Talend-クイックガイド
Talendは、データ統合、データ品質、データ管理、データ準備、ビッグデータのソリューションを提供するソフトウェア統合プラットフォームです。Talendに関する知識を持つETLプロフェッショナルの需要は高いです。また、ビッグデータエコシステムと簡単に統合できるすべてのプラグインを備えた唯一のETLツールです。
Gartnerによると、Talendはデータ統合ツールのリーダーのマジッククアドラントに分類されます。
Talendは、以下のようなさまざまな商用製品を提供しています。
- Talendデータ品質
- Talendデータ統合
- Talendデータの準備
- Talend Cloud
- Talendビッグデータ
- Talend MDM(マスターデータ管理)プラットフォーム
- Talendデータサービスプラットフォーム
- Talendメタデータマネージャー
- Talendデータファブリック
Talendは、データ統合とビッグデータに広く使用されているオープンソースの無料ツールであるOpenStudioも提供しています。
以下は、Talend OpenStudioをダウンロードして作業するためのシステム要件です。
推奨されるオペレーティングシステム
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
メモリ要件
- メモリ-最小4GB、推奨8 GB
- ストレージスペース-30GB
さらに、稼働中のHadoopクラスター(できればCloudera)も必要です。
Note − Java 8は、環境変数がすでに設定された状態で使用可能である必要があります。
ビッグデータとデータ統合のためのTalendOpen Studioをダウンロードするには、以下の手順に従ってください。
Step 1 −次のページに移動します。 https://www.talend.com/products/big-data/big-data-open-studio/ダウンロードボタンをクリックします。TOS_BD_xxxxxxx.zipファイルのダウンロードが開始されていることがわかります。
Step 2 −ダウンロードが完了したら、zipファイルの内容を抽出すると、すべてのTalendファイルを含むフォルダーが作成されます。
Step 3− Talendフォルダーを開き、実行可能ファイルTOS_BD-win-x86_64.exeをダブルクリックします。ユーザー使用許諾契約に同意します。
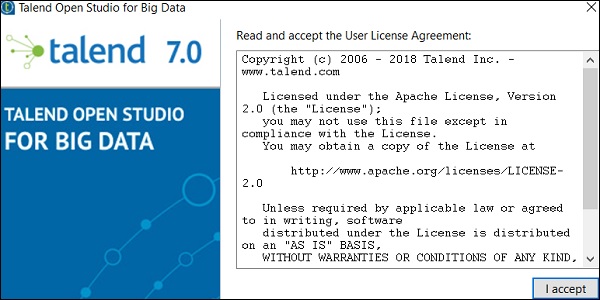
Step 4 −新しいプロジェクトを作成し、[完了]をクリックします。
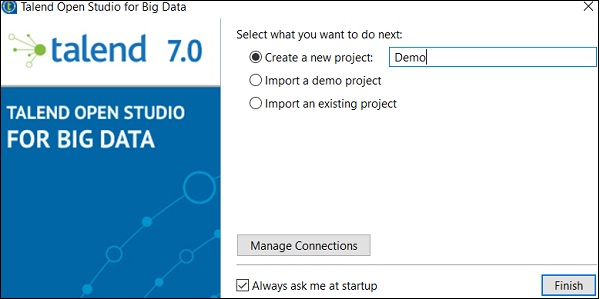
Step 5 − Windowsセキュリティアラートが表示された場合は、[アクセスを許可]をクリックします。
Step 6 −これで、Talend OpenStudioのウェルカムページが開きます。
Step 7 − [完了]をクリックして、必要なサードパーティライブラリをインストールします。
Step 8 −利用規約に同意し、[完了]をクリックします。
Step 9 − [はい]をクリックします。
これで、Talend OpenStudioに必要なライブラリが用意されました。
Talend Open Studioは、データ統合とビッグデータのための無料のオープンソースETLツールです。これは、Eclipseベースの開発者ツールおよびジョブデザイナーです。ETLまたはETLジョブを作成して実行するには、コンポーネントをドラッグアンドドロップして接続するだけです。このツールはジョブのJavaコードを自動的に作成するため、1行のコードを記述する必要はありません。
RDBMS、Excel、SaaSビッグデータエコシステムなどのデータソース、およびSAP、CRM、Dropboxなどのアプリやテクノロジーに接続するための複数のオプションがあります。
Talend OpenStudioが提供するいくつかの重要な利点は次のとおりです-
900コンポーネント、組み込みコネクタ、ジョブのJavaコードへの自動変換など、データの統合と同期に必要なすべての機能を提供します。
このツールは完全に無料であるため、大幅なコスト削減が可能です。
過去12年間で、複数の巨大な組織がデータ統合にTOSを採用しました。これは、このツールに対する非常に高い信頼度を示しています。
データ統合のためのTalendコミュニティは非常に活発です。
Talendはこれらのツールに機能を追加し続けており、ドキュメントは適切に構成されており、非常に簡単に理解できます。
ほとんどの組織は複数の場所からデータを取得し、別々に保存しています。組織が意思決定を行う必要がある場合は、さまざまなソースからデータを取得し、それを統一されたビューに配置してから分析して結果を得る必要があります。このプロセスは、データ統合と呼ばれます。
利点
データ統合には、以下に説明する多くの利点があります-
組織のデータにアクセスしようとしている組織内の異なるチーム間のコラボレーションを改善します。
データが効果的に統合されるため、時間を節約し、データ分析を容易にします。
自動化されたデータ統合プロセスは、データを同期し、リアルタイムおよび定期的なレポートを容易にします。そうしないと、手動で実行すると時間がかかります。
複数のソースから統合されたデータは、時間の経過とともに成熟して改善され、最終的にはデータ品質の向上に役立ちます。
プロジェクトでの作業
このセクションでは、Talendプロジェクトでの作業方法を理解しましょう-
プロジェクトの作成
TOSビッグデータ実行可能ファイルをダブルクリックすると、以下のウィンドウが開きます。
[新しいプロジェクトの作成]オプションを選択し、プロジェクトの名前を指定して、[作成]をクリックします。

作成したプロジェクトを選択し、[完了]をクリックします。

プロジェクトのインポート
TOSビッグデータ実行可能ファイルをダブルクリックすると、以下のようなウィンドウが表示されます。[デモプロジェクトのインポート]オプションを選択し、[選択]をクリックします。

以下のオプションからお選びいただけます。ここでは、データ統合デモを選択しています。次に、[完了]をクリックします。

次に、プロジェクトの名前と説明を入力します。[完了]をクリックします。

インポートしたプロジェクトは、既存のプロジェクトリストの下に表示されます。
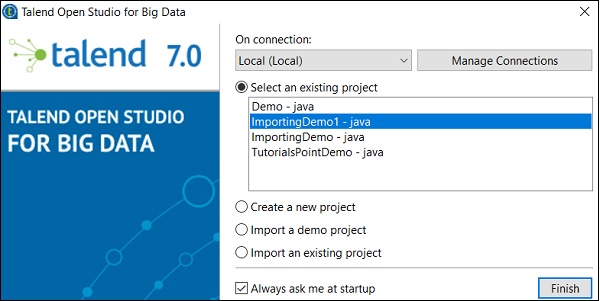
それでは、既存のTalendプロジェクトをインポートする方法を理解しましょう。
[既存のプロジェクトをインポートする]オプションを選択し、[選択]をクリックします。

プロジェクト名を指定し、「ルートディレクトリの選択」オプションを選択します。

既存のTalendプロジェクトのホームディレクトリを参照し、[完了]をクリックします。

既存のTalendプロジェクトがインポートされます。
プロジェクトを開く
既存のプロジェクトからプロジェクトを選択し、[完了]をクリックします。これにより、そのTalendプロジェクトが開きます。

プロジェクトの削除
プロジェクトを削除するには、[接続の管理]をクリックします。

[既存のプロジェクトを削除]をクリックします

削除するプロジェクトを選択し、[OK]をクリックします。
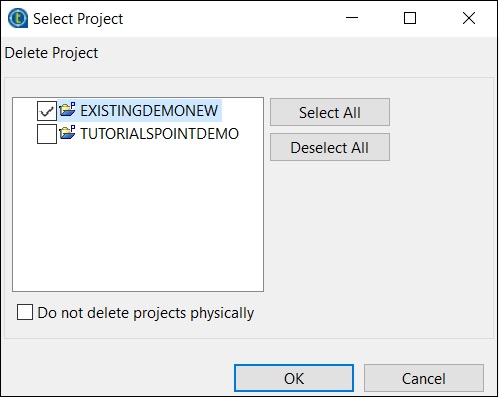
もう一度[OK]をクリックします。
プロジェクトのエクスポート
[プロジェクトのエクスポート]オプションをクリックします。

