SAPHANA-クイックガイド
SAP HANAは、HANAデータベース、データモデリング、HANA管理、およびデータプロビジョニングを1つのスイートに組み合わせたものです。SAP HANAでは、HANAはHigh-Performance AnalyticApplianceの略です。
SAPの元幹部であるDr.Vishal Sikkaによると、HANAはHassoの新しいアーキテクチャの略です。HANAは2011年半ばまでに関心を高め、その後、さまざまなフォーチュン500企業がビジネスウェアハウスのニーズを維持するためのオプションとして検討し始めました。
SAPHANAの機能
SAPHANAの主な機能を以下に示します-
SAP HANAは、ソフトウェアとハードウェアの革新を組み合わせて、大量のリアルタイムデータを処理します。
分散システム環境のマルチコアアーキテクチャに基づいています。
データベース内のデータストレージの行と列のタイプに基づきます。
大量のリアルタイムデータを処理および分析するために、メモリコンピューティングエンジン(IMCE)で広く使用されています。
所有コストを削減し、アプリケーションのパフォーマンスを向上させ、以前は不可能だった新しいアプリケーションをリアルタイム環境で実行できるようにします。
これはC ++で記述されており、1つのオペレーティングシステムSuse Linux Enterprise Server 11 SP1 / 2のみをサポートおよび実行します。
SAPHANAの必要性
今日、ほとんどの成功した企業は、市場の変化と新しい機会に迅速に対応しています。これの鍵は、アナリストとマネージャーによるデータと情報の効果的かつ効率的な使用です。
HANAは以下の制限を克服します-
「データ量」の増加により、分析やビジネスで使用するためにリアルタイムデータへのアクセスを提供することは企業にとっての課題です。
IT企業が大量のデータを保存および維持するには高い維持費がかかります。
リアルタイムデータが利用できないため、分析と処理の結果が遅れます。
SAPHANAベンダー
SAPは、IBM、Dell、Ciscoなどの主要なITハードウェアベンダーと提携し、SAPライセンスサービスおよびテクノロジーと組み合わせてSAPHANAプラットフォームを販売しています。
HANAアプライアンスを製造し、HANAシステムのインストールと構成をオンサイトでサポートするベンダーは合計11社あります。
Top few Vendors include −
- IBM
- Dell
- HP
- Cisco
- Fujitsu
- レノボ(中国)
- NEC
- Huawei
SAPが提供する統計によると、IBMはSAP HANAハードウェアアプライアンスの主要ベンダーの1つであり、市場シェアは50〜52%ですが、HANAクライアントが実施した別の市場調査によると、IBMの市場シェアは最大70%です。
SAPHANAのインストール
HANAハードウェアベンダーは、ハードウェア、オペレーティングシステム、およびSAPソフトウェア製品用に事前構成されたアプライアンスを提供します。
ベンダーは、HANAコンポーネントのオンサイトセットアップと構成によってインストールを完了します。このオンサイト訪問には、データセンターでのHANAシステムの導入、組織ネットワークへの接続、SAPシステムIDの適応、Solution Managerからの更新、SAPルーター接続、SSLイネーブルメント、およびその他のシステム構成が含まれます。
顧客/クライアントは、データソースシステムとBIクライアントの接続から始まります。HANA Studioのインストールがローカルシステムで完了し、HANAシステムが追加されてデータのモデリングと管理が実行されます。
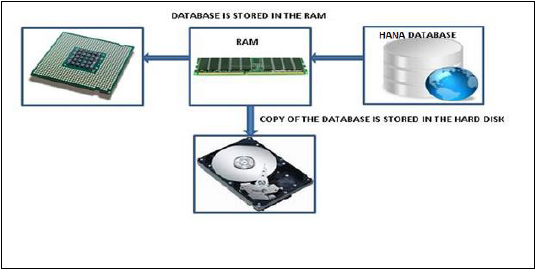
インメモリデータベースとは、ソースシステムからのすべてのデータがRAMメモリに保存されることを意味します。従来のデータベースシステムでは、すべてのデータがハードディスクに保存されます。SAP HANAインメモリデータベースは、ハードディスクからRAMにデータをロードするのに時間を無駄にしません。情報処理と分析のためにマルチコアCPUへのデータへのより高速なアクセスを提供します。
インメモリデータベースの機能
SAPHANAインメモリデータベースの主な機能は次のとおりです。
SAP HANAは、ハイブリッドインメモリデータベースです。
これは、行ベース、列ベース、およびオブジェクト指向の基本テクノロジーを組み合わせたものです。
マルチコアCPUアーキテクチャによる並列処理を使用します。
従来のデータベースは5ミリ秒でメモリデータを読み取ります。SAPHANAインメモリデータベースは5ナノ秒でデータを読み取ります。
つまり、HANAデータベースのメモリ読み取りは、従来のデータベースのハードディスクメモリ読み取りよりも100万倍高速です。
アナリストは、現在のデータをリアルタイムですぐに確認したいと考えており、SAPBWシステムにロードされるまでデータを待ちたくありません。SAP HANAインメモリ処理により、さまざまなデータプロビジョニング技術を使用してリアルタイムデータをロードできます。
インメモリデータベースの利点
HANAデータベースは、インメモリ処理を利用して最速のデータ取得速度を提供します。これは、大規模なオンライントランザクションやタイムリーな予測と計画に苦労している企業を魅了します。
ディスクベースのストレージは依然として企業の標準であり、RAMの価格は着実に下落しているため、メモリを大量に消費するアーキテクチャは、最終的には低速で機械的に回転するディスクに取って代わり、データストレージのコストを削減します。
インメモリ列ベースのストレージは、最大11倍のデータ圧縮を提供するため、巨大なデータのストレージスペースを削減します。
RAMストレージシステムによって提供されるこの速度の利点は、分散環境でマルチコアCPU、ノードごとに複数のCPU、サーバーごとに複数のノードを使用することでさらに強化されます。
SAP HANAスタジオは、Eclipseベースのツールです。SAP HANAスタジオは、HANAシステムの中央開発環境であると同時に主要な管理ツールでもあります。追加機能は次のとおりです。
これは、ローカルまたはリモートのHANAシステムにアクセスするために使用できるクライアントツールです。
これは、HANAデータベースでのHANA管理、HANA情報モデリング、およびデータプロビジョニングのための環境を提供します。
SAP HANA Studioは、次のプラットフォームで使用できます-
Microsoft Windows 32および64ビットバージョン:Windows XP、Windows Vista、Windows 7
SUSE Linux Enterprise Server SLES11:x8664ビット
Mac OS、HANAスタジオクライアントは利用できません
HANA Studioのインストールによっては、すべての機能が利用できるとは限りません。Studioのインストール時に、役割ごとにインストールする機能を指定します。HANAスタジオの最新バージョンで作業するには、Software Life CycleManagerをクライアントの更新に使用できます。
SAP HANAStudioの展望/機能
SAP HANA Studioは、次のHANA機能に取り組むための視点を提供します。次のオプションからHANAStudioのパースペクティブを選択できます-
HANA Studio → Window → Open Perspective → Other
SAP HanaStudioの管理
トランスポータブルな設計時リポジトリオブジェクトを除く、さまざまな管理タスク用のツールセット。トレース、カタログブラウザ、SQLコンソールなどの一般的なトラブルシューティングツールも含まれています。
SAP HANAStudioデータベースの開発
コンテンツ開発用のツールセットを提供します。特に、SAP HANAネイティブアプリケーション開発(XS)を含まないSAPHANAシナリオでのDataMartsとABAPに対応しています。
SAP HANAStudioアプリケーション開発
SAP HANAシステムには、小さなアプリケーションをホストするために使用できる小さなWebサーバーが含まれています。JavaやHTMLで記述されたアプリケーションコードなどのSAPHANAネイティブアプリケーションを開発するためのツールセットを提供します。
デフォルトでは、すべての機能がインストールされています。
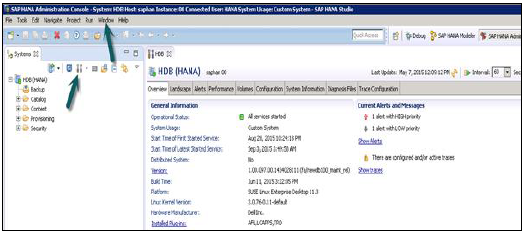
HANAデータベースの管理および監視機能を実行するには、SAPHANA管理コンソールパースペクティブを使用できます。
管理者エディターには、いくつかの方法でアクセスできます-
From System View Toolbar − [管理を開く]デフォルトボタンを選択します
In System View −HANAシステムまたはオープンパースペクティブをダブルクリックします
HANA Studio:管理者エディター
管理ビュー:HANAスタジオには、HANAシステムの構成と状態を確認するための複数のタブがあります。[概要]タブには、運用ステータス、最初と最後に開始されたサービスの開始時刻、バージョン、ビルドの日時、プラットフォーム、ハードウェアの製造元などの一般情報が表示されます。
スタジオへのHANAシステムの追加
管理および情報モデリングの目的で、単一または複数のシステムをHANAスタジオに追加できます。新しいHANAシステムを追加するには、ホスト名、インスタンス番号、データベースのユーザー名とパスワードが必要です。
- データベースに接続するには、ポート3615が開いている必要があります
- ポート31015インスタンス番号10
- ポート30015インスタンス番号00
- SShポートも開く必要があります
HanaStudioへのシステムの追加
HANAスタジオにシステムを追加するには、所定の手順に従います。
ナビゲータースペースを右クリックし、「システムの追加」をクリックします。HANAシステムの詳細、つまりホスト名とインスタンス番号を入力し、[次へ]をクリックします。
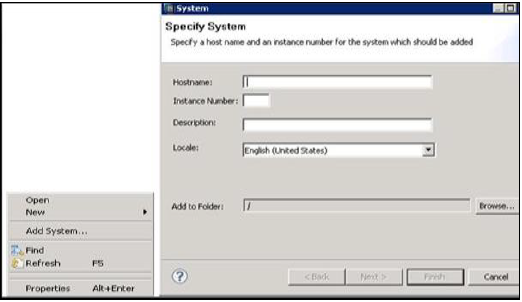
データベースのユーザー名とパスワードを入力して、SAPHANAデータベースに接続します。[次へ]、[完了]の順にクリックします。
[完了]をクリックすると、HANAシステムが管理およびモデリングの目的でシステムビューに追加されます。各HANAシステムには、カタログとコンテンツの2つの主要なサブノードがあります。
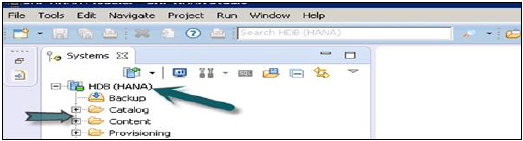
カタログとコンテンツ
カタログ
これには、使用可能なすべてのスキーマ、つまりすべてのデータ構造、テーブルとデータ、列ビュー、[コンテンツ]タブで使用できるプロシージャが含まれています。
コンテンツ
[コンテンツ]タブには、HANAモデラーで作成されたデータモデルのすべての情報を保持するデザインタイムリポジトリが含まれています。これらのモデルはパッケージにまとめられています。コンテンツノードは、同じ物理データに対して異なるビューを提供します。
HANAスタジオのシステムモニターは、すべてのHANAシステムの概要を一目で確認できます。システムモニターから、管理エディターで個々のシステムの詳細にドリルダウンできます。データディスク、ログディスク、トレースディスク、リソース使用量に関するアラートを優先的に通知します。
次の情報は、システムモニターで利用できます-

SAPHANA情報モデラー; HANAデータモデラーとも呼ばれ、HANAシステムの心臓部です。これにより、データベーステーブルの上部にモデリングビューを作成し、ビジネスロジックを実装して、分析用の意味のあるレポートを作成できます。
インフォメーションモデラーの特徴
分析およびビジネスロジックの目的で、HANAデータベースの物理テーブルに格納されているトランザクションデータの複数のビューを提供します。
情報モデラーは、列ベースのストレージテーブルに対してのみ機能します。
情報モデリングビューは、レポートの目的で、JavaまたはHTMLベースのアプリケーション、またはSAPLumiraやAnalysisOfficeなどのSAPツールによって使用されます。
MS Excelなどのサードパーティツールを使用してHANAに接続し、レポートを作成することもできます。
SAP HANAモデリングビューは、SAPHANAの真の力を活用します。
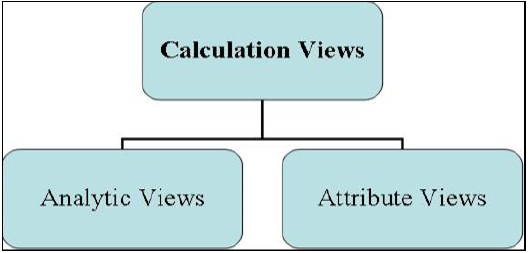
情報ビューには、次の3つのタイプがあります。
- 属性ビュー
- 分析ビュー
- 計算ビュー
行と列のストア
SAP HANA Modelerビューは、列ベースのテーブルの上部にのみ作成できます。列テーブルにデータを保存することは新しいことではありません。以前は、列ベースの構造にデータを格納すると、パフォーマンスが最適化されるのではなく、より多くのメモリサイズが必要になると想定されていました。
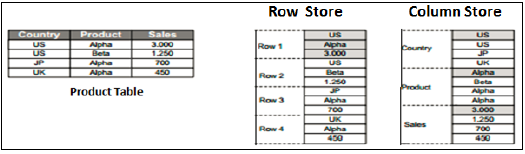
SAP HANAの進化に伴い、HANAは情報ビューで列ベースのデータストレージを使用し、行ベースのテーブルに対する列テーブルの真の利点を示しました。
列ストア
列ストアテーブルでは、データは垂直方向に保存されます。したがって、上記の例に示すように、同様のデータ型が一緒になります。インメモリコンピューティングエンジンの助けを借りて、より高速なメモリの読み取りおよび書き込み操作を提供します。
従来のデータベースでは、データは行ベースの構造、つまり水平方向に格納されます。SAP HANAは、データを行ベースと列ベースの両方の構造で保存します。これにより、HANAデータベースのパフォーマンスの最適化、柔軟性、およびデータ圧縮が実現します。
列ベースのテーブルにデータを保存すると、次の利点があります-
データ圧縮
従来の行ベースのストレージと比較して、テーブルへの読み取りおよび書き込みアクセスが高速
柔軟性と並列処理
集計と計算をより高速に実行する
列ベースの構造にデータを格納する方法には、さまざまな方法とアルゴリズムがあります。辞書圧縮、ランレングス圧縮などです。
Dictionary Compressedでは、セルはテーブルに数値の形式で格納され、数値セルは常に文字と比較してパフォーマンスが最適化されます。
ランレングス圧縮では、セル値とともに乗数を数値形式で保存し、乗数は表に繰り返し値を表示します。

機能の違い-行ストアと列ストア
SQLステートメントで集計関数と計算を実行する必要がある場合は、列ベースのストレージを使用することを常にお勧めします。Sum、Count、Max、Minなどの集計関数を実行すると、列ベースのテーブルのパフォーマンスが常に向上します。
出力が完全な行を返す必要がある場合は、行ベースのストレージが推奨されます。以下の例は、理解しやすいものです。

上記の例では、Where句を使用してsales列で集計関数(Sum)を実行すると、SQLクエリの実行中にDate列とSales列のみが使用されるため、列ベースのストレージテーブルの場合、パフォーマンスが最適化され、データとして高速になります2つの列からのみ必要です。
単純なSelectクエリを実行している間は、行全体を出力に出力する必要があるため、このシナリオに基づいてテーブルを行として格納することをお勧めします。
情報モデリングビュー
属性ビュー
属性は、データベーステーブル内の測定不可能な要素です。これらはマスタデータを表し、BWの特性に類似しています。属性ビューはデータベース内のディメンションであるか、モデリングでディメンションまたはその他の属性ビューを結合するために使用されます。
重要な機能は次のとおりです。
- 属性ビューは、分析ビューと計算ビューで使用されます。
- 属性ビューはマスタデータを表します。
- 分析ビューと計算ビューでディメンションテーブルのサイズをフィルタリングするために使用されます。
分析ビュー
Analytic Viewsは、SAP HANAの機能を使用して、データベース内のテーブルに対して計算および集計機能を実行します。ディメンションテーブルのメジャーと主キーがあり、ディメンションテーブルに囲まれているファクトテーブルが少なくとも1つあり、マスターデータが含まれています。
重要な機能は次のとおりです。
分析ビューは、スタースキーマクエリを実行するように設計されています。
分析ビューには、マスターデータを含む少なくとも1つのファクトテーブルと複数のディメンションテーブルが含まれ、計算と集計を実行します
これらは、SAPBWのインフォキューブおよびインフォオブジェクトに類似しています。
分析ビューは、属性ビューとファクトテーブルの上に作成でき、販売台数、合計価格などの計算を実行します。
計算ビュー
計算ビューは、分析ビューと属性ビューの上に使用され、分析ビューでは不可能な複雑な計算を実行します。計算ビューは、ベース列テーブル、属性ビュー、および分析ビューを組み合わせて、ビジネスロジックを提供します。
重要な機能は次のとおりです。
計算ビューは、HANAモデリング機能を使用してグラフィカルに定義するか、SQLでスクリプト化して定義します。
これは、SAPHANAモデラーの他のビュー-属性ビューと分析ビューでは不可能な複雑な計算を実行するために作成されています。
1つ以上の属性ビューと分析ビューは、計算ビューのプロジェクト、結合、結合、ランクなどの組み込み関数を使用して使用されます。
SAP HANAは当初、JavaおよびC ++で開発され、オペレーティングシステムSuse Linux Enterprise Server11のみを実行するように設計されていました。SAPHANAシステムは、HANAシステムの計算能力を強調する複数のコンポーネントで構成されています。
SAP HANAシステムの最も重要なコンポーネントは、データベースのクエリステートメントを処理するSQL / MDXプロセッサを含むインデックスサーバーです。
HANAシステムには、ネームサーバー、プリプロセッササーバー、統計サーバー、XSエンジンが含まれており、これらは小さなWebアプリケーションやその他のさまざまなコンポーネントとの通信とホストに使用されます。

インデックスサーバー
Index Serverは、SAPHANAデータベースシステムの心臓部です。実際のデータとそのデータを処理するためのエンジンが含まれています。SAP HANAシステムに対してSQLまたはMDXが起動されると、インデックスサーバーがこれらすべての要求を処理して処理します。すべてのHANA処理はインデックスサーバーで行われます。
Index Serverには、HANAデータベースシステムに送信されるすべてのSQL / MDXステートメントを処理するためのデータエンジンが含まれています。また、HANAシステムの耐久性を担い、システム障害の再開時にHANAシステムが最新の状態に復元されることを保証する永続性レイヤーも備えています。
Index Serverには、トランザクションを管理し、実行中および終了したすべてのトランザクションを追跡するSessionおよびTransactionManagerもあります。

