인공 지능-퀵 가이드
컴퓨터 나 기계의 발명 이후 다양한 작업을 수행 할 수있는 능력이 기하 급수적으로 증가했습니다. 인간은 다양한 작업 영역, 증가하는 속도 및 시간에 따른 크기 감소 측면에서 컴퓨터 시스템의 힘을 개발했습니다.
인공 지능 이라는 컴퓨터 과학의 한 분야는 인간만큼 지능적인 컴퓨터 또는 기계를 만드는 것을 추구합니다.
인공 지능이란 무엇입니까?
인공 지능의 아버지 인 John McCarthy에 따르면 이것은 "지능형 기계, 특히 지능적인 컴퓨터 프로그램을 만드는 과학과 공학"입니다.
인공 지능은 making a computer, a computer-controlled robot, or a software think intelligently, 비슷한 방식으로 지적인 인간이 생각합니다.
인공 지능은 인간의 두뇌가 어떻게 생각하는지, 인간이 문제를 해결하려고 노력하면서 학습, 결정, 작업하는 방법을 연구 한 다음이 연구의 결과를 지능형 소프트웨어 및 시스템 개발의 기초로 사용함으로써 달성됩니다.
AI의 철학
인간의 호기심 인 컴퓨터 시스템의 힘을 이용하면서 그는 “기계가 인간처럼 생각하고 행동 할 수 있는가?”라고 궁금해 하게 만듭니다.
따라서 AI의 개발은 우리가 인간에게서 발견하고 높이 평가하는 기계에서 유사한 지능을 생성하려는 의도에서 시작되었습니다.
AI의 목표
To Create Expert Systems − 지능적인 행동을 보이고 사용자에게 학습, 시연, 설명 및 조언하는 시스템.
To Implement Human Intelligence in Machines − 인간처럼 이해하고, 생각하고, 배우고, 행동하는 시스템을 만듭니다.
AI에 기여하는 것은 무엇입니까?
인공 지능은 컴퓨터 과학, 생물학, 심리학, 언어학, 수학 및 공학과 같은 분야를 기반으로하는 과학 및 기술입니다. AI의 주요 추진력은 추론, 학습 및 문제 해결과 같은 인간 지능과 관련된 컴퓨터 기능의 개발에 있습니다.
다음 영역 중 하나 또는 여러 영역이 지능형 시스템 구축에 기여할 수 있습니다.
AI없이 프로그래밍
AI를 사용하거나 사용하지 않는 프로그래밍은 다음과 같이 다릅니다.
| AI없이 프로그래밍 | AI로 프로그래밍 |
|---|---|
| AI가없는 컴퓨터 프로그램은 specific 해결해야 할 질문입니다. | AI가있는 컴퓨터 프로그램은 generic 해결해야 할 질문입니다. |
| 프로그램을 수정하면 구조가 변경됩니다. | AI 프로그램은 고도로 독립적 인 정보를 조합하여 새로운 수정 사항을 흡수 할 수 있습니다. 따라서 프로그램의 구조에 영향을주지 않고 프로그램의 아주 작은 정보도 수정할 수 있습니다. |
| 수정은 빠르고 쉽지 않습니다. 프로그램에 악영향을 미칠 수 있습니다. | 빠르고 쉬운 프로그램 수정. |
AI 기술이란?
현실 세계에서 지식에는 환영받지 못하는 속성이 있습니다.
- 그 볼륨은 상상할 수 없을 정도로 거대합니다.
- 잘 구성되어 있지 않거나 형식이 올바르지 않습니다.
- 끊임없이 변화합니다.
AI 기술은 다음과 같은 방식으로 효율적으로 지식을 구성하고 사용하는 방식입니다.
- 그것을 제공하는 사람들이 그것을인지 할 수 있어야합니다.
- 오류를 수정하려면 쉽게 수정할 수 있어야합니다.
- 불완전하거나 부정확하지만 많은 상황에서 유용해야합니다.
AI 기술은 장착 된 복잡한 프로그램의 실행 속도를 높입니다.
AI의 응용
AI는 다음과 같은 다양한 분야에서 지배적이었습니다.
Gaming − 인공 지능은 체스, 포커, 틱택 토 등과 같은 전략 게임에서 중요한 역할을합니다.이 게임에서는 기계가 휴리스틱 지식을 기반으로 가능한 많은 위치를 생각할 수 있습니다.
Natural Language Processing − 사람이 말하는 자연어를 이해하는 컴퓨터와 상호 작용할 수 있습니다.
Expert Systems− 추론 및 조언을 제공하기 위해 기계, 소프트웨어 및 특수 정보를 통합하는 일부 응용 프로그램이 있습니다. 사용자에게 설명과 조언을 제공합니다.
Vision Systems−이 시스템은 컴퓨터의 시각적 입력을 이해, 해석 및 이해합니다. 예를 들면
스파이 비행기는 사진을 찍어 공간 정보 또는 해당 지역의지도를 파악하는 데 사용됩니다.
의사는 임상 전문가 시스템을 사용하여 환자를 진단합니다.
경찰은 법의학자가 만든 초상화를 저장하여 범죄자의 얼굴을 인식 할 수있는 컴퓨터 소프트웨어를 사용합니다.
Speech Recognition− 일부 지능형 시스템은 인간이 말을하는 동안 문장과 그 의미의 관점에서 언어를 듣고 이해할 수 있습니다. 다양한 악센트, 속어, 배경 소음, 추위로 인한 인간 소음 변화 등을 처리 할 수 있습니다.
Handwriting Recognition− 필기 인식 소프트웨어는 펜으로 종이에 쓰여진 텍스트 또는 스타일러스로 화면에 쓰여진 텍스트를 읽습니다. 글자의 모양을 인식하여 편집 가능한 텍스트로 변환 할 수 있습니다.
Intelligent Robots− 로봇은 인간이 지정한 작업을 수행 할 수 있습니다. 빛, 열, 온도, 움직임, 소리, 범프 및 압력과 같은 실제 데이터를 감지하는 센서가 있습니다. 그들은 지능을 보여주기 위해 효율적인 프로세서, 다중 센서 및 거대한 메모리를 가지고 있습니다. 또한 실수로부터 배울 수 있고 새로운 환경에 적응할 수 있습니다.
AI의 역사
다음은 20 세기 AI의 역사입니다.
| 년 | 이정표 / 혁신 |
|---|---|
| 1923 년 | "Rossum 's Universal Robots"(RUR)라는 이름의 Karel Čapek 연극이 런던에서 개봉하여 영어로 "robot"이라는 단어가 처음 사용되었습니다. |
| 1943 년 | 신경망의 기초가 마련되었습니다. |
| 1945 년 | Columbia University 졸업생 인 Isaac Asimov는 Robotics 라는 용어를 만들었습니다 . |
| 1950 년 | Alan Turing은 지능 평가를 위해 Turing Test를 도입하고 Computing Machinery and Intelligence를 출판했습니다 . Claude Shannon 은 Chess Playing의 상세 분석을 검색으로 출판했습니다 . |
| 1956 년 | John McCarthy는 인공 지능 이라는 용어를 만들었습니다 . Carnegie Mellon University에서 처음으로 실행되는 AI 프로그램 시연. |
| 1958 년 | John McCarthy는 AI 용 LISP 프로그래밍 언어를 발명합니다. |
| 1964 년 | MIT에서 Danny Bobrow의 논문은 컴퓨터가 대수 단어 문제를 올바르게 풀기에 충분히 자연어를 이해할 수 있음을 보여주었습니다. |
| 1965 년 | MIT의 Joseph Weizenbaum 은 영어로 대화를 이어가는 대화 형 문제인 ELIZA를 만들었습니다 . |
| 1969 년 | Stanford Research Institute의 과학자들은 이동, 지각 및 문제 해결 기능을 갖춘 로봇 인 Shakey를 개발했습니다 . |
| 1973 년 | Edinburgh University의 Assembly Robotics 그룹은 비전을 사용하여 모델을 찾고 조립할 수있는 유명한 스코틀랜드 로봇 인 Freddy를 만들었습니다 . |
| 1979 년 | 최초의 컴퓨터 제어 자율 주행 차량 인 Stanford Cart가 제작되었습니다. |
| 1985 년 | Harold Cohen은 드로잉 프로그램 Aaron을 만들고 시연했습니다 . |
| 1990 년 | AI의 모든 영역에서 주요 발전-
|
| 1997 년 | Deep Blue Chess Program은 당시 세계 체스 챔피언 인 Garry Kasparov를 이겼습니다. |
| 2000 년 | 대화 형 로봇 애완 동물이 상용화되었습니다. MIT는 감정을 표현하는 얼굴을 가진 로봇 Kismet을 전시 합니다. 로봇 Nomad 는 남극 대륙의 외딴 지역을 탐험하고 운석을 찾습니다. |
인공 지능을 연구하는 동안 지능이 무엇인지 알아야합니다. 이 장에서는 지능의 아이디어, 유형 및 지능의 구성 요소를 다룹니다.
지능이란 무엇입니까?
계산, 추론, 관계 및 비유를 인식하고, 경험을 통해 배우고, 기억에서 정보를 저장 및 검색하고, 문제를 해결하고, 복잡한 아이디어를 이해하고, 자연어를 유창하게 사용하고, 새로운 상황을 분류, 일반화 및 적응하는 시스템의 능력.
지능의 유형
미국의 발달 심리학자 인 Howard Gardner가 설명했듯이 지능은 여러 가지로 나옵니다.
| 지성 | 기술 | 예 |
|---|---|---|
| 언어 지능 | 음운 (음성), 구문 (문법) 및 의미 (의미)의 메커니즘을 말하고 인식하고 사용하는 능력. | 내레이터, 연설자 |
| 음악적 지능 | 소리로 이루어진 의미를 만들고, 소통하고, 이해하는 능력, 음조, 리듬에 대한 이해. | 음악가, 가수, 작곡가 |
| 논리적-수학적 지능 | 행동이나 물건이 없을 때 관계를 사용하고 이해하는 능력. 복잡하고 추상적 인 아이디어 이해. | 수학자, 과학자 |
| 공간 지능 | 시각적 또는 공간적 정보를 인식하고,이를 변경하고, 객체를 참조하지 않고 시각적 이미지를 재생성하고, 3D 이미지를 구성하고, 이동 및 회전하는 기능. | 지도 판독기, 우주 비행사, 물리학 자 |
| 신체-운동 지능 | 신체의 전체 또는 일부를 사용하여 문제 또는 패션 제품을 해결하고, 미세하고 거친 운동 기술을 제어하고, 물체를 조작하는 능력. | 플레이어, 댄서 |
| 개인 내 지능 | 자신의 감정, 의도 및 동기를 구별하는 능력. | 가우 탐 불교 |
| 대 인 지능 | 다른 사람의 감정, 신념 및 의도를 인식하고 구별하는 능력. | 매스 커뮤니케이터, 인터뷰어 |
기계 나 시스템이 artificially intelligent 적어도 하나 이상의 지능을 갖추고있을 때.
인텔리전스는 무엇으로 구성됩니까?
지능은 무형입니다. 구성은-
- Reasoning
- Learning
- 문제 해결
- Perception
- 언어 지능

