Biopython-빠른 가이드
Biopython은 가장 크고 인기있는 Python 용 생물 정보학 패키지입니다. 일반적인 생물 정보학 작업을위한 여러 하위 모듈이 포함되어 있습니다. Chapman과 Chang이 개발했으며 주로 Python으로 작성되었습니다. 또한 소프트웨어의 복잡한 계산 부분을 최적화하는 C 코드가 포함되어 있습니다. Windows, Linux, Mac OS X 등에서 실행됩니다.
기본적으로 Biopython은 DNA 스트링의 역 보완, 단백질 서열에서 모티프 찾기 등과 같은 DNA, RNA 및 단백질 서열 작업을 처리하는 기능을 제공하는 파이썬 모듈 모음입니다. 모든 주요 유전 데이터베이스를 읽을 수있는 많은 파서를 제공합니다. GenBank, SwissPort, FASTA 등과 같이 Python 환경 내에서 NCBI BLASTN, Entrez 등과 같은 다른 인기있는 생물 정보학 소프트웨어 / 도구를 실행하기위한 래퍼 / 인터페이스도 있습니다. BioPerl, BioJava 및 BioRuby와 같은 형제 프로젝트가 있습니다.
풍모
Biopython은 이식 가능하고 명확하며 구문을 배우기 쉽습니다. 몇 가지 두드러진 특징은 다음과 같습니다.
해석되고 상호 작용하며 객체 지향적입니다.
FASTA, PDB, GenBank, Blast, SCOP, PubMed / Medline, ExPASy 관련 형식을 지원합니다.
시퀀스 형식을 처리하는 옵션.
단백질 구조를 관리하는 도구.
BioSQL-시퀀스와 기능 및 주석을 저장하기위한 SQL 테이블의 표준 세트.
NCBI 서비스 (Blast, Entrez, PubMed) 및 ExPASY 서비스 (SwissProt, Prosite)를 포함한 온라인 서비스 및 데이터베이스에 대한 액세스.
Blast, Clustalw, EMBOSS를 포함한 로컬 서비스에 대한 액세스.
목표
Biopython의 목표는 Python 언어를 통해 생물 정보학에 대한 간단하고 표준 적이며 광범위한 액세스를 제공하는 것입니다. Biopython의 구체적인 목표는 다음과 같습니다.
생물 정보학 자원에 대한 표준화 된 액세스를 제공합니다.
재사용 가능한 고품질 모듈 및 스크립트.
클러스터 코드, PDB, NaiveBayes 및 Markov 모델에서 사용할 수있는 빠른 배열 조작.
게놈 데이터 분석.
장점
Biopython은 매우 적은 코드를 필요로하며 다음과 같은 장점이 있습니다.
클러스터링에 사용되는 마이크로 어레이 데이터 유형을 제공합니다.
Tree-View 유형 파일을 읽고 씁니다.
PDB 구문 분석, 표현 및 분석에 사용되는 구조 데이터를 지원합니다.
Medline 애플리케이션에서 사용되는 저널 데이터를 지원합니다.
모든 생물 정보학 프로젝트에서 널리 사용되는 표준 데이터베이스 인 BioSQL 데이터베이스를 지원합니다.
생물 정보학 파일을 형식 별 레코드 개체 또는 일반 클래스의 시퀀스 및 기능 으로 구문 분석하는 모듈을 제공하여 구문 분석기 개발을 지원 합니다.
요리 책 스타일을 기반으로 한 명확한 문서.
샘플 사례 연구
일부 사용 사례 (인구 유전학, RNA 구조 등)를 확인하고 Biopython이이 분야에서 어떻게 중요한 역할을하는지 이해해 보겠습니다.
인구 유전학
집단 유전학은 집단 내 유전 적 변이에 대한 연구이며, 공간과 시간에 따른 집단의 유전자 및 대립 유전자 빈도 변화를 조사하고 모델링하는 것을 포함합니다.
Biopython은 집단 유전학을위한 Bio.PopGen 모듈을 제공합니다. 이 모듈에는 고전적인 인구 유전학에 대한 정보를 수집하는 데 필요한 모든 기능이 포함되어 있습니다.
RNA 구조
우리 삶에 필수적인 세 가지 주요 생물학적 거대 분자는 DNA, RNA 및 단백질입니다. 단백질은 세포의 주역이며 효소로서 중요한 역할을합니다. DNA (데 옥시 리보 핵산)는 세포의 "청사진"으로 간주됩니다. 그것은 세포가 성장하고 영양분을 섭취하고 번식하는 데 필요한 모든 유전 정보를 전달합니다. RNA (리보 핵산)는 세포에서 "DNA 복사"역할을합니다.
Biopython은 DNA와 RNA의 구성 요소 인 뉴클레오티드를 나타내는 Bio.Sequence 객체를 제공합니다.
이 섹션에서는 컴퓨터에 Biopython을 설치하는 방법을 설명합니다. 설치가 매우 쉽고 5 분 이상 걸리지 않습니다.
Step 1 − Python 설치 확인
Biopython은 Python 2.5 이상 버전에서 작동하도록 설계되었습니다. 따라서 먼저 Python을 설치해야합니다. 명령 프롬프트에서 아래 명령을 실행하십시오-
> python --version아래에 정의되어 있습니다-

제대로 설치된 경우 파이썬 버전을 보여줍니다. 그렇지 않으면 최신 버전의 Python을 다운로드하고 설치 한 다음 명령을 다시 실행하십시오.
Step 2 − pip를 사용하여 Biopython 설치
모든 플랫폼의 명령 줄에서 pip를 사용하여 Biopython을 설치하는 것은 쉽습니다. 아래 명령을 입력하십시오-
> pip install biopython다음 응답이 화면에 표시됩니다.

이전 버전의 Biopython 업데이트-
> pip install biopython –-upgrade다음 응답이 화면에 표시됩니다.

이 명령을 실행하면 최신 버전을 설치하기 전에 이전 버전의 Biopython 및 NumPy (Biopython이 이에 종 속됨)가 제거됩니다.
Step 3 − Biopython 설치 확인
이제 시스템에 Biopython을 성공적으로 설치했습니다. Biopython이 제대로 설치되었는지 확인하려면, Python 콘솔에 아래 명령을 입력하십시오.

Biopython의 버전을 보여줍니다.
Alternate Way − Installing Biopython using Source
소스 코드를 사용하여 Biopython을 설치하려면 아래 지침을 따르십시오.
다음 링크에서 Biopython의 최신 릴리스를 다운로드하십시오. https://biopython.org/wiki/Download
현재 최신 버전은 biopython-1.72.
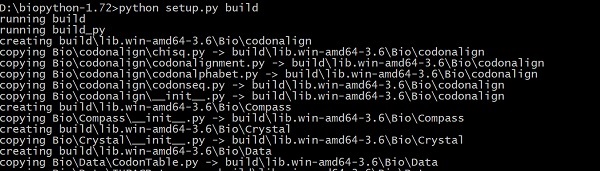
파일을 다운로드하고 압축 된 아카이브 파일의 압축을 풀고 소스 코드 폴더로 이동하여 아래 명령을 입력하십시오.
> python setup.py build이것은 아래와 같이 소스 코드에서 Biopython을 빌드합니다.
이제 아래 명령을 사용하여 코드를 테스트하십시오.
> python setup.py test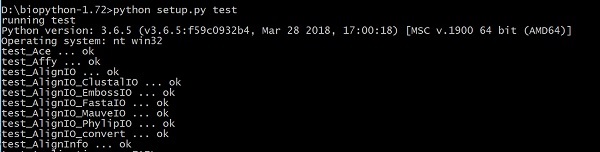
마지막으로 아래 명령을 사용하여 설치하십시오-
> python setup.py install
간단한 Biopython 애플리케이션을 만들어 생물 정보학 파일을 구문 분석하고 내용을 인쇄 해 보겠습니다. 이것은 우리가 Biopython의 일반적인 개념과 그것이 생물 정보학 분야에서 어떻게 도움이되는지 이해하는 데 도움이 될 것입니다.
Step 1 − 먼저 샘플 시퀀스 파일“example.fasta”를 생성하고 아래 내용을 입력합니다.
>sp|P25730|FMS1_ECOLI CS1 fimbrial subunit A precursor (CS1 pilin)
MKLKKTIGAMALATLFATMGASAVEKTISVTASVDPTVDLLQSDGSALPNSVALTYSPAV
NNFEAHTINTVVHTNDSDKGVVVKLSADPVLSNVLNPTLQIPVSVNFAGKPLSTTGITID
SNDLNFASSGVNKVSSTQKLSIHADATRVTGGALTAGQYQGLVSIILTKSTTTTTTTKGT
>sp|P15488|FMS3_ECOLI CS3 fimbrial subunit A precursor (CS3 pilin)
MLKIKYLLIGLSLSAMSSYSLAAAGPTLTKELALNVLSPAALDATWAPQDNLTLSNTGVS
NTLVGVLTLSNTSIDTVSIASTNVSDTSKNGTVTFAHETNNSASFATTISTDNANITLDK
NAGNTIVKTTNGSQLPTNLPLKFITTEGNEHLVSGNYRANITITSTIKGGGTKKGTTDKK확장자 fasta 는 시퀀스 파일의 파일 형식을 나타냅니다. FASTA는 생물 정보학 소프트웨어 인 FASTA에서 유래되었으므로 그 이름을 얻었습니다. FASTA 형식에는 여러 시퀀스가 하나씩 배열되어 있으며 각 시퀀스에는 고유 한 ID, 이름, 설명 및 실제 시퀀스 데이터가 있습니다.
Step 2 − 새로운 파이썬 스크립트 * simple_example.py "를 생성하고 아래 코드를 입력하고 저장합니다.
from Bio.SeqIO import parse
from Bio.SeqRecord import SeqRecord
from Bio.Seq import Seq
file = open("example.fasta")
records = parse(file, "fasta") for record in records:
print("Id: %s" % record.id)
print("Name: %s" % record.name)
print("Description: %s" % record.description)
print("Annotations: %s" % record.annotations)
print("Sequence Data: %s" % record.seq)
print("Sequence Alphabet: %s" % record.seq.alphabet)코드를 좀 더 자세히 살펴 보겠습니다.
Line 1Bio.SeqIO 모듈에서 사용 가능한 구문 분석 클래스를 가져옵니다. Bio.SeqIO 모듈은 시퀀스 파일을 다른 형식으로 읽고 쓰는 데 사용되며`parse '클래스는 시퀀스 파일의 내용을 구문 분석하는 데 사용됩니다.
Line 2Bio.SeqRecord 모듈에서 사용 가능한 SeqRecord 클래스를 가져옵니다. 이 모듈은 시퀀스 레코드를 조작하는 데 사용되며 SeqRecord 클래스는 시퀀스 파일에서 사용 가능한 특정 시퀀스를 나타내는 데 사용됩니다.
*Line 3"Bio.Seq 모듈에서 사용 가능한 Seq 클래스를 가져옵니다. 이 모듈은 시퀀스 데이터를 조작하는 데 사용되며 Seq 클래스는 시퀀스 파일에서 사용 가능한 특정 시퀀스 레코드의 시퀀스 데이터를 나타내는 데 사용됩니다.
Line 5 일반 파이썬 함수를 사용하여 "example.fasta"파일을 엽니 다.
Line 7 시퀀스 파일의 내용을 구문 분석하고 내용을 SeqRecord 객체 목록으로 반환합니다.
Line 9-15 python for 루프를 사용하여 레코드를 반복하고 id, 이름, 설명, 시퀀스 데이터 등과 같은 시퀀스 레코드 (SqlRecord)의 속성을 인쇄합니다.
Line 15 Alphabet 클래스를 사용하여 시퀀스 유형을 인쇄합니다.
Step 3 − 명령 프롬프트를 열고 시퀀스 파일“example.fasta”가 포함 된 폴더로 이동하여 아래 명령을 실행합니다. −
> python simple_example.pyStep 4− Python은 스크립트를 실행하고 샘플 파일“example.fasta”에서 사용 가능한 모든 시퀀스 데이터를 인쇄합니다. 출력은 다음 내용과 유사합니다.
Id: sp|P25730|FMS1_ECOLI
Name: sp|P25730|FMS1_ECOLI
Decription: sp|P25730|FMS1_ECOLI CS1 fimbrial subunit A precursor (CS1 pilin)
Annotations: {}
Sequence Data: MKLKKTIGAMALATLFATMGASAVEKTISVTASVDPTVDLLQSDGSALPNSVALTYSPAVNNFEAHTINTVVHTNDSD
KGVVVKLSADPVLSNVLNPTLQIPVSVNFAGKPLSTTGITIDSNDLNFASSGVNKVSSTQKLSIHADATRVTGGALTA
GQYQGLVSIILTKSTTTTTTTKGT
Sequence Alphabet: SingleLetterAlphabet()
Id: sp|P15488|FMS3_ECOLI
Name: sp|P15488|FMS3_ECOLI
Decription: sp|P15488|FMS3_ECOLI CS3 fimbrial subunit A precursor (CS3 pilin)
Annotations: {}
Sequence Data: MLKIKYLLIGLSLSAMSSYSLAAAGPTLTKELALNVLSPAALDATWAPQDNLTLSNTGVSNTLVGVLTLSNTSIDTVS
IASTNVSDTSKNGTVTFAHETNNSASFATTISTDNANITLDKNAGNTIVKTTNGSQLPTNLPLKFITTEGNEHLVSGN
YRANITITSTIKGGGTKKGTTDKK
Sequence Alphabet: SingleLetterAlphabet()이 예제에서는 parse, SeqRecord 및 Seq의 세 가지 클래스를 보았습니다. 이 세 클래스는 대부분의 기능을 제공하며 다음 섹션에서 해당 클래스에 대해 알아 봅니다.
시퀀스는 유기체의 단백질, DNA 또는 RNA를 나타내는 데 사용되는 일련의 문자입니다. Seq 클래스로 표시됩니다. Seq 클래스는 Bio.Seq 모듈에 정의되어 있습니다.
아래와 같이 Biopython에서 간단한 시퀀스를 생성 해 보겠습니다.
>>> from Bio.Seq import Seq
>>> seq = Seq("AGCT")
>>> seq
Seq('AGCT')
>>> print(seq)
AGCT여기에서 우리는 간단한 단백질 서열을 만들었습니다. AGCT 그리고 각 문자는 A라닌, G라이신, C이스 테인과 T헤 오닌.
각 Seq 객체에는 두 가지 중요한 속성이 있습니다.
데이터-실제 시퀀스 문자열 (AGCT)
알파벳-시퀀스 유형을 나타내는 데 사용됩니다. 예를 들어 DNA 염기 서열, RNA 염기 서열 등. 기본적으로 어떤 염기 서열도 나타내지 않으며 본질적으로 일반적입니다.
알파벳 모듈
Seq 객체는 알파벳 속성을 포함하여 시퀀스 유형, 문자 및 가능한 작업을 지정합니다. Bio.Alphabet 모듈에 정의되어 있습니다. 알파벳은 아래와 같이 정의 할 수 있습니다-
>>> from Bio.Seq import Seq
>>> myseq = Seq("AGCT")
>>> myseq
Seq('AGCT')
>>> myseq.alphabet
Alphabet()알파벳 모듈은 다양한 유형의 시퀀스를 나타내는 아래 클래스를 제공합니다. 알파벳-모든 유형의 알파벳에 대한 기본 클래스입니다.
SingleLetterAlphabet-크기가 1 인 글자가 포함 된 일반 알파벳입니다. 그것은 알파벳에서 파생되고 다른 모든 알파벳 유형은 여기서 파생됩니다.
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import single_letter_alphabet
>>> test_seq = Seq('AGTACACTGGT', single_letter_alphabet)
>>> test_seq
Seq('AGTACACTGGT', SingleLetterAlphabet())ProteinAlphabet-일반 단일 문자 단백질 알파벳.
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_protein
>>> test_seq = Seq('AGTACACTGGT', generic_protein)
>>> test_seq
Seq('AGTACACTGGT', ProteinAlphabet())NucleotideAlphabet-일반 단일 문자 뉴클레오티드 알파벳.
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_nucleotide
>>> test_seq = Seq('AGTACACTGGT', generic_nucleotide) >>> test_seq
Seq('AGTACACTGGT', NucleotideAlphabet())DNAAlphabet-일반 단일 문자 DNA 알파벳.
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_dna
>>> test_seq = Seq('AGTACACTGGT', generic_dna)
>>> test_seq
Seq('AGTACACTGGT', DNAAlphabet())RNAAlphabet-일반 단일 문자 RNA 알파벳.
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_rna
>>> test_seq = Seq('AGTACACTGGT', generic_rna)
>>> test_seq
Seq('AGTACACTGGT', RNAAlphabet())Biopython 모듈 인 Bio.Alphabet.IUPAC는 IUPAC 커뮤니티에서 정의한 기본 시퀀스 유형을 제공합니다. 그것은 다음 클래스를 포함합니다-
IUPACProtein (protein) − 20 개의 표준 아미노산으로 구성된 IUPAC 단백질 알파벳.
ExtendedIUPACProtein (extended_protein) − X를 포함한 확장 대문자 IUPAC 단백질 단일 문자 알파벳.
IUPACAmbiguousDNA (ambiguous_dna) − 대문자 IUPAC 모호한 DNA.
IUPACUnambiguousDNA (unambiguous_dna) − 대문자 IUPAC 명확성 DNA (GATC).
ExtendedIUPACDNA (extended_dna) − 확장 된 IUPAC DNA 알파벳.
IUPACAmbiguousRNA (ambiguous_rna) − 대문자 IUPAC 모호한 RNA.
IUPACUnambiguousRNA (unambiguous_rna) − 대문자 IUPAC 명확성 RNA (GAUC).
