MuleSoft-クイックガイド
ESBは Enterprise Service Busこれは基本的に、バスのようなインフラストラクチャ上でさまざまなアプリケーションを統合するためのミドルウェアツールです。基本的に、これは統合アプリケーション間で作業を移動するための統一された手段を提供するように設計されたアーキテクチャです。このように、ESBアーキテクチャの助けを借りて、通信バスを介してさまざまなアプリケーションを接続し、相互に依存せずに通信できるようにすることができます。
ESBの実装
ESBアーキテクチャの主な焦点は、システムを相互に分離し、安定した制御可能な方法でシステムが通信できるようにすることです。ESBの実装はの助けを借りて行うことができます‘Bus’ そして ‘Adapter’ 次のように-
JMSやAMQPなどのメッセージングサーバーを介して実現される「バス」の概念は、さまざまなアプリケーションを相互に分離するために使用されます。
バックエンドアプリケーションと通信し、データをアプリケーション形式からバス形式に変換する「アダプタ」の概念は、アプリケーションとバスの間で使用されます。
バスを介して1つのアプリケーションから別のアプリケーションに渡されるデータまたはメッセージは、正規の形式です。つまり、1つの一貫したメッセージ形式が存在します。
アダプタは、セキュリティ、監視、エラー処理、メッセージルーティング管理などの他のアクティビティも実行できます。
ESBの指導原則
これらの原則をコアインテグレーションの原則と呼ぶことができます。それらは次のとおりです-
Orchestration −データとプロセス間の同期を実現するための2つ以上のサービスの統合。
Transformation −データを標準形式からアプリケーション固有の形式に変換します。
Transportation − FTP、HTTP、JMSなどのフォーマット間のプロトコルネゴシエーションの処理。
Mediation −サービスの複数のバージョンをサポートするための複数のインターフェースの提供。
Non-functional consistency −トランザクションとセキュリティを管理するためのメカニズムも提供します。
ESBの必要性
ESBアーキテクチャにより、各アプリケーションがESBを介して通信できるさまざまなアプリケーションを統合できます。以下は、ESBをいつ使用するかに関するいくつかのガイドラインです。
Integrating two or more applications − ESBアーキテクチャの使用は、2つ以上のサービスまたはアプリケーションを統合する必要がある場合に役立ちます。
Integration of more applications in future −将来、サービスやアプリケーションを追加したい場合は、ESBアーキテクチャを使用して簡単に追加できると仮定します。
Using multiple protocols − HTTP、FTP、JMSなどの複数のプロトコルを使用する必要がある場合は、ESBが適切なオプションです。
Message routing −メッセージの内容や他の同様のパラメータに基づくメッセージルーティングが必要な場合は、ESBを使用できます。
Composition and consumption − ESBは、構成と消費のためのサービスを公開する必要がある場合に使用できます。
P2P統合とESB統合
アプリケーションの数が増えるにつれ、開発者の前での大きな問題は、さまざまなアプリケーションをどのように接続するかということでした。この状況は、さまざまなアプリケーション間の接続を手動でコーディングすることで処理されました。これは呼ばれますpoint-to-point integration。
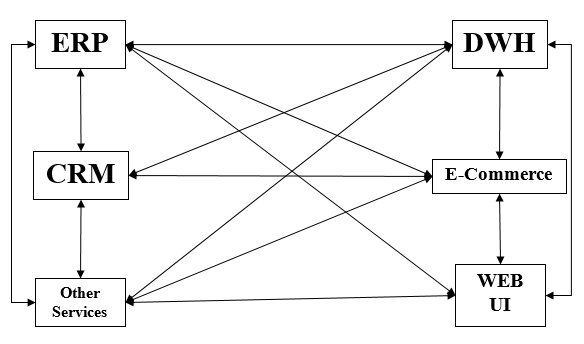
Rigidityポイントツーポイント統合の最も明らかな欠点です。接続とインターフェースの数が増えると、複雑さが増します。P-2-P統合の欠点は、ESB統合につながります。
ESBは、アプリケーション統合へのより柔軟なアプローチです。これは、各アプリケーション機能を個別の再利用可能な機能のセットとしてカプセル化して公開します。他のアプリケーションと直接統合するアプリケーションはありません。代わりに、以下に示すようにESBを介して統合します。
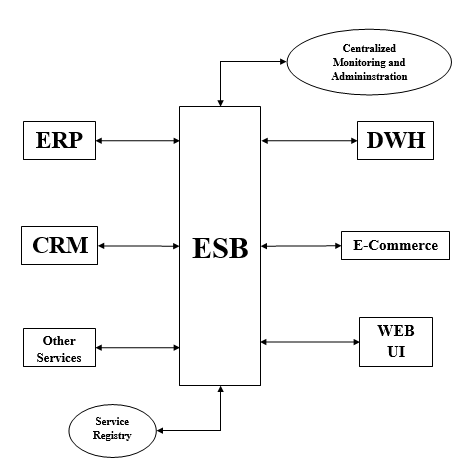
統合を管理するために、ESBには次の2つのコンポーネントがあります-
Service Registry− Mule ESBには、ESBに公開されているすべてのサービスが公開および登録されるサービスレジストリ/リポジトリがあります。これは、他のアプリケーションのサービスと機能を利用できる発見のポイントとして機能します。
Centralized Administration −名前が示すように、ESB内で発生する相互作用のパフォーマンスのトランザクションフローのビューを提供します。
ESB Functionality− VETROの略語は、通常、ESBの機能を要約するために使用されます。以下の通りです−
V(検証)-名前が示すように、スキーマ検証を検証します。検証パーサーと最新のスキーマが必要です。1つの例は、最新のスキーマを確認するXMLドキュメントです。
E(エンリッチ)-メッセージにデータを追加します。目的は、メッセージをターゲットサービスにとってより意味のある有用なものにすることです。
T(変換)-データ構造を正規形式または正規形式に変換します。例としては、日付/時刻、通貨などの変換があります。
R(ルーティング)-メッセージをルーティングし、サービスのエンドポイントのゲートキーパーとして機能します。
O(操作)-この関数の主な仕事は、ターゲットサービスを呼び出すか、ターゲットアプリと対話することです。それらはバックエンドで実行されます。
VETROパターンは、統合に全体的な柔軟性を提供し、一貫性のある検証済みのデータのみがESB全体にルーティングされるようにします。
Mule ESBとは何ですか?
Mule ESBは、MuleSoftが提供する軽量で拡張性の高いJavaベースのエンタープライズサービスバス(ESB)および統合プラットフォームです。Mule ESBを使用すると、開発者はアプリケーションを簡単かつ迅速に接続できます。アプリケーションで使用されるさまざまなテクノロジーに関係なく、Mule ESBを使用すると、アプリケーションを簡単に統合して、データを交換できます。MuleESBには次の2つのエディションがあります-
- コミュニティエディション
- Enterprise Edition
Mule ESBの利点は、両方のエディションが共通のコードベースで構築されているため、MuleESBコミュニティからMuleESBエンタープライズに簡単にアップグレードできることです。
MuleESBの特徴と機能
以下の機能はMuleESBが所有しています-
- シンプルなドラッグアンドドロップのグラフィックデザインです。
- Mule ESBは、視覚的なデータマッピングと変換が可能です。
- ユーザーは、何百もの事前に構築された認定コネクタの機能を利用できます。
- 一元化された監視と管理。
- 堅牢なエンタープライズセキュリティ施行機能を提供します。
- API管理の機能を提供します。
- クラウド/オンプレミス接続用の安全なデータゲートウェイがあります。
- ESBに公開されているすべてのサービスが公開および登録されるサービスレジストリを提供します。
- ユーザーは、Webベースの管理コンソールを介して制御できます。
- サービスフローアナライザを使用して、迅速なデバッグを実行できます。
Muleプロジェクトの背後にある動機は次のとおりです。
プログラマーにとって物事をより簡単にするために、
アプリケーションレベルのメッセージングフレームワークから企業全体の高度に分散可能なフレームワークに拡張できる軽量でモジュール式のソリューションの必要性。
Mule ESBは、イベント駆動型およびプログラム型のフレームワークとして設計されています。メッセージの統一された表現と組み合わされ、プラグ可能なモジュールで拡張できるため、イベント駆動型です。プログラマーは特定のメッセージ処理やカスタムデータ変換などの追加の動作を簡単に組み込むことができるため、これはプログラマティックです。
歴史
Muleプロジェクトの歴史的展望は次のとおりです。
SourceForgeプロジェクト
Muleプロジェクトは2003年4月にSourceForgeプロジェクトとして開始され、2年後に最初のバージョンがリリースされ、CodeHausに移行されました。ユニバーサルメッセージオブジェクト(UMO)APIは、そのアーキテクチャの中核でした。UMO APIの背後にある考え方は、基盤となるトランスポートからロジックを分離したまま、ロジックを統合することでした。
バージョン1.0
2005年4月にリリースされ、多数のトランスポートが含まれています。それに続く他の多くのバージョンの主な焦点は、デバッグと新機能の追加でした。
バージョン2.0(Spring 2の採用)
構成および配線フレームワークとしてSpring2がMule2で採用されましたが、必要なXML構成の表現力が不足しているため、大幅なオーバーホールであることが判明しました。この問題は、Spring2でXMLスキーマベースの構成が導入されたときに解決されました。
Mavenを使用した構築
開発時とデプロイ時の両方でMuleの使用を簡素化した最大の改善点は、Mavenの使用でした。バージョン1.3から、Mavenで構築され始めました。
MuleSource
2006年、MuleSourceは、「ミッションクリティカルなエンタープライズアプリケーションでMuleを使用して急速に成長するコミュニティをサポートおよび有効化するために」組み込まれました。これは、Muleプロジェクトの重要なマイルストーンであることが証明されました。
MuleESBの競合他社
以下は、MuleESBの主要な競合他社の一部です-
- WSO2 ESB
- Oracle Service Bus
- WebSphere Message Broker
- AureaCXプラットフォーム
- フィオラノESB
- WebSphere DataPower Gateway
- Workdayビジネスプロセスフレームワーク
- Talendエンタープライズサービスバス
- JBoss Enterprise Service Bus
- iWayサービスマネージャー
ミュールのコアコンセプト
説明したように、Mule ESBは、軽量で拡張性の高いJavaベースのエンタープライズサービスバス(ESB)および統合プラットフォームです。アプリケーションで使用されるさまざまなテクノロジーに関係なく、Mule ESBを使用すると、アプリケーションを簡単に統合して、データを交換できます。このセクションでは、このような統合を実現するために機能するMuleのコアコンセプトについて説明します。
このためには、そのアーキテクチャとビルディングブロックを理解する必要があります。
建築
Mule ESBのアーキテクチャには、次の図に示すように、トランスポート層、統合層、アプリケーション層の3つの層があります。
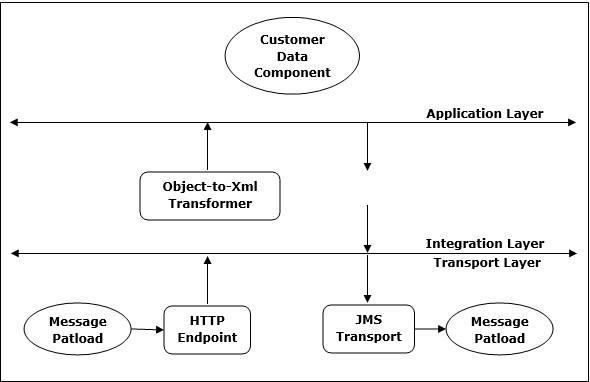
一般に、Muleデプロイメントを構成およびカスタマイズするために実行できるタスクには次の3つのタイプがあります-
サービスコンポーネントの開発
このタスクには、既存のPOJOまたはSpringBeanの開発または再利用が含まれます。POJOは、getメソッドとsetメソッド、クラウドコネクタを生成する属性を持つクラスです。一方、Spring Beansには、メッセージを充実させるためのビジネスロジックが含まれています。
サービスオーケストレーション
このタスクは基本的に、メッセージプロセッサ、ルーター、トランスフォーマー、およびフィルターの構成を含むサービスメディエーションを提供します。
統合
Mule ESBの最も重要なタスクは、使用しているプロトコルに関係なく、さまざまなアプリケーションを統合することです。この目的のために、Muleは、さまざまなプロトコルコネクタでメッセージを受信およびディスパッチできるようにするトランスポートメソッドを提供します。Muleは多くの既存の転送方法をサポートしていますが、カスタムの転送方法を使用することもできます。
ビルディングブロック
ミュール構成には次のビルディングブロックがあります-
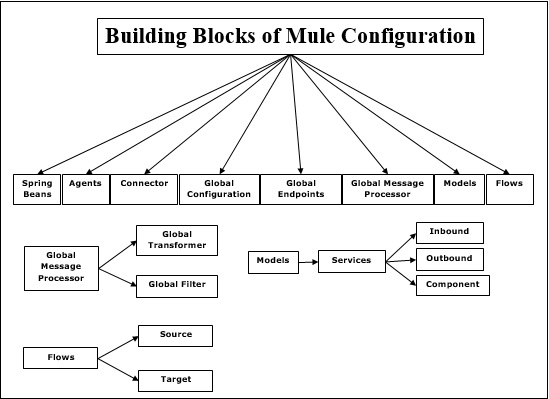
春の豆
Spring Beanの主な用途は、サービスコンポーネントを構築することです。Spring Serviceコンポーネントを構築した後、構成ファイルを介して、または構成ファイルがない場合は手動で定義できます。
エージェント
これは基本的に、MuleStudioの前にAnypointStudioで作成されたサービスです。エージェントは、サーバーを起動すると作成され、サーバーを停止すると破棄されます。
コネクタ
これは、プロトコルに固有のパラメーターで構成されたソフトウェアコンポーネントです。これは主にプロトコルの使用を制御するために使用されます。たとえば、JMSコネクタはConnection このコネクタは、実際の通信を担当するさまざまなエンティティ間で共有されます。
グローバル構成
名前が示すように、このビルディングブロックは、グローバルプロパティと設定を設定するために使用されます。
グローバルエンドポイント
フロー内で何度でも使用できる[グローバル要素]タブで使用できます-
グローバルメッセージプロセッサ
名前が示すように、メッセージまたはメッセージフローを監視または変更します。トランスフォーマーとフィルターは、グローバルメッセージプロセッサーの例です。
Transformers−トランスフォーマーの主な仕事は、データをある形式から別の形式に変換することです。グローバルに定義でき、複数のフローで使用できます。