エクスポートするプロジェクトを選択し、エクスポートする場所へのパスを指定します。[完了]をクリックします。

ビジネスモデルは、データ統合プロジェクトをグラフィカルに表現したものです。これは、ビジネスのワークフローを技術的に表したものではありません。
なぜビジネスモデルが必要なのですか?
ビジネスモデルは、あなたが何をしているのかを上級管理職に示すために構築されており、あなたのチームにあなたが達成しようとしていることを理解させます。ビジネスモデルの設計は、組織がデータ統合プロジェクトの開始時に採用するベストプラクティスの1つと見なされています。さらに、コスト削減に役立つだけでなく、プロジェクトのボトルネックを見つけて解決します。モデルは、必要に応じて、プロジェクトの実装中および実装後に変更できます。
TalendOpenStudioでのビジネスモデルの作成
Talend open studioは、ビジネスモデルを作成および設計するための複数の形状とコネクタを提供します。ビジネスモデルの各モジュールには、ドキュメントを添付できます。
Talend Open Studioは、ビジネスモデルを作成するために次の形状とコネクタオプションを提供します-
Decision −この形状は、モデルにif条件を配置するために使用されます。
Action −この形状は、変換、変換、またはフォーマットを示すために使用されます。
Terminal −この形状は出力端子の種類を示しています。
Data −この形状はデータ型を表示するために使用されます。
Document −この形状は、処理されたデータの入出力に使用できるドキュメントオブジェクトを挿入するために使用されます。
Input −この形状は、ユーザーがデータを手動で渡すことができる入力オブジェクトを挿入するために使用されます。
List −この形状には抽出されたデータが含まれており、リスト内の特定の種類のデータのみを保持するように定義できます。
Database −この形状は、入力/出力データを保持するために使用されます。
Actor −この形は、意思決定と技術プロセスに関与する個人を象徴しています
Ellipse −楕円形を挿入します。
Gear −この形状は、Talendジョブに置き換える必要のある手動プログラムを示しています。
Talendのすべての操作は、コネクタとコンポーネントによって実行されます。Talendは、いくつかの操作を実行するための800以上のコネクタとコンポーネントを提供しています。これらのコンポーネントはパレットに存在し、コンポーネントが属する21の主要なカテゴリがあります。コネクタを選択し、デザイナーペインにドラッグアンドドロップするだけで、Javaコードが自動的に作成され、Talendコードを保存するとコンパイルされます。
コンポーネントを含む主なカテゴリを以下に示します-
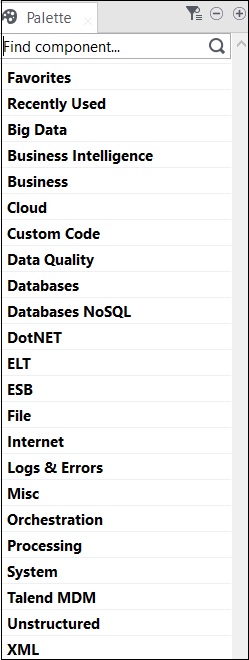
以下は、Talend OpenStudioでのデータ統合に広く使用されているコネクタとコンポーネントのリストです。
tMysqlConnection −コンポーネントで定義されたMySQLデータベースに接続します。
tMysqlInput −データベースクエリを実行してデータベースを読み取り、クエリに応じてフィールド(テーブル、ビューなど)を抽出します。
tMysqlOutput − MySQLデータベースのデータの書き込み、更新、変更に使用されます。
tFileInputDelimited −区切られたファイルを行ごとに読み取り、それらを別々のフィールドに分割して、次のコンポーネントに渡します。
tFileInputExcel − Excelファイルを行ごとに読み取り、それらを別々のフィールドに分割して、次のコンポーネントに渡します。
tFileList −指定されたファイルマスクパターンからすべてのファイルとディレクトリを取得します。
tFileArchive −ファイルまたはフォルダのセットをzip、gzip、またはtar.gzアーカイブファイルに圧縮します。
tRowGenerator −関数を記述したり、式を選択してサンプルデータを生成したりできるエディターを提供します。
tMsgBox −メッセージが指定されたダイアログボックスと[OK]ボタンを返します。
tLogRow−処理されるデータを監視します。実行コンソールにデータ/出力を表示します。
tPreJob −実際のジョブが開始する前に実行されるサブジョブを定義します。
tMap− Talendstudioのプラグインとして機能します。1つ以上のソースからデータを取得して変換し、変換されたデータを1つ以上の宛先に送信します。
tJoin −メインフローとルックアップフローの間で内部結合と外部結合を実行することにより、2つのテーブルを結合します。
tJava −TalendプログラムでパーソナライズされたJavaコードを使用できるようにします。
tRunJob − Talendジョブを次々に実行することにより、複雑なジョブシステムを管理します。
これは、ビジネスモデルの技術的な実装/グラフィック表現です。この設計では、1つ以上のコンポーネントを相互に接続して、データ統合プロセスを実行します。したがって、コンポーネントをデザインペインにドラッグアンドドロップしてからコネクタに接続すると、ジョブデザインはすべてをコードに変換し、データフローを形成する完全な実行可能プログラムを作成します。
ジョブの作成
リポジトリウィンドウで、ジョブデザインを右クリックし、[ジョブの作成]をクリックします。
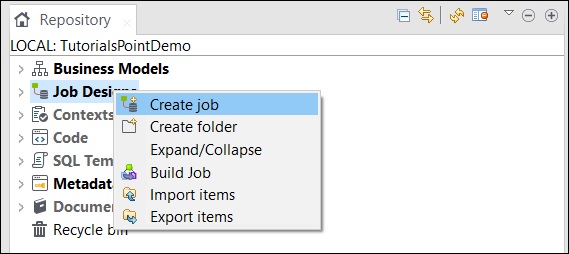
ジョブの名前、目的、説明を入力して、[完了]をクリックします。
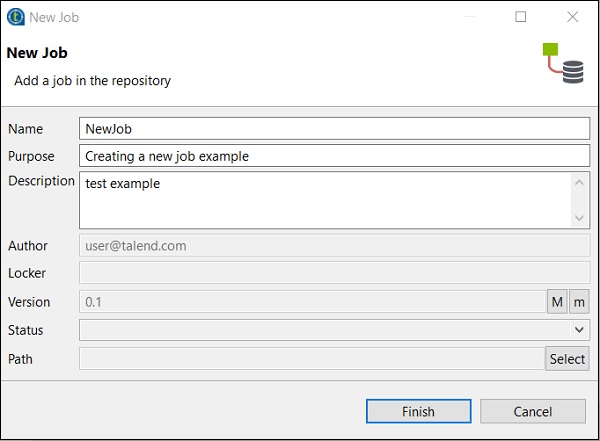
ジョブがジョブデザインの下に作成されていることがわかります。
次に、このジョブを使用してコンポーネントを追加し、接続して構成します。ここでは、Excelファイルを入力として受け取り、同じデータを使用してExcelファイルを出力として生成します。
ジョブへのコンポーネントの追加
パレットには、選択できるコンポーネントがいくつかあります。コンポーネントの名前を入力して選択できる検索オプションもあります。
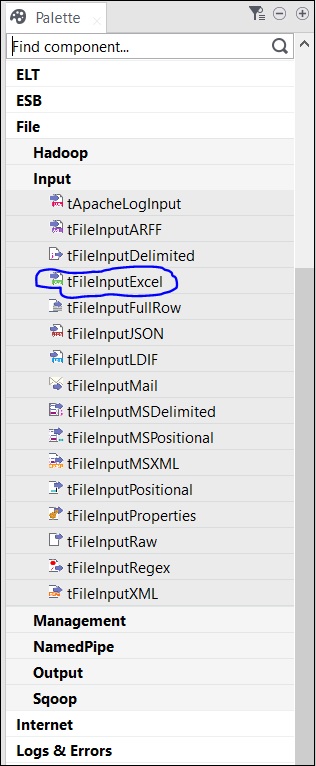
ここではExcelファイルを入力として使用しているため、tFileInputExcelコンポーネントをパレットからデザイナウィンドウにドラッグアンドドロップします。

