クイックガイド
システムのアーキテクチャは、その主要なコンポーネント、それらの関係(構造)、およびそれらが互いにどのように相互作用するかを記述します。ソフトウェアのアーキテクチャと設計には、ビジネス戦略、品質属性、人間のダイナミクス、設計、IT環境などのいくつかの要因が含まれます。

ソフトウェアアーキテクチャと設計は、ソフトウェアアーキテクチャとソフトウェア設計の2つの異なるフェーズに分けることができます。にArchitecture、非機能的決定は、機能要件によってキャストおよび分離されます。設計では、機能要件が満たされます。
ソフトウェアアーキテクチャ
アーキテクチャは、 blueprint for a system。これは、システムの複雑さを管理し、コンポーネント間の通信および調整メカニズムを確立するための抽象化を提供します。
それは定義します structured solution パフォーマンスやセキュリティなどの一般的な品質属性を最適化しながら、すべての技術的および運用上の要件を満たすため。
さらに、ソフトウェア開発に関連する組織に関する一連の重要な決定が含まれ、これらの各決定は、品質、保守性、パフォーマンス、および最終製品の全体的な成功に大きな影響を与える可能性があります。これらの決定は、以下で構成されます。
システムを構成する構造要素とそのインターフェースの選択。
これらの要素間のコラボレーションで指定された動作。
これらの構造的および行動的要素の大きなサブシステムへの構成。
アーキテクチャ上の決定は、ビジネス目標と一致します。
建築様式が組織を導きます。
ソフトウェア設計
ソフトウェア設計は、 design planこれは、システムの要素、それらがどのように適合し、システムの要件を満たすために連携するかを説明します。設計計画を立てる目的は次のとおりです。
システム要件を交渉し、顧客、マーケティング、および管理担当者と期待を設定します。
開発プロセス中に青写真として機能します。
詳細な設計、コーディング、統合、テストなどの実装タスクをガイドします。
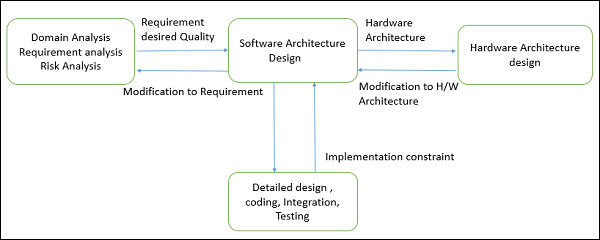
これは、詳細な設計、コーディング、統合、およびテストの前と、ドメイン分析、要件分析、およびリスク分析の後に行われます。
アーキテクチャの目標
アーキテクチャの主な目標は、アプリケーションの構造に影響を与える要件を特定することです。適切に配置されたアーキテクチャは、技術ソリューションの構築に関連するビジネスリスクを軽減し、ビジネス要件と技術要件の間の架け橋を構築します。
その他の目標のいくつかは次のとおりです-
システムの構造を公開しますが、実装の詳細は非表示にします。
すべてのユースケースとシナリオを実現します。
さまざまな利害関係者の要件に対処するようにしてください。
機能要件と品質要件の両方を処理します。
所有権の目標を減らし、組織の市場での地位を向上させます。
システムが提供する品質と機能を向上させます。
組織またはシステムのいずれかに対する外部の信頼を向上させます。
制限事項
ソフトウェアアーキテクチャは、ソフトウェアエンジニアリング内の新しい分野です。以下の制限があります-
アーキテクチャを表現するためのツールと標準化された方法の欠如。
アーキテクチャが要件を満たす実装になるかどうかを予測するための分析方法の欠如。
ソフトウェア開発におけるアーキテクチャ設計の重要性に対する認識の欠如。
ソフトウェアアーキテクトの役割についての理解の欠如と利害関係者間のコミュニケーション不足。
設計プロセス、設計経験、および設計の評価に関する理解の欠如。
ソフトウェアアーキテクトの役割
ソフトウェアアーキテクトは、技術チームがアプリケーション全体を作成および設計できるソリューションを提供します。ソフトウェアアーキテクトは、次の分野の専門知識を持っている必要があります-
設計の専門知識
オブジェクト指向設計、イベント駆動型設計などのさまざまな方法やアプローチを含む、ソフトウェア設計の専門家。
開発チームを主導し、設計の整合性のために開発作業を調整します。
設計提案とそれらの間のトレードオフを確認できる必要があります。
ドメインの専門知識
開発中のシステムの専門家であり、ソフトウェアの進化を計画しています。
要件調査プロセスを支援し、完全性と一貫性を確保します。
開発中のシステムのドメインモデルの定義を調整します。
技術の専門知識
システムの実装に役立つ利用可能なテクノロジーの専門家。
プログラミング言語、フレームワーク、プラットフォーム、データベースなどの選択を調整します。
方法論の専門知識
SDLC(ソフトウェア開発ライフサイクル)中に採用される可能性のあるソフトウェア開発方法論の専門家。
チーム全体を支援する開発のための適切なアプローチを選択します。
ソフトウェアアーキテクトの隠された役割
チームメンバー間の技術的な作業を促進し、チーム内の信頼関係を強化します。
知識を共有し、豊富な経験を持つ情報スペシャリスト。
チームメンバーの気を散らし、プロジェクトの価値を低下させる外力からチームメンバーを保護します。
アーキテクトの成果物
明確で、完全で、一貫性があり、達成可能な一連の機能目標
少なくとも2層の分解を伴うシステムの機能説明
システムのコンセプト
少なくとも2層の分解を伴うシステム形式の設計
タイミング、オペレーター属性、および実装と運用計画の概念
機能分解が行われ、インターフェースの形式が制御されることを保証するドキュメントまたはプロセス
品質属性
品質とは、卓越性、または欠陥や欠陥がない状態の尺度です。品質属性は、システムの機能とは別のシステムプロパティです。
品質属性を実装すると、良いシステムと悪いシステムを簡単に区別できます。属性は、実行時の動作、システム設計、およびユーザーエクスペリエンスに影響を与える全体的な要因です。
それらは次のように分類できます-
静的品質属性
アーキテクチャ、設計、およびソースコードに直接関連するシステムと組織の構造を反映します。それらはエンドユーザーには見えませんが、開発と保守のコストに影響します。たとえば、モジュール性、テスト容易性、保守性などです。
動的品質属性
実行中のシステムの動作を反映します。これらは、システムのアーキテクチャ、設計、ソースコード、構成、展開パラメータ、環境、およびプラットフォームに直接関連しています。
それらはエンドユーザーに表示され、実行時に存在します(スループット、堅牢性、スケーラビリティなど)。
品質シナリオ
品質シナリオは、障害が障害になるのを防ぐ方法を指定します。それらは、属性仕様に基づいて6つの部分に分けることができます-
Source −刺激を生成する人、ハードウェア、ソフトウェア、または物理インフラストラクチャなどの内部または外部エンティティ。
Stimulus −システムに到着したときに考慮する必要のある状態。
Environment −刺激は特定の条件下で発生します。
Artifact −システム全体、またはプロセッサ、通信チャネル、永続ストレージ、プロセスなどの一部。
Response −障害の検出、障害からの回復、イベントソースの無効化など、刺激の到着後に行われるアクティビティ。
Response measure −要件をテストできるように、発生した応答を測定する必要があります。
共通の品質属性
次の表に、ソフトウェアアーキテクチャに必要な一般的な品質属性を示します。
| カテゴリー | 品質属性 | 説明 |
|---|---|---|
| 設計品質 | 概念の完全性 | 全体的な設計の一貫性と一貫性を定義します。これには、コンポーネントまたはモジュールの設計方法が含まれます。 |
| 保守性 | システムがある程度簡単に変更できる能力。 | |
| 再利用性 | 他のアプリケーションでの使用に適したコンポーネントとサブシステムの機能を定義します。 | |
| 実行時の品質 | 相互運用性 | 外部の関係者によって作成および実行されている他の外部システムと情報を通信および交換することにより、1つまたは複数のシステムが正常に動作する能力。 |
| 管理性 | システム管理者がアプリケーションを管理するのがどれだけ簡単かを定義します。 | |
| 信頼性 | 長期間にわたって運用を継続するシステムの機能。 | |
| スケーラビリティ | システムのパフォーマンスに影響を与えることなく負荷の増加を処理するシステムの能力、または容易に拡張できる能力。 | |
| セキュリティ | 設計された使用法以外の悪意のあるまたは偶発的なアクションを防止するシステムの機能。 | |
| パフォーマンス | 指定された時間間隔内に任意のアクションを実行するためのシステムの応答性の表示。 | |
| 可用性 | システムが機能し、機能している時間の割合を定義します。これは、事前定義された期間におけるシステム全体のダウンタイムのパーセンテージとして測定できます。 | |
| システム品質 | サポート性 | 正しく機能しない場合に問題を特定して解決するのに役立つ情報を提供するシステムの機能。 |
| テスト容易性 | システムとそのコンポーネントのテスト基準を作成するのがどれほど簡単かを測定します。 | |
| ユーザーの資質 | 使いやすさ | 直感的に理解することで、アプリケーションがユーザーとコンシューマーの要件をどの程度満たしているかを定義します。 |
| アーキテクチャの品質 | 正しさ | システムのすべての要件を満たすための説明責任。 |
| 実行時以外の品質 | 移植性 | さまざまなコンピューティング環境で実行するシステムの機能。 |
| 完全性 | システムの個別に開発されたコンポーネントを正しく連携させる機能。 | |
| 変更可能性 | 各ソフトウェアシステムがソフトウェアの変更に対応しやすいこと。 | |
| ビジネス品質属性 | 費用とスケジュール | 市場投入までの時間、予想されるプロジェクトの存続期間、およびレガシーの利用に関するシステムのコスト。 |
| 市場性 | 市場競争に関するシステムの使用。 |
ソフトウェアアーキテクチャは、システムの組織として説明されます。システムは、定義された機能を実行するコンポーネントのセットを表します。
建築様式
ザ・ architectural style、とも呼ばれます architectural patternは、アプリケーションを形作る一連の原則です。これは、構造組織のパターンの観点から、システムファミリーの抽象的なフレームワークを定義します。
建築様式は責任があります-
コンポーネントとコネクタのレキシコンに、それらを組み合わせる方法に関するルールを提供します。
頻繁に発生する問題の解決策を提供することにより、パーティション分割を改善し、設計の再利用を可能にします。
コンポーネントのコレクション(明確に定義されたインターフェイス、再利用可能、および交換可能のモジュール)とコネクタ(モジュール間の通信リンク)を構成する特定の方法を説明します。
コンピュータベースのシステム用に構築されたソフトウェアは、多くのアーキテクチャスタイルの1つを示しています。各スタイルは、以下を含むシステムカテゴリを記述します-
システムが必要とする機能を実行するコンポーネントタイプのセット。
さまざまなコンポーネント間の通信、調整、および連携を可能にする一連のコネクタ(サブルーチン呼び出し、リモートプロシージャコール、データストリーム、およびソケット)。
コンポーネントを統合してシステムを形成する方法を定義するセマンティック制約。
実行時の相互関係を示すコンポーネントのトポロジレイアウト。
一般的な建築設計
次の表に、主要な重点分野ごとに整理できる建築様式を示します。
| カテゴリー | 建築デザイン | 説明 |
|---|---|---|
| コミュニケーション | メッセージバス | 1つ以上の通信チャネルを使用してメッセージを送受信できるソフトウェアシステムの使用を規定します。 |
| サービス指向アーキテクチャー(SOA) | コントラクトとメッセージを使用して、機能をサービスとして公開および消費するアプリケーションを定義します。 | |
| 展開 | クライアントサーバー | システムを2つのアプリケーションに分割し、クライアントがサーバーに要求を出します。 |
| 3層またはN層 | 機能を個別のセグメントに分割します。各セグメントは、物理的に分離されたコンピューター上にある層です。 | |
| ドメイン | ドメイン駆動設計 | ビジネスドメインのモデリングと、ビジネスドメイン内のエンティティに基づくビジネスオブジェクトの定義に重点を置いています。 |
| 構造 | コンポーネントベース | アプリケーション設計を、明確に定義された通信インターフェイスを公開する再利用可能な機能コンポーネントまたは論理コンポーネントに分解します。 |
| レイヤード | アプリケーションの懸念事項を積み重ねられたグループ(レイヤー)に分割します。 | |
| オブジェクト指向 | アプリケーションまたはシステムの責任をオブジェクトに分割することに基づいており、各オブジェクトには、オブジェクトに関連するデータと動作が含まれています。 |
アーキテクチャの種類
企業の観点から見たアーキテクチャには4つのタイプがあり、これらのアーキテクチャを総称して次のように呼びます。 enterprise architecture。
Business architecture −企業内のビジネス、ガバナンス、組織、および主要なビジネスプロセスの戦略を定義し、ビジネスプロセスの分析と設計に焦点を当てます。
Application (software) architecture −個々のアプリケーションシステム、それらの相互作用、および組織のビジネスプロセスとの関係の青写真として機能します。
Information architecture −論理および物理データ資産とデータ管理リソースを定義します。
Information technology (IT) architecture −組織の全体的な情報システムを構成するハードウェアとソフトウェアの構成要素を定義します。
アーキテクチャ設計プロセス
アーキテクチャ設計プロセスは、機能要件と非機能要件を満たすために、システムをさまざまなコンポーネントに分解し、それらの相互作用に焦点を当てています。ソフトウェアアーキテクチャ設計への重要な入力は次のとおりです。
分析タスクによって生成された要件。
ハードウェアアーキテクチャ(ソフトウェアアーキテクトは、ハードウェアアーキテクチャを構成するシステムアーキテクトに要件を提供します)。
アーキテクチャ設計プロセスの結果または出力は、 architectural description。基本的なアーキテクチャ設計プロセスは、次の手順で構成されています。
問題を理解する
これは、後続の設計の品質に影響を与えるため、最も重要なステップです。
問題を明確に理解しなければ、効果的な解決策を生み出すことはできません。
多くのソフトウェアプロジェクトおよび製品は、有効なビジネス上の問題を実際に解決しなかったか、認識可能な投資収益率(ROI)を持っていないため、失敗と見なされます。
設計要素とそれらの関係を特定する
このフェーズでは、システムの境界とコンテキストを定義するためのベースラインを構築します。
機能要件に基づいて、システムを主要コンポーネントに分解します。分解は、要素の粒度を指定せずに設計要素間の依存関係を示す設計構造マトリックス(DSM)を使用してモデル化できます。
このステップでは、アーキテクチャの最初の検証は、いくつかのシステムインスタンスを記述することによって実行され、このステップは、機能ベースのアーキテクチャ設計と呼ばれます。
アーキテクチャ設計を評価する
各品質属性には見積もりが与えられるため、定性的測定または定量的データを収集するために、設計が評価されます。
これには、アーキテクチャの品質属性要件への準拠についてアーキテクチャを評価することが含まれます。
推定されたすべての品質属性が必要な基準に従っている場合、建築設計プロセスは終了です。
そうでない場合は、ソフトウェアアーキテクチャ設計の第3フェーズであるアーキテクチャ変換に入ります。観察された品質属性がその要件を満たしていない場合は、新しい設計を作成する必要があります。
アーキテクチャ設計を変革する
このステップは、建築設計の評価後に実行されます。アーキテクチャ設計は、品質属性要件を完全に満たすまで変更する必要があります。
ドメイン機能を維持しながら品質属性を改善するための設計ソリューションの選択に関係しています。
デザインは、デザイン演算子、スタイル、またはパターンを適用することによって変換されます。変換には、既存の設計を採用し、分解、複製、圧縮、抽象化、リソース共有などの設計演算子を適用します。
設計が再度評価され、必要に応じて同じプロセスが複数回繰り返され、再帰的に実行されます。
変換(つまり、品質属性最適化ソリューション)は、一般に1つまたはいくつかの品質属性を改善しますが、他の属性には悪影響を及ぼします。
主要なアーキテクチャの原則
以下は、アーキテクチャを設計する際に考慮すべき重要な原則です。
最後まで構築するのではなく、変更するために構築する
新しい要件や課題に対処するためにアプリケーションを時間の経過とともにどのように変更する必要があるかを検討し、これをサポートする柔軟性を組み込みます。
分析するリスクとモデルを削減する
設計ツール、視覚化、UMLなどのモデリングシステムを使用して、要件と設計上の決定をキャプチャします。影響を分析することもできます。設計を簡単に反復および適合させる機能を抑制する程度にモデルを形式化しないでください。
コミュニケーションおよびコラボレーションツールとしてモデルと視覚化を使用する
設計、決定、および設計への継続的な変更の効率的なコミュニケーションは、優れたアーキテクチャにとって重要です。アーキテクチャのモデル、ビュー、およびその他の視覚化を使用して、すべての利害関係者と効率的に設計を伝達および共有します。これにより、設計の変更を迅速に伝達できます。
重要なエンジニアリング上の決定と、間違いが最も頻繁に発生する領域を特定して理解します。設計をより柔軟にし、変更によって壊れにくくするために、最初に重要な決定を正しく行うことに投資します。
インクリメンタルで反復的なアプローチを使用する
ベースラインアーキテクチャから始めて、アーキテクチャを改善するための反復テストによって候補アーキテクチャを進化させます。複数のパスにわたってデザインに詳細を繰り返し追加して、全体像または適切な全体像を把握し、詳細に焦点を合わせます。
主要な設計原則
以下は、コスト、メンテナンス要件を最小限に抑え、拡張性、アーキテクチャの使いやすさを最大化するために考慮すべき設計原則です。
関心事の分離
システムのコンポーネントを特定の機能に分割して、コンポーネントの機能間で重複がないようにします。これにより、高い凝集度と低い結合度が得られます。このアプローチは、システムのコンポーネント間の相互依存を回避し、システムの保守を容易にします。
単一責任の原則
システムのすべてのモジュールには、ユーザーがシステムを明確に理解するのに役立つ1つの特定の責任が必要です。また、コンポーネントを他のコンポーネントと統合するのにも役立ちます。
最小知識の原則
コンポーネントまたはオブジェクトは、他のコンポーネントの内部の詳細についての知識を持ってはなりません。このアプローチは相互依存を回避し、保守性を向上させます。
大規模設計を事前に最小限に抑える
アプリケーションの要件が不明確な場合は、大規模な設計を事前に最小限に抑えてください。要件を変更する可能性がある場合は、システム全体を大規模に設計することは避けてください。
機能を繰り返さないでください
機能を繰り返さないでください。コンポーネントの機能を繰り返さないように指定します。したがって、コードの一部を1つのコンポーネントにのみ実装する必要があります。アプリケーション内で機能が重複すると、変更の実装が困難になり、明確さが低下し、潜在的な不整合が発生する可能性があります。
機能を再利用しながら、継承よりも構成を優先する
継承は、子と親クラスの間に依存関係を作成するため、子クラスの自由な使用をブロックします。対照的に、構成は大きなレベルの自由を提供し、継承階層を減らします。
コンポーネントを識別し、それらを論理レイヤーにグループ化します
要件を満たすためにシステムで必要とされるIDコンポーネントと関心領域。次に、これらの関連コンポーネントを論理レイヤーにグループ化します。これにより、ユーザーはシステムの構造を高レベルで理解できます。異なるタイプの懸念事項のコンポーネントを同じレイヤーに混在させないでください。
レイヤー間の通信プロトコルを定義する
コンポーネントが相互に通信する方法を理解します。これには、展開シナリオと実稼働環境に関する完全な知識が必要です。
レイヤーのデータ形式を定義する
さまざまなコンポーネントがデータ形式を介して相互作用します。アプリケーションの実装、拡張、保守が容易になるように、データ形式を混在させないでください。レイヤーのデータ形式を同じに保つようにしてください。これにより、さまざまなコンポーネントが相互に通信するときにデータをコーディング/デコードする必要がなくなります。処理のオーバーヘッドを削減します。
システムサービスコンポーネントは抽象的である必要があります
セキュリティ、通信、またはロギング、プロファイリング、構成などのシステムサービスに関連するコードは、個別のコンポーネントに抽象化する必要があります。このコードをビジネスロジックと混在させないでください。設計の拡張と保守が容易です。
設計例外と例外処理メカニズム
事前に例外を定義すると、コンポーネントがエラーや望ましくない状況をエレガントな方法で管理するのに役立ちます。例外管理はシステム全体で同じです。
命名規則
命名規則は事前に定義する必要があります。これらは、ユーザーがシステムを簡単に理解するのに役立つ一貫したモデルを提供します。チームメンバーは他の人が書いたコードを検証するのが簡単なので、保守性が向上します。
ソフトウェアアーキテクチャには、アーキテクチャスタイルと品質属性を備えた、分解と構成を使用したソフトウェアシステム抽象化の高レベルの構造が含まれます。ソフトウェアアーキテクチャの設計は、システムの主要な機能要件とパフォーマンス要件に準拠し、信頼性、スケーラビリティ、移植性、可用性などの非機能要件を満たす必要があります。
ソフトウェアアーキテクチャは、コンポーネントのグループ、それらの接続、コンポーネント間の相互作用、およびすべてのコンポーネントの展開構成を記述する必要があります。
ソフトウェアアーキテクチャは多くの方法で定義できます-
UML (Unified Modeling Language) − UMLは、ソフトウェアのモデリングと設計で使用されるオブジェクト指向ソリューションの1つです。
Architecture View Model (4+1 view model) −アーキテクチャビューモデルは、ソフトウェアアプリケーションの機能要件と非機能要件を表します。
ADL (Architecture Description Language) − ADLは、ソフトウェアアーキテクチャを形式的および意味的に定義します。
UML
UMLは統一モデリング言語の略です。これは、ソフトウェアの青写真を作成するために使用される絵の言語です。UMLは、Object Management Group(OMG)によって作成されました。UML 1.0仕様ドラフトは、1997年1月にOMGに提案されました。これは、ソフトウェア開発の基礎となるソフトウェア要件分析および設計ドキュメントの標準として機能します。
UMLは、ソフトウェアシステムを視覚化、指定、構築、および文書化するための汎用ビジュアルモデリング言語として説明できます。UMLは一般的にソフトウェアシステムのモデル化に使用されますが、この境界内に限定されません。また、製造ユニットのプロセスフローなどの非ソフトウェアシステムのモデル化にも使用されます。
要素は、さまざまな方法で関連付けて完全なUML画像を作成できるコンポーネントのようなものです。 diagram。したがって、実際のシステムに知識を実装するには、さまざまな図を理解することが非常に重要です。ダイアグラムには2つの大きなカテゴリがあり、さらにサブカテゴリに分類されます。Structural Diagrams そして Behavioral Diagrams。
構造図
構造図は、システムの静的な側面を表しています。これらの静的な側面は、主要な構造を形成し、したがって安定しているダイアグラムの部分を表します。
これらの静的パーツは、クラス、インターフェイス、オブジェクト、コンポーネント、およびノードによって表されます。構造図は次のように細分化できます-
- クラス図
- オブジェクト図
- コンポーネント図
- 配置図
- パッケージ図
- 複合構造
次の表に、これらの図の簡単な説明を示します。
| シニア番号 | 図と説明 |
|---|---|
| 1 | Class システムのオブジェクト指向を表します。クラスが静的にどのように関連しているかを示します。 |
| 2 | Object 実行時のオブジェクトのセットとそれらの関係を表し、システムの静的ビューも表します。 |
| 3 | Component すべてのコンポーネント、それらの相互関係、相互作用、およびシステムのインターフェースについて説明します。 |
| 4 | Composite structure すべてのクラス、コンポーネントのインターフェイスなどを含むコンポーネントの内部構造を記述します。 |
| 5 | Package パッケージの構造と構成について説明します。パッケージ内のクラスと別のパッケージ内のパッケージをカバーします。 |
| 6 | Deployment 配置図は、ノードとそれらの関係のセットです。これらのノードは、コンポーネントがデプロイされる物理エンティティです。 |
行動図
動作図は基本的に、システムの動的な側面をキャプチャします。動的な側面は、基本的にシステムの変化/移動部分です。UMLには、次のタイプの動作図があります-
- ユースケース図
- シーケンス図
- コミュニケーション図
- 状態遷移図
- アクティビティ図
- インタラクションの概要
- 時系列図
次の表に、これらの図の簡単な説明を示します。
| シニア番号 | 図と説明 |
|---|---|
| 1 | Use case 機能とその内部/外部コントローラー間の関係について説明します。これらのコントローラーはアクターとして知られています。 |
| 2 | Activity システム内の制御の流れについて説明します。それは活動とリンクで構成されています。フローは、順次、同時、または分岐にすることができます。 |
| 3 | State Machine/state chart システムのイベント駆動型の状態変化を表します。基本的には、クラスやインターフェースなどの状態変化を記述します。内部/外部要因によるシステムの反応を視覚化するために使用されます。 |
| 4 | Sequence 特定の機能を実行するためのシステム内の呼び出しのシーケンスを視覚化します。 |
| 5 | Interaction Overview アクティビティ図とシーケンス図を組み合わせて、システムとビジネスプロセスの制御フローの概要を提供します。 |
| 6 | Communication オブジェクトの役割に焦点を当てていることを除いて、シーケンス図と同じです。各通信は、シーケンスの順序、番号、および過去のメッセージに関連付けられています。 |
| 7 | Time Sequenced 状態、状態、およびイベントのメッセージによる変更について説明します。 |
アーキテクチャビューモデル
モデルは、特定の視点または視点からの複数のビューで構成される、ソフトウェアアーキテクチャの完全で基本的な簡略化された記述です。
ビューは、関連する一連の懸念事項の観点からのシステム全体の表現です。エンドユーザー、開発者、プロジェクトマネージャー、テスターなどのさまざまな利害関係者の観点からシステムを説明するために使用されます。
4 +1ビューモデル
4 + 1ビューモデルは、複数の同時ビューの使用に基づくソフトウェア集約型システムのアーキテクチャを説明するために、PhilippeKruchtenによって設計されました。それはmultiple viewシステムのさまざまな機能と懸念に対処するモデル。ソフトウェア設計ドキュメントを標準化し、すべての利害関係者が設計を理解しやすくします。
これは、ソフトウェアアーキテクチャ設計を研究および文書化するためのアーキテクチャ検証方法であり、すべての利害関係者のためにソフトウェアアーキテクチャのすべての側面をカバーします。それは4つの本質的な見解を提供します-
The logical view or conceptual view −デザインのオブジェクトモデルを記述します。
The process view −システムのアクティビティを説明し、設計の並行性と同期の側面をキャプチャします。
The physical view −ソフトウェアのハードウェアへのマッピングについて説明し、その分散した側面を反映しています。
The development view −環境の開発におけるソフトウェアの静的な構成または構造を説明します。
このビューモデルは、というビューをもう1つ追加することで拡張できます。 scenario view または use case viewソフトウェアシステムのエンドユーザーまたは顧客向け。これは他の4つのビューと一貫性があり、「プラスワン」ビュー、(4 + 1)ビューモデルとして機能するアーキテクチャを説明するために使用されます。次の図は、5つの同時ビュー(4 + 1)モデルを使用したソフトウェアアーキテクチャを示しています。

