機械学習-教師あり
教師あり学習は、トレーニングマシンに関連する学習の重要なモデルの1つです。この章では、同じことについて詳しく説明します。
教師あり学習のアルゴリズム
教師あり学習に使用できるアルゴリズムはいくつかあります。教師あり学習で広く使用されているアルゴリズムのいくつかを以下に示します。
- k最近傍法
- デシジョンツリー
- ナイーブベイズ
- ロジスティック回帰
- サポートベクターマシン
この章を進めるにあたり、各アルゴリズムについて詳しく説明しましょう。
k最近傍法
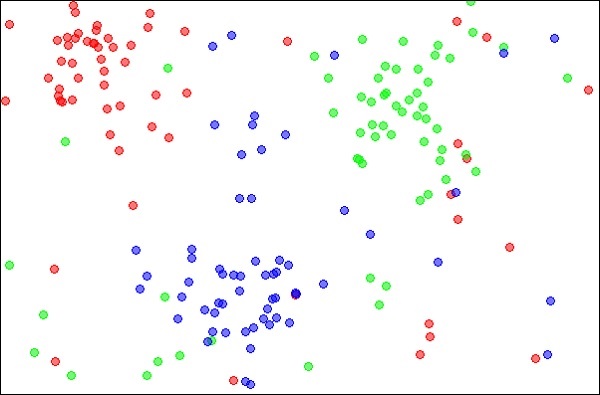
kNNと呼ばれるk最近傍法は、分類と回帰の問題を解くために使用できる統計手法です。kNNを使用して未知のオブジェクトを分類する場合について説明します。以下の画像に示すように、オブジェクトの分布を考慮してください。
ソース:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
この図は、赤、青、緑の色でマークされた3種類のオブジェクトを示しています。上記のデータセットでkNN分類器を実行すると、各タイプのオブジェクトの境界が次のようにマークされます。

ソース:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
ここで、赤、緑、または青に分類する新しい未知のオブジェクトについて考えてみます。これを下の図に示します。
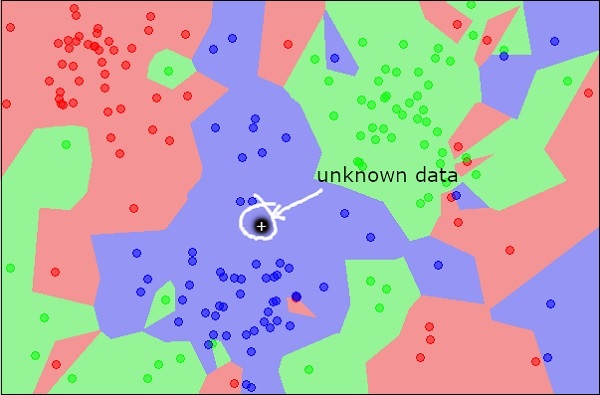
視覚的に見ると、未知のデータポイントは青いオブジェクトのクラスに属しています。数学的には、これは、この未知のポイントとデータセット内の他のすべてのポイントとの距離を測定することで結論付けることができます。そうするとき、あなたはその隣人のほとんどが青い色であることがわかるでしょう。赤と緑のオブジェクトまでの平均距離は、青のオブジェクトまでの平均距離よりも間違いなく長くなります。したがって、この未知のオブジェクトは、青のクラスに属するものとして分類できます。
kNNアルゴリズムは、回帰問題にも使用できます。kNNアルゴリズムは、ほとんどのMLライブラリですぐに使用できます。
デシジョンツリー
フローチャート形式の簡単な決定木を以下に示します-
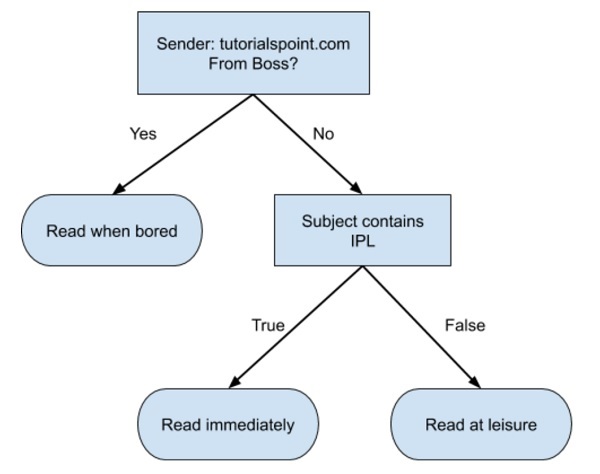
このフローチャートに基づいて入力データを分類するコードを記述します。フローチャートは自明で簡単です。このシナリオでは、受信メールを分類して、いつ読むかを決定しようとしています。
実際には、決定木は大きく複雑になる可能性があります。これらのツリーを作成およびトラバースするために使用できるアルゴリズムがいくつかあります。機械学習の愛好家として、意思決定ツリーを作成およびトラバースするこれらの手法を理解し、習得する必要があります。
ナイーブベイズ
ナイーブベイズは、分類器の作成に使用されます。フルーツバスケットからさまざまな種類の果物を分類(分類)したいとします。果物の色、サイズ、形などの機能を使用できます。たとえば、色が赤で、形が丸く、直径が約10cmの果物はすべてAppleと見なすことができます。したがって、モデルをトレーニングするには、これらの機能を使用して、特定の機能が目的の制約に一致する確率をテストします。次に、さまざまな機能の確率を組み合わせて、特定の果物がリンゴである確率に到達します。ナイーブベイズは通常、分類のために少数のトレーニングデータを必要とします。
ロジスティック回帰
次の図を見てください。XY平面でのデータポイントの分布を示しています。

この図から、赤い点と緑の点の分離を視覚的に調べることができます。これらのドットを区切るために境界線を引くことができます。ここで、新しいデータポイントを分類するには、ポイントが線のどちら側にあるかを判断する必要があります。
サポートベクターマシン
次のデータの分布を見てください。ここでは、3つのクラスのデータを線形に分離することはできません。境界曲線は非線形です。このような場合、曲線の方程式を見つけることは複雑な仕事になります。
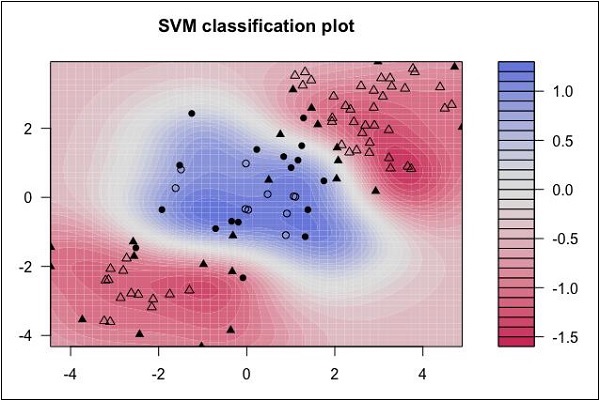
ソース: http://uc-r.github.io/svm
サポートベクターマシン(SVM)は、このような状況での分離境界の決定に役立ちます。