PyTorch-ニューラルネットワークの基本
ニューラルネットワークの主な原理には、基本的な要素、つまり人工ニューロンまたはパーセプトロンのコレクションが含まれます。これには、x1、x2….. xnなどのいくつかの基本的な入力が含まれ、合計が活動電位よりも大きい場合にバイナリ出力を生成します。
サンプルニューロンの概略図を以下に示します-

生成された出力は、活動電位またはバイアスを伴う加重和と見なすことができます。
$$出力= \ sum_jw_jx_j +バイアス$$
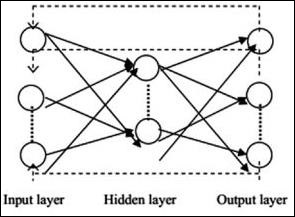
典型的なニューラルネットワークアーキテクチャを以下に説明します-

入力と出力の間のレイヤーは非表示レイヤーと呼ばれ、レイヤー間の接続の密度とタイプが構成です。たとえば、完全に接続された構成では、レイヤーLのすべてのニューロンがL +1のニューロンに接続されます。より明確なローカリゼーションのために、ローカル近傍、たとえば9つのニューロンのみを次の層に接続できます。図1-9は、密な接続を持つ2つの隠れ層を示しています。
さまざまな種類のニューラルネットワークは次のとおりです。
フィードフォワードニューラルネットワーク
フィードフォワードニューラルネットワークには、ニューラルネットワークファミリーの基本単位が含まれています。このタイプのニューラルネットワークでのデータの移動は、現在の隠れ層を経由して、入力層から出力層へと行われます。1つの層の出力は、ネットワークアーキテクチャ内のあらゆる種類のループに制限のある入力層として機能します。

リカレントニューラルネットワーク
リカレントニューラルネットワークは、データパターンが一定期間にわたって結果的に変化する場合です。RNNでは、同じレイヤーが適用され、指定されたニューラルネットワークで入力パラメーターを受け入れて出力パラメーターを表示します。
ニューラルネットワークは、torch.nnパッケージを使用して構築できます。

これは単純なフィードフォワードネットワークです。入力を受け取り、それをいくつかのレイヤーに次々にフィードし、最後に出力を提供します。
PyTorchの助けを借りて、ニューラルネットワークの一般的なトレーニング手順に次の手順を使用できます-
- いくつかの学習可能なパラメーター(または重み)を持つニューラルネットワークを定義します。
- 入力のデータセットを反復処理します。
- ネットワークを介して入力を処理します。
- 損失を計算します(出力が正しいことからどれだけ離れているか)。
- 勾配をネットワークのパラメータに伝播します。
- ネットワークの重みを更新します。通常は、以下に示す簡単な更新を使用します。
rule: weight = weight -learning_rate * gradient