Apache MXNet-Python 패키지
이 장에서는 Apache MXNet에서 사용할 수있는 Python 패키지에 대해 알아 봅니다.
중요한 MXNet Python 패키지
MXNet은 우리가 하나씩 논의 할 다음과 같은 중요한 파이썬 패키지를 가지고 있습니다.
Autograd (자동 미분)
NDArray
KVStore
Gluon
Visualization
먼저 Autograd Apache MXNet 용 Python 패키지.
Autograd
Autograd 약자 automatic differentiation손실 메트릭에서 각 매개 변수로 다시 그라디언트를 역 전파하는 데 사용됩니다. 역전 파와 함께 동적 프로그래밍 접근 방식을 사용하여 기울기를 효율적으로 계산합니다. 역방향 모드 자동 미분이라고도합니다. 이 기술은 많은 매개 변수가 단일 손실 지표에 영향을 미치는 '팬인'상황에서 매우 효율적입니다.
그라디언트 란 무엇입니까?
그라디언트는 신경망 훈련 과정의 기초입니다. 기본적으로 성능을 향상시키기 위해 네트워크의 매개 변수를 변경하는 방법을 알려줍니다.
우리가 알고 있듯이 신경망 (NN)은 합계, 곱, 컨볼 루션 등과 같은 연산자로 구성됩니다. 이러한 연산자는 계산을 위해 컨볼 루션 커널의 가중치와 같은 매개 변수를 사용합니다. 이러한 매개 변수에 대한 최적의 값을 찾아야합니다. 그래디언트는 우리에게 방법을 보여주고 솔루션으로이 끕니다.
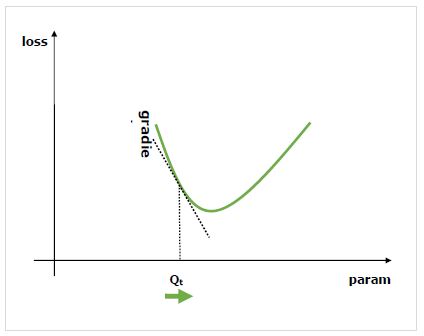
우리는 매개 변수 변경이 네트워크의 성능에 미치는 영향에 관심이 있으며 기울기는 주어진 변수가 의존하는 변수를 변경할 때 얼마나 증가하거나 감소하는지 알려줍니다. 성능은 일반적으로 최소화하려는 손실 메트릭을 사용하여 정의됩니다. 예를 들어, 회귀의 경우L2 예측과 정확한 값 사이의 손실, 분류를 위해 우리는 cross-entropy loss.
손실과 관련하여 각 매개 변수의 기울기를 계산하면 확률 적 경사 하강 법과 같은 옵티 마이저를 사용할 수 있습니다.
그라디언트를 계산하는 방법?
그라디언트를 계산하기 위해 다음과 같은 옵션이 있습니다.
Symbolic Differentiation− 첫 번째 옵션은 각 그라디언트에 대한 공식을 계산하는 Symbolic Differentiation입니다. 이 방법의 단점은 네트워크가 더 깊어지고 운영자가 더 복잡 해짐에 따라 매우 긴 공식으로 빠르게 이어질 것입니다.
Finite Differencing− 또 다른 옵션은 유한 차분을 사용하여 각 매개 변수에서 약간의 차이를 시도하고 손실 메트릭이 어떻게 반응하는지 확인하는 것입니다. 이 방법의 단점은 계산 비용이 많이 들고 수치 정밀도가 떨어질 수 있다는 것입니다.
Automatic differentiation− 위 방법의 단점에 대한 해결책은 자동 미분을 사용하여 손실 메트릭의 기울기를 각 매개 변수로 역 전파하는 것입니다. 전파를 사용하면 동적 프로그래밍 접근 방식을 사용하여 기울기를 효율적으로 계산할 수 있습니다. 이 방법은 역방향 모드 자동 미분이라고도합니다.