これで、デザイナウィンドウの任意の場所をクリックすると、検索ボックスが表示されます。tLogRowを見つけて選択し、デザイナーウィンドウに表示します。

最後に、パレットからtFileOutputExcelコンポーネントを選択し、デザイナーウィンドウにドラッグアンドドロップします。
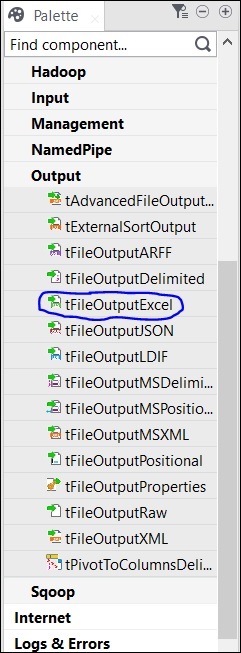
これで、コンポーネントの追加が完了しました。
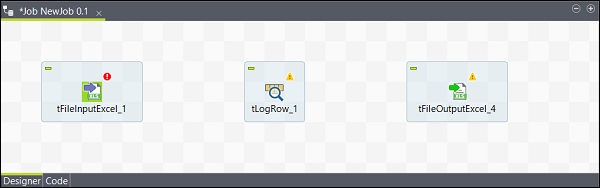
コンポーネントの接続
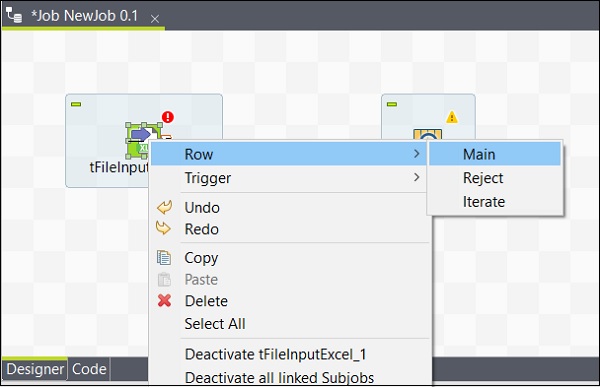
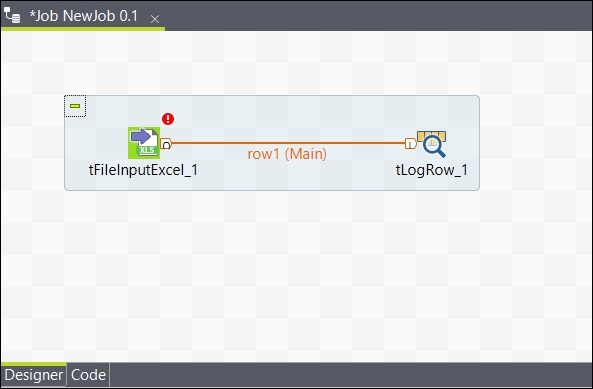
コンポーネントを追加したら、それらを接続する必要があります。以下に示すように、最初のコンポーネントtFileInputExcelを右クリックし、tLogRowにメインラインを描画します。
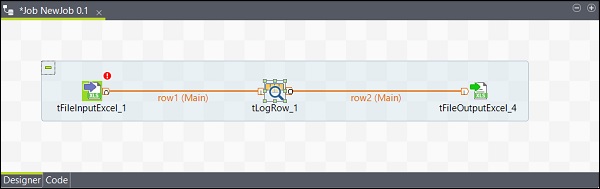
同様に、tLogRowを右クリックして、tFileOutputExcelにメインラインを描画します。これで、コンポーネントが接続されました。
コンポーネントの構成
ジョブにコンポーネントを追加して接続した後、それらを構成する必要があります。このためには、最初のコンポーネントtFileInputExcelをダブルクリックして構成します。以下に示すように、ファイル名/ストリームに入力ファイルのパスを指定します。
あなたの1場合番目のExcelの行は列名をしている、ヘッダオプションに1を入れました。
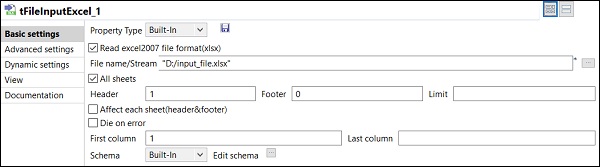
[スキーマの編集]をクリックし、入力したExcelファイルに従って列とそのタイプを追加します。スキーマを追加したら、[OK]をクリックします。
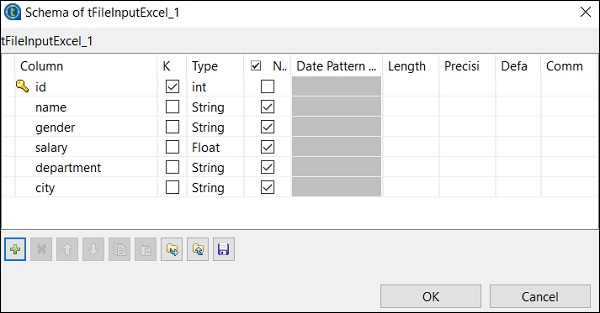
[はい]をクリックします。
tLogRowコンポーネントで、同期列をクリックし、入力から行を生成するモードを選択します。ここでは、フィールド区切り文字として「、」を使用した基本モードを選択しました。
最後に、tFileOutputExcelコンポーネントで、保存するファイル名のパスを指定します
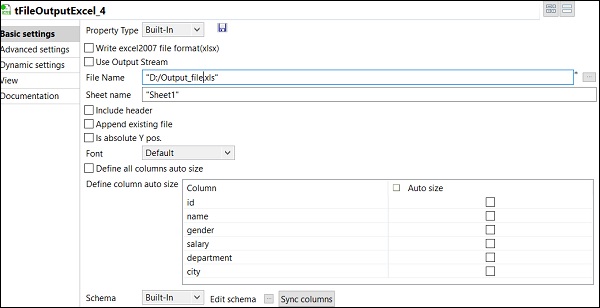
シート名が付いた出力Excelファイル。 Click on sync columns。
ジョブの実行
コンポーネントの追加、接続、構成が完了したら、Talendジョブを実行する準備が整います。[実行]ボタンをクリックして実行を開始します。

