Apache Flume-Twitter 데이터 가져 오기
Flume을 사용하여 다양한 서비스에서 데이터를 가져와 중앙 저장소 (HDFS 및 HBase)로 전송할 수 있습니다. 이 장에서는 Twitter 서비스에서 데이터를 가져와 Apache Flume을 사용하여 HDFS에 저장하는 방법을 설명합니다.
Flume 아키텍처에서 논의 된 바와 같이 웹 서버는 로그 데이터를 생성하고이 데이터는 Flume의 에이전트에 의해 수집됩니다. 채널은이 데이터를 싱크로 버퍼링하고 마지막으로 중앙 저장소로 푸시합니다.
이 장에서 제공하는 예제에서는 Apache Flume에서 제공하는 실험적인 트위터 소스를 사용하여 애플리케이션을 만들고 여기에서 트윗을 가져옵니다. 메모리 채널을 사용하여 이러한 트윗을 버퍼링하고 HDFS 싱크를 사용하여 이러한 트윗을 HDFS로 푸시합니다.

Twitter 데이터를 가져 오려면 아래 단계를 따라야합니다.
- 트위터 애플리케이션 만들기
- HDFS 설치 / 시작
- Flume 구성
Twitter 애플리케이션 생성
Twitter에서 트윗을 가져 오려면 Twitter 애플리케이션을 만들어야합니다. 아래 단계에 따라 Twitter 애플리케이션을 만듭니다.
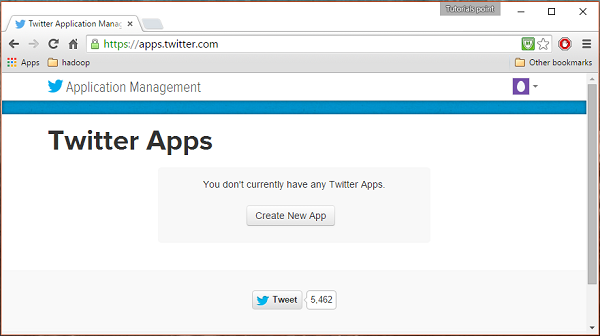
1 단계
Twitter 애플리케이션을 만들려면 다음 링크를 클릭하십시오. https://apps.twitter.com/. Twitter 계정에 로그인하십시오. Twitter 앱을 생성, 삭제 및 관리 할 수있는 Twitter 애플리케이션 관리 창이 나타납니다.
2 단계
클릭 Create New App단추. 앱을 생성하기 위해 세부 정보를 입력해야하는 신청서 양식을받을 수있는 창으로 리디렉션됩니다. 웹 사이트 주소를 입력하는 동안 완전한 URL 패턴을 제공합니다. 예를 들면 다음과 같습니다.http://example.com.
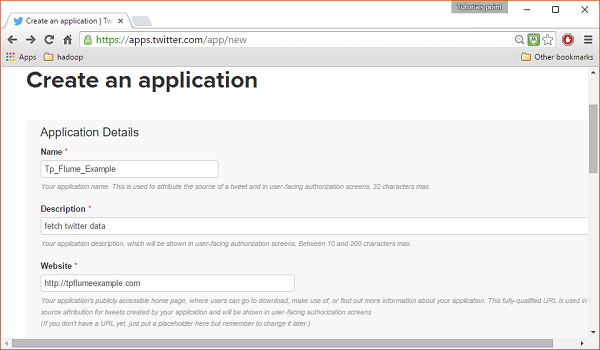
3 단계
세부 정보를 입력하고 동의합니다. Developer Agreement 완료되면 Create your Twitter application button페이지 하단에 있습니다. 모든 것이 잘되면 아래와 같이 주어진 세부 정보로 앱이 생성됩니다.
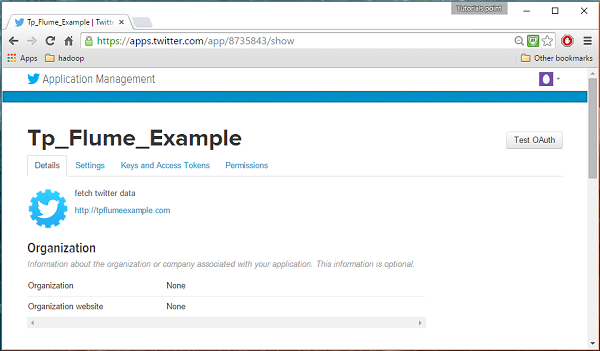
4 단계
아래에 keys and Access Tokens 페이지 하단에있는 탭에서 Create my access token. 클릭하여 액세스 토큰을 생성하십시오.