자동 미분 (autograd)
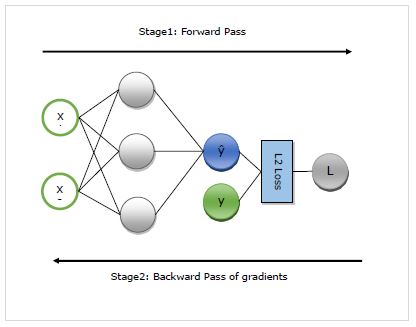
여기서 우리는 autograd의 작동을 자세히 이해할 것입니다. 기본적으로 다음 두 단계로 작동합니다.
Stage 1 −이 단계는 ‘Forward Pass’훈련 이름에서 알 수 있듯이이 단계에서는 네트워크에서 예측을 수행하고 손실 메트릭을 계산하는 데 사용하는 연산자의 레코드를 만듭니다.
Stage 2 −이 단계는 ‘Backward Pass’훈련 이름에서 알 수 있듯이이 단계에서는이 레코드를 통해 거꾸로 작동합니다. 거꾸로 돌아가서 각 연산자의 편도 함수를 네트워크 매개 변수까지 평가합니다.
autograd의 장점
다음은 자동 미분 (autograd) 사용의 장점입니다.
Flexible− 네트워크를 정의 할 때 제공하는 유연성은 autograd 사용의 큰 이점 중 하나입니다. 반복 할 때마다 작업을 변경할 수 있습니다. 이를 동적 그래프라고하며 정적 그래프가 필요한 프레임 워크에서 구현하기가 훨씬 더 복잡합니다. 이러한 경우에도 Autograd는 그래디언트를 올바르게 역 전파 할 수 있습니다.
Automatic− Autograd는 자동입니다. 즉, 역 전파 절차의 복잡성이 자동으로 처리됩니다. 계산하려는 그라디언트를 지정하기 만하면됩니다.
Efficient − Autogard는 그라디언트를 매우 효율적으로 계산합니다.
Can use native Python control flow operators− if 조건 및 while 루프와 같은 네이티브 Python 제어 흐름 연산자를 사용할 수 있습니다. autograd는 그래디언트를 효율적이고 정확하게 역 전파 할 수 있습니다.
MXNet Gluon에서 autograd 사용
여기에서 예제의 도움을 받아 autograd MXNet Gluon에서.
구현 예
다음 예제에서는 두 개의 계층이있는 회귀 모델을 구현합니다. 구현 후 autograd를 사용하여 각 가중치 매개 변수를 참조하여 손실의 기울기를 자동으로 계산합니다.
먼저 다음과 같이 autogrard 및 기타 필수 패키지를 가져옵니다.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss이제 다음과 같이 네트워크를 정의해야합니다.
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()이제 다음과 같이 손실을 정의해야합니다.
loss_function = L2Loss()다음으로, 다음과 같이 더미 데이터를 생성해야합니다.
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])이제 우리는 네트워크를 통한 첫 번째 순방향 패스를 할 준비가되었습니다. 우리는 기울기를 계산할 수 있도록 autograd가 계산 그래프를 기록하기를 원합니다. 이를 위해 우리는 범위 내에서 네트워크 코드를 실행해야합니다.autograd.record 다음과 같이 컨텍스트-
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)이제 관심 수량에 대해 backward 메소드를 호출하여 시작하는 역방향 패스에 대한 준비가되었습니다. 이 예제에서 관심있는 quatity는 손실입니다. 왜냐하면 매개 변수를 참조하여 손실의 기울기를 계산하려고하기 때문입니다.
loss.backward()이제 네트워크의 각 매개 변수에 대한 기울기가 있으며, 이는 최적화 프로그램이 성능 향상을 위해 매개 변수 값을 업데이트하는 데 사용됩니다. 다음과 같이 첫 번째 레이어의 그라디언트를 확인하십시오.
N_net[0].weight.grad()Output
출력은 다음과 같습니다.
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>완전한 구현 예
아래에 전체 구현 예가 나와 있습니다.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()