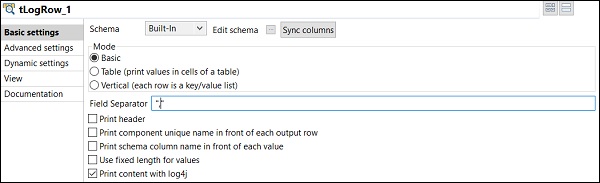
「、」区切り文字を使用した基本モードでの出力が表示されます。
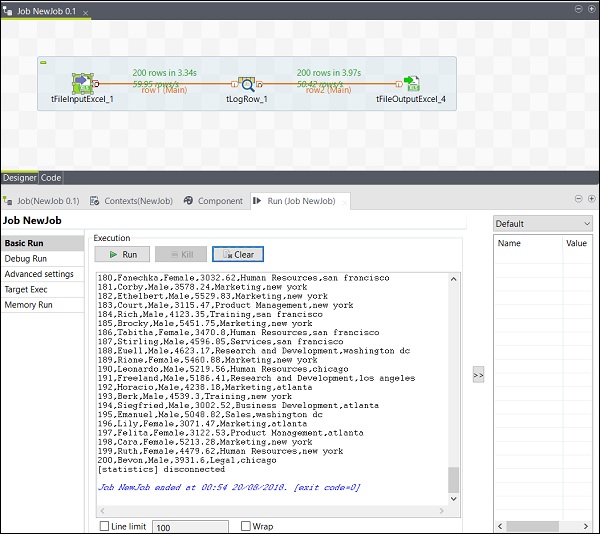
また、あなたが言及した出力パスで、出力がExcelとして保存されていることもわかります。
メタデータとは、基本的にデータに関するデータを意味します。データの内容、時期、理由、対象者、場所、対象、方法について説明します。Talendでは、メタデータにはTalendスタジオに存在するデータに関するすべての情報が含まれています。メタデータオプションは、Talend OpenStudioのリポジトリペイン内にあります。
Talendメタデータの下には、DB接続、さまざまな種類のファイル、LDAP、Azure、Salesforce、WebサービスFTP、Hadoopクラスターなどのさまざまなソースがあります。
Talend Open Studioでのメタデータの主な用途は、リポジトリのメタデータパネルからドラッグアンドドロップするだけで、これらのデータソースを複数のジョブで使用できることです。
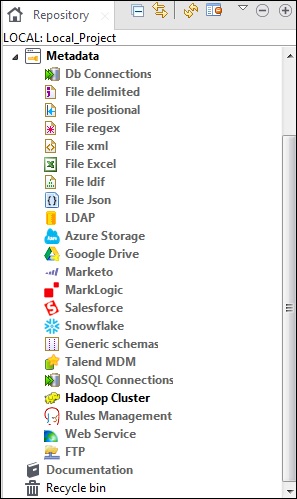
コンテキスト変数は、さまざまな環境でさまざまな値を持つことができる変数です。複数のコンテキスト変数を保持できるコンテキストグループを作成できます。各コンテキスト変数を1つずつジョブに追加する必要はありません。コンテキストグループをジョブに追加するだけです。
これらの変数は、コード生成の準備をするために使用されます。つまり、コンテキスト変数を使用することで、開発、テスト、または本番環境でコードを移動でき、すべての環境で実行されます。
どのジョブでも、以下に示すように[コンテキスト]タブに移動して、コンテキスト変数を追加できます。
この章では、Talendに含まれるジョブの管理と対応する機能について見ていきましょう。
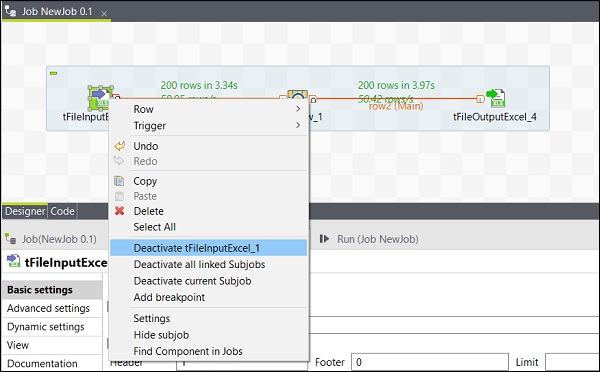
コンポーネントのアクティブ化/非アクティブ化
コンポーネントのアクティブ化/非アクティブ化は非常に簡単です。コンポーネントを選択して右クリックし、そのコンポーネントの非アクティブ化またはアクティブ化オプションを選択するだけです。
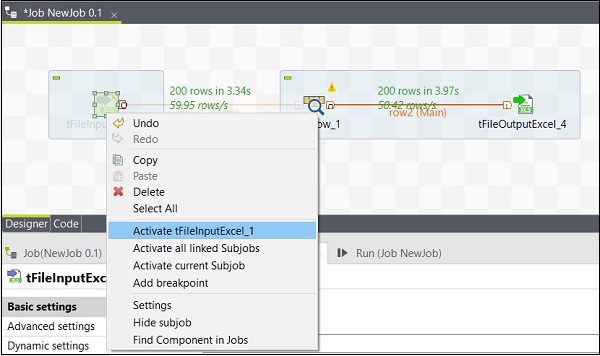
アイテムのインポート/エクスポートとジョブの構築
ジョブからアイテムをエクスポートするには、ジョブデザインでジョブを右クリックし、[アイテムのエクスポート]をクリックします。
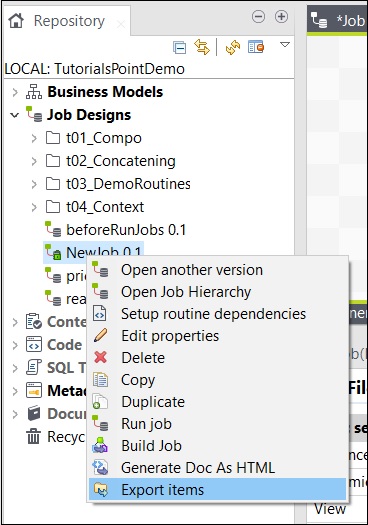
アイテムをエクスポートするパスを入力し、[完了]をクリックします。
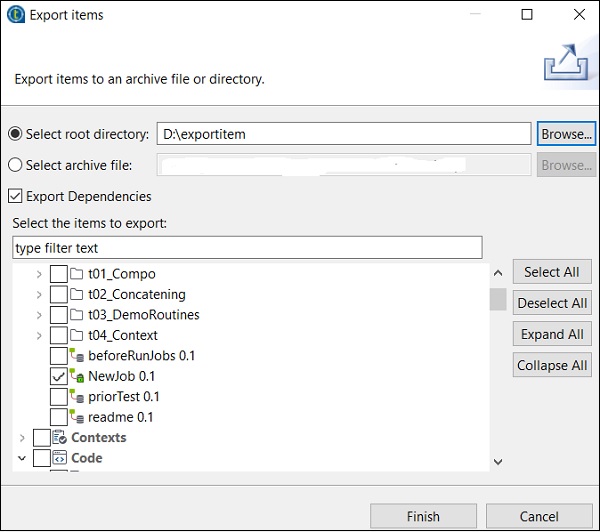
ジョブからアイテムをインポートするには、ジョブデザインでジョブを右クリックし、[アイテムのインポート]をクリックします。
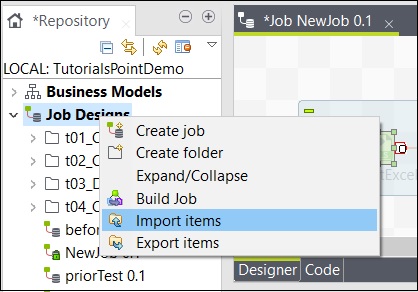
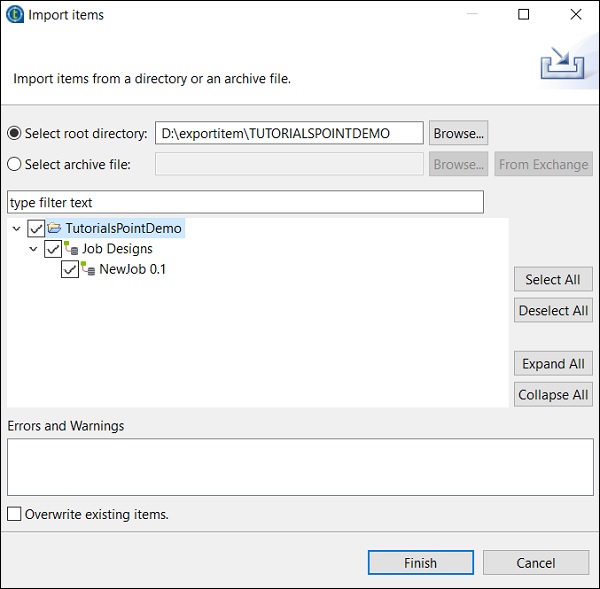
アイテムをインポートするルートディレクトリを参照します。
すべてのチェックボックスを選択し、[完了]をクリックします。
この章では、Talendでのジョブ実行の処理について理解しましょう。
ジョブをビルドするには、ジョブを右クリックして[ジョブのビルド]オプションを選択します。
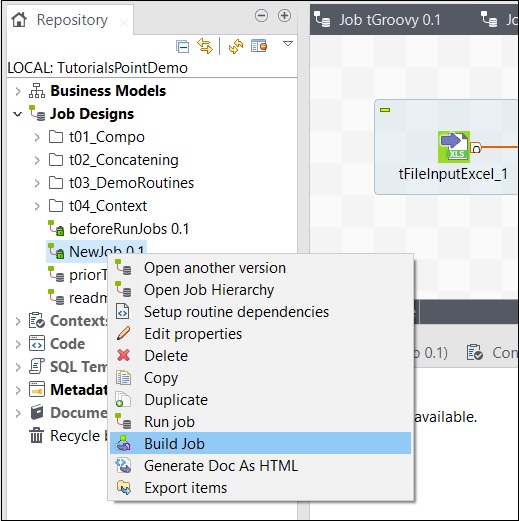
ジョブをアーカイブするパスを指定し、ジョブのバージョンとビルドタイプを選択して、[完了]をクリックします。
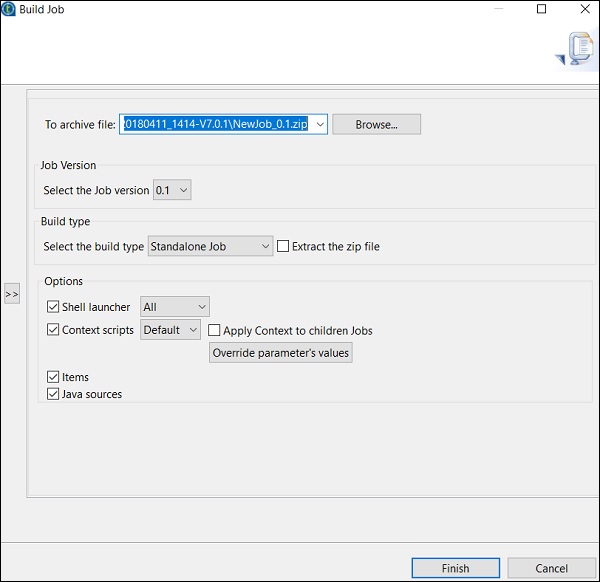
通常モードでジョブを実行する方法
通常のノードでジョブを実行するには、「基本実行」を選択し、実行ボタンをクリックして実行を開始する必要があります。
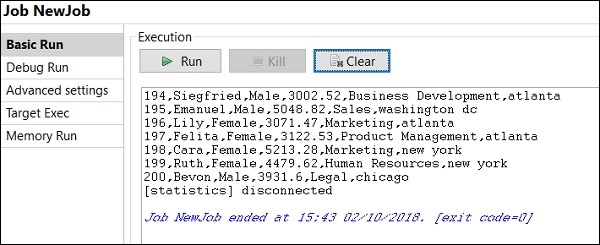
デバッグモードでジョブを実行する方法
デバッグモードでジョブを実行するには、デバッグするコンポーネントにブレークポイントを追加します。
次に、コンポーネントを選択して右クリックし、[ブレークポイントの追加]オプションをクリックします。ここで、tFileInputExcelおよびtLogRowコンポーネントにブレークポイントを追加したことに注意してください。次に、[デバッグの実行]に移動し、[Javaデバッグ]ボタンをクリックします。
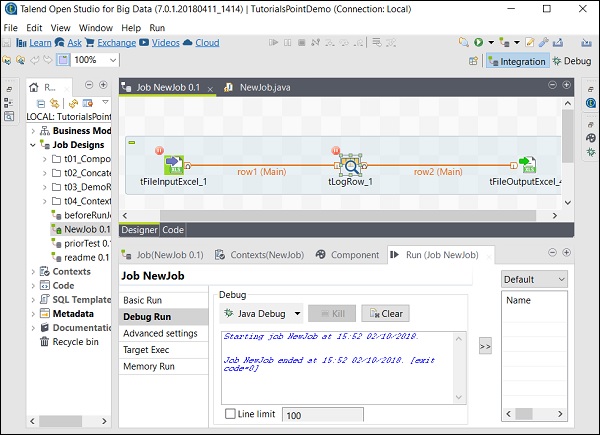
次のスクリーンショットから、ジョブがデバッグモードで、前述のブレークポイントに従って実行されることがわかります。
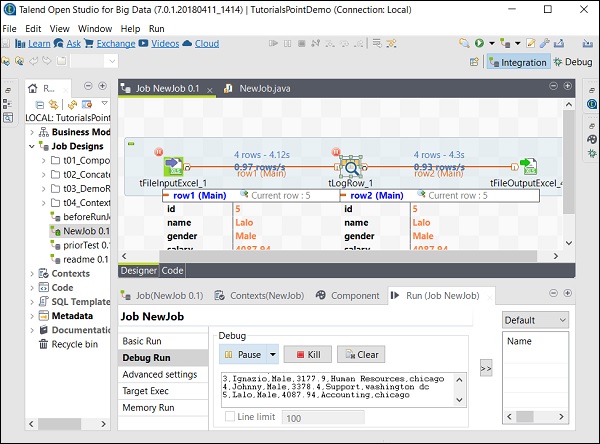
高度な設定
詳細設定では、統計、実行時間、実行前にジョブを保存、実行前にクリア、およびJVM設定から選択できます。この各オプションには、ここで説明する機能があります-
Statistics −処理のパフォーマンス率を表示します。
Exec Time −ジョブの実行にかかった時間。