インデックスサーバー-アーキテクチャ
SQL / MDXプロセッサ
クエリの実行を担当するデータエンジンを使用してSQL / MDXトランザクションを処理します。すべてのクエリリクエストをセグメント化し、パフォーマンス最適化のためにエンジンを修正するように指示します。
また、すべてのSQL / MDX要求が許可されていることを確認し、これらのステートメントを効率的に処理するためのエラー処理も提供します。クエリ実行用のいくつかのエンジンとプロセッサが含まれています-
MDX(Multi Dimension Expression)は、SQLがリレーショナルデータベースに使用されるようなOLAPシステムのクエリ言語です。MDX Engineは、クエリを処理し、OLAPキューブに格納されている多次元データを操作します。
Planning Engineは、SAPHANAデータベース内で計画操作を実行する責任があります。
計算エンジンは、データを計算モデルに変換して、ステートメントの並列処理をサポートする論理実行プランを作成します。
ストアドプロシージャプロセッサは、最適化された処理のためにプロシージャ呼び出しを実行します。OLAPキューブをHANA最適化キューブに変換します。
トランザクションとセッションの管理
すべてのデータベーストランザクションを調整し、実行中および終了したすべてのトランザクションを追跡する責任があります。
トランザクションが実行または失敗すると、トランザクションマネージャーは関連するデータエンジンに必要なアクションを実行するように通知します。
セッション管理コンポーネントは、事前定義されたセッションパラメータを使用して、SAPHANAシステムのセッションと接続を初期化および管理します。
永続層
HANAシステムでのトランザクションの耐久性とアトミック性を担当します。永続性レイヤーは、HANAデータベースに組み込みのディザスタリカバリシステムを提供します。
これにより、データベースが最新の状態に復元され、システム障害または再起動が発生した場合にすべてのトランザクションが完了または取り消されることが保証されます。
また、データとトランザクションログを管理し、HANAシステムのデータバックアップ、ログバックアップ、および構成を含めることもできます。バックアップは、セーブポイントコーディネーターを介してデータボリュームにセーブポイントとして保存されます。セーブポイントコーディネーターは通常、5〜10分ごとにバックアップするように設定されています。
プリプロセッササーバー
SAP HANAシステムのプリプロセッササーバーは、テキストデータ分析に使用されます。
Index Serverは、テキスト検索機能が使用されている場合、テキストデータを分析し、テキストデータから情報を抽出するためにプリプロセッササーバーを使用します。
ネームサーバー
NAMEサーバーには、HANAシステムのシステムランドスケープ情報が含まれています。分散環境では、複数のノードがあり、各ノードには複数のCPUがあり、ネームサーバーはHANAシステムのトポロジを保持し、実行中のすべてのコンポーネントに関する情報を持ち、情報はすべてのコンポーネントに分散されます。
SAPHANAシステムのトポロジがここに記録されます。
分散環境のどのサーバーにどのデータがあるかを保持するため、インデックスの再作成にかかる時間が短縮されます。
統計サーバー
このサーバーは、HANAシステムのすべてのコンポーネントの状態をチェックおよび分析します。統計サーバーは、システムリソース、リソースの割り当てと消費、およびHANAシステムの全体的なパフォーマンスに関連するデータを収集する責任があります。
また、HANAシステムのパフォーマンス関連の問題を確認および修正するために、分析目的でシステムパフォーマンスに関連する履歴データを提供します。
XSエンジン
XSエンジンは、外部のJavaおよびHTMLベースのアプリケーションがXSクライアントの助けを借りてHANAシステムにアクセスするのを支援します。SAP HANAシステムには、小さなJAVA / HTMLベースのアプリケーションをホストするために使用できるWebサーバーが含まれているためです。
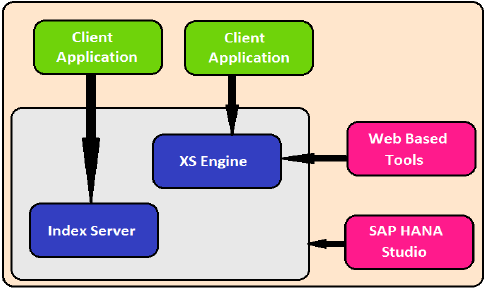
XS Engineは、データベースに格納されている永続性モデルを、HTTP / HTTPSを介して公開されるクライアントの消費モデルに変換します。
SAPホストエージェント
SAP Hostエージェントは、SAPHANAシステムランドスケープの一部であるすべてのマシンにインストールする必要があります。SAP Hostエージェントは、分散環境のHANAシステムのすべてのコンポーネントに自動更新をインストールするためにSoftware Update ManagerSUMによって使用されます。
LM構造
SAP HANAシステムのLM構造には、現在のインストールの詳細に関する情報が含まれています。この情報は、HANAシステムコンポーネントに自動更新をインストールするためにSoftware UpdateManagerによって使用されます。
SAP Solution Manager(SAP SOLMAN)診断エージェント
この診断エージェントは、SAPHANAシステムを監視するためにすべてのデータをSAPSolutionManagerに提供します。このエージェントは、データベースの現在の状態や一般的な情報など、HANAデータベースに関するすべての情報を提供します。
SAPSOLMANがSAPHANAシステムと統合されている場合のHANAシステムの構成の詳細を提供します。
SAP HANAStudioリポジトリ
SAP HANAスタジオリポジトリは、HANA開発者がHANAスタジオの現在のバージョンを最新バージョンに更新するのに役立ちます。Studioリポジトリは、この更新を行うコードを保持します。
SAPHANAのソフトウェアアップデートマネージャー
SAP Market Placeは、SAPシステムのアップデートをインストールするために使用されます。HANAシステムのソフトウェアアップデートマネージャーは、SAPマーケットプレイスからのHANAシステムのアップデートに役立ちます。
これは、ソフトウェアのダウンロード、カスタマーメッセージ、SAPノート、およびHANAシステムのライセンスキーの要求に使用されます。また、HANAスタジオをエンドユーザーのシステムに配布するためにも使用されます。
SAP HANA Modelerオプションを使用して、HANAデータベースのスキーマ→テーブルの上部に情報ビューを作成します。これらのビューは、JAVA / HTMLベースのアプリケーションまたはSAPLumira、Office AnalysisなどのSAPアプリケーション、またはMS Excelなどのサードパーティソフトウェアによって、ビジネスロジックを満たし、分析を実行して情報を抽出する目的で使用されます。
HANAモデリングは、HANAスタジオのスキーマの下にある[カタログ]タブで使用可能なテーブルの上部で実行され、すべてのビューは[パッケージ]の下の[コンテンツ]テーブルに保存されます。
[コンテンツ]と[新規]を右クリックして、HANAスタジオの[コンテンツ]タブで新しいパッケージを作成できます。
1つのパッケージ内で作成されたすべてのモデリングビューは、HANAスタジオの同じパッケージに含まれ、ビュータイプに従って分類されます。
各ビューには、ディメンションテーブルとファクトテーブルの構造が異なります。薄暗いテーブルはマスターデータで定義され、ファクトテーブルには、販売されたユニット数、平均遅延時間、合計価格などのディメンションテーブルとメジャーの主キーがあります。
事実と寸法の表
ファクトテーブルには、ディメンションテーブルとメジャーの主キーが含まれています。これらは、ビジネスロジックを満たすために、HANAビューのディメンションテーブルと結合されます。
Example of Measures −販売台数、合計価格、平均遅延時間など。
ディメンションテーブルにはマスターデータが含まれ、1つ以上のファクトテーブルと結合されてビジネスロジックが作成されます。ディメンションテーブルは、ファクトテーブルを使用してスキーマを作成するために使用され、正規化できます。
Example of Dimension Table −顧客、製品など
会社が顧客に製品を販売するとします。すべての販売は社内で発生するファクトであり、ファクトテーブルはこれらのファクトを記録するために使用されます。
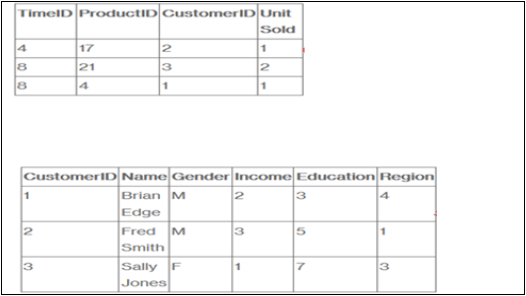
たとえば、ファクトテーブルの行3は、顧客1(ブライアン)が4日目に1つのアイテムを購入したという事実を記録します。また、完全な例では、彼女が何を購入したかがわかるように、製品テーブルとタイムテーブルもあります。そして正確にいつ。
ファクトテーブルには、当社で発生するイベント(または、少なくとも分析したいイベント-販売台数、マージン、および売上高)が一覧表示されます。ディメンションテーブルには、データを分析するための要素(顧客、時間、および製品)が一覧表示されます。
スキーマは、データウェアハウス内のテーブルの論理記述です。スキーマは、いくつかのビジネスロジックを満たすために、複数のファクトテーブルとディメンションテーブルを結合することによって作成されます。
データベースは、リレーショナルモデルを使用してデータを格納します。ただし、データウェアハウスは、ビジネスロジックを満たすためにディメンションとファクトテーブルを結合するスキーマを使用します。データウェアハウスで使用されるスキーマには3つのタイプがあります-
- スタースキーマ
- 雪片スキーマ
- ギャラクシースキーマ
スタースキーマ
スタースキーマでは、各ディメンションが1つのファクトテーブルに結合されます。各ディメンションは1つのディメンションのみで表され、それ以上正規化されません。
ディメンションテーブルには、データの分析に使用される属性のセットが含まれています。
Example −以下の例では、すべてのDimテーブルの主キーを持ち、分析を行うためにunits_soldとdollars_soldを測定するファクトテーブルFactSalesがあります。
4つのディメンションテーブルがあります-DimTime、DimItem、DimBranch、DimLocation
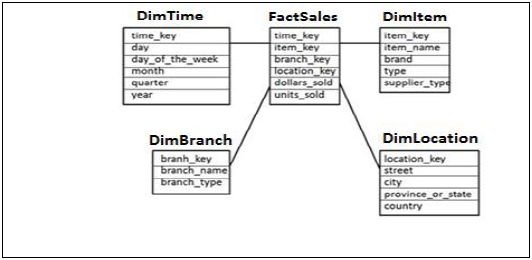
ファクトテーブルには、2つのテーブルを結合するために使用される各ディメンションテーブルの主キーがあるため、各ディメンションテーブルはファクトテーブルに接続されます。
ファクトテーブルのファクト/メジャーは、ディメンションテーブルの属性とともに分析目的で使用されます。
雪片スキーマ
Snowflakesスキーマでは、一部のディメンションテーブルがさらに正規化され、Dimテーブルが単一のファクトテーブルに接続されます。正規化は、データベースの属性とテーブルを整理して、データの冗長性を最小限に抑えるために使用されます。
正規化では、情報を失うことなくテーブルを冗長性の低い小さなテーブルに分割し、小さなテーブルをディメンションテーブルに結合します。
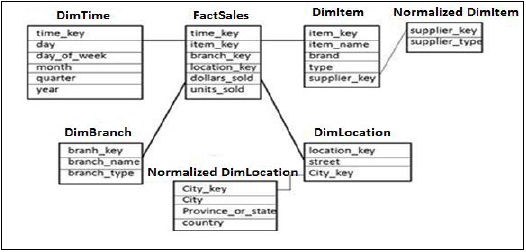
上記の例では、DimItemテーブルとDimLocationディメンションテーブルは、情報を失うことなく正規化されています。これはSnowflakesスキーマと呼ばれ、ディメンションテーブルがさらに小さなテーブルに正規化されます。
ギャラクシースキーマ
Galaxy Schemaには、複数のファクトテーブルとディメンションテーブルがあります。各ファクトテーブルには、分析を行うためのいくつかのディメンションテーブルとメジャー/ファクトの主キーが格納されます。
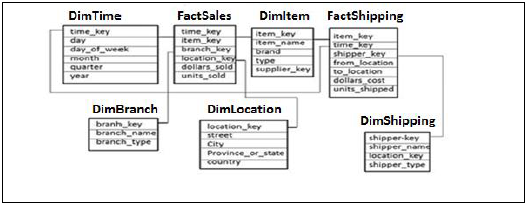
上記の例では、2つのファクトテーブルFactSales、FactShipping、およびファクトテーブルに結合された複数のディメンションテーブルがあります。各ファクトテーブルには、結合されたDimテーブルの主キーと分析を実行するためのメジャー/ファクトが含まれています。
HANAデータベースのテーブルには、HANAStudioの[スキーマ]の下の[カタログ]タブからアクセスできます。新しいテーブルは、以下の2つの方法を使用して作成できます-
- SQLエディターの使用
- GUIオプションの使用
HANAStudioのSQLエディター
SQLコンソールを開くには、スキーマ名を選択します。この場合、システムビューSQLエディタオプションを使用して新しいテーブルを作成するか、以下に示すようにスキーマ名を右クリックします。

SQL Editorを開くと、SQLEditorの上部に書かれている名前からスキーマ名を確認できます。SQL CreateTableステートメントを使用して新しいテーブルを作成できます-
Create column Table Test1 (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);このSQLステートメントでは、列テーブル「Test1」を作成し、テーブルのデータ型と主キーを定義しました。
Create table SQLクエリを作成したら、SQLエディタの右側にある[実行]オプションをクリックします。ステートメントが実行されると、以下のスナップショットに示すような確認メッセージが表示されます-
ステートメント '列テーブルTest1を作成します(ID INTEGER、NAME VARCHAR(10)、PRIMARY KEY(ID))'
13ミリ秒761μsで正常に実行されました(サーバー処理時間:12ミリ秒979μs)-影響を受ける行:0

実行ステートメントは、ステートメントの実行にかかった時間についても通知します。ステートメントが正常に実行されたら、システムビューのスキーマ名の下にある[テーブル]タブを右クリックして更新します。新しいテーブルは、スキーマ名の下のテーブルのリストに反映されます。
挿入ステートメントは、SQLエディターを使用してテーブルにデータを入力するために使用されます。
Insert into TEST1 Values (1,'ABCD')
Insert into TEST1 Values (2,'EFGH');[実行]をクリックします。
テーブル名を右クリックし、[データ定義を開く]を使用して、テーブルのデータ型を確認できます。データプレビューを開く/コンテンツを開くと、テーブルの内容が表示されます。
GUIオプションを使用したテーブルの作成
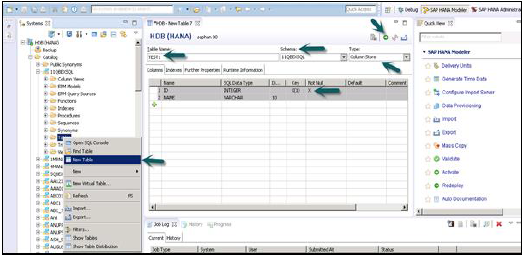
HANAデータベースにテーブルを作成するもう1つの方法は、HANAStudioのGUIオプションを使用することです。
以下のスナップショットに示すように、[スキーマ]の下の[テーブル]タブを右クリックし、[新しいテーブル]オプションを選択します。
[新しいテーブル]をクリックすると、ウィンドウが開き、テーブル名を入力します。ドロップダウンからスキーマ名を選択し、ドロップダウンリストからテーブルタイプを定義します:列ストアまたは行ストア。
以下に示すようにデータ型を定義します。+記号をクリックして列を追加できます。主キーは、列名の前にある主キーの下のセルをクリックして選択できます。デフォルトでは、NotNullがアクティブになります。
列が追加されたら、[実行]をクリックします。
実行(F8)したら、「テーブル」タブを右クリック→「更新」を選択します。新しいテーブルは、選択したスキーマの下のテーブルのリストに反映されます。以下の挿入オプションを使用して、テーブルにデータを挿入できます。テーブルの内容を表示するには、ステートメントを選択します。

HANAスタジオでGUIを使用してテーブルにデータを挿入する
テーブル名を右クリックし、[データ定義を開く]を使用して、テーブルのデータ型を確認できます。データプレビューを開く/コンテンツを開くと、テーブルの内容が表示されます。
1つのスキーマのテーブルを使用してビューを作成するには、HANAモデリングですべてのビューを実行するデフォルトユーザーにスキーマへのアクセスを提供する必要があります。これは、SQLエディターに移動してこのクエリを実行することで実行できます-
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
SAP HANAパッケージは、HANAスタジオの[コンテンツ]タブに表示されます。すべてのHANAモデリングはパッケージ内に保存されます。
[コンテンツ]タブ→[新規]→[パッケージ]を右クリックして、新しいパッケージを作成できます。
パッケージ名を右クリックして、パッケージの下にサブパッケージを作成することもできます。パッケージを右クリックすると、7つのオプションが表示されます。パッケージの下にHANAビューの属性ビュー、分析ビュー、計算ビューを作成できます。
デシジョンテーブルを作成し、分析権限を定義し、パッケージにプロシージャを作成することもできます。
「パッケージ」を右クリックして「新規」をクリックすると、パッケージ内にサブパッケージを作成することもできます。パッケージの作成中に、パッケージ名、説明を入力する必要があります。
SAP HANAモデリングの属性ビューは、ディメンションテーブルの上部に作成されます。これらは、ディメンションテーブルまたはその他の属性ビューを結合するために使用されます。他のパッケージ内の既存の属性ビューから新しい属性ビューをコピーすることもできますが、それではビュー属性を変更することはできません。
属性ビューの特徴
HANAの属性ビューは、ディメンションテーブルまたは他の属性ビューを結合するために使用されます。
属性ビューは、マスターデータを渡すための分析のために分析ビューと計算ビューで使用されます。
これらはBMの特性に類似しており、マスタデータが含まれています。
属性ビューは、大きなサイズのディメンションテーブルのパフォーマンスを最適化するために使用されます。レポートおよび分析の目的でさらに使用される属性ビューの属性の数を制限できます。
属性ビューは、マスターデータをモデル化してコンテキストを提供するために使用されます。
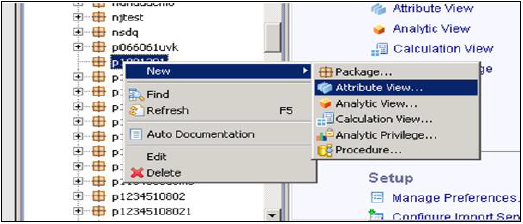
属性ビューを作成する方法は?
属性ビューを作成するパッケージ名を選択します。パッケージを右クリック→新規に移動→属性ビュー
属性ビューをクリックすると、新しいウィンドウが開きます。属性ビューの名前と説明を入力します。ドロップダウンリストから、[表示タイプ]と[サブタイプ]を選択します。サブタイプには、標準、時間、および派生の3つのタイプの属性ビューがあります。
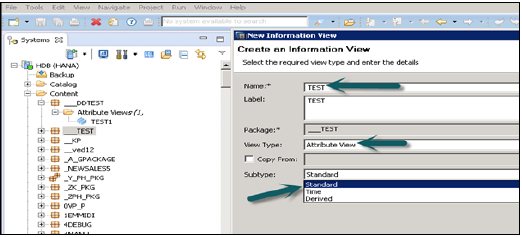
時間サブタイプ属性ビューは、データファンデーションに時間ディメンションを追加する特殊なタイプの属性ビューです。属性名、タイプ、サブタイプを入力して[完了]をクリックすると、3つの作業ペインが開きます-
データファンデーションとセマンティックレイヤーがあるシナリオペイン。
詳細ペインには、Data Foundationに追加され、それらの間で結合されているすべてのテーブルの属性が表示されます。
詳細ペインから属性を追加してレポートでフィルタリングできる出力ペイン。
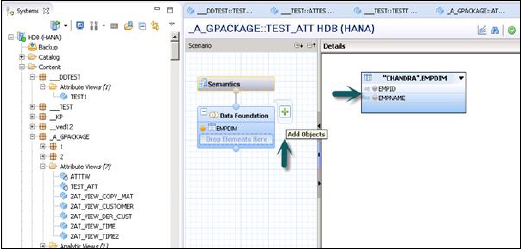
Data Foundationの横に書かれた「+」記号をクリックすると、オブジェクトをDataFoundationに追加できます。シナリオペインに複数のディメンションテーブルと属性ビューを追加し、主キーを使用してそれらを結合できます。
Data Foundationで[オブジェクトの追加]をクリックすると、検索バーが表示され、そこからディメンションテーブルと属性ビューをシナリオペインに追加できます。テーブルまたは属性ビューがDataFoundationに追加されると、以下に示すように、詳細ペインの主キーを使用してそれらを結合できます。
結合が完了したら、詳細ペインで複数の属性を選択し、右クリックして[出力に追加]を選択します。すべての列が出力ペインに追加されます。次に、[アクティブ化]オプションをクリックすると、ジョブログに確認メッセージが表示されます。
これで、属性ビューを右クリックして、データプレビューに進むことができます。
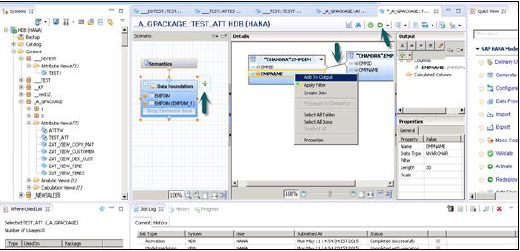
Note−ビューがアクティブ化されていない場合、そのビューにはひし形のマークが付いています。ただし、アクティブにすると、そのひし形が消え、ビューが正常にアクティブ化されたことを確認します。
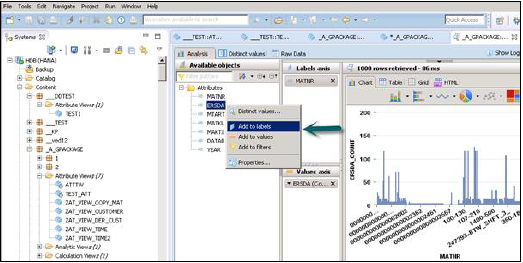
[データプレビュー]をクリックすると、[使用可能なオブジェクト]の下の[出力]ペインに追加されたすべての属性が表示されます。
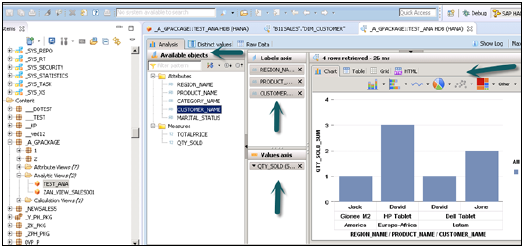
これらのオブジェクトは、右クリックして追加するか、以下に示すようにオブジェクトをドラッグすることで、ラベルと値の軸に追加できます。
分析ビューはスタースキーマの形式であり、1つのファクトテーブルを複数のディメンションテーブルに結合します。分析ビューは、SAP HANAの真の力を利用して、スタースキーマの形式でテーブルを結合し、スタースキーマクエリを実行することにより、複雑な計算と集計関数を実行します。
分析ビューの特性
以下は、SAP HANA AnalyticViewのプロパティです。
分析ビューは、複雑な計算や、合計、カウント、最小、最大などの集計関数を実行するために使用されます。
分析ビューは、開始スキーマクエリを実行するように設計されています。
各分析ビューには、複数のディメンションテーブルに囲まれた1つのファクトテーブルがあります。ファクトテーブルには、各Dimテーブルとメジャーの主キーが含まれています。
分析ビューは、SAPBWの情報オブジェクトおよび情報セットに似ています。
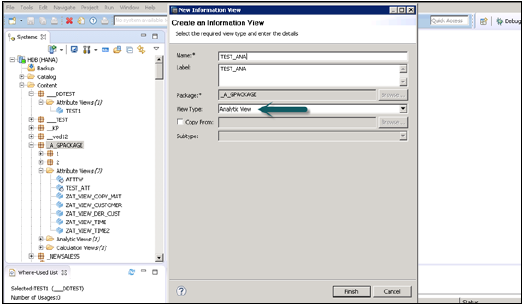
分析ビューを作成する方法は?
分析ビューを作成するパッケージ名を選択します。「パッケージ」を右クリック→「新規」→「分析ビュー」に移動します。分析ビューをクリックすると、新しいウィンドウが開きます。ビューの名前と説明を入力し、ドロップダウンリストから[ビューの種類]と[完了]を選択します。
[完了]をクリックすると、[データファンデーションとスター結合を使用した分析ビュー]オプションが表示されます。
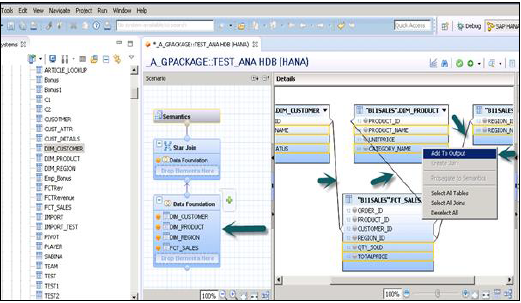
Data Foundationをクリックして、ディメンションテーブルとファクトテーブルを追加します。スター結合をクリックして、属性ビューを追加します。
「+」記号を使用して、DimテーブルとFactテーブルをDataFoundationに追加します。以下の例では、3つのdimテーブルが追加されています:DIM_CUSTOMER、DIM_PRODUCT、DIM_REGION、および1つのファクトテーブルFCT_SALESが詳細ペインに追加されています。ファクトテーブルに格納されている主キーを使用して、Dimテーブルをファクトテーブルに結合します。
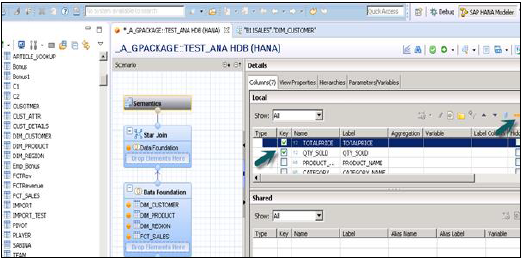
上記のスナップショットに示すように、[薄暗いファクト]テーブルから[属性]を選択して、[出力]ペインに追加します。次に、ファクトのデータ型をファクトテーブルからメジャーに変更します。
セマンティックレイヤーをクリックし、ファクトを選択し、以下に示すようにメジャー記号をクリックして、データ型をメジャーに変更し、ビューをアクティブ化します。
ビューをアクティブにして[データプレビュー]をクリックすると、すべての属性とメジャーが使用可能なオブジェクトのリストの下に追加されます。分析の目的で、ラベル軸に属性を追加し、値軸に測定を追加します。
さまざまな種類のチャートやグラフを選択するオプションがあります。
計算ビューは、他の分析ビュー、属性ビュー、および他の計算ビューとベース列テーブルを使用するために使用されます。これらは、他のタイプのビューでは不可能な複雑な計算を実行するために使用されます。
計算ビューの特徴
以下に、計算ビューのいくつかの特性を示します-
計算ビューは、分析ビュー、属性ビュー、およびその他の計算ビューを使用するために使用されます。
これらは、他のビューでは不可能な複雑な計算を実行するために使用されます。
計算ビューを作成するには、SQLエディターまたはグラフィカルエディターの2つの方法があります。
組み込みのUnion、Join、Projection、Aggregationノード。
計算ビューを作成するにはどうすればよいですか?
計算ビューを作成するパッケージ名を選択します。「パッケージ」を右クリック→「新規」→「計算ビュー」に移動します。計算ビューをクリックすると、新しいウィンドウが開きます。
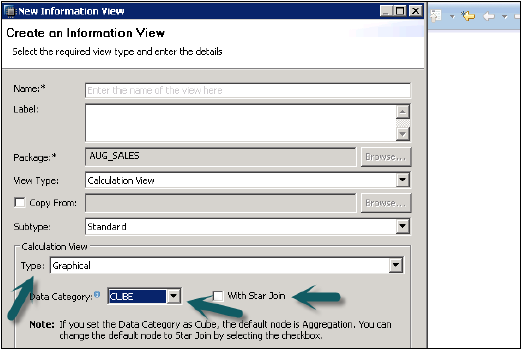
ビュー名、説明を入力し、ビュータイプを計算ビュー、サブタイプ標準、または時間として選択します(これは時間ディメンションを追加する特別な種類のビューです)。グラフィカルビューとSQLスクリプトの2種類の計算ビューを使用できます。
グラフィカルな計算ビュー
アグリゲーション、プロジェクション、ジョイン、ユニオンなどのデフォルトノードがあります。これは、他の属性、分析、および他の計算ビューを使用するために使用されます。
SQLスクリプトベースの計算ビュー
これは、SQLコマンドまたはHANA定義関数に基づいて構築されたSQLスクリプトで記述されています。
データカテゴリ
このデフォルトノードのキューブはAggregationです。キューブディメンションを使用したスター結合を選択できます。
ディメンション。このデフォルトノードでは、プロジェクションです。
スター結合を使用した計算ビュー
ベース列テーブル、属性ビュー、または分析ビューをデータファンデーションに追加することはできません。スター結合で使用するには、すべてのディメンションテーブルをディメンション計算ビューに変更する必要があります。すべてのファクトテーブルを追加でき、計算ビューでデフォルトノードを使用できます。
例
次の例は、スター結合で計算ビューを使用する方法を示しています-
4つのテーブル、2つのDimテーブル、および2つのFactテーブルがあります。参加日、従業員名、empId、給与、ボーナスを含むすべての従業員のリストを見つける必要があります。
以下のスクリプトをコピーしてSQLエディタに貼り付けて実行します。
Dim Tables − Empdim and Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');Fact Tables − Empfact1, Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);次に、スター結合を使用して計算ビューを実装する必要があります。まず、両方のDimテーブルをディメンション計算ビューに変更します。
スター結合を使用して計算ビューを作成します。グラフィカルペインで、2つのファクトテーブルに2つのプロジェクションを追加します。両方のファクトテーブルを両方のプロジェクションに追加し、これらのプロジェクションの属性を[出力]ペインに追加します。

