Teradata-クイックガイド
Teradataとは何ですか?
Teradataは、人気のあるリレーショナルデータベース管理システムの1つです。これは主に、大規模なデータウェアハウジングアプリケーションの構築に適しています。Teradataは、並列処理の概念によってこれを実現します。これは、Teradataという会社によって開発されました。
Teradataの歴史
以下は、Teradataの歴史の簡単な要約であり、主要なマイルストーンを示しています。
1979 −Teradataが組み込まれました。
1984 −最初のデータベースコンピュータDBC / 1012のリリース。
1986− Fortune誌は、Teradataを「ProductoftheYear」と名付けました。
1999 −130テラバイトのTeradataを使用する世界最大のデータベース。
2002 −パーティションプライマリインデックスと圧縮を使用してリリースされたTeradataV2R5。
2006 −Teradataマスターデータ管理ソリューションの立ち上げ。
2008 − Active DataWarehousingでリリースされたTeradata13.0。
2011 − Teradata Asterを買収し、Advanced AnalyticsSpaceに参入します。
2012 − Teradata14.0が導入されました。
2014 − Teradata15.0が導入されました。
Teradataの機能
以下はTeradataの機能の一部です-
Unlimited Parallelism− Teradataデータベースシステムは、超並列処理(MPP)アーキテクチャに基づいています。MPPアーキテクチャは、ワークロードをシステム全体に均等に分割します。Teradataシステムは、タスクをプロセス間で分割し、それらを並行して実行して、タスクが迅速に完了するようにします。
Shared Nothing Architecture− Teradataのアーキテクチャは、シェアードナッシングアーキテクチャと呼ばれます。Teradataノード、そのアクセスモジュールプロセッサ(AMP)、およびAMPに関連付けられたディスクは独立して動作します。それらは他の人と共有されません。
Linear Scalability−Teradataシステムは非常にスケーラブルです。それらは2048ノードまでスケールアップできます。たとえば、AMPの数を2倍にすることで、システムの容量を2倍にすることができます。
Connectivity − Teradataは、メインフレームやネットワーク接続システムなどのチャネル接続システムに接続できます。
Mature Optimizer− Teradataオプティマイザーは、市場で成熟したオプティマイザーの1つです。それは最初から並列になるように設計されています。リリースごとに改良されています。
SQL− Teradataは、テーブルに格納されているデータと対話するための業界標準SQLをサポートしています。これに加えて、独自の拡張機能を提供します。
Robust Utilities − Teradataは、FastLoad、MultiLoad、FastExport、TPTなどのTeradataシステムとの間でデータをインポート/エクスポートするための堅牢なユーティリティを提供します。
Automatic Distribution − Teradataは、手動による介入なしに、データをディスクに自動的に均等に分散します。
Teradataは、完全に機能するTeradata仮想マシンであるVMWAREにTeradataExpressを提供します。最大1テラバイトのストレージを提供します。Teradataは、40GBバージョンと1TBバージョンの両方のVMwareを提供します。
前提条件
VMは64ビットであるため、CPUは64ビットをサポートする必要があります。
Windowsのインストール手順
Step 1 −リンクから必要なVMバージョンをダウンロードします。 https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 −ファイルを抽出し、ターゲットフォルダを指定します。
Step 3 −リンクからVMWareWorkstationプレーヤーをダウンロードします。 https://my.vmware.com/web/vmware/downloads。WindowsとLinuxの両方で利用できます。Windows用のVMWAREワークステーションプレーヤーをダウンロードします。
Step 4 −ダウンロードが完了したら、ソフトウェアをインストールします。
Step 5 −インストールが完了したら、VMWAREクライアントを実行します。
Step 6− [仮想マシンを開く]を選択します。抽出されたTeradataVMWareフォルダーをナビゲートし、拡張子が.vmdkのファイルを選択します。
Step 7− TeradataVMWareがVMWareクライアントに追加されます。追加したTeradataVMwareを選択し、[仮想マシンの再生]をクリックします。

Step 8 −ソフトウェアの更新に関するポップアップが表示された場合は、[後で通知する]を選択できます。
Step 9 −ユーザー名をrootとして入力し、Tabキーを押し、パスワードをrootとして入力して、もう一度Enterキーを押します。
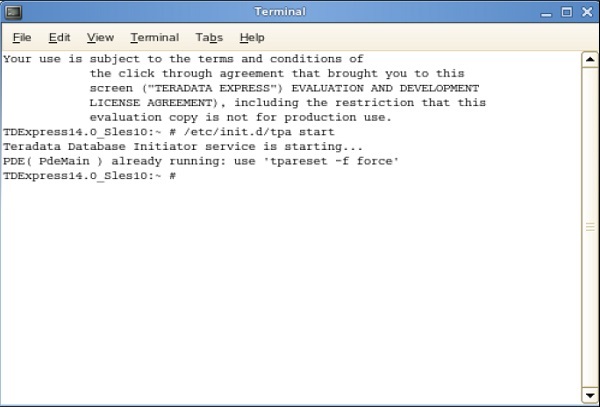
Step 10−デスクトップに次の画面が表示されたら、「ルートのホーム」をダブルクリックします。次に、「ゲノムのターミナル」をダブルクリックします。これにより、シェルが開きます。

Step 11−次のシェルから、コマンド/etc/init.d/tpastartを入力します。これにより、Teradataサーバーが起動します。
BTEQの開始
BTEQユーティリティは、SQLクエリをインタラクティブに送信するために使用されます。BTEQユーティリティを起動する手順は次のとおりです。
Step 1 −コマンド/ sbin / ifconfigを入力し、VMWareのIPアドレスを書き留めます。
Step 2−コマンドbteqを実行します。ログオンプロンプトで、コマンドを入力します。
ログオン<IPアドレス> / dbc、dbc; パスワードプロンプトで、dbcとしてパスワードを入力します。
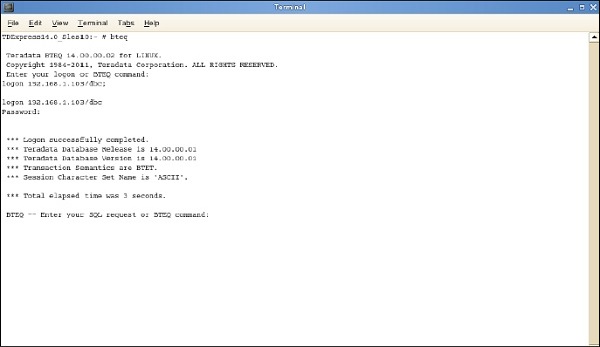
BTEQを使用してTeradataシステムにログインし、SQLクエリを実行できます。
Teradataアーキテクチャは、超並列処理(MPP)アーキテクチャに基づいています。Teradataの主要なコンポーネントは、解析エンジン、BYNET、およびアクセスモジュールプロセッサ(AMP)です。次の図は、Teradataノードの高レベルのアーキテクチャを示しています。
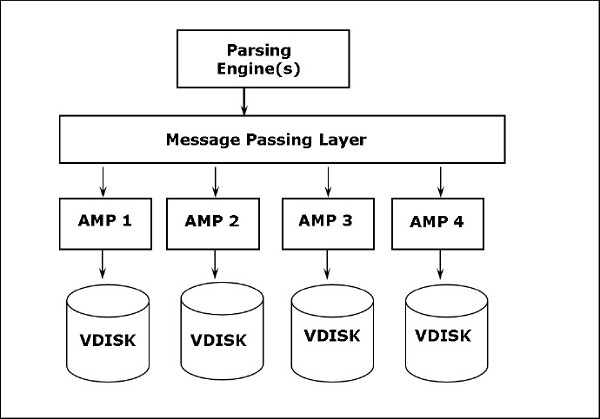
Teradataのコンポーネント
Teradataの主要コンポーネントは次のとおりです-
Node−TeradataSystemの基本単位です。Teradataシステム内の個々のサーバーは、ノードと呼ばれます。ノードは、独自のオペレーティングシステム、CPU、メモリ、Teradata RDBMSソフトウェアの独自のコピー、およびディスクスペースで構成されます。キャビネットは、1つ以上のノードで構成されます。
Parsing Engine−解析エンジンは、クライアントからクエリを受信し、効率的な実行プランを準備する責任があります。解析エンジンの責任は次のとおりです。
クライアントからSQLクエリを受信します
SQLクエリチェックを解析して構文エラーがないか確認します
SQLクエリで使用されるオブジェクトに対してユーザーが必要な権限を持っているかどうかを確認します
SQLで使用されているオブジェクトが実際に存在するかどうかを確認します
SQLクエリを実行する実行プランを準備し、BYNETに渡します
AMPから結果を受け取り、クライアントに送信します
Message Passing Layer− BYNETと呼ばれるメッセージパッシングレイヤーは、Teradataシステムのネットワークレイヤーです。これにより、PEとAMP間、およびノード間の通信が可能になります。解析エンジンから実行プランを受信し、AMPに送信します。同様に、AMPから結果を受信し、解析エンジンに送信します。
Access Module Processor (AMP)−仮想プロセッサ(vproc)と呼ばれるAMPは、実際にデータを格納および取得するものです。AMPは、解析エンジンからデータと実行プランを受け取り、データ型の変換、集約、フィルタリング、並べ替えを実行し、関連するディスクにデータを格納します。テーブルのレコードは、システム内のAMP間で均等に分散されます。各AMPは、データが保存されているディスクのセットに関連付けられています。そのAMPのみがディスクからデータを読み書きできます。
ストレージアーキテクチャ
クライアントがクエリを実行してレコードを挿入すると、解析エンジンはレコードをBYNETに送信します。BYNETはレコードを取得し、行をターゲットAMPに送信します。AMPはこれらのレコードをディスクに保存します。次の図は、Teradataのストレージアーキテクチャを示しています。
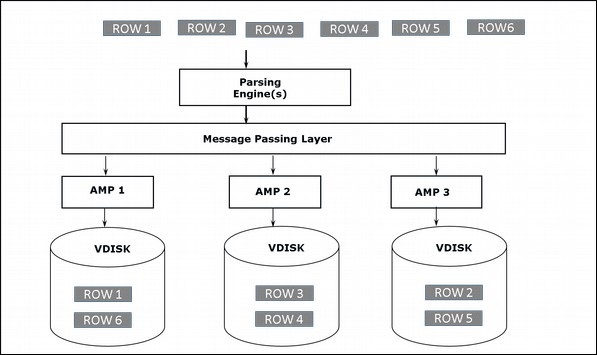
検索アーキテクチャ
クライアントがクエリを実行してレコードを取得すると、解析エンジンはBYNETにリクエストを送信します。BYNETは、取得要求を適切なAMPに送信します。次に、AMPはディスクを並行して検索し、必要なレコードを特定してBYNETに送信します。次に、BYNETはレコードを解析エンジンに送信します。解析エンジンはクライアントに送信します。以下は、Teradataの検索アーキテクチャです。
