ソフトウェアエンジニアリング-クイックガイド
まず、ソフトウェアエンジニアリングの意味を理解しましょう。この用語は、ソフトウェアとエンジニアリングの2つの単語で構成されています。
Software 単なるプログラムコードではありません。プログラムは実行可能コードであり、計算目的に役立ちます。ソフトウェアは、実行可能なプログラミングコード、関連するライブラリ、およびドキュメントのコレクションと見なされます。ソフトウェアは、特定の要件のために作成された場合、software product.
Engineering 一方、すべては、明確に定義された科学的原理と方法を使用して製品を開発することです。
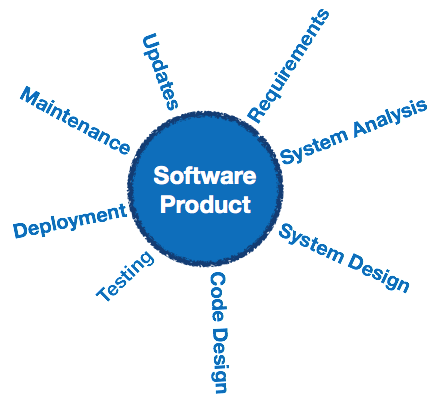
Software engineeringは、明確に定義された科学的原理、方法、および手順を使用したソフトウェア製品の開発に関連するエンジニアリング部門です。ソフトウェアエンジニアリングの成果は、効率的で信頼性の高いソフトウェア製品です。
定義
IEEEは、ソフトウェアエンジニアリングを次のように定義しています。
(1)ソフトウェアの開発、運用、および保守に対する体系的で統制のとれた定量化可能なアプローチの適用。つまり、ソフトウェアへのエンジニアリングの適用です。
(2)上記のようなアプローチの研究。
ドイツのコンピューター科学者であるフリッツバウアーは、ソフトウェアエンジニアリングを次のように定義しています。
ソフトウェアエンジニアリングは、信頼性が高く、実際のマシンで効率的に動作するソフトウェアを経済的に取得するための、健全なエンジニアリングの原則の確立と使用です。
ソフトウェアの進化
ソフトウェアエンジニアリングの原則と方法を使用してソフトウェア製品を開発するプロセスは、 software evolution. これには、ソフトウェアの初期開発とその保守および更新が含まれ、期待される要件を満たす目的のソフトウェア製品が開発されるまで続きます。

進化は、要件収集プロセスから始まります。その後、開発者は目的のソフトウェアのプロトタイプを作成し、それをユーザーに見せて、ソフトウェア製品開発の初期段階でフィードバックを得ます。ユーザーは変更を提案し、その上でいくつかの連続した更新とメンテナンスも変更され続けます。このプロセスは、目的のソフトウェアが完成するまで、元のソフトウェアに変更されます。
ユーザーが手元にあるソフトウェアを希望した後でも、技術の進歩と要件の変化により、ソフトウェア製品はそれに応じて変更されます。ソフトウェアを最初から再作成し、要件に合わせて1対1で実行することは現実的ではありません。実行可能で経済的な唯一の解決策は、既存のソフトウェアを最新の要件に一致するように更新することです。
ソフトウェア進化法
リーマンはソフトウェアの進化に関する法律を制定しました。彼はソフトウェアを3つの異なるカテゴリに分類しました。
- S-type (static-type) - これは、定義された仕様とソリューションに厳密に従って機能するソフトウェアです。解決策とそれを達成する方法は、どちらもコーディング前にすぐに理解されます。sタイプのソフトウェアは変更の影響が最も少ないため、これが最も簡単です。たとえば、数学計算のための計算機プログラム。
- P-type (practical-type) - これは、一連の手順を備えたソフトウェアです。これは、プロシージャが実行できることによって正確に定義されます。このソフトウェアでは、仕様を説明することはできますが、解決策はすぐにはわかりません。たとえば、ゲームソフトウェア。
- E-type (embedded-type) - このソフトウェアは、実際の環境の要件として密接に機能します。このソフトウェアは、現実の状況で法律や税金などにさまざまな変更が加えられているため、高度な進化を遂げています。たとえば、オンライン取引ソフトウェア。
E-Typeソフトウェアの進化
Lehmanは、E-Typeソフトウェアの進化について8つの法則を定めています-
- Continuing change - Eタイプのソフトウェアシステムは、現実世界の変化に適応し続ける必要があります。そうしないと、次第に有用性が低下します。
- Increasing complexity - Eタイプのソフトウェアシステムが進化するにつれて、それを維持または削減するための作業が行われない限り、その複雑さは増す傾向があります。
- Conservation of familiarity - システムに変更を実装するには、ソフトウェアに精通していること、またはソフトウェアがどのように開発されたか、なぜその特定の方法で開発されたのかなどの知識を保持する必要があります。
- Continuing growth- あるビジネス上の問題を解決することを目的としたE型システムのために、ビジネスのライフスタイルの変化に応じて、変更を実装するサイズが大きくなります。
- Reducing quality - Eタイプのソフトウェアシステムは、変化する運用環境に厳密に維持および適応されない限り、品質が低下します。
- Feedback systems- Eタイプのソフトウェアシステムは、マルチループ、マルチレベルのフィードバックシステムを構成し、正常に変更または改善するには、そのように扱う必要があります。
- Self-regulation - E型システムの進化プロセスは、製品の分布とプロセスの測定値が通常に近い状態で自己調整しています。
- Organizational stability - 進化するE型システムの平均実効グローバル活動率は、製品の寿命を通じて不変です。
ソフトウェアパラダイム
ソフトウェアパラダイムとは、ソフトウェアの設計時に実行される方法と手順を指します。多くの方法が提案され、現在機能していますが、ソフトウェアエンジニアリングのどこにこれらのパラダイムが存在するかを確認する必要があります。これらはさまざまなカテゴリに組み合わせることができますが、それぞれが互いに含まれています。

プログラミングパラダイムは、ソフトウェア設計パラダイムのサブセットであり、さらにソフトウェア開発パラダイムのサブセットです。
ソフトウェア開発パラダイム
このパラダイムは、ソフトウェアの開発に関連するすべてのエンジニアリングの概念が適用されるソフトウェアエンジニアリングパラダイムとして知られています。これには、ソフトウェア製品の構築に役立つさまざまな調査と要件の収集が含まれます。構成されています–
- 要件の収集
- ソフトウェア設計
- Programming
ソフトウェア設計パラダイム
このパラダイムはソフトウェア開発の一部であり、以下が含まれます–
- Design
- Maintenance
- Programming
プログラミングパラダイム
このパラダイムは、ソフトウェア開発のプログラミングの側面と密接に関連しています。これも -
- Coding
- Testing
- Integration
ソフトウェアエンジニアリングの必要性
ソフトウェアエンジニアリングの必要性は、ソフトウェアが動作しているユーザー要件と環境の変化率が高いために発生します。
- Large software - 同様に、ソフトウェアのサイズが大きくなるにつれて、エンジニアリングはそれに科学的プロセスを与えるために一歩踏み出さなければならないので、家や建物よりも壁を構築する方が簡単です。
- Scalability- ソフトウェアプロセスが科学的および工学的概念に基づいていない場合、既存のソフトウェアを拡張するよりも、新しいソフトウェアを再作成する方が簡単です。
- Cost- ハードウェア業界がそのスキルを示し、巨大な製造業がコンピューターと電子ハードウェアの価格を下げているように。しかし、適切なプロセスが採用されていない場合、ソフトウェアのコストは高いままです。
- Dynamic Nature- ソフトウェアの常に成長し適応する性質は、ユーザーが作業する環境に大きく依存します。ソフトウェアの性質が常に変化している場合は、既存のソフトウェアで新しい拡張を行う必要があります。これは、ソフトウェアエンジニアリングが良い役割を果たす場所です。
- Quality Management- ソフトウェア開発のより良いプロセスは、より良い高品質のソフトウェア製品を提供します。
良いソフトウェアの特徴
ソフトウェア製品は、それが提供するものとそれがどれだけうまく使用できるかによって判断することができます。このソフトウェアは、次の理由で満たす必要があります。
- Operational
- Transitional
- Maintenance
適切に設計および作成されたソフトウェアには、次の特性が期待されます。
運用
これは、ソフトウェアが運用においてどれだけうまく機能するかを示しています。それはで測定することができます:
- Budget
- Usability
- Efficiency
- Correctness
- Functionality
- Dependability
- Security
- Safety
過渡期
この側面は、ソフトウェアをあるプラットフォームから別のプラットフォームに移動するときに重要です。
- Portability
- Interoperability
- Reusability
- Adaptability
メンテナンス
この側面では、ソフトウェアが絶えず変化する環境でそれ自体を維持する機能をどれだけ備えているかについて簡単に説明します。
- Modularity
- Maintainability
- Flexibility
- Scalability
要するに、ソフトウェアエンジニアリングはコンピュータサイエンスの一分野であり、効率的で耐久性があり、スケーラブルで、予算内で時間通りのソフトウェア製品を作成するために必要な、明確に定義されたエンジニアリングの概念を使用しています。
ソフトウェア開発ライフサイクル(略してSDLC)は、目的のソフトウェア製品を開発するための、ソフトウェアエンジニアリングにおける明確に定義された構造化された一連の段階です。
SDLC活動
SDLCは、ソフトウェア製品を効率的に設計および開発するために従うべき一連のステップを提供します。SDLCフレームワークには、次の手順が含まれます。
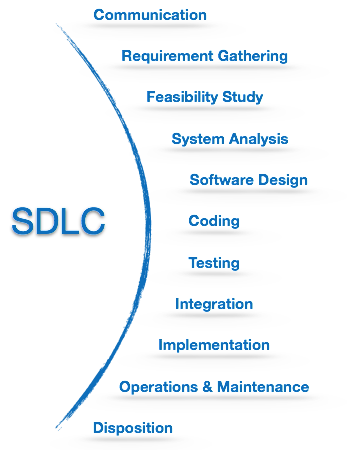
コミュニケーション
これは、ユーザーが目的のソフトウェア製品の要求を開始する最初のステップです。彼はサービスプロバイダーに連絡し、条件の交渉を試みます。彼は書面でサービス提供組織に要求を提出します。
要件の収集
このステップ以降、ソフトウェア開発チームはプロジェクトの遂行に取り組みます。チームは、問題領域のさまざまな利害関係者と話し合いを行い、彼らの要件について可能な限り多くの情報を引き出すように努めます。要件は検討され、ユーザー要件、システム要件、および機能要件に分けられます。要件は、与えられたいくつかのプラクティスを使用して収集されます-
- 既存または廃止されたシステムとソフトウェアを研究し、
- ユーザーと開発者へのインタビューの実施、
- データベースを参照するか
- アンケートから回答を集める。
フィージビリティスタディ
要件を収集した後、チームはソフトウェアプロセスの大まかな計画を立てます。このステップで、チームは、ユーザーのすべての要件を満たすようにソフトウェアを作成できるかどうか、およびソフトウェアが役に立たなくなる可能性があるかどうかを分析します。プロジェクトが組織にとって財政的、実用的、技術的に実行可能であるかどうかがわかります。開発者がソフトウェアプロジェクトの実現可能性を結論付けるのに役立つ多くのアルゴリズムが利用可能です。
システム分析
このステップで、開発者は計画のロードマップを決定し、プロジェクトに適した最適なソフトウェアモデルを提示しようとします。システム分析には、ソフトウェア製品の制限の理解、システム関連の問題や既存のシステムで行われる変更の事前学習、組織や人員に対するプロジェクトの影響の特定と対処などが含まれます。プロジェクトチームはプロジェクトの範囲を分析し、スケジュールを計画し、それに応じてリソース。
ソフトウェア設計
次のステップは、要件と分析に関する知識全体を机の上に置き、ソフトウェア製品を設計することです。ユーザーからの入力と要件収集フェーズで収集された情報は、このステップの入力です。このステップの出力は、2つの設計の形式で提供されます。論理設計と物理設計。エンジニアは、メタデータとデータディクショナリ、論理図、データフロー図、場合によっては擬似コードを作成します。
コーディング
このステップは、プログラミングフェーズとも呼ばれます。ソフトウェア設計の実装は、適切なプログラミング言語でプログラムコードを記述し、エラーのない実行可能プログラムを効率的に開発することから始まります。
テスト
見積もりによると、ソフトウェア開発プロセス全体の50%をテストする必要があります。エラーは、ソフトウェアをクリティカルレベルからそれ自体の削除まで台無しにする可能性があります。ソフトウェアテストは開発者によるコーディング中に行われ、徹底的なテストは、モジュールテスト、プログラムテスト、製品テスト、社内テスト、ユーザー側での製品のテストなど、さまざまなレベルのコードのテスト専門家によって行われます。エラーの早期発見とその解決策は、信頼できるソフトウェアの鍵です。
統合
ソフトウェアは、ライブラリ、データベース、およびその他のプログラムと統合する必要がある場合があります。SDLCのこの段階は、ソフトウェアと外界のエンティティとの統合に関係しています。
実装
これは、ユーザーのマシンにソフトウェアをインストールすることを意味します。場合によっては、ソフトウェアはユーザー側でインストール後の構成を必要とします。ソフトウェアは移植性と適応性についてテストされ、統合に関連する問題は実装中に解決されます。
運用と保守
このフェーズでは、効率の向上とエラーの減少という観点からソフトウェアの動作を確認します。必要に応じて、ユーザーは、ソフトウェアの操作方法およびソフトウェアの操作を維持する方法に関するドキュメントのトレーニングまたは支援を受けます。ソフトウェアは、ユーザーエンド環境またはテクノロジーで発生する変更に応じてコードを更新することにより、タイムリーに維持されます。このフェーズでは、隠れたバグや実際の未確認の問題による課題に直面する可能性があります。
配置
時間の経過とともに、ソフトウェアはパフォーマンスの面で低下する可能性があります。完全に廃止されるか、大幅なアップグレードが必要になる場合があります。したがって、システムの大部分を排除する差し迫った必要性が生じます。このフェーズには、データと必要なソフトウェアコンポーネントのアーカイブ、システムのシャットダウン、廃棄アクティビティの計画、およびシステムの適切な終了時間でのシステムの終了が含まれます。
ソフトウェア開発パラダイム
ソフトウェア開発パラダイムは、開発者がソフトウェアを開発するための戦略を選択するのに役立ちます。ソフトウェア開発パラダイムには、明確に表現され、ソフトウェア開発ライフサイクルを定義する独自のツール、方法、および手順のセットがあります。ソフトウェア開発パラダイムまたはプロセスモデルのいくつかは、次のように定義されています。
ウォーターフォールモデル
ウォーターフォールモデルは、ソフトウェア開発パラダイムの最も単純なモデルです。SDLCのすべてのフェーズが次々と直線的に機能すると書かれています。つまり、最初のフェーズが終了すると、2番目のフェーズのみが開始されます。

このモデルは、すべてが前の段階で計画どおりに完全に実行および実行され、次の段階で発生する可能性のある過去の問題について考える必要がないことを前提としています。前のステップで問題が残っていると、このモデルはスムーズに機能しません。モデルのシーケンシャルな性質により、アクションに戻って元に戻したり、やり直したりすることはできません。
このモデルは、開発者が過去に同様のソフトウェアをすでに設計および開発していて、そのすべてのドメインを認識している場合に最適です。
反復モデル
このモデルは、ソフトウェア開発プロセスを繰り返しリードします。SDLCプロセスのすべてのサイクルの後に、すべてのステップを繰り返す循環的な方法で開発プロセスを予測します。

ソフトウェアは最初に非常に小規模に開発され、考慮されるすべてのステップが実行されます。その後、次の反復ごとに、より多くの機能とモジュールが設計、コーディング、テストされ、ソフトウェアに追加されます。すべてのサイクルでソフトウェアが作成されます。ソフトウェアはそれ自体で完全であり、前のものよりも多くの機能を備えています。
各反復の後、管理チームはリスク管理に取り組み、次の反復の準備をすることができます。サイクルにはソフトウェアプロセス全体のごく一部が含まれるため、開発プロセスの管理は簡単ですが、より多くのリソースを消費します。
スパイラルモデル
スパイラルモデルは、反復モデルとSDLCモデルの1つを組み合わせたものです。SDLCモデルを1つ選択し、それを循環プロセス(反復モデル)と組み合わせているように見えます。