デフォルトノードから結合を追加し、両方のファクトテーブルを結合します。ファクト結合のパラメーターを出力ペインに追加します。
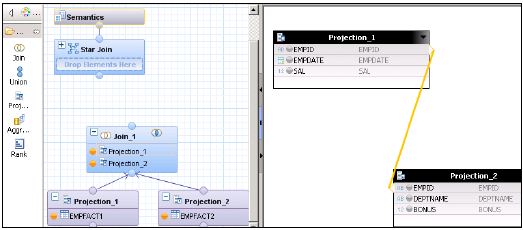
以下に示すように、スター結合で、両方の次元計算ビューを追加し、ファクト結合をスター結合に追加します。出力ペインでパラメータを選択し、ビューをアクティブにします。
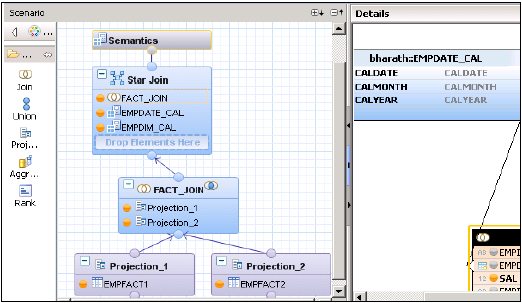
SAPHANA計算ビュー-スター結合
ビューが正常にアクティブ化されたら、ビュー名を右クリックし、データプレビューをクリックします。値とラベルの軸に属性とメジャーを追加し、分析を実行します。
スター結合を使用する利点
設計プロセスが簡素化されます。分析ビューと属性ビューを作成する必要はなく、ファクトテーブルを直接プロジェクションとして使用できます。
3NFはスター結合で可能です。
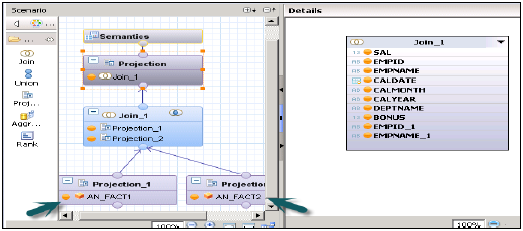
スター結合なしの計算ビュー
2つのDimテーブルに2つの属性ビューを作成する-出力を追加し、両方のビューをアクティブにします。
ファクトテーブルに2つの分析ビューを作成する→分析ビューのDataFoundationで属性ビューとFact1 / Fact2の両方を追加します。
次に、計算ビュー→寸法(投影)を作成します。両方の分析ビューのプロジェクションを作成し、それらに参加します。この結合の属性を出力ペインに追加します。次に、プロジェクションに参加して、出力を再度追加します。
ビューを正常にアクティブ化し、分析のためにデータプレビューに移動します。
分析権限は、HANA情報ビューへのアクセスを制限するために使用されます。分析権限のビューのさまざまなコンポーネントで、さまざまなユーザーにさまざまな種類の権限を割り当てることができます。
同じビューのデータに、そのデータに関連する要件がない他のユーザーがアクセスできないようにする必要がある場合があります。
例
会社の従業員に関する詳細(Emp名、Emp ID、部門、給与、参加日、Empログオンなど)を含む分析ビューEmpDetailsがあるとします。ここで、レポート開発者に給与の詳細またはEmpを表示させたくない場合すべての従業員のログオンの詳細。分析権限オプションを使用してこれを非表示にできます。
分析権限は、情報ビューの属性にのみ適用されます。Analytic特権でアクセスを制限する手段を追加することはできません。
分析権限は、SAPHANA情報ビューでの読み取りアクセスを制御するために使用されます。
したがって、給与、ボーナスなどの数値ではなく、Empname、EmpId、Empログオン、またはEmpDeptによってデータを制限できます。
分析権限の作成
パッケージ名を右クリックして新しい分析権限に移動するか、HANAModelerクイック起動を使用して開くことができます。
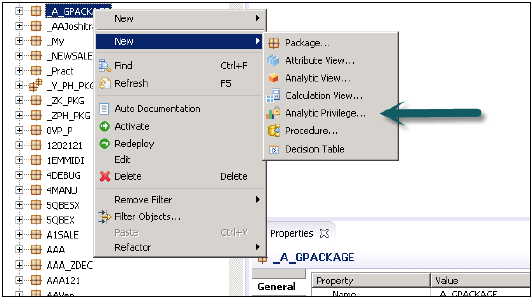
分析権限の名前と説明を入力→終了。新しいウィンドウが開きます。
[完了]をクリックする前に、[次へ]ボタンをクリックして、このウィンドウにモデリングビューを追加できます。既存の分析特権パッケージをコピーするオプションもあります。
[追加]ボタンをクリックすると、[コンテンツ]タブの下にすべてのビューが表示されます。
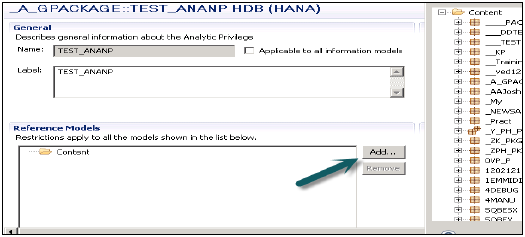
Analytic Privilegeパッケージに追加するビューを選択し、[OK]をクリックします。選択したビューが参照モデルの下に追加されます。
次に、[分析権限]で選択したビューから属性を追加するには、[関連付けられた属性の制限]ウィンドウで[追加]ボタンをクリックします。
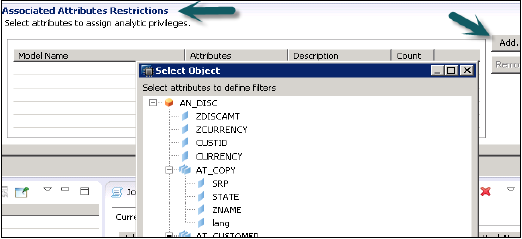
[オブジェクトの選択]オプションから分析権限に追加するオブジェクトを追加し、[OK]をクリックします。
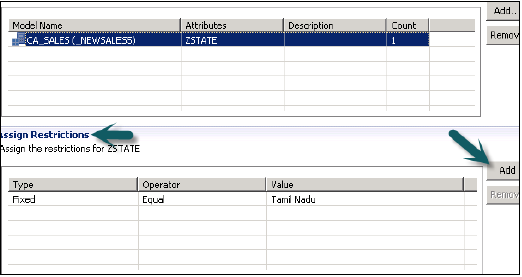
[制限の割り当て]オプションでは、モデリングビューで特定のユーザーから非表示にする値を追加できます。モデリングビューのデータプレビューに反映されないオブジェクト値を追加できます。
上部の緑色の丸いアイコンをクリックして、分析特権をアクティブ化する必要があります。ステータスメッセージ–完了しました。ジョブログでアクティブ化が正常に確認されました。ロールに追加することで、このビューを使用できるようになりました。
このロールをユーザーに追加するには、[セキュリティ]タブ→[ユーザー]→[これらの分析権限を適用するユーザーを選択]に移動します。
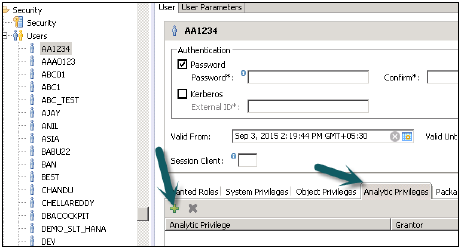
適用する分析権限を名前で検索し、[OK]をクリックします。そのビューは、分析特権の下のユーザーロールに追加されます。
特定のユーザーから分析権限を削除するには、タブの下のビューを選択し、赤の削除オプションを使用します。Deployを使用します(これをユーザープロファイルに適用するには、上部の矢印またはF8)。
SAP HANA Information Composerは、エンドユーザーがデータセットを分析するためのセルフサービスモデリング環境です。これにより、ワークブック形式(.xls、.csv)からHANAデータベースにデータをインポートし、分析用のモデリングビューを作成できます。
InformationComposerはHANAModelerとは大きく異なり、どちらも個別のユーザーセットを対象とするように設計されています。データモデリングに豊富な経験を持つ技術的に健全な人々は、HANAモデラーを使用します。技術的な知識がないビジネスユーザーは、InformationComposerを使用します。使いやすいインターフェースを備えたシンプルな機能を提供します。
InformationComposerの機能
Data extraction − Information Composerは、データの抽出、データのクリーンアップ、データのプレビュー、およびHANAデータベースでの物理テーブルの作成プロセスの自動化を支援します。
Manipulating data − 2つのオブジェクト(物理テーブル、分析ビュー、属性ビュー、計算ビュー)を組み合わせて、SAP Business Objects Analysis、SAP Business Objects ExplorerなどのSAPBOツールやMSExcelなどの他のツールで使用できる情報ビューを作成するのに役立ちます。
どこからでもアクセスできるURL形式で一元化されたITサービスを提供します。
Information Composerを使用してデータをアップロードするにはどうすればよいですか?
大量のデータ(最大500万セル)をアップロードできます。InformationComposerにアクセスするためのリンク-
http://<server>:<port>/IC
SAP HANA InformationComposerにログインします。このツールを使用して、データのロードまたは操作を実行できます。
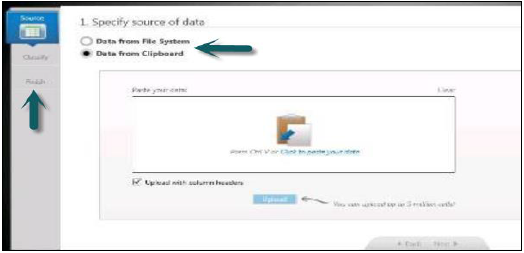
データをアップロードするには、これは2つの方法で行うことができます-
- .xls、.csvファイルをHANAデータベースに直接アップロードする
- もう1つの方法は、データをクリップボードにコピーし、そこからHANAデータベースにコピーすることです。
- ヘッダーと一緒にデータをロードできます。
Information Composerの左側には、3つのオプションがあります-
データのソース→データの分類→公開を選択します
データがHANAデータベースに公開されると、テーブルの名前を変更することはできません。この場合、HANAデータベースのスキーマからテーブルを削除する必要があります。
IC_MODELS、IC_SPREADSHEETSなどのテーブルが存在する「SAP_IC」スキーマ。ICを使用して作成されたテーブルの詳細は、これらのテーブルの下にあります。

クリップボードの使用
ICにデータをアップロードする別の方法は、クリップボードを使用することです。データをクリップボードにコピーし、InformationComposerを使用してアップロードします。Information Composerを使用すると、データのプレビューを表示したり、一時ストレージ内のデータの要約を提供したりすることもできます。データの不整合を取り除くために使用されるデータクレンジングの機能が組み込まれています。
データがクレンジングされたら、データが帰属するかどうかを分類する必要があります。ICには、アップロードされたデータのデータ型をチェックする機能が組み込まれています。
最後のステップは、HANAデータベースの物理テーブルにデータを公開することです。テーブルの技術名と説明を入力すると、これはIC_Tablesスキーマ内にロードされます。
InformationComposerで公開されたデータを使用するためのユーザーロール
ICから公開されたデータを使用するために、2セットのユーザーを定義できます。
IC_MODELERは、物理テーブルの作成、データのアップロード、および情報ビューの作成に使用されます。
IC_PUBLICを使用すると、ユーザーは他のユーザーが作成した情報ビューを表示できます。この役割では、ユーザーがICを使用して情報ビューをアップロードまたは作成することはできません。
InformationComposerのシステム要件
Server Requirements −
少なくとも2GBの使用可能なRAMが必要です。
Java 6(64ビット)をサーバーにインストールする必要があります。
Information Composerサーバーは、HANAサーバーの隣に物理的に配置する必要があります。
Client Requirements −
- Silverlight4がインストールされたInternetExplorer。
HANAエクスポートおよびインポートオプションを使用すると、テーブル、情報モデル、ランドスケープを別のシステムまたは既存のシステムに移動できます。新しいシステムにエクスポートしたり、既存のターゲットシステムにインポートしたりするだけで労力を軽減できるため、すべてのテーブルと情報モデルを再作成する必要はありません。
このオプションには、上部の[ファイル]メニューから、またはHANAスタジオの任意のテーブルまたは情報モデルを右クリックしてアクセスできます。
HANAStudioでのテーブル/情報モデルのエクスポート
ファイルメニュー→エクスポート→以下のようなオプションが表示されます−

SAPHANAコンテンツのエクスポートオプション
デリバリーユニット
配送ユニットは単一のユニットであり、複数のパッケージにマッピングでき、単一のエンティティとしてエクスポートできるため、配送ユニットに割り当てられたすべてのパッケージを単一のユニットとして扱うことができます。
ユーザーはこのオプションを使用して、デリバリーユニットを構成するすべてのパッケージとそれに含まれる関連オブジェクトをHANAサーバーまたはローカルクライアントの場所にエクスポートできます。
ユーザーは、使用する前にデリバリーユニットを作成する必要があります。
これは、HANAモデラー→デリバリーユニット→システムの選択と次へ→作成→名前、バージョンなどの詳細の入力→OK→デリバリーユニットへのパッケージの追加→完了から実行できます。
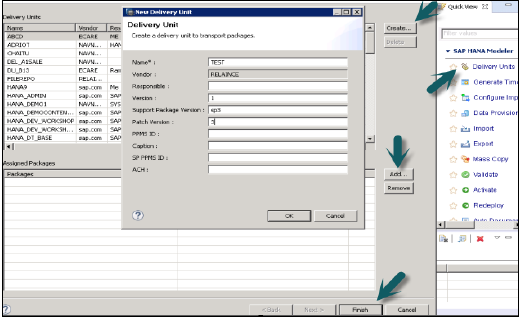
デリバリーユニットが作成され、パッケージが割り当てられると、ユーザーはエクスポートオプション-を使用してパッケージのリストを表示できます。
[ファイル]→[エクスポート]→[デリバリーユニット]→[デリバリーユニットの選択]に移動します。
デリバリーユニットに割り当てられているすべてのパッケージのリストが表示されます。エクスポート場所を選択するオプションがあります-
- サーバーにエクスポート
- クライアントにエクスポート
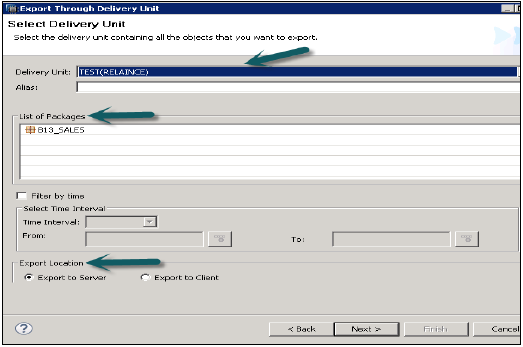
図のように、デリバリーユニットをHANAサーバーの場所またはクライアントの場所にエクスポートできます。
ユーザーは「時間でフィルター」を使用してエクスポートを制限できます。これは、指定された時間間隔内に更新された情報ビューのみがエクスポートされることを意味します。
配信ユニットとエクスポート場所を選択し、[次へ]→[完了]をクリックします。これにより、選択したデリバリーユニットが指定した場所にエクスポートされます。
開発者モード
このオプションを使用して、個々のオブジェクトをローカルシステム内の場所にエクスポートできます。ユーザーは、単一の情報ビューまたはビューとパッケージのグループを選択し、エクスポートおよび終了するローカルクライアントの場所を選択できます。
これは、以下のスナップショットに示されています。
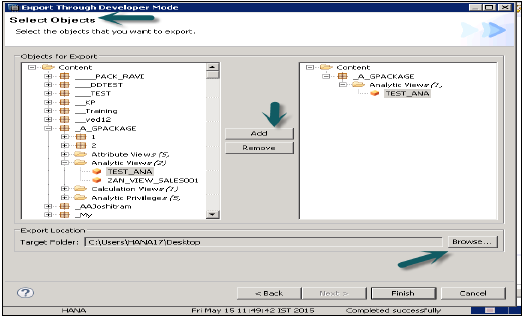
サポートモード
これは、SAPサポートの目的でデータとともにオブジェクトをエクスポートするために使用できます。これは、要求されたときに使用できます。
Example−ユーザーが情報ビューを作成すると、エラーがスローされ、解決できません。その場合、彼はこのオプションを使用して、データとともにビューをエクスポートし、デバッグ目的でSAPと共有することができます。

Export Options under SAP HANA Studio −
Landscape −ランドスケープをあるシステムから別のシステムにエクスポートすること。
Tables −このオプションは、テーブルとそのコンテンツをエクスポートするために使用できます。
SAPHANAコンテンツの下のインポートオプション
[ファイル]→[インポート]に移動します。以下に示すように、[インポート]の下にすべてのオプションが表示されます。
ローカルファイルからのデータ
これは、.xlsや.csvファイルなどのフラットファイルからデータをインポートするために使用されます。
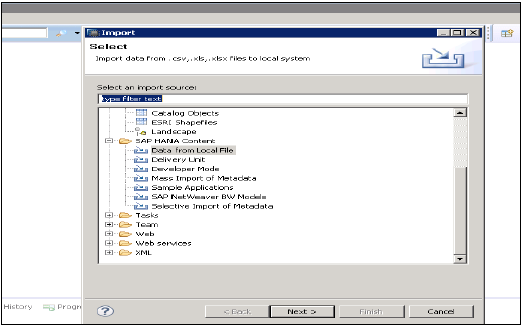
Nexをクリック→ターゲットシステムを選択→インポートプロパティを定義
ローカルシステムを参照してソースファイルを選択します。ヘッダー行を保持する場合のオプションもあります。また、既存のスキーマの下に新しいテーブルを作成するオプションや、ファイルから既存のテーブルにデータをインポートするオプションもあります。
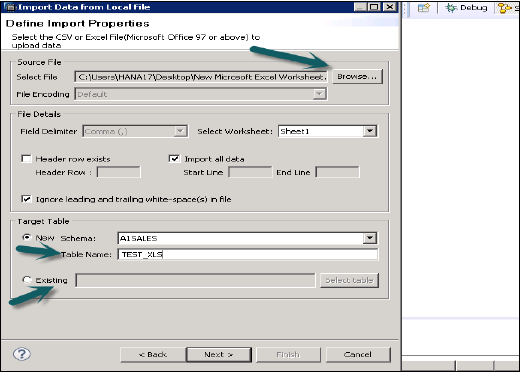
[次へ]をクリックすると、主キーの定義、列のデータタイプの変更、テーブルのストレージタイプの定義、およびテーブルの提案された構造の変更を行うオプションが表示されます。
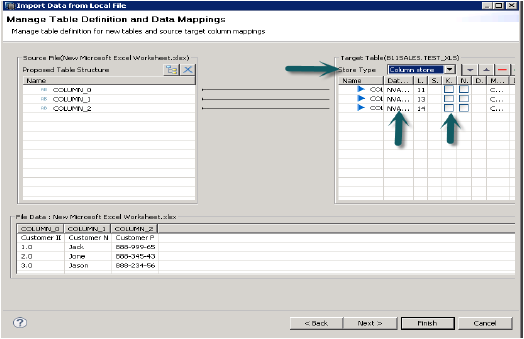
[完了]をクリックすると、そのテーブルが上記のスキーマのテーブルのリストの下に表示されます。データプレビューを実行し、テーブルのデータ定義を確認できます。これは、.xlsファイルのデータ定義と同じになります。

デリバリーユニット
[ファイル]→[インポート]→[デリバリーユニット]に移動して、デリバリーユニットを選択します。サーバーまたはローカルクライアントから選択できます。
「非アクティブなバージョンを上書きする」を選択すると、存在するオブジェクトの非アクティブなバージョンを上書きできます。ユーザーが「オブジェクトのアクティブ化」を選択すると、インポート後、インポートされたすべてのオブジェクトがデフォルトでアクティブ化されます。ユーザーは、インポートされたビューに対して手動でアクティブ化をトリガーする必要はありません。

[完了]をクリックし、正常に完了すると、ターゲットシステムに入力されます。
開発者モード
ビューがエクスポートされるローカルクライアントの場所を参照し、インポートするビューを選択します。ユーザーは、個々のビューまたはビューとパッケージのグループを選択して、[完了]をクリックできます。
メタデータの大量インポート
[ファイル]→[インポート]→[メタデータの一括インポート]→[次へ]に移動し、ソースシステムとターゲットシステムを選択します。
一括インポート用にシステムを構成し、「終了」をクリックします。
メタデータの選択的インポート
これにより、テーブルとターゲットスキーマを選択して、SAPアプリケーションからメタデータをインポートできます。
[ファイル]→[インポート]→[メタデータの選択的インポート]→[次へ]に移動します
タイプ「SAPアプリケーション」のソース接続を選択します。データストアは、SAPアプリケーションタイプですでに作成されている必要があることに注意してください→[次へ]をクリックします
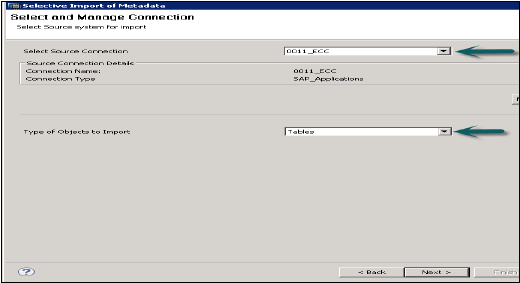
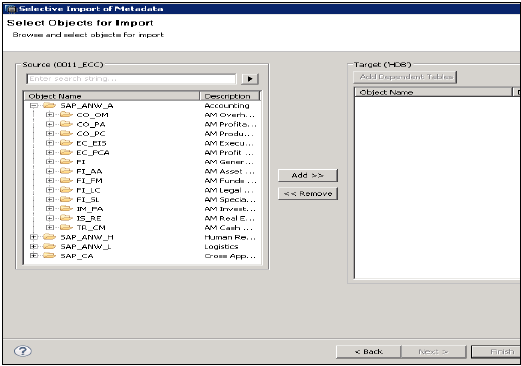
インポートするテーブルを選択し、必要に応じてデータを検証します。その後、[完了]をクリックします。
SAP HANAの情報モデリング機能を使用すると、さまざまな情報ビュー、属性ビュー、分析ビュー、計算ビューを作成できることがわかっています。これらのビューは、SAP Business Object、SAP Lumira、Design Studio、Office Analysisなどのさまざまなレポートツール、さらにはMSExcelなどのサードパーティツールで使用できます。
これらのレポートツールを使用すると、ビジネスマネージャー、アナリスト、セールスマネージャー、および上級管理職の従業員は、履歴情報を分析してビジネスシナリオを作成し、会社のビジネス戦略を決定できます。
これにより、さまざまなレポートツールでHANAモデリングビューを使用したり、エンドユーザーが理解しやすいレポートやダッシュボードを生成したりする必要が生じます。