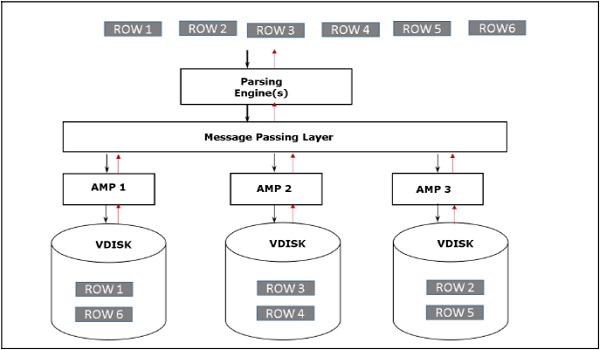
リレーショナルデータベース管理システム(RDBMS)は、データベースとの対話を支援するDBMSソフトウェアです。構造化照会言語(SQL)を使用して、テーブルに格納されているデータと対話します。
データベース
データベースは、論理的に関連するデータのコレクションです。それらは、さまざまな目的で多くのユーザーによってアクセスされます。たとえば、販売データベースには、多くのテーブルに格納されている販売に関するすべての情報が含まれています。
テーブル
テーブルは、データが格納されるRDBMSの基本単位です。テーブルは、行と列のコレクションです。以下は、employeeテーブルの例です。
| 従業員番号 | ファーストネーム | 苗字 | 誕生日 |
|---|---|---|---|
| 101 | マイク | ジェームズ | 1980年1月5日 |
| 104 | アレックス | スチュアート | 1984年11月6日 |
| 102 | ロバート | ウィリアムズ | 1983年3月5日 |
| 105 | ロバート | ジェームズ | 1984年12月1日 |
| 103 | ピーター | ポール | 1983年4月1日 |
列
列には同様のデータが含まれています。たとえば、EmployeeテーブルのBirthDate列には、すべての従業員のbirth_date情報が含まれています。
| 誕生日 |
|---|
| 1980年1月5日 |
| 1984年11月6日 |
| 1983年3月5日 |
| 1984年12月1日 |
| 1983年4月1日 |
行
行は、すべての列の1つのインスタンスです。たとえば、employeeテーブルの1つの行には、単一の従業員に関する情報が含まれています。
| 従業員番号 | ファーストネーム | 苗字 | 誕生日 |
|---|---|---|---|
| 101 | マイク | ジェームズ | 1980年1月5日 |
主キー
主キーは、テーブル内の行を一意に識別するために使用されます。主キー列に重複する値を含めることはできず、NULL値を受け入れることはできません。これは、テーブルの必須フィールドです。
外部キー
外部キーは、テーブル間の関係を構築するために使用されます。子テーブルの外部キーは、親テーブルの主キーとして定義されます。テーブルには複数の外部キーを含めることができます。重複する値とnull値を受け入れることができます。テーブルでは外部キーはオプションです。
テーブルの各列は、データ型に関連付けられています。データ型は、列に格納される値の種類を指定します。Teradataは、いくつかのデータ型をサポートしています。以下は、頻繁に使用されるデータ型の一部です。
| データ型 | 長さ(バイト) | 値の範囲 |
|---|---|---|
| BYTEINT | 1 | -128〜 + 127 |
| SMALLINT | 2 | -32768〜 + 32767 |
| 整数 | 4 | -2,147,483,648から+2147,483,647 |
| BIGINT | 8 | -9,233,372,036,854,775,808から+9,233,372,036,854,775,807 |
| 10進数 | 1-16 | |
| 数値 | 1-16 | |
| 浮く | 8 | IEEEフォーマット |
| CHAR | 固定フォーマット | 1〜64,000 |
| VARCHAR | 変数 | 1〜64,000 |
| 日付 | 4 | YYYYYMMDD |
| 時間 | 6または8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| タイムスタンプ | 10または12 | YYMMDDHHMMSS.nnnnnn or YYMMDDHHMMSS.nnnnnn + HHMM |
リレーショナルモデルのテーブルは、データのコレクションとして定義されます。それらは行と列として表されます。
テーブルタイプ
タイプTeradataは、さまざまなタイプのテーブルをサポートしています。
Permanent Table −これはデフォルトのテーブルであり、ユーザーが挿入したデータが含まれ、データを永続的に保存します。
Volatile Table−揮発性テーブルに挿入されたデータは、ユーザーセッション中にのみ保持されます。テーブルとデータは、セッションの終了時に削除されます。これらのテーブルは主に、データ変換中に中間データを保持するために使用されます。
Global Temporary Table −グローバル一時テーブルの定義は永続的ですが、テーブル内のデータはユーザーセッションの終了時に削除されます。
Derived Table−派生テーブルは、クエリの中間結果を保持します。それらの存続期間は、それらが作成、使用、および削除されるクエリ内にあります。
セット対マルチセット
Teradataは、重複レコードの処理方法に基づいて、テーブルをSETテーブルまたはMULTISETテーブルとして分類します。SETテーブルとして定義されたテーブルは重複レコードを格納しませんが、MULTISETテーブルは重複レコードを格納できます。
| シニア番号 | テーブルコマンドと説明 |
|---|---|
| 1 | テーブルを作成する CREATE TABLEコマンドは、Teradataでテーブルを作成するために使用されます。 |
| 2 | 他の机 ALTER TABLEコマンドは、既存のテーブルから列を追加または削除するために使用されます。 |
| 3 | ドロップテーブル DROP TABLEコマンドは、テーブルを削除するために使用されます。 |
この章では、Teradataテーブルに格納されているデータを操作するために使用されるSQLコマンドを紹介します。
レコードを挿入
INSERT INTOステートメントは、レコードをテーブルに挿入するために使用されます。
構文
以下は、INSERTINTOの一般的な構文です。
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);例
次の例では、レコードをemployeeテーブルに挿入します。
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);上記のクエリが挿入されると、SELECTステートメントを使用してテーブルのレコードを表示できます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
別のテーブルから挿入
INSERT SELECTステートメントは、別のテーブルからレコードを挿入するために使用されます。
構文
以下は、INSERTINTOの一般的な構文です。
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;例
次の例では、レコードをemployeeテーブルに挿入します。次の挿入クエリを実行する前に、employeeテーブルと同じ列定義を持つEmployee_Bkupというテーブルを作成します。
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;上記のクエリが実行されると、employeeテーブルのすべてのレコードがemployee_bkupテーブルに挿入されます。
ルール
VALUESリストで指定された列の数は、INSERTINTO句で指定された列と一致する必要があります。
NOTNULL列には値が必須です。
値が指定されていない場合、NULL可能フィールドにNULLが挿入されます。
VALUES句で指定された列のデータ型は、INSERT句の列のデータ型と互換性がある必要があります。
レコードの更新
UPDATEステートメントは、テーブルからレコードを更新するために使用されます。
構文
以下は、UPDATEの一般的な構文です。
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];例
次の例では、従業員101の従業員部門を03に更新します。
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;次の出力では、EmployeeNo101のDepartmentNoが1から3に更新されていることがわかります。
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3ルール
テーブルの1つ以上の値を更新できます。
WHERE条件が指定されていない場合、テーブルのすべての行が影響を受けます。
別のテーブルの値でテーブルを更新できます。
レコードを削除する
DELETE FROMステートメントは、テーブルからレコードを更新するために使用されます。
構文
以下は、DELETEFROMの一般的な構文です。
DELETE FROM <tablename>
[WHERE condition];例
次の例では、従業員101をテーブルemployeeから削除します。
DELETE FROM Employee
WHERE EmployeeNo = 101;次の出力では、従業員101がテーブルから削除されていることがわかります。
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.ルール
テーブルの1つ以上のレコードを更新できます。
WHERE条件が指定されていない場合、テーブルのすべての行が削除されます。
別のテーブルの値でテーブルを更新できます。
SELECTステートメントは、テーブルからレコードを取得するために使用されます。
構文
SELECTステートメントの基本的な構文は次のとおりです。
SELECT
column 1, column 2, .....
