Apache Flink-빠른 가이드
지난 10 년 동안 데이터의 발전은 엄청났습니다. 이로 인해 '빅 데이터'라는 용어가 생겼습니다. 빅 데이터라고 부를 수있는 고정 된 크기의 데이터는 없습니다. 기존 시스템 (RDBMS)이 처리 할 수없는 데이터는 빅 데이터입니다. 이 빅 데이터는 구조화, 반 구조화 또는 비 구조화 형식 일 수 있습니다. 처음에 데이터에는 볼륨, 속도, 다양성의 세 가지 차원이있었습니다. 이제 차원은 3V를 넘어 섰습니다. 이제 Veracity, Validity, Vulnerability, Value, Variability 등 다른 V를 추가했습니다.
빅 데이터는 데이터 저장 및 처리에 도움이되는 여러 도구 및 프레임 워크의 출현으로 이어졌습니다. Hadoop, Spark, Hive, Pig, Storm 및 Zookeeper와 같은 몇 가지 인기있는 빅 데이터 프레임 워크가 있습니다. 또한 의료, 금융, 소매, 전자 상거래 등과 같은 여러 도메인에서 차세대 제품을 만들 수있는 기회를 제공했습니다.
다국적 기업이든 신생 기업이든 모두가 빅 데이터를 활용하여 데이터를 저장 및 처리하고 더 현명한 결정을 내리고 있습니다.
빅 데이터의 경우 두 가지 유형의 처리가 있습니다.
- 일괄 처리
- 실시간 처리
시간이 지남에 따라 수집 된 데이터를 기반으로 한 처리를 일괄 처리라고합니다. 예를 들어, 한 은행 관리자가 지난 1 개월 동안 취소 된 수표 수를 확인하기 위해 지난 1 개월 데이터 (시간이 지남에 따라 수집 됨)를 처리하려고합니다.
즉각적인 결과를 위해 즉각적인 데이터를 기반으로 한 처리를 실시간 처리라고합니다. 예를 들어, 은행 관리자가 사기 거래 (즉시 결과)가 발생한 직후 사기 경고를받습니다.
아래 표는 일괄 처리와 실시간 처리의 차이점을 나열합니다.
| 일괄 처리 | 실시간 처리 |
|---|---|
정적 파일 |
이벤트 스트림 |
분, 시간, 일 등으로 주기적으로 처리됩니다. |
즉시 처리 나노초 |
디스크 저장소의 과거 데이터 |
메모리 스토리지 |
예-빌 생성 |
예-ATM 거래 경고 |
요즘에는 모든 조직에서 실시간 처리가 많이 사용되고 있습니다. 사기 탐지, 의료 분야의 실시간 경고 및 네트워크 공격 경고와 같은 사용 사례에는 즉각적인 데이터의 실시간 처리가 필요합니다. 몇 밀리 초의 지연도 큰 영향을 미칠 수 있습니다.
이러한 실시간 사용 사례에 이상적인 도구는 일괄 처리가 아닌 스트림으로 데이터를 입력 할 수있는 도구입니다. Apache Flink는 실시간 처리 도구입니다.
Apache Flink는 스트리밍 데이터를 처리 할 수있는 실시간 처리 프레임 워크입니다. 확장 가능하고 정확한 고성능 실시간 애플리케이션을위한 오픈 소스 스트림 처리 프레임 워크입니다. 진정한 스트리밍 모델을 가지고 있으며 입력 데이터를 배치 또는 마이크로 배치로 사용하지 않습니다.
Apache Flink는 Data Artisans 회사에 의해 설립되었으며 현재 Apache Flink Community의 Apache 라이선스에 따라 개발되었습니다. 이 커뮤니티에는 지금까지 479 명 이상의 기여자와 15500 개 이상의 커밋이 있습니다.
Apache Flink의 생태계
아래에 주어진 다이어그램은 Apache Flink 생태계의 여러 계층을 보여줍니다.