아래와 같이 IUPACProtein 클래스에 대한 간단한 예를 고려하십시오.
>>> from Bio.Alphabet import IUPAC
>>> protein_seq = Seq("AGCT", IUPAC.protein)
>>> protein_seq
Seq('AGCT', IUPACProtein())
>>> protein_seq.alphabet또한 Biopython은 Bio.Data 모듈을 통해 모든 생물 정보학 관련 구성 데이터를 노출합니다. 예를 들어 IUPACData.protein_letters에는 IUPACProtein 알파벳의 가능한 문자가 있습니다.
>>> from Bio.Data import IUPACData
>>> IUPACData.protein_letters
'ACDEFGHIKLMNPQRSTVWY'기본 작동
이 섹션에서는 Seq 클래스에서 사용할 수있는 모든 기본 작업에 대해 간략하게 설명합니다. 시퀀스는 파이썬 문자열과 유사합니다. 우리는 slicing, counting, concatenation, find, split and strip in sequence와 같은 파이썬 문자열 연산을 수행 할 수 있습니다.
다양한 출력을 얻으려면 아래 코드를 사용하십시오.
To get the first value in sequence.
>>> seq_string = Seq("AGCTAGCT")
>>> seq_string[0]
'A'To print the first two values.
>>> seq_string[0:2]
Seq('AG')To print all the values.
>>> seq_string[ : ]
Seq('AGCTAGCT')To perform length and count operations.
>>> len(seq_string)
8
>>> seq_string.count('A')
2To add two sequences.
>>> from Bio.Alphabet import generic_dna, generic_protein
>>> seq1 = Seq("AGCT", generic_dna)
>>> seq2 = Seq("TCGA", generic_dna)
>>> seq1+seq2
Seq('AGCTTCGA', DNAAlphabet())여기에서 위의 두 시퀀스 객체 인 seq1, seq2는 일반적인 DNA 시퀀스이므로 추가하여 새로운 시퀀스를 생성 할 수 있습니다. 아래와 같이 단백질 서열 및 DNA 서열과 같이 호환되지 않는 알파벳을 가진 서열을 추가 할 수 없습니다.
>>> dna_seq = Seq('AGTACACTGGT', generic_dna)
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> dna_seq + protein_seq
.....
.....
TypeError: Incompatible alphabets DNAAlphabet() and ProteinAlphabet()
>>>두 개 이상의 시퀀스를 추가하려면 먼저 파이썬 목록에 저장 한 다음 'for 루프'를 사용하여 검색하고 마지막으로 아래와 같이 추가합니다.
>>> from Bio.Alphabet import generic_dna
>>> list = [Seq("AGCT",generic_dna),Seq("TCGA",generic_dna),Seq("AAA",generic_dna)]
>>> for s in list:
... print(s)
...
AGCT
TCGA
AAA
>>> final_seq = Seq(" ",generic_dna)
>>> for s in list:
... final_seq = final_seq + s
...
>>> final_seq
Seq('AGCTTCGAAAA', DNAAlphabet())아래 섹션에서는 요구 사항에 따라 출력을 얻기 위해 다양한 코드가 제공됩니다.
To change the case of sequence.
>>> from Bio.Alphabet import generic_rna
>>> rna = Seq("agct", generic_rna)
>>> rna.upper()
Seq('AGCT', RNAAlphabet())To check python membership and identity operator.
>>> rna = Seq("agct", generic_rna)
>>> 'a' in rna
True
>>> 'A' in rna
False
>>> rna1 = Seq("AGCT", generic_dna)
>>> rna is rna1
FalseTo find single letter or sequence of letter inside the given sequence.
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> protein_seq.find('G')
1
>>> protein_seq.find('GG')
8To perform splitting operation.
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> protein_seq.split('A')
[Seq('', ProteinAlphabet()), Seq('GU', ProteinAlphabet()),
Seq('C', ProteinAlphabet()), Seq('CUGGU', ProteinAlphabet())]To perform strip operations in the sequence.
>>> strip_seq = Seq(" AGCT ")
>>> strip_seq
Seq(' AGCT ')
>>> strip_seq.strip()
Seq('AGCT')이 장에서는 Biopython이 제공하는 고급 시퀀스 기능에 대해 설명합니다.
보완 및 역 보완
뉴클레오티드 서열은 새로운 서열을 얻기 위해 역 보완 될 수 있습니다. 또한, 보완 된 서열은 원래의 서열을 얻기 위해 역 보완 될 수 있습니다. Biopython은이 기능을 수행하는 두 가지 방법을 제공합니다.complement 과 reverse_complement. 이에 대한 코드는 다음과 같습니다.
>>> from Bio.Alphabet import IUPAC
>>> nucleotide = Seq('TCGAAGTCAGTC', IUPAC.ambiguous_dna)
>>> nucleotide.complement()
Seq('AGCTTCAGTCAG', IUPACAmbiguousDNA())
>>>여기서, complement () 메서드는 DNA 또는 RNA 시퀀스를 보완 할 수 있습니다. reverse_complement () 메서드는 결과 시퀀스를 왼쪽에서 오른쪽으로 보완하고 반전합니다. 아래에 나와 있습니다-
>>> nucleotide.reverse_complement()
Seq('GACTGACTTCGA', IUPACAmbiguousDNA())Biopython은 Bio.Data.IUPACData에서 제공하는 ambiguous_dna_complement 변수를 사용하여 보완 작업을 수행합니다.
>>> from Bio.Data import IUPACData
>>> import pprint
>>> pprint.pprint(IUPACData.ambiguous_dna_complement) {
'A': 'T',
'B': 'V',
'C': 'G',
'D': 'H',
'G': 'C',
'H': 'D',
'K': 'M',
'M': 'K',
'N': 'N',
'R': 'Y',
'S': 'S',
'T': 'A',
'V': 'B',
'W': 'W',
'X': 'X',
'Y': 'R'}
>>>GC 콘텐츠
게놈 DNA 염기 구성 (GC 함량)은 게놈 기능과 종 생태에 상당한 영향을 미칠 것으로 예상됩니다. GC 함량은 GC 뉴클레오타이드의 수를 총 뉴클레오타이드로 나눈 값입니다.
GC 뉴클레오티드 내용을 얻으려면 다음 모듈을 가져오고 다음 단계를 수행하십시오.
>>> from Bio.SeqUtils import GC
>>> nucleotide = Seq("GACTGACTTCGA",IUPAC.unambiguous_dna)
>>> GC(nucleotide)
50.0전사
전사는 DNA 염기 서열을 RNA 염기 서열로 바꾸는 과정입니다. 실제 생물학적 전사 과정은 DNA를 주형 가닥으로 간주하여 mRNA를 얻기 위해 역 보체 (TCAG → CUGA)를 수행하는 것입니다. 그러나 생물 정보학 등에서 Biopython에서는 일반적으로 코딩 가닥으로 직접 작업하며 문자 T를 U로 변경하여 mRNA 서열을 얻을 수 있습니다.
위의 간단한 예는 다음과 같습니다.
>>> from Bio.Seq import Seq
>>> from Bio.Seq import transcribe
>>> from Bio.Alphabet import IUPAC
>>> dna_seq = Seq("ATGCCGATCGTAT",IUPAC.unambiguous_dna) >>> transcribe(dna_seq)
Seq('AUGCCGAUCGUAU', IUPACUnambiguousRNA())
>>>전사를 되돌리려면 T는 아래 코드와 같이 U로 변경됩니다.
>>> rna_seq = transcribe(dna_seq)
>>> rna_seq.back_transcribe()
Seq('ATGCCGATCGTAT', IUPACUnambiguousDNA())DNA 주형 가닥을 얻으려면 아래에 주어진대로 역전사 된 RNA를 역 보완하십시오.
>>> rna_seq.back_transcribe().reverse_complement()
Seq('ATACGATCGGCAT', IUPACUnambiguousDNA())번역
번역은 RNA 서열을 단백질 서열로 번역하는 과정입니다. 아래와 같이 RNA 시퀀스를 고려하십시오.
>>> rna_seq = Seq("AUGGCCAUUGUAAU",IUPAC.unambiguous_rna)
>>> rna_seq
Seq('AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGAUAG', IUPACUnambiguousRNA())이제 위의 코드에 translate () 함수를 적용합니다.
>>> rna_seq.translate()
Seq('MAIV', IUPACProtein())위의 RNA 시퀀스는 간단합니다. RNA 시퀀스, AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGA를 고려하고 translate ()를 적용하십시오.
>>> rna = Seq('AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGA', IUPAC.unambiguous_rna)
>>> rna.translate()
Seq('MAIVMGR*KGAR', HasStopCodon(IUPACProtein(), '*'))여기서 중지 코돈은 별표 '*'로 표시됩니다.
translate () 메서드에서 첫 번째 중지 코돈에서 중지 할 수 있습니다. 이를 수행하려면 다음과 같이 translate ()에서 to_stop = True를 할당 할 수 있습니다.
>>> rna.translate(to_stop = True)
Seq('MAIVMGR', IUPACProtein())여기서 중지 코돈은 포함되지 않으므로 결과 시퀀스에 포함되지 않습니다.
번역 표
NCBI의 유전 코드 페이지는 Biopython에서 사용하는 번역 테이블의 전체 목록을 제공합니다. 코드를 시각화하는 표준 테이블의 예를 살펴 보겠습니다.
>>> from Bio.Data import CodonTable
>>> table = CodonTable.unambiguous_dna_by_name["Standard"]
>>> print(table)
Table 1 Standard, SGC0
| T | C | A | G |
--+---------+---------+---------+---------+--
T | TTT F | TCT S | TAT Y | TGT C | T
T | TTC F | TCC S | TAC Y | TGC C | C
T | TTA L | TCA S | TAA Stop| TGA Stop| A
T | TTG L(s)| TCG S | TAG Stop| TGG W | G
--+---------+---------+---------+---------+--
C | CTT L | CCT P | CAT H | CGT R | T
C | CTC L | CCC P | CAC H | CGC R | C
C | CTA L | CCA P | CAA Q | CGA R | A
C | CTG L(s)| CCG P | CAG Q | CGG R | G
--+---------+---------+---------+---------+--
A | ATT I | ACT T | AAT N | AGT S | T
A | ATC I | ACC T | AAC N | AGC S | C
A | ATA I | ACA T | AAA K | AGA R | A
A | ATG M(s)| ACG T | AAG K | AGG R | G
--+---------+---------+---------+---------+--
G | GTT V | GCT A | GAT D | GGT G | T
G | GTC V | GCC A | GAC D | GGC G | C
G | GTA V | GCA A | GAA E | GGA G | A
G | GTG V | GCG A | GAG E | GGG G | G
--+---------+---------+---------+---------+--
>>>Biopython은이 표를 사용하여 DNA를 단백질로 번역하고 중지 코돈을 찾습니다.
Biopython은 모듈 Bio.SeqIO를 제공하여 각각 파일 (모든 스트림)에서 시퀀스를 읽고 쓸 수 있습니다. 생물 정보학에서 사용할 수있는 거의 모든 파일 형식을 지원합니다. 대부분의 소프트웨어는 파일 형식에 따라 다른 접근 방식을 제공합니다. 그러나 Biopython은 SeqRecord 객체를 통해 구문 분석 된 시퀀스 데이터를 사용자에게 제공하는 단일 접근 방식을 의식적으로 따릅니다.
다음 섹션에서 SeqRecord에 대해 자세히 알아 보겠습니다.
SeqRecord
Bio.SeqRecord 모듈은 SeqRecord를 제공하여 시퀀스의 메타 정보와 시퀀스 데이터 자체를 아래와 같이 보관합니다.
seq- 실제 시퀀스입니다.
id- 주어진 시퀀스의 기본 식별자입니다. 기본 유형은 문자열입니다.
name- 시퀀스의 이름입니다. 기본 유형은 문자열입니다.
설명 -사람이 읽을 수있는 시퀀스 정보를 표시합니다.
주석 -그것은 시퀀스에 대한 추가 정보의 사전입니다.
SeqRecord는 아래 지정된대로 가져올 수 있습니다.
from Bio.SeqRecord import SeqRecord다음 섹션에서 실제 시퀀스 파일을 사용하여 시퀀스 파일을 구문 분석하는 뉘앙스를 이해하겠습니다.
시퀀스 파일 형식 구문 분석
이 섹션에서는 가장 많이 사용되는 두 가지 시퀀스 파일 형식을 구문 분석하는 방법에 대해 설명합니다. FASTA 과 GenBank.
파스타
FASTA시퀀스 데이터를 저장하는 가장 기본적인 파일 형식입니다. 원래 FASTA는 Bioinformatics의 초기 진화 과정에서 개발 된 DNA와 단백질의 서열 정렬을위한 소프트웨어 패키지로 주로 서열 유사성을 검색하는 데 사용되었습니다.
Biopython은 예제 FASTA 파일을 제공하며 다음 위치에서 액세스 할 수 있습니다. https://github.com/biopython/biopython/blob/master/Doc/examples/ls_orchid.fasta.
이 파일을 다운로드하여 Biopython 샘플 디렉토리에 다음과 같이 저장하십시오. ‘orchid.fasta’.
Bio.SeqIO 모듈은 시퀀스 파일을 처리하기위한 parse () 메소드를 제공하며 다음과 같이 가져올 수 있습니다.
from Bio.SeqIO import parseparse () 메서드는 두 개의 인수를 포함합니다. 첫 번째는 파일 핸들이고 두 번째는 파일 형식입니다.
>>> file = open('path/to/biopython/sample/orchid.fasta')
>>> for record in parse(file, "fasta"):
... print(record.id)
...
gi|2765658|emb|Z78533.1|CIZ78533
gi|2765657|emb|Z78532.1|CCZ78532
..........
..........
gi|2765565|emb|Z78440.1|PPZ78440
gi|2765564|emb|Z78439.1|PBZ78439
>>>여기서 parse () 메서드는 반복 할 때마다 SeqRecord를 반환하는 반복 가능한 객체를 반환합니다. 반복 가능하기 때문에 정교하고 쉬운 방법을 많이 제공하며 일부 기능을 볼 수 있습니다.
다음()
next () 메서드는 반복 가능한 객체에서 사용할 수있는 다음 항목을 반환합니다.이 항목을 사용하여 아래에 주어진 첫 번째 시퀀스를 얻을 수 있습니다.
>>> first_seq_record = next(SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta'))
>>> first_seq_record.id 'gi|2765658|emb|Z78533.1|CIZ78533'
>>> first_seq_record.name 'gi|2765658|emb|Z78533.1|CIZ78533'
>>> first_seq_record.seq Seq('CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGATGAGACCGTGG...CGC', SingleLetterAlphabet())
>>> first_seq_record.description 'gi|2765658|emb|Z78533.1|CIZ78533 C.irapeanum 5.8S rRNA gene and ITS1 and ITS2 DNA'
>>> first_seq_record.annotations
{}
>>>여기서는 FASTA 형식이 시퀀스 주석을 지원하지 않기 때문에 seq_record.annotations가 비어 있습니다.
목록 이해
아래와 같이 목록 이해력을 사용하여 반복 가능한 객체를 목록으로 변환 할 수 있습니다.
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> all_seq = [seq_record for seq_record in seq_iter] >>> len(all_seq)
94
>>>여기에서는 총 개수를 얻기 위해 len 메서드를 사용했습니다. 다음과 같이 최대 길이의 시퀀스를 얻을 수 있습니다.
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> max_seq = max(len(seq_record.seq) for seq_record in seq_iter)
>>> max_seq
789
>>>아래 코드를 사용하여 시퀀스를 필터링 할 수도 있습니다.
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> seq_under_600 = [seq_record for seq_record in seq_iter if len(seq_record.seq) < 600]
>>> for seq in seq_under_600:
... print(seq.id)
...
gi|2765606|emb|Z78481.1|PIZ78481
gi|2765605|emb|Z78480.1|PGZ78480
gi|2765601|emb|Z78476.1|PGZ78476
gi|2765595|emb|Z78470.1|PPZ78470
gi|2765594|emb|Z78469.1|PHZ78469
gi|2765564|emb|Z78439.1|PBZ78439
>>>SqlRecord 객체 (파싱 된 데이터) 컬렉션을 파일에 쓰는 것은 SeqIO.write 메서드를 호출하는 것만 큼 간단합니다.
file = open("converted.fasta", "w)
SeqIO.write(seq_record, file, "fasta")이 방법은 아래에 지정된 형식을 효과적으로 변환하는 데 사용할 수 있습니다.
file = open("converted.gbk", "w)
SeqIO.write(seq_record, file, "genbank")GenBank
유전자에 대한 더 풍부한 시퀀스 형식이며 다양한 종류의 주석을위한 필드를 포함합니다. Biopython은 예제 GenBank 파일을 제공하며 다음 위치에서 액세스 할 수 있습니다.https://github.com/biopython/biopython/blob/master/Doc/examples/ls_orchid.fasta.
파일을 다운로드하여 Biopython 샘플 디렉토리에 다음과 같이 저장하십시오. ‘orchid.gbk’
Biopython은 모든 생물 정보학 형식을 구문 분석하기 위해 구문 분석하는 단일 함수를 제공하기 때문에. GenBank 형식을 구문 분석하는 것은 구문 분석 방법에서 형식 옵션을 변경하는 것만 큼 간단합니다.
동일한 코드가 아래에 제공되었습니다.