FROM
tablename;例
次の従業員テーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
以下は、SELECTステートメントの例です。
SELECT EmployeeNo,FirstName,LastName
FROM Employee;このクエリが実行されると、employeeテーブルからEmployeeNo、FirstName、およびLastName列がフェッチされます。
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter Paulテーブルからすべての列をフェッチする場合は、すべての列を一覧表示する代わりに、次のコマンドを使用できます。
SELECT * FROM Employee;上記のクエリは、employeeテーブルからすべてのレコードをフェッチします。
WHERE句
WHERE句は、SELECTステートメントによって返されるレコードをフィルタリングするために使用されます。条件はWHERE句に関連付けられています。WHERE句の条件を満たすレコードのみが返されます。
構文
以下は、WHERE句を使用したSELECTステートメントの構文です。
SELECT * FROM tablename
WHERE[condition];例
次のクエリは、EmployeeNoが101のレコードをフェッチします。
SELECT * FROM Employee
WHERE EmployeeNo = 101;このクエリを実行すると、次のレコードが返されます。
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesORDER BY
SELECTステートメントが実行されると、返される行は特定の順序ではありません。ORDER BY句は、任意の列でレコードを昇順/降順で配置するために使用されます。
構文
以下は、ORDERBY句を含むSELECTステートメントの構文です。
SELECT * FROM tablename
ORDER BY column 1, column 2..;例
次のクエリは、employeeテーブルからレコードをフェッチし、FirstNameで結果を並べ替えます。
SELECT * FROM Employee
ORDER BY FirstName;上記のクエリを実行すると、次の出力が生成されます。
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesGROUP BY
GROUP BY句はSELECTステートメントで使用され、同様のレコードをグループに配置します。
構文
以下は、GROUPBY句を使用したSELECTステートメントの構文です。
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;例
次の例では、DepartmentNo列でレコードをグループ化し、各部門からの合計数を識別します。
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;上記のクエリを実行すると、次の出力が生成されます。
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradataは、次の論理演算子と条件演算子をサポートしています。これらの演算子は、比較を実行し、複数の条件を組み合わせるために使用されます。
| 構文 | 意味 |
|---|---|
| > | 大なり記号 |
| < | 未満 |
| >= | 以上 |
| <= | 以下 |
| = | に等しい |
| BETWEEN | 値が範囲内の場合 |
| IN | <式>の値の場合 |
| NOT IN | <式>に値がない場合 |
| IS NULL | 値がNULLの場合 |
| IS NOT NULL | 値がNULLでない場合 |
| AND | 複数の条件を組み合わせます。すべての条件が満たされた場合にのみtrueと評価されます |
| OR | 複数の条件を組み合わせます。いずれかの条件が満たされた場合にのみtrueと評価されます。 |
| NOT | 状態の意味を逆にします |
の間に
BETWEENコマンドは、値が値の範囲内にあるかどうかを確認するために使用されます。
例
次の従業員テーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
次の例では、従業員番号が101、102〜103の範囲のレコードをフェッチします。
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;上記のクエリを実行すると、従業員番号が101〜103の従業員レコードが返されます。
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 Peterに
INコマンドは、指定された値のリストに対して値をチェックするために使用されます。
例
次の例では、101、102、および103の従業員番号を持つレコードをフェッチします。
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);上記のクエリは、次のレコードを返します。
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 Peterありませんで
NOT INコマンドは、INコマンドの結果を逆にします。指定されたリストと一致しない値を持つレコードをフェッチします。
例
次の例では、101、102、および103にない従業員番号のレコードをフェッチします。
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);上記のクエリは、次のレコードを返します。
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesSET演算子は、複数のSELECTステートメントの結果を結合します。これは結合に似ているように見えますが、結合は複数のテーブルの列を結合しますが、SET演算子は複数の行の行を結合します。
ルール
各SELECTステートメントの列数は同じである必要があります。
各SELECTのデータ型は互換性がある必要があります。
ORDER BYは、最後のSELECTステートメントにのみ含める必要があります。
連合
UNIONステートメントは、複数のSELECTステートメントの結果を組み合わせるために使用されます。重複は無視されます。
構文
以下は、UNIONステートメントの基本的な構文です。
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];例
次の従業員テーブルと給与テーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
次のUNIONクエリは、EmployeeテーブルとSalaryテーブルの両方のEmployeeNo値を組み合わせたものです。
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;クエリを実行すると、次の出力が生成されます。
EmployeeNo
-----------
101
102
103
104
105UNION ALL
UNION ALLステートメントはUNIONに似ており、重複する行を含む複数のテーブルからの結果を結合します。
構文
以下は、UNIONALLステートメントの基本的な構文です。
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];例
以下は、UNIONALLステートメントの例です。
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;上記のクエリを実行すると、次の出力が生成されます。重複も返されることがわかります。
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103交差する
INTERSECTコマンドは、複数のSELECTステートメントの結果を組み合わせるためにも使用されます。これは、2番目のSELECTステートメントで対応する一致がある最初のSELECTステートメントからの行を返します。つまり、両方のSELECTステートメントに存在する行を返します。
構文
以下は、INTERSECTステートメントの基本的な構文です。
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];例
以下は、INTERSECTステートメントの例です。両方のテーブルに存在するEmployeeNo値を返します。
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;上記のクエリを実行すると、次のレコードが返されます。EmployeeNo 105は、SALARYテーブルに存在しないため、除外されています。
EmployeeNo
-----------
101
104
102
103マイナス/除く
MINUS / EXCEPTコマンドは、複数のテーブルの行を結合し、最初のSELECTにはあるが、2番目のSELECTにはない行を返します。どちらも同じ結果を返します。
構文
以下は、MINUSステートメントの基本的な構文です。
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];例
以下は、MINUSステートメントの例です。
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;このクエリを実行すると、次のレコードが返されます。
EmployeeNo
-----------
105Teradataは、文字列を操作するためのいくつかの関数を提供します。これらの機能はANSI規格と互換性があります。
| シニア番号 | 文字列関数と説明 |
|---|---|
| 1 | || 文字列を連結します |
| 2 | SUBSTR 文字列の一部を抽出します(Teradata拡張機能) |
| 3 | SUBSTRING 文字列の一部を抽出します(ANSI標準) |
| 4 | INDEX 文字列内の文字の位置を検索します(Teradata拡張機能) |
| 5 | POSITION 文字列内の文字の位置を特定します(ANSI標準) |
| 6 | TRIM 文字列から空白を削除します |
| 7 | UPPER 文字列を大文字に変換します |
| 8 | LOWER 文字列を小文字に変換します |
例
次の表に、いくつかの文字列関数とその結果を示します。
| 文字列関数 | 結果 |
|---|---|
| SELECT SUBSTRING( 'warehouse' FROM 1 FOR 4) | ウェア |
| SELECT SUBSTR( 'warehouse'、1,4) | ウェア |
| SELECT 'データ' || '' || '倉庫' | データウェアハウス |
| SELECT UPPER( 'data') | データ |
| SELECT LOWER( 'DATA') | データ |
この章では、Teradataで使用可能な日付/時刻関数について説明します。
日付の保存
日付は、次の式を使用して内部的に整数として格納されます。
((YEAR - 1900) * 10000) + (MONTH * 100) + DAY次のクエリを使用して、日付がどのように保存されているかを確認できます。
SELECT CAST(CURRENT_DATE AS INTEGER);日付は整数として格納されるため、いくつかの算術演算を実行できます。Teradataは、これらの操作を実行するための機能を提供します。
エキス
EXTRACT関数は、DATE値から日、月、年の一部を抽出します。この関数は、TIME / TIMESTAMP値から時、分、秒を抽出するためにも使用されます。
例
次の例は、日付とタイムスタンプの値から年、月、日付、時、分、秒の値を抽出する方法を示しています。
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000間隔
Teradataは、DATE値とTIME値に対して算術演算を実行するためのINTERVAL関数を提供します。INTERVAL関数には2つのタイプがあります。
年月間隔
- YEAR
- 年から月
- MONTH
日中の間隔
- DAY
- DAY TO HOUR
- 分までの日
- 2番目の日
- HOUR
- 分までの時間
- 2番目までの時間
- MINUTE
- 2番目に分
- SECOND
例
次の例では、現在の日付に3年を追加します。
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01次の例では、現在の日付に3年01か月を追加します。
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01次の例では、現在のタイムスタンプに01日、05時間、および10分を追加します。
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradataは、SQLの拡張機能である組み込み関数を提供します。一般的な組み込み関数は次のとおりです。
| 関数 | 結果 |
|---|---|
| 日付を選択; | 日付 -------- 16/01/01 |
| SELECT CURRENT_DATE; | 日付 -------- 16/01/01 |
| 時間の選択; | 時間 -------- 04:50:29 |
| SELECT CURRENT_TIME; | 時間 -------- 04:50:29 |
| SELECT CURRENT_TIMESTAMP; | 現在のTimeStamp(6) -------------------------------- 2016-01-01 04:51:06.990000 + 00: 0000 |
| SELECT DATABASE; | データベース ------------------------------ TDUSER |