Save Job before Execution −実行が始まる前にジョブを自動的に保存します。
Clear before Run −出力コンソールからすべてを削除します。
JVM Settings −独自のJava引数を構成するのに役立ちます。
ビッグデータを使用するOpenStudioのキャッチフレーズは、「ビッグデータ用の主要な無料のオープンソースETLツールを使用してETLとELTを簡素化する」です。この章では、ビッグデータ環境でデータを処理するためのツールとしてのTalendの使用法を見てみましょう。
前書き
Talend Open Studio –ビッグデータは、ビッグデータ環境でデータを非常に簡単に処理するための無料のオープンソースツールです。Talend Open Studioには、いくつかのHadoopコンポーネントをドラッグアンドドロップするだけで、Hadoopジョブを作成して実行できるビッグデータコンポーネントがたくさんあります。
その上、MapReduceコードの大きな行を書く必要はありません。Talend Open Studioビッグデータは、そこに存在するコンポーネントを使用してこれを行うのに役立ちます。MapReduceコードが自動的に生成されます。コンポーネントをドラッグアンドドロップし、いくつかのパラメーターを構成するだけです。
また、Cloudera、HortonWorks、MapR、Amazon EMR、さらにはApacheなどのいくつかのビッグデータディストリビューションに接続するオプションも提供します。
ビッグデータのTalendコンポーネント
ビッグデータに含まれるビッグデータ環境でジョブを実行するためのコンポーネントを含むカテゴリのリストを以下に示します-
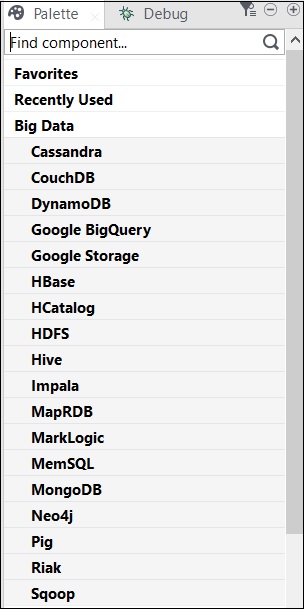
Talend OpenStudioのビッグデータコネクタとコンポーネントのリストを以下に示します-
tHDFSConnection − HDFS(Hadoop分散ファイルシステム)への接続に使用されます。
tHDFSInput −指定されたhdfsパスからデータを読み取り、それをtalendスキーマに配置してから、ジョブの次のコンポーネントに渡します。
tHDFSList −指定されたhdfsパス内のすべてのファイルとフォルダーを取得します。
tHDFSPut −指定されたパスでローカルファイルシステム(ユーザー定義)からhdfsにファイル/フォルダーをコピーします。
tHDFSGet −指定されたパスでhdfsからローカルファイルシステム(ユーザー定義)にファイル/フォルダーをコピーします。
tHDFSDelete −HDFSからファイルを削除します
tHDFSExist −ファイルがHDFSに存在するかどうかを確認します。
tHDFSOutput −HDFSにデータフローを書き込みます。
tCassandraConnection −Cassandraサーバーへの接続を開きます。
tCassandraRow −指定されたデータベースでCQL(Cassandraクエリ言語)クエリを実行します。
tHBaseConnection −HBaseデータベースへの接続を開きます。
tHBaseInput −HBaseデータベースからデータを読み取ります。
tHiveConnection −Hiveデータベースへの接続を開きます。
tHiveCreateTable −ハイブデータベース内にテーブルを作成します。
tHiveInput −ハイブデータベースからデータを読み取ります。
tHiveLoad −ハイブテーブルまたは指定されたディレクトリにデータを書き込みます。
tHiveRow −指定されたデータベースでHiveQLクエリを実行します。
tPigLoad −入力データを出力ストリームにロードします。
tPigMap −pigプロセスでデータを変換およびルーティングするために使用されます。
tPigJoin −結合キーに基づいて2つのファイルの結合操作を実行します。
tPigCoGroup −複数の入力からのデータをグループ化して集約します。
tPigSort − 1つ以上の定義済みソートキーに基づいて、指定されたデータをソートします。
tPigStoreResult −豚の手術の結果を定義された保管スペースに保管します。
tPigFilterRow −指定された条件に基づいてデータを分割するために、指定された列をフィルタリングします。
tPigDistinct −リレーションから重複するタプルを削除します。
tSqoopImport − MySQL、OracleDBなどのリレーショナルデータベースからHDFSにデータを転送します。
tSqoopExport − HDFSからMySQL、OracleDBなどのリレーショナルデータベースにデータを転送します
この章では、TalendがHadoop分散ファイルシステムとどのように連携するかについて詳しく学びましょう。
設定と前提条件
Talend with HDFSに進む前に、この目的のために満たす必要のある設定と前提条件について学習する必要があります。
ここでは、仮想ボックスでClouderaクイックスタート5.10VMを実行しています。このVMではホストオンリーネットワークを使用する必要があります。
ホストオンリーネットワークIP:192.168.56.101