저장
Apache Flink에는 데이터를 읽고 쓸 수있는 여러 옵션이 있습니다. 아래는 기본 저장 목록입니다.
- HDFS (Hadoop 분산 파일 시스템)
- 로컬 파일 시스템
- S3
- RDBMS (MySQL, Oracle, MS SQL 등)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
배포
로컬 모드, 클러스터 모드 또는 클라우드에서 Apache Fink를 배포 할 수 있습니다. 클러스터 모드는 독립형, YARN, MESOS 일 수 있습니다.
클라우드에서 Flink는 AWS 또는 GCP에 배포 할 수 있습니다.
핵심
이것은 분산 처리, 내결함성, 안정성, 기본 반복 처리 기능 등을 제공하는 런타임 계층입니다.
API 및 라이브러리
이것은 Apache Flink의 최상위 계층이자 가장 중요한 계층입니다. 일괄 처리를 담당하는 Dataset API와 스트림 처리를 담당하는 Datastream API가 있습니다. Flink ML (기계 학습용), Gelly (그래프 처리 용), SQL 용 테이블과 같은 다른 라이브러리가 있습니다. 이 계층은 Apache Flink에 다양한 기능을 제공합니다.
Apache Flink는 Kappa 아키텍처에서 작동합니다. Kappa 아키텍처에는 모든 입력을 스트림으로 처리하고 스트리밍 엔진이 실시간으로 데이터를 처리하는 단일 프로세서 스트림이 있습니다. kappa 아키텍처의 배치 데이터는 스트리밍의 특별한 경우입니다.
다음 다이어그램은 Apache Flink Architecture.
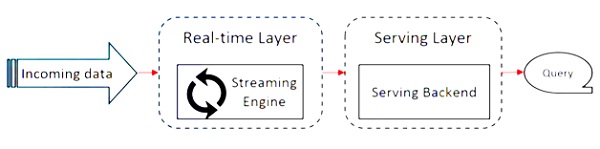
Kappa 아키텍처의 핵심 아이디어는 단일 스트림 처리 엔진을 통해 배치 및 실시간 데이터를 모두 처리하는 것입니다.
대부분의 빅 데이터 프레임 워크는 배치 및 스트리밍 데이터를위한 별도의 프로세서가있는 Lambda 아키텍처에서 작동합니다. Lambda 아키텍처에는 배치 및 스트림보기를위한 별도의 코드베이스가 있습니다. 쿼리하고 결과를 얻으려면 코드베이스를 병합해야합니다. 별도의 코드베이스 / 뷰를 유지하지 않고 병합하는 것은 고통 스럽지만 Kappa 아키텍처는 실시간 뷰가 하나뿐이므로이 문제를 해결하므로 코드베이스를 병합 할 필요가 없습니다.
그렇다고 Kappa 아키텍처가 Lambda 아키텍처를 대체한다는 의미는 아니며, 어떤 아키텍처가 더 바람직한 지 결정하는 사용 사례와 애플리케이션에 완전히 의존합니다.
다음 다이어그램은 Apache Flink 작업 실행 아키텍처를 보여줍니다.