Filters−どのMuleメッセージを処理するかを決定するのはフィルターです。フィルタは基本的に、メッセージが処理されてサービスにルーティングされるために満たす必要のある条件を指定します。
モデル
エージェントとは対照的に、これはスタジオで作成されるサービスの論理的なグループです。特定のモデル内のすべてのサービスを開始および停止する自由があります。
Services−サービスは、ビジネスロジックまたはコンポーネントをラップするサービスです。また、そのサービス専用にルーター、エンドポイント、トランスフォーマー、フィルターを構成します。
Endpoints−サービスがメッセージを受信(受信)および送信(送信)するオブジェクトとして定義できます。サービスはエンドポイントを介して接続されます。
フロー
メッセージプロセッサはフローを使用して、ソースとターゲット間のメッセージフローを定義します。
Muleメッセージの構造
Muleメッセージオブジェクトで完全にラップされたMuleメッセージは、Muleフローを介してアプリケーションを通過するデータです。構造Muleのメッセージを次の図に示します-
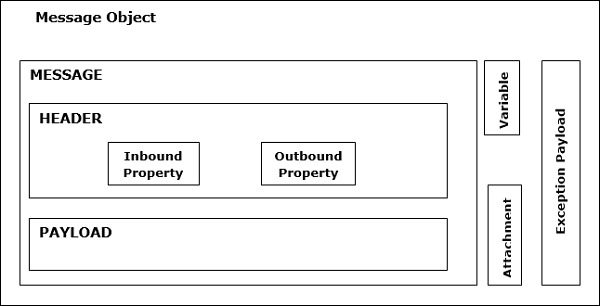
上の図に見られるように、Muleメッセージは2つの主要な部分で構成されています-
ヘッダ
これは、メッセージのメタデータに他なりません。これは、次の2つのプロパティによってさらに表されます。
Inbound Properties−これらは、メッセージソースによって自動的に設定されるプロパティです。ユーザーが操作または設定することはできません。自然界では、インバウンドプロパティは不変です。
Outbound Properties−これらは、インバウンドプロパティなどのメタデータを含むプロパティであり、フローの過程で設定できます。これらは、Muleによって自動的に設定することも、ユーザーが手動で設定することもできます。本質的に、アウトバウンドプロパティは変更可能です。
メッセージがトランスポートを介して、あるフローのアウトバウンドエンドポイントから別のフローのインバウンドエンドポイントに渡されると、アウトバウンドプロパティはインバウンドプロパティになります。
メッセージがコネクタではなくflow-refを介して新しいフローに渡される場合、アウトバウンドプロパティはアウトバウンドプロパティのままです。
ペイロード
メッセージオブジェクトによって運ばれる実際のビジネスメッセージは、ペイロードと呼ばれます。
変数
これは、メッセージに関するユーザー定義のメタデータとして定義できます。基本的に、変数は、メッセージを処理しているアプリケーションによって使用されるメッセージに関する一時的な情報です。メッセージと一緒に宛先に渡されることを意図したものではありません。以下の3種類があります−
Flow variables −これらの変数は、それらが存在するフローにのみ適用されます。
Session variables −これらの変数は、同じアプリケーション内のすべてのフローに適用されます。
Record variables −これらの変数は、バッチの一部として処理されるレコードにのみ適用されます。
添付ファイルと追加のペイロード
これらは、メッセージペイロードに関するいくつかの追加のメタデータであり、必ずしもメッセージオブジェクトに毎回表示されるとは限りません。
前の章では、MuleESBの基本を学びました。この章では、インストールと構成の方法を学びましょう。
前提条件
コンピュータにMuleをインストールする前に、次の前提条件を満たしている必要があります。
Java Development Kit(JDK)
MULEをインストールする前に、システムでサポートされているバージョンのJavaを使用していることを確認してください。システムにMuleを正常にインストールするには、JDK1.8.0をお勧めします。
オペレーティング・システム
以下のオペレーティングシステムはMuleによってサポートされています-
- MacOS 10.11.x
- HP-UX 11iV3
- AIX 7.2
- Windows 2016 Server
- Windows 2012R2サーバー
- ウィンドウズ10
- Windows 8.1
- Solaris 11.3
- RHEL 7
- Ubuntuサーバー18.04
- Linuxカーネル3.13以降
データベース
Muleランタイムはスタンドアロンサーバーとして実行されるため、アプリケーションサーバーやデータベースは必要ありません。ただし、データストアにアクセスする必要がある場合、またはアプリケーションサーバーを使用する場合は、次のサポートされているアプリケーションサーバーまたはデータベースを使用できます。
- Oracle 11g
- Oracle 12c
- MySQL 5.5+
- IBM DB2 10
- PostgreSQL 9
- ダービー10
- Microsoft SQL Server 2014
システム要求
Muleをシステムにインストールする前に、次のシステム要件を満たしている必要があります-
- 仮想化環境で少なくとも2GHzCPUまたは1つの仮想CPU
- 最小1GBのRAM
- 最小4GBのストレージ
Muleをダウンロード
Mule 4バイナリファイルをダウンロードするには、リンクをクリックしてください https://www.mulesoft.com/lp/dl/mule-esb-enterprise 次のようにMuleSoftの公式Webページに移動します-

必要な詳細を提供することにより、Zip形式のMule4バイナリファイルを取得できます。
Muleをインストールして実行する
Mule 4バイナリファイルをダウンロードした後、解凍して、という環境変数を設定します。 MULE_HOME 抽出されたフォルダ内のMuleディレクトリ用。
たとえば、WindowsおよびLinux / Unix環境の環境変数は、ダウンロードディレクトリのバージョン4.1.5に次のように設定できます。
Windows環境
$ env:MULE_HOME=C:\Downloads\mule-enterprise-standalone-4.1.5\Unix / Linux環境
$ export MULE_HOME=~/Downloads/mule-enterprise-standalone-4.1.5/ここで、Muleがシステムでエラーなしで実行されているかどうかをテストするには、次のコマンドを使用します。
Windows環境
$ $MULE_HOME\bin\mule.batUnix / Linux環境
$ $MULE_HOME/bin/mule上記のコマンドは、Muleをフォアグラウンドモードで実行します。Muleが実行されている場合、端末で他のコマンドを発行することはできません。押すctrl-c ターミナルでコマンドを実行すると、Muleが停止します。
ミュールサービスを開始する
MuleをWindowsサービスとして、またLinux / Unixデーモンとして起動することもできます。
WindowsサービスとしてのMule
MuleをWindowsサービスとして実行するには、以下の手順に従う必要があります-
Step 1 −まず、次のコマンドを使用してインストールします−
$ $MULE_HOME\bin\mule.bat installStep 2 −インストールすると、次のコマンドを使用して、muleをWindowsサービスとして実行できます。
$ $MULE_HOME\bin\mule.bat startLinux / UnixデーモンとしてのMule
MuleをLinux / Unixデーモンとして実行するには、以下の手順に従う必要があります-
Step 1 −次のコマンドを使用してインストールします−
$ $MULE_HOME/bin/mule installStep 2 −インストールすると、次のコマンドを使用して、muleをWindowsサービスとして実行できます。
$ $MULE_HOME/bin/mule startExample
次の例では、MuleをUnixデーモンとして起動します-
$ $MULE_HOME/bin/mule start
MULE_HOME is set to ~/Downloads/mule-enterprise-standalone-4.1.5
MULE_BASE is set to ~/Downloads/mule-enterprise-standalone-4.1.5
Starting Mule Enterprise Edition...
Waiting for Mule Enterprise Edition.................
running: PID:87329Muleアプリをデプロイする
次の手順でMuleアプリをデプロイできます-
Step 1 −まず、Muleを起動します。
Step 2 − Muleが起動したら、JARパッケージファイルをに移動することでMuleアプリケーションをデプロイできます。 apps のディレクトリ $MULE_HOME。
ミュールサービスを停止する
使用できます stopMuleを停止するコマンド。たとえば、次の例では、MuleをUnixデーモンとして起動します-
$ $MULE_HOME/bin/mule stop
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Stopping Mule Enterprise Edition...
Stopped Mule Enterprise Edition.使用することもできます removeMuleサービスまたはデーモンをシステムから削除するコマンド。次の例では、MuleをUnixデーモンとして削除します-
$ $MULE_HOME/bin/mule remove
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Detected Mac OSX:
Mule Enterprise Edition is not running.
Removing Mule Enterprise Edition daemon...MuleSoftのAnypointStudioはユーザーフレンドリーです IDE (integration development environment)Muleアプリケーションの設計とテストに使用されます。これはEclipseベースのIDEです。ミュールパレットからコネクタを簡単にドラッグできます。つまり、Anypoint Studioは、フローなどを開発するためのEclipseベースのIDEです。
前提条件
MuleをすべてのOS(Windows、Mac、Linux / Unix)にインストールする前に、次の前提条件を満たしている必要があります。
Java Development Kit (JDK)− Muleをインストールする前に、システムでサポートされているバージョンのJavaを使用していることを確認してください。Anypointをシステムに正常にインストールするには、JDK1.8.0をお勧めします。
AnypointStudioのダウンロードとインストール
AnypointStudioをさまざまなオペレーティングシステムにダウンロードしてインストールする手順は異なる場合があります。次に、さまざまなオペレーティングシステムにAnypointStudioをダウンロードしてインストールするために従うべき手順があります-
Windowsの場合
Anypoint StudioをWindowsにダウンロードしてインストールするには、以下の手順に従う必要があります-
Step 1 −まず、リンクをクリックします https://www.mulesoft.com/lp/dl/studio トップダウンリストからWindowsオペレーティングシステムを選択して、スタジオをダウンロードします。
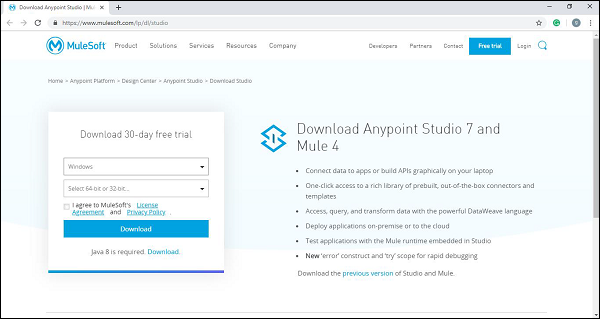
Step 2 −次に、それをに抽出します ‘C:\’ ルートフォルダ。
Step 3 −抽出したAnypointStudioを開きます。
Step 4−デフォルトのワークスペースを受け入れるには、[OK]をクリックします。初めてロードすると、ウェルカムメッセージが表示されます。
Step 5 −次に、[開始]ボタンをクリックして、AnypointStudioを使用します。
OSXの場合
AnypointStudioをOSXにダウンロードしてインストールするには、以下の手順に従う必要があります-
Step 1 −まず、リンクをクリックします https://www.mulesoft.com/lp/dl/studio スタジオをダウンロードします。
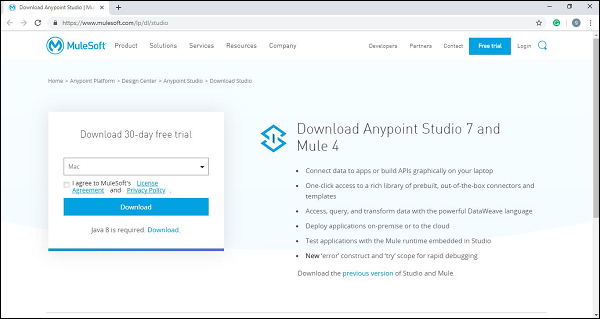
Step 2−次に、それを抽出します。OSバージョンのSierraを使用している場合は、抽出したアプリを必ずに移動してください/Applications folder それを起動する前に。
Step 3 −抽出したAnypointStudioを開きます。
Step 4−デフォルトのワークスペースを受け入れるには、[OK]をクリックします。初めてロードすると、ウェルカムメッセージが表示されます。
Step 5 −次に、をクリックします Get Started AnypointStudioを使用するためのボタン。
ワークスペースへのカスタムパスを使用する場合、Anypoint StudioはLinux / Unixシステムで使用される〜チルダを拡張しないことに注意してください。したがって、ワークスペースを定義する際には絶対パスを使用することをお勧めします。
Linuxの場合
LinuxにAnypointStudioをダウンロードしてインストールするには、以下の手順に従う必要があります。
Step 1 −まず、リンクをクリックします https://www.mulesoft.com/lp/dl/studio トップダウンリストからLinuxオペレーティングシステムを選択して、スタジオをダウンロードします。
Step 2 −次に、それを抽出します。