모든 구성 요소를 간략하게 살펴 보겠습니다.
Reasoning− 판단, 결정 및 예측을위한 기초를 제공 할 수있는 일련의 프로세스입니다. 크게 두 가지 유형이 있습니다-
| 귀납적 추론 | 연역적 추리 |
|---|---|
| 광범위한 일반 진술을하기 위해 특정 관찰을 수행합니다. | 일반적인 진술로 시작하여 구체적이고 논리적 결론에 도달 할 수있는 가능성을 조사합니다. |
| 성명서에서 모든 전제가 사실이더라도 귀납적 추론은 결론이 거짓이 될 수 있습니다. | 일반적으로 사물의 클래스에 해당하는 것이 있으면 해당 클래스의 모든 구성원에게도 해당됩니다. |
| 예- "Nita는 교사입니다. Nita는 학업 적입니다. 따라서 모든 교사는 학업 적입니다." | 예- "60 세 이상의 모든 여성은 할머니입니다. Shalini는 65 세입니다. 따라서 Shalini는 할머니입니다." |
Learning− 공부, 연습, 가르침 또는 경험을 통해 지식이나 기술을 얻는 활동입니다. 학습은 연구 주제에 대한 인식을 향상시킵니다.
학습 능력은 인간, 일부 동물 및 AI 지원 시스템에 있습니다. 학습은 다음과 같이 분류됩니다.
Auditory Learning− 듣고 듣고 배우는 것입니다. 예를 들어, 녹음 된 오디오 강의를 듣는 학생들.
Episodic Learning− 목격했거나 경험 한 일련의 사건을 기억하여 학습합니다. 이것은 선형적이고 질서 정연합니다.
Motor Learning− 근육의 정확한 움직임으로 학습합니다. 예를 들어, 물건 따기, 쓰기 등
Observational Learning− 다른 사람을보고 모방하여 배우기. 예를 들어, 아이는 부모를 모방하여 배우려고합니다.
Perceptual Learning− 이전에 본 적이있는 자극을 인식하는 것을 배우는 것입니다. 예를 들어 대상과 상황을 식별하고 분류합니다.
Relational Learning− 절대적 속성보다는 관계형 속성을 기반으로 다양한 자극을 구별하는 방법을 배우는 것입니다. 예를 들어, 지난번에 짠 감자를 요리 할 때 '조금 덜'소금을 추가하고, 소금 한 스푼을 추가하여 요리 할 때.
Spatial Learning − 이미지, 색상,지도 등의 시각적 자극을 통해 학습하는 것입니다. 예를 들어 실제로 길을 따라 가기 전에 마음에 로드맵을 만들 수 있습니다.
Stimulus-Response Learning− 특정 자극이있을 때 특정 행동을 수행하는 방법을 배우는 것입니다. 예를 들어, 개는 초인종을 들으면서 귀를 들어 올립니다.
Problem Solving − 알려 지거나 알려지지 않은 장애물에 의해 막혀있는 어떤 길을 택하여 현재 상황에서 원하는 해결책에 도달하려고 시도하는 과정이다.
문제 해결에는 다음이 포함됩니다. decision making, 원하는 목표에 도달하기 위해 여러 대안 중에서 가장 적합한 대안을 선택하는 프로세스입니다.
Perception − 감각 정보를 획득, 해석, 선택, 구성하는 과정입니다.
지각 추정 sensing. 인간의 경우 지각은 감각 기관의 도움을받습니다. AI 영역에서 인식 메커니즘은 센서에서 수집 한 데이터를 의미있는 방식으로 결합합니다.
Linguistic Intelligence− 언어 및 서면 언어를 사용하고, 이해하고, 말하고, 쓰는 능력입니다. 대인 커뮤니케이션에서 중요합니다.
인간과 기계 지능의 차이
인간은 패턴으로 인식하는 반면 기계는 일련의 규칙과 데이터로 인식합니다.
인간은 패턴별로 정보를 저장하고 기억하고, 기계는 알고리즘을 검색하여 수행합니다. 예를 들어, 숫자 40404040은 패턴이 단순하기 때문에 기억, 저장 및 기억하기 쉽습니다.
인간은 일부가 누락되거나 왜곡 된 경우에도 완전한 물체를 파악할 수 있습니다. 기계는 제대로 할 수 없습니다.
인공 지능의 영역은 넓고 넓습니다. 진행하는 동안 우리는 AI 영역에서 광범위하고 번영하는 연구 분야를 고려합니다.

음성 및 음성 인식
이 두 용어는 로봇 공학, 전문가 시스템 및 자연어 처리에서 일반적입니다. 이러한 용어는 같은 의미로 사용되지만 목적은 다릅니다.
| 음성 인식 | 음성 인식 |
|---|---|
| 음성 인식은 이해와 이해를 목표로합니다. WHAT 말했다. | 음성 인식의 목적은 WHO 말하고 있습니다. |
| 핸즈프리 컴퓨팅,지도 또는 메뉴 탐색에 사용됩니다. | 어조, 음조, 억양 등을 분석하여 사람을 식별하는 데 사용됩니다. |
| 기계는 화자에 의존하지 않기 때문에 음성 인식에 대한 교육이 필요하지 않습니다. | 이 인식 시스템은 사람 중심이므로 교육이 필요합니다. |
| 화자 독립 음성 인식 시스템은 개발하기 어렵습니다. | 화자 의존 음성 인식 시스템은 비교적 개발하기 쉽습니다. |
음성 및 음성 인식 시스템의 작동
마이크에서 말한 사용자 입력은 시스템의 사운드 카드로 전달됩니다. 변환기는 음성 처리를 위해 아날로그 신호를 동등한 디지털 신호로 변환합니다. 데이터베이스는 단어를 인식하기 위해 사운드 패턴을 비교하는 데 사용됩니다. 마지막으로 데이터베이스에 역 피드백이 제공됩니다.
이 소스 언어 텍스트는 번역 엔진에 입력되어 대상 언어 텍스트로 변환됩니다. 대화 형 GUI, 대규모 어휘 데이터베이스 등으로 지원됩니다.
연구 분야의 실제 응용
AI가 일상 생활에서 일반인에게 서비스를 제공하는 다양한 애플리케이션이 있습니다.
| Sr. 아니. | 연구 분야 | 실생활 응용 |
|---|---|---|
| 1 | Expert Systems 예-비행 추적 시스템, 임상 시스템. |

|
| 2 | Natural Language Processing 예 : Google Now 기능, 음성 인식, 자동 음성 출력. |

|
| 삼 | Neural Networks 예-얼굴 인식, 문자 인식, 필기 인식과 같은 패턴 인식 시스템. |

|
| 4 | Robotics 예-이동, 스프레이, 페인팅, 정밀 검사, 드릴링, 청소, 코팅, 조각 등을위한 산업용 로봇 |

|
| 5 | Fuzzy Logic Systems 예-가전 제품, 자동차 등 |

|
AI의 작업 분류
AI의 영역은 다음과 같이 분류됩니다. Formal tasks, Mundane tasks, 과 Expert tasks.

| 인공 지능의 작업 영역 | ||
|---|---|---|
| 평범한 (일반) 작업 | 공식 작업 | 전문가 작업 |
지각
|
|
|
자연어 처리
|
계략
|
과학적 분석 |
| 상식 | 확인 | 재무 분석 |
| 추리 | 정리 증명 | 의료 진단 |
| 기획 | 창의성 | |
로봇 공학
|
||
인간은 배웁니다 mundane (ordinary) tasks출생 이후. 그들은 지각, 말하기, 언어 사용 및 기관차를 통해 배웁니다. 나중에 공식 작업과 전문가 작업을 순서대로 배웁니다.
인간에게는 평범한 작업이 가장 배우기 쉽습니다. 기계에서 일상적인 작업을 구현하기 전에도 마찬가지였습니다. 이전에는 AI의 모든 작업이 일상적인 작업 영역에 집중되었습니다.
나중에 기계는 일상적인 작업을 처리하기 위해 더 많은 지식, 복잡한 지식 표현 및 복잡한 알고리즘이 필요하다는 것이 밝혀졌습니다. 이것이 이유 다why AI work is more prospering in the Expert Tasks domain 이제 전문가 작업 영역에는 상식없이 전문 지식이 필요하므로 표현하고 처리하기가 더 쉽습니다.
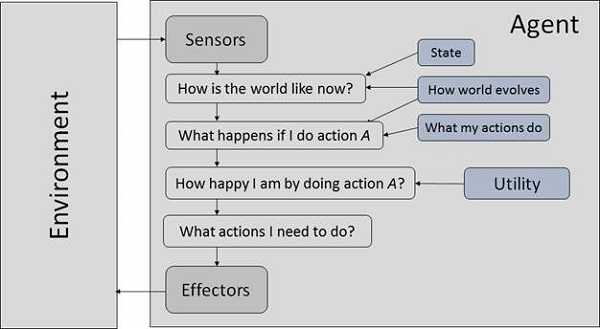
AI 시스템은 에이전트와 환경으로 구성됩니다. 에이전트는 자신의 환경에서 행동합니다. 환경에는 다른 에이전트가 포함될 수 있습니다.
에이전트와 환경은 무엇입니까?
안 agent 환경을 인식 할 수있는 모든 것입니다. sensors 그 환경에 따라 행동합니다. effectors.
ㅏ human agent 센서와 평행 한 눈, 귀, 코, 혀 및 피부와 같은 감각 기관과 이펙터 용 손, 다리, 입과 같은 기타 기관이 있습니다.
ㅏ robotic agent 센서 용 카메라 및 적외선 거리 측정기, 이펙터 용 다양한 모터 및 액추에이터를 대체합니다.
ㅏ software agent 프로그램 및 작업으로 인코딩 된 비트 문자열이 있습니다.

에이전트 용어
Performance Measure of Agent − 상담원의 성공 여부를 결정하는 기준입니다.
Behavior of Agent − 주어진 지각 순서 후에 에이전트가 수행하는 작업입니다.
Percept − 주어진 인스턴스에서 에이전트의 지각 입력입니다.
Percept Sequence − 에이전트가 날짜까지인지 한 모든 것의 역사입니다.
Agent Function − 계율 순서에서 행동으로의지도입니다.
합리성
합리성은 합리적이고 합리적이며 판단력이 좋은 상태에 지나지 않습니다.
합리성은 에이전트가 인식 한 것에 따라 예상되는 조치 및 결과와 관련됩니다. 유용한 정보를 얻기위한 목적으로 행동을 수행하는 것은 합리성의 중요한 부분입니다.
이상적인 Rational Agent는 무엇입니까?
이상적인 합리적 에이전트는 다음을 기반으로 성능 측정을 최대화하기 위해 예상되는 조치를 수행 할 수있는 에이전트입니다.
- 지각 순서
- 기본 제공 지식 기반
에이전트의 합리성은 다음에 따라 달라집니다-
그만큼 performance measures, 성공의 정도를 결정합니다.
자치령 대표 Percept Sequence 지금까지.
에이전트의 prior knowledge about the environment.
그만큼 actions 에이전트가 수행 할 수 있습니다.
합리적인 에이전트는 항상 올바른 행동을 수행합니다. 여기서 올바른 행동은 주어진 지각 순서에서 에이전트가 가장 성공하도록하는 행동을 의미합니다. 에이전트가 해결하는 문제는 성능 측정, 환경, 액추에이터 및 센서 (PEAS)가 특징입니다.
지능형 에이전트의 구조
에이전트의 구조는 다음과 같이 볼 수 있습니다.
- 에이전트 = 아키텍처 + 에이전트 프로그램
- 아키텍처 = 에이전트가 실행되는 기계.
- 에이전트 프로그램 = 에이전트 기능의 구현.
단순 반사 작용제
- 그들은 현재의 지각에 따라서 만 행동을 선택합니다.
- 현행 교훈에 근거하여 올바른 결정을 내릴 때만 합리적입니다.
- 그들의 환경은 완전히 관찰 가능합니다.
Condition-Action Rule − 상태 (조건)를 작업에 매핑하는 규칙입니다.

모델 기반 반사 에이전트
그들은 자신의 행동을 선택하기 위해 세상의 모델을 사용합니다. 그들은 내부 상태를 유지합니다.
Model −“세상에서 일어나는 일”에 대한 지식.
Internal State − 지각 이력에 따라 현재 상태의 관찰되지 않은 측면을 표현한 것입니다.
Updating the state requires the information about −
- 세상이 어떻게 진화하는지.
- 에이전트의 행동이 세상에 미치는 영향.

