Apache Flink-아키텍처
Apache Flink는 Kappa 아키텍처에서 작동합니다. Kappa 아키텍처에는 모든 입력을 스트림으로 처리하고 스트리밍 엔진이 실시간으로 데이터를 처리하는 단일 프로세서 스트림이 있습니다. kappa 아키텍처의 배치 데이터는 스트리밍의 특별한 경우입니다.
다음 다이어그램은 Apache Flink Architecture.
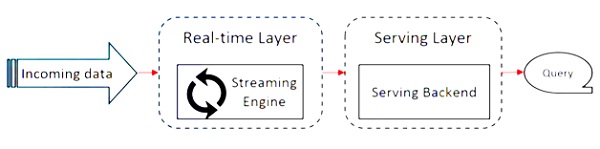
Kappa 아키텍처의 핵심 아이디어는 단일 스트림 처리 엔진을 통해 배치 및 실시간 데이터를 모두 처리하는 것입니다.
대부분의 빅 데이터 프레임 워크는 배치 및 스트리밍 데이터를위한 별도의 프로세서가있는 Lambda 아키텍처에서 작동합니다. Lambda 아키텍처에는 배치 및 스트림보기를위한 별도의 코드베이스가 있습니다. 쿼리하고 결과를 얻으려면 코드베이스를 병합해야합니다. 별도의 코드베이스 / 뷰를 유지하지 않고 병합하는 것은 고통 스럽지만 Kappa 아키텍처는 실시간 뷰가 하나뿐이므로이 문제를 해결하므로 코드베이스를 병합 할 필요가 없습니다.
그렇다고 Kappa 아키텍처가 Lambda 아키텍처를 대체한다는 의미는 아니며, 어떤 아키텍처가 더 바람직한 지 결정하는 사용 사례와 애플리케이션에 완전히 의존합니다.
다음 다이어그램은 Apache Flink 작업 실행 아키텍처를 보여줍니다.

프로그램
Flink 클러스터에서 실행하는 코드입니다.
고객
코드 (프로그램)를 가져와 작업 데이터 흐름 그래프를 구성한 다음이를 JobManager에 전달하는 역할을합니다. 또한 작업 결과를 검색합니다.
JobManager
Client로부터 Job Dataflow Graph를 수신 한 후 실행 그래프 생성을 담당합니다. 작업을 클러스터의 TaskManager에 할당하고 작업 실행을 감독합니다.
작업 관리자
JobManager에 의해 할당 된 모든 작업을 실행합니다. 모든 TaskManager는 지정된 병렬 처리로 별도의 슬롯에서 작업을 실행합니다. 작업 상태를 JobManager로 보내는 책임이 있습니다.
Apache Flink의 기능
Apache Flink의 기능은 다음과 같습니다.
여기에는 배치 및 스트리밍 프로그램을 모두 실행할 수있는 스트리밍 프로세서가 있습니다.
매우 빠른 속도로 데이터를 처리 할 수 있습니다.
Java, Scala 및 Python에서 사용할 수있는 API.
프로그래머가 사용하기 매우 쉬운 모든 일반적인 작업을위한 API를 제공합니다.
짧은 지연 시간 (나노초)과 높은 처리량으로 데이터를 처리합니다.
내결함성이 있습니다. 노드, 응용 프로그램 또는 하드웨어에 장애가 발생해도 클러스터에 영향을주지 않습니다.
Apache Hadoop, Apache MapReduce, Apache Spark, HBase 및 기타 빅 데이터 도구와 쉽게 통합 할 수 있습니다.
더 나은 계산을 위해 메모리 내 관리를 사용자 지정할 수 있습니다.
확장 성이 뛰어나고 클러스터에서 수천 개의 노드까지 확장 할 수 있습니다.
윈도우 화는 Apache Flink에서 매우 유연합니다.
그래프 처리, 기계 학습, 복잡한 이벤트 처리 라이브러리를 제공합니다.