Step 3 −次に、抽出したAnypointStudioを開きます。
Step 4−デフォルトのワークスペースを受け入れるには、[OK]をクリックします。初めてロードすると、ウェルカムメッセージが表示されます。
Step 5 −次に、[開始]ボタンをクリックして、AnypointStudioを使用します。
ワークスペースへのカスタムパスを使用する場合、Anypoint StudioはLinux / Unixシステムで使用される〜チルダを拡張しないことに注意してください。したがって、ワークスペースを定義する際には絶対パスを使用することをお勧めします。
Linuxで完全なStudioテーマを使用するには、GTKバージョン2をインストールすることもお勧めします。
AnypointStudioの機能
以下は、Muleアプリケーションを構築しながら生産性を向上させるAnypointスタジオのいくつかの機能です-
ローカルランタイム内でMuleアプリケーションの即時実行を提供します。
Anypoint studioは、API定義ファイルとMuleドメインを構成するためのビジュアルエディターを提供します。
生産性を高めるユニットテストフレームワークが組み込まれています。
Anypoint studioは、CloudHubにデプロイするための組み込みサポートを提供します。
他のAnypointプラットフォーム組織からテンプレート、例、定義、その他のリソースをインポートするためにExchangeと統合する機能があります。
Anypoint Studioエディターは、アプリケーション、API、プロパティ、および構成ファイルの設計に役立ちます。デザインだけでなく、編集にも役立ちます。この目的のために、Mule構成ファイルエディターがあります。このエディターを開くには、でアプリケーションXMLファイルをダブルクリックします。/src/main/mule。
アプリケーションを操作するために、MuleConfigurationファイルエディターの下に次の3つのタブがあります。
[メッセージフロー]タブ
このタブは、ワークフローを視覚的に表したものです。基本的に、フローを視覚的に確認するのに役立つキャンバスが含まれています。ミュールパレットからキャンバスにイベントプロセッサを追加する場合は、ドラッグアンドドロップするだけでキャンバスに反映されます。
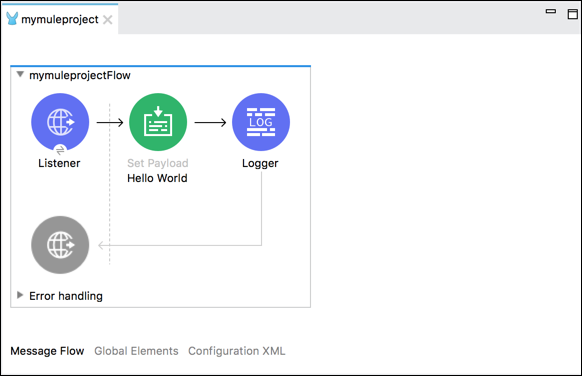
イベントプロセッサをクリックすると、選択したプロセッサの属性を含むミュールプロパティビューを取得できます。編集することもできます。
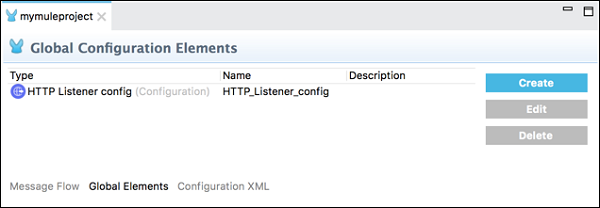
[グローバル要素]タブ
このタブには、モジュールのグローバルMule構成要素が含まれています。このタブでは、構成ファイルを作成、編集、または削除できます。
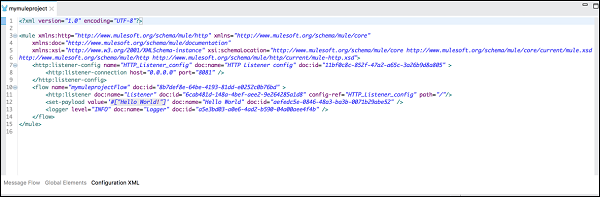
[構成XML]タブ
名前が示すように、Muleアプリケーションを定義するXMLが含まれています。ここで行うすべての変更は、キャンバスと、[メッセージフロー]タブのイベントプロセッサのプロパティビューに反映されます。
ビュー
アクティブなエディターの場合、Anypoint studioは、ビューの助けを借りて、プロジェクトのメタデータ、プロパティのグラフィック表現を提供します。ユーザーは、Muleプロジェクトでビューを移動、閉じる、および追加できます。以下は、Anypointスタジオのデフォルトビューです。
パッケージエクスプローラー
パッケージエクスプローラービューの主なタスクは、Muleプロジェクトで構成されたプロジェクトフォルダーとファイルを表示することです。Muleプロジェクトフォルダーの横にある矢印をクリックすると、フォルダーを展開または縮小できます。フォルダまたはファイルをダブルクリックすると開くことができます。そのスクリーンショットを見てください-
ミュールパレット
ミュールパレットビューには、スコープ、フィルター、フロー制御ルーターなどのイベントプロセッサーが、モジュールとそれに関連する操作とともに表示されます。ミュールパレットビューの主なタスクは次のとおりです-
- このビューは、プロジェクト内のモジュールとコネクタを管理するのに役立ちます。
- Exchangeから新しい要素を追加することもできます。
そのスクリーンショットを見てください-
ミュールのプロパティ
名前が示すように、キャンバスで現在選択されているモジュールのプロパティを編集できます。ミュールのプロパティビューには、次のものが含まれます。
ペイロードのデータ構造に関するリアルタイム情報を提供するDataSenseExplorer。
インバウンドおよびアウトバウンドのプロパティ(使用可能な場合)または変数。
以下はスクリーンショットです-
コンソール
Muleアプリケーションを作成または実行するたびに、組み込みMuleサーバーは、Studioによって報告されたイベントと問題のリストを表示します(存在する場合)。コンソールビューには、その組み込みMuleサーバーのコンソールが含まれています。そのスクリーンショットを見てください-
問題ビュー
Muleプロジェクトの作業中に、多くの問題が発生する可能性があります。これらの問題はすべて、問題ビューに表示されます。以下はスクリーンショットです

展望
Anypoint Studioでは、指定された配置のビューとエディターのコレクションです。AnypointStudioには2種類の視点があります-
Mule Design Perspective −これはStudioで取得するデフォルトのパースペクティブです。
Mule Debug Perspective − Anypoint Studioが提供するもう1つのパースペクティブは、Mule DebugPerspectiveです。
一方、独自のパースペクティブを作成して、デフォルトのビューを追加または削除することもできます。
この章では、MuleSoftのAnypointStudioで最初のMuleアプリケーションを作成します。それを作成するには、最初にAnypointStudioを起動する必要があります。
AnypointStudioの起動
AnypointStudioをクリックして起動します。初めて起動する場合は、次のウィンドウが表示されます-
AnypointStudioのユーザーインターフェイス
[ワークスペースに移動]ボタンをクリックすると、次のようにAnypointStudioのユーザーインターフェイスに移動します-
Muleアプリケーションを作成する手順
Muleアプリケーションを作成するには、以下の手順に従います-
新しいプロジェクトの作成
Muleアプリケーションを作成するための最初のステップは、新しいプロジェクトを作成することです。パスをたどることで実行できますFILE → NEW → Mule Project 以下に示すように-
プロジェクトに名前を付ける
上記のように、新しいMuleプロジェクトをクリックすると、プロジェクト名やその他の仕様を尋ねる新しいウィンドウが開きます。プロジェクトの名前を付けてください。TestAPP1'次に、[完了]ボタンをクリックします。
[完了]ボタンをクリックすると、MuleProject用に構築されたワークスペースが開きます。 ‘TestAPP1’。あなたはすべてを見ることができますEditors そして Views 前の章で説明しました。
コネクタの構成
ここでは、HTTPリスナー用の単純なMuleアプリケーションを作成します。このために、以下に示すように、HTTPリスナーコネクタをMuleパレットからドラッグしてワークスペースにドロップする必要があります-
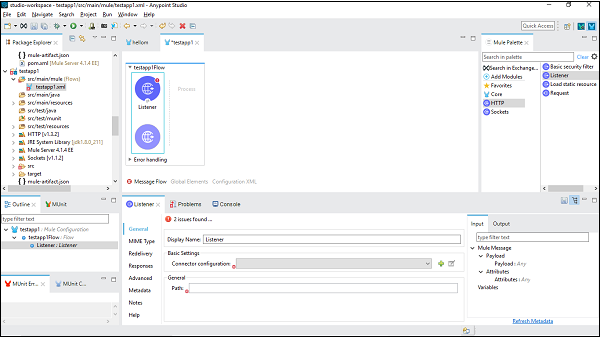
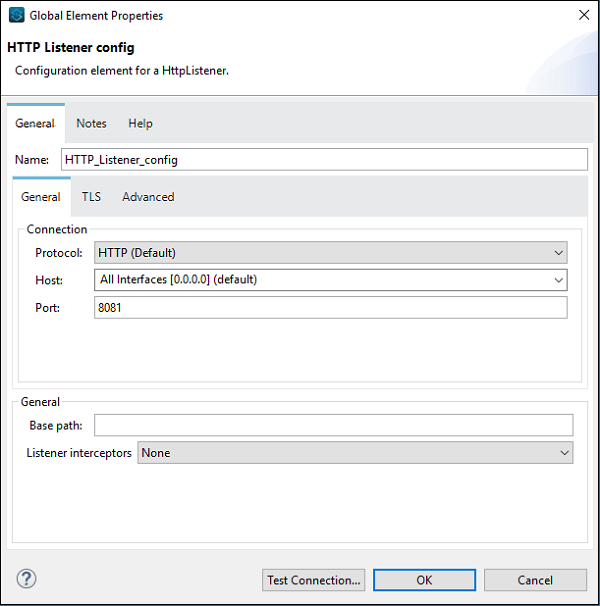
次に、構成する必要があります。上記のように、[基本設定]の[コネクタ構成]の後に緑色の+記号をクリックします。

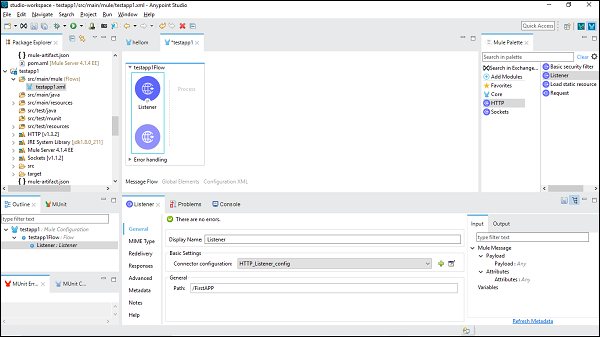
[OK]をクリックすると、HTTPリスナーのプロパティページに戻ります。次に、[全般]タブでパスを指定する必要があります。この特定の例では、/FirstAPP パス名として。
Set PayloadConnectorの構成
次に、SetPayloadコネクタを使用する必要があります。また、次のように[設定]タブでその値を指定する必要があります-
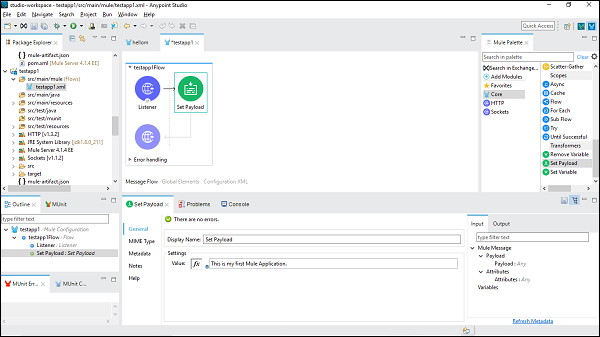
This is my first Mule Application、はこの例で提供されている名前です。
Muleアプリケーションの実行
今、それを保存してクリックします Run as Mule Application 以下に示すように-
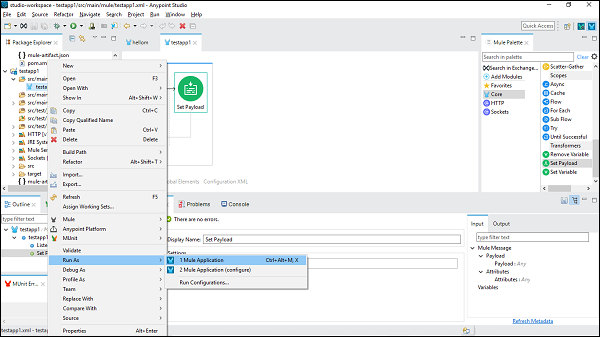
次のように、アプリケーションをデプロイするコンソールで確認できます-
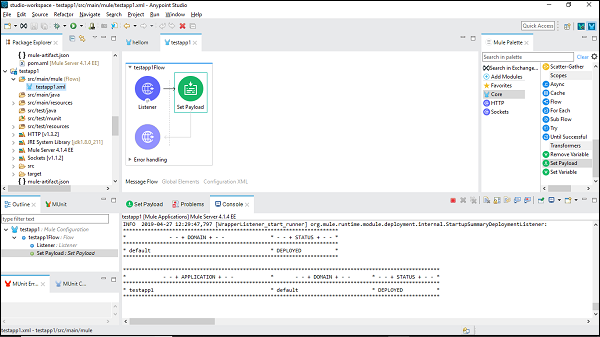
これは、最初のMuleアプリケーションが正常に構築されたことを示しています。
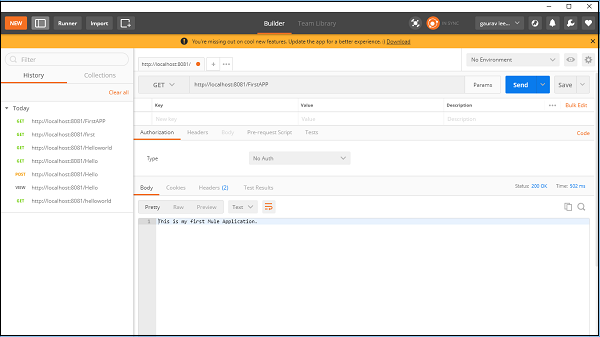
Muleアプリケーションの検証
次に、アプリが実行されているかどうかをテストする必要があります。 Go to POSTMAN、Chromeアプリを入力し、URLを入力します。 http:/localhost:8081。以下に示すように、Muleアプリケーションの構築中に提供したメッセージが表示されます-
DataWeaveは基本的にMuleSoft式言語です。これは主に、Muleアプリケーションを介して受信したデータにアクセスして変換するために使用されます。Muleランタイムは、Muleアプリケーションでスクリプトと式を実行する役割を果たします。DataWeaveはMuleランタイムと強力に統合されています。
DataWeave言語の機能
以下は、DataWeave言語のいくつかの重要な機能です-
データは、ある形式から別の形式に非常に簡単に変換できます。たとえば、application / jsonをapplication / xmlに変換できます。入力ペイロードは次のとおりです-
{
"title": "MuleSoft",
"author": " tutorialspoint.com ",
"year": 2019
}以下は、変換用のDataWeaveのコードです-
%dw 2.0
output application/xml
---
{
order: {
'type': 'Tutorial',
'title': payload.title,
'author': upper(payload.author),
'year': payload.year
}
}次に、 output ペイロードは次のとおりです-
<?xml version = '1.0' encoding = 'UTF-8'?>
<order>
<type>Tutorial</type>
<title>MuleSoft</title>
<author>tutorialspoint.com</author>
<year>2019</year>
</order>変換コンポーネントは、単純なデータ変換と複雑なデータ変換の両方を実行するスクリプトの作成に使用できます。
ほとんどのMuleメッセージプロセッサはDataWeave式をサポートしているため、必要なMuleイベントの一部でコアDataWeave関数にアクセスして使用できます。
前提条件
コンピューターでDataWeaveスクリプトを使用する前に、次の前提条件を満たしている必要があります。
Dataweaveスクリプトを使用するには、Anypoint Studio7が必要です。
Anypoint Studioをインストールした後、DataWeaveスクリプトを使用するために、TransformMessageコンポーネントを使用してプロジェクトをセットアップする必要があります。
例を使用してDataWeaveスクリプトを使用する手順
DataWeaveスクリプトを使用するには、以下の手順に従う必要があります-
Step 1
まず、前の章で行ったように、を使用して新しいプロジェクトを設定する必要があります。 File → New → Mule Project。
Step 2
次に、プロジェクトの名前を指定する必要があります。この例では、名前を付けています。Mule_test_script。
Step 3
今、私たちはドラッグする必要があります Transform Message component から Mule Palette tab に canvas。以下のように表示されます-
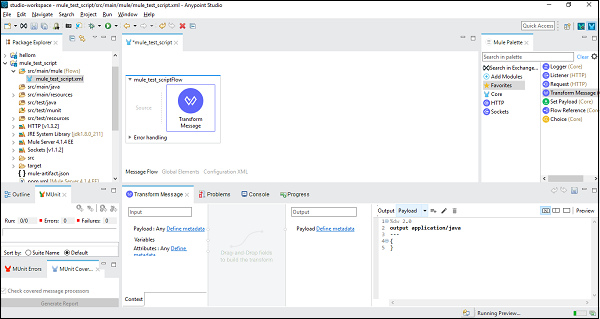
Step 4
次に、 Transform Message componentタブで[プレビュー]をクリックして、[プレビュー]ペインを開きます。プレビューの横にある空の長方形をクリックすると、ソースコード領域を展開できます。
Step 5
これで、DataWeave言語でスクリプトを開始できます。
例
以下は、2つの文字列を1つに連結する簡単な例です。
上記のDataWeaveスクリプトには、キーと値のペアがあります ({ myString: ("hello" ++ "World") }) これにより、2つの文字列が1つに連結されます。
スクリプトモジュールは、ユーザーがMuleでスクリプト言語を使用するのを容易にします。簡単に言うと、スクリプトモジュールは、スクリプト言語で記述されたカスタムロジックを交換できます。スクリプトは、実装またはトランスフォーマーとして使用できます。これらは、式の評価、つまりメッセージルーティングの制御に使用できます。
Muleには次のサポートされているスクリプト言語があります-
- Groovy
- Python
- JavaScript
- Ruby
スクリプトモジュールをインストールする方法は?