このモデルはリスクを考慮しますが、他のほとんどのモデルでは気付かれることはほとんどありません。モデルは、1回の反復の開始時にソフトウェアの目的と制約を決定することから始まります。次の段階は、ソフトウェアのプロトタイピングです。これにはリスク分析が含まれます。次に、1つの標準SDLCモデルを使用してソフトウェアを構築します。次の反復の計画の第4フェーズで準備されます。
V –モデル
ウォーターフォールモデルの主な欠点は、前のステージが終了したときにのみ次のステージに移動し、後のステージで何か問題が見つかった場合に戻る機会がなかったことです。V-Modelは、逆の方法で各段階でソフトウェアをテストする手段を提供します。

すべての段階で、テスト計画とテストケースが作成され、その段階の要件に従って製品を検証および検証します。たとえば、要件収集段階では、テストチームは要件に対応してすべてのテストケースを準備します。その後、製品が開発されてテストの準備ができたら、この段階のテストケースで、この段階の要件に対するソフトウェアの有効性を検証します。
これにより、検証と妥当性確認の両方が並行して行われます。このモデルは、検証および妥当性確認モデルとも呼ばれます。
ビッグバンモデル
このモデルは、その形式で最も単純なモデルです。それはほとんど計画、たくさんのプログラミングとたくさんの資金を必要としません。このモデルは、宇宙のビッグバンを中心に概念化されています。科学者が言うように、ビッグバンの後、たくさんの銀河、惑星、星がちょうどイベントとして進化しました。同様に、私たちがたくさんのプログラミングと資金をまとめれば、あなたは最高のソフトウェア製品を達成するかもしれません。

このモデルの場合、必要な計画はごくわずかです。それはいかなるプロセスにも従わないか、時には顧客は要件と将来のニーズについて確信が持てません。したがって、入力要件は任意です。
このモデルは大規模なソフトウェアプロジェクトには適していませんが、学習や実験には適しています。
SDLCとそのさまざまなモデルの詳細については、ここをクリックしてください。
ソフトウェア開発に従事するIT企業の仕事のパターンは2つの部分に分かれていることがわかります。
- ソフトウェアの作成
- ソフトウェアプロジェクト管理
プロジェクトは明確に定義されたタスクであり、目標を達成するために実行されるいくつかの操作のコレクションです(たとえば、ソフトウェアの開発と配信)。プロジェクトは次のように特徴付けることができます。
- すべてのプロジェクトには、独自の明確な目標があります。
- プロジェクトは日常的な活動や日常業務ではありません。
- プロジェクトには開始時間と終了時間があります。
- プロジェクトは、その目標が達成されたときに終了するため、組織の存続期間中の一時的なフェーズです。
- プロジェクトには、時間、人的資源、資金、材料、知識バンクの面で十分なリソースが必要です。
ソフトウェアプロジェクト
ソフトウェアプロジェクトは、要件の収集からテストおよび保守までのソフトウェア開発の完全な手順であり、実行方法に従って、目的のソフトウェア製品を実現するために指定された期間内に実行されます。
ソフトウェアプロジェクト管理の必要性
ソフトウェアは無形の製品と言われています。ソフトウェア開発は、世界のビジネスにおけるまったく新しい流れの一種であり、ソフトウェア製品の構築の経験はほとんどありません。ほとんどのソフトウェア製品は、クライアントの要件に合わせてカスタマイズされています。最も重要なのは、基盤となるテクノロジーが頻繁かつ急速に変化および進歩するため、一方の製品の経験がもう一方の製品に適用されない可能性があることです。このようなビジネスおよび環境の制約はすべて、ソフトウェア開発にリスクをもたらすため、ソフトウェアプロジェクトを効率的に管理することが不可欠です。

上の画像は、ソフトウェアプロジェクトの3つの制約を示しています。コストをクライアントの予算内に抑え、スケジュールどおりにプロジェクトを提供することは、ソフトウェア組織の重要な部分です。このトリプルコンストレイント三角形に影響を与える可能性のある、内部と外部の両方のいくつかの要因があります。3つの要因のいずれかが、他の2つの要因に深刻な影響を与える可能性があります。
したがって、ソフトウェアプロジェクト管理は、予算と時間の制約とともにユーザー要件を組み込むために不可欠です。
ソフトウェアプロジェクトマネージャー
ソフトウェアプロジェクトマネージャーは、ソフトウェアプロジェクトを実行する責任を負う人です。ソフトウェアプロジェクトマネージャーは、ソフトウェアが通過するSDLCのすべてのフェーズを完全に認識しています。プロジェクトマネージャーは、最終製品の生産に直接関与することは決してありませんが、生産に関連する活動を管理および管理します。
プロジェクトマネージャーは、開発プロセスを綿密に監視し、さまざまな計画を準備して実行し、必要かつ適切なリソースを手配し、コスト、予算、リソース、時間、品質、および顧客満足度の問題に対処するために、すべてのチームメンバー間のコミュニケーションを維持します。
プロジェクトマネージャーが負ういくつかの責任を見てみましょう-
管理人
- プロジェクトリーダーとして行動する
- 利害関係者との病変
- 人的資源の管理
- レポート階層の設定など。
プロジェクトの管理
- プロジェクトスコープの定義と設定
- プロジェクト管理活動の管理
- 進捗状況とパフォーマンスの監視
- すべてのフェーズでのリスク分析
- 問題を回避または解決するために必要な措置を講じる
- プロジェクトのスポークスパーソンとして行動する
ソフトウェア管理活動
ソフトウェアプロジェクト管理は、プロジェクトの計画、ソフトウェア製品の範囲の決定、さまざまな用語でのコストの見積もり、タスクとイベントのスケジューリング、およびリソース管理を含む多くのアクティビティで構成されます。プロジェクト管理活動には次のものが含まれます。
- Project Planning
- Scope Management
- Project Estimation
プロジェクト計画
ソフトウェアプロジェクトの計画は、ソフトウェアの生産が実際に開始される前に実行されるタスクです。これはソフトウェアの作成のためにありますが、ソフトウェアの作成と方向性のある具体的な活動は含まれていません。むしろ、それはソフトウェアの生産を容易にする複数のプロセスのセットです。プロジェクトの計画には、次のものが含まれる場合があります。
スコープ管理
プロジェクトの範囲を定義します。これにはすべてのアクティビティが含まれ、成果物のソフトウェア製品を作成するためにプロセスを実行する必要があります。スコープ管理は、プロジェクトで何が行われ、何が行われないかを明確に定義することによってプロジェクトの境界を作成するため、不可欠です。これにより、プロジェクトに限定された定量化可能なタスクが含まれるようになり、簡単に文書化できるため、コストと時間の超過を回避できます。
プロジェクトスコープの管理中に、次のことが必要です。
- スコープを定義する
- その検証と制御を決定する
- 管理を容易にするために、プロジェクトをさまざまな小さな部分に分割します。
- スコープを確認する
- スコープへの変更を組み込むことによってスコープを制御します
プロジェクトの見積もり
効果的な管理のためには、さまざまな対策を正確に見積もる必要があります。正しい見積もりがあれば、マネージャーはプロジェクトをより効率的かつ効果的に管理および制御できます。
プロジェクトの見積もりには、以下が含まれる場合があります。
- Software size estimation
ソフトウェアのサイズは、KLOC(Kilo Line of Code)の観点から、またはソフトウェアのファンクションポイントの数を計算することによって見積もることができます。コード行はコーディング慣行によって異なり、ファンクションポイントはユーザーまたはソフトウェア要件によって異なります。
- Effort estimation
管理者は、ソフトウェアの作成に必要な人員要件と工数の観点から作業量を見積もります。労力の見積もりについては、ソフトウェアのサイズを知っておく必要があります。これは、マネージャーの経験から導き出すことができ、組織の履歴データまたはソフトウェアのサイズを、いくつかの標準的な公式を使用して取り組みに変換することができます。
- Time estimation
サイズと労力を見積もると、ソフトウェアの作成に必要な時間を見積もることができます。必要な作業は、要件仕様およびソフトウェアのさまざまなコンポーネントの相互依存性に従って、サブカテゴリに分類されます。ソフトウェアタスクは、ワークブレークスルーストラクチャ(WBS)によって、より小さなタスク、アクティビティ、またはイベントに分割されます。タスクは、毎日または暦月にスケジュールされます。
すべてのタスクを数時間または数日で完了するために必要な時間の合計は、プロジェクトを完了するために費やされた合計時間です。
- Cost estimation
これは、以前のどの要素よりも多くの要素に依存しているため、すべての中で最も難しいと見なされる可能性があります。プロジェクトの費用を見積もるには、以下を考慮する必要があります。
- ソフトウェアのサイズ
- ソフトウェアの品質
- Hardware
- 追加のソフトウェアまたはツール、ライセンスなど。
- タスク固有のスキルを持つ熟練した担当者
- 関係する旅行
- Communication
- トレーニングとサポート
プロジェクト推定手法
サイズ、労力、時間、コストなど、プロジェクトの見積もりに関連するさまざまなパラメータについて話し合いました。
プロジェクトマネージャーは、広く認識されている2つの手法を使用して、リストされた要因を見積もることができます。
分解技術
この手法は、ソフトウェアをさまざまな構成の製品として想定しています。
2つの主要なモデルがあります-
- Line of Code 見積もりは、ソフトウェア製品のコード行数に代わって行われます。
- Function Points 見積もりは、ソフトウェア製品のファンクションポイントの数に代わって行われます。
経験的推定手法
この手法では、経験的に導き出された式を使用して推定を行います。これらの式は、LOCまたはFPに基づいています。
- Putnam Model
このモデルは、Nordenの度数分布(レイリー曲線)に基づいたLawrence H.Putnamによって作成されています。パトナムモデルは、ソフトウェアのサイズに必要な時間と労力をマッピングします。
- COCOMO
COCOMOは、Barry W.Boehmによって開発されたCOnstructiveCOstMOdelの略です。ソフトウェア製品は、オーガニック、セミデタッチド、組み込みの3つのソフトウェアカテゴリに分類されます。
プロジェクトのスケジューリング
プロジェクトのプロジェクトスケジューリングとは、指定された順序で、各アクティビティに割り当てられた時間枠内で実行されるすべてのアクティビティのロードマップを指します。プロジェクトマネージャーは、さまざまなタスクを定義し、マイルストーンをプロジェクトして、さまざまな要素を念頭に置いてそれらを調整する傾向があります。彼らは、スケジュールのクリティカルパスにあるタスクを探します。これは、特定の方法で(タスクの相互依存性のために)、厳密に割り当てられた時間内に完了する必要があります。クリティカルパスから外れたタスクの配置は、プロジェクトのすべてのスケジュールに影響を与える可能性が低くなります。
プロジェクトをスケジュールするには、次のことが必要です。
- プロジェクトタスクをより小さく、管理しやすい形式に分割します
- さまざまなタスクを見つけて、それらを相互に関連付けます
- 各タスクに必要な時間枠を見積もる
- 時間をワークユニットに分割する
- 各タスクに適切な数のワークユニットを割り当てます
- プロジェクトの開始から終了までに必要な合計時間を計算します
資源管理
ソフトウェア製品の開発に使用されるすべての要素は、そのプロジェクトのリソースと見なすことができます。これには、人的資源、生産的なツール、およびソフトウェアライブラリが含まれる場合があります。
リソースは限られた量で利用可能であり、資産のプールとして組織内にとどまります。リソースの不足はプロジェクトの開発を妨げ、スケジュールより遅れる可能性があります。追加のリソースを割り当てると、最終的に開発コストが増加します。したがって、プロジェクトに適切なリソースを見積もり、割り当てる必要があります。
リソース管理には以下が含まれます-
- プロジェクトチームを作成し、各チームメンバーに責任を割り当てることにより、適切な組織プロジェクトを定義します
- 特定の段階で必要なリソースとその可用性の決定
- リソースが必要になったときにリソース要求を生成し、不要になったときに割り当てを解除することで、リソースを管理します。
プロジェクトリスク管理
リスク管理には、プロジェクトにおける予測可能なリスクと予測不可能なリスクの特定、分析、および準備に関連するすべての活動が含まれます。リスクには以下が含まれる場合があります。
- 経験豊富なスタッフがプロジェクトを去り、新しいスタッフが入ってきます。
- 組織管理の変更。
- 要件の変更または要件の誤解。
- 必要な時間とリソースの過小評価。
- 技術の変化、環境の変化、ビジネス競争。
リスク管理プロセス
リスク管理プロセスには、次のアクティビティが含まれます。
- Identification - プロジェクトで発生する可能性のあるすべてのリスクをメモします。
- Categorize - プロジェクトへの影響の可能性に応じて、既知のリスクを高、中、低のリスク強度に分類します。
- Manage - さまざまな段階でリスクが発生する確率を分析します。リスクを回避または直面する計画を立てます。それらの副作用を最小限に抑えるようにしてください。
- Monitor - 潜在的なリスクとその初期症状を注意深く監視します。また、それらを軽減または回避するために実行された手順の影響を監視します。
プロジェクトの実行と監視
このフェーズでは、プロジェクト計画に記載されているタスクがスケジュールに従って実行されます。
すべてが計画どおりに進んでいるかどうかを確認するために、実行を監視する必要があります。モニタリングとは、リスクの可能性を確認し、リスクに対処したり、さまざまなタスクのステータスを報告したりするための対策を講じることです。
これらの対策には以下が含まれます-
- Activity Monitoring - 一部のタスク内でスケジュールされたすべてのアクティビティは、日常的に監視できます。タスク内のすべてのアクティビティが完了すると、完了したと見なされます。
- Status Reports - レポートには、特定の時間枠(通常は1週間)内に完了したアクティビティとタスクのステータスが含まれます。ステータスは、完了、保留中、または進行中などとしてマークできます。
- Milestones Checklist - すべてのプロジェクトは複数のフェーズに分割され、SDLCのフェーズに基づいて主要なタスクが実行されます(マイルストーン)。このマイルストーンチェックリストは、数週間に1回作成され、マイルストーンのステータスを報告します。
プロジェクトコミュニケーション管理
効果的なコミュニケーションは、プロジェクトの成功に不可欠な役割を果たします。これは、クライアントと組織の間、チームメンバー間、およびハードウェアサプライヤなどのプロジェクトの他の利害関係者の間のギャップを埋めます。
コミュニケーションは口頭または書面で行うことができます。通信管理プロセスには、次の手順があります。
- Planning -このステップには、プロジェクトのすべての利害関係者の識別と、それらの間のコミュニケーションのモードが含まれます。また、追加の通信機能が必要かどうかも検討します。
- Sharing -計画のさまざまな側面を決定した後、マネージャーは正しい情報を正しい人と正しい時間に共有することに焦点を合わせます。これにより、プロジェクトに関係するすべての人がプロジェクトの進捗状況とそのステータスを最新の状態に保つことができます。
- Feedback -プロジェクトマネージャーは、さまざまな測定値とフィードバックメカニズムを使用して、ステータスとパフォーマンスのレポートを作成します。このメカニズムにより、さまざまな利害関係者からの入力がフィードバックとしてプロジェクトマネージャーに確実に届きます。
- Closure -各主要イベントの終了時、SDLCのフェーズの終了時、またはプロジェクト自体の終了時に、電子メールの送信、ドキュメントのハードコピーの配布、またはその他の効果的なコミュニケーション手段によってすべての利害関係者を更新するための管理上の閉鎖が正式に発表されます。
閉鎖後、チームは次のフェーズまたはプロジェクトに進みます。
構成管理
構成管理は、製品の要件、設計、機能、および開発の観点から、ソフトウェアの変更を追跡および制御するプロセスです。
IEEEは、これを「システム内のアイテムを識別および定義し、ライフサイクル全体でこれらのアイテムの変更を制御し、アイテムのステータスと変更要求を記録および報告し、アイテムの完全性と正確性を検証するプロセス」と定義しています。
一般に、SRSが完成すると、ユーザーからの変更が必要になる可能性は低くなります。それらが発生した場合、コストと時間の超過の可能性があるため、変更は上級管理職の事前の承認がある場合にのみ対処されます。
ベースライン
SDLCのフェーズは、ベースライン化されている場合に想定されます。つまり、ベースラインはフェーズの完全性を定義する測定値です。フェーズは、それに関連するすべてのアクティビティが終了し、十分に文書化されたときにベースライン化されます。それが最終段階ではなかった場合、その出力は次の即時段階で使用されます。
構成管理は組織管理の分野であり、フェーズのベースライン化後に変更(プロセス、要件、技術、戦略など)の発生を処理します。CMは、ソフトウェアで行われた変更を常にチェックします。
変更管理
変更管理は構成管理の機能であり、ソフトウェアシステムに加えられたすべての変更に一貫性があり、組織の規則や規制に従って行われることを保証します。
製品の構成の変更は、次の手順で実行されます-
Identification-変更要求は、内部ソースまたは外部ソースから到着します。変更要求が正式に特定されると、適切に文書化されます。
Validation -変更要求の有効性がチェックされ、その処理手順が確認されます。
Analysis-変更要求の影響は、スケジュール、コスト、および必要な労力の観点から分析されます。システムに対する予想される変更の全体的な影響が分析されます。
Control-予想される変更がシステム内の非常に多くのエンティティに影響を与えるか、それが避けられない場合は、変更をシステムに組み込む前に、高官の承認を得る必要があります。変更を組み込む価値があるかどうかが決定されます。そうでない場合、変更要求は正式に拒否されます。
Execution -前のフェーズで変更要求を実行することを決定した場合、このフェーズは変更を実行するために適切なアクションを実行し、必要に応じて徹底的な改訂を行います。
Close request-変更は、正しく実装され、システムの他の部分とマージされているかどうかが検証されます。この新しく組み込まれたソフトウェアの変更は適切に文書化され、リクエストは正式にクローズされます。
プロジェクト管理ツール
プロジェクトが設定された方法論に従って開発された場合でも、リスクと不確実性はプロジェクトのサイズに関して何倍にも上昇します。
効果的なプロジェクト管理を支援するツールが利用可能です。いくつか説明されています-
ガントチャート
ガントチャートは、ヘンリーガント(1917)によって考案されました。これは、期間に関するプロジェクトのスケジュールを表します。これは、プロジェクト活動にスケジュールされた活動と時間を表す棒を備えた水平棒グラフです。

