
record1.txtからrecord10.txtまでの10個のテキストファイルを使用して、学生の名前やその他の詳細を含め、ディレクトリに配置しました。 E:\Lucene\Data. テストデータ。インデックスディレクトリパスは次のように作成する必要がありますE:\Lucene\Index。このプログラムを実行すると、そのフォルダに作成されたインデックスファイルのリストが表示されます。
プログラムの実行
ソース、生データ、データディレクトリ、インデックスディレクトリの作成が完了したら、プログラムをコンパイルして実行することができます。これを行うには、LuceneTester.Javaファイルタブをアクティブのままにして、次のいずれかを使用します。Run EclipseIDEで利用可能なオプションまたは使用 Ctrl + F11 コンパイルして実行するには LuceneTester応用。アプリケーションが正常に実行されると、EclipseIDEのコンソールに次のメッセージが出力されます-
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 msプログラムを正常に実行すると、次のコンテンツが含まれます。 index directory −