Teradataは、一般的な集計関数をサポートしています。これらはSELECTステートメントで使用できます。
COUNT −行をカウントします
SUM −指定された列の値を合計します
MAX −指定された列の大きな値を返します
MIN −指定された列の最小値を返します
AVG −指定された列の平均値を返します
例
次の給与表を検討してください。
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 104 | 75,000 | 5,000 | 70,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 105 | 70,000 | 4,000 | 66,000 |
| 103 | 90,000 | 7,000 | 83,000 |
カウント
次の例では、Salaryテーブルのレコード数をカウントします。
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
次の例では、従業員の正味給与の最大値を返します。
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
次の例では、Salaryテーブルから従業員の最小正味給与値を返します。
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
次の例では、テーブルから従業員の正味給与額の平均を返します。
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800和
次の例では、Salaryテーブルのすべてのレコードから従業員の正味給与の合計を計算します。
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000この章では、TeradataのCASEおよびCOALESCE機能について説明します。
CASE式
CASE式は、条件またはWHEN句に対して各行を評価し、最初の一致の結果を返します。一致するものがない場合は、のELSE部分からの結果が返されます。
構文
以下は、CASE式の構文です。
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
END例
次のEmployeeテーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
次の例では、DepartmentNo列を評価し、部門番号が1の場合に値1を返します。部門番号が3の場合は2を返します。それ以外の場合は、無効な部門として値を返します。
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;上記のクエリを実行すると、次の出力が生成されます。
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 IT上記のCASE式は、上記と同じ結果を生成する次の形式で記述することもできます。
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;COALESCE
COALESCEは、式の最初のnull以外の値を返すステートメントです。式のすべての引数がNULLと評価された場合、NULLを返します。構文は次のとおりです。
構文
COALESCE(expression 1, expression 2, ....)例
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
NULLIFステートメントは、引数が等しい場合にNULLを返します。
構文
以下は、NULLIFステートメントの構文です。
NULLIF(expression 1, expression 2)例
次の例では、DepartmentNoが3に等しい場合はNULLを返します。それ以外の場合は、DepartmentNo値を返します。
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;上記のクエリは、次のレコードを返します。従業員105には部門番号があることがわかります。NULLとして。
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2プライマリインデックスは、Teradataのどこにデータが存在するかを指定するために使用されます。これは、どのAMPがデータ行を取得するかを指定するために使用されます。Teradataの各テーブルには、プライマリインデックスを定義する必要があります。プライマリインデックスが定義されていない場合、Teradataは自動的にプライマリインデックスを割り当てます。プライマリインデックスは、データにアクセスするための最速の方法を提供します。プライマリには最大64列を含めることができます。
プライマリインデックスは、テーブルの作成中に定義されます。プライマリインデックスには2つのタイプがあります。
- 一意のプライマリインデックス(UPI)
- 非一意プライマリインデックス(NUPI)
一意のプライマリインデックス(UPI)
テーブルにUPIがあると定義されている場合、UPIと見なされる列に重複する値があってはなりません。重複する値が挿入された場合、それらは拒否されます。
一意のプライマリインデックスを作成する
次の例では、列EmployeeNoを一意のプライマリインデックスとして使用してSalaryテーブルを作成します。
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);非一意プライマリインデックス(NUPI)
テーブルにNUPIがあると定義されている場合、UPIと見なされる列は重複する値を受け入れることができます。
一意でないプライマリインデックスを作成する
次の例では、列EmployeeNoを非一意のプライマリインデックスとして持つ従業員アカウントテーブルを作成します。従業員はテーブルに複数のアカウントを持つことができるため、EmployeeNoは非一意のプライマリインデックスとして定義されます。1つは給与勘定用で、もう1つは償還勘定用です。
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);結合は、複数のテーブルのレコードを結合するために使用されます。テーブルは、これらのテーブルの共通の列/値に基づいて結合されます。
利用可能な結合にはさまざまなタイプがあります。
- 内部結合
- 左外部結合
- 右外部結合
- 完全外部結合
- 自己結合
- クロス結合
- デカルト生産参加
内部結合
内部結合は、複数のテーブルのレコードを結合し、両方のテーブルに存在する値を返します。
構文
以下は、INNERJOINステートメントの構文です。
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;例
次の従業員テーブルと給与テーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | 部門番号 | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
次のクエリは、共通列EmployeeNoのEmployeeテーブルとSalaryテーブルを結合します。各テーブルにはエイリアスAとBが割り当てられ、列は正しいエイリアスで参照されます。
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);上記のクエリを実行すると、次のレコードが返されます。従業員105は、給与テーブルに一致するレコードがないため、結果に含まれていません。
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000アウタージョイン
LEFT OUTERJOINとRIGHTOUTER JOINも、複数のテーブルの結果を組み合わせたものです。
LEFT OUTER JOIN 左側のテーブルからすべてのレコードを返し、右側のテーブルから一致するレコードのみを返します。
RIGHT OUTER JOIN 右側のテーブルからすべてのレコードを返し、左側のテーブルから一致する行のみを返します。
FULL OUTER JOINLEFTOUTERとRIGHTOUTERJOINSの両方の結果を組み合わせます。結合されたテーブルから一致する行と一致しない行の両方を返します。
構文
以下は、OUTERJOINステートメントの構文です。LEFT OUTER JOIN、RIGHT OUTER JOIN、またはFULL OUTERJOINのいずれかのオプションを使用する必要があります。
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;例
次のLEFTOUTERJOINクエリの例について考えてみます。Employeeテーブルからすべてのレコードを返し、Salaryテーブルから一致するレコードを返します。
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;上記のクエリを実行すると、次の出力が生成されます。従業員105の場合、給与テーブルに一致するレコードがないため、NetPay値はNULLです。
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?クロス結合
クロス結合は、左側のテーブルのすべての行を右側のテーブルのすべての行に結合します。
構文
以下は、CROSSJOINステートメントの構文です。
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;上記のクエリを実行すると、次の出力が生成されます。従業員テーブルの従業員番号101は、給与テーブルのすべてのレコードと結合されます。
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000サブクエリは、別のテーブルの値に基づいて、あるテーブルのレコードを返します。これは、別のクエリ内のSELECTクエリです。内部クエリと呼ばれるSELECTクエリが最初に実行され、その結果が外部クエリによって使用されます。その顕著な特徴のいくつかは次のとおりです。
クエリには複数のサブクエリを含めることができ、サブクエリには別のサブクエリを含めることができます。
サブクエリは重複レコードを返しません。
サブクエリが1つの値のみを返す場合は、=演算子を使用して外部クエリで使用できます。複数の値を返す場合は、INまたはNOTINを使用できます。
構文
以下は、サブクエリの一般的な構文です。
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);例
次の給与表を検討してください。
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
次のクエリは、給与が最も高い従業員番号を識別します。内部SELECTは集計関数を実行して最大NetPay値を返し、外部SELECTクエリはこの値を使用してこの値を持つ従業員レコードを返します。
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);このクエリを実行すると、次の出力が生成されます。
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradataは、一時データを保持するために次のテーブルタイプをサポートしています。
- 派生テーブル
- 揮発性テーブル
- グローバル一時テーブル
派生テーブル
派生テーブルは、クエリ内で作成、使用、および削除されます。これらは、クエリ内に中間結果を格納するために使用されます。
例
次の例では、給与が75000を超える従業員のレコードを使用して派生テーブルEmpSalを作成します。
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;上記のクエリを実行すると、給与が75000を超える従業員が返されます。
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000揮発性テーブル
揮発性テーブルは、ユーザーセッション内で作成、使用、および削除されます。それらの定義はデータディクショナリに保存されません。これらは、頻繁に使用されるクエリの中間データを保持します。構文は次のとおりです。
構文
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWS例
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;上記のクエリを実行すると、次の出力が生成されます。
*** Table has been created.
*** Total elapsed time was 1 second.グローバル一時テーブル
グローバルテンポラリーテーブルの定義はデータディクショナリに保存され、多くのユーザー/セッションで使用できます。ただし、グローバル一時テーブルにロードされたデータは、セッション中にのみ保持されます。セッションごとに最大2000のグローバル一時テーブルを実体化できます。構文は次のとおりです。
構文
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>例
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);上記のクエリを実行すると、次の出力が生成されます。
*** Table has been created.
*** Total elapsed time was 1 second.Teradataで使用できるスペースには3つのタイプがあります。
パーマネントスペース
永続スペースは、ユーザー/データベースがデータ行を保持するために使用できるスペースの最大量です。パーマネントテーブル、ジャーナル、フォールバックテーブル、およびセカンダリインデックスサブテーブルはパーマネントスペースを使用します。
