Apache MXNet-빠른 가이드
이 장에서는 Apache MXNet의 기능을 강조하고이 딥 러닝 소프트웨어 프레임 워크의 최신 버전에 대해 설명합니다.
MXNet이란 무엇입니까?
Apache MXNet은 개발자가 딥 러닝 모델을 구축, 교육 및 배포하는 데 도움이되는 강력한 오픈 소스 딥 러닝 소프트웨어 프레임 워크 도구입니다. 지난 몇 년 동안 의료에서 운송, 제조에 이르기까지, 실제로 일상 생활의 모든 측면에서 딥 러닝의 영향이 널리 퍼졌습니다. 오늘날 기업은 얼굴 인식, 물체 감지, 광학 문자 인식 (OCR), 음성 인식 및 기계 번역과 같은 몇 가지 어려운 문제를 해결하기 위해 딥 러닝을 추구합니다.
이것이 Apache MXNet이 다음에서 지원되는 이유입니다.
Intel, Baidu, Microsoft, Wolfram Research 등과 같은 일부 대기업
Amazon Web Services (AWS) 및 Microsoft Azure를 포함한 퍼블릭 클라우드 공급자
Carnegie Mellon, MIT, University of Washington, Hong Kong University of Science & Technology와 같은 대규모 연구 기관.
왜 Apache MXNet인가?
Torch7, Caffe, Theano, TensorFlow, Keras, Microsoft Cognitive Toolkit 등과 같은 다양한 딥 러닝 플랫폼이 존재하며 Apache MXNet이 왜 존재하는지 궁금 할 것입니다. 그 뒤에있는 몇 가지 이유를 확인해 보겠습니다.
Apache MXNet은 기존 딥 러닝 플랫폼의 가장 큰 문제 중 하나를 해결합니다. 문제는 딥 러닝 플랫폼을 사용하려면 다른 프로그래밍 풍미를 위해 다른 시스템을 학습해야한다는 것입니다.
Apache MXNet의 도움으로 개발자는 GPU 및 클라우드 컴퓨팅의 모든 기능을 활용할 수 있습니다.
Apache MXNet은 모든 수치 계산을 가속화 할 수 있으며 대규모 DNN (심층 신경망)의 개발 및 배포 속도를 높이는 데 특히 중점을 둡니다.
사용자에게 명령형 프로그래밍과 기호 프로그래밍의 기능을 모두 제공합니다.
다양한 기능
최첨단 딥 러닝 연구를 신속하게 개발하기위한 유연한 딥 러닝 라이브러리 또는 프로덕션 워크로드를 푸시하기위한 강력한 플랫폼을 찾고 있다면 검색은 Apache MXNet에서 끝납니다. 다음과 같은 기능 때문입니다.
분산 교육
선형에 가까운 확장 효율성을 갖춘 다중 GPU 든 다중 호스트 교육이든 Apache MXNet을 사용하면 개발자가 하드웨어를 최대한 활용할 수 있습니다. MXNet은 Uber에서 만든 오픈 소스 분산 딥 러닝 프레임 워크 인 Horovod와의 통합도 지원합니다.
이 통합을 위해 다음은 Horovod에 정의 된 공통 분산 API 중 일부입니다.
horovod.broadcast()
horovod.allgather()
horovod.allgather()
이와 관련하여 MXNet은 다음과 같은 기능을 제공합니다.
Device Placement − MXNet의 도움으로 우리는 각 데이터 구조 (DS)를 쉽게 지정할 수 있습니다.
Automatic Differentiation − Apache MXNet은 미분, 즉 미분 계산을 자동화합니다.
Multi-GPU training − MXNet을 사용하면 사용 가능한 GPU 수로 확장 효율성을 달성 할 수 있습니다.
Optimized Predefined Layers − MXNet에서 자체 레이어를 코딩 할 수있을뿐만 아니라 속도를 위해 미리 정의 된 레이어도 최적화 할 수 있습니다.
이종 교잡
Apache MXNet은 사용자에게 하이브리드 프런트 엔드를 제공합니다. Gluon Python API의 도움으로 명령 적 기능과 상징적 기능 사이의 격차를 해소 할 수 있습니다. 하이브리드 화 기능을 호출하여 수행 할 수 있습니다.
더 빠른 계산
수십 또는 수백 개의 행렬 곱셈과 같은 선형 연산은 심층 신경망의 계산 병목 현상입니다. 이 병목 현상을 해결하기 위해 MXNet은-
GPU에 최적화 된 수치 계산
분산 생태계에 최적화 된 수치 계산
표준 NN을 간략하게 표현할 수있는 일반적인 워크 플로우 자동화.
언어 바인딩
MXNet은 Python 및 R과 같은 고급 언어에 깊이 통합되어 있습니다. 또한 다음과 같은 다른 프로그래밍 언어도 지원합니다.
Scala
Julia
Clojure
Java
C/C++
Perl
우리는 새로운 프로그래밍 언어를 배울 필요가 없습니다. MXNet은 하이브리드 화 기능과 결합되어 Python에서 우리가 선택한 프로그래밍 언어의 배포로 매우 원활하게 전환 할 수 있습니다.
최신 버전 MXNet 1.6.0
Apache Software Foundation (ASF)은 Apache License 2.0에 따라 2020 년 2 월 21 일 Apache MXNet의 안정적인 버전 1.6.0을 출시했습니다. MXNet 커뮤니티가 추가 릴리스에서 더 이상 Python 2를 지원하지 않기로 투표함에 따라 이것은 Python 2를 지원하는 마지막 MXNet 릴리스입니다. 이 릴리스가 사용자에게 제공하는 몇 가지 새로운 기능을 확인해 보겠습니다.
NumPy 호환 인터페이스
유연성과 일반성으로 인해 NumPy는 기계 학습 실무자, 과학자 및 학생이 널리 사용했습니다. 그러나 우리가 알고 있듯이 요즘 GPU (그래픽 처리 장치)와 같은 하드웨어 가속기는 GPU의 속도를 활용하기 위해 다양한 ML (머신 러닝) 툴킷 인 NumPy 사용자에 점점 더 동화되어 새로운 프레임 워크로 전환해야합니다. 다른 구문으로.
MXNet 1.6.0을 통해 Apache MXNet은 NumPy 호환 프로그래밍 환경으로 이동하고 있습니다. 새로운 인터페이스는 NumPy 구문에 익숙한 실무자에게 동일한 유용성과 표현력을 제공합니다. MXNet 1.6.0과 함께 기존 Numpy 시스템은 GPU와 같은 하드웨어 가속기를 활용하여 대규모 계산 속도를 높일 수 있습니다.
Apache TVM과 통합
CPU, GPU 및 특수 가속기와 같은 하드웨어 백엔드를위한 오픈 소스 엔드 투 엔드 딥 러닝 컴파일러 스택 인 Apache TVM은 생산성 중심의 딥 러닝 프레임 워크와 성능 중심의 하드웨어 백엔드 간의 격차를 메우는 것을 목표로합니다. . 최신 릴리스 MXNet 1.6.0을 통해 사용자는 Apache (incubating) TVM을 활용하여 Python 프로그래밍 언어로 고성능 운영자 커널을 구현할 수 있습니다. 이 새로운 기능의 두 가지 주요 이점은 다음과 같습니다.
이전 C ++ 기반 개발 프로세스를 단순화합니다.
CPU, GPU 등과 같은 여러 하드웨어 백엔드에서 동일한 구현을 공유 할 수 있습니다.
기존 기능 개선
위에 나열된 MXNet 1.6.0의 기능 외에도 기존 기능에 비해 몇 가지 개선 사항을 제공합니다. 개선 사항은 다음과 같습니다.
GPU에 대한 요소 별 연산 그룹화
요소 별 작업의 성능이 메모리 대역폭이라는 것을 알고 있으므로 이러한 작업을 연결하면 전체 성능이 저하 될 수 있습니다. Apache MXNet 1.6.0은 가능한 경우 실제로 Just-In-Time 융합 작업을 생성하는 요소 별 작업 융합을 수행합니다. 이러한 요소 별 운영 융합은 또한 스토리지 요구를 줄이고 전반적인 성능을 향상시킵니다.
일반적인 표현 단순화
MXNet 1.6.0은 중복 표현식을 제거하고 공통 표현식을 단순화합니다. 이러한 향상은 또한 메모리 사용량과 총 실행 시간을 향상시킵니다.
최적화
MXNet 1.6.0은 또한 다음과 같은 기존 기능 및 연산자에 대한 다양한 최적화를 제공합니다.
자동 혼합 정밀도
Gluon Fit API
MKL-DNN
큰 텐서 지원
TensorRT 완성
고차 그라디언트 지원
Operators
운영자 성능 프로파일 러
ONNX 가져 오기 / 내보내기
Gluon API 개선
Symbol API 개선
100 개 이상의 버그 수정
MXNet을 시작하려면 가장 먼저해야 할 일은 컴퓨터에 설치하는 것입니다. Apache MXNet은 Windows, Mac 및 Linux를 포함하여 사용 가능한 거의 모든 플랫폼에서 작동합니다.
Linux OS
다음과 같은 방법으로 Linux OS에 MXNet을 설치할 수 있습니다.
그래픽 처리 장치 (GPU)
여기서는 처리를 위해 GPU를 사용할 때 MXNet을 설치하기 위해 Pip, Docker 및 Source라는 다양한 방법을 사용합니다.
Pip 방식을 사용하여
다음 명령을 사용하여 Linus OS에 MXNet을 설치할 수 있습니다.
pip install mxnetApache MXNet은 또한 인텔 하드웨어에서 실행할 때 훨씬 빠른 MKL pip 패키지를 제공합니다. 예를 들어 여기mxnet-cu101mkl 의미-
이 패키지는 CUDA / cuDNN으로 구축되었습니다.
패키지는 MKL-DNN을 지원합니다.
CUDA 버전은 10.1입니다.
다른 옵션에 대해서는 다음을 참조하십시오. https://pypi.org/project/mxnet/.
Docker를 사용하여
MXNet을 사용하는 Docker 이미지는 DockerHub에서 찾을 수 있습니다. https://hub.docker.com/u/mxnet Docker와 GPU를 사용하여 MXNet을 설치하려면 아래 단계를 확인하십시오.
Step 1− 먼저 다음 위치에서 제공되는 도커 설치 지침을 따릅니다. https://docs.docker.com/engine/install/ubuntu/. 컴퓨터에 Docker를 설치해야합니다.
Step 2− 도커 컨테이너에서 GPU 사용을 활성화하려면 다음으로 nvidia-docker-plugin을 설치해야합니다. 다음에서 제공되는 설치 지침을 따를 수 있습니다.https://github.com/NVIDIA/nvidia-docker/wiki.
Step 3− 다음 명령을 사용하여 MXNet 도커 이미지를 가져올 수 있습니다. −
$ sudo docker pull mxnet/python:gpu이제 mxnet / python 도커 이미지 풀이 성공했는지 확인하기 위해 다음과 같이 도커 이미지를 나열 할 수 있습니다.
$ sudo docker imagesMXNet에서 가장 빠른 추론 속도를 위해 Intel MKL-DNN과 함께 최신 MXNet을 사용하는 것이 좋습니다. 아래 명령을 확인하십시오-
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker images소스에서
GPU를 사용하여 소스에서 MXNet 공유 라이브러리를 빌드하려면 먼저 다음과 같이 CUDA 및 cuDNN 환경을 설정해야합니다.
CUDA 툴킷을 다운로드하여 설치하십시오. 여기서 CUDA 9.2를 권장합니다.
다음 다운로드 cuDNN 7.1.4.
이제 파일의 압축을 풀어야합니다. 또한 cuDNN 루트 디렉토리로 변경해야합니다. 또한 다음과 같이 헤더와 라이브러리를 로컬 CUDA Toolkit 폴더로 이동하십시오.
tar xvzf cudnn-9.2-linux-x64-v7.1
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
sudo ldconfigCUDA 및 cuDNN에 대한 환경을 설정 한 후 아래 단계에 따라 소스에서 MXNet 공유 라이브러리를 빌드하십시오.
Step 1− 먼저 필수 패키지를 설치해야합니다. 이러한 종속성은 Ubuntu 버전 16.04 이상에서 필요합니다.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev
libopencv-dev cmakeStep 2−이 단계에서는 MXNet 소스를 다운로드하고 구성합니다. 먼저 다음 명령을 사용하여 저장소를 복제하겠습니다.
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux_gpu.cmake #for build with CUDAStep 3− 다음 명령어를 사용하여 MXNet core 공유 라이브러리를 구축 할 수 있습니다.
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
디버그 버전을 빌드하려면 다음과 같이 지정하십시오.
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..병렬 컴파일 작업의 수를 설정하려면 다음을 지정하십시오.
cmake --build . --parallel NMXNet 코어 공유 라이브러리를 성공적으로 빌드하면 build 귀하의 폴더 MXNet project root, 당신은 발견 할 것이다 libmxnet.so 언어 바인딩을 설치하는 데 필요합니다 (선택 사항).
중앙 처리 장치 (CPU)
여기서는 처리를 위해 CPU를 사용할 때 MXNet을 설치하기 위해 Pip, Docker 및 Source라는 다양한 방법을 사용합니다.
Pip 방식을 사용하여
다음 명령을 사용하여 Linus OS에 MXNet을 설치할 수 있습니다.
pip install mxnetApache MXNet은 인텔 하드웨어에서 실행할 때 훨씬 더 빠른 MKL-DNN 지원 pip 패키지도 제공합니다.
pip install mxnet-mklDocker를 사용하여
MXNet을 사용하는 Docker 이미지는 DockerHub에서 찾을 수 있습니다. https://hub.docker.com/u/mxnet. CPU와 함께 Docker를 사용하여 MXNet을 설치하려면 아래 단계를 확인하십시오.
Step 1− 먼저 다음 위치에서 제공되는 도커 설치 지침을 따릅니다. https://docs.docker.com/engine/install/ubuntu/. 컴퓨터에 Docker를 설치해야합니다.
Step 2− 다음 명령을 사용하여 MXNet 도커 이미지를 가져올 수 있습니다.
$ sudo docker pull mxnet/python이제 mxnet / python 도커 이미지 풀이 성공했는지 확인하기 위해 다음과 같이 도커 이미지를 나열 할 수 있습니다.
$ sudo docker imagesMXNet에서 가장 빠른 추론 속도를 위해 Intel MKL-DNN과 함께 최신 MXNet을 사용하는 것이 좋습니다.
아래 명령을 확인하십시오-
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker images소스에서
CPU가있는 소스에서 MXNet 공유 라이브러리를 빌드하려면 아래 단계를 따르십시오.
Step 1− 먼저 필수 패키지를 설치해야합니다. 이러한 종속성은 Ubuntu 버전 16.04 이상에서 필요합니다.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmakeStep 2−이 단계에서는 MXNet 소스를 다운로드하고 구성합니다. 먼저 다음 명령을 사용하여 저장소를 복제하겠습니다.
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3− 다음 명령을 사용하여 MXNet 코어 공유 라이브러리를 구축 할 수 있습니다.
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
디버그 버전을 빌드하려면 다음과 같이 지정하십시오.
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..병렬 컴파일 작업 수를 설정하려면 다음을 지정하십시오.
cmake --build . --parallel NMXNet 코어 공유 라이브러리를 성공적으로 빌드하면 build MXNet 프로젝트 루트의 폴더에서 libmxnet.so를 찾을 수 있으며, 이는 언어 바인딩을 설치하는 데 필요합니다 (선택 사항).
맥 OS
다음과 같은 방법으로 MacOS에 MXNet을 설치할 수 있습니다.
그래픽 처리 장치 (GPU)
GPU를 사용하는 MacOS에서 MXNet을 빌드하려는 경우 사용 가능한 Pip 및 Docker 방법이 없습니다. 이 경우 유일한 방법은 소스에서 빌드하는 것입니다.
소스에서
GPU가있는 소스에서 MXNet 공유 라이브러리를 빌드하려면 먼저 CUDA 및 cuDNN을위한 환경을 설정해야합니다. 당신은 따라야NVIDIA CUDA Installation Guide 사용할 수있는 https://docs.nvidia.com 과 cuDNN Installation Guide, 사용할 수있는 https://docs.nvidia.com/deeplearning Mac OS 용.
2019 년에 CUDA는 macOS 지원을 중단했습니다. 사실 향후 CUDA 버전도 macOS를 지원하지 않을 수 있습니다.
CUDA 및 cuDNN에 대한 환경을 설정했으면 아래 단계에 따라 OS X (Mac)의 소스에서 MXNet을 설치합니다.
Step 1− OS x에 대한 종속성이 필요하므로 먼저 필수 패키지를 설치해야합니다.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesopencv는 선택적 종속성이므로 OpenCV없이 MXNet을 빌드 할 수도 있습니다.
Step 2−이 단계에서는 MXNet 소스를 다운로드하고 구성합니다. 먼저 다음 명령을 사용하여 저장소를 복제하겠습니다.
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeGPU 지원의 경우 GPU가없는 컴퓨터에서 GPU 지원 빌드를 빌드하려고하면 MXNet 빌드가 GPU 아키텍처를 자동 감지 할 수 없기 때문에 먼저 CUDA 종속성을 설치해야합니다. 이러한 경우 MXNet은 사용 가능한 모든 GPU 아키텍처를 대상으로합니다.
Step 3− 다음 명령어를 사용하여 MXNet core 공유 라이브러리를 구축 할 수 있습니다.
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .위 단계에서 두 가지 중요한 점은 다음과 같습니다.
디버그 버전을 빌드하려면 다음과 같이 지정하십시오.
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..병렬 컴파일 작업 수를 설정하려면 다음을 지정하십시오.
cmake --build . --parallel NMXNet 코어 공유 라이브러리를 성공적으로 빌드하면 build 귀하의 폴더 MXNet project root, 당신은 발견 할 것이다 libmxnet.dylib, 언어 바인딩을 설치하는 데 필요합니다 (선택 사항).
중앙 처리 장치 (CPU)
여기서는 처리를 위해 CPU를 사용할 때 MXNet을 설치하기 위해 Pip, Docker, Source 등 다양한 방법을 사용할 것입니다.
Pip 방식을 사용하여
다음 명령을 사용하여 Linus OS에 MXNet을 설치할 수 있습니다.
pip install mxnetDocker를 사용하여
MXNet을 사용하는 Docker 이미지는 DockerHub에서 찾을 수 있습니다. https://hub.docker.com/u/mxnet. CPU와 함께 Docker를 사용하여 MXNet을 설치하려면 아래 단계를 확인하십시오.
Step 1− 먼저 docker installation instructions 사용할 수있는 https://docs.docker.com/docker-for-mac 컴퓨터에 Docker를 설치해야합니다.
Step 2− 다음 명령을 사용하여 MXNet 도커 이미지를 가져올 수 있습니다.
$ docker pull mxnet/python이제 mxnet / python 도커 이미지 풀이 성공했는지 확인하기 위해 다음과 같이 도커 이미지를 나열 할 수 있습니다.
$ docker imagesMXNet에서 가장 빠른 추론 속도를 위해 Intel MKL-DNN과 함께 최신 MXNet을 사용하는 것이 좋습니다. 아래 명령을 확인하십시오.
$ docker pull mxnet/python:1.3.0_cpu_mkl
$ docker images소스에서
OS X (Mac)의 소스에서 MXNet을 설치하려면 아래 단계를 따르십시오.
Step 1− OS x에 대한 종속성이 필요하기 때문에 먼저 필수 패키지를 설치해야합니다.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesopencv는 선택적 종속성이므로 OpenCV없이 MXNet을 빌드 할 수도 있습니다.
Step 2−이 단계에서는 MXNet 소스를 다운로드하고 구성합니다. 먼저 다음 명령을 사용하여 저장소를 복제합니다.
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3− 다음 명령을 사용하여 MXNet 코어 공유 라이브러리를 구축 할 수 있습니다.
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
디버그 버전을 빌드하려면 다음과 같이 지정하십시오.
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..병렬 컴파일 작업 수를 설정하려면 다음을 지정하십시오.
cmake --build . --parallel NMXNet 코어 공유 라이브러리를 성공적으로 빌드하면 build 귀하의 폴더 MXNet project root, 당신은 발견 할 것이다 libmxnet.dylib, 언어 바인딩을 설치하는 데 필요합니다 (선택 사항).
Windows OS
Windows에 MXNet을 설치하기위한 전제 조건은 다음과 같습니다.
최소 시스템 요구 사항
Windows 7, 10, Server 2012 R2 또는 Server 2016
Visual Studio 2015 또는 2017 (모든 유형)
Python 2.7 또는 3.6
pip
권장 시스템 요구 사항
Windows 10, Server 2012 R2 또는 Server 2016
비주얼 스튜디오 2017
At least one NVIDIA CUDA-enabled GPU
MKL-enabled CPU: Intel® Xeon® processor, Intel® Core™ processor family, Intel Atom® processor, or Intel® Xeon Phi™ processor
Python 2.7 or 3.6
pip
Graphical Processing Unit (GPU)
By using Pip method−
If you plan to build MXNet on Windows with NVIDIA GPUs, there are two options for installing MXNet with CUDA support with a Python package−
Install with CUDA Support
Below are the steps with the help of which, we can setup MXNet with CUDA.
Step 1− First install Microsoft Visual Studio 2017 or Microsoft Visual Studio 2015.
Step 2− Next, download and install NVIDIA CUDA. It is recommended to use CUDA versions 9.2 or 9.0 because some issues with CUDA 9.1 have been identified in the past.
Step 3− Now, download and install NVIDIA_CUDA_DNN.
Step 4− Finally, by using following pip command, install MXNet with CUDA−
pip install mxnet-cu92Install with CUDA and MKL Support
Below are the steps with the help of which, we can setup MXNet with CUDA and MKL.
Step 1− First install Microsoft Visual Studio 2017 or Microsoft Visual Studio 2015.
Step 2− Next, download and install intel MKL
Step 3− Now, download and install NVIDIA CUDA.
Step 4− Now, download and install NVIDIA_CUDA_DNN.
Step 5− Finally, by using following pip command, install MXNet with MKL.
pip install mxnet-cu92mklFrom source
To build the MXNet core library from source with GPU, we have the following two options−
Option 1− Build with Microsoft Visual Studio 2017
In order to build and install MXNet yourself by using Microsoft Visual Studio 2017, you need the following dependencies.
Install/update Microsoft Visual Studio.
If Microsoft Visual Studio is not already installed on your machine, first download and install it.
It will prompt about installing Git. Install it also.
If Microsoft Visual Studio is already installed on your machine but you want to update it then proceed to the next step to modify your installation. Here you will be given the opportunity to update Microsoft Visual Studio as well.
Follow the instructions for opening the Visual Studio Installer available at https://docs.microsoft.com/en-us to modify Individual components.
In the Visual Studio Installer application, update as required. After that look for and check VC++ 2017 version 15.4 v14.11 toolset and click Modify.
Now by using the following command, change the version of the Microsoft VS2017 to v14.11−
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat" -vcvars_ver=14.11Next, you need to download and install CMake available at https://cmake.org/download/ It is recommended to use CMake v3.12.2 which is available at https://cmake.org/download/ because it is tested with MXNet.
Now, download and run the OpenCV package available at https://sourceforge.net/projects/opencvlibrary/which will unzip several files. It is up to you if you want to place them in another directory or not. Here, we will use the path C:\utils(mkdir C:\utils) as our default path.
Next, we need to set the environment variable OpenCV_DIR to point to the OpenCV build directory that we have just unzipped. For this open command prompt and type set OpenCV_DIR=C:\utils\opencv\build.
One important point is that if you do not have the Intel MKL (Math Kernel Library) installed the you can install it.
Another open source package you can use is OpenBLAS. Here for the further instructions we are assuming that you are using OpenBLAS.
So, Download the OpenBlas package which is available at https://sourceforge.net and unzip the file, rename it to OpenBLAS and put it under C:\utils.
Next, we need to set the environment variable OpenBLAS_HOME to point to the OpenBLAS directory that contains the include and lib directories. For this open command prompt and type set OpenBLAS_HOME=C:\utils\OpenBLAS.
Now, download and install CUDA available at https://developer.nvidia.com. Note that, if you already had CUDA, then installed Microsoft VS2017, you need to reinstall CUDA now, so that you can get the CUDA toolkit components for Microsoft VS2017 integration.
Next, you need to download and install cuDNN.
Next, you need to download and install git which is at https://gitforwindows.org/ also.
Once you have installed all the required dependencies, follow the steps given below to build the MXNet source code−
Step 1− Open command prompt in windows.
Step 2− Now, by using the following command, download the MXNet source code from GitHub:
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 3− Next, verify the following−
DCUDNN_INCLUDE and DCUDNN_LIBRARY environment variables are pointing to the include folder and cudnn.lib file of your CUDA installed location
C:\incubator-mxnet is the location of the source code you just cloned in the previous step.
Step 4− Next by using the following command, create a build directory and also go to the directory, for example−
mkdir C:\incubator-mxnet\build
cd C:\incubator-mxnet\buildStep 5− Now, by using cmake, compile the MXNet source code as follows−
cmake -G "Visual Studio 15 2017 Win64" -T cuda=9.2,host=x64 -DUSE_CUDA=1 -DUSE_CUDNN=1 -DUSE_NVRTC=1 -DUSE_OPENCV=1 -DUSE_OPENMP=1 -DUSE_BLAS=open -DUSE_LAPACK=1 -DUSE_DIST_KVSTORE=0 -DCUDA_ARCH_LIST=Common -DCUDA_TOOLSET=9.2 -DCUDNN_INCLUDE=C:\cuda\include -DCUDNN_LIBRARY=C:\cuda\lib\x64\cudnn.lib "C:\incubator-mxnet"Step 6− Once the CMake successfully completed, use the following command to compile the MXNet source code−
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountOption 2: Build with Microsoft Visual Studio 2015
In order to build and install MXNet yourself by using Microsoft Visual Studio 2015, you need the following dependencies.
Install/update Microsoft Visual Studio 2015. The minimum requirement to build MXnet from source is of Update 3 of Microsoft Visual Studio 2015. You can use Tools -> Extensions and Updates... | Product Updates menu to upgrade it.
Next, you need to download and install CMake which is available at https://cmake.org/download/. It is recommended to use CMake v3.12.2 which is at https://cmake.org/download/, because it is tested with MXNet.
Now, download and run the OpenCV package available at https://excellmedia.dl.sourceforge.net which will unzip several files. It is up to you, if you want to place them in another directory or not.
Next, we need to set the environment variable OpenCV_DIR to point to the OpenCV build directory that we have just unzipped. For this, open command prompt and type set OpenCV_DIR=C:\opencv\build\x64\vc14\bin.
One important point is that if you do not have the Intel MKL (Math Kernel Library) installed the you can install it.
Another open source package you can use is OpenBLAS. Here for the further instructions we are assuming that you are using OpenBLAS.
So, Download the OpenBLAS package available at https://excellmedia.dl.sourceforge.net and unzip the file, rename it to OpenBLAS and put it under C:\utils.
Next, we need to set the environment variable OpenBLAS_HOME to point to the OpenBLAS directory that contains the include and lib directories. You can find the directory in C:\Program files (x86)\OpenBLAS\
Note that, if you already had CUDA, then installed Microsoft VS2015, you need to reinstall CUDA now so that, you can get the CUDA toolkit components for Microsoft VS2017 integration.
Next, you need to download and install cuDNN.
Now, we need to Set the environment variable CUDACXX to point to the CUDA Compiler(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin\nvcc.exe for example).
Similarly, we also need to set the environment variable CUDNN_ROOT to point to the cuDNN directory that contains the include, lib and bin directories (C:\Downloads\cudnn-9.1-windows7-x64-v7\cuda for example).
Once you have installed all the required dependencies, follow the steps given below to build the MXNet source code−
Step 1− First, download the MXNet source code from GitHub−
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 2− Next, use CMake to create a Visual Studio in ./build.