목표 기반 에이전트
그들은 목표를 달성하기 위해 행동을 선택합니다. 목표 기반 접근 방식은 결정을 지원하는 지식이 명시 적으로 모델링되어 수정이 가능하기 때문에 반사 에이전트보다 유연합니다.
Goal − 바람직한 상황에 대한 설명입니다.

유틸리티 기반 에이전트
그들은 각 주에 대한 선호도 (유틸리티)에 따라 조치를 선택합니다.
다음과 같은 경우 목표가 부적절합니다.
상충되는 목표가 있으며 그중 몇 개만 달성 할 수 있습니다.
목표는 달성 할 수있는 불확실성이 있으며 목표의 중요성과 성공 가능성을 비교해 볼 필요가 있습니다.
환경의 본질
일부 프로그램은 전적으로 artificial environment 키보드 입력, 데이터베이스, 컴퓨터 파일 시스템 및 화면의 문자 출력에 국한됩니다.
반대로 일부 소프트웨어 에이전트 (소프트웨어 로봇 또는 소프트 봇)는 풍부하고 무제한의 소프트 봇 도메인에 존재합니다. 시뮬레이터에는very detailed, complex environment. 소프트웨어 에이전트는 실시간으로 다양한 작업 중에서 선택해야합니다. 고객의 온라인 선호도를 스캔하고 고객에게 흥미로운 항목을 보여 주도록 설계된 소프트 봇은real 뿐만 아니라 artificial 환경.
가장 유명한 artificial environment 이다 Turing Test environment, 하나의 실제 에이전트와 다른 인공 에이전트가 동일한 근거에서 테스트됩니다. 이것은 소프트웨어 에이전트가 사람처럼 수행하기 매우 어렵 기 때문에 매우 어려운 환경입니다.
튜링 테스트
시스템의 지능적인 동작의 성공 여부는 Turing Test로 측정 할 수 있습니다.
두 사람과 평가할 기계가 테스트에 참여합니다. 두 사람 중 한 사람이 테스터 역할을합니다. 그들 각각은 다른 방에 앉아 있습니다. 테스터는 누가 기계이고 누가 인간인지 알지 못합니다. 그는 질문을 입력하고 두 정보에 전송하여 질문을 심문하고 입력 된 응답을받습니다.
이 테스트는 테스터를 속이는 것을 목표로합니다. 테스터가 사람의 반응에서 기계의 반응을 결정하지 못하면 기계는 지능적이라고합니다.
환경의 특성
환경에는 여러 가지 속성이 있습니다.
Discrete / Continuous− 환경의 뚜렷하고 명확하게 정의 된 상태가 제한된 수의 경우 환경은 개별적입니다 (예 : 체스). 그렇지 않으면 연속적입니다 (예 : 운전).
Observable / Partially Observable− 지각으로부터 각 시점에서 환경의 완전한 상태를 결정할 수 있다면 관찰 가능합니다. 그렇지 않으면 부분적으로 만 관찰 할 수 있습니다.
Static / Dynamic− 에이전트가 작동하는 동안 환경이 변경되지 않으면 정적입니다. 그렇지 않으면 동적입니다.
Single agent / Multiple agents − 환경에는 에이전트와 동일하거나 다른 종류의 다른 에이전트가 포함될 수 있습니다.
Accessible / Inaccessible − 에이전트의 감각 장치가 환경의 전체 상태에 액세스 할 수있는 경우 해당 에이전트가 환경에 액세스 할 수 있습니다.
Deterministic / Non-deterministic− 환경의 다음 상태가 현재 상태와 에이전트의 작업에 의해 완전히 결정되면 환경은 결정적입니다. 그렇지 않으면 비 결정적입니다.
Episodic / Non-episodic− 에피소드 적 환경에서 각 에피소드는 에이전트가인지하고 행동하는 것으로 구성됩니다. 행동의 질은 에피소드 자체에 달려 있습니다. 후속 에피소드는 이전 에피소드의 작업에 의존하지 않습니다. 에피소드 환경은 에이전트가 미리 생각할 필요가 없기 때문에 훨씬 간단합니다.
검색은 AI에서 문제를 해결하는 보편적 인 기술입니다. 타일 게임, 스도쿠, 십자말 풀이 등과 같은 일부 싱글 플레이어 게임이 있습니다. 검색 알고리즘은 이러한 게임에서 특정 위치를 검색하는 데 도움이됩니다.
단일 에이전트 경로 찾기 문제
3X3 8 타일, 4X4 15 타일, 5X5 24 타일 퍼즐과 같은 게임은 단일 에이전트 경로 찾기 도전입니다. 빈 타일이있는 타일 매트릭스로 구성됩니다. 플레이어는 어떤 목표를 달성하기 위해 빈 공간에 수직 또는 수평으로 타일을 밀어 넣어 타일을 배열해야합니다.
단일 에이전트 길 찾기 문제의 다른 예는 Traveling Salesman Problem, Rubik 's Cube 및 Theorem Proving입니다.
용어 검색
Problem Space− 검색이 이루어지는 환경입니다. (상태를 변경하기위한 일련의 상태 및 연산자 세트)
Problem Instance − 초기 상태 + 목표 상태입니다.
Problem Space Graph− 문제 상태를 나타냅니다. 상태는 노드로 표시되고 연산자는 가장자리로 표시됩니다.
Depth of a problem − 초기 상태에서 목표 상태까지의 최단 경로 또는 최단 연산자 시퀀스의 길이.
Space Complexity − 메모리에 저장되는 최대 노드 수.
Time Complexity − 생성되는 최대 노드 수.
Admissibility − 항상 최적의 솔루션을 찾기위한 알고리즘의 속성.
Branching Factor − 문제 공간 그래프의 평균 자식 노드 수.
Depth − 초기 상태에서 목표 상태까지의 최단 경로 길이.
무차별 대입 검색 전략
도메인 별 지식이 필요하지 않기 때문에 가장 간단합니다. 가능한 적은 수의 상태에서 잘 작동합니다.
요구 사항-
- 상태 설명
- 유효한 연산자 집합
- 초기 상태
- 목표 상태 설명
폭 우선 검색
루트 노드에서 시작하여 이웃 노드를 먼저 탐색하고 다음 레벨 이웃으로 이동합니다. 솔루션을 찾을 때까지 한 번에 하나의 트리를 생성합니다. FIFO 대기열 데이터 구조를 사용하여 구현할 수 있습니다. 이 방법은 솔루션에 대한 최단 경로를 제공합니다.
만약 branching factor(주어진 노드에 대한 평균 자식 노드 수) = b 및 깊이 = d, 수준 d = b d 의 노드 수 .
최악의 경우 생성 된 총 노드 수는 b + b 2 + b 3 +… + b d 입니다.
Disadvantage− 다음 노드 생성을 위해 각 레벨의 노드가 저장되므로 많은 메모리 공간을 소비합니다. 노드를 저장하는 데 필요한 공간은 기하 급수적입니다.
복잡성은 노드 수에 따라 다릅니다. 중복 노드를 확인할 수 있습니다.

깊이 우선 검색
LIFO 스택 데이터 구조를 사용하여 재귀로 구현됩니다. Breadth-First 방법과 동일한 노드 집합을 다른 순서로만 만듭니다.
단일 경로의 노드는 루트에서 리프 노드로의 각 반복에 저장되므로 노드를 저장하는 데 필요한 공간은 선형입니다. 분기 계수 b 및 깊이가 m 인 경우 저장 공간은 bm입니다.
Disadvantage−이 알고리즘은 종료되지 않고 한 경로에서 무한히 진행될 수 있습니다. 이 문제에 대한 해결책은 컷오프 깊이를 선택하는 것입니다. 이상적인 컷오프가 d 이고 선택한 컷오프가 d 보다 작 으면 이 알고리즘이 실패 할 수 있습니다. 선택한 컷오프가 d 보다 크면 실행 시간이 늘어납니다.
복잡성은 경로 수에 따라 다릅니다. 중복 노드는 확인할 수 없습니다.