SAPが実装されているほとんどの企業では、HANAに関するレポートは、リレーショナル接続とOLAP接続の助けを借りてSQLクエリとMDXクエリの両方を使用するBIプラットフォームツールを使用して行われます。Webインテリジェンス、Crystal Reports、ダッシュボード、エクスプローラー、OfficeAnalysisなどのさまざまなBIツールがあります。
レポートツール
WebIntelligenceとCrystalReportsは、レポートに使用される最も一般的なBIツールです。WebIは、ユニバースと呼ばれるセマンティックレイヤーを使用してデータソースに接続し、これらのユニバースはツールでのレポートに使用されます。これらのユニバースは、ユニバース設計ツールUDTまたは情報デザインツールIDTを使用して設計されています。IDTは、マルチソース対応のデータソースをサポートしています。ただし、UDTは単一ソースのみをサポートします。
インタラクティブダッシュボードの設計に使用される主なツール-DesignStudioおよびDashboardDesigner。Design Studioは、ダッシュボードを設計するための将来のツールであり、BIコンシューマーサービスのBICS接続を介してHANAビューを使用します。ダッシュボードデザイン(xcelsius)は、IDTを使用して、リレーショナル接続またはOLAP接続でHANAデータベースのスキーマを使用します。
SAP Lumiraには、HANAデータベースに直接接続またはデータをロードする機能が組み込まれています。HANAビューは、視覚化とストーリーの作成のためにLumiraで直接使用できます。
Office Analysisは、OLAP接続を使用してHANA情報ビューに接続します。このOLAP接続は、CMCまたはIDTで作成できます。
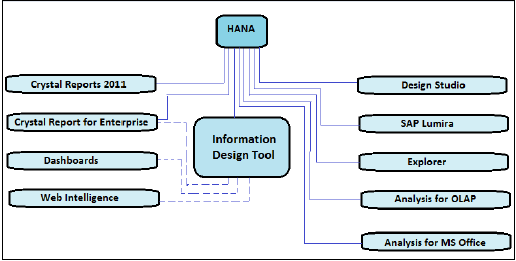
上の図では、実線ですべてのBIツールを示しています。これらのツールは、OLAP接続を使用してSAPHANAに直接接続および統合できます。また、HANAに接続するためにIDTを使用したリレーショナル接続が必要なツールを点線で示しています。
リレーショナル接続とOLAP接続
基本的に、テーブルまたは従来のデータベースからデータにアクセスする必要がある場合、接続はリレーショナル接続である必要がありますが、ソースがアプリケーションであり、データがキューブ(情報キューブ、情報モデルなどの多次元)に格納されている場合は、 OLAP接続を使用します。
- リレーショナル接続は、IDT / UDTでのみ作成できます。
- OLAPは、IDTとCMCの両方で作成できます。
もう1つの注意点は、リレーショナル接続は常にレポートから起動されるSQLステートメントを生成するのに対し、OLAP接続は通常MDXステートメントを作成することです。
情報デザインツール
情報設計ツール(IDT)では、JDBCまたはODBCドライバーを使用してSAP HANAビューまたはテーブルへのリレーショナル接続を作成し、この接続を使用してユニバースを構築して、上の図に示すようにダッシュボードやWebインテリジェンスなどのクライアントツールへのアクセスを提供できます。
JDBCまたはODBCドライバーを使用して、SAPHANAへの直接接続を作成できます。
エンタープライズ向けCrystalReports
Crystal Reports for Enterpriseでは、情報デザインツールを使用して作成された既存のリレーショナル接続を使用してSAPHANAデータにアクセスできます。
インフォメーションデザインツールまたはCMCを使用して作成されたOLAP接続を使用してSAPHANAに接続することもできます。
デザインスタジオ
Design Studioは、OfficeAnalysisと同様に情報デザインツールまたはCMCで作成された既存のOLAP接続を使用してSAPHANAデータにアクセスできます。
ダッシュボード
ダッシュボードは、リレーショナルユニバースを介してのみSAPHANAに接続できます。SAP HANA上でダッシュボードを使用しているお客様は、DesignStudioを使用して新しいダッシュボードを構築することを強く検討する必要があります。
Webインテリジェンス
Web Intelligenceは、リレーショナルユニバースを介してのみSAPHANAに接続できます。
SAPルミラ
Lumiraは、SAPHANAの分析ビューと計算ビューに直接接続できます。また、リレーショナルユニバースを使用してSAPBIプラットフォームを介してSAPHANAに接続することもできます。
Office Analysis、OLAP版
Office Analysis Edition for OLAPでは、中央管理コンソールまたはインフォメーションデザインツールで定義されたOLAP接続を使用してSAPHANAに接続できます。
冒険者
JDBCドライバーを使用して、SAPHANAビューに基づいて情報スペースを作成できます。
CMCでのOLAP接続の作成
すべてのBIツールのOLAP接続を作成できます。これは、分析用のOLAP、エンタープライズ用のCrystal Report、DesignStudioなどのHANAビューの上で使用します。IDTを介したリレーショナル接続は、WebインテリジェンスとダッシュボードをHANAデータベースに接続するために使用されます。
これらの接続は、IDTとCMCを使用して作成でき、両方の接続がBOリポジトリに保存されます。
ユーザー名とパスワードを使用してCMCにログインします。
接続のドロップダウンリストから、OLAP接続を選択します。また、CMCですでに作成されている接続も表示されます。新しい接続を作成するには、緑色のアイコンに移動してこれをクリックします。
OLAP接続の名前と説明を入力します。複数のユーザーが、さまざまなBIプラットフォームツールでHANAビューに接続するために、この接続を使用できます。
Provider − SAP HANA
Server −HANAサーバー名を入力します
Instance −インスタンス番号
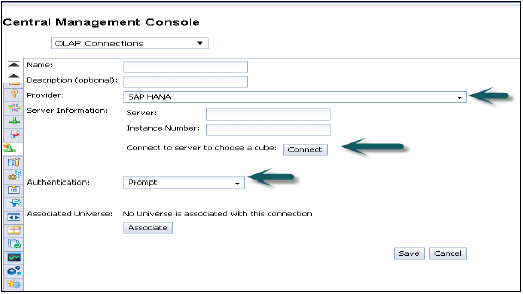
また、単一のキューブ(単一の分析ビューまたは計算ビューに接続することもできます)または完全なHANAシステムに接続するオプションもあります。
[接続]をクリックし、ユーザー名とパスワードを入力してモデリングビューを選択します。
認証タイプ-CMCでOLAP接続を作成する際に、3つのタイプの認証が可能です。
Predefined −この接続を使用している間、ユーザー名とパスワードを再度要求することはありません。
Prompt −ユーザー名とパスワードを尋ねるたびに
SSO −ユーザー固有
Enter user − HANAシステムのユーザー名とパスワード、および保存と新しい接続が既存の接続リストに追加されます。
次に、BI Launchpadを開いて、Office Analysis for OLAPなどのレポート用のすべてのBIプラットフォームツールを開くと、接続の選択を求められます。デフォルトでは、この接続の作成時に指定した場合は情報ビューが表示されます。指定していない場合は、[次へ]をクリックして、[フォルダー]→[ビューの選択(分析ビューまたは計算ビュー)]に移動します。
SAP Lumira connectivity with HANA system
StartProgramからSAPLumiraを開き、[ファイル]メニュー→[新規]→[新しいデータセットの追加]→[SAPHANAに接続]→[次へ]をクリックします。

SAPHANAへの接続とSAPHANAからのダウンロードの違いは、HanaシステムからBOリポジトリにデータをダウンロードし、HANAシステムの変更によってデータが更新されないことです。HANAサーバー名とインスタンス番号を入力します。ユーザー名とパスワードを入力→[接続]をクリックします。
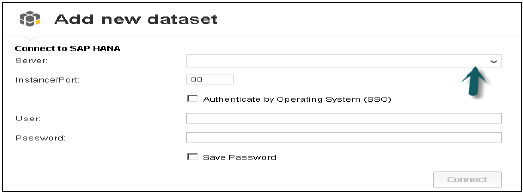
すべてのビューが表示されます。ビュー名で検索できます→ビュー→次へを選択します。すべてのメジャーとディメンションが表示されます。必要に応じて、これらの属性から選択できます→作成オプションをクリックします。
SAPLumira内には4つのタブがあります-
Prepare −データを表示し、カスタム計算を実行できます。
Visualize−グラフとチャートを追加できます。X軸とY軸+記号をクリックして、属性を追加します。
Compose−このオプションを使用して、ビジュアライゼーション(ストーリー)のシーケンスを作成できます→ボードをクリックしてボードの数を追加→作成→左側にすべてのビジュアライゼーションを表示します。最初のビジュアライゼーションをドラッグしてからページを追加し、次に2番目のビジュアライゼーションを追加します。
Share− SAP HANA上に構築されている場合、SAPLumiraサーバーにのみ公開できます。それ以外の場合は、SAPLumiraからSAPCommunity NetworkSCNまたはBIプラットフォームにストーリーを公開することもできます。
後で使用するためにファイルを保存→[ファイル]-[保存]に移動→[ローカル]→[保存]を選択
Creating a Relational Connection in IDT to use with HANA views in WebI and Dashboard −
インフォメーションデザインツール→BIプラットフォームクライアントツールに移動して開きます。「新規」→「プロジェクト」をクリックして、「プロジェクト名を入力」→「終了」をクリックします。
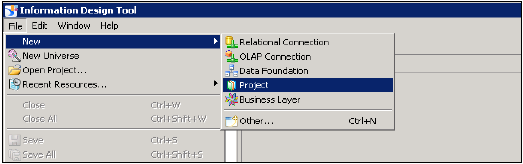
プロジェクト名を右クリック→新規に移動→リレーショナル接続を選択→接続/リソース名を入力→次へ→リストからSAPを選択してHANAシステムに接続→SAPHANA→JDBC / ODBCドライバーを選択→次へ→HANAシステムの詳細を入力→[次へ]をクリックして[完了]をクリックします。

[接続のテスト]オプションをクリックして、この接続をテストすることもできます。
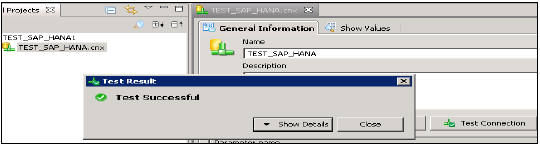
接続のテスト→成功。次のステップは、この接続をリポジトリに公開して、使用できるようにすることです。
接続名を右クリック→[リポジトリへの接続の公開]をクリック→BOリポジトリ名とパスワードの入力→[接続]→[次へ]→[完了]→[はい]をクリックします。
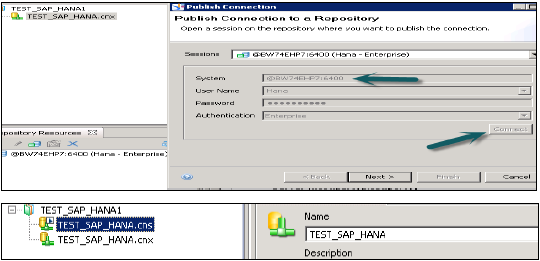
拡張子が.cnsの新しいリレーショナル接続が作成されます。
.cns-接続タイプは、データファンデーションの作成に使用する必要がある保護されたリポジトリ接続を表します。
.cnx-ローカルのセキュリティで保護されていない接続を表します。ユニバースの作成および公開中にこの接続を使用すると、リポジトリに公開できなくなります。
.cns接続タイプを選択→これを右クリック→新規データファンデーションをクリック→データファンデーションの名前を入力→次へ→シングルソース/マルチソース→次へ→終了をクリックします。

中央のペインにスキーマ名とともにHANAデータベース内のすべてのテーブルが表示されます。
すべてのテーブルをHANAデータベースからマスターペインにインポートして、ユニバースを作成します。DimテーブルとFactテーブルをDimテーブルの主キーで結合して、スキーマを作成します。
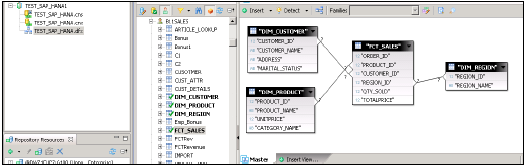
結合をダブルクリックして、上部にあるカーディナリティ→検出→OK→すべて保存を検出します。次に、BIアプリケーションツールによって使用されるデータ基盤上に新しいビジネスレイヤーを作成する必要があります。
.dfxを右クリックし、新しいビジネスレイヤ→名前の入力→終了→を選択します。マスターペイン→の下に、すべてのオブジェクトが自動的に表示されます。ディメンションをメジャーに変更します(タイプ-必要に応じてメジャー変更プロジェクション)→すべて保存。
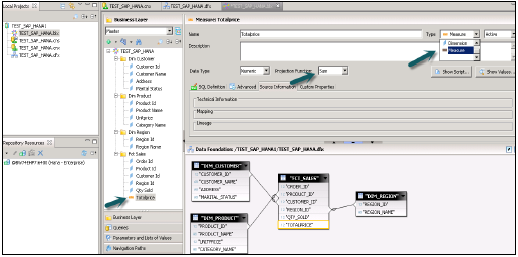
.bfxファイルを右クリック→[公開]→[リポジトリへ]→[次へ]→[完了]→[ユニバースの公開に成功]をクリックします。
次に、BILaunchpadからWebIレポートを開くか、BIプラットフォームクライアントツールからWebiリッチクライアントを開きます→新規→ユニバース→TEST_SAP_HANA→OKを選択します。
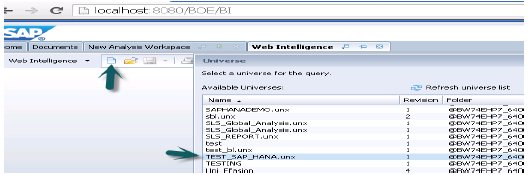
すべてのオブジェクトがクエリパネルに追加されます。左側のペインから属性とメジャーを選択して、結果オブジェクトに追加できます。ザ・Run query 以下に示すように、SQLクエリが実行され、出力がWebIのレポートの形式で生成されます。
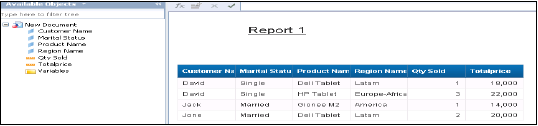
Microsoft Excelは、多くの組織で最も一般的なBIレポートおよび分析ツールと見なされています。ビジネスマネージャーとアナリストは、HANAデータベースに接続して、分析用のピボットテーブルとグラフを描画できます。
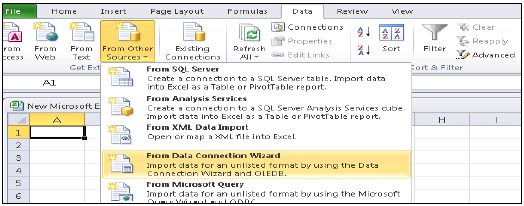
MSExcelをHANAに接続する
Excelを開き、[データ]タブ→[他のソースから]→[データ接続ウィザード]→[その他/詳細]をクリックし、[次へ]→[データリンクのプロパティ]をクリックします。
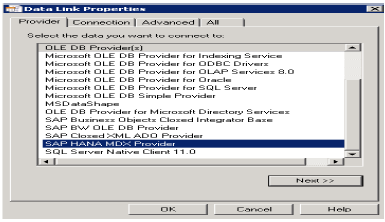
このリストからSAPHANA MDXプロバイダーを選択して、任意のMDXデータソースに接続します→HANAシステムの詳細(サーバー名、インスタンス、ユーザー名、パスワード)を入力→[接続のテスト]→[接続に成功]→[OK]をクリックします。
それはあなたにHANAシステムで利用可能なドロップダウンリストのすべてのパッケージのリストを提供します。情報ビューを選択→「次へ」をクリック→「ピボットテーブル/その他」を選択→「OK」を選択できます。
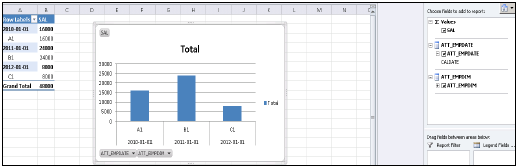
情報ビューのすべての属性がMSExcelに追加されます。示されているように、レポートするさまざまな属性とメジャーを選択できます。また、上部のデザインオプションから、円グラフや棒グラフなどのさまざまなグラフを選択できます。
セキュリティとは、会社の重要なデータを不正アクセスや不正使用から保護し、会社のポリシーに従ってコンプライアンスと基準が満たされていることを確認することを意味します。SAP HANAを使用すると、お客様はさまざまなセキュリティポリシーと手順を実装し、企業のコンプライアンス要件を満たすことができます。
SAP HANAは、単一のHANAシステムで複数のデータベースをサポートします。これはマルチテナントデータベースコンテナと呼ばれます。HANAシステムには、複数のマルチテナントデータベースコンテナを含めることもできます。マルチコンテナシステムには、常に1つのシステムデータベースと任意の数のマルチテナントデータベースコンテナがあります。この環境にインストールされているSAPHANAシステムは、単一のシステムID(SID)によって識別されます。HANAシステムのデータベースコンテナは、SIDとデータベース名で識別されます。HANAスタジオと呼ばれるSAPHANAクライアントは、特定のデータベースに接続します。
SAP HANAは、認証、承認、暗号化、監査などのすべてのセキュリティ関連機能と、他のマルチテナントデータベースではサポートされていない一部のアドオン機能を提供します。
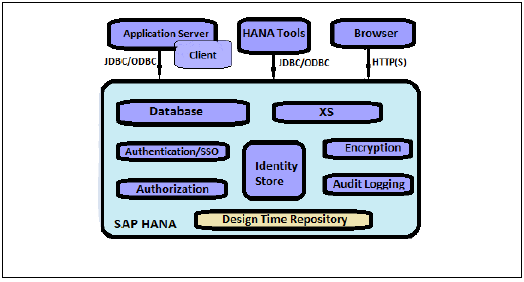
以下は、SAPHANAが提供するセキュリティ関連機能のリストです。
- ユーザーと役割の管理
- 認証とSSO
- Authorization
- ネットワークでのデータ通信の暗号化
- 永続層でのデータの暗号化
マルチテナントHANAデータベースの追加機能-
Database Isolation −オペレーティングシステムメカニズムによるテナント間の攻撃の防止が含まれます
Configuration Change blacklist −テナントデータベース管理者が特定のシステムプロパティを変更できないようにする必要があります
Restricted Features −ファイルシステム、ネットワーク、またはその他のリソースへの直接アクセスを提供する特定のデータベース機能を無効にする必要があります。
SAPHANAのユーザーとロールの管理
SAP HANAのユーザーとロールの管理構成は、HANAシステムのアーキテクチャによって異なります。
SAP HANAがBIプラットフォームツールと統合され、レポートデータベースとして機能する場合、エンドユーザーとロールはアプリケーションサーバーで管理されます。
エンドユーザーがSAPHANAデータベースに直接接続する場合、エンドユーザーと管理者の両方にHANAシステムのデータベースレイヤーでのユーザーとロールが必要です。
HANAデータベースを使用するすべてのユーザーには、必要な権限を持つデータベースユーザーが必要です。HANAシステムにアクセスするユーザーは、アクセス要件に応じて、テクニカルユーザーまたはエンドユーザーのいずれかになります。システムへのログオンが成功すると、必要な操作を実行するためのユーザーの権限が確認されます。その操作の実行は、ユーザーに付与されている特権によって異なります。これらの権限は、HANAセキュリティのロールを使用して付与できます。HANA Studioは、HANAデータベースシステムのユーザーとロールを管理するための強力なツールの1つです。
ユーザータイプ
ユーザータイプは、セキュリティポリシーと、ユーザープロファイルに割り当てられたさまざまな特権によって異なります。ユーザータイプは、テクニカルデータベースユーザーまたはエンドユーザーがレポート目的またはデータ操作のためにHANAシステムにアクセスする必要がある場合があります。
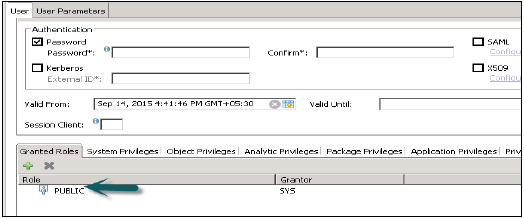
標準ユーザー
標準ユーザーは、独自のスキーマでオブジェクトを作成でき、システム情報モデルで読み取りアクセス権を持つユーザーです。読み取りアクセスは、すべての標準ユーザーに割り当てられているPUBLICロールによって提供されます。
制限付きユーザー
制限付きユーザーとは、一部のアプリケーションでHANAシステムにアクセスし、HANAシステムに対するSQL権限を持たないユーザーです。これらのユーザーが作成されると、最初はアクセスできません。
制限付きユーザーと標準ユーザーを比較すると-
制限されたユーザーは、HANAデータベースまたは独自のスキーマにオブジェクトを作成できません。
標準ユーザーのようにプロファイルに追加された一般的なパブリックロールがないため、データベース内のデータを表示するためのアクセス権はありません。
HTTP / HTTPSを使用してのみHANAデータベースに接続できます。
テクニカルデータベースユーザーは、データベースでの新しいオブジェクトの作成、他のユーザーへの特権の割り当て、パッケージ、アプリケーションなどの管理目的でのみ使用されます。
SAPHANAユーザー管理アクティビティ
ビジネスニーズとHANAシステムの構成に応じて、HANAスタジオなどのユーザー管理ツールを使用して実行できるさまざまなユーザーアクティビティがあります。
最も一般的な活動は次のとおりです。
- ユーザーの作成
- ユーザーに役割を付与する
- 役割の定義と作成
- ユーザーの削除
- ユーザーパスワードのリセット
- ログオン試行の失敗が多すぎた後のユーザーの再アクティブ化
- 必要に応じてユーザーを非アクティブ化する
HANA Studioでユーザーを作成するにはどうすればよいですか?
HANAスタジオでユーザーとロールを作成できるのは、システム権限ROLEADMINを持つデータベースユーザーのみです。HANAスタジオでユーザーとロールを作成するには、HANA管理者コンソールに移動します。システムビューにセキュリティタブが表示されます-
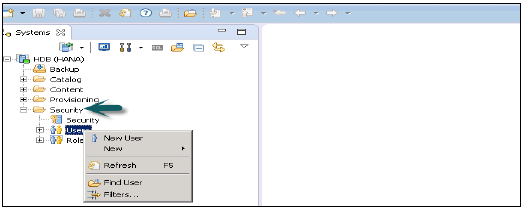
[セキュリティ]タブを展開すると、ユーザーとロールのオプションが表示されます。新しいユーザーを作成するには、[ユーザー]を右クリックして、[新しいユーザー]に移動します。ユーザーとユーザーパラメータを定義する新しいウィンドウが開きます。
ユーザー名(委任)を入力し、[認証]フィールドにパスワードを入力します。新しいユーザーのパスワードを保存しながら、パスワードが適用されます。制限付きユーザーを作成することもできます。
指定するロール名は、既存のユーザーまたはロールの名前と同じであってはなりません。パスワードルールには、パスワードの最小の長さと、パスワードの一部にする必要のある文字タイプ(下位、上位、数字、特殊文字)の定義が含まれています。
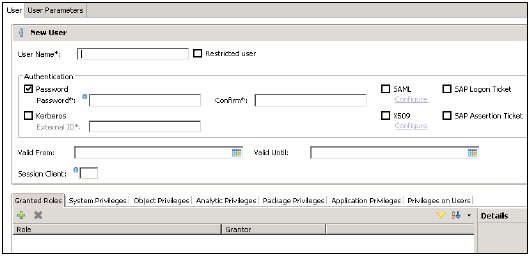
SAML、X509証明書、SAPログオンチケットなど、さまざまな認証方法を構成できます。データベース内のユーザーは、さまざまなメカニズムで認証できます。
パスワードを使用した内部認証メカニズム。
Kerberos、SAML、SAPログオンチケット、SAPアサーションチケット、X.509などの外部メカニズム。
ユーザーは、一度に複数のメカニズムで認証できます。ただし、Kerberosの1つのパスワードと1つのプリンシパル名のみが一度に有効になります。ユーザーがデータベースインスタンスに接続して操作できるようにするには、1つの認証メカニズムを指定する必要があります。
また、ユーザーの有効性を定義するオプションもあります。日付を選択することで、有効期間について言及できます。有効性の指定は、オプションのユーザーパラメーターです。
デフォルトでSAPHANAデータベースとともに提供される一部のユーザーは、-SYS、SYSTEM、_SYS_REPO、_SYS_STATISTICSです。
これが完了したら、次のステップはユーザープロファイルの特権を定義することです。ユーザープロファイルに追加できる特権にはさまざまな種類があります。
ユーザーに付与された役割
これは、組み込みのSAP.HANAロールをユーザープロファイルに追加したり、[ロール]タブで作成されたカスタムロールを追加したりするために使用されます。カスタムロールを使用すると、アクセス要件に従ってロールを定義でき、これらのロールをユーザープロファイルに直接追加できます。これにより、さまざまなアクセスタイプで毎回オブジェクトを覚えてユーザープロファイルに追加する必要がなくなります。
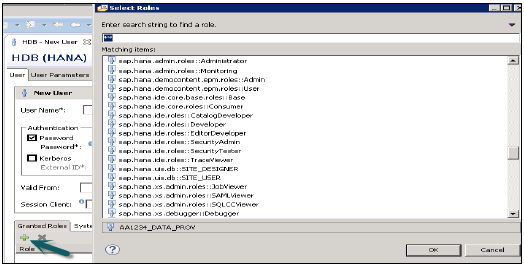
PUBLIC−これは汎用ロールであり、デフォルトですべてのデータベースユーザーに割り当てられます。このロールには、システムビューへの読み取り専用アクセスと、一部のプロシージャの実行権限が含まれています。これらの役割を取り消すことはできません。