Step 3− Now, in Visual Studio, we need to open the solution file,.sln, and compile it. These commands will produce a library called mxnet.dll in the ./build/Release/ or ./build/Debug folder
Step 4− Once the CMake successfully completed, use the following command to compile the MXNet source code
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountCentral Processing Unit (CPU)
Here, we will use various methods namely Pip, Docker, and Source to install MXNet when we are using CPU for processing−
By using Pip method
If you plan to build MXNet on Windows with CPUs, there are two options for installing MXNet using a Python package−
Install with CPUs
Use the following command to install MXNet with CPU with Python−
pip install mxnetInstall with Intel CPUs
As discussed above, MXNet has experimental support for Intel MKL as well as MKL-DNN. Use the following command to install MXNet with Intel CPU with Python−
pip install mxnet-mklBy using Docker
You can find the docker images with MXNet at DockerHub, available at https://hub.docker.com/u/mxnet Let us check out the steps below, to install MXNet by using Docker with CPU−
Step 1− First, by following the docker installation instructions which can be read at https://docs.docker.com/docker-for-mac/install. We need to install Docker on our machine.
Step 2− By using the following command, you can pull the MXNet docker image−
$ docker pull mxnet/pythonNow in order to see if mxnet/python docker image pull was successful, we can list docker images as follows−
$ docker imagesFor the fastest inference speeds with MXNet, it is recommended to use the latest MXNet with Intel MKL-DNN.
Check the commands below−
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker imagesInstalling MXNet On Cloud and Devices
This section highlights how to install Apache MXNet on Cloud and on devices. Let us begin by learning about installing MXNet on cloud.
Installing MXNet On Cloud
You can also get Apache MXNet on several cloud providers with Graphical Processing Unit (GPU) support. Two other kind of support you can find are as follows−
- GPU/CPU-hybrid support for use cases like scalable inference.
- Factorial GPU support with AWS Elastic Inference.
Following are cloud providers providing GPU support with different virtual machine for Apache MXNet−
The Alibaba Console
You can create the NVIDIA GPU Cloud Virtual Machine (VM) available at https://docs.nvidia.com/ngc with the Alibaba Console and use Apache MXNet.
Amazon Web Services
It also provides GPU support and gives the following services for Apache MXNet−
Amazon SageMaker
It manages training and deployment of Apache MXNet models.
AWS Deep Learning AMI
It provides preinstalled Conda environment for both Python 2 and Python 3 with Apache MXNet, CUDA, cuDNN, MKL-DNN, and AWS Elastic Inference.
Dynamic Training on AWS
It provides the training for experimental manual EC2 setup as well as for semi-automated CloudFormation setup.
You can use NVIDIA VM available at https://aws.amazon.com with Amazon web services.
Google Cloud Platform
Google is also providing NVIDIA GPU cloud image which is available at https://console.cloud.google.com to work with Apache MXNet.
Microsoft Azure
Microsoft Azure Marketplace is also providing NVIDIA GPU cloud image available at https://azuremarketplace.microsoft.com to work with Apache MXNet.
Oracle Cloud
Oracle is also providing NVIDIA GPU cloud image available at https://docs.cloud.oracle.com to work with Apache MXNet.
Central Processing Unit (CPU)
Apache MXNet works on every cloud provider’s CPU-only instance. There are various methods to install such as−
Python pip install instructions.
Docker instructions.
Preinstalled option like Amazon Web Services which provides AWS Deep Learning AMI (having preinstalled Conda environment for both Python 2 and Python 3 with MXNet and MKL-DNN).
Installing MXNet on Devices
Let us learn how to install MXNet on devices.
Raspberry Pi
You can also run Apache MXNet on Raspberry Pi 3B devices as MXNet also support Respbian ARM based OS. In order to run MXNet smoothly on the Raspberry Pi3, it is recommended to have a device that has more than 1 GB of RAM and a SD card with at least 4GB of free space.
Following are the ways with the help of which you can build MXNet for the Raspberry Pi and install the Python bindings for the library as well−
Quick installation
The pre-built Python wheel can be used on a Raspberry Pi 3B with Stretch for quick installation. One of the important issues with this method is that, we need to install several dependencies to get Apache MXNet to work.
Docker installation
You can follow the docker installation instructions, which is available at https://docs.docker.com/engine/install/ubuntu/ to install Docker on your machine. For this purpose, we can install and use Community Edition (CE) also.
Native Build (from source)
In order to install MXNet from source, we need to follow the following two steps−
Step 1
Build the shared library from the Apache MXNet C++ source code
To build the shared library on Raspberry version Wheezy and later, we need the following dependencies:
Git− It is required to pull code from GitHub.
Libblas− It is required for linear algebraic operations.
Libopencv− It is required for computer vision related operations. However, it is optional if you would like to save your RAM and Disk Space.
C++ Compiler− It is required to compiles and builds MXNet source code. Following are the supported compilers that supports C++ 11−
G++ (4.8 or later version)
Clang(3.9-6)
Use the following commands to install the above-mentioned dependencies−
sudo apt-get update
sudo apt-get -y install git cmake ninja-build build-essential g++-4.9 c++-4.9 liblapack*
libblas* libopencv*
libopenblas* python3-dev python-dev virtualenvNext, we need to clone the MXNet source code repository. For this use the following git command in your home directory−
git clone https://github.com/apache/incubator-mxnet.git --recursive
cd incubator-mxnetNow, with the help of following commands, build the shared library:
mkdir -p build && cd build
cmake \
-DUSE_SSE=OFF \
-DUSE_CUDA=OFF \
-DUSE_OPENCV=ON \
-DUSE_OPENMP=ON \
-DUSE_MKL_IF_AVAILABLE=OFF \
-DUSE_SIGNAL_HANDLER=ON \
-DCMAKE_BUILD_TYPE=Release \
-GNinja ..
ninja -j$(nproc)Once you execute the above commands, it will start the build process which will take couple of hours to finish. You will get a file named libmxnet.so in the build directory.
Step 2
Install the supported language-specific packages for Apache MXNet
In this step, we will install MXNet Pythin bindings. To do so, we need to run the following command in the MXNet directory−
cd python
pip install --upgrade pip
pip install -e .Alternatively, with the following command, you can also create a whl package installable with pip−
ci/docker/runtime_functions.sh build_wheel python/ $(realpath build)NVIDIA Jetson Devices
You can also run Apache MXNet on NVIDIA Jetson Devices, such as TX2 or Nano as MXNet also support the Ubuntu Arch64 based OS. In order to run, MXNet smoothly on the NVIDIA Jetson Devices, it is necessary to have CUDA installed on your Jetson device.
Following are the ways with the help of which you can build MXNet for NVIDIA Jetson devices:
By using a Jetson MXNet pip wheel for Python development
From source
But, before building MXNet from any of the above-mentioned ways, you need to install following dependencies on your Jetson devices−
Python Dependencies
In order to use the Python API, we need the following dependencies−
sudo apt update
sudo apt -y install \
build-essential \
git \
graphviz \
libatlas-base-dev \
libopencv-dev \
python-pip
sudo pip install --upgrade \
pip \
setuptools
sudo pip install \
graphviz==0.8.4 \
jupyter \
numpy==1.15.2Clone the MXNet source code repository
By using the following git command in your home directory, clone the MXNet source code repository−
git clone --recursive https://github.com/apache/incubator-mxnet.git mxnetSetup environment variables
Add the following in your .profile file in your home directory−
export PATH=/usr/local/cuda/bin:$PATH export MXNET_HOME=$HOME/mxnet/
export PYTHONPATH=$MXNET_HOME/python:$PYTHONPATHNow, apply the change immediately with the following command−
source .profileConfigure CUDA
Before configuring CUDA, with nvcc, you need to check what version of CUDA is running−
nvcc --versionSuppose, if more than one CUDA version is installed on your device or computer and you want to switch CUDA versions then, use the following and replace the symbolic link to the version you want−
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cudaThe above command will switch to CUDA 10.0, which is preinstalled on NVIDIA Jetson device Nano.
Once you done with the above-mentioned prerequisites, you can now install MXNet on NVIDIA Jetson Devices. So, let us understand the ways with the help of which you can install MXNet−
By using a Jetson MXNet pip wheel for Python development− If you want to use a prepared Python wheel then download the following to your Jetson and run it−
MXNet 1.4.0 (for Python 3) available at https://docs.docker.com
MXNet 1.4.0 (for Python 2) available at https://docs.docker.com
Native Build (from source)
In order to install MXNet from source, we need to follow the following two steps−
Step 1
Build the shared library from the Apache MXNet C++ source code
To build the shared library from the Apache MXNet C++ source code, you can either use Docker method or do it manually−
Docker method
In this method, you first need to install Docker and able to run it without sudo (which is also explained in previous steps). Once done, run the following to execute cross-compilation via Docker−
$MXNET_HOME/ci/build.py -p jetsonManual
In this method, you need to edit the Makefile (with below command) to install the MXNet with CUDA bindings to leverage the Graphical Processing units (GPU) on NVIDIA Jetson devices:
cp $MXNET_HOME/make/crosscompile.jetson.mk config.mkAfter editing the Makefile, you need to edit config.mk file to make some additional changes for the NVIDIA Jetson device.
For this, update the following settings−
Update the CUDA path: USE_CUDA_PATH = /usr/local/cuda
Add -gencode arch=compute-63, code=sm_62 to the CUDA_ARCH setting.
Update the NVCC settings: NVCCFLAGS := -m64
Turn on OpenCV: USE_OPENCV = 1
Now to ensure that the MXNet builds with Pascal’s hardware level low precision acceleration, we need to edit the Mshadow Makefile as follow−
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1Finally, with the help of following command you can build the complete Apache MXNet library−
cd $MXNET_HOME make -j $(nproc)Once you execute the above commands, it will start the build process which will take couple of hours to finish. You will get a file named libmxnet.so in the mxnet/lib directory.
Step 2
Install the Apache MXNet Python Bindings
In this step, we will install MXNet Python bindings. To do so we need to run the following command in the MXNet directory−
cd $MXNET_HOME/python
sudo pip install -e .Once done with above steps, you are now ready to run MXNet on your NVIDIA Jetson devices TX2 or Nano. It can be verified with the following command−
import mxnet
mxnet.__version__It will return the version number if everything is properly working.
To support the research and development of Deep Learning applications across many fields, Apache MXNet provides us a rich ecosystem of toolkits, libraries and many more. Let us explore them −
ToolKits
Following are some of the most used and important toolkits provided by MXNet −
GluonCV
As name implies GluonCV is a Gluon toolkit for computer vision powered by MXNet. It provides implementation of state-of-the-art DL (Deep Learning) algorithms in computer vision (CV). With the help of GluonCV toolkit engineers, researchers, and students can validate new ideas and learn CV easily.
Given below are some of the features of GluonCV −
It trains scripts for reproducing state-of-the-art results reported in latest research.
More than 170+ high quality pretrained models.
Embrace flexible development pattern.
GluonCV is easy to optimize. We can deploy it without retaining heavy weight DL framework.
It provides carefully designed APIs that greatly lessen the implementation intricacy.
Community support.
Easy to understand implementations.
Following are the supported applications by GluonCV toolkit:
Image Classification
Object Detection
Semantic Segmentation
Instance Segmentation
Pose Estimation
Video Action Recognition
We can install GluonCV by using pip as follows −
pip install --upgrade mxnet gluoncvGluonNLP
As name implies GluonNLP is a Gluon toolkit for Natural Language Processing (NLP) powered by MXNet. It provides implementation of state-of-the-art DL (Deep Learning) models in NLP.
GluonNLP 툴킷 엔지니어, 연구원 및 학생의 도움으로 텍스트 데이터 파이프 라인 및 모델을위한 블록을 구축 할 수 있습니다. 이러한 모델을 기반으로 연구 아이디어와 제품의 프로토 타입을 신속하게 만들 수 있습니다.
다음은 GluonNLP의 일부 기능입니다.
최신 연구에서보고 된 최첨단 결과를 재현하기위한 스크립트를 훈련합니다.
일반적인 NLP 작업을위한 사전 훈련 된 모델 세트입니다.
구현 복잡성을 크게 줄여주는 신중하게 설계된 API를 제공합니다.
커뮤니티 지원.
또한 새로운 NLP 작업을 시작하는 데 도움이되는 자습서를 제공합니다.
다음은 GluonNLP 툴킷으로 구현할 수있는 NLP 작업입니다.
단어 삽입
언어 모델
기계 번역
텍스트 분류
감정 분석
자연어 추론
텍스트 생성
종속성 구문 분석
명명 된 엔티티 인식
의도 분류 및 슬롯 레이블링
다음과 같이 pip를 사용하여 GluonNLP를 설치할 수 있습니다.
pip install --upgrade mxnet gluonnlpGluonTS
이름에서 알 수 있듯이 GluonTS는 MXNet에서 제공하는 확률 적 시계열 모델링을위한 Gluon 툴킷입니다.
그것은 다음과 같은 기능을 제공합니다-
훈련 준비가 된 최첨단 (SOTA) 딥 러닝 모델.
시계열 데이터 세트에 대한로드 및 반복을위한 유틸리티입니다.
자신의 모델을 정의하기위한 빌딩 블록.
GluonTS 툴킷 엔지니어의 도움으로 연구원 및 학생은 자체 데이터에 대해 내장 된 모델을 교육 및 평가하고 다양한 솔루션을 빠르게 실험하고 시계열 작업에 대한 솔루션을 찾을 수 있습니다.
또한 제공된 추상화 및 빌딩 블록을 사용하여 사용자 지정 시계열 모델을 만들고 기준 알고리즘에 대해 빠르게 벤치마킹 할 수 있습니다.
다음과 같이 pip를 사용하여 GluonTS를 설치할 수 있습니다.
pip install gluontsGluonFR
이름에서 알 수 있듯이 FR (Face Recognition) 용 Apache MXNet Gluon 툴킷입니다. 그것은 다음과 같은 기능을 제공합니다-
얼굴 인식의 최첨단 (SOTA) 딥 러닝 모델.
SoftmaxCrossEntropyLoss, ArcLoss, TripletLoss, RingLoss, CosLoss / AMsoftmax, L2-Softmax, A-Softmax, CenterLoss, ContrastiveLoss, LGM Loss 등의 구현.
Gluon Face를 설치하려면 Python 3.5 이상이 필요합니다. 먼저 다음과 같이 GluonCV와 MXNet을 먼저 설치해야합니다.
pip install gluoncv --pre
pip install mxnet-mkl --pre --upgrade
pip install mxnet-cuXXmkl --pre –upgrade # if cuda XX is installed종속성을 설치 한 후 다음 명령을 사용하여 GluonFR을 설치할 수 있습니다.
From Source
pip install git+https://github.com/THUFutureLab/gluon-face.git@masterPip
pip install gluonfr생태계
이제 MXNet의 풍부한 라이브러리, 패키지 및 프레임 워크를 살펴 보겠습니다.
코치 RL
Coach, Intel AI 연구소에서 만든 Python RL (강화 학습) 프레임 워크입니다. 최첨단 RL 알고리즘으로 쉽게 실험 할 수 있습니다. Coach RL은 Apache MXNet을 백엔드로 지원하며 새로운 환경을 간단하게 통합하여 해결할 수 있습니다.
기존 구성 요소를 쉽게 확장하고 재사용하기 위해 Coach RL은 알고리즘, 환경, NN 아키텍처, 탐색 정책과 같은 기본 강화 학습 구성 요소를 매우 잘 분리했습니다.
다음은 Coach RL 프레임 워크에 대한 에이전트 및 지원되는 알고리즘입니다.
가치 최적화 에이전트
Deep Q 네트워크 (DQN)
더블 딥 Q 네트워크 (DDQN)
듀얼 링 Q 네트워크
혼합 몬테카를로 (MMC)
Persistent Advantage Learning (PAL)
범주 형 딥 Q 네트워크 (C51)
분위수 회귀 심층 Q 네트워크 (QR-DQN)
N-Step Q 학습
신경 에피소드 제어 (NEC)
정규화 된 이점 함수 (NAF)
Rainbow
정책 최적화 에이전트
정책 그라디언트 (PG)
A3C (Asynchronous Advantage Actor-Critic)
DDPG (Deep Deterministic Policy Gradients)
근접 정책 최적화 (PPO)
클리핑 된 근접 정책 최적화 (CPPO)
일반화 된 이점 추정 (GAE)
Experience Replay (ACER)를 통한 효율적인 배우 비평가 샘플
연약한 배우 비평 (SAC)
TD3 (Twin Delayed Deep Deterministic Policy Gradient)
일반 요원
직접 미래 예측 (DFP)
모방 학습 에이전트
행동 복제 (BC)
조건부 모방 학습
계층 적 강화 학습 에이전트
계층 적 배우 비평가 (HAC)
딥 그래프 라이브러리
NYU 및 AWS 팀 상하이에서 개발 한 DGL (Deep Graph Library)은 MXNet 위에 그래프 신경망 (GNN)을 쉽게 구현할 수있는 Python 패키지입니다. 또한 PyTorch, Gluon 등과 같은 기존의 다른 주요 딥 러닝 라이브러리 위에 GNN을 쉽게 구현할 수 있습니다.
Deep Graph Library는 무료 소프트웨어입니다. Ubuntu 16.04, macOS X 및 Windows 7 이상 이후의 모든 Linux 배포에서 사용할 수 있습니다. 또한 Python 3.5 버전 이상이 필요합니다.
다음은 DGL의 기능입니다-
No Migration cost − DGL은 널리 사용되는 기존 DL 프레임 워크를 기반으로 구축되므로 마이그레이션 비용이 없습니다.
Message Passing− DGL은 메시지 전달 기능을 제공하며 다양한 제어 기능을 제공합니다. 메시지 전달 범위는 선택한 에지를 따라 전송하는 것과 같은 낮은 수준의 작업에서 그래프 전체 기능 업데이트와 같은 높은 수준의 제어에 이르기까지 다양합니다.
Smooth Learning Curve − 강력한 사용자 정의 함수가 유연하고 사용하기 쉽기 때문에 DGL을 배우고 사용하는 것이 매우 쉽습니다.
Transparent Speed Optimization − DGL은 계산 및 희소 행렬 곱셈의 자동 일괄 처리를 수행하여 투명한 속도 최적화를 제공합니다.
High performance − 최대 효율성을 달성하기 위해 DGL은 하나 또는 여러 그래프에 DNN (심층 신경망) 훈련을 자동으로 일괄 처리합니다.
Easy & friendly interface − DGL은 엣지 피처 액세스 및 그래프 구조 조작을위한 쉽고 친숙한 인터페이스를 제공합니다.
InsightFace
MXNet으로 구동되는 컴퓨터 비전에서 SOTA (최신) 얼굴 분석 알고리즘의 구현을 제공하는 얼굴 분석 용 딥 러닝 툴킷 인 InsightFace. 그것은 제공합니다-
사전 훈련 된 고품질 대형 모델 세트.
최첨단 (SOTA) 교육 스크립트.
InsightFace는 최적화하기 쉽습니다. 무거운 DL 프레임 워크를 유지하지 않고도 배포 할 수 있습니다.
구현 복잡성을 크게 줄여주는 신중하게 설계된 API를 제공합니다.
자신의 모델을 정의하기위한 빌딩 블록.
다음과 같이 pip를 사용하여 InsightFace를 설치할 수 있습니다.
pip install --upgrade insightfaceInsightFace를 설치하기 전에 시스템 구성에 따라 올바른 MXNet 패키지를 설치하십시오.
Keras-MXNet
Keras가 Python으로 작성된 고수준 신경망 (NN) API라는 것을 알고 있듯이 Keras-MXNet은 Keras에 대한 백엔드 지원을 제공합니다. 고성능의 확장 가능한 Apache MXNet DL 프레임 워크 위에서 실행할 수 있습니다.
Keras-MXNet의 기능은 다음과 같습니다.
사용자가 쉽고 부드럽고 빠른 프로토 타이핑을 할 수 있습니다. 이는 모두 사용자 친 화성, 모듈성 및 확장 성을 통해 발생합니다.
CNN (Convolutional Neural Networks) 및 RNN (Recurrent Neural Networks)을 모두 지원하며 둘 다의 조합도 지원합니다.
중앙 처리 장치 (CPU)와 그래픽 처리 장치 (GPU) 모두에서 완벽하게 실행됩니다.
하나 또는 다중 GPU에서 실행할 수 있습니다.
이 백엔드를 사용하려면 먼저 다음과 같이 keras-mxnet을 설치해야합니다.
pip install keras-mxnet이제 GPU를 사용하는 경우 다음과 같이 CUDA 9를 지원하는 MXNet을 설치하십시오.
pip install mxnet-cu90그러나 CPU 만 사용하는 경우 다음과 같이 기본 MXNet을 설치하십시오.
pip install mxnetMXBoard
MXBoard는 Python으로 작성된 로깅 도구로 MXNet 데이터 프레임을 기록하고 TensorBoard에 표시하는 데 사용됩니다. 즉, MXBoard는 tensorboard-pytorch API를 따르도록되어 있습니다. TensorBoard에서 대부분의 데이터 유형을 지원합니다.
그들 중 일부는 아래에 언급되어 있습니다.
Graph
Scalar
Histogram
Embedding
Image
Text
Audio
정밀도-재현율 곡선
MXFusion
MXFusion은 딥 러닝이 포함 된 모듈 식 확률 프로그래밍 라이브러리입니다. MXFusion을 사용하면 확률 적 프로그래밍을 위해 딥 러닝 라이브러리의 핵심 기능인 모듈성을 완전히 활용할 수 있습니다. 사용이 간편하고 사용자에게 확률 모델을 설계하고이를 실제 문제에 적용 할 수있는 편리한 인터페이스를 제공합니다.
MXFusion은 MacOS 및 Linux OS의 Python 버전 3.4 이상에서 확인되었습니다. MXFusion을 설치하려면 먼저 다음 종속성을 설치해야합니다.
MXNet> = 1.3
Networkx> = 2.1
다음 pip 명령의 도움으로 MXFusion을 설치할 수 있습니다-
pip install mxfusionTVM
CPU, GPU 및 특수 가속기와 같은 하드웨어 백엔드를위한 오픈 소스 엔드 투 엔드 딥 러닝 컴파일러 스택 인 Apache TVM은 생산성 중심의 딥 러닝 프레임 워크와 성능 중심의 하드웨어 백엔드 간의 격차를 메우는 것을 목표로합니다. . 최신 릴리스 MXNet 1.6.0을 통해 사용자는 Apache (incubating) TVM을 활용하여 Python 프로그래밍 언어로 고성능 운영자 커널을 구현할 수 있습니다.
Apache TVM은 실제로 워싱턴 대학에있는 Paul G. Allen 컴퓨터 과학 및 공학 학교의 SAMPL 그룹에서 연구 프로젝트로 시작했으며 현재 OSC ( 오픈 소스 커뮤니티)는 Apache 방식의 여러 산업 및 학술 기관을 포함합니다.
다음은 Apache (incubating) TVM의 주요 기능입니다.
이전 C ++ 기반 개발 프로세스를 단순화합니다.
CPU, GPU 등과 같은 여러 하드웨어 백엔드에서 동일한 구현을 공유 할 수 있습니다.
TVM은 Kears, MXNet, PyTorch, Tensorflow, CoreML, DarkNet과 같은 다양한 프레임 워크의 DL 모델을 다양한 하드웨어 백엔드에 배포 가능한 최소 모듈로 컴파일합니다.
또한 더 나은 성능으로 텐서 연산자를 자동으로 생성하고 최적화 할 수있는 인프라를 제공합니다.
XFer
전이 학습 프레임 워크 인 Xfer는 Python으로 작성되었습니다. 기본적으로 MXNet 모델을 사용하고 메타 모델을 학습하거나 새 대상 데이터 세트에 대한 모델을 수정합니다.
간단히 말해서 Xfer는 사용자가 DNN (심층 신경망)에 저장된 지식을 빠르고 쉽게 전송할 수있는 Python 라이브러리입니다.
Xfer를 사용할 수 있습니다-
임의의 숫자 형식의 데이터 분류 용.
이미지 또는 텍스트 데이터의 일반적인 경우.
기능 추출에서 재목 적자 (대상 작업에서 분류를 수행하는 객체)를 교육하기 위해 스팸을 보내는 파이프 라인으로 사용됩니다.
다음은 Xfer의 기능입니다.
자원 효율성
데이터 효율성
신경망에 쉽게 액세스
불확실성 모델링
신속한 프로토 타입
NN에서 기능 추출을위한 유틸리티
이 장은 MXNet 시스템 아키텍처를 이해하는 데 도움이 될 것입니다. MXNet 모듈에 대해 배우면서 시작하겠습니다.
MXNet 모듈
아래 다이어그램은 MXNet 시스템 아키텍처이며 주요 모듈 및 구성 요소를 보여줍니다. MXNet modules and their interaction.

위의 다이어그램에서-
파란색 상자의 모듈은 User Facing Modules.
녹색 색상 상자의 모듈은 System Modules.
단색 화살표는 높은 종속성을 나타냅니다. 즉, 인터페이스에 크게 의존합니다.
점선 화살표는 가벼운 의존성을 나타냅니다. 즉, 편의성과 인터페이스 일관성을 위해 사용 된 데이터 구조입니다. 사실, 대안으로 대체 할 수 있습니다.
사용자 대면 및 시스템 모듈에 대해 자세히 설명하겠습니다.
사용자 용 모듈
사용자 용 모듈은 다음과 같습니다.
NDArray− Apache MXNet을위한 유연한 명령형 프로그램을 제공합니다. 동적 및 비동기식 n 차원 배열입니다.
KVStore− 효율적인 파라미터 동기화를위한 인터페이스 역할을합니다. KVStore에서 KV는 Key-Value를 나타냅니다. 따라서 키-값 저장소 인터페이스입니다.
Data Loading (IO) −이 사용자 용 모듈은 효율적인 분산 데이터로드 및 증대를 위해 사용됩니다.
Symbol Execution− 정적 기호 그래프 실행기입니다. 효율적인 기호 그래프 실행 및 최적화를 제공합니다.
Symbol Construction −이 사용자 용 모듈은 사용자에게 계산 그래프, 즉 넷 구성을 구성하는 방법을 제공합니다.
시스템 모듈
시스템 모듈은 다음과 같습니다-
Storage Allocator − 이름에서 알 수 있듯이이 시스템 모듈은 호스트, 즉 CPU 및 다른 장치 (예 : GPU)에서 메모리 블록을 효율적으로 할당하고 재활용합니다.
Runtime Dependency Engine − 런타임 종속성 엔진 모듈은 읽기 / 쓰기 종속성에 따라 작업을 예약하고 실행합니다.
Resource Manager − RM (Resource Manager) 시스템 모듈은 난수 생성기 및 시간 공간과 같은 전역 리소스를 관리합니다.
Operator − 운영자 시스템 모듈은 정적 순방향 및 기울기 계산 (예 : 역 전파)을 정의하는 모든 연산자로 구성됩니다.
여기에서는 Apache MXNet의 시스템 구성 요소에 대해 자세히 설명합니다. 먼저 MXNet의 실행 엔진에 대해 공부합니다.
실행 엔진
Apache MXNet의 실행 엔진은 매우 다양합니다. 딥 러닝은 물론 도메인 별 문제에 사용할 수 있습니다. 종속성에 따라 여러 함수를 실행합니다. 종속성이있는 함수는 직렬화되는 반면 종속성이없는 함수는 병렬로 실행될 수 있도록 설계되었습니다.
핵심 인터페이스
아래에 주어진 API는 Apache MXNet의 실행 엔진을위한 핵심 인터페이스입니다.
virtual void PushSync(Fn exec_fun, Context exec_ctx,
std::vector<VarHandle> const& const_vars,
std::vector<VarHandle> const& mutate_vars) = 0;위의 API는 다음과 같습니다.
exec_fun − MXNet의 핵심 인터페이스 API를 사용하면 컨텍스트 정보 및 종속성과 함께 exec_fun이라는 함수를 실행 엔진에 푸시 할 수 있습니다.
exec_ctx − 위에서 언급 한 exec_fun 함수가 실행되어야하는 컨텍스트 정보.
const_vars − 함수가 읽는 변수입니다.
mutate_vars − 수정할 변수입니다.
실행 엔진은 사용자에게 공통 변수를 수정하는 두 함수의 실행이 푸시 순서로 직렬화되도록 보장합니다.
함수
다음은 Apache MXNet 실행 엔진의 기능 유형입니다.
using Fn = std::function<void(RunContext)>;위의 기능에서 RunContext런타임 정보를 포함합니다. 런타임 정보는 실행 엔진에 의해 결정되어야합니다. 구문RunContext 다음과 같습니다-
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};다음은 실행 엔진의 기능에 대한 몇 가지 중요한 사항입니다.
모든 기능은 MXNet의 실행 엔진의 내부 스레드에 의해 실행됩니다.