永続スペースは、データベース/ユーザーに事前に割り当てられていません。これらは、データベース/ユーザーが使用できるスペースの最大量として定義されています。永続スペースの量は、AMPの数で除算されます。AMPごとの制限を超えると、エラーメッセージが生成されます。
スプールスペース
スプールスペースは、SQLクエリの中間結果を保持するためにシステムによって使用される未使用の永続スペースです。スプールスペースのないユーザーは、クエリを実行できません。
永続スペースと同様に、スプールスペースはユーザーが使用できるスペースの最大量を定義します。スプールスペースは、AMPの数で除算されます。AMPごとの制限を超えると、ユーザーはスプールスペースエラーを受け取ります。
温度スペース
一時スペースは、グローバル一時テーブルによって使用される未使用の永続スペースです。一時スペースもAMPの数で除算されます。
テーブルに含めることができるプライマリインデックスは1つだけです。多くの場合、データに頻繁にアクセスする他の列がテーブルに含まれているシナリオに遭遇します。Teradataは、これらのクエリに対して全表スキャンを実行します。セカンダリインデックスはこの問題を解決します。
セカンダリインデックスは、データにアクセスするための代替パスです。プライマリインデックスとセカンダリインデックスの間にはいくつかの違いがあります。
セカンダリインデックスはデータ配信に関与しません。
セカンダリインデックス値はサブテーブルに格納されます。これらのテーブルはすべてのAMPに組み込まれています。
セカンダリインデックスはオプションです。
これらは、テーブルの作成中またはテーブルの作成後に作成できます。
サブテーブルを作成するため、追加のスペースを占有します。また、新しい行ごとにサブテーブルを更新する必要があるため、メンテナンスも必要です。
セカンダリインデックスには2つのタイプがあります-
- 一意のセカンダリインデックス(USI)
- 非一意のセカンダリインデックス(NUSI)
一意のセカンダリインデックス(USI)
一意のセカンダリインデックスでは、USIとして定義された列に一意の値のみが許可されます。USIによる行へのアクセスは、2アンペアの操作です。
一意のセカンダリインデックスを作成する
次の例では、employeeテーブルのEmployeeNo列にUSIを作成します。
CREATE UNIQUE INDEX(EmployeeNo) on employee;非一意のセカンダリインデックス(NUSI)
非一意のセカンダリインデックスでは、NUSIとして定義された列の値を重複させることができます。NUSIによる行へのアクセスは、オールアンプ操作です。
一意でないセカンダリインデックスを作成する
次の例では、employeeテーブルのFirstName列にNUSIを作成します。
CREATE INDEX(FirstName) on Employee;Teradata Optimizerは、すべてのSQLクエリの実行戦略を考え出します。この実行戦略は、SQLクエリ内で使用されるテーブルで収集された統計に基づいています。テーブルの統計は、COLLECTSTATISTICSコマンドを使用して収集されます。オプティマイザーでは、最適な実行戦略を立てるために、環境情報とデータ人口統計が必要です。
環境情報
- ノード、AMP、およびCPUの数
- メモリの量
データ人口統計
- 行の数
- 行サイズ
- 表の値の範囲
- 値ごとの行数
- ヌルの数
テーブルの統計を収集するには、3つのアプローチがあります。
- ランダムAMPサンプリング
- 完全な統計収集
- SAMPLEオプションの使用
統計の収集
COLLECT STATISTICSコマンドは、テーブルの統計を収集するために使用されます。
構文
以下は、テーブルの統計を収集するための基本的な構文です。
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;例
次の例では、EmployeeテーブルのEmployeeNo列の統計を収集します。
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;上記のクエリを実行すると、次の出力が生成されます。
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.統計の表示
収集された統計は、HELPSTATISTICSコマンドを使用して表示できます。
構文
以下は、収集された統計を表示するための構文です。
HELP STATISTICS <tablename>;例
以下は、Employeeテーブルで収集された統計を表示する例です。
HELP STATISTICS employee;上記のクエリを実行すると、次の結果が生成されます。
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNo圧縮は、テーブルが使用するストレージを削減するために使用されます。Teradataでは、圧縮により、NULLを含む最大255の異なる値を圧縮できます。ストレージが削減されるため、Teradataは1つのブロックにより多くのレコードを保存できます。これにより、I / O操作でブロックごとにより多くの行を処理できるため、クエリの応答時間が改善されます。圧縮は、CREATE TABLEを使用したテーブル作成時、またはALTERTABLEコマンドを使用したテーブル作成後に追加できます。
制限事項
- 列ごとに圧縮できるのは255個の値のみです。
- プライマリインデックス列は圧縮できません。
- 揮発性テーブルは圧縮できません。
マルチバリューコンプレッション(MVC)
次の表は、値1、2、および3のフィールドDepatmentNoを圧縮します。圧縮が列に適用されると、この列の値は行とともに保存されません。代わりに、値は各AMPのテーブルヘッダーに格納され、値を示すためにプレゼンスビットのみが行に追加されます。
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);複数値圧縮は、有限値の大きなテーブルに列がある場合に使用できます。
EXPLAINコマンドは、解析エンジンの実行プランを英語で返します。別のEXPLAINコマンドを除いて、任意のSQLステートメントで使用できます。クエリの前にEXPLAINコマンドを指定すると、AMPではなく解析エンジンの実行プランがユーザーに返されます。
EXPLAINの例
次の定義を持つテーブルEmployeeについて考えてみます。
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );EXPLAINプランの例を以下に示します。
全表スキャン(FTS)
SELECTステートメントで条件が指定されていない場合、オプティマイザーは、表のすべての行にアクセスする全表スキャンを使用することを選択できます。
例
以下は、オプティマイザーがFTSを選択できるクエリの例です。
EXPLAIN SELECT * FROM employee;上記のクエリを実行すると、次の出力が生成されます。ご覧のとおり、オプティマイザはすべてのAMPとAMP内のすべての行にアクセスすることを選択します。
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.一意のプライマリインデックス
一意のプライマリインデックスを使用して行にアクセスする場合、それは1つのAMP操作です。
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;上記のクエリを実行すると、次の出力が生成されます。ご覧のとおり、これは単一AMPの取得であり、オプティマイザーは一意のプライマリインデックスを使用して行にアクセスしています。
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.ユニークなセカンダリインデックス
一意のセカンダリインデックスを使用して行にアクセスする場合、これは2アンペアの操作です。
例
次の定義のテーブルSalaryについて考えてみます。
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);次のSELECTステートメントについて考えてみます。
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;上記のクエリを実行すると、次の出力が生成されます。ご覧のとおり、オプティマイザは、一意のセカンダリインデックスを使用して2アンプ操作で行を取得します。
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.追加条件
以下は、EXPLAINプランで一般的に見られる用語のリストです。
... (Last Use) …
スプールファイルは不要になり、このステップが完了すると解放されます。
... with no residual conditions …
該当するすべての条件が行に適用されています。
... END TRANSACTION …
トランザクションロックが解放され、変更がコミットされます。
... eliminating duplicate rows ...
重複する行はスプールファイルにのみ存在し、セットテーブルには存在しません。DISTINCT操作を実行します。
... by way of a traversal of index #n extracting row ids only …
セカンダリインデックス(インデックス#n)で見つかった行IDを含むスプールファイルが作成されます。
... we do a SMS (set manipulation step) …
UNION、MINUS、またはINTERSECT演算子を使用して行を結合します。
... which is redistributed by hash code to all AMPs.
結合に備えてデータを再配布します。
... which is duplicated on all AMPs.
結合の準備として、小さい方のテーブル(SPOOLの観点から)からデータを複製します。
... (one_AMP) or (group_AMPs)
すべてのAMPの代わりに、1つのAMPまたはAMPのサブセットが使用されることを示します。
行は、プライマリインデックス値に基づいて特定のAMPに割り当てられます。Teradataは、ハッシュアルゴリズムを使用して、どのAMPが行を取得するかを決定します。
以下は、ハッシュアルゴリズムの概要図です。

データを挿入する手順は次のとおりです。
クライアントはクエリを送信します。
パーサーはクエリを受信し、レコードのPI値をハッシュアルゴリズムに渡します。
ハッシュアルゴリズムはプライマリインデックス値をハッシュし、行ハッシュと呼ばれる32ビットの数値を返します。
行ハッシュの上位ビット(最初の16ビット)は、ハッシュマップエントリを識別するために使用されます。ハッシュマップには1つのAMP番号が含まれています。ハッシュマップは、特定のAMP番号を含むバケットの配列です。
BYNETは、識別されたAMPにデータを送信します。
AMPは、32ビットの行ハッシュを使用してディスク内の行を検索します。
同じ行ハッシュを持つレコードがある場合は、32ビット番号である一意性IDをインクリメントします。新しい行ハッシュの場合、一意性IDは1として割り当てられ、同じ行ハッシュを持つレコードが挿入されるたびに増分されます。
行ハッシュと一意性IDの組み合わせは、行IDと呼ばれます。
行IDは、ディスク内の各レコードのプレフィックスになります。
AMPの各テーブル行は、行IDによって論理的にソートされます。
テーブルの保存方法
テーブルは行ID(行ハッシュ+一意性ID)でソートされ、AMP内に格納されます。行IDは、各データ行とともに保存されます。
| 行ハッシュ | 一意性ID | 従業員番号 | ファーストネーム | 苗字 |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | マイク | ジェームズ |
| 2A01 2612 | 0000 0001 | 104 | アレックス | スチュアート |
| 2A01 2613 | 0000 0001 | 102 | ロバート | ウィリアムズ |
| 2A01 2614 | 0000 0001 | 105 | ロバート | ジェームズ |
| 2A01 2615 | 0000 0001 | 103 | ピーター | ポール |
JOININDEXはマテリアライズドビューです。その定義は永続的に保存され、結合インデックスで参照されるベーステーブルが更新されるたびにデータが更新されます。JOIN INDEXには、1つ以上のテーブルが含まれる場合があり、事前に集計されたデータも含まれる場合があります。結合インデックスは、主にパフォーマンスを向上させるために使用されます。
使用可能な結合インデックスにはさまざまなタイプがあります。
- 単一テーブル結合インデックス(STJI)
- マルチテーブル結合インデックス(MTJI)
- 集約結合インデックス(AJI)
単一テーブル結合インデックス
単一テーブル結合インデックスを使用すると、ベーステーブルのプライマリインデックス列とは異なるプライマリインデックス列に基づいて大きなテーブルを分割できます。
構文
以下は、JOININDEXの構文です。
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;例
次の従業員と給与の表を検討してください。
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);以下は、EmployeeテーブルにEmployee_JIという名前の結合インデックスを作成する例です。
