Splunk-ピボットとデータセット
Splunkは、さまざまなタイプのデータソースを取り込んで、リレーショナルテーブルに似たテーブルを構築できます。これらは呼ばれますtable dataset あるいは単に tables。これらは、データやルックアップなどを分析およびフィルタリングする簡単な方法を提供します。これらのテーブルデータセットは、この章で学習するピボット分析の作成にも使用されます。
データセットの作成
Splunk Datasets Add-onという名前のSplunkアドオンを使用して、データセットを作成および管理します。SplunkのWebサイトからダウンロードできます。https://splunkbase.splunk.com/app/3245/#/details.このリンクの[詳細]タブに記載されている手順に従ってインストールする必要があります。インストールが成功すると、という名前のボタンが表示されますCreate New Table Dataset。
データセットの選択
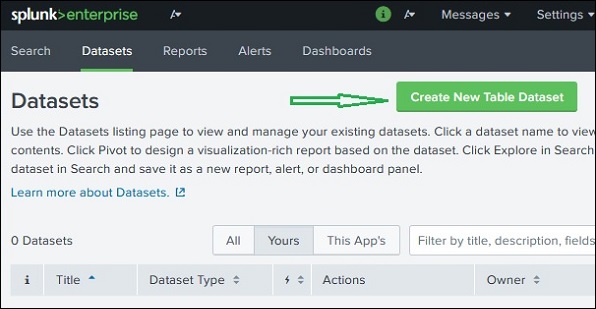
次に、をクリックします Create New Table Dataset ボタンをクリックすると、以下の3つのオプションから選択するオプションが表示されます。
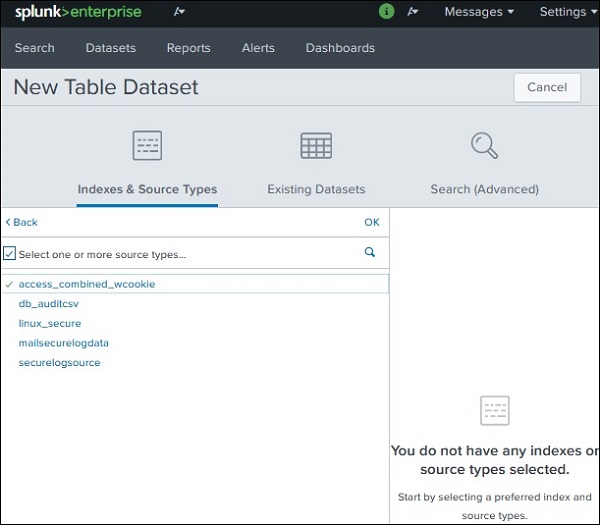
Indexes and Source Types −データの追加アプリを介してSplunkにすでに追加されている既存のインデックスまたはソースタイプから選択します。
Existing Datasets −新しいデータセットを作成して変更したいデータセットを、すでに作成している可能性があります。
Search −検索クエリを記述し、その結果を使用して新しいデータセットを作成できます。
この例では、下の画像に示すように、データセットのソースとしてインデックスを選択します。
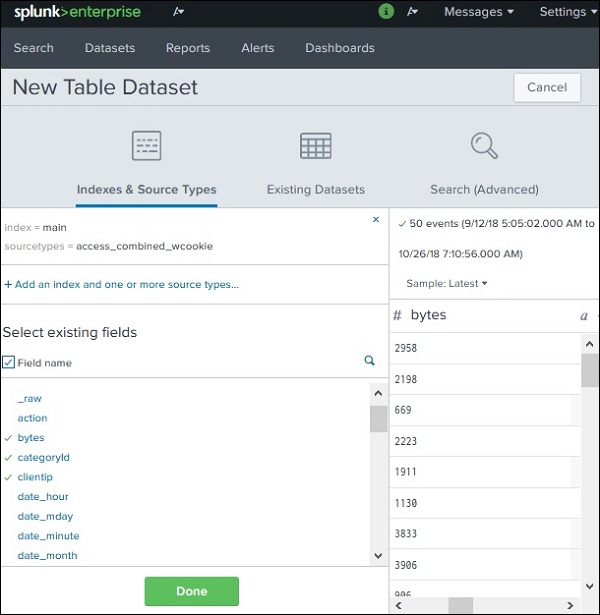