PERTチャート
PERT(Program Evaluation&Review Technique)チャートは、プロジェクトをネットワーク図として表すツールです。プロジェクトの主要なイベントを並行して連続してグラフィカルに表現することができます。次々に発生するイベントは、前のイベントに対する後のイベントの依存関係を示しています。

イベントは番号付きノードとして表示されます。これらは、プロジェクト内の一連のタスクを表すラベル付きの矢印で接続されています。
リソースヒストグラム
これは、プロジェクトイベント(またはフェーズ)に時間の経過とともに必要なリソース(通常は熟練したスタッフ)の数を表す棒グラフまたはグラフを含むグラフィカルツールです。リソースヒストグラムは、スタッフの計画と調整に効果的なツールです。


クリティカルパス分析
このツールは、プロジェクト内の相互に依存するタスクを認識するのに役立ちます。また、プロジェクトを正常に完了するための最短パスまたはクリティカルパスを見つけるのにも役立ちます。PERT図と同様に、各イベントには特定の時間枠が割り当てられます。このツールは、前のイベントが完了した場合にのみイベントが次のイベントに進むことができると想定して、イベントの依存関係を示します。
イベントは、可能な限り早い開始時間に従って配置されます。開始ノードと終了ノードの間のパスはクリティカルパスであり、これ以上減らすことはできず、すべてのイベントを同じ順序で実行する必要があります。
ソフトウェア要件は、ターゲットシステムの特徴と機能の説明です。要件は、ソフトウェア製品に対するユーザーの期待を伝えます。要件は、クライアントの観点から、明白または非表示、既知または未知、予期または予期しないものにすることができます。
要件エンジニアリング
クライアントからソフトウェア要件を収集し、それらを分析して文書化するプロセスは、要件エンジニアリングとして知られています。
要件エンジニアリングの目標は、洗練された説明的な「システム要件仕様」ドキュメントを開発および維持することです。
要件エンジニアリングプロセス
これは4つのステップのプロセスであり、以下が含まれます–
- フィージビリティスタディ
- 要件の収集
- ソフトウェア要件仕様
- ソフトウェア要件の検証
プロセスを簡単に見てみましょう-
フィージビリティスタディ
クライアントが目的の製品を開発するために組織に近づくと、ソフトウェアが実行する必要のあるすべての機能と、ソフトウェアに期待されるすべての機能について大まかなアイデアが浮かび上がります。
アナリストは、この情報を参照して、目的のシステムとその機能を開発できるかどうかについて詳細な調査を行います。
この実現可能性調査は、組織の目標に焦点を合わせています。この調査では、ソフトウェア製品が、実装、組織へのプロジェクトの貢献、コストの制約、および組織の価値と目的の観点から実際に実現できるかどうかを分析します。使いやすさ、保守性、生産性、統合能力など、プロジェクトと製品の技術的側面を探ります。
このフェーズの出力は、プロジェクトを実施する必要があるかどうかについての管理者向けの適切なコメントと推奨事項を含む実現可能性調査レポートである必要があります。
要件の収集
実現可能性レポートがプロジェクトの実施に前向きである場合、次のフェーズはユーザーから要件を収集することから始まります。アナリストとエンジニアは、クライアントとエンドユーザーと通信して、ソフトウェアが提供するものと、ソフトウェアに含める機能についてのアイデアを知ります。
ソフトウェア要件仕様
SRSは、さまざまな利害関係者から要件が収集された後にシステムアナリストによって作成されたドキュメントです。
SRSは、目的のソフトウェアがハードウェア、外部インターフェイス、動作速度、システムの応答時間、さまざまなプラットフォーム間でのソフトウェアの移植性、保守性、クラッシュ後の回復速度、セキュリティ、品質、制限などとどのように相互作用するかを定義します。
クライアントから受け取った要件は自然言語で書かれています。ソフトウェア開発チームが要件を理解して役立つように、要件を技術用語で文書化するのはシステムアナリストの責任です。
SRSは次の機能を考え出す必要があります。
- ユーザー要件は自然言語で表現されています。
- 技術要件は、組織内で使用される構造化された言語で表現されます。
- デザインの説明は、擬似コードで記述する必要があります。
- フォームとGUIスクリーン印刷のフォーマット。
- DFDなどの条件付きおよび数学表記。
ソフトウェア要件の検証
要件仕様が作成された後、このドキュメントに記載されている要件が検証されます。ユーザーが違法で非現実的な解決策を求めたり、専門家が要件を誤って解釈したりする可能性があります。これは、つぼみに挟まれない場合、コストの大幅な増加につながります。要件は、次の条件に対してチェックできます-
- それらが実際に実行できるかどうか
- それらが有効であり、ソフトウェアの機能およびドメインに従っているかどうか
- あいまいさがあれば
- それらが完了している場合
- それらが実証できれば
要件の引き出しプロセス
要件の引き出しプロセスは、次の図を使用して表すことができます。

- Requirements gathering - 開発者はクライアントおよびエンドユーザーと話し合い、ソフトウェアに対する彼らの期待を知っています。
- Organizing Requirements - 開発者は、重要性、緊急性、利便性の順に要件に優先順位を付けて配置します。
Negotiation & discussion - 要件があいまいな場合、またはさまざまな利害関係者の要件に矛盾がある場合は、それが交渉され、利害関係者と話し合われます。その後、要件に優先順位が付けられ、合理的に妥協される可能性があります。
要件はさまざまな利害関係者から来ています。あいまいさと矛盾を取り除くために、それらは明確さと正確さのために議論されます。非現実的な要件は合理的に妥協されます。
- Documentation - すべての公式および非公式、機能要件および非機能要件が文書化され、次のフェーズの処理に利用できるようになります。
要件の引き出し手法
要件の引き出しは、クライアント、エンドユーザー、システムユーザー、およびソフトウェアシステム開発に関与するその他のユーザーと通信することにより、目的のソフトウェアシステムの要件を見つけるプロセスです。
要件を見つけるにはさまざまな方法があります
インタビュー
面接は、要件を収集するための強力な媒体です。組織は、次のようないくつかのタイプの面接を実施する場合があります。
- 収集するすべての情報が事前に決定される構造化された(クローズド)インタビューでは、パターンと議論の問題にしっかりと従います。
- 収集する情報が事前に決定されていない、構造化されていない(オープンな)インタビュー。柔軟性が高く、偏りが少ない。
- 口頭インタビュー
- 書面によるインタビュー
- テーブルを横切って2人の間で行われる1対1のインタビュー。
- 参加者のグループ間で行われるグループインタビュー。多くの人々が関与しているため、不足している要件を明らかにするのに役立ちます。
調査
組織は、今後のシステムからの期待と要件について質問することにより、さまざまな利害関係者の間で調査を実施する場合があります。
アンケート
客観的な質問とそれぞれのオプションが事前に定義されたドキュメントは、すべての利害関係者に渡されて回答され、収集および編集されます。
この手法の欠点は、ある問題のオプションが質問票に記載されていない場合、その問題が放置される可能性があることです。
タスク分析
エンジニアと開発者のチームは、新しいシステムが必要な操作を分析できます。クライアントが特定の操作を実行するためのソフトウェアをすでに持っている場合、それは調査され、提案されたシステムの要件が収集されます。
ドメイン分析
すべてのソフトウェアは、いくつかのドメインカテゴリに分類されます。ドメインの専門家は、一般的および特定の要件を分析するのに非常に役立ちます。
ブレーンストーミング
さまざまな利害関係者の間で非公式の討論が行われ、さらなる要件分析のためにすべての入力が記録されます。
プロトタイピング
プロトタイピングとは、ユーザーが目的のソフトウェア製品の機能を解釈するための詳細な機能を追加せずに、ユーザーインターフェイスを構築することです。要件をよりよく理解するのに役立ちます。開発者が参照できるようにクライアント側にソフトウェアがインストールされておらず、クライアントが自身の要件を認識していない場合、開発者は最初に述べた要件に基づいてプロトタイプを作成します。プロトタイプがクライアントに表示され、フィードバックが記録されます。クライアントのフィードバックは、要件収集の入力として機能します。
観察
専門家のチームがクライアントの組織または職場を訪問します。彼らは、既存のインストール済みシステムの実際の動作を観察します。彼らは、クライアント側のワークフローと、実行の問題がどのように処理されるかを観察します。チーム自体が、ソフトウェアから期待される要件を形成するのに役立ついくつかの結論を導き出します。
ソフトウェア要件の特徴
ソフトウェア要件の収集は、ソフトウェア開発プロジェクト全体の基盤です。したがって、それらは明確で、正確で、明確に定義されている必要があります。
完全なソフトウェア要件仕様は次のとおりである必要があります。
- Clear
- Correct
- Consistent
- Coherent
- Comprehensible
- Modifiable
- Verifiable
- Prioritized
- Unambiguous
- Traceable
- 信頼できる情報源
ソフトウェア要件
要件の引き出し段階でどのような要件が発生する可能性があるのか、ソフトウェアシステムからどのような要件が予想されるのかを理解する必要があります。
大まかに言って、ソフトウェア要件は2つのカテゴリに分類する必要があります。
機能要件
ソフトウェアの機能面に関連する要件は、このカテゴリに分類されます。
これらは、ソフトウェアシステム内およびソフトウェアシステムからの機能を定義します。
例-
- さまざまな請求書から検索するためにユーザーに与えられる検索オプション。
- ユーザーは、レポートを管理者にメールで送信できる必要があります。
- ユーザーはグループに分割でき、グループには個別の権限を付与できます。
- ビジネスルールと管理機能に準拠する必要があります。
- ソフトウェアは、下位互換性を損なわずに開発されています。
非機能要件
ソフトウェアの機能面に関係のない要件は、このカテゴリに分類されます。これらは、ユーザーが想定しているソフトウェアの暗黙的または予想される特性です。
非機能要件には以下が含まれます-
- Security
- Logging
- Storage
- Configuration
- Performance
- Cost
- Interoperability
- Flexibility
- 災害からの回復
- Accessibility
要件は論理的に次のように分類されます
- Must Have :ソフトウェアは、それらなしでは動作可能とは言えません。
- Should have :ソフトウェアの機能を強化します。
- Could have :ソフトウェアは、これらの要件で引き続き適切に機能します。
- Wish list :これらの要件は、ソフトウェアの目的に対応していません。
ソフトウェアの開発中は、「必要」を実装する必要があります。「必要」は利害関係者との議論と否定の問題ですが、「必要」と「ウィッシュリスト」はソフトウェアの更新のために保持できます。
ユーザーインターフェイスの要件
UIは、ソフトウェア、ハードウェア、またはハイブリッドシステムの重要な部分です。もしそうなら、ソフトウェアは広く受け入れられています-
- 操作が簡単
- 迅速な対応
- 運用エラーを効果的に処理する
- シンプルでありながら一貫性のあるユーザーインターフェイスを提供
ユーザーの受け入れは、ユーザーがソフトウェアをどのように使用できるかに大きく依存します。UIは、ユーザーがシステムを認識する唯一の方法です。パフォーマンスの高いソフトウェアシステムには、魅力的で、明確で、一貫性があり、応答性の高いユーザーインターフェイスも装備されている必要があります。そうしないと、ソフトウェアシステムの機能を便利に使用できません。システムが効率的に使用する手段を提供する場合、そのシステムは優れていると言われます。ユーザーインターフェイスの要件を以下に簡単に説明します-
- コンテンツのプレゼンテーション
- 簡単なナビゲーション
- シンプルなインターフェース
- Responsive
- 一貫性のあるUI要素
- フィードバックメカニズム
- デフォルトの設定
- 意図的なレイアウト
- 色と質感の戦略的使用。
- ヘルプ情報を提供する
- ユーザー中心のアプローチ
- グループベースのビュー設定。
ソフトウェアシステムアナリスト
IT組織のシステムアナリストは、提案されたシステムの要件を分析し、要件が適切かつ正しく文書化されていることを確認する人です。アナリストの役割は、SDLCのソフトウェア分析フェーズで始まります。開発されたソフトウェアがクライアントの要件を満たしていることを確認するのはアナリストの責任です。
システムアナリストには、次の責任があります。
- 目的のソフトウェアの要件を分析して理解する
- プロジェクトが組織の目標にどのように貢献するかを理解する
- 要件のソースを特定する
- 要件の検証
- 要件管理計画を作成して実装する
- ビジネス、技術、プロセス、および製品の要件の文書化
- 要件に優先順位を付け、あいまいさを排除するためのクライアントとの調整
- クライアントおよびその他の利害関係者との受け入れ基準の最終決定
ソフトウェアメトリクスと測定
ソフトウェアメジャーは、ソフトウェアのさまざまな属性と側面を定量化およびシンボル化するプロセスとして理解できます。
ソフトウェアメトリクスは、ソフトウェアプロセスとソフトウェア製品のさまざまな側面の測定値を提供します。
ソフトウェア対策は、ソフトウェアエンジニアリングの基本的な要件です。これらは、ソフトウェア開発プロセスの制御を支援するだけでなく、究極の製品の品質を優れたものに保つのにも役立ちます。
(ソフトウェアエンジニア)のTom DeMarcoによると、「測定できないものを制御することはできません」。彼の言うことにより、ソフトウェア対策がいかに重要であるかは非常に明白です。
いくつかのソフトウェアメトリクスを見てみましょう。
Size Metrics - LOC(Lines of Code)は、ほとんどがKLOCと呼ばれる、配信された何千ものソースコード行で計算されます。
ファンクションポイントカウントは、ソフトウェアによって提供される機能の尺度です。ファンクションポイントカウントは、ソフトウェアの機能面のサイズを定義します。
- Complexity Metrics - マッケイブの循環的複雑度は、プログラムまたはそのモジュールの複雑さとして認識される、プログラム内の独立したパスの数の上限を定量化します。これは、制御フローグラフを使用してグラフ理論の概念で表されます。
Quality Metrics - 欠陥、その種類と原因、結果、重大度の強さ、およびそれらの影響によって、製品の品質が決まります。
開発プロセスで見つかった欠陥の数と、製品がクライアント側でインストールまたは配信された後にクライアントから報告された欠陥の数によって、製品の品質が決まります。
- Process Metrics - SDLCのさまざまなフェーズで、使用される方法とツール、会社の標準、および開発のパフォーマンスは、ソフトウェアプロセスのメトリックです。
- Resource Metrics - 労力、時間、および使用されるさまざまなリソースは、リソース測定のメトリックを表します。
ソフトウェア設計は、ユーザーの要件を適切な形式に変換するプロセスであり、プログラマーがソフトウェアのコーディングと実装を行うのに役立ちます。
ユーザー要件を評価するために、SRS(ソフトウェア要件仕様)ドキュメントが作成されますが、コーディングと実装のために、ソフトウェア用語でより具体的で詳細な要件が必要です。このプロセスの出力は、プログラミング言語での実装に直接使用できます。
ソフトウェア設計はSDLC(ソフトウェア設計ライフサイクル)の最初のステップであり、問題領域からソリューション領域に集中力を移します。SRSに記載されている要件を満たす方法を指定しようとします。
ソフトウェア設計レベル
ソフトウェア設計は、次の3つのレベルの結果をもたらします。
- Architectural Design - 建築設計は、システムの最高の抽象バージョンです。これは、ソフトウェアを、多くのコンポーネントが相互作用するシステムとして識別します。このレベルで、設計者は提案されたソリューションドメインのアイデアを得ることができます。
- High-level Design- 高レベルの設計は、アーキテクチャ設計の「単一エンティティ-複数コンポーネント」の概念を、サブシステムとモジュールのより抽象化されていないビューに分割し、それらの相互作用を示します。高レベルの設計は、システムとそのすべてのコンポーネントをモジュールの形式で実装する方法に焦点を当てています。各サブシステムのモジュール構造と、それらの相互関係および相互作用を認識します。
- Detailed Design- 詳細設計では、前の2つの設計でシステムとそのサブシステムと見なされていたものの実装部分を扱います。モジュールとその実装について詳しく説明します。各モジュールの論理構造と、他のモジュールと通信するためのインターフェースを定義します。
モジュール化
モジュール化は、ソフトウェアシステムを複数の個別の独立したモジュールに分割する手法であり、タスクを独立して実行できることが期待されます。これらのモジュールは、ソフトウェア全体の基本的な構成として機能する場合があります。設計者は、モジュールを個別に独立して実行および/またはコンパイルできるようにモジュールを設計する傾向があります。
モジュラー設計は、ソフトウェアのモジュラー設計に付随する他の多くの利点があるため、意図せずに「分割統治」問題解決戦略のルールに従います。
モジュール化の利点:
- コンポーネントが小さいほどメンテナンスが簡単です
- プログラムは機能面に基づいて分割できます
- 必要なレベルの抽象化をプログラムに取り入れることができます
- 凝集度の高い部品は再利用可能
- 同時実行が可能になります
- セキュリティ面からの要望
並行性
昔は、すべてのソフトウェアは順番に実行されるようになっています。順次実行とは、コード化された命令が次々に実行されることを意味し、プログラムの一部のみが常にアクティブ化されることを意味します。たとえば、ソフトウェアに複数のモジュールがある場合、実行時にアクティブであることがわかるのは、すべてのモジュールのうちの1つだけです。
ソフトウェア設計では、並行性は、ソフトウェアをモジュールのように複数の独立した実行単位に分割し、それらを並行して実行することによって実装されます。言い換えると、並行性は、コードの複数の部分を互いに並行して実行する機能をソフトウェアに提供します。
プログラマーと設計者は、並列実行できるモジュールを認識する必要があります。
例
ワードプロセッサのスペルチェック機能は、ワードプロセッサ自体と並行して実行されるソフトウェアのモジュールです。
結合と凝集度
ソフトウェアプログラムがモジュール化されると、そのタスクはいくつかの特性に基づいていくつかのモジュールに分割されます。ご存知のように、モジュールはいくつかのタスクを実行するためにまとめられた一連の命令です。ただし、これらは単一のエンティティと見なされますが、相互に参照して連携する場合があります。モジュールの設計の品質とモジュール間の相互作用を測定できる手段があります。これらの測定は、結合と凝集と呼ばれます。
凝集
凝集度は、モジュールの要素内の内部依存性の程度を定義する尺度です。凝集力が大きいほど、プログラムの設計は優れています。
結束には7つのタイプがあります。
- Co-incidental cohesion -これは計画外のランダムな結束であり、モジュール化のためにプログラムをより小さなモジュールに分割した結果である可能性があります。計画外であるため、プログラマーに混乱をもたらす可能性があり、一般的に受け入れられていません。
- Logical cohesion - 論理的に分類された要素がモジュールにまとめられるとき、それは論理的凝集度と呼ばれます。
- emporal Cohesion - モジュールの要素が同じ時点で処理されるように編成されている場合、それは時間的凝集度と呼ばれます。
- Procedural cohesion - モジュールの要素がグループ化され、タスクを実行するために順番に実行される場合、それは手続き型凝集度と呼ばれます。
- Communicational cohesion - モジュールの要素がグループ化され、順番に実行されて同じデータ(情報)を処理する場合、それは通信の凝集度と呼ばれます。
- Sequential cohesion - ある要素の出力が別の要素への入力として機能するなどの理由でモジュールの要素がグループ化される場合、それは順次凝集度と呼ばれます。
- Functional cohesion - 最高の凝集度とされており、大いに期待されています。機能的凝集度のモジュールの要素は、すべてが単一の明確に定義された機能に寄与するため、グループ化されます。再利用することもできます。
カップリング
結合は、プログラムのモジュール間の相互依存性のレベルを定義する尺度です。モジュールがどのレベルで干渉し、相互作用するかを示します。カップリングが低いほど、プログラムは優れています。
結合には5つのレベルがあります。
- Content coupling - モジュールが別のモジュールのコンテンツに直接アクセス、変更、または参照できる場合、それはコンテンツレベル結合と呼ばれます。
- Common coupling- 複数のモジュールがいくつかのグローバルデータへの読み取りおよび書き込みアクセス権を持っている場合、それは共通またはグローバル結合と呼ばれます。
- Control coupling- 2つのモジュールは、一方が他方のモジュールの機能を決定したり、その実行フローを変更したりする場合、制御結合と呼ばれます。
- Stamp coupling- 複数のモジュールが共通のデータ構造を共有し、その異なる部分で機能する場合、それはスタンプ結合と呼ばれます。
- Data coupling- データ結合とは、2つのモジュールが(パラメーターとして)データを渡すことによって相互作用する場合です。モジュールがデータ構造をパラメーターとして渡す場合、受信モジュールはそのすべてのコンポーネントを使用する必要があります。
理想的には、どのカップリングも最良とは見なされません。
設計検証
ソフトウェア設計プロセスの出力は、設計ドキュメント、擬似コード、詳細な論理図、プロセス図、およびすべての機能要件または非機能要件の詳細な説明です。
ソフトウェアの実装である次のフェーズは、上記のすべての出力に依存します。
次に、次のフェーズに進む前に、出力を確認する必要があります。ミスが早期に検出されるほど、それは優れているか、製品のテストまで検出されない可能性があります。設計フェーズの出力が正式な表記形式である場合は、検証に関連するツールを使用する必要があります。そうでない場合は、検証と妥当性確認に徹底的な設計レビューを使用できます。
構造化された検証アプローチにより、レビュー担当者は、いくつかの条件を見落とすことによって引き起こされる可能性のある欠陥を検出できます。優れた設計レビューは、優れたソフトウェア設計、精度、および品質にとって重要です。
ソフトウェアの分析と設計には、要件仕様を実装に変換するのに役立つすべてのアクティビティが含まれます。要件仕様は、ソフトウェアからのすべての機能的および非機能的期待を指定します。これらの要件仕様は、人間が読める形式で理解できるドキュメントの形をしており、コンピューターはそれとは何の関係もありません。
ソフトウェアの分析と設計は中間段階であり、人間が読める形式の要件を実際のコードに変換するのに役立ちます。
ソフトウェア設計者が使用する分析および設計ツールをいくつか見てみましょう。
データフロー図
データフロー図は、情報システム内のデータの流れをグラフで表したものです。着信データフロー、発信データフロー、および保存されたデータを表すことができます。DFDは、データがシステムをどのように流れるかについては何も言及していません。
DFDとフローチャートの間には顕著な違いがあります。フローチャートは、プログラムモジュールの制御フローを示しています。DFDは、さまざまなレベルでシステム内のデータの流れを表します。DFDには、制御要素または分岐要素は含まれていません。
DFDの種類
データフロー図は論理的または物理的です。
- Logical DFD -このタイプのDFDは、システムプロセス、およびシステム内のデータのフローに重点を置いています。たとえば、銀行のソフトウェアシステムでは、異なるエンティティ間でデータを移動する方法です。
- Physical DFD-このタイプのDFDは、データフローが実際にシステムにどのように実装されているかを示します。より具体的で、実装に近いものです。
DFDコンポーネント
DFDは、次のコンポーネントセットを使用して、データのソース、宛先、ストレージ、およびフローを表すことができます-