モデリング
SAPHANAスタジオで情報モデラーを使用するために必要なすべての権限が含まれています。
システム権限
ユーザープロファイルに追加できるシステム権限にはさまざまな種類があります。システム権限をユーザープロファイルに追加するには、+記号をクリックします。
システム権限は、バックアップ/復元、ユーザー管理、インスタンスの開始と停止などに使用されます。
コンテンツ管理者
これには、MODELINGロールと同様の特権が含まれていますが、このロールが他のユーザーにこれらの特権を付与できることに加えて。また、インポートされたオブジェクトを操作するためのリポジトリ権限も含まれています。
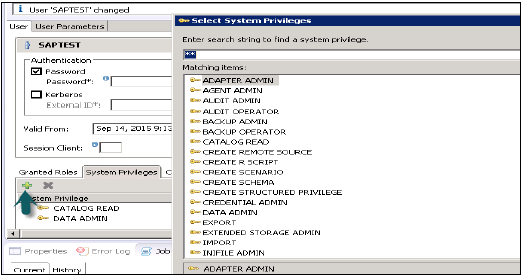
データ管理者
これは、オブジェクトからユーザープロファイルにデータを追加するために必要な特権の一種です。
以下に、サポートされている一般的なシステム権限を示します-
デバッガーをアタッチ
別のユーザーによって呼び出されたプロシージャコールのデバッグを許可します。さらに、対応するプロシージャのDEBUG特権が必要です。
監査管理者
次の監査関連コマンドの実行を制御します-CREATEAUDIT POLICY、DROP AUDIT POLICY、ALTER AUDIT POLICY、および監査構成の変更。AUDIT_LOGシステムビューへのアクセスも許可します。
監査オペレーター
次のコマンドの実行を許可します-ALTERSYSTEM CLEAR AUDITLOG。AUDIT_LOGシステムビューへのアクセスも許可します。
バックアップ管理者
バックアップおよびリカバリ手順を定義および開始するためのBACKUPおよびRECOVERYコマンドを許可します。
バックアップオペレーター
BACKUPコマンドがバックアッププロセスを開始することを許可します。
カタログを読む
これは、すべてのシステムビューへのフィルタリングされていない読み取り専用アクセスをユーザーに許可します。通常、これらのビューのコンテンツは、アクセスするユーザーの権限に基づいてフィルタリングされます。
スキーマの作成
CREATESCHEMAコマンドを使用してデータベーススキーマの作成を許可します。デフォルトでは、各ユーザーは1つのスキーマを所有し、この特権を使用して、ユーザーは追加のスキーマを作成できます。
構造化された特権を作成する
構造化特権(分析特権)の作成を許可します。分析特権の所有者のみが、他のユーザーまたはロールにその特権をさらに付与または取り消すことができます。
資格情報管理者
資格情報コマンド-CREATE / ALTER / DROPCREDENTIALを承認します。
データ管理者
システムビュー内のすべてのデータの読み取りを許可します。また、SAP HANAデータベース内の任意のデータ定義言語(DDL)コマンドの実行を可能にします
この権限を持つユーザーは、アクセス権限を持たないデータ格納テーブルを選択または変更することはできませんが、テーブルを削除したり、テーブル定義を変更したりすることはできます。
データベース管理者
これは、CREATE、DROP、ALTER、RENAME、BACKUP、RECOVERYなど、マルチデータベース内のデータベースに関連するすべてのコマンドを許可します。
書き出す
EXPORTTABLEコマンドを介してデータベースでのエクスポートアクティビティを許可します。
この特権のほかに、ユーザーはエクスポートされるソーステーブルに対するSELECT特権を必要とすることに注意してください。
インポート
IMPORTコマンドを使用して、データベース内のインポートアクティビティを承認します。
この特権のほかに、ユーザーはインポートするターゲットテーブルに対するINSERT特権を必要とすることに注意してください。
Inifile管理者
システム設定の変更を許可します。
ライセンス管理者
これは、SET SYSTEMLICENSEコマンドが新しいライセンスをインストールすることを許可します。
ログ管理者
これは、ALTER SYSTEM LOGGING [ON | OFF]コマンドが、ログフラッシュメカニズムを有効または無効にすることを許可します。
管理者の監視
これは、EVENTのALTERSYSTEMコマンドを許可します。
オプティマイザー管理者
これは、クエリオプティマイザの動作に影響を与えるSQL PLANCACHEおよびALTERSYSTEM UPDATESTATISTICSコマンドに関するALTERSYSTEMコマンドを許可します。
リソース管理者
この特権は、システムリソースに関するコマンドを許可します。たとえば、ALTER SYSTEM RECLAIMDATAVOLUMEおよびALTERSYSTEM RESET MONITORINGVIEWです。また、管理コンソールで使用できるコマンドの多くを承認します。
役割管理者
この特権は、CREATEROLEおよびDROPROLEコマンドを使用した役割の作成と削除を許可します。また、GRANTコマンドとREVOKEコマンドを使用してロールの付与と取り消しを許可します。
アクティブ化されたロール、つまり作成者が事前定義されたユーザー_SYS_REPOであるロールは、他のロールまたはユーザーに付与したり、直接ドロップしたりすることはできません。ROLEADMIN権限を持つユーザーでさえそうすることはできません。アクティブ化されたオブジェクトに関するドキュメントを確認してください。
セーブポイント管理者
これは、ALTER SYSTEMSAVEPOINTコマンドを使用してセーブポイントプロセスの実行を許可します。
SAP HANAデータベースのコンポーネントは、新しいシステム権限を作成できます。これらの特権は、システム特権の最初の識別子としてcomponent-nameを使用し、2番目の識別子としてcomponent-privilege-nameを使用します。
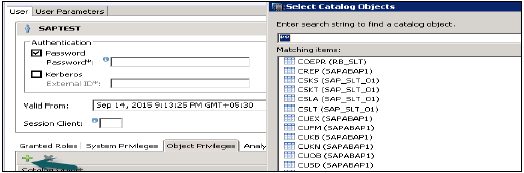
オブジェクト/ SQL権限
オブジェクト特権は、SQL特権とも呼ばれます。これらの権限は、テーブル、ビュー、スキーマの選択、挿入、更新、削除などのオブジェクトへのアクセスを許可するために使用されます。
以下に、オブジェクト特権の可能なタイプを示します-
実行時にのみ存在するデータベースオブジェクトに対するオブジェクト権限
計算ビューなど、リポジトリで作成されたアクティブ化されたオブジェクトに対するオブジェクト権限
リポジトリで作成されたアクティブ化されたオブジェクトを含むスキーマに対するオブジェクト権限、
オブジェクト/ SQL特権は、データベースオブジェクトに対するすべてのDDLおよびDML特権のコレクションです。
以下に示すのは、一般的にサポートされているオブジェクト特権です。
HANAデータベースには複数のデータベースオブジェクトがあるため、すべての特権がすべての種類のデータベースオブジェクトに適用できるわけではありません。
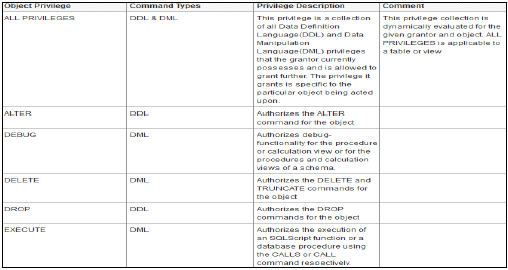
オブジェクト特権とデータベースオブジェクトへの適用性-
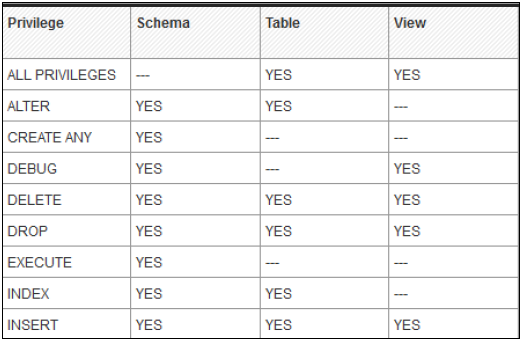
分析特権
同じビューのデータに、そのデータに関連する要件がない他のユーザーがアクセスできないようにする必要がある場合があります。
分析権限は、オブジェクトレベルでHANA情報ビューへのアクセスを制限するために使用されます。分析権限で行および列レベルのセキュリティを適用できます。
分析特権は次の目的で使用されます-
- 特定の値の範囲に対する行および列レベルのセキュリティの割り当て。
- ビューをモデル化するための行および列レベルのセキュリティの割り当て。
パッケージ特権
SAP HANAリポジトリでは、特定のユーザーまたはロールのパッケージ認証を設定できます。パッケージ権限は、データモデル(分析ビューまたは計算ビュー)またはリポジトリオブジェクトへのアクセスを許可するために使用されます。リポジトリパッケージに割り当てられているすべての権限は、すべてのサブパッケージにも割り当てられています。割り当てられたユーザー認証を他のユーザーに渡すことができるかどうかについても言及できます。
パッケージ権限をユーザープロファイルに追加する手順-
HANAスタジオの[ユーザーの作成]→[+]を選択して[パッケージ特権]タブをクリックし、1つ以上のパッケージを追加します。Ctrlキーを使用して、複数のパッケージを選択します。
[リポジトリパッケージの選択]ダイアログで、パッケージ名の全部または一部を使用して、アクセスを許可するリポジトリパッケージを見つけます。
アクセスを許可する1つ以上のリポジトリパッケージを選択すると、選択したパッケージが[パッケージ特権]タブに表示されます。
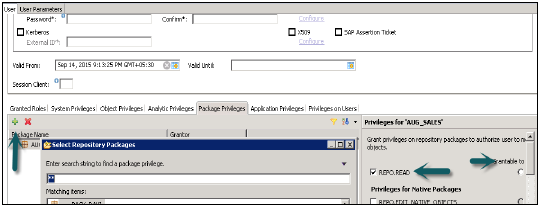
以下に示すのは、ユーザーがオブジェクトを変更することを許可するためにリポジトリパッケージで使用される付与特権です。
REPO.READ −選択したパッケージおよびデザイン時オブジェクト(ネイティブおよびインポートの両方)への読み取りアクセス
REPO.EDIT_NATIVE_OBJECTS −パッケージ内のオブジェクトを変更する権限。
Grantable to Others −これに「はい」を選択すると、割り当てられたユーザー認証を他のユーザーに渡すことができます。
アプリケーション特権
ユーザープロファイルのアプリケーション権限は、HANAXSアプリケーションへのアクセスの承認を定義するために使用されます。これは、個々のユーザーまたはユーザーのグループに割り当てることができます。アプリケーション特権を使用して、データベース管理者に高度な機能を提供したり、通常のユーザーに読み取り専用アクセスを提供したりするなど、同じアプリケーションにさまざまなレベルのアクセスを提供することもできます。
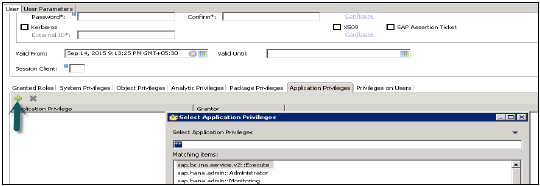
ユーザープロファイルでアプリケーション固有の権限を定義したり、ユーザーのグループを追加したりするには、以下の権限を使用する必要があります-
- アプリケーション特権ファイル(.xsprivileges)
- アプリケーションアクセスファイル(.xsaccess)
- ロール定義ファイル(<RoleName> .hdbrole)
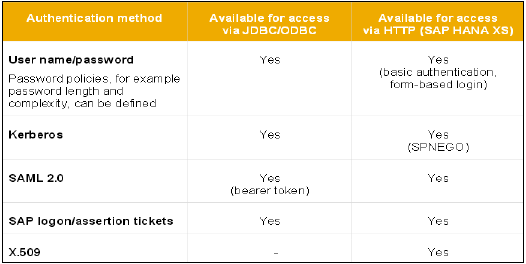
HANAデータベースにアクセスできるすべてのSAPHANAユーザーは、さまざまな認証方法で検証されます。SAP HANAシステムはさまざまなタイプの認証方法をサポートしており、これらのログイン方法はすべてプロファイルの作成時に構成されます。
以下は、SAPHANAでサポートされている認証方法のリストです。
- ユーザー名パスワード
- Kerberos
- SAML 2.0
- SAPログオンチケット
- X.509
ユーザー名パスワード
この方法では、HANAユーザーがデータベースにログインするためにユーザー名とパスワードを入力する必要があります。このユーザープロファイルは、HANAStudio→[セキュリティ]タブの[ユーザー管理]で作成されます。
パスワードは、パスワードポリシー、つまりパスワードの長さ、複雑さ、小文字と大文字などに従う必要があります。
組織のセキュリティ基準に従って、パスワードポリシーを変更できます。パスワードポリシーを無効にすることはできませんのでご注意ください。
Kerberos
外部認証方法を使用してHANAデータベースシステムに接続するすべてのユーザーには、データベースユーザーも必要です。外部ログインを内部データベースユーザーにマップする必要があります。
この方法により、ユーザーは、ネットワーク経由でJDBC / ODBCドライバーを使用して、またはSAP Business Objectsのフロントエンドアプリケーションを使用して、HANAシステムを直接認証できます。
また、HANAXSエンジンを使用したHANA拡張サービスでのHTTPアクセスも許可します。Kerberos認証にSPENGOメカニズムを使用します。
SAML
SAMLはSecurityAssertion Markup Languageの略で、ODBC / JDBCクライアントから直接HANAシステムにアクセスするユーザーを認証するために使用できます。また、HANAXSエンジンを介してHTTP経由でアクセスするHANAシステムのユーザーを認証するためにも使用できます。
SAMLは認証目的でのみ使用され、承認には使用されません。
SAPログオンおよびアサーションチケット
SAPログオン/アサーションチケットを使用して、HANAシステムのユーザーを認証できます。これらのチケットは、SAPポータルなどのチケットを発行するように構成されたSAPシステムにログインするときにユーザーに発行されます。SAPログオンチケットで指定されたユーザーは、ユーザーのマッピングをサポートしないため、HANAシステムで作成する必要があります。
X.509クライアント証明書
X.509証明書を使用して、HANAXSエンジンからのHTTPアクセス要求を介してHANAシステムにログインすることもできます。ユーザーは、HANAXSシステムに保存されている信頼できる認証局から署名された証明書によって認証されます。
ユーザーマッピングはサポートされていないため、信頼できる証明書のユーザーはHANAシステムに存在する必要があります。
HANAシステムでのシングルサインオン
シングルサインオンはHANAシステムで構成できます。これにより、ユーザーはクライアントの初期認証からHANAシステムにログインできます。さまざまな認証方法とSSOを使用してクライアントアプリケーションにユーザーがログインすると、ユーザーはHANAシステムに直接アクセスできます。
SSOは、以下の構成方法で構成できます-
- SAML
- Kerberos
- HANAXSエンジンからのHTTPアクセス用のX.509クライアント証明書
- SAPログオン/アサーションチケット
ユーザーがHANAデータベースに接続してデータベース操作を実行しようとすると、認証がチェックされます。ユーザーがJDBC / ODBCまたはHTTP経由でクライアントツールを使用してHANAデータベースに接続し、データベースオブジェクトに対して一部の操作を実行する場合、対応するアクションは、ユーザーに付与されたアクセスによって決定されます。
ユーザーに付与される特権は、ユーザーに付与されたユーザープロファイルまたはロールに割り当てられたオブジェクト特権によって決定されます。承認は、両方のアクセスの組み合わせです。ユーザーがHANAデータベースで何らかの操作を実行しようとすると、システムは認証チェックを実行します。必要な特権がすべて見つかると、システムはこのチェックを停止し、要求されたアクセスを許可します。
「ユーザーロールと管理」で説明したように、SAPHANAで使用されるさまざまなタイプの特権があります。
システム権限
これらは、ユーザーのシステムおよびデータベースの許可と制御システムのアクティビティーに適用できます。これらは、スキーマの作成、データのバックアップ、ユーザーとロールの作成などの管理タスクに使用されます。システム権限は、リポジトリ操作の実行にも使用されます。
オブジェクト権限
これらはデータベース操作に適用でき、テーブルやスキーマなどのデータベースオブジェクトに適用されます。テーブルやビューなどのデータベースオブジェクトを管理するために使用されます。データベースオブジェクトに基づいて、選択、実行、変更、削除、削除などのさまざまなアクションを定義できます。
また、SMARTデータアクセスを介してSAPHANAに接続されているリモートデータオブジェクトを制御するためにも使用されます。
分析特権
これらは、HANAリポジトリで作成されるすべてのパッケージ内のデータに適用できます。これらは、属性ビュー、分析ビュー、計算ビューなどのパッケージ内に作成されるモデリングビューを制御するために使用されます。これらは、HANAパッケージのモデリングビューで定義されている属性に行および列レベルのセキュリティを適用します。
パッケージ特権
これらは、HANAデータベースのリポジトリに作成されたパッケージへのアクセスと使用を許可するために適用できます。パッケージには、属性、分析、計算ビューなどのさまざまなモデリングビューと、HANAリポジトリデータベースで定義された分析権限が含まれています。
アプリケーション特権
これらは、HTTPリクエストを介してHANAデータベースにアクセスするHANAXSアプリケーションに適用できます。これらは、HANAXSエンジンで作成されたアプリケーションへのアクセスを制御するために使用されます。
アプリケーション特権は、HANA Studioを使用してユーザー/ロールに直接適用できますが、設計時にリポジトリで作成されたロールに適用することをお勧めします。
SAPHANAデータベースでのリポジトリ認証
_SYS_REPOは、ユーザーがHANAリポジトリ内のすべてのオブジェクトを所有していることです。このユーザーは、HANAシステムでリポジトリオブジェクトがモデル化されているオブジェクトに対して外部から承認されている必要があります。_SYS_REPOはすべてのオブジェクトの所有者であるため、これらのオブジェクトへのアクセスを許可するためにのみ使用でき、他のユーザーは_SYS_REPOユーザーとしてログインできません。
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
HANAデータベースを使用するには、SAPHANAライセンス管理とキーが必要です。HANAスタジオを使用してHANAライセンスキーをインストールまたは削除できます。
ライセンスキーの種類
SAP HANAシステムは、2種類のライセンスキーをサポートしています-
Temporary License Key− HANAデータベースをインストールすると、一時ライセンスキーが自動的にインストールされます。これらのキーは90日間のみ有効であり、インストール後90日間が経過する前に、SAPマーケットプレイスに永続的なライセンスキーを要求する必要があります。
Permanent License Key−永久ライセンスキーは、事前定義された有効期限までのみ有効です。ライセンスキーは、HANAインストールを対象とするためにライセンスされるメモリの量を指定します。これらは、SAPMarketの[KeysandRequests]タブからインストールできます。永続的なライセンスキーの有効期限が切れると、一時的なライセンスキーが発行されます。これは28日間のみ有効です。この期間中に、永続的なライセンスキーを再度インストールする必要があります。
HANAシステムの永続的なライセンスキーには2つのタイプがあります-
Unenforced −強制されていないライセンスキーがインストールされていて、HANAシステムの消費量がメモリのライセンス量を超えている場合、この場合、SAPHANAの動作は影響を受けません。
Enforced−強制ライセンスキーがインストールされていて、HANAシステムの消費量がメモリのライセンス量を超えると、HANAシステムがロックされます。このような状況が発生した場合は、HANAシステムを再起動するか、新しいライセンスキーを要求してインストールする必要があります。
システムのランドスケープ(スタンドアロン、HANAクラウド、HANA上のBWなど)に応じてHANAシステムで使用できるさまざまなライセンスシナリオがあり、これらのモデルのすべてがHANAシステムインストールのメモリに基づいているわけではありません。
HANAのライセンスプロパティを確認する方法
HANAシステム→プロパティ→ライセンスを右クリックします
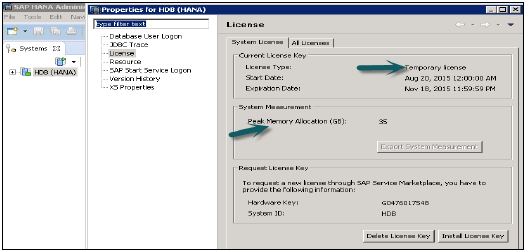
ライセンスの種類、開始日と有効期限、メモリ割り当て、およびSAP Market Placeを介して新しいライセンスを要求するために必要な情報(ハードウェアキー、システムID)について説明します。
ライセンスキーのインストール→参照→パスの入力は、新しいライセンスキーをインストールするために使用され、削除オプションは、古い有効期限キーを削除するために使用されます。
[ライセンス]の下の[すべてのライセンス]タブには、製品名、説明、ハードウェアキー、初回インストール時間などが表示されます。
SAP HANA監査ポリシーは、監査対象のアクションと、監査に関連するためにアクションを実行する必要がある条件を指示します。監査ポリシーは、HANAシステムで実行されたアクティビティと、それらのアクティビティを誰がいつ実行したかを定義します。
SAP HANAデータベース監査機能により、HANAシステムで実行されるアクションを監視できます。SAP HANA監査ポリシーを使用するには、HANAシステムでアクティブ化する必要があります。アクションが実行されると、ポリシーは監査イベントをトリガーして監査証跡に書き込みます。監査証跡の監査エントリを削除することもできます。
複数のデータベースがある分散環境では、個々のシステムごとに監査ポリシーを有効にできます。システムデータベースの場合、監査ポリシーはnameserver.iniファイルで定義され、テナントデータベースの場合、監査ポリシーはglobal.iniファイルで定義されます。
監査ポリシーのアクティブ化
HANAシステムで監査ポリシーを定義するには、システム権限-監査管理者が必要です。
HANAシステムのセキュリティオプション→監査に移動します
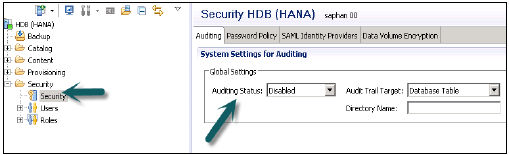
[グローバル設定]→[監査ステータス]を有効に設定します。
監査証跡ターゲットを選択することもできます。次の監査証跡ターゲットが可能です-
Syslog (デフォルト)-Linuxオペレーティングシステムのログシステム。
Database Table −内部データベーステーブル、監査管理者または監査オペレーターシステム権限を持つユーザーは、このテーブルに対してのみ選択操作を実行できます。
CSV text −このタイプの監査証跡は、非実稼働環境でのテスト目的でのみ使用されます。
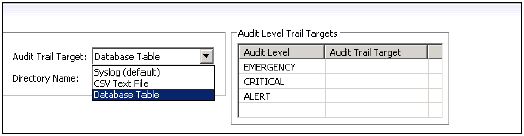
[監査ポリシー]領域で新しい監査ポリシーを作成することもできます→[新しいポリシーの作成]を選択します。監査するポリシー名とアクションを入力します。
[展開]ボタンを使用して、新しいポリシーを保存します。新しいポリシーが自動的に有効になり、アクション条件が満たされると、監査証跡テーブルに監査エントリが作成されます。ステータスを無効に変更してポリシーを無効にするか、ポリシーを削除することもできます。
SAP HANAレプリケーションを使用すると、ソースシステムからSAPHANAデータベースにデータを移行できます。既存のSAPシステムからHANAにデータを移動する簡単な方法は、さまざまなデータ複製技術を使用することです。
システムレプリケーションは、コマンドラインまたはHANAスタジオを使用してコンソールでセットアップできます。プライマリECCまたはトランザクションシステムは、このプロセスの間オンラインのままでいられます。HANAシステムには3種類のデータ複製方法があります-
- SAPLTレプリケーション方式
- ETLツールSAPBusiness Object Data Service(BODS)メソッド
- 直接抽出接続方式(DXC)
SAPLTレプリケーション方式
SAPランドスケープトランスフォーメーションレプリケーションは、HANAシステムのトリガーベースのデータレプリケーション方法です。これは、SAPおよび非SAPソースからのリアルタイムデータまたはスケジュールベースのレプリケーションをレプリケートするための完璧なソリューションです。SAP LT Replicationサーバーがあり、すべてのトリガー要求を処理します。レプリケーションサーバーは、スタンドアロンサーバーとしてインストールすることも、SAP NW7.02以降を搭載した任意のSAPシステムで実行することもできます。
HANA DBとECCトランザクションシステムの間には信頼できるRFC接続があり、HANAシステム環境でトリガーベースのデータレプリケーションを可能にします。