양방향 검색
공통 상태를 식별하기 위해 둘 다 만날 때까지 초기 상태에서 앞으로 및 목표 상태에서 뒤로 검색합니다.
초기 상태의 경로는 목표 상태의 역 경로와 연결됩니다. 각 검색은 전체 경로의 최대 절반까지만 수행됩니다.
균일 비용 검색
정렬은 노드 경로의 비용 증가로 수행됩니다. 항상 최소 비용 노드를 확장합니다. 각 전환의 비용이 동일한 경우 Breadth First 검색과 동일합니다.
증가하는 비용 순서로 경로를 탐색합니다.
Disadvantage− 비용이 C * 이하인 긴 경로가 여러 개있을 수 있습니다. 균일 비용 검색은 모두를 탐색해야합니다.
반복 심화 깊이 우선 검색
레벨 1까지 깊이 우선 검색을 수행하고 다시 시작하여 레벨 2까지 완전한 깊이 우선 검색을 실행하고 솔루션을 찾을 때까지 이러한 방식으로 계속합니다.
모든 하위 노드가 생성 될 때까지 노드를 생성하지 않습니다. 노드 스택 만 저장합니다. 알고리즘은 깊이 d 에서 해를 찾으면 종료됩니다 . 깊이 d 에서 생성 된 노드의 수 는 b d 이고 깊이 d-1 에서 생성되는 노드의 수 는 b d-1입니다.
다양한 알고리즘 복잡성 비교
다양한 기준에 따른 알고리즘의 성능을 살펴 보겠습니다.
| 표준 | 너비 우선 | 깊이 우선 | 양방향 | 균일 한 비용 | 인터랙티브 심화 |
|---|---|---|---|---|---|
| 시각 | b d | b m | b d / 2 | b d | b d |
| 우주 | b d | b m | b d / 2 | b d | b d |
| 최적 성 | 예 | 아니 | 예 | 예 | 예 |
| 완전성 | 예 | 아니 | 예 | 예 | 예 |
정보에 입각 한 (휴리스틱) 검색 전략
가능한 상태가 많은 큰 문제를 해결하려면 검색 알고리즘의 효율성을 높이기 위해 문제 별 지식을 추가해야합니다.
휴리스틱 평가 함수
두 주 간의 최적 경로 비용을 계산합니다. 슬라이딩 타일 게임의 휴리스틱 함수는 각 타일이 목표 상태에서 이동하는 수를 계산하고 모든 타일에 대해 이러한 이동 수를 더하여 계산됩니다.
순수 휴리스틱 검색
휴리스틱 값 순서로 노드를 확장합니다. 이미 확장 된 노드에 대한 닫힌 목록과 생성되었지만 확장되지 않은 노드에 대한 열린 목록의 두 목록을 만듭니다.
각 반복에서 최소 휴리스틱 값을 가진 노드가 확장되고 모든 하위 노드가 생성되어 닫힌 목록에 배치됩니다. 그런 다음 휴리스틱 기능이 자식 노드에 적용되고 휴리스틱 값에 따라 열린 목록에 배치됩니다. 짧은 경로는 저장되고 긴 경로는 삭제됩니다.
검색
Best First 검색의 가장 잘 알려진 형태입니다. 이미 비용이 많이 드는 경로 확장을 피하지만 가장 유망한 경로를 먼저 확장합니다.
f (n) = g (n) + h (n), 여기서
- g (n) 노드에 도달하기위한 비용 (지금까지)
- h (n) 노드에서 목표까지의 예상 비용
- f (n) n을 통해 목표에 이르는 경로의 총 예상 비용. f (n)을 증가시켜 우선 순위 큐를 사용하여 구현됩니다.
탐욕스러운 첫 번째 검색
목표에 가장 가까운 것으로 추정되는 노드를 확장합니다. f (n) = h (n)을 기반으로 노드를 확장합니다. 우선 순위 큐를 사용하여 구현됩니다.
Disadvantage− 루프에 걸릴 수 있습니다. 최적이 아닙니다.
지역 검색 알고리즘
그들은 예상 솔루션에서 시작하여 인접한 솔루션으로 이동합니다. 종료되기 전에 언제든지 중단 되더라도 유효한 솔루션을 반환 할 수 있습니다.
힐 클라이밍 검색
문제에 대한 임의의 솔루션으로 시작하여 솔루션의 단일 요소를 점진적으로 변경하여 더 나은 솔루션을 찾으려고 시도하는 반복 알고리즘입니다. 변경으로 더 나은 솔루션이 생성되면 증분 변경이 새로운 솔루션으로 간주됩니다. 이 프로세스는 더 이상 개선되지 않을 때까지 반복됩니다.
기능 Hill-Climbing (문제)은 지역 최대 값 인 상태를 반환합니다.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage −이 알고리즘은 완전하지도 최적도 아닙니다.
로컬 빔 검색
이 알고리즘에서는 주어진 시간에 k 개의 상태를 보유합니다. 처음에는 이러한 상태가 무작위로 생성됩니다. 이러한 k 상태의 후속 항목은 목적 함수의 도움으로 계산됩니다. 이러한 후속 작업이 목적 함수의 최대 값이면 알고리즘이 중지됩니다.
그렇지 않으면 (초기 k 상태 및 상태의 후속 k 수 = 2k) 상태가 풀에 배치됩니다. 그런 다음 풀이 숫자로 정렬됩니다. 가장 높은 k 상태가 새로운 초기 상태로 선택됩니다. 이 프로세스는 최대 값에 도달 할 때까지 계속됩니다.
function BeamSearch ( problem, k )는 솔루션 상태를 반환합니다.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
end시뮬레이션 된 어닐링
어닐링은 금속을 가열 및 냉각하여 물리적 특성을 수정하기 위해 내부 구조를 변경하는 과정입니다. 금속이 냉각되면 새로운 구조가 포착되고 금속은 새로 얻은 특성을 유지합니다. 시뮬레이션 된 어닐링 공정에서 온도는 가변적으로 유지됩니다.
처음에는 온도를 높게 설정 한 다음 알고리즘이 진행됨에 따라 천천히 '냉각'되도록합니다. 온도가 높을 때 알고리즘은 높은 빈도로 더 나쁜 솔루션을 수용 할 수 있습니다.
스타트
- 초기화 k = 0; L = 정수 변수 수;
- i → j에서 성능 차이 Δ를 검색합니다.
- 만약 Δ <= 0이면 else if exp (-Δ / T (k))> random (0,1) then accept;
- L (k) 단계에 대해 1 단계와 2 단계를 반복합니다.
- k = k + 1;
기준이 충족 될 때까지 1-4 단계를 반복합니다.
종료
여행하는 세일즈맨 문제
이 알고리즘에서 목표는 도시에서 시작하여 모든 도시를 정확히 한 번 방문하고 동일한 시작 도시에서 끝나는 저렴한 여행을 찾는 것입니다.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
퍼지 로직 시스템 (FLS)은 불완전하거나 모호하거나 왜곡되거나 부정확 한 (퍼지) 입력에 대한 응답으로 수용 가능하지만 명확한 출력을 생성합니다.
퍼지 로직이란?
퍼지 로직 (FL)은 인간의 추론과 유사한 추론 방법입니다. FL의 접근 방식은 디지털 값 YES와 NO 사이의 모든 중간 가능성을 포함하는 인간의 의사 결정 방식을 모방합니다.
컴퓨터가 이해할 수있는 기존 논리 블록은 정확한 입력을 받아 TRUE 또는 FALSE로 명확한 출력을 생성하며 이는 인간의 YES 또는 NO와 동일합니다.
퍼지 논리의 발명가 인 Lotfi Zadeh는 컴퓨터와 달리 인간의 의사 결정에는 다음과 같은 YES와 NO 사이의 다양한 가능성이 포함됩니다.
| 확실히 그렇습니다 |
| 예 |
| 말할 수 없다 |
| 아니요 |
| 확실히 아니오 |
퍼지 논리는 명확한 출력을 얻기 위해 입력 가능성 수준에서 작동합니다.
이행
소형 마이크로 컨트롤러부터 대규모 네트워크 워크 스테이션 기반 제어 시스템에 이르기까지 다양한 크기와 기능을 갖춘 시스템에서 구현할 수 있습니다.
하드웨어, 소프트웨어 또는 둘의 조합으로 구현할 수 있습니다.
왜 퍼지 로직인가?
퍼지 논리는 상업적이고 실용적인 목적에 유용합니다.
- 기계와 소비재를 제어 할 수 있습니다.
- 정확한 추론을 제공하지는 않지만 수용 가능한 추론을 제공합니다.
- 퍼지 논리는 엔지니어링의 불확실성을 처리하는 데 도움이됩니다.
퍼지 로직 시스템 아키텍처
다음과 같이 네 가지 주요 부분이 있습니다.
Fuzzification Module− 선명한 숫자 인 시스템 입력을 퍼지 세트로 변환합니다. 입력 신호를 다음과 같이 5 단계로 분할합니다.
| LP | x는 큰 양수입니다. |
| MP | x는 중간 양수입니다. |
| S | x는 작다 |
| MN | x는 중간 음수입니다. |
| LN | x는 큰 음수입니다. |
Knowledge Base − 전문가가 제공 한 IF-THEN 규칙을 저장합니다.
Inference Engine − 입력 및 IF-THEN 규칙에 대해 퍼지 추론을 수행하여 인간의 추론 과정을 시뮬레이션합니다.
Defuzzification Module − 추론 엔진에서 얻은 퍼지 세트를 선명한 값으로 변환합니다.

그만큼 membership functions work on 퍼지 변수 세트.
회원 기능
멤버십 함수를 사용하면 언어 용어를 수량화하고 퍼지 세트를 그래픽으로 나타낼 수 있습니다. ㅏmembership function담화 X의 우주 에서 퍼지 세트 A 에 대해 μ A : X → [0,1] 로 정의됩니다 .
여기서 X의 각 요소는 0과 1 사이의 값에 매핑됩니다.membership value 또는 degree of membership. 퍼지 집합 A 에 대한 X 의 요소 구성원 정도를 정량화합니다 .
- x 축은 담론의 우주를 나타냅니다.
- y 축은 [0, 1] 간격의 소속 정도를 나타냅니다.
숫자 값을 퍼지 화하는 데 적용 할 수있는 여러 멤버십 함수가있을 수 있습니다. 복잡한 함수를 사용하더라도 출력에 더 많은 정밀도가 추가되지 않으므로 단순 멤버십 함수가 사용됩니다.
모든 회원 기능 LP, MP, S, MN, 과 LN 다음과 같이 표시됩니다-

삼각 멤버십 함수 셰이프는 사다리꼴, 싱글 톤 및 가우스와 같은 다양한 다른 멤버십 함수 셰이프 중에서 가장 일반적입니다.
여기에서 5 레벨 퍼지 파이어에 대한 입력은 -10V에서 + 10V까지 다양합니다. 따라서 해당 출력도 변경됩니다.
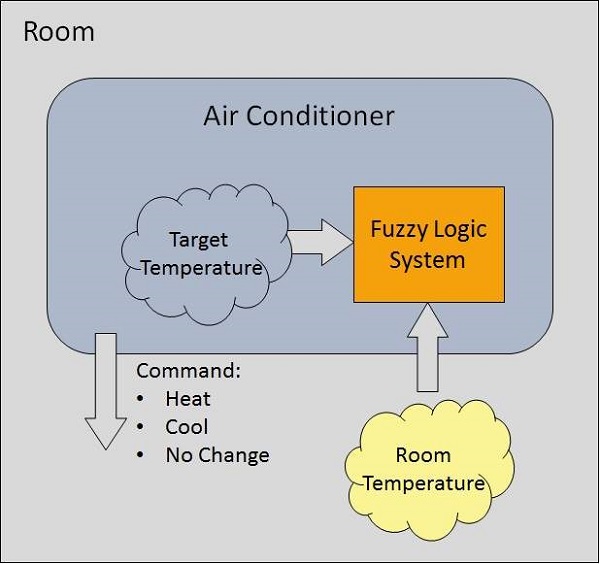
퍼지 논리 시스템의 예
5 단계 퍼지 논리 시스템이있는 에어컨 시스템을 고려해 보겠습니다. 실내 온도와 목표 온도를 비교하여 에어컨의 온도를 조절하는 시스템입니다.
연산
- 언어 변수 및 용어 정의 (시작)
- 그들을위한 멤버십 기능을 구성하십시오. (스타트)
- 규칙 지식 기반 구축 (시작)
- 멤버십 함수를 사용하여 선명한 데이터를 퍼지 데이터 세트로 변환합니다. (퍼지 화)
- 룰베이스에서 룰을 평가하십시오. (추론 엔진)
- 각 규칙의 결과를 결합합니다. (추론 엔진)
- 출력 데이터를 퍼지가 아닌 값으로 변환합니다. (디퍼 지화)
개발
Step 1 − Define linguistic variables and terms
언어 변수는 간단한 단어 또는 문장 형태의 입력 및 출력 변수입니다. 실온의 경우 추위, 따뜻함, 더운 등은 언어 용어입니다.
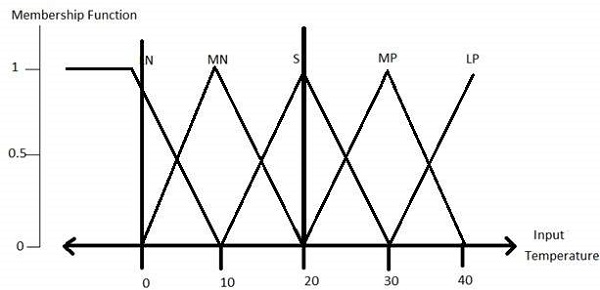
온도 (t) = {매우 추위, 추위, 따뜻함, 매우 따뜻함, 더움}
이 세트의 모든 구성원은 언어 용어이며 전체 온도 값의 일부를 포함 할 수 있습니다.
Step 2 − Construct membership functions for them
온도 변수의 멤버십 함수는 다음과 같습니다.
Step3 − Construct knowledge base rules
실내 온도 값과 공기 조화 시스템이 제공 할 것으로 예상되는 목표 온도 값의 매트릭스를 만듭니다.
| RoomTemp. /표적 | 매우 추운 | 춥다 | 따뜻한 | 뜨거운 | 매우 뜨거운 |
|---|---|---|---|---|---|
| 매우 추운 | 변경 없음 | 열 | 열 | 열 | 열 |
| 춥다 | 멋있는 | 변경 없음 | 열 | 열 | 열 |
| 따뜻한 | 멋있는 | 멋있는 | 변경 없음 | 열 | 열 |
| 뜨거운 | 멋있는 | 멋있는 | 멋있는 | 변경 없음 | 열 |
| 매우 뜨거운 | 멋있는 | 멋있는 | 멋있는 | 멋있는 | 변경 없음 |
IF-THEN-ELSE 구조의 형태로 지식 기반에 규칙 세트를 빌드하십시오.
| Sr. No. | 질환 | 동작 |
|---|---|---|
| 1 | IF temperature = (Cold OR Very_Cold) AND target = Warm THEN | 열 |
| 2 | IF temperature = (Hot OR Very_Hot) AND target = Warm THEN | 멋있는 |
| 삼 | IF (온도 = 따뜻함) AND (목표 = 따뜻함) THEN | 변경 없음 |
Step 4 − Obtain fuzzy value
퍼지 집합 작업은 규칙 평가를 수행합니다. OR 및 AND에 사용되는 연산은 각각 Max 및 Min입니다. 모든 평가 결과를 결합하여 최종 결과를 만듭니다. 이 결과는 퍼지 값입니다.
Step 5 − Perform defuzzification
그런 다음 출력 변수에 대한 멤버십 함수에 따라 디퍼 지화가 수행됩니다.