>>> from Bio import SeqIO
>>> from Bio.SeqIO import parse
>>> seq_record = next(parse(open('path/to/biopython/sample/orchid.gbk'),'genbank'))
>>> seq_record.id
'Z78533.1'
>>> seq_record.name
'Z78533'
>>> seq_record.seq Seq('CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGATGAGACCGTGG...CGC', IUPACAmbiguousDNA())
>>> seq_record.description
'C.irapeanum 5.8S rRNA gene and ITS1 and ITS2 DNA'
>>> seq_record.annotations {
'molecule_type': 'DNA',
'topology': 'linear',
'data_file_division': 'PLN',
'date': '30-NOV-2006',
'accessions': ['Z78533'],
'sequence_version': 1,
'gi': '2765658',
'keywords': ['5.8S ribosomal RNA', '5.8S rRNA gene', 'internal transcribed spacer', 'ITS1', 'ITS2'],
'source': 'Cypripedium irapeanum',
'organism': 'Cypripedium irapeanum',
'taxonomy': [
'Eukaryota',
'Viridiplantae',
'Streptophyta',
'Embryophyta',
'Tracheophyta',
'Spermatophyta',
'Magnoliophyta',
'Liliopsida',
'Asparagales',
'Orchidaceae',
'Cypripedioideae',
'Cypripedium'],
'references': [
Reference(title = 'Phylogenetics of the slipper orchids (Cypripedioideae:
Orchidaceae): nuclear rDNA ITS sequences', ...),
Reference(title = 'Direct Submission', ...)
]
}Sequence alignment 두 개 이상의 서열 (DNA, RNA 또는 단백질 서열)을 특정 순서로 배열하여 그들 사이의 유사성 영역을 식별하는 과정입니다.
유사한 영역을 식별하면 종간에 보존되는 특성, 유 전적으로 서로 다른 종이 얼마나 가까운 지, 종이 어떻게 진화하는지 등과 같은 많은 정보를 추론 할 수 있습니다. Biopython은 서열 정렬에 대한 광범위한 지원을 제공합니다.
이 장에서 Biopython이 제공하는 몇 가지 중요한 기능에 대해 알아 보겠습니다.
구문 분석 시퀀스 정렬
Biopython은 시퀀스 정렬을 읽고 쓰기위한 모듈 인 Bio.AlignIO를 제공합니다. 생물 정보학에서는 이전에 학습 한 서열 데이터와 유사한 서열 정렬 데이터를 지정하는 데 사용할 수있는 많은 형식이 있습니다. Bio.AlignIO는 Bio.SeqIO가 시퀀스 데이터에서 작동하고 Bio.AlignIO가 시퀀스 정렬 데이터에서 작동한다는 점을 제외하면 Bio.SeqIO와 유사한 API를 제공합니다.
학습을 시작하기 전에 인터넷에서 샘플 시퀀스 정렬 파일을 다운로드 해 보겠습니다.
샘플 파일을 다운로드하려면 다음 단계를 따르십시오.
Step 1 − 좋아하는 브라우저를 열고 http://pfam.xfam.org/family/browse웹 사이트. 모든 Pfam 제품군이 알파벳 순서로 표시됩니다.
Step 2− 시드 값이 적은 한 가족을 선택하십시오. 여기에는 최소한의 데이터가 포함되어 있으며 정렬 작업을 쉽게 수행 할 수 있습니다. 여기에서 PF18225를 선택 / 클릭하면 열립니다.http://pfam.xfam.org/family/PF18225 시퀀스 정렬을 포함하여 그것에 대한 완전한 세부 사항을 보여줍니다.
Step 3 − 정렬 섹션으로 이동하여 Stockholm 형식 (PF18225_seed.txt)의 시퀀스 정렬 파일을 다운로드합니다.
아래의 Bio.AlignIO를 이용하여 다운로드 한 시퀀스 정렬 파일을 읽어 보겠습니다.
Bio.AlignIO 모듈 가져 오기
>>> from Bio import AlignIO읽기 방법을 사용하여 정렬을 읽습니다. read 메소드는 주어진 파일에서 사용 가능한 단일 정렬 데이터를 읽는 데 사용됩니다. 주어진 파일에 많은 정렬이 포함되어 있으면 구문 분석 방법을 사용할 수 있습니다. parse 메서드는 Bio.SeqIO 모듈의 parse 메서드와 유사한 반복 가능한 정렬 개체를 반환합니다.
>>> alignment = AlignIO.read(open("PF18225_seed.txt"), "stockholm")정렬 개체를 인쇄합니다.
>>> print(alignment)
SingleLetterAlphabet() alignment with 6 rows and 65 columns
MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVA...EGP B7RZ31_9GAMM/59-123
AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADIT...KKP A0A0C3NPG9_9PROT/58-119
ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMA...KKP A0A143HL37_9GAMM/57-121
TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMA...NKP A0A0X3UC67_9GAMM/57-121
AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIM...NRK B3PFT7_CELJU/62-126
AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVA...NRT K4KEM7_SIMAS/61-125
>>>또한 정렬에서 사용 가능한 시퀀스 (SeqRecord)를 확인할 수 있습니다.
>>> for align in alignment:
... print(align.seq)
...
MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVATVANQLRGRKRRAFARHREGP
AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADITA---RLDRRREHGEHGVRKKP
ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMAPMLIALNYRNRESHAQVDKKP
TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMAPLFKVLSFRNREDQGLVNNKP
AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIMVLAPRLTAKHPYDKVQDRNRK
AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVADLMRKLDLDRPFKKLERKNRT
>>>다중 정렬
일반적으로 대부분의 시퀀스 정렬 파일에는 단일 정렬 데이터가 포함되어 있으며 read그것을 구문 분석하는 방법. 다중 서열 정렬 개념에서 둘 이상의 서열이 그들 사이의 최상의 하위 서열 일치를 위해 비교되고 단일 파일에서 다중 서열 정렬이 발생합니다.
입력 시퀀스 정렬 형식에 둘 이상의 시퀀스 정렬이 포함 된 경우 다음을 사용해야합니다. parse 대신 방법 read 아래 명시된 방법-
>>> from Bio import AlignIO
>>> alignments = AlignIO.parse(open("PF18225_seed.txt"), "stockholm")
>>> print(alignments)
<generator object parse at 0x000001CD1C7E0360>
>>> for alignment in alignments:
... print(alignment)
...
SingleLetterAlphabet() alignment with 6 rows and 65 columns
MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVA...EGP B7RZ31_9GAMM/59-123
AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADIT...KKP A0A0C3NPG9_9PROT/58-119
ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMA...KKP A0A143HL37_9GAMM/57-121
TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMA...NKP A0A0X3UC67_9GAMM/57-121
AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIM...NRK B3PFT7_CELJU/62-126
AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVA...NRT K4KEM7_SIMAS/61-125
>>>여기서 parse 메서드는 반복 가능한 정렬 객체를 반환하며 실제 정렬을 얻기 위해 반복 할 수 있습니다.
쌍방향 시퀀스 정렬
Pairwise sequence alignment 한 번에 두 개의 시퀀스 만 비교하고 최상의 시퀀스 정렬을 제공합니다. Pairwise 이해하기 쉽고 결과 시퀀스 정렬에서 추론하기가 매우 뛰어납니다.
Biopython은 특별한 모듈을 제공합니다. Bio.pairwise2pairwise 방법을 사용하여 정렬 순서를 식별합니다. Biopython은 정렬 순서를 찾기 위해 최상의 알고리즘을 적용하며 다른 소프트웨어와 동등합니다.
pairwise 모듈을 사용하여 두 개의 단순 및 가상 시퀀스의 시퀀스 정렬을 찾는 예제를 작성해 보겠습니다. 이것은 시퀀스 정렬의 개념과 Biopython을 사용하여 프로그래밍하는 방법을 이해하는 데 도움이 될 것입니다.
1 단계
모듈 가져 오기 pairwise2 아래에 주어진 명령으로-
>>> from Bio import pairwise22 단계
두 시퀀스, seq1 및 seq2 만들기-
>>> from Bio.Seq import Seq
>>> seq1 = Seq("ACCGGT")
>>> seq2 = Seq("ACGT")3 단계
seq1 및 seq2와 함께 pairwise2.align.globalxx 메서드를 호출하여 아래 코드 줄을 사용하여 정렬을 찾습니다.
>>> alignments = pairwise2.align.globalxx(seq1, seq2)여기, globalxx메서드는 실제 작업을 수행하고 주어진 시퀀스에서 가능한 모든 최상의 정렬을 찾습니다. 실제로 Bio.pairwise2는 다양한 시나리오에서 정렬을 찾기 위해 아래 규칙을 따르는 꽤 많은 방법을 제공합니다.
<sequence alignment type>XY여기서, 시퀀스 정렬 유형은 글로벌 또는 로컬 일 수있는 정렬 유형을 의미한다 . 글로벌 유형은 전체 시퀀스를 고려하여 시퀀스 정렬을 찾는 것입니다. 로컬 유형은 주어진 시퀀스의 하위 집합도 조사하여 시퀀스 정렬을 찾는 것입니다. 이것은 지루할 것이지만 주어진 시퀀스 간의 유사성에 대한 더 나은 아이디어를 제공합니다.
X는 일치 점수를 나타냅니다. 가능한 값은 x (정확한 일치), m (동일한 문자를 기반으로 한 점수), d (문자 및 일치 점수가있는 사용자 제공 사전) 및 마지막으로 c (사용자 지정 점수 알고리즘을 제공하는 사용자 정의 함수)입니다.
Y는 갭 페널티를 나타냅니다. 가능한 값은 x (갭 페널티 없음), s (두 시퀀스에 대해 동일한 페널티), d (각 시퀀스에 대해 다른 페널티) 및 마지막으로 c (사용자 정의 간격 페널티를 제공하는 사용자 정의 함수)입니다.
따라서 localds는 로컬 정렬 기술을 사용하여 시퀀스 정렬을 찾는 유효한 방법이며, 사용자가 일치하는 사전을 제공하고 두 시퀀스에 대해 사용자가 제공 한 갭 패널티를 찾습니다.
>>> test_alignments = pairwise2.align.localds(seq1, seq2, blosum62, -10, -1)여기서 blosum62는 match score를 제공하기 위해 pairwise2 모듈에서 사용할 수있는 사전을 의미합니다. -10은 갭 오픈 페널티를 의미하고 -1은 갭 연장 페널티를 의미합니다.
4 단계
반복 가능한 정렬 개체를 반복하고 각 개별 정렬 개체를 가져 와서 인쇄합니다.
>>> for alignment in alignments:
... print(alignment)
...
('ACCGGT', 'A-C-GT', 4.0, 0, 6)
('ACCGGT', 'AC--GT', 4.0, 0, 6)
('ACCGGT', 'A-CG-T', 4.0, 0, 6)
('ACCGGT', 'AC-G-T', 4.0, 0, 6)5 단계
Bio.pairwise2 모듈은 결과를 더 잘 시각화하기 위해 형식 지정 방법 인 format_alignment를 제공합니다.
>>> from Bio.pairwise2 import format_alignment
>>> alignments = pairwise2.align.globalxx(seq1, seq2)
>>> for alignment in alignments:
... print(format_alignment(*alignment))
...
ACCGGT
| | ||
A-C-GT
Score=4
ACCGGT
|| ||
AC--GT
Score=4
ACCGGT
| || |
A-CG-T
Score=4
ACCGGT
|| | |
AC-G-T
Score=4
>>>Biopython은 또한 시퀀스 정렬을위한 또 다른 모듈 인 Align을 제공합니다. 이 모듈은 알고리즘, 모드, 매치 스코어, 갭 페널티 등과 같은 파라미터 설정을 간단하게하기 위해 다른 API 세트를 제공합니다. Align 객체를 간단히 살펴보면 다음과 같습니다.
>>> from Bio import Align
>>> aligner = Align.PairwiseAligner()
>>> print(aligner)
Pairwise sequence aligner with parameters
match score: 1.000000
mismatch score: 0.000000
target open gap score: 0.000000
target extend gap score: 0.000000
target left open gap score: 0.000000
target left extend gap score: 0.000000
target right open gap score: 0.000000
target right extend gap score: 0.000000
query open gap score: 0.000000
query extend gap score: 0.000000
query left open gap score: 0.000000
query left extend gap score: 0.000000
query right open gap score: 0.000000
query right extend gap score: 0.000000
mode: global
>>>시퀀스 정렬 도구 지원
Biopython은 Bio.Align.Applications 모듈을 통해 많은 시퀀스 정렬 도구에 대한 인터페이스를 제공합니다. 일부 도구는 다음과 같습니다.
- ClustalW
- MUSCLE
- EMBOSS 바늘과 물
Biopython에서 가장 널리 사용되는 정렬 도구 인 ClustalW를 통해 시퀀스 정렬을 만드는 간단한 예제를 작성해 보겠습니다.
Step 1 − 다음에서 Clustalw 프로그램 다운로드 http://www.clustal.org/download/current/설치하십시오. 또한 "clustal"설치 경로로 시스템 PATH를 업데이트합니다.
Step 2 − Bio.Align.Applications 모듈에서 ClustalwCommanLine을 가져옵니다.
>>> from Bio.Align.Applications import ClustalwCommandlineStep 3 − Biopython 패키지에서 사용 가능한 입력 파일 인 opuntia.fasta로 ClustalwCommanLine을 호출하여 cmd를 설정합니다. https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/opuntia.fasta
>>> cmd = ClustalwCommandline("clustalw2",
infile="/path/to/biopython/sample/opuntia.fasta")
>>> print(cmd)
clustalw2 -infile=fasta/opuntia.fastaStep 4 − cmd ()를 호출하면 clustalw 명령이 실행되고 결과 정렬 파일 인 opuntia.aln의 출력이 제공됩니다.
>>> stdout, stderr = cmd()Step 5 − 아래와 같이 정렬 파일을 읽고 인쇄합니다 −
>>> from Bio import AlignIO
>>> align = AlignIO.read("/path/to/biopython/sample/opuntia.aln", "clustal")
>>> print(align)
SingleLetterAlphabet() alignment with 7 rows and 906 columns
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273285|gb|AF191659.1|AF191
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273284|gb|AF191658.1|AF191
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273287|gb|AF191661.1|AF191
TATACATAAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273286|gb|AF191660.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273290|gb|AF191664.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273289|gb|AF191663.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273291|gb|AF191665.1|AF191
>>>BLAST는 Basic Local Alignment Search Tool. 생물학적 서열 사이의 유사성 영역을 찾습니다. Biopython은 NCBI BLAST 작업을 처리하기 위해 Bio.Blast 모듈을 제공합니다. BLAST는 로컬 연결 또는 인터넷 연결을 통해 실행할 수 있습니다.
다음 섹션에서이 두 연결을 간략하게 이해하겠습니다.
인터넷을 통해 실행
Biopython은 BLAST의 온라인 버전을 호출하기 위해 Bio.Blast.NCBIWWW 모듈을 제공합니다. 이렇게하려면 다음 모듈을 가져와야합니다.
>>> from Bio.Blast import NCBIWWWNCBIWW 모듈은 BLAST 온라인 버전을 조회하는 qblast 기능을 제공합니다. https://blast.ncbi.nlm.nih.gov/Blast.cgi. qblast는 온라인 버전에서 지원하는 모든 매개 변수를 지원합니다.
이 모듈에 대한 도움말을 얻으려면 아래 명령을 사용하고 기능을 이해하십시오.
>>> help(NCBIWWW.qblast)
Help on function qblast in module Bio.Blast.NCBIWWW:
qblast(
program, database, sequence,
url_base = 'https://blast.ncbi.nlm.nih.gov/Blast.cgi',
auto_format = None,
composition_based_statistics = None,
db_genetic_code = None,
endpoints = None,
entrez_query = '(none)',
expect = 10.0,
filter = None,
gapcosts = None,
genetic_code = None,
hitlist_size = 50,
i_thresh = None,
layout = None,
lcase_mask = None,
matrix_name = None,
nucl_penalty = None,
nucl_reward = None,
other_advanced = None,
perc_ident = None,
phi_pattern = None,
query_file = None,
query_believe_defline = None,
query_from = None,
query_to = None,
searchsp_eff = None,
service = None,
threshold = None,
ungapped_alignment = None,
word_size = None,
alignments = 500,
alignment_view = None,
descriptions = 500,
entrez_links_new_window = None,
expect_low = None,
expect_high = None,
format_entrez_query = None,
format_object = None,
format_type = 'XML',
ncbi_gi = None,
results_file = None,
show_overview = None,
megablast = None,
template_type = None,
template_length = None
)
BLAST search using NCBI's QBLAST server or a cloud service provider.
Supports all parameters of the qblast API for Put and Get.
Please note that BLAST on the cloud supports the NCBI-BLAST Common
URL API (http://ncbi.github.io/blast-cloud/dev/api.html).
To use this feature, please set url_base to 'http://host.my.cloud.service.provider.com/cgi-bin/blast.cgi' and
format_object = 'Alignment'. For more details, please see 8. Biopython – Overview of BLAST
https://blast.ncbi.nlm.nih.gov/Blast.cgi?PAGE_TYPE = BlastDocs&DOC_TYPE = CloudBlast
Some useful parameters:
- program blastn, blastp, blastx, tblastn, or tblastx (lower case)
- database Which database to search against (e.g. "nr").
- sequence The sequence to search.
- ncbi_gi TRUE/FALSE whether to give 'gi' identifier.
- descriptions Number of descriptions to show. Def 500.
- alignments Number of alignments to show. Def 500.
- expect An expect value cutoff. Def 10.0.
- matrix_name Specify an alt. matrix (PAM30, PAM70, BLOSUM80, BLOSUM45).
- filter "none" turns off filtering. Default no filtering
- format_type "HTML", "Text", "ASN.1", or "XML". Def. "XML".
