データ中心のアーキテクチャ
データ中心のアーキテクチャでは、データは一元化され、データを変更する他のコンポーネントによって頻繁にアクセスされます。このスタイルの主な目的は、データの整合性を実現することです。データ中心のアーキテクチャは、共有データリポジトリを介して通信するさまざまなコンポーネントで構成されています。コンポーネントは共有データ構造にアクセスし、データストアを介してのみ相互作用するという点で比較的独立しています。
データ中心のアーキテクチャの最もよく知られている例は、データベースアーキテクチャです。このアーキテクチャでは、共通のデータベーススキーマがデータ定義プロトコル(たとえば、RDBMSのフィールドとデータ型を持つ関連テーブルのセット)で作成されます。
データ中心のアーキテクチャの別の例は、共通のデータスキーマ(つまり、Webのメタ構造)を持ち、ハイパーメディアデータモデルに従い、プロセスが共有Webベースのデータサービスを使用して通信するWebアーキテクチャです。

コンポーネントの種類
コンポーネントには2つのタイプがあります-
A central data構造またはデータストアまたはデータリポジトリ。永続的なデータストレージの提供を担当します。現在の状態を表します。
A data accessor または、中央データストアで動作し、計算を実行し、結果を戻す可能性のある独立したコンポーネントのコレクション。
データアクセサ間の相互作用または通信は、データストアを介してのみ行われます。データは、クライアント間の唯一のコミュニケーション手段です。制御の流れは、アーキテクチャを2つのカテゴリに区別します-
- リポジトリアーキテクチャスタイル
- 黒板アーキテクチャスタイル
リポジトリアーキテクチャスタイル
リポジトリアーキテクチャスタイルでは、データストアはパッシブであり、データストアのクライアント(ソフトウェアコンポーネントまたはエージェント)はアクティブであり、ロジックフローを制御します。参加しているコンポーネントは、データストアに変更がないかチェックします。
クライアントは、アクション(データの挿入など)を実行するための要求をシステムに送信します。
計算プロセスは独立しており、着信要求によってトリガーされます。
トランザクションの入力ストリーム内のトランザクションのタイプが実行するプロセスの選択をトリガーする場合、それは従来のデータベースまたはリポジトリアーキテクチャ、あるいはパッシブリポジトリです。
このアプローチは、DBMS、ライブラリ情報システム、CORBAのインターフェイスリポジトリ、コンパイラ、およびCASE(コンピュータ支援ソフトウェアエンジニアリング)環境で広く使用されています。

利点
データの整合性、バックアップ、および復元機能を提供します。
エージェントは相互に直接通信しないため、エージェントのスケーラビリティと再利用性を提供します。
ソフトウェアコンポーネント間の一時データのオーバーヘッドを削減します。
短所
障害に対してより脆弱であり、データの複製または複製が可能です。
データストアのデータ構造とそのエージェント間の高い依存性。
データ構造の変更は、クライアントに大きな影響を与えます。
データの進化は難しく、費用がかかります。
分散データのためにネットワーク上でデータを移動するコスト。
黒板アーキテクチャスタイル
Blackboard Architecture Styleでは、データストアはアクティブであり、そのクライアントはパッシブです。したがって、論理フローは、データストア内の現在のデータステータスによって決定されます。中央のデータリポジトリとして機能する黒板コンポーネントがあり、内部表現が構築され、さまざまな計算要素によって処理されます。
共通のデータ構造に独立して作用するいくつかのコンポーネントが黒板に格納されています。
このスタイルでは、コンポーネントは黒板を介してのみ相互作用します。データストアは、データストアが変更されるたびにクライアントに警告します。
ソリューションの現在の状態は黒板に保存され、処理は黒板の状態によってトリガーされます。
システムは、 trigger データに変更が発生した場合のクライアントへのデータ。
このアプローチは、音声認識、画像認識、セキュリティシステム、ビジネスリソース管理システムなどの特定のAIアプリケーションや複雑なアプリケーションに見られます。
中央データ構造の現在の状態が実行するプロセスを選択する主なトリガーである場合、リポジトリは黒板であり、この共有データソースはアクティブなエージェントです。
従来のデータベースシステムとの主な違いは、黒板アーキテクチャでの計算要素の呼び出しは、外部入力ではなく、黒板の現在の状態によってトリガーされることです。
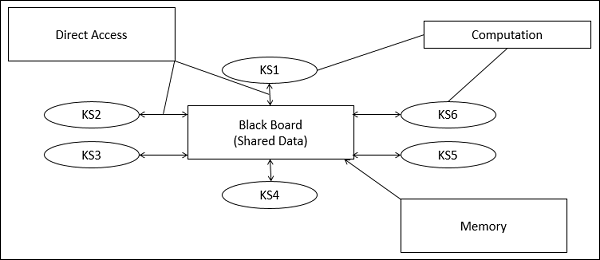
黒板モデルの部品
黒板モデルは通常、3つの主要な部分で表されます-
Knowledge Sources (KS)
ナレッジソース、別名 Listeners または Subscribers別個の独立したユニットです。それらは問題の一部を解決し、部分的な結果を集約します。知識源間の相互作用は、黒板を通じて独自に行われます。
Blackboard Data Structure
問題解決の状態データは、アプリケーションに依存する階層に編成されています。知識源は、問題の解決に徐々につながる黒板に変更を加えます。
Control
コントロールはタスクを管理し、作業状態をチェックします。
利点
ナレッジソースの追加または更新を容易にするスケーラビリティを提供します。
すべてのナレッジソースが互いに独立しているため、並行して動作できるようにする同時実行性を提供します。
仮説の実験をサポートします。
ナレッジソースエージェントの再利用性をサポートします。
短所
黒板と知識源の間には密接な依存関係が存在するため、黒板の構造変更は、そのすべてのエージェントに重大な影響を与える可能性があります。
おおよその解決策しか期待されていないため、推論をいつ終了するかを決定するのは難しい場合があります。
複数のエージェントの同期の問題。
システムの設計とテストにおける主な課題。