なぜ5ではなく4+ 1と呼ばれるのですか?
ザ・ use case viewシステムの高レベルの要件を詳しく説明し、他のビューではそれらの要件をどのように実現するかを詳しく説明するため、特別な意味があります。他の4つのビューがすべて完了すると、事実上冗長になります。ただし、他のすべてのビューはそれなしでは不可能です。次の画像と表は、4 +1ビューの詳細を示しています-
| 論理的 | 処理する | 開発 | 物理的 | シナリオ | |
|---|---|---|---|---|---|
| 説明 | システムのコンポーネント(オブジェクト)とそれらの相互作用を表示します | システムのプロセス/ワークフロールールとそれらのプロセスがどのように通信するかを示し、システムの動的ビューに焦点を当てます | システムのビルディングブロックビューを提供し、システムモジュールの静的な編成を説明します | ソフトウェアアプリケーションのインストール、構成、および展開を示します | 検証と図解を実行することにより、設計が完了したことを示します |
| ビューア/利害関係者 | エンドユーザー、アナリスト、デザイナー | インテグレーターと開発者 | プログラマーおよびソフトウェアプロジェクトマネージャー | システムエンジニア、オペレーター、システム管理者、システムインストーラー | 彼らの見解と評価者のすべての見解 |
| 検討する | 機能要件 | 非機能要件 | ソフトウェアモジュールの編成(ソフトウェア管理の再利用、ツールの制約) | 基盤となるハードウェアに関する非機能要件 | システムの一貫性と妥当性 |
| UML –図 | クラス、状態、オブジェクト、シーケンス、通信図 | アクティビティ図 | コンポーネント、パッケージ図 | 配置図 | ユースケース図 |
アーキテクチャ記述言語(ADL)
ADLは、ソフトウェアアーキテクチャを定義するための構文とセマンティクスを提供する言語です。これは、システムの実装とは異なり、ソフトウェアシステムの概念アーキテクチャをモデル化するための機能を提供する表記仕様です。
ADLは、アーキテクチャ記述の構成要素であるアーキテクチャコンポーネント、それらの接続、インターフェイス、および構成をサポートする必要があります。これは、アーキテクチャー記述で使用するための表現形式であり、コンポーネントを分解し、コンポーネントを結合し、コンポーネントのインターフェースを定義する機能を提供します。
アーキテクチャ記述言語は、プロセス、スレッド、データ、サブプログラムなどのソフトウェア機能と、プロセッサ、デバイス、バス、メモリなどのハードウェアコンポーネントを記述する正式な仕様言語です。
ADLとプログラミング言語またはモデリング言語を分類または区別することは困難です。ただし、言語をADLとして分類するには、次の要件があります。
アーキテクチャをすべての関係者に伝達するのに適切なはずです。
アーキテクチャの作成、改良、および検証のタスクに適している必要があります。
これは、さらなる実装の基礎を提供する必要があるため、ADL仕様に情報を追加して、最終的なシステム仕様をADLから派生させることができる必要があります。
一般的な建築様式のほとんどを表現する機能が必要です。
分析機能をサポートするか、プロトタイプの実装を迅速に生成する必要があります。
オブジェクト指向(OO)パラダイムは、新しいプログラミングアプローチの最初の概念から形作られましたが、設計および分析方法への関心はずっと後になりました。オブジェクト指向分析と設計のパラダイムは、オブジェクト指向プログラミング言語が広く採用された論理的な結果です。
最初のオブジェクト指向言語は Simula (実際のシステムのシミュレーション)1960年にノルウェーコンピューティングセンターの研究者によって開発されました。
1970年、 Alan Kay Xerox PARCの彼の研究グループは、 Dynabook そして最初の純粋なオブジェクト指向プログラミング言語(OOPL)-DynabookをプログラミングするためのSmalltalk。
1980年代には、 Grady Booch主にプログラミング言語であるAdaのデザインを紹介するObjectOrientedDesignというタイトルの論文を発表しました。その後の版では、彼はアイデアを完全なオブジェクト指向設計手法にまで拡張しました。
1990年代には、 Coad オブジェクト指向メソッドに行動のアイデアを取り入れました。
その他の重要な革新は、によるオブジェクトモデリング技法(OMT)でした。 James Rum Baugh およびオブジェクト指向ソフトウェアエンジニアリング(OOSE) Ivar Jacobson。
オブジェクト指向パラダイムの概要
オブジェクト指向パラダイムは、あらゆるソフトウェアを開発するための重要な方法論です。パイプとフィルター、データリポジトリ、コンポーネントベースなど、ほとんどのアーキテクチャスタイルまたはパターンは、このパラダイムを使用して実装できます。
オブジェクト指向システムの基本的な概念と用語-
オブジェクト
オブジェクトは、物理的または概念的な存在を持つ可能性のあるオブジェクト指向環境の実世界の要素です。各オブジェクトには-があります
システム内の他のオブジェクトからそれを区別するアイデンティティ。
オブジェクトの特性プロパティと、オブジェクトが保持するプロパティの値を決定する状態。
状態の変化に関して、オブジェクトによって実行される外部から見えるアクティビティを表す動作。
オブジェクトは、アプリケーションのニーズに応じてモデル化できます。オブジェクトには、顧客や車などの物理的な存在が含まれる場合があります。または、プロジェクト、プロセスなどの無形の概念的存在。
クラス
クラスは、共通の動作を示す同じ特性を持つオブジェクトのコレクションを表します。ブループリントまたはそこから作成できるオブジェクトの説明を提供します。クラスのメンバーとしてのオブジェクトの作成は、インスタンス化と呼ばれます。したがって、オブジェクトはinstance クラスの。
クラスの構成要素は次のとおりです。
クラスからインスタンス化されるオブジェクトの属性のセット。一般に、クラスのオブジェクトが異なれば、属性の値にも多少の違いがあります。属性は、クラスデータと呼ばれることがよくあります。
クラスのオブジェクトの動作を表す一連の操作。操作は、関数またはメソッドとも呼ばれます。
Example
2次元空間で幾何学的図形の円を表す単純なクラスCircleを考えてみましょう。このクラスの属性は次のように識別できます-
- x座標、中心のx座標を示します
- y座標、中心のy座標を示します
- a、円の半径を示す
その操作のいくつかは次のように定義できます-
- findArea()、面積を計算するメソッド
- findCircumference()、円周を計算するメソッド
- scale()、半径を増減するメソッド
カプセル化
カプセル化は、クラス内で属性とメソッドの両方をバインドするプロセスです。カプセル化により、クラスの内部の詳細を外部から隠すことができます。これにより、クラスの要素は、クラスによって提供されるインターフェイスを介してのみ外部からアクセスできます。
ポリモーフィズム
ポリモーフィズムはもともとギリシャ語で、複数の形をとる能力を意味します。オブジェクト指向パラダイムでは、ポリモーフィズムは、操作対象のインスタンスに応じて、さまざまな方法で操作を使用することを意味します。ポリモーフィズムにより、内部構造が異なるオブジェクトに共通の外部インターフェイスを持たせることができます。継承を実装する場合、ポリモーフィズムは特に効果的です。
Example
それぞれがメソッドfindArea()を持つ2つのクラスCircleとSquareを考えてみましょう。クラス内のメソッドの名前と目的は同じですが、内部実装、つまり面積の計算手順はクラスごとに異なります。クラスCircleのオブジェクトがそのfindArea()メソッドを呼び出すと、操作はSquareクラスのfindArea()メソッドと競合することなく円の領域を検索します。
Relationships
システムを説明するには、システムの動的(動作)仕様と静的(論理)仕様の両方を提供する必要があります。動的仕様は、メッセージパッシングなどのオブジェクト間の関係を記述します。また、静的仕様は、集約、関連付け、継承など、クラス間の関係を記述します。
メッセージパッシング
どのアプリケーションでも、調和のとれた方法で相互作用する多数のオブジェクトが必要です。システム内のオブジェクトは、メッセージパッシングを使用して相互に通信できます。システムに2つのオブジェクト(obj1とobj2)があるとします。obj1がobj2にそのメソッドの1つを実行させたい場合、オブジェクトobj1はオブジェクトobj2にメッセージを送信します。
構成または集約
集約または構成は、クラス間の関係であり、これにより、クラスは他のクラスのオブジェクトの任意の組み合わせで構成できます。これにより、オブジェクトを他のクラスの本体内に直接配置できます。集約は「一部」または「持っている」関係と呼ばれ、全体からその一部にナビゲートする機能があります。集約オブジェクトは、1つ以上の他のオブジェクトで構成されるオブジェクトです。
協会
アソシエーションは、共通の構造と共通の動作を持つリンクのグループです。関連付けは、1つ以上のクラスのオブジェクト間の関係を表します。リンクは、関連付けのインスタンスとして定義できます。関連付けの程度は、接続に関係するクラスの数を示します。度は、単項、2進数、または3進数の場合があります。
- 単項関係は、同じクラスのオブジェクトを接続します。
- 二項関係は、2つのクラスのオブジェクトを接続します。
- 三項関係は、3つ以上のクラスのオブジェクトを接続します。
継承
これは、機能を拡張および改良することにより、既存のクラスから新しいクラスを作成できるようにするメカニズムです。既存のクラスは基本クラス/親クラス/スーパークラスと呼ばれ、新しいクラスは派生クラス/子クラス/サブクラスと呼ばれます。
サブクラスは、スーパークラスで許可されている場合に限り、スーパークラスの属性とメソッドを継承または派生させることができます。さらに、サブクラスは独自の属性とメソッドを追加したり、スーパークラスのメソッドを変更したりできます。継承は「is-a」関係を定義します。
Example
哺乳類のクラスから、人間、猫、犬、牛などの多くのクラスを導き出すことができます。人間、猫、犬、牛はすべて、哺乳類の独特の特徴を持っています。さらに、それぞれに固有の特性があります。牛は「哺乳類」であると言えます。
OO分析
ソフトウェア開発のオブジェクト指向分析フェーズでは、システム要件が決定され、クラスが識別され、クラス間の関係が確認されます。オブジェクト指向分析の目的は、アプリケーションドメインとシステムの特定の要件を理解することです。このフェーズの結果は、システムの論理構造と実現可能性の要件仕様と初期分析です。
オブジェクト指向分析のために互いに組み合わせて使用される3つの分析手法は、オブジェクトモデリング、動的モデリング、および機能モデリングです。
オブジェクトモデリング
オブジェクトモデリングは、オブジェクトの観点からソフトウェアシステムの静的構造を開発します。オブジェクト、オブジェクトをグループ化できるクラス、およびオブジェクト間の関係を識別します。また、各クラスを特徴付ける主な属性と操作も識別します。
オブジェクトモデリングのプロセスは、次の手順で視覚化できます。
- オブジェクトを識別し、クラスにグループ化します
- クラス間の関係を特定する
- ユーザーオブジェクトモデル図を作成する
- ユーザーオブジェクトの属性を定義する
- クラスで実行する必要のある操作を定義します
動的モデリング
システムの静的な動作を分析した後、時間と外部の変化に関するシステムの動作を調べる必要があります。これが動的モデリングの目的です。
動的モデリングは、「個々のオブジェクトが、他のオブジェクトによってトリガーされる内部イベント、または外界によってトリガーされる外部イベントのいずれかのイベントにどのように応答するかを記述する方法」として定義できます。
動的モデリングのプロセスは、次の手順で視覚化できます。
- 各オブジェクトの状態を特定する
- イベントを特定し、アクションの適用可能性を分析します
- 状態遷移図で構成される動的モデル図を作成します
- オブジェクト属性の観点から各状態を表現する
- 描画された状態遷移図を検証します
機能モデリング
機能モデリングは、オブジェクト指向分析の最後のコンポーネントです。機能モデルは、オブジェクト内で実行されるプロセスと、メソッド間を移動するときにデータがどのように変化するかを示します。これは、オブジェクトモデリングの操作の意味と動的モデリングのアクションを指定します。機能モデルは、従来の構造化分析のデータフロー図に対応しています。
機能モデリングのプロセスは、次の手順で視覚化できます。
- すべての入力と出力を特定する
- 機能依存性を示すデータフロー図を作成する
- 各機能の目的を述べる
- 制約を特定する
- 最適化基準を指定する
オブジェクト指向設計
分析フェーズの後、概念モデルは、オブジェクト指向設計(OOD)を使用してオブジェクト指向モデルにさらに発展します。OODでは、分析モデルのテクノロジに依存しない概念が実装クラスにマッピングされ、制約が識別され、インターフェイスが設計されて、ソリューションドメインのモデルが作成されます。オブジェクト指向設計の主な目的は、システムの構造アーキテクチャを開発することです。
オブジェクト指向設計の段階は、次のように識別できます。
- システムのコンテキストを定義する
- システムアーキテクチャの設計
- システム内のオブジェクトの識別
- 設計モデルの構築
- オブジェクトインターフェイスの仕様
オブジェクト指向設計は、概念設計と詳細設計の2つの段階に分けることができます。
Conceptual design
この段階では、システムの構築に必要なすべてのクラスが識別されます。さらに、各クラスには特定の責任が割り当てられています。クラス図はクラス間の関係を明確にするために使用され、相互作用図はイベントの流れを示すために使用されます。としても知られていますhigh-level design。
Detailed design
この段階では、属性と操作は、相互作用図に基づいて各クラスに割り当てられます。ステートマシン図は、設計の詳細を説明するために作成されています。としても知られていますlow-level design。
設計原則
以下は主要な設計原則です-
Principle of Decoupling
相互依存性の高いクラスのセットでシステムを維持することは困難です。1つのクラスを変更すると、他のクラスの更新がカスケードされる可能性があるためです。オブジェクト指向設計では、新しいクラスまたは継承を導入することで、密結合を排除できます。
Ensuring Cohesion
凝集クラスは、密接に関連する一連の機能を実行します。結束の欠如は、システム全体の動作には影響しませんが、クラスは無関係の機能を実行することを意味します。これにより、ソフトウェアの構造全体の管理、拡張、保守、および変更が困難になります。
Open-closed Principle
この原則によれば、システムは新しい要件を満たすために拡張できる必要があります。システム拡張の結果として、既存の実装とシステムのコードを変更しないでください。さらに、以下のガイドラインは、オープンクローズ原則で従う必要があります-
具象クラスごとに、個別のインターフェースと実装を維持する必要があります。
マルチスレッド環境では、属性をプライベートに保ちます。
グローバル変数とクラス変数の使用を最小限に抑えます。
データフローアーキテクチャでは、ソフトウェアシステム全体が、データと操作が互いに独立している、連続する部分または入力データのセットに対する一連の変換と見なされます。このアプローチでは、データはシステムに入り、モジュールが最終的な宛先(出力またはデータストア)に割り当てられるまで、モジュールを1つずつ通過します。
コンポーネントまたはモジュール間の接続は、I / Oストリーム、I / Oバッファ、パイプ、またはその他のタイプの接続として実装できます。データは、サイクルのあるグラフトポロジ、サイクルのない線形構造、またはツリータイプの構造でフローできます。
このアプローチの主な目的は、再利用と変更可能性の品質を達成することです。これは、コンパイラーやビジネスデータ処理アプリケーションなど、明確に定義された一連の独立したデータ変換または規則正しく定義された入力と出力の計算を伴うアプリケーションに適しています。モジュール間の実行シーケンスには3つのタイプがあります-
- バッチシーケンシャル
- パイプとフィルターまたは非順次パイプラインモード
- プロセス制御
バッチシーケンシャル
バッチシーケンシャルは古典的なデータ処理モデルであり、データ変換サブシステムは、前のサブシステムが完全に通過した後にのみプロセスを開始できます。
データのフローは、あるサブシステムから別のサブシステムに全体としてデータのバッチを運びます。
モジュール間の通信は、連続するサブシステムによって削除できる一時的な中間ファイルを介して行われます。
これは、データがバッチ処理され、各サブシステムが関連する入力ファイルを読み取り、出力ファイルを書き込むアプリケーションに適用できます。
このアーキテクチャの一般的なアプリケーションには、銀行や公共料金の請求などのビジネスデータ処理が含まれます。