ClouderaManagerでも同じホストを実行している必要があります。

Windowsシステムで、c:\ Windows \ System32 \ Drivers \ etc \ hostsに移動し、以下に示すようにメモ帳を使用してこのファイルを編集します。

同様に、clouderaクイックスタートVMで、以下に示すように/ etc / hostsファイルを編集します。
sudo gedit /etc/hosts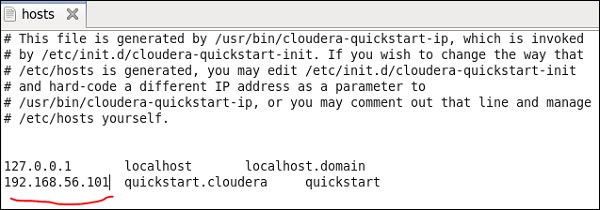
Hadoop接続のセットアップ
リポジトリパネルで、メタデータに移動します。Hadoopクラスターを右クリックして、新しいクラスターを作成します。このHadoopクラスター接続の名前、目的、説明を入力してください。
[次へ]をクリックします。

ディストリビューションをclouderaとして選択し、使用しているバージョンを選択します。構成の取得オプションを選択し、「次へ」をクリックします。

以下に示すように、マネージャーの資格情報(ポート、ユーザー名、パスワードを含むURI)を入力し、[接続]をクリックします。詳細が正しければ、検出されたクラスターの下でClouderaQuickStartを取得できます。
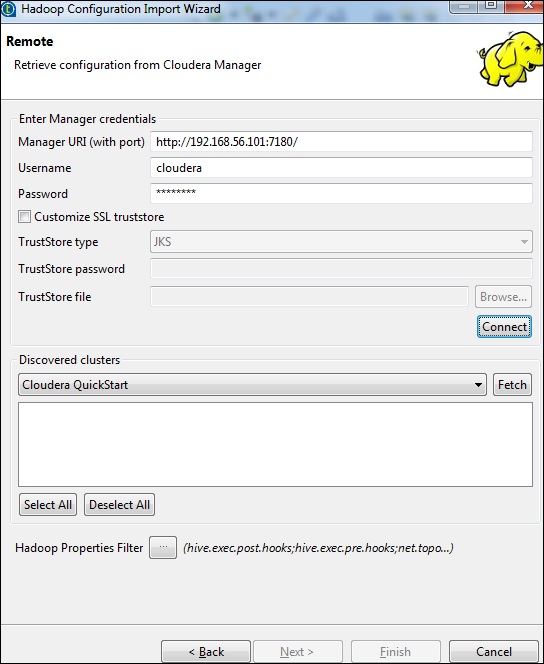
[フェッチ]をクリックします。これにより、HDFS、YARN、HBASE、HIVEのすべての接続と構成がフェッチされます。
[すべて]を選択して、[完了]をクリックします。

すべての接続パラメータが自動入力されることに注意してください。ユーザー名にclouderaと記載し、[完了]をクリックします。

これで、Hadoopクラスターに正常に接続できました。

HDFSへの接続
このジョブでは、HDFSに存在するすべてのディレクトリとファイルを一覧表示します。
まず、ジョブを作成してから、HDFSコンポーネントを追加します。ジョブデザインを右クリックして、新しいジョブ–hadoopjobを作成します。
次に、パレットから2つのコンポーネント(tHDFSConnectionとtHDFSList)を追加します。tHDFSConnectionを右クリックし、「OnSubJobOk」トリガーを使用してこれら2つのコンポーネントを接続します。
次に、両方のtalendhdfsコンポーネントを構成します。

tHDFSConnectionで、プロパティタイプとして[リポジトリ]を選択し、前に作成したHadoopclouderaクラスターを選択します。このコンポーネントに必要なすべての詳細が自動入力されます。

tHDFSListで、[既存の接続を使用する]を選択し、コンポーネントリストで構成したtHDFSConnectionを選択します。
[HDFSディレクトリ内のHDFSのホームパス]オプションを指定し、右側の参照ボタンをクリックします。

上記の構成で正しく接続を確立すると、以下のようなウィンドウが表示されます。HDFSホームに存在するすべてのディレクトリとファイルが一覧表示されます。

これは、clouderaでHDFSを確認することで確認できます。

HDFSからファイルを読み取る
このセクションでは、TalendでHDFSからファイルを読み取る方法を理解しましょう。この目的で新しいジョブを作成できますが、ここでは既存のジョブを使用しています。
3つのコンポーネント(tHDFSConnection、tHDFSInput、tLogRow)をパレットからデザイナウィンドウにドラッグアンドドロップします。
tHDFSConnectionを右クリックし、「OnSubJobOk」トリガーを使用してtHDFSInputコンポーネントを接続します。
tHDFSInputを右クリックし、メインリンクをtLogRowにドラッグします。

tHDFSConnectionは以前と同様の構成になることに注意してください。tHDFSInputで、「既存の接続を使用する」を選択し、コンポーネントリストからtHDFSConnectionを選択します。
[ファイル名]に、読み取りたいファイルのHDFSパスを指定します。ここでは単純なテキストファイルを読んでいるので、ファイルタイプはテキストファイルです。同様に、入力に応じて、以下に説明するように、行区切り文字、フィールド区切り文字、およびヘッダーの詳細を入力します。最後に、[スキーマの編集]ボタンをクリックします。

ファイルにはプレーンテキストが含まれているだけなので、String型の列を1つだけ追加します。次に、[OK]をクリックします。
Note −入力に異なるタイプの複数の列がある場合、それに応じてここでスキーマに言及する必要があります。

tLogRowコンポーネントで、[スキーマの編集]の[列の同期]をクリックします。
出力を印刷するモードを選択します。

最後に、[実行]をクリックしてジョブを実行します。
HDFSファイルの読み取りに成功すると、次の出力が表示されます。

HDFSへのファイルの書き込み
TalendでHDFSからファイルを書き込む方法を見てみましょう。3つのコンポーネント(tHDFSConnection、tFileInputDelimited、tHDFSOutput)をパレットからデザイナウィンドウにドラッグアンドドロップします。
tHDFSConnectionを右クリックし、「OnSubJobOk」トリガーを使用してtFileInputDelimitedコンポーネントを接続します。
tFileInputDelimitedを右クリックし、メインリンクをtHDFSOutputにドラッグします。

tHDFSConnectionは以前と同様の構成になることに注意してください。
ここで、tFileInputDelimitedで、[ファイル名/ストリーム]オプションに入力ファイルのパスを指定します。ここでは、csvファイルを入力として使用しているため、フィールド区切り文字は「、」です。
入力ファイルに応じて、ヘッダー、フッター、制限を選択します。ここでは、1行に列名が含まれているためヘッダーが1であり、HDFSに最初の3行のみを書き込んでいるため制限が3であることに注意してください。
次に、[スキーマの編集]をクリックします。
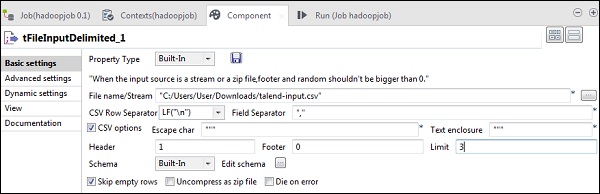
ここで、入力ファイルに従って、スキーマを定義します。入力ファイルには、以下の3つの列があります。

tHDFSOutputコンポーネントで、[列の同期]をクリックします。次に、[既存の接続を使用する]で[tHDFSConnection]を選択します。また、[ファイル名]に、ファイルを書き込むHDFSパスを指定します。
ファイルタイプはテキストファイル、アクションは「作成」、行区切り文字は「\ n」、フィールド区切り文字は「;」であることに注意してください。

最後に、[実行]をクリックしてジョブを実行します。ジョブが正常に実行されたら、ファイルがHDFSにあるかどうかを確認します。

ジョブで言及した出力パスを使用して、次のhdfsコマンドを実行します。
hdfs dfs -cat /input/talendwriteHDFSでの書き込みに成功すると、次の出力が表示されます。