データセットフィールドの選択
上の画面で[OK]をクリックすると、最終的にテーブルデータセットに入力するさまざまなフィールドを選択するオプションが表示されます。_timeフィールドはデフォルトで選択されており、このフィールドを削除することはできません。フィールドを選択します。bytes, categoryID, clientIP そして files。
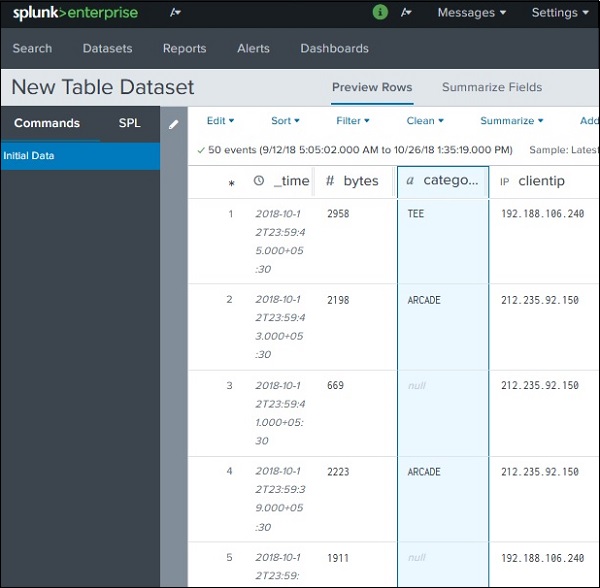
上の画面で[完了]をクリックすると、以下に示すように、選択したすべてのフィールドを含む最終的なデータセットテーブルが表示されます。ここで、データセットはリレーショナルテーブルに似ています。データセットを次のように保存しますsave as 右上隅にあるオプションを利用できます。
ピボットの作成
上記のデータセットを使用して、ピボットレポートを作成します。ピボットレポートは、別の列の値に対する1つの列の値の集計を反映します。つまり、1つの列の値が行になり、別の列の値が行になります。
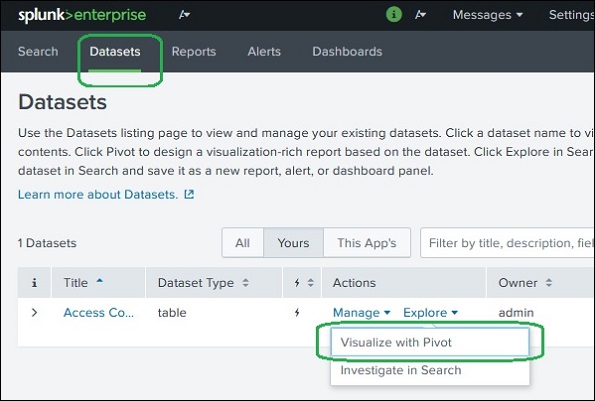
データセットアクションを選択
これを実現するには、最初に[データセット]タブを使用してデータセットを選択し、次にオプションを選択します Visualize with Pivot そのデータセットの[アクション]列から。
ピボットフィールドを選択します
次に、ピボットテーブルを作成するための適切なフィールドを選択します。でカテゴリIDを選択しますsplit columnsこれは、値がレポートで異なる列として表示されるフィールドであるため、オプションです。次に、でファイルを選択しますSplit Rowsこれは、値を行で表示する必要があるフィールドであるため、オプションです。結果には、ファイルフィールドの各値の各categoryid値の数が表示されます。

次に、ピボットテーブルをレポートまたはパネルとして既存のダッシュボードに保存して、後で参照できるようにします。