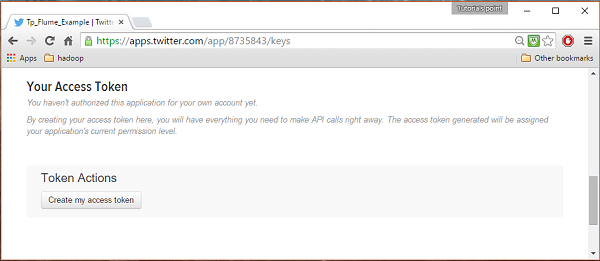
5 단계
마지막으로 Test OAuth페이지 오른쪽 상단에있는 버튼입니다. 이것은 귀하의Consumer key, Consumer secret, Access token, 과 Access token secret. 이 세부 사항을 복사하십시오. Flume에서 에이전트를 구성하는 데 유용합니다.

HDFS 시작
HDFS에 데이터를 저장하고 있으므로 Hadoop을 설치 / 확인해야합니다. Hadoop을 시작하고 Flume 데이터를 저장할 폴더를 만듭니다. Flume을 구성하기 전에 아래 단계를 따르십시오.
1 단계 : Hadoop 설치 / 확인
Hadoop을 설치합니다 . 시스템에 Hadoop이 이미 설치되어있는 경우 아래와 같이 Hadoop 버전 명령을 사용하여 설치를 확인합니다.
$ hadoop version시스템에 Hadoop이 포함되어 있고 경로 변수를 설정 한 경우 다음 출력이 표시됩니다.
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar2 단계 : Hadoop 시작
찾아보기 sbin 아래 그림과 같이 Hadoop 디렉토리를 열고 yarn 및 Hadoop dfs (분산 파일 시스템)를 시작하십시오.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.out3 단계 : HDFS에서 디렉토리 생성
Hadoop DFS에서 다음 명령을 사용하여 디렉토리를 생성 할 수 있습니다. mkdir. 그것을 탐색하고 이름으로 디렉토리를 만듭니다.twitter_data 아래 표시된대로 필요한 경로에서.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataFlume 구성
소스, 채널 및 싱크를 구성해야합니다. conf폴더. 이 장에 제공된 예제는 Apache Flume에서 제공하는 실험 소스를 사용합니다.Twitter 1% Firehose 메모리 채널 및 HDFS 싱크.
트위터 1 % Firehose 소스
이 소스는 매우 실험적입니다. 스트리밍 API를 사용하여 1 % 샘플 Twitter Firehose에 연결하고 트윗을 지속적으로 다운로드하여 Avro 형식으로 변환하고 Avro 이벤트를 다운 스트림 Flume 싱크로 보냅니다.
Flume 설치와 함께 기본적으로이 소스를 얻을 수 있습니다. 그만큼jar 이 소스에 해당하는 파일은 lib 아래 그림과 같이 폴더.

클래스 경로 설정
설정 classpath 변수 lib Flume의 폴더 Flume-env.sh 아래와 같이 파일.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*이 소스에는 다음과 같은 세부 정보가 필요합니다. Consumer key, Consumer secret, Access token, 과 Access token secret트위터 애플리케이션의. 이 소스를 구성하는 동안 다음 속성에 값을 제공해야합니다.
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey − OAuth 소비자 키
consumerSecret − OAuth 소비자 비밀
accessToken − OAuth 액세스 토큰
accessTokenSecret − OAuth 토큰 비밀
maxBatchSize− 트위터 배치에 있어야하는 최대 트위터 메시지 수. 기본값은 1000 (선택 사항)입니다.
maxBatchDurationMillis− 배치를 닫기 전에 대기 할 최대 시간 (밀리 초). 기본값은 1000 (선택 사항)입니다.
채널
우리는 메모리 채널을 사용하고 있습니다. 메모리 채널을 구성하려면 채널 유형에 값을 제공 해야합니다 .
type− 채널 유형을 유지합니다. 이 예에서 유형은MemChannel.