実際、AnypointStudioにはスクリプトモジュールが付属しています。Mule Paletteにモジュールが見つからない場合は、を使用して追加できます。+Add Module。追加した後、Muleアプリケーションでスクリプトモジュール操作を使用できます。
実装例
説明したように、ワークスペースを作成してアプリケーションで使用するには、モジュールをキャンバスにドラッグアンドドロップする必要があります。以下はその例です-
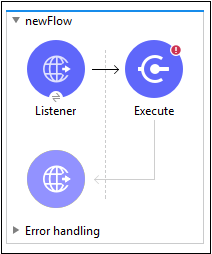
HTTPリスナーコンポーネントを構成する方法はすでに知っています。したがって、スクリプトモジュールの構成について説明します。スクリプトモジュールを構成するには、以下の手順に従う必要があります-
Step 1
Muleパレットからスクリプトモジュールを検索し、ドラッグします EXECUTE 上記のように、フローへのスクリプトモジュールの操作。
Step 2
次に、同じものをダブルクリックして、[構成の実行]タブを開きます。
Step 3
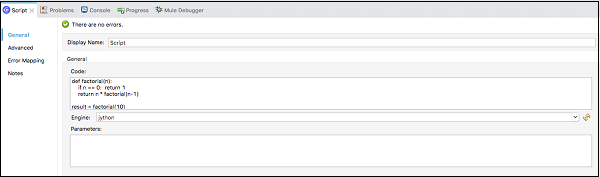
下 General タブ、コードを提供する必要があります Code text window 以下に示すように-
Step 4
最後に、私たちは選択する必要があります Engine実行コンポーネントから。エンジンのリストは以下の通りです−
- Groovy
- Nashorn(javaScript)
- jython(Python)
- jRuby(Ruby)
構成XMLエディターでの上記の実行例のXMLは次のとおりです。
<scripting:execute engine="jython" doc:name = "Script">
<scripting:code>
def factorial(n):
if n == 0: return 1
return n * factorial(n-1)
result = factorial(10)
</scripting:code>
</scripting:execute>メッセージソース
Mule 4は、Mule 3メッセージよりも単純化されたモデルであるため、情報を上書きすることなく、コネクタ間で一貫した方法でデータを操作することが容易になります。Mule 4メッセージモデルでは、各Muleイベントは次の2つで構成されます。a message and variables associated with it。
Muleメッセージにはペイロードとその属性があり、属性は主にファイルサイズなどのメタデータです。
また、変数は、操作結果、補助値などの任意のユーザー情報を保持します。
インバウンド
Mule 3のインバウンドプロパティは、Mule 4の属性になります。インバウンドプロパティは、メッセージソースを介して取得したペイロードに関する追加情報を格納することがわかっていますが、Mule 4では、属性を使用してこれを実行します。属性には次の利点があります-
属性は強く型付けされているため、属性を使用すると、使用可能なデータを簡単に確認できます。
属性に含まれる情報に簡単にアクセスできます。
以下は、Mule4の典型的なメッセージの例です。
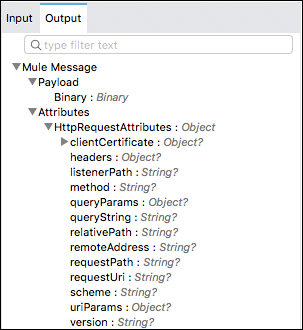
アウトバウンド
追加のデータを送信するには、Mule3のアウトバウンドプロパティをMuleコネクタとトランスポートで明示的に指定する必要があります。しかし、Mule 4では、それぞれにDataWeave式を使用して、それぞれを個別に設定できます。メインフローに副作用はありません。
たとえば、以下のDataWeave式は、メッセージプロパティを設定することなく、HTTPリクエストを実行し、ヘッダーとクエリパラメータを生成します。これは以下のコードに示されています-
<http:request path = "M_issue" config-ref="http" method = "GET">
<http:headers>#[{'path':'input/issues-list.json'}]</http:headers>
<http:query-params>#[{'provider':'memory-provider'}]</http:query-params>
</http:request>メッセージプロセッサ
Muleがメッセージソースからメッセージを受信すると、メッセージプロセッサの作業が開始されます。Muleは、1つ以上のメッセージプロセッサを使用して、フローを介してメッセージを処理します。メッセージプロセッサの主なタスクは、メッセージがMuleフローを通過するときに、メッセージを変換、フィルタリング、強化、および処理することです。
ミュールプロセッサの分類
以下は、機能に基づくミュールプロセッサのカテゴリです-
Connectors−これらのメッセージプロセッサはデータを送受信します。また、標準プロトコルまたはサードパーティAPIを介してデータを外部データソースにプラグインします。
Components −これらのメッセージプロセッサは本質的に柔軟性があり、Java、JavaScript、Groovy、Python、Rubyなどのさまざまな言語で実装されたビジネスロジックを実行します。
Filters −メッセージをフィルタリングし、特定の基準に基づいて、特定のメッセージのみがフロー内で引き続き処理されるようにします。
Routers −このメッセージプロセッサは、ルーティング、リシーケンス、または分割するメッセージのフローを制御するために使用されます。
Scopes −基本的に、フロー内のきめ細かい動作を定義する目的でコードのスニペットをラップします。
Transformers −トランスフォーマーの役割は、メッセージのペイロードタイプとデータ形式を変換して、システム間の通信を容易にすることです。
Business Events −基本的に、主要業績評価指標に関連するデータを収集します。
Exception strategies −これらのメッセージプロセッサは、メッセージ処理中に発生するあらゆるタイプのエラーを処理します。
Muleの最も重要な機能の1つは、コンポーネントを使用してルーティング、変換、および処理を実行できることです。そのため、さまざまな要素を組み合わせたMuleアプリケーションの構成ファイルのサイズが非常に大きくなります。
以下は、Mule-によって提供される構成パターンのタイプです。
- シンプルなサービスパターン
- Bridge
- Validator
- HTTPプロキシ
- WSプロキシ
コンポーネントの構成
Anypointスタジオでは、以下の手順に従ってコンポーネントを構成できます-
Step 1
Muleアプリケーションで使用するコンポーネントをドラッグする必要があります。たとえば、ここでは次のようにHTTPリスナーコンポーネントを使用します-

Step 2
次に、コンポーネントをダブルクリックして、構成ウィンドウを表示します。HTTPリスナーの場合、以下に示します-
Step 3
プロジェクトの要件に従ってコンポーネントを構成できます。たとえば、HTTPリスナーコンポーネントに対して行ったとしましょう-
コアコンポーネントは、Muleアプリのワークフローの重要な構成要素の1つです。Muleイベントを処理するためのロジックは、これらのコアコンポーネントによって提供されます。Anypoint studioでは、これらのコアコンポーネントにアクセスするには、以下に示すようにMulePaletteからCoreをクリックします。
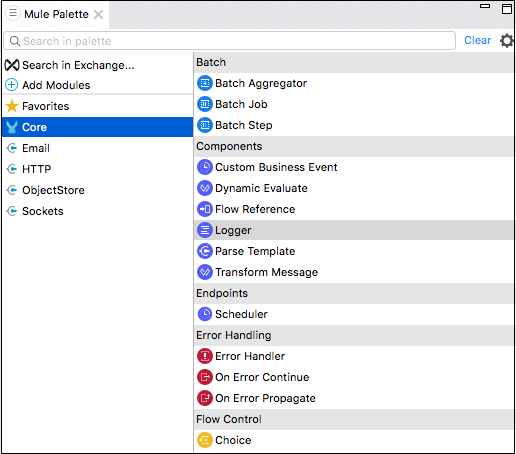
以下は様々です core components and their working in Mule 4 −
カスタムビジネスイベント
このコアコンポーネントは、フローに関する情報の収集と、Muleアプリでビジネストランザクションを処理するメッセージプロセッサに使用されます。つまり、カスタムビジネスイベントコンポーネントを使用して、作業フローに以下を追加できます。
- Metadata
- 主要業績評価指標(KPI)
KPIを追加する方法は?
以下は、MuleアプリのフローにKPIを追加する手順です-
Step 1 −Muleをフォローする Palette → Core → Components → Custom Business Event、カスタムビジネスイベントコンポーネントをMuleアプリの作業フローに追加します。
Step 2 −コンポーネントをクリックして開きます。
Step 3 −次に、表示名とイベント名の値を指定する必要があります。
Step 4 −メッセージペイロードから情報を取得するには、次のようにKPIを追加します。
KPI(追跡:メタデータ要素)の名前(キー)と値を指定します。この名前は、RuntimeManagerの検索インターフェイスで使用されます。
任意のMule式の値を指定します。
例
次の表は、名前と値を含むKPIのリストで構成されています-
| 名前 | 式/値 |
|---|---|
| 学生ロールNo | #[ペイロード['RollNo']] |
| 学生の名前 | #[ペイロード['名前']] |
動的評価
このコアコンポーネントは、Muleアプリでスクリプトを動的に選択するために使用されます。Transform Message Componentを介してハードコアスクリプトを使用することもできますが、DynamicEvaluateコンポーネントを使用する方が良い方法です。このコアコンポーネントは次のように機能します-
- まず、別のスクリプトになるはずの式を評価します。
- 次に、そのスクリプトを評価して最終結果を求めます。
このようにして、スクリプトをハードコーディングするのではなく、動的に選択することができます。
例
以下は、Idクエリパラメーターを使用してデータベースからスクリプトを選択し、そのスクリプトをMyScriptという名前の変数に格納する例です。これで、動的評価コンポーネントは変数にアクセスしてスクリプトを呼び出し、から名前変数を追加できるようになります。UName クエリパラメータ。
フローのXML構成を以下に示します-
<flow name = "DynamicE-example-flow">
<http:listener config-ref = "HTTP_Listener_Configuration" path = "/"/>
<db:select config-ref = "dbConfig" target = "myScript">
<db:sql>#["SELECT script FROM SCRIPTS WHERE ID =
$(attributes.queryParams.Id)"]
</db:sql>
</db:select>
<ee:dynamic-evaluate expression = "#[vars.myScript]">
<ee:parameters>#[{name: attributes.queryParams.UName}]</ee:parameters>
</ee:dynamic-evaluate>
</flow>スクリプトは、メッセージ、ペイロード、変数、属性などのコンテキスト変数を使用できます。ただし、カスタムコンテキスト変数を追加する場合は、キーと値のペアのセットを提供する必要があります。
動的評価の構成
次の表は、DynamicEvaluateコンポーネントを構成する方法を示しています-
| フィールド | 値 | 説明 | 例 |
|---|---|---|---|
| 式 | DataWeave式 | これは、最終的なスクリプトで評価される式を指定します。 | expression = "#[vars.generateOrderScript]" |
| パラメーター | DataWeave式 | キーと値のペアを指定します。 | #[{joiner: 'および'、id:payload.user.id}] |
フロー参照コンポーネント
Muleイベントを別のフローまたはサブフローにルーティングして同じMuleアプリ内に戻す場合は、フロー参照コンポーネントが適切なオプションです。
特徴
このコアコンポーネントの特徴は次のとおりです。
このコアコンポーネントを使用すると、参照されるフロー全体を現在のフローの単一のコンポーネントのように扱うことができます。