프로그램
Flink 클러스터에서 실행하는 코드입니다.
고객
코드 (프로그램)를 가져와 작업 데이터 흐름 그래프를 구성한 다음이를 JobManager에 전달하는 역할을합니다. 또한 작업 결과를 검색합니다.
JobManager
Client로부터 Job Dataflow Graph를 수신 한 후 실행 그래프 생성을 담당합니다. 작업을 클러스터의 TaskManager에 할당하고 작업 실행을 감독합니다.
작업 관리자
JobManager에 의해 할당 된 모든 작업을 실행합니다. 모든 TaskManager는 지정된 병렬 처리로 별도의 슬롯에서 작업을 실행합니다. 작업 상태를 JobManager로 보내는 책임이 있습니다.
Apache Flink의 기능
Apache Flink의 기능은 다음과 같습니다.
여기에는 배치 및 스트리밍 프로그램을 모두 실행할 수있는 스트리밍 프로세서가 있습니다.
매우 빠른 속도로 데이터를 처리 할 수 있습니다.
Java, Scala 및 Python에서 사용할 수있는 API.
프로그래머가 사용하기 매우 쉬운 모든 일반적인 작업을위한 API를 제공합니다.
짧은 지연 시간 (나노초)과 높은 처리량으로 데이터를 처리합니다.
내결함성이 있습니다. 노드, 응용 프로그램 또는 하드웨어에 장애가 발생해도 클러스터에 영향을주지 않습니다.
Apache Hadoop, Apache MapReduce, Apache Spark, HBase 및 기타 빅 데이터 도구와 쉽게 통합 할 수 있습니다.
더 나은 계산을 위해 메모리 내 관리를 사용자 지정할 수 있습니다.
확장 성이 뛰어나고 클러스터에서 수천 개의 노드까지 확장 할 수 있습니다.
윈도우 화는 Apache Flink에서 매우 유연합니다.
그래프 처리, 기계 학습, 복잡한 이벤트 처리 라이브러리를 제공합니다.
다음은 Apache Flink를 다운로드하고 작업하기위한 시스템 요구 사항입니다.
권장 운영 체제
- 마이크로 소프트 윈도우 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
메모리 요구 사항
- 메모리-최소 4GB, 권장 8GB
- 저장 공간-30GB
Note − Java 8은 이미 설정된 환경 변수와 함께 사용할 수 있어야합니다.
Apache Flink의 설정 / 설치를 시작하기 전에 시스템에 Java 8이 설치되어 있는지 확인하겠습니다.
Java-버전

이제 Apache Flink를 다운로드하여 진행합니다.
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz
이제 tar 파일의 압축을 풉니 다.
tar -xzf flink-1.7.1-bin-scala_2.11.tgz
Flink의 홈 디렉토리로 이동합니다.
cd flink-1.7.1/Flink 클러스터를 시작합니다.
./bin/start-cluster.sh
Mozilla 브라우저를 열고 아래 URL로 이동하면 Flink 웹 대시 보드가 열립니다.
http://localhost:8081
이것이 Apache Flink Dashboard의 사용자 인터페이스의 모습입니다.

이제 Flink 클러스터가 실행 중입니다.
Flink에는 개발자가 일괄 데이터와 실시간 데이터 모두에서 변환을 수행 할 수있는 풍부한 API 세트가 있습니다. 다양한 변환에는 매핑, 필터링, 정렬, 결합, 그룹화 및 집계가 포함됩니다. Apache Flink에 의한 이러한 변환은 분산 데이터에서 수행됩니다. Apache Flink가 제공하는 다양한 API에 대해 논의하겠습니다.
데이터 세트 API
Apache Flink의 데이터 세트 API는 일정 기간 동안 데이터에 대한 일괄 작업을 수행하는 데 사용됩니다. 이 API는 Java, Scala 및 Python에서 사용할 수 있습니다. 필터링, 매핑, 집계, 조인 및 그룹화와 같은 데이터 세트에 다양한 종류의 변환을 적용 할 수 있습니다.
데이터 세트는 로컬 파일과 같은 소스에서 생성되거나 특정 소스에서 파일을 읽어 생성되며 결과 데이터는 분산 파일 또는 명령 줄 터미널과 같은 다른 싱크에 기록 될 수 있습니다. 이 API는 Java 및 Scala 프로그래밍 언어 모두에서 지원됩니다.
다음은 Dataset API의 Wordcount 프로그램입니다.
public class WordCountProg {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Hello",
"My Dataset API Flink Program");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}DataStream API
이 API는 연속 스트림에서 데이터를 처리하는 데 사용됩니다. 필터링, 매핑, 창 설정, 스트림 데이터 집계와 같은 다양한 작업을 수행 할 수 있습니다. 이 데이터 스트림에는 메시지 큐, 파일, 소켓 스트림과 같은 다양한 소스가 있으며 결과 데이터는 명령 줄 터미널과 같은 다른 싱크에 기록 될 수 있습니다. Java 및 Scala 프로그래밍 언어 모두이 API를 지원합니다.
다음은 DataStream API의 스트리밍 Wordcount 프로그램으로, 연속적인 단어 수 스트림이 있고 데이터가 두 번째 창에 그룹화되어 있습니다.
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCountProg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Streaming WordCount Example");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}Table API는 SQL과 같은 표현 언어를 사용하는 관계형 API입니다. 이 API는 일괄 처리와 스트림 처리를 모두 수행 할 수 있습니다. Java 및 Scala Dataset 및 Datastream API에 포함 할 수 있습니다. 기존 데이터 세트 및 데이터 스트림 또는 외부 데이터 소스에서 테이블을 만들 수 있습니다. 이 관계형 API를 통해 조인, 집계, 선택 및 필터링과 같은 작업을 수행 할 수 있습니다. 입력이 배치이든 스트림이든 쿼리의 의미는 동일하게 유지됩니다.
다음은 샘플 테이블 API 프로그램입니다.
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...) // or
tableEnv.registerExternalCatalog("extCat", ...)
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
val tapiResult = tableEnv.scan("table1").select(...)
// Create a Table from a SQL query
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...")
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable")
// execute
env.execute()이 장에서는 Flink 애플리케이션을 만드는 방법을 배웁니다.
Eclipse IDE를 열고 새 프로젝트를 클릭하고 Java 프로젝트를 선택하십시오.