- Entities-エンティティは、情報データのソースと宛先です。エンティティは、それぞれの名前が付いた長方形で表されます。
- Process -データに対して実行されたアクティビティとアクションは、円または角の丸い長方形で表されます。
- Data Storage -データストレージには2つのバリエーションがあります-両方の小さい辺がない長方形として表すことも、片側だけが欠けている開いた辺の長方形として表すこともできます。
- Data Flow-データの移動は、先のとがった矢印で示されています。データの移動は、ソースとしての矢印の基部から宛先としての矢印の頭に向かって示されています。
DFDのレベル
- Level 0-最高の抽象化レベルDFDは、レベル0 DFDと呼ばれ、情報システム全体を、基礎となるすべての詳細を隠す1つの図として示します。レベル0DFDは、コンテキストレベルDFDとも呼ばれます。
- Level 1-レベル0DFDは、より具体的なレベル1DFDに分類されます。レベル1DFDは、システム内の基本モジュールとさまざまなモジュール間のデータフローを示します。レベル1DFDは、基本的なプロセスと情報源についても言及しています。
Level 2 -このレベルでは、DFDは、レベル1で説明したモジュール内でデータがどのように流れるかを示します。
高レベルのDFDは、必要なレベルの仕様が達成されない限り、より深いレベルの理解を備えた、より具体的な低レベルのDFDに変換できます。


構造図
構造図は、データフロー図から派生したグラフです。これは、DFDよりも詳細にシステムを表します。システム全体を最も機能の低いモジュールに分解し、システムの各モジュールの機能とサブ機能をDFDよりも詳細に説明します。
構造図は、モジュールの階層構造を表しています。各レイヤーで特定のタスクが実行されます。
構造図の作成に使用される記号は次のとおりです-
- Module-プロセス、サブルーチン、またはタスクを表します。制御モジュールは、複数のサブモジュールに分岐します。ライブラリモジュールは再利用可能であり、どのモジュールからでも呼び出すことができます。

- Condition-モジュールのベースにある小さなひし形で表されます。これは、制御モジュールが何らかの条件に基づいて任意のサブルーチンを選択できることを示しています。

- Jump -コントロールがサブモジュールの中央でジャンプすることを示すために、モジュール内を指す矢印が表示されます。

- Loop-曲線の矢印は、モジュール内のループを表します。ループの対象となるすべてのサブモジュールは、モジュールの実行を繰り返します。

- Data flow -末尾に空の円が付いた有向矢印は、データフローを表します。

- Control flow -末尾に黒丸が付いた有向矢印は、制御フローを表します。

HIPO図
HIPO(Hierarchical Input Process Output)ダイアグラムは、システムを分析し、文書化の手段を提供するための2つの組織化された方法の組み合わせです。HIPOモデルは、1970年にIBMによって開発されました。
HIPOダイアグラムは、ソフトウェアシステムのモジュールの階層を表します。アナリストは、HIPOダイアグラムを使用して、システム機能の高レベルのビューを取得します。関数を階層的にサブ関数に分解します。これは、システムによって実行される機能を示しています。
HIPOダイアグラムは、文書化の目的に適しています。それらのグラフィック表現により、設計者と管理者はシステム構造の図解を簡単に理解できます。

モジュール内の制御とデータのフローを示すIPO(入力プロセス出力)図とは対照的に、HIPOはデータフローまたは制御フローに関する情報を提供しません。

例
HIPOダイアグラム、階層表示、IPOチャートの両方の部分は、ソフトウェアプログラムの構造設計とその文書化に使用されます。
構造化された英語
ほとんどのプログラマーはソフトウェアの全体像に気付いていないので、マネージャーが指示したことだけに頼っています。正確で高速なコードを開発するためにプログラマーに正確な情報を提供することは、より高度なソフトウェア管理の責任です。
グラフや図を使用する他の形式のメソッドは、人によって解釈が異なる場合があります。
したがって、ソフトウェアのアナリストや設計者は、StructuredEnglishなどのツールを考え出します。コーディングに必要なものとそのコーディング方法の説明に他なりません。構造化英語は、プログラマーがエラーのないコードを書くのに役立ちます。
グラフや図を使用する他の形式の方法は、人によって解釈が異なる場合があります。ここでは、構造化英語と擬似コードの両方が、その理解のギャップを緩和しようとしています。
構造化英語は、構造化プログラミングパラダイムで平易な英語の単語を使用します。これは最終的なコードではなく、コーディングに必要なものとそのコーディング方法の一種の説明です。以下は、構造化プログラミングのいくつかのトークンです。
IF-THEN-ELSE,
DO-WHILE-UNTILアナリストは、データディクショナリに格納されているのと同じ変数とデータ名を使用するため、コードの記述と理解がはるかに簡単になります。
例
オンラインショッピング環境での顧客認証の同じ例を取り上げます。顧客を認証するこの手順は、構造化英語で次のように記述できます。
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIF構造化英語で書かれたコードは、日常の話し言葉に似ています。ソフトウェアのコードとして直接実装することはできません。構造化英語はプログラミング言語に依存しません。
擬似コード
擬似コードは、プログラミング言語により近い形で記述されています。コメントや説明が満載の拡張プログラミング言語と見なすことができます。
擬似コードは変数宣言を回避しますが、C、Fortran、Pascalなどの実際のプログラミング言語の構造を使用して記述されています。
擬似コードには、構造化英語よりも多くのプログラミングの詳細が含まれています。これは、コンピューターがコードを実行しているかのように、タスクを実行するためのメソッドを提供します。
例
n個までのフィボナッチを印刷するプログラム。
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}デシジョンテーブル
デシジョンテーブルは、条件とそれに対処するために実行するそれぞれのアクションを構造化された表形式で表します。
これは、エラーをデバッグおよび防止するための強力なツールです。同様の情報を1つのテーブルにグループ化し、テーブルを組み合わせることで、簡単で便利な意思決定を実現します。
デシジョンテーブルの作成
デシジョンテーブルを作成するには、開発者は基本的な4つの手順に従う必要があります。
- 対処すべきすべての可能な条件を特定する
- 識別されたすべての条件に対するアクションを決定します
- 可能な最大のルールを作成する
- 各ルールのアクションを定義する
デシジョンテーブルはエンドユーザーが検証する必要があり、最近では重複するルールとアクションを排除することで簡素化できます。
例
インターネット接続に関する日常の問題の簡単な例を見てみましょう。まず、インターネットの起動中に発生する可能性のあるすべての問題と、それぞれの可能な解決策を特定します。
列の条件下で発生する可能性のあるすべての問題と、列のアクションの下に予想されるアクションをリストします。
| 条件/アクション | ルール | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 条件 | 接続済みを表示 | N | N | N | N | Y | Y | Y | Y |
| pingは機能しています | N | N | Y | Y | N | N | Y | Y | |
| ウェブサイトを開く | Y | N | Y | N | Y | N | Y | N | |
| 行動 | ネットワークケーブルを確認してください | バツ | |||||||
| インターネットルーターを確認する | バツ | バツ | バツ | バツ | |||||
| Webブラウザを再起動します | バツ | ||||||||
| サービスプロバイダーに連絡する | バツ | バツ | バツ | バツ | バツ | バツ | |||
| アクションを実行しない | |||||||||
実体関連モデル
実体関連モデルは、実世界の実体とそれらの間の関係の概念に基づくデータベースモデルの一種です。現実世界のシナリオをERデータベースモデルにマッピングできます。ERモデルは、属性、制約のセット、およびエンティティ間の関係を使用してエンティティのセットを作成します。
ERモデルは、データベースの概念設計に最適です。ERモデルは次のように表すことができます。