- entrez_query Entrez query to limit Blast search
- hitlist_size Number of hits to return. Default 50
- megablast TRUE/FALSE whether to use MEga BLAST algorithm (blastn only)
- service plain, psi, phi, rpsblast, megablast (lower case)
This function does no checking of the validity of the parameters
and passes the values to the server as is. More help is available at:
https://ncbi.github.io/blast-cloud/dev/api.html일반적으로 qblast 함수의 인수는 기본적으로 BLAST 웹 페이지에서 설정할 수있는 다른 매개 변수와 유사합니다. 이것은 qblast 함수를 이해하기 쉽게 만들고 그것을 사용하기위한 학습 곡선을 줄여줍니다.
연결 및 검색
BLAST 온라인 버전 연결 및 검색 과정을 이해하기 위해 Biopython을 통해 온라인 BLAST 서버에 대해 간단한 시퀀스 검색 (로컬 시퀀스 파일에서 사용 가능)을 수행해 보겠습니다.
Step 1 − 이름이 지정된 파일을 생성합니다. blast_example.fasta Biopython 디렉토리에서 아래 시퀀스 정보를 입력으로 제공하십시오.
Example of a single sequence in FASTA/Pearson format:
>sequence A ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatattcatat
tctgttgccagaaaaaacacttttaggctatattagagccatcttctttgaagcgttgtc
>sequence B ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatattca
tattctgttgccagaaaaaacacttttaggctatattagagccatcttctttgaagcgttgtcStep 2 − NCBIWWW 모듈을 가져옵니다.
>>> from Bio.Blast import NCBIWWWStep 3 − 시퀀스 파일을 엽니 다. blast_example.fasta 파이썬 IO 모듈을 사용합니다.
>>> sequence_data = open("blast_example.fasta").read()
>>> sequence_data
'Example of a single sequence in FASTA/Pearson format:\n\n\n> sequence
A\nggtaagtcctctagtacaaacacccccaatattgtgatataattaaaatt
atattcatat\ntctgttgccagaaaaaacacttttaggctatattagagccatcttctttg aagcgttgtc\n\n'Step 4− 이제 시퀀스 데이터를 주 매개 변수로 전달하는 qblast 함수를 호출합니다. 다른 매개 변수는 데이터베이스 (nt)와 내부 프로그램 (blastn)을 나타냅니다.
>>> result_handle = NCBIWWW.qblast("blastn", "nt", sequence_data)
>>> result_handle
<_io.StringIO object at 0x000001EC9FAA4558>blast_results검색 결과를 보관합니다. 나중에 사용하기 위해 파일에 저장할 수 있으며 세부 정보를 얻기 위해 구문 분석 할 수도 있습니다. 다음 섹션에서 방법을 배웁니다.
Step 5 − 아래와 같이 전체 fasta 파일을 사용하는 대신 Seq 객체를 사용하여 동일한 기능을 수행 할 수 있습니다. −
>>> from Bio import SeqIO
>>> seq_record = next(SeqIO.parse(open('blast_example.fasta'),'fasta'))
>>> seq_record.id
'sequence'
>>> seq_record.seq
Seq('ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatat...gtc',
SingleLetterAlphabet())이제 Seq 객체 인 record.seq를 주 매개 변수로 전달하는 qblast 함수를 호출합니다.
>>> result_handle = NCBIWWW.qblast("blastn", "nt", seq_record.seq)
>>> print(result_handle)
<_io.StringIO object at 0x000001EC9FAA4558>BLAST는 시퀀스에 대한 식별자를 자동으로 할당합니다.
Step 6 − result_handle 객체는 전체 결과를 가지며 나중에 사용하기 위해 파일에 저장할 수 있습니다.
>>> with open('results.xml', 'w') as save_file:
>>> blast_results = result_handle.read()
>>> save_file.write(blast_results)이후 섹션에서 결과 파일을 구문 분석하는 방법을 살펴 보겠습니다.
독립형 BLAST 실행
이 섹션에서는 로컬 시스템에서 BLAST를 실행하는 방법에 대해 설명합니다. 로컬 시스템에서 BLAST를 실행하면 더 빠를 수 있으며 시퀀스를 검색하기 위해 자체 데이터베이스를 만들 수도 있습니다.
BLAST 연결
일반적으로 BLAST를 로컬에서 실행하는 것은 큰 크기, 소프트웨어 실행에 필요한 추가 노력 및 관련 비용 때문에 권장되지 않습니다. 온라인 BLAST는 기본 및 고급 목적에 충분합니다. 물론 때로는 로컬로 설치해야 할 수도 있습니다.
많은 시간과 네트워크 볼륨이 필요할 수있는 온라인 검색을 자주 수행하고 있으며 독점 시퀀스 데이터 또는 IP 관련 문제가있는 경우 로컬에 설치하는 것이 좋습니다.
이렇게하려면 아래 단계를 따라야합니다.
Step 1− 주어진 링크를 사용하여 최신 blast 바이너리를 다운로드하고 설치합니다. − ftp://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/
Step 2− 아래 링크를 사용하여 필요한 최신 데이터베이스를 다운로드하고 압축을 풉니 다. − ftp://ftp.ncbi.nlm.nih.gov/blast/db/
BLAST 소프트웨어는 사이트에 많은 데이터베이스를 제공합니다. blast 데이터베이스 사이트에서 alu.n.gz 파일을 다운로드 하고 alu 폴더에 압축을 풉니 다. 이 파일은 FASTA 형식입니다. blast 애플리케이션에서이 파일을 사용하려면 먼저 파일을 FASTA 형식에서 blast 데이터베이스 형식으로 변환해야합니다. BLAST는이 변환을 수행하기 위해 makeblastdb 애플리케이션을 제공합니다.
아래 코드 스 니펫을 사용하십시오-
cd /path/to/alu
makeblastdb -in alu.n -parse_seqids -dbtype nucl -out alun위의 코드를 실행하면 입력 파일 alu.n을 구문 분석하고 BLAST 데이터베이스를 alun.nsq, alun.nsi 등의 여러 파일로 만듭니다. 이제이 데이터베이스를 쿼리하여 시퀀스를 찾을 수 있습니다.
로컬 서버에 BLAST를 설치했으며 샘플 BLAST 데이터베이스도 있습니다. alun 그것에 대해 쿼리합니다.
Step 3− 데이터베이스 쿼리를위한 샘플 시퀀스 파일을 생성 해 보겠습니다. search.fsa 파일을 만들고 그 안에 아래 데이터를 넣으십시오.
>gnl|alu|Z15030_HSAL001056 (Alu-J)
AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCT
TGAGCCTAGGAGTTTGCGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAA
AGAAAAAAAAAATAGCTCTGCTGGTGGTGCATGCCTATAGTCTCAGCTATCAGGAGGCTG
GGACAGGAGGATCACTTGGGCCCGGGAGTTGAGGCTGTGGTGAGCCACGATCACACCACT
GCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAACAAATAA
>gnl|alu|D00596_HSAL003180 (Alu-Sx)
AGCCAGGTGTGGTGGCTCACGCCTGTAATCCCACCGCTTTGGGAGGCTGAGTCAGATCAC
CTGAGGTTAGGAATTTGGGACCAGCCTGGCCAACATGGCGACACCCCAGTCTCTACTAAT
AACACAAAAAATTAGCCAGGTGTGCTGGTGCATGTCTGTAATCCCAGCTACTCAGGAGGC
TGAGGCATGAGAATTGCTCACGAGGCGGAGGTTGTAGTGAGCTGAGATCGTGGCACTGTA
CTCCAGCCTGGCGACAGAGGGAGAACCCATGTCAAAAACAAAAAAAGACACCACCAAAGG
TCAAAGCATA
>gnl|alu|X55502_HSAL000745 (Alu-J)
TGCCTTCCCCATCTGTAATTCTGGCACTTGGGGAGTCCAAGGCAGGATGATCACTTATGC
CCAAGGAATTTGAGTACCAAGCCTGGGCAATATAACAAGGCCCTGTTTCTACAAAAACTT
TAAACAATTAGCCAGGTGTGGTGGTGCGTGCCTGTGTCCAGCTACTCAGGAAGCTGAGGC
AAGAGCTTGAGGCTACAGTGAGCTGTGTTCCACCATGGTGCTCCAGCCTGGGTGACAGGG
CAAGACCCTGTCAAAAGAAAGGAAGAAAGAACGGAAGGAAAGAAGGAAAGAAACAAGGAG
AG시퀀스 데이터는 alu.n 파일에서 수집됩니다. 따라서 데이터베이스와 일치합니다.
Step 4 − BLAST 소프트웨어는 데이터베이스 검색을위한 많은 응용 프로그램을 제공하며 blastn을 사용합니다. blastn application requires minimum of three arguments, db, query and out. db 검색에 대한 데이터베이스를 참조합니다. query 일치시킬 시퀀스이며 out결과를 저장할 파일입니다. 이제 아래 명령을 실행하여이 간단한 쿼리를 수행합니다.
blastn -db alun -query search.fsa -out results.xml -outfmt 5위의 명령을 실행하면 results.xml 아래에 주어진 파일 (부분 데이터)-
<?xml version = "1.0"?>
<!DOCTYPE BlastOutput PUBLIC "-//NCBI//NCBI BlastOutput/EN"
"http://www.ncbi.nlm.nih.gov/dtd/NCBI_BlastOutput.dtd">
<BlastOutput>
<BlastOutput_program>blastn</BlastOutput_program>
<BlastOutput_version>BLASTN 2.7.1+</BlastOutput_version>
<BlastOutput_reference>Zheng Zhang, Scott Schwartz, Lukas Wagner, and Webb
Miller (2000), "A greedy algorithm for aligning DNA sequences", J
Comput Biol 2000; 7(1-2):203-14.
</BlastOutput_reference>
<BlastOutput_db>alun</BlastOutput_db>
<BlastOutput_query-ID>Query_1</BlastOutput_query-ID>
<BlastOutput_query-def>gnl|alu|Z15030_HSAL001056 (Alu-J)</BlastOutput_query-def>
<BlastOutput_query-len>292</BlastOutput_query-len>
<BlastOutput_param>
<Parameters>
<Parameters_expect>10</Parameters_expect>
<Parameters_sc-match>1</Parameters_sc-match>
<Parameters_sc-mismatch>-2</Parameters_sc-mismatch>
<Parameters_gap-open>0</Parameters_gap-open>
<Parameters_gap-extend>0</Parameters_gap-extend>
<Parameters_filter>L;m;</Parameters_filter>
</Parameters>
</BlastOutput_param>
<BlastOutput_iterations>
<Iteration>
<Iteration_iter-num>1</Iteration_iter-num><Iteration_query-ID>Query_1</Iteration_query-ID>
<Iteration_query-def>gnl|alu|Z15030_HSAL001056 (Alu-J)</Iteration_query-def>
<Iteration_query-len>292</Iteration_query-len>
<Iteration_hits>
<Hit>
<Hit_num>1</Hit_num>
<Hit_id>gnl|alu|Z15030_HSAL001056</Hit_id>
<Hit_def>(Alu-J)</Hit_def>
<Hit_accession>Z15030_HSAL001056</Hit_accession>
<Hit_len>292</Hit_len>
<Hit_hsps>
<Hsp>
<Hsp_num>1</Hsp_num>
<Hsp_bit-score>540.342</Hsp_bit-score>
<Hsp_score>292</Hsp_score>
<Hsp_evalue>4.55414e-156</Hsp_evalue>
<Hsp_query-from>1</Hsp_query-from>
<Hsp_query-to>292</Hsp_query-to>
<Hsp_hit-from>1</Hsp_hit-from>
<Hsp_hit-to>292</Hsp_hit-to>
<Hsp_query-frame>1</Hsp_query-frame>
<Hsp_hit-frame>1</Hsp_hit-frame>
<Hsp_identity>292</Hsp_identity>
<Hsp_positive>292</Hsp_positive>
<Hsp_gaps>0</Hsp_gaps>
<Hsp_align-len>292</Hsp_align-len>
<Hsp_qseq>
AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCTTGAGCCTAGGAGTTTG
CGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAAAGAAAAAAAAAATAGCTCTGCTGGTGGTGCATG
CCTATAGTCTCAGCTATCAGGAGGCTGGGACAGGAGGATCACTTGGGCCCGGGAGTTGAGGCTGTGGTGAGCC
ACGATCACACCACTGCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAACAAATAA
</Hsp_qseq>
<Hsp_hseq>
AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCTTGAGCCTAGGA
GTTTGCGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAAAGAAAAAAAAAATAGCTCTGCT
GGTGGTGCATGCCTATAGTCTCAGCTATCAGGAGGCTGGGACAGGAGGATCACTTGGGCCCGGGAGTTGAGG
CTGTGGTGAGCCACGATCACACCACTGCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAAC
AAATAA
</Hsp_hseq>
<Hsp_midline>
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||
</Hsp_midline>
</Hsp>
</Hit_hsps>
</Hit>
.........................
.........................
.........................
</Iteration_hits>
<Iteration_stat>
<Statistics>
<Statistics_db-num>327</Statistics_db-num>
<Statistics_db-len>80506</Statistics_db-len>
<Statistics_hsp-lenv16</Statistics_hsp-len>
<Statistics_eff-space>21528364</Statistics_eff-space>
<Statistics_kappa>0.46</Statistics_kappa>
<Statistics_lambda>1.28</Statistics_lambda>
<Statistics_entropy>0.85</Statistics_entropy>
</Statistics>
</Iteration_stat>
</Iteration>
</BlastOutput_iterations>
</BlastOutput>위의 명령은 아래 코드를 사용하여 파이썬 내부에서 실행할 수 있습니다.
>>> from Bio.Blast.Applications import NcbiblastnCommandline
>>> blastn_cline = NcbiblastnCommandline(query = "search.fasta", db = "alun",
outfmt = 5, out = "results.xml")
>>> stdout, stderr = blastn_cline()여기서 첫 번째는 blast 출력에 대한 핸들이고 두 번째는 blast 명령에 의해 생성 된 가능한 오류 출력입니다.
출력 파일을 명령 줄 인수 (out = "results.xml")로 제공하고 출력 형식을 XML (outfmt = 5)로 설정 했으므로 출력 파일은 현재 작업 디렉토리에 저장됩니다.
BLAST 결과 구문 분석
일반적으로 BLAST 출력은 NCBIXML 모듈을 사용하여 XML 형식으로 구문 분석됩니다. 이렇게하려면 다음 모듈을 가져와야합니다.
>>> from Bio.Blast import NCBIXML지금, open the file directly using python open method 과 use NCBIXML parse method 아래와 같이-
>>> E_VALUE_THRESH = 1e-20
>>> for record in NCBIXML.parse(open("results.xml")):
>>> if record.alignments:
>>> print("\n")
>>> print("query: %s" % record.query[:100])
>>> for align in record.alignments:
>>> for hsp in align.hsps:
>>> if hsp.expect < E_VALUE_THRESH:
>>> print("match: %s " % align.title[:100])이것은 다음과 같은 출력을 생성합니다-
query: gnl|alu|Z15030_HSAL001056 (Alu-J)
match: gnl|alu|Z15030_HSAL001056 (Alu-J)
match: gnl|alu|L12964_HSAL003860 (Alu-J)
match: gnl|alu|L13042_HSAL003863 (Alu-FLA?)
match: gnl|alu|M86249_HSAL001462 (Alu-FLA?)
match: gnl|alu|M29484_HSAL002265 (Alu-J)
query: gnl|alu|D00596_HSAL003180 (Alu-Sx)
match: gnl|alu|D00596_HSAL003180 (Alu-Sx)
match: gnl|alu|J03071_HSAL001860 (Alu-J)
match: gnl|alu|X72409_HSAL005025 (Alu-Sx)
query: gnl|alu|X55502_HSAL000745 (Alu-J)
match: gnl|alu|X55502_HSAL000745 (Alu-J)EntrezNCBI에서 제공하는 온라인 검색 시스템입니다. 부울 연산자 및 필드 검색을 지원하는 통합 글로벌 쿼리를 통해 거의 모든 알려진 분자 생물학 데이터베이스에 액세스 할 수 있습니다. 각 데이터베이스의 히트 수, 원래 데이터베이스에 대한 링크가있는 레코드 등과 같은 정보가있는 모든 데이터베이스의 결과를 반환합니다.
Entrez를 통해 액세스 할 수있는 인기있는 데이터베이스 중 일부는 다음과 같습니다.
- Pubmed
- Pubmed Central
- 뉴클레오티드 (GenBank 시퀀스 데이터베이스)
- 단백질 (시퀀스 데이터베이스)
- Genome (전체 게놈 데이터베이스)
- 구조 (3 차원 고분자 구조)
- 분류 (GenBank의 유기체)
- SNP (단일 뉴클레오티드 다형성)
- UniGene (전사 서열의 유전자 지향 클러스터)
- CDD (보존 단백질 도메인 데이터베이스)
- 3D 도메인 (Entrez 구조의 도메인)
위의 데이터베이스 외에도 Entrez는 필드 검색을 수행하기 위해 더 많은 데이터베이스를 제공합니다.
Biopython은 Entrez 데이터베이스에 액세스하기 위해 Entrez 특정 모듈 인 Bio.Entrez를 제공합니다. 이 장에서 Biopython을 사용하여 Entrez에 액세스하는 방법을 배워 보겠습니다.
데이터베이스 연결 단계
Entrez의 기능을 추가하려면 다음 모듈을 가져 오십시오.
>>> from Bio import Entrez다음으로 아래에 주어진 코드와 연결된 사람을 식별하기 위해 이메일을 설정하십시오-
>>> Entrez.email = '<youremail>'그런 다음 Entrez 도구 매개 변수를 설정하고 기본적으로 Biopython입니다.
>>> Entrez.tool = 'Demoscript'지금, call einfo function to find index term counts, last update, and available links for each database 아래에 정의 된대로-
>>> info = Entrez.einfo()einfo 메소드는 아래와 같이 읽기 메소드를 통해 정보에 대한 액세스를 제공하는 객체를 반환합니다.