퍼지 로직의 응용 분야
퍼지 논리의 주요 응용 분야는 다음과 같습니다.
Automotive Systems
- 자동 변속기
- 4 륜 스티어링
- 차량 환경 제어
Consumer Electronic Goods
- Hi-Fi 시스템
- Photocopiers
- 스틸 및 비디오 카메라
- Television
Domestic Goods
- 전자 레인지
- Refrigerators
- Toasters
- 진공 청소기
- 세탁기
Environment Control
- 에어컨 / 건조기 / 히터
- Humidifiers
FLS의 장점
퍼지 추론 내의 수학적 개념은 매우 간단합니다.
퍼지 논리의 유연성으로 인해 규칙을 추가하거나 삭제하는 것만으로 FLS를 수정할 수 있습니다.
퍼지 로직 시스템은 부정확하고 왜곡 된 잡음이있는 입력 정보를 취할 수 있습니다.
FLS는 구성하고 이해하기 쉽습니다.
퍼지 논리는 인간의 추론 및 의사 결정과 유사하기 때문에 의학을 포함한 모든 삶의 분야에서 복잡한 문제에 대한 해결책입니다.
FLS의 단점
- 퍼지 시스템 설계에 대한 체계적인 접근 방식은 없습니다.
- 단순 할 때만 이해할 수 있습니다.
- 높은 정확도가 필요하지 않은 문제에 적합합니다.
NLP (Natural Language Processing)는 영어와 같은 자연어를 사용하여 지능형 시스템과 통신하는 AI 방식을 말합니다.
자연어 처리는 로봇과 같은 지능형 시스템이 지침에 따라 수행되기를 원할 때, 대화 기반 임상 전문가 시스템의 결정을 듣고 싶을 때 필요합니다.
NLP 분야는 인간이 사용하는 자연어로 유용한 작업을 수행하는 컴퓨터를 만드는 것입니다. NLP 시스템의 입력과 출력은 다음과 같습니다.
- Speech
- 서면 텍스트
NLP의 구성 요소
NLP에는 두 가지 구성 요소가 있습니다.
자연어 이해 (NLU)
이해에는 다음 작업이 포함됩니다.
- 자연어로 주어진 입력을 유용한 표현으로 매핑합니다.
- 언어의 다양한 측면을 분석합니다.
자연어 생성 (NLG)
내부 표현에서 자연어 형태로 의미있는 구와 문장을 만드는 과정입니다.
그것은 포함합니다-
Text planning − 여기에는 지식 기반에서 관련 콘텐츠 검색이 포함됩니다.
Sentence planning − 필수 단어 선택, 의미있는 구문 형성, 문장 어조 설정 등이 포함됩니다.
Text Realization − 문장 계획을 문장 구조에 매핑합니다.
NLU는 NLG보다 어렵습니다.
NLU의 어려움
NL은 매우 풍부한 형태와 구조를 가지고 있습니다.
매우 모호합니다. 다양한 수준의 모호성이있을 수 있습니다.
Lexical ambiguity − 단어 수준과 같이 매우 원시적 인 수준입니다.
예를 들어, "보드"라는 단어를 명사 나 동사로 취급합니까?
Syntax Level ambiguity − 문장은 다양한 방식으로 구문 분석 할 수 있습니다.
예를 들어,“빨간 모자로 딱정벌레를 들어 올렸습니다.” − 그는 딱정벌레를 들어 올리기 위해 모자를 사용 했습니까, 아니면 빨간 모자가 달린 딱정벌레를 들어 올렸습니까?
Referential ambiguity− 대명사를 사용하는 것을 언급합니다. 예를 들어, Rima는 Gauri에 갔다. 그녀는“나는 피곤하다”고 말했다. − 정확히 누가 피곤합니까?
하나의 입력은 다른 의미를 의미 할 수 있습니다.
많은 입력이 동일한 의미를 가질 수 있습니다.
NLP 용어
Phonology − 체계적으로 소리를 정리하는 연구입니다.
Morphology − 원시 의미 단위의 단어 구성에 대한 연구입니다.
Morpheme − 언어에서 의미의 원시 단위입니다.
Syntax− 문장을 만들기 위해 단어를 배열하는 것을 말합니다. 또한 문장과 구에서 단어의 구조적 역할을 결정합니다.
Semantics − 단어의 의미와 단어를 의미있는 구문과 문장으로 결합하는 방법과 관련이 있습니다.
Pragmatics − 다양한 상황에서 문장을 사용하고 이해하며 문장의 해석에 미치는 영향을 다룹니다.
Discourse − 직전 문장이 다음 문장의 해석에 미치는 영향을 다룹니다.
World Knowledge − 여기에는 세계에 대한 일반적인 지식이 포함됩니다.
NLP의 단계
일반적인 다섯 단계가 있습니다-
Lexical Analysis− 그것은 단어의 구조를 확인하고 분석하는 것을 포함합니다. 언어 사전은 언어의 단어와 구의 모음을 의미합니다. 어휘 분석은 전체 txt 청크를 단락, 문장 및 단어로 나누는 것입니다.
Syntactic Analysis (Parsing)− 문법을 위해 문장의 단어를 분석하고 단어 간의 관계를 보여주는 방식으로 단어를 배열합니다. “The school goes to boy”와 같은 문장은 영어 구문 분석기에서 거부됩니다.

Semantic Analysis− 텍스트에서 정확한 의미 또는 사전 적 의미를 도출합니다. 텍스트의 의미를 확인합니다. 태스크 도메인에서 구문 구조와 개체를 매핑하여 수행됩니다. 시맨틱 분석기는“hot ice-cream”과 같은 문장을 무시합니다.
Discourse Integration− 모든 문장의 의미는 바로 앞에있는 문장의 의미에 따라 다릅니다. 또한 바로 다음 문장의 의미도 가져옵니다.
Pragmatic Analysis−이 과정에서 말한 내용이 실제로 의미하는 바를 재 해석합니다. 실제 지식이 필요한 언어의 측면을 도출하는 것이 포함됩니다.
구문 분석의 구현 측면
연구자들이 구문 분석을 위해 개발 한 여러 알고리즘이 있지만 다음과 같은 간단한 방법 만 고려합니다.
- 문맥 자유 문법
- 하향식 파서
자세히 살펴 보겠습니다.
문맥 자유 문법
다시 쓰기 규칙의 왼쪽에 단일 기호가있는 규칙으로 구성된 문법입니다. 문장을 구문 분석하는 문법을 만들어 보겠습니다.
“새가 곡식을 쪼아”
Articles (DET)− a | an | 그만큼
Nouns− 새 | 새 | 곡물 | 작살
Noun Phrase (NP)− 기사 + 명사 | 기사 + 형용사 + 명사
= DET N | DET 조정 N
Verbs− 펙 | 쪼아 | 쪼아
Verb Phrase (VP)− NP V | V NP
Adjectives (ADJ)− 아름다운 | 작은 | 지저귐
구문 분석 트리는 컴퓨터가 쉽게 이해하고 처리 할 수 있도록 문장을 구조화 된 부분으로 나눕니다. 구문 분석 알고리즘이이 구문 분석 트리를 구성하려면 합법적 인 트리 구조를 설명하는 일련의 재 작성 규칙을 구성해야합니다.
이 규칙은 특정 기호가 일련의 다른 기호에 의해 트리에서 확장 될 수 있다고 말합니다. 1 차 논리 규칙에 따르면 두 개의 문자열 Noun Phrase (NP)와 Verb Phrase (VP)가 있으면 NP와 VP가 결합 된 문자열이 문장입니다. 문장의 재 작성 규칙은 다음과 같습니다.
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | 그만큼
ADJ → 아름다운 | 그친
N → 새 | 새 | 곡물 | 작살
V → 펙 | 펙 | 쪼아
구문 분석 트리는 다음과 같이 만들 수 있습니다.

이제 위의 재 작성 규칙을 고려하십시오. V는 "peck"또는 "pecks"로 대체 될 수 있기 때문에 "The bird peck the grains"와 같은 문장은 잘못 허용 될 수 있습니다. 즉, 주어 동사 일치 오류가 올바른 것으로 승인됩니다.
Merit − 가장 단순한 스타일의 문법이므로 널리 사용됩니다.
Demerits −
그들은 매우 정확하지 않습니다. 예를 들어, "The grains peck the bird"는 구문 분석기에 따르면 구문 적으로 정확하지만 말이 안 되더라도 구문 분석기는 올바른 문장으로 간주합니다.
높은 정밀도를 얻기 위해서는 여러 가지 문법을 준비해야합니다. 단수 및 복수 변형, 수동 문장 등을 구문 분석하기 위해 완전히 다른 규칙 집합이 필요할 수 있으며, 이로 인해 관리 할 수없는 거대한 규칙 집합이 생성 될 수 있습니다.
하향식 파서
여기서 구문 분석기는 S 기호로 시작하여 전체가 터미널 기호로 구성 될 때까지 입력 문장의 단어 클래스와 일치 하는 일련의 터미널 기호 로 다시 쓰려고합니다 .
그런 다음 입력 문장으로 확인하여 일치하는지 확인합니다. 그렇지 않은 경우 다른 규칙 세트로 프로세스가 다시 시작됩니다. 이것은 문장의 구조를 설명하는 특정 규칙을 찾을 때까지 반복됩니다.
Merit − 구현이 간단합니다.
Demerits −
- 오류가 발생하면 검색 과정을 반복해야하므로 비효율적입니다.
- 작업 속도가 느립니다.
전문가 시스템 (ES)은 AI의 저명한 연구 영역 중 하나입니다. 스탠포드 대학교 컴퓨터 과학과의 연구원이 소개했습니다.
전문가 시스템이란 무엇입니까?
전문가 시스템은 특별한 인간 지능과 전문 지식 수준에서 특정 영역의 복잡한 문제를 해결하기 위해 개발 된 컴퓨터 응용 프로그램입니다.
전문가 시스템의 특징
- 고성능
- Understandable
- Reliable
- 높은 반응성
전문가 시스템의 기능
전문가 시스템은-
- Advising
- 인간의 의사 결정을지도하고 지원
- Demonstrating
- 솔루션 도출
- Diagnosing
- Explaining
- 입력 해석
- 결과 예측
- 결론을 정당화
- 문제에 대한 대체 옵션 제안
그들은 할 수 없습니다-
- 인간의 의사 결정권자 대체
- 인간 능력 보유
- 부적절한 지식 기반에 대한 정확한 결과물 생성
- 자신의 지식을 다듬기
전문가 시스템의 구성 요소
ES의 구성 요소는 다음과 같습니다.
- 지식베이스
- 추론 엔진
- 사용자 인터페이스
하나씩 간단히 살펴 보겠습니다.