함수가 실행 스레드를 차지하고 총 처리량도 줄어들 기 때문에 함수 차단을 실행 엔진으로 푸시하는 것은 좋지 않습니다.
이를 위해 MXNet은 다음과 같은 또 다른 비동기 기능을 제공합니다.
using Callback = std::function<void()>;
using AsyncFn = std::function<void(RunContext, Callback)>;이것에 AsyncFn 함수는 스레드의 무거운 부분을 전달할 수 있지만 실행 엔진은 다음을 호출 할 때까지 함수가 완료된 것으로 간주하지 않습니다. callback 함수.
문맥
에 Context에서 실행할 함수의 컨텍스트를 지정할 수 있습니다. 이것은 일반적으로 다음을 포함합니다-
함수가 CPU 또는 GPU에서 실행되어야하는지 여부.
컨텍스트에서 GPU를 지정하면 사용할 GPU.
Context와 RunContext 사이에는 큰 차이가 있습니다. 컨텍스트에는 장치 유형과 장치 ID가있는 반면 RunContext에는 런타임 중에 만 결정할 수있는 정보가 있습니다.
VarHandle
함수의 종속성을 지정하는 데 사용되는 VarHandle은 함수가 수정하거나 사용할 수있는 외부 리소스를 나타내는 데 사용할 수있는 토큰 (특히 실행 엔진에서 제공)과 같습니다.
하지만 왜 VarHandle을 사용해야합니까? 이는 Apache MXNet 엔진이 다른 MXNet 모듈과 분리되도록 설계 되었기 때문입니다.
다음은 VarHandle에 대한 몇 가지 중요한 사항입니다.
가볍기 때문에 변수를 생성, 삭제 또는 복사하는 데 운영 비용이 거의 들지 않습니다.
우리는 불변 변수를 지정해야합니다. const_vars.
변경 가능한 변수를 지정해야합니다. 즉, mutate_vars.
함수 간의 종속성을 해결하기 위해 실행 엔진에서 사용하는 규칙은 두 함수 중 하나가 적어도 하나의 공통 변수를 수정할 때 두 함수의 실행이 푸시 순서로 직렬화된다는 것입니다.
새 변수를 생성하기 위해 NewVar() API.
변수를 삭제하려면 PushDelete API.
간단한 예를 들어 그 작업을 이해합시다.
F1과 F2라는 두 개의 함수가 있고 둘 다 변수 즉 V2를 변경한다고 가정합니다. 이 경우 F1 이후에 F2를 누르면 F1 이후에 F2가 실행되도록 보장됩니다. 반면에 F1과 F2가 모두 V2를 사용하는 경우 실제 실행 순서는 무작위 일 수 있습니다.
밀고 기다리기
Push 과 wait 실행 엔진의 두 가지 더 유용한 API입니다.
다음은의 두 가지 중요한 기능입니다. Push API :
모든 Push API는 비동기식이므로 푸시 된 함수의 완료 여부에 관계없이 API 호출이 즉시 반환됩니다.
Push API는 스레드로부터 안전하지 않으므로 한 번에 하나의 스레드 만 엔진 API를 호출해야합니다.
이제 Wait API에 대해 이야기하면 다음과 같은 점이 나타납니다.
사용자가 특정 함수가 완료되기를 기다리려면 클로저에 콜백 함수를 포함해야합니다. 포함되면 함수 끝에서 함수를 호출합니다.
반면 사용자가 특정 변수를 포함하는 모든 기능이 완료 될 때까지 기다리려면 다음을 사용해야합니다. WaitForVar(var) API.
누군가 푸시 된 모든 기능이 완료 될 때까지 기다리려면 WaitForAll () API.
함수의 종속성을 지정하는 데 사용되며 토큰과 같습니다.
연산자
Apache MXNet의 연산자는 실제 계산 논리와 보조 정보를 포함하고 시스템이 최적화를 수행하는 데 도움이되는 클래스입니다.
운영자 인터페이스
Forward 구문이 다음과 같은 핵심 운영자 인터페이스입니다.
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) = 0;구조 OpContext, 정의 Forward() 다음과 같다:
struct OpContext {
int is_train;
RunContext run_ctx;
std::vector<Resource> requested;
}그만큼 OpContext운영자의 상태 (열차 또는 테스트 단계), 운영자가 실행되어야하는 장치 및 요청 된 리소스를 설명합니다. 실행 엔진의 두 가지 더 유용한 API.
위에서 Forward 핵심 인터페이스, 우리는 다음과 같이 요청 된 리소스를 이해할 수 있습니다-
in_data 과 out_data 입력 및 출력 텐서를 나타냅니다.
req 계산 결과가 out_data.
그만큼 OpReqType 다음과 같이 정의 할 수 있습니다-
enum OpReqType {
kNullOp,
kWriteTo,
kWriteInplace,
kAddTo
};처럼 Forward 연산자를 선택적으로 구현할 수 있습니다. Backward 다음과 같이 인터페이스-
virtual void Backward(const OpContext &ctx,
const std::vector<TBlob> &out_grad,
const std::vector<TBlob> &in_data,
const std::vector<TBlob> &out_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states);다양한 작업
Operator 인터페이스를 통해 사용자는 다음 작업을 수행 할 수 있습니다.
사용자는 내부 업데이트를 지정할 수 있으며 메모리 할당 비용을 줄일 수 있습니다.
더 깔끔하게 만들기 위해 사용자는 Python에서 내부 인수를 숨길 수 있습니다.
사용자는 텐서와 출력 텐서 간의 관계를 정의 할 수 있습니다.
계산을 수행하기 위해 사용자는 시스템에서 추가 임시 공간을 확보 할 수 있습니다.
연산자 속성
컨볼 루션 신경망 (CNN)에서 하나의 컨볼 루션에는 여러 가지 구현이 있다는 것을 알고 있습니다. 그들로부터 최고의 성능을 얻기 위해 우리는 이러한 여러 컨볼 루션 사이를 전환 할 수 있습니다.
이것이 Apache MXNet이 구현 인터페이스에서 연산자 시맨틱 인터페이스를 분리하는 이유입니다. 이 분리는 다음과 같은 형태로 이루어집니다.OperatorProperty 다음으로 구성된 클래스
InferShape − InferShape 인터페이스는 다음과 같이 두 가지 용도로 사용됩니다.
첫 번째 목적은 시스템에 각 입력 및 출력 텐서의 크기를 알려 주어 공간이 이전에 할당 될 수 있도록하는 것입니다. Forward 과 Backward 요구.
두 번째 목적은 실행하기 전에 오류가 없는지 확인하기 위해 크기 검사를 수행하는 것입니다.
구문은 다음과 같습니다.
virtual bool InferShape(mxnet::ShapeVector *in_shape,
mxnet::ShapeVector *out_shape,
mxnet::ShapeVector *aux_shape) const = 0;Request Resource− 시스템이 cudnnConvolutionForward와 같은 작업을 위해 계산 작업 공간을 관리 할 수 있다면 어떨까요? 시스템은 공간 재사용 등의 최적화를 수행 할 수 있습니다. 여기에서 MXNet은 다음 두 인터페이스의 도움으로이를 쉽게 달성 할 수 있습니다.
virtual std::vector<ResourceRequest> ForwardResource(
const mxnet::ShapeVector &in_shape) const;
virtual std::vector<ResourceRequest> BackwardResource(
const mxnet::ShapeVector &in_shape) const;그러나 만약 ForwardResource 과 BackwardResource비어 있지 않은 배열을 반환합니까? 이 경우 시스템은 다음을 통해 해당 리소스를 제공합니다.ctx 매개 변수 Forward 과 Backward 인터페이스 Operator.
Backward dependency − Apache MXNet은 역 의존성을 처리하기 위해 다음과 같은 두 가지 연산자 서명을 가지고 있습니다.
void FullyConnectedForward(TBlob weight, TBlob in_data, TBlob out_data);
void FullyConnectedBackward(TBlob weight, TBlob in_data, TBlob out_grad, TBlob in_grad);
void PoolingForward(TBlob in_data, TBlob out_data);
void PoolingBackward(TBlob in_data, TBlob out_data, TBlob out_grad, TBlob in_grad);여기서 주목해야 할 두 가지 중요한 사항은-
FullyConnectedForward의 out_data는 FullyConnectedBackward에서 사용되지 않습니다.
PoolingBackward에는 PoolingForward의 모든 인수가 필요합니다.
그래서 FullyConnectedForward, out_data일단 소비 된 텐서는 역방향 함수가 필요하지 않기 때문에 안전하게 해제 될 수 있습니다. 이 시스템의 도움으로 가능한 한 빨리 쓰레기로 일부 텐서를 수집했습니다.
In place Option− Apache MXNet은 메모리 할당 비용을 절약하기 위해 사용자에게 또 다른 인터페이스를 제공합니다. 인터페이스는 입력 및 출력 텐서의 모양이 동일한 요소 별 연산에 적합합니다.
다음은 내부 업데이트를 지정하는 구문입니다.
연산자 생성 예
OperatorProperty의 도움으로 연산자를 만들 수 있습니다. 그렇게하려면 아래 단계를 따르십시오.
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::ForwardInplaceOption(
const std::vector<int> &in_data,
const std::vector<void*> &out_data)
const {
return { {in_data[0], out_data[0]} };
}
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::BackwardInplaceOption(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data,
const std::vector<void*> &in_grad)
const {
return { {out_grad[0], in_grad[0]} }
}1 단계
Create Operator
먼저 OperatorProperty에서 다음 인터페이스를 구현합니다.
virtual Operator* CreateOperator(Context ctx) const = 0;예는 다음과 같습니다.
class ConvolutionOp {
public:
void Forward( ... ) { ... }
void Backward( ... ) { ... }
};
class ConvolutionOpProperty : public OperatorProperty {
public:
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp;
}
};2 단계
Parameterize Operator
컨볼 루션 연산자를 구현하려면 커널 크기, 보폭 크기, 패딩 크기 등을 알아야합니다. 이유는 이러한 매개 변수를 호출하기 전에 연산자에게 전달해야하기 때문입니다.Forward 또는 backward 상호 작용.
이를 위해 우리는 ConvolutionParam 아래 구조-
#include <dmlc/parameter.h>
struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
mxnet::TShape kernel, stride, pad;
uint32_t num_filter, num_group, workspace;
bool no_bias;
};이제 이것을 넣어야합니다 ConvolutionOpProperty 다음과 같이 연산자에게 전달합니다.
class ConvolutionOp {
public:
ConvolutionOp(ConvolutionParam p): param_(p) {}
void Forward( ... ) { ... }
void Backward( ... ) { ... }
private:
ConvolutionParam param_;
};
class ConvolutionOpProperty : public OperatorProperty {
public:
void Init(const vector<pair<string, string>& kwargs) {
// initialize param_ using kwargs
}
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp(param_);
}
private:
ConvolutionParam param_;
};3 단계
Register the Operator Property Class and the Parameter Class to Apache MXNet
마지막으로 Operator Property Class와 Parameter Class를 MXNet에 등록해야합니다. 다음 매크로의 도움으로 수행 할 수 있습니다.
DMLC_REGISTER_PARAMETER(ConvolutionParam);
MXNET_REGISTER_OP_PROPERTY(Convolution, ConvolutionOpProperty);위의 매크로에서 첫 번째 인수는 이름 문자열이고 두 번째 인수는 속성 클래스 이름입니다.
이 장에서는 Apache MXNet의 통합 운영자 API (응용 프로그래밍 인터페이스)에 대한 정보를 제공합니다.
SimpleOp
SimpleOp는 다양한 호출 프로세스를 통합하는 새로운 통합 운영자 API입니다. 호출되면 연산자의 기본 요소로 돌아갑니다. 통합 연산자는 단항 및 이항 연산을 위해 특별히 설계되었습니다. 대부분의 수학적 연산자가 하나 또는 두 개의 피연산자에 참여하고 더 많은 피연산자가 종속성과 관련된 최적화를 유용하게 만들기 때문입니다.
예제를 통해 SimpleOp 통합 연산자를 이해하게 될 것입니다. 이 예에서는 역할을하는 연산자를 만들 것입니다.smooth l1 loss, l1 및 l2 손실의 혼합입니다. 다음과 같이 손실을 정의하고 작성할 수 있습니다.
loss = outside_weight .* f(inside_weight .* (data - label))
grad = outside_weight .* inside_weight .* f'(inside_weight .* (data - label))여기 위의 예에서
. *는 요소 별 곱셈을 나타냅니다.
f, f’ 우리가 가정하고있는 부드러운 l1 손실 함수입니다. mshadow.
이 특정 손실을 단항 또는 이항 연산자로 구현하는 것은 불가능 해 보이지만 MXNet은 사용자에게 기호 실행에서 자동 차별화를 제공하여 f 및 f '에 대한 손실을 직접 단순화합니다. 그렇기 때문에이 특정 손실을 단항 연산자로 구현할 수 있습니다.
모양 정의
우리가 알고 있듯이 MXNet의 mshadow library명시적인 메모리 할당이 필요하므로 계산이 발생하기 전에 모든 데이터 형태를 제공해야합니다. 함수와 그라디언트를 정의하기 전에 다음과 같이 입력 모양 일관성과 출력 모양을 제공해야합니다.
typedef mxnet::TShape (*UnaryShapeFunction)(const mxnet::TShape& src,
const EnvArguments& env);
typedef mxnet::TShape (*BinaryShapeFunction)(const mxnet::TShape& lhs,
const mxnet::TShape& rhs,
const EnvArguments& env);mxnet :: Tshape 함수는 입력 데이터 모양과 지정된 출력 데이터 모양을 확인하는 데 사용됩니다. 이 함수를 정의하지 않으면 기본 출력 모양이 입력 모양과 동일합니다. 예를 들어 이항 연산자의 경우 lhs 및 rhs의 모양은 기본적으로 동일하게 확인됩니다.
이제 우리의 smooth l1 loss example. 이를 위해 헤더 구현에서 XPU를 cpu 또는 gpu로 정의해야합니다. smooth_l1_unary-inl.h. 그 이유는 동일한 코드를 smooth_l1_unary.cc 과 smooth_l1_unary.cu.
#include <mxnet/operator_util.h>
#if defined(__CUDACC__)
#define XPU gpu
#else
#define XPU cpu
#endif우리와 마찬가지로 smooth l1 loss example,출력은 소스와 모양이 같으므로 기본 동작을 사용할 수 있습니다. 다음과 같이 쓸 수 있습니다-
inline mxnet::TShape SmoothL1Shape_(const mxnet::TShape& src,const EnvArguments& env) {
return mxnet::TShape(src);
}함수 정의
다음과 같이 하나의 입력으로 단항 또는 이진 함수를 만들 수 있습니다.
typedef void (*UnaryFunction)(const TBlob& src,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);
typedef void (*BinaryFunction)(const TBlob& lhs,
const TBlob& rhs,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);다음은 RunContext ctx struct 실행을 위해 런타임 동안 필요한 정보를 포함합니다-
struct RunContext {
void *stream; // the stream of the device, can be NULL or Stream<gpu>* in GPU mode
template<typename xpu> inline mshadow::Stream<xpu>* get_stream() // get mshadow stream from Context
} // namespace mxnet이제 계산 결과를 작성하는 방법을 살펴 보겠습니다. ret.
enum OpReqType {
kNullOp, // no operation, do not write anything
kWriteTo, // write gradient to provided space
kWriteInplace, // perform an in-place write
kAddTo // add to the provided space
};이제 우리의 smooth l1 loss example. 이를 위해 UnaryFunction을 사용하여이 연산자의 기능을 다음과 같이 정의합니다.
template<typename xpu>
void SmoothL1Forward_(const TBlob& src,
const EnvArguments& env,
TBlob *ret,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(ret->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> out = ret->get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> in = src.get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(out, req,
F<mshadow_op::smooth_l1_loss>(in, ScalarExp<DType>(sigma2)));
});
}그라디언트 정의
외 Input, TBlob, 과 OpReqType이항 연산자의 그라디언트 함수는 비슷한 구조를 가지고 있습니다. 아래에서 다양한 유형의 입력을 사용하여 그래디언트 함수를 만들었습니다.
// depending only on out_grad
typedef void (*UnaryGradFunctionT0)(const OutputGrad& out_grad,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on out_value
typedef void (*UnaryGradFunctionT1)(const OutputGrad& out_grad,
const OutputValue& out_value,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on in_data
typedef void (*UnaryGradFunctionT2)(const OutputGrad& out_grad,
const Input0& in_data0,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);위에 정의 된대로 Input0, Input, OutputValue, 과 OutputGrad 모두의 구조를 공유 GradientFunctionArgument. 다음과 같이 정의됩니다-
struct GradFunctionArgument {
TBlob data;
}이제 우리의 smooth l1 loss example. 이를 위해 그라디언트의 체인 규칙을 활성화하려면out_grad 상단에서 결과까지 in_grad.
template<typename xpu>
void SmoothL1BackwardUseIn_(const OutputGrad& out_grad, const Input0& in_data0,
const EnvArguments& env,
TBlob *in_grad,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(in_grad->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> src = in_data0.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> ograd = out_grad.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> igrad = in_grad->get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(igrad, req,
ograd * F<mshadow_op::smooth_l1_gradient>(src, ScalarExp<DType>(sigma2)));
});
}MXNet에 SimpleOp 등록
모양, 기능 및 그라디언트를 만든 후에는 NDArray 연산자와 기호 연산자로 복원해야합니다. 이를 위해 다음과 같이 등록 매크로를 사용할 수 있습니다.
MXNET_REGISTER_SIMPLE_OP(Name, DEV)
.set_shape_function(Shape)
.set_function(DEV::kDevMask, Function<XPU>, SimpleOpInplaceOption)
.set_gradient(DEV::kDevMask, Gradient<XPU>, SimpleOpInplaceOption)
.describe("description");그만큼 SimpleOpInplaceOption 다음과 같이 정의 할 수 있습니다-
enum SimpleOpInplaceOption {
kNoInplace, // do not allow inplace in arguments
kInplaceInOut, // allow inplace in with out (unary)
kInplaceOutIn, // allow inplace out_grad with in_grad (unary)
kInplaceLhsOut, // allow inplace left operand with out (binary)
kInplaceOutLhs // allow inplace out_grad with lhs_grad (binary)
};이제 우리의 smooth l1 loss example. 이를 위해 입력 데이터에 의존하는 그래디언트 함수가 있으므로 함수를 제자리에 작성할 수 없습니다.
MXNET_REGISTER_SIMPLE_OP(smooth_l1, XPU)
.set_function(XPU::kDevMask, SmoothL1Forward_<XPU>, kNoInplace)
.set_gradient(XPU::kDevMask, SmoothL1BackwardUseIn_<XPU>, kInplaceOutIn)
.set_enable_scalar(true)
.describe("Calculate Smooth L1 Loss(lhs, scalar)");EnvArguments에 대한 SimpleOp
우리가 알고 있듯이 일부 작업에는 다음이 필요할 수 있습니다.
그래디언트 스케일과 같은 입력으로서의 스칼라
동작을 제어하는 키워드 인수 세트
계산 속도를 높이기위한 임시 공간입니다.
EnvArguments 사용의 이점은 계산을보다 확장 가능하고 효율적으로 만들기 위해 추가 인수와 리소스를 제공한다는 것입니다.
예
먼저 아래와 같이 구조체를 정의 해 보겠습니다.
struct EnvArguments {
real_t scalar; // scalar argument, if enabled
std::vector<std::pair<std::string, std::string> > kwargs; // keyword arguments
std::vector<Resource> resource; // pointer to the resources requested
};다음으로 다음과 같은 추가 리소스를 요청해야합니다. mshadow::Random<xpu> 및 임시 메모리 공간 EnvArguments.resource. 다음과 같이 할 수 있습니다-
struct ResourceRequest {
enum Type { // Resource type, indicating what the pointer type is
kRandom, // mshadow::Random<xpu> object
kTempSpace // A dynamic temp space that can be arbitrary size
};
Type type; // type of resources
};이제 등록은 선언 된 리소스 요청을 mxnet::ResourceManager. 그 후 리소스를 std::vector<Resource> resource in EnvAgruments.
다음 코드의 도움으로 리소스에 액세스 할 수 있습니다.
auto tmp_space_res = env.resources[0].get_space(some_shape, some_stream);
auto rand_res = env.resources[0].get_random(some_stream);부드러운 l1 손실 예제에서 보면 손실 함수의 전환점을 표시하기 위해 스칼라 입력이 필요합니다. 그래서 등록 과정에서set_enable_scalar(true), 및 env.scalar 함수 및 그라디언트 선언에서.
Tensor 운영 구축
여기서 왜 우리가 텐서 연산을 만들어야 하는가에 대한 질문이 생깁니다. 그 이유는 다음과 같습니다.
Computation은 mshadow 라이브러리를 사용하며 때때로 쉽게 사용할 수있는 함수가 없습니다.
소프트 맥스 손실 및 기울기와 같은 요소 별 방식으로 작업이 수행되지 않는 경우.
예
여기에서는 위의 부드러운 l1 손실 예제를 사용합니다. 부드러운 l1 손실과 기울기의 스칼라 케이스라는 두 개의 매퍼를 만들 것입니다.
namespace mshadow_op {
struct smooth_l1_loss {
// a is x, b is sigma2
MSHADOW_XINLINE static real_t Map(real_t a, real_t b) {
if (a > 1.0f / b) {
return a - 0.5f / b;
} else if (a < -1.0f / b) {
return -a - 0.5f / b;
} else {
return 0.5f * a * a * b;
}
}
};
}이 장은 Apache MXNet의 분산 교육에 관한 것입니다. MXNet의 계산 모드가 무엇인지 이해하는 것으로 시작하겠습니다.
계산 모드
다국어 ML 라이브러리 인 MXNet은 사용자에게 다음 두 가지 계산 모드를 제공합니다.
명령형 모드
이 계산 모드는 NumPy API와 같은 인터페이스를 노출합니다. 예를 들어 MXNet에서 다음 명령형 코드를 사용하여 CPU와 GPU 모두에서 0의 텐서를 생성합니다.
import mxnet as mx
tensor_cpu = mx.nd.zeros((100,), ctx=mx.cpu())
tensor_gpu= mx.nd.zeros((100,), ctx=mx.gpu(0))위의 코드에서 볼 수 있듯이 MXNet은 CPU 또는 GPU 장치에서 텐서를 보관할 위치를 지정합니다. 위의 예에서는 위치 0에 있습니다. MXNet은 모든 계산이 즉시가 아니라 느리게 발생하기 때문에 장치의 놀라운 활용도를 달성합니다.
심볼릭 모드
명령형 모드는 매우 유용하지만이 모드의 단점 중 하나는 강성입니다. 즉, 모든 계산이 미리 정의 된 데이터 구조와 함께 미리 알려 져야합니다.
반면에 Symbolic 모드는 TensorFlow와 같은 계산 그래프를 노출합니다. MXNet이 고정 / 미리 정의 된 데이터 구조 대신 기호 또는 변수로 작업 할 수 있도록하여 명령형 API의 단점을 제거합니다. 그 후, 기호는 다음과 같이 일련의 연산으로 해석 될 수 있습니다.
import mxnet as mx
x = mx.sym.Variable(“X”)
y = mx.sym.Variable(“Y”)
z = (x+y)
m = z/100병렬 처리의 종류
Apache MXNet은 분산 교육을 지원합니다. 이를 통해 더 빠르고 효과적인 교육을 위해 여러 기계를 활용할 수 있습니다.
다음은 여러 장치, CPU 또는 GPU 장치에 걸쳐 NN 훈련 워크로드를 분산 할 수있는 두 가지 방법입니다.
데이터 병렬성
이러한 종류의 병렬 처리에서 각 장치는 모델의 전체 사본을 저장하고 데이터 세트의 다른 부분과 함께 작동합니다. 또한 장치는 공유 모델을 집합 적으로 업데이트합니다. 단일 시스템 또는 여러 시스템에서 모든 장치를 찾을 수 있습니다.
모델 병렬성
모델이 너무 커서 장치 메모리에 맞지 않을 때 유용한 또 다른 종류의 병렬 처리입니다. 모델 병렬화에서는 모델의 다른 부분을 학습하는 작업이 다른 장치에 할당됩니다. 여기서 주목해야 할 중요한 점은 현재 Apache MXNet이 단일 시스템에서만 모델 병렬 처리를 지원한다는 것입니다.
분산 교육 작업
아래에 주어진 개념은 Apache MXNet의 분산 교육 작업을 이해하는 데 핵심입니다.
프로세스 유형
프로세스는 모델 학습을 수행하기 위해 서로 통신합니다. Apache MXNet에는 다음 세 가지 프로세스가 있습니다.
노동자
작업자 노드의 역할은 훈련 샘플 배치에 대한 훈련을 수행하는 것입니다. 작업자 노드는 모든 배치를 처리하기 전에 서버에서 가중치를 가져옵니다. 작업자 노드는 배치가 처리되면 서버로 그라디언트를 보냅니다.
섬기는 사람
MXNet은 모델의 매개 변수를 저장하고 작업자 노드와 통신하기위한 여러 서버를 가질 수 있습니다.
스케줄러
스케줄러의 역할은 클러스터를 설정하는 것입니다. 여기에는 각 노드가 표시되는 메시지와 노드가 수신하는 포트를 기다리는 것이 포함됩니다. 클러스터를 설정 한 후 스케줄러는 모든 프로세스가 클러스터의 다른 모든 노드에 대해 알 수 있도록합니다. 프로세스가 서로 통신 할 수 있기 때문입니다. 스케줄러는 하나뿐입니다.
KV 스토어
KV 매장은 Key-Value저장. 다중 장치 교육에 사용되는 중요한 구성 요소입니다. 단일 및 여러 시스템의 장치 간 매개 변수 통신은 매개 변수에 대한 KVStore를 사용하여 하나 이상의 서버를 통해 전송되기 때문에 중요합니다. 다음 포인트의 도움으로 KVStore의 작동을 이해합시다-
KVStore의 각 값은 key 그리고 value.
네트워크의 각 매개 변수 배열에는 key 해당 매개 변수 배열의 가중치는 value.
그 후 작업자 노드 push배치 처리 후 그라디언트. 그들 또한pull 새 배치를 처리하기 전에 가중치를 업데이트했습니다.
KVStore 서버의 개념은 분산 학습 중에 만 존재하며 분산 모드는 호출을 통해 활성화됩니다. mxnet.kvstore.create 단어를 포함하는 문자열 인수가있는 함수 dist −
kv = mxnet.kvstore.create(‘dist_sync’)키 배포
모든 서버가 모든 매개 변수 배열 또는 키를 저장할 필요는 없지만 서로 다른 서버에 분산되어 있습니다. 서로 다른 서버에 걸친 이러한 키 분배는 KVStore에 의해 투명하게 처리되며 특정 키를 저장하는 서버의 결정은 무작위로 이루어집니다.
위에서 설명한대로 KVStore는 키를 가져올 때마다 해당 값을 가진 해당 서버로 요청이 전송되도록합니다. 일부 키의 값이 크면 어떻게됩니까? 이 경우 다른 서버에서 공유 할 수 있습니다.
훈련 데이터 분할
사용자로서 우리는 특히 데이터 병렬 모드에서 분산 훈련을 실행할 때 각 머신이 데이터 세트의 다른 부분에서 작업하기를 원합니다. 단일 작업자에 대한 데이터 병렬 학습을 위해 데이터 반복자가 제공하는 샘플 배치를 분할하려면 다음을 사용할 수 있습니다.mxnet.gluon.utils.split_and_load 그런 다음 배치의 각 부분을 추가로 처리 할 장치에로드합니다.
반면에 분산 훈련의 경우 처음에는 데이터 세트를 n모든 작업자가 다른 부분을 갖도록 일단 획득하면 각 작업자는 다음을 사용할 수 있습니다.split_and_load데이터 세트의 해당 부분을 단일 머신의 여러 장치로 다시 나눕니다. 이 모든 것은 데이터 반복기를 통해 발생합니다.mxnet.io.MNISTIterator 과 mxnet.io.ImageRecordIter 이 기능을 지원하는 MXNet의 두 반복자입니다.
가중치 업데이트
가중치를 업데이트하기 위해 KVStore는 다음 두 가지 모드를 지원합니다.
첫 번째 방법은 그라디언트를 집계하고 해당 그라디언트를 사용하여 가중치를 업데이트합니다.