Muleアプリケーションを個別の再利用可能なユニットに分割します。たとえば、フローは定期的にファイルを一覧表示します。リスト操作の出力を処理する別のフローを参照する場合があります。
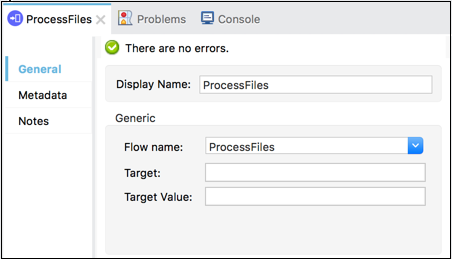
このようにして、処理ステップ全体を追加するのではなく、処理フローを指すフロー参照を追加できます。以下のスクリーンショットは、フロー参照コアコンポーネントがという名前のサブフローを指していることを示していますProcessFiles。
ワーキング
Flow Refコンポーネントの動作は、次の図を使用して理解できます。

この図は、あるフローが同じアプリケーション内の別のフローを参照する場合のMuleアプリケーションでの処理順序を示しています。Muleアプリケーションのメインの作業フローがトリガーされると、Muleイベントはすべてを通過し、Muleイベントがフロー参照に到達するまでフローを実行します。
フロー参照に到達した後、Muleイベントは参照されたフローを最初から最後まで実行します。Muleイベントが参照フローの実行を終了すると、メインフローに戻ります。
例
理解を深めるために、 let us use this component in Anypoint Studio。この例では、前の章で行ったように、HTTPリスナーを使用してメッセージを取得しています。したがって、コンポーネントをドラッグアンドドロップして構成できます。ただし、この例では、以下に示すように、サブフローコンポーネントを追加し、その下にペイロードコンポーネントを設定する必要があります。
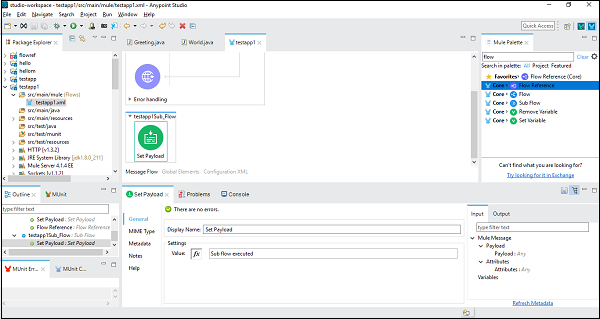
次に、構成する必要があります Set Payload、ダブルクリックして。ここでは、以下に示すように「実行されたサブフロー」という値を示しています。
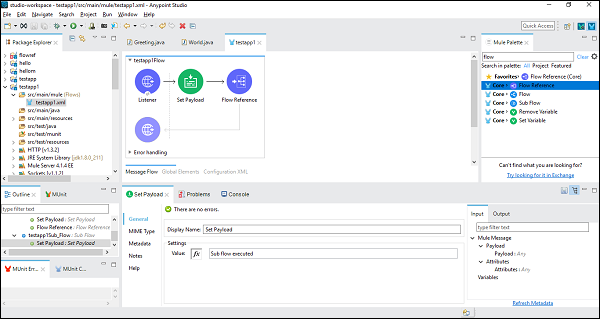
サブフローコンポーネントを正常に構成したら、メインフローのペイロードの設定後に設定するフロー参照コンポーネントが必要です。これは、以下に示すように、ミュールパレットからドラッグアンドドロップできます。
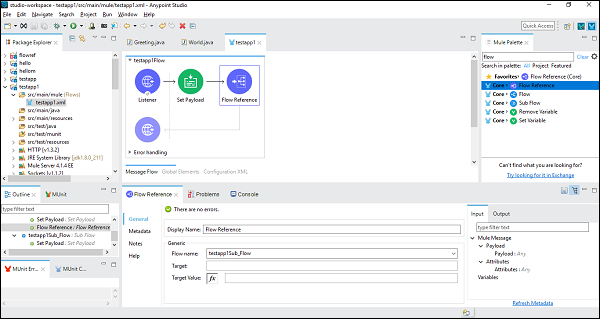
次に、フロー参照コンポーネントを構成するときに、以下に示すように、[汎用]タブで[フロー名]を選択する必要があります。
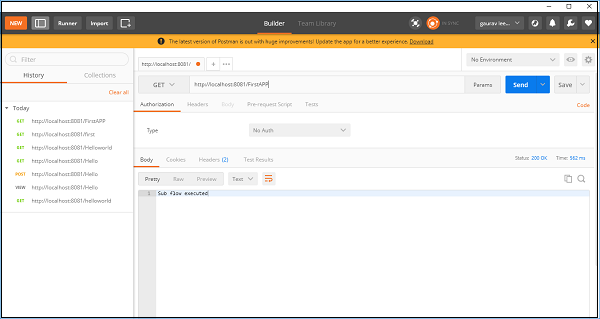
次に、このアプリケーションを保存して実行します。これをテストするには、POSTMANに移動して次のように入力しますhttp:/localhost:8181/FirstAPP URLバーに、「サブフローが実行されました」というメッセージが表示されます。
ロガーコンポーネント
ロガーと呼ばれるコアコンポーネントは、エラーメッセージ、ステータス通知、ペイロードなどの重要な情報をログに記録することで、Muleアプリケーションを監視およびデバッグするのに役立ちます。AnyPointスタジオでは、これらは Console。
利点
以下は、ロガーコンポーネントのいくつかの利点です-
- このコアコンポーネントは、作業フローのどこにでも追加できます。
- 指定した文字列をログに記録するように構成できます。
- 自分で作成したDataWeave式の出力に設定できます。
- 文字列と式の任意の組み合わせに構成することもできます。
例
次の例では、ブラウザのペイロードの設定に「Hello World」というメッセージが表示され、メッセージもログに記録されます。
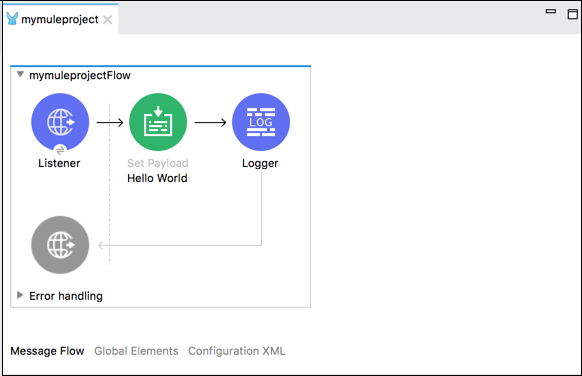
以下は、上記の例のフローのXML構成です。
<http:listener-config name = "HTTP_Listener_Configuration" host = "localhost" port = "8081"/>
<flow name = "mymuleprojectFlow">
<http:listener config-ref="HTTP_Listener_Configuration" path="/"/>
<set-payload value="Hello World"/>
<logger message = "#[payload]" level = "INFO"/>
</flow>メッセージコンポーネントの転送
転送コンポーネントとも呼ばれる変換メッセージコンポーネントを使用すると、入力データを新しい出力形式に変換できます。
トランスフォーメーションを構築する方法
次の2つの方法を使用して、変換を構築できます。
Drag-and-Drop Editor (Graphical View)−これは、変換を構築するための最初で最も使用されている方法です。この方法では、このコンポーネントのビジュアルマッパーを使用して、受信データ構造の要素をドラッグアンドドロップできます。たとえば、次の図では、2つのツリービューが入力と出力の予想されるメタデータ構造を示しています。入力フィールドを出力フィールドに接続する線は、2つのツリービュー間のマッピングを表します。
Script View−変換の視覚的マッピングは、Muleコードの言語であるDataWeaveを使用して表すこともできます。集約、正規化、グループ化、結合、パーティショニング、ピボット、フィルタリングなどの高度な変換のコーディングを行うことができます。例を以下に示します-
このコアコンポーネントは、基本的に、変数、属性、またはメッセージペイロードの入力および出力メタデータを受け入れます。以下のフォーマット固有のリソースを提供できます-
- CSV
- Schema
- フラットファイルスキーマ
- JSON
- オブジェクトクラス
- シンプルタイプ
- XMLスキーマ
- Excelの列の名前とタイプ
- 固定幅の列の名前とタイプ
エンドポイントには基本的に、Muleアプリケーションの作業フローで処理をトリガーまたは開始するコンポーネントが含まれます。というSource AnypointStudioと Triggersミュールのデザインセンターで。Mule4の重要なエンドポイントの1つはScheduler component。
スケジューラエンドポイント
このコンポーネントは時間ベースの条件で機能します。つまり、時間ベースの条件が満たされるたびにフローをトリガーできます。たとえば、スケジューラーはイベントをトリガーして、たとえば10秒ごとにMuleの作業フローを開始できます。柔軟なCron式を使用して、スケジューラエンドポイントをトリガーすることもできます。
スケジューラに関する重要なポイント
スケジューライベントを使用している間、以下に示すようにいくつかの重要な点に注意する必要があります-
スケジューラエンドポイントは、Muleランタイムが実行されているマシンのタイムゾーンに従います。
MuleアプリケーションがCloudHubで実行されている場合、スケジューラーはCloudHubワーカーが実行されているリージョンのタイムゾーンに従います。
常に、スケジューラエンドポイントによってトリガーされた1つのフローのみをアクティブにできます。
Muleランタイムクラスターでは、スケジューラエンドポイントはプライマリノードでのみ実行またはトリガーされます。
スケジューラーを構成する方法
上で説明したように、スケジューラエンドポイントを一定の間隔でトリガーされるように構成することも、Cron式を指定することもできます。
スケジューラーを構成するためのパラメーター(固定間隔の場合)
以下は、一定の間隔でフローをトリガーするようにスケジューラーを設定するためのパラメーターです。
Frequency−基本的に、スケジューラエンドポイントがミュールフローをトリガーする頻度を記述します。この時間の単位は、[時間の単位]フィールドから選択できます。これに値を指定しない場合は、デフォルト値の1000が使用されます。一方、0または負の値を指定すると、デフォルト値も使用されます。
Start Delay−これは、アプリケーションが開始されてから初めてMuleフローをトリガーするまで待機する必要がある時間です。開始遅延の値は、周波数と同じ時間単位で表されます。デフォルト値は0です。
Time Unit−周波数と開始遅延の両方の時間単位を表します。時間単位の可能な値は、ミリ秒、秒、分、時間、日です。デフォルト値はミリ秒です。
スケジューラーを構成するためのパラメーター(cron式の場合)
実際、Cronは、時刻と日付の情報を記述するために使用される標準です。柔軟なCron式を使用してSchedulerをトリガーする場合、Scheduler Endpointは毎秒を追跡し、QuartzCron式が日時設定と一致するたびにMuleイベントを作成します。Cron式を使用すると、イベントを1回だけ、または定期的にトリガーできます。
次の表は、6つの必要な設定の日時式を示しています-
| 属性 | 値 |
|---|---|
| 秒 | 0-59 |
| 議事録 | 0-59 |
| 時間 | 0-23 |
| 曜日 | 1-31 |
| 月 | 1〜12日または1月〜12月 |
| 曜日 | 1-7またはSUN-SAT |
スケジューラエンドポイントでサポートされているQuartzCron式の例を以下に示します。
½ * * * * ? −は、スケジューラーが1日の2秒ごとに毎日実行されることを意味します。
0 0/5 16 ** ? −スケジューラーは、毎日午後4時から午後4時55分まで5分ごとに実行されることを意味します。
1 1 1 1, 5 * ? −は、スケジューラーが毎年1月の初日と4月の初日を実行することを意味します。
例
次のコードは、メッセージ「hi」を毎秒ログに記録します。
<flow name = "cronFlow" doc:id = "ae257a5d-6b4f-4006-80c8-e7c76d2f67a0">
<doc:name = "Scheduler" doc:id = "e7b6scheduler8ccb-c6d8-4567-87af-aa7904a50359">
<scheduling-strategy>
<cron expression = "* * * * * ?" timeZone = "America/Los_Angeles"/>
</scheduling-strategy>
</scheduler>
<logger level = "INFO" doc:name = "Logger"
doc:id = "e2626dbb-54a9-4791-8ffa-b7c9a23e88a1" message = '"hi"'/>
</flow>フロー制御(ルーター)
フロー制御コンポーネントの主なタスクは、入力Muleイベントを取得し、それを1つ以上の個別のコンポーネントシーケンスにルーティングすることです。基本的に、入力Muleイベントを他のコンポーネントシーケンスにルーティングします。したがって、ルーターとも呼ばれます。Choice and Scatter-Gatherルーターは、フロー制御コンポーネントで最も使用されているルーターです。
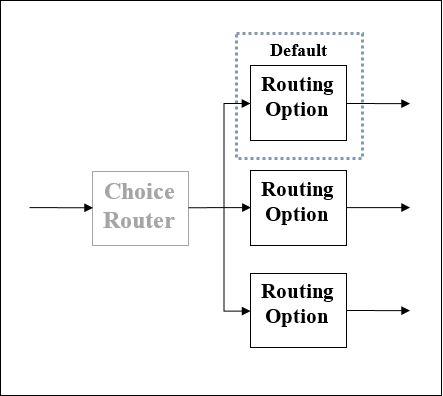
選択ルーター
名前が示すように、このルーターはDataWeaveロジックを適用して、2つ以上のルートの1つを選択します。前に説明したように、各ルートはMuleイベントプロセッサの個別のシーケンスです。選択ルーターは、メッセージの内容を評価するために使用される一連のDataWeave式に従って、フローを介してメッセージを動的にルーティングするルーターとして定義できます。
チョイスルーターの概略図
Choiceルーターを使用する効果は、フローまたはフローに条件付き処理を追加するのと同じです。 if/then/elseほとんどのプログラミング言語のコードブロック。以下は、3つのオプションがあるChoiceRouterの概略図です。その中で、1つはデフォルトルーターです。
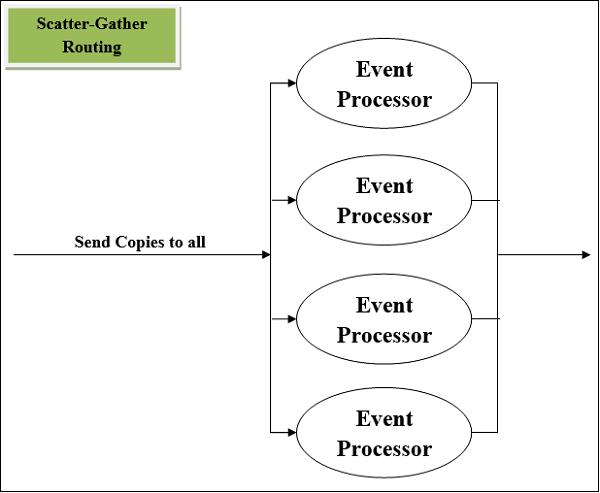
スキャッターギャザールーター