>>> data = info.read()
>>> print(data)
<?xml version = "1.0" encoding = "UTF-8" ?>
<!DOCTYPE eInfoResult PUBLIC "-//NLM//DTD einfo 20130322//EN"
"https://eutils.ncbi.nlm.nih.gov/eutils/dtd/20130322/einfo.dtd">
<eInfoResult>
<DbList>
<DbName>pubmed</DbName>
<DbName>protein</DbName>
<DbName>nuccore</DbName>
<DbName>ipg</DbName>
<DbName>nucleotide</DbName>
<DbName>nucgss</DbName>
<DbName>nucest</DbName>
<DbName>structure</DbName>
<DbName>sparcle</DbName>
<DbName>genome</DbName>
<DbName>annotinfo</DbName>
<DbName>assembly</DbName>
<DbName>bioproject</DbName>
<DbName>biosample</DbName>
<DbName>blastdbinfo</DbName>
<DbName>books</DbName>
<DbName>cdd</DbName>
<DbName>clinvar</DbName>
<DbName>clone</DbName>
<DbName>gap</DbName>
<DbName>gapplus</DbName>
<DbName>grasp</DbName>
<DbName>dbvar</DbName>
<DbName>gene</DbName>
<DbName>gds</DbName>
<DbName>geoprofiles</DbName>
<DbName>homologene</DbName>
<DbName>medgen</DbName>
<DbName>mesh</DbName>
<DbName>ncbisearch</DbName>
<DbName>nlmcatalog</DbName>
<DbName>omim</DbName>
<DbName>orgtrack</DbName>
<DbName>pmc</DbName>
<DbName>popset</DbName>
<DbName>probe</DbName>
<DbName>proteinclusters</DbName>
<DbName>pcassay</DbName>
<DbName>biosystems</DbName>
<DbName>pccompound</DbName>
<DbName>pcsubstance</DbName>
<DbName>pubmedhealth</DbName>
<DbName>seqannot</DbName>
<DbName>snp</DbName>
<DbName>sra</DbName>
<DbName>taxonomy</DbName>
<DbName>biocollections</DbName>
<DbName>unigene</DbName>
<DbName>gencoll</DbName>
<DbName>gtr</DbName>
</DbList>
</eInfoResult>데이터는 XML 형식이며 데이터를 python 객체로 가져 오려면 Entrez.read 즉시 방법 Entrez.einfo() 메서드가 호출됩니다-
>>> info = Entrez.einfo()
>>> record = Entrez.read(info)여기서 레코드는 아래와 같이 DbList라는 하나의 키가있는 사전입니다.
>>> record.keys()
[u'DbList']DbList 키에 액세스하면 아래에 표시된 데이터베이스 이름 목록이 반환됩니다.
>>> record[u'DbList']
['pubmed', 'protein', 'nuccore', 'ipg', 'nucleotide', 'nucgss',
'nucest', 'structure', 'sparcle', 'genome', 'annotinfo', 'assembly',
'bioproject', 'biosample', 'blastdbinfo', 'books', 'cdd', 'clinvar',
'clone', 'gap', 'gapplus', 'grasp', 'dbvar', 'gene', 'gds', 'geoprofiles',
'homologene', 'medgen', 'mesh', 'ncbisearch', 'nlmcatalog', 'omim',
'orgtrack', 'pmc', 'popset', 'probe', 'proteinclusters', 'pcassay',
'biosystems', 'pccompound', 'pcsubstance', 'pubmedhealth', 'seqannot',
'snp', 'sra', 'taxonomy', 'biocollections', 'unigene', 'gencoll', 'gtr']
>>>기본적으로 Entrez 모듈은 Entrez 검색 시스템에서 반환 한 XML을 구문 분석하고이를 Python 사전 및 목록으로 제공합니다.
데이터베이스 검색
Entrez 데이터베이스 중 하나를 검색하려면 Bio.Entrez.esearch () 모듈을 사용할 수 있습니다. 아래에 정의되어 있습니다-
>>> info = Entrez.einfo()
>>> info = Entrez.esearch(db = "pubmed",term = "genome")
>>> record = Entrez.read(info)
>>>print(record)
DictElement({u'Count': '1146113', u'RetMax': '20', u'IdList':
['30347444', '30347404', '30347317', '30347292',
'30347286', '30347249', '30347194', '30347187',
'30347172', '30347088', '30347075', '30346992',
'30346990', '30346982', '30346980', '30346969',
'30346962', '30346954', '30346941', '30346939'],
u'TranslationStack': [DictElement({u'Count':
'927819', u'Field': 'MeSH Terms', u'Term': '"genome"[MeSH Terms]',
u'Explode': 'Y'}, attributes = {})
, DictElement({u'Count': '422712', u'Field':
'All Fields', u'Term': '"genome"[All Fields]', u'Explode': 'N'}, attributes = {}),
'OR', 'GROUP'], u'TranslationSet': [DictElement({u'To': '"genome"[MeSH Terms]
OR "genome"[All Fields]', u'From': 'genome'}, attributes = {})], u'RetStart': '0',
u'QueryTranslation': '"genome"[MeSH Terms] OR "genome"[All Fields]'},
attributes = {})
>>>잘못된 db를 할당하면 다음을 반환합니다.
>>> info = Entrez.esearch(db = "blastdbinfo",term = "books")
>>> record = Entrez.read(info)
>>> print(record)
DictElement({u'Count': '0', u'RetMax': '0', u'IdList': [],
u'WarningList': DictElement({u'OutputMessage': ['No items found.'],
u'PhraseIgnored': [], u'QuotedPhraseNotFound': []}, attributes = {}),
u'ErrorList': DictElement({u'FieldNotFound': [], u'PhraseNotFound':
['books']}, attributes = {}), u'TranslationSet': [], u'RetStart': '0',
u'QueryTranslation': '(books[All Fields])'}, attributes = {})데이터베이스를 검색하려면 다음을 사용할 수 있습니다. Entrez.egquery. 이것은Entrez.esearch 키워드를 지정하고 데이터베이스 매개 변수를 건너 뛰는 것만으로 충분합니다.
>>>info = Entrez.egquery(term = "entrez")
>>> record = Entrez.read(info)
>>> for row in record["eGQueryResult"]:
... print(row["DbName"], row["Count"])
...
pubmed 458
pmc 12779 mesh 1
...
...
...
biosample 7
biocollections 0레코드 가져 오기
Enterz는 Entrez에서 레코드의 전체 세부 정보를 검색하고 다운로드하는 특별한 방법 인 efetch를 제공합니다. 다음 간단한 예를 고려하십시오-
>>> handle = Entrez.efetch(
db = "nucleotide", id = "EU490707", rettype = "fasta")이제 SeqIO 객체를 사용하여 레코드를 간단히 읽을 수 있습니다.
>>> record = SeqIO.read( handle, "fasta" )
>>> record
SeqRecord(seq = Seq('ATTTTTTACGAACCTGTGGAAATTTTTGGTTATGACAATAAATCTAGTTTAGTA...GAA',
SingleLetterAlphabet()), id = 'EU490707.1', name = 'EU490707.1',
description = 'EU490707.1
Selenipedium aequinoctiale maturase K (matK) gene, partial cds; chloroplast',
dbxrefs = [])Biopython은 Bio.PDB 모듈을 제공하여 폴리펩티드 구조를 조작합니다. PDB (Protein Data Bank)는 온라인에서 사용할 수있는 가장 큰 단백질 구조 리소스입니다. 그것은 단백질-단백질, 단백질 -DNA, 단백질 -RNA 복합체를 포함하여 많은 별개의 단백질 구조를 호스팅합니다.
PDB를로드하려면 아래 명령을 입력하십시오.
from Bio.PDB import *단백질 구조 파일 형식
PDB는 단백질 구조를 세 가지 다른 형식으로 배포합니다.
- Biopython에서 지원하지 않는 XML 기반 파일 형식
- 특수 형식의 텍스트 파일 인 pdb 파일 형식
- PDBx / mmCIF 파일 형식
Protein Data Bank에서 배포하는 PDB 파일에는 모호하거나 구문 분석하기 어려운 형식 오류가 포함될 수 있습니다. Bio.PDB 모듈은 이러한 오류를 자동으로 처리하려고 시도합니다.
Bio.PDB 모듈은 두 개의 서로 다른 파서를 구현합니다. 하나는 mmCIF 형식이고 두 번째는 pdb 형식입니다.
각 형식을 자세히 파싱하는 방법을 알아 보겠습니다.
mmCIF 파서
아래 명령을 사용하여 pdb 서버에서 mmCIF 형식의 예제 데이터베이스를 다운로드 해 보겠습니다.
>>> pdbl = PDBList()
>>> pdbl.retrieve_pdb_file('2FAT', pdir = '.', file_format = 'mmCif')이렇게하면 서버에서 지정된 파일 (2fat.cif)을 다운로드하여 현재 작업 디렉토리에 저장합니다.
여기에서 PDBList는 온라인 PDB FTP 서버에서 파일을 나열하고 다운로드하는 옵션을 제공합니다. retrieve_pdb_file 메소드는 확장자없이 다운로드 할 파일 이름이 필요합니다. retrieve_pdb_file에는 다운로드 디렉토리, pdir 및 파일 형식 file_format을 지정하는 옵션도 있습니다. 파일 형식의 가능한 값은 다음과 같습니다.
- "mmCif"(기본값, PDBx / mmCif 파일)
- "pdb"(PDB 형식)
- "xml"(PMDML / XML 형식)
- "mmtf"(고압축)
- "번들"(대형 구조용 PDB 형식 아카이브)
cif 파일을로드하려면 아래 지정된대로 Bio.MMCIF.MMCIFParser를 사용하십시오.
>>> parser = MMCIFParser(QUIET = True)
>>> data = parser.get_structure("2FAT", "2FAT.cif")여기서 QUIET는 파일을 구문 분석하는 동안 경고를 표시하지 않습니다. get_structure will parse the file and return the structure with id as 2FAT (첫 번째 인수).
위의 명령을 실행 한 후 파일을 구문 분석하고 가능한 경우 가능한 경고를 인쇄합니다.
이제 아래 명령을 사용하여 구조를 확인하십시오.
>>> data
<Structure id = 2FAT>
To get the type, use type method as specified below,
>>> print(type(data))
<class 'Bio.PDB.Structure.Structure'>파일을 성공적으로 파싱하고 단백질의 구조를 얻었습니다. 단백질 구조에 대한 자세한 내용과이를 얻는 방법은 이후 장에서 배울 것입니다.
PDB 파서
아래 명령을 사용하여 pdb 서버에서 PDB 형식의 예제 데이터베이스를 다운로드 해 보겠습니다.
>>> pdbl = PDBList()
>>> pdbl.retrieve_pdb_file('2FAT', pdir = '.', file_format = 'pdb')그러면 서버에서 지정된 파일 (pdb2fat.ent)이 다운로드되어 현재 작업 디렉터리에 저장됩니다.
pdb 파일을로드하려면 아래 지정된대로 Bio.PDB.PDBParser를 사용하십시오.
>>> parser = PDBParser(PERMISSIVE = True, QUIET = True)
>>> data = parser.get_structure("2fat","pdb2fat.ent")여기서 get_structure는 MMCIFParser와 유사합니다. PERMISSIVE 옵션은 가능한 한 유연하게 단백질 데이터를 구문 분석합니다.
이제 아래에 주어진 코드 스 니펫으로 구조와 유형을 확인하십시오.
>>> data
<Structure id = 2fat>
>>> print(type(data))
<class 'Bio.PDB.Structure.Structure'>글쎄, 헤더 구조는 사전 정보를 저장합니다. 이를 수행하려면 아래 명령을 입력하십시오-
>>> print(data.header.keys()) dict_keys([
'name', 'head', 'deposition_date', 'release_date', 'structure_method', 'resolution',
'structure_reference', 'journal_reference', 'author', 'compound', 'source',
'keywords', 'journal'])
>>>이름을 얻으려면 다음 코드를 사용하십시오-
>>> print(data.header["name"])
an anti-urokinase plasminogen activator receptor (upar) antibody: crystal
structure and binding epitope
>>>아래 코드로 날짜와 해상도를 확인할 수도 있습니다.
>>> print(data.header["release_date"]) 2006-11-14
>>> print(data.header["resolution"]) 1.77PDB 구조
PDB 구조는 두 개의 체인을 포함하는 단일 모델로 구성됩니다.
- 잔기 수를 포함하는 사슬 L
- 잔기의 수를 포함하는 사슬 H
각 잔기는 (x, y, z) 좌표로 표시되는 3D 위치를 각각 갖는 여러 원자로 구성됩니다.
아래 섹션에서 원자의 구조를 자세히 알아 봅시다.
모델
Structure.get_models () 메서드는 모델에 대한 반복자를 반환합니다. 아래에 정의되어 있습니다-
>>> model = data.get_models()
>>> model
<generator object get_models at 0x103fa1c80>
>>> models = list(model)
>>> models [<Model id = 0>]
>>> type(models[0])
<class 'Bio.PDB.Model.Model'>여기서 모델은 정확히 하나의 3D 형태를 설명합니다. 하나 이상의 체인을 포함합니다.
체인
Model.get_chain () 메서드는 체인에 대한 반복자를 반환합니다. 아래에 정의되어 있습니다-
>>> chains = list(models[0].get_chains())
>>> chains
[<Chain id = L>, <Chain id = H>]
>>> type(chains[0])
<class 'Bio.PDB.Chain.Chain'>여기서 사슬은 적절한 폴리펩티드 구조, 즉 결합 된 잔기의 연속적인 서열을 설명합니다.
잔여
Chain.get_residues () 메서드는 잔류 물에 대한 반복자를 반환합니다. 아래에 정의되어 있습니다-
>>> residue = list(chains[0].get_residues())
>>> len(residue)
293
>>> residue1 = list(chains[1].get_residues())
>>> len(residue1)
311음, 잔류 물은 아미노산에 속하는 원자를 보유하고 있습니다.
원자
Residue.get_atom ()은 아래 정의 된 원자에 대한 반복자를 반환합니다.
>>> atoms = list(residue[0].get_atoms())
>>> atoms
[<Atom N>, <Atom CA>, <Atom C>, <Atom Ov, <Atom CB>, <Atom CG>, <Atom OD1>, <Atom OD2>]원자는 원자의 3D 좌표를 보유하며 벡터라고합니다. 아래에 정의되어 있습니다.
>>> atoms[0].get_vector()
<Vector 18.49, 73.26, 44.16>x, y 및 z 좌표 값을 나타냅니다.
서열 모티프는 뉴클레오티드 또는 아미노산 서열 패턴입니다. 서열 모티프는 인접하지 않을 수있는 아미노산의 3 차원 배열에 의해 형성됩니다. Biopython은 아래 지정된대로 시퀀스 모티프의 기능에 액세스하기 위해 별도의 모듈 인 Bio.motifs를 제공합니다.
from Bio import motifs간단한 DNA 모티프 만들기
아래 명령을 사용하여 간단한 DNA 모티프 시퀀스를 생성 해 보겠습니다.
>>> from Bio import motifs
>>> from Bio.Seq import Seq
>>> DNA_motif = [ Seq("AGCT"),
... Seq("TCGA"),
... Seq("AACT"),
... ]
>>> seq = motifs.create(DNA_motif)
>>> print(seq) AGCT TCGA AACT시퀀스 값을 계산하려면 아래 명령을 사용하십시오.
>>> print(seq.counts)
0 1 2 3
A: 2.00 1.00 0.00 1.00
C: 0.00 1.00 2.00 0.00
G: 0.00 1.00 1.00 0.00
T: 1.00 0.00 0.00 2.00다음 코드를 사용하여 시퀀스에서 'A'를 계산합니다.
>>> seq.counts["A", :]
(2, 1, 0, 1)카운트 열에 액세스하려면 아래 명령을 사용하십시오-
>>> seq.counts[:, 3]
{'A': 1, 'C': 0, 'T': 2, 'G': 0}시퀀스 로고 만들기
이제 시퀀스 로고를 만드는 방법에 대해 설명합니다.
아래 순서를 고려하십시오-
AGCTTACG
ATCGTACC
TTCCGAAT
GGTACGTA
AAGCTTGG다음 링크를 사용하여 자신의 로고를 만들 수 있습니다. http://weblogo.berkeley.edu/
위의 시퀀스를 추가하고 새 로고를 만들고 biopython 폴더에 seq.png라는 이미지를 저장합니다.
seq.png이미지를 만든 후 이제 다음 명령을 실행하십시오.
>>> seq.weblogo("seq.png")이 DNA 염기 서열 모티프는 LexA 결합 모티프의 염기 서열 로고로 표시됩니다.
JASPAR 데이터베이스
JASPAR은 가장 인기있는 데이터베이스 중 하나입니다. 시퀀스 읽기, 쓰기 및 스캔을위한 모티프 형식의 기능을 제공합니다. 각 주제에 대한 메타 정보를 저장합니다.The module Bio.motifs contains a specialized class jaspar.Motif to represent meta-information attributes.
다음과 같은 주목할만한 속성 유형이 있습니다-
- matrix_id − 고유 한 JASPAR 모티프 ID
- name-주제의 이름
- tf_family − 'Helix-Loop-Helix'와 같은 모티프 계열
- data_type-모티프에 사용되는 데이터 유형.
biopython 폴더의 sample.sites에 이름이 지정된 JASPAR 사이트 형식을 생성 해 보겠습니다. 아래에 정의되어 있습니다-
sample.sites
>MA0001 ARNT 1
AACGTGatgtccta
>MA0001 ARNT 2
CAGGTGggatgtac
>MA0001 ARNT 3
TACGTAgctcatgc
>MA0001 ARNT 4
AACGTGacagcgct
>MA0001 ARNT 5
CACGTGcacgtcgt
>MA0001 ARNT 6
cggcctCGCGTGc위 파일에서는 모티프 인스턴스를 생성했습니다. 이제 위의 인스턴스에서 모티프 객체를 만들어 보겠습니다.