두 번째 방법에서는 서버가 그라디언트 만 집계합니다.
Gluon을 사용하는 경우 위에 언급 된 방법 중에서 선택할 수있는 옵션이 있습니다. update_on_kvstore변하기 쉬운. 그것을 만들어서 이해합시다trainer 다음과 같이 개체-
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd',
optimizer_params={'learning_rate': opt.lr,
'wd': opt.wd,
'momentum': opt.momentum,
'multi_precision': True},
kvstore=kv,
update_on_kvstore=True)분산 교육 모드
KVStore 생성 문자열에 단어 dist가 포함되어 있으면 분산 교육이 활성화되었음을 의미합니다. 다음은 다양한 유형의 KVStore를 사용하여 활성화 할 수있는 분산 교육의 다양한 모드입니다.
dist_sync
이름에서 알 수 있듯이 동기식 분산 교육을 나타냅니다. 여기에서 모든 작업자는 모든 배치 시작시 동일한 동기화 된 모델 매개 변수 집합을 사용합니다.
이 모드의 단점은 각 배치 후에 서버가 모델 매개 변수를 업데이트하기 전에 각 작업자로부터 그라디언트를 수신 할 때까지 기다려야한다는 것입니다. 즉, 작업자가 충돌하면 모든 작업자의 진행이 중단됩니다.
dist_async
이름에서 알 수 있듯이 동기식 분산 교육을 나타냅니다. 여기에서 서버는 한 작업자로부터 그라디언트를 수신하고 즉시 저장소를 업데이트합니다. 서버는 업데이트 된 저장소를 사용하여 추가 가져 오기에 응답합니다.
에 비해 장점 dist_sync mode, 배치 처리를 완료 한 작업자는 서버에서 현재 매개 변수를 가져와 다음 배치를 시작할 수 있습니다. 작업자는 다른 작업자가 이전 배치 처리를 아직 완료하지 않은 경우에도 그렇게 할 수 있습니다. 또한 동기화 비용없이 수렴하는 데 더 많은 epoch가 걸릴 수 있기 때문에 dist_sync 모드보다 빠릅니다.
dist_sync_device
이 모드는 dist_sync방법. 유일한 차이점은 모든 노드에서 여러 GPU가 사용되는 경우dist_sync_device 그래디언트를 집계하고 GPU에서 가중치를 업데이트하는 반면, dist_sync 그래디언트를 집계하고 CPU 메모리의 가중치를 업데이트합니다.
GPU와 CPU 간의 값 비싼 통신을 줄입니다. 그렇기 때문에dist_sync. 단점은 GPU에서 메모리 사용량이 증가한다는 것입니다.
dist_async_device
이 모드는 다음과 동일하게 작동합니다. dist_sync_device 모드이지만 비동기 모드입니다.
이 장에서는 Apache MXNet에서 사용할 수있는 Python 패키지에 대해 알아 봅니다.
중요한 MXNet Python 패키지
MXNet은 우리가 하나씩 논의 할 다음과 같은 중요한 파이썬 패키지를 가지고 있습니다.
Autograd (자동 미분)
NDArray
KVStore
Gluon
Visualization
먼저 Autograd Apache MXNet 용 Python 패키지.
Autograd
Autograd 약자 automatic differentiation손실 측정 항목의 기울기를 각 매개 변수로 역 전파하는 데 사용됩니다. 역전 파와 함께 동적 프로그래밍 접근 방식을 사용하여 기울기를 효율적으로 계산합니다. 역방향 모드 자동 미분이라고도합니다. 이 기술은 많은 매개 변수가 단일 손실 지표에 영향을 미치는 '팬인'상황에서 매우 효율적입니다.
그라디언트 란 무엇입니까?
그라디언트는 신경망 훈련 과정의 기초입니다. 기본적으로 성능을 향상시키기 위해 네트워크의 매개 변수를 변경하는 방법을 알려줍니다.
우리가 알고 있듯이 신경망 (NN)은 합, 곱, 컨볼 루션 등과 같은 연산자로 구성됩니다. 이러한 연산자는 계산을 위해 컨볼 루션 커널의 가중치와 같은 매개 변수를 사용합니다. 이러한 매개 변수에 대한 최적의 값을 찾아야합니다. 그래디언트는 우리에게 방법을 보여주고 솔루션으로이 끕니다.
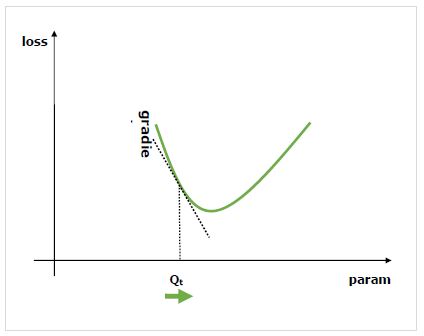
우리는 네트워크의 성능에 대한 매개 변수 변경의 효과에 관심이 있으며 기울기는 주어진 변수가 의존하는 변수를 변경할 때 얼마나 증가하거나 감소하는지 알려줍니다. 성능은 일반적으로 최소화하려는 손실 메트릭을 사용하여 정의됩니다. 예를 들어 회귀의 경우L2 예측과 정확한 값 사이의 손실, 분류를 위해 우리는 cross-entropy loss.
손실과 관련하여 각 매개 변수의 기울기를 계산하면 확률 적 기울기 하강과 같은 옵티 마이저를 사용할 수 있습니다.
그라디언트를 계산하는 방법?
그라디언트를 계산하는 데 다음과 같은 옵션이 있습니다.
Symbolic Differentiation− 첫 번째 옵션은 각 그라데이션에 대한 공식을 계산하는 Symbolic Differentiation입니다. 이 방법의 단점은 네트워크가 더 깊어지고 운영자가 더 복잡 해짐에 따라 믿을 수 없을 정도로 긴 공식으로 빠르게 이어진다는 것입니다.
Finite Differencing− 또 다른 옵션은 유한 차분을 사용하여 각 매개 변수에 대해 약간의 차이를 시도하고 손실 메트릭이 어떻게 반응하는지 확인하는 것입니다. 이 방법의 단점은 계산 비용이 많이 들고 수치 정밀도가 떨어질 수 있다는 것입니다.
Automatic differentiation− 위 방법의 단점에 대한 해결책은 자동 미분을 사용하여 손실 측정 항목의 기울기를 각 매개 변수로 역 전파하는 것입니다. 전파를 사용하면 동적 프로그래밍 접근 방식을 사용하여 기울기를 효율적으로 계산할 수 있습니다. 이 방법은 역방향 모드 자동 미분이라고도합니다.
자동 미분 (autograd)
여기서 우리는 autograd의 작동을 자세히 이해할 것입니다. 기본적으로 다음 두 단계로 작동합니다.
Stage 1 −이 단계는 ‘Forward Pass’훈련 이름에서 알 수 있듯이이 단계에서는 네트워크에서 예측을 수행하고 손실 메트릭을 계산하는 데 사용하는 연산자의 레코드를 만듭니다.
Stage 2 −이 단계는 ‘Backward Pass’훈련 이름에서 알 수 있듯이이 단계에서는이 레코드를 통해 거꾸로 작동합니다. 거꾸로, 각 연산자의 편도 함수를 네트워크 매개 변수까지 평가합니다.
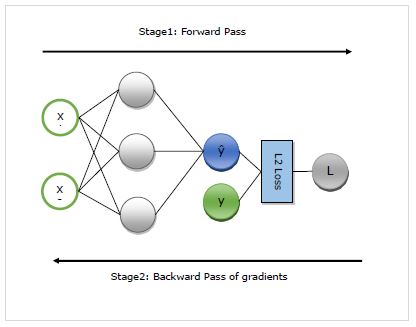
autograd의 장점
다음은 자동 미분 (autograd) 사용의 장점입니다.
Flexible− 네트워크를 정의 할 때 제공하는 유연성은 autograd 사용의 큰 이점 중 하나입니다. 반복 할 때마다 작업을 변경할 수 있습니다. 이를 동적 그래프라고하며 정적 그래프가 필요한 프레임 워크에서 구현하기가 훨씬 더 복잡합니다. 이러한 경우에도 Autograd는 그래디언트를 올바르게 역 전파 할 수 있습니다.
Automatic− Autograd는 자동입니다. 즉, 역 전파 절차의 복잡성이 자동으로 처리됩니다. 계산할 그라디언트를 지정하기 만하면됩니다.
Efficient − Autogard는 그라디언트를 매우 효율적으로 계산합니다.
Can use native Python control flow operators− if 조건 및 while 루프와 같은 기본 Python 제어 흐름 연산자를 사용할 수 있습니다. autograd는 그래디언트를 효율적이고 정확하게 역 전파 할 수 있습니다.
MXNet Gluon에서 autograd 사용
여기에서 예제의 도움을 받아 autograd MXNet Gluon에서.
구현 예
다음 예제에서는 두 개의 계층이있는 회귀 모델을 구현합니다. 구현 후 autograd를 사용하여 각 가중치 매개 변수를 참조하여 손실의 기울기를 자동으로 계산합니다.
먼저 다음과 같이 autogrard 및 기타 필수 패키지를 가져옵니다.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss이제 네트워크를 다음과 같이 정의해야합니다.
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()이제 다음과 같이 손실을 정의해야합니다.
loss_function = L2Loss()다음으로, 다음과 같이 더미 데이터를 생성해야합니다.
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])이제 우리는 네트워크를 통한 첫 번째 순방향 패스를 할 준비가되었습니다. 우리는 기울기를 계산할 수 있도록 autograd가 계산 그래프를 기록하기를 원합니다. 이를 위해 우리는 범위 내에서 네트워크 코드를 실행해야합니다.autograd.record 다음과 같이 컨텍스트-
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)이제 관심 수량에 대해 backward 메소드를 호출하여 시작하는 역방향 패스에 대한 준비가되었습니다. 이 예제에서 관심있는 quatity는 손실입니다. 왜냐하면 매개 변수를 참조하여 손실의 기울기를 계산하려고하기 때문입니다.
loss.backward()이제 네트워크의 각 매개 변수에 대한 기울기가 있으며, 이는 최적화 프로그램에서 성능 향상을 위해 매개 변수 값을 업데이트하는 데 사용됩니다. 다음과 같이 첫 번째 레이어의 그라디언트를 확인하십시오.
N_net[0].weight.grad()Output
출력은 다음과 같습니다.
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>완전한 구현 예
아래에 전체 구현 예가 나와 있습니다.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()이 장에서는 MXNet의 다차원 배열 형식에 대해 설명합니다. ndarray.
NDArray로 데이터 처리
먼저 NDArray로 데이터를 처리하는 방법을 살펴 보겠습니다. 다음은 동일한 전제 조건입니다-
전제 조건
이 다차원 배열 형식으로 데이터를 처리하는 방법을 이해하려면 다음 전제 조건을 충족해야합니다.
Python 환경에 설치된 MXNet
Python 2.7.x 또는 Python 3.x
구현 예
아래의 예제를 통해 기본 기능을 이해하겠습니다.
먼저 다음과 같이 MXNet에서 MXNet 및 ndarray를 가져와야합니다.
import mxnet as mx
from mxnet import nd필요한 라이브러리를 가져 오면 다음과 같은 기본 기능을 사용할 수 있습니다.
파이썬 목록이있는 간단한 1 차원 배열
Example
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
출력은 다음과 같습니다.
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>파이썬 목록이있는 2 차원 배열
Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
출력은 다음과 같습니다.
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>초기화없이 NDArray 만들기
여기서는 다음을 사용하여 3 행 4 열의 행렬을 만듭니다. .empty함수. 우리는 또한 사용할 것입니다.full 함수는 배열에 채우려는 값에 대한 추가 연산자를 사용합니다.
Example
x = nd.empty((3, 4))
print(x)
x = nd.full((3,4), 8)
print(x)Output
출력은 다음과 같습니다.
[[0.000e+00 0.000e+00 0.000e+00 0.000e+00]
[0.000e+00 0.000e+00 2.887e-42 0.000e+00]
[0.000e+00 0.000e+00 0.000e+00 0.000e+00]]
<NDArray 3x4 @cpu(0)>
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]]
<NDArray 3x4 @cpu(0)>.zeros 함수를 사용하는 모든 0으로 구성된 행렬
Example
x = nd.zeros((3, 8))
print(x)Output
출력은 다음과 같습니다.
[[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 3x8 @cpu(0)>.ones 함수를 사용하는 모든 1의 행렬
Example
x = nd.ones((3, 8))
print(x)Output
출력은 아래에 언급되어 있습니다.
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
<NDArray 3x8 @cpu(0)>값이 무작위로 샘플링되는 배열 만들기
Example
y = nd.random_normal(0, 1, shape=(3, 4))
print(y)Output
출력은 다음과 같습니다.
[[ 1.2673576 -2.0345826 -0.32537818 -1.4583491 ]
[-0.11176403 1.3606371 -0.7889914 -0.17639421]
[-0.2532185 -0.42614475 -0.12548696 1.4022992 ]]
<NDArray 3x4 @cpu(0)>각 NDArray의 차원 찾기
Example
y.shapeOutput
출력은 다음과 같습니다.
(3, 4)각 NDArray의 크기 찾기
Example
y.sizeOutput
12각 NDArray의 데이터 유형 찾기
Example
y.dtypeOutput
numpy.float32NDArray 작업
이 섹션에서는 MXNet의 어레이 작업을 소개합니다. NDArray는 많은 수의 표준 수학 및 내부 연산을 지원합니다.
표준 수학 연산
다음은 NDArray가 지원하는 표준 수학 연산입니다-
요소 별 덧셈
먼저 다음과 같이 MXNet에서 MXNet 및 ndarray를 가져와야합니다.
import mxnet as mx
from mxnet import nd
x = nd.ones((3, 5))
y = nd.random_normal(0, 1, shape=(3, 5))
print('x=', x)
print('y=', y)
x = x + y
print('x = x + y, x=', x)Output
출력은 여기에 주어진다-
x=
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
<NDArray 3x5 @cpu(0)>
y=
[[-1.0554522 -1.3118273 -0.14674698 0.641493 -0.73820823]
[ 2.031364 0.5932667 0.10228804 1.179526 -0.5444829 ]
[-0.34249446 1.1086396 1.2756858 -1.8332436 -0.5289873 ]]
<NDArray 3x5 @cpu(0)>
x = x + y, x=
[[-0.05545223 -0.3118273 0.853253 1.6414931 0.26179177]
[ 3.031364 1.5932667 1.102288 2.1795259 0.4555171 ]
[ 0.6575055 2.1086397 2.2756858 -0.8332436 0.4710127 ]]
<NDArray 3x5 @cpu(0)>요소 별 곱셈
Example
x = nd.array([1, 2, 3, 4])
y = nd.array([2, 2, 2, 1])
x * yOutput
다음 출력이 표시됩니다.
[2. 4. 6. 4.]
<NDArray 4 @cpu(0)>지수화
Example
nd.exp(x)Output
코드를 실행하면 다음 출력이 표시됩니다.
[ 2.7182817 7.389056 20.085537 54.59815 ]
<NDArray 4 @cpu(0)>행렬-행렬 곱을 계산하기위한 행렬 전치
Example
nd.dot(x, y.T)Output
다음은 코드의 출력입니다.
[16.]
<NDArray 1 @cpu(0)>현재 위치 작업
위의 예에서 작업을 실행할 때마다 결과를 호스팅하기 위해 새 메모리를 할당했습니다.
예를 들어 A = A + B라고 쓰면 A가 가리키는 데 사용한 행렬을 역 참조하고 대신 새로 할당 된 메모리를 가리 킵니다. 파이썬의 id () 함수를 사용하여 아래에 주어진 예를 들어 이해합시다.
print('y=', y)
print('id(y):', id(y))
y = y + x
print('after y=y+x, y=', y)
print('id(y):', id(y))Output
실행하면 다음과 같은 출력이 표시됩니다.
y=
[2. 2. 2. 1.]
<NDArray 4 @cpu(0)>
id(y): 2438905634376
after y=y+x, y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
id(y): 2438905685664사실, 다음과 같이 이전에 할당 된 배열에 결과를 할당 할 수도 있습니다.
print('x=', x)
z = nd.zeros_like(x)
print('z is zeros_like x, z=', z)
print('id(z):', id(z))
print('y=', y)
z[:] = x + y
print('z[:] = x + y, z=', z)
print('id(z) is the same as before:', id(z))Output
출력은 다음과 같습니다.
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)>
z is zeros_like x, z=
[0. 0. 0. 0.]
<NDArray 4 @cpu(0)>
id(z): 2438905790760
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
z[:] = x + y, z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)>
id(z) is the same as before: 2438905790760위의 출력에서 x + y는 결과를 z에 복사하기 전에 결과를 저장할 임시 버퍼를 할당한다는 것을 알 수 있습니다. 이제 메모리를 더 잘 사용하고 임시 버퍼를 피하기 위해 작업을 제자리에서 수행 할 수 있습니다. 이를 위해 모든 연산자가 지원하는 out 키워드 인수를 다음과 같이 지정합니다.
print('x=', x, 'is in id(x):', id(x))
print('y=', y, 'is in id(y):', id(y))
print('z=', z, 'is in id(z):', id(z))
nd.elemwise_add(x, y, out=z)
print('after nd.elemwise_add(x, y, out=z), x=', x, 'is in id(x):', id(x))
print('after nd.elemwise_add(x, y, out=z), y=', y, 'is in id(y):', id(y))
print('after nd.elemwise_add(x, y, out=z), z=', z, 'is in id(z):', id(z))Output
위의 프로그램을 실행하면 다음과 같은 결과를 얻을 수 있습니다.
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760
after nd.elemwise_add(x, y, out=z), x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
after nd.elemwise_add(x, y, out=z), y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
after nd.elemwise_add(x, y, out=z), z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760NDArray 컨텍스트
Apache MXNet에서 각 어레이에는 컨텍스트가 있고 하나의 컨텍스트는 CPU가 될 수있는 반면 다른 컨텍스트는 여러 GPU가 될 수 있습니다. 작업을 여러 서버에 배포하면 상황이 최악이 될 수 있습니다. 그렇기 때문에 컨텍스트에 지능적으로 배열을 할당해야합니다. 장치간에 데이터를 전송하는 데 소요되는 시간을 최소화합니다.
예를 들어, 다음과 같이 배열을 초기화하십시오.
from mxnet import nd
z = nd.ones(shape=(3,3), ctx=mx.cpu(0))
print(z)Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
<NDArray 3x3 @cpu(0)>다음과 같이 copyto () 메서드를 사용하여 주어진 NDArray를 한 컨텍스트에서 다른 컨텍스트로 복사 할 수 있습니다.
x_gpu = x.copyto(gpu(0))
print(x_gpu)NumPy 어레이 대 NDArray
우리는 모두 NumPy 배열에 익숙하지만 Apache MXNet은 NDArray라는 자체 배열 구현을 제공합니다. 사실, 처음에는 NumPy와 비슷하게 설계되었지만 중요한 차이점이 있습니다.
주요 차이점은 NumPy 및 NDArray에서 계산이 실행되는 방식에 있습니다. MXNet의 모든 NDArray 조작은 비동기식 및 비 차단 방식으로 수행됩니다. 즉, c = a * b와 같은 코드를 작성할 때 함수가Execution Engine, 계산을 시작합니다.
여기서 a와 b는 모두 NDArray입니다. 이를 사용하는 이점은 함수가 즉시 반환되고 이전 계산이 아직 완료되지 않았더라도 사용자 스레드가 계속 실행될 수 있다는 것입니다.
실행 엔진의 작동
실행 엔진의 작동에 대해 이야기하면 계산 그래프를 작성합니다. 계산 그래프는 일부 계산을 재정렬하거나 결합 할 수 있지만 항상 종속성 순서를 따릅니다.
예를 들어, 나중에 프로그래밍 코드에서 'X'를 사용한 다른 조작이있는 경우 'X'의 결과를 사용할 수있게되면 Execution Engine이이를 수행하기 시작합니다. 실행 엔진은 후속 코드 실행을 시작하기위한 콜백 작성과 같이 사용자를위한 몇 가지 중요한 작업을 처리합니다.
Apache MXNet에서 NDArray의 도움으로 계산 결과를 얻으려면 결과 변수에만 액세스하면됩니다. 계산 결과가 결과 변수에 할당 될 때까지 코드 흐름이 차단됩니다. 이러한 방식으로 명령형 프로그래밍 모드를 계속 지원하면서 코드 성능을 향상시킵니다.
NDArray를 NumPy 배열로 변환
MXNet에서 NDArray를 NumPy Array로 변환하는 방법을 알아 보겠습니다.
Combining higher-level operator with the help of few lower-level operators
때로는 기존 연산자를 사용하여 상위 수준의 연산자를 조합 할 수 있습니다. 이것의 가장 좋은 예 중 하나는np.full_like()NDArray API에는 없습니다. 다음과 같이 기존 연산자 조합으로 쉽게 대체 할 수 있습니다.
from mxnet import nd
import numpy as np
np_x = np.full_like(a=np.arange(7, dtype=int), fill_value=15)
nd_x = nd.ones(shape=(7,)) * 15
np.array_equal(np_x, nd_x.asnumpy())Output
다음과 유사한 출력을 얻을 수 있습니다.
TrueFinding similar operator with different name and/or signature
모든 연산자 중 일부는 이름이 약간 다르지만 기능면에서 비슷합니다. 이것의 예는nd.ravel_index() 와 np.ravel()기능. 같은 방식으로 일부 연산자는 이름이 비슷할 수 있지만 서명이 다릅니다. 이것의 예는np.split() 과 nd.split() 비슷합니다.
다음 프로그래밍 예제를 통해 이해해 보겠습니다.
def pad_array123(data, max_length):
data_expanded = data.reshape(1, 1, 1, data.shape[0])
data_padded = nd.pad(data_expanded,
mode='constant',
pad_width=[0, 0, 0, 0, 0, 0, 0, max_length - data.shape[0]],
constant_value=0)
data_reshaped_back = data_padded.reshape(max_length)
return data_reshaped_back
pad_array123(nd.array([1, 2, 3]), max_length=10)Output
출력은 다음과 같습니다.
[1. 2. 3. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 10 @cpu(0)>통화 차단의 영향 최소화
일부 경우에는 다음 중 하나를 사용해야합니다. .asnumpy() 또는 .asscalar()하지만 이렇게하면 결과를 검색 할 수있을 때까지 MXNet이 실행을 강제로 차단합니다. 다음을 호출하여 차단 호출의 영향을 최소화 할 수 있습니다..asnumpy() 또는 .asscalar() 이 값의 계산이 이미 완료되었다고 생각하는 순간의 방법.
구현 예
Example
from __future__ import print_function
import mxnet as mx
from mxnet import gluon, nd, autograd
from mxnet.ndarray import NDArray
from mxnet.gluon import HybridBlock
import numpy as np
class LossBuffer(object):
"""
Simple buffer for storing loss value
"""
def __init__(self):
self._loss = None
def new_loss(self, loss):
ret = self._loss
self._loss = loss
return ret
@property
def loss(self):
return self._loss
net = gluon.nn.Dense(10)
ce = gluon.loss.SoftmaxCELoss()
net.initialize()
data = nd.random.uniform(shape=(1024, 100))
label = nd.array(np.random.randint(0, 10, (1024,)), dtype='int32')
train_dataset = gluon.data.ArrayDataset(data, label)
train_data = gluon.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd')
loss_buffer = LossBuffer()
for data, label in train_data:
with autograd.record():
out = net(data)
# This call saves new loss and returns previous loss
prev_loss = loss_buffer.new_loss(ce(out, label))
loss_buffer.loss.backward()
trainer.step(data.shape[0])
if prev_loss is not None:
print("Loss: {}".format(np.mean(prev_loss.asnumpy())))Output
출력은 다음과 같습니다.
Loss: 2.3373236656188965
Loss: 2.3656985759735107
Loss: 2.3613128662109375
Loss: 2.3197104930877686
Loss: 2.3054862022399902
Loss: 2.329197406768799
Loss: 2.318927526473999또 다른 가장 중요한 MXNet Python 패키지는 Gluon입니다. 이 장에서는이 패키지에 대해 설명합니다. Gluon은 DL 프로젝트를위한 명확하고 간결하며 간단한 API를 제공합니다. 이를 통해 Apache MXNet은 교육 속도를 잃지 않고 DL 모델을 프로토 타입, 구축 및 교육 할 수 있습니다.
블록
블록은 더 복잡한 네트워크 설계의 기초를 형성합니다. 신경망에서 신경망의 복잡성이 증가함에 따라 우리는 단일 계층의 뉴런 설계에서 전체 계층으로 이동해야합니다. 예를 들어 ResNet-152와 같은 NN 설계는 다음과 같이 구성되어 매우 공정한 규칙 성을 갖습니다.blocks 반복되는 층의.
예
아래 주어진 예에서 간단한 블록, 즉 다중 레이어 퍼셉트론에 대한 블록을 작성합니다.
from mxnet import nd
from mxnet.gluon import nn
x = nd.random.uniform(shape=(2, 20))
N_net = nn.Sequential()
N_net.add(nn.Dense(256, activation='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
그러면 다음과 같은 출력이 생성됩니다.
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>레이어 정의에서 하나 이상의 레이어 블록을 정의하는 데 필요한 단계-
Step 1 − 블록은 데이터를 입력으로받습니다.
Step 2− 이제 블록은 상태를 매개 변수 형태로 저장합니다. 예를 들어, 위의 코딩 예제에서 블록에는 두 개의 은닉 계층이 포함되어 있으며 이에 대한 매개 변수를 저장할 장소가 필요합니다.
Step 3− 다음 블록은 정방향 전파를 수행하기 위해 정방향 기능을 호출합니다. 순방향 계산이라고도합니다. 첫 번째 포워드 호출의 일부로 블록은 지연 방식으로 매개 변수를 초기화합니다.
Step 4− 마침내 블록은 역방향 함수를 호출하고 입력을 참조하여 기울기를 계산합니다. 일반적으로이 단계는 자동으로 수행됩니다.
순차 블록
순차 블록은 데이터가 일련의 블록을 통해 흐르는 특별한 종류의 블록입니다. 여기에서 각 블록은 입력 데이터 자체에 적용되는 첫 번째 블록과 함께 이전 하나의 출력에 적용됩니다.
방법을 보자 sequential 수업 작품-
from mxnet import nd
from mxnet.gluon import nn
class MySequential(nn.Block):
def __init__(self, **kwargs):
super(MySequential, self).__init__(**kwargs)
def add(self, block):
self._children[block.name] = block
def forward(self, x):
for block in self._children.values():
x = block(x)
return x
x = nd.random.uniform(shape=(2, 20))
N_net = MySequential()
N_net.add(nn.Dense(256, activation
='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
출력은 여기에 주어진다-
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>맞춤 블록
위에서 정의한대로 순차 블록과의 연결을 쉽게 넘어 설 수 있습니다. 그러나 사용자 지정을 원하는 경우Block클래스는 또한 필요한 기능을 제공합니다. 블록 클래스에는 nn 모듈에서 제공되는 모델 생성자가 있습니다. 모델 생성자를 상속하여 원하는 모델을 정의 할 수 있습니다.
다음 예에서 MLP class 재정의 __init__ Block 클래스의 포워드 기능.
어떻게 작동하는지 봅시다.
class MLP(nn.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Dense(256, activation='relu') # Hidden layer
self.output = nn.Dense(10) # Output layer
def forward(self, x):
hidden_out = self.hidden(x)
return self.output(hidden_out)
x = nd.random.uniform(shape=(2, 20))
N_net = MLP()
N_net.initialize()
N_net(x)Output
코드를 실행하면 다음 출력이 표시됩니다.
[[ 0.07787763 0.00216403 0.01682201 0.03059879 -0.00702019 0.01668715
0.04822846 0.0039432 -0.09300035 -0.04494302]
[ 0.08891078 -0.00625484 -0.01619131 0.0380718 -0.01451489 0.02006172
0.0303478 0.02463485 -0.07605448 -0.04389168]]
<NDArray 2x10 @cpu(0)>맞춤 레이어
Apache MXNet의 Gluon API에는 적당한 수의 사전 정의 된 레이어가 함께 제공됩니다. 그러나 여전히 어느 시점에서 새 레이어가 필요하다는 것을 알 수 있습니다. Gluon API에서 새 레이어를 쉽게 추가 할 수 있습니다. 이 섹션에서는 처음부터 새 레이어를 만드는 방법을 알아 봅니다.