利点
サブシステムのより単純な分割を提供します。
各サブシステムは、入力データを処理し、出力データを生成する独立したプログラムにすることができます。
短所
高遅延と低スループットを提供します。
並行性とインタラクティブなインターフェースを提供しません。
実装には外部制御が必要です。
パイプとフィルターのアーキテクチャ
このアプローチは、連続するコンポーネントによるデータの増分変換に重点を置いています。このアプローチでは、データのフローはデータによって駆動され、システム全体がデータソース、フィルター、パイプ、およびデータシンクのコンポーネントに分解されます。
モジュール間の接続はデータストリームであり、バイト、文字、またはその他の種類のストリームである先入れ先出しバッファです。このアーキテクチャの主な機能は、同時実行と増分実行です。
フィルタ
フィルタは、独立したデータストリームトランスフォーマーまたはストリームトランスデューサーです。入力データストリームのデータを変換して処理し、変換されたデータストリームをパイプに書き込んで、次のフィルターで処理します。インクリメンタルモードで動作し、接続されたパイプを介してデータが到着するとすぐに動作を開始します。フィルタには2つのタイプがあります-active filter そして passive filter。
Active filter
アクティブフィルターを使用すると、接続されたパイプでデータをプルインおよびプッシュアウトできます。パッシブパイプで動作し、プルとプッシュの読み取り/書き込みメカニズムを提供します。このモードは、UNIXパイプおよびフィルターメカニズムで使用されます。
Passive filter
パッシブフィルターを使用すると、接続されたパイプでデータをプッシュインおよびプルアウトできます。これは、フィルターからデータをプルし、次のフィルターにデータをプッシュするアクティブパイプで動作します。読み取り/書き込みメカニズムを提供する必要があります。

