Caffe2-개요
이제 딥 러닝에 대한 통찰력을 얻었으므로 Caffe에 대한 개요를 살펴 보겠습니다.
CNN 훈련
이미지 분류를 위해 CNN을 훈련하는 과정을 알아 보겠습니다. 프로세스는 다음 단계로 구성됩니다.
Data Preparation−이 단계에서는 이미지를 중앙에서 자르고 크기를 조정하여 훈련 및 테스트를위한 모든 이미지가 동일한 크기가되도록합니다. 이것은 일반적으로 이미지 데이터에서 작은 Python 스크립트를 실행하여 수행됩니다.
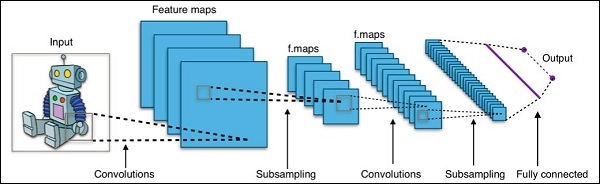
Model Definition−이 단계에서는 CNN 아키텍처를 정의합니다. 구성은.pb (protobuf)파일. 일반적인 CNN 아키텍처는 아래 그림에 나와 있습니다.
Solver Definition− 솔버 구성 파일을 정의합니다. Solver는 모델 최적화를 수행합니다.
Model Training− 내장 된 Caffe 유틸리티를 사용하여 모델을 훈련합니다. 교육에는 상당한 시간과 CPU 사용량이 소요될 수 있습니다. 훈련이 완료된 후 Caffe는 모델을 파일에 저장하고 나중에 테스트 데이터 및 예측을위한 최종 배포에 사용할 수 있습니다.
Caffe2의 새로운 기능
Caffe2에서는 바로 사용할 수있는 사전 훈련 된 많은 모델을 찾을 수 있으며 새로운 모델 및 알고리즘의 커뮤니티 기여를 매우 자주 활용합니다. 생성 한 모델은 클라우드에서 GPU 성능을 사용하여 쉽게 확장 할 수 있으며 크로스 플랫폼 라이브러리를 통해 모바일에서 대량 사용으로 줄일 수도 있습니다.
Caffe보다 Caffe2에서 개선 된 사항은 다음과 같이 요약 할 수 있습니다.
- 모바일 배포
- 새로운 하드웨어 지원
- 대규모 분산 교육 지원
- 양자화 된 계산
- Facebook에서 스트레스 테스트
사전 훈련 된 모델 데모
Berkeley Vision and Learning Center (BVLC) 사이트는 사전 훈련 된 네트워크의 데모를 제공합니다. 이미지 분류를위한 이러한 네트워크 중 하나는 여기에 명시된 링크에서 사용할 수 있습니다.https://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification 아래 스크린 샷에 묘사되어 있습니다.
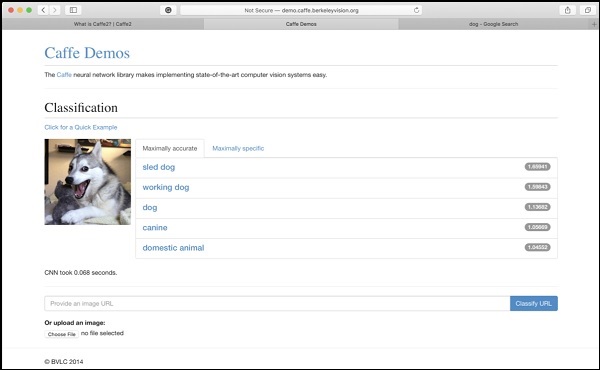
스크린 샷에서 개의 이미지는 예측 정확도로 분류되고 레이블이 지정됩니다. 그것은 또한 단지0.068 seconds이미지를 분류합니다. 이미지 URL을 지정하거나 화면 하단에 제공되는 옵션에서 이미지 자체를 업로드하여 원하는 이미지를 시도 할 수 있습니다.