가장 단순한 사용자 지정 레이어
Gluon API에서 새 레이어를 생성하려면 가장 기본적인 기능을 제공하는 Block 클래스에서 상속 된 클래스를 생성해야합니다. 직접 또는 다른 하위 클래스를 통해 미리 정의 된 모든 레이어를 상속 할 수 있습니다.
새 레이어를 만들기 위해 구현해야하는 유일한 인스턴스 방법은 다음과 같습니다. forward (self, x). 이 방법은 순방향 전파 중에 레이어가 정확히 무엇을 할 것인지 정의합니다. 앞서 논의한 바와 같이 블록에 대한 역 전파 패스는 Apache MXNet 자체에서 자동으로 수행됩니다.
예
아래 예에서는 새 레이어를 정의합니다. 우리는 또한 구현할 것입니다forward() 입력 데이터를 [0, 1] 범위에 맞춰 정규화하는 방법입니다.
from __future__ import print_function
import mxnet as mx
from mxnet import nd, gluon, autograd
from mxnet.gluon.nn import Dense
mx.random.seed(1)
class NormalizationLayer(gluon.Block):
def __init__(self):
super(NormalizationLayer, self).__init__()
def forward(self, x):
return (x - nd.min(x)) / (nd.max(x) - nd.min(x))
x = nd.random.uniform(shape=(2, 20))
N_net = NormalizationLayer()
N_net.initialize()
N_net(x)Output
위의 프로그램을 실행하면 다음과 같은 결과를 얻을 수 있습니다.
[[0.5216355 0.03835821 0.02284337 0.5945146 0.17334817 0.69329053
0.7782702 1. 0.5508242 0. 0.07058554 0.3677264
0.4366546 0.44362497 0.7192635 0.37616986 0.6728799 0.7032008
0.46907538 0.63514024]
[0.9157533 0.7667402 0.08980197 0.03593295 0.16176797 0.27679572
0.07331014 0.3905285 0.6513384 0.02713427 0.05523694 0.12147208
0.45582628 0.8139887 0.91629887 0.36665893 0.07873632 0.78268915
0.63404864 0.46638715]]
<NDArray 2x20 @cpu(0)>혼성화
이것은 Apache MXNet이 순방향 계산의 기호 그래프를 만드는 데 사용하는 프로세스로 정의 할 수 있습니다. 하이브리드 화를 통해 MXNet은 계산 기호 그래프를 최적화하여 계산 성능을 높일 수 있습니다. 직접 상속하지 않고Block, 실제로 기존 레이어를 구현하는 동안 블록이 HybridBlock.
이에 대한 이유는 다음과 같습니다.
Allows us to write custom layers: HybridBlock을 사용하면 명령형 프로그래밍과 기호 프로그래밍 모두에서 추가로 사용할 수있는 사용자 지정 계층을 작성할 수 있습니다.
Increase computation performance− HybridBlock은 MXNet이 계산 성능을 향상시킬 수 있도록 계산 기호 그래프를 최적화합니다.
예
이 예에서는 HybridBlock을 사용하여 위에서 만든 예제 레이어를 다시 작성합니다.
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self):
super(NormalizationHybridLayer, self).__init__()
def hybrid_forward(self, F, x):
return F.broadcast_div(F.broadcast_sub(x, F.min(x)), (F.broadcast_sub(F.max(x), F.min(x))))
layer_hybd = NormalizationHybridLayer()
layer_hybd(nd.array([1, 2, 3, 4, 5, 6], ctx=mx.cpu()))Output
출력은 다음과 같습니다.
[0. 0.2 0.4 0.6 0.8 1. ]
<NDArray 6 @cpu(0)>하이브리드 화는 GPU의 계산과 관련이 없으며 CPU와 GPU 모두에서 하이브리드 및 비 하이브리드 네트워크를 훈련시킬 수 있습니다.
Block과 HybridBlock의 차이점
우리가 비교한다면 Block 수업 및 HybridBlock, 우리는 HybridBlock 이미 그것의 forward() 방법이 구현되었습니다. HybridBlock 정의 hybrid_forward()레이어를 만드는 동안 구현해야하는 방법입니다. F 인수는forward() 과 hybrid_forward(). MXNet 커뮤니티에서는 F 인수를 백엔드라고합니다. F는mxnet.ndarray API (명령형 프로그래밍에 사용됨) 또는 mxnet.symbol API (기호 프로그래밍에 사용됨).
네트워크에 사용자 정의 레이어를 추가하는 방법은 무엇입니까?
사용자 정의 레이어를 별도로 사용하는 대신 이러한 레이어는 미리 정의 된 레이어와 함께 사용됩니다. 우리는 둘 중 하나를 사용할 수 있습니다Sequential 또는 HybridSequential순차 신경망에서 컨테이너로. 앞에서도 논의했듯이Sequential 컨테이너는 블록에서 상속하고 HybridSequential 상속하다 HybridBlock 각기.
예
아래 예에서는 사용자 지정 레이어로 간단한 신경망을 생성합니다. 출력Dense (5) 레이어가 입력됩니다 NormalizationHybridLayer. 출력NormalizationHybridLayer 입력이 될 것입니다 Dense (1) 층.
net = gluon.nn.HybridSequential()
with net.name_scope():
net.add(Dense(5))
net.add(NormalizationHybridLayer())
net.add(Dense(1))
net.initialize(mx.init.Xavier(magnitude=2.24))
net.hybridize()
input = nd.random_uniform(low=-10, high=10, shape=(10, 2))
net(input)Output
다음 출력이 표시됩니다.
[[-1.1272651]
[-1.2299833]
[-1.0662932]
[-1.1805027]
[-1.3382034]
[-1.2081106]
[-1.1263978]
[-1.2524893]
[-1.1044774]
[-1.316593 ]]
<NDArray 10x1 @cpu(0)>사용자 정의 레이어 매개 변수
신경망에서 계층에는 연관된 매개 변수 세트가 있습니다. 때때로이를 레이어의 내부 상태 인 가중치라고합니다. 이 매개 변수는 다른 역할을합니다.
때때로 이것들은 우리가 역 전파 단계에서 배우고 싶은 것들입니다.
때때로 이것들은 우리가 정방향 패스 중에 사용하고자하는 상수 일뿐입니다.
프로그래밍 개념에 대해 이야기하면 블록의 이러한 매개 변수 (가중치)는 다음을 통해 저장되고 액세스됩니다. ParameterDict 초기화, 업데이트, 저장 및로드에 도움이되는 클래스입니다.
예
아래 예에서는 다음 두 가지 매개 변수 세트를 정의합니다.
Parameter weights− 이것은 훈련이 가능하며 그 모양은 건설 단계에서 알려지지 않았습니다. 순방향 전파의 첫 번째 실행에서 추론됩니다.
Parameter scale− 이것은 값이 변하지 않는 상수입니다. 매개 변수 가중치와 반대로 그 모양은 구성 중에 정의됩니다.
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self, hidden_units, scales):
super(NormalizationHybridLayer, self).__init__()
with self.name_scope():
self.weights = self.params.get('weights',
shape=(hidden_units, 0),
allow_deferred_init=True)
self.scales = self.params.get('scales',
shape=scales.shape,
init=mx.init.Constant(scales.asnumpy()),
differentiable=False)
def hybrid_forward(self, F, x, weights, scales):
normalized_data = F.broadcast_div(F.broadcast_sub(x, F.min(x)),
(F.broadcast_sub(F.max(x), F.min(x))))
weighted_data = F.FullyConnected(normalized_data, weights, num_hidden=self.weights.shape[0], no_bias=True)
scaled_data = F.broadcast_mul(scales, weighted_data)
return scaled_data이 장에서는 파이썬 패키지 KVStore와 시각화를 다룹니다.
KVStore 패키지
KV 스토어는 키-값 스토어를 의미합니다. 다중 장치 교육에 사용되는 중요한 구성 요소입니다. 단일 및 여러 시스템의 장치 간 매개 변수 통신은 매개 변수에 대한 KVStore를 사용하여 하나 이상의 서버를 통해 전송되기 때문에 중요합니다.
다음 사항의 도움으로 KVStore의 작동을 이해합시다.
KVStore의 각 값은 key 그리고 value.
네트워크의 각 매개 변수 배열에는 key 해당 매개 변수 배열의 가중치는 value.
그 후 작업자 노드 push배치 처리 후 그라디언트. 그들 또한pull 새 배치를 처리하기 전에 가중치를 업데이트했습니다.
간단히 말해서 KVStore는 각 장치가 데이터를 밀어 넣고 꺼낼 수있는 데이터 공유 공간이라고 말할 수 있습니다.
데이터 푸시 인 및 풀 아웃
KVStore는 GPU 및 컴퓨터와 같은 여러 장치에서 공유되는 단일 객체로 생각할 수 있으며, 여기서 각 장치는 데이터를 넣고 빼낼 수 있습니다.
다음은 데이터를 밀어 넣고 꺼내기 위해 장치에서 따라야하는 구현 단계입니다.
구현 단계
Initialisation− 첫 번째 단계는 값을 초기화하는 것입니다. 여기 예제에서는 쌍 (int, NDArray) 쌍을 KVStrore로 초기화하고 그 후에 값을 가져옵니다.
import mxnet as mx
kv = mx.kv.create('local') # create a local KVStore.
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())Output
이것은 다음과 같은 출력을 생성합니다-
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]Push, Aggregate, and Update − 일단 초기화되면 키와 동일한 모양으로 KVStore에 새 값을 푸시 할 수 있습니다. −
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a)
print(a.asnumpy())Output
출력은 다음과 같습니다.
[[8. 8. 8.]
[8. 8. 8.]
[8. 8. 8.]]푸시에 사용되는 데이터는 GPU 또는 컴퓨터와 같은 모든 장치에 저장할 수 있습니다. 동일한 키에 여러 값을 넣을 수도 있습니다. 이 경우 KVStore는 먼저 이러한 값을 모두 합한 다음 집계 된 값을 다음과 같이 푸시합니다.
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())Output
다음 출력이 표시됩니다.
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]적용한 각 푸시에 대해 KVStore는 푸시 된 값을 이미 저장된 값과 결합합니다. 업데이트 프로그램의 도움으로 수행됩니다. 여기서 기본 업데이트 프로그램은 ASSIGN입니다.
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv.set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Example
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())Output
다음은 코드의 출력입니다.
update on key: 3
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Pull − Push와 마찬가지로 다음과 같이 단일 호출로 여러 장치에 값을 가져올 수도 있습니다.
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Output
출력은 다음과 같습니다.
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]완전한 구현 예
다음은 완전한 구현 예입니다.
import mxnet as mx
kv = mx.kv.create('local')
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a) # pull out the value
print(a.asnumpy())
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv._set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())키-값 쌍 처리
위에서 구현 한 모든 작업에는 단일 키가 포함되지만 KVStore는 a list of key-value pairs −
단일 장치의 경우
다음은 단일 장치의 키-값 쌍 목록에 대한 KVStore 인터페이스를 보여주는 예입니다.
keys = [5, 7, 9]
kv.init(keys, [mx.nd.ones(shape)]*len(keys))
kv.push(keys, [mx.nd.ones(shape)]*len(keys))
b = [mx.nd.zeros(shape)]*len(keys)
kv.pull(keys, out = b)
print(b[1].asnumpy())Output
다음과 같은 출력을 받게됩니다.
update on key: 5
update on key: 7
update on key: 9
[[3. 3. 3.]
[3. 3. 3.]
[3. 3. 3.]]여러 장치의 경우
다음은 여러 장치의 키-값 쌍 목록에 대한 KVStore 인터페이스를 보여주는 예입니다.
b = [[mx.nd.ones(shape, ctx) for ctx in contexts]] * len(keys)
kv.push(keys, b)
kv.pull(keys, out = b)
print(b[1][1].asnumpy())Output
다음 출력이 표시됩니다.
update on key: 5
update on key: 7
update on key: 9
[[11. 11. 11.]
[11. 11. 11.]
[11. 11. 11.]]시각화 패키지
시각화 패키지는 노드와 에지로 구성된 계산 그래프로 신경망 (NN)을 나타내는 데 사용되는 Apache MXNet 패키지입니다.
신경망 시각화
아래 예에서 우리는 mx.viz.plot_network신경망을 시각화합니다. 다음은 이에 대한 전제 조건입니다-
Prerequisites
Jupyter 노트북
Graphviz 라이브러리
구현 예
아래 예에서는 선형 행렬 분해를위한 샘플 NN을 시각화합니다.
import mxnet as mx
user = mx.symbol.Variable('user')
item = mx.symbol.Variable('item')
score = mx.symbol.Variable('score')
# Set the dummy dimensions
k = 64
max_user = 100
max_item = 50
# The user feature lookup
user = mx.symbol.Embedding(data = user, input_dim = max_user, output_dim = k)
# The item feature lookup
item = mx.symbol.Embedding(data = item, input_dim = max_item, output_dim = k)
# predict by the inner product and then do sum
N_net = user * item
N_net = mx.symbol.sum_axis(data = N_net, axis = 1)
N_net = mx.symbol.Flatten(data = N_net)
# Defining the loss layer
N_net = mx.symbol.LinearRegressionOutput(data = N_net, label = score)
# Visualize the network
mx.viz.plot_network(N_net)이 장에서는 Apache MXNet에서 사용할 수있는 ndarray 라이브러리에 대해 설명합니다.
Mxnet.ndarray
Apache MXNet의 NDArray 라이브러리는 모든 수학적 계산을위한 핵심 DS (데이터 구조)를 정의합니다. NDArray의 두 가지 기본 작업은 다음과 같습니다.
광범위한 하드웨어 구성에서 빠른 실행을 지원합니다.
사용 가능한 하드웨어에서 여러 작업을 자동으로 병렬화합니다.
아래의 예제는 일반 Python 목록에서 1-D 및 2-D '배열'을 사용하여 NDArray를 생성하는 방법을 보여줍니다.
import mxnet as mx
from mxnet import nd
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
출력은 다음과 같습니다.
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
이것은 다음과 같은 출력을 생성합니다-
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>이제 MXNet의 ndarray API의 클래스, 함수 및 매개 변수에 대해 자세히 논의하겠습니다.
클래스
다음 표는 MXNet의 ndarray API 클래스로 구성되어 있습니다.
| 수업 | 정의 |
|---|---|
| CachedOp (sym [, 플래그]) | 캐시 된 연산자 핸들에 사용됩니다. |
| NDArray (핸들 [, 쓰기 가능]) | 고정 크기 항목의 다차원, 동종 배열을 나타내는 배열 객체로 사용됩니다. |
기능 및 매개 변수
다음은 mxnet.ndarray API에서 다루는 몇 가지 중요한 기능과 매개 변수입니다.
| 기능 및 매개 변수 | 정의 |
|---|---|
| Activation([데이터, 행위 _ 유형, 출력, 이름]) | 활성화 함수를 요소별로 입력에 적용합니다. relu, sigmoid, tanh, softrelu, softsign 활성화 기능을 지원합니다. |
| BatchNorm([데이터, 감마, 베타, moving_mean,…]) | 일괄 정규화에 사용됩니다. 이 함수는 평균 및 분산으로 데이터 배치를 정규화합니다. 스케일 감마 및 오프셋 베타를 적용합니다. |
| BilinearSampler([데이터, 그리드, cudnn_off,…]) | 이 함수는 입력 특성 맵에 이중 선형 샘플링을 적용합니다. 사실 그것은 "공간 변압기 네트워크"의 핵심입니다. OpenCV의 remap 기능에 익숙하다면이 기능의 사용법은 그것과 매우 유사합니다. 유일한 차이점은 역방향 패스가 있다는 것입니다. |
| BlockGrad ([데이터, 출력, 이름]) | 이름에서 알 수 있듯이이 함수는 기울기 계산을 중지합니다. 기본적으로 입력의 누적 기울기가이 연산자를 통해 역방향으로 흐르는 것을 막습니다. |
| cast ([데이터, dtype, 출력, 이름]) | 이 함수는 입력의 모든 요소를 새 유형으로 캐스팅합니다. |
구현 예
아래 예에서는 데이터를 두 번 축소하고 데이터를 -1 픽셀만큼 수평으로 이동하기 위해 BilinierSampler () 함수를 사용합니다.
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
affine_matrix = nd.array([[2, 0, 0],
[0, 2, 0]])
affine_matrix = nd.reshape(affine_matrix, shape=(1, 6))
grid = nd.GridGenerator(data=affine_matrix, transform_type='affine', target_shape=(4, 4))
output = nd.BilinearSampler(data, grid)Output
위 코드를 실행하면 다음 출력이 표시됩니다.
[[[[0. 0. 0. 0. ]
[0. 4.0000005 6.25 0. ]
[0. 1.5 4. 0. ]
[0. 0. 0. 0. ]]]]
<NDArray 1x1x4x4 @cpu(0)>위의 출력은 데이터 축소를 두 번 보여줍니다.
-1 픽셀만큼 데이터를 이동하는 예는 다음과 같습니다.
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
warp_matrix = nd.array([[[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]]])
grid = nd.GridGenerator(data=warp_matrix, transform_type='warp')
output = nd.BilinearSampler(data, grid)Output
출력은 다음과 같습니다.
[[[[5. 3. 6. 0.]
[8. 7. 9. 0.]
[4. 1. 8. 0.]
[0. 3. 4. 0.]]]]
<NDArray 1x1x4x4 @cpu(0)>유사하게, 다음 예제는 cast () 함수의 사용을 보여줍니다-
nd.cast(nd.array([300, 10.1, 15.4, -1, -2]), dtype='uint8')Output
실행하면 다음과 같은 출력이 표시됩니다.
[ 44 10 15 255 254]
<NDArray 5 @cpu(0)>ndarray.contrib
Contrib NDArray API는 ndarray.contrib 패키지에 정의되어 있습니다. 일반적으로 새로운 기능에 대한 많은 유용한 실험 API를 제공합니다. 이 API는 새로운 기능을 사용해 볼 수있는 커뮤니티의 장소로 작동합니다. 기능 기고자에게도 피드백이 제공됩니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.ndarray.contrib API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| rand_zipfian(true_classes, num_sampled,…) | 이 함수는 대략 Zipfian 분포에서 랜덤 샘플을 가져옵니다. 이 함수의 기본 분포는 Zipfian 분포입니다. 이 함수는 num_sampled 후보를 무작위로 샘플링하고 sampled_candidates의 요소는 위에 주어진 기본 분포에서 추출됩니다. |
| foreach(본문, 데이터, init_states) | 이름에서 알 수 있듯이이 함수는 차원 0의 NDArray에 대해 사용자 정의 계산으로 for 루프를 실행합니다.이 함수는 for 루프를 시뮬레이션하고 본문에는 for 루프의 반복에 대한 계산이 있습니다. |
| while_loop (cond, func, loop_vars [,…]) | 이름에서 알 수 있듯이이 함수는 사용자 정의 계산 및 루프 조건으로 while 루프를 실행합니다. 이 함수는 조건이 충족되면 문자 그대로 사용자 정의 된 계산을 수행하는 while 루프를 시뮬레이션합니다. |
| cond(pred, then_func, else_func) | 이름에서 알 수 있듯이이 함수는 사용자 정의 조건 및 계산을 사용하여 if-then-else를 실행합니다. 이 함수는 지정된 조건에 따라 두 개의 사용자 정의 계산 중 하나를 수행하도록 선택하는 if-like 분기를 시뮬레이션합니다. |
| isinf(데이터) | 이 함수는 NDArray에 무한 요소가 포함되어 있는지 여부를 결정하기 위해 요소 별 검사를 수행합니다. |
| getnnz([데이터, 축, 출력, 이름]) | 이 함수는 희소 텐서에 대해 저장된 값의 수를 제공합니다. 또한 명시적인 0도 포함됩니다. CPU에서 CSR 매트릭스 만 지원합니다. |
| requantize ([데이터, 최소 _ 범위, 최대 _ 범위,…]) | 이 함수는 런타임 또는 보정에서 계산 된 최소 및 최대 임계 값을 사용하여 int32 및 해당 임계 값으로 양자화 된 주어진 데이터를 int8로 재 양량 화합니다. |
구현 예
아래 예에서는 대략 Zipfian 분포에서 무작위 샘플을 추출하기 위해 rand_zipfian 함수를 사용합니다.
import mxnet as mx
from mxnet import nd
trueclass = mx.nd.array([2])
samples, exp_count_true, exp_count_sample = mx.nd.contrib.rand_zipfian(trueclass, 3, 4)
samplesOutput
다음 출력이 표시됩니다.
[0 0 1]
<NDArray 3 @cpu(0)>Example
exp_count_trueOutput
출력은 다음과 같습니다.
[0.53624076]
<NDArray 1 @cpu(0)>Example
exp_count_sampleOutput
그러면 다음과 같은 출력이 생성됩니다.
[1.29202967 1.29202967 0.75578891]
<NDArray 3 @cpu(0)>아래 예에서는 함수를 사용합니다. while_loop 사용자 정의 계산 및 루프 조건에 대해 while 루프를 실행하는 경우 :
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_var = (mx.nd.array([0], dtype="int64"), mx.nd.array([1], dtype="int64"))
outputs, states = mx.nd.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
outputsOutput
출력은 다음과 같습니다.
[
[[ 1]
[ 2]
[ 4]
[ 7]
[ 11]
[ 16]
[ 22]
[ 29]
[3152434450384]
[ 257]]
<NDArray 10x1 @cpu(0)>]Example
StatesOutput
이것은 다음과 같은 출력을 생성합니다-
[
[8]
<NDArray 1 @cpu(0)>,
[29]
<NDArray 1 @cpu(0)>]ndarray.image
Image NDArray API는 ndarray.image 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 일반적으로 이미지와 기능에 사용됩니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능 및 해당 매개 변수입니다. mxnet.ndarray.image API−
| 기능 및 매개 변수 | 정의 |
|---|---|
| adjust_lighting([데이터, 알파, 출력, 이름]) | 이름에서 알 수 있듯이이 기능은 입력의 조명 수준을 조정합니다. AlexNet 스타일을 따릅니다. |
| crop([데이터, x, y, 너비, 높이, 출력, 이름]) | 이 기능의 도움으로 우리는 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로자를 수 있습니다. |
| normalize([데이터, 평균, 표준, 출력, 이름]) | 모양의 텐서 (C x H x W) 또는 (N x C x H x W)를 다음과 같이 정규화합니다. mean 과 standard deviation(SD). |
| random_crop ([데이터, xrange, yrange, 너비,…]) | crop ()과 유사하게 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로 무작위로 자릅니다. src가 크기보다 작 으면 결과를 업 샘플링합니다. |
| random_lighting([데이터, alpha_std, 출력, 이름]) | 이름에서 알 수 있듯이이 기능은 PCA 노이즈를 무작위로 추가합니다. 또한 AlexNet 스타일을 따릅니다. |
| random_resized_crop([데이터, xrange, yrange,…]) | 또한 이미지를 임의의 NDArray of shape (H x W x C) 또는 (N x H x W x C)로 지정된 크기로 자릅니다. src가 크기보다 작 으면 결과를 업 샘플링합니다. 면적과 종횡비도 무작위로 지정합니다. |
| resize([데이터, 크기, 유지 _ 비율, interp,…]) | 이름에서 알 수 있듯이이 기능은 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로 조정합니다. |
| to_tensor([데이터, 출력, 이름]) | [0, 255] 범위의 값을 가진 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 텐서 NDArray of shape (C x H x W) 또는 ( N x C x H x W) 범위의 값으로 [0, 1]. |
구현 예
아래 예에서는 to_tensor 함수를 사용하여 [0, 255] 범위의 값을 갖는 모양 (H x W x C) 또는 (N x H x W x C)의 이미지 NDArray를 텐서 NDArray로 변환합니다. [0, 1] 범위의 값을 가진 모양 (C x H x W) 또는 (N x C x H x W).
import numpy as np
img = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
다음 출력이 표시됩니다.
[[[0.972549 0.5058824 ]
[0.6039216 0.01960784]
[0.28235295 0.35686275]
[0.11764706 0.8784314 ]]
[[0.8745098 0.9764706 ]
[0.4509804 0.03529412]
[0.9764706 0.29411766]
[0.6862745 0.4117647 ]]
[[0.46666667 0.05490196]
[0.7372549 0.4392157 ]
[0.11764706 0.47843137]
[0.31764707 0.91764706]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
코드를 실행하면 다음 출력이 표시됩니다.
[[[[0.0627451 0.5647059 ]
[0.2627451 0.9137255 ]
[0.57254905 0.27450982]
[0.6666667 0.64705884]]
[[0.21568628 0.5647059 ]
[0.5058824 0.09019608]
[0.08235294 0.31764707]
[0.8392157 0.7137255 ]]
[[0.6901961 0.8627451 ]
[0.52156866 0.91764706]
[0.9254902 0.00784314]
[0.12941177 0.8392157 ]]]
[[[0.28627452 0.39607844]
[0.01960784 0.36862746]
[0.6745098 0.7019608 ]
[0.9607843 0.7529412 ]]
[[0.2627451 0.58431375]
[0.16470589 0.00392157]
[0.5686275 0.73333335]
[0.43137255 0.57254905]]
[[0.18039216 0.54901963]
[0.827451 0.14509805]
[0.26666668 0.28627452]
[0.24705882 0.39607844]]]]
<NDArgt;ray 2x3x4x2 @cpu(0)>아래 예에서는 함수를 사용합니다. normalize 모양의 텐서 (C x H x W) 또는 (N x C x H x W)를 다음과 같이 정규화합니다. mean 과 standard deviation(SD).
img = mx.nd.random.uniform(0, 1, (3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
이것은 다음과 같은 출력을 생성합니다-
[[[ 0.29391178 0.3218054 ]
[ 0.23084386 0.19615503]
[ 0.24175143 0.21988946]
[ 0.16710812 0.1777354 ]]
[[-0.02195817 -0.3847335 ]
[-0.17800489 -0.30256534]
[-0.28807247 -0.19059572]
[-0.19680339 -0.26256624]]
[[-1.9808068 -1.5298678 ]
[-1.6984252 -1.2839255 ]
[-1.3398265 -1.712009 ]
[-1.7099224 -1.6165378 ]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 1, (2, 3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[[[ 2.0600514e-01 2.4972327e-01]
[ 1.4292289e-01 2.9281738e-01]
[ 4.5158025e-02 3.4287784e-02]
[ 9.9427439e-02 3.0791296e-02]]
[[-2.1501756e-01 -3.2297665e-01]
[-2.0456362e-01 -2.2409186e-01]
[-2.1283737e-01 -4.8318747e-01]
[-1.7339960e-01 -1.5519112e-02]]
[[-1.3478968e+00 -1.6790028e+00]
[-1.5685816e+00 -1.7787373e+00]
[-1.1034534e+00 -1.8587360e+00]
[-1.6324382e+00 -1.9027401e+00]]]
[[[ 1.4528830e-01 3.2801408e-01]
[ 2.9730779e-01 8.6780310e-02]
[ 2.6873133e-01 1.7900752e-01]
[ 2.3462953e-01 1.4930873e-01]]
[[-4.4988656e-01 -4.5021546e-01]
[-4.0258706e-02 -3.2384416e-01]
[-1.4287934e-01 -2.6537544e-01]
[-5.7649612e-04 -7.9429924e-02]]
[[-1.8505517e+00 -1.0953522e+00]
[-1.1318740e+00 -1.9624406e+00]
[-1.8375070e+00 -1.4916846e+00]
[-1.3844404e+00 -1.8331525e+00]]]]
<NDArray 2x3x4x2 @cpu(0)>ndarray.random
Random NDArray API는 ndarray.random 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 MXNet의 랜덤 분포 생성기 NDArray API입니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.ndarray.random API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| uniform ([낮음, 높음, 모양, dtype, ctx, out]) | 균일 분포에서 무작위 샘플을 생성합니다. |
| normal ([loc, scale, shape, dtype, ctx, out]) | 정규 (가우스) 분포에서 무작위 샘플을 생성합니다. |
| randn (* 모양, ** kwargs) | 정규 (가우스) 분포에서 무작위 샘플을 생성합니다. |
| 지수 ([스케일, 모양, dtype, ctx, out]) | 지수 분포에서 샘플을 생성합니다. |
| 감마 ([알파, 베타, 모양, dtype, ctx, out]) | 감마 분포에서 무작위 샘플을 생성합니다. |
| 다항식 (데이터 [, 모양, get_prob, out, dtype]) | 여러 다항 분포에서 동시 샘플링을 생성합니다. |
| 음 이항 ([k, p, 모양, dtype, ctx, out]) | 음 이항 분포에서 무작위 샘플을 생성합니다. |
| generalized_negative_binomial ([mu, alpha,…]) | 일반화 된 음 이항 분포에서 무작위 샘플을 생성합니다. |
| shuffle (데이터, ** kwargs) | 요소를 무작위로 섞습니다. |
| randint (낮음, 높음 [, 모양, dtype, ctx, out]) | 이산 균일 분포에서 무작위 샘플을 생성합니다. |
| exponential_like ([데이터, 램, 아웃, 이름]) | 입력 배열 모양에 따라 지수 분포에서 무작위 샘플을 생성합니다. |
| gamma_like ([데이터, 알파, 베타, 출력, 이름]) | 입력 배열 모양에 따라 감마 분포에서 무작위 샘플을 생성합니다. |
| generalized_negative_binomial_like ([데이터,…]) | 입력 배열 모양에 따라 일반화 된 음 이항 분포에서 무작위 샘플을 생성합니다. |
| negative_binomial_like ([데이터, k, p, 출력, 이름]) | 입력 배열 모양에 따라 음의 이항 분포에서 무작위 샘플을 생성합니다. |
| normal_like ([데이터, 위치, 스케일, 아웃, 이름]) | 입력 배열 모양에 따라 정규 (가우시안) 분포에서 무작위 샘플을 생성합니다. |
| poisson_like ([데이터, 램, 아웃, 이름]) | 입력 배열 모양에 따라 포아송 분포에서 무작위 샘플을 생성합니다. |
| uniform_like ([데이터, 낮음, 높음, 출력, 이름]) | 입력 배열 모양에 따라 균등 분포에서 무작위 샘플을 생성합니다. |
구현 예
아래 예에서는 균일 분포에서 임의의 샘플을 추출합니다. 이를 위해 기능을 사용합니다.uniform().
mx.nd.random.uniform(0, 1)Output
출력은 아래에 언급되어 있습니다.