利点
過剰なデータ処理に対して同時実行性と高スループットを提供します。
再利用性を提供し、システムのメンテナンスを簡素化します。
フィルタ間の変更可能性と低結合を提供します。
パイプで接続された任意の2つのフィルターを明確に分割することにより、シンプルさを提供します。
順次実行と並列実行の両方をサポートすることにより、柔軟性を提供します。
短所
動的な相互作用には適していません。
ASCII形式でデータを送信するには、最小公分母が必要です。
フィルタ間のデータ変換のオーバーヘッド。
フィルタが協調して相互作用して問題を解決する方法を提供しません。
このアーキテクチャを動的に構成することは困難です。
パイプ
パイプはステートレスであり、2つのフィルター間に存在するバイナリストリームまたは文字ストリームを伝送します。データストリームをあるフィルターから別のフィルターに移動できます。パイプは少しのコンテキスト情報を使用し、インスタンス化の間に状態情報を保持しません。
プロセス制御アーキテクチャ
これは、データがバッチシーケンシャルでもパイプラインストリームでもないタイプのデータフローアーキテクチャです。データの流れは、プロセスの実行を制御する一連の変数から取得されます。システム全体をサブシステムまたはモジュールに分解し、それらを接続します。
サブシステムの種類
プロセス制御アーキテクチャには、 processing unit プロセス制御変数を変更するための controller unit 変化量を計算するため。
コントローラユニットには、次の要素が必要です。
Controlled Variable−制御変数は、基礎となるシステムの値を提供し、センサーで測定する必要があります。たとえば、クルーズコントロールシステムの速度。
Input Variable−プロセスへの入力を測定します。たとえば、温度制御システムの還気の温度
Manipulated Variable −操作変数値は、コントローラーによって調整または変更されます。
Process Definition −一部のプロセス変数を操作するためのメカニズムが含まれています。
Sensor −制御に関連するプロセス変数の値を取得し、操作された変数を再計算するためのフィードバック参照として使用できます。
Set Point −これは制御変数の望ましい値です。
Control Algorithm −プロセス変数の操作方法を決定するために使用されます。
アプリケーションエリア
プロセス制御アーキテクチャは、次のドメインに適しています-
システムがプロセス制御変数データによって操作される組み込みシステムソフトウェア設計。
アプリケーションは、プロセスの出力の指定されたプロパティを指定された参照値に維持することを目的としています。
車のクルーズコントロールおよび建物の温度制御システムに適用できます。
自動車のアンチロックブレーキ、原子力発電所などを制御するためのリアルタイムシステムソフトウェア。
データ中心のアーキテクチャでは、データは一元化され、データを変更する他のコンポーネントによって頻繁にアクセスされます。このスタイルの主な目的は、データの整合性を実現することです。データ中心のアーキテクチャは、共有データリポジトリを介して通信するさまざまなコンポーネントで構成されています。コンポーネントは共有データ構造にアクセスし、データストアを介してのみ相互作用するという点で比較的独立しています。
データ中心のアーキテクチャの最もよく知られている例は、データベースアーキテクチャです。このアーキテクチャでは、共通のデータベーススキーマがデータ定義プロトコルで作成されます。たとえば、RDBMSのフィールドとデータ型を持つ関連テーブルのセットです。
データ中心のアーキテクチャの別の例は、共通のデータスキーマ(つまり、Webのメタ構造)を持ち、ハイパーメディアデータモデルに従い、プロセスが共有Webベースのデータサービスを使用して通信するWebアーキテクチャです。

コンポーネントの種類
コンポーネントには2つのタイプがあります-
A central data構造またはデータストアまたはデータリポジトリ。永続的なデータストレージの提供を担当します。現在の状態を表します。
A data accessor または、中央データストアで動作し、計算を実行し、結果を戻す可能性のある独立したコンポーネントのコレクション。
データアクセサ間の相互作用または通信は、データストアを介してのみ行われます。データは、クライアント間の唯一の通信手段です。制御の流れは、アーキテクチャを2つのカテゴリに区別します-
- リポジトリアーキテクチャスタイル
- 黒板アーキテクチャスタイル
リポジトリアーキテクチャスタイル
リポジトリアーキテクチャスタイルでは、データストアはパッシブであり、データストアのクライアント(ソフトウェアコンポーネントまたはエージェント)はアクティブであり、ロジックフローを制御します。参加しているコンポーネントは、データストアに変更がないかチェックします。
クライアントは、アクション(データの挿入など)を実行するための要求をシステムに送信します。
計算プロセスは独立しており、着信要求によってトリガーされます。
トランザクションの入力ストリーム内のトランザクションのタイプが実行するプロセスの選択をトリガーする場合、それは従来のデータベースまたはリポジトリアーキテクチャ、あるいはパッシブリポジトリです。
このアプローチは、DBMS、ライブラリ情報システム、CORBAのインターフェイスリポジトリ、コンパイラ、およびCASE(コンピュータ支援ソフトウェアエンジニアリング)環境で広く使用されています。

利点
データの整合性、バックアップ、および復元機能を提供します。
エージェントは相互に直接通信しないため、エージェントのスケーラビリティと再利用性を提供します。
ソフトウェアコンポーネント間の一時データのオーバーヘッドを削減します。
短所
障害に対してより脆弱であり、データの複製または複製が可能です。
データストアのデータ構造とそのエージェント間の高い依存性。
データ構造の変更は、クライアントに大きな影響を与えます。
データの進化は難しく、費用がかかります。
分散データのためにネットワーク上でデータを移動するコスト。
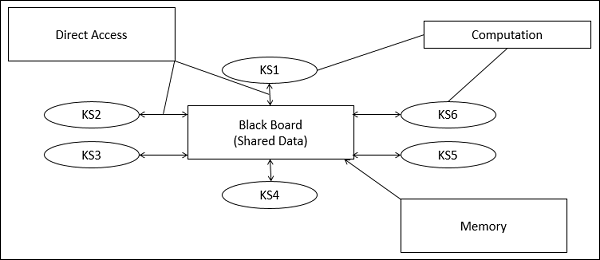
黒板アーキテクチャスタイル
Blackboard Architecture Styleでは、データストアはアクティブであり、そのクライアントはパッシブです。したがって、論理フローは、データストア内の現在のデータステータスによって決定されます。中央のデータリポジトリとして機能する黒板コンポーネントがあり、内部表現が構築され、さまざまな計算要素によって処理されます。
共通のデータ構造に独立して作用するいくつかのコンポーネントが黒板に格納されています。
このスタイルでは、コンポーネントは黒板を介してのみ相互作用します。データストアは、データストアが変更されるたびにクライアントに警告します。
ソリューションの現在の状態は黒板に保存され、処理は黒板の状態によってトリガーされます。
システムは、 trigger データに変更が発生した場合のクライアントへのデータ。
このアプローチは、音声認識、画像認識、セキュリティシステム、ビジネスリソース管理システムなどの特定のAIアプリケーションや複雑なアプリケーションに見られます。
中央データ構造の現在の状態が実行するプロセスを選択する主なトリガーである場合、リポジトリは黒板であり、この共有データソースはアクティブなエージェントです。
従来のデータベースシステムとの主な違いは、黒板アーキテクチャでの計算要素の呼び出しは、外部入力ではなく、黒板の現在の状態によってトリガーされることです。
黒板モデルの部品
黒板モデルは通常、3つの主要な部分で表されます-
Knowledge Sources (KS)
ナレッジソース、別名 Listeners または Subscribers別個の独立したユニットです。それらは問題の一部を解決し、部分的な結果を集約します。知識源間の相互作用は、黒板を通じて独自に行われます。
Blackboard Data Structure
問題解決の状態データは、アプリケーションに依存する階層に編成されています。知識源は、問題の解決に徐々につながる黒板に変更を加えます。
Control
コントロールはタスクを管理し、作業状態をチェックします。
利点
ナレッジソースの追加または更新を容易にするスケーラビリティを提供します。
すべてのナレッジソースが互いに独立しているため、並行して動作できるようにする同時実行性を提供します。
仮説の実験をサポートします。
ナレッジソースエージェントの再利用性をサポートします。
短所
黒板と知識源の間には密接な依存関係が存在するため、黒板の構造変更は、そのすべてのエージェントに重大な影響を与える可能性があります。
おおよその解決策しか期待されていないため、推論をいつ終了するかを決定するのは難しい場合があります。
複数のエージェントの同期の問題。
システムの設計とテストにおける主な課題。
階層アーキテクチャは、システム全体を階層構造と見なします。この構造では、ソフトウェアシステムが階層内のさまざまなレベルで論理モジュールまたはサブシステムに分解されます。このアプローチは通常、ネットワークプロトコルやオペレーティングシステムなどのシステムソフトウェアの設計に使用されます。
システムソフトウェア階層設計では、低レベルのサブシステムが隣接する上位レベルのサブシステムにサービスを提供し、下位レベルのメソッドを呼び出します。下位層は、I / Oサービス、トランザクション、スケジューリング、セキュリティサービスなど、より具体的な機能を提供します。中間層は、ビジネスロジックやコア処理サービスなどのドメイン依存機能を提供します。また、上位層は、GUI、シェルプログラミング機能などのユーザーインターフェイスの形で、より抽象的な機能を提供します。
また、名前空間階層内の.NETクラスライブラリなどのクラスライブラリの編成にも使用されます。すべての設計タイプでこの階層アーキテクチャを実装でき、多くの場合、他のアーキテクチャスタイルと組み合わせることができます。
階層的な建築様式は次のように分けられます-
- Main-subroutine
- Master-slave
- 仮想マシン
メイン-サブルーチン
このスタイルの目的は、モジュールを再利用し、個々のモジュールまたはサブルーチンを自由に開発することです。このスタイルでは、ソフトウェアシステムは、システムの目的の機能に応じてトップダウンの改良を使用することにより、サブルーチンに分割されます。
これらの改良は、分解されたモジュールがその排他的な独立した責任を持つのに十分単純になるまで垂直に進みます。機能は、上位層の複数の呼び出し元によって再利用および共有される場合があります。
データがパラメータとしてサブルーチンに渡される方法は2つあります。
Pass by Value −サブルーチンは過去のデータのみを使用し、それを変更することはできません。
Pass by Reference −サブルーチンは、パラメーターによって参照されるデータの値を使用および変更します。

利点
階層の改良に基づいてシステムを簡単に分解できます。
オブジェクト指向設計のサブシステムで使用できます。
短所
グローバルに共有されるデータが含まれているため、脆弱です。
緊密な結合は、変化の波及効果を引き起こす可能性があります。
マスタースレーブ
このアプローチは、「分割統治」の原則を適用し、障害計算と計算精度をサポートします。これは、システムの信頼性とフォールトトレランスを提供するメインサブルーチンアーキテクチャの変更です。
このアーキテクチャでは、スレーブはマスターに重複したサービスを提供し、マスターは特定の選択戦略によってスレーブの中から特定の結果を選択します。スレーブは、異なるアルゴリズムと方法、またはまったく異なる機能によって同じ機能タスクを実行する場合があります。これには、すべてのスレーブを並列に実行できる並列コンピューティングが含まれます。