もう1つの最も使用されているルーティングイベントプロセッサは Scatter-Gather component。その名前が示すように、スキャッター(コピー)とギャザー(統合)の基本に取り組んでいます。次の2つのポイントの助けを借りてその動作を理解することができます-
まず、このルーターはMuleイベントを2つ以上の並列ルートにコピー(スキャッター)します。条件は、各ルートがサブフローのような1つ以上のイベントプロセッサのシーケンスである必要があることです。この場合の各ルートは、個別のスレッドを使用してMuleイベントを作成します。すべてのMuleイベントには、独自のペイロード、属性、および変数があります。
次に、このルーターは、作成されたMuleイベントを各ルートから収集し、それらを新しいMuleイベントに統合します。この後、この統合されたMuleイベントを次のイベントプロセッサに渡します。ここでの条件は、すべてのルートが正常に完了した場合にのみ、SGルーターが統合されたMuleイベントを次のイベントプロセッサに渡すことです。
スキャッターギャザールーターの概略図
以下は、4つのイベントプロセッサを備えたスキャッターギャザールーターの概略図です。すべてのルートを順番にではなく並行して実行します。
スキャッターギャザールーターによるエラー処理
まず、Scatter-Gatherコンポーネント内で生成される可能性のあるエラーの種類に関する知識が必要です。イベントプロセッサ内でエラーが生成され、Scatter-Gatherコンポーネントがタイプのエラーをスローする可能性がありますMule: COMPOSITE_ERROR。このエラーは、すべてのルートが失敗または完了した後にのみSGコンポーネントによってスローされます。
このエラータイプを処理するには、 try scopeScatter-Gatherコンポーネントの各ルートで使用できます。エラーがによって正常に処理された場合try scope、そうすれば、ルートは確かにMuleイベントを生成できるようになります。
トランスフォーマー
Muleイベントの一部を設定または削除する場合は、Transformerコンポーネントが最適です。変圧器のコンポーネントは次のタイプです-
可変変圧器を取り外します
名前が示すように、このコンポーネントは変数名を取り、その変数をMuleイベントから削除します。
可変変圧器の取り外しの構成
次の表は、可変変圧器の取り外しを構成する際に考慮すべきフィールドの名前とその説明を示しています。
| シニア番号 | フィールドと説明 |
|---|---|
| 1 | Display Name (doc:name) これをカスタマイズして、Muleの作業フローでこのコンポーネントの一意の名前を表示できます。 |
| 2 | Name (variableName) 削除する変数の名前を表します。 |
ペイロードトランスを設定する
の助けを借りて set-payloadコンポーネントでは、メッセージのペイロード(リテラル文字列またはDataWeave式)を更新できます。複雑な式や変換にこのコンポーネントを使用することはお勧めしません。それはのような単純なものに使用することができますselections。
次の表は、セットペイロードトランスフォーマーを構成する際に考慮すべきフィールドの名前とその説明を示しています。
| フィールド | 使用法 | 説明 |
|---|---|---|
| 値(値) | 必須 | ペイロードを設定するには、filedされた値が必要です。ペイロードの設定方法を定義するリテラル文字列またはDataWeave式を受け入れます。例は「いくつかの文字列」のようなものです |
| MIMEタイプ(mimeType) | オプション | これはオプションですが、メッセージのペイロードに割り当てられた値のmimeタイプを表します。例はテキスト/プレーンのようなものです。 |
| エンコーディング(エンコーディング) | オプション | これもオプションですが、メッセージのペイロードに割り当てられる値のエンコーディングを表します。例はUTF-8のようなものです。 |
XML構成コードを介してペイロードを設定できます-
With Static Content −次のXML構成コードは、静的コンテンツを使用してペイロードを設定します−
<set-payload value = "{ 'name' : 'Gaurav', 'Id' : '2510' }"
mimeType = "application/json" encoding = "UTF-8"/>With Expression Content −次のXML構成コードは、式のコンテンツを使用してペイロードを設定します−
<set-payload value = "#['Hi' ++ ' Today is ' ++ now()]"/>上記の例では、今日の日付にメッセージペイロード「Hi」を追加します。
可変変圧器を設定する
の助けを借りて set variableコンポーネントでは、変数を作成または更新して、Muleアプリケーションのフロー内で使用するために、文字列、メッセージペイロード、属性オブジェクトなどの単純なリテラル値を格納できます。このコンポーネントを複雑な式や変換に使用することはお勧めしません。それはのような単純なものに使用することができますselections。
セット可変変圧器の構成
次の表は、セットペイロードトランスフォーマーを構成する際に考慮すべきフィールドの名前とその説明を示しています。
| フィールド | 使用法 | 説明 |
|---|---|---|
| 変数名(variableName) | 必須 | 提出が必要であり、変数の名前を表します。名前を付けるときは、数字、文字、アンダースコアを含める必要があるため、命名規則に従ってください。 |
| 値(値) | 必須 | 変数を設定するには、提出された値が必要です。リテラル文字列またはDataWeave式を受け入れます。 |
| MIMEタイプ(mimeType) | オプション | これはオプションですが、変数のmimeタイプを表します。例はテキスト/プレーンのようなものです。 |
| エンコーディング(エンコーディング) | オプション | これもオプションですが、変数のエンコーディングを表します。例はISO10646 / Unicode(UTF-8)のようなものです。 |
例
以下の例では、変数をメッセージペイロードに設定します-
Variable Name = msg_var
Value = payload in Design center and #[payload] in Anypoint Studio同様に、以下の例では、変数をメッセージペイロードに設定します-
Variable Name = msg_var
Value = attributes in Design center and #[attributes] in Anypoint Studio.RESTWebサービス
RESTの完全な形式は、HTTPにバインドされたRepresentational StateTransferです。したがって、Webでのみ使用されるアプリケーションを設計する場合は、RESTが最適なオプションです。
RESTfulWebサービスの利用
次の例では、RESTコンポーネントと、MuleSoftが提供するアメリカン航空の詳細と呼ばれる1つのパブリックRESTfulサービスを使用します。さまざまな詳細がありますが、GETを使用します。http://training-american-ws.cloudhub.io/api/flightsすべてのフライトの詳細が返されます。前に説明したように、RESTはHTTPにバインドされているため、このアプリケーションでも2つのHTTPコンポーネントが必要です。1つはリスナーで、もう1つはリクエストです。以下のスクリーンショットは、HTTPリスナーの構成を示しています-
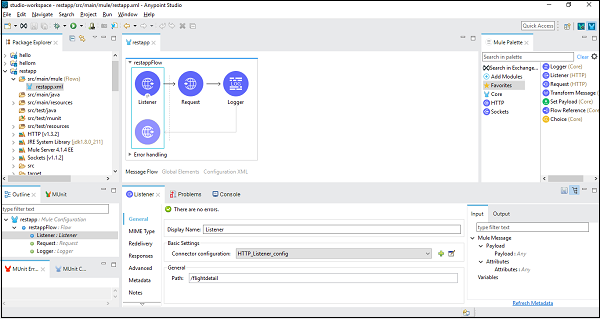
引数の構成と受け渡し
HTTPリクエストの設定を以下に示します-
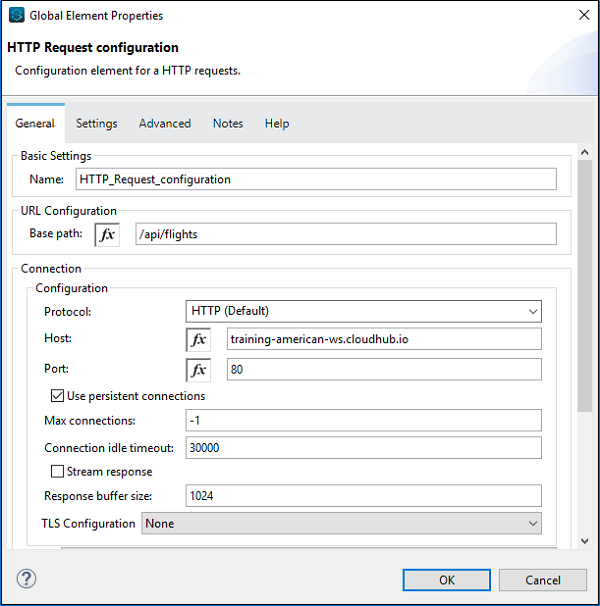
これで、ワークスペースフローに従って、ロガーを取得したため、次のように構成できます。
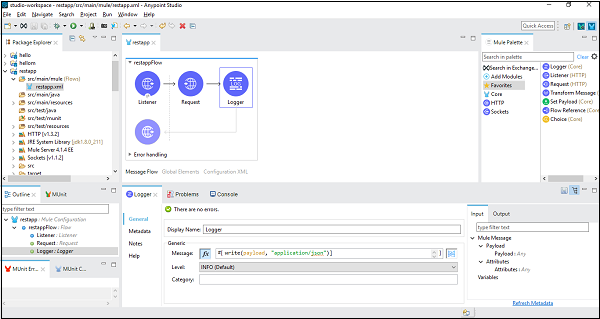
メッセージタブでは、ペイロードを文字列に変換するコードを記述します。
アプリケーションのテスト
次に、アプリケーションを保存して実行し、POSTMANに移動して、以下に示すように最終出力を確認します。
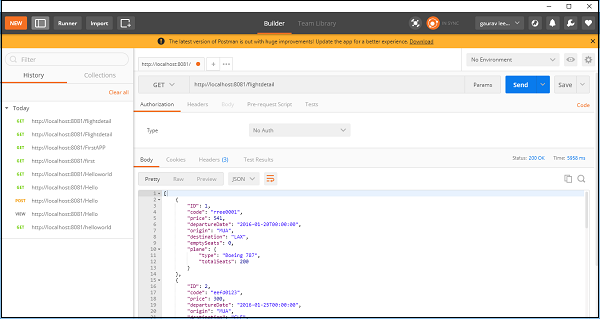
RESTコンポーネントを使用すると、フライトの詳細が表示されます。
SOAPコンポーネント
SOAPの完全な形式は Simple Object Access Protocol。これは基本的に、Webサービスの実装で情報を交換するためのメッセージングプロトコル仕様です。次に、AnypointStudioのSOAPAPIを使用して、Webサービスを使用して情報にアクセスします。
SOAPベースのWebサービスの利用
この例では、国情報に関連するサービスを保持する、Country InfoServiceという名前のパブリックSOAPサービスを使用します。そのWSDLアドレスは次のとおりです。http://www.oorsprong.org/websamples.countryinfo/countryinfoservice.wso?WSDL
まず、以下に示すように、キャンバス内のSOAP消費をMulePaletteからドラッグする必要があります-
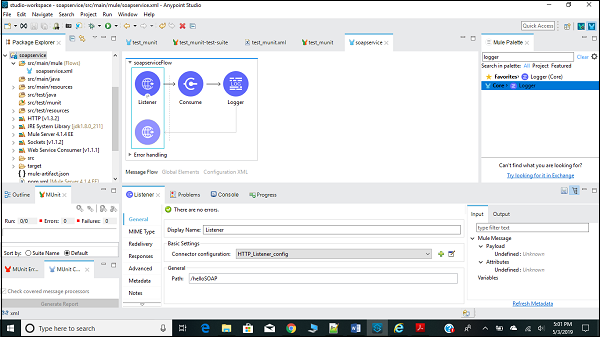
引数の構成と受け渡し
次に、上記の例で行ったように、以下に示すようにHTTPリクエストを構成する必要があります-
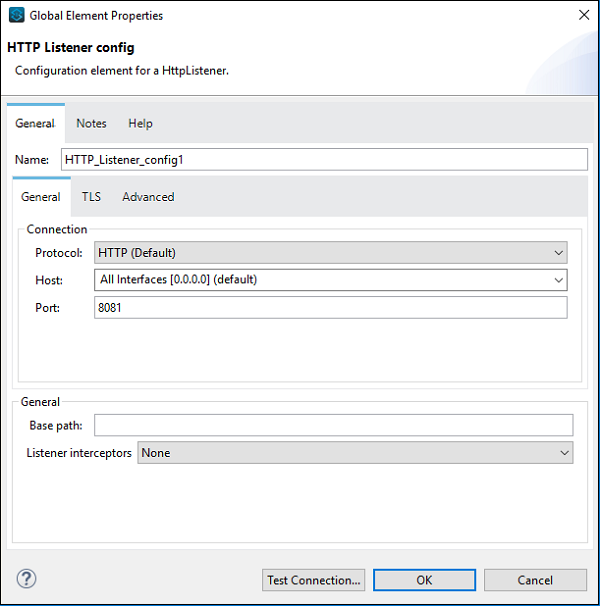
ここで、以下に示すようにWebサービスコンシューマーも構成する必要があります-
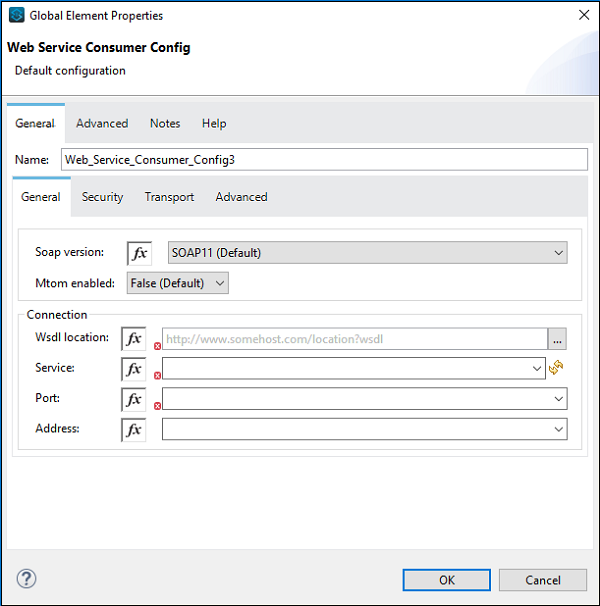
WSDL Locationの場所で、上記で提供されているWSDLのWebアドレスを提供する必要があります(この例の場合)。Webアドレスを指定すると、Studioはサービス、ポート、およびアドレスを自動的に検索します。手動で提供する必要はありません。
Webサービスからの応答の転送
このために、Muleフローにロガーを追加し、以下に示すようにペイロードを与えるように構成する必要があります。
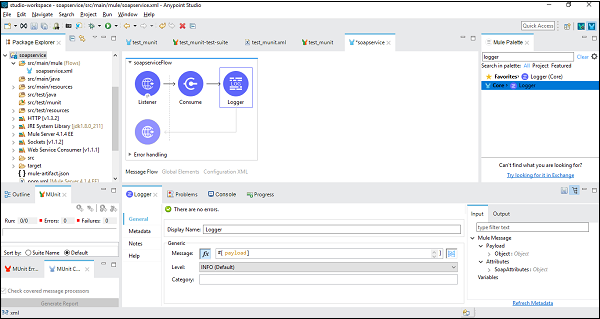
アプリケーションのテスト
アプリケーションを保存して実行し、GoogleChromeに移動して最終出力を確認します。タイプhttp://localhist:8081/helloSOAP (この例では)下のスクリーンショットに示すように、コードで国名が表示されます-

新しいMuleエラー処理は、Mule 4で行われた最大かつ主要な変更の1つです。新しいエラー処理は複雑に見えるかもしれませんが、より優れており、より効率的です。この章では、Muleエラーのコンポーネント、エラータイプ、Muleエラーのカテゴリ、およびMuleエラーを処理するためのコンポーネントについて説明します。
ラバエラーのコンポーネント
Muleエラーは、Mule例外の失敗の結果です。次のコンポーネントがあります-
説明
これは、問題について説明するMuleエラーの重要なコンポーネントです。その表現は次のとおりです-
#[error.description]タイプ
MuleエラーのTypeコンポーネントは、問題を特徴づけるために使用されます。また、エラーハンドラー内でのルーティングも可能です。その表現は次のとおりです-
#[error.errorType]原因
MuleエラーのCauseコンポーネントは、失敗の原因となる基礎となるJavaスロー可能オブジェクトを提供します。その表現は次のとおりです-
#[error.cause]メッセージ
Muleエラーのメッセージコンポーネントは、エラーに関するオプションのメッセージを表示します。その表現は次のとおりです-
#[error.errorMessage]子エラー
子供のエラーミュールエラーの構成要素は、内部エラーのオプションのコレクションを提供します。これらの内部エラーは、主にScatter-Gatherなどの要素によって使用され、集約されたルートエラーを提供します。その表現は次のとおりです-