[0.12381998]
<NDArray 1 @cpu(0)>Example
mx.nd.random.uniform(-1, 1, shape=(2,))Output
출력은 다음과 같습니다.
[0.558102 0.69601643]
<NDArray 2 @cpu(0)>Example
low = mx.nd.array([1,2,3])
high = mx.nd.array([2,3,4])
mx.nd.random.uniform(low, high, shape=2)Output
다음 출력이 표시됩니다.
[[1.8649333 1.8073189]
[2.4113967 2.5691009]
[3.1399727 3.4071832]]
<NDArray 3x2 @cpu(0)>아래 예에서는 일반화 된 음 이항 분포에서 무작위 샘플을 추출합니다. 이를 위해 우리는 함수를 사용할 것입니다generalized_negative_binomial().
mx.nd.random.generalized_negative_binomial(10, 0.5)Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[1.]
<NDArray 1 @cpu(0)>Example
mx.nd.random.generalized_negative_binomial(10, 0.5, shape=(2,))Output
출력은 여기에 주어진다-
[16. 23.]
<NDArray 2 @cpu(0)>Example
mu = mx.nd.array([1,2,3])
alpha = mx.nd.array([0.2,0.4,0.6])
mx.nd.random.generalized_negative_binomial(mu, alpha, shape=2)Output
다음은 코드의 출력입니다.
[[0. 0.]
[4. 1.]
[9. 3.]]
<NDArray 3x2 @cpu(0)>ndarray.utils
유틸리티 NDArray API는 ndarray.utils 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 NDArray 및 BaseSparseNDArray에 대한 유틸리티 기능을 제공합니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.ndarray.utils API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| 0 (모양 [, ctx, dtype, stype]) | 이 함수는 0으로 채워진 주어진 모양과 유형의 새 배열을 반환합니다. |
| 비어 있음 (모양 [, ctx, dtype, stype]) | 항목을 초기화하지 않고 주어진 모양과 유형의 새 배열을 반환합니다. |
| 배열 (소스 _ 배열 [, ctx, dtype]) | 이름에서 알 수 있듯이이 함수는 배열 인터페이스를 노출하는 모든 개체에서 배열을 만듭니다. |
| 로드 (fname) | 파일에서 배열을로드합니다. |
| load_frombuffer (buf) | 이름에서 알 수 있듯이이 함수는 버퍼에서 배열 사전 또는 목록을로드합니다. |
| 저장 (fname, data) | 이 함수는 배열 목록 또는 str-> array의 사전을 파일에 저장합니다. |
구현 예
아래 예제에서는 0으로 채워진 주어진 모양과 유형의 새 배열을 반환합니다. 이를 위해 우리는 함수를 사용할 것입니다zeros().
mx.nd.zeros((1,2), mx.cpu(), stype='csr')Output
이것은 다음과 같은 출력을 생성합니다-
<CSRNDArray 1x2 @cpu(0)>Example
mx.nd.zeros((1,2), mx.cpu(), 'float16', stype='row_sparse').asnumpy()Output
다음과 같은 출력을 받게됩니다.
array([[0., 0.]], dtype=float16)아래 예에서는 배열 목록과 문자열 사전을 저장합니다. 이를 위해 우리는 함수를 사용할 것입니다save().
Example
x = mx.nd.zeros((2,3))
y = mx.nd.ones((1,4))
mx.nd.save('list', [x,y])
mx.nd.save('dict', {'x':x, 'y':y})
mx.nd.load('list')Output
실행하면 다음과 같은 출력이 표시됩니다.
[
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>,
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>]Example
mx.nd.load('my_dict')Output
출력은 다음과 같습니다.
{'x':
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>, 'y':
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>}이전 장에서 이미 논의했듯이 MXNet Gluon은 DL 프로젝트를위한 명확하고 간결하며 간단한 API를 제공합니다. 이를 통해 Apache MXNet은 교육 속도를 잃지 않고 DL 모델을 프로토 타입, 구축 및 교육 할 수 있습니다.
핵심 모듈
Apache MXNet Python API (응용 프로그래밍 인터페이스) gluon의 핵심 모듈에 대해 알아 보겠습니다.
gluon.nn
Gluon은 gluon.nn 모듈에서 많은 수의 내장 NN 레이어를 제공합니다. 이것이 핵심 모듈이라고 불리는 이유입니다.
방법 및 매개 변수
다음은 몇 가지 중요한 방법과 해당 매개 변수입니다. mxnet.gluon.nn 핵심 모듈-
| 방법 및 매개 변수 | 정의 |
|---|---|
| 활성화 (활성화, ** kwargs) | 이름에서 알 수 있듯이이 방법은 입력에 활성화 함수를 적용합니다. |
| AvgPool1D ([풀 _ 크기, 스트라이드, 패딩,…]) | 이것은 시간 데이터에 대한 평균 풀링 작업입니다. |
| AvgPool2D ([pool_size, strides, padding,…]) | 이것은 공간 데이터에 대한 평균 풀링 작업입니다. |
| AvgPool3D ([풀 _ 크기, 스트라이드, 패딩,…]) | 3D 데이터에 대한 평균 풀링 작업입니다. 데이터는 공간적이거나 시공간적 일 수 있습니다. |
| BatchNorm ([축, 운동량, 엡실론, 중심,…]) | 배치 정규화 계층을 나타냅니다. |
| BatchNormReLU ([축, 운동량, 엡실론,…]) | 또한 배치 정규화 계층을 나타내지 만 Relu 활성화 기능이 있습니다. |
| 블록 ([접두사, 매개 변수]) | 모든 신경망 계층 및 모델에 대한 기본 클래스를 제공합니다. |
| Conv1D (채널, 커널 _ 크기 [, 스트라이드,…]) | 이 방법은 1 차원 컨볼 루션 계층에 사용됩니다. 예를 들어 시간 컨볼 루션입니다. |
| Conv1DTranspose (채널, 커널 _ 크기 [,…]) | 이 방법은 Transposed 1D convolution layer에 사용됩니다. |
| Conv2D (채널, 커널 _ 크기 [, 스트라이드,…]) | 이 방법은 2D convolution 레이어에 사용됩니다. 예를 들어, 이미지에 대한 공간적 회선). |
| Conv2DTranspose (채널, 커널 _ 크기 [,…]) | 이 방법은 Transposed 2D convolution layer에 사용됩니다. |
| Conv3D (채널, 커널 _ 크기 [, 스트라이드,…]) | 이 방법은 3D 컨볼 루션 레이어에 사용됩니다. 예를 들어, 볼륨에 대한 공간 컨볼 루션입니다. |
| Conv3DTranspose (채널, 커널 _ 크기 [,…]) | 이 방법은 Transposed 3D convolution layer에 사용됩니다. |
| 밀도 (units [, activation, use_bias,…]) | 이 방법은 조밀하게 연결된 일반 NN 레이어를 나타냅니다. |
| 드롭 아웃 (속도 [, 축]) | 이름에서 알 수 있듯이이 메서드는 Dropout을 입력에 적용합니다. |
| ELU (α) | 이 방법은 지수 선형 단위 (ELU)에 사용됩니다. |
| 임베딩 (input_dim, output_dim [, dtype,…]) | 음이 아닌 정수를 고정 된 크기의 조밀 한 벡터로 변환합니다. |
| 평평하게 (** kwargs) | 이 방법은 입력을 2 차원으로 평면화합니다. |
| GELU (** kwargs) | 이 방법은 GELU (Gaussian Exponential Linear Unit)에 사용됩니다. |
| GlobalAvgPool1D ([레이아웃]) | 이 방법의 도움으로 시간 데이터에 대한 글로벌 평균 풀링 작업을 수행 할 수 있습니다. |
| GlobalAvgPool2D ([레이아웃]) | 이 방법의 도움으로 공간 데이터에 대한 글로벌 평균 풀링 작업을 수행 할 수 있습니다. |
| GlobalAvgPool3D ([레이아웃]) | 이 방법의 도움으로 3D 데이터에 대한 글로벌 평균 풀링 작업을 수행 할 수 있습니다. |
| GlobalMaxPool1D ([레이아웃]) | 이 방법의 도움으로 1D 데이터에 대한 전역 최대 풀링 작업을 수행 할 수 있습니다. |
| GlobalMaxPool2D ([레이아웃]) | 이 방법의 도움으로 2D 데이터에 대한 전역 최대 풀링 작업을 수행 할 수 있습니다. |
| GlobalMaxPool3D ([레이아웃]) | 이 방법의 도움으로 3D 데이터에 대한 전역 최대 풀링 작업을 수행 할 수 있습니다. |
| GroupNorm ([그룹 수, 엡실론, 중심,…]) | 이 방법은 nD 입력 배열에 그룹 정규화를 적용합니다. |
| HybridBlock ([접두사, 매개 변수]) | 이 방법은 Symbol 과 NDArray. |
| HybridLambda(함수 [, 접두사]) | 이 메서드의 도움으로 연산자 또는 표현식을 HybridBlock 개체로 래핑 할 수 있습니다. |
| HybridSequential ([접두사, 매개 변수]) | HybridBlock을 순차적으로 스택합니다. |
| InstanceNorm ([축, 입실론, 중심, 배율,…]) | 이 방법은 인스턴스 정규화를 nD 입력 배열에 적용합니다. |
구현 예
아래 예제에서는 모든 신경망 계층과 모델에 대한 기본 클래스를 제공하는 Block ()을 사용할 것입니다.
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
다음 출력이 표시됩니다.
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)*gt;아래 예에서는 Symbol과 NDArray 모두 포워딩을 지원하는 HybridBlock ()을 사용할 것입니다.
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
출력은 아래에 언급되어 있습니다.
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)>gluon.rnn
Gluon은 많은 내장 기능을 제공합니다. recurrent neural networkgluon.rnn 모듈의 (RNN) 레이어. 그것이 바로 핵심 모듈이라고 불리는 이유입니다.
방법 및 매개 변수
다음은 몇 가지 중요한 방법과 해당 매개 변수입니다. mxnet.gluon.nn 핵심 모듈 :
| 방법 및 매개 변수 | 정의 |
|---|---|
| 양방향 셀 (l_cell, r_cell [,…]) | 양방향 RNN (Recurrent Neural Network) 셀에 사용됩니다. |
| DropoutCell (rate [, 축, 접두사, 매개 변수]) | 이 방법은 주어진 입력에 드롭 아웃을 적용합니다. |
| GRU (hidden_size [, num_layers, 레이아웃,…]) | 주어진 입력 시퀀스에 다 계층 게이트 순환 단위 (GRU) RNN을 적용합니다. |
| GRUCell (hidden_size [,…]) | GRU (Gated Rectified Unit) 네트워크 셀에 사용됩니다. |
| HybridRecurrentCell ([접두사, 매개 변수]) | 이 방법은 하이브리드 화를 지원합니다. |
| HybridSequentialRNNCell ([접두사, 매개 변수]) | 이 방법의 도움으로 여러 HybridRNN 셀을 순차적으로 쌓을 수 있습니다. |
| LSTM (hidden_size [, num_layers, 레이아웃,…]) 0 | 주어진 입력 시퀀스에 다층 장단기 기억 (LSTM) RNN을 적용합니다. |
| LSTMCell (hidden_size [,…]) | LSTM (Long-Short Term Memory) 네트워크 셀에 사용됩니다. |
| ModifierCell (base_cell) | 수정 자 셀의 기본 클래스입니다. |
| RNN (hidden_size [, num_layers, activation,…]) | 다층 Elman RNN을 다음과 같이 적용합니다. tanh 또는 ReLU 주어진 입력 시퀀스에 대한 비선형 성. |
| RNNCell (hidden_size [, 활성화,…]) | Elman RNN 순환 신경망 셀에 사용됩니다. |
| RecurrentCell ([접두사, 매개 변수]) | RNN 셀의 추상 기본 클래스를 나타냅니다. |
| SequentialRNNCell ([접두사, 매개 변수]) | 이 방법의 도움으로 여러 RNN 셀을 순차적으로 쌓을 수 있습니다. |
| ZoneoutCell (base_cell [, zoneout_outputs,…]) | 이 방법은 기본 셀에 Zoneout을 적용합니다. |
구현 예
아래 예에서는 주어진 입력 시퀀스에 다층 게이트 순환 단위 (GRU) RNN을 적용하는 GRU ()를 사용할 것입니다.
layer = mx.gluon.rnn.GRU(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq, h0)
out_seqOutput
이것은 다음과 같은 출력을 생성합니다-
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01
1.30406499e-01 3.30152437e-02]
[ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02
1.76546033e-02 1.66693389e-01]
[ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01
3.43954474e-01 1.52770668e-01]]
[[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01
6.61415309e-02 2.70989928e-02]
[ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02
6.79589901e-03 1.25501186e-01]
[ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01
1.61080107e-01 1.15969211e-01]]
………………………….Example
hnOutput
이것은 다음과 같은 출력을 생성합니다-
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02
3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03
9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02
9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02
2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01
6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03
-4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03
1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02
7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01
4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02
-7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03
-4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03
4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02
4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02
6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01
5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02
………………………….아래 예제에서 우리는 주어진 입력 시퀀스에 장기 단기 기억 (LSTM) RNN을 적용하는 LSTM ()을 사용할 것입니다.
layer = mx.gluon.rnn.LSTM(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
c0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq,[h0,c0])
out_seqOutput
출력은 아래에 언급되어 있습니다.
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02
1.25569820e-01 2.15555862e-01]
[ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01
2.30574399e-01 2.81707942e-02]
[ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02
1.28254429e-01 7.55299702e-02]]
[[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03
5.23949116e-02 1.00922674e-01]
[ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01
9.71239135e-02 2.25218050e-02]
[ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02
5.96345589e-02 4.72368896e-02]]
……………Example
hnOutput
코드를 실행하면 다음 출력이 표시됩니다.
[
[[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02
1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02
6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02
-7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02
8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02
6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02
-7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02
4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02
-5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02
1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02
……………………교육 모듈
Gluon의 교육 모듈은 다음과 같습니다.
gluon.loss
에 mxnet.gluon.loss모듈, Gluon은 미리 정의 된 손실 기능을 제공합니다. 기본적으로 신경망 훈련에 손실이 있습니다. 그것이 교육 모듈이라고 불리는 이유입니다.
방법 및 매개 변수
다음은 몇 가지 중요한 방법과 해당 매개 변수입니다. mxnet.gluon.loss 교육 모듈 :
| 방법 및 매개 변수 | 정의 |
|---|---|
| 손실 (weight, batch_axis, ** kwargs) | 이것은 손실에 대한 기본 클래스 역할을합니다. |
| L2Loss ([weight, batch_axis]) | 다음 사이의 평균 제곱 오차 (MSE)를 계산합니다. label 과 prediction(pred). |
| L1Loss ([weight, batch_axis]) | 평균 절대 오차 (MAE)를 계산합니다. label 과 pred. |
| SigmoidBinaryCrossEntropyLoss ([…]) | 이 방법은 이진 분류를위한 교차 엔트로피 손실에 사용됩니다. |
| SigmoidBCELoss | 이 방법은 이진 분류를위한 교차 엔트로피 손실에 사용됩니다. |
| SoftmaxCrossEntropyLoss ([축,…]) | 소프트 맥스 교차 엔트로피 손실 (CEL)을 계산합니다. |
| SoftmaxCELoss | 또한 소프트 맥스 교차 엔트로피 손실을 계산합니다. |
| KLDivLoss ([from_logits, 축, 무게,…]) | Kullback-Leibler 분기 손실에 사용됩니다. |
| CTCLoss ([레이아웃, 레이블 _ 레이아웃, 가중치]) | 연결 주의자 시간 분류 손실 (TCL)에 사용됩니다. |
| HuberLoss ([rho, weight, batch_axis]) | 평활화 된 L1 손실을 계산합니다. 평활화 된 L1 손실은 절대 오차가 rho를 초과하면 L1 손실과 같고 그렇지 않으면 L2 손실과 같습니다. |
| HingeLoss ([margin, weight, batch_axis]) | 이 방법은 SVM에서 자주 사용되는 힌지 손실 함수를 계산합니다. |
| SquaredHingeLoss ([margin, weight, batch_axis]) | 이 방법은 SVM에서 사용되는 소프트 마진 손실 함수를 계산합니다. |
| LogisticLoss ([weight, batch_axis, label_format]) | 이 방법은 로지스틱 손실을 계산합니다. |
| TripletLoss ([margin, weight, batch_axis]) | 이 방법은 3 개의 입력 텐서와 양의 마진이 주어지면 3 중 손실을 계산합니다. |
| PoissonNLLLoss ([weight, from_logits,…]) | 이 함수는 음의 로그 우도 손실을 계산합니다. |
| CosineEmbeddingLoss ([weight, batch_axis, margin]) | 이 함수는 벡터 간의 코사인 거리를 계산합니다. |
| SDMLLoss ([smoothing_parameter, weight,…]) | 이 방법은 두 개의 입력 텐서와 평활 가중치 SDM 손실이 주어지면 배치 별 평활 심층 측정 학습 (SDML) 손실을 계산합니다. 미니 배치에서 짝을 이루지 않은 샘플을 잠재적 인 부정적인 예로 사용하여 짝을 이룬 샘플 간의 유사성을 학습합니다. |
예
우리가 알고 있듯이 mxnet.gluon.loss.loss레이블과 예측 (pred) 사이의 MSE (Mean Squared Error)를 계산합니다. 다음 공식의 도움으로 수행됩니다.

gluon.parameter
mxnet.gluon.parameter 매개 변수, 즉 블록의 가중치를 보유하는 컨테이너입니다.
방법 및 매개 변수
다음은 몇 가지 중요한 방법과 해당 매개 변수입니다. mxnet.gluon.parameter 교육 모듈 −
| 방법 및 매개 변수 | 정의 |
|---|---|
| 캐스트 (dtype) | 이 메소드는이 매개 변수의 데이터 및 그라디언트를 새 데이터 유형으로 캐스트합니다. |
| 데이터 ([ctx]) | 이 메소드는 한 컨텍스트에서이 매개 변수의 사본을 리턴합니다. |
| grad ([ctx]) | 이 메서드는 한 컨텍스트에서이 매개 변수에 대한 그래디언트 버퍼를 반환합니다. |
| initialize ([init, ctx, default_init,…]) | 이 메서드는 매개 변수 및 기울기 배열을 초기화합니다. |
| list_ctx () | 이 메소드는이 매개 변수가 초기화 된 컨텍스트 목록을 리턴합니다. |
| list_data () | 이 메서드는 모든 컨텍스트에서이 매개 변수의 복사본을 반환합니다. 생성과 동일한 순서로 진행됩니다. |
| list_grad () | 이 메서드는 모든 컨텍스트에서 그래디언트 버퍼를 반환합니다. 이 작업은 다음과 같은 순서로 수행됩니다.values(). |
| list_row_sparse_data (row_id) | 이 메서드는 모든 컨텍스트에서 'row_sparse'매개 변수의 복사본을 반환합니다. 이것은 생성과 동일한 순서로 수행됩니다. |
| reset_ctx (ctx) | 이 메서드는 매개 변수를 다른 컨텍스트에 다시 할당합니다. |
| row_sparse_data (row_id) | 이 메서드는 row_id와 동일한 컨텍스트에서 'row_sparse'매개 변수의 복사본을 반환합니다. |
| set_data (데이터) | 이 메소드는 모든 컨텍스트에서이 매개 변수의 값을 설정합니다. |
| var () | 이 메소드는이 매개 변수를 나타내는 기호를 리턴합니다. |
| zero_grad () | 이 메서드는 모든 컨텍스트의 그래디언트 버퍼를 0으로 설정합니다. |
구현 예
아래 예제에서는 다음과 같이 initialize () 메서드를 사용하여 매개 변수와 그라디언트 배열을 초기화합니다.
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()Output
출력은 아래에 언급되어 있습니다.
[[-0.0256899 0.06511251]
[-0.00243821 -0.00123186]]
<NDArray 2x2 @cpu(0)>Example
weight.grad()Output
출력은 다음과 같습니다.
[[0. 0.]
[0. 0.]]
<NDArray 2x2 @cpu(0)>Example
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)])
weight.data(mx.gpu(0))Output
다음 출력이 표시됩니다.
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(0)>Example
weight.data(mx.gpu(1))Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(1)>gluon.trainer
mxnet.gluon.trainer는 매개 변수 세트에 Optimizer를 적용합니다. autograd와 함께 사용해야합니다.
방법 및 매개 변수
다음은 몇 가지 중요한 방법과 해당 매개 변수입니다. mxnet.gluon.trainer 교육 모듈 −
| 방법 및 매개 변수 | 정의 |
|---|---|
| allreduce_grads () | 이 방법은 각 매개 변수 (가중치)에 대해 서로 다른 컨텍스트의 그라디언트를 줄입니다. |
| load_states (fname) | 이름에서 알 수 있듯이이 메서드는 트레이너 상태를로드합니다. |
| save_states (fname) | 이름에서 알 수 있듯이이 방법은 트레이너 상태를 저장합니다. |
| set_learning_rate (lr) | 이 방법은 최적화 프로그램의 새로운 학습 속도를 설정합니다. |
| step (batch_size [, ignore_stale_grad]) | 이 방법은 매개 변수 업데이트의 한 단계를 만듭니다. 이후에 호출해야합니다.autograd.backward() 그리고 외부 record() 범위. |
| update (batch_size [, ignore_stale_grad]) | 이 방법은 또한 매개 변수 업데이트의 한 단계를 만듭니다. 이후에 호출해야합니다.autograd.backward() 그리고 외부 record() 범위 및 trainer.update () 이후. |
데이터 모듈
Gluon의 데이터 모듈은 아래에 설명되어 있습니다.
gluon.data
Gluon은 gluon.data 모듈에서 많은 수의 내장 데이터 세트 유틸리티를 제공합니다. 그것이 데이터 모듈이라고 불리는 이유입니다.
클래스 및 매개 변수
다음은 mxnet.gluon.data 코어 모듈에서 다루는 몇 가지 중요한 메소드와 매개 변수입니다. 이러한 메서드는 일반적으로 데이터 세트, 샘플링 및 DataLoader와 관련이 있습니다.
데이터 세트| 방법 및 매개 변수 | 정의 |
|---|---|
| ArrayDataset (* args) | 이 메서드는 두 개 이상의 데이터 집합과 유사한 개체를 결합하는 데이터 집합을 나타냅니다. 예 : 데이터 세트, 목록, 배열 등 |
| BatchSampler (샘플러, batch_size [, last_batch]) | 이 방법은 다른 방법으로 래핑됩니다. Sampler. 포장되면 샘플의 미니 배치를 반환합니다. |
| DataLoader (dataset [, batch_size, shuffle,…]) | BatchSampler와 비슷하지만이 메서드는 데이터 세트에서 데이터를로드합니다. 로드되면 데이터의 미니 배치를 반환합니다. |
| 이것은 추상 데이터 세트 클래스를 나타냅니다. | |
| FilterSampler (fn, 데이터 셋) | 이 메서드는 fn (함수)이 반환하는 데이터 집합의 샘플 요소를 나타냅니다. True. |
| RandomSampler (길이) | 이 방법은 [0, 길이)의 샘플 요소를 대체하지 않고 무작위로 나타냅니다. |
| RecordFileDataset (파일 이름) | RecordIO 파일을 감싸는 데이터 세트를 나타냅니다. 파일 확장자는.rec. |
| 샘플러 | 이것은 샘플러의 기본 클래스입니다. |
| SequentialSampler (길이 [, 시작]) | 집합 [시작, 시작 + 길이)의 샘플 요소를 순차적으로 나타냅니다. |
| 집합 [시작, 시작 + 길이)의 샘플 요소를 순차적으로 나타냅니다. | 이것은 특히 목록과 배열에 대한 간단한 데이터 세트 래퍼를 나타냅니다. |
구현 예
아래 예에서 우리는 gluon.data.BatchSampler()다른 샘플러를 래핑하는 API. 샘플의 미니 배치를 반환합니다.
import mxnet as mx
from mxnet.gluon import data
sampler = mx.gluon.data.SequentialSampler(15)
batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep')
list(batch_sampler)Output
출력은 아래에 언급되어 있습니다.
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]gluon.data.vision.datasets
Gluon은 다양한 사전 정의 비전 데이터 세트 기능을 제공합니다. gluon.data.vision.datasets 기준 치수.
클래스 및 매개 변수
MXNet은 유용하고 중요한 데이터 세트를 제공하며, 클래스와 매개 변수는 다음과 같습니다.
| 클래스 및 매개 변수 | 정의 |
|---|---|
| MNIST ([루트, 훈련, 변환]) | 이것은 손으로 쓴 숫자를 제공하는 유용한 데이터 세트입니다. MNIST 데이터 세트의 URL은 http://yann.lecun.com/exdb/mnist입니다. |
| FashionMNIST ([root, train, transform]) | 이 데이터 세트는 패션 제품으로 구성된 Zalando의 기사 이미지로 구성됩니다. 원래 MNIST 데이터 세트의 드롭 인 대체입니다. 이 데이터 세트는 https://github.com/zalandoresearch/fashion-mnist에서 얻을 수 있습니다. |
| CIFAR10 ([root, train, transform]) | 이것은 https://www.cs.toronto.edu/~kriz/cifar.html의 이미지 분류 데이터 세트입니다. 이 데이터 세트에서 각 샘플은 모양 (32, 32, 3)의 이미지입니다. |
| CIFAR100 ([root, fine_label, train, transform]) | https://www.cs.toronto.edu/~kriz/cifar.html의 CIFAR100 이미지 분류 데이터 세트입니다. 또한 각 샘플은 모양 (32, 32, 3)의 이미지입니다. |
| ImageRecordDataset (파일 이름 [, 플래그, 변환]) | 이 데이터 세트는 이미지가 포함 된 RecordIO 파일을 래핑합니다. 이 각 샘플은 해당 레이블이있는 이미지입니다. |
| ImageFolderDataset (루트 [, 플래그, 변환]) | 폴더 구조에 저장된 이미지 파일을로드하기위한 데이터 세트입니다. |
| ImageListDataset ([root, imglist, flag]) | 항목 목록에 지정된 이미지 파일을로드하기위한 데이터 세트입니다. |
예
아래 예제에서 우리는 항목 목록에 의해 지정된 이미지 파일을로드하는 데 사용되는 ImageListDataset ()의 사용을 보여줄 것입니다.