SLTレプリケーションの利点
SLTレプリケーション方式では、複数のソースシステムから1つのHANAシステムへ、および1つのソースシステムから複数のHANAシステムへのデータレプリケーションが可能です。
SAP LTは、トリガーベースのアプローチを使用します。ソースシステムで測定可能なパフォーマンスへの影響はありません。
また、HANAデータベースにロードする前のデータ変換およびフィルタリング機能も提供します。
SAPおよび非SAPソースシステムから関連データのみをHANAに複製し、リアルタイムのデータ複製を可能にします。
HANAシステムおよびHANAスタジオと完全に統合されています。
ECCシステムでの信頼できるRFC接続の作成
ソースSAPシステムAA1で、ターゲットシステムBB1に対して信頼できるRFCを設定します。これが完了すると、AA1にログオンし、ユーザーがBB1で十分な認証を取得している場合、ユーザーとパスワードを再入力しなくても、RFC接続を使用してBB1にログオンできます。
2つのSAPシステム間のRFC信頼関係/信頼関係、信頼システムから信頼システムへのRFCを使用すると、信頼システムへのログオンにパスワードは必要ありません。
SAPログオンを使用してSAPECCシステムを開きます。トランザクション番号sm59を入力→これは新しい信頼できるRFC接続を作成するためのトランザクション番号です→3番目のアイコンをクリックして新しい接続ウィザードを開きます→[作成]をクリックすると新しいウィンドウが開きます。
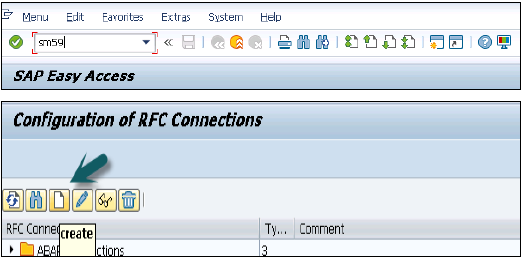
RFC宛先ECCHANA(RFC宛先の名称を入力)接続タイプ-3(ABAPシステムの場合)
技術設定に移動
ターゲットホスト-ECCシステム名、IPを入力し、システム番号を入力します。
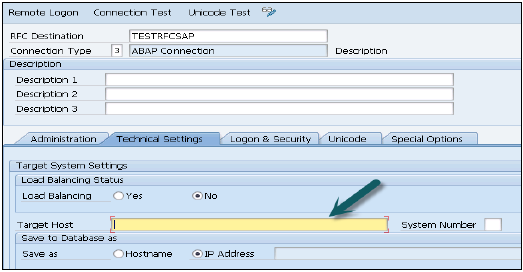
[ログオンとセキュリティ]タブに移動し、言語、クライアント、ECCシステムのユーザー名とパスワードを入力します。
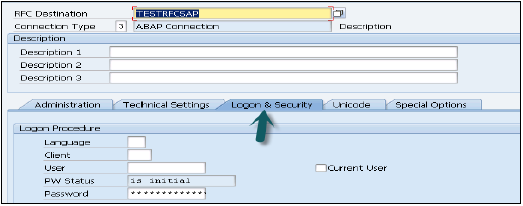
上部の[保存]オプションをクリックします。

[接続のテスト]をクリックすると、接続が正常にテストされます。
RFC接続を構成するには
トランザクションの実行-ltr(RFC接続を構成するため)→新しいブラウザが開きます→ECCシステムのユーザー名とパスワードを入力してログオンします。

[新規]→[新しいウィンドウ]をクリックして開きます→構成名を入力→[次へ]→[RFC宛先(以前に作成した接続名)を入力]をクリックし、検索オプションを使用して名前を選択し、[次へ]をクリックします。
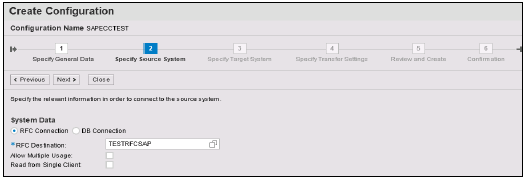
[ターゲットシステムの指定]に、HANAシステム管理者のユーザー名とパスワード、ホスト名、インスタンス番号を入力し、[次へ]をクリックします。007のようなデータ転送ジョブの数を入力します(000にすることはできません)→次へ→構成の作成。
次に、HANA Studioに移動して、この接続を使用します-
HANAStudioに移動→データプロビジョニングをクリック→HANAシステムを選択
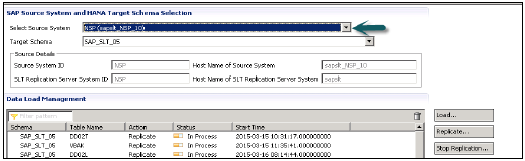
ソースシステム(信頼できるRFC接続の名前)と、ECCシステムからテーブルをロードするターゲットスキーマ名を選択します。HANAデータベースに移動するテーブルを選択→追加→終了。

選択したテーブルは、HANAデータベースの下の選択したスキーマに移動します。
SAP HANA ETLベースのレプリケーションは、SAP Data Servicesを使用して、SAPまたは非SAPソースシステムからターゲットHANAデータベースにデータを移行します。BODSシステムは、ソースシステムからターゲットシステムへのデータの抽出、変換、およびロードに使用されるETLツールです。
アプリケーション層でビジネスデータを読み取ることができます。Data Servicesでデータフローを定義し、レプリケーションジョブをスケジュールし、Data ServicesDesignerのデータストアでソースシステムとターゲットシステムを定義する必要があります。
SAP HANA Data Services ETLベースのレプリケーションを使用するにはどうすればよいですか?
Data Services Designerにログイン(リポジトリを選択)→データストアを作成
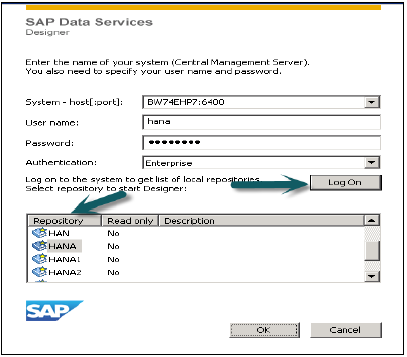
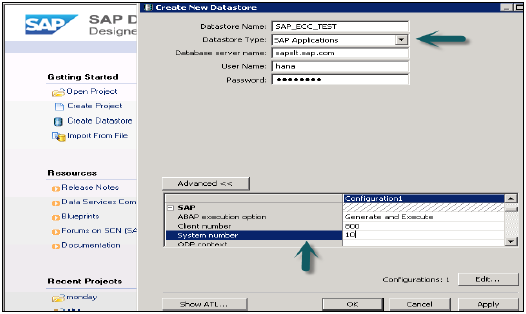
SAP ECCシステムの場合、SAPアプリケーションとしてデータベースを選択し、ECCシステムのECCサーバー名、ユーザー名、およびパスワードを入力します。[詳細設定]タブでは、インスタンス番号、クライアント番号などの詳細を選択して適用します。
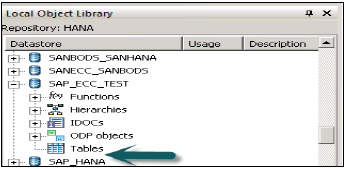
このデータストアはローカルオブジェクトライブラリの下にあります。これを展開すると、その中にテーブルはありません。
テーブルを右クリック→名前でインポート→ECCシステムからインポートするECCテーブルを入力(MARAはECCシステムのデフォルトテーブル)→インポート→テーブルを展開→MARA→データの表示を右クリック。データが表示されれば、データストア接続は正常です。
ここで、ターゲットシステムをHANAデータベースとして選択するには、新しいデータストアを作成します。データストアの作成→データストアの名前SAP_HANA_TEST→データストアタイプ(データベース)→データベースタイプSAPHANA→データベースバージョンHANA1.x。
HANAシステムのHANAサーバー名、ユーザー名、パスワードを入力して[OK]をクリックします。
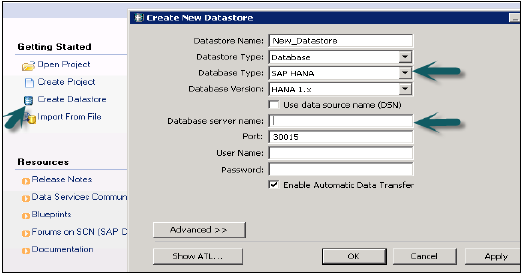
このデータストアはローカルオブジェクトライブラリに追加されます。ソーステーブルからHANAデータベース内の特定のテーブルにデータを移動する場合は、テーブルを追加できます。ターゲットテーブルは、ソーステーブルと同様のデータ型である必要があることに注意してください。
レプリケーションジョブの作成
新しいプロジェクトの作成→プロジェクト名の入力→プロジェクト名の右クリック→新しいバッチジョブ→ジョブ名の入力。
右側のタブから、ワークフロー→ワークフロー名の入力→ダブルクリックしてバッチジョブの下に追加→データフローの入力→データフロー名の入力→ダブルクリックしてプロジェクト領域のバッチジョブの下に追加を選択します。上部の[すべて保存]オプション。

テーブルをFirstData Store ECC(MARA)から作業領域にドラッグします。それを選択して右クリック→[新規追加]→[テンプレートテーブル]を選択して、HANA DBに同様のデータタイプの新しいテーブルを作成します→テーブル名、データストアECC_HANA_TEST2を入力→所有者名(スキーマ名)→[OK]
テーブルを前面にドラッグし、両方のテーブルを接続→すべて保存します。次に、バッチジョブ→右クリック→実行→はい→OKに移動します。
レプリケーションジョブを実行すると、ジョブが正常に完了したことを確認できます。
HANAスタジオ→スキーマの展開→テーブル→データの確認に移動します。これは、バッチジョブの手動実行です。
バッチジョブのスケジューリング
データサービス管理コンソールに移動して、バッチジョブをスケジュールすることもできます。DataServices管理コンソールにログインします。
左側からリポジトリを選択→[バッチジョブ構成]タブに移動すると、ジョブのリストが表示されます→スケジュールするジョブに対して→[スケジュールの追加]をクリック→[スケジュール名]を入力し、次のようなパラメータを設定します(時間、日付、繰り返しなど)必要に応じて、[適用]をクリックします。
これは、HANAシステムではSybaseレプリケーションとも呼ばれます。このレプリケーション方式の主なコンポーネントは、SAPソースアプリケーションシステムの一部であるSybase Replication Agent、Replication Agent、およびSAPHANAシステムに実装されるSybaseReplicationServerです。
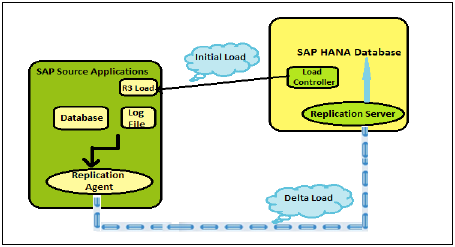
Sybaseでの初期ロードReplicationメソッドは、SAPHANAでLoadControllerによって開始され、管理者によってトリガーされます。初期ロードをHANAデータベースに転送するようにR3ロードに通知します。ソースシステムのR3ロードは、ソースシステムの選択されたテーブルのデータをエクスポートし、このデータをHANAシステムのR3ロードコンポーネントに転送します。ターゲットシステムのR3ロードは、SAPHANAデータベースにデータをインポートします。
SAPホストエージェントは、ソースシステムとソースシステムの一部であるターゲットシステムとの間の認証を管理します。Sybase Replicationエージェントは、初期ロード時にデータの変更を検出し、すべての変更が完了していることを確認します。ソースシステムのテーブルのエントリで変更、更新、および削除が行われると、テーブルログが作成されます。このテーブルログは、データをソースシステムからHANAデータベースに移動します。
初期ロード後のデルタレプリケーション
デルタレプリケーションは、初期ロードとレプリケーションが完了すると、ソースシステムのデータ変更をリアルタイムでキャプチャします。ソースシステムでのそれ以降のすべての変更は、上記の方法を使用してキャプチャされ、ソースシステムからHANAデータベースに複製されます。
この方法は、SAP HANAレプリケーションの最初の提供の一部でしたが、ライセンスの問題と複雑さのために位置付け/サポートされなくなり、SLTも同じ機能を提供します。
Note −この方法は、データソースとしてSAPERPシステムとデータベースとしてDB2のみをサポートします。
Direct Extractor Connectionデータレプリケーションは、SAP HANAへの単純なHTTP(S)接続を介して、SAP Business Suiteシステムに組み込まれている既存の抽出、変換、およびロードメカニズムを再利用します。これは、バッチ駆動型のデータ複製技術です。これは、データ抽出の機能が制限された抽出、変換、およびロードの方法と見なされます。
DXCはバッチ駆動型のプロセスであり、多くの場合、一定の間隔でDXCを使用したデータ抽出で十分です。バッチジョブの実行間隔を設定できます。例:20分ごとで、ほとんどの場合、特定の時間間隔でこれらのバッチジョブを使用してデータを抽出するだけで十分です。
DXCデータレプリケーションの利点
この方法では、SAPHANAシステムランドスケープに追加のサーバーやアプリケーションは必要ありません。
DXCメソッドは、ソースシステムですべてのビジネスエクストラクタロジックを適用した後にデータがHANAに送信されるため、SAPHANAでのデータモデリングの複雑さを軽減します。
SAPHANA実装プロジェクトのタイムラインをスピードアップします
SAP BusinessSuiteからSAPHANAに意味的に豊富なデータを提供します
SAP HANAへの単純なHTTP(S)接続を介して、SAP Business Suiteシステムに組み込まれている既存の独自の抽出、変換、およびロードメカニズムを再利用します。
DXCデータレプリケーションの制限
データソースには、抽出、変換、および読み込みのための事前定義されたメカニズムが必要です。そうでない場合は、メカニズムを定義する必要があります。
これには、少なくともSP未満のNet Weaver 7.0以降に基づくBusinessSuiteシステムが必要です。リリース700SAPKW70021(SPスタック19、2008年11月から)。
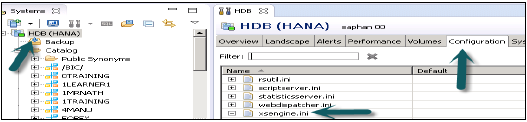
DXCデータレプリケーションの構成
Enabling XS Engine service in Configuration tab in HANA Studio−システムのHANAスタジオの[管理者]タブに移動します。[構成]→[xsengine.ini]に移動し、インスタンス値を1に設定します。
Enabling ICM Web Dispatcher service in HANA Studio − [構成]→[webdispatcher.ini]に移動し、インスタンス値を1に設定します。
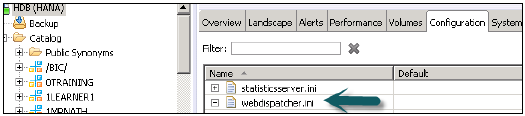
HANAシステムでICMWebDispatcherサービスを有効にします。Webディスパッチャは、HANAシステムでのデータの読み取りと読み込みにICMメソッドを使用します。
Setup SAP HANA Direct Extractor Connection−DXCデリバリーユニットをSAPHANAにダウンロードします。ユニットは/ usr / sap / HDB / SYS / global / hdb / contentの場所にインポートできます。
SAPHANAコンテンツノードのインポートダイアログを使用してユニットをインポートします→DXCを利用するようにXSアプリケーションサーバーを構成します→application_container値をlibxsdxcに変更します
Creating a HTTP connection in SAP BW −次に、トランザクションコードSM59を使用してSAPBWでhttp接続を作成する必要があります。
Input Parameters − RFC接続の名前、HANAホスト名、および<インスタンス番号>を入力します
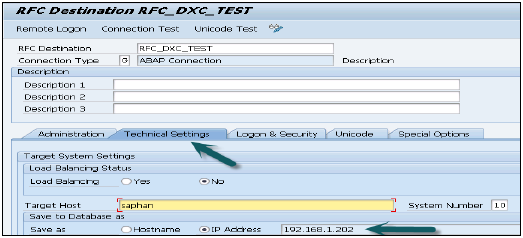
[ログオンセキュリティ]タブで、基本認証方法を使用してHANAスタジオで作成されたDXCユーザーを入力します-
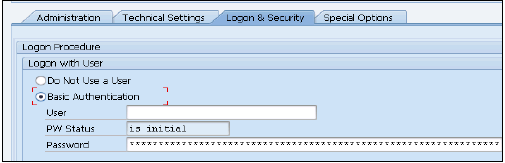
Setting up BW Parameters for HANA −トランザクションSE 38を使用してBWで以下のパラメータを設定する必要があります。パラメータ一覧−
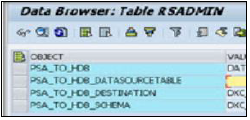
PSA_TO_HDB_DESTINATION −受信データ(SM 59を使用して作成された接続名)を移動する必要がある場所について言及する必要があります
PSA_TO_HDB_SCHEMA −レプリケートされたデータを割り当てる必要のあるスキーマ
PSA_TO_HDB−すべてのデータソースをHANAに複製するグローバル。システム–DXCを使用するように指定されたクライアント。データソース–指定されたデータソースのみが使用されます
PSA_TO_HDB_DATASOURCETABLE −DXCに使用されるデータソースのリストを含むテーブル名を付ける必要があります。
データソースレプリケーション
RSA5を使用してECCにデータソースをインストールします。
指定されたアプリケーションコンポーネントを使用してメタデータを複製します(データソースバージョン7.0に必要、3.5バージョンのデータソースがある場合はそれを移行する必要があります。SAPBWでデータソースをアクティブにします。SAPBWでデータソースをアクティブにすると、次のテーブルが作成されます。定義済みスキーマ内-
/ BIC / A <データソース> 00–IMDSOアクティブテーブル
/ BIC / A <データソース> 40 –IMDSOアクティベーションキュー
/ BIC / A <データソース> 70 –レコードモード処理テーブル
/ BIC / A <データソース> 80 –リクエストおよびパケットID情報テーブル
/ BIC / A <データソース> A0–要求タイムスタンプテーブル
RSODSO_IMOLOG-IMDSO関連のテーブル。DXCに関連するすべてのデータソースに関する情報を格納します。
これで、データがアクティブ化されると、データがテーブル/ BIC / A0FI_AA_2000に正常にロードされます。
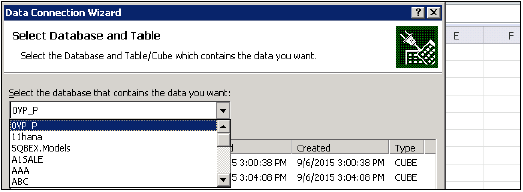
[カタログ]タブでSAPHANAStudio→[スキーマの作成]を開きます。<ここから始めます>
データを準備し、csv形式で保存します。次に、次の構文で「ctl」拡張子のファイルを作成します-
---------------------------------------
import data into table Schema."Table name"
from 'file.csv'
records delimited by '\n'
fields delimited by ','
Optionally enclosed by '"'
error log 'table.err'
-----------------------------------------この「ctl」ファイルをFTPに転送し、このファイルを実行してデータをインポートします-
'table.ctl'からインポート
HANA Studio→カタログ→スキーマ→テーブル→コンテンツの表示に移動して、テーブル内のデータを確認します
MDXプロバイダーは、MSExcelをSAPHANAデータベースシステムに接続するために使用されます。HANAシステムをExcelに接続するためのドライバーを提供し、さらにデータモデリングに使用されます。Microsoft Office Excel 2010/2013を使用して、32ビットと64ビットの両方のWindowsのHANAに接続できます。
SAP HANAは、SQLとMDXの両方のクエリ言語をサポートしています。両方の言語を使用できます。SQL用のJDBCとODBC、およびMDX処理にはODBOが使用されます。Excelピボットテーブルは、SAPHANAシステムからデータを読み取るためのクエリ言語としてMDXを使用します。MDXは、MicrosoftのODBO(OLE DB for OLAP)仕様の一部として定義されており、データの選択、計算、およびレイアウトに使用されます。MDXは、多次元データモデルをサポートし、レポートと分析の要件をサポートします。
MDXプロバイダーは、SAPおよび非SAPレポートツールによってHANAスタジオで定義された情報ビューの利用を可能にします。既存の物理テーブルとスキーマは、情報モデルのデータ基盤を提供します。
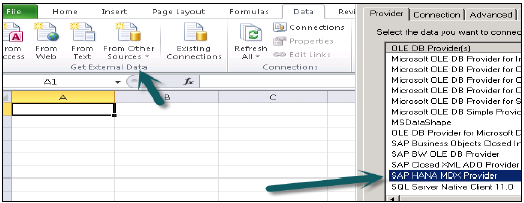
接続するデータソースのリストからSAPHANA MDXプロバイダーを選択したら、ホスト名、インスタンス番号、ユーザー名、パスワードなどのHANAシステムの詳細を渡します。
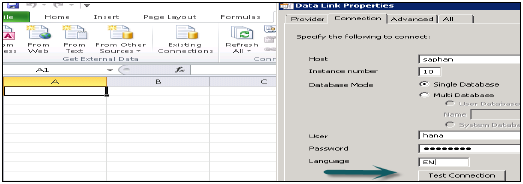
接続が成功したら、[パッケージ名]→[HANAモデリングビュー]を選択して、ピボットテーブルを生成できます。
MDXはHANAデータベースに緊密に統合されています。HANAデータベースの接続およびセッション管理は、HANAによって実行されるステートメントを処理します。これらのステートメントが実行されると、MDXインターフェイスによって解析され、MDXステートメントごとに計算モデルが生成されます。この計算モデルは、MDXの標準結果を生成する実行プランを作成します。これらの結果は、OLAPクライアントによって直接消費されます。
MDXをHANAデータベースに接続するには、HANAクライアントツールが必要です。このクライアントツールは、SAPマーケットプレイスからダウンロードできます。HANAクライアントのインストールが完了すると、MSExcelのデータソースのリストにSAPHANAMDXプロバイダーのオプションが表示されます。
SAP HANAアラート監視は、HANAシステムで実行されているシステムリソースとサービスのステータスを監視するために使用されます。アラート監視は、CPU使用率、ディスクフル、FSがしきい値に達しているなどの重要なアラートを処理するために使用されます。HANAシステムの監視コンポーネントは、HANAデータベースのすべてのコンポーネントの状態、使用状況、パフォーマンスに関する情報を継続的に収集します。コンポーネントのいずれかが設定されたしきい値に違反すると、アラートが発生します。
HANAシステムで発生するアラートの優先度は、問題の重大度を示し、コンポーネントで実行されるチェックによって異なります。例-CPU使用率が80%の場合、優先度の低いアラートが発生します。ただし、96%に達すると、システムは優先度の高いアラートを生成します。
システムモニターは、HANAシステムを監視し、すべてのSAPHANAシステムコンポーネントの可用性を確認するための最も一般的な方法です。システムモニターは、HANAシステムのすべての主要コンポーネントとサービスをチェックするために使用されます。

管理エディターで個々のシステムの詳細にドリルダウンすることもできます。データディスク、ログディスク、トレースディスクについて通知し、リソースの使用状況を優先的に警告します。