>>> from Bio import motifs
>>> with open("sample.sites") as handle:
... data = motifs.read(handle,"sites")
...
>>> print(data)
TF name None
Matrix ID None
Matrix:
0 1 2 3 4 5
A: 2.00 5.00 0.00 0.00 0.00 1.00
C: 3.00 0.00 5.00 0.00 0.00 0.00
G: 0.00 1.00 1.00 6.00 0.00 5.00
T: 1.00 0.00 0.00 0.00 6.00 0.00여기에서 데이터는 sample.sites 파일에서 모든 모티프 인스턴스를 읽습니다.
데이터에서 모든 인스턴스를 인쇄하려면 아래 명령을 사용하십시오.
>>> for instance in data.instances:
... print(instance)
...
AACGTG
CAGGTG
TACGTA
AACGTG
CACGTG
CGCGTG모든 값을 계산하려면 아래 명령을 사용하십시오-
>>> print(data.counts)
0 1 2 3 4 5
A: 2.00 5.00 0.00 0.00 0.00 1.00
C: 3.00 0.00 5.00 0.00 0.00 0.00
G: 0.00 1.00 1.00 6.00 0.00 5.00
T: 1.00 0.00 0.00 0.00 6.00 0.00
>>>BioSQL주로 모든 RDBMS 엔진에 대한 시퀀스 및 관련 데이터를 저장하도록 설계된 일반 데이터베이스 스키마입니다. GenBank, Swissport 등과 같은 모든 인기있는 생물 정보학 데이터베이스의 데이터를 보유하도록 설계되었습니다. 사내 데이터를 저장하는데도 사용할 수 있습니다.
BioSQL 현재 아래 데이터베이스에 대한 특정 스키마를 제공합니다-
- MySQL (biosqldb-mysql.sql)
- PostgreSQL (biosqldb-pg.sql)
- Oracle (biosqldb-ora / *. sql)
- SQLite (biosqldb-sqlite.sql)
또한 Java 기반 HSQLDB 및 Derby 데이터베이스에 대한 최소한의 지원을 제공합니다.
BioPython은 BioSQL 기반 데이터베이스와 함께 작동하는 매우 간단하고 쉬운 고급 ORM 기능을 제공합니다. BioPython provides a module, BioSQL 다음 기능을 수행하려면-
- BioSQL 데이터베이스 생성 / 제거
- BioSQL 데이터베이스에 연결
- GenBank, Swisport, BLAST 결과, Entrez 결과 등과 같은 시퀀스 데이터베이스를 구문 분석하고 BioSQL 데이터베이스에 직접로드합니다.
- BioSQL 데이터베이스에서 시퀀스 데이터 가져 오기
- NCBI BLAST에서 분류 데이터를 가져와 BioSQL 데이터베이스에 저장
- BioSQL 데이터베이스에 대해 SQL 쿼리 실행
BioSQL 데이터베이스 스키마 개요
BioSQL에 대해 깊이 들어가기 전에 BioSQL 스키마의 기본을 이해합시다. BioSQL 스키마는 25 개 이상의 테이블을 제공하여 시퀀스 데이터, 시퀀스 기능, 시퀀스 카테고리 / 온톨로지 및 분류 정보를 보유합니다. 중요한 테이블 중 일부는 다음과 같습니다.
- biodatabase
- bioentry
- biosequence
- seqfeature
- taxon
- taxon_name
- antology
- term
- dxref
BioSQL 데이터베이스 생성
이 섹션에서는 BioSQL 팀에서 제공 한 스키마를 사용하여 샘플 BioSQL 데이터베이스 인 biosql을 생성 해 보겠습니다. 시작하기가 정말 쉽고 복잡한 설정이 없기 때문에 SQLite 데이터베이스로 작업 할 것입니다.
여기에서는 아래 단계를 사용하여 SQLite 기반 BioSQL 데이터베이스를 생성합니다.
Step 1 − SQLite 데이터베이스 엔진을 다운로드하여 설치합니다.
Step 2 − GitHub URL에서 BioSQL 프로젝트를 다운로드하십시오. https://github.com/biosql/biosql
Step 3 − 콘솔을 열고 mkdir을 사용하여 디렉토리를 생성하고 입력하십시오.
cd /path/to/your/biopython/sample
mkdir sqlite-biosql
cd sqlite-biosqlStep 4 − 아래 명령을 실행하여 새 SQLite 데이터베이스를 생성합니다.
> sqlite3.exe mybiosql.db
SQLite version 3.25.2 2018-09-25 19:08:10
Enter ".help" for usage hints.
sqlite>Step 5 − BioSQL 프로젝트 (/ sql / biosqldb-sqlite.sql`)에서 biosqldb-sqlite.sql 파일을 복사하여 현재 디렉토리에 저장합니다.
Step 6 − 아래 명령을 실행하여 모든 테이블을 생성합니다.
sqlite> .read biosqldb-sqlite.sql이제 모든 테이블이 새 데이터베이스에 생성됩니다.
Step 7 − 아래 명령을 실행하여 데이터베이스의 모든 새 테이블을 확인하십시오.
sqlite> .headers on
sqlite> .mode column
sqlite> .separator ROW "\n"
sqlite> SELECT name FROM sqlite_master WHERE type = 'table';
biodatabase
taxon
taxon_name
ontology
term
term_synonym
term_dbxref
term_relationship
term_relationship_term
term_path
bioentry
bioentry_relationship
bioentry_path
biosequence
dbxref
dbxref_qualifier_value
bioentry_dbxref
reference
bioentry_reference
comment
bioentry_qualifier_value
seqfeature
seqfeature_relationship
seqfeature_path
seqfeature_qualifier_value
seqfeature_dbxref
location
location_qualifier_value
sqlite>처음 세 명령은 형식화 된 방식으로 결과를 표시하도록 SQLite를 구성하는 구성 명령입니다.
Step 8 − BioPython 팀에서 제공 한 샘플 GenBank 파일 ls_orchid.gbk를 복사합니다. https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbk 현재 디렉토리에 넣고 orchid.gbk로 저장하십시오.
Step 9 − 아래 코드를 사용하여 python 스크립트 load_orchid.py를 생성하고 실행합니다.
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()위의 코드는 파일의 레코드를 구문 분석하여 Python 개체로 변환하고 BioSQL 데이터베이스에 삽입합니다. 이후 섹션에서 코드를 분석 할 것입니다.
마지막으로 새로운 BioSQL 데이터베이스를 생성하고 여기에 샘플 데이터를로드했습니다. 다음 장에서 중요한 표에 대해 논의 할 것입니다.
간단한 ER 다이어그램
biodatabase 테이블은 계층 구조의 맨 위에 있으며 주요 목적은 일련의 시퀀스 데이터를 단일 그룹 / 가상 데이터베이스로 구성하는 것입니다. Every entry in the biodatabase refers to a separate database and it does not mingle with another database. BioSQL 데이터베이스의 모든 관련 테이블에는 biodatabase 항목에 대한 참조가 있습니다.
bioentry테이블은 시퀀스 데이터를 제외한 시퀀스에 대한 모든 세부 정보를 보유합니다. 특정의 시퀀스 데이터bioentry 에 저장됩니다 biosequence 표.
taxon 및 taxon_name은 분류 세부 정보이며 모든 항목은이 테이블을 참조하여 해당 분류 정보를 지정합니다.
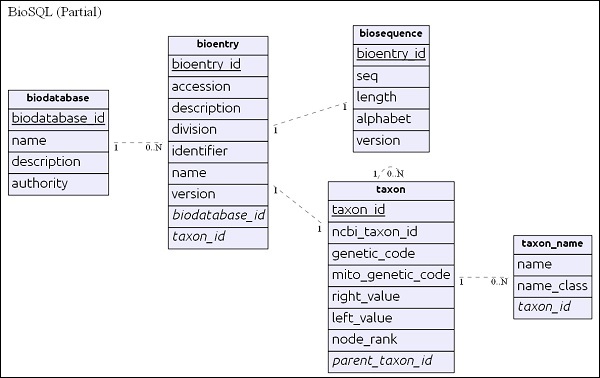
스키마를 이해 한 후 다음 섹션에서 몇 가지 쿼리를 살펴 보겠습니다.
BioSQL 쿼리
데이터가 어떻게 구성되고 테이블이 서로 관련되어 있는지 더 잘 이해하기 위해 몇 가지 SQL 쿼리를 살펴 보겠습니다. 계속하기 전에 아래 명령을 사용하여 데이터베이스를 열고 몇 가지 형식 지정 명령을 설정합니다.
> sqlite3 orchid.db
SQLite version 3.25.2 2018-09-25 19:08:10
Enter ".help" for usage hints.
sqlite> .header on
sqlite> .mode columns.header and .mode are formatting options to better visualize the data. SQLite 편집기를 사용하여 쿼리를 실행할 수도 있습니다.
시스템에서 사용 가능한 가상 시퀀스 데이터베이스를 아래에 나열하십시오.
select
*
from
biodatabase;
*** Result ***
sqlite> .width 15 15 15 15
sqlite> select * from biodatabase;
biodatabase_id name authority description
--------------- --------------- --------------- ---------------
1 orchid
sqlite>여기에는 데이터베이스가 하나만 있습니다. orchid.
데이터베이스에서 사용 가능한 항목 (상위 3 개) 나열 orchid 아래 주어진 코드로
select
be.*,
bd.name
from
bioentry be
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid' Limit 1,
3;
*** Result ***
sqlite> .width 15 15 10 10 10 10 10 50 10 10
sqlite> select be.*, bd.name from bioentry be inner join biodatabase bd on
bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' Limit 1,3;
bioentry_id biodatabase_id taxon_id name accession identifier division description version name
--------------- --------------- ---------- ---------- ---------- ---------- ----------
---------- ---------- ----------- ---------- --------- ---------- ----------
2 1 19 Z78532 Z78532 2765657 PLN
C.californicum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
3 1 20 Z78531 Z78531 2765656 PLN
C.fasciculatum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
4 1 21 Z78530 Z78530 2765655 PLN
C.margaritaceum 5.8S rRNA gene and ITS1 and ITS2 D 1
orchid
sqlite>주어진 코드와 함께 항목 (수탁-Z78530, 이름-C. fasciculatum 5.8S rRNA 유전자 및 ITS1 및 ITS2 DNA)과 관련된 시퀀스 세부 정보를 나열합니다.
select
substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length,
be.accession,
be.description,
bd.name
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 15 5 10 50 10
sqlite> select substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length, be.accession, be.description, bd.name from biosequence bs inner
join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd
on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and
be.accession = 'Z78532';
seq length accession description name
------------ ---------- ---------- ------------ ------------ ---------- ---------- -----------------
CGTAACAAG... 753 Z78532 C.californicum 5.8S rRNA gene and ITS1 and ITS2 DNA orchid
sqlite>아래 코드를 사용하여 항목 (수탁-Z78530, 이름-C. fasciculatum 5.8S rRNA 유전자 및 ITS1 및 ITS2 DNA)과 관련된 전체 시퀀스를 가져옵니다.
select
bs.seq
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 1000
sqlite> select bs.seq from biosequence bs inner join bioentry be on
be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id =
be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532';
seq
----------------------------------------------------------------------------------------
----------------------------
CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGTTGAGACAACAGAATATATGATCGAGTGAATCT
GGAGGACCTGTGGTAACTCAGCTCGTCGTGGCACTGCTTTTGTCGTGACCCTGCTTTGTTGTTGGGCCTCC
TCAAGAGCTTTCATGGCAGGTTTGAACTTTAGTACGGTGCAGTTTGCGCCAAGTCATATAAAGCATCACTGATGAATGACATTATTGT
CAGAAAAAATCAGAGGGGCAGTATGCTACTGAGCATGCCAGTGAATTTTTATGACTCTCGCAACGGATATCTTGGCTC
TAACATCGATGAAGAACGCAG
sqlite>바이오 데이터베이스, 난초와 관련된 분류군 나열
select distinct
tn.name
from
biodatabase d
inner join
bioentry e
on e.biodatabase_id = d.biodatabase_id
inner join
taxon t
on t.taxon_id = e.taxon_id
inner join
taxon_name tn
on tn.taxon_id = t.taxon_id
where
d.name = 'orchid' limit 10;
*** Result ***
sqlite> select distinct tn.name from biodatabase d inner join bioentry e on
e.biodatabase_id = d.biodatabase_id inner join taxon t on t.taxon_id =
e.taxon_id inner join taxon_name tn on tn.taxon_id = t.taxon_id where d.name =
'orchid' limit 10;
name
------------------------------
Cypripedium irapeanum
Cypripedium californicum
Cypripedium fasciculatum
Cypripedium margaritaceum
Cypripedium lichiangense
Cypripedium yatabeanum
Cypripedium guttatum
Cypripedium acaule
pink lady's slipper
Cypripedium formosanum
sqlite>BioSQL 데이터베이스에 데이터로드
이 장에서는 시퀀스 데이터를 BioSQL 데이터베이스에로드하는 방법을 알아 보겠습니다. 이전 섹션에서 데이터를 데이터베이스에로드하는 코드가 이미 있으며 코드는 다음과 같습니다.
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
DBSCHEMA = "biosqldb-sqlite.sql"
SQL_FILE = os.path.join(os.getcwd(), DBSCHEMA)
server.load_database_sql(SQL_FILE)
server.commit()
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()우리는 코드의 모든 줄과 그 목적에 대해 자세히 살펴볼 것입니다.
Line 1 − SeqIO 모듈을로드합니다.
Line 2− BioSeqDatabase 모듈을로드합니다. 이 모듈은 BioSQL 데이터베이스와 상호 작용하는 모든 기능을 제공합니다.
Line 3 − os 모듈을로드합니다.
Line 5− open_database는 구성된 드라이버 (드라이버)로 지정된 데이터베이스 (db)를 열고 BioSQL 데이터베이스 (서버)에 대한 핸들을 반환합니다. Biopython은 sqlite, mysql, postgresql 및 oracle 데이터베이스를 지원합니다.
Line 6-10− load_database_sql 메소드는 외부 파일에서 SQL을로드하여 실행합니다. commit 메소드는 트랜잭션을 커밋합니다. 이미 스키마가있는 데이터베이스를 만들었으므로이 단계를 건너 뛸 수 있습니다.
Line 12 − new_database 메소드는 새로운 가상 데이터베이스 인 orchid를 생성하고 orchid 데이터베이스에 대해 명령을 실행하기 위해 핸들 db를 반환합니다.
Line 13− load 메소드는 시퀀스 항목 (반복 가능한 SeqRecord)을 orchid 데이터베이스에로드합니다. SqlIO.parse는 GenBank 데이터베이스를 구문 분석하고 모든 시퀀스를 반복 가능한 SeqRecord로 반환합니다. 로드 방법의 두 번째 매개 변수 (True)는 시스템에서 아직 사용할 수없는 경우 NCBI blast 웹 사이트에서 시퀀스 데이터의 분류 세부 정보를 가져 오도록 지시합니다.
Line 14 − commit은 트랜잭션을 커밋합니다.
Line 15 − close는 데이터베이스 연결을 닫고 서버 핸들을 파괴합니다.
시퀀스 데이터 가져 오기
다음과 같이 난초 데이터베이스에서 식별자 2765658이있는 시퀀스를 가져 오겠습니다.
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server["orchid"]
seq_record = db.lookup(gi = 2765658)
print(seq_record.id, seq_record.description[:50] + "...")
print("Sequence length %i," % len(seq_record.seq))여기서 server [ "orchid"]는 가상 databaseorchid에서 데이터를 가져 오기위한 핸들을 반환합니다. lookup 메서드는 기준에 따라 시퀀스를 선택하는 옵션을 제공하며 식별자 2765658을 사용하여 시퀀스를 선택했습니다. lookup시퀀스 정보를 SeqRecordobject로 반환합니다. 우리는 이미 SeqRecord`로 작업하는 방법을 알고 있기 때문에 데이터를 쉽게 가져올 수 있습니다.
데이터베이스 제거
데이터베이스를 제거하는 것은 적절한 데이터베이스 이름으로 remove_database 메서드를 호출 한 다음 아래에 지정된대로 커밋하는 것처럼 간단합니다.
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
server.remove_database("orchids")
server.commit()인구 유전학은 진화론에서 중요한 역할을합니다. 종 간의 유전 적 차이와 같은 종에 속한 둘 이상의 개체를 분석합니다.
Biopython은 집단 유전학을위한 Bio.PopGen 모듈을 제공하며 주로 Michel Raymond와 Francois Rousset이 개발 한 인기있는 유전학 패키지 인`GenePop을 지원합니다.
간단한 파서
GenePop 형식을 구문 분석하고 개념을 이해하는 간단한 애플리케이션을 작성해 보겠습니다.