지식베이스
여기에는 도메인 별 고품질 지식이 포함되어 있습니다.
지능을 나타내려면 지식이 필요합니다. ES의 성공 여부는 주로 매우 정확하고 정확한 지식의 수집에 달려 있습니다.
지식이란 무엇입니까?
데이터는 사실의 모음입니다. 정보는 태스크 도메인에 대한 데이터 및 사실로 구성됩니다.Data, information, 과 past experience 함께 결합 된 것을 지식이라고합니다.
지식 기반의 구성 요소
ES의 지식 기반은 사실적 지식과 경험적 지식의 저장소입니다.
Factual Knowledge − 작업 영역의 지식 엔지니어와 학자들이 널리 수용하는 정보입니다.
Heuristic Knowledge − 연습, 정확한 판단, 평가, 추측에 관한 것입니다.
지식 표현
지식 기반에서 지식을 구성하고 형식화하는 데 사용되는 방법입니다. IF-THEN-ELSE 규칙의 형태입니다.
지식 습득
전문가 시스템의 성공 여부는 주로 지식 기반에 저장된 정보의 품질, 완전성 및 정확성에 달려 있습니다.
지식 기반은 다양한 전문가, 학자 및 Knowledge Engineers. 지식 엔지니어는 공감, 빠른 학습 및 사례 분석 기술의 자질을 가진 사람입니다.
그는 녹음, 인터뷰, 직장에서 관찰하는 등 주제 전문가로부터 정보를 얻습니다. 그런 다음 간섭 기계에서 사용할 IF-THEN-ELSE 규칙의 형태로 의미있는 방식으로 정보를 분류하고 구성합니다. 지식 엔지니어는 또한 ES의 개발을 모니터링합니다.
추론 엔진
추론 엔진의 효율적인 절차와 규칙을 사용하는 것은 정확하고 완벽한 솔루션을 도출하는 데 필수적입니다.
지식 기반 ES의 경우 추론 엔진은 특정 솔루션에 도달하기 위해 지식 기반에서 지식을 획득하고 조작합니다.
규칙 기반 ES의 경우-
이전 규칙 적용에서 얻은 사실에 규칙을 반복적으로 적용합니다.
필요한 경우 지식 기반에 새 지식을 추가합니다.
특정 사례에 여러 규칙을 적용 할 때 규칙 충돌을 해결합니다.
솔루션을 추천하기 위해 추론 엔진은 다음 전략을 사용합니다.
- 포워드 체인
- 역방향 체인
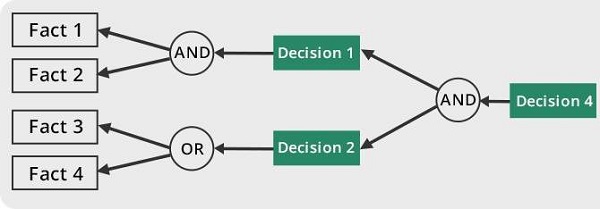
포워드 체인
질문에 답하는 것은 전문가 시스템의 전략입니다. “What can happen next?”
여기서 추론 엔진은 일련의 조건과 파생을 따르고 최종적으로 결과를 추론합니다. 모든 사실과 규칙을 고려하고 해결책을 찾기 전에 분류합니다.
이 전략은 결론, 결과 또는 효과에 대한 작업을 위해 따릅니다. 예를 들어, 이자율 변화의 영향으로 주식 시장 상태를 예측합니다.

역방향 체인
이 전략을 통해 전문가 시스템은 질문에 대한 답을 찾고 “Why this happened?”
이미 발생한 상황을 기반으로 추론 엔진은이 결과에 대해 과거에 어떤 조건이 발생했을 수 있는지 알아 내려고합니다. 이 전략은 원인 또는 이유를 찾기 위해 따릅니다. 예를 들어, 인간의 혈액 암 진단.
사용자 인터페이스
사용자 인터페이스는 ES 사용자와 ES 자체 간의 상호 작용을 제공합니다. 일반적으로 작업 영역에 정통한 사용자가 사용하기 위해 자연어 처리입니다. ES 사용자가 반드시 인공 지능의 전문가 일 필요는 없습니다.
ES가 특정 권장 사항에 어떻게 도달했는지 설명합니다. 설명은 다음과 같은 형식으로 나타날 수 있습니다.
- 화면에 자연어가 표시됩니다.
- 자연어로 된 구두 내레이션.
- 화면에 표시되는 규칙 번호 목록입니다.
사용자 인터페이스를 통해 공제액의 신뢰성을 쉽게 추적 할 수 있습니다.
효율적인 ES 사용자 인터페이스의 요구 사항
사용자가 가능한 한 짧은 방법으로 목표를 달성 할 수 있도록 도와야합니다.
사용자의 기존 또는 원하는 작업 관행에 맞게 설계되어야합니다.
그 기술은 사용자의 요구 사항에 맞게 조정 가능해야합니다. 그 반대는 아닙니다.
사용자 입력을 효율적으로 사용해야합니다.
전문가 시스템 제한
어떤 기술도 쉽고 완전한 솔루션을 제공 할 수 없습니다. 대규모 시스템은 비용이 많이 들고 상당한 개발 시간과 컴퓨터 리소스가 필요합니다. ES에는 다음과 같은 한계가 있습니다.
- 기술의 한계
- 어려운 지식 습득
- ES는 유지하기 어렵다
- 높은 개발 비용
전문가 시스템의 적용
다음 표는 ES를 적용 할 수있는 위치를 보여줍니다.
| 신청 | 기술 |
|---|---|
| 디자인 도메인 | 카메라 렌즈 디자인, 자동차 디자인. |
| 의료 도메인 | 관찰 된 데이터로부터 질병의 원인을 추론하는 진단 시스템, 인간에 대한 의료 작업 수행. |
| 모니터링 시스템 | 관찰 된 시스템 또는 긴 석유 파이프 라인의 누출 모니터링과 같은 규정 된 행동과 지속적으로 데이터를 비교합니다. |
| 공정 제어 시스템 | 모니터링을 기반으로 물리적 프로세스를 제어합니다. |
| 지식 영역 | 차량, 컴퓨터의 결함 찾기. |
| 금융 / 상업 | 사기 가능성, 의심스러운 거래, 주식 시장 거래, 항공사 예약,화물 예약 감지. |
전문가 시스템 기술
여러 수준의 ES 기술을 사용할 수 있습니다. 전문 시스템 기술에는 다음이 포함됩니다.
Expert System Development Environment− ES 개발 환경에는 하드웨어와 도구가 포함됩니다. 그들은-
워크 스테이션, 미니 컴퓨터, 메인 프레임.
다음과 같은 고급 기호 프로그래밍 언어 LIS티 P로그 래밍 (LISP) 및 PROgrammation en LOGique (PROLOG).
대규모 데이터베이스.
Tools − 전문가 시스템을 개발하는 데 드는 노력과 비용을 크게 줄입니다.
다중 창이있는 강력한 편집기 및 디버깅 도구.
신속한 프로토 타이핑 제공
모델, 지식 표현 및 추론 설계에 대한 정의가 내장되어 있습니다.
Shells− 쉘은 지식 기반이없는 전문가 시스템 일뿐입니다. 쉘은 개발자에게 지식 습득, 추론 엔진, 사용자 인터페이스 및 설명 기능을 제공합니다. 예를 들어, 아래에 몇 개의 껍질이 있습니다.
전문가 시스템을 만들기 위해 완전히 개발 된 Java API를 제공하는 JESS (Java Expert System Shell).
Vidwan 은 1993 년 Mumbai의 National Center for Software Technology에서 개발 한 쉘입니다. IF-THEN 규칙 형식으로 지식 인코딩을 가능하게합니다.
전문가 시스템 개발 : 일반 단계
ES 개발 과정은 반복적입니다. ES 개발 단계에는 다음이 포함됩니다.
문제 도메인 식별
- 문제는 전문가 시스템이 해결하기에 적합해야합니다.
- ES 프로젝트의 작업 영역에서 전문가를 찾으십시오.
- 시스템의 비용 효율성을 설정합니다.
시스템 설계
ES 기술 식별
다른 시스템 및 데이터베이스와의 통합 정도를 파악하고 설정합니다.
개념이 도메인 지식을 가장 잘 표현할 수있는 방법을 깨닫습니다.
프로토 타입 개발
지식 기반에서 : 지식 엔지니어는 다음 작업을 수행합니다.
- 전문가로부터 도메인 지식을 습득하십시오.
- If-THEN-ELSE 규칙의 형식으로 나타냅니다.
프로토 타입 테스트 및 수정
지식 엔지니어는 샘플 사례를 사용하여 성능 결함이 있는지 프로토 타입을 테스트합니다.
최종 사용자는 ES의 프로토 타입을 테스트합니다.
ES 개발 및 완성
최종 사용자, 데이터베이스 및 기타 정보 시스템을 포함하여 환경의 모든 요소와 ES의 상호 작용을 테스트하고 확인합니다.
ES 프로젝트를 잘 문서화하십시오.
사용자가 ES를 사용하도록 교육합니다.
시스템 유지
정기적 인 검토 및 업데이트를 통해 지식 기반을 최신 상태로 유지하십시오.
다른 정보 시스템이 진화함에 따라 새로운 인터페이스를 제공합니다.
전문가 시스템의 이점
Availability − 소프트웨어 양산으로 쉽게 구할 수 있습니다.
Less Production Cost− 생산 비용이 합리적입니다. 이것은 그들을 저렴하게 만듭니다.
Speed− 빠른 속도를 제공합니다. 개인이 투입하는 작업량을 줄입니다.
Less Error Rate − 인적 오류에 비해 오류율이 낮습니다.
Reducing Risk − 사람에게 위험한 환경에서 작업 할 수 있습니다.
Steady response − 그들은 움직이거나, 긴장하거나, 피로하지 않고 꾸준히 일합니다.
로봇 공학은 지능적이고 효율적인 로봇을 만드는 연구를 다루는 인공 지능 분야입니다.
로봇이란?
로봇은 실제 환경에서 행동하는 인공 에이전트입니다.
객관적인
로봇은 물체의 지각, 집기, 이동, 물체의 물리적 특성을 수정, 파괴하거나 효과를 주어 지루하거나 산만하거나 지치지 않고 반복적 인 기능을 수행하는 인력을 해방시켜 물체를 조작하는 것을 목표로합니다.
로보틱스 란?
로봇 공학은 로봇의 설계, 구축 및 응용을위한 전기 공학, 기계 공학 및 컴퓨터 과학으로 구성된 AI의 한 분야입니다.
로봇 공학의 측면
로봇은 mechanical construction특정 작업을 수행하도록 설계된, 형태 또는 모양.
그들은 가지고 electrical components 어떤 힘과 기계 장치를 통제하는지.
그들은 일정 수준의 computer program 로봇이 무엇을, 언제, 어떻게 하는지를 결정합니다.
로봇 시스템과 다른 AI 프로그램의 차이
다음은 둘의 차이점입니다.
| AI 프로그램 | 로봇 |
|---|---|
| 그들은 일반적으로 컴퓨터로 자극되는 세계에서 작동합니다. | 그들은 실제 물리적 세계에서 작동합니다. |
| AI 프로그램에 대한 입력은 기호와 규칙에 있습니다. | 로봇에 대한 입력은 음성 파형 또는 이미지 형태의 아날로그 신호입니다. |
| 작동하려면 범용 컴퓨터가 필요합니다. | 센서와 이펙터가있는 특수 하드웨어가 필요합니다. |
로봇 운동
로코 모션은 로봇이 주변 환경에서 움직일 수있게하는 메커니즘입니다. 다양한 유형의 운동이 있습니다-
- Legged
- Wheeled
- 다리와 바퀴 달린 운동의 조합
- 트랙 슬립 / 스키드
다리가있는 운동
이러한 유형의 이동은 걷기, 점프, 트로트, 홉, 오르기 또는 내리기 등을 시연하는 동안 더 많은 힘을 소비합니다.
움직임을 수행하려면 더 많은 모터가 필요합니다. 표면이 불규칙하거나 너무 매끄러 워 바퀴 달린 이동에 더 많은 전력을 소비하는 거칠고 매끄러운 지형에 적합합니다. 안정성 문제로 인해 구현하기가 거의 어렵습니다.
1 개, 2 개, 4 개 및 6 개의 다리가 다양하게 제공됩니다. 로봇에 다리가 여러 개인 경우 이동을 위해 다리 조정이 필요합니다.
가능한 총 수 gaits (각각의 전체 다리에 대한주기적인 리프트 및 릴리스 이벤트 시퀀스) 로봇이 이동할 수있는 것은 다리 수에 따라 다릅니다.
로봇에 k 개의 다리가있는 경우 가능한 이벤트 수 N = (2k-1) !.
다리가 두 개인 로봇 (k = 2)의 경우 가능한 이벤트 수는 N = (2k-1)입니다! = (2 * 2-1)! = 3! = 6.
따라서 가능한 6 개의 다른 이벤트가 있습니다.
- 왼쪽 다리 들어 올리기
- 왼쪽 다리 풀기
- 오른쪽 다리 들어 올리기
- 오른쪽 다리 풀기
- 두 다리를 함께 들어 올리기
- 두 다리를 함께 풀기
k = 6 구간의 경우 39916800 개의 가능한 이벤트가 있습니다. 따라서 로봇의 복잡성은 다리 수에 정비례합니다.