프로젝트 이름을 지정하고 마침을 클릭합니다.

이제 다음 스크린 샷과 같이 마침을 클릭합니다.
이제 마우스 오른쪽 버튼으로 src New >> Class로 이동합니다.

수업 이름을 입력하고 마침을 클릭합니다.

편집기에서 아래 코드를 복사하여 붙여 넣으십시오.
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}이 프로젝트에 Flink 라이브러리를 추가해야하므로 편집기에서 많은 오류가 발생합니다.

프로젝트 >> 빌드 경로 >> 빌드 경로 구성을 마우스 오른쪽 버튼으로 클릭하십시오.
라이브러리 탭을 선택하고 외부 JAR 추가를 클릭하십시오.

Flink의 lib 디렉토리로 이동하여 4 개의 라이브러리를 모두 선택한 다음 확인을 클릭합니다.
주문 및 내보내기 탭으로 이동하여 모든 라이브러리를 선택하고 확인을 클릭합니다.
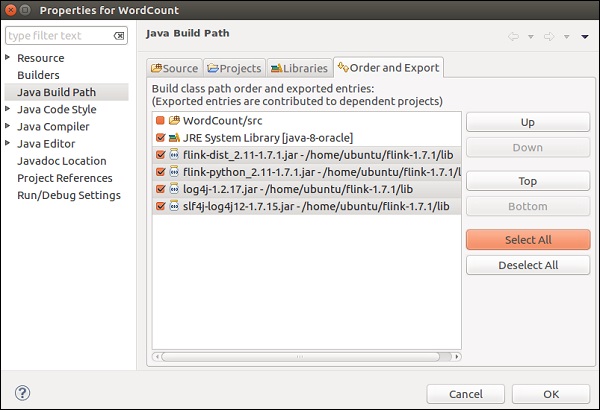
오류가 더 이상 존재하지 않음을 알 수 있습니다.
이제이 응용 프로그램을 내보내겠습니다. 프로젝트를 마우스 오른쪽 버튼으로 클릭하고 내보내기를 클릭합니다.

JAR 파일을 선택하고 다음을 클릭하십시오.

대상 경로를 지정하고 다음을 클릭하십시오.

다음을 클릭>
찾아보기를 클릭하고 기본 클래스 (WordCount)를 선택한 후 완료를 클릭하십시오.

Note − 경고가 표시되면 확인을 클릭합니다.
아래 명령을 실행하십시오. 방금 만든 Flink 응용 프로그램을 추가로 실행합니다.
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output
이 장에서는 Flink 프로그램을 실행하는 방법을 배웁니다.
Flink 클러스터에서 Flink wordcount 예제를 실행 해 보겠습니다.
Flink의 홈 디렉토리로 이동하여 터미널에서 아래 명령을 실행하십시오.
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt
Flink 대시 보드로 이동하면 완료된 작업과 세부 정보를 볼 수 있습니다.