Entity -ERモデルのエンティティは実世界の存在であり、次のようなプロパティがあります。 attributes。すべての属性は、対応する値のセットによって定義されます。domain。
たとえば、学校のデータベースについて考えてみます。ここでは、学生はエンティティです。学生には、名前、ID、年齢、クラスなどのさまざまな属性があります。
Relationship -エンティティ間の論理的な関連付けは呼び出されます relationship。関係は、さまざまな方法でエンティティにマッピングされます。マッピングカーディナリティは、2つのエンティティ間の関連付けの数を定義します。
カーディナリティのマッピング:
- 1対1
- 1対多
- 多対1
- 多対多
データディクショナリ
データディクショナリは、データに関する情報を一元的に収集したものです。データの意味と出所、他のデータとの関係、使用するデータ形式などが格納されます。データディクショナリには、ユーザーとソフトウェアの設計者が容易に使用できるように、すべての名前が厳密に定義されています。
データディクショナリは、メタデータ(データに関するデータ)リポジトリとして参照されることがよくあります。これは、ソフトウェアプログラムのDFD(データフロー図)モデルとともに作成され、DFDが変更または更新されるたびに更新されることが期待されています。
データディクショナリの要件
データは、ソフトウェアの設計および実装中にデータディクショナリを介して参照されます。データディクショナリは、あいまいさの可能性を排除します。これは、プログラム内のあらゆる場所で同じオブジェクト参照を使用しながら、プログラマーとデザイナーの作業を同期させるのに役立ちます。
データディクショナリは、データベースシステム全体を1か所で文書化する方法を提供します。DFDの検証は、データディクショナリを使用して実行されます。
内容
データディクショナリには、次の情報が含まれている必要があります
- データフロー
- データ構造
- データ要素
- データストア
- 情報処理
データフローは、前述のようにDFDを使用して記述され、記述されているように代数形式で表されます。
| = | 構成されている |
|---|---|
| {} | 繰り返し |
| () | オプション |
| + | そして |
| [/] | または |
例
住所=家番号+(通り/エリア)+市+州
コースID =コース番号+コース名+コースレベル+コース成績
データ要素
データ要素は、データと制御項目の名前と説明、内部または外部のデータストアなどで構成され、詳細は次のとおりです。
- プライマリーネーム
- セカンダリ名(エイリアス)
- ユースケース(使用方法と使用場所)
- コンテンツの説明(表記など)
- 補足情報(プリセット値、制約など)
データストア
データがシステムに入力され、システムの外に存在する場所からの情報を格納します。データストアには次のものが含まれる場合があります-
- Files
- ソフトウェアの内部。
- ソフトウェアの外部ですが、同じマシン上にあります。
- 別のマシンにあるソフトウェアとシステムの外部。
- Tables
- 命名規則
- インデックスプロパティ
情報処理
データ処理には2つのタイプがあります。
- Logical: ユーザーが見るように
- Physical: ソフトウェアがそれを見るように
ソフトウェア設計は、ソフトウェア要件をソフトウェア実装に概念化するプロセスです。ソフトウェア設計は、ユーザーの要件を課題として捉え、最適なソリューションを見つけようとします。ソフトウェアが概念化されている間、意図されたソリューションを実装するための最良の設計を見つけるための計画が練り上げられます。
ソフトウェア設計には複数のバリエーションがあります。それらを簡単に調べてみましょう。
構造化設計
構造化設計は、問題をいくつかのよく組織化された解決要素に概念化したものです。基本的にはソリューションの設計に関係します。構造化設計の利点は、問題がどのように解決されているかをよりよく理解できることです。構造化設計により、設計者は問題にさらに正確に集中することが容易になります。
構造化設計は、ほとんどの場合、問題をいくつかの小さな問題に分割し、問題全体が解決されるまで各小さな問題を個別に解決する「分割統治」戦略に基づいています。
問題の小さな部分は、ソリューションモジュールによって解決されます。構造化設計は、正確なソリューションを実現するために、これらのモジュールが適切に編成されていることを強調しています。
これらのモジュールは階層的に配置されています。彼らは互いに通信します。優れた構造化設計は、常に複数のモジュール間の通信に関するいくつかのルールに従います。
Cohesion -機能的に関連するすべての要素のグループ化。
Coupling -異なるモジュール間の通信。
優れた構造化設計は、高い凝集度と低い結合度を備えています。
機能指向設計
関数指向の設計では、システムは関数と呼ばれる多くの小さなサブシステムで構成されます。これらの機能は、システムで重要なタスクを実行できます。このシステムは、すべての機能の上面図と見なされます。
機能指向設計は、分割統治法が使用される構造化設計のいくつかのプロパティを継承します。
この設計メカニズムは、システム全体をより小さな機能に分割し、情報とその操作を隠すことによって抽象化の手段を提供します。これらの機能モジュールは、グローバルに利用可能な情報を渡し、使用することによって、情報を相互に共有できます。
関数のもう1つの特徴は、プログラムが関数を呼び出すと、その関数がプログラムの状態を変更することです。これは、他のモジュールでは受け入れられない場合があります。関数指向の設計は、システムの状態が重要ではなく、プログラム/関数が状態ではなく入力で機能する場合にうまく機能します。
設計プロセス
- システム全体は、データフロー図によってシステム内でデータがどのように流れるかと見なされます。
- DFDは、関数がシステム全体のデータと状態をどのように変更するかを示します。
- システム全体は、システム内での操作に基づいて、関数と呼ばれる小さな単位に論理的に分割されます。
- 次に、各機能について詳しく説明します。
オブジェクト指向設計
オブジェクト指向設計は、ソフトウェアシステムに関連する機能ではなく、エンティティとその特性を回避します。この設計戦略は、エンティティとその特性に焦点を当てています。ソフトウェアソリューションの全体的な概念は、関与するエンティティを中心に展開します。
オブジェクト指向設計の重要な概念を見てみましょう。
- Objects - ソリューション設計に関係するすべてのエンティティは、オブジェクトと呼ばれます。たとえば、人、銀行、会社、顧客はオブジェクトとして扱われます。すべてのエンティティには、いくつかの属性が関連付けられており、属性に対して実行するいくつかのメソッドがあります。
Classes - クラスは、オブジェクトの一般化された説明です。オブジェクトはクラスのインスタンスです。クラスは、オブジェクトが持つことができるすべての属性と、オブジェクトの機能を定義するメソッドを定義します。
ソリューション設計では、属性は変数として格納され、機能はメソッドまたはプロシージャによって定義されます。
- Encapsulation - OODでは、属性(データ変数)とメソッド(データに対する操作)が一緒にバンドルされていることをカプセル化と呼びます。カプセル化は、オブジェクトの重要な情報をまとめるだけでなく、外部からのデータやメソッドへのアクセスを制限します。これは情報隠蔽と呼ばれます。
- Inheritance - OODを使用すると、同様のクラスを階層的に積み重ねることができ、下位クラスまたはサブクラスは、許可された変数とメソッドを直接のスーパークラスからインポート、実装、および再利用できます。OODのこのプロパティは、継承として知られています。これにより、特定のクラスを定義し、特定のクラスから一般化されたクラスを作成することが容易になります。
- Polymorphism - OOD言語は、同様のタスクを実行するが引数が異なるメソッドに同じ名前を割り当てることができるメカニズムを提供します。これはポリモーフィズムと呼ばれ、単一のインターフェイスでさまざまなタイプのタスクを実行できます。関数の呼び出し方法に応じて、コードのそれぞれの部分が実行されます。
設計プロセス
ソフトウェア設計プロセスは、明確に定義された一連のステップとして認識できます。設計アプローチ(機能指向またはオブジェクト指向)によって異なりますが、次の手順が含まれる場合があります。
- ソリューション設計は、要件または以前に使用されたシステムおよび/またはシステムシーケンス図から作成されます。
- オブジェクトは、属性特性の類似性に代わって識別され、クラスにグループ化されます。
- クラス階層とそれらの間の関係が定義されます。
- アプリケーションフレームワークが定義されています。
ソフトウェア設計アプローチ
ソフトウェア設計の2つの一般的なアプローチは次のとおりです。
トップダウン設計
システムは複数のサブシステムで構成されており、多数のコンポーネントが含まれていることがわかっています。さらに、これらのサブシステムおよびコンポーネントは、サブシステムおよびコンポーネントのセットを有し、システム内に階層構造を作成することができる。
トップダウン設計では、ソフトウェアシステム全体を1つのエンティティとして取り、それを分解して、いくつかの特性に基づいて複数のサブシステムまたはコンポーネントを実現します。次に、各サブシステムまたはコンポーネントはシステムとして扱われ、さらに分解されます。このプロセスは、トップダウン階層の最下位レベルのシステムに到達するまで実行され続けます。
トップダウン設計は、システムの一般化されたモデルから始まり、システムのより具体的な部分を定義し続けます。すべてのコンポーネントが構成されると、システム全体が実現します。
トップダウン設計は、ソフトウェアソリューションを最初から設計する必要があり、具体的な詳細が不明な場合に適しています。
ボトムアップ設計
ボトムアップ設計モデルは、最も具体的で基本的なコンポーネントから始まります。基本または低レベルのコンポーネントを使用して、高レベルのコンポーネントの作成を進めます。目的のシステムが単一のコンポーネントとして進化しなくなるまで、より高いレベルのコンポーネントを作成し続けます。レベルが高くなるごとに、抽象化の量が増加します。
ボトムアップ戦略は、基本的なプリミティブを新しいシステムで使用できる既存のシステムからシステムを作成する必要がある場合に適しています。
トップダウンとボトムアップの両方のアプローチは、個別に実用的ではありません。代わりに、両方の適切な組み合わせが使用されます。
ユーザーインターフェイスは、ユーザーがソフトウェアを使用するために対話するフロントエンドアプリケーションビューです。ユーザーは、ユーザーインターフェイスを使用して、ソフトウェアとハードウェアを操作および制御できます。今日、ユーザーインターフェイスは、コンピューター、携帯電話、車、音楽プレーヤー、飛行機、船など、デジタルテクノロジーが存在するほぼすべての場所にあります。
ユーザーインターフェイスはソフトウェアの一部であり、ソフトウェアのユーザーインサイトを提供することが期待されるように設計されています。UIは、人間とコンピューターの相互作用のための基本的なプラットフォームを提供します。
UIは、基盤となるハードウェアとソフトウェアの組み合わせに応じて、グラフィック、テキストベース、オーディオビデオベースにすることができます。UIは、ハードウェアまたはソフトウェア、あるいは両方の組み合わせにすることができます。
ユーザーインターフェイスが次の場合、ソフトウェアの人気が高まります。
- Attractive
- 使いやすい
- 短時間で応答
- 理解しやすい
- すべてのインターフェース画面で一貫性があります
UIは大きく2つのカテゴリに分けられます。
- コマンドラインインターフェイス
- グラフィカル・ユーザー・インターフェース
コマンドラインインターフェイス(CLI)
CLIは、ビデオディスプレイモニターが登場するまで、コンピューターと対話するための優れたツールでした。CLIは、多くの技術ユーザーやプログラマーにとって最初の選択肢です。CLIは、ソフトウェアがユーザーに提供できる最小限のインターフェイスです。
CLIは、ユーザーがコマンドを入力してシステムにフィードする場所であるコマンドプロンプトを提供します。ユーザーは、コマンドの構文とその使用法を覚えておく必要があります。以前のCLIは、ユーザーエラーを効果的に処理するようにプログラムされていませんでした。
コマンドは、システムによって実行されることが期待される一連の命令へのテキストベースの参照です。ユーザーが簡単に操作できるようにするマクロやスクリプトなどのメソッドがあります。
CLIは、GUIと比較して使用するコンピューターリソースの量が少なくなります。
CLI要素

テキストベースのコマンドラインインターフェイスには、次の要素を含めることができます。
Command Prompt-これはテキストベースの通知機能であり、主にユーザーが作業しているコンテキストを示します。これは、ソフトウェアシステムによって生成されます。
Cursor-入力中の文字の位置を表す、小さな水平線または線の高さの垂直バーです。カーソルはほとんど点滅状態にあります。ユーザーが何かを書き込んだり削除したりすると移動します。
Command-コマンドは実行可能命令です。1つ以上のパラメーターが含まれる場合があります。コマンド実行時の出力は画面にインラインで表示されます。出力が生成されると、コマンドプロンプトが次の行に表示されます。
グラフィカル・ユーザー・インターフェース
グラフィカルユーザーインターフェイスは、システムと対話するためのユーザーグラフィカル手段を提供します。GUIは、ハードウェアとソフトウェアの両方を組み合わせることができます。GUIを使用して、ユーザーはソフトウェアを解釈します。
通常、GUIはCLIよりも多くのリソースを消費します。高度なテクノロジーにより、プログラマーとデザイナーは、より効率的、正確、高速に機能する複雑なGUIデザインを作成します。
GUI要素
GUIは、ソフトウェアまたはハードウェアと対話するための一連のコンポーネントを提供します。
すべてのグラフィカルコンポーネントは、システムを操作する方法を提供します。GUIシステムには、次のような要素があります。

Window-アプリケーションの内容が表示される領域。ウィンドウがファイル構造を表す場合、ウィンドウのコンテンツはアイコンまたはリストの形式で表示できます。ユーザーが探索ウィンドウでファイルシステム内を移動する方が簡単です。ウィンドウは、画面のサイズに合わせて最小化、サイズ変更、または最大化できます。画面上のどこにでも移動できます。ウィンドウには、子ウィンドウと呼ばれる同じアプリケーションの別のウィンドウが含まれる場合があります。
Tabs -アプリケーションがそれ自体の複数のインスタンスの実行を許可している場合、それらは別々のウィンドウとして画面に表示されます。 Tabbed Document Interface同じウィンドウで複数のドキュメントを開くようになりました。このインターフェイスは、アプリケーションで設定パネルを表示するのにも役立ちます。最新のWebブラウザはすべてこの機能を使用しています。
Menu-メニューは標準コマンドの配列であり、グループ化され、アプリケーションウィンドウ内の表示可能な場所(通常は上部)に配置されます。メニューは、マウスクリックで表示または非表示になるようにプログラムできます。
Icon-アイコンは、関連するアプリケーションを表す小さな画像です。これらのアイコンをクリックまたはダブルクリックすると、アプリケーションウィンドウが開きます。アイコンは、システムにインストールされているアプリケーションとプログラムを小さな画像の形式で表示します。
Cursor-マウス、タッチパッド、デジタルペンなどの相互作用するデバイスは、GUIではカーソルとして表されます。画面上のカーソルは、ハードウェアからの指示にほぼリアルタイムで追従します。GUIシステムでは、カーソルはポインタとも呼ばれます。これらは、メニュー、ウィンドウ、およびその他のアプリケーション機能を選択するために使用されます。
アプリケーション固有のGUIコンポーネント
アプリケーションのGUIには、リストされているGUI要素が1つ以上含まれています。
Application Window -ほとんどのアプリケーションウィンドウは、オペレーティングシステムによって提供される構造を使用しますが、多くの場合、アプリケーションのコンテンツを格納するために独自の顧客作成ウィンドウを使用します。
Dialogue Box -これは、ユーザーへのメッセージと実行するアクションの要求を含む子ウィンドウです。例:アプリケーションは、ファイルを削除するためのユーザーからの確認を取得するためのダイアログを生成します。
Text-Box -ユーザーがテキストベースのデータを入力および入力するための領域を提供します。
Buttons -実際のボタンを模倣し、ソフトウェアに入力を送信するために使用されます。

Radio-button-選択可能なオプションを表示します。提供されているすべての中から1つだけを選択できます。
Check-box-リストボックスと同様の機能。オプションを選択すると、ボックスはチェック済みとしてマークされます。チェックボックスで表される複数のオプションを選択できます。
List-box -選択可能なアイテムのリストを提供します。複数のアイテムを選択できます。

その他の印象的なGUIコンポーネントは次のとおりです。
- Sliders
- Combo-box
- Data-grid
- ドロップダウンリスト
ユーザーインターフェイスデザインアクティビティ
ユーザーインターフェイスを設計するために実行されるアクティビティは多数あります。GUIの設計と実装のプロセスはSDLCに似ています。ウォーターフォール、反復、またはスパイラルモデル間のGUI実装には、任意のモデルを使用できます。
GUIの設計と開発に使用されるモデルは、これらのGUI固有の手順を満たす必要があります。