管理者エディターの[アラート]タブは、HANAシステムの現在のアラートとすべてのアラートを確認するために使用されます。
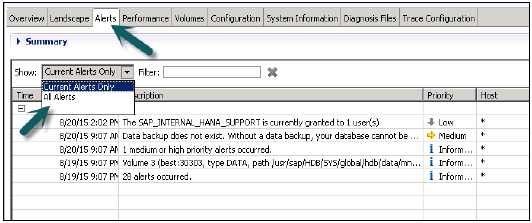
また、アラートが発生した時間、アラートの説明、アラートの優先度などについても通知します。
SAP HANAモニタリングダッシュボードは、システムの状態と構成の重要な側面を示します-
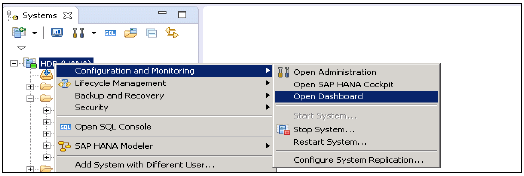
- 高および中優先度のアラート。
- メモリとCPU使用率
- データのバックアップ
SAP HANAデータベース永続化レイヤーは、すべてのトランザクションのログを管理して、標準のデータバックアップとシステムの復元機能を提供します。
これにより、再起動後またはシステムクラッシュ後にデータベースを最新のコミット状態に復元し、トランザクションを完全にまたは完全に元に戻すことができます。SAP HANA Persistent Layerはインデックスサーバーの一部であり、HANAシステムのデータとトランザクションログボリュームがあり、メモリ内データはこれらのボリュームに定期的に保存されます。HANAシステムには、独自の永続性を持つサービスがあります。また、最後の保存ポイントからのすべてのデータベーストランザクションの保存ポイントとログも提供します。
SAP HANAデータベースに永続レイヤーが必要なのはなぜですか?
メインメモリは揮発性であるため、再起動または停電中にデータが失われます。
データは永続メディアに保存する必要があります。
バックアップと復元が利用可能です。
これにより、再起動後にデータベースが最新のコミット済み状態に復元され、トランザクションが完全に実行されるか、完全に取り消されます。
データとトランザクションログのボリューム
データベース内のデータに対するこれらの変更が定期的にディスクにコピーされるように、データベースは常に最新の状態に復元できます。データの変更と特定のトランザクションイベントを含むログファイルも定期的にディスクに保存されます。システムのデータとログはログボリュームに保存されます。
データボリュームには、SQLデータと取り消しログ情報、およびSAPHANA情報モデリングデータが格納されます。この情報は、ブロックと呼ばれるデータページに保存されます。これらのブロックは、セーブポイントと呼ばれる一定の時間間隔でデータボリュームに書き込まれます。
ログボリュームには、データの変更に関する情報が格納されます。2つのログポイント間で行われた変更は、ログボリュームに書き込まれ、ログエントリと呼ばれます。トランザクションがコミットされると、ログバッファに保存されます。
セーブポイント
SAP HANAデータベースでは、変更されたデータがメモリからディスクに自動的に保存されます。これらの定期的な間隔はセーブポイントと呼ばれ、デフォルトでは5分ごとに発生するように設定されています。SAP HANAデータベースの永続レイヤーは、これらのセーブポイントを定期的に実行します。この操作中に、変更されたデータがディスクに書き込まれ、REDOログもディスクに保存されます。
セーブポイントに属するデータは、ディスク上のデータの一貫した状態を示し、次のセーブポイント操作が完了するまでそこに残ります。永続データへのすべての変更について、REDOログエントリがログボリュームに書き込まれます。データベースが再起動した場合、最後に完了したセーブポイントからのデータをデータボリュームから読み取り、ログエントリをやり直してログボリュームに書き込むことができます。
セーブポイントの頻度は、global.iniファイルで構成できます。セーブポイントは、データベースのシャットダウンやシステムの再起動などの他の操作によって開始できます。以下のコマンドを実行してセーブポイントを実行することもできます-
ALTERシステムのセーブポイント
データとREDOログをログボリュームに保存するには、これらをキャプチャするのに十分なディスク容量があることを確認する必要があります。そうしないと、システムがディスクフルイベントを発行し、データベースが機能しなくなります。
HANAシステムのインストール中に、データおよびログボリュームの保存場所として次のデフォルトディレクトリが作成されます-
- /usr/sap/<SID>/SYS/global/hdb/data
- /usr/sap/<SID>/SYS/global/hdb/log
これらのディレクトリはglobal.iniファイルで定義されており、後の段階で変更できます。
セーブポイントは、HANAシステムで実行されるトランザクションのパフォーマンスに影響を与えないことに注意してください。セーブポイント操作中、トランザクションは通常どおり実行され続けます。HANAシステムが適切なハードウェアで実行されている場合、システムのパフォーマンスに対するセーブポイントの影響はごくわずかです。
SAP HANAのバックアップとリカバリは、データベースに障害が発生した場合にHANAシステムのバックアップとシステムのリカバリを実行するために使用されます。
[概要]タブ
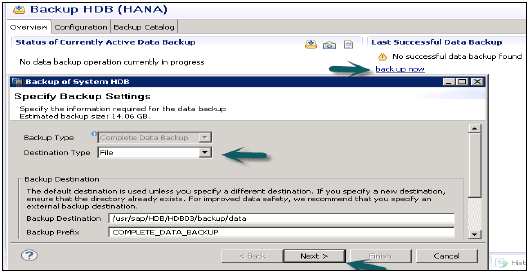
現在実行中のデータバックアップと最後に成功したデータバックアップのステータスを示します。
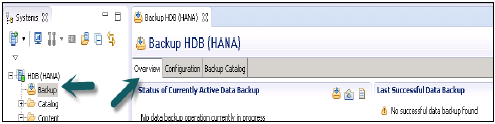
[今すぐバックアップ]オプションを使用して、データバックアップウィザードを実行できます。
[構成]タブ
バックアップ間隔の設定、ファイルベースのデータバックアップ設定、およびログベースのデータバックアップ設定について説明します。

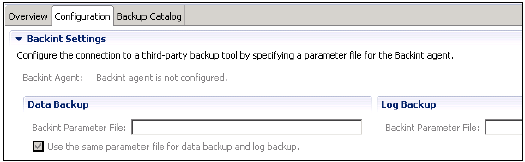
バックアップ間隔の設定
Backint設定は、データにサードパーティツールを使用し、バッキングエージェントの構成でバックアップを記録するオプションを提供します。
Backintエージェントのパラメータファイルを指定して、サードパーティのバックアップツールへの接続を構成します。
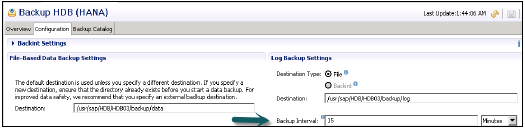
ファイルおよびログベースのデータバックアップ設定
ファイルベースのデータバックアップ設定は、HANAシステムでデータバックアップを保存するフォルダーを指定します。バックアップフォルダを変更できます。
データバックアップファイルのサイズを制限することもできます。システムデータのバックアップがこの設定されたファイルサイズを超えると、複数のファイルに分割されます。
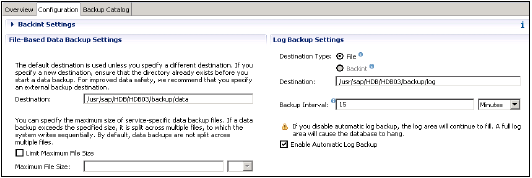
ログバックアップ設定は、外部サーバーにログバックアップを保存する宛先フォルダーを指示します。ログバックアップの宛先タイプを選択できます
ファイル-バックアップを保存するのに十分なスペースをシステムに確保します
Backint-ファイルシステムに存在する特別な名前付きパイプですが、ディスクスペースは必要ありません。
ドロップダウンからバックアップ間隔を選択できます。これは、新しいログバックアップが書き込まれるまでに経過できる最長の時間を示します。バックアップ間隔:秒、分、または時間単位で指定できます。
自動ログバックアップオプションを有効にする:ログ領域を空に保つのに役立ちます。このログ領域を無効にすると、引き続きいっぱいになり、データベースがハングする可能性があります。
バックアップウィザードを開く-システムのバックアップを実行します。
バックアップウィザードは、バックアップ設定を指定するために使用されます。バックアップの種類、宛先の種類、バックアップの宛先フォルダ、バックアッププレフィックス、バックアップのサイズなどを通知します。
[次へ]→[バックアップ設定の確認]→[完了]をクリックしたとき
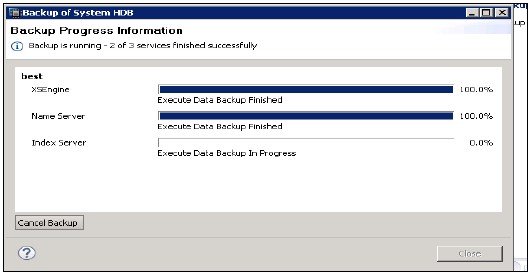
システムバックアップを実行し、各サーバーのバックアップを完了する時間を通知します。
HANAシステムの復旧
SAP HANAデータベースをリカバリするには、データベースをシャットダウンする必要があります。したがって、リカバリ中、エンドユーザーまたはSAPアプリケーションはデータベースにアクセスできません。
次の状況では、SAPHANAデータベースのリカバリが必要です-
データ領域のディスクが使用できないか、ログ領域のディスクが使用できません。
論理エラーの結果として、データベースは特定の時点でその状態にリセットする必要があります。
データベースのコピーを作成します。
HANAシステムを回復する方法は?
HANAシステム→右クリック→戻るとリカバリ→システムのリカバリを選択します
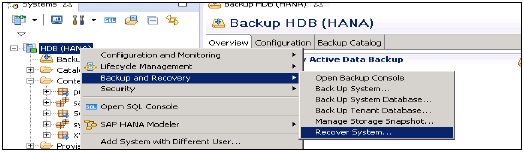
HANAシステムでのリカバリの種類
Most Recent State−データベースを現在の時刻にできるだけ近い時刻に回復するために使用されます。上記のタイプのリカバリを実行するには、最後のデータバックアップとログ領域が必要であるため、このリカバリでは、データバックアップとログバックアップが使用可能である必要があります。
Point in Time−データベースを特定の時点に回復するために使用されます。上記のタイプのリカバリを実行するには、最後のデータバックアップとログ領域が必要であるため、このリカバリでは、データバックアップとログバックアップが使用可能である必要があります。
Specific Data Backup−指定されたデータバックアップにデータベースを回復するために使用されます。上記のタイプのリカバリオプションには、特定のデータバックアップが必要です。
Specific Log Position −このリカバリタイプは、以前のリカバリが失敗した例外的な場合に使用できる高度なオプションです。
Note −リカバリウィザードを実行するには、HANAシステムの管理者権限が必要です。
SAP HANAは、システム障害とソフトウェアエラーのビジネス継続性と災害復旧のためのメカニズムを提供します。HANAシステムの高可用性は、データセンターの停電などの災害、火災、洪水などの自然災害、またはハードウェア障害の場合にビジネス継続性を実現するのに役立つ一連のプラクティスを定義します。
SAP HANAの高可用性は、フォールトトレランスと、停止後にシステム運用を再開するシステムの機能を最小限のビジネス損失で提供します。
次の図は、HANAシステムの高可用性のフェーズを示しています-
最初のフェーズは障害に備えています。障害は、自動的に、または管理アクションによって検出できます。データはバックアップされ、スタンバイシステムが操作を引き継ぎます。障害のあるシステムの修復と、以前の構成に復元する元のシステムを含む回復プロセスが実行されます。
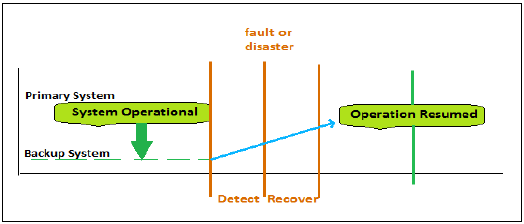
HANAシステムで高可用性を実現するには、他のコンポーネントに障害が発生した場合に機能して使用する必要のない追加のコンポーネントを含めることが重要です。これには、ハードウェアの冗長性、ネットワークの冗長性、およびデータセンターの冗長性が含まれます。SAP HANAは、以下のようにいくつかのレベルのハードウェアとソフトウェアの冗長性を提供します-
HANAシステムハードウェアの冗長性
SAP HANAアプライアンスベンダーは、冗長電源とファン、エラー修正メモリ、完全冗長ネットワークスイッチとルーター、無停電電源装置(UPS)など、冗長ハードウェア、ソフトウェア、およびネットワークコンポーネントの複数のレイヤーを提供しています。ディスクストレージシステムは、電源障害が発生した場合でも書き込みを保証し、ストライピングおよびミラーリング機能を使用して、ディスク障害からの自動回復のための冗長性を提供します。
SAPHANAソフトウェアの冗長性
SAPHANAはSUSELinux Enterprise 11 for SAPに基づいており、セキュリティの事前設定が含まれています。
SAP HANAシステムソフトウェアには、停止が検出された場合(強制終了またはクラッシュ)に、構成されたサービス(インデックスサーバー、ネームサーバーなど)を自動的に再起動するウォッチドッグ機能が含まれています。
SAPHANAの永続性の冗長性
SAP HANAは、トランザクションログ、セーブポイント、スナップショットの永続性を提供して、システムの再起動と障害からの回復をサポートし、遅延を最小限に抑え、データを失うことはありません。
HANAシステムのスタンバイとフェイルオーバー
SAP HANAシステムには、プライマリシステムに障害が発生した場合のフェイルオーバーに使用される個別のスタンバイホストが含まれます。これにより、停止からの回復時間が短縮され、HANAシステムの可用性が向上します。
SAP HANAシステムは、アプリケーションデータまたはデータベースカタログを変更するすべてのトランザクションをログエントリに記録し、それらをログ領域に保存します。ログ領域のこれらのログエントリを使用して、SQLステートメントをロールバックまたは繰り返します。ログファイルはHANAシステムで利用でき、管理者エディターの[診断ファイル]ページのHANAスタジオからアクセスできます。
ログバックアッププロセス中、ログセグメントの実際のデータのみがログ領域からサービス固有のログバックアップファイルまたはサードパーティのバックアップツールに書き込まれます。
システム障害が発生した後、データベースを目的の状態に復元するために、ログバックアップからログエントリをやり直す必要がある場合があります。
永続性のあるデータベースサービスが停止した場合は、必ず再起動することが重要です。そうしないと、サービスが停止する前の時点までしか回復できません。
ログバックアップタイムアウトの構成
ログバックアップタイムアウトは、この間隔でコミットが行われた場合にログセグメントがバックアップされる間隔を決定します。SAPHANAスタジオのバックアップコンソールを使用してログバックアップタイムアウトを構成できます-
global.ini構成ファイルでlog_backup_timeout_s間隔を構成することもできます。
「ファイル」へのログバックアップとバックアップモード「NORMAL」は、SAPHANAシステムのインストール後の自動ログバックアップ機能のデフォルト設定です。自動ログバックアップは、少なくとも1つの完全なデータバックアップが実行された場合にのみ機能します。
最初の完全なデータバックアップが実行されると、自動ログバックアップ機能がアクティブになります。SAP HANAスタジオを使用して、自動ログバックアップ機能を有効/無効にすることができます。自動ログバックアップを有効にしておくことをお勧めします。有効にしないと、ログ領域がいっぱいになり続けます。ログ領域がいっぱいになると、HANAシステムでデータベースがフリーズする可能性があります。
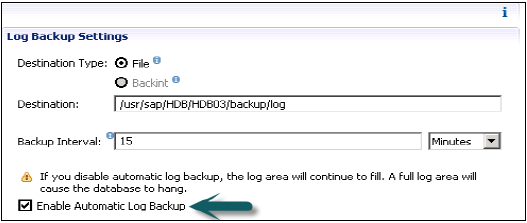
global.ini構成ファイルのpersistenceセクションでenable_auto_log_backupパラメーターを変更することもできます。
SQLはStructuredQueryLanguageの略です。
これは、データベースと通信するための標準化された言語です。SQLは、データの取得、データベース内のデータの保存または操作に使用されます。
SQLステートメントは次の機能を実行します-
- データの定義と操作
- システムマネジメント
- セッション管理
- トランザクション管理
- スキーマの定義と操作
開発者がデータをデータベースにプッシュできるようにするSQL拡張機能のセットは、 SQL scripts。
データ操作言語(DML)
DMLステートメントは、スキーマオブジェクト内のデータを管理するために使用されます。いくつかの例-
SELECT −データベースからデータを取得する
INSERT −データをテーブルに挿入する
UPDATE −テーブル内の既存のデータを更新します
データ定義言語(DDL)
DDLステートメントは、データベース構造またはスキーマを定義するために使用されます。いくつかの例-
CREATE −データベースにオブジェクトを作成する
ALTER −データベースの構造を変更します
DROP −データベースからオブジェクトを削除します
データ制御言語(DCL)
DCLステートメントのいくつかの例は次のとおりです。
GRANT −データベースへのユーザーのアクセス権限を付与します
REVOKE −GRANTコマンドで指定されたアクセス権を撤回する
なぜSQLが必要なのですか?
SAP HANA Modelerで情報ビューを作成するときは、いくつかのOLTPアプリケーションの上に作成しています。バックエンドのこれらはすべてSQLで実行されます。データベースはこの言語のみを理解します。
レポートがビジネス要件を満たしているかどうかをテストするには、出力が要件に従っている場合にデータベースでSQLステートメントを実行する必要があります。
HANA計算ビューは、グラフィカルまたはSQLスクリプトを使用した2つの方法で作成できます。より複雑な計算ビューを作成する場合は、直接SQLスクリプトを使用する必要がある場合があります。
HANA StudioでSQLコンソールを開く方法は?
HANAシステムを選択し、システムビューでSQLコンソールオプションをクリックします。[カタログ]タブまたは任意のスキーマ名を右クリックしてSQLコンソールを開くこともできます。
SAP HANAは、リレーショナルデータベースとOLAPデータベースの両方として機能できます。HANAでBWを使用する場合、BWとHANAでキューブを作成します。これらはリレーショナルデータベースとして機能し、常にSQLステートメントを生成します。ただし、OLAP接続を使用してHANAビューに直接アクセスすると、OLAPデータベースとして機能し、MDXが生成されます。
テーブルの作成オプションを使用して、SAPHANAで行または列ストアテーブルを作成できます。テーブルは、データ定義のcreate tableステートメントを実行するか、HANAスタジオのグラフィカルオプションを使用して作成できます。
テーブルを作成するときは、テーブル内の属性も定義する必要があります。
SQL statement to create a table in HANA Studio SQL Console −
Create column Table TEST (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);Creating a table in HANA studio using GUI option −
テーブルを作成するときは、列の名前とSQLデータ型を定義する必要があります。[ディメンション]フィールドは、値の長さと、それを主キーとして定義するための[キー]オプションを示します。
SAP HANAは、テーブルで次のデータ型をサポートします-
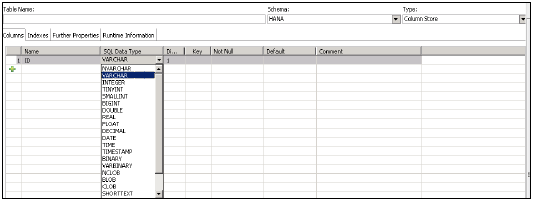
SAP HANAは7つのカテゴリのSQLデータ型をサポートしており、列に格納する必要のあるデータの種類によって異なります。
- Numeric
- 文字/文字列
- Boolean
- 日付時刻
- Binary
- 大きなオブジェクト
- Multi-Valued
次の表に、各カテゴリのデータ型のリストを示します。