아래 링크에서 Biopython 팀이 제공하는 genePop 파일을 다운로드하십시오.https://raw.githubusercontent.com/biopython/biopython/master/Tests/PopGen/c3line.gen
아래 코드 스 니펫을 사용하여 GenePop 모듈을로드합니다.
from Bio.PopGen import GenePop아래와 같이 GenePop.read 메서드를 사용하여 파일을 구문 분석합니다.
record = GenePop.read(open("c3line.gen"))아래 주어진 위치와 인구 정보를 보여줍니다-
>>> record.loci_list
['136255903', '136257048', '136257636']
>>> record.pop_list
['4', 'b3', '5']
>>> record.populations
[[('1', [(3, 3), (4, 4), (2, 2)]), ('2', [(3, 3), (3, 4), (2, 2)]),
('3', [(3, 3), (4, 4), (2, 2)]), ('4', [(3, 3), (4, 3), (None, None)])],
[('b1', [(None, None), (4, 4), (2, 2)]), ('b2', [(None, None), (4, 4), (2, 2)]),
('b3', [(None, None), (4, 4), (2, 2)])],
[('1', [(3, 3), (4, 4), (2, 2)]), ('2', [(3, 3), (1, 4), (2, 2)]),
('3', [(3, 2), (1, 1), (2, 2)]), ('4',
[(None, None), (4, 4), (2, 2)]), ('5', [(3, 3), (4, 4), (2, 2)])]]
>>>여기에는 파일에서 사용할 수있는 3 개의 loci와 3 개의 모집단 집합이 있습니다. 첫 번째 모집단에는 4 개의 레코드가 있고, 두 번째 모집단에는 3 개의 레코드가 있으며, 세 번째 모집단에는 5 개의 레코드가 있습니다. record.populations는 각 유전자좌에 대한 대립 유전자 데이터가있는 모든 집단 집합을 보여줍니다.
GenePop 파일 조작
Biopython은 유전자좌 및 인구 데이터를 제거하는 옵션을 제공합니다.
Remove a population set by position,
>>> record.remove_population(0)
>>> record.populations
[[('b1', [(None, None), (4, 4), (2, 2)]),
('b2', [(None, None), (4, 4), (2, 2)]),
('b3', [(None, None), (4, 4), (2, 2)])],
[('1', [(3, 3), (4, 4), (2, 2)]),
('2', [(3, 3), (1, 4), (2, 2)]),
('3', [(3, 2), (1, 1), (2, 2)]),
('4', [(None, None), (4, 4), (2, 2)]),
('5', [(3, 3), (4, 4), (2, 2)])]]
>>>Remove a locus by position,
>>> record.remove_locus_by_position(0)
>>> record.loci_list
['136257048', '136257636']
>>> record.populations
[[('b1', [(4, 4), (2, 2)]), ('b2', [(4, 4), (2, 2)]), ('b3', [(4, 4), (2, 2)])],
[('1', [(4, 4), (2, 2)]), ('2', [(1, 4), (2, 2)]),
('3', [(1, 1), (2, 2)]), ('4', [(4, 4), (2, 2)]), ('5', [(4, 4), (2, 2)])]]
>>>Remove a locus by name,
>>> record.remove_locus_by_name('136257636') >>> record.loci_list
['136257048']
>>> record.populations
[[('b1', [(4, 4)]), ('b2', [(4, 4)]), ('b3', [(4, 4)])],
[('1', [(4, 4)]), ('2', [(1, 4)]),
('3', [(1, 1)]), ('4', [(4, 4)]), ('5', [(4, 4)])]]
>>>GenePop 소프트웨어와의 인터페이스
Biopython은 GenePop 소프트웨어와 상호 작용할 수있는 인터페이스를 제공하여 많은 기능을 제공합니다. 이를 위해 Bio.PopGen.GenePop 모듈이 사용됩니다. 사용하기 쉬운 인터페이스 중 하나가 EasyController입니다. GenePop 파일을 파싱하는 방법을 확인하고 EasyController를 사용하여 몇 가지 분석을 수행합니다.
먼저 GenePop 소프트웨어를 설치하고 시스템 경로에 설치 폴더를 배치합니다. GenePop 파일에 대한 기본 정보를 얻으려면 EasyController 개체를 만든 다음 아래 지정된대로 get_basic_info 메서드를 호출합니다.
>>> from Bio.PopGen.GenePop.EasyController import EasyController
>>> ec = EasyController('c3line.gen')
>>> print(ec.get_basic_info())
(['4', 'b3', '5'], ['136255903', '136257048', '136257636'])
>>>여기서 첫 번째 항목은 인구 목록이고 두 번째 항목은 유전자좌 목록입니다.
특정 유전자좌의 모든 대립 유전자 목록을 얻으려면 아래 지정된대로 유전자좌 이름을 전달하여 get_alleles_all_pops 메소드를 호출하십시오.
>>> allele_list = ec.get_alleles_all_pops("136255903")
>>> print(allele_list)
[2, 3]특정 인구 및 유전자좌별로 대립 유전자 목록을 얻으려면 아래에 주어진대로 유전자좌 이름과 인구 위치를 전달하여 get_alleles를 호출합니다
>>> allele_list = ec.get_alleles(0, "136255903")
>>> print(allele_list)
[]
>>> allele_list = ec.get_alleles(1, "136255903")
>>> print(allele_list)
[]
>>> allele_list = ec.get_alleles(2, "136255903")
>>> print(allele_list)
[2, 3]
>>>마찬가지로 EasyController는 대립 유전자 빈도, 유전자형 빈도, 다중 위치 F 통계, Hardy-Weinberg 평형, Linkage Disequilibrium 등 많은 기능을 노출합니다.
게놈은 모든 유전자를 포함하여 완전한 DNA 세트입니다. 게놈 분석은 개별 유전자와 유전에서의 역할에 대한 연구를 말합니다.
게놈 다이어그램
게놈 다이어그램은 유전 정보를 차트로 나타냅니다. Biopython은 Bio.Graphics.GenomeDiagram 모듈을 사용하여 GenomeDiagram을 나타냅니다. GenomeDiagram 모듈을 사용하려면 ReportLab을 설치해야합니다.
다이어그램을 만드는 단계
다이어그램을 만드는 과정은 일반적으로 다음과 같은 간단한 패턴을 따릅니다.
표시하려는 각 개별 기능 세트에 대한 FeatureSet을 만들고 여기에 Bio.SeqFeature 객체를 추가합니다.
표시하려는 각 그래프에 대해 GraphSet을 만들고 그래프 데이터를 추가합니다.
다이어그램에서 원하는 각 트랙에 대한 트랙을 만들고 필요한 트랙에 GraphSet 및 FeatureSet을 추가합니다.
다이어그램을 만들고 여기에 트랙을 추가합니다.
다이어그램에 이미지를 그리도록 지시하십시오.
이미지를 파일에 씁니다.
입력 GenBank 파일의 예를 들어 보겠습니다.
https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbkSeqRecord 객체에서 레코드를 읽은 다음 마지막으로 게놈 다이어그램을 그립니다. 아래에 설명되어 있습니다.
아래에 표시된대로 먼저 모든 모듈을 가져옵니다.
>>> from reportlab.lib import colors
>>> from reportlab.lib.units import cm
>>> from Bio.Graphics import GenomeDiagram이제 데이터를 읽기 위해 SeqIO 모듈을 가져옵니다.
>>> from Bio import SeqIO
record = SeqIO.read("example.gb", "genbank")여기에서 레코드는 genbank 파일에서 시퀀스를 읽습니다.
이제 빈 다이어그램을 만들어 트랙과 기능 세트를 추가합니다.
>>> diagram = GenomeDiagram.Diagram(
"Yersinia pestis biovar Microtus plasmid pPCP1")
>>> track = diagram.new_track(1, name="Annotated Features")
>>> feature = track.new_set()이제 아래 정의 된대로 녹색에서 회색으로 대체 색상을 사용하여 색상 테마 변경을 적용 할 수 있습니다.
>>> for feature in record.features:
>>> if feature.type != "gene":
>>> continue
>>> if len(feature) % 2 == 0:
>>> color = colors.blue
>>> else:
>>> color = colors.red
>>>
>>> feature.add_feature(feature, color=color, label=True)이제 화면에서 아래 응답을 볼 수 있습니다.
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d3dc90>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d3dfd0>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x1007627d0>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57290>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57050>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57390>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57590>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57410>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57490>
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d574d0>위의 입력 레코드에 대한 다이어그램을 그리겠습니다.
>>> diagram.draw(
format = "linear", orientation = "landscape", pagesize = 'A4',
... fragments = 4, start = 0, end = len(record))
>>> diagram.write("orchid.pdf", "PDF")
>>> diagram.write("orchid.eps", "EPS")
>>> diagram.write("orchid.svg", "SVG")
>>> diagram.write("orchid.png", "PNG")위의 명령을 실행하면 Biopython 디렉토리에 저장된 다음 이미지를 볼 수 있습니다.
** Result **
genome.png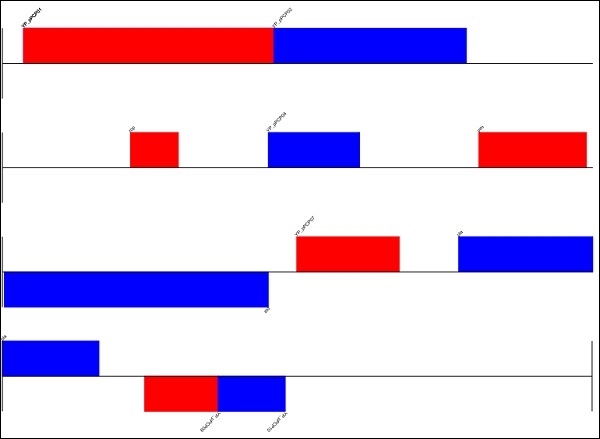
아래와 같이 변경하여 원형 형식으로 이미지를 그릴 수도 있습니다.
>>> diagram.draw(
format = "circular", circular = True, pagesize = (20*cm,20*cm),
... start = 0, end = len(record), circle_core = 0.7)
>>> diagram.write("circular.pdf", "PDF")염색체 개요
DNA 분자는 염색체라고하는 실과 같은 구조로 포장됩니다. 각 염색체는 구조를 지원하는 히스톤이라는 단백질 주위에 여러 번 단단히 감겨있는 DNA로 구성됩니다.
염색체는 세포가 분열하지 않을 때 현미경으로도 세포의 핵에서 보이지 않습니다. 그러나 염색체를 구성하는 DNA는 세포 분열 중에 더 촘촘하게 밀집되어 현미경으로 볼 수 있습니다.
인간의 경우 각 세포는 일반적으로 23 쌍의 염색체를 포함하며 총 46 개입니다. 상 염색체라고하는이 쌍 중 22 개는 남성과 여성 모두 동일하게 보입니다. 23 번째 쌍인 성 염색체는 남성과 여성에 따라 다릅니다. 암컷은 두 개의 X 염색체를 가지고 있고 수컷은 하나의 X 염색체와 하나의 Y 염색체를 가지고 있습니다.
표현형은 특정 화학 물질 또는 환경에 대해 유기체가 나타내는 관찰 가능한 특성 또는 특성으로 정의됩니다. 표현형 마이크로 어레이는 많은 수의 화학 물질 및 환경에 대한 유기체의 반응을 동시에 측정하고 데이터를 분석하여 유전자 돌연변이, 유전자 특성 등을 이해합니다.
Biopython은 표현형 데이터를 분석하기위한 우수한 모듈 인 Bio.Phenotype을 제공합니다. 이 장에서 표현형 마이크로 어레이 데이터를 구문 분석, 보간, 추출 및 분석하는 방법을 알아 보겠습니다.
파싱
표현형 마이크로 어레이 데이터는 CSV와 JSON의 두 가지 형식 일 수 있습니다. Biopython은 두 형식을 모두 지원합니다. Biopython 파서는 표현형 마이크로 어레이 데이터를 구문 분석하고 PlateRecord 객체의 컬렉션으로 반환합니다. 각 PlateRecord 개체에는 WellRecord 개체 모음이 포함되어 있습니다. 각 WellRecord 개체는 8 행 12 열 형식의 데이터를 보유합니다. 8 개의 행은 A에서 H로, 12 개의 열은 01에서 12로 표시됩니다. 예를 들어, 4 번째 행과 6 번째 열은 D06으로 표시됩니다.
다음 예제를 통해 구문 분석의 형식과 개념을 이해하겠습니다.
Step 1 − Biopython 팀에서 제공하는 Plates.csv 파일 다운로드 − https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/Plates.csv
Step 2 − 아래와 같이 phenotpe 모듈을로드합니다 −
>>> from Bio import phenotypeStep 3− 데이터 파일 및 형식 옵션 ( "pm-csv")을 전달하는 phenotype.parse 메서드를 호출합니다. 아래와 같이 반복 가능한 PlateRecord를 반환합니다.
>>> plates = list(phenotype.parse('Plates.csv', "pm-csv"))
>>> plates
[PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'],WellRecord['A03'], ..., WellRecord['H12']')]
>>>Step 4 − 아래 목록에서 첫 번째 플레이트에 액세스합니다. −
>>> plate = plates[0]
>>> plate
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ...,
WellRecord['H12']')
>>>Step 5− 앞에서 설명한 것처럼 플레이트에는 각각 12 개의 항목이있는 8 개의 행이 있습니다. WellRecord는 아래에 지정된 두 가지 방법으로 액세스 할 수 있습니다.
>>> well = plate["A04"]
>>> well = plate[0, 4]
>>> well WellRecord('(0.0, 0.0), (0.25, 0.0), (0.5, 0.0), (0.75, 0.0),
(1.0, 0.0), ..., (71.75, 388.0)')
>>>Step 6 − 각 웰은 서로 다른 시점에서 일련의 측정을 수행하며 아래 지정된대로 for 루프를 사용하여 액세스 할 수 있습니다.
>>> for v1, v2 in well:
... print(v1, v2)
...
0.0 0.0
0.25 0.0
0.5 0.0
0.75 0.0
1.0 0.0
...
71.25 388.0
71.5 388.0
71.75 388.0
>>>보간
보간은 데이터에 대한 더 많은 통찰력을 제공합니다. Biopython은 중간 시점에 대한 정보를 얻기 위해 WellRecord 데이터를 보간하는 방법을 제공합니다. 구문은 목록 인덱싱과 유사하므로 배우기 쉽습니다.
20.1 시간에 데이터를 얻으려면 아래에 지정된 인덱스 값으로 전달하십시오.
>>> well[20.10]
69.40000000000003
>>>시작 시점과 종료 시점을 전달할 수 있습니다.
>>> well[20:30]
[67.0, 84.0, 102.0, 119.0, 135.0, 147.0, 158.0, 168.0, 179.0, 186.0]
>>>위의 명령은 1 시간 간격으로 20 시간에서 30 시간까지 데이터를 보간합니다. 기본적으로 간격은 1 시간이며 임의의 값으로 변경할 수 있습니다. 예를 들어, 아래에 지정된대로 15 분 (0.25 시간) 간격을 제공합니다.
>>> well[20:21:0.25]
[67.0, 73.0, 75.0, 81.0]
>>>분석 및 추출
Biopython은 Gompertz, Logistic 및 Richards 시그 모이 드 함수를 사용하여 WellRecord 데이터를 분석하는 데 적합한 방법을 제공합니다. 기본적으로 fit 방법은 Gompertz 함수를 사용합니다. 작업을 완료하려면 WellRecord 개체의 fit 메서드를 호출해야합니다. 코딩은 다음과 같습니다-
>>> well.fit()
Traceback (most recent call last):
...
Bio.MissingPythonDependencyError: Install scipy to extract curve parameters.
>>> well.model
>>> getattr(well, 'min') 0.0
>>> getattr(well, 'max') 388.0
>>> getattr(well, 'average_height')
205.42708333333334
>>>Biopython은 고급 분석을 수행하기 위해 scipy 모듈에 의존합니다. scipy 모듈을 사용하지 않고 min, max 및 average_height 세부 정보를 계산합니다.
이 장에서는 시퀀스를 플로팅하는 방법에 대해 설명합니다. 이 항목으로 이동하기 전에 플로팅의 기본 사항을 이해하겠습니다.
플로팅
Matplotlib는 다양한 형식으로 품질 수치를 생성하는 Python 플로팅 라이브러리입니다. 라인 차트, 히스토그램, 막대 차트, 파이 차트, 분산 형 차트 등과 같은 다양한 유형의 플롯을 만들 수 있습니다.
pyLab is a module that belongs to the matplotlib which combines the numerical module numpy with the graphical plotting module pyplot.Biopython은 시퀀스 플로팅을 위해 pylab 모듈을 사용합니다. 이렇게하려면 아래 코드를 가져와야합니다.
import pylab가져 오기 전에 아래 주어진 명령과 함께 pip 명령을 사용하여 matplotlib 패키지를 설치해야합니다.
pip install matplotlib샘플 입력 파일
다음과 같은 샘플 파일을 만듭니다. plot.fasta Biopython 디렉토리에 다음 변경 사항을 추가하십시오.
>seq0 FQTWEEFSRAAEKLYLADPMKVRVVLKYRHVDGNLCIKVTDDLVCLVYRTDQAQDVKKIEKF
>seq1 KYRTWEEFTRAAEKLYQADPMKVRVVLKYRHCDGNLCIKVTDDVVCLLYRTDQAQDVKKIEKFHSQLMRLME
>seq2 EEYQTWEEFARAAEKLYLTDPMKVRVVLKYRHCDGNLCMKVTDDAVCLQYKTDQAQDVKKVEKLHGK
>seq3 MYQVWEEFSRAVEKLYLTDPMKVRVVLKYRHCDGNLCIKVTDNSVCLQYKTDQAQDV
>seq4 EEFSRAVEKLYLTDPMKVRVVLKYRHCDGNLCIKVTDNSVVSYEMRLFGVQKDNFALEHSLL
>seq5 SWEEFAKAAEVLYLEDPMKCRMCTKYRHVDHKLVVKLTDNHTVLKYVTDMAQDVKKIEKLTTLLMR
>seq6 FTNWEEFAKAAERLHSANPEKCRFVTKYNHTKGELVLKLTDDVVCLQYSTNQLQDVKKLEKLSSTLLRSI
>seq7 SWEEFVERSVQLFRGDPNATRYVMKYRHCEGKLVLKVTDDRECLKFKTDQAQDAKKMEKLNNIFF
>seq8 SWDEFVDRSVQLFRADPESTRYVMKYRHCDGKLVLKVTDNKECLKFKTDQAQEAKKMEKLNNIFFTLM
>seq9 KNWEDFEIAAENMYMANPQNCRYTMKYVHSKGHILLKMSDNVKCVQYRAENMPDLKK
>seq10 FDSWDEFVSKSVELFRNHPDTTRYVVKYRHCEGKLVLKVTDNHECLKFKTDQAQDAKKMEK선 플롯
이제 위의 fasta 파일에 대한 간단한 라인 플롯을 생성 해 보겠습니다.