マスタースレーブパターンの実装は、5つのステップに従います-
タスクの計算を等しいサブタスクのセットに分割する方法を指定し、サブタスクの処理に必要なサブサービスを特定します。
個々のサブタスクの処理から得られた結果を利用して、サービス全体の最終結果を計算する方法を指定します。
手順1で特定したサブサービスのインターフェイスを定義します。これはスレーブによって実装され、マスターによって使用されて、個々のサブタスクの処理を委任します。
前のステップで開発した仕様に従ってスレーブコンポーネントを実装します。
手順1〜3で作成した仕様に従ってマスターを実装します。
アプリケーション
ソフトウェアの信頼性が重要な問題であるアプリケーションに適しています。
並列および分散コンピューティングの分野で広く適用されています。
利点
より高速な計算と簡単なスケーラビリティ。
スレーブを複製できるため、堅牢性を提供します。
セマンティックエラーを最小限に抑えるために、スレーブを別の方法で実装できます。
短所
通信オーバーヘッド。
すべての問題を分割できるわけではありません。
実装が難しく、移植性の問題。
仮想マシンアーキテクチャ
仮想マシンアーキテクチャは、それが実装されているハードウェアやソフトウェアに固有ではない一部の機能を装います。仮想マシンは既存のシステム上に構築され、仮想抽象化、一連の属性、および操作を提供します。
仮想マシンアーキテクチャでは、マスターはスレーブからの「同じ」サブサービスを使用し、分割作業、スレーブの呼び出し、結果の結合などの機能を実行します。これにより、開発者は、まだ構築されていないプラットフォームをシミュレートおよびテストし、実際のシステムでテストするには複雑すぎ、コストがかかり、危険な「災害」モードをシミュレートできます。
ほとんどの場合、仮想マシンはプログラミング言語またはアプリケーション環境を実行プラットフォームから分割します。主な目的は提供することですportability。仮想マシンを介した特定のモジュールの解釈は、次のように認識される場合があります。
解釈エンジンは、解釈されるモジュールから命令を選択します。
命令に基づいて、エンジンは仮想マシンの内部状態を更新し、上記のプロセスが繰り返されます。
次の図は、単一の物理マシン上の標準VMインフラストラクチャのアーキテクチャを示しています。

ザ・ hypervisor, とも呼ばれます virtual machine monitorは、ホストOSで実行され、一致したリソースを各ゲストOSに割り当てます。ゲストがシステムコールを行うと、ハイパーバイザーはそれをインターセプトして、ホストOSでサポートされている対応するシステムコールに変換します。ハイパーバイザーは、CPU、メモリ、永続ストレージ、I / Oデバイス、およびネットワークへの各仮想マシンのアクセスを制御します。
アプリケーション
仮想マシンアーキテクチャは、次のドメインに適しています-
直接的な解決策がない場合は、シミュレーションまたは変換によって問題を解決するのに適しています。
サンプルアプリケーションには、マイクロプログラミング、XML処理、スクリプトコマンド言語の実行、ルールベースのシステム実行、SmalltalkおよびJavaインタープリタータイプのプログラミング言語のインタープリターが含まれます。
仮想マシンの一般的な例は、インタープリター、ルールベースのシステム、構文シェル、およびコマンド言語プロセッサーです。
利点
移植性とマシンプラットフォームの独立性。
ソフトウェア開発のシンプルさ。
プログラムを中断および照会する機能を通じて柔軟性を提供します。
災害作業モデルのシミュレーション。
実行時に変更を導入します。
短所
インタプリタの性質上、インタプリタの実行が遅い。
実行に伴う追加の計算のため、パフォーマンスコストが発生します。
レイヤードスタイル
このアプローチでは、システムは階層内のいくつかの上位層と下位層に分解され、各層はシステム内で独自の責任を負います。
各レイヤーは、パッケージ、デプロイされたコンポーネント、またはメソッドライブラリまたはヘッダーファイルの形式のサブルーチンのグループとしてカプセル化された関連クラスのグループで構成されます。
各レイヤーは、その上のレイヤーにサービスを提供し、下のレイヤーへのクライアントとして機能します。つまり、レイヤーi +1への要求は、レイヤーiのインターフェイスを介してレイヤーiによって提供されるサービスを呼び出します。タスクが完了すると、応答はレイヤーi + 1に戻る場合があります。それ以外の場合、レイヤーiは、下のレイヤーi-1からサービスを継続的に呼び出します。
アプリケーション
レイヤードスタイルは以下の分野に適しています−
階層的に編成できる個別のサービスクラスを含むアプリケーション。
アプリケーション固有の部分とプラットフォーム固有の部分に分解できるアプリケーション。
コアサービス、重要なサービス、ユーザーインターフェイスサービスなどが明確に区別されているアプリケーション。
利点
抽象化の段階的なレベルに基づいて設計します。
1つのレイヤーの機能への変更が、最大で2つの他のレイヤーに影響を与えるため、拡張の独立性を提供します。
標準インターフェースの分離とその実装。
新しいコンポーネントのプラグアンドプレイを可能にするシステムをはるかに簡単にするコンポーネントベースのテクノロジーを使用して実装されます。
各レイヤーは、移植性をサポートする独立してデプロイされた抽象マシンにすることができます。
トップダウンの洗練された方法でタスクの定義に基づいてシステムを分解するのは簡単
同じレイヤーの異なる実装(同一のインターフェース)は交換可能に使用できます
短所
多くのアプリケーションまたはシステムは、階層化された方法で簡単に構造化されていません。
クライアントの要求またはクライアントへの応答は潜在的に複数のレイヤーを通過する必要があるため、実行時のパフォーマンスが低下します。
また、各レイヤーによるデータのマーシャリングとバッファリングのオーバーヘッドに関するパフォーマンスの懸念もあります。
層間通信の開放はデッドロックを引き起こす可能性があり、「ブリッジング」は緊密な結合を引き起こす可能性があります。
1つの層の障害はすべての呼び出し層に上向きに広がる必要があるため、例外とエラー処理は階層化アーキテクチャの問題です。
インタラクション指向アーキテクチャの主な目的は、ユーザーのインタラクションをデータの抽象化やビジネスデータ処理から分離することです。相互作用指向のソフトウェアアーキテクチャは、システムを3つの主要なパーティションに分解します-
Data module −データモジュールは、データの抽象化とすべてのビジネスロジックを提供します。
Control module −制御モジュールは、制御およびシステム構成アクションのフローを識別します。
View presentation module −ビュー表示モジュールは、データ出力の視覚的または音声表示を担当し、ユーザー入力用のインターフェイスも提供します。
インタラクション指向のアーキテクチャには、2つの主要なスタイルがあります- Model-View-Controller (MVC)と Presentation-Abstraction-Control(PAC)。MVCとPACはどちらも、3つのコンポーネントの分解を提案し、複数の会話やユーザーとの対話を伴うWebアプリケーションなどのインタラクティブなアプリケーションに使用されます。それらは、制御と編成の流れが異なります。PACはエージェントベースの階層アーキテクチャですが、MVCには明確な階層構造がありません。
Model-View-Controller(MVC)
MVCは、特定のソフトウェアアプリケーションを、ユーザーに提示またはユーザーから受け入れられた情報から情報の内部表現を分離するのに役立つ3つの相互接続された部分に分解します。
| モジュール | 関数 |
|---|---|
| モデル | 基盤となるデータとビジネスロジックのカプセル化 |
| コントローラ | ユーザーアクションに応答し、アプリケーションフローを指示します |
| 見る | モデルからユーザーにデータをフォーマットして表示します。 |
モデル
モデルは、アプリケーションのデータ、ロジック、および制約を直接管理するMVCの中心的なコンポーネントです。これは、インターフェイスの生のアプリケーションデータとアプリケーションロジックを維持するデータコンポーネントで構成されています。
これは独立したユーザーインターフェイスであり、アプリケーションの問題ドメインの動作をキャプチャします。
これは、ドメイン固有のソフトウェアシミュレーションまたはアプリケーションの中央構造の実装です。
状態が変更されると、関連するビューに通知を送信して更新された出力を生成し、コントローラーは使用可能なコマンドのセットを変更します。
見る
ビューは、図やチャートなどのグラフィック形式で情報の出力を表すために使用できます。これは、データの視覚的表現を提供するプレゼンテーションコンポーネントで構成されています
ビューはモデルから情報を要求し、ユーザーへの出力表現を生成します。
管理用の棒グラフや会計士用の表形式のビューなど、同じ情報の複数のビューが可能です。
コントローラ
コントローラは入力を受け取り、それをモデルまたはビューのコマンドに変換します。これは、モデルを変更することによってユーザーからの入力を処理する入力処理コンポーネントで構成されています。
これは、関連するモデルとビューと入力デバイスの間のインターフェイスとして機能します。
モデルにコマンドを送信してモデルの状態を更新し、関連するビューにコマンドを送信して、モデルのビューの表示を変更できます。

MVC-私
これは、システムが2つのサブシステムに分割されているMVCアーキテクチャの単純なバージョンです。
The Controller-View −コントローラービューは入出力インターフェースとして機能し、処理が行われます。
The Model −モデルは、すべてのデータおよびドメインサービスを提供します。
MVC-I Architecture
モデルモジュールは、データの変更をコントローラービューモジュールに通知し、それに応じてグラフィックデータの表示が変更されるようにします。コントローラは、変更時に適切なアクションも実行します。

コントローラビューとモデル間の接続は、サブスクライブ通知のパターン(上の図に示す)で設計できます。これにより、コントローラビューはモデルにサブスクライブし、モデルはコントローラビューに変更を通知します。
MVC-II
MVC–IIは、ビューモジュールとコントローラモジュールが分離されているMVC-Iアーキテクチャの拡張機能です。モデルモジュールは、データベースでサポートされているすべてのコア機能とデータを提供することにより、MVC-Iと同様に積極的な役割を果たします。
ビューモジュールはデータを提示し、コントローラーモジュールは入力要求を受け入れ、入力データを検証し、モデル、ビュー、それらの接続を開始し、タスクをディスパッチします。
MVC-II Architecture

MVCアプリケーション
MVCアプリケーションは、単一のデータモデルに複数のビューが必要であり、新しいインターフェイスビューや変更されたインターフェイスビューを簡単にプラグインできるインタラクティブなアプリケーションに効果的です。
MVCアプリケーションは、モジュール間に明確な区分があり、そのようなアプリケーションのさまざまな側面に同時に取り組むためにさまざまな専門家を割り当てることができるアプリケーションに適しています。
Advantages
利用可能なMVCベンダーフレームワークツールキットはたくさんあります。
同じデータモデルと同期された複数のビュー。
新しいインターフェイスビューをプラグインしたり、インターフェイスビューを置き換えたりするのは簡単です。
グラフィックスの専門家、プログラミングの専門家、およびデータベース開発の専門家が設計されたプロジェクトチームで作業しているアプリケーション開発に使用されます。
Disadvantages
インタラクティブなモバイルアプリケーションやロボットアプリケーションなどのエージェント指向アプリケーションには適していません。
同じデータモデルに基づくコントローラーとビューの複数のペアにより、データモデルの変更にコストがかかります。
ビューとコントローラーの区分が明確でない場合があります。
プレゼンテーション-抽象化-制御(PAC)
PACでは、システムは多くの協力エージェント(トライアド)の階層に配置されます。これは、インタラクティブな要件に加えて、複数のエージェントのアプリケーション要件をサポートするためにMVCから開発されました。
各エージェントには3つのコンポーネントがあります-
The presentation component −データの視覚的および音声的表現をフォーマットします。
The abstraction component −データを取得して処理します。
The control component −他の2つのコンポーネント間の制御フローや通信などのタスクを処理します。
プレゼンテーションモジュールがMVCのビューモジュールに似ているという意味で、PACアーキテクチャはMVCに似ています。抽象化モジュールはMVCのモデルモジュールのように見え、制御モジュールはMVCのコントローラーモジュールのように見えますが、制御と編成のフローが異なります。
各エージェントの抽象化コンポーネントとプレゼンテーションコンポーネントの間に直接的な関係はありません。各エージェントの制御コンポーネントは、他のエージェントとの通信を担当します。
次の図は、PAC設計における単一エージェントのブロック図を示しています。

複数のエージェントを使用したPAC
複数のエージェントで構成されるPACでは、トップレベルのエージェントがコアデータとビジネスロジックを提供します。最下位のエージェントは、詳細な特定のデータとプレゼンテーションを定義します。中間レベルまたは中間レベルのエージェントは、低レベルのエージェントのコーディネーターとして機能します。
各エージェントには、固有の割り当てられたジョブがあります。
一部のミドルレベルエージェントでは、インタラクティブプレゼンテーションが不要なため、プレゼンテーションコンポーネントがありません。
制御コンポーネントは、すべてのエージェントが相互に通信するために必要なすべてのエージェントに必要です。
次の図は、PACに参加する複数のエージェントを示しています。

Applications
システムを階層的に多くの協調エージェントに分解できるインタラクティブシステムに効果的です。
エージェント間の結合が緩く、エージェントの変更が他のエージェントに影響を与えないことが予想される場合に効果的です。
すべてのエージェントが離れた場所に分散されており、各エージェントがデータとインタラクティブなインターフェイスを備えた独自の機能を備えている分散システムに効果的です。
それぞれが独自の現在のデータとインタラクティブなインターフェイスを保持し、他のコンポーネントと通信する必要がある、豊富なGUIコンポーネントを備えたアプリケーションに適しています。
利点
マルチタスクとマルチビューのサポート
エージェントの再利用性と拡張性のサポート
新しいエージェントをプラグインしたり、既存のエージェントを変更したりするのは簡単
複数のエージェントが異なるスレッドまたは異なるデバイスまたはコンピューターで並行して実行されている場合の同時実行のサポート
短所
表示と抽象化の間の制御ブリッジ、およびエージェント間の制御の通信によるオーバーヘッド。
疎結合とエージェント間の高い独立性のため、適切なエージェント数を決定することは困難です。
エージェント間の通信はエージェントのコントロール間でのみ行われるため、各エージェントのコントロールによるプレゼンテーションと抽象化の完全な分離は、開発の複雑さを生み出します
分散アーキテクチャでは、コンポーネントは異なるプラットフォームに表示され、特定の目的または目標を達成するために、複数のコンポーネントが通信ネットワークを介して相互に連携できます。
このアーキテクチャでは、情報処理は単一のマシンに限定されず、複数の独立したコンピュータに分散されます。
分散システムは、多層アーキテクチャの基盤を形成するクライアントサーバーアーキテクチャによって実証できます。代替手段は、CORBAなどのブローカーアーキテクチャーとサービス指向アーキテクチャー(SOA)です。
.NET、J2EE、CORBA、.NET Webサービス、AXIS Java Webサービス、Globus Gridサービスなど、分散アーキテクチャをサポートするためのテクノロジフレームワークがいくつかあります。
ミドルウェアは、分散アプリケーションの開発と実行を適切にサポートするインフラストラクチャです。アプリケーションとネットワークの間にバッファを提供します。
システムの中央に位置し、分散システムのさまざまなコンポーネントを管理またはサポートします。例としては、トランザクション処理モニター、データコンバーター、通信コントローラーなどがあります。
分散システムのインフラストラクチャとしてのミドルウェア