前の章では、Talendがビッグデータで機能する方法を見てきました。この章では、MapReduceとTalendの使用方法を理解しましょう。
TalendMapReduceジョブの作成
TalendでMapReduceジョブを実行する方法を学びましょう。ここでは、MapReduceの単語数の例を実行します。
この目的のために、ジョブデザインを右クリックして、新しいジョブMapreduceJobを作成します。ジョブの詳細に言及し、[完了]をクリックします。
MapReduceジョブへのコンポーネントの追加
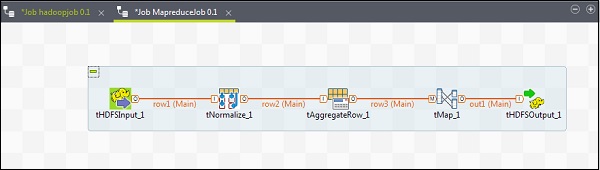
MapReduceジョブにコンポーネントを追加するには、Talendの5つのコンポーネント(tHDFSInput、tNormalize、tAggregateRow、tMap、tOutput)をパレットからデザイナーウィンドウにドラッグアンドドロップします。tHDFSInputを右クリックして、tNormalizeへのメインリンクを作成します。
tNormalizeを右クリックして、tAggregateRowへのメインリンクを作成します。次に、tAggregateRowを右クリックして、tMapへのメインリンクを作成します。次に、tMapを右クリックして、tHDFSOutputへのメインリンクを作成します。
コンポーネントと変換の構成
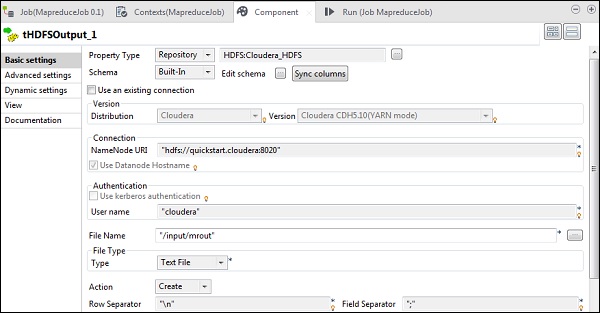
tHDFSInputで、ディストリビューションclouderaとそのバージョンを選択します。Namenode URIは「hdfs://quickstart.cloudera:8020」であり、ユーザー名は「cloudera」である必要があることに注意してください。[ファイル名]オプションで、入力ファイルのMapReduceジョブへのパスを指定します。この入力ファイルがHDFSに存在することを確認してください。
次に、入力ファイルに応じて、ファイルタイプ、行区切り文字、ファイル区切り記号、およびヘッダーを選択します。
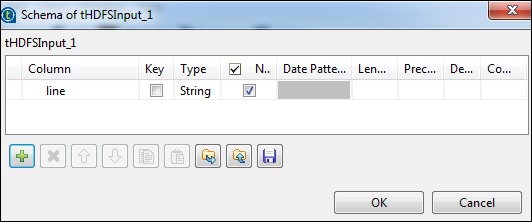
[スキーマの編集]をクリックして、フィールド「行」を文字列タイプとして追加します。
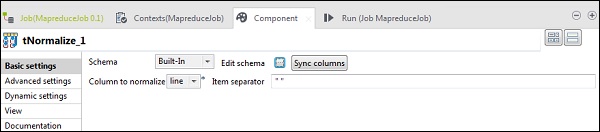
tNomalizeでは、正規化する列は行になり、項目区切り文字は空白->““になります。次に、[スキーマの編集]をクリックします。以下に示すように、tNormalizeには行列があり、tAggregateRowには2列のwordとwordcountがあります。
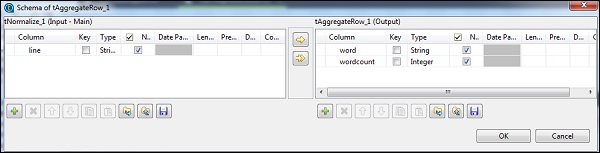
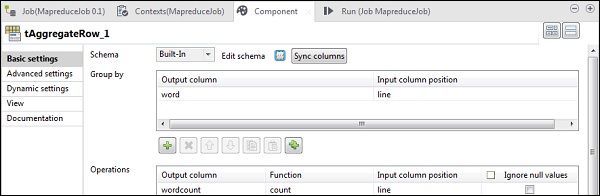
tAggregateRowで、Groupbyオプションの出力列としてwordを配置します。操作では、wordcountを出力列として、関数をcountとして、入力列の位置を行として配置します。
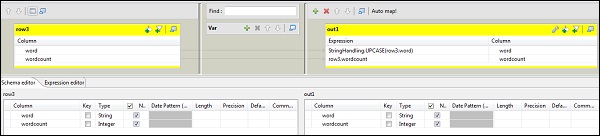
次に、tMapコンポーネントをダブルクリックしてマップエディタに入り、入力を必要な出力にマップします。この例では、wordはwordにマップされ、wordcountはwordcountにマップされます。式の列で、[…]をクリックして式ビルダーに入ります。
次に、カテゴリリストとUPCASE関数からStringHandlingを選択します。式を「StringHandling.UPCASE(row3.word)」に編集し、[OK]をクリックします。以下に示すように、row3.wordcountをwordcountに対応する式列に保持します。
tHDFSOutputで、プロパティタイプからリポジトリとして作成したHadoopクラスターに接続します。フィールドが自動入力されることに注意してください。[ファイル名]に、出力を保存する出力パスを指定します。以下に示すように、アクション、行区切り文字、およびフィールド区切り文字を保持します。
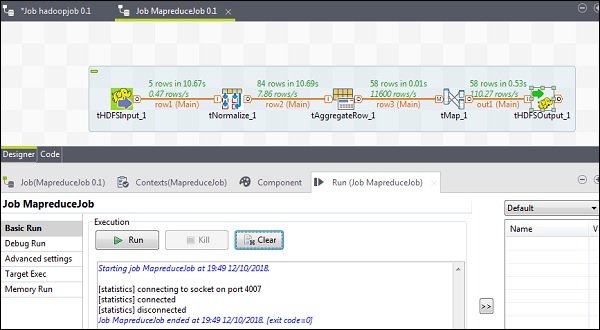
MapReduceジョブの実行
構成が正常に完了したら、[実行]をクリックしてMapReduceジョブを実行します。
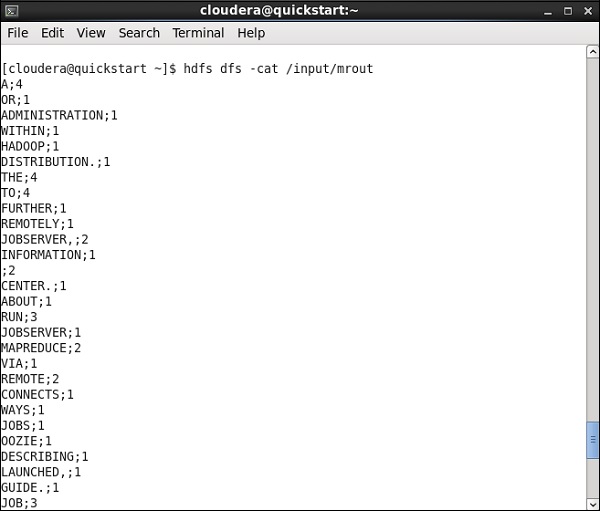
HDFSパスに移動し、出力を確認します。すべての単語は、単語数とともに大文字になることに注意してください。
この章では、TalendでPigジョブを操作する方法を学びましょう。
TalendPigジョブの作成
このセクションでは、TalendでPigジョブを実行する方法を学びましょう。ここでは、NYSEデータを処理して、IBMの平均在庫量を調べます。
これを行うには、[ジョブデザイン]を右クリックして、新しいジョブであるpigjobを作成します。ジョブの詳細に言及し、[完了]をクリックします。
Pigジョブへのコンポーネントの追加
Pigジョブにコンポーネントを追加するには、4つのTalendコンポーネント(tPigLoad、tPigFilterRow、tPigAggregate、tPigStoreResult)をパレットからデザイナーウィンドウにドラッグアンドドロップします。
次に、tPigLoadを右クリックして、tPigFilterRowへのPigCombine行を作成します。次に、tPigFilterRowを右クリックして、tPigAggregateへのPigCombine行を作成します。tPigAggregateを右クリックして、tPigStoreResultへのPig結合行を作成します。
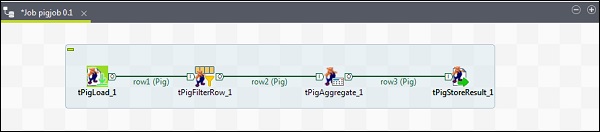
コンポーネントと変換の構成
tPigLoadで、配布をclouderaおよびclouderaのバージョンとして記述します。Namenode URIは「hdfs://quickstart.cloudera:8020」であり、ResourceManagerは「quickstart.cloudera:8020」である必要があることに注意してください。また、ユーザー名は「cloudera」である必要があります。
