並列アルゴリズム-モデル
並列アルゴリズムのモデルは、データと処理方法を分割するための戦略を検討し、相互作用を減らすために適切な戦略を適用することによって開発されます。この章では、次の並列アルゴリズムモデルについて説明します。
- データ並列モデル
- タスクグラフモデル
- 作業プールモデル
- マスタースレーブモデル
- プロデューサーコンシューマーまたはパイプラインモデル
- ハイブリッドモデル
データ並列
データ並列モデルでは、タスクがプロセスに割り当てられ、各タスクが異なるデータに対して同様のタイプの操作を実行します。 Data parallelism これは、複数のデータ項目に適用されている単一の操作の結果です。
データ並列モデルは、共有アドレス空間とメッセージパッシングパラダイムに適用できます。データ並列モデルでは、局所性を維持する分解を選択するか、最適化された集合的な相互作用ルーチンを使用するか、計算と相互作用を重複させることにより、相互作用のオーバーヘッドを減らすことができます。
データ並列モデルの問題の主な特徴は、データの並列性の強度が問題のサイズとともに増加することです。これにより、より多くのプロセスを使用してより大きな問題を解決できるようになります。
Example −密な行列の乗算。

タスクグラフモデル
タスクグラフモデルでは、並列処理は次のように表されます。 task graph。タスクグラフは、取るに足らないものでも、取るに足らないものでもかまいません。このモデルでは、タスク間の相関関係を利用して、局所性を促進したり、対話コストを最小限に抑えたりします。このモデルは、タスクに関連付けられた計算の数と比較して、タスクに関連付けられたデータの量が膨大であるという問題を解決するために適用されます。タスクは、タスク間のデータ移動のコストを改善するために割り当てられます。
Examples −分割統治法によって導出された並列クイックソート、スパース行列因数分解、および並列アルゴリズム。
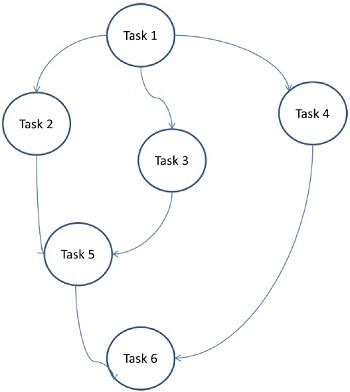
ここでは、問題がアトミックタスクに分割され、グラフとして実装されます。各タスクは、1つ以上の先行タスクに依存する独立したジョブ単位です。タスクの完了後、先行タスクの出力が依存タスクに渡されます。先行タスクのあるタスクは、先行タスク全体が完了したときにのみ実行を開始します。グラフの最終出力は、最後の依存タスクが完了したときに受信されます(上の図のタスク6)。
作業プールモデル
ワークプールモデルでは、負荷を分散するためにタスクがプロセスに動的に割り当てられます。したがって、任意のプロセスが任意のタスクを実行する可能性があります。このモデルは、タスクに関連付けられたデータの量がタスクに関連付けられた計算よりも比較的少ない場合に使用されます。
プロセスへのタスクの望ましい事前割り当てはありません。タスクの割り当ては集中化または分散化されています。タスクへのポインタは、物理的に共有されたリスト、優先度キュー、またはハッシュテーブルやツリーに保存されます。あるいは、物理的に分散されたデータ構造に保存されることもあります。
タスクは最初から利用できる場合もあれば、動的に生成される場合もあります。タスクが動的に生成され、タスクの分散割り当てが行われる場合、すべてのプロセスが実際にプログラム全体の完了を検出し、それ以上のタスクの検索を停止できるように、終了検出アルゴリズムが必要です。
Example −並列ツリー検索

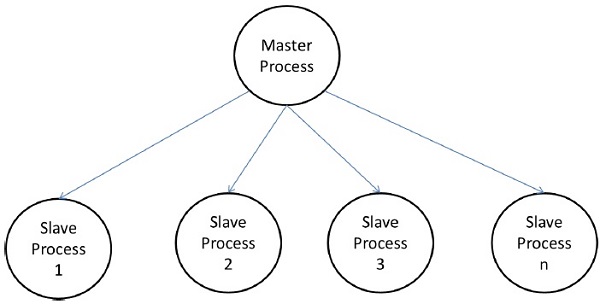
マスタースレーブモデル
マスタースレーブモデルでは、1つ以上のマスタープロセスがタスクを生成し、それをスレーブプロセスに割り当てます。次の場合、タスクは事前に割り当てられます。
- マスターはタスクの量を見積もることができます、または
- ランダムな割り当ては、負荷のバランスをとるという満足のいく仕事をすることができます。
- スレーブには、異なる時間に小さなタスクが割り当てられます。
このモデルは、一般的に shared-address-space または message-passing paradigms, 相互作用は当然2つの方法であるためです。
場合によっては、タスクを段階的に完了する必要があり、次の段階のタスクを生成する前に、各段階のタスクを完了する必要があります。マスタースレーブモデルは、次のように一般化できます。hierarchical または multi-level master-slave model トップレベルのマスターがタスクの大部分をセカンドレベルのマスターにフィードします。セカンドレベルのマスターは、タスクを自身のスレーブ間でさらに細分化し、タスク自体の一部を実行する場合があります。
マスタースレーブモデルを使用する際の注意事項
マスターが混雑ポイントにならないように注意する必要があります。タスクが小さすぎるか、作業者が比較的速い場合に発生する可能性があります。
タスクは、タスクを実行するコストが通信のコストと同期のコストを支配するように選択する必要があります。
非同期の相互作用は、マスターによる作業生成に関連する相互作用と計算の重複に役立つ場合があります。
パイプラインモデル
としても知られています producer-consumer model。ここでは、一連のデータが一連のプロセスを介して渡され、各プロセスが何らかのタスクを実行します。ここで、新しいデータの到着は、キュー内のプロセスによる新しいタスクの実行を生成します。プロセスは、線形または多次元の配列、ツリー、またはサイクルの有無にかかわらず一般的なグラフの形でキューを形成できます。
このモデルは、生産者と消費者のチェーンです。キュー内の各プロセスは、キュー内で先行するプロセスの一連のデータアイテムのコンシューマー、およびキュー内で後続するプロセスのデータのプロデューサーと見なすことができます。キューは線形チェーンである必要はありません。有向グラフにすることができます。このモデルに適用できる最も一般的な相互作用最小化手法は、相互作用と計算の重複です。
Example −並列LU分解アルゴリズム。

ハイブリッドモデル
問題を解決するために複数のモデルが必要になる可能性がある場合は、ハイブリッドアルゴリズムモデルが必要です。
ハイブリッドモデルは、階層的に適用される複数のモデル、または並列アルゴリズムの異なるフェーズに順次適用される複数のモデルのいずれかで構成されます。
Example −並列クイックソート