分散アーキテクチャの基本は、その透明性、信頼性、および可用性です。
次の表に、分散システムのさまざまな形式の透過性を示します。
| シニア番号 | 透明性と説明 |
|---|---|
| 1 | Access リソースへのアクセス方法とデータプラットフォームの違いを非表示にします。 |
| 2 | Location リソースが配置されている場所を非表示にします。 |
| 3 | Technology プログラミング言語やOSなどのさまざまなテクノロジーをユーザーから隠します。 |
| 4 | Migration / Relocation 使用中の別の場所に移動される可能性のあるリソースを非表示にします。 |
| 5 | Replication 複数の場所でコピーされる可能性のあるリソースを非表示にします。 |
| 6 | Concurrency 他のユーザーと共有される可能性のあるリソースを非表示にします。 |
| 7 | Failure ユーザーからのリソースの障害と回復を非表示にします。 |
| 8 | Persistence リソース(ソフトウェア)がメモリにあるかディスクにあるかを非表示にします。 |
利点
Resource sharing −ハードウェアおよびソフトウェアリソースの共有。
Openness −さまざまなベンダーのハードウェアとソフトウェアを使用する柔軟性。
Concurrency −パフォーマンスを向上させるための並行処理。
Scalability −新しいリソースを追加することでスループットが向上します。
Fault tolerance −障害が発生した後も動作を継続する機能。
短所
Complexity −集中型システムよりも複雑です。
Security −外部からの攻撃を受けやすくなります。
Manageability −システム管理により多くの労力が必要です。
Unpredictability −システム構成とネットワーク負荷によっては予測できない応答。
集中型システムと分散型システム
| 基準 | 一元化されたシステム | 分散システム |
|---|---|---|
| 経済 | 低 | 高い |
| 可用性 | 低 | 高い |
| 複雑 | 低 | 高い |
| 一貫性 | シンプル | 高い |
| スケーラビリティ | 貧しい | 良い |
| 技術 | 同種の | 不均一 |
| セキュリティ | 高い | 低 |
クライアントサーバーアーキテクチャ
クライアント/サーバーアーキテクチャは、システムを2つの主要なサブシステムまたは論理プロセスに分解する最も一般的な分散システムアーキテクチャです。
Client −これは、2番目のプロセス(サーバー)に要求を発行する最初のプロセスです。
Server −これは、要求を受信して実行し、クライアントに応答を送信する2番目のプロセスです。
このアーキテクチャでは、アプリケーションは、サーバーによって提供される一連のサービスと、これらのサービスを使用する一連のクライアントとしてモデル化されます。サーバーはクライアントについて知る必要はありませんが、クライアントはサーバーのIDを知っている必要があり、プロセッサからプロセスへのマッピングは必ずしも1:1である必要はありません。

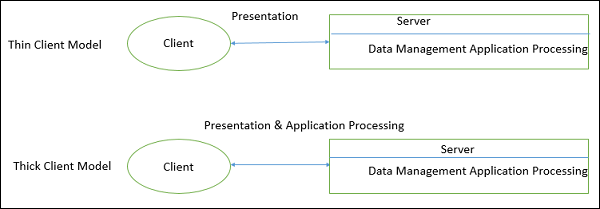
クライアントサーバーアーキテクチャは、クライアントの機能に基づいて2つのモデルに分類できます-
シンクライアントモデル
シンクライアントモデルでは、すべてのアプリケーション処理とデータ管理はサーバーによって実行されます。クライアントは、プレゼンテーションソフトウェアの実行を担当するだけです。
レガシーシステムがクライアントサーバーアーキテクチャに移行されるときに使用されます。このアーキテクチャでは、レガシーシステムは、クライアントに実装されたグラフィカルインターフェイスを備えたサーバーとして機能します。
主な欠点は、サーバーとネットワークの両方に重い処理負荷がかかることです。
シック/ファットクライアントモデル
シッククライアントモデルでは、サーバーはデータ管理のみを担当します。クライアント上のソフトウェアは、アプリケーションロジックとシステムユーザーとの対話を実装します。
クライアントシステムの機能が事前にわかっている新しいC / Sシステムに最適
特に管理に関しては、シンクライアントモデルよりも複雑です。アプリケーションの新しいバージョンをすべてのクライアントにインストールする必要があります。
利点
ユーザーインターフェイスの表示やビジネスロジックの処理などの責任の分離。
サーバーコンポーネントの再利用性と同時実行の可能性
分散アプリケーションの設計と開発を簡素化します
これにより、既存のアプリケーションを分散環境に簡単に移行または統合できます。
また、多数のクライアントが高性能サーバーにアクセスしている場合にも、リソースを有効に活用します。
短所
要件の変更に対処するための異種インフラストラクチャの欠如。
セキュリティの問題。
サーバーの可用性と信頼性が制限されています。
限られたテスト容易性とスケーラビリティ。
プレゼンテーションとビジネスロジックを一緒に持つファットクライアント。
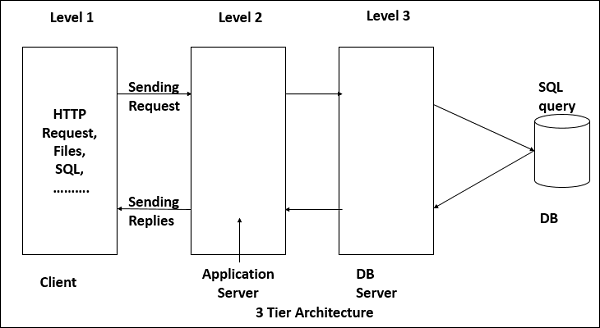
多層アーキテクチャ(n層アーキテクチャ)
多層アーキテクチャは、プレゼンテーション、アプリケーション処理、データ管理などの機能が物理的に分離されたクライアントサーバーアーキテクチャです。開発者は、アプリケーションを層に分割することで、アプリケーション全体を作り直すのではなく、特定のレイヤーを変更または追加するオプションを利用できます。これは、開発者が柔軟で再利用可能なアプリケーションを作成できるモデルを提供します。

多層アーキテクチャの最も一般的な用途は、3層アーキテクチャです。3層アーキテクチャは通常、プレゼンテーション層、アプリケーション層、およびデータストレージ層で構成され、別のプロセッサで実行される場合があります。
プレゼンテーション層
プレゼンテーション層は、WebページやオペレーティングシステムGUI(グラフィカルユーザーインターフェイス)など、ユーザーが直接アクセスできるアプリケーションの最上位レベルです。このレイヤーの主な機能は、タスクと結果をユーザーが理解できるものに変換することです。他の層と通信して、結果をブラウザ/クライアント層およびネットワーク内の他のすべての層に配置します。
アプリケーション層(ビジネスロジック、ロジック層、または中間層)
アプリケーション層は、アプリケーションを調整し、コマンドを処理し、論理的な決定、評価を行い、計算を実行します。詳細な処理を実行することにより、アプリケーションの機能を制御します。また、周囲の2つのレイヤー間でデータを移動および処理します。
データ層
このレイヤーでは、情報が保存され、データベースまたはファイルシステムから取得されます。その後、情報は処理のために返され、ユーザーに返されます。これには、データ永続化メカニズム(データベースサーバー、ファイル共有など)が含まれ、保存されたデータを管理する方法を提供するアプリケーション層にAPI(アプリケーションプログラミングインターフェイス)を提供します。
Advantages
シンクライアントアプローチよりもパフォーマンスが高く、シッククライアントアプローチよりも管理が簡単です。
再利用性とスケーラビリティを強化します。需要が増えると、サーバーを追加できます。
マルチスレッドサポートを提供し、ネットワークトラフィックも削減します。
保守性と柔軟性を提供します
Disadvantages
テストツールがないため、テスト容易性が不十分です。
より重要なサーバーの信頼性と可用性。
ブローカーの建築様式
Broker Architectural Styleは、分散コンピューティングで使用されるミドルウェアアーキテクチャであり、登録済みのサーバーとクライアント間の通信を調整および有効化します。ここで、オブジェクト通信は、オブジェクトリクエストブローカ(ソフトウェアバス)と呼ばれるミドルウェアシステムを介して行われます。
クライアントとサーバーは互いに直接対話しません。クライアントとサーバーは、メディエーターブローカーと通信するプロキシに直接接続しています。
サーバーはブローカーにインターフェースを登録して公開することでサービスを提供し、クライアントはルックアップによって静的または動的にブローカーにサービスを要求できます。
CORBA(Common Object Request Broker Architecture)は、ブローカーアーキテクチャの優れた実装例です。
ブローカーの建築様式のコンポーネント
ブローカーのアーキテクチャスタイルのコンポーネントについては、次のヘッドで説明します。
Broker
ブローカーは、結果や例外の転送やディスパッチなど、コミュニケーションの調整を担当します。これは、呼び出し指向のサービス、ドキュメント、またはクライアントがメッセージを送信するメッセージ指向のブローカーのいずれかです。
これは、サービスリクエストの仲介、適切なサーバーの検索、リクエストの送信、およびクライアントへの応答の返送を担当します。
サーバーの機能やサービス、場所情報など、サーバーの登録情報を保持します。
これは、クライアントが要求するAPI、応答するサーバー、サーバーコンポーネントの登録または登録解除、メッセージの転送、およびサーバーの検索のためのAPIを提供します。
Stub
スタブは静的コンパイル時に生成され、クライアントのプロキシとして使用されるクライアント側にデプロイされます。クライアント側プロキシは、クライアントとブローカーの間の仲介役として機能し、クライアントとブローカーの間の透明性を高めます。リモートオブジェクトはローカルオブジェクトのように見えます。
プロキシは、プロトコルレベルでIPC(プロセス間通信)を非表示にし、パラメーター値のマーシャリングとサーバーからの結果のマーシャリング解除を実行します。
Skeleton
スケルトンは、サービスインターフェイスのコンパイルによって生成され、サーバー側にデプロイされます。サーバー側は、サーバーのプロキシとして使用されます。サーバー側プロキシは、低レベルのシステム固有のネットワーク機能をカプセル化し、サーバーとブローカーの間を仲介する高レベルのAPIを提供します。
リクエストを受信し、リクエストを解凍し、メソッド引数をアンマーシャリングし、適切なサービスを呼び出し、結果をマーシャリングしてからクライアントに送り返します。
Bridge
ブリッジは、異なる通信プロトコルに基づいて2つの異なるネットワークを接続できます。DCOM、.NETリモート、JavaCORBAブローカーなどのさまざまなブローカーを仲介します。
ブリッジはオプションのコンポーネントであり、2つのブローカーが相互運用し、要求とパラメーターを1つの形式で受け取り、それらを別の形式に変換するときに、実装の詳細を非表示にします。

Broker implementation in CORBA
CORBAは、OMG(オブジェクト管理グループ)によって定義された分散オブジェクト間の通信を管理するミドルウェアであるObject RequestBrokerの国際標準です。

サービス指向アーキテクチャー(SOA)
サービスは、明確に定義され、自己完結型で、独立していて、公開されており、標準のプログラミングインターフェイスを介して使用できるビジネス機能のコンポーネントです。サービス間の接続は、SOAP Webサービスプロトコルなどの一般的でユニバーサルなメッセージ指向プロトコルによって実行されます。これにより、サービス間で要求と応答を大まかに配信できます。
サービス指向アーキテクチャーは、アプリケーションがソフトウェアサービスとソフトウェアサービスコンシューマー(クライアントまたはサービスリクエスターとも呼ばれます)で構成されるビジネス主導のITアプローチをサポートするクライアント/サーバー設計です。
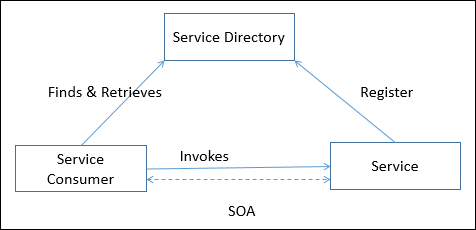
SOAの機能
サービス指向アーキテクチャは、次の機能を提供します-
Distributed Deployment −エンタープライズデータとビジネスロジックを、サービスと呼ばれる疎、結合、検出可能、構造化、標準ベース、粗粒度、ステートレスの機能単位として公開します。
Composability −明確に定義され、公開された、標準の苦情インターフェースを通じて、必要な粒度で公開されている既存のサービスから新しいプロセスを組み立てます。
Interoperability −基盤となるプロトコルや実装テクノロジーに関係なく、ネットワーク全体で機能を共有し、共有サービスを再利用します。
Reusability −サービスプロバイダーを選択し、サービスとして公開されている既存のリソースにアクセスします。
SOA操作
次の図は、SOAがどのように動作するかを示しています-

