Apache Flume-시퀀스 생성기 소스
이전 장에서 트위터 소스에서 HDFS로 데이터를 가져 오는 방법을 살펴 보았습니다. 이 장에서는 데이터를 가져 오는 방법을 설명합니다.Sequence generator.
전제 조건
이 장에 제공된 예제를 실행하려면 다음을 설치해야합니다. HDFS 와 함께 Flume. 따라서 계속 진행하기 전에 Hadoop 설치를 확인하고 HDFS를 시작하십시오. (HDFS 시작 방법은 이전 장을 참조하십시오).
Flume 구성
소스, 채널 및 싱크를 구성해야합니다. conf폴더. 이 장에 제공된 예는sequence generator source, ㅏ memory channel, 그리고 HDFS sink.
시퀀스 생성기 소스
이벤트를 지속적으로 생성하는 소스입니다. 0부터 시작하여 1 씩 증가하는 카운터를 유지합니다. 테스트 목적으로 사용됩니다. 이 소스를 구성하는 동안 다음 속성에 값을 제공해야합니다.
Channels
Source type − seq
채널
우리는 memory채널. 메모리 채널을 구성하려면 채널 유형에 값을 제공 해야합니다 . 다음은 메모리 채널을 구성하는 동안 제공해야하는 속성 목록입니다.
type− 채널 유형을 유지합니다. 이 예에서 유형은 MemChannel입니다.
Capacity− 채널에 저장된 최대 이벤트 수입니다. 기본값은 100입니다. (선택 사항)
TransactionCapacity− 채널이 수신하거나 전송하는 최대 이벤트 수입니다. 기본값은 100입니다 (선택 사항).
HDFS 싱크
이 싱크는 HDFS에 데이터를 씁니다. 이 싱크를 구성하려면 다음 세부 정보를 제공 해야합니다 .
Channel
type − hdfs
hdfs.path − 데이터가 저장 될 HDFS의 디렉토리 경로.
그리고 시나리오에 따라 몇 가지 선택적 값을 제공 할 수 있습니다. 다음은 애플리케이션에서 구성하는 HDFS 싱크의 선택적 속성입니다.
fileType − 이것은 HDFS 파일의 필수 파일 형식입니다. SequenceFile, DataStream 과 CompressedStream이 스트림에서 사용할 수있는 세 가지 유형입니다. 이 예에서는DataStream.
writeFormat − 텍스트 또는 쓰기 가능.
batchSize− HDFS로 플러시되기 전에 파일에 기록 된 이벤트 수입니다. 기본값은 100입니다.
rollsize− 롤을 트리거하는 파일 크기입니다. 기본값은 100입니다.
rollCount− 롤링되기 전에 파일에 기록 된 이벤트 수입니다. 기본값은 10입니다.
예 – 구성 파일
다음은 구성 파일의 예입니다. 이 콘텐츠를 복사하고 다른 이름으로 저장seq_gen .conf Flume의 conf 폴더에 있습니다.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannel실행
Flume 홈 디렉토리를 검색하고 아래와 같이 애플리케이션을 실행합니다.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgent모든 것이 잘되면 소스는 로그 파일 형태로 HDFS에 푸시 될 시퀀스 번호를 생성하기 시작합니다.
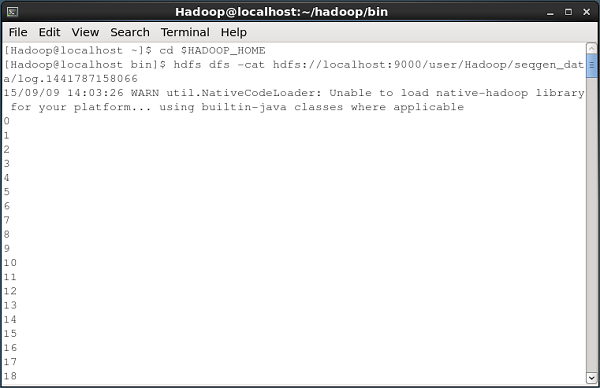
다음은 시퀀스 생성기에 의해 생성 된 데이터를 HDFS로 가져 오는 명령 프롬프트 창의 스냅 샷입니다.

HDFS 확인
다음 URL을 사용하여 Hadoop 관리 웹 UI에 액세스 할 수 있습니다.
http://localhost:50070/이름이 지정된 드롭 다운을 클릭합니다. Utilities페이지 오른쪽에 있습니다. 아래 그림과 같이 두 가지 옵션을 볼 수 있습니다.
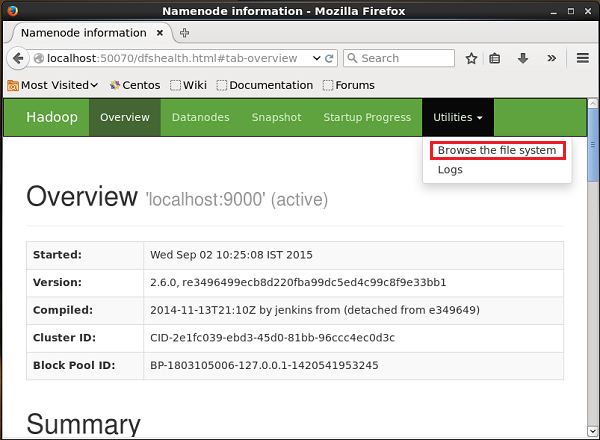
클릭 Browse the file system 시퀀스 생성기에서 생성 한 데이터를 저장 한 HDFS 디렉토리의 경로를 입력합니다.
이 예에서 경로는 /user/Hadoop/ seqgen_data /. 그러면 아래와 같이 HDFS에 저장된 시퀀스 생성기에 의해 생성 된 로그 파일 목록을 볼 수 있습니다.

파일 내용 확인
이러한 모든 로그 파일에는 순차적 형식의 숫자가 포함됩니다. 다음을 사용하여 파일 시스템에서 이러한 파일의 내용을 확인할 수 있습니다.cat 아래와 같이 명령.