# written to text file *.lst
0 0 root/cat/0001.jpg
1 0 root/cat/xxxa.jpg
2 0 root/cat/yyyb.jpg
3 1 root/dog/123.jpg
4 1 root/dog/023.jpg
5 1 root/dog/wwww.jpg
# A pure list, each item is a list [imagelabel: float or list of float, imgpath]
[[0, root/cat/0001.jpg]
[0, root/cat/xxxa.jpg]
[0, root/cat/yyyb.jpg]
[1, root/dog/123.jpg]
[1, root/dog/023.jpg]
[1, root/dog/wwww.jpg]]유틸리티 모듈
Gluon의 유틸리티 모듈은 다음과 같습니다.
gluon.utils
Gluon은 gluon.utils 모듈에서 많은 내장 병렬화 유틸리티 최적화 프로그램을 제공합니다. 교육을위한 다양한 유틸리티를 제공합니다. 그것이 유틸리티 모듈이라고 불리는 이유입니다.
기능 및 매개 변수
다음은이 유틸리티 모듈에서 구성되는 기능과 해당 매개 변수입니다. gluon.utils −
| 기능 및 매개 변수 | 정의 |
|---|---|
| split_data (data, num_slice [, batch_axis,…]) | 이 함수는 일반적으로 데이터 병렬 처리에 사용되며 각 슬라이스는 GPU와 같은 하나의 장치로 전송됩니다. NDArray를num_slice 함께 슬라이스 batch_axis. |
| split_and_load (데이터, ctx_list [, batch_axis,…]) | 이 함수는 NDArray를 len(ctx_list) 함께 슬라이스 batch_axis. 위의 split_data () 함수와의 유일한 차이점은 각 슬라이스를 하나의 컨텍스트로로드한다는 것입니다. ctx_list. |
| clip_global_norm (배열, max_norm [,…]) | 이 함수의 역할은 2- 노름의 합이 다음보다 작은 방식으로 NDArray의 크기를 조정하는 것입니다. max_norm. |
| check_sha1 (파일 이름, sha1_hash) | 이 함수는 파일 콘텐츠의 sha1 해시가 예상 해시와 일치하는지 여부를 확인합니다. |
| 다운로드 (URL [, 경로, 덮어 쓰기, sha1_hash,…]) | 이름이 지정한대로이 함수는 주어진 URL을 다운로드합니다. |
| 대체 _ 파일 (src, dst) | 이 함수는 원 자성을 구현합니다. os.replace. Linux 및 OSX에서 수행됩니다. |
이 장에서는 MXNet의 autograd 및 initializer API를 다룹니다.
mxnet.autograd
이것은 NDArray 용 MXNet의 autograd API입니다. 그것은 다음과 같은 클래스가 있습니다-
클래스 : Function ()
autograd에서 사용자 정의 차별화에 사용됩니다. 다음과 같이 쓸 수 있습니다.mxnet.autograd.Function. 어떤 이유로 든 사용자가 기본 체인 규칙에 의해 계산되는 그라디언트를 사용하지 않으려면 mxnet.autograd의 Function 클래스를 사용하여 계산을위한 미분을 사용자 지정할 수 있습니다. Forward ()와 Backward ()라는 두 가지 메서드가 있습니다.
다음 요점의 도움으로이 클래스의 작업을 이해합시다.
먼저, 우리는 forward 메서드에서 계산을 정의해야합니다.
그런 다음 역방향 방법으로 맞춤형 차별화를 제공해야합니다.
이제 그래디언트 계산 중에 사용자 정의 역방향 함수 대신 mxnet.autograd는 사용자가 정의한 역방향 함수를 사용합니다. 또한 일부 작업을 앞뒤로 numpy 배열로 캐스트 할 수 있습니다.
Example
mxnet.autograd.function 클래스를 사용하기 전에 다음과 같이 역방향 및 순방향 메서드로 안정적인 시그 모이 드 함수를 정의 해 보겠습니다.
class sigmoid(mx.autograd.Function):
def forward(self, x):
y = 1 / (1 + mx.nd.exp(-x))
self.save_for_backward(y)
return y
def backward(self, dy):
y, = self.saved_tensors
return dy * y * (1-y)이제 함수 클래스는 다음과 같이 사용할 수 있습니다.
func = sigmoid()
x = mx.nd.random.uniform(shape=(10,))
x.attach_grad()
with mx.autograd.record():
m = func(x)
m.backward()
dx_grad = x.grad.asnumpy()
dx_gradOutput
코드를 실행하면 다음 출력이 표시됩니다.
array([0.21458015, 0.21291625, 0.23330082, 0.2361367 , 0.23086983,
0.24060014, 0.20326573, 0.21093895, 0.24968489, 0.24301809],
dtype=float32)방법 및 매개 변수
다음은 mxnet.autogard.function 클래스의 메소드와 매개 변수입니다.
| 방법 및 매개 변수 | 정의 |
|---|---|
| 앞으로 (heads [, head_grads, retain_graph,…]) | 이 방법은 순방향 계산에 사용됩니다. |
| 뒤로 (heads [, head_grads, preserve_graph,…]) | 이 방법은 역방향 계산에 사용됩니다. 이전에 표시된 변수와 관련하여 헤드의 기울기를 계산합니다. 이 메서드는 앞으로의 출력만큼 많은 입력을받습니다. 또한 순방향 입력만큼 많은 NDArray를 반환합니다. |
| get_symbol (x) | 이 방법은 기록 된 계산 내역을 검색하는 데 사용됩니다. Symbol. |
| grad (heads, 변수 [, head_grads,…]) | 이 방법은 변수에 대한 헤드의 기울기를 계산합니다. 일단 계산되면 variable.grad에 저장하는 대신 그래디언트가 새 NDArray로 반환됩니다. |
| is_recording () | 이 방법의 도움으로 우리는 기록이 아닌 기록 상태를 얻을 수 있습니다. |
| is_training () | 이 방법의 도움으로 우리는 훈련 및 예측에 대한 상태를 얻을 수 있습니다. |
| mark_variables (변수, 그라디언트 [, grad_reqs]) | 이 방법은 NDArray를 변수로 표시하여 autograd에 대한 기울기를 계산합니다. 이 메소드는 변수의 .attach_grad () 함수와 동일하지만 유일한 차이점은이 호출을 사용하여 그라디언트를 임의의 값으로 설정할 수 있다는 것입니다. |
| pause ([기차 _ 모드]) | 이 메서드는 계산할 그라데이션이 필요하지 않은 코드에 대해 'with'문에서 사용할 범위 컨텍스트를 반환합니다. |
| predict_mode () | 이 메서드는 정방향 전달 동작이 추론 모드로 설정되고 기록 상태를 변경하지 않는 'with'문에서 사용할 범위 컨텍스트를 반환합니다. |
| 기록 ([기차 _ 모드]) | 그것은 autograd 'with'문에서 사용할 범위 컨텍스트를 기록하고 기울기를 계산해야하는 코드를 캡처합니다. |
| set_recording (기록 중) | is_recoring ()과 유사하게,이 메소드의 도움으로 우리는 기록이 아닌 기록 상태를 얻을 수 있습니다. |
| set_training (is_training) | is_traininig ()와 유사하게,이 메서드의 도움으로 상태를 훈련 또는 예측으로 설정할 수 있습니다. |
| train_mode () | 이 메서드는 정방향 전달 동작이 학습 모드로 설정되고 기록 상태를 변경하지 않는 'with'문에서 사용할 범위 컨텍스트를 반환합니다. |
구현 예
아래 예제에서는 mxnet.autograd.grad () 메서드를 사용하여 변수에 대한 헤드의 기울기를 계산합니다.
x = mx.nd.ones((2,))
x.attach_grad()
with mx.autograd.record():
z = mx.nd.elemwise_add(mx.nd.exp(x), x)
dx_grad = mx.autograd.grad(z, [x], create_graph=True)
dx_gradOutput
출력은 아래에 언급되어 있습니다.
[
[3.7182817 3.7182817]
<NDArray 2 @cpu(0)>]mxnet.autograd.predict_mode () 메서드를 사용하여 'with'문에서 사용할 범위를 반환 할 수 있습니다.
with mx.autograd.record():
y = model(x)
with mx.autograd.predict_mode():
y = sampling(y)
backward([y])mxnet.intializer
계량 초기화를위한 MXNet의 API입니다. 그것은 다음과 같은 클래스가 있습니다-
클래스 및 매개 변수
다음은 방법 및 매개 변수입니다. mxnet.autogard.function 수업:
| 클래스 및 매개 변수 | 정의 |
|---|---|
| 쌍 선형 () | 이 클래스의 도움으로 업 샘플링 레이어에 대한 가중치를 초기화 할 수 있습니다. |
| 상수 (값) | 이 클래스는 가중치를 주어진 값으로 초기화합니다. 값은 설정할 매개 변수의 모양과 일치하는 NDArray 및 스칼라 일 수 있습니다. |
| FusedRNN (init, num_hidden, num_layers, 모드) | 이름에서 알 수 있듯이이 클래스는 융합 된 RNN (Recurrent Neural Network) 계층에 대한 매개 변수를 초기화합니다. |
| InitDesc | 초기화 패턴에 대한 설명자 역할을합니다. |
| 이니셜 라이저 (** kwargs) | 이니셜 라이저의 기본 클래스입니다. |
| LSTMBias ([forget_bias]) | 이 클래스는 LSTMCell의 모든 바이어스를 0.0으로 초기화하지만 바이어스가 사용자 정의 값으로 설정된 잊어 버림 게이트를 제외합니다. |
| 로드 (param [, default_init, verbose]) | 이 클래스는 파일 또는 사전에서 데이터를로드하여 변수를 초기화합니다. |
| MSRAPrelu ([요인 _ 유형, 기울기]) | 이름에서 알 수 있듯이이 클래스는 MSRA 용지에 따라 무게를 초기화합니다. |
| 혼합 (패턴, 이니셜 라이저) | 여러 이니셜 라이저를 사용하여 매개 변수를 초기화합니다. |
| 일반 ([시그마]) | Normal () 클래스는 평균이 0이고 표준 편차 (SD)가 다음과 같은 정규 분포에서 샘플링 된 임의 값으로 가중치를 초기화합니다. sigma. |
| 하나() | 매개 변수의 가중치를 1로 초기화합니다. |
| 직교 ([scale, rand_type]) | 이름에서 알 수 있듯이이 클래스는 가중치를 직교 행렬로 초기화합니다. |
| 균일 ([스케일]) | 주어진 범위에서 균일하게 샘플링 된 임의의 값으로 가중치를 초기화합니다. |
| Xavier ([rnd_type, factor_type, 크기]) | 실제로 가중치에 대해 "Xavier"초기화를 수행하는 이니셜 라이저를 반환합니다. |
| 제로() | 매개 변수의 가중치를 0으로 초기화합니다. |
구현 예
아래 예제에서는 mxnet.init.Normal () 클래스를 사용하여 이니셜 라이저를 생성하고 매개 변수를 검색합니다.
init = mx.init.Normal(0.8)
init.dumps()Output
출력은 다음과 같습니다.
'["normal", {"sigma": 0.8}]'Example
init = mx.init.Xavier(factor_type="in", magnitude=2.45)
init.dumps()Output
출력은 다음과 같습니다.
'["xavier", {"rnd_type": "uniform", "factor_type": "in", "magnitude": 2.45}]'아래 예제에서는 mxnet.initializer.Mixed () 클래스를 사용하여 여러 이니셜 라이저를 사용하여 매개 변수를 초기화합니다.
init = mx.initializer.Mixed(['bias', '.*'], [mx.init.Zero(),
mx.init.Uniform(0.1)])
module.init_params(init)
for dictionary in module.get_params():
for key in dictionary:
print(key)
print(dictionary[key].asnumpy())Output
출력은 다음과 같습니다.
fullyconnected1_weight
[[ 0.0097627 0.01856892 0.04303787]]
fullyconnected1_bias
[ 0.]이 장에서는 Symbol이라고하는 MXNet의 인터페이스에 대해 알아 봅니다.
Mxnet.ndarray
Apache MXNet의 Symbol API는 기호 프로그래밍을위한 인터페이스입니다. Symbol API는 다음을 사용합니다.
계산 그래프
메모리 사용량 감소
사용 전 기능 최적화
아래의 예제는 MXNet의 Symbol API를 사용하여 간단한 표현식을 생성하는 방법을 보여줍니다.
정규 파이썬 목록에서 1-D 및 2-D '배열'을 사용하는 NDArray-
import mxnet as mx
# Two placeholders namely x and y will be created with mx.sym.variable
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
# The symbol here is constructed using the plus ‘+’ operator.
z = x + yOutput
다음 출력이 표시됩니다.
<Symbol _plus0>Example
(x, y, z)Output
출력은 다음과 같습니다.
(<Symbol x>, <Symbol y>, <Symbol _plus0>)이제 MXNet의 ndarray API의 클래스, 함수 및 매개 변수에 대해 자세히 논의하겠습니다.
클래스
다음 표는 MXNet의 Symbol API 클래스로 구성되어 있습니다.
| 수업 | 정의 |
|---|---|
| 기호 (핸들) | 이 클래스 즉 기호는 Apache MXNet의 기호 그래프입니다. |
기능 및 매개 변수
다음은 mxnet.Symbol API에서 다루는 몇 가지 중요한 기능과 매개 변수입니다.
| 기능 및 매개 변수 | 정의 |
|---|---|
| 활성화 ([데이터, 행위 _ 유형, 출력, 이름]) | 활성화 함수를 요소별로 입력에 적용합니다. 그것은 지원합니다relu, sigmoid, tanh, softrelu, softsign 활성화 기능. |
| BatchNorm ([데이터, 감마, 베타, 이동 _ 평균,…]) | 일괄 정규화에 사용됩니다. 이 함수는 평균 및 분산으로 데이터 배치를 정규화합니다. 척도를 적용합니다gamma 및 오프셋 beta. |
| BilinearSampler ([데이터, 그리드, cudnn_off,…]) | 이 함수는 입력 특성 맵에 이중 선형 샘플링을 적용합니다. 사실 그것은 "공간 변압기 네트워크"의 핵심입니다. OpenCV의 remap 기능에 익숙하다면이 기능의 사용법은 그것과 매우 유사합니다. 유일한 차이점은 역방향 패스가 있다는 것입니다. |
| BlockGrad ([데이터, 출력, 이름]) | 이름에서 알 수 있듯이이 함수는 기울기 계산을 중지합니다. 기본적으로 입력의 누적 기울기가이 연산자를 통해 역방향으로 흐르는 것을 막습니다. |
| cast ([데이터, dtype, 출력, 이름]) | 이 함수는 입력의 모든 요소를 새 유형으로 캐스팅합니다. |
| 이 함수는 입력의 모든 요소를 새 유형으로 캐스팅합니다. | 이 함수는 지정된 이름으로 0으로 채워진 주어진 모양과 유형의 새 기호를 반환합니다. |
| ones (shape [, dtype]) | 이 함수는 이름이 지정된대로 지정된 모양과 유형의 새 기호를 반환하며, 그 기호로 채워진다. |
| 전체 (모양, val [, dtype]) | 이 함수는 이름이 지정된대로 주어진 값으로 채워진 주어진 모양과 유형의 새 배열을 반환합니다. val. |
| arange (시작 [, 중지, 단계, 반복,…]) | 주어진 간격 내에서 균일 한 간격의 값을 반환합니다. 값은 반 개방 간격 (시작, 중지) 내에서 생성됩니다. 즉, 간격에는 다음이 포함됩니다.start 그러나 제외 stop. |
| linspace (시작, 중지, num [, 끝점, 이름,…]) | 지정된 간격 내에서 균일 한 간격의 숫자를 반환합니다. array () 함수와 유사하게 반 개방 간격 [start, stop) 내에서 값이 생성됩니다.start 그러나 제외 stop. |
| 히스토그램 (a [, 빈, 범위]) | 이름에서 알 수 있듯이이 함수는 입력 데이터의 히스토그램을 계산합니다. |
| power (base, exp) | 이름에서 알 수 있듯이이 함수는 다음의 요소 별 결과를 반환합니다. base 다음에서 거듭 제곱 된 요소 exp요소. 두 입력, 즉 base와 exp는 모두 Symbol 또는 스칼라 일 수 있습니다. 여기서 방송은 허용되지 않습니다. 당신이 사용할 수있는broadcast_pow 방송 기능을 사용하려면 |
| SoftmaxActivation ([데이터, 모드, 이름, 속성, 출력]) | 이 함수는 소프트 맥스 활성화를 입력에 적용합니다. 내부 레이어 용입니다. 실제로 사용되지 않습니다.softmax() 대신. |
구현 예
아래 예에서는 함수를 사용합니다. power() exp 요소에서 거듭 제곱 된 기본 요소의 요소 별 결과를 반환합니다.
import mxnet as mx
mx.sym.power(3, 5)Output
다음 출력이 표시됩니다.
243Example
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
z = mx.sym.power(x, 3)
z.eval(x=mx.nd.array([1,2]))[0].asnumpy()Output
이것은 다음과 같은 출력을 생성합니다-
array([1., 8.], dtype=float32)Example
z = mx.sym.power(4, y)
z.eval(y=mx.nd.array([2,3]))[0].asnumpy()Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
array([16., 64.], dtype=float32)Example
z = mx.sym.power(x, y)
z.eval(x=mx.nd.array([4,5]), y=mx.nd.array([2,3]))[0].asnumpy()Output
출력은 아래에 언급되어 있습니다.
array([ 16., 125.], dtype=float32)아래 주어진 예에서는 함수를 사용합니다. SoftmaxActivation() (or softmax()) 입력에 적용되며 내부 레이어 용입니다.
input_data = mx.nd.array([[2., 0.9, -0.5, 4., 8.], [4., -.7, 9., 2., 0.9]])
soft_max_act = mx.nd.softmax(input_data)
print (soft_max_act.asnumpy())Output
다음 출력이 표시됩니다.
[[2.4258138e-03 8.0748333e-04 1.9912292e-04 1.7924475e-02 9.7864312e-01]
[6.6843745e-03 6.0796250e-05 9.9204916e-01 9.0463174e-04 3.0112563e-04]]symbol.contrib
Contrib NDArray API는 symbol.contrib 패키지에 정의되어 있습니다. 일반적으로 새로운 기능에 대한 많은 유용한 실험 API를 제공합니다. 이 API는 새로운 기능을 사용해 볼 수있는 커뮤니티의 장소로 작동합니다. 기능 기고자에게도 피드백이 제공됩니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.symbol.contrib API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| rand_zipfian (true_classes, num_sampled,…) | 이 함수는 대략 Zipfian 분포에서 랜덤 샘플을 가져옵니다. 이 함수의 기본 분포는 Zipfian 분포입니다. 이 함수는 num_sampled 후보를 무작위로 샘플링하고 sampled_candidates의 요소는 위에 주어진 기본 분포에서 추출됩니다. |
| foreach (본문, 데이터, init_states) | 이름에서 알 수 있듯이이 함수는 차원 0의 NDArray에 대해 사용자 정의 계산으로 루프를 실행합니다.이 함수는 for 루프를 시뮬레이션하고 본문에는 for 루프의 반복에 대한 계산이 있습니다. |
| while_loop (cond, func, loop_vars [,…]) | 이름에서 알 수 있듯이이 함수는 사용자 정의 계산 및 루프 조건으로 while 루프를 실행합니다. 이 함수는 조건이 충족되면 문자 그대로 사용자 정의 된 계산을 수행하는 while 루프를 시뮬레이션합니다. |
| cond (pred, then_func, else_func) | 이름에서 알 수 있듯이이 함수는 사용자 정의 조건 및 계산을 사용하여 if-then-else를 실행합니다. 이 함수는 지정된 조건에 따라 두 개의 사용자 정의 계산 중 하나를 수행하도록 선택하는 if-like 분기를 시뮬레이션합니다. |
| getnnz ([데이터, 축, 출력, 이름]) | 이 함수는 희소 텐서에 대해 저장된 값의 수를 제공합니다. 또한 명시적인 0도 포함됩니다. CPU에서 CSR 매트릭스 만 지원합니다. |
| requantize ([데이터, 최소 _ 범위, 최대 _ 범위,…]) | 이 함수는 런타임 또는 보정에서 계산 된 최소 및 최대 임계 값을 사용하여 int32 및 해당 임계 값으로 양자화 된 주어진 데이터를 int8로 재 양자화합니다. |
| index_copy ([old_tensor, index_vector,…]) | 이 함수는 new_tensor into the old_tensor by selecting the indices in the order given in index. The output of this operator will be a new tensor that contains the rest elements of old tensor and the copied elements of new tensor. |
| interleaved_matmul_encdec_qk ([쿼리,…]) | 이 연산자는 인코더-디코더로 다중 머리주의 사용에서 쿼리와 키의 투영 사이의 행렬 곱셈을 계산합니다. 조건은 입력이 레이아웃 ((seq_length, batch_size, num_heads *, head_dim))을 따르는 쿼리 프로젝션의 텐서 여야한다는 것입니다. |
구현 예
아래 예제에서 우리는 대략 Zipfian 분포에서 무작위 샘플을 그리기 위해 rand_zipfian 함수를 사용할 것입니다.
import mxnet as mx
true_cls = mx.sym.Variable('true_cls')
samples, exp_count_true, exp_count_sample = mx.sym.contrib.rand_zipfian(true_cls, 5, 6)
samples.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
다음 출력이 표시됩니다.
array([4, 0, 2, 1, 5], dtype=int64)Example
exp_count_true.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
출력은 아래에 언급되어 있습니다.
array([0.57336551])Example
exp_count_sample.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
다음 출력이 표시됩니다.
array([1.78103594, 0.46847373, 1.04183923, 0.57336551, 1.04183923])아래 예에서는 함수를 사용합니다. while_loop 사용자 정의 계산 및 루프 조건에 대한 while 루프 실행-
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_vars = (mx.sym.var('i'), mx.sym.var('s'))
outputs, states = mx.sym.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
print(outputs)Output
출력은 다음과 같습니다.
[<Symbol _while_loop0>]Example
Print(States)Output
이것은 다음과 같은 출력을 생성합니다-
[<Symbol _while_loop0>, <Symbol _while_loop0>]아래 예에서는 함수를 사용합니다. index_copy new_tensor의 요소를 old_tensor에 복사합니다.
import mxnet as mx
a = mx.nd.zeros((6,3))
b = mx.nd.array([[1,2,3],[4,5,6],[7,8,9]])
index = mx.nd.array([0,4,2])
mx.nd.contrib.index_copy(a, index, b)Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[1. 2. 3.]
[0. 0. 0.]
[7. 8. 9.]
[0. 0. 0.]
[4. 5. 6.]
[0. 0. 0.]]
<NDArray 6x3 @cpu(0)>symbol.image
Image Symbol API는 symbol.image 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 일반적으로 이미지와 기능에 사용됩니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.symbol.image API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| adjust_lighting ([데이터, 알파, 출력, 이름]) | 이름에서 알 수 있듯이이 기능은 입력의 조명 수준을 조정합니다. AlexNet 스타일을 따릅니다. |
| 자르기 ([데이터, x, y, 너비, 높이, 출력, 이름]) | 이 기능의 도움으로 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로자를 수 있습니다. |
| normalize ([데이터, 평균, 표준, 출력, 이름]) | 모양의 텐서 (C x H x W) 또는 (N x C x H x W)를 다음과 같이 정규화합니다. mean 과 standard deviation(SD). |
| random_crop ([데이터, xrange, yrange, 너비,…]) | crop ()과 유사하게 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로 무작위로 자릅니다. 다음과 같은 경우 결과를 업 샘플링합니다.src 보다 작습니다 size. |
| random_lighting([데이터, alpha_std, 출력, 이름]) | 이름에서 알 수 있듯이이 기능은 PCA 노이즈를 무작위로 추가합니다. 또한 AlexNet 스타일을 따릅니다. |
| random_resized_crop ([데이터, xrange, yrange,…]) | 또한 이미지를 임의의 NDArray of shape (H x W x C) 또는 (N x H x W x C)로 지정된 크기로 자릅니다. src가 크기보다 작 으면 결과를 업 샘플링합니다. 면적과 종횡비도 무작위로 지정합니다. |
| resize ([데이터, 크기, 유지 _ 비율, interp,…]) | 이름에서 알 수 있듯이이 기능은 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 사용자가 지정한 크기로 조정합니다. |
| to_tensor ([데이터, 출력, 이름]) | [0, 255] 범위의 값을 가진 이미지 NDArray of shape (H x W x C) 또는 (N x H x W x C)를 텐서 NDArray of shape (C x H x W) 또는 ( N x C x H x W) 범위의 값으로 [0, 1]. |
구현 예
아래 예에서는 to_tensor 함수를 사용하여 [0, 255] 범위의 값을 갖는 모양 (H x W x C) 또는 (N x H x W x C)의 이미지 NDArray를 텐서 NDArray로 변환합니다. [0, 1] 범위의 값을 가진 모양 (C x H x W) 또는 (N x C x H x W).
import numpy as np
img = mx.sym.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
출력은 다음과 같습니다.
<Symbol to_tensor4>Example
img = mx.sym.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
출력은 다음과 같습니다.
<Symbol to_tensor5>아래 예제에서는 normalize () 함수를 사용하여 (C x H x W) 또는 (N x C x H x W) 모양의 텐서를 정규화합니다. mean 과 standard deviation(SD).
img = mx.sym.random.uniform(0, 1, (3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
다음은 코드의 출력입니다.
<Symbol normalize0>Example
img = mx.sym.random.uniform(0, 1, (2, 3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
출력은 다음과 같습니다.
<Symbol normalize1>symbol.random
Random Symbol API는 symbol.random 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 MXNet의 Random Distribution Generator Symbol API입니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능과 해당 매개 변수입니다. mxnet.symbol.random API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| uniform ([낮음, 높음, 모양, dtype, ctx, out]) | 균일 분포에서 무작위 샘플을 생성합니다. |
| normal ([loc, scale, shape, dtype, ctx, out]) | 정규 (가우스) 분포에서 무작위 샘플을 생성합니다. |
| randn (* 모양, ** kwargs) | 정규 (가우스) 분포에서 무작위 샘플을 생성합니다. |
| 포아송 ([lam, shape, dtype, ctx, out]) | 포아송 분포에서 무작위 샘플을 생성합니다. |
| 지수 ([스케일, 모양, dtype, ctx, out]) | 지수 분포에서 샘플을 생성합니다. |
| 감마 ([알파, 베타, 모양, dtype, ctx, out]) | 감마 분포에서 무작위 샘플을 생성합니다. |
| 다항식 (데이터 [, 모양, get_prob, out, dtype]) | 여러 다항 분포에서 동시 샘플링을 생성합니다. |
| 음 이항 ([k, p, 모양, dtype, ctx, out]) | 음 이항 분포에서 무작위 샘플을 생성합니다. |
| generalized_negative_binomial ([mu, alpha,…]) | 일반화 된 음 이항 분포에서 무작위 샘플을 생성합니다. |
| shuffle (데이터, ** kwargs) | 요소를 무작위로 섞습니다. |
| randint (낮음, 높음 [, 모양, dtype, ctx, out]) | 이산 균일 분포에서 무작위 샘플을 생성합니다. |
| exponential_like ([데이터, 램, 아웃, 이름]) | 입력 배열 모양에 따라 지수 분포에서 무작위 샘플을 생성합니다. |
| gamma_like ([데이터, 알파, 베타, 출력, 이름]) | 입력 배열 모양에 따라 감마 분포에서 무작위 샘플을 생성합니다. |
| generalized_negative_binomial_like ([데이터,…]) | 입력 배열 모양에 따라 일반화 된 음 이항 분포에서 무작위 샘플을 생성합니다. |
| negative_binomial_like ([데이터, k, p, 출력, 이름]) | 입력 배열 모양에 따라 음의 이항 분포에서 무작위 샘플을 생성합니다. |
| normal_like ([데이터, 위치, 스케일, 아웃, 이름]) | 입력 배열 모양에 따라 정규 (가우시안) 분포에서 무작위 샘플을 생성합니다. |
| poisson_like ([데이터, 램, 아웃, 이름]) | 입력 배열 모양에 따라 포아송 분포에서 무작위 샘플을 생성합니다. |
| uniform_like ([데이터, 낮음, 높음, 출력, 이름]) | 입력 배열 모양에 따라 균등 분포에서 무작위 샘플을 생성합니다. |
구현 예
아래 예에서는 shuffle () 함수를 사용하여 요소를 무작위로 섞을 것입니다. 첫 번째 축을 따라 배열을 섞습니다.
data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8],[9,10,11]])
x = mx.sym.Variable('x')
y = mx.sym.random.shuffle(x)
y.eval(x=data)Output
다음 출력이 표시됩니다.