Advantages
サービス指向の疎結合は、プラットフォームやテクノロジーの制限に関係なく、企業が利用可能なすべてのサービス手段を利用するための優れた柔軟性を提供します。
ステートレスサービス機能により、各サービスコンポーネントは他のサービスから独立しています。
公開されたインターフェースが変更されない限り、サービスの実装はサービスのアプリケーションに影響を与えません。
クライアントまたは任意のサービスは、プラットフォーム、テクノロジー、ベンダー、または言語の実装に関係なく、他のサービスにアクセスできます。
サービスのクライアントはパブリックインターフェイス、サービス構成を知るだけでよいため、資産とサービスの再利用性。
SOAベースのビジネスアプリケーション開発は、時間とコストの点ではるかに効率的です。
スケーラビリティを強化し、システム間の標準接続を提供します。
「ビジネスサービス」の効率的かつ効果的な使用法。
統合がはるかに簡単になり、本質的な相互運用性が向上します。
開発者にとって複雑さを抽象化し、エンドユーザーにより近いビジネスプロセスを活性化します。
コンポーネントベースのアーキテクチャは、メソッド、イベント、およびプロパティを含む明確に定義された通信インターフェイスを表す個々の機能コンポーネントまたは論理コンポーネントへの設計の分解に焦点を当てています。これは、より高いレベルの抽象化を提供し、問題をサブ問題に分割し、それぞれがコンポーネントパーティションに関連付けられます。
コンポーネントベースのアーキテクチャの主な目的は、 component reusability。コンポーネントは、ソフトウェア要素の機能と動作を再利用可能で自己展開可能なバイナリユニットにカプセル化します。COM / DCOM、JavaBean、EJB、CORBA、.NET、Webサービス、グリッドサービスなど、多くの標準コンポーネントフレームワークがあります。これらのテクノロジは、グラフィックJavaBeanコンポーネント、MS ActiveXコンポーネント、COMコンポーネントなど、ドラッグアンドドロップ操作だけで再利用できるローカルデスクトップGUIアプリケーションの設計で広く使用されています。
コンポーネント指向のソフトウェア設計には、次のような従来のオブジェクト指向のアプローチに比べて多くの利点があります。
既存のコンポーネントを再利用することにより、市場での時間と開発コストを削減します。
既存のコンポーネントを再利用することで信頼性が向上します。
コンポーネントとは何ですか?
コンポーネントは、モジュール式で、移植可能で、交換可能で、再利用可能な明確に定義された機能のセットであり、その実装をカプセル化し、より高いレベルのインターフェースとしてエクスポートします。
コンポーネントはソフトウェアオブジェクトであり、特定の機能または一連の機能をカプセル化して、他のコンポーネントと相互作用することを目的としています。明確に定義されたインターフェースを持ち、アーキテクチャ内のすべてのコンポーネントに共通の推奨動作に準拠しています。
ソフトウェアコンポーネントは、契約上指定されたインターフェイスと明示的なコンテキスト依存関係のみを持つ構成の単位として定義できます。つまり、ソフトウェアコンポーネントは独立して展開でき、サードパーティによる構成の対象となります。
コンポーネントのビュー
コンポーネントは、オブジェクト指向ビュー、従来のビュー、およびプロセス関連ビューの3つの異なるビューを持つことができます。
Object-oriented view
コンポーネントは、1つ以上の協調クラスのセットと見なされます。各問題ドメインクラス(分析)とインフラストラクチャクラス(設計)は、その実装に適用されるすべての属性と操作を識別するために説明されています。また、クラスが通信および連携できるようにするインターフェースの定義も含まれます。
Conventional view
これは、処理ロジック、処理ロジックの実装に必要な内部データ構造、およびコンポーネントの呼び出しとデータの受け渡しを可能にするインターフェイスを統合するプログラムの機能要素またはモジュールと見なされます。
Process-related view
このビューでは、各コンポーネントを最初から作成するのではなく、システムはライブラリに保持されている既存のコンポーネントから構築しています。ソフトウェアアーキテクチャが定式化されると、コンポーネントがライブラリから選択され、アーキテクチャへの入力に使用されます。
ユーザーインターフェイス(UI)コンポーネントには、グリッド、コントロールと呼ばれるボタンが含まれ、ユーティリティコンポーネントは、他のコンポーネントで使用される機能の特定のサブセットを公開します。
他の一般的なタイプのコンポーネントは、リソースを大量に消費し、頻繁にアクセスされず、ジャストインタイム(JIT)アプローチを使用してアクティブ化する必要があるコンポーネントです。
Enterprise JavaBean(EJB)、. NETコンポーネント、CORBAコンポーネントなど、エンタープライズビジネスアプリケーションやインターネットWebアプリケーションに配布されている多くのコンポーネントは表示されません。
コンポーネントの特性
Reusability−コンポーネントは通常、さまざまなアプリケーションのさまざまな状況で再利用できるように設計されています。ただし、一部のコンポーネントは特定のタスク用に設計されている場合があります。
Replaceable −コンポーネントは、他の同様のコンポーネントと自由に置き換えることができます。
Not context specific −コンポーネントは、さまざまな環境およびコンテキストで動作するように設計されています。
Extensible −コンポーネントを既存のコンポーネントから拡張して、新しい動作を提供できます。
Encapsulated − AAコンポーネントは、呼び出し元がその機能を使用できるようにするインターフェースを示し、内部プロセスや内部変数または状態の詳細を公開しません。
Independent −コンポーネントは、他のコンポーネントへの依存を最小限に抑えるように設計されています。
コンポーネントベースの設計の原則
コンポーネントレベルの設計は、ソースコードに変換できる中間表現(グラフィカル、表形式、テキストベースなど)を使用して表現できます。データ構造、インターフェース、およびアルゴリズムの設計は、エラーの発生を回避するために確立されたガイドラインに準拠する必要があります。
ソフトウェアシステムは、再利用可能で、まとまりのある、カプセル化されたコンポーネントユニットに分解されます。
各コンポーネントには、必要なポートと提供されるポートを指定する独自のインターフェイスがあります。各コンポーネントは、その詳細な実装を非表示にします。
コンポーネントは、コンポーネントの既存の部分に内部コードや設計変更を加えることなく拡張する必要があります。
抽象化に依存するコンポーネントは、他の具体的なコンポーネントに依存しないため、消耗性が高くなります。
コンポーネントを接続するコネクタ。コンポーネント間の相互作用を指定および決定します。相互作用タイプは、コンポーネントのインターフェースによって指定されます。
コンポーネントの相互作用は、メソッド呼び出し、非同期呼び出し、ブロードキャスト、メッセージ駆動型相互作用、データストリーム通信、およびその他のプロトコル固有の相互作用の形をとることができます。
サーバークラスの場合、主要なカテゴリのクライアントにサービスを提供するために、専用のインターフェイスを作成する必要があります。特定のカテゴリのクライアントに関連する操作のみをインターフェイスで指定する必要があります。
コンポーネントは他のコンポーネントに拡張でき、それでも独自の拡張ポイントを提供できます。これは、プラグインベースのアーキテクチャの概念です。これにより、プラグインは別のプラグインAPIを提供できます。

コンポーネントレベルの設計ガイドライン
アーキテクチャモデルの一部として指定されたコンポーネントの命名規則を作成し、コンポーネントレベルのモデルの一部として改良または詳細化します。
問題のドメインからアーキテクチャコンポーネント名を取得し、それらがアーキテクチャモデルを表示するすべての利害関係者にとって意味があることを確認します。
他のエンティティに関連する依存関係なしに独立して存在できるビジネスプロセスエンティティを抽出します。
これらの独立したエンティティを新しいコンポーネントとして認識し、発見します。
実装固有の意味を反映するインフラストラクチャコンポーネント名を使用します。
左から右への依存関係と、上(基本クラス)から下(派生クラス)への継承をモデル化します。
コンポーネント間の直接的な依存関係として表すのではなく、コンポーネントの依存関係をインターフェイスとしてモデル化します。
コンポーネントレベルの設計の実施
分析モデルとアーキテクチャモデルで定義されている問題ドメインに対応するすべての設計クラスを認識します。
インフラストラクチャドメインに対応するすべての設計クラスを認識します。
再利用可能なコンポーネントとして取得されていないすべてのデザインクラスについて説明し、メッセージの詳細を指定します。
各コンポーネントの適切なインターフェイスを識別し、属性を詳しく説明し、それらを実装するために必要なデータ型とデータ構造を定義します。
擬似コードまたはUMLアクティビティ図を使用して、各操作内の処理フローを詳細に説明します。
永続データソース(データベースとファイル)について説明し、それらを管理するために必要なクラスを識別します。
クラスまたはコンポーネントの動作表現を開発し、詳しく説明します。これは、分析モデル用に作成されたUML状態図を作成し、設計クラスに関連するすべてのユースケースを調べることで実行できます。
追加の実装の詳細を提供するために配置図を詳しく説明します。
クラスインスタンスを使用し、特定のハードウェアとオペレーティングシステム環境を指定することにより、システム内の主要なパッケージまたはコンポーネントのクラスの場所を示します。
最終的な決定は、確立された設計原則とガイドラインを使用して行うことができます。経験豊富な設計者は、最終的な設計モデルを決定する前に、すべて(またはほとんど)の代替設計ソリューションを検討します。
利点
Ease of deployment −互換性のある新しいバージョンが利用可能になると、他のコンポーネントやシステム全体に影響を与えることなく、既存のバージョンを簡単に置き換えることができます。
Reduced cost −サードパーティのコンポーネントを使用すると、開発と保守のコストを分散できます。
Ease of development −コンポーネントは、既知のインターフェースを実装して定義された機能を提供し、システムの他の部分に影響を与えることなく開発を可能にします。
Reusable −再利用可能なコンポーネントの使用は、それらを使用して、開発および保守のコストを複数のアプリケーションまたはシステムに分散できることを意味します。
Modification of technical complexity −コンポーネントは、コンポーネントコンテナとそのサービスを使用して、複雑さを変更します。
Reliability −個々のコンポーネントの信頼性が再利用によってシステム全体の信頼性を高めるため、システム全体の信頼性が向上します。
System maintenance and evolution −システムの他の部分に影響を与えることなく、実装を簡単に変更および更新できます。
Independent−コンポーネントの独立性と柔軟な接続性。並行して異なるグループによるコンポーネントの独立した開発。ソフトウェア開発と将来のソフトウェア開発の生産性。
ユーザーインターフェイスは、ユーザーの視点から見たソフトウェアシステムの第一印象です。したがって、ソフトウェアシステムはユーザーの要件を満たす必要があります。UIは主に2つの機能を実行します-
ユーザーの入力を受け入れる
出力の表示
ユーザーインターフェイスは、どのソフトウェアシステムでも重要な役割を果たします。それはおそらくソフトウェアシステムの唯一の目に見える側面です。
ユーザーは、内部アーキテクチャを考慮せずに、ソフトウェアシステムの外部ユーザーインターフェイスのアーキテクチャを最初に確認できます。
優れたユーザーインターフェイスは、間違いなくソフトウェアシステムを使用するためにユーザーを引き付ける必要があります。これは、ユーザーが誤解を招く情報なしにソフトウェアシステムを簡単に理解するのに役立つはずです。悪いUIは、ソフトウェアシステムの競争に対して市場の失敗を引き起こす可能性があります。
UIには構文とセマンティクスがあります。構文は、テキスト、アイコン、ボタンなどのコンポーネントタイプで構成され、使いやすさはUIのセマンティクスを要約します。UIの品質は、そのルックアンドフィール(構文)と使いやすさ(セマンティクス)によって特徴付けられます。
ユーザーインターフェイスには、基本的に2つの主要な種類があります-a)テキストb)グラフィック。
異なるドメインのソフトウェアは、異なるスタイルのユーザーインターフェイスを必要とする場合があります。たとえば、電卓には数値を表示するための小さな領域だけが必要ですが、コマンドには大きな領域が必要です。Webページにはフォーム、リンク、タブなどが必要です。
グラフィカル・ユーザー・インターフェース
グラフィカルユーザーインターフェイスは、現在利用可能な最も一般的なタイプのユーザーインターフェイスです。写真、グラフィック、アイコンを使用しているため、非常にユーザーフレンドリーです。そのため、「グラフィック」と呼ばれています。
としても知られています WIMP interface −を利用しているので
Windows −一般的に使用されるアプリケーションが実行される画面上の長方形の領域。
Icons −ソフトウェアアプリケーションまたはハードウェアデバイスを表すために使用される画像または記号。
Menus −ユーザーが必要なものを選択できるオプションのリスト。
Pointers−ユーザーがマウスを動かすと画面上を移動する矢印などの記号。ユーザーがオブジェクトを選択するのに役立ちます。
ユーザーインターフェースのデザイン
それは、ユーザーの主要なタスクと問題のドメインを理解するタスク分析から始まります。プログラマーではなく、ユーザーの用語とユーザーの仕事の始まりの観点から設計する必要があります。
ユーザーインターフェイス分析を実行するには、開業医は4つの要素を研究して理解する必要があります-
ザ・ users インターフェースを介してシステムと対話するのは誰か
ザ・ tasks エンドユーザーが作業を行うために実行する必要があること
ザ・ content それはインターフェースの一部として提示されます
ザ・ work environment これらのタスクが実行される場所
適切または優れたUIデザインは、マシンではなく、ユーザーの機能と制限から機能します。UIを設計する際には、ユーザーの作業と環境の性質に関する知識も重要です。
次に、実行するタスクを分割して、それぞれの機能と制限に関する知識に基づいて、ユーザーまたはマシンに割り当てることができます。ユーザーインターフェイスのデザインは、多くの場合、4つの異なるレベルに分けられます-
The conceptual level −システムに対するユーザーの見方と、それらに対して可能なアクションを考慮した基本エンティティについて説明します。
The semantic level −システムによって実行される機能、つまりシステムの機能要件の説明について説明しますが、ユーザーが機能を呼び出す方法については説明しません。
The syntactic level −説明されている関数を呼び出すために必要な入力と出力のシーケンスを説明します。
The lexical level −基本的なハードウェア操作から入力と出力が実際にどのように形成されるかを決定します。
ユーザーインターフェイスの設計は反復プロセスであり、すべての反復で前の手順で開発された情報が説明および改良されます。ユーザーインターフェイス設計の一般的な手順
ユーザーインターフェイスのオブジェクトとアクション(操作)を定義します。
ユーザーインターフェイスの状態を変更するイベント(ユーザーアクション)を定義します。
インターフェイスを介して提供される情報から、ユーザーがシステムの状態をどのように解釈するかを示します。
実際にエンドユーザーに見えるように、各インターフェイスの状態を説明します。
ユーザーまたはソフトウェアエンジニアによって作成され、年齢、性別、身体能力、教育、動機、目標、および性格に基づいてシステムのエンドユーザーのプロファイルを確立します。
ユーザーの構文的および意味的知識を考慮し、ユーザーを初心者、知識のある断続的、および知識のある頻繁なユーザーとして分類します。
ソフトウェアのデータ、アーキテクチャ、インターフェイス、および手順の表現を組み込んだソフトウェアエンジニアによって作成されます。
要件の分析モデルから派生し、システムのユーザーを定義するのに役立つ要件仕様の情報によって制御されます。
システムの構文とセマンティクスを説明するすべてのサポート情報(書籍、ビデオ、ヘルプファイル)と組み合わせて、インターフェイスのルックアンドフィールに取り組むソフトウェア実装者によって作成されます。
設計モデルの翻訳として機能し、ユーザーのメンタルモデルに同意しようとするため、ユーザーはソフトウェアに慣れて効果的に使用できます。
アプリケーションと対話するときにユーザーによって作成されます。これには、ユーザーが頭に抱えているシステムのイメージが含まれています。
多くの場合、ユーザーのシステム認識と呼ばれ、説明の正確さは、ユーザーのプロファイルとアプリケーションドメインのソフトウェアに対する全体的な知識に依存します。
- 最初にアーキテクチャの目標を特定します。
- 私たちのアーキテクチャの消費者を特定します。
- 制約を特定します。
プロジェクトの主要なマイルストーンで、およびその他の重要なアーキテクチャの変更に対応して、アーキテクチャを頻繁に確認します。
アーキテクチャレビューの主な目的は、アーキテクチャを正しく検証するベースラインアーキテクチャと候補アーキテクチャの実現可能性を判断することです。
機能要件と品質属性を提案された技術ソリューションにリンクします。また、問題を特定し、改善すべき領域を認識するのにも役立ちます
ユーザーインターフェイス開発プロセス
次の図に示すように、スパイラルプロセスに従います。