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);ユーザーがEmployeeNoにWHERE句を指定してクエリを送信すると、システムは一意のプライマリインデックスを使用してEmployeeテーブルにクエリを実行します。ユーザーがemployee_nameを使用してemployeeテーブルにクエリを実行すると、システムはemployee_nameを使用して結合インデックスEmployee_JIにアクセスできます。結合インデックスの行は、employee_name列でハッシュされます。結合インデックスが定義されておらず、employee_nameがセカンダリインデックスとして定義されていない場合、システムは全表スキャンを実行して行にアクセスするため、時間がかかります。
次のEXPLAINプランを実行して、オプティマイザープランを確認できます。次の例では、テーブルがEmployee_Name列を使用してクエリを実行するときに、オプティマイザがベースのEmployeeテーブルではなくJoinIndexを使用していることがわかります。
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.マルチテーブル結合インデックス
マルチテーブル結合インデックスは、複数のテーブルを結合することによって作成されます。マルチテーブル結合インデックスを使用して、頻繁に結合されるテーブルの結果セットを格納し、パフォーマンスを向上させることができます。
例
次の例では、EmployeeテーブルとSalaryテーブルを結合して、Employee_Salary_JIという名前のJOININDEXを作成します。
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);ベーステーブルのEmployeeまたはSalaryが更新されるたびに、結合インデックスEmployee_Salary_JIも自動的に更新されます。EmployeeテーブルとSalaryテーブルを結合するクエリを実行している場合、オプティマイザは、テーブルを結合する代わりに、Employee_Salary_JIからのデータに直接アクセスすることを選択する場合があります。クエリのEXPLAINプランを使用して、オプティマイザがベーステーブルまたは結合インデックスを選択するかどうかを確認できます。
集約結合インデックス
テーブルが特定の列で一貫して集計されている場合は、集計結合インデックスをテーブルに定義して、パフォーマンスを向上させることができます。集約結合インデックスの1つの制限は、SUM関数とCOUNT関数のみをサポートすることです。
例
次の例では、従業員と給与を結合して、部門ごとの合計給与を識別します。
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);ビューは、クエリによって作成されたデータベースオブジェクトです。ビューは、結合によって単一のテーブルまたは複数のテーブルを使用して構築できます。それらの定義はデータディクショナリに永続的に保存されますが、データのコピーは保存されません。ビューのデータは動的に作成されます。
ビューには、テーブルの行のサブセットまたはテーブルの列のサブセットが含まれる場合があります。
ビューを作成する
ビューは、CREATEVIEWステートメントを使用して作成されます。
構文
以下は、ビューを作成するための構文です。
CREATE/REPLACE VIEW <viewname>
AS
<select query>;例
次のEmployeeテーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | 誕生日 |
|---|---|---|---|
| 101 | マイク | ジェームズ | 1980年1月5日 |
| 104 | アレックス | スチュアート | 1984年11月6日 |
| 102 | ロバート | ウィリアムズ | 1983年3月5日 |
| 105 | ロバート | ジェームズ | 1984年12月1日 |
| 103 | ピーター | ポール | 1983年4月1日 |
次の例では、Employeeテーブルにビューを作成します。
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;ビューの使用
通常のSELECTステートメントを使用して、ビューからデータを取得できます。
例
次の例では、Employee_Viewからレコードを取得します。
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;上記のクエリを実行すると、次の出力が生成されます。
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter Paulビューの変更
既存のビューは、REPLACEVIEWステートメントを使用して変更できます。
以下は、ビューを変更するための構文です。
REPLACE VIEW <viewname>
AS
<select query>;例
次の例では、列を追加するためにビューEmployee_Viewを変更します。
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;ドロップビュー
DROP VIEWステートメントを使用して、既存のビューを削除できます。
構文
以下は、DROPVIEWの構文です。
DROP VIEW <viewname>;例
以下は、ビューEmployee_Viewを削除する例です。
DROP VIEW Employee_View;ビューの利点
ビューは、テーブルの行または列を制限することにより、セキュリティのレベルを向上させます。
ユーザーには、ベーステーブルではなくビューへのアクセスのみを許可できます。
ビューを使用してテーブルを事前に結合することにより、複数のテーブルの使用を簡素化します。
マクロは、マクロ名を呼び出すことによって格納および実行されるSQLステートメントのセットです。マクロの定義はデータディクショナリに保存されます。ユーザーは、マクロを実行するためにEXEC特権のみを必要とします。ユーザーは、マクロ内で使用されるデータベースオブジェクトに対する個別の権限を必要としません。マクロステートメントは、単一のトランザクションとして実行されます。マクロのSQLステートメントの1つが失敗した場合、すべてのステートメントがロールバックされます。マクロはパラメーターを受け入れることができます。マクロにはDDLステートメントを含めることができますが、それがマクロの最後のステートメントである必要があります。
マクロを作成する
マクロは、CREATEMACROステートメントを使用して作成されます。
構文
以下は、CREATEMACROコマンドの一般的な構文です。
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);例
次のEmployeeテーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | 誕生日 |
|---|---|---|---|
| 101 | マイク | ジェームズ | 1980年1月5日 |
| 104 | アレックス | スチュアート | 1984年11月6日 |
| 102 | ロバート | ウィリアムズ | 1983年3月5日 |
| 105 | ロバート | ジェームズ | 1984年12月1日 |
| 103 | ピーター | ポール | 1983年4月1日 |
次の例では、Get_Empというマクロを作成します。これには、employeeテーブルからレコードを取得するためのselectステートメントが含まれています。
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);マクロの実行
マクロはEXECコマンドを使用して実行されます。
構文
以下は、EXECUTEMACROコマンドの構文です。
EXEC <macroname>;例
次の例では、マクロ名Get_Empを実行します。次のコマンドを実行すると、employeeテーブルからすべてのレコードが取得されます。
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert Jamesパラメータ化されたマクロ
Teradataマクロはパラメータを受け入れることができます。マクロ内では、これらのパラメーターは;で参照されます。(セミコロン)。
以下は、パラメーターを受け入れるマクロの例です。
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);パラメータ化されたマクロの実行
マクロはEXECコマンドを使用して実行されます。マクロを実行するには、EXEC権限が必要です。
構文
以下は、EXECUTEMACROステートメントの構文です。
EXEC <macroname>(value);例
次の例では、マクロ名Get_Empを実行します。パラメータとして従業員番号を受け入れ、その従業員の従業員テーブルからレコードを抽出します。
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000ストアドプロシージャには、SQLステートメントとプロシージャルステートメントのセットが含まれています。手続き型ステートメントのみを含めることができます。ストアドプロシージャの定義はデータベースに保存され、パラメータはデータディクショナリテーブルに保存されます。
利点
ストアドプロシージャは、クライアントとサーバー間のネットワーク負荷を軽減します。
データは直接アクセスするのではなく、ストアドプロシージャを介してアクセスされるため、セキュリティが向上します。
ビジネスロジックがテストされてサーバーに保存されるため、メンテナンスが向上します。
手順の作成
ストアドプロシージャは、CREATEPROCEDUREステートメントを使用して作成されます。
構文
以下は、CREATEPROCEDUREステートメントの一般的な構文です。
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;例
次の給与表を検討してください。
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
次の例では、InsertSalaryという名前のストアドプロシージャを作成して、値を受け入れ、給与テーブルに挿入します。
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;手順の実行
ストアドプロシージャは、CALLステートメントを使用して実行されます。
構文
以下は、CALLステートメントの一般的な構文です。
CALL <procedure name> [(parameter values)];例
次の例では、ストアドプロシージャInsertSalaryを呼び出し、給与テーブルにレコードを挿入します。
CALL InsertSalary(105,20000,2000,18000);上記のクエリを実行すると、次の出力が生成され、Salaryテーブルに挿入された行が表示されます。
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
| 105 | 20,000 | 2,000 | 18,000 |
この章では、Teradataで使用可能なさまざまなJOIN戦略について説明します。
結合メソッド
Teradataは、さまざまな結合方法を使用して結合操作を実行します。一般的に使用されるJoinメソッドのいくつかは次のとおりです。
- マージ結合
- ネストされた結合
- 製品への参加
マージ結合
マージ結合メソッドは、結合が等式条件に基づいている場合に実行されます。マージ結合では、結合行が同じAMP上にある必要があります。行は、行ハッシュに基づいて結合されます。マージ結合は、異なる結合戦略を使用して、行を同じAMPに移動します。
戦略#1
結合列が対応するテーブルのプライマリインデックスである場合、結合行はすでに同じAMP上にあります。この場合、配布は必要ありません。
次の従業員と給与の表を検討してください。
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);これらの2つのテーブルがEmployeeNo列で結合されている場合、EmployeeNoは結合されている両方のテーブルのプライマリインデックスであるため、再配布は行われません。
戦略#2
次のEmployeeテーブルとDepartmentテーブルについて考えてみます。
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );これらの2つのテーブルがDeparmentNo列で結合されている場合、DepartmentNoは1つのテーブルのプライマリインデックスであり、別のテーブルの非プライマリインデックスであるため、行を再配布する必要があります。このシナリオでは、行の結合が同じAMP上にない場合があります。このような場合、TeradataはDepartmentNo列のemployeeテーブルを再配布する場合があります。
戦略#3
上記のEmployeeテーブルとDepartmentテーブルの場合、Departmentテーブルのサイズが小さいと、TeradataはすべてのAMPでDepartmentテーブルを複製する可能性があります。
ネストされた結合
ネストされた結合は、すべてのAMPを使用するわけではありません。ネストされた結合を実行するには、条件の1つが、一方のテーブルの一意のプライマリインデックスで等しいことであり、次にこの列をもう一方のテーブルの任意のインデックスに結合する必要があります。
このシナリオでは、システムは1つのテーブルの一意のプライマリインデックスを使用して1つの行をフェッチし、その行ハッシュを使用して他のテーブルから一致するレコードをフェッチします。ネストされた結合は、すべての結合メソッドの中で最も効率的です。
製品への参加
製品結合は、1つのテーブルの各適格行を他のテーブルの各適格行と比較します。以下の要因により、製品の結合が発生する場合があります-
- 条件が欠落している場所。
- 結合条件は、等式条件に基づいていません。