완료된 작업을 클릭하면 작업에 대한 자세한 개요를 볼 수 있습니다.

wordcount 프로그램의 출력을 확인하려면 터미널에서 아래 명령을 실행하십시오.
cat output.txt
이 장에서는 Apache Flink의 다양한 라이브러리에 대해 알아 봅니다.
복잡한 이벤트 처리 (CEP)
FlinkCEP는 Apache Flink의 API로 연속 스트리밍 데이터의 이벤트 패턴을 분석합니다. 이러한 이벤트는 거의 실시간이며 처리량이 높고 지연 시간이 짧습니다. 이 API는 실시간으로 제공되고 처리하기가 매우 복잡한 센서 데이터에 주로 사용됩니다.
CEP는 입력 스트림의 패턴을 분석하고 결과를 곧 제공합니다. 이벤트 패턴이 복잡한 경우 실시간 알림 및 경고를 제공하는 기능이 있습니다. FlinkCEP는 다양한 종류의 입력 소스에 연결하여 그 안의 패턴을 분석 할 수 있습니다.
CEP를 사용한 샘플 아키텍처는 다음과 같습니다.

센서 데이터는 다양한 소스에서 들어오고 Kafka는 Apache Flink에 스트림을 배포하는 분산 메시징 프레임 워크 역할을하며 FlinkCEP는 복잡한 이벤트 패턴을 분석합니다.
Pattern API를 사용하여 복잡한 이벤트 처리를 위해 Apache Flink에서 프로그램을 작성할 수 있습니다. 연속 스트림 데이터에서 감지 할 이벤트 패턴을 결정할 수 있습니다. 다음은 가장 일반적으로 사용되는 CEP 패턴 중 일부입니다.
시작
시작 상태를 정의하는 데 사용됩니다. 다음 프로그램은 Flink 프로그램에서 어떻게 정의되는지 보여줍니다.
Pattern<Event, ?> next = start.next("next");어디
현재 상태에서 필터 조건을 정의하는 데 사용됩니다.
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});다음
새 패턴 상태와 이전 패턴을 전달하는 데 필요한 일치 이벤트를 추가하는 데 사용됩니다.
Pattern<Event, ?> next = start.next("next");FollowedBy
새 패턴 상태를 추가하는 데 사용되지만 여기서는 두 개의 일치하는 이벤트와 함께 다른 이벤트가 발생할 수 있습니다.
Pattern<Event, ?> followedBy = start.followedBy("next");젤리
Apache Flink의 Graph API는 Gelly입니다. Gelly는 일련의 방법과 유틸리티를 사용하여 Flink 응용 프로그램에서 그래프 분석을 수행하는 데 사용됩니다. Gelly와 함께 분산 된 방식으로 Apache Flink API를 사용하여 거대한 그래프를 분석 할 수 있습니다. 동일한 목적으로 Apache Giraph와 같은 다른 그래프 라이브러리도 있지만 Gelly는 Apache Flink 위에 사용되기 때문에 단일 API를 사용합니다. 이것은 개발 및 운영 관점에서 매우 유용합니다.
Apache Flink API-Gelly를 사용하여 예제를 실행 해 보겠습니다.
먼저 Apache Flink의 opt 디렉토리에서 2 개의 Gelly jar 파일을 lib 디렉토리로 복사해야합니다. 그런 다음 flink-gelly-examples jar를 실행합니다.
cp opt/flink-gelly* lib/
./bin/flink run examples/gelly/flink-gelly-examples_*.jar
이제 PageRank 예제를 실행 해 보겠습니다.
PageRank는 인 엣지를 통해 전송 된 PageRank 점수의 합계 인 정점 별 점수를 계산합니다. 각 정점의 점수는 바깥 쪽 가장자리간에 균등하게 나뉩니다. 점수가 높은 정점은 점수가 높은 다른 정점과 연결됩니다.
결과에는 정점 ID와 PageRank 점수가 포함됩니다.
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options]
./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print
Apache Flink의 기계 학습 라이브러리는 FlinkML이라고합니다. 기계 학습의 사용이 지난 5 년 동안 기하 급수적으로 증가했기 때문에 Flink 커뮤니티는이 기계 학습 APO를 생태계에도 추가하기로 결정했습니다. FlinkML에서 기여자 및 알고리즘 목록이 증가하고 있습니다. 이 API는 아직 바이너리 배포의 일부가 아닙니다.