Interface analysis
これは、システムと対話するユーザー、タスク、コンテンツ、および作業環境に集中または集中します。システム機能を実現するために必要な、人間およびコンピューター指向のタスクを定義します。
Interface design
これは、ユーザーがシステムに定義されたすべてのユーザビリティ目標を満たす方法で、定義されたすべてのタスクを実行できるようにする一連のインターフェイスオブジェクト、アクション、およびそれらの画面表現を定義します。
Interface construction
使用シナリオの評価を可能にするプロトタイプから始まり、開発ツールを使用して構築を完了します。
Interface validation
これは、すべてのユーザータスクを正しく実装し、すべてのタスクバリエーションに対応し、すべての一般的なユーザー要件を達成するためのインターフェイスの機能、およびインターフェイスの使いやすさと学習のしやすさの程度に焦点を当てています。
User Interface Models
ユーザーインターフェイスを分析および設計する場合、次の4つのモデルが使用されます-
User profile model
Design model
Implementation model
User's mental model
ユーザーインターフェイスの設計上の考慮事項
ユーザー中心
ユーザーインターフェイスは、製品の開発ライフサイクル全体を通じてユーザーが関与するユーザー中心の製品である必要があります。ユーザーインターフェイスのプロトタイプは、ユーザーが利用できるようにし、ユーザーからのフィードバックを最終製品に組み込む必要があります。
シンプルで直感的
UIはシンプルさと直感性を提供するため、指示なしですばやく効果的に使用できます。GUIはメニュー、ウィンドウ、ボタンで構成され、マウスを使用するだけで操作できるため、テキストUIよりも優れています。
ユーザーを管理下に置く
ユーザーに事前定義されたシーケンスを完了するように強制しないでください。キャンセルするか、保存して中断したところに戻るかを選択できます。システムや開発者の用語ではなく、ユーザーが理解できるインターフェイス全体の用語を使用します。
アクションの結果を表示するか、アクションが正常に実行されたことを確認することにより、アクションが実行されたことをユーザーに示します。
透明性
UIは透過的である必要があります。これにより、ユーザーは、コンピューターを介して直接到達し、操作しているオブジェクトを直接操作しているように感じることができます。ユーザーにシステムオブジェクトではなく作業オブジェクトを提供することで、インターフェイスを透過的にすることができます。たとえば、ユーザーは、システムパスワードが6文字以上である必要があり、パスワードが必要なストレージのバイト数ではないことを理解する必要があります。
プログレッシブ開示を使用する
共通の機能と頻繁に使用されるアクションへの簡単なアクセスを常に提供します。あまり一般的でない機能とアクションを非表示にし、ユーザーがそれらをナビゲートできるようにします。すべての情報を1つのメインウィンドウに配置しようとしないでください。重要な情報ではない情報には、セカンダリウィンドウを使用します。
一貫性
UIは製品内および製品間で一貫性を維持し、インタラクション結果を同じに保ち、UIコマンドとメニューは同じ形式で、コマンドの句読点は類似し、パラメーターはすべてのコマンドに同じ方法で渡される必要があります。UIには、ユーザーを驚かせるような動作を持たせないでください。また、ユーザーがミスから回復できるメカニズムを含める必要があります。
統合
ソフトウェアシステムは、MSメモ帳やMS-Officeなどの他のアプリケーションとスムーズに統合する必要があります。クリップボードコマンドを直接使用して、データ交換を実行できます。
コンポーネント指向
UIの設計は、ソフトウェアシステムの本体の設計と同じ要件を持つように、モジュール式であり、コンポーネント指向のアーキテクチャを組み込む必要があります。モジュールは、システムの他の部分に影響を与えることなく、簡単に変更および交換できます。
カスタマイズ可能
ソフトウェアシステム全体のアーキテクチャにはプラグインモジュールが組み込まれているため、多くの異なる人々が独立してソフトウェアを拡張できます。個々のユーザーは、個人の好みやニーズに合わせて、さまざまな利用可能なフォームから選択できます。
ユーザーのメモリ負荷を減らす
コンピューターがユーザーのために何をすべきかをユーザーに覚えて繰り返してもらう必要はありません。たとえば、オンラインフォームに入力する場合、顧客の名前、住所、電話番号は、ユーザーが入力した後、または顧客レコードを開いた後、システムに記憶されている必要があります。
ユーザーインターフェイスは、情報を思い出すのではなく、ユーザーが認識できるアイテムをユーザーに提供することで、長期記憶の取得をサポートします。
分離
UIは、再利用性と保守性を向上させるために、実装を通じてシステムのロジックから分離する必要があります。
反復型および増分型アプローチ
これは、候補ソリューションの生成に役立つ5つの主要なステップで構成される反復型の増分アプローチです。この候補解は、これらの手順を繰り返すことでさらに洗練され、最終的にアプリケーションに最適なアーキテクチャ設計を作成できます。プロセスの最後に、アーキテクチャを確認して、すべての関係者に伝達できます。
これは、考えられるアプローチの1つにすぎません。アーキテクチャを定義、レビュー、伝達する、より正式なアプローチは他にもたくさんあります。
アーキテクチャの目標を特定する
アーキテクチャと設計プロセスを形成するアーキテクチャの目標を特定します。完璧で定義された目標は、アーキテクチャを強調し、設計の適切な問題を解決し、現在のフェーズがいつ完了し、次のフェーズに進む準備ができているかを判断するのに役立ちます。
このステップには、次のアクティビティが含まれます-
アーキテクチャアクティビティの例には、Webアプリケーションの注文処理UIに関するフィードバックを取得するためのプロトタイプの作成、顧客の注文追跡アプリケーションの作成、セキュリティレビューを実行するためのアプリケーションの認証および承認アーキテクチャの設計が含まれます。
主なシナリオ
このステップでは、最も重要な設計に重点を置きます。シナリオは、システムとのユーザーの相互作用の広範囲にわたる包括的な説明です。
重要なシナリオは、アプリケーションを成功させるための最も重要なシナリオと見なされるシナリオです。アーキテクチャに関する決定を下すのに役立ちます。目標は、ユーザー、ビジネス、およびシステムの目標の間でバランスをとることです。たとえば、ユーザー認証は、品質属性(セキュリティ)と重要な機能(ユーザーがシステムにログインする方法)の共通部分であるため、重要なシナリオです。
アプリケーションの概要
アプリケーションの概要を構築します。これにより、アーキテクチャがより使いやすくなり、実際の制約や決定に結び付けられます。以下の活動で構成されています-
アプリケーションタイプを特定する
アプリケーションの種類を、モバイルアプリケーション、リッチクライアント、リッチインターネットアプリケーション、サービス、Webアプリケーション、またはこれらの種類の組み合わせのいずれであるかを特定します。
展開の制約を特定する
適切なデプロイメントトポロジを選択し、アプリケーションとターゲットインフラストラクチャ間の競合を解決します。
重要なアーキテクチャ設計スタイルを特定する
クライアント/サーバー、階層化、メッセージバス、ドメイン駆動設計などの重要なアーキテクチャ設計スタイルを特定して、頻繁に発生する問題の解決策を提供することにより、パーティション分割を改善し、設計の再利用を促進します。多くの場合、アプリケーションはスタイルの組み合わせを使用します。
関連するテクノロジーを特定する
開発しているアプリケーションのタイプ、アプリケーション展開トポロジの推奨オプション、およびアーキテクチャスタイルを考慮して、関連するテクノロジを特定します。テクノロジーの選択は、組織のポリシー、インフラストラクチャの制限、リソーススキルなどによっても指示されます。
重要な問題または重要なホットスポット
アプリケーションを設計する際、ホットスポットは間違いが最も頻繁に発生するゾーンです。品質属性と横断的関心事に基づいて重要な問題を特定します。潜在的な問題には、新しいテクノロジーの出現や重要なビジネス要件が含まれます。
品質属性は、実行時の動作、システム設計、およびユーザーエクスペリエンスに影響を与えるアーキテクチャの全体的な機能です。横断的関心事は、すべてのレイヤー、コンポーネント、および層に適用される可能性のある設計の機能です。
これらは、影響の大きい設計ミスが最も頻繁に発生する領域でもあります。横断的関心事の例としては、認証と承認、通信、構成管理、例外管理と検証などがあります。
候補ソリューション
主要なホットスポットを定義した後、最初のベースラインアーキテクチャまたは最初の高レベルの設計を構築し、詳細の入力を開始して候補アーキテクチャを生成します。
候補アーキテクチャには、アプリケーションタイプ、展開アーキテクチャ、アーキテクチャスタイル、テクノロジの選択、品質属性、および横断的関心事が含まれます。候補アーキテクチャが改善である場合、それは新しい候補アーキテクチャを作成およびテストできるベースラインになる可能性があります。
サイクルを繰り返し実行して設計を改善する前に、すでに定義されている主要なシナリオと要件に対して候補ソリューションの設計を検証します。
アーキテクチャスパイクを使用して、設計の特定の領域を発見したり、新しい概念を検証したりする場合があります。アーキテクチャスパイクは、特定の設計パスの実現可能性を判断し、リスクを軽減し、さまざまなアプローチの実行可能性を迅速に判断する設計プロトタイプです。主要なシナリオとホットスポットに対してアーキテクチャのスパイクをテストします。
アーキテクチャレビュー
アーキテクチャのレビューは、ミスのコストを削減し、アーキテクチャの問題をできるだけ早く見つけて修正するための最も重要なタスクです。これは、プロジェクトのコストとプロジェクトの失敗の可能性を削減するための確立された費用効果の高い方法です。
シナリオベースの評価は、ビジネスの観点から最も重要で、アーキテクチャに最大の影響を与えるシナリオに焦点を当てたアーキテクチャ設計をレビューするための主要な方法です。以下は、一般的なレビュー方法です。
ソフトウェアアーキテクチャ分析方法(SAAM)
もともとは変更可能性を評価するために設計されましたが、後で品質属性に関してアーキテクチャをレビューするために拡張されました。
アーキテクチャトレードオフ分析方法(ATAM)
これはSAAMの洗練された改良版であり、品質属性要件に関するアーキテクチャ上の決定と、それらが特定の品質目標をどの程度満たしているかを確認します。
アクティブデザインレビュー(ADR)
これは、一般的なレビューを実行するのではなく、一度に一連の問題またはアーキテクチャの個々のセクションに焦点を当てる、不完全または進行中のアーキテクチャに最適です。
中間デザインのアクティブレビュー(ARID)
これは、進行中のアーキテクチャをレビューするADRの側面と、一連の問題に焦点を当てたものと、品質属性に焦点を当てたシナリオベースのレビューのATAMおよびSAAMアプローチを組み合わせたものです。
費用便益分析法(CBAM)
これは、アーキテクチャ上の決定のコスト、利点、およびスケジュールへの影響の分析に焦点を当てています。
アーキテクチャレベルの変更可能性分析(ALMA)
これは、ビジネス情報システム(BIS)のアーキテクチャの変更可能性を見積もります。
家族建築評価法(FAAM)
相互運用性と拡張性について、情報システムファミリのアーキテクチャを推定します。
アーキテクチャ設計の伝達
アーキテクチャの設計が完了したら、開発チーム、システム管理者、オペレーター、事業主、その他の関係者など、他の利害関係者に設計を伝達する必要があります。
他の人にアーキテクチャを説明するためのいくつかのよく知られた方法があります:−
4 +1モデル
このアプローチでは、アーキテクチャ全体の5つのビューを使用します。その中で、4つのビュー(logical view, インクルード process view, インクルード physical view, そしてその development view)さまざまなアプローチからアーキテクチャを説明します。5番目のビューは、ソフトウェアのシナリオと使用例を示しています。これにより、利害関係者は、特に関心のあるアーキテクチャの機能を確認できます。
アーキテクチャ記述言語(ADL)
このアプローチは、システム実装前のソフトウェアアーキテクチャを説明するために使用されます。動作、プロトコル、コネクタなどの懸念事項に対処します。
ADLの主な利点は、設計の使用を正式に開始する前に、アーキテクチャの完全性、一貫性、あいまいさ、およびパフォーマンスを分析できることです。
アジャイルモデリング
このアプローチは、「コンテンツは表現よりも重要である」という概念に従います。これにより、作成されたモデルがシンプルで理解しやすく、十分に正確で、詳細で、一貫性があることが保証されます。
アジャイルモデルドキュメントは特定の顧客を対象とし、その顧客の作業を遂行します。ドキュメントがシンプルなため、アーティファクトのモデリングに関係者が積極的に参加できます。
IEEE 1471
IEEE 1471は、正式にはANSI / IEEE1471-2000「ソフトウェア集約型システムのアーキテクチャ記述の推奨プラクティス」として知られている規格の略称です。IEEE 1471は、アーキテクチャ記述の内容を強化し、特に、コンテキスト、ビュー、および視点に特定の意味を与えます。
統一モデリング言語(UML)
このアプローチは、システムモデルの3つのビューを表しています。ザ・functional requirements view (ユースケースを含む、ユーザーの観点から見たシステムの機能要件); the static structural view(オブジェクト、属性、関係、およびクラス図を含む操作); そしてそのdynamic behavior view (オブジェクト間のコラボレーション、およびシーケンス、アクティビティ、状態図などのオブジェクトの内部状態の変更)。