- テーブルエイリアスが正しくありません。
- 複数の結合条件。
パーティションプライマリインデックス(PPI)は、特定のクエリのパフォーマンスを向上させるのに役立つインデックスメカニズムです。行がテーブルに挿入されると、それらはAMPに格納され、行ハッシュの順序で配置されます。テーブルがPPIで定義されている場合、行はパーティション番号でソートされます。各パーティション内では、行ハッシュによって配置されます。行は、定義されたパーティション式に基づいてパーティションに割り当てられます。
利点
特定のクエリの全表スキャンは避けてください。
追加の物理構造と追加のI / Oメンテナンスを必要とするセカンダリインデックスの使用は避けてください。
大きなテーブルのサブセットにすばやくアクセスします。
古いデータをすばやく削除し、新しいデータを追加します。
例
OrderNoにプライマリインデックスがある次のOrdersテーブルについて考えてみます。
| 店番号 | 注文番号 | 注文日 | OrderTotal |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1,200 |
| 102 | 7503 | 2015-10-02 | 3,000 |
| 102 | 7504 | 2015-10-03 | 2,454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2,454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
次の表に示すように、レコードがAMP間で分散されていると想定します。記録されたものはAMPに保存され、行ハッシュに基づいてソートされます。
| RowHash | 注文番号 | 注文日 |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | 注文番号 | 注文日 |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
クエリを実行して特定の日付の注文を抽出すると、オプティマイザは全表スキャンを使用することを選択でき、AMP内のすべてのレコードにアクセスできます。これを回避するために、注文日をパーティション化されたプライマリインデックスとして定義できます。行が注文テーブルに挿入されると、注文日で分割されます。各パーティション内では、行ハッシュ順に並べられます。
次のデータは、レコードが注文日で分割されている場合に、レコードがAMPにどのように保存されるかを示しています。注文日までにレコードにアクセスするためにクエリが実行されると、その特定の注文のレコードを含むパーティションのみがアクセスされます。
| パーティション | RowHash | 注文番号 | 注文日 |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| パーティション | RowHash | 注文番号 | 注文日 |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
以下は、パーティションプライマリインデックスを使用してテーブルを作成する例です。PARTITION BY句は、パーティションを定義するために使用されます。
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);上記の例では、テーブルはOrderDate列でパーティション化されています。毎日1つの個別のパーティションがあります。
OLAP関数は、集計関数が1つの値のみを返すのに対し、OLAP関数は集計に加えて個々の行を提供することを除いて、集計関数に似ています。
構文
以下は、OLAP関数の一般的な構文です。
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)集計関数には、SUM、COUNT、MAX、MIN、AVGを指定できます。
例
次の給与表を検討してください。
| 従業員番号 | キモい | 控除 | 給料 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
以下は、給与テーブルのNetPayの累積合計または累計を見つける例です。レコードはEmployeeNoでソートされ、累積合計はNetPay列で計算されます。
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;上記のクエリを実行すると、次の出力が生成されます。
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000ランク
RANK関数は、指定された列に基づいてレコードを順序付けます。RANK関数は、ランクに基づいて返されるレコードの数をフィルタリングすることもできます。
構文
以下は、RANK関数を使用するための一般的な構文です。
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])例
次のEmployeeテーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | JoinedDate | DepartmentID | 誕生日 |
|---|---|---|---|---|---|
| 101 | マイク | ジェームズ | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | ロバート | ウィリアムズ | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | ピーター | ポール | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | アレックス | スチュアート | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | ロバート | ジェームズ | 2008年1月4日 | 3 | 1984年12月1日 |
次のクエリは、Joined Dateによってemployeeテーブルのレコードを並べ替え、JoinedDateにランキングを割り当てます。
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;上記のクエリを実行すると、次の出力が生成されます。
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5PARTITION BY句は、PARTITION BY句で定義された列によってデータをグループ化し、各グループ内でOLAP機能を実行します。以下は、PARTITIONBY句を使用するクエリの例です。
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;上記のクエリを実行すると、次の出力が生成されます。部門ごとにランクがリセットされていることがわかります。
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1この章では、Teradataのデータ保護に使用できる機能について説明します。
トランジェントジャーナル
Teradataは、Transient Journalを使用して、トランザクションの失敗からデータを保護します。トランザクションが実行されるたびに、一時ジャーナルは、トランザクションが成功するか、ロールバックが成功するまで、影響を受ける行の変更前イメージのコピーを保持します。その後、変更前の画像は破棄されます。一時的なジャーナルは各AMPに保持されます。これは自動プロセスであり、無効にすることはできません。
後退する
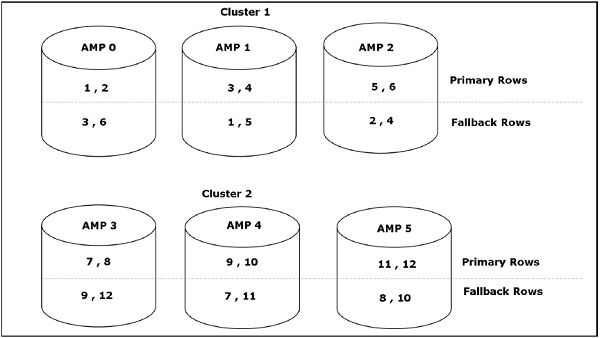
フォールバックは、テーブルの行の2番目のコピーをフォールバックAMPと呼ばれる別のAMPに格納することにより、テーブルデータを保護します。1つのAMPに障害が発生すると、フォールバック行にアクセスします。これにより、1つのAMPに障害が発生した場合でも、フォールバックAMPを介してデータを利用できます。フォールバックオプションは、テーブルの作成時またはテーブルの作成後に使用できます。フォールバックにより、テーブルの行の2番目のコピーが常に別のAMPに格納され、AMPの障害からデータが保護されます。ただし、フォールバックは、挿入/削除/更新のストレージとI / Oの2倍を占めます。
次の図は、行のフォールバックコピーが別のAMPにどのように保存されるかを示しています。
ダウンAMPリカバリジャーナル
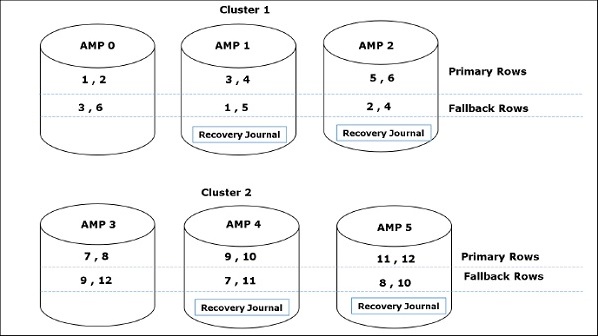
ダウンAMPリカバリジャーナルは、AMPに障害が発生し、テーブルがフォールバック保護されている場合にアクティブになります。このジャーナルは、障害が発生したAMPのデータに対するすべての変更を追跡します。ジャーナルは、クラスター内の残りのAMPでアクティブ化されます。これは自動プロセスであり、無効にすることはできません。障害が発生したAMPが稼働すると、ダウンAMPリカバリジャーナルからのデータがAMPと同期されます。これが行われると、ジャーナルは破棄されます。
クリーク
クリークは、ノードの障害からデータを保護するためにTeradataによって使用されるメカニズムです。クリークは、ディスクアレイの共通セットを共有するTeradataノードのセットに他なりません。ノードに障害が発生すると、障害が発生したノードのvprocがクリーク内の他のノードに移行し、ディスクアレイへのアクセスを継続します。
ホットスタンバイノード
ホットスタンバイノードは、実稼働環境に参加しないノードです。ノードに障害が発生した場合、障害が発生したノードのvprocはホットスタンバイノードに移行します。障害が発生したノードが回復すると、ホットスタンバイノードになります。ホットスタンバイノードは、ノードに障害が発生した場合にパフォーマンスを維持するために使用されます。
RAID
独立ディスクの冗長アレイ(RAID)は、ディスク障害からデータを保護するために使用されるメカニズムです。ディスクアレイは、論理ユニットとしてグループ化されたディスクのセットで構成されます。このユニットは、ユーザーには1つのユニットのように見えますが、複数のディスクに分散している場合があります。
RAID1はTeradataで一般的に使用されています。RAID 1では、各ディスクはミラーディスクに関連付けられています。プライマリディスクのデータへの変更は、ミラーコピーにも反映されます。プライマリディスクに障害が発生した場合、ミラーディスクのデータにアクセスできます。

この章では、Teradataでのユーザー管理のさまざまな戦略について説明しました。
ユーザー
ユーザーは、CREATEUSERコマンドを使用して作成されます。Teradataでは、ユーザーもデータベースに似ています。どちらにもスペースを割り当てることができ、ユーザーにパスワードが割り当てられることを除いて、データベースオブジェクトを含めることができます。
構文
以下は、CREATEUSERの構文です。
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;ユーザーの作成時には、ユーザー名、永続スペース、およびパスワードの値は必須です。その他のフィールドはオプションです。
例
以下は、ユーザーTD01を作成する例です。
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;アカウント
新しいユーザーの作成中に、ユーザーがアカウントに割り当てられる場合があります。CREATEUSERのACCOUNTオプションを使用してアカウントを割り当てます。ユーザーは複数のアカウントに割り当てられる場合があります。
構文
以下は、アカウントオプション付きのCREATEUSERの構文です。
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountid例
次の例では、ユーザーTD02を作成し、アカウントをITおよび管理者として割り当てます。
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);ユーザーは、Teradataシステムへのログイン中、またはSET SESSIONコマンドを使用してシステムにログインした後、アカウントIDを指定できます。
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountid権限を付与する
GRANTコマンドは、データベースオブジェクトに対する1つ以上の特権をユーザーまたはデータベースに割り当てるために使用されます。
構文
以下は、GRANTコマンドの構文です。
GRANT privileges ON objectname TO username;特権には、INSERT、SELECT、UPDATE、REFERENCESがあります。
例
以下は、GRANTステートメントの例です。
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;特権を取り消す
REVOKEコマンドは、ユーザーまたはデータベースから特権を削除します。REVOKEコマンドは、明示的な特権のみを削除できます。
構文
以下は、REVOKEコマンドの基本的な構文です。
REVOKE [ALL|privileges] ON objectname FROM username;例
以下は、REVOKEコマンドの例です。
REVOKE INSERT,SELECT ON Employee FROM TD01;この章では、Teradataでのパフォーマンスチューニングの手順について説明します。
説明する
パフォーマンス調整の最初のステップは、クエリでEXPLAINを使用することです。EXPLAINプランは、オプティマイザーがクエリを実行する方法の詳細を提供します。Explainプランで、信頼水準、使用された結合戦略、スプールファイルサイズ、再配布などのキーワードを確認します。
統計を収集する