GUI Requirement Gathering-設計者は、GUIのすべての機能要件と非機能要件のリストが必要になる場合があります。これは、ユーザーとその既存のソフトウェアソリューションから取得できます。
User Analysis-設計者は、ソフトウェアGUIを誰が使用するかを研究します。ユーザーの知識と能力レベルに応じて設計の詳細が変化するため、対象読者は重要です。ユーザーが技術に精通している場合は、高度で複雑なGUIを組み込むことができます。初心者ユーザー向けに、ソフトウェアのハウツーに関する詳細情報が含まれています。
Task Analysis-設計者は、ソフトウェアソリューションによって実行されるタスクを分析する必要があります。ここGUIでは、それがどのように行われるかは問題ではありません。タスクは、1つの主要なタスクを取り、それをさらに小さなサブタスクに分割する階層的な方法で表すことができます。タスクは、GUIプレゼンテーションの目標を提供します。サブタスク間の情報の流れによって、ソフトウェアのGUIコンテンツの流れが決まります。
GUI Design & implementation-設計者は、要件、タスク、およびユーザー環境に関する情報を入手した後、GUIを設計してコードに実装し、バックグラウンドで動作中またはダミーのソフトウェアを使用してGUIを埋め込みます。その後、開発者によって自己テストされます。
Testing-GUIテストはさまざまな方法で実行できます。組織は社内検査を受けることができ、ユーザーの直接の関与とベータ版のリリースはそれらのいくつかです。テストには、使いやすさ、互換性、ユーザーの受け入れなどが含まれる場合があります。
GUI実装ツール
設計者がマウスクリックでGUI全体を作成するために使用できるツールがいくつかあります。一部のツールは、ソフトウェア環境(IDE)に組み込むことができます。
GUI実装ツールは、強力なGUIコントロールの配列を提供します。ソフトウェアのカスタマイズについては、設計者はそれに応じてコードを変更できます。
GUIツールには、用途やプラットフォームに応じてさまざまなセグメントがあります。
例
モバイルGUI、コンピューターGUI、タッチスクリーンGUIなど。GUIを構築するのに便利ないくつかのツールのリストを次に示します。
- FLUID
- AppInventor(Android)
- LucidChart
- Wavemaker
- Visual Studio
ユーザーインターフェイスのゴールデンルール
次のルールは、ShneidermanとPlaisantの著書(Designing the User Interface)で説明されている、GUIデザインのゴールデンルールであると述べられています。
Strive for consistency-同様の状況では、一貫した一連のアクションが必要です。プロンプト、メニュー、およびヘルプ画面では、同じ用語を使用する必要があります。一貫したコマンドを全体で使用する必要があります。
Enable frequent users to use short-cuts-インタラクションの数を減らしたいというユーザーの欲求は、使用頻度とともに増加します。略語、ファンクションキー、非表示のコマンド、およびマクロ機能は、エキスパートユーザーにとって非常に役立ちます。
Offer informative feedback-オペレーターのアクションごとに、システムからのフィードバックが必要です。頻繁でマイナーなアクションの場合、応答は控えめである必要がありますが、まれでメジャーなアクションの場合、応答はより実質的である必要があります。
Design dialog to yield closure-一連のアクションは、開始、中間、および終了のグループに編成する必要があります。一連のアクションの完了時の有益なフィードバックは、オペレーターに達成の満足感、安心感、緊急時対応計画とオプションを彼らの心から落とす合図を与えます。アクションのグループ。
Offer simple error handling-可能な限り、ユーザーが重大なエラーを起こさないようにシステムを設計してください。エラーが発生した場合、システムはそれを検出し、エラーを処理するためのシンプルでわかりやすいメカニズムを提供できる必要があります。
Permit easy reversal of actions-この機能は、エラーを元に戻すことができることをユーザーが知っているため、不安を和らげます。アクションを簡単に元に戻すことで、なじみのないオプションの探索が促進されます。可逆性の単位は、単一のアクション、データ入力、またはアクションの完全なグループの場合があります。
Support internal locus of control-経験豊富なオペレーターは、自分たちがシステムを担当し、システムが自分たちの行動に反応するという感覚を強く望んでいます。ユーザーがレスポンダーではなくアクションのイニシエーターになるようにシステムを設計します。
Reduce short-term memory load -短期記憶における人間の情報処理の制限により、表示を単純に保ち、複数ページの表示を統合し、ウィンドウの動きの頻度を減らし、コード、ニーモニック、および一連のアクションに十分なトレーニング時間を割り当てる必要があります。
複雑さという用語は、複数の相互接続されたリンクと非常に複雑な構造を持つイベントまたは物事の状態を表します。ソフトウェアプログラミングでは、ソフトウェアの設計が実現するにつれて、要素の数とそれらの相互接続が次第に膨大になり、一度に理解するのが難しくなります。
ソフトウェア設計の複雑さは、複雑さのメトリックと測定値を使用せずに評価することは困難です。3つの重要なソフトウェアの複雑さの測定値を見てみましょう。
ハルステッドの複雑さの測定
1977年、モーリスハワードハルステッド氏は、ソフトウェアの複雑さを測定するためのメトリックを導入しました。Halsteadのメトリックは、プログラムの実際の実装とそのメジャーに依存します。これらは、静的な方法で、ソースコードの演算子とオペランドから直接計算されます。これにより、C / C ++ / Javaソースコードのテスト時間、語彙、サイズ、難易度、エラー、および労力を評価できます。
ハルステッドによれば、「コンピュータープログラムは、演算子またはオペランドのいずれかに分類できるトークンのコレクションと見なされるアルゴリズムの実装です」。Halsteadメトリックは、プログラムを一連の演算子とそれに関連するオペランドと見なします。
彼は、モジュールの複雑さをチェックするためのさまざまな指標を定義しています。
| パラメータ | 意味 |
|---|---|
| n1 | 一意の演算子の数 |
| n2 | 一意のオペランドの数 |
| N1 | 演算子の合計発生数 |
| N2 | オペランドの合計出現数 |
ソースファイルを選択してその複雑さの詳細をメトリックビューアで表示すると、メトリックレポートに次の結果が表示されます。
| メトリック | 意味 | 数学的表現 |
|---|---|---|
| n | 単語 | n1 + n2 |
| N | サイズ | N1 + N2 |
| V | ボリューム | 長さ* Log2語彙 |
| D | 困難 | (n1 / 2)*(N1 / n2) |
| E | 尽力 | 難易度*ボリューム |
| B | エラー | ボリューム/ 3000 |
| T | テスト時間 | 時間=努力/ S、ここでS = 18秒。 |
循環的複雑度の測定
すべてのプログラムには、実行する必要のあるステートメントを決定するタスクやその他の意思決定ステートメントを実行するために実行するステートメントが含まれています。これらの意思決定構造は、プログラムの流れを変えます。
同じサイズの2つのプログラムを比較すると、プログラムの制御が頻繁にジャンプするため、意思決定ステートメントが多いプログラムはより複雑になります。
McCabeは、1976年に、特定のソフトウェアの複雑さを定量化するための循環的複雑度測定を提案しました。これは、if-else、do-while、repeat-until、switch-case、gotoステートメントなどのプログラムの意思決定構造に基づくグラフ駆動型モデルです。
フロー制御グラフを作成するプロセス:
- 意思決定構造によって区切られた、プログラムを小さなブロックに分割します。
- これらの各ノードを表すノードを作成します。
- 次のようにノードを接続します。
コントロールがブロックiからブロックjに分岐できる場合
円弧を描く
出口ノードから入口ノードへ
円弧を描きます。
プログラムモジュールの循環的複雑度を計算するには、次の式を使用します-
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes
上記のモジュールの循環的複雑度は次のとおりです。
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4P. Jorgensenによると、モジュールの循環的複雑度は10を超えてはなりません。
ファンクションポイント
ソフトウェアのサイズを測定するために広く使用されています。ファンクションポイントは、システムによって提供される機能に重点を置いています。システムの特徴と機能は、ソフトウェアの複雑さを測定するために使用されます。
ファンクションポイントは、外部入力、外部出力、論理内部ファイル、外部インターフェイスファイル、および外部照会という名前の5つのパラメーターに依存します。ソフトウェアの複雑さを考慮するために、各パラメーターはさらに単純、平均、または複雑に分類されます。
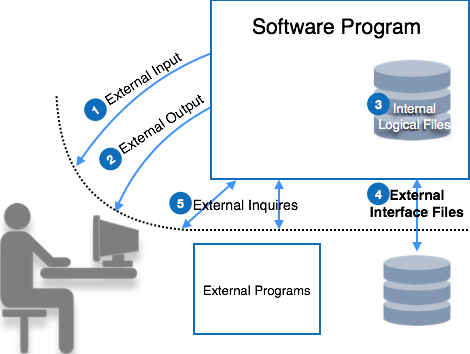
ファンクションポイントのパラメータを見てみましょう:
外部入力
外部からのシステムへのすべての一意の入力は、外部入力と見なされます。2つの入力が同じ形式であってはならないため、入力の一意性が測定されます。これらの入力は、データまたは制御パラメーターのいずれかです。
Simple -入力数が少なく、内部ファイルへの影響が少ない場合
Complex -入力数が多く、より多くの内部ファイルに影響を与える場合
Average -単純なものと複雑なものの中間。
外部出力
システムによって提供されるすべての出力タイプは、このカテゴリにカウントされます。出力フォーマットや処理が一意である場合、出力は一意であると見なされます。
Simple -出力数が少ない場合
Complex -出力数が多い場合
Average -単純なものと複雑なものの間。
論理内部ファイル
すべてのソフトウェアシステムは、その機能情報を維持し、適切に機能するために内部ファイルを維持します。これらのファイルは、システムの論理データを保持します。この論理データには、機能データと制御データの両方が含まれる場合があります。
Simple -レコードタイプの数が少ない場合
Complex -レコードタイプの数が多い場合
Average -単純なものと複雑なものの間。
外部インターフェースファイル
ソフトウェアシステムは、ファイルを外部ソフトウェアと共有する必要がある場合や、処理のために、またはパラメータとして関数にファイルを渡す必要がある場合があります。これらのファイルはすべて、外部インターフェイスファイルとしてカウントされます。
Simple -共有ファイルのレコードタイプの数が少ない場合
Complex -共有ファイルのレコードタイプの数が多い場合
Average -単純なものと複雑なものの間。
外部からのお問い合わせ
照会は入力と出力の組み合わせであり、ユーザーは入力として照会するデータを送信し、システムは照会の出力を処理してユーザーに応答します。クエリの複雑さは、外部入力と外部出力以上のものです。クエリの入力と出力が形式とデータの点で一意である場合、クエリは一意であると言われます。
Simple -クエリに必要な処理が少なく、出力データが少量の場合
Complex -クエリに高いプロセスが必要で、大量の出力データが生成される場合
Average -単純なものと複雑なものの間。
システム内のこれらの各パラメーターには、クラスと複雑さに応じて重みが付けられます。次の表に、各パラメーターに与えられた重みを示します。
| パラメータ | シンプル | 平均 | 繁雑 |
|---|---|---|---|
| 入力 | 3 | 4 | 6 |
| 出力 | 4 | 5 | 7 |
| 問い合わせ | 3 | 4 | 6 |
| ファイル | 7 | 10 | 15 |
| インターフェイス | 5 | 7 | 10 |
上記の表は、生のファンクションポイントを示しています。これらのファンクションポイントは、環境の複雑さに応じて調整されます。システムは、14の異なる特性を使用して記述されます。
- データ通信
- 分散処理
- パフォーマンス目標
- 操作構成のロード
- 取引率
- オンラインデータ入力、
- エンドユーザーの効率
- オンラインアップデート
- 複雑な処理ロジック
- Re-usability
- インストールの容易さ
- 操作のしやすさ
- 複数のサイト
- 変化を促進したい
これらの特性係数は、以下に説明するように、0から5まで評価されます。
- 影響なし
- Incidental
- Moderate
- Average
- Significant
- Essential
次に、すべての評価がNとして合計されます。Nの値の範囲は0〜70です(14種類の特性x 5種類の評価)。これは、次の式を使用して、複雑さ調整係数(CAF)を計算するために使用されます。
CAF = 0.65 + 0.01N次に、
Delivered Function Points (FP)= CAF x Raw FPこのFPは、次のようなさまざまなメトリックで使用できます。
Cost = $ / FP
Quality =エラー/ FP
Productivity = FP /人-月
この章では、プログラミング方法、ドキュメント、およびソフトウェア実装の課題について学習します。
構造化プログラミング
コーディングの過程で、コードの行が増え続けるため、ソフトウェアのサイズが大きくなります。次第に、プログラムの流れを思い出すことがほぼ不可能になります。ソフトウェアとその基礎となるプログラム、ファイル、プロシージャの構築方法を忘れると、プログラムの共有、デバッグ、および変更が非常に困難になります。これに対する解決策は構造化プログラミングです。これにより、開発者はコードで単純なジャンプを使用する代わりにサブルーチンとループを使用するようになり、コードが明確になり、効率が向上します。構造化プログラミングは、プログラマーがコーディング時間を短縮し、コードを適切に編成するのにも役立ちます。
構造化プログラミングは、プログラムのコーディング方法を示しています。構造化プログラミングは、次の3つの主要な概念を使用します。
Top-down analysis-ソフトウェアは常に何らかの合理的な作業を実行するように作られています。この合理的な作業は、ソフトウェア用語では問題として知られています。したがって、問題を解決する方法を理解することが非常に重要です。トップダウン分析では、問題は小さな断片に分解され、それぞれに何らかの重要性があります。各問題は個別に解決され、問題を解決する方法についての手順が明確に示されています。
Modular Programming-プログラミング中、コードはより小さな命令グループに分割されます。これらのグループは、モジュール、サブプログラム、またはサブルーチンと呼ばれます。トップダウン分析の理解に基づくモジュラープログラミング。プログラムで「goto」ステートメントを使用してジャンプすることをお勧めしません。これにより、プログラムフローが追跡できなくなることがよくあります。構造化プログラミングでは、ジャンプは禁止されており、モジュラー形式が推奨されます。
Structured Coding -トップダウン分析を参照すると、構造化コーディングは、モジュールを実行順にさらに小さなコード単位に分割します。構造化プログラミングは、プログラムのフローを制御する制御構造を使用しますが、構造化コーディングは、制御構造を使用して、定義可能なパターンで命令を編成します。
関数型プログラミング
関数型プログラミングは、数学関数の概念を使用するプログラミング言語のスタイルです。数学の関数は、同じ引数を受け取ったときに常に同じ結果を生成する必要があります。手続き型言語では、プログラムのフローはプロシージャを介して実行されます。つまり、プログラムの制御は呼び出されたプロシージャに移されます。制御フローが1つのプロシージャから別のプロシージャに転送されている間、プログラムはその状態を変更します。
手続き型プログラミングでは、プログラム自体が呼び出し中に異なる状態になる可能性があるため、同じ引数で呼び出されたときにプロシージャが異なる結果を生成する可能性があります。これは、手続き型プログラミングの特性であると同時に欠点でもあり、手続きの実行の順序またはタイミングが重要になります。
関数型プログラミングは、数学関数として計算手段を提供し、プログラムの状態に関係なく結果を生成します。これにより、プログラムの動作を予測することができます。
関数型プログラミングは次の概念を使用します。
First class and High-order functions -これらの関数には、引数として別の関数を受け入れる機能があるか、結果として他の関数を返します。
Pure functions -これらの機能には破壊的な更新は含まれていません。つまり、I / Oやメモリに影響を与えず、使用されていない場合は、プログラムの他の部分を妨げることなく簡単に削除できます。
Recursion-再帰は、関数がそれ自体を呼び出し、事前定義された条件が一致しない限り、関数内でプログラムコードを繰り返すプログラミング手法です。再帰は、関数型プログラミングでループを作成する方法です。
Strict evaluation-関数に渡された式を引数として評価する方法です。関数型プログラミングには、厳密(熱心)または非厳密(遅延)の2種類の評価方法があります。厳密な評価では、関数を呼び出す前に常に式を評価します。非厳密な評価では、必要な場合を除いて式は評価されません。
λ-calculus-ほとんどの関数型プログラミング言語は、型システムとしてλ計算を使用します。λ式は、発生時に評価することによって実行されます。
Common Lisp、Scala、Haskell、Erlang、F#は、関数型プログラミング言語の例です。
プログラミングスタイル
プログラミングスタイルは、コーディングルールのセットであり、すべてのプログラマーがコードを記述します。複数のプログラマーが同じソフトウェアプロジェクトで作業する場合、他の開発者が作成したプログラムコードを使用する必要があることがよくあります。すべての開発者がプログラムをコーディングするために何らかの標準的なプログラミングスタイルに従わない場合、これは退屈になるか、時には不可能になります。
適切なプログラミングスタイルには、目的のタスクに関連する関数名と変数名の使用、適切に配置されたインデントの使用、読者の便宜のためのコードのコメント、およびコードの全体的な表示が含まれます。これにより、プログラムコードがすべての人に読みやすく理解しやすくなり、デバッグとエラー解決が容易になります。また、適切なコーディングスタイルは、ドキュメントと更新を容易にするのに役立ちます。
コーディングガイドライン
コーディングスタイルの実践は、組織、オペレーティングシステム、およびコーディング自体の言語によって異なります。
次のコーディング要素は、組織のコーディングガイドラインの下で定義できます。
Naming conventions -このセクションでは、関数、変数、定数、およびグローバル変数に名前を付ける方法を定義します。
Indenting -これは、行の先頭に残されたスペースであり、通常は2〜8個の空白または単一のタブです。
Whitespace -通常、行末では省略されます。
Operators-数学、代入、論理演算子の記述規則を定義します。たとえば、代入演算子 '='は、「x = 2」のように、その前後にスペースが必要です。
Control Structures -if-then-else、case-switch、while-untilを記述し、制御フローステートメントをネストされた方法でのみ記述する規則。
Line length and wrapping-1行に含める文字数を定義します。ほとんどの場合、1行の長さは80文字です。折り返しは、長すぎる場合に行を折り返す方法を定義します。
Functions -これは、パラメーターの有無にかかわらず、関数を宣言および呼び出す方法を定義します。
Variables -これは、さまざまなデータ型の変数がどのように宣言および定義されるかについて説明しています。
Comments-これは重要なコーディングコンポーネントの1つです。コードに含まれるコメントは、コードが実際に何をするか、および他のすべての関連する説明を説明しているためです。このセクションは、他の開発者向けのヘルプドキュメントの作成にも役立ちます。
ソフトウェアドキュメンテーション
ソフトウェアのドキュメントは、ソフトウェアプロセスの重要な部分です。よく書かれたドキュメントは、ソフトウェアプロセスについて知るために必要な情報リポジトリの優れたツールと手段を提供します。ソフトウェアのドキュメントには、製品の使用方法に関する情報も記載されています。
適切に管理されたドキュメントには、次のドキュメントが含まれている必要があります。
Requirement documentation -このドキュメントは、ソフトウェア設計者、開発者、およびテストチームがそれぞれのタスクを実行するための重要なツールとして機能します。このドキュメントには、対象のソフトウェアの機能、非機能、および動作の説明がすべて含まれています。
このドキュメントのソースは、ソフトウェアに関する以前に保存されたデータ、クライアント側ですでに実行されているソフトウェア、クライアントのインタビュー、アンケート、および調査である可能性があります。通常、それは、ハイエンドのソフトウェア管理チームとともにスプレッドシートまたはワードプロセッシングドキュメントの形式で保存されます。
このドキュメントは、開発するソフトウェアの基盤として機能し、主に検証および妥当性確認フェーズで使用されます。ほとんどのテストケースは、要件ドキュメントから直接構築されています。
Software Design documentation -これらのドキュメントには、ソフトウェアのビルドに必要なすべての必要な情報が含まれています。を含む:(a) 高レベルのソフトウェアアーキテクチャ、 (b) ソフトウェア設計の詳細、 (c) データフロー図、 (d) データベース設計
これらのドキュメントは、開発者がソフトウェアを実装するためのリポジトリとして機能します。これらのドキュメントには、プログラムのコーディング方法の詳細は記載されていませんが、コーディングと実装に必要なすべての情報が記載されています。
Technical documentation-これらのドキュメントは、開発者と実際のコーダーによって管理されています。これらのドキュメントは、全体として、コードに関する情報を表しています。コードを作成する際、プログラマーは、コードの目的、作成者、必要な場所、コードの機能と方法、コードが使用するその他のリソースなどについても言及します。
技術文書は、同じコードで作業するさまざまなプログラマー間の理解を深めます。コードの再利用機能を強化します。デバッグが簡単で追跡可能になります。
利用可能なさまざまな自動化ツールがあり、プログラミング言語自体が付属しているものもあります。たとえば、javaには、コードの技術文書を生成するためのJavaDocツールが付属しています。
User documentation-このドキュメントは、上記で説明したすべてのものとは異なります。以前のすべてのドキュメントは、ソフトウェアとその開発プロセスに関する情報を提供するために維持されています。ただし、ユーザードキュメントには、ソフトウェア製品がどのように機能し、目的の結果を得るためにどのように使用するかが説明されています。
これらのドキュメントには、ソフトウェアのインストール手順、ハウツーガイド、ユーザーガイド、アンインストール方法、およびライセンスの更新などの詳細情報を取得するための特別なリファレンスが含まれる場合があります。
ソフトウェア実装の課題
ソフトウェアの実装中に開発チームが直面するいくつかの課題があります。それらのいくつかを以下に示します。
Code-reuse-現在の言語のプログラミングインターフェイスは非常に洗練されており、巨大なライブラリ関数を備えています。それでも、最終製品のコストを下げるために、組織の管理者は、他のソフトウェア用に以前に作成されたコードを再利用することを好みます。互換性チェックと再利用するコードの量を決定するためにプログラマーが直面する大きな問題があります。
Version Management-新しいソフトウェアが顧客に発行されるたびに、開発者はバージョンと構成に関連するドキュメントを維持する必要があります。このドキュメントは、非常に正確で、時間どおりに利用できる必要があります。
Target-Host-組織内で開発されているソフトウェアプログラムは、顧客側のホストマシン用に設計する必要があります。ただし、ターゲットマシンで動作するソフトウェアを設計できない場合があります。
ソフトウェアテストは、ユーザーおよびシステム仕様から収集された要件に対するソフトウェアの評価です。テストは、ソフトウェア開発ライフサイクルのフェーズレベルまたはプログラムコードのモジュールレベルで実施されます。ソフトウェアテストは、妥当性確認と検証で構成されます。
ソフトウェアの妥当性確認
検証は、ソフトウェアがユーザーの要件を満たしているかどうかを調べるプロセスです。SDLCの最後に実行されます。ソフトウェアが作成された要件に一致する場合、検証されます。
- 検証により、開発中の製品がユーザーの要件に従っていることが確認されます。
- 検証は、「このソフトウェアからユーザーが必要とするすべてのことを試みる製品を開発していますか?」という質問に答えます。
- 検証では、ユーザーの要件に重点が置かれます。
ソフトウェア検証
検証は、ソフトウェアがビジネス要件を満たしているかどうかを確認するプロセスであり、適切な仕様と方法論に従って開発されます。
- 検証により、開発中の製品が設計仕様に従っていることが確認されます。
- 検証は、「すべての設計仕様に厳密に従ってこの製品を開発していますか?」という質問に答えます。
- 検証は、設計とシステム仕様に重点を置いています。
テストの対象は-
Errors-これらは、開発者が行った実際のコーディングミスです。また、ソフトウェアの出力と希望の出力に差があり、エラーとみなされます。
Fault-エラーが存在する場合、障害が発生します。バグとも呼ばれる障害は、システムの障害を引き起こす可能性のあるエラーの結果です。
Failure -障害は、システムが目的のタスクを実行できないことであると言われます。システムに障害が存在すると、障害が発生します。
手動と自動テスト
テストは、手動または自動テストツールを使用して実行できます。
Manual-このテストは、自動テストツールを使用せずに実行されます。ソフトウェアテスターは、コードのさまざまなセクションとレベルのテストケースを準備し、テストを実行して、結果をマネージャーに報告します。
手動テストは時間とリソースを消費します。テスターは、適切なテストケースが使用されているかどうかを確認する必要があります。テストの大部分は手動テストを含みます。
Automatedこのテストは、自動テストツールを使用して行われるテスト手順です。手動テストの制限は、自動テストツールを使用して克服できます。
テストでは、InternetExplorerでWebページを開くことができるかどうかを確認する必要があります。これは、手動テストで簡単に実行できます。しかし、Webサーバーが100万人のユーザーの負荷に耐えられるかどうかを確認するために、手動でテストすることはまったく不可能です。
テスターが負荷テスト、ストレステスト、回帰テストを実施するのに役立つソフトウェアとハードウェアのツールがあります。
テストアプローチ
テストは、2つのアプローチに基づいて実行できます–
- 機能テスト
- 実装テスト
実際の実装を考慮せずに機能をテストする場合、それはブラックボックステストと呼ばれます。反対側はホワイトボックステストとして知られており、機能がテストされるだけでなく、その実装方法も分析されます。
徹底的なテストは、完璧なテストのために最も望ましい方法です。入力値と出力値の範囲内のすべての可能な値がテストされます。値の範囲が広い場合、実際のシナリオですべての値をテストすることはできません。
ブラックボックステスト
プログラムの機能をテストするために実行されます。「行動」テストとも呼ばれます。この場合のテスターには、一連の入力値とそれぞれの望ましい結果があります。入力を提供する際に、出力が目的の結果と一致する場合、プログラムは「OK」でテストされ、それ以外の場合は問題があります。

