ステミングとレマタイゼーション
ステミングとは何ですか?
ステミングは、接辞を削除して単語の基本形を抽出するために使用される手法です。木の枝を茎まで切り倒すようなものです。たとえば、単語の語幹eating, eats, eaten です eat。
検索エンジンは、単語のインデックス作成にステミングを使用します。そのため、検索エンジンはすべての形式の単語を保存するのではなく、語幹のみを保存できます。このようにして、ステミングはインデックスのサイズを縮小し、検索の精度を高めます。
さまざまなステミングアルゴリズム
NLTKでは、 stemmerI、持っている stem()メソッド、インターフェイスには、次に説明するすべてのステマーがあります。次の図で理解しましょう
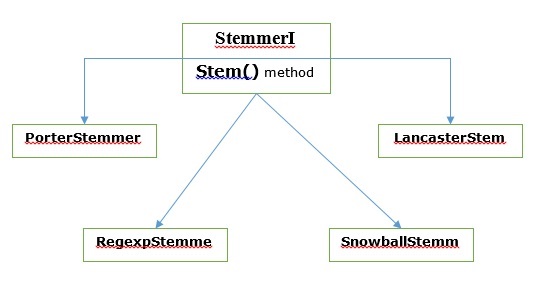
ポーターステミングアルゴリズム
これは最も一般的なステミングアルゴリズムの1つであり、基本的に英語の単語のよく知られた接尾辞を削除して置き換えるように設計されています。
PorterStemmerクラス
NLTKは PorterStemmerステミングしたい単語に対してPorterStemmerアルゴリズムを簡単に実装できるクラス。このクラスは、入力単語を最終的な語幹に変換できる助けを借りて、いくつかの通常の単語形式と接尾辞を知っています。結果として得られる語幹は、多くの場合、同じ語根の意味を持つ短い単語です。例を見てみましょう-
まず、自然言語ツールキット(nltk)をインポートする必要があります。
import nltk今、インポートします PorterStemmer PorterStemmerアルゴリズムを実装するクラス。
from nltk.stem import PorterStemmer次に、次のようにPorterStemmerクラスのインスタンスを作成します-
word_stemmer = PorterStemmer()ここで、語幹にしたい単語を入力します。
word_stemmer.stem('writing')出力
'write'word_stemmer.stem('eating')出力
'eat'完全な実装例
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')出力
'write'ランカスターステミングアルゴリズム
これはランカスター大学で開発されたもので、もう1つの非常に一般的なステミングアルゴリズムです。
LancasterStemmerクラス
NLTKは LancasterStemmerステミングしたい単語に対してランカスターステマーアルゴリズムを簡単に実装できるクラス。例を見てみましょう-
まず、自然言語ツールキット(nltk)をインポートする必要があります。
import nltk今、インポートします LancasterStemmer LancasterStemmerアルゴリズムを実装するクラス
from nltk.stem import LancasterStemmer次に、のインスタンスを作成します LancasterStemmer 次のようにクラス-
Lanc_stemmer = LancasterStemmer()ここで、語幹にしたい単語を入力します。
Lanc_stemmer.stem('eats')出力
'eat'完全な実装例
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')出力
'eat'正規表現ステミングアルゴリズム
このステミングアルゴリズムの助けを借りて、独自のステマーを構築できます。
RegexpStemmerクラス
NLTKは RegexpStemmer正規表現ステマーアルゴリズムを簡単に実装できるクラス。基本的に単一の正規表現を取り、式に一致するプレフィックスまたはサフィックスを削除します。例を見てみましょう-
まず、自然言語ツールキット(nltk)をインポートする必要があります。
import nltk今、インポートします RegexpStemmer 正規表現ステマーアルゴリズムを実装するクラス。
from nltk.stem import RegexpStemmer次に、のインスタンスを作成します RegexpStemmer クラスと次のように単語から削除したい接尾辞または接頭辞を提供します-
Reg_stemmer = RegexpStemmer(‘ing’)ここで、語幹にしたい単語を入力します。
Reg_stemmer.stem('eating')出力
'eat'Reg_stemmer.stem('ingeat')出力
'eat'
Reg_stemmer.stem('eats')出力
'eat'完全な実装例
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')出力
'eat'スノーボールステミングアルゴリズム
これは、もう1つの非常に便利なステミングアルゴリズムです。
SnowballStemmerクラス
NLTKは SnowballStemmerSnowballStemmerアルゴリズムを簡単に実装できるクラス。15の英語以外の言語をサポートします。このsteamingクラスを使用するには、使用している言語の名前でインスタンスを作成してから、stem()メソッドを呼び出す必要があります。例を見てみましょう-
まず、自然言語ツールキット(nltk)をインポートする必要があります。
import nltk今、インポートします SnowballStemmer SnowballStemmerアルゴリズムを実装するクラス
from nltk.stem import SnowballStemmerサポートされている言語を見てみましょう-
SnowballStemmer.languages出力
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)次に、使用する言語でSnowballStemmerクラスのインスタンスを作成します。ここでは、「フランス語」言語のステマーを作成しています。
French_stemmer = SnowballStemmer(‘french’)次に、stem()メソッドを呼び出して、ステミングする単語を入力します。
French_stemmer.stem (‘Bonjoura’)出力
'bonjour'完全な実装例
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)出力
'bonjour'Lemmatizationとは何ですか?
Lemmatizationテクニックはステミングのようなものです。補題の後に得られる出力は「補題」と呼ばれます。これは、語幹の出力である語根ではなく、語根の単語です。レンマ化後、同じことを意味する有効な単語を取得します。
NLTKは提供します WordNetLemmatizer の周りの薄いラッパーであるクラス wordnetコーパス。このクラスはmorphy() 機能する WordNet CorpusReader補題を見つけるためのクラス。例を挙げて理解しましょう−
例
まず、自然言語ツールキット(nltk)をインポートする必要があります。
import nltk今、インポートします WordNetLemmatizer レンマ化手法を実装するクラス。
from nltk.stem import WordNetLemmatizer次に、のインスタンスを作成します WordNetLemmatizer クラス。
lemmatizer = WordNetLemmatizer()ここで、lemmatize()メソッドを呼び出して、補題を見つけたい単語を入力します。
lemmatizer.lemmatize('eating')出力
'eating'lemmatizer.lemmatize('books')出力
'book'完全な実装例
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')出力
'book'ステミングとレマタイゼーションの違い
次の例を使用して、ステミングとレマタイゼーションの違いを理解しましょう。
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')出力
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')出力
believ両方のプログラムの出力は、ステミングとレンマ化の主な違いを示しています。 PorterStemmerクラスは単語から「es」を切り落とします。一方、WordNetLemmatizerクラスは有効な単語を見つけます。簡単に言えば、ステミング技法は単語の形式のみを調べますが、レンマ化技法は単語の意味を調べます。これは、レンマ化を適用した後、常に有効な単語を取得することを意味します。