#[error.childErrors]例
401ステータスコードでHTTPリクエストが失敗した場合、ミュールエラーは次のようになります。
Description: HTTP GET on resource ‘http://localhost:8181/TestApp’
failed: unauthorized (401)
Type: HTTP:UNAUTHORIZED
Cause: a ResponseValidatorTypedException instance
Error Message: { "message" : "Could not authorize the user." }| Sr.NO | エラーの種類と説明 |
|---|---|
| 1 | TRANSFORMATION このエラータイプは、値の変換中にエラーが発生したことを示します。変換はMuleランタイムの内部変換であり、DataWeave変換ではありません。 |
| 2 | EXPRESSION この種のエラータイプは、式の評価中にエラーが発生したことを示します。 |
| 3 | VALIDATION この種のエラータイプは、検証エラーが発生したことを示します。 |
| 4 | DUPLICATE_MESSAGE メッセージが2回処理されるときに発生する一種の検証エラー。 |
| 5 | REDELIVERY_EXHAUSTED この種のエラータイプは、ソースからのメッセージの再処理の最大試行回数がなくなったときに発生します。 |
| 6 | CONNECTIVITY このエラータイプは、接続の確立中に問題が発生したことを示します。 |
| 7 | ROUTING このエラータイプは、メッセージのルーティング中にエラーが発生したことを示します。 |
| 8 | SECURITY このエラータイプは、セキュリティエラーが発生したことを示します。たとえば、無効な資格情報を受信しました。 |
| 9 | STREAM_MAXIMUM_SIZE_EXCEEDED このエラータイプは、ストリームに許可されている最大サイズが使い果たされたときに発生します。 |
| 10 | TIMEOUT メッセージ処理中のタイムアウトを示します。 |
| 11 | UNKNOWN このエラータイプは、予期しないエラーが発生したことを示します。 |
| 12 | SOURCE これは、フローのソースでのエラーの発生を表します。 |
| 13 | SOURCE_RESPONSE これは、成功した応答の処理中にフローのソースでエラーが発生したことを表します。 |
上記の例では、ラバエラーのメッセージコンポーネントを見ることができます。
エラーの種類
その特性を利用してエラータイプを理解しましょう-
Muleエラータイプの最初の特徴は、両方で構成されていることです。 a namespace and an identifier。これにより、ドメインに応じてタイプを区別できます。上記の例では、エラータイプはHTTP: UNAUTHORIZED。
2番目の重要な特性は、エラータイプが親タイプを持つ可能性があることです。たとえば、エラータイプHTTP: UNAUTHORIZED 持っている MULE:CLIENT_SECURITY 親として、名前の付いた親もあります MULE:SECURITY。この特性により、エラータイプがよりグローバルなアイテムの仕様として確立されます。
エラータイプの種類
以下は、すべてのエラーが該当するカテゴリです。
どれか
このカテゴリのエラーは、フローで発生する可能性のあるエラーです。それらはそれほど深刻ではなく、簡単に扱うことができます。
クリティカル
このカテゴリのエラーは、処理できない重大なエラーです。以下は、このカテゴリのエラータイプのリストです-
| Sr.NO | エラーの種類と説明 |
|---|---|
| 1 | OVERLOAD このエラータイプは、過負荷の問題が原因でエラーが発生したことを示します。この場合、実行は拒否されます。 |
| 2 | FATAL_JVM_ERROR この種のエラータイプは、致命的なエラーの発生を示します。たとえば、スタックオーバーフロー。 |
CUSTOMエラータイプ
CUSTOMエラータイプは、当社が定義したエラーです。これらは、マッピング時またはエラー発生時に定義できます。Muleアプリケーション内の他の既存のエラータイプと区別するために、これらのエラータイプに特定のカスタム名前空間を与える必要があります。たとえば、HTTPを使用するMuleアプリケーションでは、カスタムエラータイプとしてHTTPを使用することはできません。
ラバエラーのカテゴリー
広い意味で、Muleのエラーは2つのカテゴリに分類できます。 Messaging Errors and System Errors。
メッセージングエラー
このカテゴリのMuleエラーは、Muleフローに関連しています。Muleフロー内で問題が発生するたびに、Muleはメッセージングエラーをスローします。設定できますOn Error これらのMuleエラーを処理するためのエラーハンドラコンポーネント内のコンポーネント。
システムエラー
システムエラーは、システムレベルで例外が発生していることを示します。Muleイベントがない場合、システムエラーはシステムエラーハンドラーによって処理されます。次の種類の例外は、システムエラーハンドラによって処理されます-
- アプリケーションの起動中に発生する例外。
- 外部システムへの接続に失敗したときに発生する例外。
システムエラーが発生した場合、Muleは登録済みのリスナーにエラー通知を送信します。また、エラーをログに記録します。一方、エラーの原因が接続障害である場合、Muleは再接続戦略を実行します。
ラバエラーの処理
Muleには、エラーを処理するための次の2つのエラーハンドラがあります-
エラー時エラーハンドラ
最初のMuleエラーハンドラーはOn-Errorコンポーネントであり、処理できるエラーのタイプを定義します。前に説明したように、スコープのようなエラーハンドラコンポーネント内にオンエラーコンポーネントを設定できます。各Muleフローにはエラーハンドラーが1つだけ含まれていますが、このエラーハンドラーには必要な数のOn-Errorスコープを含めることができます。On-Errorコンポーネントを使用して、フロー内のMuleエラーを処理する手順は次のとおりです。
まず、Muleフローでエラーが発生すると、通常のフローの実行が停止します。
次に、プロセスはに転送されます Error Handler Component すでに持っている On Error component エラーの種類と式を一致させます。
最後に、エラーハンドラコンポーネントはエラーを最初のコンポーネントにルーティングします On Error scope エラーと一致します。

以下は、Muleでサポートされている2種類のOn-Errorコンポーネントです。
エラー時の伝播
On-Error Propagateコンポーネントは実行されますが、エラーを次のレベルに伝播し、所有者の実行を中断します。によって処理された場合、トランザクションはロールバックされますOn Error Propagate 成分。
エラー時続行
On-Error Propagateコンポーネントと同様に、On-ErrorContinueコンポーネントもトランザクションを実行します。唯一の条件は、所有者が実行を正常に完了した場合、このコンポーネントは実行の結果を所有者の結果として使用することです。On-Error Continueコンポーネントによって処理される場合、トランザクションはコミットされます。
スコープコンポーネントを試す
Try Scopeは、Mule 4で利用できる多くの新機能の1つです。これは、例外となる可能性のあるコードを囲むために使用したJAVAのtryブロックと同様に機能するため、コード全体を壊すことなく処理できます。
1つ以上のMuleイベントプロセッサをTryScopeでラップできます。その後、try scopeは、これらのイベントプロセッサによってスローされた例外をキャッチして処理します。tryスコープの主な動作は、フロー全体ではなく内部コンポーネントでのエラー処理をサポートする独自のエラー処理戦略を中心に展開されます。そのため、フローを別のフローに抽出する必要はありません。
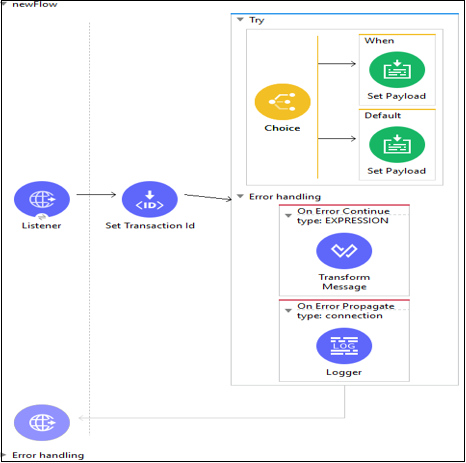
Example
以下は、tryスコープの使用例です-
トランザクションを処理するためのtryスコープの構成
ご存知のように、トランザクションは、部分的に実行してはならない一連のアクションです。トランザクションのスコープ内のすべての操作は同じスレッドで実行され、エラーが発生した場合は、ロールバックまたはコミットにつながるはずです。次の方法でtryスコープを構成して、子操作をトランザクションとして扱うことができます。
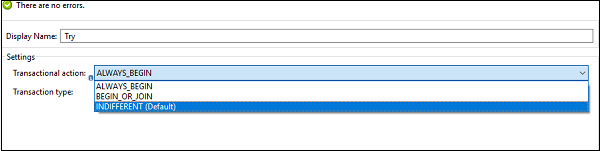
INDIFFERENT [Default]− tryブロックでこの構成を選択した場合、子アクションはトランザクションとして扱われません。この場合、エラーによってロールバックもコミットも発生しません。
ALWAYS_BEGIN −スコープが実行されるたびに新しいトランザクションが開始されることを示します。
BEGIN_OR_JOIN−フローの現在の処理がすでにトランザクションを開始している場合は、それに参加することを示します。それ以外の場合は、新しいものを開始します。
すべてのプロジェクトの場合、例外についての事実は、それらが必ず発生するということです。そのため、システム/アプリケーションが一貫性のない状態のままにならないように、例外をキャッチ、分類、および処理することが重要です。すべてのMuleアプリケーションに暗黙的に適用されるデフォルトの例外戦略があります。保留中のトランザクションを自動的にロールバックすることが、デフォルトの例外戦略です。
Muleの例外
例外処理について深く掘り下げる前に、開発者が例外ハンドラーを設計する際に必要な3つの基本的な質問とともに、どのような種類の例外が発生する可能性があるかを理解する必要があります。
どのトランスポートが重要ですか?
すべてのトランスポートがトランスナショナル性をサポートしているわけではないため、この質問は例外ハンドラーを設計する前に十分な関連性があります。
File または HTTPトランザクションはサポートしていません。そのため、このような場合に例外が発生した場合は、手動で管理する必要があります。
Databasesトランザクションをサポートします。この場合、例外ハンドラーを設計する際、データベーストランザクションは(必要に応じて)自動的にロールバックできることに注意する必要があります。
の場合には REST APIs、正しいHTTPステータスコードを返す必要があることに注意してください。たとえば、リソースが見つからない場合は404です。
どのメッセージ交換パターンを使用しますか?
例外ハンドラーを設計するときは、メッセージ交換パターンに注意する必要があります。同期(要求-応答)または非同期(ファイア-フォーゲット)のメッセージパターンがあります。
Synchronous message pattern は要求/応答形式に基づいています。つまり、このパターンは応答を予期し、応答が返されるかタイムアウトが発生するまでブロックされます。
Asynchronous message pattern はファイアフォーゲットフォーマットに基づいています。つまり、このパターンは、リクエストが最終的に処理されることを前提としています。
どのタイプの例外ですか?
非常に単純なルールは、タイプに基づいて例外を処理することです。例外の原因がシステム/技術的な問題なのか、ビジネス上の問題なのかを知ることは非常に重要ですか?
によって発生した例外 system/technical issue (ネットワークの停止など)は、再試行メカニズムによって自動的に処理される必要があります。
一方、例外が発生しました by a business issue (無効なデータなど)根本的な原因を修正せずに再試行することは有用ではないため、再試行メカニズムを適用して解決しないでください。
なぜ例外を分類するのですか?