Capacity− 채널에 저장된 최대 이벤트 수입니다. 기본값은 100 (선택 사항)입니다.
TransactionCapacity− 채널이 수신하거나 전송하는 최대 이벤트 수입니다. 기본값은 100 (선택 사항)입니다.
HDFS 싱크
이 싱크는 HDFS에 데이터를 씁니다. 이 싱크를 구성하려면 다음 세부 정보를 제공 해야합니다 .
Channel
type − hdfs
hdfs.path − 데이터가 저장 될 HDFS의 디렉토리 경로.
그리고 시나리오에 따라 몇 가지 선택적 값을 제공 할 수 있습니다. 다음은 애플리케이션에서 구성하는 HDFS 싱크의 선택적 속성입니다.
fileType − 이것은 HDFS 파일의 필수 파일 형식입니다. SequenceFile, DataStream 과 CompressedStream이 스트림에서 사용할 수있는 세 가지 유형입니다. 이 예에서는DataStream.
writeFormat − 텍스트 또는 쓰기 가능.
batchSize− HDFS로 플러시되기 전에 파일에 기록 된 이벤트 수입니다. 기본값은 100입니다.
rollsize− 롤을 트리거하는 파일 크기입니다. 기본값은 100입니다.
rollCount− 롤링되기 전에 파일에 기록 된 이벤트 수입니다. 기본값은 10입니다.
예 – 구성 파일
다음은 구성 파일의 예입니다. 이 콘텐츠를 복사하고 다른 이름으로 저장twitter.conf Flume의 conf 폴더에 있습니다.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannel실행
Flume 홈 디렉토리를 검색하고 아래와 같이 애플리케이션을 실행합니다.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgent모든 것이 잘되면 HDFS로 트윗 스트리밍이 시작됩니다. 다음은 트윗을 가져 오는 동안 명령 프롬프트 창의 스냅 샷입니다.
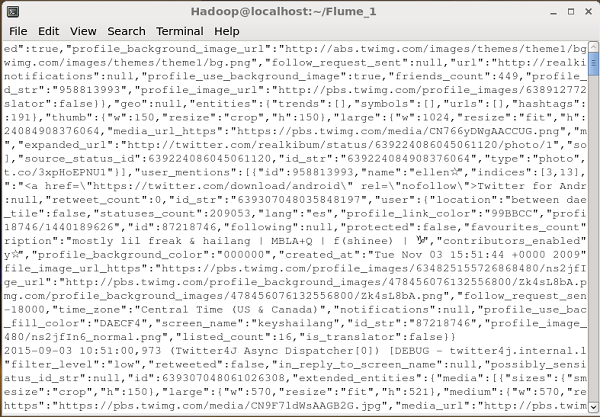
HDFS 확인
아래 제공된 URL을 사용하여 Hadoop 관리 웹 UI에 액세스 할 수 있습니다.
http://localhost:50070/이름이 지정된 드롭 다운을 클릭합니다. Utilities페이지 오른쪽에 있습니다. 아래 주어진 스냅 샷에 표시된대로 두 가지 옵션을 볼 수 있습니다.
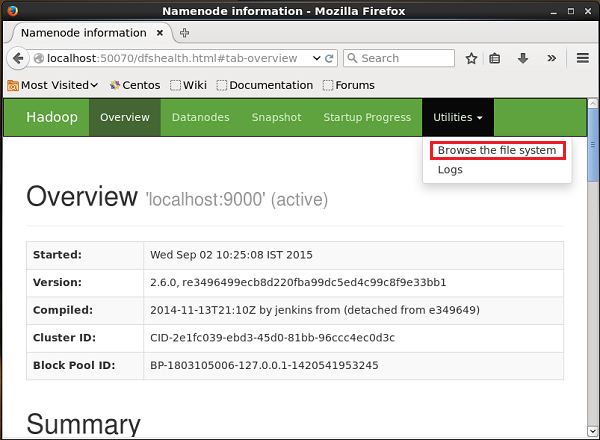
클릭 Browse the file system트윗을 저장 한 HDFS 디렉토리의 경로를 입력합니다. 이 예에서 경로는/user/Hadoop/twitter_data/. 그러면 아래와 같이 HDFS에 저장된 트위터 로그 파일 목록을 볼 수 있습니다.
