自然言語ツールキット-ユニグラムタガー
ユニグラムタガーとは何ですか?
名前が示すように、ユニグラムタガーは、POS(Part-of-Speech)タグを決定するためのコンテキストとして1つの単語のみを使用するタガーです。簡単に言うと、Unigram Taggerはコンテキストベースのタガーであり、そのコンテキストは単一の単語、つまりUnigramです。
それはどのように機能しますか?
NLTKはという名前のモジュールを提供します UnigramTaggerこの目的のために。しかし、その動作を深く掘り下げる前に、次の図を使用して階層を理解しましょう-
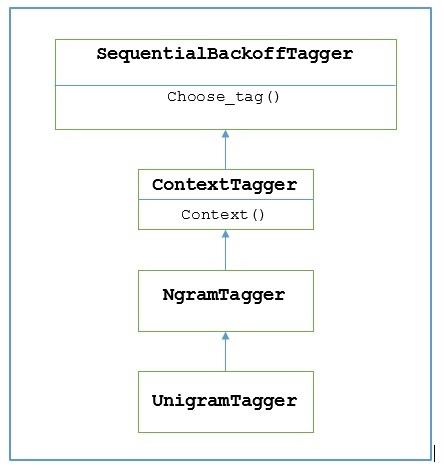
上図から、 UnigramTagger から継承されます NgramTagger これはのサブクラスです ContextTagger、から継承します SequentialBackoffTagger。
の働き UnigramTagger 次の手順の助けを借りて説明されています-
私たちが見たとおり、 UnigramTagger から継承 ContextTagger、それは実装します context()方法。このcontext() メソッドは、と同じ3つの引数を取ります choose_tag() 方法。
結果として context()メソッドは、モデルの作成にさらに使用される単語トークンになります。モデルが作成されると、トークンという単語も最適なタグを検索するために使用されます。
この方法では、 UnigramTagger タグ付けされた文のリストからコンテキストモデルを構築します。
ユニグラムタガーのトレーニング
NLTKの UnigramTagger初期化時にタグ付けされた文のリストを提供することでトレーニングできます。以下の例では、ツリーバンクコーパスのタグ付き文を使用します。そのコーパスの最初の2500文を使用します。
例
まず、nltkからUniframTaggerモジュールをインポートします-
from nltk.tag import UnigramTagger次に、使用するコーパスをインポートします。ここではツリーバンクコーパスを使用しています-
from nltk.corpus import treebankさて、訓練目的のために文章を取りなさい。トレーニング目的で最初の2500文を取得し、タグを付けます-
train_sentences = treebank.tagged_sents()[:2500]次に、トレーニング目的で使用される文にUnigramTaggerを適用します-
Uni_tagger = UnigramTagger(train_sentences)テスト目的で、トレーニング目的、つまり2500と同じかそれ以下の文章をいくつか取ります。ここでは、テスト目的で最初の1500を使用しています-
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)出力
0.8942306156033808ここでは、単一の単語のルックアップを使用してPOSタグを決定するタガーの精度が約89%になりました。
完全な実装例
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)出力
0.8942306156033808コンテキストモデルのオーバーライド
の階層を示す上の図から UnigramTagger、から継承するすべてのタガーを知っています ContextTagger、独自にトレーニングする代わりに、事前に構築されたモデルを使用できます。この事前に構築されたモデルは、コンテキストキーをタグにマッピングするPython辞書です。そしてのためにUnigramTagger、コンテキストキーは個々の単語ですが、他の場合は NgramTagger サブクラス、それはタプルになります。
別の単純なモデルをに渡すことで、このコンテキストモデルをオーバーライドできます。 UnigramTaggerトレーニングセットに合格する代わりにクラス。以下の簡単な例の助けを借りてそれを理解しましょう-
例
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])出力
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]モデルには唯一のコンテキストキーとして「Vinken」が含まれているため、上記の出力から、この単語のみがタグを取得し、他のすべての単語はタグとしてNoneを持っていることがわかります。
最小周波数しきい値の設定
特定のコンテキストで最も可能性の高いタグを決定するために、 ContextTaggerクラスは発生頻度を使用します。コンテキストワードとタグが1回だけ出現する場合でも、デフォルトでそれを実行しますが、最小頻度しきい値を設定するには、cutoff の価値 UnigramTaggerクラス。以下の例では、UnigramTaggerをトレーニングした前のレシピのカットオフ値を渡します-
例
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)出力
0.7357651629613641