日付時刻
これらのデータ型は、HANAデータベースのテーブルに日付と時刻を格納するために使用されます。
DATE−データ型は、列の日付値を表す年、月、日の情報で構成されます。日付データ型のデフォルトの形式はYYYY-MM-DDです。
TIME−データ型は、HANAデータベースのテーブルの時間、分、秒の値で構成されます。時間データ型のデフォルトの形式はHH:MI:SSです。
SECOND DATE−データ型は、HANAデータベースのテーブルの年、月、日、時、分、秒の値で構成されます。SECONDDATEデータ型のデフォルト形式はYYYY-MM-DDHH:MM:SSです。
TIMESTAMP−データ型は、HANAデータベースのテーブル内の日付と時刻の情報で構成されます。TIMESTAMPデータ型のデフォルト形式はYYYY-MM-DDHH:MM:SS:FFnです。ここで、FFnは秒の小数部を表します。
数値
TinyINT−8ビットの符号なし整数を格納します。最小値:0および最大値:255
SMALLINT−16ビットの符号付き整数を格納します。最小値:-32,768および最大値:32,767
Integer−32ビットの符号付き整数を格納します。最小値:-2,147,483,648および最大値:2,147,483,648
BIGINT−64ビットの符号付き整数を格納します。最小値:-9,223,372,036,854,775,808および最大値:9,223,372,036,854,775,808
SMALL − 10進数および10進数:最小値:-10 ^ 38 +1および最大値:10 ^ 38 -1
REAL −最小値:-3.40E + 38および最大値:3.40E + 38
DOUBLE−64ビット浮動小数点数を格納します。最小値:-1.7976931348623157E308および最大値:1.7976931348623157E308
ブール値
ブールデータ型は、TRUE、FALSEのブール値を格納します
キャラクター
Varchar −最大8000文字。
Nvarchar −最大長4000文字
ALPHANUM−英数字を格納します。整数の値は1から127の間です。
SHORTTEXT −テキスト検索機能と文字列検索機能をサポートする可変長文字列を格納します。
バイナリ
バイナリタイプは、バイナリデータのバイトを格納するために使用されます。
VARBINARY−バイナリデータをバイト単位で格納します。最大整数長は1〜5000です。
大きなオブジェクト
LARGEOBJECTSは、テキストドキュメントや画像などの大量のデータを保存するために使用されます。
NCLOB −大きなUNICODE文字オブジェクトを格納します。
BLOB −大量のバイナリデータを保存します。
CLOB −大量のASCII文字データを格納します。
TEXT−テキスト検索機能を有効にします。このデータ型は、列テーブルに対してのみ定義でき、行ストアテーブルに対しては定義できません。
BINTEXT −テキスト検索機能をサポートしますが、バイナリデータを挿入することは可能です。
多値
複数値のデータ型は、同じデータ型の値のコレクションを格納するために使用されます。
アレイ
配列は、同じデータ型の値のコレクションを格納します。null値を含めることもできます。
演算子は、比較や算術演算などの演算を実行するために、主にSQLステートメントのWHERE句で使用される特殊文字です。これらは、SQLクエリで条件を渡すために使用されます。
以下に示す演算子タイプは、HANAのSQLステートメントで使用できます-
- 算術演算子
- 比較/関係演算子
- 論理演算子
- 演算子の設定
算術演算子
算術演算子は、加算、減算、乗算、除算、パーセンテージなどの単純な計算関数を実行するために使用されます。
| オペレーター | 説明 |
|---|---|
| + | 加算-演算子のいずれかの側に値を加算します |
| - | 減算-左側のオペランドから右側のオペランドを減算します |
| * | 乗算-演算子のいずれかの側で値を乗算します |
| / | 除算-左側のオペランドを右側のオペランドで除算します |
| % | モジュラス-左側のオペランドを右側のオペランドで除算し、余りを返します |
比較演算子
比較演算子は、SQLステートメントの値を比較するために使用されます。
| オペレーター | 説明 |
|---|---|
| = | 2つのオペランドの値が等しいかどうかをチェックし、等しい場合は条件が真になります。 |
| != | 2つのオペランドの値が等しいかどうかをチェックし、値が等しくない場合は条件が真になります。 |
| <> | 2つのオペランドの値が等しいかどうかをチェックし、値が等しくない場合は条件が真になります。 |
| >> | 左のオペランドの値が右のオペランドの値より大きいかどうかを確認します。大きい場合は、条件が真になります。 |
| < | 左のオペランドの値が右のオペランドの値よりも小さいかどうかを確認します。小さい場合は、条件が真になります。 |
| > = | 左のオペランドの値が右のオペランドの値以上であるかどうかをチェックします。はいの場合、条件は真になります。 |
| <= | 左のオペランドの値が右のオペランドの値以下であるかどうかをチェックします。はいの場合、条件は真になります。 |
| !< | 左のオペランドの値が右のオペランドの値以上であるかどうかをチェックし、そうである場合は条件が真になります。 |
| !> | 左のオペランドの値が右のオペランドの値より大きくないかどうかをチェックします。大きい場合は、条件が真になります。 |
論理演算子
論理演算子は、SQLステートメントで複数の条件を渡すために使用されるか、条件の結果を操作するために使用されます。
| オペレーター | 説明 |
|---|---|
| すべて | ALL演算子は、値を別の値セットのすべての値と比較するために使用されます。 |
| そして | AND演算子を使用すると、SQLステートメントのWHERE句に複数の条件を含めることができます。 |
| どれか | ANY演算子は、条件に従って、値をリスト内の該当する値と比較するために使用されます。 |
| の間に | BETWEEN演算子は、最小値と最大値を指定して、値のセット内にある値を検索するために使用されます。 |
| 存在する | EXISTS演算子は、特定の条件を満たす指定されたテーブル内の行の存在を検索するために使用されます。 |
| に | IN演算子は、値を指定されたリテラル値のリストと比較するために使用されます。 |
| お気に入り | LIKE演算子は、ワイルドカード演算子を使用して値を類似の値と比較するために使用されます。 |
| ない | NOT演算子は、使用される論理演算子の意味を逆にします。例-存在しない、間、ないなど。This is a negate operator。 |
| または | OR演算子は、SQLステートメントのWHERE句の複数の条件を比較するために使用されます。 |
| 無効である | NULL演算子は、値をNULL値と比較するために使用されます。 |
| ユニーク | UNIQUE演算子は、指定されたテーブルのすべての行で一意性(重複なし)を検索します。 |
演算子の設定
集合演算子は、2つのクエリの結果を1つの結果に結合するために使用されます。データ型は両方のテーブルで同じである必要があります。
UNION−2つ以上のSelectステートメントの結果を組み合わせます。ただし、重複する行は削除されます。
UNION ALL −この演算子はUnionに似ていますが、重複する行も表示します。
INTERSECT−交差操作は、2つのSELECTステートメントを結合するために使用され、両方のSELECTステートメントに共通のレコードを返します。Intersectの場合、列の数とデータ型は両方のテーブルで同じである必要があります。
MINUS −マイナス演算は、2つのSELECTステートメントの結果を組み合わせて、最初の結果セットに属する結果のみを返し、2番目のステートメントの行を最初の出力から削除します。
SAPHANAデータベースによって提供されるさまざまなSQL関数があります-
- 数値関数
- 文字列関数
- 全文関数
- 日時関数
- 集計関数
- データ型変換関数
- ウィンドウ関数
- 級数データ関数
- その他の機能
数値関数
これらはSQLに組み込まれている数値関数であり、スクリプトで使用されます。数値または数値を含む文字列を受け取り、数値を返します。
ABS −数値引数の絶対値を返します。
Example − SELECT ABS (-1) "abs" FROM TEST;
abs
1ACOS、ASIN、ATAN、ATAN2(これらの関数は引数の三角関数の値を返します)
BINTOHEX −2進値を16進値に変換します。
BITAND −渡された引数のビットに対してAND演算を実行します。
BITCOUNT −引数のセットビット数のカウントを実行します。
BITNOT −引数のビットに対してビット単位のNOT演算を実行します。
BITOR −渡された引数のビットに対してOR演算を実行します。
BITSET − <start_bit>の位置から<target_num>のビットを1に設定するために使用されます。
BITUNSET − <start_bit>の位置から<target_num>のビットを0に設定するために使用されます。
BITXOR −渡された引数のビットに対してXOR演算を実行します。
CEIL −渡された値以上の最初の整数を返します。
COS、COSH、COT((これらの関数は引数の三角関数の値を返します)
EXP −渡された値の累乗で累乗された自然対数eの底の結果を返します。
FLOOR −数値引数以下の最大の整数を返します。
HEXTOBIN −16進値を2進値に変換します。
LN −引数の自然対数を返します。
LOG−渡された正の値のアルゴリズム値を返します。ベース値とログ値の両方が正である必要があります。
他のさまざまな数値関数も使用できます-MOD、POWER、RAND、ROUND、SIGN、SIN、SINH、SQRT、TAN、TANH、UMINUS
文字列関数
さまざまなSQL文字列関数をSQLスクリプトを使用したHANAで使用できます。最も一般的な文字列関数は次のとおりです。
ASCII −渡された文字列の整数ASCII値を返します。
CHAR −渡されたASCII値に関連付けられた文字を返します。
CONCAT −これは連結演算子であり、渡された文字列を組み合わせて返します。
LCASE −文字列のすべての文字を小文字に変換します。
LEFT −上記の値に従って、渡された文字列の最初の文字を返します。
LENGTH −渡された文字列の文字数を返します。
LOCATE −渡された文字列内の部分文字列の位置を返します。
LOWER −文字列内のすべての文字を小文字に変換します。
NCHAR −渡された整数値を持つUnicode文字を返します。
REPLACE −渡された元の文字列で検索文字列のすべての出現箇所を検索し、それらを置換文字列に置き換えます。
RIGHT −指定された文字列の右端に渡された値の文字を返します。
UPPER −渡された文字列のすべての文字を大文字に変換します。
UCASE−UPPER機能と同じです。渡された文字列のすべての文字を大文字に変換します。
使用できるその他の文字列関数は、-LPAD、LTRIM、RTRIM、STRTOBIN、SUBSTR_AFTER、SUBSTR_BEFORE、SUBSTRING、TRIM、UNICODE、RPAD、BINTOSTRです。
日時関数
SQLスクリプトのHANAで使用できるさまざまな日時関数があります。最も一般的な日時関数は次のとおりです。
CURRENT_DATE −現在のローカルシステムの日付を返します。
CURRENT_TIME −現在のローカルシステム時刻を返します。
CURRENT_TIMESTAMP −現在のローカルシステムのタイムスタンプの詳細(YYYY-MM-DD HH:MM:SS:FF)を返します。
CURRENT_UTCDATE −現在のUTC(グリニッジ標準時)の日付を返します。
CURRENT_UTCTIME −現在のUTC(グリニッジ標準時)時間を返します。
CURRENT_UTCTIMESTAMP
DAYOFMONTH −引数に渡された日付の日の整数値を返します。
HOUR −引数に渡された時間の時間の整数値を返します。
YEAR −通過した日付の年の値を返します。
その他の日時関数は、-DAYOFYEAR、DAYNAME、DAYS_BETWEEN、EXTRACT、NANO100_BETWEEN、NEXT_DAY、NOW、QUARTER、SECOND、SECONDS_BETWEEN、UTCTOLOCAL、WEEK、WEEKDAY、WORKDAYS_BETWEEN、ISOWEEK、LAST_DAY、LOCAL ADD_SECONDS、ADD_WORKDAYS
データ型変換関数
これらの関数は、あるデータ型を別のデータ型に変換したり、変換が可能かどうかをチェックしたりするために使用されます。
SQLスクリプトのHANAで使用される最も一般的なデータ型変換関数-
CAST −指定されたデータ型に変換された式の値を返します。
TO_ALPHANUM −渡された値をALPHANUMデータ型に変換します
TO_REAL −値をREALデータ型に変換します。
TO_TIME −渡された時間文字列をTIMEデータ型に変換します。
TO_CLOB −値をCLOBデータ型に変換します。
他の同様のデータ型変換関数は次のとおりです。
HANASQLスクリプトで使用できるさまざまなWindowsやその他のさまざまな関数もあります。
Current_Schema −現在のスキーマ名を含む文字列を返します。
Session_User −現在のセッションのユーザー名を返します
式は、値を返す句を評価するために使用されます。HANAで使用できるさまざまなSQL式があります-
- ケース式
- 関数式
- 集計式
- 式のサブクエリ
ケース式
これは、SQL式で複数の条件を渡すために使用されます。これにより、SQLステートメントでプロシージャを使用せずにIF-ELSE-THENロジックを使用できます。
例
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1,
COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2,
COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;このステートメントは、渡された条件に従って整数値を持つcount1、count2、count3を返します。
関数式
関数式には、式で使用されるSQL組み込み関数が含まれます。
集計式
集計関数は、合計、パーセンテージ、最小、最大、カウント、モード、中央値などの複雑な計算を実行するために使用されます。集計式は、集計関数を使用して、複数の値から単一の値を計算します。
Aggregate Functions−合計、カウント、最小、最大。これらはメジャー値(ファクト)に適用され、常にディメンションに関連付けられます。
一般的な集計関数は次のとおりです。
- 平均()
- カウント ()
- 最大()
- 中央値()
- 最小()
- モード()
- 合計()
式のサブクエリ
式としてのサブクエリはSelectステートメントです。式で使用すると、ゼロまたは単一の値を返します。
サブクエリは、取得するデータをさらに制限するための条件としてメインクエリで使用されるデータを返すために使用されます。
サブクエリは、SELECT、INSERT、UPDATE、およびDELETEステートメントとともに、=、<、>、> =、<=、IN、BETWEENなどの演算子とともに使用できます。
サブクエリが従わなければならないいくつかのルールがあります-
サブクエリは括弧で囲む必要があります。
サブクエリのメインクエリに複数の列があり、選択した列を比較しない限り、サブクエリはSELECT句に1つの列しか含めることができません。
メインクエリではORDERBYを使用できますが、ORDERBYをサブクエリで使用することはできません。GROUP BYを使用して、サブクエリでORDERBYと同じ機能を実行できます。
複数の行を返すサブクエリは、IN演算子などの複数の値演算子でのみ使用できます。
SELECTリストには、BLOB、ARRAY、CLOB、またはNCLOBに評価される値への参照を含めることはできません。
サブクエリを集合関数ですぐに囲むことはできません。
BETWEEN演算子は、サブクエリでは使用できません。ただし、BETWEEN演算子はサブクエリ内で使用できます。
SELECTステートメントを使用したサブクエリ
サブクエリは、SELECTステートメントで最も頻繁に使用されます。基本的な構文は次のとおりです-
例
SELECT * FROM CUSTOMERS
WHERE ID IN (SELECT ID
FROM CUSTOMERS
WHERE SALARY > 4500) ;+----+----------+-----+---------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+---------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+---------+----------+プロシージャを使用すると、SQLステートメントを1つのブロックにグループ化できます。ストアドプロシージャは、アプリケーション全体で特定の結果を達成するために使用されます。SQLステートメントのセットと、特定のタスクを実行するために使用されるロジックは、SQLストアドプロシージャに格納されます。これらのストアドプロシージャは、そのタスクを実行するためにアプリケーションによって実行されます。
ストアドプロシージャは、出力パラメータ(整数または文字)またはカーソル変数の形式でデータを返すことができます。また、他のストアドプロシージャで使用される一連のSelectステートメントが生成される可能性もあります。
ストアドプロシージャは、一連のSQLステートメントを含み、1セットのステートメントの結果によって次に実行されるステートメントのセットが決定されるため、パフォーマンスの最適化にも使用されます。ストアドプロシージャにより、ユーザーはデータベース内のテーブルの複雑さと詳細を確認できなくなります。ストアドプロシージャには特定のビジネスロジックが含まれているため、ユーザーはプロシージャ名を実行または呼び出す必要があります。
個々のステートメントを再発行し続ける必要はありませんが、データベースプロシージャを参照できます。
プロシージャを作成するためのサンプルステートメント
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP")
as
begin
opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ;
end;シーケンスは、オンデマンドで順番に生成される整数1、2、3のセットです。多くのアプリケーションではテーブルの各行に一意の値を含める必要があり、シーケンスを使用するとシーケンスを簡単に生成できるため、シーケンスはデータベースで頻繁に使用されます。
AUTO_INCREMENT列の使用
MySQLでシーケンスを使用する最も簡単な方法は、列をAUTO_INCREMENTとして定義し、残りのことはMySQLに任せることです。
例
次の例を試してください。これによりテーブルが作成され、その後、MySQLによって自動インクリメントされるため、レコードIDを指定する必要がないこのテーブルにいくつかの行が挿入されます。
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO INSECT (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM INSECT ORDER BY id;+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)AUTO_INCREMENT値を取得する
LAST_INSERT_ID()はSQL関数であるため、SQLステートメントの発行方法を理解している任意のクライアント内から使用できます。それ以外の場合、PERLおよびPHPスクリプトは、最後のレコードの自動インクリメントされた値を取得するための排他的な関数を提供します。
PERLの例
mysql_insertid属性を使用して、クエリによって生成されたAUTO_INCREMENT値を取得します。この属性には、クエリの発行方法に応じて、データベースハンドルまたはステートメントハンドルのいずれかを介してアクセスします。次の例では、データベースハンドルを介してそれを参照しています-
$dbh->do ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')");
my $seq = $dbh->{mysql_insertid};PHPの例
AUTO_INCREMENT値を生成するクエリを発行した後、mysql_insert_id()−を呼び出して値を取得します。
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);既存のシーケンスの番号を付け直す
テーブルから多くのレコードを削除し、すべてのレコードを再シーケンスしたい場合があります。これは簡単なトリックを使用して実行できますが、テーブルが他のテーブルと結合している場合は、慎重に行う必要があります。
AUTO_INCREMENT列の再シーケンスが避けられないと判断した場合、その方法は、テーブルから列を削除してから、再度追加することです。次の例は、この手法を使用して昆虫テーブルのid値に番号を付け直す方法を示しています。
mysql> ALTER TABLE INSECT DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);特定の値でシーケンスを開始する
デフォルトでは、MySQLは1からシーケンスを開始しますが、テーブルの作成時に他の番号を指定することもできます。以下は、MySQLが100からシーケンスを開始する例です。
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);または、テーブルを作成してから、ALTERTABLEを使用して初期シーケンス値を設定することもできます。
トリガーはストアドプログラムであり、いくつかのイベントが発生すると自動的に実行または起動されます。実際、トリガーは、次のイベントのいずれかに応答して実行されるように記述されています。
データベース操作(DML)ステートメント(DELETE、INSERT、またはUPDATE)。
データベース定義(DDL)ステートメント(CREATE、ALTER、またはDROP)。
データベース操作(SERVERERROR、LOGON、LOGOFF、STARTUP、またはSHUTDOWN)。
トリガーは、イベントが関連付けられているテーブル、ビュー、スキーマ、またはデータベースで定義できます。
トリガーの利点
トリガーは次の目的で作成できます-
- 一部の派生列値を自動的に生成する
- 参照整合性の実施
- イベントログとテーブルアクセスに関する情報の保存
- Auditing
- テーブルの同期レプリケーション
- セキュリティ認証を課す
- 無効なトランザクションの防止
SQLシノニムは、データベース内のテーブルまたはスキーマオブジェクトのエイリアスです。これらは、オブジェクトの名前または場所に加えられた変更からクライアントアプリケーションを保護するために使用されます。
シノニムを使用すると、テーブルの所有者やテーブルまたはオブジェクトを保持しているデータベースに関係なく、アプリケーションを機能させることができます。
Create Synonymステートメントは、テーブル、ビュー、パッケージ、プロシージャ、オブジェクトなどのシノニムを作成するために使用されます。
例
Server1にefashionのCustomerテーブルがあります。Server2からこれにアクセスするには、クライアントアプリケーションでServer1.efashion.Customerという名前を使用する必要があります。ここで、Customerテーブルの場所を変更し、変更を反映するようにクライアントアプリケーションを変更する必要があります。
これらに対処するために、Server1のテーブルのServer2のCustomerテーブルCust_Tableの同義語を作成できます。したがって、クライアントアプリケーションは、このテーブルを参照するために単一パーツ名Cust_Tableを使用する必要があります。ここで、このテーブルの場所が変更された場合は、テーブルの新しい場所を指すようにシノニムを変更する必要があります。
ALTER SYNONYMステートメントがないため、シノニムCust_Tableを削除してから、同じ名前でシノニムを再作成し、シノニムがCustomerテーブルの新しい場所を指すようにする必要があります。
パブリックシノニム
パブリックシノニムは、データベース内のPUBLICスキーマによって所有されます。パブリックシノニムは、データベース内のすべてのユーザーが参照できます。これらは、アプリケーションのユーザーがオブジェクトを表示できるように、テーブルおよびプロシージャやパッケージなどの他のオブジェクトのアプリケーション所有者によって作成されます。
構文
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;PUBLICシノニムを作成するには、図のようにキーワードPUBLICを使用する必要があります。
プライベートシノニム
プライベートシノニムは、データベーススキーマで使用され、テーブル、プロシージャ、ビュー、またはその他のデータベースオブジェクトの実際の名前を非表示にします。
プライベートシノニムは、テーブルまたはオブジェクトを所有するスキーマによってのみ参照できます。
構文
CREATE SYNONYM Cust_table FOR efashion.Customer;同義語を削除する
シノニムは、DROPシノニムコマンドを使用して削除できます。パブリックシノニムを削除する場合は、キーワードを使用する必要がありますpublic ドロップステートメントで。
構文
DROP PUBLIC Synonym Cust_table;
DROP Synonym Cust_table;SQL説明プランは、SQLステートメントの詳細な説明を生成するために使用されます。これらは、SAPHANAデータベースがSQLステートメントを実行するために従う実行プランを評価するために使用されます。
Explain Planの結果は、評価のためにEXPLAIN_PLAN_TABLEに保存されます。Explain Planを使用するには、渡されるSQLクエリがデータ操作言語(DML)である必要があります。
一般的なDMLステートメント
SELECT −データベースからデータを取得する
INSERT −データをテーブルに挿入する
UPDATE −テーブル内の既存のデータを更新します
SQL Explain Planは、DDLおよびDCLSQLステートメントでは使用できません。
データベース内のEXPLAINPLAN TABLE
データベースのEXPLAINPLAN_TABLEは、複数の列で構成されています。いくつかの一般的な列名-OPERATOR_NAME、OPERATOR_ID、PARENT_OPERATOR_ID、LEVELおよびPOSITIONなど。
COLUMN SEARCH値は、列エンジン演算子の開始位置を示します。
ROW SEARCH値は、行エンジン演算子の開始位置を示します。
SQLクエリのEXPLAINPLANSTATEMENTを作成するには
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>EXPLAIN PLANTABLEの値を表示するには
SELECT Operator_Name, Operator_ID
FROM explain_plan_table
WHERE statement_name = 'statement_name';EXPLAIN PLANTABLEのステートメントを削除するには
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';SQLデータプロファイリングタスクは、複数のデータソースからのデータを理解して分析するために使用されます。これは、データウェアハウスにロードされる前に、不正確で不完全なデータを削除し、データ品質の問題を防ぐために使用されます。
SQLデータプロファイリングタスクの利点は次のとおりです-
ソースデータをより効果的に分析するのに役立ちます。
ソースデータをよりよく理解するのに役立ちます。
データウェアハウスにロードされる前に、不正確で不完全なデータを削除し、データ品質を向上させます。
これは、抽出、変換、および読み込みタスクで使用されます。
データプロファイリングタスクは、データソースを理解し、修正が必要なデータの問題を特定するのに役立つプロファイルをチェックします。
Integration Servicesパッケージ内のデータプロファイリングタスクを使用して、SQL Serverに格納されているデータをプロファイリングし、データ品質に関する潜在的な問題を特定できます。
Note −データプロファイリングタスクはSQL Serverデータソースでのみ機能し、他のファイルベースまたはサードパーティのデータソースをサポートしません。
アクセス要件
パッケージに含まれるデータプロファイリングタスクを実行するには、ユーザーアカウントに、tempdbデータベースに対するCREATETABLE権限を持つ読み取り/書き込み権限が必要です。
データプロファイラービューア
データプロファイルビューアは、プロファイラー出力を確認するために使用されます。データプロファイルビューアは、プロファイル出力で識別されるデータ品質の問題を理解するのに役立つドリルダウン機能もサポートしています。このドリルダウン機能は、ライブクエリを元のデータソースに送信します。
データプロファイリングタスクのセットアップとレビュー
データプロファイリングタスクの設定
これには、プロファイルを計算するためのデータプロファイリングタスクを含むパッケージの実行が含まれます。このタスクは、出力をXML形式でファイルまたはパッケージ変数に保存します。
プロファイルの確認
データプロファイルを表示するには、出力をファイルに送信してから、データプロファイルビューアを使用します。このビューアは、オプションのドリルダウン機能を使用して、プロファイル出力を要約形式と詳細形式の両方で表示するスタンドアロンユーティリティです。
データプロファイリング-構成オプション
データプロファイリングタスクには、次の便利な構成オプションがあります-
ワイルドカード列
プロファイル要求の構成中に、タスクは列名の代わりに「*」ワイルドカードを受け入れます。これにより、構成が簡素化され、見慣れないデータの特性を簡単に発見できるようになります。タスクが実行されると、タスクは適切なデータ型を持つすべての列をプロファイルします。
クイックプロファイル
クイックプロファイルを選択して、タスクをすばやく構成できます。クイックプロファイルは、すべてのデフォルトのプロファイルと設定を使用して、テーブルまたはビューのプロファイルを作成します。
データプロファイリングタスクは、8つの異なるデータプロファイルを計算できます。これらのプロファイルのうち5つは個々の列をチェックでき、残りの3つは複数の列または列間の関係を分析できます。
データプロファイリング-タスク出力
データプロファイリングタスクは、選択したプロファイルをDataProfile.xsdスキーマのように構造化されたXML形式に出力します。
スキーマのローカルコピーを保存し、Microsoft Visual Studioまたは別のスキーマエディター、XMLエディター、またはメモ帳などのテキストエディターでスキーマのローカルコピーを表示できます。
開発者が複雑なロジックをデータベースに渡すことを可能にするHANAデータベースのSQLステートメントのセットは、SQLスクリプトと呼ばれます。SQLスクリプトは、SQL拡張機能のコレクションとして知られています。これらの拡張機能は、データ拡張機能、関数拡張機能、およびプロシージャ拡張機能です。
SQLスクリプトは、格納された関数とプロシージャをサポートし、アプリケーションロジックの複雑な部分をデータベースにプッシュできるようにします。
SQLスクリプトを使用する主な利点は、SAPHANAデータベース内で複雑な計算を実行できることです。単一のクエリの代わりにSQLスクリプトを使用すると、関数は複数の値を返すことができます。複雑なSQL関数は、さらに小さな関数に分解できます。SQLスクリプトは、単一のSQLステートメントでは使用できない制御ロジックを提供します。
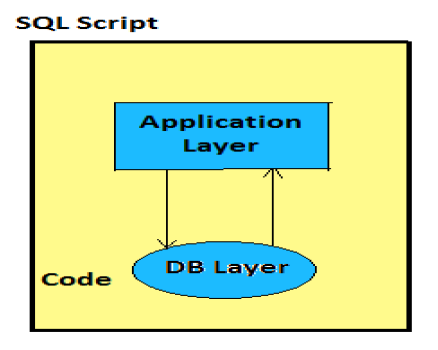
SQLスクリプトは、DBレイヤーでスクリプトを実行することによりHANAのパフォーマンスを最適化するために使用されます-
データベース層でSQLスクリプトを実行することにより、データベースからアプリケーションに大量のデータを転送する必要がなくなります。
計算はデータベースレイヤーで実行され、列操作、クエリの並列処理などのHANAデータベースの利点を活用します。
情報モデラーとの統合
Information ModelerでSQLスクリプトを使用している間、以下はプロシージャに適用されます-
- 入力パラメーターは、スカラー型またはテーブル型にすることができます。
- 出力パラメータはテーブルタイプである必要があります。
- 署名に必要なテーブルタイプは自動的に生成されます。
計算ビューを備えたSQLスクリプト
SQLスクリプトは、スクリプトベースの計算ビューを作成するために使用されます。既存のrawテーブルまたは列ストアに対してSQLステートメントを入力します。出力構造を定義します。ビューをアクティブ化すると、構造ごとにテーブルタイプが作成されます。
SQLスクリプトを使用して計算ビューを作成するにはどうすればよいですか?
Launch SAP HANA studio。コンテンツノードを展開します→新しい計算ビューを作成するパッケージを選択します。右クリック→新しい計算ビューナビゲーションパスの終わり→名前と説明を入力します。
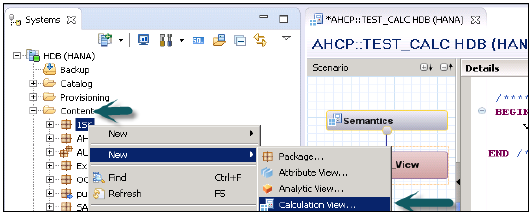
Select calculation view type →[タイプ]ドロップダウンリストから、[SQLスクリプト]→[計算ビューの出力パラメーターの命名規則の要件に基づいてパラメーターの大文字と小文字を区別するをTrueまたはFalseに設定]→[完了]を選択します。
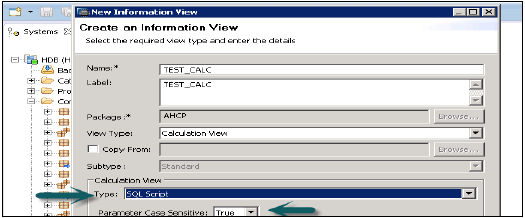
Select default schema − [セマンティクス]ノードを選択→[ビューのプロパティ]タブを選択→[デフォルトスキーマ]ドロップダウンリストで、デフォルトスキーマを選択します。
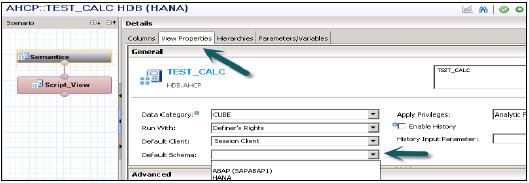
Choose SQL Script node in the Semantics node→出力構造を定義します。出力ペインで、[ターゲットの作成]を選択します。必要な出力パラメーターを追加し、その長さとタイプを指定します。

スクリプトベースの計算ビューの出力構造に、既存の情報ビューまたはカタログテーブルまたはテーブル関数の一部である複数の列を追加するには-
[出力]ペインで、[ナビゲーションパスの開始] [新規] [次のナビゲーションステップ] [ナビゲーションパスの終了から列の追加]→[出力に追加する列を含むオブジェクトの名前]→[ドロップダウンリストから1つ以上のオブジェクトを選択]→[次を選択します。
[ソース]ペインで、出力に追加する列を選択します→出力に選択した列を追加するには、それらの列を選択して[追加]を選択します。オブジェクトのすべての列を出力に追加するには、オブジェクトを選択して、「追加」→「終了」を選択します。
Activate the script-based calculation view− SAP HANA Modelerパースペクティブで−保存してアクティブ化-現在のビューをアクティブ化し、影響を受けるオブジェクトのアクティブなバージョンが存在する場合は、影響を受けるオブジェクトを再デプロイします。それ以外の場合は、現在のビューのみがアクティブになります。
Save and activate all −必要なオブジェクトと影響を受けるオブジェクトとともに、現在のビューをアクティブにします。
In the SAP HANA Development perspective−プロジェクトエクスプローラービューで、必要なオブジェクトを選択します。コンテキストメニューで、[ナビゲーションパスの開始]を選択します。チーム次のナビゲーションステップ[アクティブ化]ナビゲーションパスの終了。
HANA Information ModelerのSQLスクリプトは、GUIオプションを使用して作成できない複雑な計算ビューを作成するために使用されます。