オプティマイザーは、データ人口統計を使用して、効果的な実行戦略を考案します。COLLECT STATISTICSコマンドは、テーブルのデータ人口統計を収集するために使用されます。列で収集された統計が最新であることを確認してください。
WHERE句で使用される列と結合条件で使用される列の統計を収集します。
一意のプライマリインデックス列の統計を収集します。
非一意のセカンダリインデックス列の統計を収集します。オプティマイザーは、NUSIまたは全表スキャンを使用できるかどうかを決定します。
ベーステーブルの統計は収集されますが、結合インデックスの統計を収集します。
パーティショニング列の統計を収集します。
データ型
適切なデータ型が使用されていることを確認してください。これにより、必要以上のストレージの使用を回避できます。
変換
明示的なデータ変換を回避するために、結合条件で使用される列のデータ型に互換性があることを確認してください。
ソート
必要な場合を除いて、不要なORDERBY句を削除します。
スプールスペースの問題
クエリがそのユーザーのAMPスプールスペース制限を超えると、スプールスペースエラーが生成されます。説明プランを確認し、より多くのスプールスペースを消費するステップを特定します。これらの中間クエリは、一時テーブルを作成するために分割して個別に配置できます。
プライマリインデックス
プライマリインデックスがテーブルに対して正しく定義されていることを確認してください。プライマリインデックス列はデータを均等に分散する必要があり、データにアクセスするために頻繁に使用する必要があります。
SETテーブル
SETテーブルを定義すると、オプティマイザは、挿入されたすべてのレコードについてレコードが重複しているかどうかを確認します。重複するチェック条件を削除するには、テーブルに一意のセカンダリインデックスを定義します。
大きなテーブルの更新
大きなテーブルの更新には時間がかかります。テーブルを更新する代わりに、レコードを削除して、行が変更されたレコードを挿入できます。
一時テーブルの削除
一時テーブル(ステージングテーブル)と揮発性物質が不要になった場合は、それらを削除します。これにより、永続スペースとスプールスペースが解放されます。
MULTISETテーブル
入力レコードに重複レコードがないことが確実な場合は、ターゲットテーブルをMULTISETテーブルとして定義して、SETテーブルで使用される重複行チェックを回避できます。
FastLoadユーティリティは、空のテーブルにデータをロードするために使用されます。一時的なジャーナルを使用しないため、データをすばやくロードできます。ターゲットテーブルがMULTISETテーブルであっても、重複する行は読み込まれません。
制限
ターゲットテーブルには、セカンダリインデックス、結合インデックス、および外部キー参照を含めることはできません。
FastLoadのしくみ
FastLoadは2つのフェーズで実行されます。
フェーズ1
解析エンジンは入力ファイルからレコードを読み取り、各AMPにブロックを送信します。
各AMPは、レコードのブロックを格納します。
次に、AMPは各レコードをハッシュし、それらを正しいAMPに再配布します。
フェーズ1の終わりに、各AMPには行がありますが、行ハッシュシーケンスではありません。
フェーズ2
フェーズ2は、FastLoadがENDLOADINGステートメントを受信したときに開始されます。
各AMPは、行ハッシュのレコードを並べ替えて、ディスクに書き込みます。
ターゲットテーブルのロックが解除され、エラーテーブルが削除されます。
例
次のレコードを使用してテキストファイルを作成し、ファイルにemployee.txtという名前を付けます。
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3以下は、上記のファイルをEmployee_StgテーブルにロードするためのサンプルFastLoadスクリプトです。
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;FastLoadスクリプトの実行
入力ファイルemployee.txtが作成され、FastLoadスクリプトにEmployeeLoad.flという名前が付けられたら、UNIXおよびWindowsで次のコマンドを使用してFastLoadスクリプトを実行できます。
FastLoad < EmployeeLoad.fl;上記のコマンドが実行されると、FastLoadスクリプトが実行され、ログが生成されます。ログには、FastLoadによって処理されたレコードの数とステータスコードが表示されます。
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsFastLoadの条件
以下は、FastLoadスクリプトで使用される一般的な用語のリストです。
LOGON − Teradataにログインし、1つ以上のセッションを開始します。
DATABASE −デフォルトのデータベースを設定します。
BEGIN LOADING −ロードするテーブルを識別します。
ERRORFILES −作成/更新する必要がある2つのエラーテーブルを識別します。
CHECKPOINT −チェックポイントを取得するタイミングを定義します。
SET RECORD −入力ファイル形式がフォーマット済み、バイナリ、テキスト、またはフォーマットされていないかどうかを指定します。
DEFINE −入力ファイルのレイアウトを定義します。
FILE −入力ファイル名とパスを指定します。
INSERT −入力ファイルのレコードをターゲットテーブルに挿入します。
END LOADING−FastLoadのフェーズ2を開始します。レコードをターゲットテーブルに配布します。
LOGOFF −すべてのセッションを終了し、FastLoadを終了します。
MultiLoadは、一度に複数のテーブルをロードでき、INSERT、DELETE、UPDATE、UPSERTなどのさまざまなタイプのタスクを実行することもできます。一度に最大5つのテーブルをロードし、スクリプトで最大20のDML操作を実行できます。MultiLoadにはターゲットテーブルは必要ありません。
MultiLoadは2つのモードをサポートします-
- IMPORT
- DELETE
MultiLoadには、ターゲットテーブルに加えて、作業テーブル、ログテーブル、および2つのエラーテーブルが必要です。
Log Table −再起動に使用されるロード中に取得されたチェックポイントを維持するために使用されます。
Error Tables−これらのテーブルは、ロード中にエラーが発生したときに挿入されます。最初のエラーテーブルには変換エラーが格納され、2番目のエラーテーブルには重複レコードが格納されます。
Log Table −再起動のためにMultiLoadの各フェーズの結果を維持します。
Work table− MultiLoadスクリプトは、ターゲットテーブルごとに1つの作業テーブルを作成します。作業テーブルは、DMLタスクと入力データを保持するために使用されます。
制限
MultiLoadにはいくつかの制限があります。
- 一意のセカンダリインデックスは、ターゲットテーブルではサポートされていません。
- 参照整合性はサポートされていません。
- トリガーはサポートされていません。
MultiLoadのしくみ
MultiLoadのインポートには5つのフェーズがあります-
Phase 1 −予備段階–基本的なセットアップアクティビティを実行します。
Phase 2 − DMLトランザクションフェーズ– DMLステートメントの構文を検証し、Teradataシステムに取り込みます。
Phase 3 −取得フェーズ–入力データを作業テーブルに取り込み、テーブルをロックします。
Phase 4 −適用フェーズ–すべてのDML操作を適用します。
Phase 5 −クリーンアップフェーズ–テーブルロックを解放します。
MultiLoadスクリプトに含まれる手順は次のとおりです。
Step 1 −ログテーブルを設定します。
Step 2 −Teradataにログオンします。
Step 3 − Target、Work、およびErrorテーブルを指定します。
Step 4 −INPUTファイルのレイアウトを定義します。
Step 5 −DMLクエリを定義します。
Step 6 −IMPORTファイルに名前を付けます。
Step 7 −使用するLAYOUTを指定します。
Step 8 −ロードを開始します。
Step 9 −ロードを終了し、セッションを終了します。
例
次のレコードを使用してテキストファイルを作成し、ファイルにemployee.txtという名前を付けます。
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3次の例は、employeeテーブルからレコードを読み取り、Employee_StgテーブルにロードするMultiLoadスクリプトです。
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;マルチロードスクリプトの実行
入力ファイルemployee.txtが作成され、multiloadスクリプトの名前がEmployeeLoad.mlになったら、UNIXおよびWindowsで次のコマンドを使用してMultiloadスクリプトを実行できます。
Multiload < EmployeeLoad.ml;FastExportユーティリティは、Teradataテーブルからフラットファイルにデータをエクスポートするために使用されます。また、レポート形式でデータを生成することもできます。結合を使用して、1つ以上のテーブルからデータを抽出できます。FastExportは64Kブロックでデータをエクスポートするため、大量のデータを抽出するのに役立ちます。
例
次のEmployeeテーブルについて考えてみます。
| 従業員番号 | ファーストネーム | 苗字 | 誕生日 |
|---|---|---|---|
| 101 | マイク | ジェームズ | 1980年1月5日 |
| 104 | アレックス | スチュアート | 1984年11月6日 |
| 102 | ロバート | ウィリアムズ | 1983年3月5日 |
| 105 | ロバート | ジェームズ | 1984年12月1日 |
| 103 | ピーター | ポール | 1983年4月1日 |
以下は、FastExportスクリプトの例です。従業員テーブルからデータをエクスポートし、ファイルemployeedata.txtに書き込みます。
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;FastExportスクリプトの実行
スクリプトが作成され、employee.fxという名前が付けられたら、次のコマンドを使用してスクリプトを実行できます。
fexp < employee.fx上記のコマンドを実行すると、ファイルemployeedata.txtに次の出力が表示されます。
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06FastExport規約
以下は、FastExportスクリプトで一般的に使用される用語のリストです。
LOGTABLE −再起動用のログテーブルを指定します。
LOGON − Teradataにログインし、1つ以上のセッションを開始します。
DATABASE −デフォルトのデータベースを設定します。
BEGIN EXPORT −エクスポートの開始を示します。
EXPORT −ターゲットファイルとエクスポート形式を指定します。
SELECT −データをエクスポートするための選択クエリを指定します。
END EXPORT −FastExportの終了を指定します。
LOGOFF −すべてのセッションを終了し、FastExportを終了します。
BTEQユーティリティは、バッチモードとインタラクティブモードの両方で使用できるTeradataの強力なユーティリティです。これは、任意のDDLステートメント、DMLステートメントの実行、マクロおよびストアドプロシージャの作成に使用できます。BTEQは、フラットファイルからTeradataテーブルにデータをインポートするために使用できます。また、テーブルからファイルまたはレポートにデータを抽出するためにも使用できます。
BTEQ規約
以下は、BTEQスクリプトで一般的に使用される用語のリストです。
LOGON −Teradataシステムへのログインに使用されます。
ACTIVITYCOUNT −前のクエリの影響を受けた行数を返します。
ERRORCODE −前のクエリのステータスコードを返します。
DATABASE −デフォルトのデータベースを設定します。
LABEL −SQLコマンドのセットにラベルを割り当てます。
RUN FILE −ファイルに含まれるクエリを実行します。
GOTO −制御をラベルに移します。
LOGOFF −データベースからログオフし、すべてのセッションを終了します。
IMPORT −入力ファイルのパスを指定します。
EXPORT −出力ファイルのパスを指定し、エクスポートを開始します。
例
以下は、サンプルのBTEQスクリプトです。
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;上記のスクリプトは、次のタスクを実行します。
TeradataSystemにログインします。
デフォルトデータベースを設定します。
employee_bkupというテーブルを作成します。
Employeeテーブルから1つのレコードを選択して、テーブルにレコードがあるかどうかを確認します。
テーブルが空の場合、employee_bkupテーブルを削除します。
コントロールをLabelInsertEmployeeに転送し、LabelInsertEmployeeがレコードをemployee_bkupテーブルに挿入します。
ERRORCODEをチェックして、各SQLステートメントの後にステートメントが成功したことを確認します。
ACTIVITYCOUNTは、前のSQLクエリによって選択/影響を受けたレコードの数を返します。