바퀴 달린 운동
움직임을 수행하는 데 더 적은 수의 모터가 필요합니다. 휠 수가 많을 경우 안정성 문제가 적기 때문에 구현하기가 쉽지 않습니다. 다리가있는 운동에 비해 전력 효율적입니다.
Standard wheel − 휠 축과 접점을 중심으로 회전합니다.
Castor wheel − 휠 축과 오프셋 스티어링 조인트를 중심으로 회전합니다.
Swedish 45o and Swedish 90o wheels − 옴니 휠, 접점 주변, 휠 축 주변 및 롤러 주변을 회전합니다.
Ball or spherical wheel − 기술적으로 구현하기 어려운 전 방향 휠.

슬립 / 스키드 운동
이 유형에서 차량은 탱크에서와 같이 트랙을 사용합니다. 로봇은 같은 방향 또는 반대 방향으로 다른 속도로 트랙을 움직여 조종됩니다. 트랙과지면의 접촉 면적이 넓어 안정성을 제공합니다.

로봇의 구성 요소
로봇은 다음과 같이 구성됩니다.
Power Supply − 로봇은 배터리, 태양 광 발전, 유압 또는 공압 전원으로 구동됩니다.
Actuators − 에너지를 운동으로 전환합니다.
Electric motors (AC/DC) − 회전 운동에 필요합니다.
Pneumatic Air Muscles − 공기가 흡입되면 거의 40 % 수축합니다.
Muscle Wires − 전류가 흐르면 5 % 수축합니다.
Piezo Motors and Ultrasonic Motors − 산업용 로봇에 가장 적합합니다.
Sensors− 작업 환경에 대한 실시간 정보를 제공합니다. 로봇에는 환경의 깊이를 계산하기 위해 비전 센서가 장착되어 있습니다. 촉각 센서는 인간 손끝의 터치 수용체의 기계적 특성을 모방합니다.
컴퓨터 시각 인식
로봇이 볼 수있는 인공 지능 기술입니다. 컴퓨터 비전은 안전, 보안, 건강, 액세스 및 엔터테인먼트 영역에서 중요한 역할을합니다.
컴퓨터 비전은 단일 이미지 또는 이미지 배열에서 유용한 정보를 자동으로 추출, 분석 및 이해합니다. 이 프로세스에는 자동 시각적 이해를 달성하기위한 알고리즘 개발이 포함됩니다.
컴퓨터 비전 시스템의 하드웨어
여기에는-
- 전원 공급
- 카메라와 같은 이미지 획득 장치
- 프로세서
- 소프트웨어
- 시스템 모니터링을위한 디스플레이 장치
- 카메라 스탠드, 케이블 및 커넥터와 같은 액세서리
컴퓨터 비전의 과제
OCR − 컴퓨터 영역에서 스캔 한 문서를 편집 가능한 텍스트로 변환하는 소프트웨어 인 Optical Character Reader는 스캐너와 함께 제공됩니다.
Face Detection− 많은 최신 카메라에이 기능이 제공되어 얼굴을 읽고 완벽한 표정을 사진으로 찍을 수 있습니다. 사용자가 올바른 일치에서 소프트웨어에 액세스 할 수 있도록하는 데 사용됩니다.
Object Recognition − 슈퍼마켓, 카메라, BMW, GM, Volvo와 같은 고급 차량에 설치됩니다.
Estimating Position − 인체에서 종양의 위치와 같이 카메라에 대한 물체의 위치를 추정하는 것입니다.
컴퓨터 비전의 응용 분야
- Agriculture
- 자율 주행 차
- Biometrics
- 문자 인식
- 법의학, 보안 및 감시
- 산업 품질 검사
- 얼굴 인식
- 제스처 분석
- Geoscience
- 의료 이미지
- 오염 모니터링
- 공정 제어
- 원격 감지
- Robotics
- Transport
로봇 공학의 응용
로봇 공학은 다음과 같은 다양한 영역에서 중요한 역할을했습니다.
Industries − 로봇은 재료 취급, 절단, 용접, 컬러 코팅, 드릴링, 연마 등에 사용됩니다.
Military− 자율 로봇은 전쟁 중에 접근이 불가능하고 위험한 지역에 도달 할 수 있습니다. DRDO (Defense Research and Development Organization)에서 개발 한 Daksh 라는 로봇 은 생명을 위협하는 물체를 안전하게 파괴하는 기능을합니다.
Medicine − 로봇은 동시에 수백 개의 임상 테스트를 수행하고, 영구적으로 장애가있는 사람들을 재활시키고, 뇌종양과 같은 복잡한 수술을 수행 할 수 있습니다.
Exploration − 우주 탐사에 사용되는 로봇 암벽 등반가, 해양 탐사에 사용되는 수중 드론이 몇 가지 예입니다.
Entertainment − Disney의 엔지니어들은 영화 제작을 위해 수백 개의 로봇을 만들었습니다.
인공 지능의 또 다른 연구 분야 인 신경망은 인간 신경계의 자연적 신경망에서 영감을 받았습니다.
인공 신경망 (ANN)이란 무엇입니까?
최초의 신경 컴퓨터를 발명 한 Robert Hecht-Nielsen 박사는 신경망을 다음과 같이 정의합니다.
"... 단순하고 고도로 상호 연결된 여러 처리 요소로 구성된 컴퓨팅 시스템으로, 외부 입력에 대한 동적 상태 응답으로 정보를 처리합니다."
ANN의 기본 구조
ANN의 아이디어는 올바른 연결을 통해 인간의 두뇌가 작동하는 것이 실리콘과 와이어를 살아있는 것으로 모방 할 수 있다는 믿음에 기반을두고 있습니다. neurons 과 dendrites.
인간의 뇌는 860 억 개의 신경 세포로 구성되어 있습니다. neurons. 그들은 다른 수천 개의 세포와 연결되어 있습니다. Axons.외부 환경의 자극이나 감각 기관의 입력은 수상 돌기에 의해 받아 들여집니다. 이러한 입력은 신경망을 통해 빠르게 이동하는 전기 충격을 생성합니다. 그런 다음 뉴런은 문제를 처리하기 위해 다른 뉴런에 메시지를 보내거나 전달하지 않습니다.

ANN은 여러 nodes, 생물학적 neurons인간 두뇌의. 뉴런은 링크로 연결되어 있으며 서로 상호 작용합니다. 노드는 입력 데이터를 가져와 데이터에 대해 간단한 작업을 수행 할 수 있습니다. 이러한 작업의 결과는 다른 뉴런으로 전달됩니다. 각 노드의 출력은activation 또는 node value.
각 링크는 weight.ANN은 가중치 값을 변경하여 학습 할 수 있습니다. 다음 그림은 간단한 ANN을 보여줍니다.