すべての例外が同じではないことがわかっているので、例外を分類することは非常に重要です。大まかに言えば、例外は次の2つのタイプに分類できます。
ビジネスの例外
ビジネス例外が発生する主な理由は、データの誤りまたはプロセスフローの誤りです。これらの種類の例外は、通常、再試行できない性質があるため、次のように構成するのは適切ではありません。rollback。適用してもretry根本的な原因を修正せずに再試行することは役に立たないため、メカニズムは意味がありません。このような例外を処理するには、処理をすぐに停止し、デッドレターキューへの応答として例外を送り返す必要があります。通知もオペレーションに送信する必要があります。
ビジネス以外の例外
ビジネス以外の例外が発生する主な理由は、システムの問題または技術的な問題です。これらの種類の例外は本質的に再試行可能であるため、次のように構成することをお勧めします。retry これらの例外を解決するためのメカニズム。
例外処理戦略
Muleには次の5つの例外処理戦略があります-
デフォルトの例外戦略
Muleは、この戦略をMuleフローに暗黙的に適用します。フロー内のすべての例外を処理できますが、キャッチ、選択、またはロールバックの例外戦略を追加することでオーバーライドすることもできます。この例外戦略は、保留中のトランザクションをロールバックし、例外もログに記録します。この例外戦略の重要な特徴は、トランザクションがない場合にも例外をログに記録することです。
デフォルトの戦略であるため、Muleはフローでエラーが発生したときにこれを実装します。AnyPointスタジオでは設定できません。
ロールバック例外戦略
エラーを修正するための可能な解決策がない場合はどうすればよいですか?解決策は、ロールバック例外戦略を使用することです。これは、親フローのインバウンドコネクタにメッセージを送信するとともにトランザクションをロールバックして、メッセージを再処理します。この戦略は、メッセージを再処理する場合にも非常に役立ちます。
Example
この戦略は、資金が当座預金/普通預金口座に預け入れられる銀行取引に適用できます。トランザクション中にエラーが発生した場合、このストラテジーはメッセージをフローの最初にロールバックして処理を再試行するため、ここでロールバック例外ストラテジーを構成できます。
例外をキャッチする戦略
このストラテジーは、親フロー内でスローされるすべての例外をキャッチします。親フローによってスローされたすべての例外を処理することにより、Muleのデフォルトの例外戦略をオーバーライドします。キャッチ例外戦略を使用して、インバウンドコネクタと親フローへの例外の伝播を回避できます。
この戦略により、例外が発生したときにフローによって処理されたトランザクションがロールバックされないようにすることもできます。
Example
この戦略は、キューからのメッセージを処理するためのフローがあるフライト予約システムに適用できます。メッセージエンリッチャーは、シートを割り当てるためにメッセージにプロパティを追加してから、メッセージを別のキューに送信します。
このフローでエラーが発生した場合、メッセージは例外をスローします。ここで、catch例外戦略は、適切なメッセージを含むヘッダーを追加し、そのメッセージをフローから次のキューにプッシュすることができます。
選択例外戦略
メッセージの内容に基づいて例外を処理する場合は、選択例外戦略が最適です。この例外戦略の動作は次のようになります-
- まず、親フロー内でスローされたすべての例外をキャッチします。
- 次に、メッセージの内容と例外の種類を確認します。
- そして最後に、メッセージを適切な例外戦略にルーティングします。
選択例外戦略内で定義された、キャッチやロールバックなどの複数の例外戦略があります。この例外ストラテジーで定義されたストラテジーがない場合は、メッセージをデフォルトの例外ストラテジーにルーティングします。コミット、ロールバック、または消費アクティビティを実行することはありません。
参照例外戦略
これは、別の構成ファイルで定義されている一般的な例外戦略を指します。メッセージが例外をスローする場合、この例外ストラテジーは、グローバルキャッチ、ロールバック、または選択例外ストラテジーで定義されたエラー処理パラメーターを参照します。選択例外戦略と同様に、コミット、ロールバック、または消費アクティビティも実行しません。
ユニットテストは、ソースコードの個々のユニットをテストして、それらが使用に適しているかどうかを判断する方法であることを理解しています。Javaプログラマーは、JUnitフレームワークを使用してテストケースを作成できます。同様に、MuleSoftにはMUnitと呼ばれるフレームワークがあり、APIと統合の自動テストケースを作成できます。継続的インテグレーション/デプロイメント環境に最適です。MUnitフレームワークの最大の利点の1つは、MavenおよびSurefireと統合できることです。
MUnitの機能
以下は、MuleMUnitテストフレームワークの非常に便利な機能の一部です。
MUnitフレームワークでは、JavaコードだけでなくMuleコードを使用してMuleテストを作成できます。
Anypoint Studio内で、MuleアプリとAPIをグラフィカルまたはXMLで設計およびテストできます。
MUnitを使用すると、テストを既存のCI / CDプロセスに簡単に統合できます。
自動生成されたテストとカバレッジレポートを提供します。したがって、手作業は最小限です。
また、ローカルDB / FTP /メールサーバーを使用して、CIプロセスを通じてテストの移植性を高めることもできます。
これにより、テストを有効または無効にできます。
プラグインを使用してMUnitフレームワークを拡張することもできます。
これにより、メッセージプロセッサの呼び出しを確認できます。
MUnitテストフレームワークの助けを借りて、エンドポイントコネクタとフローインバウンドエンドポイントを無効にすることができます。
Muleスタックトレースでエラーレポートを確認できます。
MuleMUnitテストフレームワークの最新リリース
MUnit 2.1.4は、MuleMUnitテストフレームワークの最新リリースです。以下のハードウェアおよびソフトウェア要件が必要です-
- MS Windows 8+
- Apple Mac OS X 10.10 +
- Linux
- Java 8
- Maven 3.3.3、3.3.9、3.5.4、3.6.0
Mule4.1.4およびAnypointStudio7.3.0と互換性があります。
MUnitとAnypointStudio
説明したように、MUnitはAnypointスタジオに完全に統合されており、MuleアプリとAPIをグラフィカルにまたはAnypointスタジオ内のXMLで設計およびテストできます。つまり、Anypoint Studioのグラフィカルインターフェイスを使用して、次のことを実行できます。
- MUnitテストの作成と設計用
- テストを実行するため
- テスト結果とカバレッジレポートを表示するため
- テストのデバッグ用
それでは、各タスクについて1つずつ説明していきましょう。
MUnitテストの作成と設計
新しいプロジェクトを開始すると、新しいフォルダが自動的に追加されます。 src/test/munit私たちのプロジェクトに。たとえば、新しいMuleプロジェクトを開始しました。test_munit、下の画像でわかるように、プロジェクトの下に上記のフォルダが追加されています。
さて、新しいプロジェクトを開始したら、AnypointStudioで新しいMUnitテストを作成する2つの基本的な方法があります-
By Right-Clicking the Flow −この方法では、特定のフローを右クリックして、ドロップダウンメニューからMUnitを選択する必要があります。
By Using the Wizard−この方法では、ウィザードを使用してテストを作成する必要があります。これにより、ワークスペース内の任意のフローのテストを作成できます。
「フローを右クリック」する方法を使用して、特定のフローのテストを作成します。
まず、次のようにワークスペースにフローを作成する必要があります-
次に、このフローを右クリックし、MUnitを選択して、以下に示すように、このフローのテストを作成します。
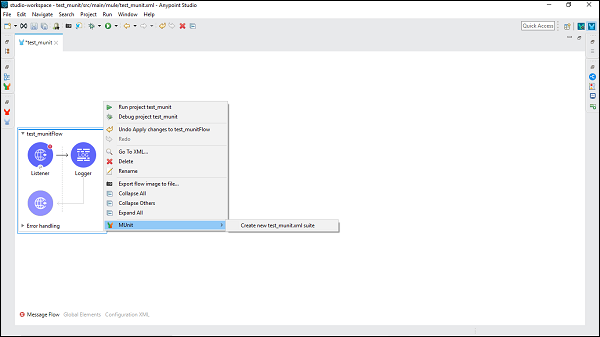
フローが存在するXMLファイルにちなんで名付けられた新しいテストスイートを作成します。この場合、test_munit-test-suite 以下に示すように、新しいテストスイートの名前です-
以下は、上記のメッセージフローのXMLエディタです-
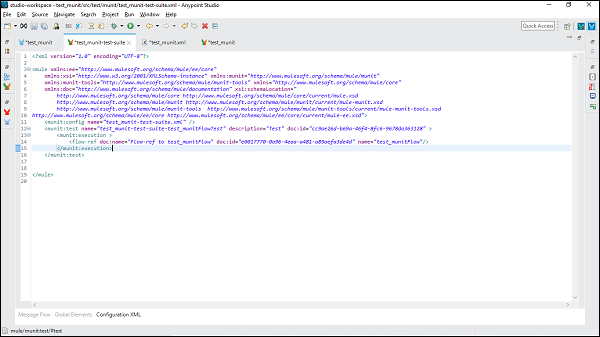
今、私たちは追加することができます MUnit メッセージプロセッサをMulePaletteからドラッグして、テストスイートに移動します。
ウィザードを使用してテストを作成する場合は、次の手順に従います。 File → New → MUnit そしてそれはあなたを次のMUnitテストスイートに導きます-
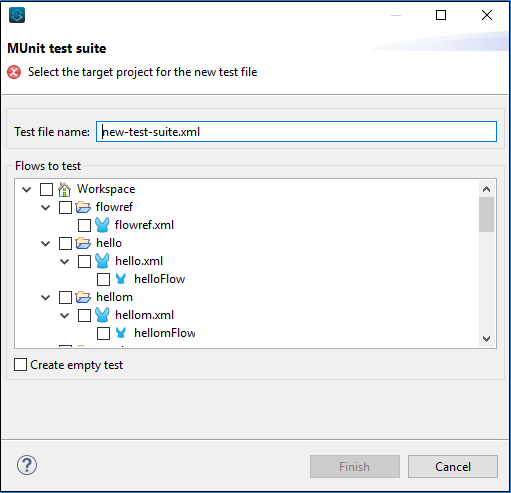
テストの構成
Mule 4には、2つの新しいセクションがあります。 MUnit そして MUnit Tools、すべてのMUnitメッセージプロセッサをまとめて持っています。MUnitテスト領域内の任意のメッセージプロセッサをドラッグできます。以下のスクリーンショットに示されています-
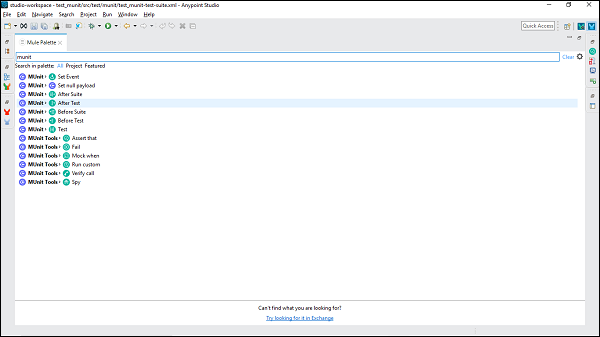
ここで、スーツの構成を編集したり、Anypoint Studioでテストしたりする場合は、以下の手順に従う必要があります-
Step 1
に移動します Package Explorer を右クリックします .xml fileあなたのスイートやテストのために。次に、Properties。
Step 2
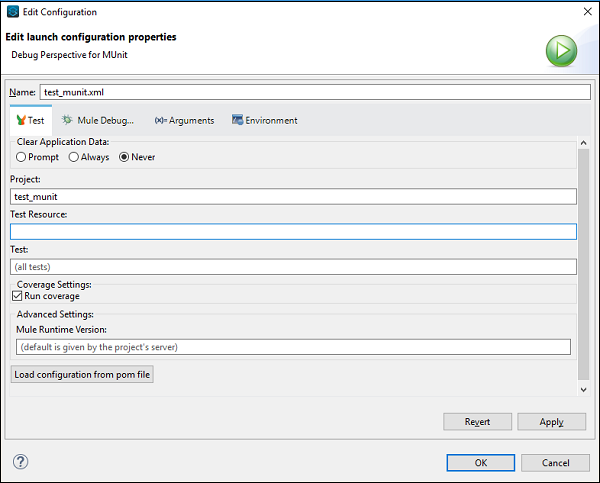
次に、[プロパティ]ウィンドウで、をクリックする必要があります Run/Debug Settings。このクリックの後New。
Step 3
最後のステップで、をクリックします MUnit 下 Select Configuration Type ウィンドウをクリックし、 OK。
テストの実行
テストだけでなく、テストスイートも実行できます。まず、テストスイートを実行する方法を説明します。
テストスイートの実行
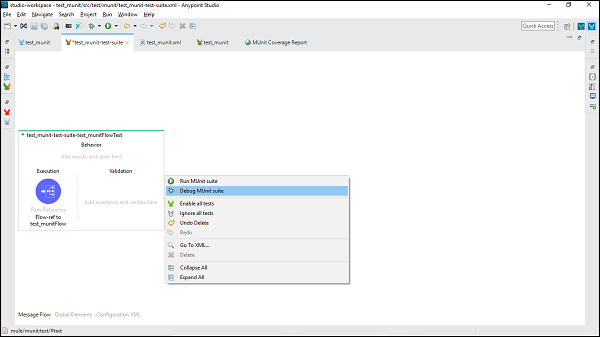
テストスイートを実行するには、テストスイートが存在するMuleCanvasの空の部分を右クリックします。ドロップダウンメニューが開きます。次に、をクリックしますRun MUnit suite 以下に示すように-
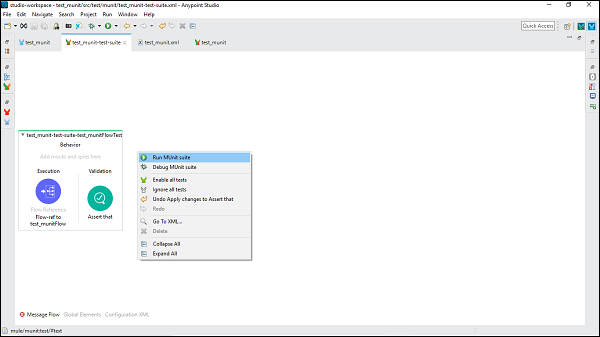
後で、コンソールに出力が表示されます。
テストの実行
特定のテストを実行するには、特定のテストを選択して右クリックする必要があります。テストスイートの実行中に表示されたものと同じドロップダウンメニューが表示されます。次に、をクリックしますRun MUnit Test 以下に示すオプション-

その後、コンソールに出力が表示されます。
テスト結果の表示と分析
Anypoint studioは、MUnitテスト結果を MUnit tab左側のエクスプローラペインの 以下に示すように、成功したテストは緑色で、失敗したテストは赤色で表示されます。
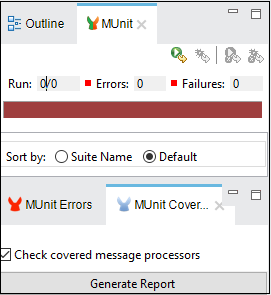
カバレッジレポートを表示することで、テスト結果を分析できます。カバレッジレポートの主な機能は、一連のMUnitテストによってMuleアプリケーションがどれだけ正常に実行されたかに関するメトリックを提供することです。MUnitのカバレッジは、基本的に、実行されたMUnitメッセージプロセッサの量に基づいています。MUnitカバレッジレポートは、次のメトリックを提供します-
- アプリケーション全体のカバレッジ
- リソースカバレッジ
- フローカバレッジ
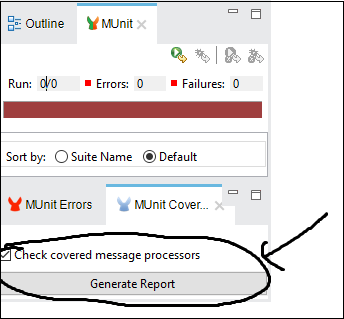
カバレッジレポートを取得するには、以下に示すように、[MUnit]タブの[GenerateReport]をクリックする必要があります-
テストのデバッグ
テストだけでなく、テストスイートもデバッグできます。まず、テストスイートをデバッグする方法を説明します。
テストスイートのデバッグ
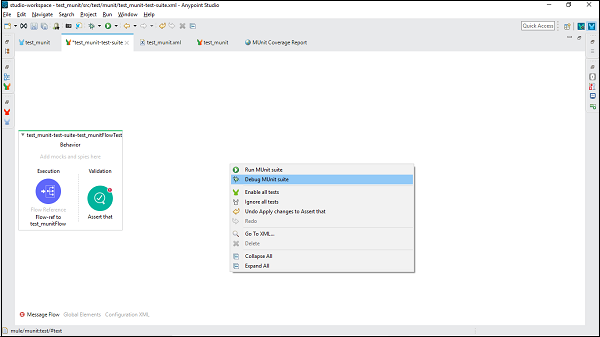
テストスイートをデバッグするには、テストスイートが存在するMuleCanvasの空の部分を右クリックします。ドロップダウンメニューが開きます。次に、をクリックしますDebug MUnit Suite 下の画像に示すように-
次に、コンソールに出力が表示されます。
テストのデバッグ
特定のテストをデバッグするには、特定のテストを選択して右クリックする必要があります。テストスイートのデバッグ中に取得したものと同じドロップダウンメニューが表示されます。次に、をクリックしますDebug MUnit Testオプション。以下のスクリーンショットに示されています。