入力ファイルURIで、NYSE入力ファイルのpigジョブへのパスを指定します。この入力ファイルはHDFSに存在する必要があることに注意してください。
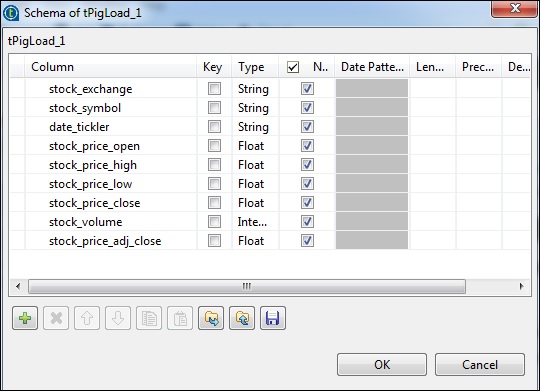
[スキーマの編集]をクリックし、以下に示すように列とそのタイプを追加します。
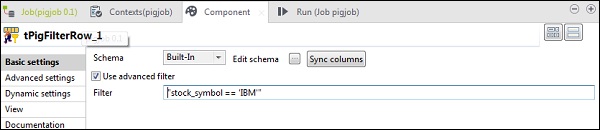
tPigFilterRowで、「高度なフィルターを使用する」オプションを選択し、「フィルター」オプションに「stock_symbol = = 'IBM'」を入力します。
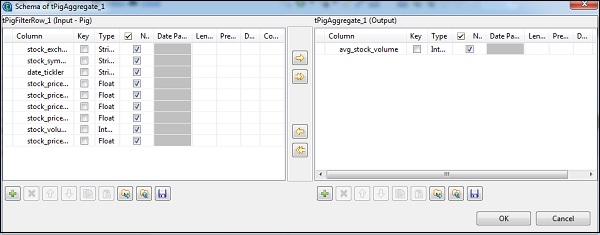
次に示すように、tAggregateRowで、[スキーマの編集]をクリックし、出力にavg_stock_volume列を追加します。
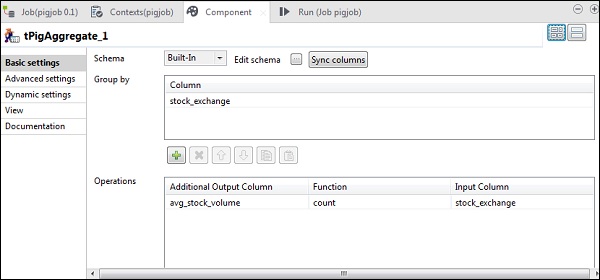
次に、stock_exchange列をGroupbyオプションに配置します。countFunctionとstock_exchangeを入力列として[Operations]フィールドにavg_stock_volume列を追加します。
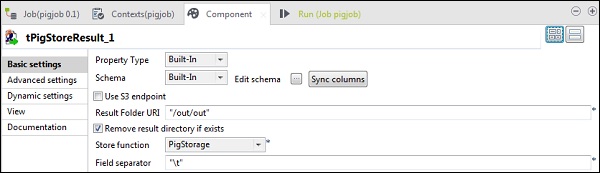
tPigStoreResultで、Pigジョブの結果を保存する結果フォルダーURIに出力パスを指定します。ストア関数をPigStorageとして選択し、フィールド区切り文字(必須ではありません)を「\ t」として選択します。
豚の仕事を実行する
次に、[実行]をクリックしてPigジョブを実行します。(警告は無視してください)
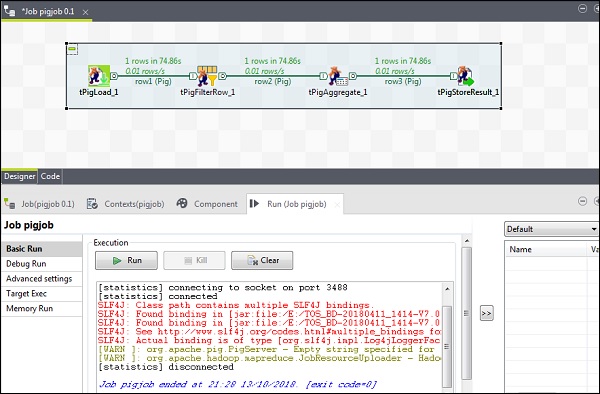
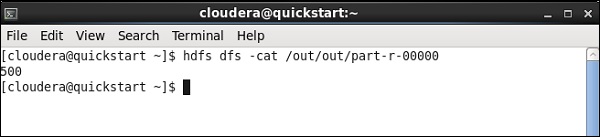
ジョブが終了したら、行って、pigジョブの結果を保存するために言及したHDFSパスで出力を確認します。IBMの平均在庫量は500です。
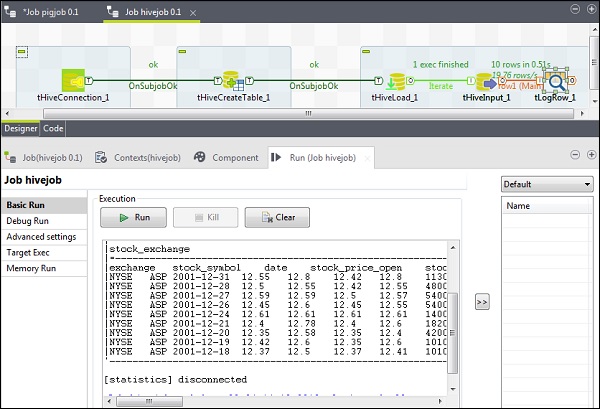
この章では、TalendでHiveジョブを操作する方法を理解しましょう。
TalendHiveジョブの作成
例として、NYSEデータをハイブテーブルにロードし、基本的なハイブクエリを実行します。ジョブデザインを右クリックして、新しいジョブ–hivejobを作成します。ジョブの詳細に言及し、[完了]をクリックします。
Hiveジョブへのコンポーネントの追加
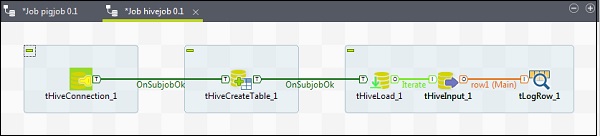
コンポーネントをHiveジョブに関連付けるには、5つのtalendコンポーネント(tHiveConnection、tHiveCreateTable、tHiveLoad、tHiveInput、tLogRow)をパレットからデザイナウィンドウにドラッグアンドドロップします。次に、tHiveConnectionを右クリックして、tHiveCreateTableへのOnSubjobOkトリガーを作成します。次に、tHiveCreateTableを右クリックして、tHiveLoadへのOnSubjobOkトリガーを作成します。tHiveLoadを右クリックし、tHiveInputで反復トリガーを作成します。最後に、tHiveInputを右クリックして、tLogRowへのメインラインを作成します。
コンポーネントと変換の構成
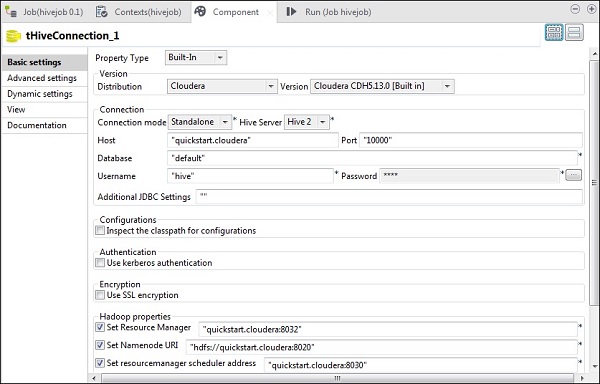
tHiveConnectionで、clouderaとしてディストリビューションと使用しているバージョンを選択します。接続モードはスタンドアロンになり、HiveサービスはHive 2になることに注意してください。また、以下のパラメーターが適切に設定されているかどうかを確認してください。
- ホスト:「quickstart.cloudera」
- ポート:「10000」
- データベース:「デフォルト」
- ユーザー名:「ハイブ」
パスワードは自動入力されるので、編集する必要はありません。また、他のHadoopプロパティが事前設定され、デフォルトで設定されます。
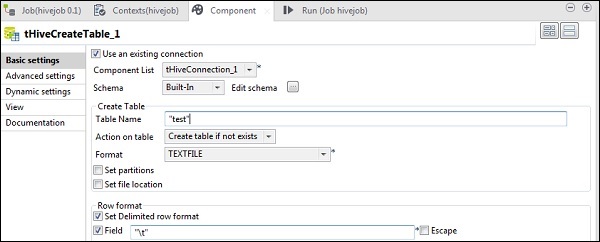
tHiveCreateTableで、[既存の接続を使用する]を選択し、[コンポーネント]リストにtHiveConnectionを配置します。デフォルトのデータベースに作成するテーブル名を指定します。以下に示すように、他のパラメータを保持します。
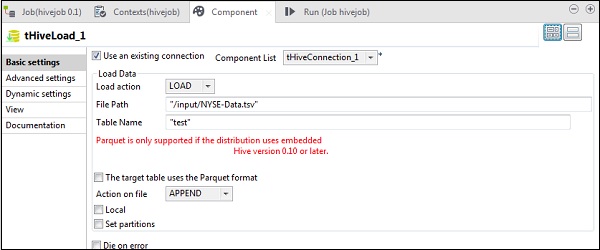
tHiveLoadで、「既存の接続を使用する」を選択し、コンポーネントリストにtHiveConnectionを配置します。ロードアクションでロードを選択します。[ファイルパス]で、NYSE入力ファイルのHDFSパスを指定します。入力をロードするテーブル名のテーブルに言及します。以下に示すように、他のパラメータを保持します。
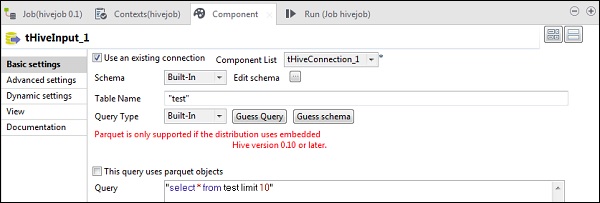
tHiveInputで、[既存の接続を使用する]を選択し、[コンポーネント]リストにtHiveConnectionを配置します。[スキーマの編集]をクリックし、以下のスキーマスナップショットに示すように、列とそのタイプを追加します。次に、tHiveCreateTableで作成したテーブル名を指定します。
Hiveテーブルで実行するクエリオプションにクエリを配置します。ここでは、テストハイブテーブルの最初の10行のすべての列を印刷しています。
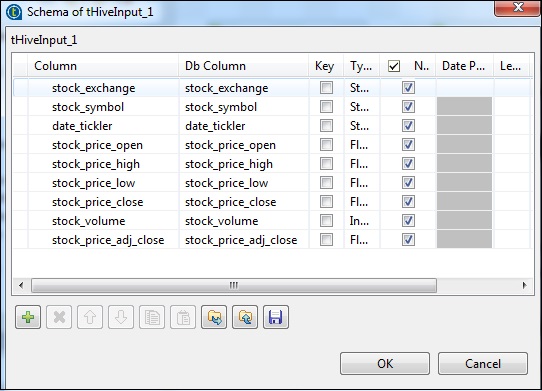
tLogRowで、[列の同期]をクリックし、[テーブルモード]を選択して出力を表示します。
Hiveジョブの実行
[実行]をクリックして実行を開始します。すべての接続とパラメーターが正しく設定されている場合、以下に示すようなクエリの出力が表示されます。