このテスト方法では、コードの設計と構造がテスターに知られていないため、テストエンジニアとエンドユーザーがソフトウェアでこのテストを実行します。
ブラックボックステスト手法:
Equivalence class-入力は同様のクラスに分けられます。クラスの1つの要素がテストに合格した場合、すべてのクラスに合格したと見なされます。
Boundary values-入力は上限値と下限値に分けられます。これらの値がテストに合格した場合、その間のすべての値も合格する可能性があると見なされます。
Cause-effect graphing-以前の両方の方法では、一度に1つの入力値のみがテストされます。原因(入力)–結果(出力)は、入力値の組み合わせが体系的な方法でテストされるテスト手法です。
Pair-wise Testing-ソフトウェアの動作は、複数のパラメータに依存します。ペアワイズテストでは、複数のパラメーターの値が異なるかどうかペアワイズでテストされます。
State-based testing-システムは、入力の提供時に状態を変更します。これらのシステムは、状態と入力に基づいてテストされます。
ホワイトボックステスト
コードの効率や構造を改善するために、プログラムとその実装をテストするために実施されます。「構造」テストとしても知られています。

このテスト方法では、コードの設計と構造がテスターに知られています。コードのプログラマーは、コードに対してこのテストを実行します。
以下は、いくつかのホワイトボックステスト手法です。
Control-flow testing-すべてのステートメントと分岐条件をカバーするテストケースを設定するための制御フローテストの目的。分岐条件は、trueとfalseの両方についてテストされるため、すべてのステートメントをカバーできます。
Data-flow testing-このテスト手法は、プログラムに含まれるすべてのデータ変数をカバーすることに重点を置いています。変数が宣言および定義された場所と、それらが使用または変更された場所をテストします。
テストレベル
テスト自体は、SDLCのさまざまなレベルで定義できます。テストプロセスは、ソフトウェア開発と並行して実行されます。次のステージにジャンプする前に、ステージがテスト、妥当性確認、および検証されます。
個別のテストは、ソフトウェアに隠れたバグや問題が残っていないことを確認するためだけに行われます。ソフトウェアはさまざまなレベルでテストされています-
ユニットテスト
コーディング中に、プログラマーはプログラムのそのユニットでいくつかのテストを実行して、エラーがないかどうかを確認します。テストは、ホワイトボックステストアプローチの下で実行されます。単体テストは、開発者がプログラムの個々のユニットが要件に従って機能しており、エラーがないことを確認するのに役立ちます。
統合テスト
ソフトウェアのユニットが個別に正常に動作している場合でも、ユニットを統合するとエラーなしで動作するかどうかを確認する必要があります。たとえば、引数の受け渡しやデータの更新など。
システムテスト
ソフトウェアは製品としてコンパイルされ、全体としてテストされます。これは、次の1つ以上のテストを使用して実行できます。
Functionality testing -要件に対してソフトウェアのすべての機能をテストします。
Performance testing-このテストは、ソフトウェアの効率性を証明します。ソフトウェアが目的のタスクを実行するのにかかる有効性と平均時間をテストします。パフォーマンステストは、負荷テストとストレステストによって実行されます。このテストでは、ソフトウェアがさまざまな環境条件下で高いユーザー負荷とデータ負荷にさらされます。
Security & Portability -これらのテストは、ソフトウェアがさまざまなプラットフォームで動作し、多数の人がアクセスすることを目的としている場合に実行されます。
受け入れ試験
ソフトウェアを顧客に引き渡す準備ができたら、テストの最後のフェーズを経て、ユーザーの操作と応答をテストする必要があります。ソフトウェアがすべてのユーザー要件に一致し、ユーザーがその外観や動作を気に入らない場合でも、拒否される可能性があるため、これは重要です。
Alpha testing-開発者のチーム自身が、システムを作業環境で使用されているかのように使用して、アルファテストを実行します。彼らは、ユーザーがソフトウェアのアクションにどのように反応するか、そしてシステムが入力にどのように反応するかを見つけようとします。
Beta testing-ソフトウェアが内部でテストされた後、テスト目的でのみ本番環境で使用するためにユーザーに渡されます。これはまだ納品された製品ではありません。開発者は、この段階のユーザーが、出席するためにスキップされた細かい問題をもたらすことを期待しています。
回帰試験
ソフトウェア製品が新しいコード、機能、または機能で更新されるたびに、追加されたコードの悪影響があるかどうかを検出するために徹底的にテストされます。これは回帰テストとして知られています。
ドキュメントのテスト
テストドキュメントはさまざまな段階で作成されます-
テストする前に
テストは、テストケースの生成から始まります。参照用に次のドキュメントが必要です–
SRS document -機能要件ドキュメント
Test Policy document -これは、製品をリリースする前にテストをどこまで行う必要があるかを示しています。
Test Strategy document -これは、テストチームの詳細な側面、責任マトリックス、およびテストマネージャーとテストエンジニアの権利/責任について言及しています。
Traceability Matrix document-これは、要件収集プロセスに関連するSDLCドキュメントです。新しい要件が発生すると、それらはこのマトリックスに追加されます。これらのマトリックスは、テスターが要件のソースを知るのに役立ちます。それらは前後にたどることができます。
テスト中
テストの開始時および実行中に、次のドキュメントが必要になる場合があります。
Test Case document-このドキュメントには、実行する必要のあるテストのリストが含まれています。これには、ユニットテスト計画、統合テスト計画、システムテスト計画、および受け入れテスト計画が含まれます。
Test description -このドキュメントは、すべてのテストケースとそれらを実行する手順の詳細な説明です。
Test case report -このドキュメントには、テストの結果としてのテストケースレポートが含まれています。
Test logs -このドキュメントには、すべてのテストケースレポートのテストログが含まれています。
テスト後
テスト後に次のドキュメントが生成される場合があります。
Test summary-このテストの概要は、すべてのテストレポートとログの集合的な分析です。ソフトウェアを起動する準備ができているかどうかを要約して結論付けます。ソフトウェアは、起動する準備ができている場合、バージョン管理システムの下でリリースされます。
テストと品質管理、品質保証、監査
ソフトウェアテストは、ソフトウェア品質保証、ソフトウェア品質管理、ソフトウェア監査とは異なることを理解する必要があります。
Software quality assurance-これらはソフトウェア開発プロセスの監視手段であり、組織の基準に従ってすべての措置が講じられていることが保証されます。この監視は、適切なソフトウェア開発方法に従っていることを確認するために行われます。
Software quality control-ソフトウェア製品の品質を維持するためのシステムです。これには、組織の親善を強化するソフトウェア製品の機能的側面と非機能的側面が含まれる場合があります。このシステムは、顧客が要件に合った高品質の製品と「使用に適した」と認定された製品を確実に受け取るようにします。
Software audit-これは、ソフトウェアを開発するために組織が使用する手順のレビューです。開発チームから独立した監査人のチームが、ソフトウェアプロセス、手順、要件、およびSDLCの他の側面を調査します。ソフトウェア監査の目的は、ソフトウェアとその開発プロセスの両方が標準、規則、規制に準拠していることを確認することです。
ソフトウェアメンテナンスは、現在SDLCの一部として広く受け入れられています。これは、ソフトウェア製品の納品後に行われたすべての変更および更新を表します。変更が必要な理由はいくつかありますが、その一部を以下に簡単に説明します。
Market Conditions -課税や簿記の維持方法などの新たに導入された制約など、時間の経過とともに変化するポリシーは、変更の必要性を引き起こす可能性があります。
Client Requirements -時間の経過とともに、お客様はソフトウェアの新機能を要求する場合があります。
Host Modifications -ターゲットホストのハードウェアやプラットフォーム(オペレーティングシステムなど)のいずれかが変更された場合、適応性を維持するためにソフトウェアの変更が必要です。
Organization Changes -組織力の低下、他の会社の買収、組織の新規事業への参入など、クライアント側でビジネスレベルの変更があった場合、元のソフトウェアを変更する必要が生じる可能性があります。
メンテナンスの種類
ソフトウェアの存続期間中、メンテナンスの種類はその性質に基づいて異なる場合があります。一部のユーザーがバグを発見したため、これは単なる定期的なメンテナンスタスクである場合もあれば、メンテナンスのサイズや性質に基づいてそれ自体が大きなイベントである場合もあります。以下は、その特性に基づいたメンテナンスの種類です。
Corrective Maintenance -これには、問題を修正または修正するために行われた変更と更新が含まれます。これらの問題は、ユーザーによって発見されるか、ユーザーエラーレポートによって結論付けられます。
Adaptive Maintenance -これには、ソフトウェア製品を最新の状態に保ち、絶えず変化するテクノロジーとビジネス環境の世界に合わせて調整するために適用される変更と更新が含まれます。
Perfective Maintenance-これには、ソフトウェアを長期間使用できるようにするために行われた変更と更新が含まれます。これには、ソフトウェアを改良し、その信頼性とパフォーマンスを向上させるための新機能、新しいユーザー要件が含まれています。
Preventive Maintenance-これには、ソフトウェアの将来の問題を防ぐための変更と更新が含まれます。現時点では重要ではないが、将来深刻な問題を引き起こす可能性のある問題に対処することを目的としています。
メンテナンス費用
報告によると、メンテナンスのコストは高いとされています。ソフトウェアメンテナンスの見積もりに関する調査では、メンテナンスのコストがソフトウェアプロセスサイクル全体のコストの67%にもなることがわかりました。
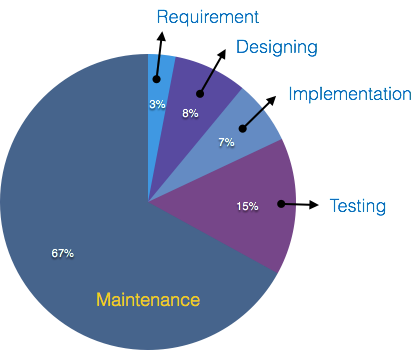
平均して、ソフトウェアメンテナンスのコストはすべてのSDLCフェーズの50%以上です。メンテナンスコストが高くなる原因には、次のようなさまざまな要因があります。
メンテナンスコストに影響を与える実際の要因
- ソフトウェアの標準年齢は、最大10〜15歳と見なされます。
- メモリとストレージ容量が少ない低速のマシンで動作することを目的とした古いソフトウェアは、最新のハードウェアで新しく拡張されたソフトウェアに挑戦し続けることはできません。
- 技術が進歩するにつれて、古いソフトウェアを維持することはコストがかかるようになります。
- ほとんどのメンテナンスエンジニアは初心者であり、問題を修正するために試行錯誤の方法を使用します。
- 多くの場合、加えられた変更はソフトウェアの元の構造を簡単に傷つけ、その後の変更を困難にする可能性があります。
- 多くの場合、変更は文書化されないままになり、将来さらに競合が発生する可能性があります。
メンテナンスコストに影響を与えるソフトウェアエンドの要因
- ソフトウェアプログラムの構造
- プログラミング言語
- 外部環境への依存
- スタッフの信頼性と可用性
メンテナンス活動
IEEEは、順次保守プロセスアクティビティのフレームワークを提供します。繰り返し使用でき、カスタマイズしたアイテムやプロセスを含めることができるように拡張できます。