[
[[ 9. 10. 11.]
[ 0. 1. 2.]
[ 6. 7. 8.]
[ 3. 4. 5.]]
<NDArray 4x3 @cpu(0)>]Example
y.eval(x=data)Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[
[[ 6. 7. 8.]
[ 0. 1. 2.]
[ 3. 4. 5.]
[ 9. 10. 11.]]
<NDArray 4x3 @cpu(0)>]아래 예에서는 일반화 된 음 이항 분포에서 무작위 샘플을 추출합니다. 이를 위해 기능을 사용합니다.generalized_negative_binomial().
mx.sym.random.generalized_negative_binomial(10, 0.1)Output
출력은 다음과 같습니다.
<Symbol _random_generalized_negative_binomial0>symbol.sparse
Sparse Symbol API는 mxnet.symbol.sparse 패키지에 정의되어 있습니다. 이름에서 알 수 있듯이 CPU에서 희소 신경망 그래프 및 자동 차별화를 제공합니다.
기능 및 매개 변수
다음은 몇 가지 중요한 기능 (기호 생성 루틴, 기호 조작 루틴, 수학 함수, 삼각 함수, 하이버 볼릭 함수, 축소 함수, 반올림, 거듭 제곱, 신경망 포함)과 해당 매개 변수입니다. mxnet.symbol.sparse API −
| 기능 및 매개 변수 | 정의 |
|---|---|
| ElementWiseSum (* args, ** kwargs) | 이 함수는 모든 입력 인수 요소를 현명하게 추가합니다. 예 : _ (1,2,… = 1 + 2 + ⋯ +). 여기에서 add_n이 add를 n 번 호출하는 것보다 잠재적으로 더 효율적임을 알 수 있습니다. |
| 임베딩 ([데이터, 가중치, 입력 _ 치수,…]) | 정수 인덱스를 벡터 표현, 즉 임베딩에 매핑합니다. 실제로 단어 임베딩이라고하는 고차원 공간의 실수 벡터에 단어를 매핑합니다. |
| LinearRegressionOutput ([데이터, 레이블,…]) | 역방향 전파 중 손실 제곱을 계산하고 최적화하여 순방향 전파 중에 출력 데이터 만 제공합니다. |
| LogisticRegressionOutput ([데이터, 레이블,…]) | 시그 모이 드 함수라고도하는 로지스틱 함수를 입력에 적용합니다. 함수는 1 / 1 + exp (−x)로 계산됩니다. |
| MAERegressionOutput ([데이터, 레이블,…]) | 이 연산자는 입력의 평균 절대 오차를 계산합니다. MAE는 실제로 예상되는 절대 오차 값에 해당하는 위험 메트릭입니다. |
| abs ([데이터, 이름, 속성, 출력]) | 이름에서 알 수 있듯이이 함수는 입력의 요소 별 절대 값을 반환합니다. |
| adagrad_update ([weight, grad, history, lr,…]) | 업데이트 기능입니다. AdaGrad optimizer. |
| adam_update ([weight, grad, mean, var, lr,…]) | 업데이트 기능입니다. Adam optimizer. |
| add_n (* args, ** kwargs) | 이름에서 알 수 있듯이 모든 입력 인수를 요소별로 추가합니다. |
| arccos ([데이터, 이름, 속성, 출력]) | 이 함수는 입력 배열의 요소 별 역 코사인을 반환합니다. |
| dot ([lhs, rhs, transpose_a, transpose_b,…]) | 이름에서 알 수 있듯이 두 배열의 내적을 제공합니다. 입력 배열 차원에 따라 달라집니다. 1-D : 벡터의 내적 2-D : 행렬 곱셈 ND : 첫 번째 입력의 마지막 축과 두 번째 입력의 첫 번째 축에 대한 합계 곱입니다. |
| elemwise_add ([lhs, rhs, 이름, 속성, 출력]) | 이름에서 알 수 있듯이 add 인수 요소 현명. |
| elemwise_div ([lhs, rhs, 이름, 속성, 출력]) | 이름에서 알 수 있듯이 divide 인수 요소 현명. |
| elemwise_mul ([lhs, rhs, 이름, 속성, 출력]) | 이름에서 알 수 있듯이 Multiply 인수 요소 현명. |
| elemwise_sub ([lhs, rhs, 이름, 속성, 출력]) | 이름에서 알 수 있듯이 인수 요소를 현명하게 뺍니다. |
| exp ([데이터, 이름, 속성, 출력]) | 이 함수는 주어진 입력의 요소 별 지수 값을 반환합니다. |
| sgd_update ([weight, grad, lr, wd,…]) | Stochastic Gradient Descent Optimizer의 업데이트 기능으로 작동합니다. |
| sigmoid ([데이터, 이름, 속성, 출력]) | 이름에서 알 수 있듯이 sigmoid x 요소 현명. |
| sign ([데이터, 이름, 속성, 출력]) | 주어진 입력의 요소 현명한 부호를 반환합니다. |
| sin ([데이터, 이름, 속성, 출력]) | 이름에서 알 수 있듯이이 함수는 주어진 입력 배열의 요소 현명한 사인을 계산합니다. |
구현 예
아래 예에서는 다음을 사용하여 요소를 무작위로 섞을 것입니다. ElementWiseSum()함수. 정수 인덱스를 벡터 표현, 즉 단어 임베딩에 매핑합니다.
input_dim = 4
output_dim = 5Example
/* Here every row in weight matrix y represents a word. So, y = (w0,w1,w2,w3)
y = [[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[ 10., 11., 12., 13., 14.],
[ 15., 16., 17., 18., 19.]]
/* Here input array x represents n-grams(2-gram). So, x = [(w1,w3), (w0,w2)]
x = [[ 1., 3.],
[ 0., 2.]]
/* Now, Mapped input x to its vector representation y.
Embedding(x, y, 4, 5) = [[[ 5., 6., 7., 8., 9.],
[ 15., 16., 17., 18., 19.]],
[[ 0., 1., 2., 3., 4.],
[ 10., 11., 12., 13., 14.]]]Apache MXNet의 모듈 API는 FeedForward 모델과 유사하며 Torch 모듈과 유사한 구성이 더 쉽습니다. 그것은 다음과 같은 클래스로 구성되어 있습니다-
BaseModule ([로거])
모듈의 기본 클래스를 나타냅니다. 모듈은 계산 구성 요소 또는 계산 기계로 생각할 수 있습니다. 모듈의 역할은 정방향 및 역방향 패스를 실행하는 것입니다. 또한 모델의 매개 변수도 업데이트합니다.
행동 양식
다음 표는 구성 방법을 보여줍니다. BaseModule class−
이 메서드는 모든 장치에서 상태를 가져옵니다.| 행동 양식 | 정의 |
|---|---|
| 뒤로 ([out_grads]) | 이름에서 알 수 있듯이이 방법은 backward 계산. |
| bind (data_shapes [, label_shapes,…]) | 실행기를 구성하기 위해 기호를 바인딩하고 모듈로 계산을 수행하기 전에 필요합니다. |
| fit (train_data [, eval_data, eval_metric,…]) | 이 메서드는 모듈 매개 변수를 훈련합니다. |
| 앞으로 (data_batch [, is_train]) | 이름에서 알 수 있듯이이 메서드는 Forward 계산을 구현합니다. 이 방법은 다른 배치 크기 또는 다른 이미지 크기와 같은 다양한 모양의 데이터 배치를 지원합니다. |
| forward_backward (데이터 _ 배치) | 이름에서 알 수 있듯이 앞뒤로 모두 호출하는 편리한 기능입니다. |
| get_input_grads ([merge_multi_context]) | 이 방법은 이전 역방향 계산에서 계산 된 입력에 대한 기울기를 가져옵니다. |
| get_outputs ([merge_multi_context]) | 이름에서 알 수 있듯이이 메서드는 이전 순방향 계산의 출력을 가져옵니다. |
| get_params () | 특히 장치에서 계산을 수행하는 데 사용되는 실제 매개 변수의 잠재적 사본 인 매개 변수를 가져옵니다. |
| get_states ([merge_multi_context]) | |
| init_optimizer ([kvstore, 최적화 프로그램,…]) | 이 방법은 최적화 프로그램을 설치하고 초기화합니다. 또한 초기화합니다.kvstore 교육을 배포합니다. |
| init_params ([초기화 자, arg_params,…]) | 이름에서 알 수 있듯이이 메서드는 매개 변수와 보조 상태를 초기화합니다. |
| install_monitor (mon) | 이 방법은 모든 실행기에 모니터를 설치합니다. |
| iter_predict (eval_data [, num_batch, reset,…]) | 이 방법은 예측을 반복합니다. |
| load_params (fname) | 이름이 지정한대로 파일에서 모델 매개 변수를로드합니다. |
| 예측 (eval_data [, num_batch,…]) | 예측을 실행하고 출력도 수집합니다. |
| 준비 (data_batch [, sparse_row_id_fn]) | 운영자는 주어진 데이터 일괄 처리를 위해 모듈을 준비합니다. |
| save_params (fname) | 이름이 지정한대로이 기능은 모델 매개 변수를 파일에 저장합니다. |
| score (eval_data, eval_metric [, num_batch,…]) | 예측을 실행합니다. eval_data 또한 주어진에 따라 성능을 평가합니다 eval_metric. |
| set_params (arg_params, aux_params [,…]) | 이 방법은 매개 변수 및 보조 상태 값을 할당합니다. |
| set_states ([상태, 값]) | 이름에서 알 수 있듯이이 방법은 상태 값을 설정합니다. |
| 최신 정보() | 이 방법은 설치된 최적화 프로그램에 따라 주어진 매개 변수를 업데이트합니다. 또한 이전의 전후 배치에서 계산 된 기울기를 업데이트합니다. |
| update_metric (eval_metric, labels [, pre_sliced]) | 이 방법은 이름에서 알 수 있듯이 마지막 순방향 계산의 출력에 대한 평가 메트릭을 평가하고 누적합니다. |
| 뒤로 ([out_grads]) | 이름에서 알 수 있듯이이 방법은 backward 계산. |
| bind (data_shapes [, label_shapes,…]) | 버킷을 설정하고 기본 버킷 키에 대한 실행기를 바인딩합니다. 이 메서드는BucketingModule. |
| 앞으로 (data_batch [, is_train]) | 이름에서 알 수 있듯이이 메서드는 Forward 계산을 구현합니다. 이 방법은 다른 배치 크기 또는 다른 이미지 크기와 같은 다양한 모양의 데이터 배치를 지원합니다. |
| get_input_grads ([merge_multi_context]) | 이 방법은 이전 역방향 계산에서 계산 된 입력에 대한 기울기를 가져옵니다. |
| get_outputs ([merge_multi_context]) | 이름에서 알 수 있듯이이 메서드는 이전 순방향 계산에서 출력을 가져옵니다. |
| get_params () | 현재 매개 변수, 특히 장치에서 계산을 수행하는 데 사용되는 실제 매개 변수의 잠재적 사본 인 매개 변수를 가져옵니다. |
| get_states ([merge_multi_context]) | 이 메서드는 모든 장치에서 상태를 가져옵니다. |
| init_optimizer ([kvstore, 최적화 프로그램,…]) | 이 방법은 최적화 프로그램을 설치하고 초기화합니다. 또한 초기화합니다.kvstore 교육을 배포합니다. |
| init_params ([초기화 자, arg_params,…]) | 이름에서 알 수 있듯이이 메서드는 매개 변수와 보조 상태를 초기화합니다. |
| install_monitor (mon) | 이 방법은 모든 실행기에 모니터를 설치합니다. |
| load (접두사, epoch [, sym_gen,…]) | 이 방법은 이전에 저장된 체크 포인트에서 모델을 생성합니다. |
| load_dict ([sym_dict, sym_gen,…]) | 이 방법은 사전 (dict) 매핑에서 모델을 생성합니다. bucket_key기호에. 또한 공유arg_params 과 aux_params. |
| 준비 (data_batch [, sparse_row_id_fn]) | 운영자는 주어진 데이터 일괄 처리를 위해 모듈을 준비합니다. |
| save_checkpoint (prefix, epoch [, remove_amp_cast]) | 이 메서드는 이름에서 알 수 있듯이 BucketingModule의 모든 버킷에 대한 체크 포인트에 현재 진행 상황을 저장합니다. 훈련 중 저장하려면 mx.callback.module_checkpoint를 epoch_end_callback으로 사용하는 것이 좋습니다. |
| set_params (arg_params, aux_params [,…]) | 이름이 지정한대로이 기능은 매개 변수와 보조 상태 값을 할당합니다. |
| set_states ([상태, 값]) | 이름에서 알 수 있듯이이 방법은 상태 값을 설정합니다. |
| switch_bucket (bucket_key, data_shapes [,…]) | 다른 버킷으로 전환됩니다. |
| 최신 정보() | 이 방법은 설치된 최적화 프로그램에 따라 주어진 매개 변수를 업데이트합니다. 또한 이전의 전후 배치에서 계산 된 기울기를 업데이트합니다. |
| update_metric (eval_metric, labels [, pre_sliced]) | 이 방법은 이름에서 알 수 있듯이 마지막 순방향 계산의 출력에 대한 평가 메트릭을 평가하고 누적합니다. |
속성
다음 표는 방법으로 구성된 속성을 보여줍니다. BaseModule 클래스-
| 속성 | 정의 |
|---|---|
| 데이터 _ 이름 | 이 모듈에 필요한 데이터의 이름 목록으로 구성됩니다. |
| data_shapes | 이 모듈에 대한 데이터 입력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_shapes | 이 모듈에 대한 레이블 입력을 지정하는 (이름, 모양) 쌍의 목록을 보여줍니다. |
| 출력 _ 이름 | 이 모듈의 출력에 대한 이름 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| 상징 | 지정된 이름에 따라이 속성은이 모듈과 연관된 기호를 가져옵니다. |
data_shapes : 사용 가능한 링크를 참조 할 수 있습니다. https://mxnet.apache.org자세한 내용은. output_shapes : 더보기
output_shapes : 자세한 정보는 https://mxnet.apache.org/api/python
BucketingModule (sym_gen […])
그것은 Bucketingmodule 다양한 길이 입력을 효율적으로 처리하는 데 도움이되는 모듈의 클래스입니다.
행동 양식
다음 표는 구성 방법을 보여줍니다. BucketingModule class −
속성
다음 표는 방법으로 구성된 속성을 보여줍니다. BaseModule class −
| 속성 | 정의 |
|---|---|
| 데이터 _ 이름 | 이 모듈에 필요한 데이터의 이름 목록으로 구성됩니다. |
| data_shapes | 이 모듈에 대한 데이터 입력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_shapes | 이 모듈에 대한 레이블 입력을 지정하는 (이름, 모양) 쌍의 목록을 보여줍니다. |
| 출력 _ 이름 | 이 모듈의 출력에 대한 이름 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| 상징 | 지정된 이름에 따라이 속성은이 모듈과 연관된 기호를 가져옵니다. |
data_shapes-링크를 참조 할 수 있습니다. https://mxnet.apache.org/api/python/docs 자세한 내용은.
output_shapes− 링크는 https://mxnet.apache.org/api/python/docs 자세한 내용은.
모듈 (symbol [, data_names, label_names,…])
랩핑하는 기본 모듈을 나타냅니다. symbol.
행동 양식
다음 표는 구성 방법을 보여줍니다. Module class −
| 행동 양식 | 정의 |
|---|---|
| 뒤로 ([out_grads]) | 이름에서 알 수 있듯이이 방법은 backward 계산. |
| bind (data_shapes [, label_shapes,…]) | 실행기를 구성하기 위해 기호를 바인딩하고 모듈로 계산을 수행하기 전에 필요합니다. |
| 차용 _ 최적화 프로그램 (공유 _ 모듈) | 이름에서 알 수 있듯이이 메서드는 공유 모듈에서 옵티 마이저를 차용합니다. |
| 앞으로 (data_batch [, is_train]) | 이름에서 알 수 있듯이이 방법은 Forward계산. 이 방법은 다른 배치 크기 또는 다른 이미지 크기와 같은 다양한 모양의 데이터 배치를 지원합니다. |
| get_input_grads ([merge_multi_context]) | 이 방법은 이전 역방향 계산에서 계산 된 입력에 대한 기울기를 가져옵니다. |
| get_outputs ([merge_multi_context]) | 이름에서 알 수 있듯이이 메서드는 이전 순방향 계산의 출력을 가져옵니다. |
| get_params () | 특히 장치에서 계산을 수행하는 데 사용되는 실제 매개 변수의 잠재적 사본 인 매개 변수를 가져옵니다. |
| get_states ([merge_multi_context]) | 이 메서드는 모든 장치에서 상태를 가져옵니다. |
| init_optimizer ([kvstore, 최적화 프로그램,…]) | 이 방법은 최적화 프로그램을 설치하고 초기화합니다. 또한 초기화합니다.kvstore 교육을 배포합니다. |
| init_params ([초기화 자, arg_params,…]) | 이름에서 알 수 있듯이이 메서드는 매개 변수와 보조 상태를 초기화합니다. |
| install_monitor (mon) | 이 방법은 모든 실행기에 모니터를 설치합니다. |
| load (접두사, epoch [, sym_gen,…]) | 이 방법은 이전에 저장된 체크 포인트에서 모델을 생성합니다. |
| load_optimizer_states (fname) | 이 메서드는 최적화 프로그램, 즉 파일에서 업데이트 프로그램 상태를로드합니다. |
| 준비 (data_batch [, sparse_row_id_fn]) | 운영자는 주어진 데이터 일괄 처리를 위해 모듈을 준비합니다. |
| reshape (data_shapes [, label_shapes]) | 이름에서 알 수 있듯이이 방법은 새 입력 모양에 맞게 모듈의 모양을 변경합니다. |
| save_checkpoint (접두사, epoch [,…]) | 현재 진행 상황을 체크 포인트에 저장합니다. |
| save_optimizer_states (fname) | 이 메서드는 최적화 프로그램 또는 업데이트 프로그램 상태를 파일에 저장합니다. |
| set_params (arg_params, aux_params [,…]) | 이름이 지정한대로이 기능은 매개 변수와 보조 상태 값을 할당합니다. |
| set_states ([상태, 값]) | 이름에서 알 수 있듯이이 방법은 상태 값을 설정합니다. |
| 최신 정보() | 이 방법은 설치된 최적화 프로그램에 따라 주어진 매개 변수를 업데이트합니다. 또한 이전의 전후 배치에서 계산 된 기울기를 업데이트합니다. |
| update_metric (eval_metric, labels [, pre_sliced]) | 이 방법은 이름에서 알 수 있듯이 마지막 순방향 계산의 출력에 대한 평가 메트릭을 평가하고 누적합니다. |
속성
다음 표는 방법으로 구성된 속성을 보여줍니다. Module class −
| 속성 | 정의 |
|---|---|
| 데이터 _ 이름 | 이 모듈에 필요한 데이터의 이름 목록으로 구성됩니다. |
| data_shapes | 이 모듈에 대한 데이터 입력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_shapes | 이 모듈에 대한 레이블 입력을 지정하는 (이름, 모양) 쌍의 목록을 보여줍니다. |
| 출력 _ 이름 | 이 모듈의 출력에 대한 이름 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_names | 이 모듈에 필요한 레이블 이름 목록으로 구성됩니다. |
data_shapes : 링크 방문 https://mxnet.apache.org/api/python/docs/api/module 자세한 내용은.
output_shapes : 여기에 제공된 링크 https://mxnet.apache.org/api/python/docs/api/module/index.html 다른 중요한 정보를 제공합니다.
PythonLossModule ([이름, 데이터 _ 이름,…])
이 클래스의 기본은 mxnet.module.python_module.PythonModule. PythonLossModule 클래스는 모든 또는 많은 모듈 API를 빈 함수로 구현하는 편리한 모듈 클래스입니다.
행동 양식
다음 표는 구성 방법을 보여줍니다. PythonLossModule 수업:
| 행동 양식 | 정의 |
|---|---|
| 뒤로 ([out_grads]) | 이름에서 알 수 있듯이이 방법은 backward 계산. |
| 앞으로 (data_batch [, is_train]) | 이름에서 알 수 있듯이이 방법은 Forward계산. 이 방법은 다른 배치 크기 또는 다른 이미지 크기와 같은 다양한 모양의 데이터 배치를 지원합니다. |
| get_input_grads ([merge_multi_context]) | 이 방법은 이전 역방향 계산에서 계산 된 입력에 대한 기울기를 가져옵니다. |
| get_outputs ([merge_multi_context]) | 이름에서 알 수 있듯이이 메서드는 이전 순방향 계산의 출력을 가져옵니다. |
| install_monitor (mon) | 이 방법은 모든 실행기에 모니터를 설치합니다. |
PythonModule ([데이터 _ 이름, 라벨 _ 이름…])
이 클래스의 기본은 mxnet.module.base_module.BaseModule입니다. PythonModule 클래스는 또한 모든 또는 많은 모듈 API를 빈 함수로 구현하는 편리한 모듈 클래스입니다.
행동 양식
다음 표는 구성 방법을 보여줍니다. PythonModule 클래스-
| 행동 양식 | 정의 |
|---|---|
| bind (data_shapes [, label_shapes,…]) | 실행기를 구성하기 위해 기호를 바인딩하고 모듈로 계산을 수행하기 전에 필요합니다. |
| get_params () | 특히 장치에서 계산을 수행하는 데 사용되는 실제 매개 변수의 잠재적 사본 인 매개 변수를 가져옵니다. |
| init_optimizer ([kvstore, 최적화 프로그램,…]) | 이 방법은 최적화 프로그램을 설치하고 초기화합니다. 또한 초기화합니다.kvstore 교육을 배포합니다. |
| init_params ([초기화 자, arg_params,…]) | 이름에서 알 수 있듯이이 메서드는 매개 변수와 보조 상태를 초기화합니다. |
| 최신 정보() | 이 방법은 설치된 최적화 프로그램에 따라 주어진 매개 변수를 업데이트합니다. 또한 이전의 전후 배치에서 계산 된 기울기를 업데이트합니다. |
| update_metric (eval_metric, labels [, pre_sliced]) | 이 방법은 이름에서 알 수 있듯이 마지막 순방향 계산의 출력에 대한 평가 메트릭을 평가하고 누적합니다. |
속성
다음 표는 방법으로 구성된 속성을 보여줍니다. PythonModule 클래스-
| 속성 | 정의 |
|---|---|
| 데이터 _ 이름 | 이 모듈에 필요한 데이터의 이름 목록으로 구성됩니다. |
| data_shapes | 이 모듈에 대한 데이터 입력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_shapes | 이 모듈에 대한 레이블 입력을 지정하는 (이름, 모양) 쌍의 목록을 보여줍니다. |
| 출력 _ 이름 | 이 모듈의 출력에 대한 이름 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
data_shapes-링크를 따라 https://mxnet.apache.org 자세한 내용은.
output_shapes − 자세한 내용은 다음 링크를 참조하십시오. https://mxnet.apache.org
SequentialModule ([로거])
이 클래스의 기본은 mxnet.module.base_module.BaseModule입니다. SequentialModule 클래스는 또한 둘 이상의 (여러) 모듈을 함께 연결할 수있는 컨테이너 모듈입니다.
행동 양식
다음 표는 구성 방법을 보여줍니다. SequentialModule 수업
| 행동 양식 | 정의 |
|---|---|
| add (모듈, ** kwargs) | 이것은이 클래스의 가장 중요한 기능입니다. 체인에 모듈을 추가합니다. |
| 뒤로 ([out_grads]) | 이름에서 알 수 있듯이이 방법은 역방향 계산을 구현합니다. |
| bind (data_shapes [, label_shapes,…]) | 실행기를 구성하기 위해 기호를 바인딩하고 모듈로 계산을 수행하기 전에 필요합니다. |
| 앞으로 (data_batch [, is_train]) | 이름에서 알 수 있듯이이 메서드는 Forward 계산을 구현합니다. 이 방법은 다른 배치 크기 또는 다른 이미지 크기와 같은 다양한 모양의 데이터 배치를 지원합니다. |
| get_input_grads ([merge_multi_context]) | 이 방법은 이전 역방향 계산에서 계산 된 입력에 대한 기울기를 가져옵니다. |
| get_outputs ([merge_multi_context]) | 이름에서 알 수 있듯이이 메서드는 이전 순방향 계산의 출력을 가져옵니다. |
| get_params () | 특히 장치에서 계산을 수행하는 데 사용되는 실제 매개 변수의 잠재적 사본 인 매개 변수를 가져옵니다. |
| init_optimizer ([kvstore, 최적화 프로그램,…]) | 이 방법은 최적화 프로그램을 설치하고 초기화합니다. 또한 초기화합니다.kvstore 교육을 배포합니다. |
| init_params ([초기화 자, arg_params,…]) | 이름에서 알 수 있듯이이 메서드는 매개 변수와 보조 상태를 초기화합니다. |
| install_monitor (mon) | 이 방법은 모든 실행기에 모니터를 설치합니다. |
| 최신 정보() | 이 방법은 설치된 최적화 프로그램에 따라 주어진 매개 변수를 업데이트합니다. 또한 이전의 전후 배치에서 계산 된 기울기를 업데이트합니다. |
| update_metric (eval_metric, labels [, pre_sliced]) | 이 방법은 이름에서 알 수 있듯이 마지막 순방향 계산의 출력에 대한 평가 메트릭을 평가하고 누적합니다. |
속성
다음 표는 BaseModule 클래스의 메소드로 구성된 속성을 보여줍니다-
| 속성 | 정의 |
|---|---|
| 데이터 _ 이름 | 이 모듈에 필요한 데이터의 이름 목록으로 구성됩니다. |
| data_shapes | 이 모듈에 대한 데이터 입력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| label_shapes | 이 모듈에 대한 레이블 입력을 지정하는 (이름, 모양) 쌍의 목록을 보여줍니다. |
| 출력 _ 이름 | 이 모듈의 출력에 대한 이름 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
| output_shapes | 이 모듈의 출력을 지정하는 (이름, 모양) 쌍의 목록으로 구성됩니다. |
data_shapes − 여기에 제공된 링크 https://mxnet.apache.org 속성을 훨씬 자세히 이해하는 데 도움이됩니다.
output_shapes − 사용 가능한 링크를 따르십시오. https://mxnet.apache.org/api 자세한 내용은.
구현 예
아래 예에서 우리는 mxnet 기준 치수.
import mxnet as mx
input_data = mx.symbol.Variable('input_data')
f_connected1 = mx.symbol.FullyConnected(data, name='f_connected1', num_hidden=128)
activation_1 = mx.symbol.Activation(f_connected1, name='relu1', act_type="relu")
f_connected2 = mx.symbol.FullyConnected(activation_1, name = 'f_connected2', num_hidden = 64)
activation_2 = mx.symbol.Activation(f_connected2, name='relu2',
act_type="relu")
f_connected3 = mx.symbol.FullyConnected(activation_2, name='fc3', num_hidden=10)
out = mx.symbol.SoftmaxOutput(f_connected3, name = 'softmax')
mod = mx.mod.Module(out)
print(out)Output
출력은 아래에 언급되어 있습니다.
<Symbol softmax>Example
print(mod)Output
출력은 다음과 같습니다.
<mxnet.module.module.Module object at 0x00000123A9892F28>아래이 예에서는 순방향 계산을 구현합니다.
import mxnet as mx
from collections import namedtuple
Batch = namedtuple('Batch', ['data'])
data = mx.sym.Variable('data')
out = data * 2
mod = mx.mod.Module(symbol=out, label_names=None)
mod.bind(data_shapes=[('data', (1, 10))])
mod.init_params()
data1 = [mx.nd.ones((1, 10))]
mod.forward(Batch(data1))
print (mod.get_outputs()[0].asnumpy())Output
위의 코드를 실행하면 다음 출력이 표시됩니다.
[[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]]Example
data2 = [mx.nd.ones((3, 5))]
mod.forward(Batch(data2))
print (mod.get_outputs()[0].asnumpy())Output
다음은 코드의 출력입니다.
[[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]]