인공 신경망의 유형
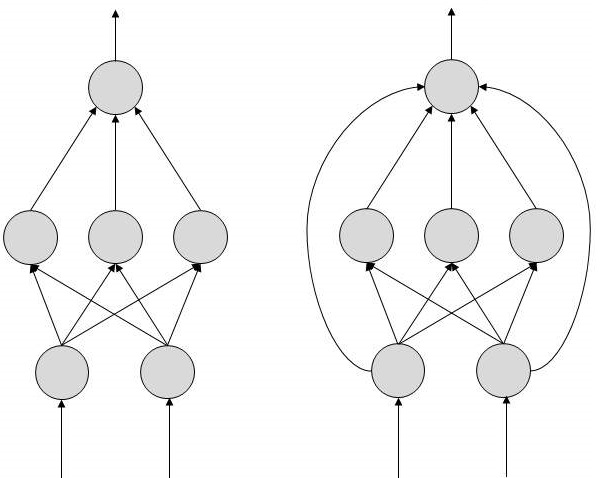
두 가지 인공 신경망 토폴로지가 있습니다. FeedForward 과 Feedback.
FeedForward ANN
이 ANN에서 정보 흐름은 단방향입니다. 유닛은 정보를 수신하지 않은 다른 유닛에 정보를 보냅니다. 피드백 루프가 없습니다. 패턴 생성 / 인식 / 분류에 사용됩니다. 입력과 출력이 고정되어 있습니다.
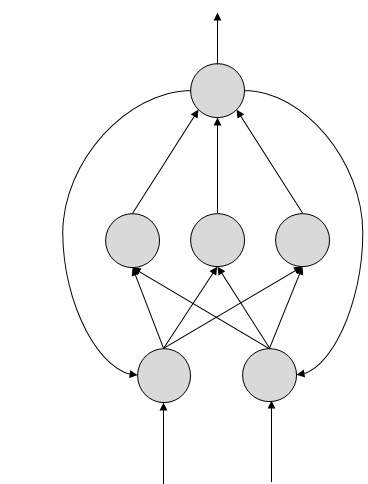
피드백 ANN
여기에서 피드백 루프가 허용됩니다. 컨텐츠 주소 지정이 가능한 메모리에 사용됩니다.
ANN의 작업
표시된 토폴로지 다이어그램에서 각 화살표는 두 뉴런 간의 연결을 나타내며 정보 흐름의 경로를 나타냅니다. 각 연결에는 두 뉴런 간의 신호를 제어하는 정수인 가중치가 있습니다.
네트워크가 "좋거나 원하는"출력을 생성하는 경우 가중치를 조정할 필요가 없습니다. 그러나 네트워크가 "나쁘거나 바람직하지 않은"출력 또는 오류를 생성하는 경우 시스템은 후속 결과를 개선하기 위해 가중치를 변경합니다.
ANN의 머신 러닝
ANN은 학습 능력이 있으며 교육을 받아야합니다. 몇 가지 학습 전략이 있습니다-
Supervised Learning− ANN 자체보다 학자 인 교사가 포함됩니다. 예를 들어, 교사는 교사가 이미 답을 알고있는 몇 가지 예제 데이터를 제공합니다.
예를 들어 패턴 인식. ANN은 인식하면서 추측을 내 놓습니다. 그런 다음 교사는 ANN에 답변을 제공합니다. 그런 다음 네트워크는 추측 한 내용을 교사의 "정답"답변과 비교하고 오류에 따라 조정합니다.
Unsupervised Learning− 답변이 알려진 예제 데이터 세트가 없을 때 필요합니다. 예를 들어 숨겨진 패턴을 검색합니다. 이 경우 존재하는 기존 데이터 세트를 기반으로 클러스터링 즉, 알 수없는 패턴에 따라 요소 세트를 그룹으로 나누는 작업이 수행됩니다.
Reinforcement Learning−이 전략은 관찰을 기반으로합니다. ANN은 환경을 관찰하여 결정을 내립니다. 관측치가 음수이면 네트워크는 다음에 필요한 다른 결정을 내릴 수 있도록 가중치를 조정합니다.
역 전파 알고리즘
훈련 또는 학습 알고리즘입니다. 예를 들어 배웁니다. 네트워크가 원하는 작업의 예를 알고리즘에 제출하면 훈련을 마칠 때 특정 입력에 대해 원하는 출력을 생성 할 수 있도록 네트워크의 가중치를 변경합니다.
역 전파 네트워크는 간단한 패턴 인식 및 매핑 작업에 이상적입니다.
베이지안 네트워크 (BN)
랜덤 변수 집합 간의 확률 적 관계를 나타내는 데 사용되는 그래픽 구조입니다. 베이지안 네트워크는Belief Networks 또는 Bayes Nets. BN은 불확실한 도메인에 대한 이유를 제시합니다.
이러한 네트워크에서 각 노드는 특정 명제를 가진 랜덤 변수를 나타냅니다. 예를 들어, 의료 진단 도메인에서 노드 Cancer는 환자가 암에 걸렸다는 명제를 나타냅니다.
노드를 연결하는 간선은 이러한 랜덤 변수 간의 확률 적 종속성을 나타냅니다. 두 노드 중 하나가 다른 노드에 영향을 미치는 경우 효과 방향으로 직접 연결되어야합니다. 변수 간 관계의 강도는 각 노드와 관련된 확률로 정량화됩니다.
BN의 호에는 방향성 호를 따라가는 것만으로는 노드로 돌아갈 수없는 유일한 제약 조건이 있습니다. 따라서 BN을 DAG (Directed Acyclic Graph)라고합니다.
BN은 다중 값 변수를 동시에 처리 할 수 있습니다. BN 변수는 두 가지 차원으로 구성됩니다.
- 전치사 범위
- 각 전치사에 할당 된 확률입니다.
이산 랜덤 변수 의 유한 집합 X = {X 1 , X 2 ,…, X n }을 고려하십시오. 여기서 각 변수 X i 는 Val (X i ) 로 표시된 유한 집합에서 값을 가져올 수 있습니다 . 변수로부터 직접 링크가있는 경우 X 나 변수, X의 j는 , 다음 변수 X는 나 변수의 상위 것이다 X의 J 변수 간의 직접적인 의존성을 도시.
BN의 구조는 사전 지식과 관찰 된 데이터를 결합하는 데 이상적입니다. BN은 인과 관계를 배우고 다양한 문제 영역을 이해하고 데이터가 누락 된 경우에도 향후 이벤트를 예측하는 데 사용할 수 있습니다.
베이지안 네트워크 구축
지식 엔지니어는 베이지안 네트워크를 구축 할 수 있습니다. 지식 엔지니어는이를 구축하는 동안 여러 단계를 거쳐야합니다.
Example problem− 폐암. 환자가 숨가쁨으로 고통 받고 있습니다. 그는 폐암에 걸렸다 고 의심하며 의사를 방문합니다. 의사는 폐암을 제외하고 결핵과 기관지염과 같이 환자가 가질 수있는 다른 다양한 질병이 있다는 것을 알고 있습니다.
Gather Relevant Information of Problem
- 환자가 흡연자입니까? 그렇다면 암과 기관지염의 가능성이 높습니다.
- 환자가 대기 오염에 노출되어 있습니까? 그렇다면 어떤 종류의 대기 오염이 있습니까?
- X- 레이 양성 X- 레이는 결핵 또는 폐암을 나타냅니다.
Identify Interesting Variables
지식 엔지니어는 질문에 답하려고합니다.
- 나타낼 노드는 무엇입니까?
- 그들은 어떤 가치를 취할 수 있습니까? 어떤 상태 일 수 있습니까?
지금은 이산 값만있는 노드를 고려해 보겠습니다. 변수는 한 번에 정확히 하나의 값을 가져야합니다.
Common types of discrete nodes are −
Boolean nodes − 그들은 이진 값 TRUE (T) 및 FALSE (F)를 취하는 명제를 나타냅니다.
Ordered values− 노드 오염 은 오염 에 대한 환자의 노출 정도를 설명하는 {낮음, 중간, 높음} 값을 나타내고 가져올 수 있습니다.
Integral values− Age 라는 노드 는 1에서 120까지 가능한 값으로 환자의 나이를 나타낼 수 있습니다.이 초기 단계에서도 모델링 선택이 이루어지고 있습니다.
폐암 예에 대한 가능한 노드 및 값-
| 노드 이름 | 유형 | 값 | 노드 생성 |
|---|---|---|---|
| 오염 | 바이너리 | {낮음, 높음, 중간} |

|
| 흡연자 | 부울 | {TRUE, FASLE} | |
| 폐암 | 부울 | {TRUE, FASLE} | |
| 엑스레이 | 바이너리 | {양수, 음수} |
Create Arcs between Nodes
네트워크 토폴로지는 변수 간의 질적 관계를 포착해야합니다.
예를 들어, 환자가 폐암에 걸리는 원인은 무엇입니까? -오염과 흡연. 그런 다음 노드 Pollution 및 노드 Smoker의 호 를 노드 Lung-Cancer에 추가합니다.
유사하게 환자에게 폐암이있는 경우 X-ray 결과는 양성입니다. 그런 다음 노드 폐암 에서 노드 X-Ray로 호를 추가 합니다.

Specify Topology
일반적으로 BN은 호가 위에서 아래로 향하도록 배치됩니다. 노드 X의 부모 노드 집합은 Parents (X)에 의해 제공됩니다.
폐암 : 노드는 두 부모 (이유 또는 원인)이 오염 과 흡연을 노드하면서, 흡연자가 입니다ancestor노드 X-Ray의 . 유사하게, X-Ray 는 결절 폐암 의 하위 (결과 또는 결과) 이며successor노드 흡연자 와 오염의 수.
Conditional Probabilities
이제 연결된 노드 간의 관계를 수량화합니다. 이는 각 노드에 대한 조건부 확률 분포를 지정하여 수행됩니다. 여기서는 이산 변수 만 고려하므로 이것은Conditional Probability Table (CPT).
먼저 각 노드에 대해 해당 부모 노드의 가능한 모든 값 조합을 살펴 봐야합니다. 이러한 각 조합을instantiation부모 세트의. 부모 노드 값의 각 고유 인스턴스화에 대해 자식이 취할 확률을 지정해야합니다.
예를 들어, 폐암 노드의 부모는 오염 및 흡연입니다. 가능한 값은 {(H, T), (H, F), (L, T), (L, F)}입니다. CPT는 이러한 각 사례에 대한 암 확률을 각각 <0.05, 0.02, 0.03, 0.001>로 지정합니다.
각 노드는 다음과 같이 연관된 조건부 확률을 갖습니다.

신경망의 응용
인간에게는 쉽지만 기계에게는 어려운 작업을 수행 할 수 있습니다.
Aerospace − 자동 조종 항공기, 항공기 결함 감지.
Automotive − 자동차 안내 시스템.
Military − 무기 방향 및 조향, 표적 추적, 물체 식별, 얼굴 인식, 신호 / 이미지 식별.
Electronics − 코드 시퀀스 예측, IC 칩 레이아웃, 칩 오류 분석, 머신 비전, 음성 합성.
Financial − 부동산 감정, 대출 고문, 모기지 심사, 회사 채권 등급, 포트폴리오 거래 프로그램, 기업 재무 분석, 통화 가치 예측, 문서 판독기, 신용 신청 평가자.
Industrial − 제조 공정 제어, 제품 설계 및 분석, 품질 검사 시스템, 용접 품질 분석, 종이 품질 예측, 화학 제품 설계 분석, 화학 공정 시스템의 동적 모델링, 기계 유지 보수 분석, 프로젝트 입찰, 계획 및 관리.
Medical − 암 세포 분석, EEG 및 ECG 분석, 보철 디자인, 이식 시간 최적화 도구.
Speech − 음성 인식, 음성 분류, 텍스트 음성 변환.
Telecommunications − 이미지 및 데이터 압축, 자동화 된 정보 서비스, 실시간 음성 번역.
Transportation − 트럭 브레이크 시스템 진단, 차량 예약, 라우팅 시스템.
Software − 안면 인식, 광학 문자 인식 등에서 패턴 인식
Time Series Prediction − ANN은 재고 및 자연 재해를 예측하는 데 사용됩니다.
Signal Processing − 신경망은 오디오 신호를 처리하고 보청기에서 적절하게 필터링하도록 훈련 될 수 있습니다.
Control − ANN은 종종 실제 차량의 조종 결정을 내리는 데 사용됩니다.
Anomaly Detection − ANN은 패턴을 인식하는 데 전문가이기 때문에 패턴에 맞지 않는 비정상적인 상황이 발생할 때 출력을 생성하도록 훈련받을 수도 있습니다.
AI는 놀라운 속도로 발전하고 있으며 때로는 마법처럼 보입니다. 연구자들과 개발자들 사이에는 인공 지능이 엄청나게 강해져 인간이 통제하기 어려울 것이라는 의견이 있습니다.
인간은 가능한 모든 지능을 도입함으로써 인공 지능 시스템을 개발했습니다.
프라이버시 위협
음성을 인식하고 자연어를 이해하는 AI 프로그램은 이론적으로 이메일과 전화를 통한 각 대화를 이해할 수 있습니다.
인간 존엄성에 대한 위협
AI 시스템은 이미 소수의 산업에서 인간을 대체하기 시작했습니다. 간호, 외과의, 판사, 경찰 등과 같은 윤리와 관련된 품위있는 위치를 차지하는 분야의 사람들을 대체해서는 안됩니다.
안전에 대한 위협
자가 개선 AI 시스템은 인간보다 강력 해져 목표 달성을 중단하기가 매우 어려워 의도하지 않은 결과를 초래할 수 있습니다.
다음은 AI 영역에서 자주 사용되는 용어 목록입니다.
| Sr. 아니요 | 용어 및 의미 |
|---|---|
| 1 | Agent 에이전트는 하나 이상의 목표를 지향하는 자율적이고 의도적이며 추론 할 수있는 시스템 또는 소프트웨어 프로그램입니다. 비서, 브로커, 봇, 드로이드, 지능형 에이전트 및 소프트웨어 에이전트라고도합니다. |
| 2 | Autonomous Robot 로봇은 외부의 제어 나 영향이없고 독립적으로 제어 할 수 있습니다. |
| 삼 | Backward Chaining 문제의 원인 / 원인에 대한 역방향 작업 전략. |
| 4 | Blackboard 협력하는 전문가 시스템 간의 통신에 사용되는 컴퓨터 내부의 메모리입니다. |
| 5 | Environment 에이전트가 거주하는 실제 또는 계산 세계의 일부입니다. |
| 6 | Forward Chaining 문제의 결론 / 해결을 위해 앞으로 나아가는 전략. |
| 7 | Heuristics 시행 착오, 평가 및 실험에 기반한 지식입니다. |
| 8 | Knowledge Engineering 인간 전문가 및 기타 리소스로부터 지식을 습득합니다. |
| 9 | Percepts 에이전트가 환경에 대한 정보를 얻는 형식입니다. |
| 10 | Pruning AI 시스템에서 불필요하고 관련없는 고려 사항을 무시합니다. |
| 11 | Rule Expert System에서 지식 기반을 표현하는 형식입니다. IF-THEN-ELSE 형식입니다. |
| 12 | Shell 쉘은 전문가 시스템의 추론 엔진, 지식 기반 및 사용자 인터페이스를 설계하는 데 도움이되는 소프트웨어입니다. |
| 13 | Task 에이전트가 달성하려는 목표입니다. |
| 14 | Turing Test Allan Turing이 인간 지능과 비교하여 기계의 지능을 테스트하기 위해 개발 한 테스트입니다. |