これらのアクティビティは、次の各フェーズと密接に関連しています。
Identification & Tracing-変更または保守の要件の特定に関連するアクティビティが含まれます。ユーザーまたはシステムによって生成され、ログまたはエラーメッセージを介して報告される場合があります。ここでは、メンテナンスタイプも分類されます。
Analysis-変更は、安全性とセキュリティへの影響を含め、システムへの影響について分析されます。予想される影響が深刻な場合は、代替ソリューションが探しられます。次に、必要な変更のセットが要件仕様に具体化されます。変更/保守のコストが分析され、見積もりが完了します。
Design-交換または変更が必要な新しいモジュールは、前の段階で設定された要件仕様に照らして設計されています。テストケースは、妥当性確認と検証のために作成されます。
Implementation -新しいモジュールは、設計ステップで作成された構造化設計の助けを借りてコーディングされています。すべてのプログラマーは、並行して単体テストを行うことが期待されています。
System Testing-統合テストは、新しく作成されたモジュール間で行われます。統合テストは、新しいモジュールとシステムの間でも実行されます。最後に、回帰テスト手順に従って、システム全体がテストされます。
Acceptance Testing-システムを内部でテストした後、ユーザーの助けを借りて受け入れられるかどうかをテストします。この状態の場合、ユーザーは、次の反復で対処する、または対処するように注意するいくつかの問題について苦情を申し立てます。
Delivery-受け入れテストの後、システムは、小さな更新パッケージまたはシステムの新規インストールのいずれかによって、組織全体に展開されます。最終テストは、ソフトウェアが配信された後、クライアント側で行われます。
ユーザーマニュアルのハードコピーに加えて、必要に応じてトレーニング機能が提供されます。
Maintenance management-構成管理は、システムメンテナンスの重要な部分です。これは、バージョン、セミバージョン、またはパッチ管理を制御するためのバージョン管理ツールで支援されます。
ソフトウェアリエンジニアリング
機能に影響を与えずに現在の市場に維持するためにソフトウェアを更新する必要がある場合、それはソフトウェアリエンジニアリングと呼ばれます。ソフトウェアの設計を変更し、プログラムを書き直すという徹底したプロセスです。
レガシーソフトウェアは、市場で入手可能な最新のテクノロジーに合わせて調整を続けることはできません。ハードウェアが時代遅れになると、ソフトウェアの更新が頭痛の種になります。ソフトウェアが時間とともに古くなっても、その機能は古くなりません。
たとえば、当初、Unixはアセンブリ言語で開発されました。言語Cが登場したとき、アセンブリ言語での作業が困難だったため、UnixはCで再設計されました。
これ以外に、プログラマーは、ソフトウェアの一部が他の部分よりも多くのメンテナンスを必要とし、リエンジニアリングも必要であることに気付くことがあります。

リエンジニアリングプロセス
- Decide何を再設計するか。それはソフトウェア全体ですか、それともその一部ですか?
- Perform 既存のソフトウェアの仕様を取得するためのリバースエンジニアリング。
- Restructure Programもし必要なら。たとえば、関数指向プログラムをオブジェクト指向プログラムに変更します。
- Re-structure data 要求に応じ。
- Apply Forward engineering 再設計されたソフトウェアを取得するための概念。
ソフトウェアリエンジニアリングで使用される重要な用語はほとんどありません
リバースエンジニアリング
既存のシステムを徹底的に分析・理解し、システム仕様を実現するプロセスです。このプロセスは、逆SDLCモデルと見なすことができます。つまり、より低い抽象化レベルを分析することによって、より高い抽象化レベルを取得しようとします。
既存のシステムは以前に実装された設計であり、それについては何も知りません。次に、設計者はコードを見てリバースエンジニアリングを行い、設計を取得しようとします。設計を手に、彼らは仕様をまとめようとします。したがって、コードからシステム仕様に逆になります。

プログラムの再構築
これは、既存のソフトウェアを再構築および再構築するプロセスです。それはすべて、同じプログラミング言語で、またはあるプログラミング言語から別のプログラミング言語にソースコードを再配置することです。再構築には、ソースコードの再構築とデータの再構築、またはその両方を含めることができます。
再構築はソフトウェアの機能に影響を与えませんが、信頼性と保守性を向上させます。非常に頻繁にエラーを引き起こすプログラムコンポーネントは、再構築によって変更または更新できます。
廃止されたハードウェアプラットフォームでのソフトウェアの信頼性は、再構築によって取り除くことができます。
フォワードエンジニアリング
フォワードエンジニアリングは、リバースエンジニアリングによってダウンした手元の仕様から目的のソフトウェアを取得するプロセスです。これは、過去にすでに行われたソフトウェアエンジニアリングがあったことを前提としています。
フォワードエンジニアリングはソフトウェアエンジニアリングプロセスと同じですが、違いが1つだけあります。それは、常にリバースエンジニアリングの後に実行されます。

コンポーネントの再利用性
コンポーネントは、システム内で独立したタスクを実行するソフトウェアプログラムコードの一部です。小さなモジュールまたはサブシステム自体にすることができます。
例
Webで使用されるログイン手順はコンポーネントと見なすことができ、ソフトウェアの印刷システムはソフトウェアのコンポーネントと見なすことができます。
コンポーネントは、機能のまとまりが高く、結合率が低くなります。つまり、コンポーネントは独立して動作し、他のモジュールに依存せずにタスクを実行できます。
OOPでは、オブジェクトはその懸念に非常に固有に設計されており、他のソフトウェアで使用される可能性が低くなります。
モジュラープログラミングでは、モジュールは、他の多くのソフトウェアプログラムで使用できる特定のタスクを実行するようにコード化されています。
ソフトウェアコンポーネントの再利用に基づくまったく新しい業種があり、コンポーネントベースソフトウェアエンジニアリング(CBSE)として知られています。

再利用はさまざまなレベルで行うことができます
Application level -アプリケーション全体が新しいソフトウェアのサブシステムとして使用される場合。
Component level -アプリケーションのサブシステムが使用される場所。
Modules level -機能モジュールが再利用される場合。
ソフトウェアコンポーネントは、異なるコンポーネント間の通信を確立するために使用できるインターフェイスを提供します。
再利用プロセス
要件を同じにしてコンポーネントを調整する方法と、コンポーネントを同じにして要件を変更する方法の2種類の方法を採用できます。

Requirement Specification -既存のシステム、ユーザー入力、またはその両方を利用して、ソフトウェア製品が準拠する必要のある機能要件と非機能要件が指定されています。
Design-これは標準のSDLCプロセスステップでもあり、要件はソフトウェア用語で定義されます。システム全体とそのサブシステムの基本アーキテクチャが作成されます。
Specify Components -ソフトウェア設計を研究することにより、設計者はシステム全体をより小さなコンポーネントまたはサブシステムに分離します。1つの完全なソフトウェア設計は、連携して動作するコンポーネントの膨大なセットのコレクションになります。
Search Suitable Components -ソフトウェアコンポーネントリポジトリは、機能と意図されたソフトウェア要件に基づいて、一致するコンポーネントを検索するために設計者によって参照されます。
Incorporate Components -一致するすべてのコンポーネントは、完全なソフトウェアとして形作るために一緒にパックされます。
CASEは Cコンピューター Aided Software Eエンジニアリング。これは、さまざまな自動ソフトウェアツールを使用したソフトウェアプロジェクトの開発と保守を意味します。
CASEツール
CASEツールは、SDLCアクティビティを自動化するために使用されるソフトウェアアプリケーションプログラムのセットです。CASEツールは、ソフトウェアプロジェクトマネージャー、アナリスト、エンジニアがソフトウェアシステムを開発するために使用します。
分析ツール、設計ツール、プロジェクト管理ツール、データベース管理ツール、ドキュメントツールなど、ソフトウェア開発ライフサイクルのさまざまな段階を簡素化するために利用できるCASEツールは数多くあります。
CASEツールを使用すると、プロジェクトの開発が加速され、望ましい結果が得られ、ソフトウェア開発の次の段階に進む前に欠陥を発見するのに役立ちます。
CASEツールのコンポーネント
CASEツールは、特定のSDLCステージでの使用に基づいて、大きく次の部分に分けることができます。
Central Repository-CASEツールには、共通の統合された一貫性のある情報のソースとして機能できる中央リポジトリが必要です。中央リポジトリは、製品仕様、要件ドキュメント、関連レポート、図、その他の管理に関する有用な情報が保存される中央ストレージです。中央リポジトリはデータディクショナリとしても機能します。

Upper Case Tools -上位CASEツールは、SDLCの計画、分析、および設計段階で使用されます。
Lower Case Tools -実装、テスト、およびメンテナンスでは、CASEの低いツールが使用されます。
Integrated Case Tools -統合されたCASEツールは、要件の収集からテストや文書化まで、SDLCのすべての段階で役立ちます。
CASEツールは、同様の機能、プロセスアクティビティ、および他のツールと統合する機能を備えている場合、グループ化できます。
ケースツールの範囲
CASEツールの範囲はSDLC全体に及びます。
ケースツールの種類
ここで、さまざまなCASEツールについて簡単に説明します。
ダイアグラムツール
これらのツールは、システムコンポーネント、データ、さまざまなソフトウェアコンポーネント間の制御フロー、およびシステム構造をグラフィカルな形式で表すために使用されます。たとえば、最先端のフローチャートを作成するためのフローチャートメーカーツール。
プロセスモデリングツール
プロセスモデリングは、ソフトウェアの開発に使用されるソフトウェアプロセスモデルを作成する方法です。プロセスモデリングツールは、管理者がソフトウェア製品の要件に従ってプロセスモデルを選択または変更するのに役立ちます。たとえば、EPF Composer
プロジェクト管理ツール
これらのツールは、プロジェクトの計画、コストと労力の見積もり、プロジェクトのスケジューリング、およびリソースの計画に使用されます。管理者は、ソフトウェアプロジェクト管理で言及されているすべてのステップにプロジェクトの実行を厳密に準拠させる必要があります。プロジェクト管理ツールは、組織全体でプロジェクト情報をリアルタイムで保存および共有するのに役立ちます。たとえば、Creative Pro Office、Trac Project、Basecampなどです。
ドキュメントツール
ソフトウェアプロジェクトのドキュメントは、ソフトウェアプロセスの前に開始され、SDLCのすべてのフェーズを通じて、プロジェクトの完了後に実行されます。
ドキュメントツールは、テクニカルユーザーとエンドユーザー向けのドキュメントを生成します。テクニカルユーザーは主に開発チームの社内専門家であり、システムマニュアル、リファレンスマニュアル、トレーニングマニュアル、インストールマニュアルなどを参照します。エンドユーザードキュメントには、ユーザーマニュアルなど、システムの機能とハウツーが記載されています。たとえば、ドキュメントについては、Doxygen、DrExplain、AdobeRoboHelpなどです。
分析ツール
これらのツールは、要件を収集し、図の不整合、不正確さ、データの冗長性、または誤った脱落を自動的にチェックするのに役立ちます。たとえば、要件分析にはAccept 360、Accompa、CaseComplete、全体分析にはVisibleAnalystがあります。
デザインツール
これらのツールは、ソフトウェア設計者がソフトウェアのブロック構造を設計するのに役立ちます。ブロック構造は、改良手法を使用してさらに小さなモジュールに分割できます。これらのツールは、各モジュールの詳細とモジュール間の相互接続を提供します。たとえば、アニメーションソフトウェアデザイン
構成管理ツール
ソフトウェアのインスタンスは、1つのバージョンでリリースされます。構成管理ツールは–を扱います
- バージョンとリビジョン管理
- ベースライン構成管理
- 変更管理管理
CASEツールは、自動追跡、バージョン管理、リリース管理によってこれを支援します。たとえば、Fossil、Git、AccuREVなどです。
変更管理ツール
これらのツールは、構成管理ツールの一部と見なされます。それらは、ベースラインが修正された後、またはソフトウェアが最初にリリースされたときにソフトウェアに加えられた変更を処理します。CASEツールは、変更の追跡、ファイル管理、コード管理などを自動化します。また、組織の変更ポリシーを実施するのにも役立ちます。
プログラミングツール
これらのツールは、IDE(統合開発環境)、組み込みモジュールライブラリ、シミュレーションツールなどのプログラミング環境で構成されています。これらのツールは、ソフトウェア製品の構築を包括的に支援し、シミュレーションとテストの機能を備えています。たとえば、Cでコードを検索するCscope、Eclipse。
プロトタイピングツール
ソフトウェアプロトタイプは、目的のソフトウェア製品のシミュレーションバージョンです。プロトタイプは、製品の初期のルックアンドフィールを提供し、実際の製品のいくつかの側面をシミュレートします。
プロトタイピングCASEツールには、基本的にグラフィカルライブラリが付属しています。ハードウェアに依存しないユーザーインターフェイスとデザインを作成できます。これらのツールは、既存の情報に基づいて迅速なプロトタイプを作成するのに役立ちます。さらに、ソフトウェアプロトタイプのシミュレーションを提供します。たとえば、Serenaプロトタイプ作曲家のMockupBuilderです。
Web開発ツール
これらのツールは、フォーム、テキスト、スクリプト、グラフィックなどのすべての関連要素を含むWebページの設計を支援します。Webツールは、開発中のものと完了後の外観のライブプレビューも提供します。たとえば、Fontello、Adobe Edge Inspect、Foundation 3、Bracketsなどです。
品質保証ツール
ソフトウェア組織の品質保証は、組織の標準に従って品質の適合性を確保するために、ソフトウェア製品の開発に採用されたエンジニアリングプロセスと方法を監視しています。QAツールは、構成および変更管理ツールとソフトウェアテストツールで構成されています。たとえば、SoapTest、AppsWatch、JMeterなどです。
メンテナンスツール
ソフトウェアメンテナンスには、ソフトウェア製品の納品後の変更が含まれます。自動ロギングおよびエラー報告技術、自動エラーチケット生成、および根本原因分析は、SDLCのメンテナンスフェーズでソフトウェア編成を支援するいくつかのCASEツールです。たとえば、欠陥追跡用のBugzilla、HP QualityCenterなどです。