다음은 FlinkML을 사용한 선형 회귀의 예입니다.
// LabeledVector is a feature vector with a label (class or real value)
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
// Alternatively, a Splitter is used to break up a DataSet into training and testing data.
val dataSet: DataSet[LabeledVector] = ...
val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet)
val trainingData: DataSet[LabeledVector] = trainTestData.training
val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector)
val mlr = MultipleLinearRegression()
.setStepsize(1.0)
.setIterations(100)
.setConvergenceThreshold(0.001)
mlr.fit(trainingData)
// The fitted model can now be used to make predictions
val predictions: DataSet[LabeledVector] = mlr.predict(testingData)내부 flink-1.7.1/examples/batch/경로에 KMeans.jar 파일이 있습니다. 이 샘플 FlinkML 예제를 실행 해 보겠습니다.
이 예제 프로그램은 기본 점과 중심 데이터 세트를 사용하여 실행됩니다.
./bin/flink run examples/batch/KMeans.jar --output Print
이 장에서는 Apache Flink의 몇 가지 테스트 사례를 이해합니다.
Apache Flink-Bouygues Telecom
Bouygues Telecom은 프랑스에서 가장 큰 통신 조직 중 하나입니다. 1100 만 명 이상의 모바일 가입자와 250 만 명 이상의 고정 고객을 보유하고 있습니다. Bouygues는 파리에서 열린 Hadoop 그룹 회의에서 처음으로 Apache Flink에 대해 들었습니다. 그 이후로 그들은 여러 사용 사례에 Flink를 사용하고 있습니다. Apache Flink를 통해 하루에 수십억 개의 메시지를 실시간으로 처리하고 있습니다.
이것은 Bouygues가 Apache Flink에 대해 다음과 같이 말한 것입니다. " 시스템이 API 및 런타임 수준 모두에서 진정한 스트리밍을 지원하기 때문에 Flink를 사용하여 우리가 찾고 있던 프로그래밍 가능성과 낮은 지연 시간을 제공했습니다. 또한, 다른 솔루션에 비해 짧은 시간 내에 Flink를 사용하여 시스템을 가동 할 수 있었기 때문에 시스템의 비즈니스 로직을 확장하는 데 더 많은 개발자 리소스를 사용할 수있었습니다. "
Bouygues에서는 고객 경험을 최우선으로 생각합니다. 그들은 실시간으로 데이터를 분석하여 엔지니어에게 아래의 통찰력을 줄 수 있습니다.
네트워크를 통한 실시간 고객 경험
네트워크에서 전 세계적으로 일어나는 일
네트워크 평가 및 운영
그들은 내부 데이터 참조와 함께 네트워크 장비의 방대한 로그 데이터를 처리하는 LUX (Logged User Experience)라는 시스템을 만들었습니다.이 시스템은 고객 경험을 기록하고 60 이내에 데이터 소비 실패를 감지하는 경보 기능을 구축하는 경험 품질 지표를 제공합니다. 초.
이를 위해서는 실시간으로 방대한 데이터를 가져올 수 있고 설정이 쉽고 스트리밍 된 데이터를 처리하기위한 풍부한 API 세트를 제공하는 프레임 워크가 필요했습니다. Apache Flink는 Bouygues Telecom에 완벽하게 맞았습니다.
Apache Flink-Alibaba
알리바바는 2015 년에 3,940 억 달러의 매출을 올린 세계 최대의 전자 상거래 소매 업체입니다. 알리바바 검색은 모든 검색을 보여주고 그에 따라 추천하는 모든 고객의 진입 점입니다.