Step 1 − Fasta 파일을 읽기 위해 SeqIO 모듈을 가져옵니다.
>>> from Bio import SeqIOStep 2 − 입력 파일을 구문 분석합니다.
>>> records = [len(rec) for rec in SeqIO.parse("plot.fasta", "fasta")]
>>> len(records)
11
>>> max(records)
72
>>> min(records)
57Step 3 − pylab 모듈을 가져 오겠습니다.
>>> import pylabStep 4 − x 및 y 축 레이블을 할당하여 라인 차트를 구성합니다.
>>> pylab.xlabel("sequence length")
Text(0.5, 0, 'sequence length')
>>> pylab.ylabel("count")
Text(0, 0.5, 'count')
>>>Step 5 − 그리드 표시를 설정하여 라인 차트를 구성합니다.
>>> pylab.grid()Step 6 − plot 메서드를 호출하고 레코드를 입력으로 제공하여 간단한 선형 차트를 그립니다.
>>> pylab.plot(records)
[<matplotlib.lines.Line2D object at 0x10b6869d 0>]Step 7 − 마지막으로 아래 명령을 사용하여 차트를 저장합니다.
>>> pylab.savefig("lines.png")결과
위의 명령을 실행하면 Biopython 디렉토리에 저장된 다음 이미지를 볼 수 있습니다.
히스토그램 차트
히스토그램은 연속 데이터에 사용되며 빈은 데이터 범위를 나타냅니다. 히스토그램 그리기는 pylab.plot을 제외하고 선 차트와 동일합니다. 대신 레코드와 bin (5)에 대한 custum 값을 사용하여 pylab 모듈의 hist 메서드를 호출하십시오. 완전한 코딩은 다음과 같습니다.
Step 1 − Fasta 파일을 읽기 위해 SeqIO 모듈을 가져옵니다.
>>> from Bio import SeqIOStep 2 − 입력 파일을 구문 분석합니다.
>>> records = [len(rec) for rec in SeqIO.parse("plot.fasta", "fasta")]
>>> len(records)
11
>>> max(records)
72
>>> min(records)
57Step 3 − pylab 모듈을 가져 오겠습니다.
>>> import pylabStep 4 − x 및 y 축 레이블을 할당하여 라인 차트를 구성합니다.
>>> pylab.xlabel("sequence length")
Text(0.5, 0, 'sequence length')
>>> pylab.ylabel("count")
Text(0, 0.5, 'count')
>>>Step 5 − 그리드 표시를 설정하여 라인 차트를 구성합니다.
>>> pylab.grid()Step 6 − plot 메서드를 호출하고 레코드를 입력으로 제공하여 간단한 선형 차트를 그립니다.
>>> pylab.hist(records,bins=5)
(array([2., 3., 1., 3., 2.]), array([57., 60., 63., 66., 69., 72.]), <a list
of 5 Patch objects>)
>>>Step 7 − 마지막으로 아래 명령을 사용하여 차트를 저장합니다.
>>> pylab.savefig("hist.png")결과
위의 명령을 실행하면 Biopython 디렉토리에 저장된 다음 이미지를 볼 수 있습니다.
시퀀스의 GC 백분율
GC 백분율은 다른 시퀀스를 비교하기 위해 일반적으로 사용되는 분석 데이터 중 하나입니다. 시퀀스 집합의 GC 백분율을 사용하여 간단한 선형 차트를 만들고 즉시 비교할 수 있습니다. 여기서는 데이터를 시퀀스 길이에서 GC 백분율로 변경할 수 있습니다. 완전한 코딩은 다음과 같습니다.
Step 1 − Fasta 파일을 읽기 위해 SeqIO 모듈을 가져옵니다.
>>> from Bio import SeqIOStep 2 − 입력 파일을 구문 분석합니다.
>>> from Bio.SeqUtils import GC
>>> gc = sorted(GC(rec.seq) for rec in SeqIO.parse("plot.fasta", "fasta"))Step 3 − pylab 모듈을 가져 오겠습니다.
>>> import pylabStep 4 − x 및 y 축 레이블을 할당하여 라인 차트를 구성합니다.
>>> pylab.xlabel("Genes")
Text(0.5, 0, 'Genes')
>>> pylab.ylabel("GC Percentage")
Text(0, 0.5, 'GC Percentage')
>>>Step 5 − 그리드 표시를 설정하여 라인 차트를 구성합니다.
>>> pylab.grid()Step 6 − plot 메서드를 호출하고 레코드를 입력으로 제공하여 간단한 선형 차트를 그립니다.
>>> pylab.plot(gc)
[<matplotlib.lines.Line2D object at 0x10b6869d 0>]Step 7 − 마지막으로 아래 명령을 사용하여 차트를 저장합니다.
>>> pylab.savefig("gc.png")결과
위의 명령을 실행하면 Biopython 디렉토리에 저장된 다음 이미지를 볼 수 있습니다.
일반적으로 군집 분석은 동일한 그룹에있는 개체 집합을 그룹화합니다. 이 개념은 주로 데이터 마이닝, 통계 데이터 분석, 기계 학습, 패턴 인식, 이미지 분석, 생물 정보학 등에 사용됩니다. 다양한 알고리즘을 통해 클러스터가 다양한 분석에 널리 사용되는 방식을 이해할 수 있습니다.
Bioinformatics에 따르면 클러스터 분석은 주로 유전자 발현 데이터 분석에서 유사한 유전자 발현을 가진 유전자 그룹을 찾는 데 사용됩니다.
이 장에서는 실제 데이터 세트에서 클러스터링의 기초를 이해하기 위해 Biopython의 중요한 알고리즘을 확인합니다.
Biopython은 모든 알고리즘을 구현하기 위해 Bio.Cluster 모듈을 사용합니다. 다음 알고리즘을 지원합니다-
- 계층 적 클러스터링
- K-클러스터링
- 자기 조직화지도
- 주요 구성 요소 분석
위의 알고리즘에 대해 간략하게 소개하겠습니다.
계층 적 클러스터링
계층 적 클러스터링은 거리 측정으로 각 노드를 가장 가까운 이웃에 연결하고 클러스터를 만드는 데 사용됩니다. Bio.Cluster 노드에는 왼쪽, 오른쪽 및 거리의 세 가지 속성이 있습니다. 아래와 같이 간단한 클러스터를 생성 해 보겠습니다.
>>> from Bio.Cluster import Node
>>> n = Node(1,10)
>>> n.left = 11
>>> n.right = 0
>>> n.distance = 1
>>> print(n)
(11, 0): 1트리 기반 클러스터링을 구성하려면 아래 명령을 사용하십시오.
>>> n1 = [Node(1, 2, 0.2), Node(0, -1, 0.5)] >>> n1_tree = Tree(n1)
>>> print(n1_tree)
(1, 2): 0.2
(0, -1): 0.5
>>> print(n1_tree[0])
(1, 2): 0.2Bio.Cluster 모듈을 사용하여 계층 적 클러스터링을 수행해 보겠습니다.
거리가 배열에 정의되어 있다고 가정하십시오.
>>> import numpy as np
>>> distance = array([[1,2,3],[4,5,6],[3,5,7]])이제 트리 클러스터에 거리 배열을 추가합니다.
>>> from Bio.Cluster import treecluster
>>> cluster = treecluster(distance)
>>> print(cluster)
(2, 1): 0.666667
(-1, 0): 9.66667위의 함수는 트리 클러스터 객체를 반환합니다. 이 개체에는 항목 수가 행 또는 열로 클러스터 된 노드가 포함됩니다.
K-클러스터링
분할 알고리즘의 한 유형으로 k- 평균, 중앙값 및 medoids 클러스터링으로 분류됩니다. 각 클러스터링을 간략하게 이해하겠습니다.
K- 평균 클러스터링
이 접근 방식은 데이터 마이닝에서 널리 사용됩니다. 이 알고리즘의 목표는 변수 K로 표시되는 그룹 수를 사용하여 데이터에서 그룹을 찾는 것입니다.
알고리즘은 제공된 기능을 기반으로 K 그룹 중 하나에 각 데이터 포인트를 할당하기 위해 반복적으로 작동합니다. 데이터 포인트는 기능 유사성을 기반으로 클러스터링됩니다.
>>> from Bio.Cluster import kcluster
>>> from numpy import array
>>> data = array([[1, 2], [3, 4], [5, 6]])
>>> clusterid, error,found = kcluster(data)
>>> print(clusterid) [0 0 1]
>>> print(found)
1K- 중앙값 클러스터링
각 클러스터의 평균을 계산하여 중심을 결정하는 또 다른 유형의 클러스터링 알고리즘입니다.
K-medoids 클러스터링
이 접근 방식은 거리 행렬과 사용자가 전달한 클러스터 수를 사용하여 주어진 항목 집합을 기반으로합니다.
아래 정의 된 거리 행렬을 고려하십시오.
>>> distance = array([[1,2,3],[4,5,6],[3,5,7]])아래 명령을 사용하여 k-medoids 클러스터링을 계산할 수 있습니다.
>>> from Bio.Cluster import kmedoids
>>> clusterid, error, found = kmedoids(distance)예를 들어 보겠습니다.
kcluster 함수는 데이터 행렬을 Seq 인스턴스가 아닌 입력으로 사용합니다. 시퀀스를 행렬로 변환하고 kcluster 함수에 제공해야합니다.
데이터를 숫자 요소 만 포함하는 행렬로 변환하는 한 가지 방법은 numpy.fromstring함수. 기본적으로 시퀀스의 각 문자를 ASCII 대응 문자로 변환합니다.
이렇게하면 kcluster 함수가 인식하고 시퀀스를 클러스터링하는 데 사용하는 인코딩 된 시퀀스의 2D 배열이 생성됩니다.
>>> from Bio.Cluster import kcluster
>>> import numpy as np
>>> sequence = [ 'AGCT','CGTA','AAGT','TCCG']
>>> matrix = np.asarray([np.fromstring(s, dtype=np.uint8) for s in sequence])
>>> clusterid,error,found = kcluster(matrix)
>>> print(clusterid) [1 0 0 1]자기 조직화지도
이 접근 방식은 일종의 인공 신경망입니다. 코호 넨에서 개발 한 것으로 코호 넨지도라고도합니다. 직사각형 토폴로지를 기반으로 항목을 클러스터로 구성합니다.
아래와 같은 배열 거리를 사용하여 간단한 클러스터를 생성 해 보겠습니다.
>>> from Bio.Cluster import somcluster
>>> from numpy import array
>>> data = array([[1, 2], [3, 4], [5, 6]])
>>> clusterid,map = somcluster(data)
>>> print(map)
[[[-1.36032469 0.38667395]]
[[-0.41170578 1.35295911]]]
>>> print(clusterid)
[[1 0]
[1 0]
[1 0]]여기, clusterid 두 개의 열이있는 배열로, 행 수는 클러스터 된 항목 수와 같습니다. data 차원이 행 또는 열인 배열입니다.
주요 구성 요소 분석
주성분 분석은 고차원 데이터를 시각화하는 데 유용합니다. 선형 대수 및 통계의 간단한 행렬 연산을 사용하여 원본 데이터를 동일한 수 또는 더 적은 차원으로 투영하는 방법입니다.
주성분 분석은 튜플 열 평균, 좌표, 성분 및 고유 값을 반환합니다. 이 개념의 기본을 살펴 보겠습니다.
>>> from numpy import array
>>> from numpy import mean
>>> from numpy import cov
>>> from numpy.linalg import eig
# define a matrix
>>> A = array([[1, 2], [3, 4], [5, 6]])
>>> print(A)
[[1 2]
[3 4]
[5 6]]
# calculate the mean of each column
>>> M = mean(A.T, axis = 1)
>>> print(M)
[ 3. 4.]
# center columns by subtracting column means
>>> C = A - M
>>> print(C)
[[-2. -2.]
[ 0. 0.]
[ 2. 2.]]
# calculate covariance matrix of centered matrix
>>> V = cov(C.T)
>>> print(V)
[[ 4. 4.]
[ 4. 4.]]
# eigendecomposition of covariance matrix
>>> values, vectors = eig(V)
>>> print(vectors)
[[ 0.70710678 -0.70710678]
[ 0.70710678 0.70710678]]
>>> print(values)
[ 8. 0.]아래 정의 된 것과 같이 동일한 직사각형 매트릭스 데이터를 Bio.Cluster 모듈에 적용 해 보겠습니다.
>>> from Bio.Cluster import pca
>>> from numpy import array
>>> data = array([[1, 2], [3, 4], [5, 6]])
>>> columnmean, coordinates, components, eigenvalues = pca(data)
>>> print(columnmean)
[ 3. 4.]
>>> print(coordinates)
[[-2.82842712 0. ]
[ 0. 0. ]
[ 2.82842712 0. ]]
>>> print(components)
[[ 0.70710678 0.70710678]
[ 0.70710678 -0.70710678]]
>>> print(eigenvalues)
[ 4. 0.]생물 정보학은 기계 학습 알고리즘을 적용 할 수있는 훌륭한 분야입니다. 여기에는 많은 유기체의 유전 정보가 있으며이 모든 정보를 수동으로 분석하는 것은 불가능합니다. 적절한 기계 학습 알고리즘을 사용하면 이러한 데이터에서 많은 유용한 정보를 추출 할 수 있습니다. Biopython은 감독 된 기계 학습을 수행하는 데 유용한 알고리즘 세트를 제공합니다.
지도 학습은 입력 변수 (X)와 출력 변수 (Y)를 기반으로합니다. 알고리즘을 사용하여 입력에서 출력으로의 매핑 기능을 학습합니다. 아래에 정의되어 있습니다-
Y = f(X)이 접근 방식의 주요 목적은 매핑 함수를 근사화하는 것이며 새 입력 데이터 (x)가있는 경우 해당 데이터에 대한 출력 변수 (Y)를 예측할 수 있습니다.
로지스틱 회귀 모델
로지스틱 회귀는 감독되는 기계 학습 알고리즘입니다. 예측 변수의 가중 합을 사용하여 K 클래스 간의 차이를 찾는 데 사용됩니다. 이벤트 발생 확률을 계산하고 암 탐지에 사용할 수 있습니다.
Biopython은 로지스틱 회귀 알고리즘을 기반으로 변수를 예측하는 Bio.LogisticRegression 모듈을 제공합니다. 현재 Biopython은 두 클래스 (K = 2)에 대해서만 로지스틱 회귀 알고리즘을 구현합니다.
k- 최근 접 이웃
k-Nearest neighbours는 또한 감독되는 기계 학습 알고리즘입니다. 가장 가까운 이웃을 기준으로 데이터를 분류하여 작동합니다. Biopython은 k- 최근 접 이웃 알고리즘을 기반으로 변수를 예측하는 Bio.KNN 모듈을 제공합니다.
나이브 베이 즈
Naive Bayes 분류기는 Bayes의 정리를 기반으로하는 분류 알고리즘 모음입니다. 단일 알고리즘이 아니라 모두가 공통 원칙을 공유하는 알고리즘 패밀리입니다. 즉, 분류되는 모든 기능 쌍은 서로 독립적입니다. Biopython은 Naive Bayes 알고리즘과 함께 작동하는 Bio.NaiveBayes 모듈을 제공합니다.
마르코프 모델
Markov 모델은 특정 확률 규칙에 따라 한 상태에서 다른 상태로 전환되는 임의 변수 모음으로 정의 된 수학적 시스템입니다. Biopython은Bio.MarkovModel and Bio.HMM.MarkovModel modules to work with Markov models.
Biopython에는 소프트웨어에 버그가 없는지 확인하기 위해 다양한 조건에서 소프트웨어를 테스트하는 광범위한 테스트 스크립트가 있습니다. 테스트 스크립트를 실행하려면 Biopython의 소스 코드를 다운로드 한 다음 아래 명령을 실행하십시오.
python run_tests.py이것은 모든 테스트 스크립트를 실행하고 다음 출력을 제공합니다.
Python version: 2.7.12 (v2.7.12:d33e0cf91556, Jun 26 2016, 12:10:39)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)]
Operating system: posix darwin
test_Ace ... ok
test_Affy ... ok
test_AlignIO ... ok
test_AlignIO_ClustalIO ... ok
test_AlignIO_EmbossIO ... ok
test_AlignIO_FastaIO ... ok
test_AlignIO_MauveIO ... ok
test_AlignIO_PhylipIO ... ok
test_AlignIO_convert ... ok
...........................................
...........................................아래에 지정된대로 개별 테스트 스크립트를 실행할 수도 있습니다.
python test_AlignIO.py결론
우리가 배운 것처럼 Biopython은 생물 정보학 분야에서 중요한 소프트웨어 중 하나입니다. 파이썬 (배우고 쓰기 쉬움)으로 작성되어 생물 정보학 분야의 모든 계산 및 작업을 처리 할 수있는 광범위한 기능을 제공합니다. 또한 기능을 활용하기 위해 거의 모든 인기있는 생물 정보학 소프트웨어에 쉽고 유연한 인터페이스를 제공합니다.