Alibaba는 검색 엔진에서 Apache Flink를 사용하여 각 사용자에게 가장 높은 정확도와 관련성으로 결과를 실시간으로 표시합니다.
알리바바는 프레임 워크를 찾고있었습니다.
전체 검색 인프라 프로세스에 대해 하나의 코드베이스를 유지하는 데 매우 민첩합니다.
웹 사이트에있는 제품의 가용성 변경에 대해 짧은 대기 시간을 제공합니다.
일관되고 비용 효율적입니다.
Apache Flink는 위의 모든 요구 사항을 충족합니다. 단일 처리 엔진이 있고 동일한 엔진으로 배치 및 스트림 데이터를 모두 처리 할 수있는 프레임 워크가 필요합니다. 이것이 바로 Apache Flink가하는 일입니다.
또한 Flink 용 분기 버전 인 Blink를 사용하여 검색에 대한 몇 가지 고유 한 요구 사항을 충족합니다. 또한 검색 기능이 거의 개선되지 않은 Apache Flink의 Table API를 사용하고 있습니다.
이것은 Alibaba가 apache Flink에 대해 말한 것입니다. " 돌아 보면, Alibaba의 Blink and Flink에게는 의심의 여지가없는 한 해였습니다. 어느 누구도 우리가 1 년 안에 이렇게 많은 진전을 이룰 것이라고 생각하지 않았으며 우리는 모두에게 매우 감사합니다. 커뮤니티에서 우리를 도왔던 사람들입니다. Flink는 매우 큰 규모로 작업하는 것으로 입증되었습니다. 우리는 Flink를 발전시키기 위해 커뮤니티와 함께 작업을 계속하기 위해 그 어느 때보 다 헌신적입니다! "
다음은 가장 널리 사용되는 세 가지 빅 데이터 프레임 워크 인 Apache Flink, Apache Spark 및 Apache Hadoop 간의 비교를 보여주는 포괄적 인 표입니다.
| Apache Hadoop | Apache Spark | Apache Flink | |
|---|---|---|---|
Year of Origin |
2005 년 | 2009 년 | 2009 년 |
Place of Origin |
MapReduce (Google) Hadoop (Yahoo) | 캘리포니아 대학교 버클리 | 베를린 기술 대학교 |
Data Processing Engine |
일괄 | 일괄 | 흐름 |
Processing Speed |
Spark 및 Flink보다 느림 | Hadoop보다 100 배 더 빠름 | 스파크보다 빠름 |
Programming Languages |
자바, C, C ++, Ruby, Groovy, Perl, Python | Java, Scala, Python 및 R | 자바와 스칼라 |
Programming Model |
MapReduce | 탄력적 인 분산 데이터 세트 (RDD) | 순환 데이터 흐름 |
Data Transfer |
일괄 | 일괄 | 파이프 라인 및 배치 |
Memory Management |
디스크 기반 | JVM 관리 | 활성 관리 |
Latency |
낮은 | 매질 | 낮은 |
Throughput |
매질 | 높은 | 높은 |
Optimization |
설명서 | 설명서 | 자동적 인 |
API |
저수준 | 높은 레벨 | 높은 레벨 |
Streaming Support |
NA | 스파크 스트리밍 | Flink 스트리밍 |
SQL Support |
하이브, 임팔라 | SparkSQL | 테이블 API 및 SQL |
Graph Support |
NA | GraphX | 젤리 |
Machine Learning Support |
NA | SparkML | FlinkML |
이전 장에서 본 비교표는 포인터를 거의 마무리합니다. Apache Flink는 실시간 처리 및 사용 사례에 가장 적합한 프레임 워크입니다. 단일 엔진 시스템은 Dataset 및 DataStream과 같은 다른 API를 사용하여 배치 및 스트리밍 데이터를 모두 처리 할 수있는 고유합니다.
Hadoop과 Spark가 게임에서 벗어난 것은 아닙니다. 가장 적합한 빅 데이터 프레임 워크의 선택은 항상 사용 사례에 따라 달라지며 다양합니다. Hadoop과 Flink 또는 Spark와 Flink의 조합이 적합한 사용 사례가 여러 개있을 수 있습니다.
그럼에도 불구하고 Flink는 현재 실시간 처리를위한 최고의 프레임 워크입니다. Apache Flink의 성장은 놀랍고 커뮤니티에 대한 기여자의 수는 날로 증가하고 있습니다.
행복한 플 링킹!